
1. ภาพรวม
เราต่างรู้กันดีว่า "ดาร์กดาต้า" นั้นสร้างความเจ็บปวดเพียงใด ซึ่งก็คือไฟล์ PDF, รูปภาพ และไฟล์ข้อความที่อยู่ในที่เก็บข้อมูลออบเจ็กต์บนระบบคลาวด์ ซึ่งมองไม่เห็นโดยสมบูรณ์สำหรับคำค้นหา SQL และแดชบอร์ด BI โดยปกติแล้ว การปลดล็อกข้อมูลนี้ต้องใช้ไปป์ไลน์ OCR ที่ซับซ้อน การป้อนข้อมูลด้วยตนเอง หรือสคริปต์ที่กำหนดเองซึ่งมีความเสี่ยง
ปัญหานี้จะหมดไป
ใน Lab นี้ ผมจะแสดงวิธีแปลงไฟล์ PDF ที่ไม่มีโครงสร้าง 400 ไฟล์ ซึ่งครอบคลุมข้อความ ตาราง และรูปภาพ ให้เป็นตาราง BigQuery ที่มีโครงสร้างชัดเจนพร้อมความสัมพันธ์ที่อนุมานโดยอัตโนมัติระหว่างตารางเหล่านั้น และเราจะทําให้เสร็จภายในไม่กี่นาทีโดยใช้แคตตาล็อกความรู้ของ BigQuery และ Dataplex
สิ่งที่คุณจะสร้าง
เพื่อทำให้เห็นภาพชัดเจนขึ้น เรามาดูธุรกิจสมมติกัน นั่นคือธุรกิจแฟรนไชส์โยเกิร์ตแช่แข็งที่กำลังเติบโตอย่างรวดเร็ว
สมมติว่าคุณจัดการข้อมูลสำหรับธุรกิจโฟรโยนี้ คุณมีสูตรอาหารและเอกสารข้อมูลจำเพาะของซัพพลายเออร์หลายร้อยรายการ ซึ่งทั้งหมดบันทึกเป็น PDF ผู้นำทางธุรกิจต้องการเปิดตัว AI Agent เพื่อช่วยผู้จัดการร้านค้าและลูกค้าในการค้นหารายละเอียดผลิตภัณฑ์
ลองนึกภาพสถานการณ์ที่แย่ที่สุด ลูกค้าถามว่า "ฉันสนใจฟรอสเซ่นโยเกิร์ตมิดไนต์สเวิร์ลมาก มีสารก่อภูมิแพ้ไหม"
โดยปกติแล้ว ระบบจะต้องทำสิ่งต่อไปนี้เพื่อตอบคำถามนี้
- ค้นหา PDF สูตร "มิดไนต์สเวิร์ล"
- อ่านส่วนผสม (เช่น "ผงโกโก้" "ส่วนผสมนม" "อิมัลซิไฟเออร์ X")
- ค้นหาใน PDF ของซัพพลายเออร์หลายสิบรายการเพื่อค้นหาเอกสารข้อมูลจำเพาะของส่วนผสมที่เฉพาะเจาะจงเหล่านั้น
- ตรวจสอบชีตซัพพลายเออร์เพื่อดูสารก่อภูมิแพ้ที่ซ่อนอยู่ซึ่งเชื่อมโยงกับส่วนผสมเหล่านั้น
การพยายามสร้างเอเจนต์ AI ที่ทำสิ่งนี้ได้ทันทีโดยการอ่านไฟล์ PDF ดิบ 400 ไฟล์ในรันไทม์นั้นช้า มีค่าใช้จ่ายสูง และมีแนวโน้มที่จะเกิดอาการหลอน แต่เราจะใช้การอนุมานเชิงความหมายเพื่อดึงข้อมูลทั้งหมดนี้ลงในฐานข้อมูลเชิงสัมพันธ์ก่อน ซึ่งจะทําให้เอเจนต์ AI ในอนาคตของเราทํางานได้อย่างรวดเร็วและอิงตามข้อมูล SQL ที่เป็นข้อเท็จจริง 100%
