
1. 概览
我们都知道“暗数据”的痛点。这些 PDF、图片和文本文件位于云存储分区中,SQL 查询和 BI 信息中心完全无法访问。传统上,解锁这些数据需要复杂的 OCR 流水线、手动数据输入或脆弱的自定义脚本。
现在,您不必再为此烦恼了。
在本实验中,我将向您展示如何将 400 个非结构化 PDF 文件(涵盖文本、表格和图片)转换为结构清晰的 BigQuery 表,并自动推断它们之间的关系。我们将使用 BigQuery Knowledge Catalog 和 Dataplex 在几分钟内完成此操作。
构建内容
为了让您切实了解这一点,我们来看一个虚构的企业:一家快速增长的冷冻酸奶特许经营店。
假设您负责管理这家冷冻酸奶店的数据。您有数百份食谱和供应商规格表,全部保存为 PDF 文件。企业领导者希望推出一个 AI 智能体,帮助门店经理和客户查询产品详细信息。
以下是噩梦般的场景:一位客户问道:“我对你们的 Midnight Swirl 冷冻酸奶非常感兴趣。里面有任何过敏原吗?”
为了回答这个问题,您的系统通常需要:
- 找到“Midnight Swirl”食谱 PDF。
- 读取配料(例如“可可粉”“乳制品基料”“X 乳化剂”)。
- 搜索数十个供应商 PDF,找到这些特定配料的规格表。
- 检查供应商规格表,了解与这些配料相关的隐藏过敏原。
尝试构建一个 AI 智能体,使其能够在运行时读取 400 个原始 PDF 文件并即时执行此操作,这种做法速度慢、成本高,而且容易产生幻觉。相反,我们将使用语义推理先将所有这些信息提取到关系型数据库中,这样我们未来的 AI 智能体将能够以闪电般的速度运行,并且 100% 基于事实 SQL 数据。
让我们开始构建吧!
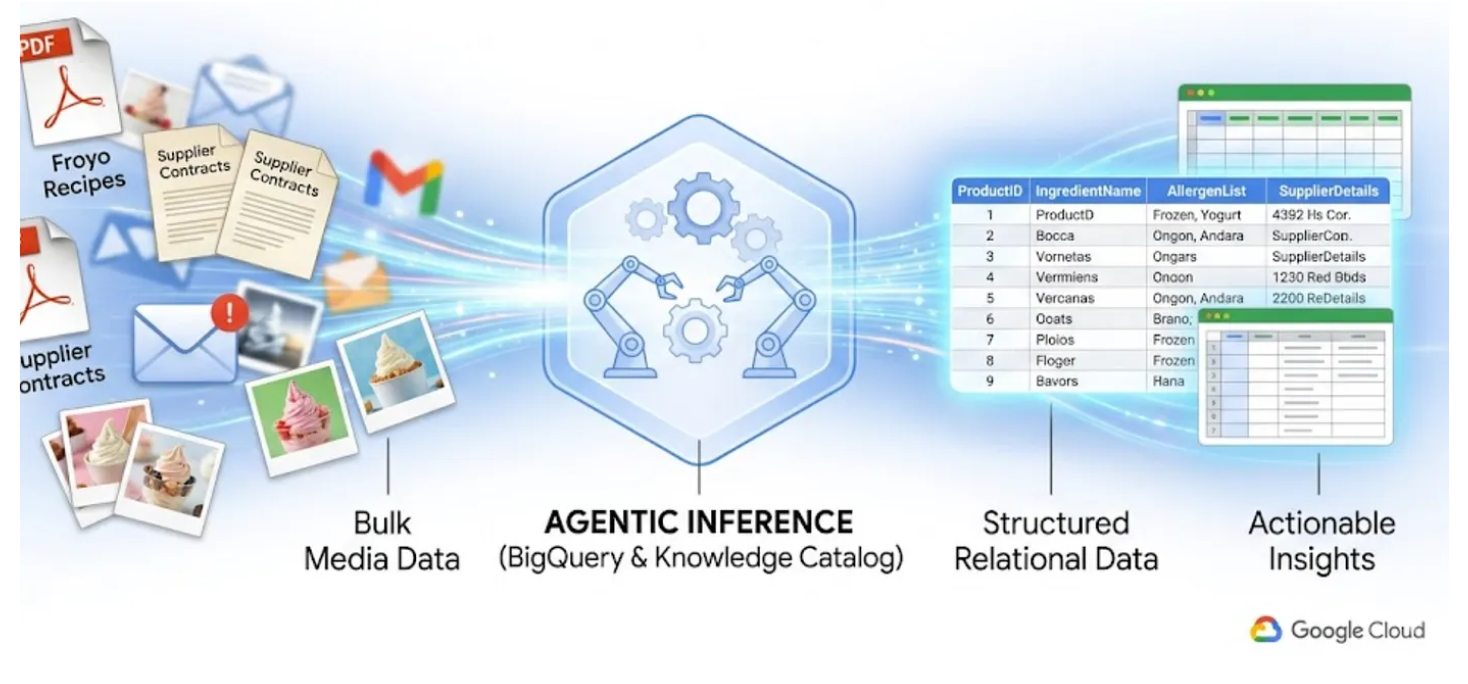
学习内容
- 如何为源文件 (PDF) 设置 Cloud Storage 存储分区
- 如何在 Knowledge Catalog 中设置和运行 Datascan 作业和语义推理,以从源 PDF 中提取数据,并以语义方式推断连接和上下文,然后将其存储在 BigQuery 中
