
1. Genel Bakış
Hepimiz "karanlık verilerin" ne kadar can sıkıcı olduğunu biliyoruz. Bunlar, bulut depolama alanında bulunan ve SQL sorgularınız ile iş zekası kontrol panelleriniz için tamamen görünmez olan PDF'ler, resimler ve metin dosyalarıdır. Geleneksel olarak bu verilerin kilidini açmak için karmaşık OCR ardışık düzenleri, manuel veri girişi veya hassas özel komut dosyaları gerekiyordu.
Artık sorun değil.
Bu laboratuvarda, metin, tablo ve resim içeren 400 yapılandırılmamış PDF dosyasını, aralarındaki ilişkilerin otomatik olarak çıkarıldığı temiz bir şekilde yapılandırılmış BigQuery tablolarına nasıl dönüştüreceğinizi göstereceğim. BigQuery Knowledge Catalog ve Dataplex'i kullanarak bu işlemi dakikalar içinde yapacağız.
Ne oluşturacaksınız?
Bu durumu daha iyi anlamak için kurgusal bir işletmeye, hızlı büyüyen bir dondurulmuş yoğurt franchise'ına göz atalım.
Bu Froyo işletmesinin verilerini yönettiğinizi düşünün. Yüzlerce tarifiniz ve tedarikçi spesifikasyon sayfanız var. Bunların hepsi PDF olarak kaydedilmiş. İşletme yöneticileri, mağaza yöneticilerinin ve müşterilerin ürün ayrıntılarını sorgulamasına yardımcı olacak bir yapay zeka ajanı kullanıma sunmak istiyor.
Korkunç bir senaryo: Bir müşteri, "Midnight Swirl adlı frozen yoğurt ürününüzle çok ilgileniyorum. Alerjen içeriyor mu?"
Bu soruyu yanıtlamak için sisteminizin normalde şunları yapması gerekir:
- "Midnight Swirl" tarifi PDF'sini bulun.
- Malzemeleri okuyun (ör. "Kakao Tozu", "Süt Bazı", "Emülgatör X").
- Düzinelerce tedarikçi PDF'si arasında arama yaparak söz konusu malzemelerin spesifikasyon sayfalarını bulabilirsiniz.
- Bu malzemelerle ilişkili gizli alerjenler için tedarikçi sayfalarını kontrol edin.
Çalışma zamanında 400 ham PDF'yi okuyarak bunu anında yapan bir yapay zeka aracısı oluşturmaya çalışmak yavaş, pahalı ve halüsinasyonlara yatkındır. Bunun yerine, tüm bunları önce ilişkisel bir veritabanına ayıklamak için anlamsal çıkarım kullanacağız. Böylece gelecekteki yapay zeka aracımız ışık hızında olacak ve% 100 olgusal SQL verilerine dayanacak.
Oluşturmaya başlayalım.
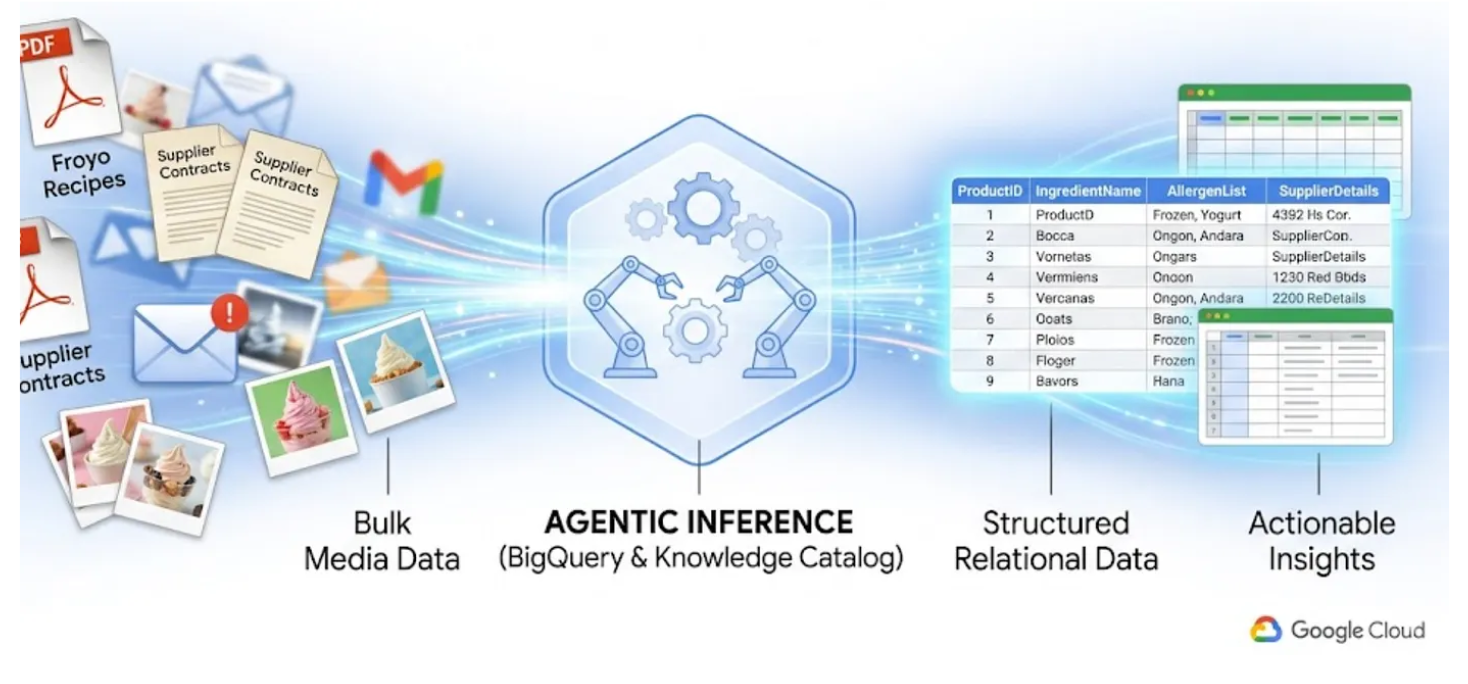
Neler öğreneceksiniz?
- Kaynak dosyalar (PDF'ler) için Cloud Storage paketi oluşturma
- Kaynak PDF'lerden veri ayıklamak, bağlantıları ve bağlamı anlamsal olarak tahmin etmek ve bunları BigQuery'de depolamak için Bilgi Kataloğu'nda Datascan işini ve anlamsal çıkarımı ayarlama ve çalıştırma
- Yeni oluşturulan veri kümesiyle sohbet etmek için BigQuery Ajanları'nı kullanma
Şartlar
2. Başlamadan önce
Proje oluşturma
- Google Cloud Console'daki proje seçici sayfasında bir Google Cloud projesi seçin veya oluşturun.
