
1. Genel Bakış
1. Bölüm'de, Knowledge Catalog ve DataScan'i kullanarak karmaşık ve yapılandırılmamış PDF'leri BigQuery'de temiz, akıllı ve yapılandırılmış tablolara dönüştürmeyi başardık. Artık güçlü bir veri ambarımız var.
Hızlı bir hatırlatma yapmak gerekirse 1. bölümdeki laboratuvarda, kurgusal bir Frozen Yogurt franchise'ının kullanım alanını ele almış ve metin, tablo ve resimlerden oluşan 400 yapılandırılmamış PDF dosyasını BigQuery Knowledge Catalog ve Dataplex'i kullanarak aralarında otomatik olarak çıkarılan ilişkilerle temiz bir şekilde yapılandırılmış BigQuery tablolarına dönüştürmüştük.
Ne oluşturacaksınız?
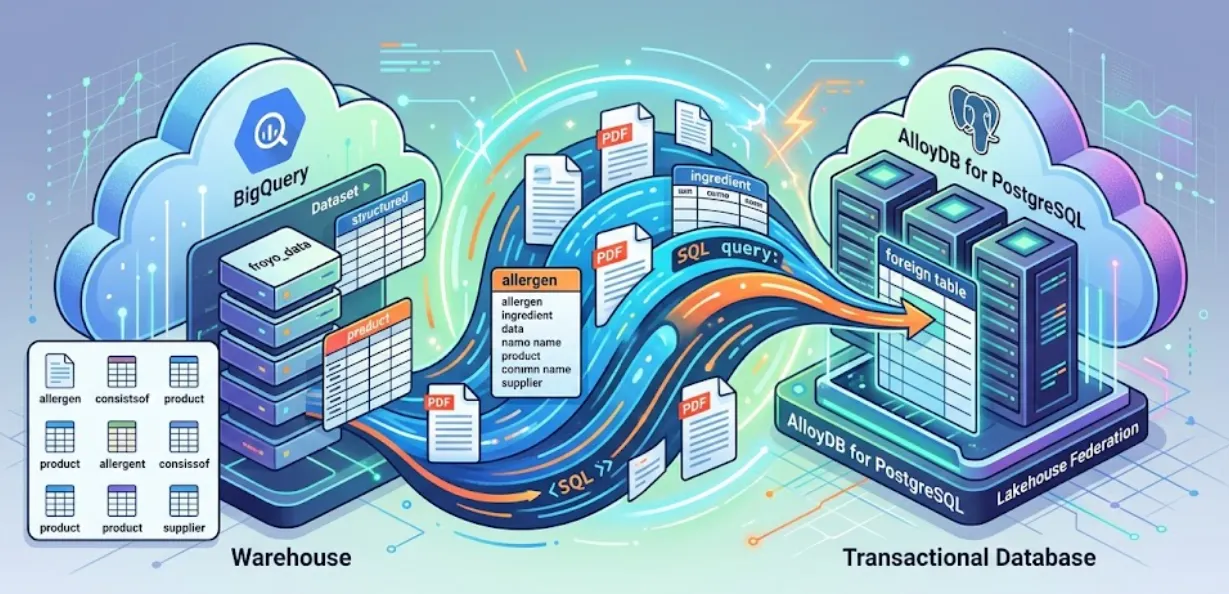
Bu oturumda, PostgreSQL için AlloyDB'yi kurup sihirli bir şey yapacağız: BigQuery verilerimizi doğrudan AlloyDB'ye birleştireceğiz. Bu sayede işlemsel uygulamamız, depo verilerimizi kopyalamadan veya çoğaltmadan gerçek zamanlı olarak sorgulayabilir.
Geliştirici olarak bu aşamada şu soruyu sormanız gerekir:
"Veriler zaten BigQuery'de ise neden AlloyDB'yi kullanayım? Uygulama neden doğrudan BigQuery'ye karşı bir SELECT ifadesi çalıştırmıyor?"
