
1. Einführung

Im vorherigen Lab haben Sie fragmentierte Versandprotokolle zusammengeführt und den Frachttransponder nach New York zurückverfolgt. Die Ankunftsdaten zeigen jedoch, dass der Container sofort umgeleitet wurde, um eine Zollkontrolle zu vermeiden. Der Weg hat Sie nun zum Hafen von Rio de Janeiro geführt, einem weitläufigen Hafen mit Tausenden von Containern. Den richtigen Container unter Tausenden zu finden, ist schwierig.
In diesem Lab verwenden Sie die integrierten KI-Funktionen von BigQuery, um unstrukturierte Bilder von Hafensicherheit zu „lesen“ und thermische Anomalien in Sensordaten zu erkennen – alles mit Standard-SQL. Anschließend exportieren Sie Vektoreinbettungen nach AlloyDB und führen eine Vektorsuche aus, um ein fragmentiertes Telemetriesignal mit dem fehlenden Container abzugleichen.
Aufgaben
- Sicherheitsbilder von Häfen scannen, um den gestohlenen Container mit BigQuery AI zu identifizieren
- Mit BigQuery AI eine thermische Anomalie erkennen, um zu bestätigen, dass der Container gestohlen und nicht verlegt wurde
- Vektoreinbettungen generieren und in AlloyDB für die Echtzeitsuche laden
- Fragmentiertes Telemetrie-Beaconsignal abgleichen, um den gestohlenen Container mithilfe der Vektorsuche zu finden
- Untersuchungsdaten mit natürlicher Sprache mithilfe der konversationellen Analyse analysieren
Voraussetzungen
- Ein Webbrowser wie Chrome
- Ein Google Cloud-Projekt mit aktivierter Abrechnung
- Grundkenntnisse in SQL und der Google Cloud Console
Dieses Codelab richtet sich an Entwickler mit mittleren Kenntnissen.
Die in diesem Codelab erstellten Ressourcen sollten weniger als 5 $ kosten.
2. Vorbereitung
Cloud Shell starten
Sie verwenden Google Cloud Shell, um den Code herunterzuladen, Einrichtungs-Scripts auszuführen und die Anwendung bereitzustellen.
- Öffnen Sie die Cloud Shell shell.cloud.google.com in einem neuen Browsertab.
- Legen Sie nach der Verbindung Ihre Projekt-ID fest und bestätigen Sie Ihre Umgebung:
gcloud config set project <<YOUR_PROJECT_ID>>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
Es sollte eine Meldung wie die folgende angezeigt werden:
Your active configuration is: [cloudshell-####] Updated property [core/project]
Repository klonen
Klonen Sie das Codelab-Repository in Ihre Cloud Shell-Umgebung:
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/bigquery-alloydb-insights
git checkout main
cd codelabs/bigquery-alloydb-insights/
APIs aktivieren
Führen Sie diesen Befehl in Cloud Shell aus, um alle für dieses Lab erforderlichen APIs zu aktivieren:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com
Bei erfolgreicher Ausführung sollte eine Meldung wie die folgende angezeigt werden:
Operation "operations/..." finished successfully.
3. Umgebung einrichten
Bevor Sie Bilder und Telemetriedaten analysieren können, müssen Sie die Infrastruktur für dieses Lab einrichten. Sie führen zwei Skripts aus: eines startet die AlloyDB-Bereitstellung im Hintergrund und das andere erstellt alle BigQuery-Ressourcen, die Sie benötigen.
Schritt 1: AlloyDB-Bereitstellung starten (Hintergrund)
Die Bereitstellung des AlloyDB-Clusters dauert etwa 10 Minuten. Sie starten sie also zuerst und lassen sie im Hintergrund laufen, während Sie die BigQuery-Abschnitte durcharbeiten. Das Skript speichert Ihre aktiven Projekteinstellungen automatisch in einer lokalen .env-Datei. Ihre Konfiguration wird also auch dann gespeichert, wenn Ihr Cloud Shell-Terminal geschlossen oder neu gestartet wird.
chmod +x scripts/setup_alloydb.sh
nohup ./scripts/setup_alloydb.sh > /dev/null 2>&1 &
echo "AlloyDB deployment started in background (PID: $!)"
Schritt 2: Setup-Skript ausführen
Mit diesem Skript werden das BigQuery-Dataset, die Cloud-Ressourcenverbindung, die IAM-Berechtigungen und der GCS-Bucket erstellt und alle Sensordaten geladen, die Sie in diesem Lab analysieren. Außerdem werden die in der Datei .env gespeicherten Umgebungsvariablen gelesen und überprüft.
chmod +x scripts/setup_lab.sh
./scripts/setup_lab.sh
Die Ausführung des Skripts dauert etwa eine Minute. Wenn der Vorgang abgeschlossen ist, wird eine Zusammenfassung aller erstellten Inhalte angezeigt.
📝 Hinweis zum Zurücksetzen der Umgebung: Wenn Ihre Cloud Shell-Sitzung während dieses Labs ein Zeitlimit überschreitet oder neu gestartet wird, können Sie Ihre Terminalvariablen sofort wiederherstellen, indem Sie Folgendes ausführen:
source scripts/setenv.sh
Schritt 3: Cloud Shell-Editor starten
Bisher haben Sie das Cloud Shell-Terminal verwendet. Wechseln Sie jetzt zum vollständigen Cloud Shell-Editor. Dort haben Sie einen VS Code-ähnlichen Arbeitsbereich mit integrierter BigQuery-Unterstützung.
- Klicken Sie im Cloud Shell-Terminalbereich unten auf dem Bildschirm auf die Schaltfläche Editor öffnen, um den Cloud Shell-Editor-Arbeitsbereich zu starten.

Schritt 4: Data Agent Kit-Erweiterung installieren
Die Erweiterung „Google Cloud Data Agent Kit“ bietet eine umfassende Integration mit Google Cloud-Datendiensten direkt in Ihrem Editor. So können Sie mit BigQuery, AlloyDB und Cloud Storage interagieren, ohne den Kontext wechseln zu müssen.
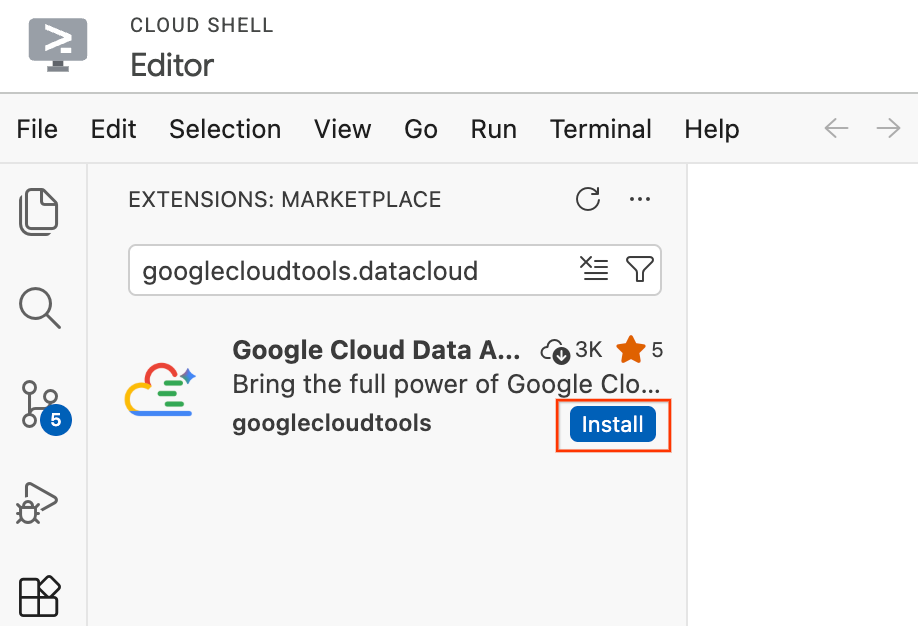
- Klicken Sie im Cloud Shell-Editor in der Aktivitätsleiste ganz links auf dem Bildschirm auf das Symbol Extensions (vier Quadrate).
