
1. 概览
在第 1 部分中,我们使用 Knowledge Catalog 和 DataScan 成功将杂乱无章的非结构化 PDF 转换为 BigQuery 中干净、智能且结构化的表格。现在,我们拥有了一个稳健的数据仓库。
如果您需要快速回忆一下,在第 1 部分的实验中,我们以虚构的冷冻酸奶连锁店为例,使用 BigQuery Knowledge Catalog 和 Dataplex 将其 400 个非结构化 PDF 文件(包含文本、表格和图片)转换为结构清晰的 BigQuery 表,并自动推断出这些表之间的关系。
构建内容
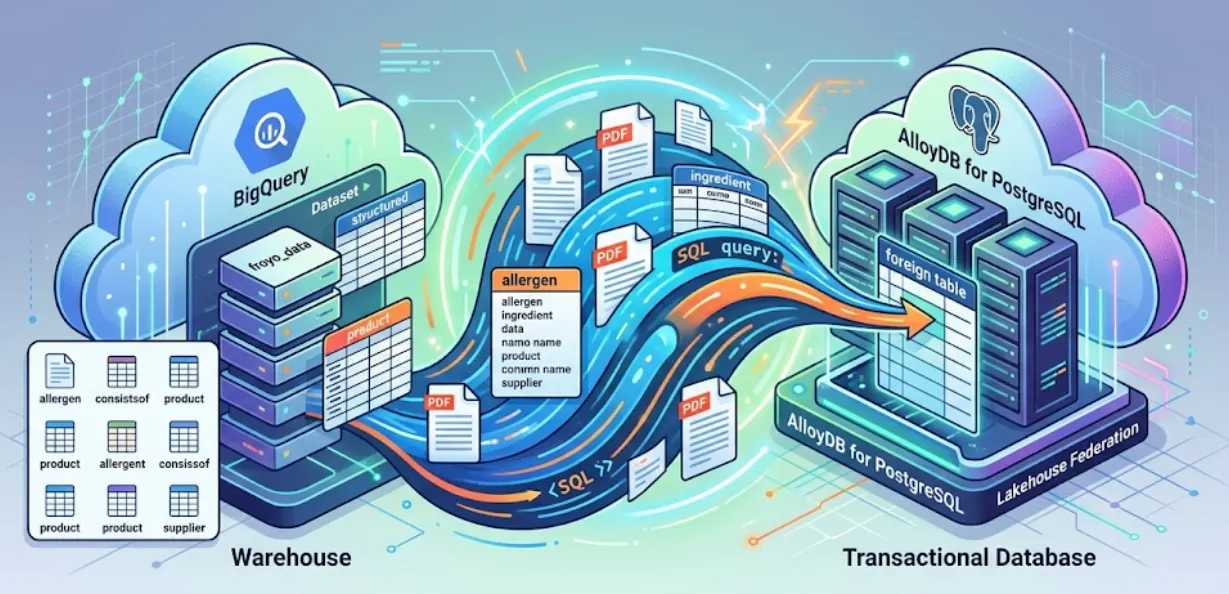
在此会话中,我们将设置 AlloyDB for PostgreSQL 并执行一项神奇的操作:将 BigQuery 数据直接联合到 AlloyDB 中。这意味着我们的事务型应用可以实时查询数据仓库中的数据,而无需复制或重复任何数据。
作为开发者,您必须在此阶段提出以下问题:
“如果数据已存储在 BigQuery 中,为什么还要使用 AlloyDB?为什么应用不直接针对 BigQuery 运行 SELECT 语句?
原因如下:
借助 Lakehouse Federation,您可以使用 AlloyDB 的查询引擎在同一界面中为应用的事务和分析工作负载提供支持。您还可以在 AlloyDB 上实现或导入这些数据,以便在应用中更快地访问这些数据,从而使用 AlloyDB AI 和列式引擎。
您可以使用 AlloyDB 作为事务型数据库,也可以在 BigQuery 或 BigLake 中存储大量数据。您的应用通常会与这两个系统分别独立集成,以访问不同 Google Cloud 服务中的数据。借助 AlloyDB 的 Lakehouse Federation,您可以使用 AlloyDB 的联合查询支持(以外部数据封装容器的形式实现)通过 AlloyDB 中的 SQL 接口访问 BigQuery 和 AlloyDB 数据。
我们不会构建脆弱的 ETL 流水线来查询 AlloyDB 中的 BigQuery 数据,而是使用联合查询。AlloyDB 将充当统一端点,在需要时无缝访问 BigQuery。
让我们开始构建吧!