Nedenleri şöyle sıralayabiliriz:
Lakehouse Federation ile AlloyDB'nin sorgu motorunu kullanarak uygulamanızın işlemsel ve analitik iş yüklerini aynı arayüzden destekleyebilirsiniz. Bu verileri AlloyDB'de somutlaştırabilir veya içe aktararak uygulamalarınızda kullanmak üzere daha hızlı erişebilir, böylece AlloyDB AI ve sütun yapılı motoru kullanabilirsiniz.
AlloyDB'yi işlemsel veritabanı olarak kullanabilir ve BigQuery veya BigLake'te büyük miktarda veriye sahip olabilirsiniz. Uygulamalarınız, bu farklı Google Cloud hizmetlerindeki verilere erişmek için genellikle bu iki sistemle bağımsız olarak entegre olur. AlloyDB için Lakehouse Federation, AlloyDB'de SQL arayüzünü kullanarak BigQuery ve AlloyDB verilerine erişmek için AlloyDB'nin yabancı veri sarmalayıcısı olarak uygulanan birleştirilmiş sorgu desteğini kullanmanıza olanak tanır.
AlloyDB'den BigQuery verilerini sorgulamak için kırılgan bir ETL ardışık düzeni oluşturmak yerine birleştirilmiş sorgular kullanacağız. AlloyDB, gerektiğinde BigQuery'ye sorunsuz bir şekilde ulaşan birleşik bir uç nokta görevi görür.
Oluşturmaya başlayalım.
Neler öğreneceksiniz?
- Tek bir tıklamayla AlloyDB kümesi, örneği ve ağ iletişimi nasıl ayarlanır?
- Federasyona hazırlanmak için uzantıyı ayarlama
- BigQuery'den AlloyDB'ye federasyon oluşturma
- Deneyin
Şartlar
2. Başlamadan önce
Proje oluşturma
- Google Cloud Console'daki proje seçici sayfasında bir Google Cloud projesi seçin veya oluşturun.
- Cloud projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Bir projede faturalandırmanın etkin olup olmadığını kontrol etmeyiöğrenin.
- Google Cloud'da çalışan bir komut satırı ortamı olan Cloud Shell'i kullanacaksınız. Google Cloud Console'un üst kısmında Cloud Shell'i Etkinleştir'i tıklayın.

- Cloud Shell'e bağlandıktan sonra aşağıdaki komutu kullanarak kimliğinizin doğrulandığını ve projenin proje kimliğinize ayarlandığını kontrol edin:
gcloud auth list
- gcloud komutunun projeniz hakkında bilgi sahibi olduğunu onaylamak için Cloud Shell'de aşağıdaki komutu çalıştırın.
gcloud config list project
- Kimlik doğrulamak istiyorsanız
gcloud auth login
- Projeniz ayarlanmamışsa ayarlamak için aşağıdaki komutu kullanın:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Gerekli API'leri etkinleştirin: Gerekli tüm API'leri etkinleştirmek için şu komutu çalıştırın:
gcloud services enable alloydb.googleapis.com
Dikkat Edilmesi Gerekenler ve Sorun Giderme
"Hayalet Proje" Sendromu |
|
Faturalandırma Barikatı | Projeyi etkinleştirdiniz ancak faturalandırma hesabını unuttunuz. AlloyDB yüksek performanslı bir motordur. "Yakıt deposu" (faturalandırma) boşsa çalışmaz. |
API Yayılımı Gecikmesi | "API'leri etkinleştir"i tıkladınız ancak komut satırında hâlâ |
Kota Quags | Yeni bir deneme hesabı kullanıyorsanız AlloyDB örnekleri için bölgesel kotaya ulaşabilirsiniz. |
3. 1. Bölümdeki verilerin kısa özeti
Bu bölümde, yapılandırılmamış PDF'lerden ayıkladığımız yapılandırılmış verilerin BigQuery'de kullanılabilir olduğundan emin olmanız gerekir. 1. bölümü kaçırdıysanız veya faturalandırma hesabınız yoksa aşağıdaki adımları tamamlayarak başlayabilirsiniz:
Kişisel Gmail hesabınızdan Google Cloud Console'a gidin ve konsolun sağ üst köşesindeki Cloud Shell'i Etkinleştir düğmesini tıklayın:
Ardından, aşağıdaki faturalandırma hesabı olmayan bölümündeki adımları uygulayın:
Verileri faturalandırma hesabı olmadan deneyimlemeye devam etme adımları:
- Veri csv dosyalarını (BigQuery verileri) yukarıdaki GitHub repo bağlantısından edinebilirsiniz.