- 如何使用 BigQuery 智能体与新创建的数据集聊天
要求
2. 准备工作
创建项目
- 在 Google Cloud 控制台的项目选择器页面上,选择或创建一个 Google Cloud 项目。
- 确保您的 Cloud 项目已启用结算功能。了解如何 检查项目是否已启用结算功能。
- 您将使用 Cloud Shell,它是在 Google Cloud 中运行的命令行环境。点击 Google Cloud 控制台顶部的激活 Cloud Shell 。

- 连接到 Cloud Shell 后,您可以使用以下命令检查自己是否已通过身份验证,以及项目是否已设置为您的项目 ID:
gcloud auth list
- 在 Cloud Shell 中运行以下命令,以确认 gcloud 命令了解您的项目。
gcloud config list project
- 如果您想进行身份验证
gcloud auth login
- 如果项目未设置,请使用以下命令进行设置:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- 启用所需的 API:运行此命令以启用所有必需的 API:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
storage.googleapis.com
注意事项和问题排查
“幽灵项目” 综合征 | 您运行了 |
结算 障碍 | 您启用了项目,但忘记了结算账号。AlloyDB 是一种高性能引擎;如果“油箱”(结算)为空,它将无法启动。 |
API 传播 延迟 | 您点击了“启用 API”,但命令行仍然显示 |
配额 陷阱 | 如果您使用的是全新的试用账号,则可能会达到 AlloyDB 实例的区域配额。如果 |
“隐藏”服务代理 | 有时,AlloyDB 服务代理不会 自动获得 |
3. Google Cloud Storage 存储分区设置
在本部分中,您将在 BigQuery 中创建一个组织结构,用于存储冷冻酸奶食谱和供应商数据,特别是冷冻酸奶产品详细信息。它还会建立 Cloud 资源连接,该连接充当安全“桥梁”,允许 BigQuery 从 Cloud Storage 等外部来源读取文件。
