
1. Einführung
Willkommen zur letzten Phase der Untersuchung der verlorenen Fracht! Nachdem wir den gestohlenen Container mit Android-Figuren von London bis nach Sydney verfolgt haben, ist die Spur kalt geworden. Durch das Deaktivieren des Transponders hat der intelligente Tresor des Containers eine automatische Notverriegelung ausgelöst.
Um die wertvolle Fracht zu bergen, bevor sie für immer verschlossen wird, musst du den endgültigen Standort des Containers finden und den manuellen Überschreibungscode abrufen, um den Tresor physisch zu entriegeln.

Um den fehlenden Container zu finden und die Ladung zu sichern, erstellen Sie ein BigQuery-Eigenschaftsgraf, um den Weg der Sendung nachzuvollziehen. Anschließend fragen Sie dieses Netzwerk in natürlicher Sprache mit Konversationelle Analyse ab. Zum Schluss führen Sie mit Knowledge Catalog eine semantische Suche in den Metadaten Ihrer Daten durch, um die Überschreibungscodes zu finden.
💡 Sie haben Lab 1 oder Lab 2 verpasst? Keine Sorge! Dieses Lab ist in sich abgeschlossen. Bei der Einrichtung der Umgebung werden alle erforderlichen Ressourcen bereitgestellt, sodass Sie die Übung selbstständig durchführen können.
Aufgaben
- Klonen Sie das Repository und führen Sie das Setupscript in Google Cloud Shell aus.
- Einen Property Graph erstellen in BigQuery, in dem Unternehmens-, Schiffs- und Manifestdaten verknüpft werden.
- Konversationelle Analyse: Sie können den Graph in natürlicher Sprache abfragen und den Weg der Fracht nachvollziehen, um den verantwortlichen Betreiber zu ermitteln.
- Suchen Sie die Tabelle mit den endgültigen Überschreibungscodes mit Knowledge Catalog.
- Verwenden Sie die BigQuery-Zugriffssteuerung auf Spaltenebene, um den endgültigen Code zu demaskieren und anzuzeigen.
Voraussetzungen
- Ein Webbrowser wie Chrome
- Ein Google Cloud-Projekt mit aktivierter Abrechnung
- Zugriff auf Google Cloud Shell
Dieses Codelab richtet sich an Datenexperten aller Erfahrungsstufen.
Die in diesem Codelab erstellten Ressourcen sollten weniger als 5 $ kosten.
Geschätzte Dauer:Dieses Codelab dauert etwa 45 Minuten.
2. Hinweis
Google Cloud-Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein.
Cloud Shell starten
Sie verwenden Google Cloud Shell, um den Code herunterzuladen, Einrichtungs-Scripts auszuführen und die Anwendung bereitzustellen.
- Öffnen Sie die Cloud Shell in einem neuen Browser-Tab:

- Legen Sie nach der Verbindung Ihre Projekt-ID fest und bestätigen Sie Ihre Umgebung:
gcloud config set project <<YOUR_PROJECT_ID>>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
Es sollte eine Meldung wie die folgende angezeigt werden:
Your active configuration is: [cloudshell-####] Updated property [core/project]
Erforderliche APIs aktivieren
Führen Sie den folgenden Befehl in Cloud Shell aus, um die erforderlichen APIs zu aktivieren:
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com \
datacatalog.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com
Bei erfolgreicher Ausführung sollte eine Meldung wie die folgende angezeigt werden:
Operation "operations/..." finished successfully.
3. Umgebung einrichten
In den vorherigen Labs dieser Reihe haben wir die Grundlagen für unsere Untersuchung gelegt.
1. Repository klonen
Klonen Sie das Codelab-Repository in Ihre Cloud Shell-Umgebung:
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/bigquery-graph-analytics
git checkout main
cd codelabs/bigquery-graph-analytics/
2. Basistabellen und Richtlinien-Tags einrichten
Führen Sie das Setupscript aus, um Ihr BigQuery-Dataset zu füllen und Tags für die Sicherheit auf Spaltenebene anzuwenden, um den Zugriff auf vertrauliche Daten einzuschränken:
bash setup_lab.sh
Prüfen Sie, ob in der Ausgabe in Ihrem Terminal eine erfolgreiche Initialisierung angezeigt wird:
🚀 Provisioning foundational tables and deploying Policy Tag security bindings... 🎯 Active Project: your-project-id ... 🎉 Success! Foundational tables initialized and Column-Level Policy Tags fully mapped out of the box!