มาเริ่มสร้างกันเลย
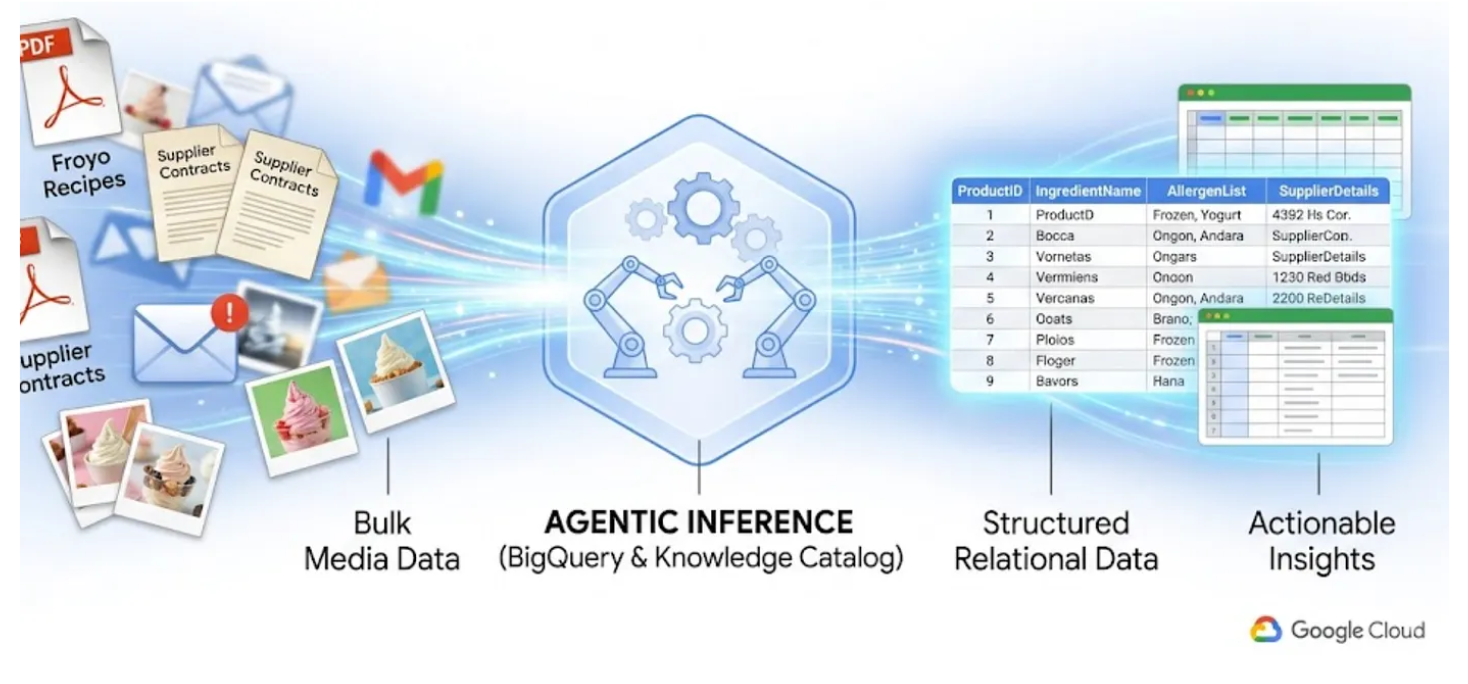
สิ่งที่คุณจะได้เรียนรู้
- วิธีตั้งค่า Bucket ของ Cloud Storage สำหรับไฟล์ต้นฉบับ (PDF)
- วิธีตั้งค่าและเรียกใช้งาน Datascan และการอนุมานเชิงความหมายในแคตตาล็อกความรู้เพื่อดึงข้อมูลจาก PDF แหล่งที่มา และอนุมานการเชื่อมต่อและบริบทเชิงความหมาย แล้วจัดเก็บไว้ใน BigQuery
- วิธีใช้ Agent ของ BigQuery เพื่อแชทกับชุดข้อมูลที่สร้างขึ้นใหม่
ข้อกำหนด
2. ก่อนเริ่มต้น
สร้างโปรเจ็กต์
- ในคอนโซล Google Cloud ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud ในหน้าตัวเลือกโปรเจ็กต์
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ Cloud แล้ว ดูวิธีตรวจสอบว่าโปรเจ็กต์เปิดใช้การเรียกเก็บเงินหรือไม่
- คุณจะใช้ Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานใน Google Cloud คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud

- เมื่อเชื่อมต่อกับ Cloud Shell แล้ว ให้ตรวจสอบว่าคุณได้รับการตรวจสอบสิทธิ์แล้วและตั้งค่าโปรเจ็กต์เป็นรหัสโปรเจ็กต์ของคุณโดยใช้คำสั่งต่อไปนี้
gcloud auth list
- เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อยืนยันว่าคำสั่ง gcloud รู้จักโปรเจ็กต์ของคุณ
gcloud config list project
- หากต้องการตรวจสอบสิทธิ์
gcloud auth login
- หากไม่ได้ตั้งค่าโปรเจ็กต์ ให้ใช้คำสั่งต่อไปนี้เพื่อตั้งค่า
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- เปิดใช้ API ที่จำเป็น: เรียกใช้คำสั่งนี้เพื่อเปิดใช้ API ที่จำเป็นทั้งหมด
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
storage.googleapis.com
ข้อควรระวังและการแก้ปัญหา
กลุ่มอาการ"โปรเจ็กต์ผี" | คุณเรียกใช้ |
แผงกั้น การเรียกเก็บเงิน | คุณเปิดใช้โปรเจ็กต์แล้ว แต่ลืมบัญชีสำหรับการเรียกเก็บเงิน AlloyDB เป็นเครื่องมือที่มีประสิทธิภาพสูง จึงจะไม่เริ่มทำงานหาก "ถังน้ำมัน" (การเรียกเก็บเงิน) ว่างเปล่า |
ความล่าช้าการเผยแพร่ API | คุณคลิก "เปิดใช้ API" แล้ว แต่บรรทัดคำสั่งยังคงแสดง |