- Geben Sie oben im Bereich „Erweiterungen“ in der Suchleiste
googlecloudtools.datacloudein. - Suchen Sie nach der Erweiterung mit dem Namen Google Cloud Data Agent Kit, die von Google Cloud veröffentlicht wurde.
- Klicken Sie auf die Schaltfläche Installieren.
- Sie werden gefragt, ob Sie dem Publisher „googlecloudtools“ und seinen Erweiterungen vertrauen. Klicken Sie auf Verlagen und Webpublishern vertrauen und installieren, um fortzufahren.
Schritt 5: Erweiterung authentifizieren und konfigurieren
Verknüpfen Sie die Erweiterung nach der Installation mit Ihrem Google Cloud-Projekt.
- Eine Onboarding-Seite mit dem Titel „Google Cloud Data Agent Kit Onboarding“ sollte automatisch geöffnet werden. Klicken Sie auf In Google Cloud anmelden. Folgen Sie allen Browseraufforderungen, um den Zugriff zu erlauben.
- Ein Pop-up-Fenster mit der Meldung „Einrichtung läuft“ wird angezeigt. Die Erweiterung sucht automatisch nach erforderlichen Abhängigkeiten wie der Google Cloud CLI.
- Suchen Sie im Bereich Konfigurationsübersicht das Projektfeld. Klicken Sie auf das Drop-down-Menü und wählen Sie Ihr Google Cloud-Projekt aus. Legen Sie Ihre Region als
us-central1fest. - Warten Sie, bis die Einrichtungsprüfungen abgeschlossen sind. Wenn die Meldung „Einrichtung abgeschlossen!“ angezeigt wird, klicken Sie auf MCP-Server konfigurieren.
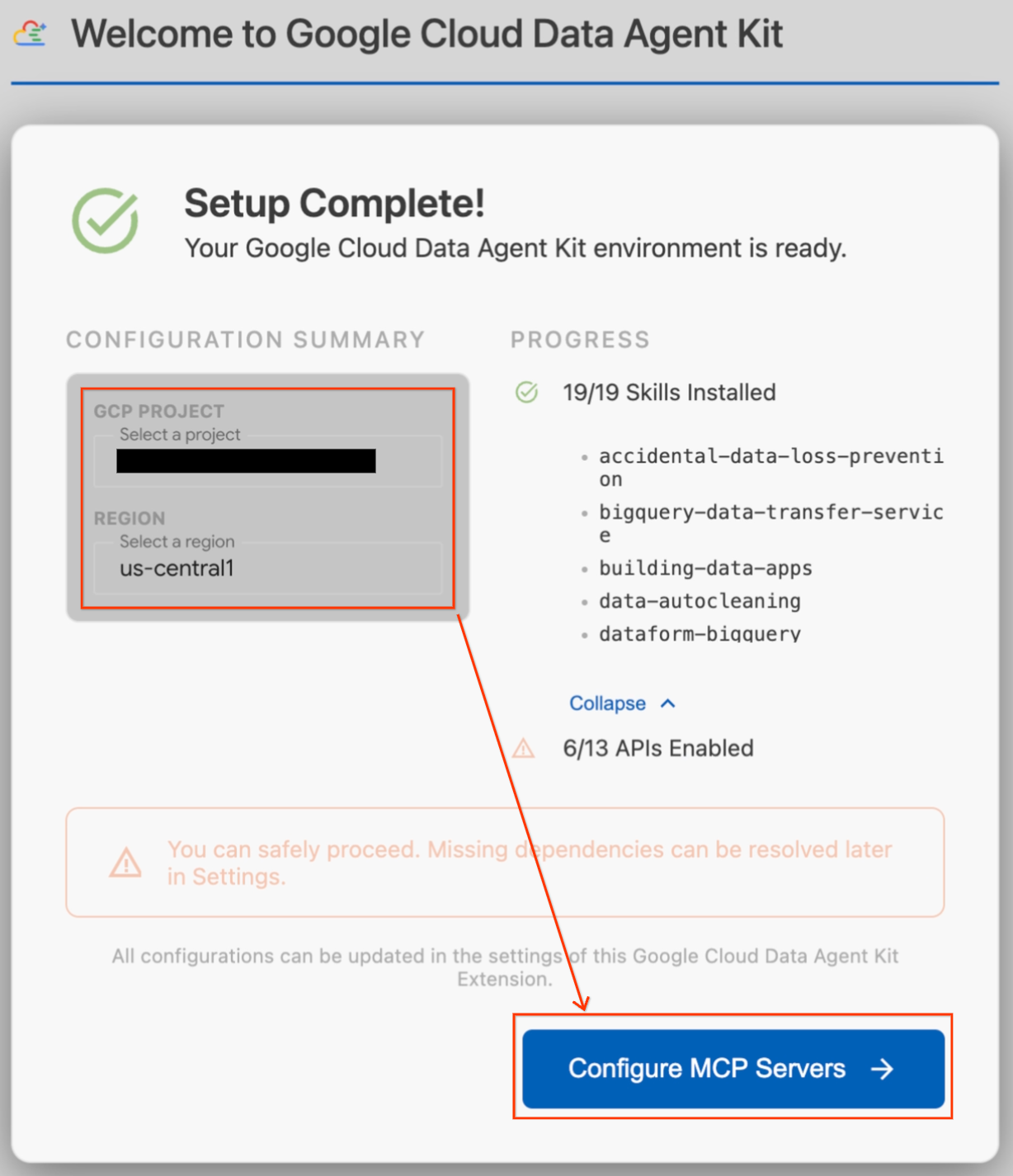
- Wählen Sie unter „MCP-Konfiguration“ BigQuery und AlloyDB aus und klicken Sie dann auf Jetzt starten.
Schritt 6: Konfigurationsoptionen ansehen
Nach Abschluss der Einrichtung werden Sie zum Dashboard „Erste Schritte mit dem Google Cloud Data Agent Kit“ weitergeleitet.
- Klicken Sie unter „Einrichtung und Konfiguration“ auf Jetzt starten.
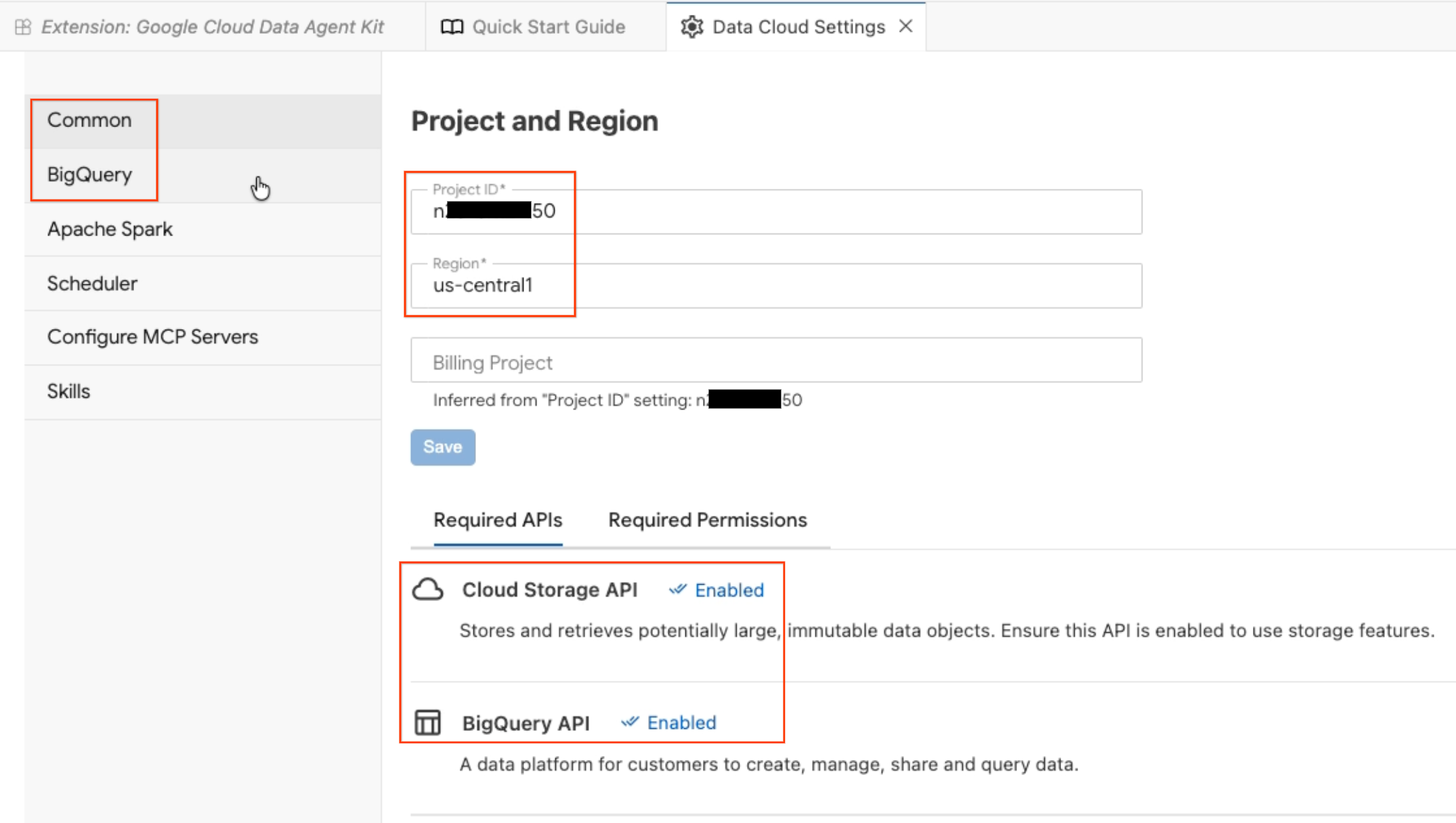
- Der Bereich Data Agent-Konfiguration wird geöffnet. Tabs ansehen:
- Projekt und Region:Prüfen Sie die ausgewählte Projekt-ID und ob die erforderlichen APIs (Cloud Storage API, BigQuery API, Catalog API und AlloyDB API) aktiviert sind.