Nachdem Sie Ihre Umgebung erfolgreich eingerichtet und die Logistikdaten in BigQuery eingefügt haben, können Sie jetzt einen Property Graph erstellen, um Ihre Tabellen zu verknüpfen und den Weg der Fracht nachzuvollziehen.
4. Daten mit BigQuery Graph verbinden
Um unsere Daten zur Lieferkette zu analysieren, müssen wir definieren, wie Unternehmen, Schiffe und Manifeste zueinander in Beziehung stehen. Durch das Erstellen eines Attributgraphen können wir diese Verbindungen ganz einfach abfragen.
1. Beziehungen in Attributgrafiken modellieren
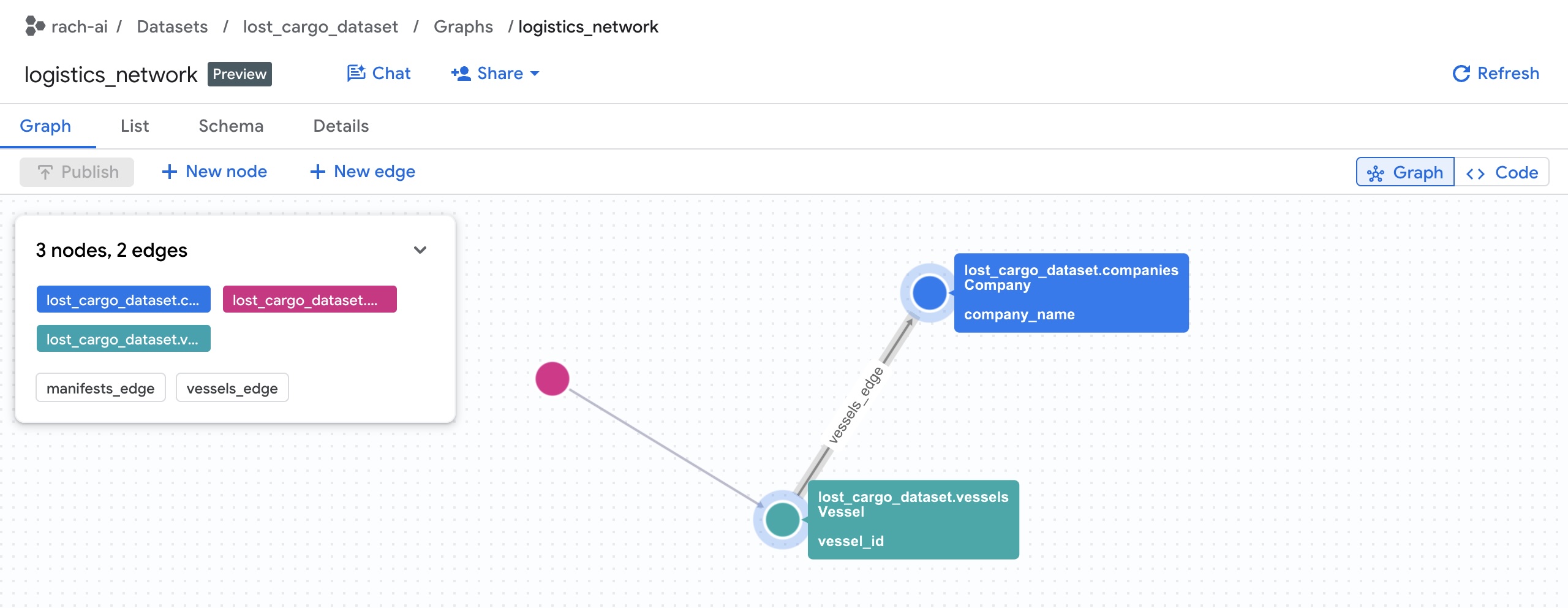
In einem BigQuery-Eigenschaftsgraphen werden Netzwerke so modelliert:
- Knoten: Die Entitäten im Netzwerk. In diesem Lab stellen Knoten Unternehmen (in denen Kontaktdaten direkt gespeichert werden), Manifeste und Schiffe dar.
