
1. ภาพรวม
ในส่วนที่ 1 เราได้แปลง PDF ที่ไม่มีโครงสร้างและไม่เป็นระเบียบให้เป็นตารางที่มีโครงสร้าง สะอาด และอัจฉริยะใน BigQuery โดยใช้แคตตาล็อกความรู้และ DataScan ตอนนี้เรามีคลังข้อมูลที่แข็งแกร่งแล้ว
หากต้องการทบทวนอย่างรวดเร็ว ในแล็บส่วนที่ 1 เราได้ใช้กรณีการใช้งานของแฟรนไชส์ร้านโยเกิร์ตแช่แข็งสมมติและแปลงไฟล์ PDF ที่ไม่มีโครงสร้าง 400 ไฟล์ ซึ่งครอบคลุมข้อความ ตาราง และรูปภาพ ให้เป็นตาราง BigQuery ที่มีโครงสร้างชัดเจนพร้อมความสัมพันธ์ที่อนุมานโดยอัตโนมัติระหว่างตารางเหล่านั้นโดยใช้แคตตาล็อกความรู้ของ BigQuery และ Dataplex
สิ่งที่คุณจะสร้าง
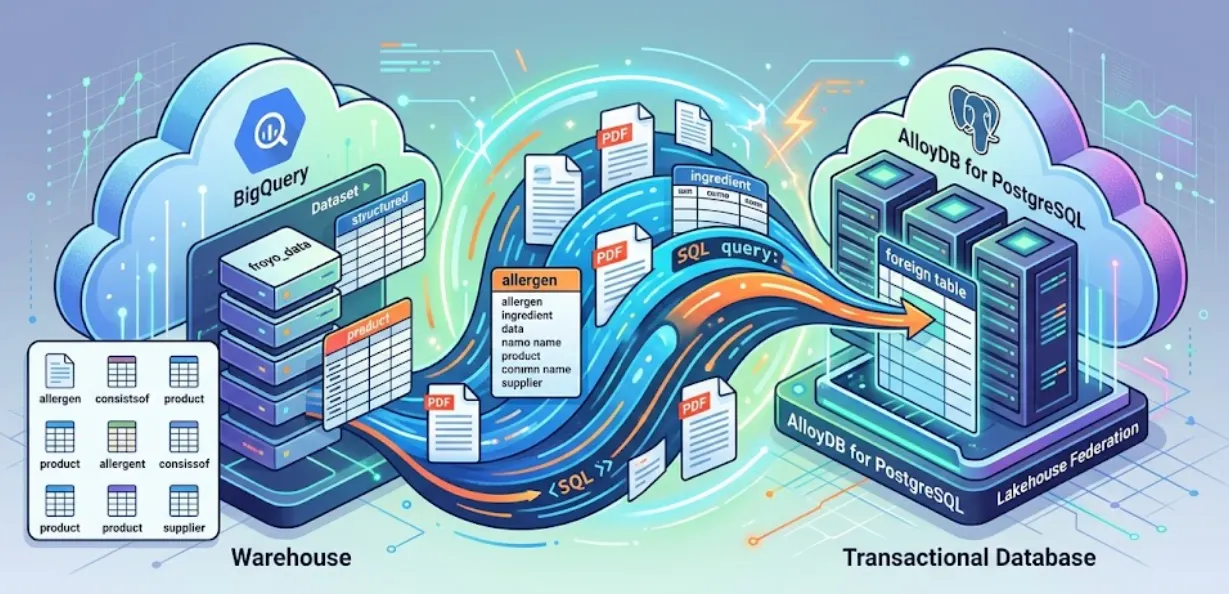
ในเซสชันนี้ เราจะตั้งค่า AlloyDB สำหรับ PostgreSQL และทำสิ่งที่น่าทึ่ง นั่นคือการรวมข้อมูล BigQuery เข้ากับ AlloyDB โดยตรง ซึ่งหมายความว่าแอปธุรกรรมของเราสามารถค้นหาข้อมูลคลังข้อมูลได้แบบเรียลไทม์โดยไม่ต้องคัดลอกหรือทำซ้ำข้อมูล
ในฐานะนักพัฒนาแอป คุณต้องถามคำถามนี้ในขั้นตอนนี้
"หากข้อมูลอยู่ใน BigQuery อยู่แล้ว ทำไมต้องใช้ AlloyDB ด้วย ทำไมแอปพลิเคชันไม่เรียกใช้คำสั่ง SELECT กับ BigQuery โดยตรง"
เหตุผลมีดังนี้