学习内容
- 如何一键设置 AlloyDB 集群、实例和网络
- 如何设置扩展程序以准备进行联盟
- 如何设置从 BigQuery 到 AlloyDB 的联合
- 开始测试
要求
2. 准备工作
创建项目
- 在 Google Cloud Console 的项目选择器页面上,选择或创建一个 Google Cloud 项目。
- 确保您的 Cloud 项目已启用结算功能。了解如何检查项目是否已启用结算功能。
- 您将使用 Cloud Shell,它是在 Google Cloud 中运行的命令行环境。点击 Google Cloud 控制台顶部的“激活 Cloud Shell”。

- 连接到 Cloud Shell 后,您可以使用以下命令检查自己是否已通过身份验证,以及项目是否已设置为您的项目 ID:
gcloud auth list
- 在 Cloud Shell 中运行以下命令,以确认 gcloud 命令了解您的项目。
gcloud config list project
- 如果您想进行身份验证
gcloud auth login
- 如果项目未设置,请使用以下命令进行设置:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- 启用必需的 API:运行以下命令可启用所有必需的 API:
gcloud services enable alloydb.googleapis.com
注意事项和问题排查
“幽灵项目” 综合征 | 您运行了 |
结算 路障 | 您已启用项目,但忘记了结算账号。AlloyDB 是一款高性能引擎;如果“油箱”(结算)为空,它将无法启动。 |
API 传播 延迟 | 您点击了“启用 API”,但命令行仍显示 |
配额 Quags | 如果您使用的是全新试用账号,则可能会达到 AlloyDB 实例的区域配额。如果 |
3. 第 1 部分数据的快速回顾
在本部分中,您需要确保从非结构化 PDF 中提取的结构化数据可在 BigQuery 中使用。如果您错过了第 1 部分,或者没有结算账号,也没关系,您可以完成以下步骤并开始使用:
使用个人 Gmail 账号前往 Google Cloud 控制台,然后点击控制台右上角的“激活 Cloud Shell”按钮:
然后,按照下文“没有结算账号”部分中的步骤操作:
如需在没有结算账号的情况下继续体验数据,请按以下步骤操作:
- 您可以从上面的 GitHub 代码库链接获取数据 CSV 文件(BigQuery 数据)。
- 首先,通过在 Cloud Shell 终端中运行以下命令来创建 BigQuery 数据集:
bq mk --location us-central1 --dataset froyo_data
- 接下来,通过逐一运行以下命令,将 GitHub 代码库中的 8 个数据文件(CSV 文件)下载到您的工作目录中:
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.allergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.consistsof.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.containsallergen.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.froyo_data_materialized.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.ingredient.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.product.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.suppliedby.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/raw-data-to-gold/refs/heads/main/data/froyo_data.supplier.csv
- 依次运行以下命令,以使用新创建的数据集中的数据创建这些表
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.allergen ./froyo_data.allergen.csv allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.consistsof ./froyo_data.consistsof.csv product_id:STRING,ingredient_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.containsallergen ./froyo_data.containsallergen.csv ingredient_id:STRING,allergen_name:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.froyo_data_materialized ./froyo_data.froyo_data_materialized.csv allergen:STRING,containsallergen:STRING,ingredient:STRING,product:STRING,suppliedby:STRING,supplier:STRING,ref:STRING,md5_hash:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.ingredient ./froyo_data.ingredient.csv ingredient_id:STRING,ingredient_name:STRING,purity:STRING,moisture_content:STRING,ph_range:STRING,specific_gravity_range:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.product ./froyo_data.product.csv product_id:STRING,product_name:STRING,category:STRING,stability:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.suppliedby ./froyo_data.suppliedby.csv ingredient_id:STRING,supplier_id:STRING
bq load --autodetect --source_format=CSV --skip_leading_rows=1 --allow_quoted_newlines --quote="" froyo_data.supplier ./froyo_data.supplier.csv supplier_id:STRING,supplier_name:STRING,production_site_id:STRING,facility_grade:STRING