- Öncelikle Cloud Shell Terminal'den aşağıdaki komutu çalıştırarak BigQuery veri kümesini oluşturun:
bq mk --location us-central1 --dataset froyo_data
- Ardından, aşağıdaki komutları tek tek çalıştırarak github deposundaki 8 veri dosyasını (CSV dosyaları) çalışma dizininize indirin:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- Yeni oluşturduğunuz veri kümesindeki verilerle bu tabloları oluşturmak için aşağıdaki komutları tek tek çalıştırın.
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
Veriler BigQuery'ye aktarıldığına göre sonraki adımlara geçebiliriz.
4. AlloyDB kümesi, örneği ve ağı oluşturma
AlloyDB kümesini, örneğini ve diğer bağımlılıkları ayarlamanıza yardımcı olacak web tabanlı bir hızlı başlangıç uygulaması vardır. Tek bir tıklamayla ayarlamak için bu laboratuvardaki 2-4 arasındaki adımları uygulayabilirsiniz:
https://codelabs.developers.google.com/quick-alloydb-setup
Kümeniz oluşturulduktan sonra Küme Genel Bakış sayfasına gidin ve hizmet hesabı ayrıntılarını buradan kopyalayın.
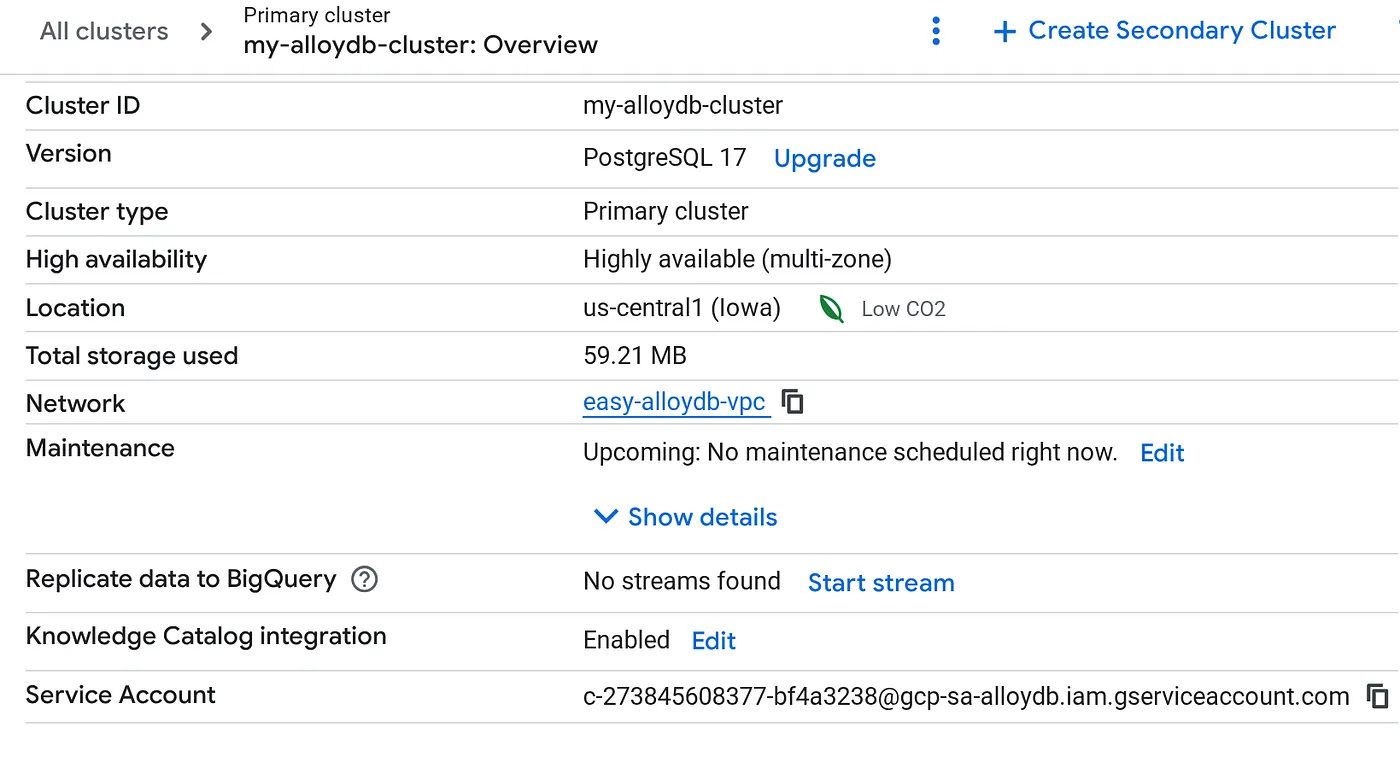
5. İzinleri ayarlama
Bu hizmet hesabına BigQuery izinleri verme
- IAM & Admin > IAM'e (IAM ve Yönetici > IAM) gidin.
- Erişim izni ver'i tıklayın.
- AlloyDB hizmet hesabı adresini Yeni ana hesaplar alanına yapıştırın.
- Aşağıdaki rolleri atayın:
- BigQuery Veri Görüntüleyici (roles/bigquery.dataViewer): Verilerin okunmasına izin verir.
- BigQuery Kullanıcısı (roles/bigquery.user): Sorguların çalıştırılmasına izin verir.
- (İsteğe bağlı ancak önerilir) BigQuery Read Session User (roles/bigquery.readSessionUser): Storage Read API aracılığıyla büyük veri kümelerinin okunmasını optimize eder.
6. AlloyDB'ye bağlanma ve BigQuery uzantısını etkinleştirme
Şimdi federasyon uzantısını yapılandırmak için yeni AlloyDB örneğimize bağlanıyoruz. Bu işlem için AlloyDB Studio'yu kullanacağız.
- Küme Genel Bakış sayfanızda (AlloyDB konsolu) birincil örneğinizde "Birincili Düzenle"yi tıklayın ve "Gelişmiş Yapılandırma Seçenekleri"ne gitmek için en alta kaydırın.