准备工作:
此代码库包含我们将在本项目中使用的食谱和供应商 PDF 文件。请确保您下载了这些文件。如需下载这些文件,请执行以下操作。
在 Cloud Shell 中,运行以下命令:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git
进入新创建的文件夹:
cd next-26-keynotes
拉取 data-cloud-demo 文件夹
git sparse-checkout set genkey/data-cloud-demo
结账完成后,进入 data-cloud-demo 文件夹,然后解压缩 ZIP 文件以访问 Codelab 资产。
创建存储分区并上传冷冻酸奶(食谱和供应商)PDF 文件
- 在 Google Cloud 控制台中,进入 Cloud Storage 存储分区 页面。
- 点击“创建”。
- 在 创建存储分区 页面上,输入存储分区信息。完成以下每个步骤后,点击“继续”以继续执行下一步:
- 在开始使用 部分中,输入存储分区名称。 例如:froyo_data
- 在选择数据存储位置 部分中,选择“区域”,然后输入您的区域。 us-central1
- 在选择如何控制对对象的访问权限 部分中,取消选中“禁止公开访问此存储分区”复选框。
- 点击“创建”。
- 在存储分区列表中,点击您创建的存储分区。
- 在存储分区的对象 标签页中,依次点击“上传”和“上传文件夹”。
- 选择您在本 Codelab 的准备工作部分中提取的食谱 文件夹。
- 点击“上传”。
- 对供应商 文件夹重复上传过程。
上传后,您的存储分区结构应如下所示(无论存储分区名称是什么):
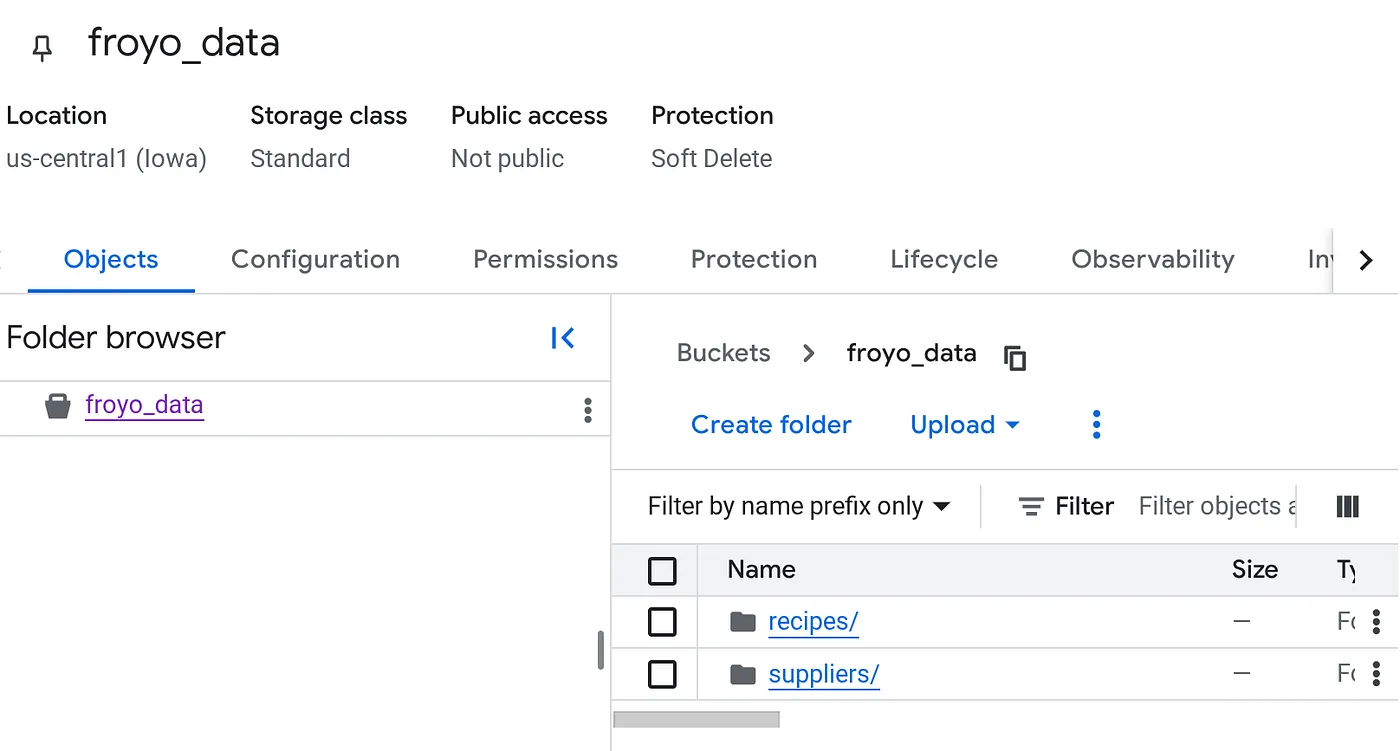
4. BigQuery 连接设置
创建 Cloud 资源连接。这会生成一个唯一的服务账号,该账号充当 BigQuery 的“身份证”,用于访问外部文件。
- 转到 BigQuery 页面。
- 在左侧窗格中,点击“探索器”。如果您没有看到左侧窗格,请点击“展开左侧窗格”以打开该窗格。