คำถามเกี่ยวกับโควต้า | หากใช้บัญชีทดลองใช้ใหม่ คุณอาจพบโควต้าระดับภูมิภาคสำหรับอินสแตนซ์ AlloyDB หาก |
ตัวแทนบริการ"ซ่อน" | บางครั้งระบบไม่ได้มอบบทบาท |
3. การตั้งค่า Bucket ของ Google Cloud Storage
ในส่วนนี้ คุณจะได้สร้างโครงสร้างองค์กรภายใน BigQuery เพื่อจัดเก็บข้อมูลสูตรและซัพพลายเออร์ของ Froyo โดยเฉพาะรายละเอียดผลิตภัณฑ์ Froyo นอกจากนี้ยังสร้างการเชื่อมต่อทรัพยากรระบบคลาวด์ ซึ่งทำหน้าที่เป็น "บริดจ์" ที่ปลอดภัยซึ่งช่วยให้ BigQuery อ่านไฟล์จากแหล่งที่มาภายนอก เช่น Cloud Storage ได้
ก่อนเริ่มใช้งาน
ที่เก็บนี้มีสูตรอาหารและไฟล์ PDF ของซัพพลายเออร์ที่เราจะใช้ในโปรเจ็กต์นี้ โปรดตรวจสอบว่าคุณได้ดาวน์โหลดไฟล์เหล่านี้ หากต้องการดาวน์โหลดไฟล์ ให้ทำดังนี้
ใน Cloud Shell ให้เรียกใช้คำสั่งต่อไปนี้
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git
ไปที่โฟลเดอร์ที่สร้างขึ้นใหม่โดยทำดังนี้
cd next-26-keynotes
ดึงโฟลเดอร์ data-cloud-demo
git sparse-checkout set genkey/data-cloud-demo
หลังจากชำระเงินเสร็จแล้ว ให้ไปที่โฟลเดอร์ data-cloud-demo แล้วแตกไฟล์ ZIP เพื่อเข้าถึงชิ้นงานของ Codelab
สร้าง Bucket และอัปโหลดไฟล์ PDF ของ Froyo (สูตรอาหารและซัพพลายเออร์)
- ในคอนโซล Google Cloud ให้ไปที่หน้าที่เก็บข้อมูล Cloud Storage
- คลิกสร้าง
- ในหน้าสร้าง Bucket ให้ป้อนข้อมูล Bucket หลังจากทำตามแต่ละขั้นตอนต่อไปนี้ ให้คลิก "ต่อไป" เพื่อไปยังขั้นตอนถัดไป
- ในส่วนเริ่มต้นใช้งาน ให้ป้อนชื่อที่เก็บข้อมูล เช่น froyo_data
- ในส่วนเลือกที่เก็บข้อมูล ให้เลือกภูมิภาค แล้วป้อนภูมิภาค us-central1
- ในส่วนเลือกวิธีควบคุมการเข้าถึงออบเจ็กต์ ให้ยกเลิกการเลือกช่องทำเครื่องหมายบังคับใช้การป้องกันการเข้าถึงแบบสาธารณะใน Bucket นี้
- คลิกสร้าง
- ในรายการ Bucket ให้คลิก Bucket ที่คุณสร้างขึ้น
- ในแท็บออบเจ็กต์ของ Bucket ให้คลิกอัปโหลด แล้วคลิกอัปโหลดโฟลเดอร์
- เลือกโฟลเดอร์ recipes ที่คุณแตกไฟล์ในส่วนก่อนที่จะเริ่มของ Codelab นี้
- คลิกอัปโหลด
- ทำซ้ำขั้นตอนการอัปโหลดสำหรับโฟลเดอร์ซัพพลายเออร์
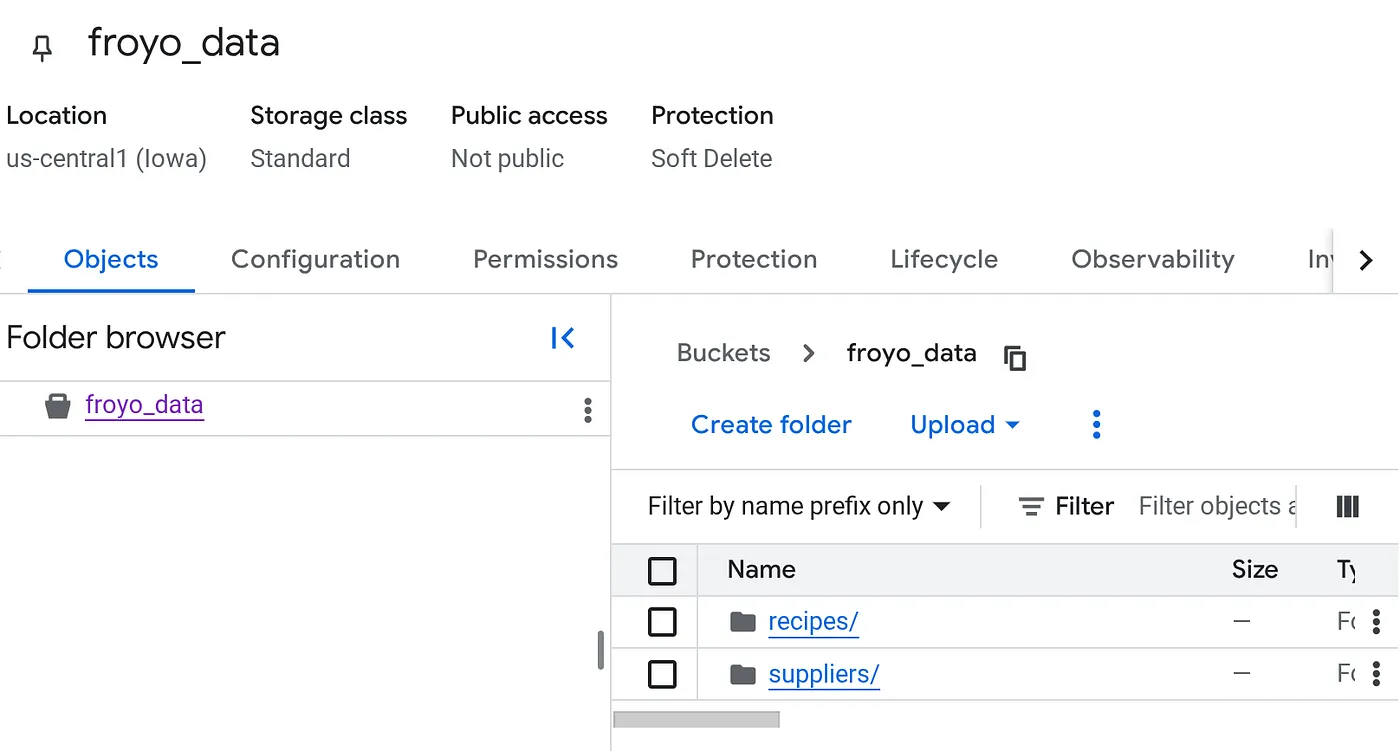