- Kanten: Die Beziehungen, die Knoten miteinander verbinden. Beispiel:
- Eine Kante verbindet ein Manifest mit einem Vessel (über Beziehungen in der Tabelle
manifests). - Eine Kante verbindet ein Schiff mit einem Unternehmen (über Beziehungen in der Tabelle
vessels).
- Eine Kante verbindet ein Manifest mit einem Vessel (über Beziehungen in der Tabelle
- Attribute: Metadaten, die in Knoten oder Kanten gespeichert sind. Ein Company-Knoten hat beispielsweise Spalten wie
company_nameundphone_number, ein Manifest-Knoten hatseal_integrity_statusund Koordinaten (last_ping_lat,last_ping_long). - Labels: Tag-Namen, die Knoten (z.B.
Company,Vessel,Manifest) und Kanten (z.B.CARRIED_BY,OPERATED_BY) zugewiesen werden, damit Abfragetools Knoten- und Beziehungstypen erkennen können.
2. Property Graph in BigQuery bereitstellen
Die Datei setup_graph.sql enthält die SQL-DDL zum Definieren und Erstellen des Property-Graphen. Sie ist jedoch derzeit unvollständig. Sie müssen die Kantenlabels (Beziehungen) in dieser Schemadatei definieren, bevor Sie sie kompilieren und bereitstellen:
- Den Cloud Shell-Editor öffnen

- Öffnen Sie die Datei
setup_graph.sqlim Cloud Shell-Editor.

- Suchen Sie nach den Platzhaltern für Edge-Labels:
- Zeile 22: Ersetzen Sie
`EDGE_TABLE_PLACEHOLDER`durch ein aussagekräftiges Tag, das angibt, wie sich Manifeste auf Schiffe beziehen (z.B.CARRIED_BY). - Zeile 27: Ersetzen Sie
`EDGE_TABLE_PLACEHOLDER`durch ein Tag, das angibt, wie Schiffe mit Unternehmen in Verbindung stehen (z.B.OPERATED_BY).
- Zeile 22: Ersetzen Sie
- Speichern Sie die Datei.
Kehren Sie nun zum Cloud Shell-Terminal zurück und stellen Sie den aktualisierten Eigenschaftsgraphen mit dem vollständigen Skript bereit:
bq query --use_legacy_sql=false < setup_graph.sql
Sie sollten eine Ausgabe sehen, die darauf hinweist, dass der Job abgeschlossen ist:
Waiting on bqjob_r... ... (0s) Current status: DONE
Sie können die Details des Property-Graphen in der BigQuery Console ansehen:
Suchen Sie das lost_cargo_dataset und wählen Sie „Diagramme“ aus:

Nachdem wir den Property Graph erfolgreich zusammengestellt haben, können wir uns BigQuery Studio ansehen, um die Verbindungen abzufragen und zu visualisieren.
5. Graph abfragen
Sie können den Graphen mit der nativen Graph Query Language (GQL) direkt in BigQuery Studio abfragen und visuell untersuchen.
1. Container -> Schiff -> Unternehmen abfragen
Sehen wir uns GQL-Abfragen an, um herauszufinden, wer die Schiffe betreibt, die Fracht transportieren. Um den Operator zu finden, müssen drei separate Knoten im Logistiknetzwerk durchlaufen werden:

- Beginnen Sie mit dem Containerknoten
Manifest. - Folgen Sie der Beziehungskante
CARRIED_BY, um die tragendeVesselzu finden. - Folgen Sie der Beziehungskante
OPERATED_BYvon diesem Schiff zum verantwortlichenCompanyund rufen Sie dessen ID ab.
Führen Sie zuerst eine Abfrage aus, um das gesamte Netzwerk (ohne Filter) zu visualisieren und den vollständigen Graphen zu sehen.
- Öffnen Sie einen neuen Tab im BigQuery Studio SQL-Editor, fügen Sie die folgende GQL-Abfrage ein und klicken Sie auf Ausführen:
SELECT * FROM GRAPH_TABLE( `lost_cargo_dataset.logistics_network` MATCH p = (m:Manifest)-[:CARRIED_BY]->(v:Vessel)-[:OPERATED_BY]->(comp:Company) RETURN TO_JSON(p) AS path ); - Wenn die Abfrage abgeschlossen ist, klicken Sie unten im Bereich Abfrageergebnisse auf den Tab Diagramm (neben dem Tab Ergebnistabelle).