- 在探索器窗格中,展开您的项目名称,然后点击“连接”。
- 在“连接”页面上,点击“创建连接”。
- 对于“连接类型”,请选择“Vertex AI 远程模型、远程函数、BigLake 和 Spanner(Cloud 资源)”。
- 在“连接 ID”字段中,输入连接 ID 名称:
- bq-connection。请务必记下此 ID,因为您稍后在本 Codelab 中设置数据扫描时需要用到它。
- 将“位置类型”设置为“区域”,然后选择一个区域。例如 us-central1。连接应与数据集等其他资源位于同一区域中。
- 点击“创建连接”。
- 点击“前往连接”。
- 在“连接信息”窗格中,复制服务账号 ID 以在后续步骤中使用。服务账号类似于 bqcx-**********-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com。
5. 权限设置
- 向 BigQuery 连接授予访问 Cloud Storage 对象和 Knowledge Catalog 所需的权限
前往“IAM 和管理”页面,然后在“按主账号查看”部分中,点击“授予访问权限”按钮,然后粘贴您在上一步中复制的服务账号,以添加主账号。在“角色”部分中,逐个添加以下角色的名称并保存:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/bigquery.user
- roles/bigquery.dataEditor
- roles/aiplatform.viewer
- roles/agentplatform.user
- roles/storage.admin
- roles/dataproc.serviceAgent
- roles/dataplex.discoveryPublishingServiceAgent
- roles/dataplex.serviceAgent
- roles/dataplex.securityAdmin
- 授予 Dataplex 服务账号访问 Cloud Storage 存储分区的权限