- BigQuery:Konfigurieren Sie den standardmäßigen Standort für Ihre BigQuery-Abfragen. Verwenden Sie die Region
us-central1. - MCP-Server konfigurieren:Hier sehen Sie die aktivierten MCP-Server (BigQuery, Notebooks, AlloyDB usw.), die es KI-Agenten ermöglichen, sicher mit Ihren Daten zu interagieren.
- Skills:Nutzen Sie vordefinierte Skills, die Agents spezielle Funktionen für komplexe Datenaufgaben bieten.
Schritt 7: Mit BigQuery überprüfen
Prüfen Sie, ob alles funktioniert, indem Sie eine schnelle Abfrage für ein öffentliches Dataset ausführen.
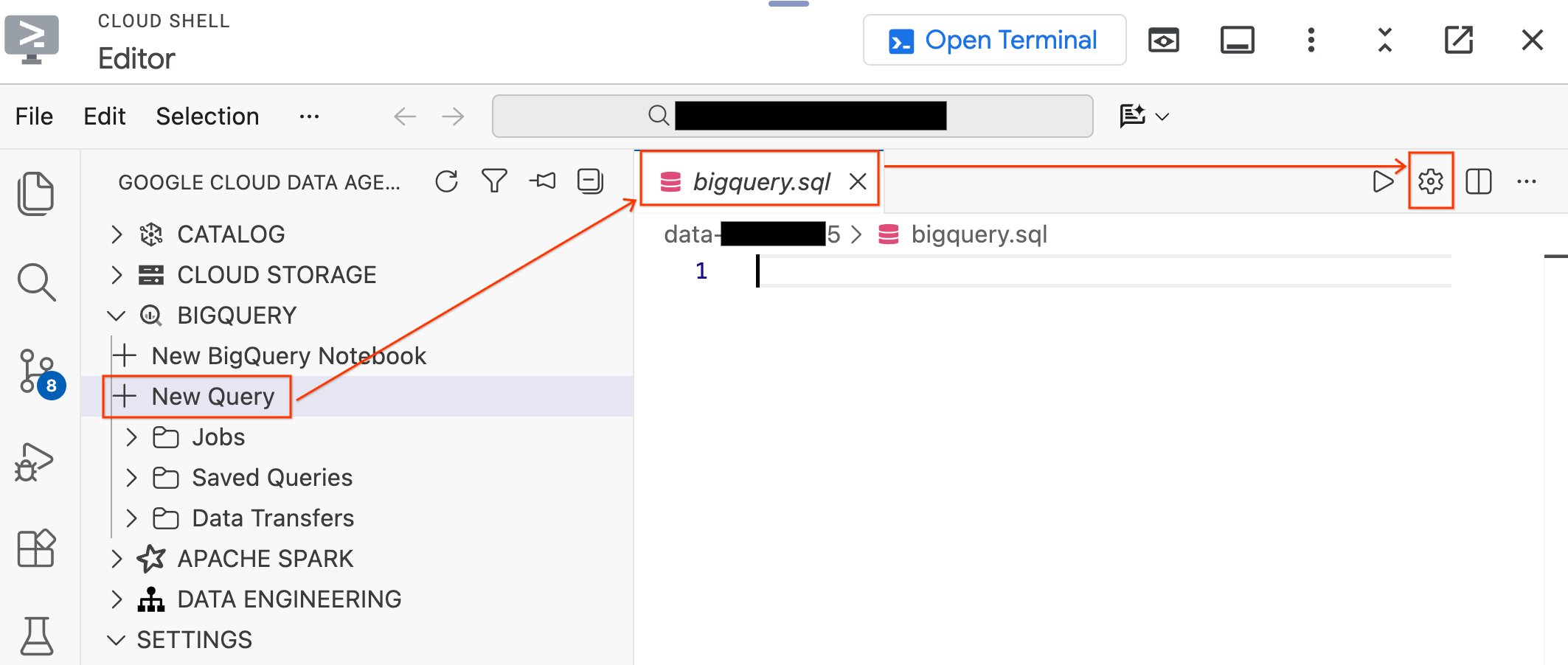
- Maximieren Sie im Bereich „Data Agent Kit“ auf der linken Seite den Abschnitt BigQuery und klicken Sie auf Neue Abfrage, um einen neuen Tab für den Abfrageeditor zu öffnen.
- Speichern Sie die Datei, indem Sie
Ctrl+S(Windows/Linux) oderCmd+S(macOS) drücken, und geben Sie ihr den Namenbigquery. Dieser Tab wird für alle Ihre BigQuery-Vorgänge verwendet. - Klicken Sie auf Abfrageeinstellungen, wenn der Tab
bigquery.sqlaktiv ist, wählen Sie BigQuery als Datenquelle aus und klicken Sie auf Speichern.