现在,我们已将数据导入 BigQuery,接下来将继续执行后续步骤。
4. 设置 AlloyDB 集群、实例和网络
我们提供了一个基于 Web 的快速入门应用,可帮助您设置 AlloyDB 集群、实例和其他依赖项。您可以按照此实验中的第 2-4 步操作,只需点击一个按钮即可完成设置:
https://codelabs.developers.google.com/quick-alloydb-setup
集群创建完毕后,前往“集群概览”页面,然后从该页面复制服务账号详细信息。
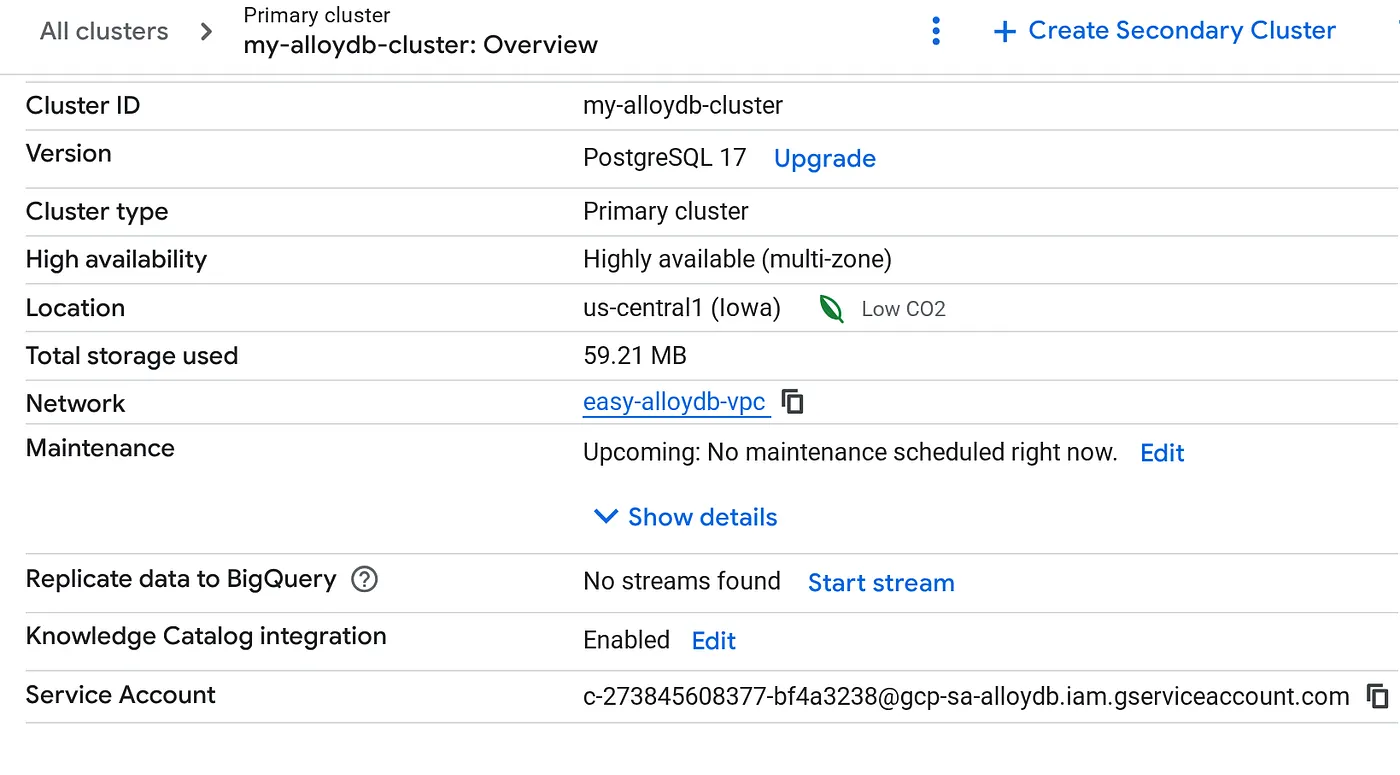
5. 权限设置
向此服务账号授予 BigQuery 权限
- 依次前往“IAM 和管理”>“IAM”。
- 点击“授予访问权限”。
- 将 AlloyDB 服务账号地址粘贴到“新主账号”字段中。
- 分配以下角色:
- BigQuery Data Viewer (roles/bigquery.dataViewer):允许读取数据。
- BigQuery User (roles/bigquery.user):允许运行查询。
- (可选,但建议使用)BigQuery Read Session User (roles/bigquery.readSessionUser):通过 Storage Read API 优化大型数据集的读取。
6. 连接到 AlloyDB 并启用 BigQuery 扩展程序
现在,我们连接到新创建的 AlloyDB 实例,以配置联合扩展程序。我们将使用 AlloyDB Studio 来完成此操作。
- 在集群概览页面(AlloyDB 控制台)中,点击主实例上的“修改主实例”,然后向下滚动到“高级配置选项”。
- 前往“标志”部分,然后将以下 2 个标志设为“启用”,如下所示:
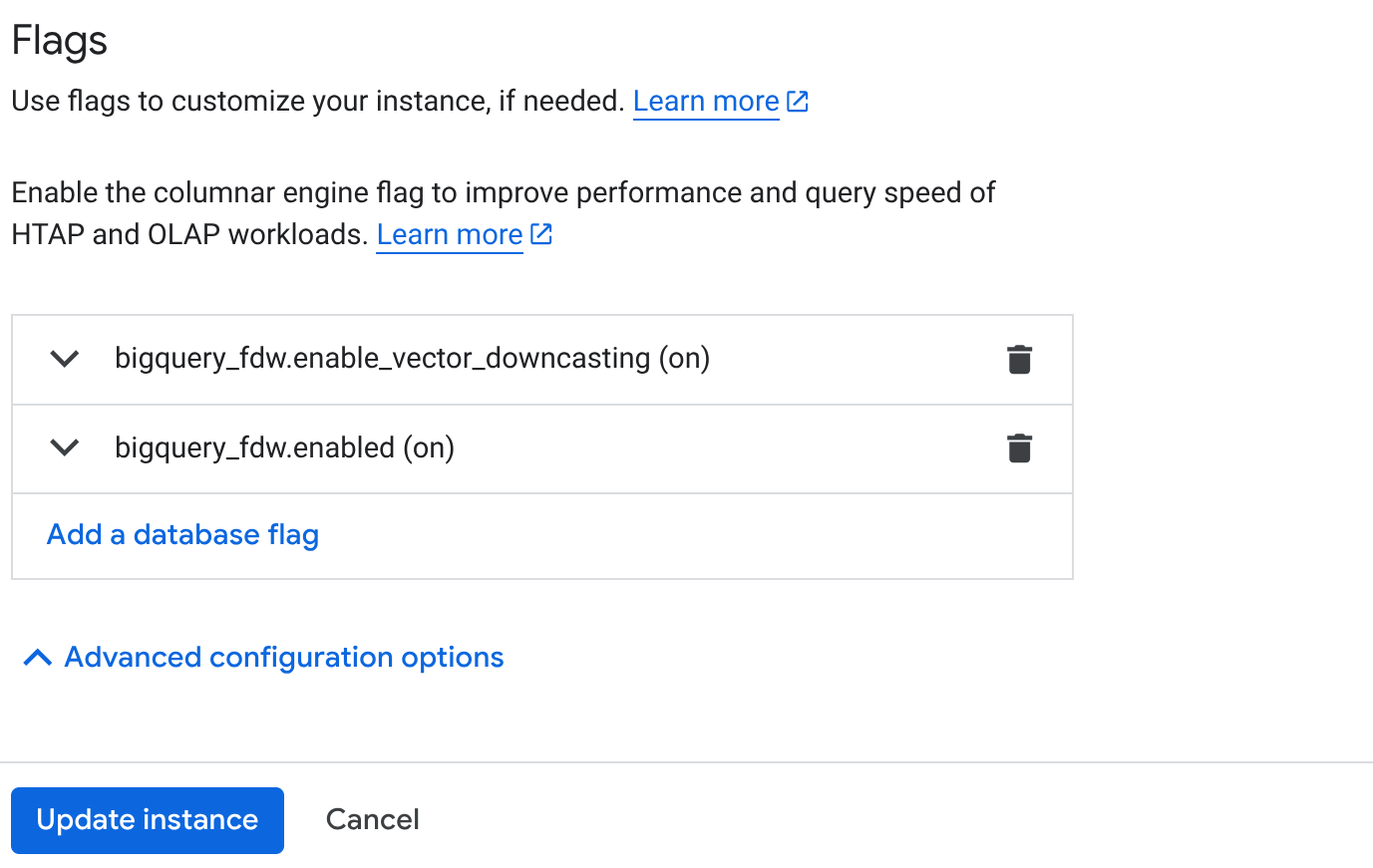 3. 点击更新实例按钮,更新过程需要几分钟才能完成。4. 在集群概览页面(AlloyDB 控制台)中,点击 AlloyDB Studio。