เมื่ออัปโหลดแล้ว โครงสร้างที่เก็บข้อมูลควรมีลักษณะดังนี้ (ไม่ว่าชื่อที่เก็บข้อมูลจะเป็นอะไรก็ตาม)
4. การตั้งค่าการเชื่อมต่อ BigQuery
สร้างการเชื่อมต่อทรัพยากรระบบคลาวด์ ซึ่งจะสร้างบัญชีบริการที่ไม่ซ้ำกันซึ่งทำหน้าที่เป็น "บัตรประจำตัว" ของ BigQuery เพื่อเข้าถึงไฟล์ภายนอก
- ไปที่หน้า BigQuery
- คลิก Explorer ในแผงด้านซ้าย หากไม่เห็นแผงด้านซ้าย ให้คลิกขยายแผงด้านซ้ายเพื่อเปิดแผง
- ในบานหน้าต่าง Explorer ให้ขยายชื่อโปรเจ็กต์ แล้วคลิกการเชื่อมต่อ
- ในหน้าการเชื่อมต่อ ให้คลิกสร้างการเชื่อมต่อ
- สำหรับประเภทการเชื่อมต่อ ให้เลือกโมเดลระยะไกล ฟังก์ชันระยะไกล BigLake และ Spanner ของ Vertex AI (ทรัพยากรระบบคลาวด์)
- ในช่องรหัสการเชื่อมต่อ ให้ป้อนชื่อรหัสการเชื่อมต่อดังนี้
- bq-connection อย่าลืมจดรหัสดังกล่าวไว้เนื่องจากคุณจะต้องใช้เมื่อตั้งค่าการสแกนข้อมูลในภายหลังใน Codelab นี้
- ตั้งค่าประเภทสถานที่ตั้งเป็นภูมิภาค แล้วเลือกภูมิภาค เช่น us-central1 การเชื่อมต่อควรอยู่ในภูมิภาคเดียวกับทรัพยากรอื่นๆ เช่น ชุดข้อมูล
- คลิกสร้างการเชื่อมต่อ
- คลิกไปที่การเชื่อมต่อ
- ในแผงข้อมูลการเชื่อมต่อ ให้คัดลอกรหัสบัญชีบริการเพื่อใช้ในขั้นตอนถัดไป บัญชีบริการจะมีลักษณะคล้ายกับ bqcx-**********-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com
5. การตั้งค่าสิทธิ์
- ให้สิทธิ์ที่จำเป็นแก่การเชื่อมต่อ BigQuery เพื่อเข้าถึงออบเจ็กต์ Cloud Storage และแคตตาล็อกความรู้
ไปที่หน้า IAM และผู้ดูแลระบบ แล้วคลิกปุ่มให้สิทธิ์เข้าถึงในส่วนดูตามผู้ใช้หลัก จากนั้นเพิ่มผู้ใช้หลักโดยวางบัญชีบริการที่คุณคัดลอกไว้ในขั้นตอนสุดท้าย ในส่วนบทบาท ให้เพิ่มชื่อบทบาทต่อไปนี้ทีละรายการแล้วบันทึก
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/bigquery.user
- roles/bigquery.dataEditor
- roles/aiplatform.viewer
- roles/agentplatform.user
- roles/storage.admin
- roles/dataproc.serviceAgent
- roles/dataplex.discoveryPublishingServiceAgent
- roles/dataplex.serviceAgent
- roles/dataplex.securityAdmin