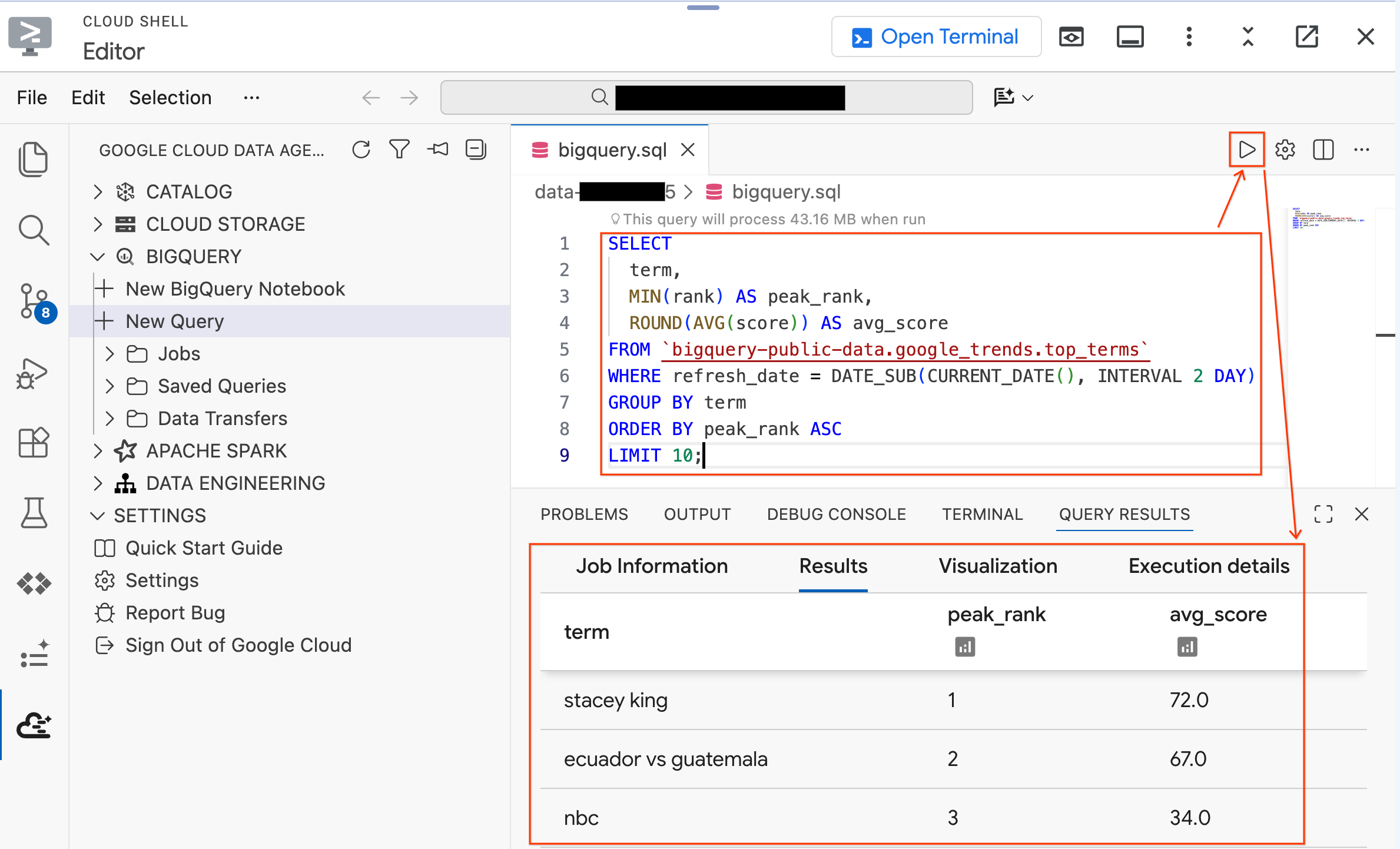
- Führen Sie die folgende Abfrage für ein öffentliches Dataset aus:
SELECT
term,
MIN(rank) AS peak_rank,
ROUND(AVG(score)) AS avg_score
FROM `bigquery-public-data.google_trends.top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 2 DAY)
GROUP BY term
ORDER BY peak_rank ASC
LIMIT 10;
- Sie sollten die zehn wichtigsten Google-Suchbegriffe der letzten Tage sehen. Wenn Ergebnisse angezeigt werden, ist Ihre Erweiterung verbunden und einsatzbereit.
Führen Sie nun eine Abfrage für die Labordaten aus, die von Ihrem Setupscript erstellt wurden. Ersetzen Sie die vorhandene Abfrage durch diese:
SELECT * FROM `lost_cargo_dataset.telemetry_data` LIMIT 5;
Sie sollten Telemetrielogeinträge mit den Spalten shipment_id und telemetry_string sehen. Diese Daten analysieren Sie im gesamten Lab.
Zusammenfassung des Abschnitts:Sie haben die AlloyDB-Bereitstellung im Hintergrund gestartet, das Setupscript ausgeführt und den Cloud Shell Editor mit der Data Agent Kit-Erweiterung konfiguriert.
4. Sicherheitsaufnahmen ansehen
Das Ermittlungsteam hat Sicherheitsaufnahmen vom Hafen von Rio de Janeiro gefunden, die Reihen von Schiffscontainern zeigen. Aus Lab 1 wissen Sie, dass der Zielcontainer rot ist. Jetzt müssen Sie genau herausfinden, welcher rote Container es ist.
Sie erstellen eine Objekttabelle, mit der BigQuery die Sicherheitsbilder in Cloud Storage „sehen“ kann. Anschließend verwenden Sie die Funktion AI.GENERATE, um Gemini aufzufordern, strukturierte Daten aus den einzelnen Bildern zu extrahieren.
Schritt 1: Objekttabelle erstellen
Eine Objekttabelle ist eine spezielle BigQuery-Tabelle, die als Index für unstrukturierte Dateien (Bilder, PDFs, Audio) dient, die in Cloud Storage gespeichert sind. Die Dateien werden nicht in BigQuery kopiert, sondern es wird eine abfragbare Referenz erstellt, damit KI-Funktionen sie „sehen“ können.
Führen Sie auf dem Tab bigquery.sql im Editor die folgende Anweisung aus, um die Objekttabelle zu erstellen, die auf die Port-Sicherheitsbilder im Bucket Ihres Projekts verweist:
SET @@location = 'us-central1';
EXECUTE IMMEDIATE CONCAT("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.port_security_images`
WITH CONNECTION `us-central1.lost_cargo_conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://""", @@project_id, """-lab2/images/*']
);
""");
Hier sehen Sie, was BigQuery jetzt erkennen kann:
SELECT uri, content_type FROM `lost_cargo_dataset.port_security_images` LIMIT 5;
Jede Zeile steht für eine Bilddatei in Cloud Storage. BigQuery kann diese Bilder jetzt direkt an KI-Modelle übergeben.
Schritt 2: Sicherheitsbilder analysieren
Verwenden Sie nun die AI.GENERATE-Funktion von BigQuery, um jedes Sicherheitsbild zu analysieren. Diese einzelne SQL-Abfrage weist Gemini an, jedes Bild zu untersuchen und strukturierte Daten zurückzugeben:
SELECT
uri,
AI.GENERATE(
(
'Examine this port security image. Identify any shipping container IDs visible on the container and provide a one-word color of the container.',
ref
),
output_schema => 'detected_container_id STRING, color STRING'
).* EXCEPT (full_response, status)
FROM `lost_cargo_dataset.port_security_images`;
Schritt 3: Zielcontainer ermitteln
Sehen Sie sich die Ergebnisse an. Suchen Sie nach der Zeile, in der in der Spalte color Rot (oder eine rote Variante) angezeigt wird. Notieren Sie sich den detected_container_id. Das ist Ihr Ziel: MV-CAPYBARA-003.
Schritt 4: Visuellen Abgleich prüfen
So rufen Sie das analysierte Bild auf, ohne den Editor zu verlassen:
- Klicken Sie im linken Bereich des Data Agent Kit auf Cloud Storage.
- Erweitern Sie den Bucket (
YOUR_PROJECT_ID-lab2/images/) und klicken Sie auf die Bilddatei, die dem roten Container entspricht, um sie direkt im Editor anzusehen.