前往 IAM 和管理 页面,然后在按主账号查看 部分中,点击“授予访问权限 ”按钮,然后在“新主账号”文本栏中输入 dataplex ,以添加主账号。在自动完成的列表中,选择类似于以下内容的 Dataplex 服务账号主账号(在下面的服务账号电子邮件 ID 中使用项目编号,而不是项目 ID ):
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
如果由于任何原因,系统无法识别您项目编号的上述服务账号,则可能是因为项目尚未初始化 Dataplex 服务。前往 Cloud Shell 终端,然后尝试运行以下命令来启用 API(如果在准备工作 阶段尚未完成此操作):gcloud services enable dataplex.googleapis.com
即使这样,如果系统仍然无法识别 Dataplex 的服务账号,请在 元数据整理页面 中强制创建测试 Dataplex 扫描作业,然后在“发现作业创建”页面中输入详细信息:
点击立即运行 。作业将失败,但这样可以确保系统现在会为您的 Dataplex 服务初始化服务账号 ID。
返回 IAM 和管理 页面,然后在按主账号查看 部分中,点击“授予访问权限 ”按钮,然后点击“添加主账号”。粘贴服务账号:
service-<<YOUR_PROJECT_NUMBER>>@ gcp-sa-dataplex.iam.gserviceaccount.com
然后向此服务账号授予以下角色:
- roles/storage.objectUser
- roles/storage.objectViewer
- roles/storage.viewer
- roles/dataplex.discoveryBigLakePublishingServiceAgent
6. Knowledge Catalog 设置
构建 Knowledge Catalog,以统一非结构化数据并自动发现非结构化文件(例如 PDF 食谱和 PDF 供应商)。
从控制台创建 DataScan 作业:
- 前往元数据整理页面。
- 点击“创建”,然后输入与您的设置对应的详细信息:
重要提示:请勿忘记选中“启用语义推理”。
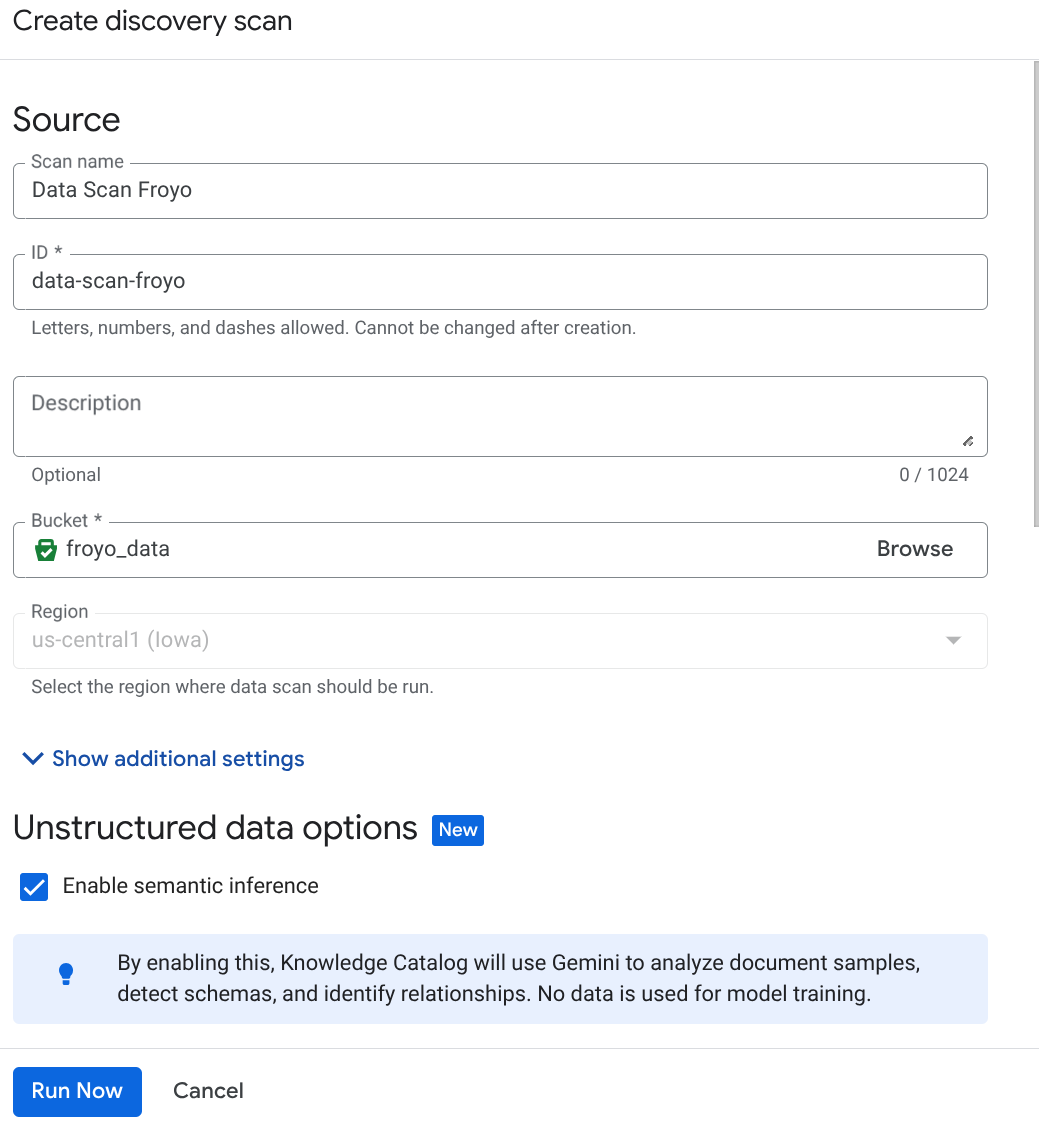
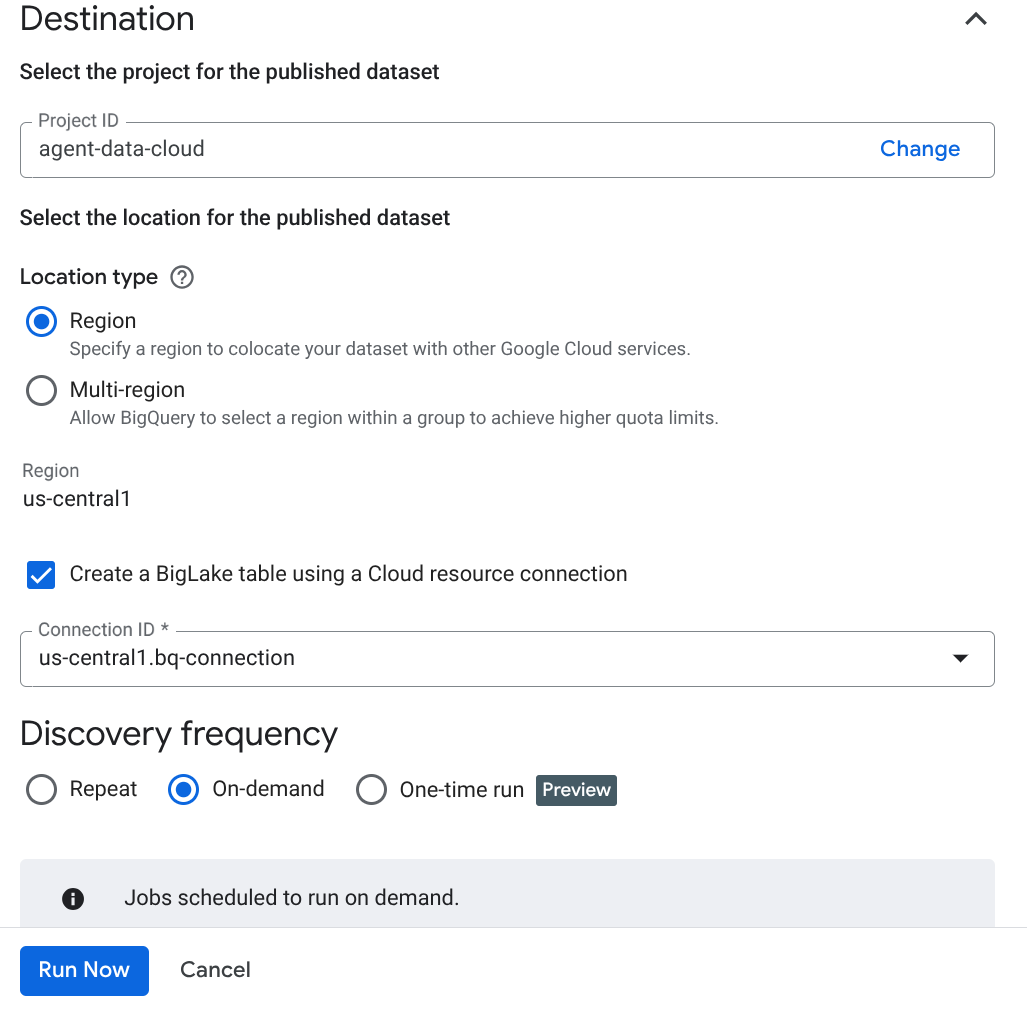
- 点击“立即运行”。
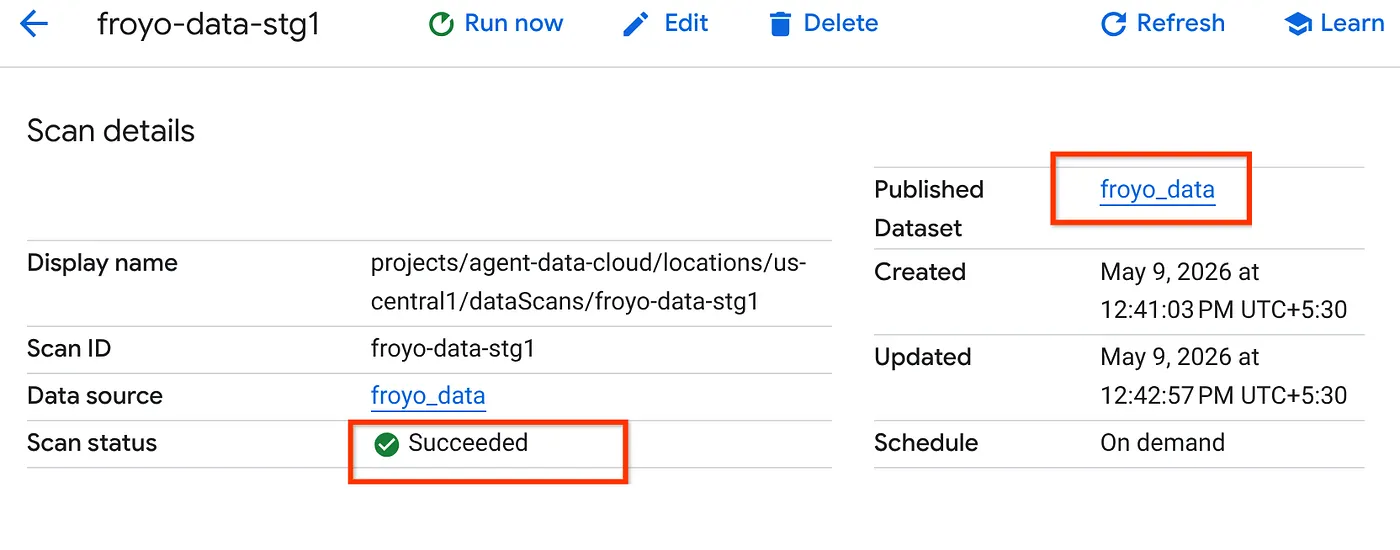
- 完成扫描作业需要一些时间。作业完成后,检查是否存在已发布的数据集。如需检查作业状态,您可以在 元数据整理 页面中进行检查;在 Cloud Storage 发现标签页中,点击最近运行的发现扫描的名称。您应该会看到已发布的数据集,如下所示:
注意:如果在扫描步骤中遇到错误,请稍等片刻,然后重试(创建作业并完成执行需要几分钟时间)。
- 您可以在 BigQuery 中查看表格,方法是点击并前往 froyo_data 数据集。点击 BigQuery 中的表格 ID,然后在“查询编辑器”标签页中运行以下查询:
SELECT count(*) FROM `froyo_data.froyo_data` LIMIT 1000;
结果为 400(如果不是,您可以返回并再次运行 Datascan 作业)。
7. 语义数据提取
太棒了!现在,我们来使用 Knowledge Catalog 提取这些非结构化对象的推理。
我们将使用“洞见”功能生成 SQL 语句,以从非结构化表格中提取结构化数据
- 在 Google Cloud 控制台中,进入 Knowledge Catalog 搜索页面。
- 搜索要查看分析洞见的数据集表格。在搜索栏中,输入上一步中的数据集 / 表格名称:“froyo_data”,然后按 Enter 键
- 在结果列表中,点击 TABLE 条目(而不是数据集条目)
- 您应该会看到 INSIGHTS 标签页。点击该标签页(如果系统要求您启用任何 API,请按照说明启用 API)。
如果您在此处启用了 API,则必须再次运行扫描作业。
- 在“INSIGHTS”标签页中,您会看到“EXTRACT”按钮下拉菜单。点击该菜单,然后选择“Extract with SQL”选项。