เมื่อใช้ Lakehouse Federation คุณจะใช้เครื่องมือค้นหาของ AlloyDB เพื่อขับเคลื่อนภาระงานด้านการทำธุรกรรมและภาระงานเชิงวิเคราะห์ของแอปพลิเคชันได้จากภายในอินเทอร์เฟซเดียวกัน นอกจากนี้ คุณยังสามารถสร้างหรือนําเข้าข้อมูลนี้ใน AlloyDB เพื่อให้เข้าถึงได้เร็วขึ้นสําหรับใช้ในแอปพลิเคชัน ซึ่งจะช่วยให้คุณใช้ AlloyDB AI และColumnar Engine ได้
คุณใช้ AlloyDB เป็นฐานข้อมูลธุรกรรมได้ และยังมีข้อมูลจำนวนมากที่อยู่ใน BigQuery หรือ BigLake ด้วย โดยปกติแล้ว แอปพลิเคชันจะผสานรวมกับทั้ง 2 ระบบนี้แยกกันเพื่อเข้าถึงข้อมูลในบริการต่างๆ ของ Google Cloud Lakehouse Federation สำหรับ AlloyDB ช่วยให้คุณใช้การรองรับการค้นหาแบบรวมของ AlloyDB ที่ใช้งานเป็นการห่อหุ้มข้อมูลภายนอกเพื่อเข้าถึงข้อมูล BigQuery และ AlloyDB โดยใช้อินเทอร์เฟซ SQL ใน AlloyDB ได้
เราจะใช้การค้นหาแบบรวมแทนการสร้างไปป์ไลน์ ETL ที่เปราะบางเพื่อค้นหาข้อมูล BigQuery จาก AlloyDB AlloyDB จะทำหน้าที่เป็นปลายทางแบบรวม ซึ่งเข้าถึง BigQuery ได้อย่างราบรื่นเมื่อจำเป็น
มาเริ่มสร้างกันเลย
สิ่งที่คุณจะได้เรียนรู้
- วิธีตั้งค่าคลัสเตอร์ อินสแตนซ์ และเครือข่าย AlloyDB ได้ด้วยการคลิกปุ่ม
- วิธีตั้งค่าส่วนขยายเพื่อเตรียมพร้อมสำหรับการรวมระบบ
- วิธีตั้งค่าการรวมศูนย์จาก BigQuery ไปยัง AlloyDB
- ทดสอบ
ข้อกำหนด