3. 点击更新实例按钮,更新过程需要几分钟才能完成。4. 在集群概览页面(AlloyDB 控制台)中,点击 AlloyDB Studio。
- 使用您在 AlloyDB 快速设置步骤中配置的数据库、用户名和密码进行连接。
- 连接成功后,在右侧的“查询编辑器”标签页中,输入以下语句并逐一运行:
CREATE EXTENSION IF NOT EXISTS bigquery_fdw;
CREATE SERVER bigquery_server FOREIGN DATA WRAPPER bigquery_fdw;
CREATE USER MAPPING FOR postgres SERVER bigquery_server;
- 成功完成上述操作后,前往左侧的探索器窗格,然后向下滚动到 BigQuery 表:
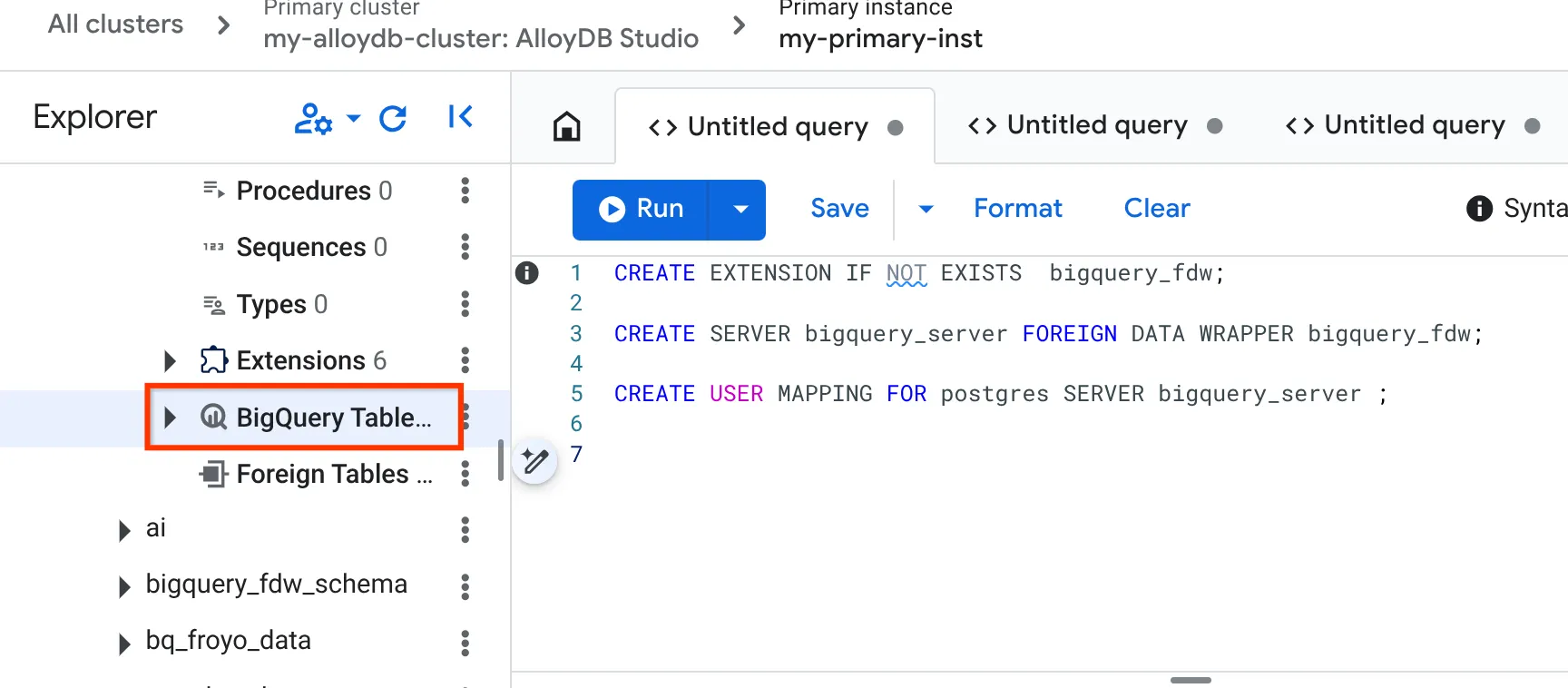
- 点击相应数据源旁边的 3 个点,然后点击“连接 BigQuery 表”。
- 在随即打开的“关联 BigQuery 表”弹出式窗口中,选择您的 project_id 和 BigQuery 数据集名称(在第 1 部分中创建),您将从该数据集中查询 AlloyDB 数据库中的数据。
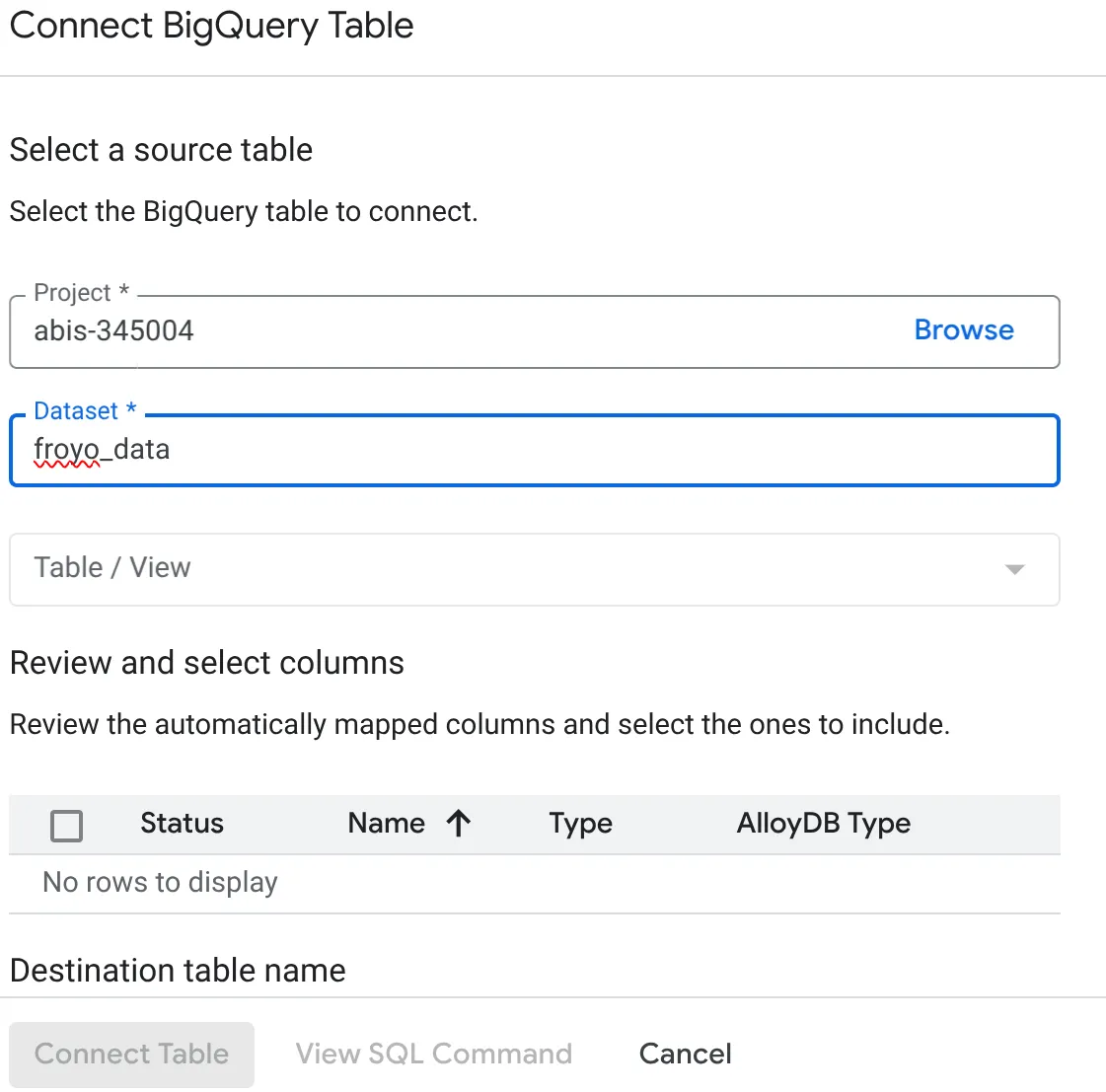
- 逐个选择每个表,以将所有数据连接到 AlloyDB。这样做的目的是验证列类型,确保它们在 AlloyDB 中受支持。
如果您想使用 SQL 而非通过点击方式执行相同的操作,请执行以下操作:
CREATE FOREIGN TABLE <<TABLE_NAME>> (
"cas_number" VARCHAR, "ingredient_name" VARCHAR, "max_moisture_percentage" DOUBLE PRECISION, "ph_range" VARCHAR, "purity_percentage" DOUBLE PRECISION, "shelf_life_months" BIGINT, "specific_gravity_range" VARCHAR
) SERVER "bigquery_server" OPTIONS (
project '<<PROJECT_ID>>',
dataset 'froyo_data',
table '<<BQ_TABLE_NAME>>'
);
神奇的功能!