- Cloud projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Bir projede faturalandırmanın etkin olup olmadığını kontrol etmeyiöğrenin.
- Google Cloud'da çalışan bir komut satırı ortamı olan Cloud Shell'i kullanacaksınız. Google Cloud Console'un üst kısmında Cloud Shell'i etkinleştir'i tıklayın.

- Cloud Shell'e bağlandıktan sonra aşağıdaki komutu kullanarak kimliğinizin doğrulandığını ve projenin proje kimliğinize ayarlandığını kontrol edin:
gcloud auth list
- gcloud komutunun projeniz hakkında bilgi sahibi olduğunu onaylamak için Cloud Shell'de aşağıdaki komutu çalıştırın.
gcloud config list project
- Kimlik doğrulamak istiyorsanız
gcloud auth login
- Projeniz ayarlanmamışsa ayarlamak için aşağıdaki komutu kullanın:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Gerekli API'leri etkinleştirin: Gerekli tüm API'leri etkinleştirmek için şu komutu çalıştırın:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
storage.googleapis.com
Dikkat Edilmesi Gerekenler ve Sorun Giderme
"Hayalet Proje" Sendromu |
|
Faturalandırma Barikatı | Projeyi etkinleştirdiniz ancak faturalandırma hesabını unuttunuz. AlloyDB yüksek performanslı bir motordur. "Benzin deposu" (faturalandırma) boşsa çalışmaz. |
API Yayılımı Gecikmesi | "API'leri etkinleştir"i tıkladınız ancak komut satırında hâlâ |
Kota Quags | Yeni bir deneme hesabı kullanıyorsanız AlloyDB örnekleri için bölgesel kotaya ulaşabilirsiniz. |
"Gizli" Hizmet Aracısı | Bazen AlloyDB hizmet aracısına |
3. Google Cloud Storage paketi kurulumu
Bu bölümde, BigQuery'de Froyo tarifi ve tedarikçi verilerini depolamak için bir kuruluş yapısı oluşturacaksınız. Bu yapı, özellikle Froyo ürün ayrıntıları için kullanılacak. Ayrıca, BigQuery'nin Cloud Storage gibi harici kaynaklardaki dosyaları okumasına olanak tanıyan güvenli bir "köprü" görevi gören bir Cloud Resource Connection (Bulut Kaynağı Bağlantısı) oluşturur.
Başlamadan önce:
Bu depoda, bu projede kullanacağımız tarifler ve tedarikçilerin PDF dosyaları yer alıyor. Bu dosyaları indirdiğinizden emin olun. Dosyaları indirmek için aşağıdakileri yapın.
Cloud Shell'de aşağıdaki komutu çalıştırın:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git
Yeni oluşturulan klasöre gidin:
cd next-26-keynotes
data-cloud-demo klasörünü çekin.
git sparse-checkout set genkey/data-cloud-demo
Ödeme işlemi tamamlandıktan sonra data-cloud-demo klasörüne gidin ve codelab öğelerine erişmek için ZIP dosyalarını çıkarın.
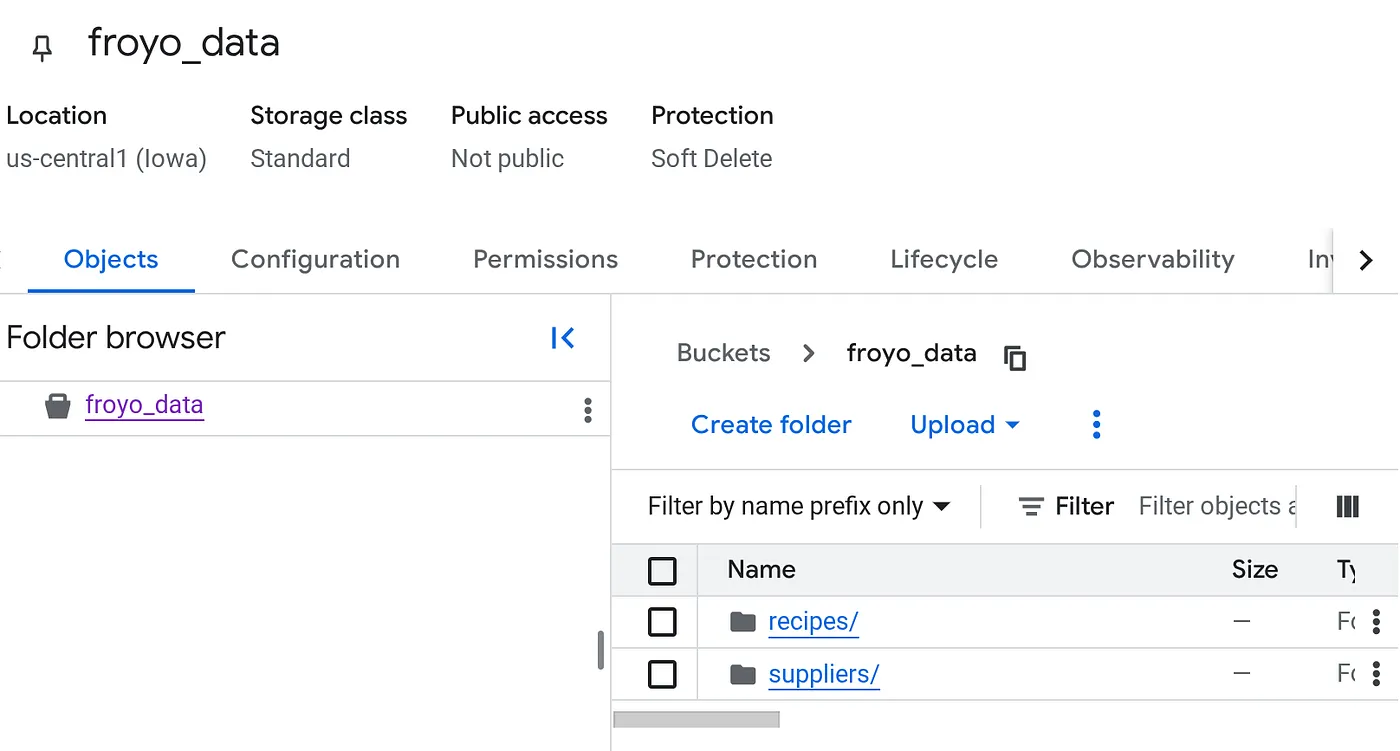
Paket oluşturma ve Froyo (tarifler ve tedarikçiler) PDF dosyalarını yükleme
- Google Cloud Console'da Cloud Storage Paketleri sayfasına gidin.
- Oluştur'u tıklayın.