2. ก่อนเริ่มต้น
สร้างโปรเจ็กต์
- ในคอนโซล Google Cloud ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud ในหน้าตัวเลือกโปรเจ็กต์
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ที่อยู่ในระบบคลาวด์แล้ว ดูวิธีตรวจสอบว่าโปรเจ็กต์เปิดใช้การเรียกเก็บเงินหรือไม่
- คุณจะใช้ Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานใน Google Cloud คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud

- เมื่อเชื่อมต่อกับ Cloud Shell แล้ว ให้ตรวจสอบว่าคุณได้รับการตรวจสอบสิทธิ์แล้วและตั้งค่าโปรเจ็กต์เป็นรหัสโปรเจ็กต์ของคุณโดยใช้คำสั่งต่อไปนี้
gcloud auth list
- เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อยืนยันว่าคำสั่ง gcloud รู้จักโปรเจ็กต์ของคุณ
gcloud config list project
- หากต้องการตรวจสอบสิทธิ์
gcloud auth login
- หากไม่ได้ตั้งค่าโปรเจ็กต์ ให้ใช้คำสั่งต่อไปนี้เพื่อตั้งค่า
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- เปิดใช้ API ที่จำเป็น: เรียกใช้คำสั่งนี้เพื่อเปิดใช้ API ที่จำเป็นทั้งหมด
gcloud services enable alloydb.googleapis.com
ข้อควรระวังและการแก้ปัญหา
กลุ่มอาการ"โปรเจ็กต์ผี" | คุณเรียกใช้ |