- ให้สิทธิ์บัญชีบริการ Dataplex ในการเข้าถึง Bucket ของ Cloud Storage
ไปที่หน้า IAM และผู้ดูแลระบบ แล้วคลิกปุ่มให้สิทธิ์เข้าถึงในส่วนดูตามผู้ใช้หลัก จากนั้นเพิ่มผู้ใช้หลักโดยพิมพ์คำว่า dataplex ลงในแถบข้อความผู้ใช้หลักใหม่ จากรายการที่เติมข้อความอัตโนมัติ ให้เลือกหลักการของบัญชีบริการ Dataplex ที่มีลักษณะคล้ายกับตัวอย่างต่อไปนี้ (ใช้หมายเลขโปรเจ็กต์ไม่ใช่รหัสโปรเจ็กต์ในรหัสอีเมลของบัญชีบริการด้านล่าง)
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
หากระบบไม่รู้จักบัญชีบริการข้างต้นสำหรับหมายเลขโปรเจ็กต์ของคุณไม่ว่าด้วยเหตุผลใดก็ตาม อาจเป็นเพราะโปรเจ็กต์ยังไม่ได้เริ่มต้นบริการ Dataplex ไปที่เทอร์มินัล Cloud Shell แล้วลองเปิดใช้ API (หากยังไม่ได้ดำเนินการในขั้นตอนก่อนที่จะเริ่ม) โดยเรียกใช้คำสั่งต่อไปนี้ gcloud services enable dataplex.googleapis.com
แม้หลังจากนั้น หากระบบไม่รู้จักบัญชีบริการสำหรับ Dataplex ให้บังคับสร้างงานสแกน Dataplex ทดสอบในหน้าการดูแลจัดการข้อมูลเมตา แล้วป้อนรายละเอียดในหน้าการสร้างงาน Discover
คลิกเรียกใช้เลย งานจะล้มเหลว แต่จะช่วยให้มั่นใจได้ว่าระบบจะเริ่มต้นรหัสบัญชีบริการสำหรับบริการ Dataplex ของคุณในตอนนี้
กลับไปที่หน้า IAM และผู้ดูแลระบบ แล้วคลิกปุ่มให้สิทธิ์เข้าถึงในส่วนดูตามผู้ใช้หลัก แล้วคลิกเพิ่มผู้ใช้หลัก วางบัญชีบริการ
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
จากนั้นให้มอบบทบาทต่อไปนี้ให้กับบัญชีบริการนี้
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/storage.viewer
- roles/dataplex.discoveryBigLakePublishingServiceAgent
6. การตั้งค่า Knowledge Catalog
สร้างแคตตาล็อกความรู้เพื่อรวม Unstructured Data และทำให้การค้นหาไฟล์ที่ไม่มีโครงสร้าง (เช่น สูตรอาหารและซัพพลายเออร์ในรูปแบบ PDF) เป็นแบบอัตโนมัติ
สร้างงาน DataScan จากคอนโซล
- ไปที่หน้าการดูแลจัดการข้อมูลเมตา
- คลิกสร้าง แล้วป้อนรายละเอียดที่สอดคล้องกับการตั้งค่าของคุณ
หมายเหตุสำคัญ: อย่าลืมเลือกช่อง "เปิดใช้การอนุมานเชิงความหมาย"