- Paket oluşturun sayfasında paket bilgilerinizi girin. Aşağıdaki adımların her birinden sonra bir sonraki adıma geçmek için Devam et'i tıklayın:
- Başlayın bölümünde paket adını girin. Örnek: froyo_data
- Verilerinizi nerede depolayacağınızı seçin bölümünde Bölge'yi seçin ve bölgenizi girin. us-central1
- Nesnelere erişimi nasıl denetleyeceğinizi seçin bölümünde, "Bu pakette herkese açık erişim engeli uygula" onay kutusunun işaretini kaldırın.
- Oluştur'u tıklayın.
- Paketler listesinde, oluşturduğunuz paketi tıklayın.
- Paketin Nesneler sekmesinde Yükle'yi ve ardından Klasörleri yükle'yi tıklayın.
- Bu codelab'in Başlamadan önce bölümünde çıkardığınız recipes klasörünü seçin.
- Yükle'yi tıklayın.
- suppliers klasörü için yükleme işlemini tekrarlayın.
Yüklendikten sonra paket yapınız şu şekilde görünmelidir (paket adı ne olursa olsun):
4. BigQuery bağlantı kurulumu
Cloud Resource Connection oluşturun. Bu işlem, harici dosyalara erişmek için BigQuery'nin "kimlik kartı" olarak işlev gören benzersiz bir hizmet hesabı oluşturur.
- BigQuery sayfasına gidin.
- Sol bölmede Explorer'ı tıklayın. Sol bölmeyi görmüyorsanız bölmeyi açmak için Sol bölmeyi genişlet'i tıklayın.
- Gezgin bölmesinde proje adınızı genişletin ve ardından Bağlantılar'ı tıklayın.
- Bağlantılar sayfasında Bağlantı oluştur'u tıklayın.
- Bağlantı türü için Vertex AI uzak modelleri, uzak işlevler, BigLake ve Spanner'ı (Cloud Kaynağı) seçin.
- Bağlantı kimliği alanına bağlantı kimliği adını girin:
- bq-connection. Bu kimliği not edin. Bu codelab'in ilerleyen bölümlerinde veri taraması ayarlarken bu kimliğe ihtiyacınız olacak.
- Konum türünü Bölge olarak ayarlayın ve bir bölge seçin. Örneğin, us-central1. Bağlantı, veri kümeleri gibi diğer kaynaklarınızla aynı bölgede bulunmalıdır.
- Bağlantı oluştur'u tıklayın.
- Bağlantıya git'i tıklayın.
- Bağlantı bilgileri bölmesinde, sonraki bir adımda kullanmak üzere hizmet hesabı kimliğini kopyalayın. Hizmet hesabı, bqcx-**********-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com'a benzer.
5. İzinleri ayarlama
- Cloud Storage nesnelerine ve Knowledge Catalog'a erişmek için BigQuery bağlantısına gerekli izinleri verme
IAM ve Yönetici sayfasına gidin. Ana hesaplara göre görüntüle bölümünde Erişim izni ver düğmesini tıklayın ve son adımda kopyaladığınız hizmet hesabını yapıştırarak bir ana hesap ekleyin. Roller bölümünde aşağıdaki rollerin adlarını tek tek ekleyin ve kaydedin:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/bigquery.user
- roles/bigquery.dataEditor
- roles/aiplatform.viewer
- roles/agentplatform.user
- roles/storage.admin
- roles/dataproc.serviceAgent
- roles/dataplex.discoveryPublishingServiceAgent
- roles/dataplex.serviceAgent
- roles/dataplex.securityAdmin
- Dataplex hizmet hesabına Cloud Storage paketine erişim izni verme
IAM ve Yönetici sayfasına gidin ve Ana Hesaplara Göre Görüntüle bölümünde, Erişim izni ver düğmesini tıklayın ve Yeni ana hesap metin çubuğuna dataplex kelimesini yazarak bir ana hesap ekleyin. Otomatik tamamlama listesinden, aşağıdakine benzer görünen Dataplex hizmet hesabı sorumlusunu seçin (aşağıdaki hizmet hesabı e-posta adresinde proje kimliği değil proje numarası kullanılmalıdır):
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
Proje numaranızla ilgili yukarıdaki hizmet hesabı herhangi bir nedenle tanınmıyorsa bunun nedeni, projenin henüz Dataplex hizmetini başlatmamış olması olabilir. Cloud Shell Terminal'e gidin ve aşağıdaki komutu çalıştırarak API'yi etkinleştirmeyi deneyin (başlamadan önce aşamasında henüz yapılmadıysa): gcloud services enable dataplex.googleapis.com
Bundan sonra bile Dataplex hizmet hesabı tanınmıyorsa Metadata Curation sayfasında test Dataplex tarama işi oluşturmayı zorlayın ve ayrıntıları Discover işi oluşturma sayfasına girin:
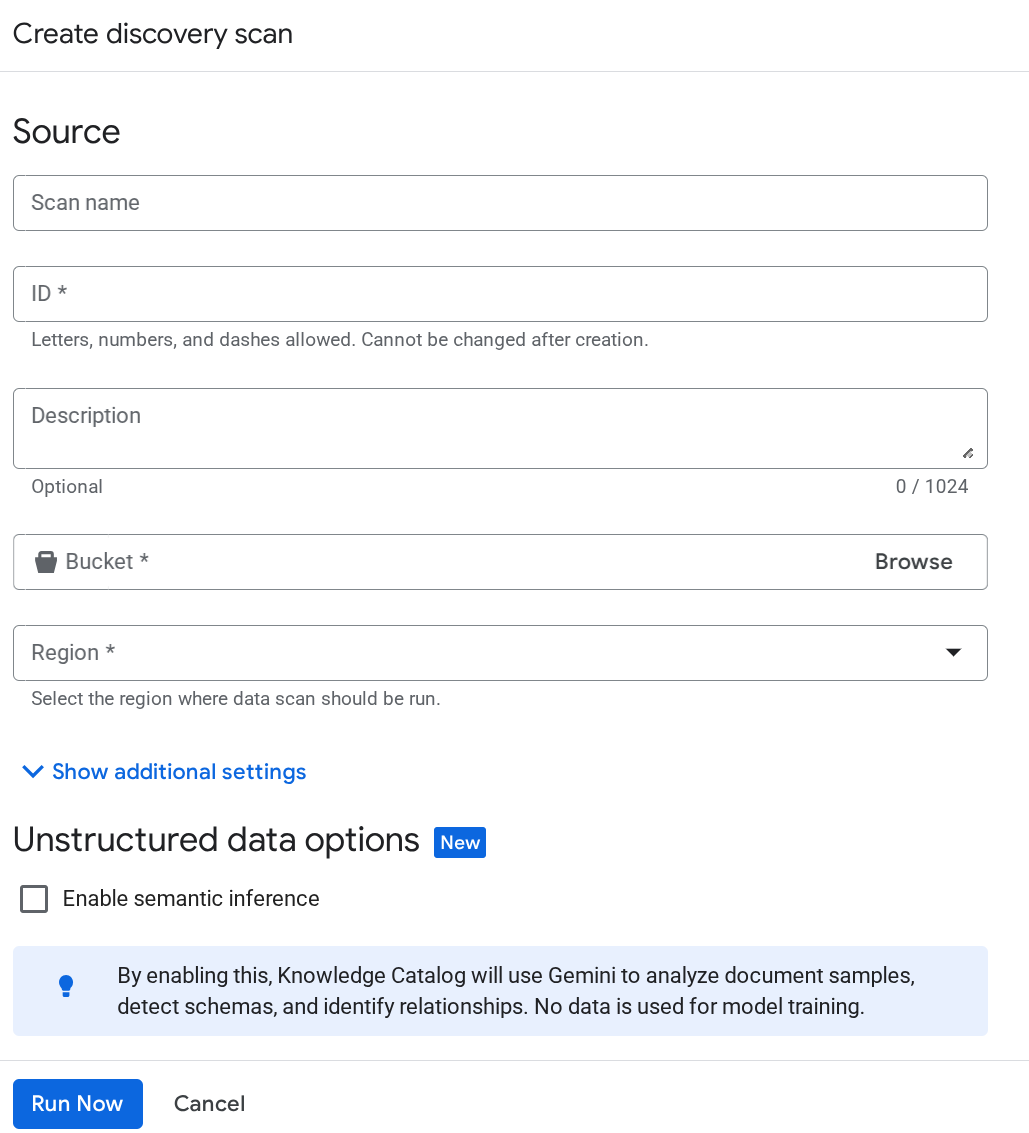
Şimdi Çalıştır'ı tıklayın. İşlem başarısız olur ancak bu, hizmet hesabı kimliğinin Dataplex hizmetiniz için hemen başlatılmasını sağlar.