แผงกั้น การเรียกเก็บเงิน | คุณเปิดใช้โปรเจ็กต์แล้ว แต่ลืมบัญชีสำหรับการเรียกเก็บเงิน AlloyDB เป็นเครื่องมือที่มีประสิทธิภาพสูง จึงจะไม่เริ่มทำงานหาก "ถังน้ำมัน" (การเรียกเก็บเงิน) ว่างเปล่า |
ความล่าช้าการเผยแพร่ API | คุณคลิก "เปิดใช้ API" แต่บรรทัดคำสั่งยังคงแสดง |
คำถามเกี่ยวกับโควต้า | หากใช้บัญชีทดลองใช้ใหม่ คุณอาจพบโควต้าระดับภูมิภาคสำหรับอินสแตนซ์ AlloyDB หาก |
3. สรุปข้อมูลจากส่วนที่ 1 โดยย่อ
ในส่วนนี้ คุณต้องตรวจสอบว่า Structured Data ที่เราดึงมาจาก PDF ที่ไม่มีโครงสร้างพร้อมใช้งานใน BigQuery หากคุณพลาดส่วนที่ 1 หรือไม่มีบัญชีสำหรับการเรียกเก็บเงิน ก็ไม่เป็นไร คุณสามารถทำตามขั้นตอนต่อไปนี้เพื่อเริ่มต้นใช้งานได้
ไปที่คอนโซล Google Cloud จากบัญชี Gmail ส่วนตัว แล้วคลิกปุ่มเปิดใช้งาน Cloud Shell ที่มุมขวาบนของคอนโซล
จากนั้นทำตามขั้นตอนในส่วน "ไม่มีบัญชีสำหรับการเรียกเก็บเงิน" ด้านล่าง
ขั้นตอนในการใช้ข้อมูลต่อไปโดยไม่ต้องมีบัญชีสำหรับการเรียกเก็บเงิน
- คุณสามารถรับไฟล์ csv (ข้อมูล BigQuery) ได้จากลิงก์ที่เก็บใน GitHub ด้านบน
- ก่อนอื่น ให้สร้างชุดข้อมูล BigQuery โดยเรียกใช้คำสั่งด้านล่างจากเทอร์มินัล Cloud Shell
bq mk --location us-central1 --dataset froyo_data