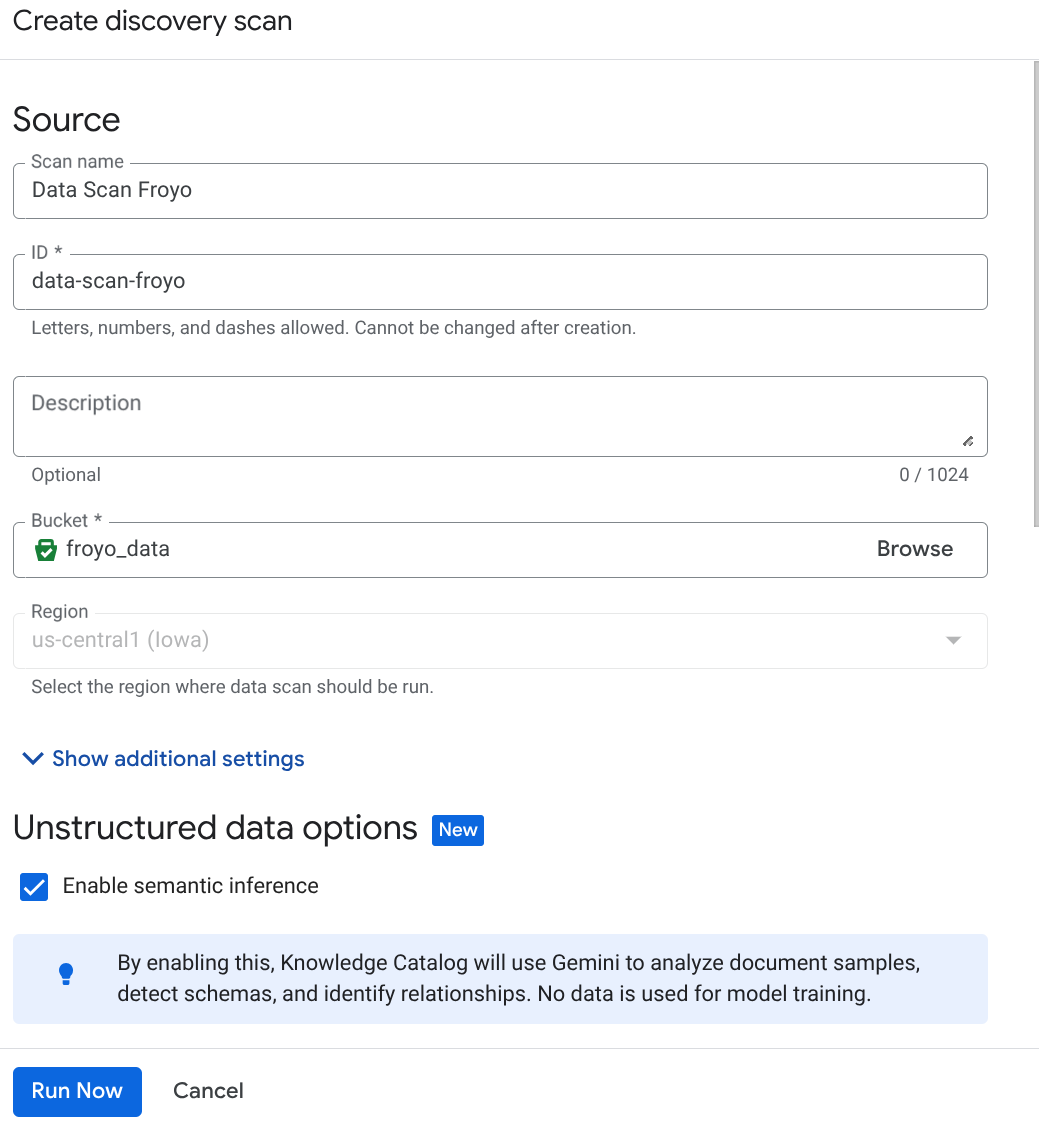
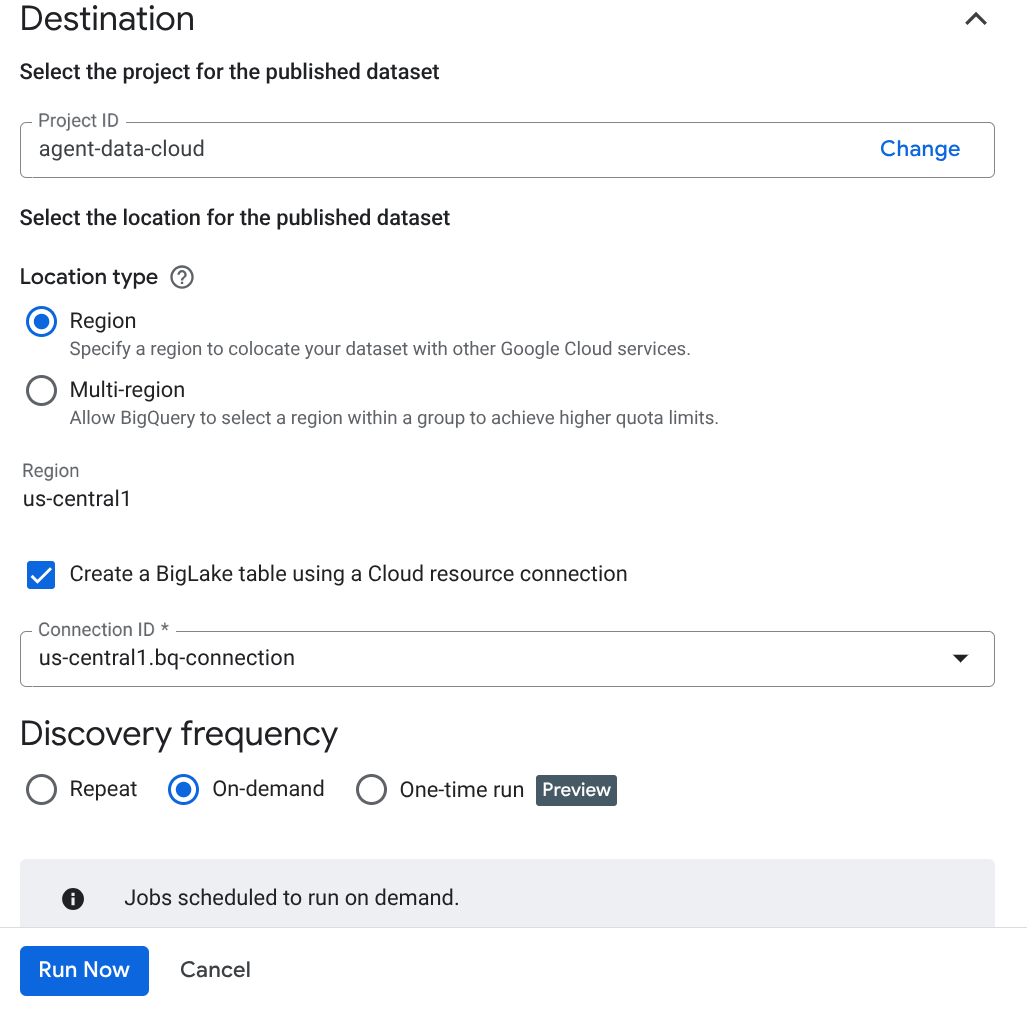
- คลิก "เรียกใช้เลย"
- การสแกนอาจใช้เวลาสักครู่ เมื่องานเสร็จสิ้นแล้ว ให้ตรวจสอบว่ามีชุดข้อมูลที่เผยแพร่หรือไม่ หากต้องการตรวจสอบสถานะของงาน คุณสามารถตรวจสอบได้ในหน้าการดูแลจัดการข้อมูลเมตา ในแท็บการค้นพบ Cloud Storage ให้คลิกชื่อของการสแกนการค้นพบของการเรียกใช้ล่าสุด คุณควรเห็นชุดข้อมูลที่เผยแพร่ดังที่แสดงด้านล่าง
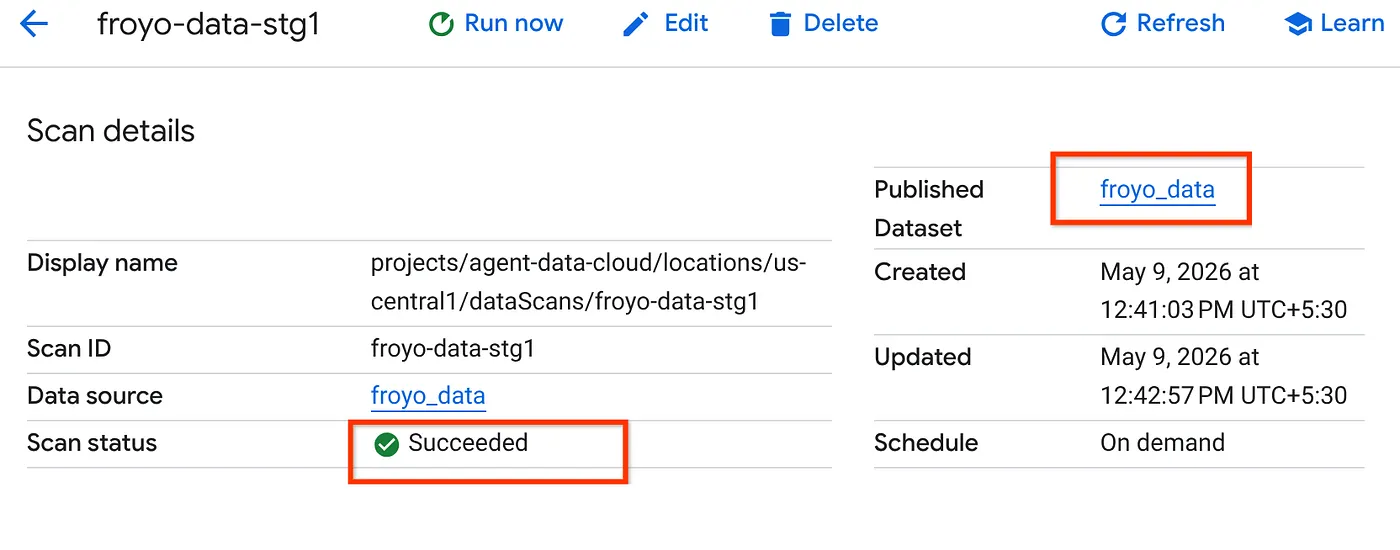
หมายเหตุ: หากพบข้อผิดพลาดในขั้นตอนการสแกน โปรดรอสักครู่แล้วลองอีกครั้ง (ระบบจะใช้เวลา 2-3 นาทีในการสร้างงานและดำเนินการให้เสร็จสมบูรณ์)
- คุณดูตารางใน BigQuery ได้โดยคลิกและไปที่ชุดข้อมูล froyo_data คลิกรหัสตารางใน BigQuery แล้วเรียกใช้การค้นหาด้านล่างในแท็บตัวแก้ไขคำค้นหา
SELECT count(*) FROM `froyo_data.froyo_data` LIMIT 1000;
ซึ่งจะส่งผลให้เกิดข้อผิดพลาด 400 (หากไม่เป็นเช่นนั้น คุณสามารถย้อนกลับไปและเรียกใช้ชิ้นงาน Datascan อีกครั้ง)
7. การดึงข้อมูลเชิงความหมาย
เยี่ยมเลย ตอนนี้มาดึงข้อมูลการอนุมานสำหรับออบเจ็กต์ที่ไม่มีโครงสร้างเหล่านี้โดยใช้ Knowledge Catalog กัน
เราจะใช้ฟีเจอร์ข้อมูลเชิงลึกเพื่อสร้างคำสั่ง SQL เพื่อดึง Structured Data จากตารางที่ไม่มีโครงสร้าง
- ในคอนโซล Google Cloud ให้ไปที่หน้าการค้นหาแคตตาล็อกความรู้
- ค้นหาตารางชุดข้อมูลที่ต้องการดูข้อมูลเชิงลึก ในแถบค้นหา ให้ป้อนชื่อชุดข้อมูล / ตารางจากขั้นตอนก่อนหน้า "froyo_data" แล้วกด Enter
- จากรายการผลลัพธ์ ให้คลิกรายการตาราง (ไม่ใช่ชุดข้อมูล)
- คุณควรเห็นแท็บข้อมูลเชิงลึก คลิก (หากต้องเปิดใช้ API ใด ให้ทำตามขั้นตอนและเปิดใช้ API)
หากคุณเปิดใช้ API ในตอนนี้ คุณจะต้องเรียกใช้การสแกนอีกครั้ง
- ในแท็บข้อมูลเชิงลึก คุณจะเห็นเมนูแบบเลื่อนลงของปุ่ม "แยก" คลิกตัวเลือกนั้น แล้วเลือกตัวเลือก "แยกด้วย SQL"
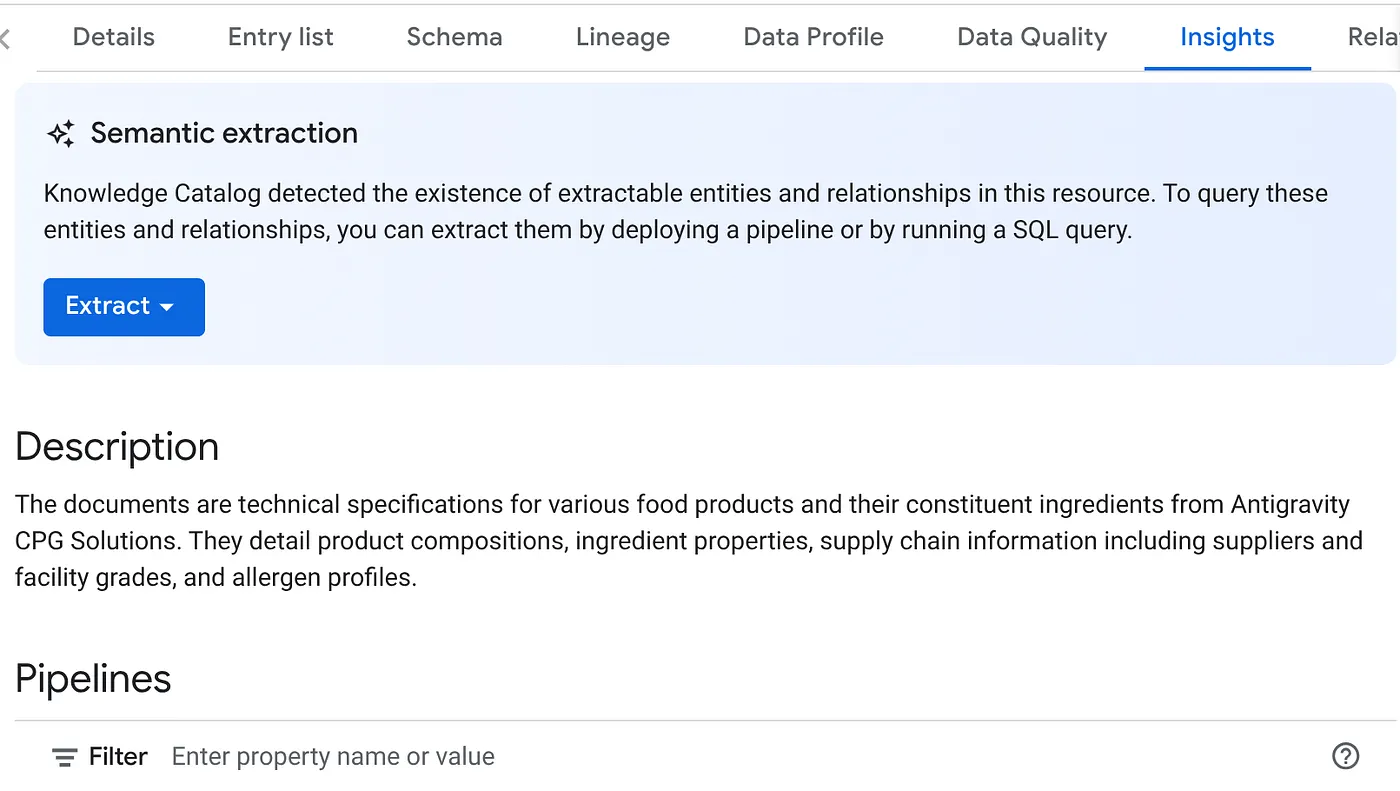