- "Flags" (İşaretler) bölümüne gidin ve aşağıdaki resimde gösterildiği gibi 2 işareti "On" (Açık) olarak etkinleştirin:
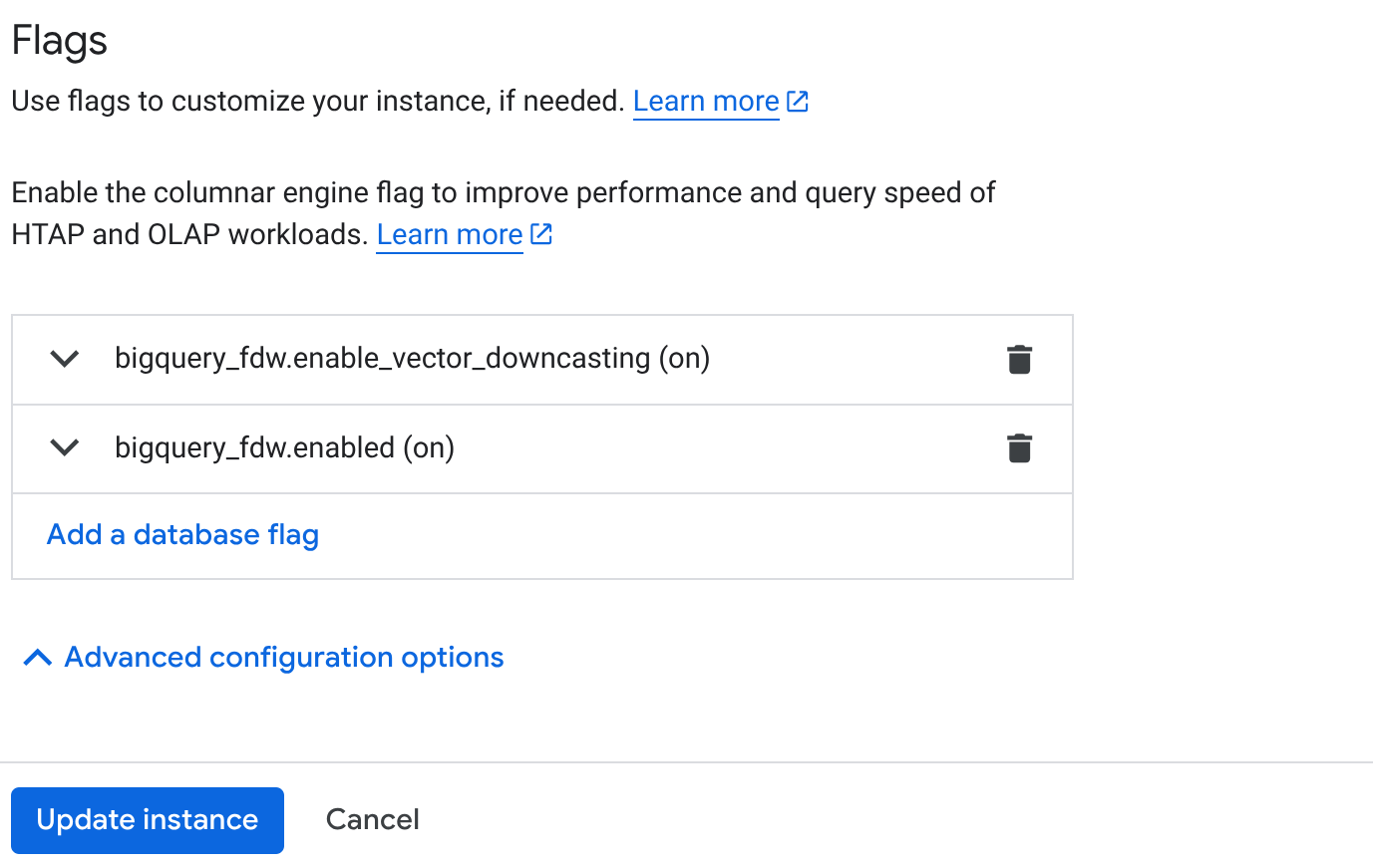 3. Örneği güncelle düğmesini tıkladığınızda güncellemenin tamamlanması birkaç dakika sürer. 4. Küme Genel Bakış sayfanızda (AlloyDB konsolu) AlloyDB Studio'yu tıklayın.
3. Örneği güncelle düğmesini tıkladığınızda güncellemenin tamamlanması birkaç dakika sürer. 4. Küme Genel Bakış sayfanızda (AlloyDB konsolu) AlloyDB Studio'yu tıklayın.
- AlloyDB Hızlı Kurulum adımında yapılandırdığınız veritabanı, kullanıcı adı ve şifrenizle bağlanın.