我们刚刚在 AlloyDB 中创建了“外部表”。这些表看起来和行为方式都与普通的 PostgreSQL 表一样,但它们不存储任何数据。当您查询这些表时,AlloyDB 会立即将查询传递给 BigQuery,提取结果并将其返回给您。
7. 测试 AlloyDB 中的联合
让我们验证一下,是否可以直接从事务型 PostgreSQL 数据库查询大规模分析型 BigQuery 数据集。
在 AlloyDB Studio 中,我们运行一个查询,以了解“午夜漩涡”中含有哪些过敏原(与我们在第 1 部分中提出的问题相同,但这次是从 AlloyDB 提出的!):
SELECT
p.product_name,
i.ingredient_name,
a.allergen_name
FROM
consistsof c
INNER JOIN product p
ON c.product_id = p.product_id
INNER JOIN ingredient i
ON c.ingredient_id = i.ingredient_name
LEFT OUTER JOIN containsallergen a
ON i.ingredient_id = a.ingredient_id
WHERE
UPPER(p.product_name) LIKE '%MIDNIGHT%SWIRL%'
AND a.allergen_name IS NOT NULL;
Boom. 您应该会看到与在 BigQuery 中完全相同的结果。
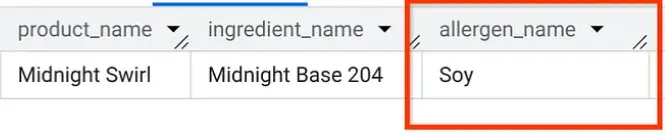
8. 清理
完成本实验后,请务必删除 AlloyDB 集群和实例。
它应清理集群及其实例。
9. 恭喜您成功实现统一数据层
想想我们刚刚完成了什么:
- 我们的事务型应用(在 AlloyDB 上运行)可以处理快速并发的用户会话。
- 当需要大量分析数据或历史背景信息(例如供应商详细信息或复杂的成分映射)时,它会查询 BigQuery froyo_dataschema。
- 零 ETL。没有数据流水线中断。没有不同步的数据库。我们只需存储一次(在 BQ 中),然后在需要时进行计算。
现在,我们的数据基础(包括分析数据和交易数据)已非常稳固且相互关联,接下来可以开始有趣的环节了。
在第 3 部分中,我们将在此架构之上构建多智能体应用,以运行 Froyo 业务运营!