ในกล่องโต้ตอบ "Extract with SQL" ที่ปรากฏขึ้น ให้ตั้งค่าชุดข้อมูลปลายทางเป็นชุดข้อมูลที่คุณเห็นในผลลัพธ์ของงาน Datascan เริ่มพิมพ์ชื่อแล้วชื่อควรปรากฏในการเติมข้อความอัตโนมัติ คลิกปุ่ม "แยก" หรือคุณจะสร้างชุดข้อมูลใหม่ในตอนนี้และแยกข้อมูลก็ได้
ซึ่งควรเปิดตัวแก้ไขคำค้นหา BigQuery พร้อมแท็บที่เปิดอยู่ซึ่งมี SQL ที่แยกออกมาจากการอนุมานการสแกนข้อมูล
8. การตรวจสอบ SQL และการสร้างสคีมา
หากคำค้นหาที่สร้างขึ้นดูดีและมีความเกี่ยวข้องเชิงความหมายกับข้อมูลที่ไม่มีโครงสร้าง ให้ดำเนินการโดยคลิกปุ่มเรียกใช้ในเครื่องมือแก้ไขคำค้นหา ระบบจะใช้เวลาสักครู่ในการสร้างสคีมาที่จำเป็นสำหรับการจัดเก็บสื่อที่ไม่มีโครงสร้างอย่างเป็นระเบียบ
เมื่อดำเนินการเสร็จแล้ว คุณควรจะยืนยันสคีมาได้โดยขยายชุดข้อมูลในแผง Explorer ของ BigQuery Studio ดังที่แสดงด้านล่าง
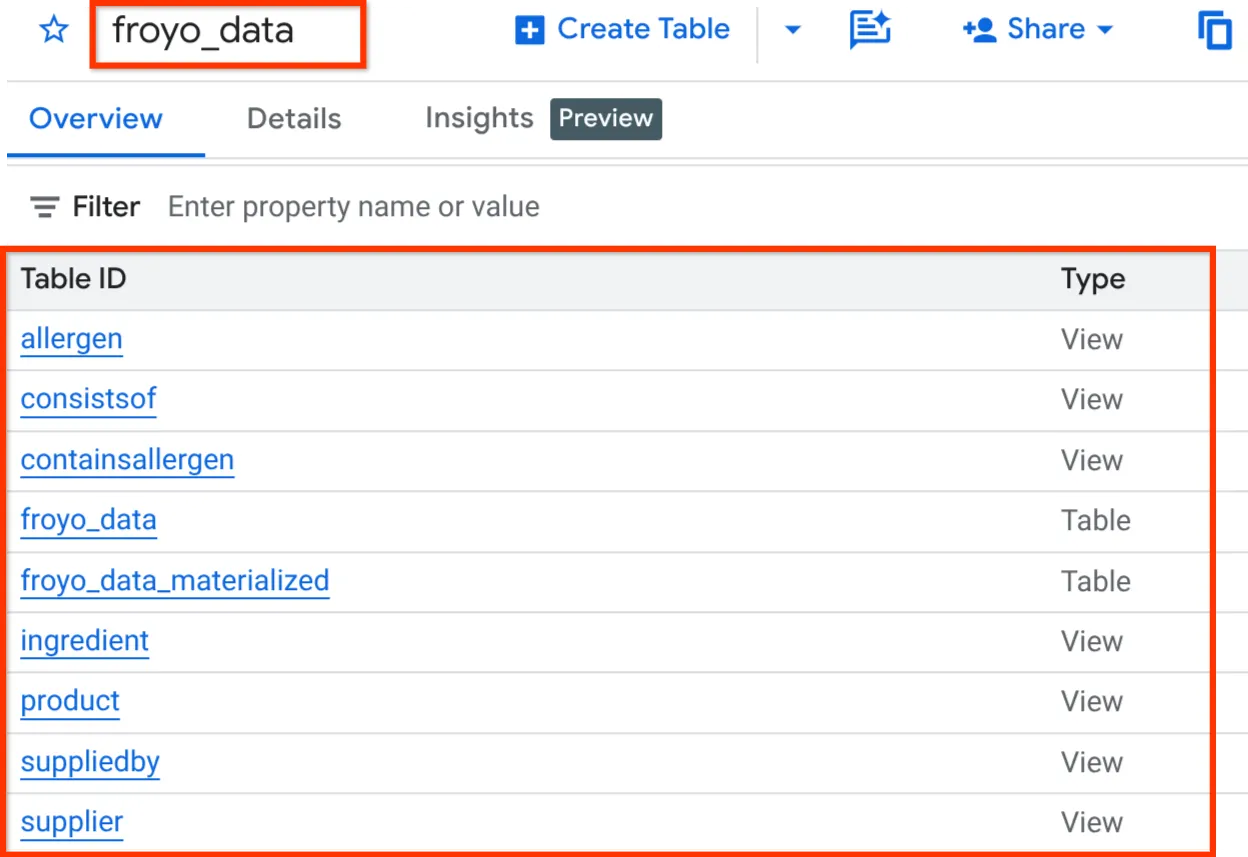
เอาล่ะ!!! เราจึงรีบทำเรื่องฐานข้อมูลทั้งหมดอย่างรวดเร็ว ตอนนี้ก็ถึงเวลาทดสอบขั้นสุดแล้ว
ขั้นตอนในการใช้ข้อมูลต่อไปโดยไม่ต้องมีบัญชีสำหรับการเรียกเก็บเงิน
- คุณสามารถรับไฟล์ csv (ข้อมูล BigQuery) ได้จากลิงก์ที่เก็บใน GitHub ด้านบน
- ก่อนอื่น ให้สร้างชุดข้อมูล BigQuery โดยเรียกใช้คำสั่งด้านล่างจากเทอร์มินัล Cloud Shell
bq mk --location us-central1 --dataset froyo_data
- จากนั้นดาวน์โหลดไฟล์ข้อมูล 8 ไฟล์ (ไฟล์ CSV) จากที่เก็บ github ลงในไดเรกทอรีที่ทำงานอยู่โดยเรียกใช้คำสั่งต่อไปนี้ทีละคำสั่ง
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- เรียกใช้คำสั่งต่อไปนี้ทีละคำสั่งเพื่อสร้างตารางเหล่านี้ด้วยข้อมูลในชุดข้อมูลที่สร้างขึ้นใหม่
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
เมื่อสร้างชุดข้อมูล ตาราง และข้อมูลแล้ว คุณจะทดสอบและดูข้อมูลที่เราเพิ่งพูดถึงได้
9. การทดสอบขั้นสุด!!!
สมมติว่าฉันต้องการให้เอเจนต์ตอบคำถามของผู้ใช้ด้วยข้อมูลจริง ครบถ้วน และจัดเรียงอย่างดีโดยอิงตามข้อเท็จจริง ฉันจะถามคำถามที่เอเจนต์จะตอบได้โดยอ้างอิงจากไฟล์สื่อหลายไฟล์และข้อมูลอ้างอิงจากแหล่งที่มาของฉันเท่านั้น
นี่คือคำถามของผู้ใช้
I'm really interested in your Midnight Swirl froyo. Are there any allergens in it?