- จากนั้นดาวน์โหลดไฟล์ข้อมูล 8 ไฟล์ (ไฟล์ CSV) จากที่เก็บ github ลงในไดเรกทอรีที่ทำงานอยู่โดยเรียกใช้คำสั่งต่อไปนี้ทีละคำสั่ง
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- เรียกใช้คำสั่งต่อไปนี้ทีละคำสั่งเพื่อสร้างตารางเหล่านี้ด้วยข้อมูลในชุดข้อมูลที่สร้างขึ้นใหม่
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
ตอนนี้เรามีข้อมูลใน BigQuery แล้ว มาดูขั้นตอนถัดไปกัน
4. ตั้งค่าคลัสเตอร์ อินสแตนซ์ และเครือข่าย AlloyDB
มีแอปพลิเคชันเริ่มต้นใช้งานด่วนบนเว็บที่จะช่วยคุณตั้งค่าคลัสเตอร์ อินสแตนซ์ และการอ้างอิงอื่นๆ ของ AlloyDB คุณทำตามขั้นตอนที่ 2-4 ในแล็บนี้เพื่อตั้งค่าได้เพียงคลิกปุ่ม
https://codelabs.developers.google.com/quick-alloydb-setup
เมื่อสร้างคลัสเตอร์แล้ว ให้ไปที่หน้าภาพรวมของคลัสเตอร์และคัดลอกรายละเอียดบัญชีบริการจากที่นั่น
5. การตั้งค่าสิทธิ์
ให้สิทธิ์เข้าถึง BigQuery แก่บัญชีบริการนี้
- ไปที่ IAM และผู้ดูแลระบบ > IAM
- คลิกให้สิทธิ์เข้าถึง
- วางที่อยู่บัญชีบริการ AlloyDB ลงในช่องผู้รับสิทธิ์รายใหม่
- มอบหมายบทบาทต่อไปนี้
- ผู้ดูข้อมูล BigQuery (roles/bigquery.dataViewer): อนุญาตให้อ่านข้อมูล
- ผู้ใช้ BigQuery (roles/bigquery.user): อนุญาตให้เรียกใช้การค้นหา