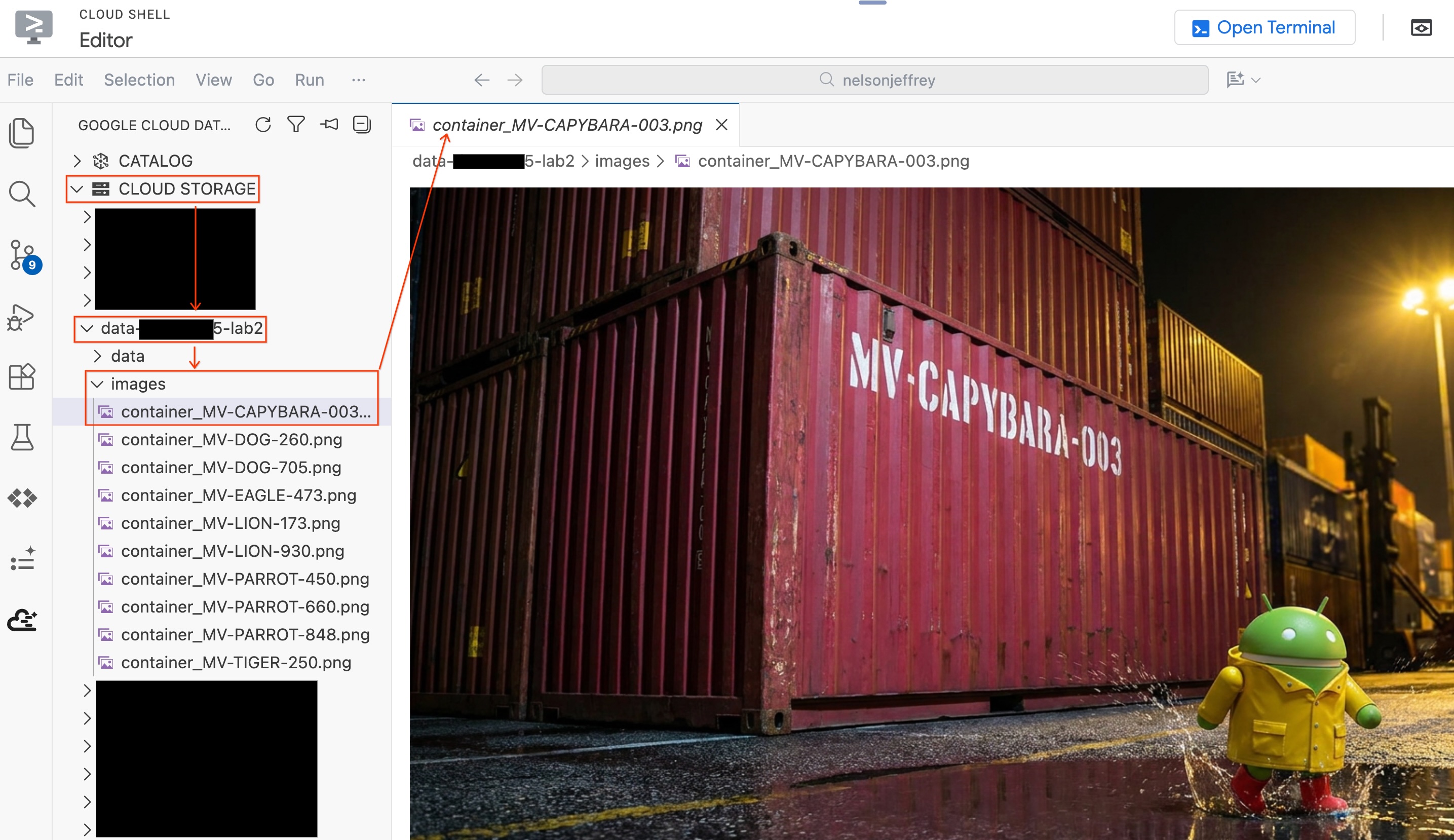
Zusammenfassung des Abschnitts:Sie haben eine Objekttabelle erstellt, um BigQuery Zugriff auf Bilder der Hafenüberwachung zu gewähren, und dann AI.GENERATE verwendet, um strukturierte Containerdaten aus jedem Bild zu extrahieren. Der rote Container wurde als MV-CAPYBARA-003 identifiziert.
5. Diebstahl bestätigen
Sie haben den fehlenden Container als MV-CAPYBARA-003 identifiziert. Wurde er gestohlen oder ist er einfach nur verloren gegangen? Manifestlogs weisen darauf hin, dass dieser Container in der Nähe des Umweltsensors SENS-99 abgestellt wurde. Wenn die Diebe die integrierte Kühleinheit des Containers vor dem Transport absichtlich deaktiviert haben, wurde möglicherweise ein plötzlicher Anstieg der Wärmeabgabe aufgezeichnet.SENS-99
Wir verwenden die Anomalieerkennung, um zu beweisen, dass der Container manipuliert wurde.
- Sehen Sie sich zuerst die historische Baseline an. Das sind die normalen Messwerte von
SENS-99in den letzten Stunden:
SELECT * FROM `lost_cargo_dataset.thermal_history`
ORDER BY reading_time DESC
LIMIT 50;
Die Temperaturen liegen in einem engen Bereich zwischen 24 und 26 °C. So sieht es normalerweise aus.
- Sehen Sie sich nun die aktuellen Messwerte desselben Sensors an:
SELECT * FROM `lost_cargo_dataset.thermal_current`
ORDER BY thermal_reading DESC
LIMIT 50;
Sehen Sie sich den Messwert 148,4 °F oben an. Alles andere sieht normal aus. Dieser Anstieg würde entweder auf einen Ausfall der Kühleinheit oder auf eine vorsätzliche Manipulation hindeuten. Das lässt sich ganz einfach herausfinden.
- Führen Sie die Anomalieerkennung aus. Für die
AI.DETECT_ANOMALIES-Funktion von BigQuery wird das vortrainierte TimesFM-Foundation Model verwendet, um Zeitreihenmuster zu analysieren und automatisch Ausreißer zu kennzeichnen. Es ist kein Modelltraining erforderlich:
SELECT *
FROM AI.DETECT_ANOMALIES(
TABLE `lost_cargo_dataset.thermal_history`,
TABLE `lost_cargo_dataset.thermal_current`,
data_col => 'thermal_reading',
timestamp_col => 'reading_time',
id_cols => ['sensor_id']
)
WHERE is_anomaly = TRUE;
- Sehen Sie sich die Ergebnisse an. Der Wert von 64,7 °C sollte als Anomalie mit einer hohen Wahrscheinlichkeit gekennzeichnet werden, da er darauf hinweist, dass in der Nähe des Containers etwas Ungewöhnliches passiert ist.
Zusammenfassung des Abschnitts:Sie haben die AI.DETECT_ANOMALIES-Funktion von BigQuery verwendet, um das vortrainierte TimesFM-Modell zu nutzen. Durch Ausführen einer einzelnen SQL-Abfrage haben Sie automatisch Ausreißer identifiziert und das anomale Manipulationsereignis isoliert, ohne komplexen Code für maschinelles Lernen schreiben oder Modelle von Grund auf neu trainieren zu müssen.
6. Tracking-System vorbereiten
Der Container wurde als gestohlen gemeldet und befindet sich nicht mehr in Rio de Janeiro. Jeder Container in der Flotte sendet Telemetrie-Beaconsignale: Sensormesswerte, GPS-Fragmente und Statuslogs. Wenn der Tracker des gestohlenen Containers noch Signale sendet, können Sie ihn anhand bekannter Signaturen finden.
BigQuery eignet sich hervorragend für die bisherigen Analysen, aber für die Echtzeitlokalisierung eines Containers sind operative Abfragen mit niedriger Latenz erforderlich. AlloyDB, eine vollständig verwaltete PostgreSQL-kompatible Datenbank, wurde genau für diesen Zweck entwickelt: Vektorsucheanfragen, die schnell genug für ein Live-Tracking-System sind. Sie laden Ihre Telemetrie-Einbettungen in AlloyDB und verwenden sie, um das Beaconsignal abzugleichen.
Der AlloyDB-Cluster, den Sie zuvor im Hintergrund gestartet haben, sollte jetzt bereit sein. Wir konfigurieren sie direkt im Editor.
Schritt 1: Verbindung zu AlloyDB über den Editor herstellen
Statt zur Cloud Console zu wechseln, können Sie mit der Data Agent Kit-Erweiterung direkt eine Verbindung zu AlloyDB herstellen.
- Klicken Sie im Bereich „Data Agent Kit“ auf der linken Seite unter dem Abschnitt BigQuery auf Neue Abfrage, um einen neuen Tab für den Abfrageeditor zu öffnen.
- Speichern Sie die Datei, indem Sie
Ctrl+S(Windows/Linux) oderCmd+S(macOS) drücken, und geben Sie ihr den Namenalloydb. Dieser Tab wird für alle AlloyDB-Abfragen verwendet. - Klicken Sie auf das Zahnradsymbol, um das Modal Abfrageeinstellungen zu öffnen.