- Bağlantı kurulduktan sonra sağ taraftaki Sorgu Düzenleyici sekmesinde aşağıdaki ifadeleri girin ve bunları tek tek ÇALIŞTIRIN:
CREATE EXTENSION IF NOT EXISTS bigquery_fdw;
CREATE SERVER bigquery_server FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bigquery_server;
- İşlem başarıyla tamamlandıktan sonra soldaki Gezgin bölmesine gidin ve BigQuery tablolarına doğru aşağı kaydırın:
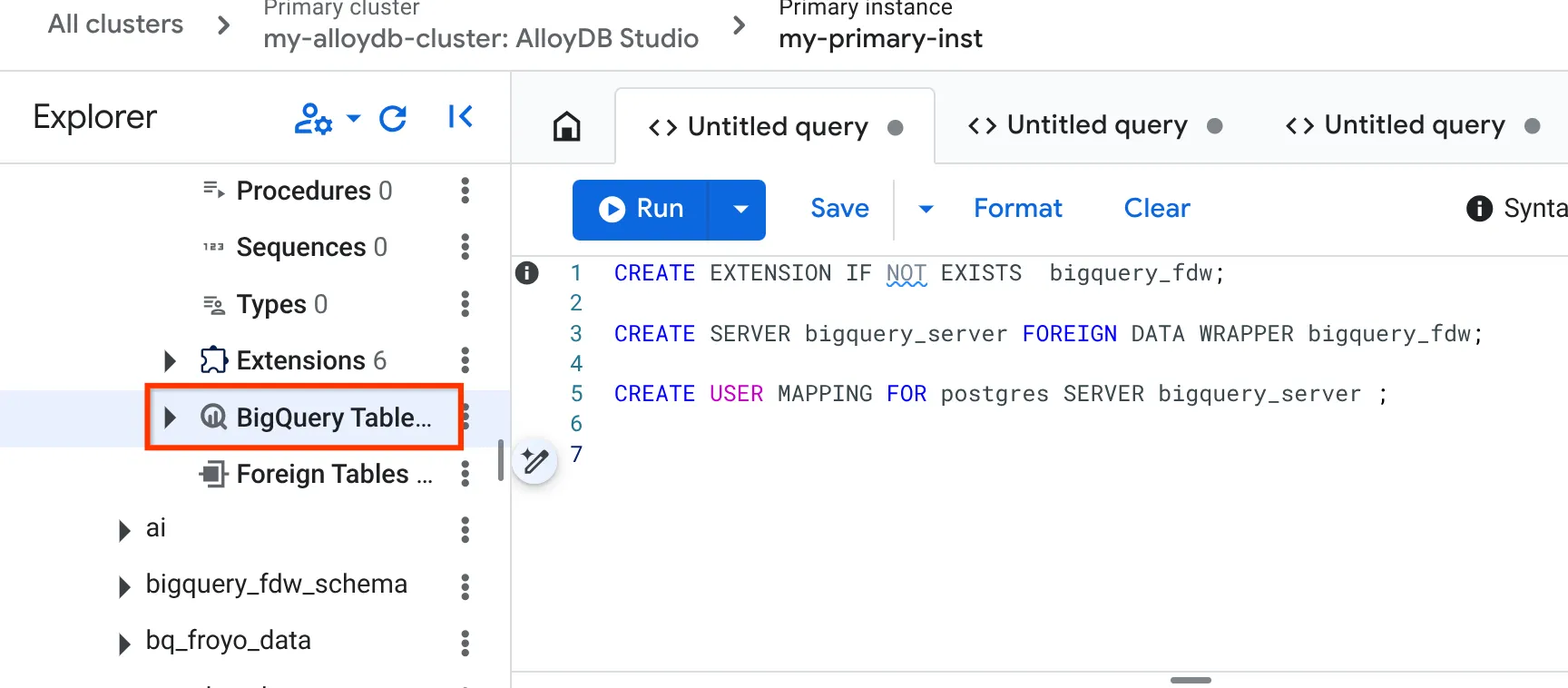
- 3 nokta simgesini ve "BigQuery tablosunu bağla"yı tıklayın.