IAM ve Yönetici sayfasına geri dönün ve Ana Hesaplara Göre Görüntüle bölümünde Erişim izni ver düğmesini, ardından ana hesap ekle'yi tıklayın. Hizmet hesabını yapıştırın:
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
Ardından bu hizmet hesabına aşağıdaki rolleri verin:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/storage.viewer
- roles/dataplex.discoveryBigLakePublishingServiceAgent
6. Bilgi Kataloğu Kurulumu
Yapılandırılmamış verileri birleştirmek ve yapılandırılmamış dosyaların (ör. PDF tarifleri ve PDF tedarikçileri) keşfini otomatikleştirmek için bir Bilgi Kataloğu oluşturun.
Konsoldan DataScan işi oluşturma:
- Meta veri düzenleme sayfasına gidin.
- Oluştur'u tıklayın ve kurulumunuza karşılık gelen ayrıntıları girin:
Önemli Not: Anlamsal çıkarımı etkinleştir'i işaretlemeyi unutmayın.
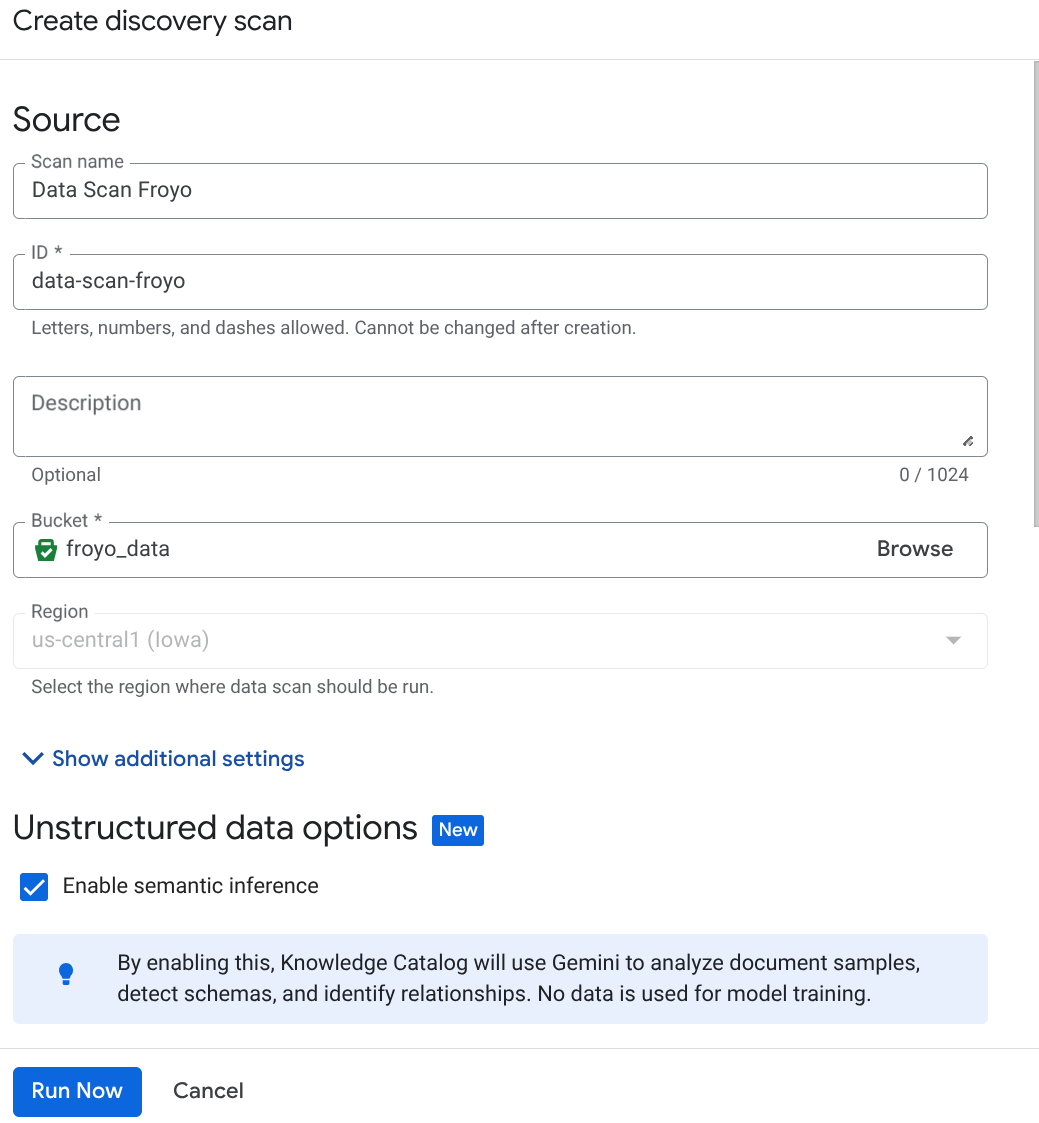
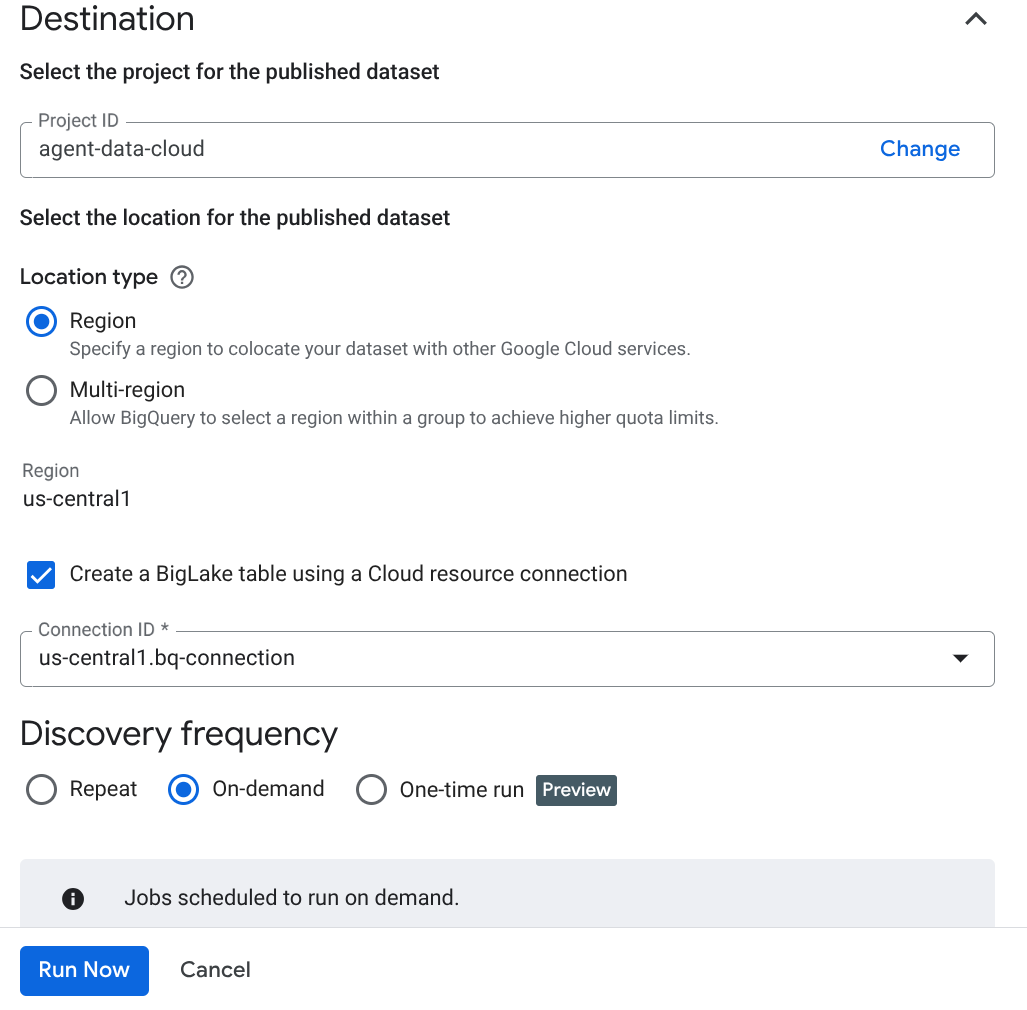
- "Şimdi Çalıştır"ı tıklayın.
- Tarama işinin tamamlanması biraz zaman alır. İş tamamlandıktan sonra Yayınlanan veri kümesinin mevcut olup olmadığını kontrol edin. İş durumunu kontrol etmek için Metadata curation (Meta veri düzenleme) sayfasını kontrol edebilirsiniz. Cloud Storage keşif sekmesinde, son çalıştırmanın keşif taramalarının adını tıklayın. Yayınlanan veri kümesini aşağıdaki gibi görmeniz gerekir:
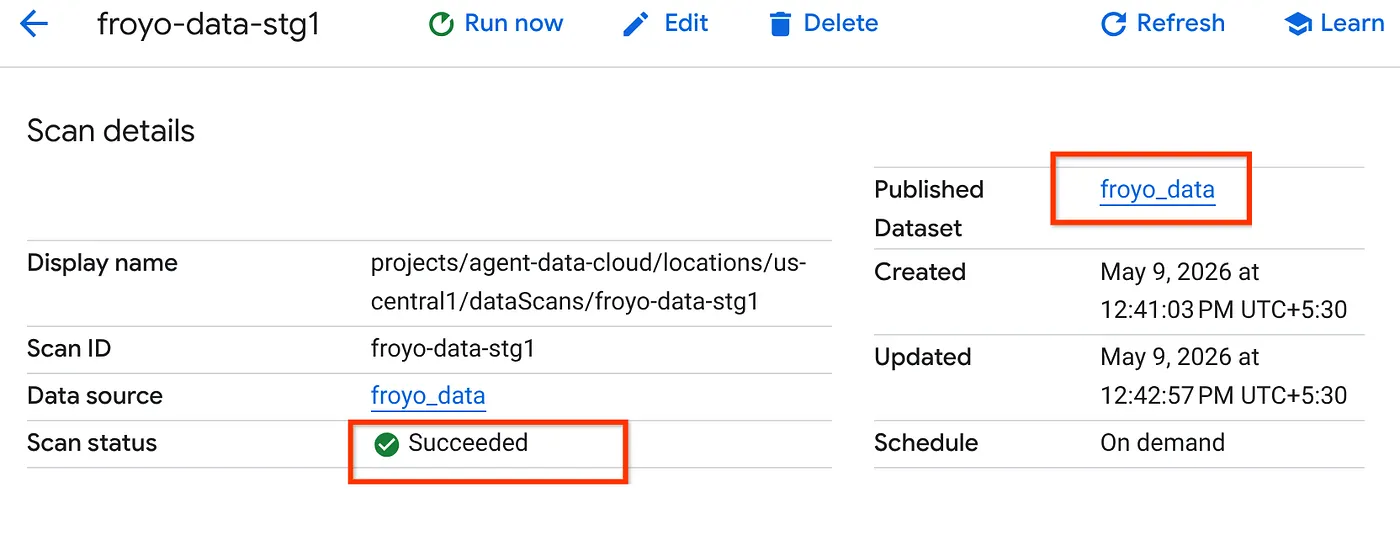
Not: Tarama adımında hatalarla karşılaşırsanız biraz bekleyip tekrar deneyin (işin oluşturulması ve yürütülmesinin tamamlanması birkaç dakika sürer).