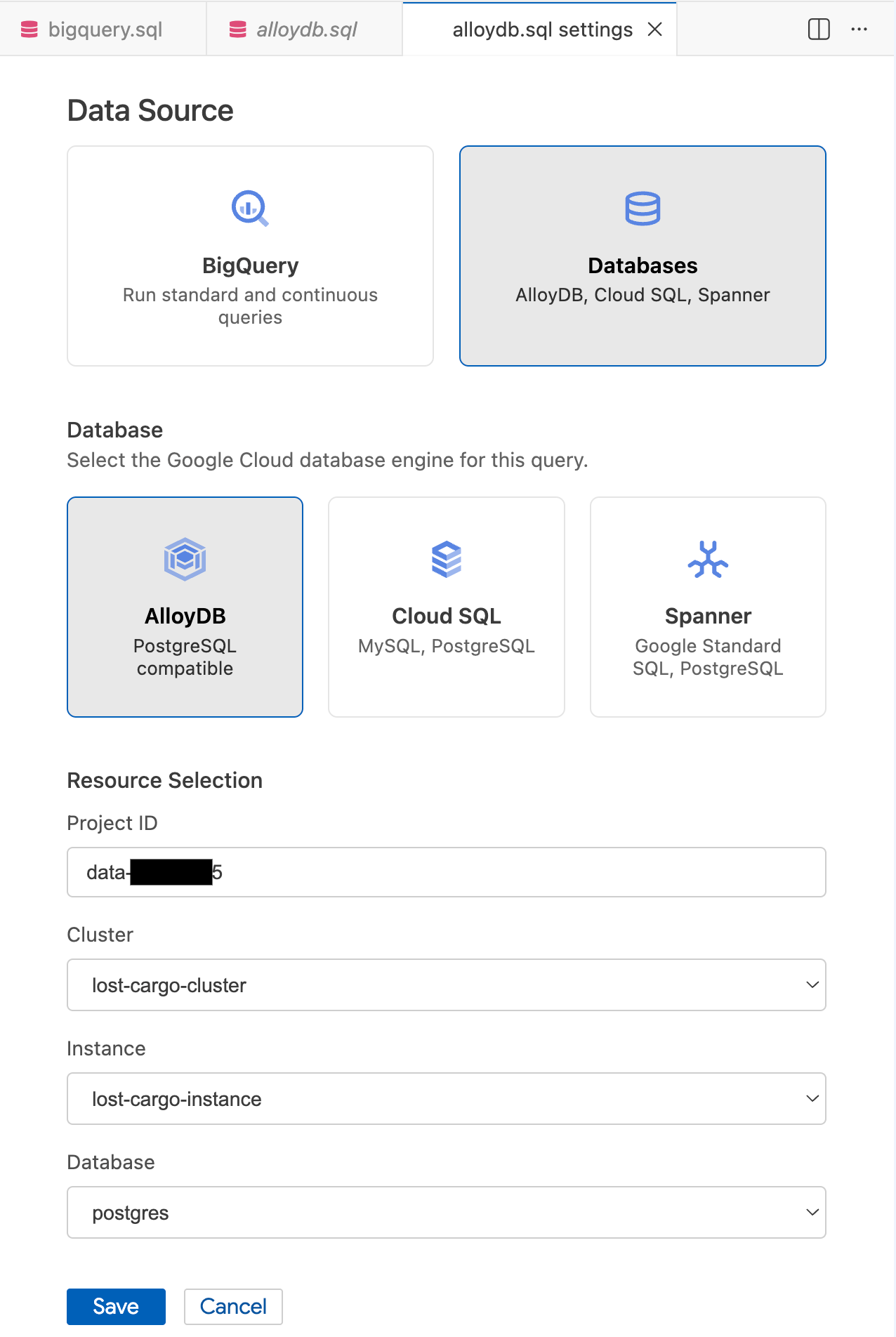
- Wählen Sie im Modal Abfrageeinstellungen unter Datenquelle die Option Datenbanken aus.
- Wählen Sie unter Datenbank die Option AlloyDB aus.
- Geben Sie die Details für die Ressourcenauswahl ein:
- Projekt-ID: Geben Sie Ihre Google Cloud-Projekt-ID ein.
- Cluster: Wählen Sie
lost-cargo-clusteraus. - Instanz: Wählen Sie
lost-cargo-instanceaus. - Datenbank: Wählen Sie
postgresaus.
- Klicken Sie auf Speichern.
Schritt 2: Vector-Erweiterung aktivieren und Tabelle erstellen
Nachdem Sie eine Verbindung zu AlloyDB hergestellt haben, müssen Sie die erforderlichen KI-Erweiterungen aktivieren und die Tabelle erstellen, in der die eingebetteten Telemetriedaten gespeichert werden.
- Fügen Sie auf dem aktiven
.sql-Tab die folgenden Befehle ein, um die erforderlichen Erweiterungen zu aktivieren:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
- Markieren Sie den Text und klicken Sie oben rechts im Editor auf die Schaltfläche Abfrage ausführen (das Wiedergabesymbol).
- Sehen Sie sich das Terminalfeld Abfrageergebnisse unten auf dem Bildschirm an. Dort sollte
Statement executed successfullystehen.
- Ersetzen Sie als Nächstes den Text im Editor durch die folgende Anweisung, um die Telemetrietabelle zu erstellen:
CREATE TABLE IF NOT EXISTS vessel_telemetry (
entry_id SERIAL PRIMARY KEY,
shipment_id VARCHAR(50),
telemetry_string TEXT,
embedding_vector vector(768)
);
- Führen Sie diese Abfrage wie die letzte aus. Prüfen Sie im unteren Bereich, ob die Ausführung erfolgreich war.
Der Typ vector(768) stammt aus der Erweiterung pgvector, die Sie gerade aktiviert haben. Die 768 Dimensionen entsprechen der Ausgabe des text-embedding-005-Modells von Google, das Sie in BigQuery zum Generieren der Einbettungen verwenden.
Zusammenfassung des Abschnitts:Sie haben eine direkte Verbindung zu AlloyDB über Cloud Shell Editor hergestellt, die Erweiterungen pgvector und google_ml_integration aktiviert und die Zieltabelle erstellt. AlloyDB kann jetzt als operatives Backend für den Abgleich von Telemetriedaten in Echtzeit dienen.
7. Suchindex erstellen
Jetzt müssen Sie die Telemetriedaten in AlloyDB übertragen, damit sie für den Echtzeitabgleich von Beacons verwendet werden können. Rohe Telemetrielogs sind unübersichtlich und haben eine variable Länge, was für die Ähnlichkeitssuche nicht ideal ist. Sie verwenden die KI-Funktionen von BigQuery, um jedes Protokoll mit Gemini zusammenzufassen und jede Zusammenfassung in eine 768-dimensionale Vektoreinbettung zu konvertieren. Anschließend exportieren Sie die angereicherten Daten in Cloud Storage und importieren sie in AlloyDB.
Schritt 1: Einbettungen in BigQuery generieren
Wechseln Sie im Editor wieder zum Tab bigquery.sql (der weiterhin mit BigQuery verbunden ist).
Führen Sie nun die folgende Abfrage aus, um jedes Telemetrielog mit Gemini zusammenzufassen und Vektoreinbettungen zu generieren:
CREATE OR REPLACE TABLE `lost_cargo_dataset.telemetry_embeddings_export` AS
WITH summarized_telemetry AS (
SELECT
shipment_id,
telemetry_string,
AI.GENERATE(
CONCAT('Summarize this telemetry log for vector search: ', telemetry_string)
).result AS summary
FROM `lost_cargo_dataset.telemetry_data`
),
telemetry_embeddings AS (
SELECT
shipment_id,
telemetry_string,
AI.EMBED(summary, endpoint => 'text-embedding-005').result AS embedding
FROM summarized_telemetry
)
SELECT
shipment_id,
telemetry_string,
TO_JSON_STRING(embedding) AS embedding_vector
FROM telemetry_embeddings;
Schritt 2: Vorschau der angereicherten Daten ansehen
Sehen Sie sich vor dem Exportieren an, was Sie erstellt haben. Diese Abfrage zeigt die Versand-IDs und die ersten 80 Zeichen jeder Zusammenfassung und Einbettung:
SELECT
shipment_id,
SUBSTR(telemetry_string, 1, 80) AS telemetry_preview,
SUBSTR(embedding_vector, 1, 80) AS embedding_preview
FROM `lost_cargo_dataset.telemetry_embeddings_export`
LIMIT 5;
Jede Zeile enthält jetzt eine Versand-ID, das ursprüngliche Telemetrie-Log und einen 768-dimensionalen Einbettungsvektor. Das sind die Daten, die Sie in AlloyDB übertragen.