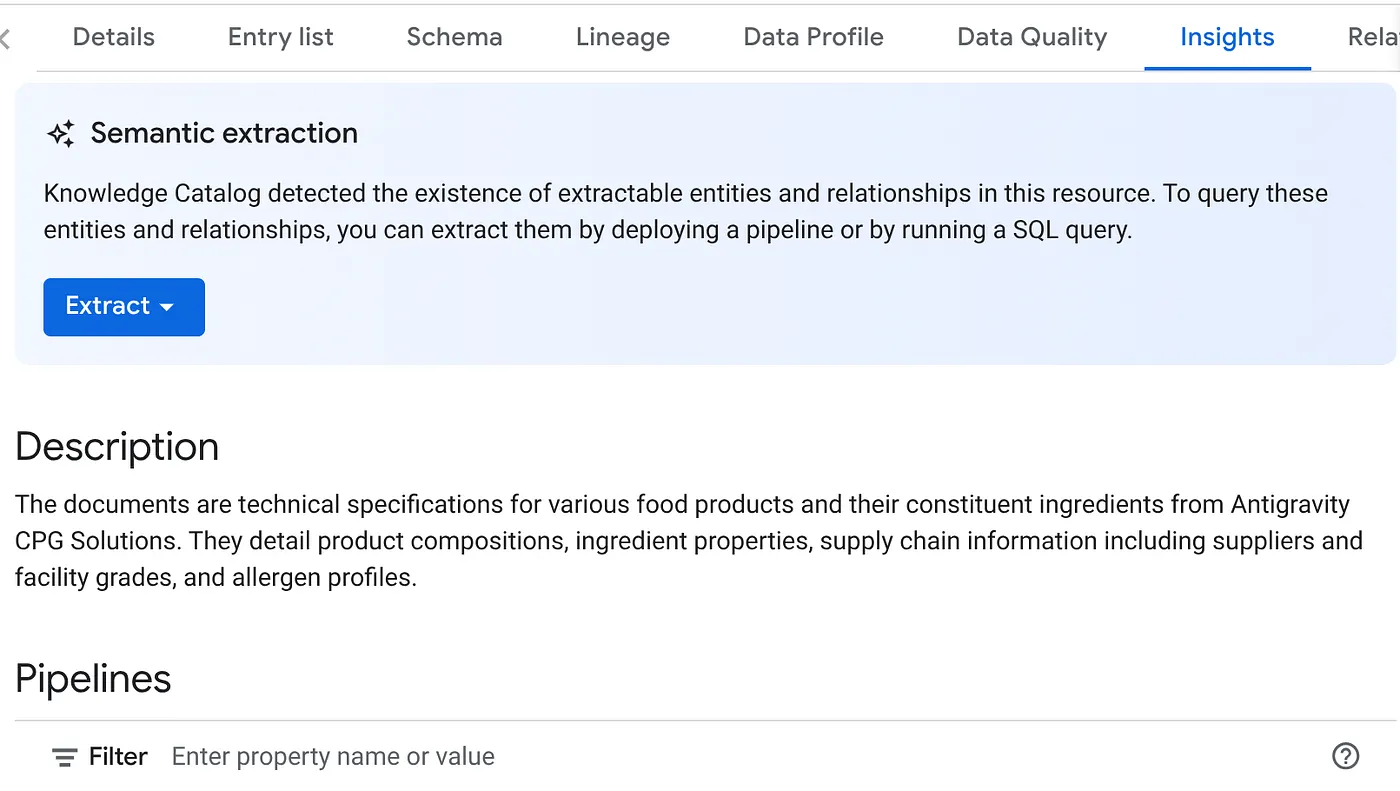
在弹出的“Extract with SQL”对话框中,将“DESTINATION”数据集设置为您在 Datascan 作业结果中看到的数据集。开始输入其名称,它应该会显示在自动完成列表中。点击“Extract”按钮。或者,您也可以在此处创建一个新数据集并进行提取。
这应该会打开 BigQuery 查询编辑器,其中会打开一个标签页,其中填充了从数据扫描推理中提取的 SQL。
8. SQL 验证和架构创建
如果生成的查询看起来不错,并且在语义上与您的非结构化数据相关,请点击查询编辑器中的“运行”按钮来运行该查询。创建以结构化方式存储非结构化媒体所需的架构需要几分钟时间。
完成后,您应该可以通过展开 BigQuery Studio 的探索器窗格中的数据集来验证架构,如下所示:
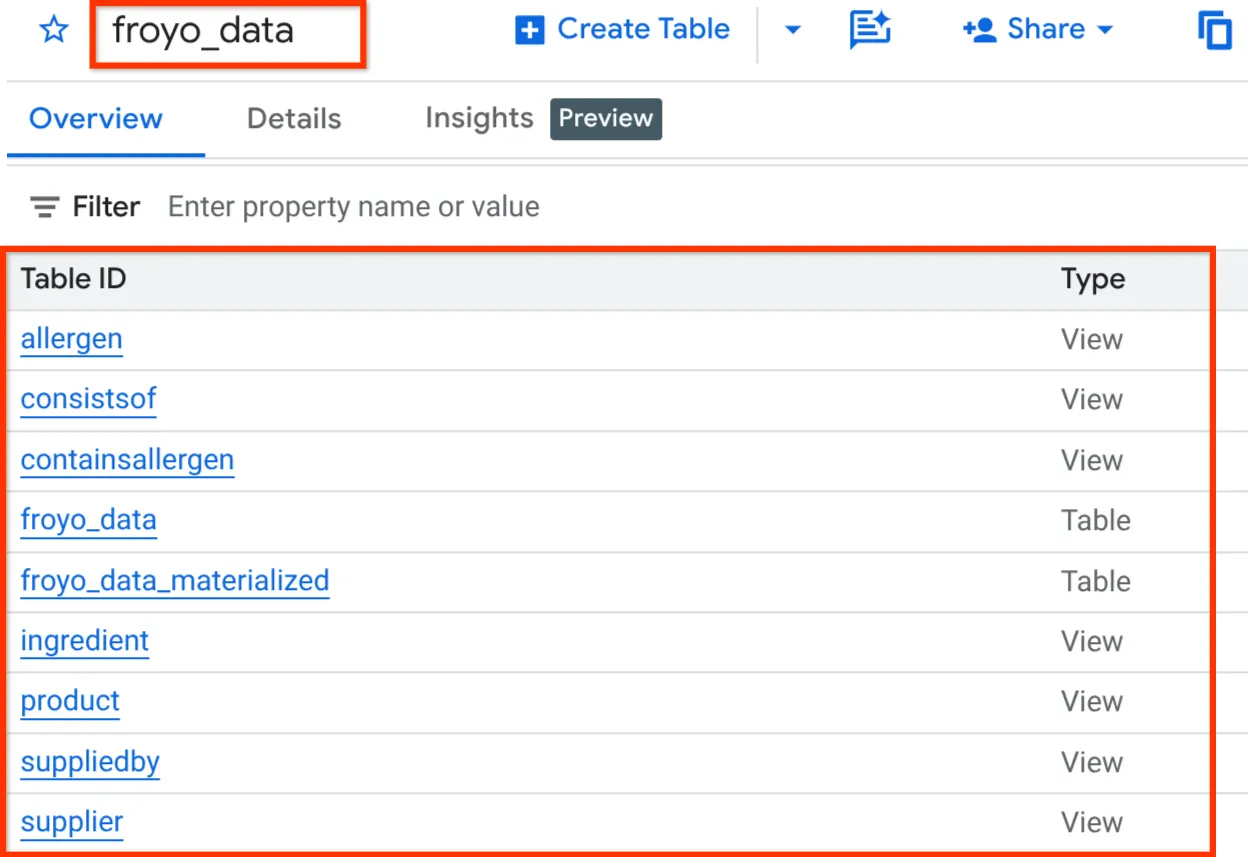
太棒了!我们非常快速地完成了所有这些数据库操作,真是太棒了。现在是进行最终测试的时候了!
在没有结算账号的情况下继续体验数据的步骤:
- 您可以从上面的 GitHub 代码库 链接获取数据 CSV 文件 (BigQuery Data)。
- 首先,通过从 Cloud Shell 终端运行以下命令来创建 BigQuery 数据集:
bq mk --location us-central1 --dataset froyo_data
- 接下来,通过逐个运行以下命令,将 GitHub 代码库中的 8 个数据文件(CSV 文件)下载到您的工作目录中:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- 逐个运行以下命令,以使用新创建的数据集中的数据创建这些表格
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
创建数据集、表格和数据后,您可以继续测试和体验我们刚刚讨论的数据。
9. 最终测试!!!
假设我希望我的智能体能够根据事实,以真实、完整且精心编排的信息来回答用户的问题。我将提出一个问题,智能体只有通过参考我的来源中的多个媒体文件和参考资料才能回答。