- Açılan BigQuery Tablosunu Bağla pop-up penceresinde, AlloyDB veritabanınızdaki verileri sorgulamak istediğiniz project_id'nizi ve BigQuery veri kümesi adını (1. bölümde oluşturulan) seçin.
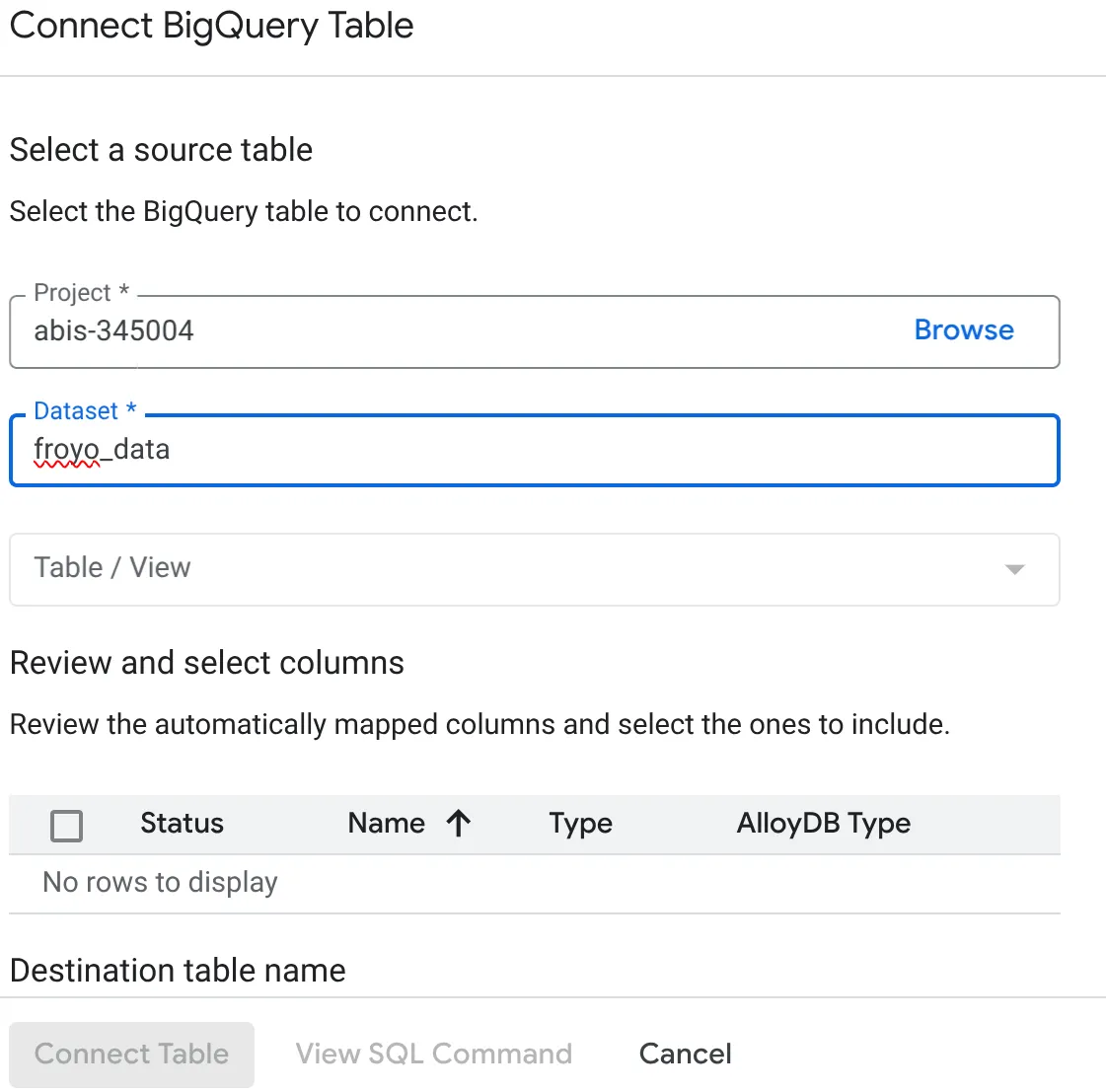
- Tüm verilerinizin AlloyDB'ye bağlanması için her tabloyu tek tek seçin. Bunun nedeni, sütun türlerinin AlloyDB'de desteklendiğinden emin olmak için doğrulanmasıdır.