Schritt 3: Einbettungen in Cloud Storage exportieren
Verwenden Sie die EXPORT DATA-Anweisung von BigQuery, um die Tabelle mit den Einbettungen als CSV-Datei in den GCS-Bucket Ihres Labs zu schreiben.
EXECUTE IMMEDIATE CONCAT("""
EXPORT DATA OPTIONS (
uri = 'gs://""", @@project_id, """-lab2/data/embeddings_export/*.csv',
format = 'CSV',
overwrite = true,
header = false
) AS
SELECT
shipment_id,
telemetry_string,
embedding_vector
FROM `lost_cargo_dataset.telemetry_embeddings_export`;
""");
Schritt 4: In AlloyDB aus Cloud Storage importieren
- Klicken Sie im Cloud Shell-Editor unten auf dem Bildschirm auf den Tab Terminal, um eine Terminalsitzung zu öffnen.
- Führen Sie die folgenden Befehle aus, um Ihre Umgebung zu laden und die CSV-Datei direkt in die Tabelle
vessel_telemetryin AlloyDB zu importieren:
source devrel-demos/codelabs/bigquery-alloydb-insights/scripts/setenv.sh
gcloud alloydb clusters import lost-cargo-cluster \
--region=$REGION \
--gcs-uri="gs://${PROJECT_ID}-lab2/data/embeddings_export/000000000000.csv" \
--database=postgres \
--user=postgres \
--table=vessel_telemetry \
--columns=shipment_id,telemetry_string,embedding_vector \
--csv
Zusammenfassung des Abschnitts:Sie haben die KI-Funktionen von BigQuery verwendet, um die Telemetriedaten zusammenzufassen und einzubetten, die Ergebnisse als CSV-Datei nach Cloud Storage exportiert und sie dann mit gcloud in AlloyDB importiert. Die Datenbank für die operative Nachverfolgung ist jetzt geladen und einsatzbereit.
8. Beacon-Signal abgleichen
Ein Außenteam in der Nähe von Sydney hat ein fragmentiertes Telemetrie-Funksignal abgefangen. Das teilweise Protokoll lautet:
„Kühlgerät offline. Manuelles Überschreiben.“
Wenn es aus dem gestohlenen Container stammt, sollte die Vektorsuche von AlloyDB es auch dann zuordnen können, wenn das Signal unvollständig ist. Genau für solche operativen Echtzeitabfragen ist AlloyDB konzipiert.
Schritt 1: Importierte Daten überprüfen
Wechseln Sie im Editor zurück zum Tab alloydb.sql, der weiterhin mit AlloyDB verbunden ist.
Prüfen Sie mit dem folgenden Befehl, ob die Telemetriedaten erfolgreich geladen wurden:
SELECT shipment_id, LEFT(telemetry_string, 80) AS telemetry_preview
FROM vessel_telemetry
LIMIT 10;
Sie sollten Zeilen mit shipment_id-Werten und Telemetrietext sehen. Das sind die Telemetriesignaturen der Flotte, die jetzt für den Echtzeitabgleich bereit sind.
Schritt 2: Nach dem fehlenden Container suchen
Verwenden Sie nun die google_ml_integration-Erweiterung von AlloyDB, um mit dem abgefangenen Signalfragment nach einer Übereinstimmung zu suchen:
SELECT
shipment_id,
telemetry_string,
1 - (embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector) AS search_relevance_score
FROM vessel_telemetry
ORDER BY embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector
LIMIT 5;
Die Funktion embedding(), die von der AlloyDB-Erweiterung google_ml_integration bereitgestellt wird, ruft die Agent Platform direkt aus SQL auf, um inline eine Vektoreinbettung zu generieren. Der Operator <=> berechnet den Kosinusabstand zwischen zwei Vektoren. Je näher der Wert an 0 liegt, desto identischer sind die beiden Vektoren. Wir subtrahieren von 1, um die Ergebnisse als Relevanzwert auszudrücken, wobei höhere Werte besser sind.
Schritt 3: Übereinstimmung bestätigen
Sehen Sie sich die Ergebnisse an. Das beste Ergebnis sollte MV-CAPYBARA-003 mit dem höchsten Relevanzwert sein.
Das ist derselbe Container, den Sie in jedem Schritt dieser Untersuchung verfolgt haben:
- 📷 Auf Sicherheitsaufnahmen ist zu sehen, wie es nachts den Hafen von Rio de Janeiro verlässt.
- 🌡️ Die Erkennung von thermischen Anomalien hat bestätigt, dass das Kühlaggregat absichtlich deaktiviert wurde.
- 📡 Beacon-Signalabgleich hat die Telemetriesignatur in der Nähe von Sydney lokalisiert.
Drei unabhängige Beweislinien. Drei verschiedene Google Cloud AI-Funktionen. Ein gestohlener Container.
🎯 Fall abgeschlossen: MV-CAPYBARA-003 wurde in der Nähe von Sydney gefunden!

Zusammenfassung des Abschnitts:Sie haben die integrierte KI-Integration von AlloyDB verwendet, um eine Sucheinbettung zu generieren und eine Suche nach Kosinusähnlichkeit in einer einzigen SQL-Abfrage durchzuführen. Der Beacon-Abgleich bestätigte den Standort des gestohlenen Containers und schloss die Untersuchung ab.
9. Beweismaterial analysieren
Nachdem Sie den Container durch multimodale Bildanalyse und Vektorsuche identifiziert haben, können Sie Conversational Analytics direkt in Ihrem Editor verwenden, um die Untersuchungsdaten in natürlicher Sprache zu analysieren, ohne SQL schreiben zu müssen.
Schritt 1: Daten im Knowledge Catalog suchen
Das Data Agent Kit enthält eine universelle Suchfunktion, mit der Sie Datenassets in Ihrer Google Cloud-Umgebung finden und untersuchen können.
- Erweitern Sie im Bereich „Data Agent Kit“ auf der linken Seite den Abschnitt Katalog.
- Klicken Sie auf Universelle Suche.
- Geben Sie in der Suchleiste
telemetry_dataein. - Klicken Sie in den Suchergebnissen auf die Tabelle
telemetry_data(unterlost_cargo_dataset).
Schritt 2: Conversational Analytics starten
Wenn Sie auf das Suchergebnis klicken, wird ein Tab mit der Datenansicht geöffnet. Dort können Sie sich eine Vorschau der Rohdaten ansehen, das Schema aufrufen und die Datenqualität prüfen.
- Im linken Bereich sehen Sie Ihre BigQuery-Datasets und -Tabellen. Klicken Sie auf die Schaltfläche Chat, um ein neues Chatfenster zu öffnen.
Schritt 3: Fragen in natürlicher Sprache stellen
Ein neuer Chat-Tab mit dem Titel „Willkommen bei Conversational Analytics!“ wird geöffnet. Der Agent hat Kontext zum Schema und Inhalt Ihrer Tabelle.
- Geben Sie im Chatfenster Folgendes ein:„Show me the telemetry status and log for the Capybara shipment.“ (Zeige mir den Telemetriestatus und das Log für die Capybara-Lieferung.)
- Drücken Sie die Eingabetaste.
Der Agent übersetzt Ihre Frage in BigQuery SQL, führt die Abfrage aus und gibt die Ergebnisse zurück. Dazu gehören sowohl eine Datentabelle als auch Zusammenfassungen der Ergebnisse. Je nach Komplexität Ihrer Frage können Sie zwischen dem Modus Thinking (tiefere Analyse, langsamer) und Fast (schnellere Antworten) wechseln. Da es sich um KI-generierte Antworten handelt, können Ihre Ergebnisse leicht von den Screenshots unten abweichen.