以下是我的用户问题:
I'm really interested in your Midnight Swirl froyo. Are there any allergens in it?
现在,宽泛搜索或 LLM 搜索会显示“零配料”。但是,我们构建了一个完整的语义推理,将所有非结构化媒体转换为结构化数据。因此,以下是一个简单的 SQL,用于提取此信息:
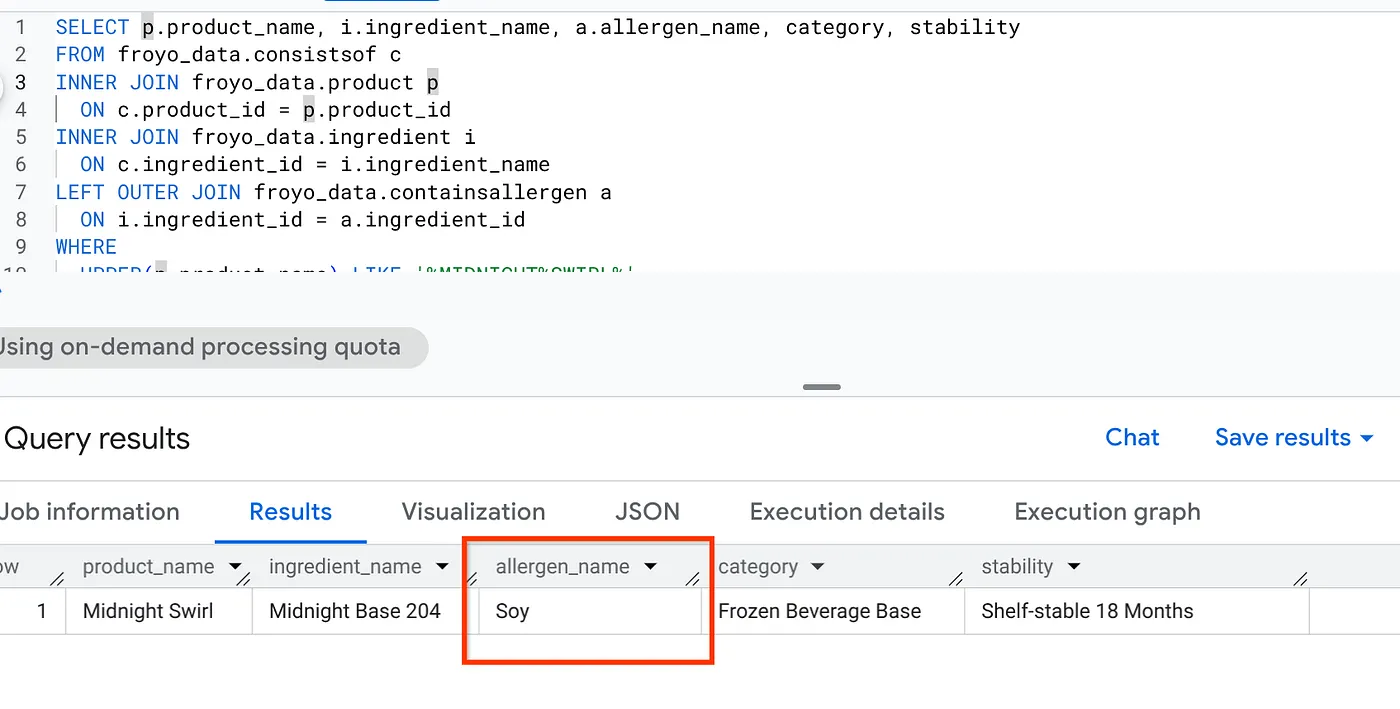
SELECT p.product_name, i.ingredient_name, a.allergen_name, category, stability
FROM froyo_data.consistsof c
INNER JOIN froyo_data.product p
ON c.product_id = p.product_id
INNER JOIN froyo_data.ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN froyo_data.containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND allergen_name IS NOT NULL;
太棒了!请看结果:
10. 清理
完成本实验后,请不要忘记删除扫描作业以及该作业最终创建的 BigQuery 表。
前往 https://console.cloud.google.com/bigquery/governance/metadata-curation/cloud-storage-discovery。点击要删除的作业旁边的垂直省略号,然后点击“删除”,以选择要删除的作业。
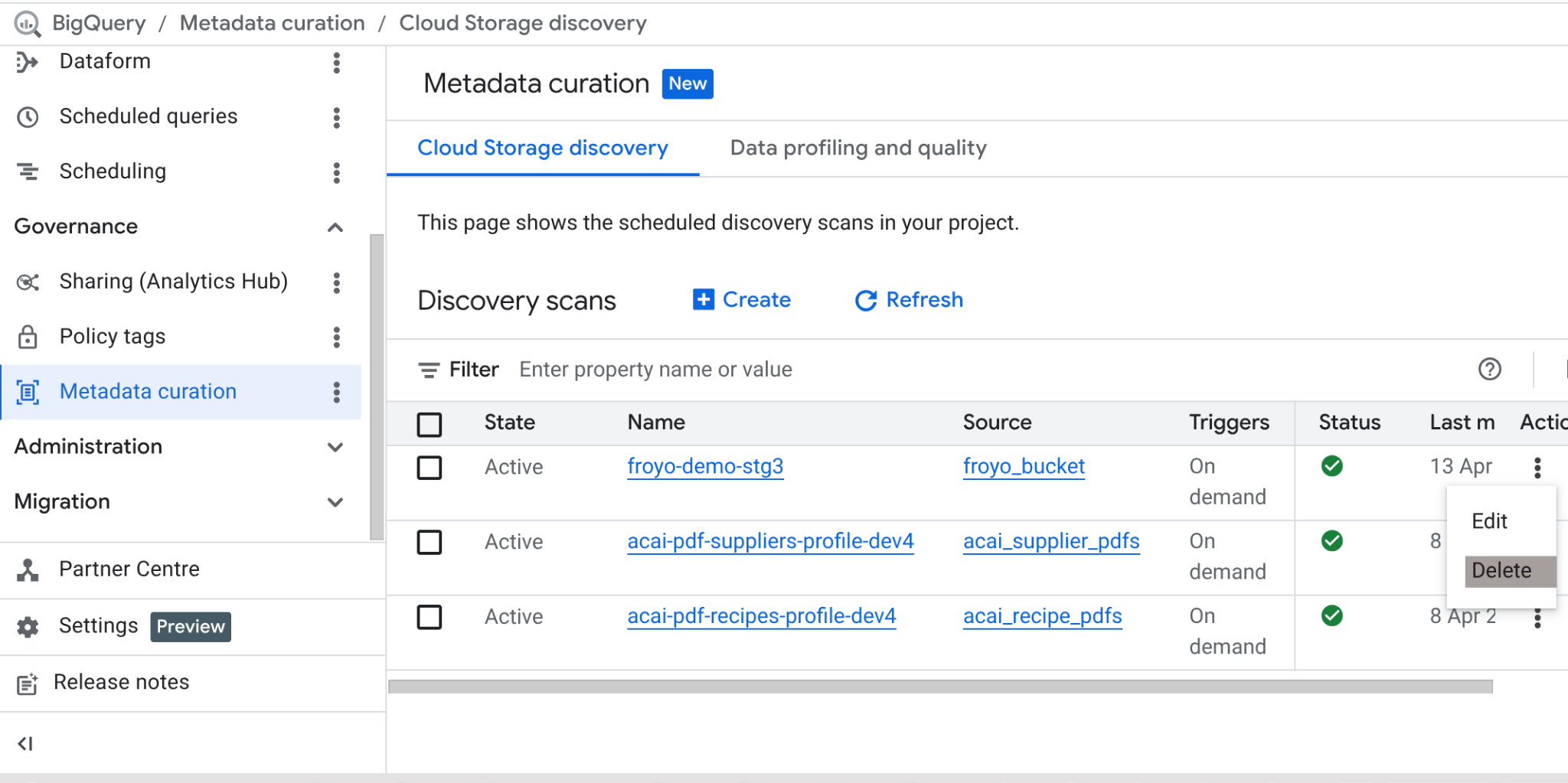
这样应该可以清理作业。
11. 恭喜
我们的实现成功识别了隐藏的过敏原。没有更多暗数据了,大家!在 第 2 部分 中,我们将把 BigQuery 数据联合到 AlloyDB 中的事务系统中,以统一我们的智能体应用的数据需求。