- (ไม่บังคับแต่แนะนํา) ผู้ใช้เซสชันการอ่าน BigQuery (roles/bigquery.readSessionUser): เพิ่มประสิทธิภาพการอ่านชุดข้อมูลขนาดใหญ่ผ่าน Storage Read API
6. เชื่อมต่อกับ AlloyDB และเปิดใช้ส่วนขยาย BigQuery
ตอนนี้เราจะเชื่อมต่อกับอินสแตนซ์ AlloyDB ใหม่เพื่อกำหนดค่าส่วนขยายสหพันธ์ เราจะใช้ AlloyDB Studio สำหรับการดำเนินการนี้
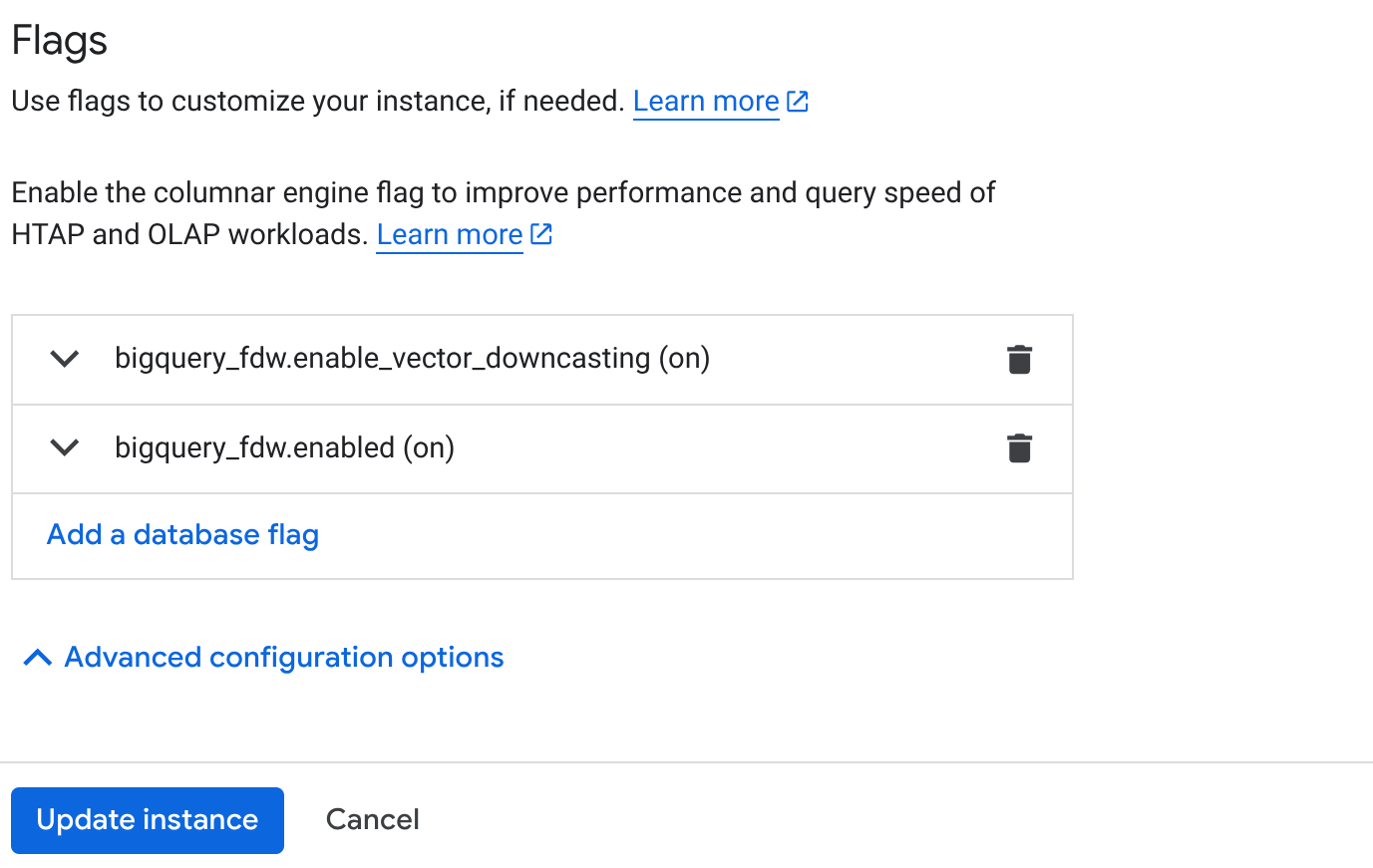
- จากหน้าภาพรวมคลัสเตอร์ (คอนโซล AlloyDB) ให้คลิก "แก้ไขหลัก" ในอินสแตนซ์หลัก แล้วเลื่อนลงไปที่ด้านล่างเพื่อดู "ตัวเลือกการกำหนดค่าขั้นสูง"
- ไปที่ส่วน "Flags" แล้วเปิดใช้ 2 Flags เป็น "เปิด" ดังที่แสดงด้านล่าง
 3. คลิกปุ่มอัปเดตอินสแตนซ์ แล้วระบบจะใช้เวลาสักครู่ในการอัปเดตให้เสร็จสมบูรณ์ 4. จากหน้าภาพรวมของคลัสเตอร์ (คอนโซล AlloyDB) ให้คลิก AlloyDB Studio
3. คลิกปุ่มอัปเดตอินสแตนซ์ แล้วระบบจะใช้เวลาสักครู่ในการอัปเดตให้เสร็จสมบูรณ์ 4. จากหน้าภาพรวมของคลัสเตอร์ (คอนโซล AlloyDB) ให้คลิก AlloyDB Studio
- เชื่อมต่อกับฐานข้อมูล ชื่อผู้ใช้ และรหัสผ่านที่คุณกำหนดค่าไว้ในขั้นตอนการตั้งค่าด่วนของ AlloyDB
- เมื่อเชื่อมต่อแล้ว ให้ป้อนคำสั่งต่อไปนี้ในแท็บตัวแก้ไขคำค้นหาทางด้านขวา แล้วเรียกใช้ทีละคำสั่ง
CREATE EXTENSION IF NOT EXISTS bigquery_fdw;