- Tabloyu BigQuery'de görüntülemek için froyo_data veri kümesini tıklayıp bu veri kümesine gidin. BigQuery'de tablo kimliğini tıklayın ve Sorgu Düzenleyici sekmesinde aşağıdaki sorguyu çalıştırın:
SELECT count(*) FROM `froyo_data.froyo_data` LIMIT 1000;
Bu işlem 400 ile sonuçlanır (değilse geri gidip veri tarama işini tekrar çalıştırabilirsiniz).
7. Semantik Veri Ayıklama
Harika!! Şimdi Bilgi Kataloğu'nu kullanarak bu yapılandırılmamış nesnelerle ilgili çıkarımı alalım.
Yapılandırılmamış tablodan yapılandırılmış verileri ayıklamak için SQL ifadeleri oluşturmak üzere Insights özelliğini kullanacağız.
- Google Cloud Console'da Knowledge Catalog Search sayfasına gidin.
- Analizlerini görüntülemek istediğiniz veri kümesi tablosunu arayın. Arama çubuğuna önceki adımdaki veri kümesi / tablo adını ("froyo_data") girip Enter tuşuna basın.
- Sonuç listesinde TABLO girişini (veri kümesi olanı değil) tıklayın.
- ANALİZLER sekmesini görürsünüz. Bu seçeneği tıklayın (herhangi bir API'yi etkinleştirmeniz gerekiyorsa talimatları uygulayın ve yalnızca API'leri etkinleştirin).
Bu noktada API'leri etkinleştirdiyseniz tarama işini tekrar çalıştırmanız gerekir.
- ANALİZLER sekmesinde AYIKLA düğmesinin açılır menüsünü görürsünüz. Bunu tıklayın ve "SQL ile ayıkla" seçeneğini belirleyin.
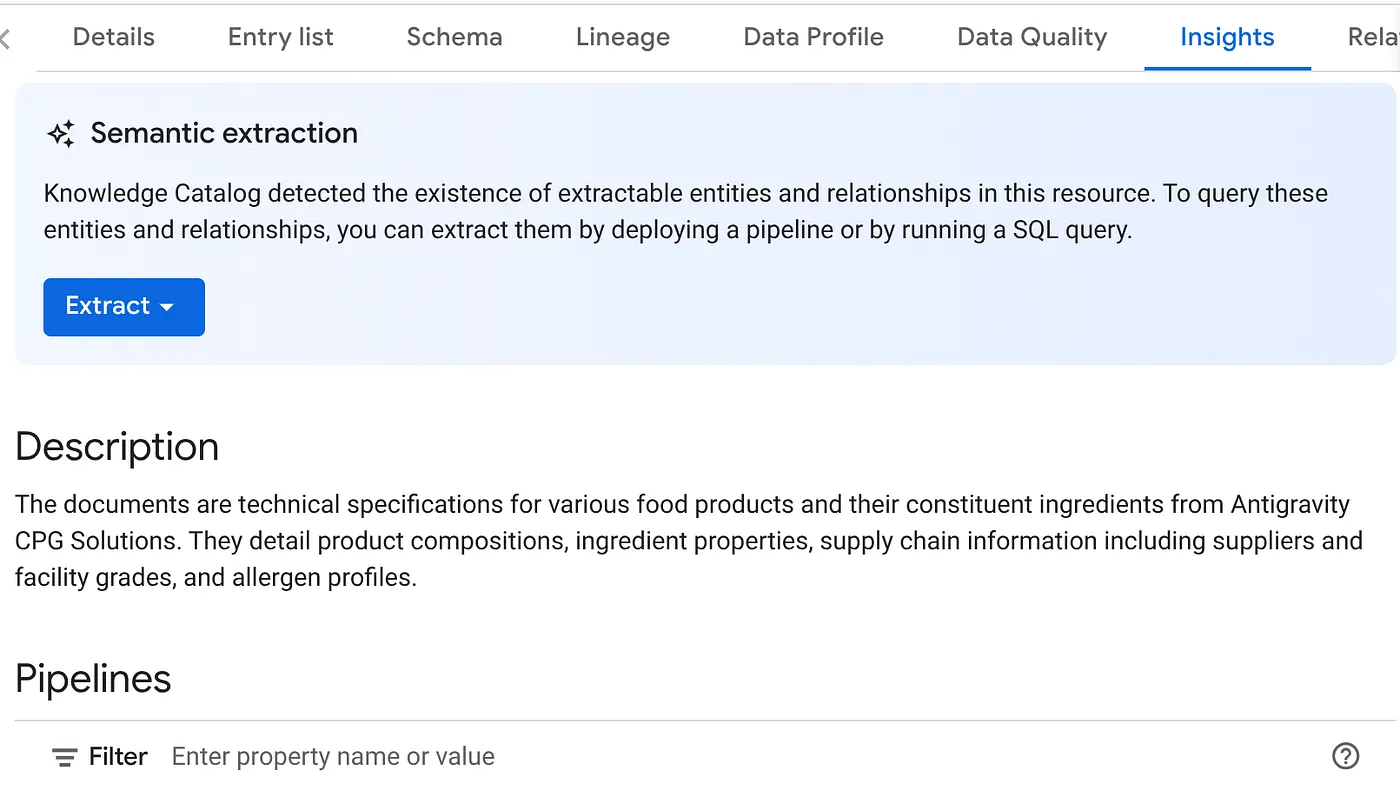
"SQL ile ayıkla" iletişim kutusunda, HEDEF veri kümesini Datascan işinin sonucunda gördüğünüz veri kümesi olarak ayarlayın. Adını yazmaya başladığınızda otomatik tamamlama özelliğinde gösterilir. "Ayıkla" düğmesini tıklayın. Alternatif olarak, bu noktada yeni bir veri kümesi oluşturup verileri çıkarabilirsiniz.
Bu işlem, veri tarama çıkarımından çıkarılan SQL ile doldurulmuş bir sekme açıkken BigQuery sorgu düzenleyicisini açar.
8. SQL Doğrulama ve Şema Oluşturma
Oluşturulan sorgu iyi görünüyorsa ve yapılandırılmamış verilerinizle anlamsal olarak alakalıysa sorgu düzenleyicideki Çalıştır düğmesini tıklayarak sorguyu uygulayın. Yapılandırılmamış medyanızın yapılandırılmış depolanması için gereken şemanın oluşturulması birkaç dakika sürer.