ตอนนี้การค้นหาทั่วไปหรือการค้นหาด้วย LLM จะแสดงว่า "ไม่มีส่วนผสม" แต่เราได้สร้างการอนุมานเชิงความหมายแบบเต็มเพื่อแปลงสื่อที่ไม่มีโครงสร้างทั้งหมดให้เป็น Structured Data ดังนั้นเรามาเริ่มกันเลยด้วย SQL ง่ายๆ ที่จะดึงข้อมูลนี้
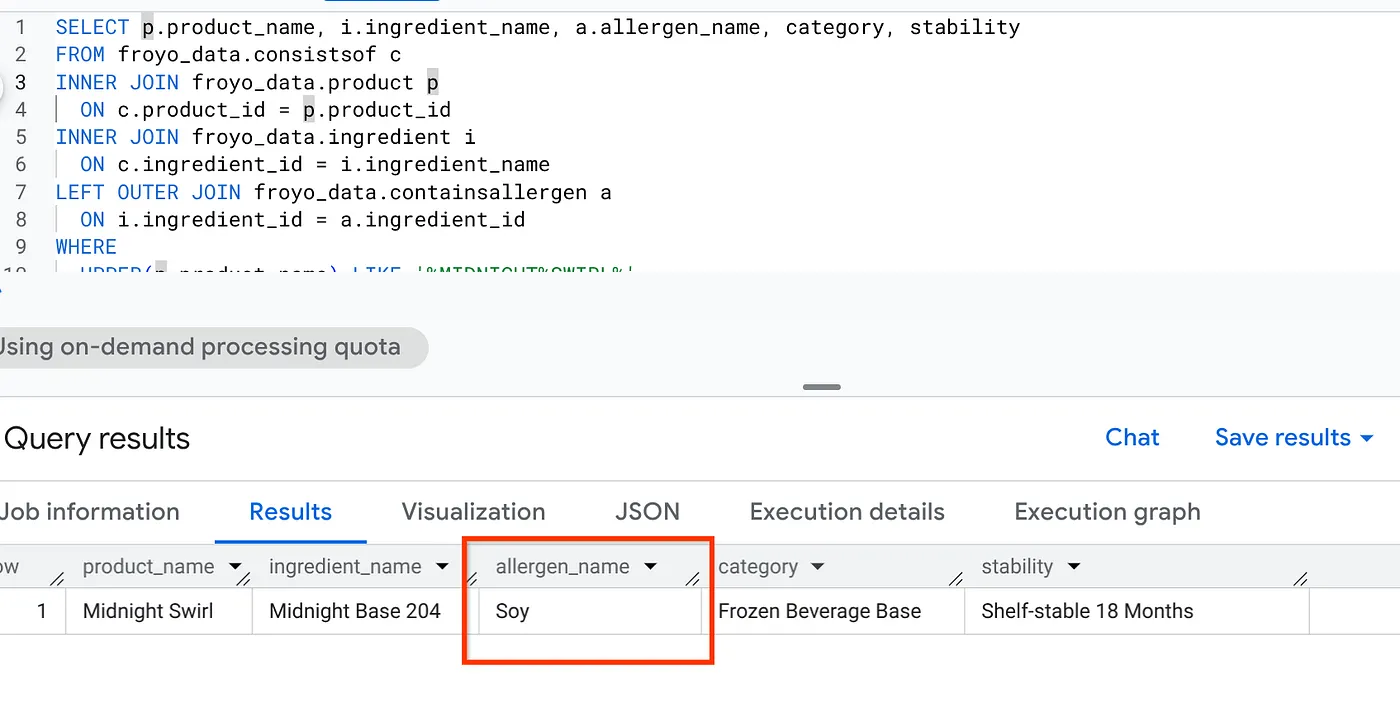
SELECT p.product_name, i.ingredient_name, a.allergen_name, category, stability
FROM froyo_data.consistsof c
INNER JOIN froyo_data.product p
ON c.product_id = p.product_id
INNER JOIN froyo_data.ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN froyo_data.containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND allergen_name IS NOT NULL;
ไชโย ดูผลลัพธ์
10. ล้างข้อมูล
เมื่อทำแล็บนี้เสร็จแล้ว อย่าลืมลบงานสแกนและตาราง BigQuery ที่งานสร้างขึ้น
ไปที่ https://console.cloud.google.com/bigquery/governance/metadata-curation/cloud-storage-discovery เลือกงานที่ต้องการลบโดยคลิกจุดไขปลาแนวตั้งข้างงานนั้น แล้วคลิกลบ
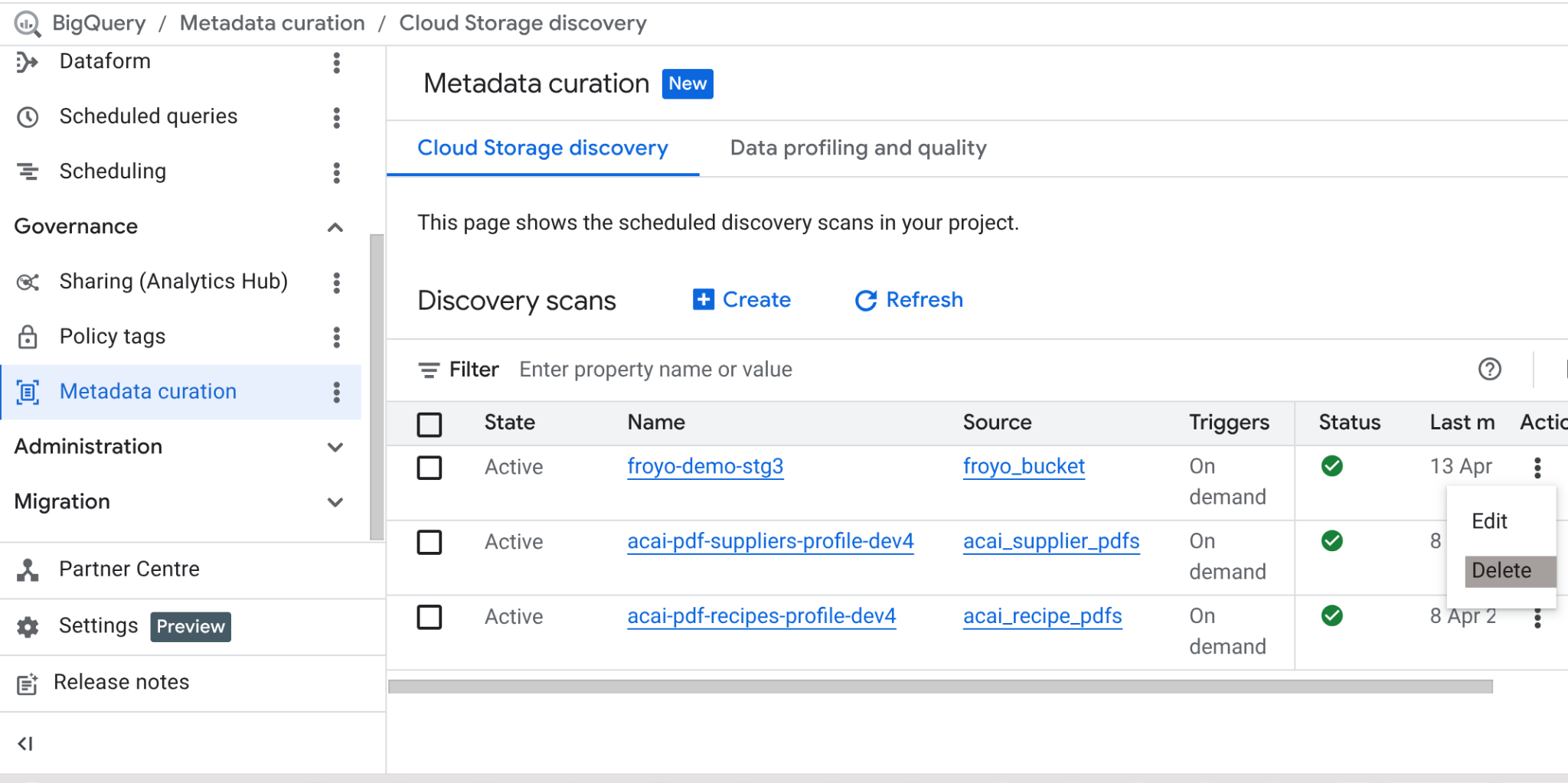
ซึ่งควรจะล้างข้อมูลงาน
11. ขอแสดงความยินดี
การติดตั้งใช้งานของเราสามารถระบุสารก่อภูมิแพ้ที่ซ่อนอยู่ได้สำเร็จ ไม่มีข้อมูลมืดอีกต่อไป ในส่วนที่ 2 เราจะรวมข้อมูล BigQuery นี้ในระบบธุรกรรมกับ AlloyDB เพื่อรวมความต้องการข้อมูลสำหรับแอปพลิเคชันแบบเอเจนต์