CREATE SERVER bigquery_server FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bigquery_server;
- เมื่อดำเนินการเสร็จสมบูรณ์แล้ว ให้ไปที่แผง Explorer ทางด้านซ้าย แล้วเลื่อนลงไปที่ตาราง BigQuery
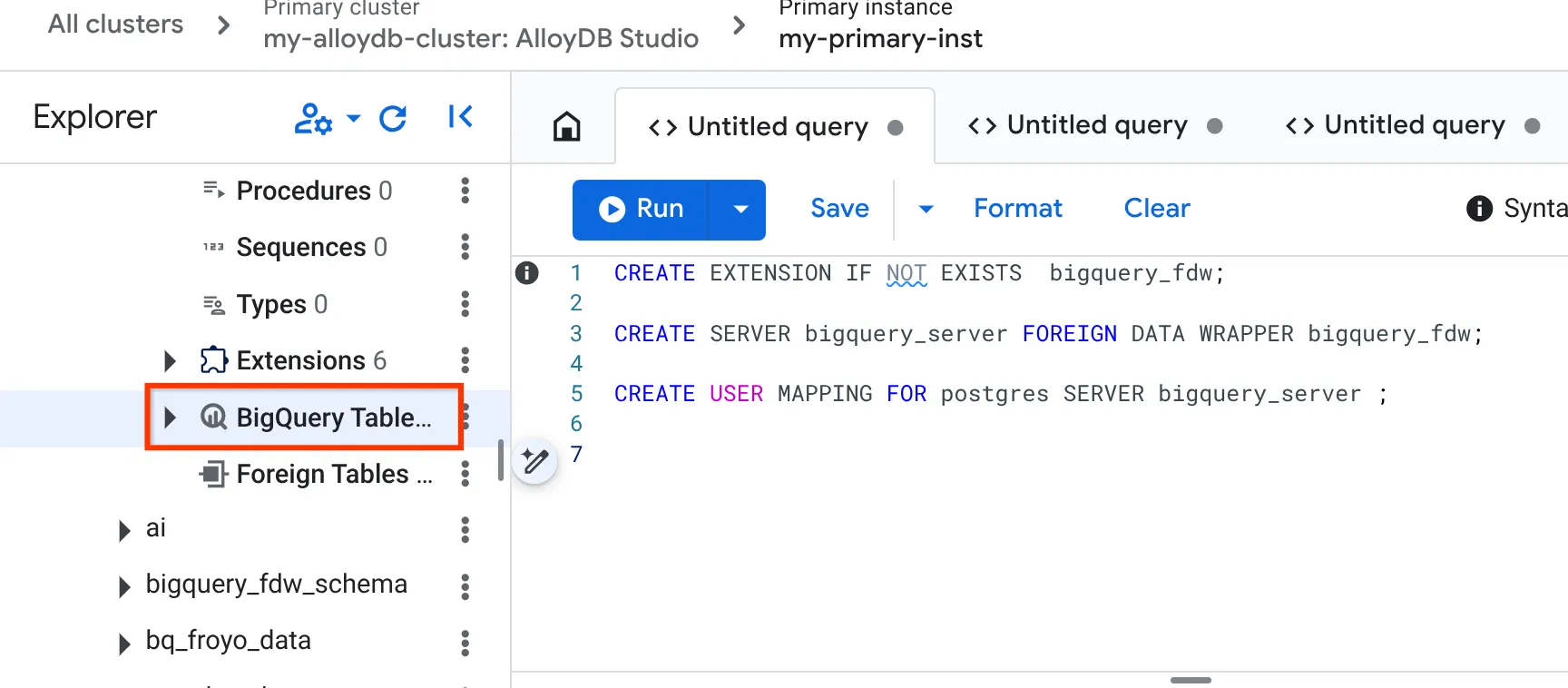
- คลิกจุด 3 จุด แล้วคลิก "เชื่อมต่อตาราง BigQuery"
- ในป๊อปอัป "เชื่อมต่อตาราง BigQuery" ที่เปิดขึ้น ให้เลือก project_id และชื่อชุดข้อมูล BigQuery (สร้างในส่วนที่ 1) ที่คุณต้องการค้นหาข้อมูลในฐานข้อมูล AlloyDB
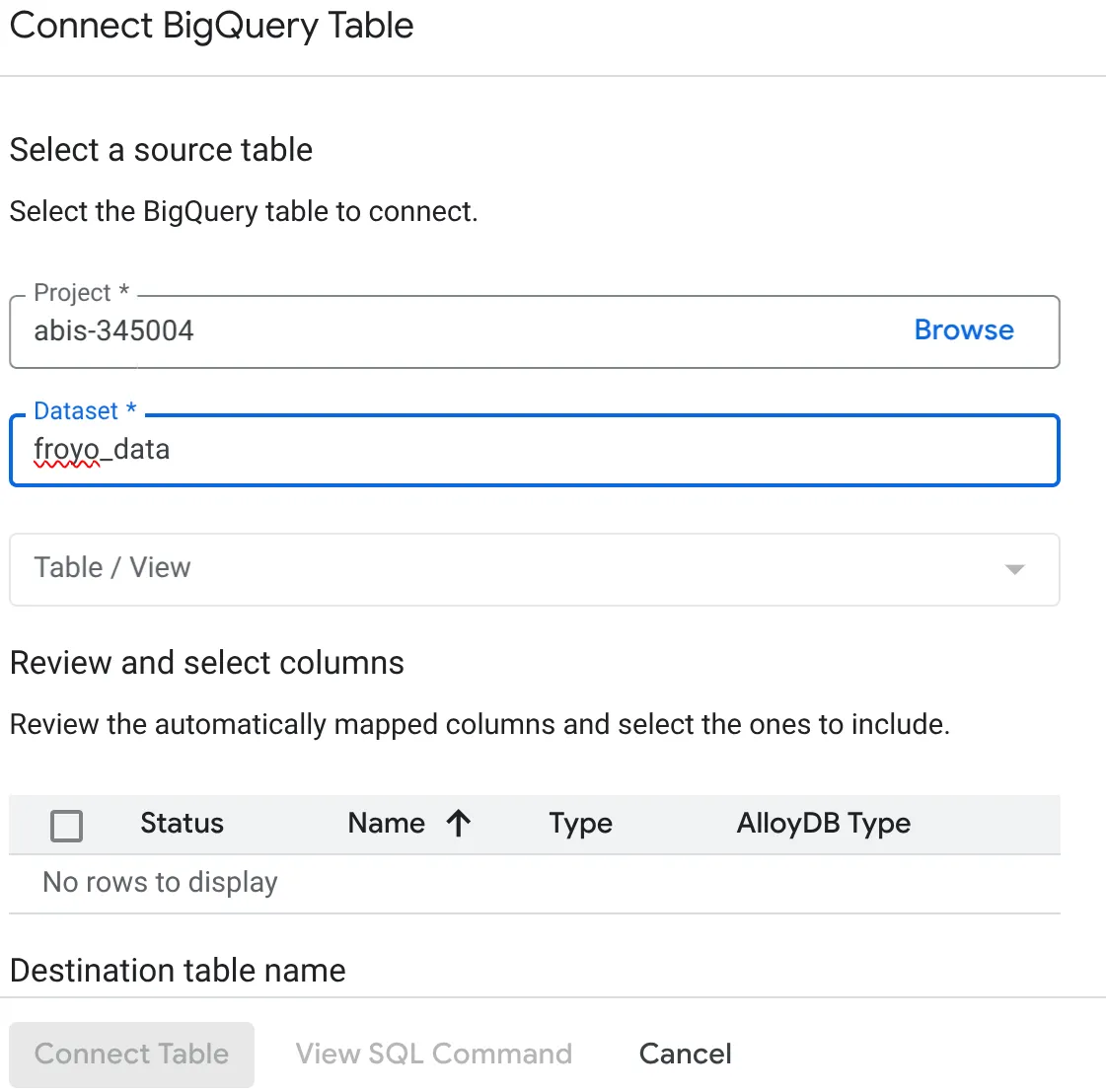
- เลือกแต่ละตารางทีละตารางเพื่อให้ข้อมูลทั้งหมดเชื่อมต่อกับ AlloyDB เพื่อให้เราตรวจสอบประเภทคอลัมน์เพื่อให้แน่ใจว่า AlloyDB รองรับ
หากต้องการทำเช่นเดียวกันกับ SQL แทนการใช้แนวทางแบบชี้แล้วคลิก ให้ทำดังนี้
CREATE FOREIGN TABLE <<TABLE_NAME>> (
"cas_number" VARCHAR, "ingredient_name" VARCHAR, "max_moisture_percentage" DOUBLE PRECISION, "ph_range" VARCHAR, "purity_percentage" DOUBLE PRECISION, "shelf_life_months" BIGINT, "specific_gravity_range" VARCHAR
) SERVER "bigquery_server" OPTIONS (
project '<<PROJECT_ID>>',
dataset 'froyo_data',
table '<<BQ_TABLE_NAME>>'
);
ความมหัศจรรย์!!!