İşlem tamamlandıktan sonra, aşağıdaki resimde gösterildiği gibi BigQuery Studio'nun Gezgin bölmesinde veri kümesini genişleterek şemayı doğrulayabilirsiniz:
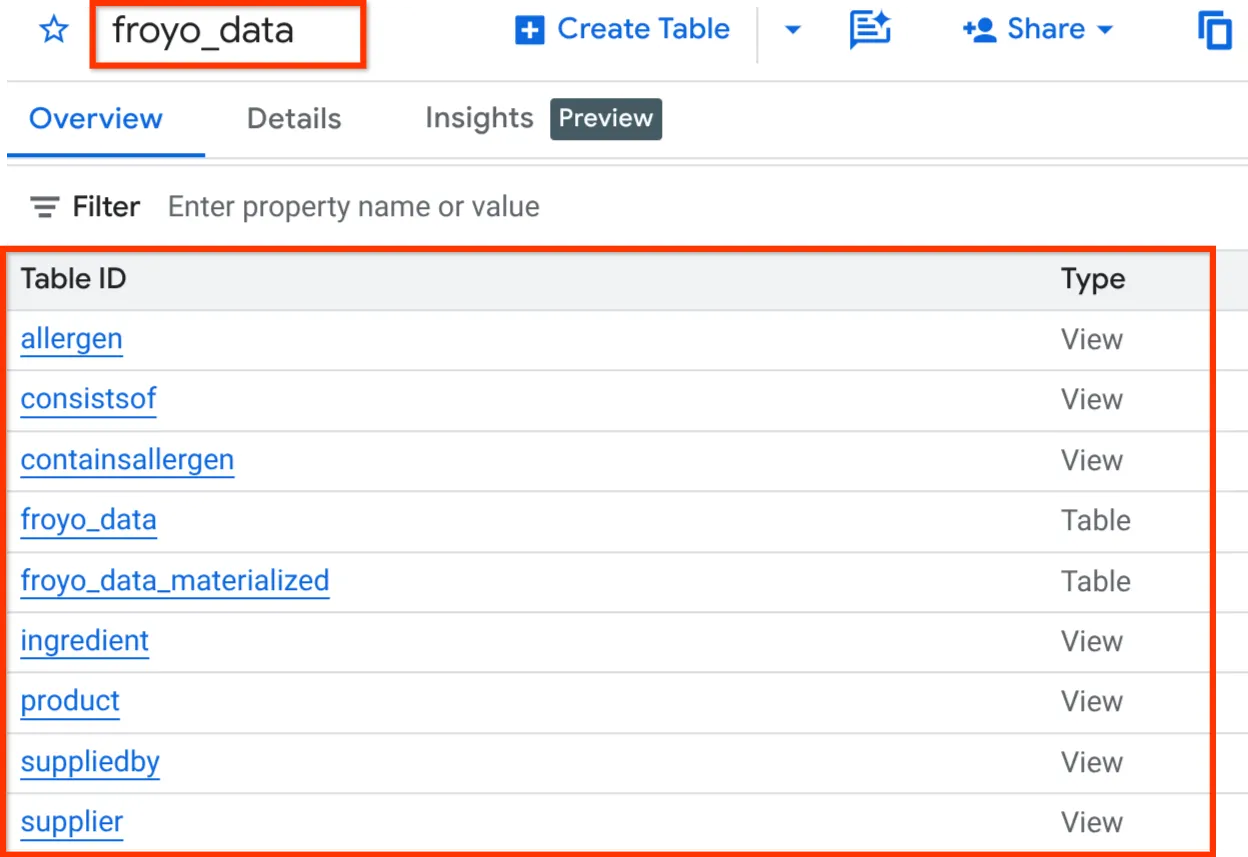
Alright!!! Bu kadar çok şeyin hızlı bir şekilde yapılması çok güzeldi. Şimdi nihai test zamanı.
Verileri faturalandırma hesabı olmadan deneyimlemeye devam etme adımları:
- Veri csv dosyalarını (BigQuery verileri) yukarıdaki GitHub repo bağlantısından edinebilirsiniz.
- Öncelikle Cloud Shell Terminal'den aşağıdaki komutu çalıştırarak BigQuery veri kümesini oluşturun:
bq mk --location us-central1 --dataset froyo_data
- Ardından, aşağıdaki komutları tek tek çalıştırarak github deposundaki 8 veri dosyasını (CSV dosyaları) çalışma dizininize indirin:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- Yeni oluşturduğunuz veri kümesindeki verilerle bu tabloları oluşturmak için aşağıdaki komutları tek tek çalıştırın.
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
Veri kümesi, tablolar ve veriler oluşturulduktan sonra az önce bahsettiğimiz verileri test etmeye ve deneyimlemeye devam edebilirsiniz.
9. The Ultimate Test!!!
Aracımın, kullanıcının sorularına gerçek, eksiksiz ve iyi düzenlenmiş, gerçeklere dayalı bilgilerle yanıt vermesini istediğimi varsayalım. Ajana, yalnızca kaynağımdaki birden fazla medya dosyasına ve referansa bakarak yanıtlayabileceği bir soru soracağım.
Kullanıcı sorum:
I'm really interested in your Midnight Swirl froyo. Are there any allergens in it?