Aynı işlemi işaretle ve tıkla yaklaşımı yerine SQL ile yapmak istiyorsanız:
CREATE FOREIGN TABLE <<TABLE_NAME>> (
"cas_number" VARCHAR, "ingredient_name" VARCHAR, "max_moisture_percentage" DOUBLE PRECISION, "ph_range" VARCHAR, "purity_percentage" DOUBLE PRECISION, "shelf_life_months" BIGINT, "specific_gravity_range" VARCHAR
) SERVER "bigquery_server" OPTIONS (
project '<<PROJECT_ID>>',
dataset 'froyo_data',
table '<<BQ_TABLE_NAME>>'
);
Sihir!!!
AlloyDB'de "Yabancı Tablolar" özelliğini kullanıma sunduk. Bunlar normal PostgreSQL tabloları gibi görünür ve davranır ancak herhangi bir veri depolamaz. Bu verileri sorguladığınızda AlloyDB, sorguyu anında BigQuery'ye iletir, sonuçları getirir ve size döndürür.
7. AlloyDB'de federasyonu test etme
Büyük boyutlu analitik BigQuery veri kümemizi doğrudan işlemsel PostgreSQL veritabanımızdan sorgulayabildiğimizi doğrulayalım.
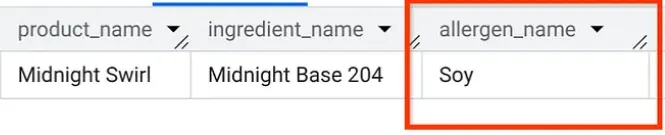
AlloyDB Studio'da kalmaya devam ederek "Midnight Swirl"de hangi alerjenlerin olduğunu öğrenmek için bir sorgu çalıştıralım (1. bölümde sorduğumuz sorunun aynısı, ancak bu kez AlloyDB'den soruluyor):
SELECT
p.product_name,
i.ingredient_name,
a.allergen_name
FROM
consistsof c
INNER JOIN product p
ON c.product_id = p.product_id
INNER JOIN ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND a.allergen_name IS NOT NULL;
Boom. BigQuery'de gördüğünüz sonuçların aynısını görmeniz gerekir.
8. Temizleme
Bu laboratuvar tamamlandıktan sonra AlloyDB kümesini ve örneğini silmeyi unutmayın.
Küme, örnekleriyle birlikte temizlenmelidir.
9. Birleşik veri katmanınız için tebrikler
Şu ana kadar başardıklarımızı düşünün:
- İşlem uygulamamız (AlloyDB'de çalışır) hızlı ve eşzamanlı kullanıcı oturumlarını işleyebilir.
- Yoğun analitik veriye veya geçmiş bağlama (ör. tedarikçi ayrıntıları ya da karmaşık içerik eşlemeleri) ihtiyaç duyduğunda BigQuery froyo_dataschema'yı sorgular.
- Zero ETL. Veri ardışık düzenleri bozulmaz. Senkronize olmayan veritabanı yok. Verileri bir kez (BQ'da) depolar ve ihtiyaç duyduğumuz yerde hesaplarız.
Hem analitik hem de işlemsel veri temellerimiz sağlam ve birbirine bağlı olduğundan artık işin eğlenceli kısmına geçebiliriz.
3. Bölüm'de, Froyo işletme faaliyetlerini yürütmek için bu mimarinin üzerinde yer alan Çoklu Aracı Uygulaması'nı oluşturacağız.