เราเพิ่งสร้าง "ตารางภายนอก" ใน AlloyDB ตารางเหล่านี้มีลักษณะและการทำงานเหมือนตาราง PostgreSQL ปกติ แต่ไม่ได้จัดเก็บข้อมูลใดๆ เมื่อคุณค้นหา AlloyDB จะส่งคำค้นหาไปยัง BigQuery ทันที ดึงข้อมูลผลลัพธ์ และส่งกลับให้คุณ
7. ทดสอบการเชื่อมโยงใน AlloyDB
มาตรวจสอบกันว่าเราสามารถค้นหาชุดข้อมูลวิเคราะห์ BigQuery ขนาดใหญ่ได้โดยตรงจากฐานข้อมูล PostgreSQL ที่ใช้ในการทำธุรกรรม
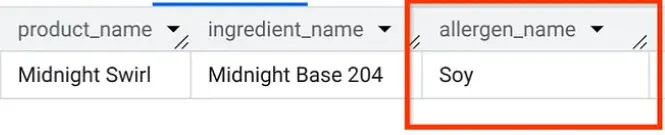
ใน AlloyDB Studio ให้เรียกใช้การค้นหาเพื่อดูว่า "Midnight Swirl" มีสารก่อภูมิแพ้อะไรบ้าง (คำถามเดียวกับที่เราถามในส่วนที่ 1 แต่คราวนี้ถามจาก AlloyDB)
SELECT
p.product_name,
i.ingredient_name,
a.allergen_name
FROM
consistsof c
INNER JOIN product p
ON c.product_id = p.product_id
INNER JOIN ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND a.allergen_name IS NOT NULL;
เรียบร้อย คุณควรเห็นผลลัพธ์ที่เหมือนกับที่เห็นใน BigQuery
8. ล้างข้อมูล
เมื่อแล็บนี้เสร็จสิ้นแล้ว อย่าลืมลบคลัสเตอร์และอินสแตนซ์ AlloyDB
ซึ่งควรล้างข้อมูลคลัสเตอร์พร้อมกับอินสแตนซ์
9. ขอแสดงความยินดีกับ Unified Data Layer
ลองนึกถึงสิ่งที่เราเพิ่งทำสำเร็จ
- แอปธุรกรรมของเรา (ที่ทำงานบน AlloyDB) สามารถจัดการเซสชันของผู้ใช้ที่เกิดขึ้นพร้อมกันได้อย่างรวดเร็ว
- เมื่อต้องการข้อมูลวิเคราะห์จำนวนมากหรือบริบทในอดีต (เช่น รายละเอียดซัพพลายเออร์หรือการแมปส่วนผสมที่ซับซ้อน) ระบบจะค้นหาสคีมาข้อมูล froyo_dataschema ของ BigQuery
- Zero ETL ไม่มีการหยุดทำงานของไปป์ไลน์ข้อมูล ไม่มีฐานข้อมูลที่ไม่ได้ซิงค์ เราจัดเก็บเพียงครั้งเดียว (ใน BQ) และประมวลผลเมื่อจำเป็น
ตอนนี้รากฐานข้อมูลของเราทั้งในเชิงวิเคราะห์และเชิงธุรกรรมมีความแข็งแกร่งและเชื่อมต่อกันแล้ว เราจึงพร้อมที่จะเข้าสู่ส่วนที่สนุก
ในส่วนที่ 3 เราจะสร้างแอปพลิเคชันแบบหลายเอเจนต์ที่อยู่บนสถาปัตยกรรมนี้เพื่อเรียกใช้การดำเนินธุรกิจของ Froyo