Artık genel bir arama veya LLM araması "Sıfır malzeme" diyecek. Ancak tüm yapılandırılmamış medyalarımızı yapılandırılmış verilere dönüştüren tam bir anlamsal çıkarım oluşturduk. Bu bilgileri getirecek basit bir SQL ile devam edelim:
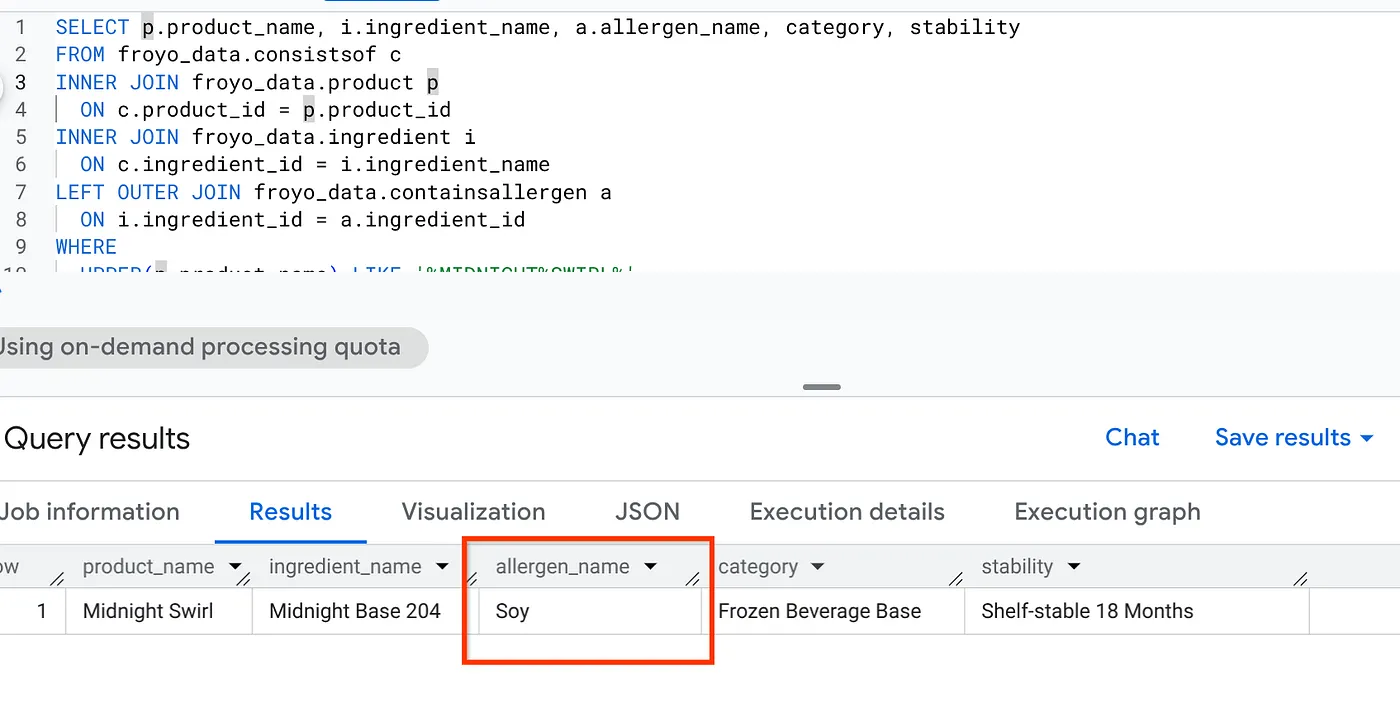
SELECT p.product_name, i.ingredient_name, a.allergen_name, category, stability
FROM froyo_data.consistsof c
INNER JOIN froyo_data.product p
ON c.product_id = p.product_id
INNER JOIN froyo_data.ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN froyo_data.containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND allergen_name IS NOT NULL;
Harika! Sonuca bakın:
10. Temizleme
Bu laboratuvarı tamamladıktan sonra tarama işini ve işin oluşturduğu BigQuery tablolarını silmeyi unutmayın.
https://console.cloud.google.com/bigquery/governance/metadata-curation/cloud-storage-discovery adresine gidin. Yanındaki üç nokta simgesini tıklayarak silmek istediğiniz işi seçin ve SİL'i tıklayın.
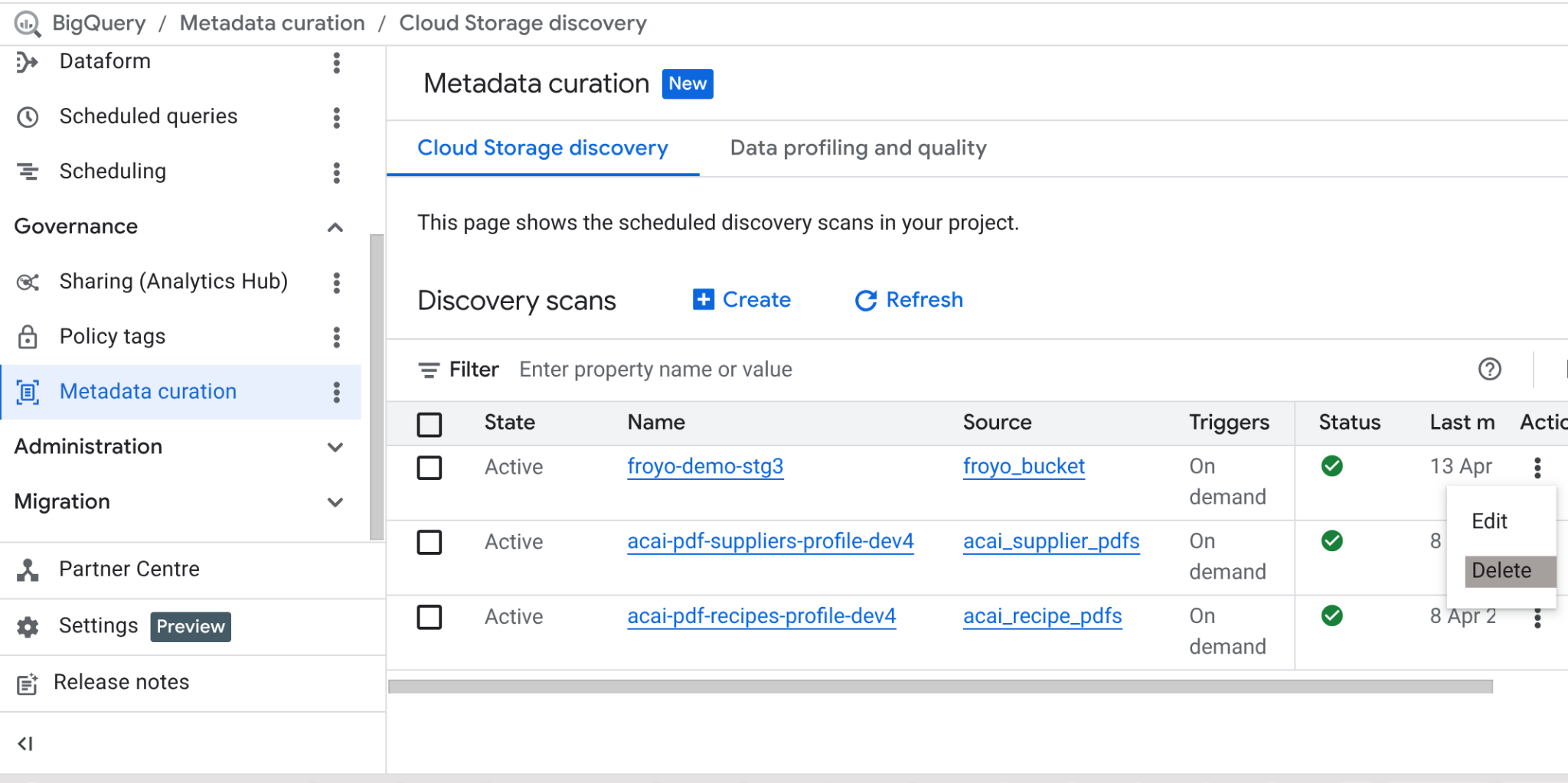
Bu işlem, işi temizlemelidir.
11. Tebrikler
Uygulamamız, gizli alerjeni başarıyla tespit edebildi. Artık karanlık veriler yok!!! 2. bölümde, bu BigQuery verilerini AlloyDB ile birlikte bir işlemsel sistemde birleştirerek yapay zeka aracılı uygulamamızın veri ihtiyaçlarını karşılayacağız.