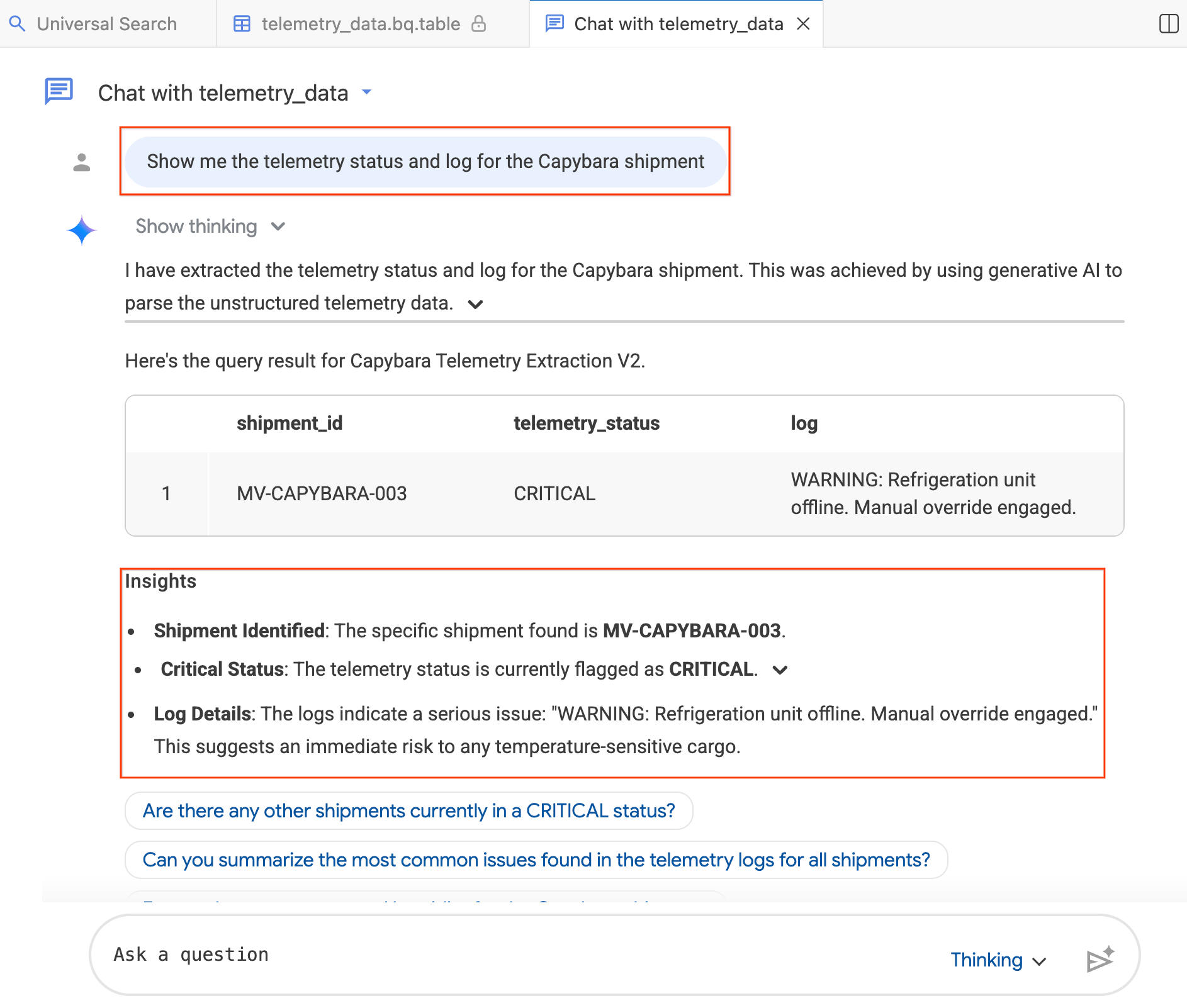
Schritt 4: Weiterführende Fragen stellen
Der KI-Agent merkt sich den Kontext Ihrer Unterhaltung. Versuchen Sie es mit einer Folgefrage:
- Wie viele einzelne Sendungen sind in den Telemetriedaten enthalten?
- Wie viele andere Sendungen in der Flotte haben derzeit den Status „KRITISCH“?
Zusammenfassung des Abschnitts:Sie haben die Funktion „Universelle Suche“ von Knowledge Catalog verwendet, um Ihr Dataset zu finden, und die konversationelle Analyse gestartet, um Untersuchungsdaten mit natürlicher Sprache abzufragen. Der KI-Agent hat Ihre Fragen in SQL übersetzt und Statistiken bereitgestellt, die Ihre Ergebnisse bestätigen.
10. Bereinigen
Löschen Sie die in diesem Lab erstellten Ressourcen, um zu vermeiden, dass Ihrem Google Cloud-Konto laufende Gebühren in Rechnung gestellt werden. Sie können diese Befehle in Ihrem integrierten Terminal im Cloud Shell-Editor ausführen (wo Sie das Data Agent Kit verwendet haben), um Ihre Umgebung zu bereinigen.
Laden Sie zuerst Ihre Umgebungsvariablen:
source scripts/setenv.sh
- BigQuery-Ressourcen löschen (nur, wenn Sie nicht mit Lab 3 fortfahren):
Wenn Sie mit Lab 3 fortfahren möchten, überspringen Sie diesen Schritt. In Lab 3 werden dieselben BigQuery-Datasets und ‑Verbindungen für die Analyse von Property-Graphen verwendet.
So löschen Sie Ihr BigQuery-Dataset und Ihre Verbindungen:
# Drop the dataset
bq rm -r -f $PROJECT_ID:lost_cargo_dataset
# Delete the connections
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_conn
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_alloydb_conn
- Cloud Storage-Bucket löschen:
gcloud storage rm --recursive gs://${PROJECT_ID}-lab2
- AlloyDB-Instanz und -Cluster löschen:
AlloyDB wird in Lab 3 nicht verwendet. Sie können die Instanz also jetzt herunterfahren.
gcloud alloydb instances delete lost-cargo-instance \
--region=$REGION \
--cluster=lost-cargo-cluster \
--quiet
gcloud alloydb clusters delete lost-cargo-cluster \
--region=$REGION \
--force \
--quiet
- Löschen Sie die Einstellungen für die lokale Umgebung:
Entfernen Sie zum Schluss die Datei mit den Einstellungen für die lokale Umgebung aus Ihrem Arbeitsbereich:
rm -f .env
11. Glückwunsch!
Sie haben Lab 2: Datenanalyse und multimodale Statistiken erfolgreich abgeschlossen. Sie folgten der Spur von einem Hafen voller Tausender von Containern zu einem bestätigten Diebstahl und einem genau bestimmten Ort.
Ihre Erfolge
- Bildmaterial gescannt: Sie haben mit der
AI.GENERATE-Funktion von BigQuery Bilder der Hafensicherheit analysiert und den Container MV-CAPYBARA-003 in Crimson Red identifiziert. - Diebstahl bestätigt: Sie haben die Sensordaten des Wärmesensors untersucht, einen verdächtigen Anstieg auf 64,7 °C festgestellt und mit
AI.DETECT_ANOMALIESnachgewiesen, dass es sich um eine vorsätzliche Manipulation handelte. - Tracking-System vorbereitet: Sie haben AlloyDB mit pgvector und
google_ml_integrationfür den Echtzeit-Beacon-Abgleich konfiguriert. - Suchindex erstellt: Sie haben
AI.GENERATEundAI.EMBEDin BigQuery verwendet, um Einbettungen zu erstellen, sie dann nach Cloud Storage exportiert und in AlloyDB importiert. - Beacon-Signal abgeglichen: Sie haben die Vektorsuche von AlloyDB verwendet, um ein fragmentiertes Telemetriesignal abzugleichen und den gestohlenen Container in der Nähe von Sydney zu lokalisieren.
- Beweise untersucht: Sie haben Conversational Analytics direkt über den Editor verwendet, um Untersuchungsdaten in natürlicher Sprache abzufragen.

Nächste Schritte
Sie haben herausgefunden, wo sich der Container befindet. Jetzt müssen Sie herausfinden, wer dahintersteckt.
In Lab 3: Data Consumption & Agentic Workflows erstellen Sie ein Property-Diagramm des Logistiknetzwerks, um Beziehungen zwischen Scheinfirmen abzubilden. Außerdem verwenden Sie Conversational Analytics, um mit dem Diagramm zu interagieren, und suchen im Knowledge Catalog nach dem sicheren Freigabecode, der zum Wiederherstellen des Containers erforderlich ist.