- BigQuery rendert die Ergebnisse als interaktive visuelle Darstellung in einem Diagramm. Zoomen Sie hinein, um das gesamte Netzwerk verbundener Container, Schiffe und Betreiber zu sehen.
Aufbau einer GQL-Abfrage
Sehen wir uns die GQL-Abfrage an, die wir gerade ausgeführt haben:
GRAPH_TABLE: Weist BigQuery an, eine Property Graph-Abfrage für den Graphenlogistics_networkauszuführen.MATCH: Deklariert das Muster für die Traversierung über mehrere Schritte. Wir beginnen mit einemManifest(m), gleichen die Kantenbeziehung:CARRIED_BYab, die aufVessel(v) verweist, und gleichen dann die Kantenbeziehung:OPERATED_BYab, die aufCompany(comp) verweist.- GQL ersetzt komplexe Join-Logik durch intuitive, für Menschen lesbare ASCII-Art-Beziehungspfeile
()->[]->(). So lassen sich Multi-Hop-Abfragen ganz einfach schreiben und optimieren. RETURN: Gibt Eigenschaften oder den JSON-Pfad der übereinstimmenden Elemente zurück.
2. GQL-Abfrageergebnisse filtern
Filtern wir die Abfrage nun so, dass wir nur den Pfad für unseren Zielcontainer MV-CAPYBARA-003 sehen.
- Fügen Sie die folgende Abfrage in den SQL-Editor ein und klicken Sie auf Ausführen:
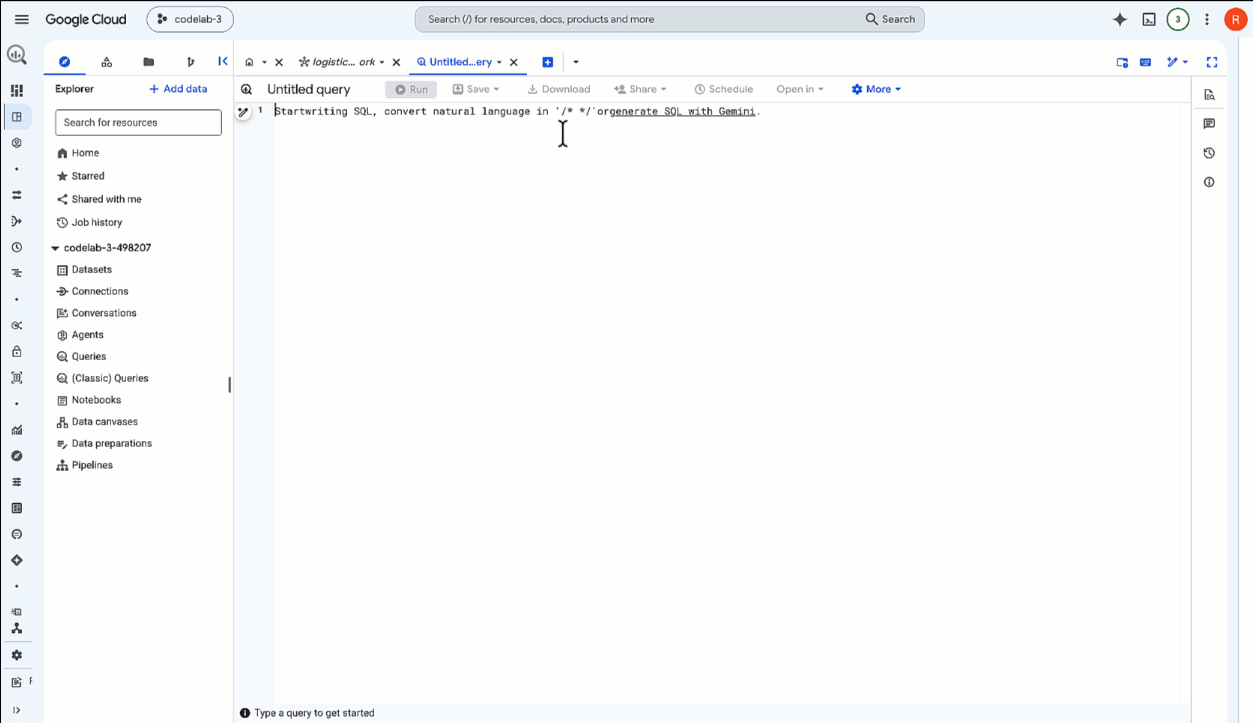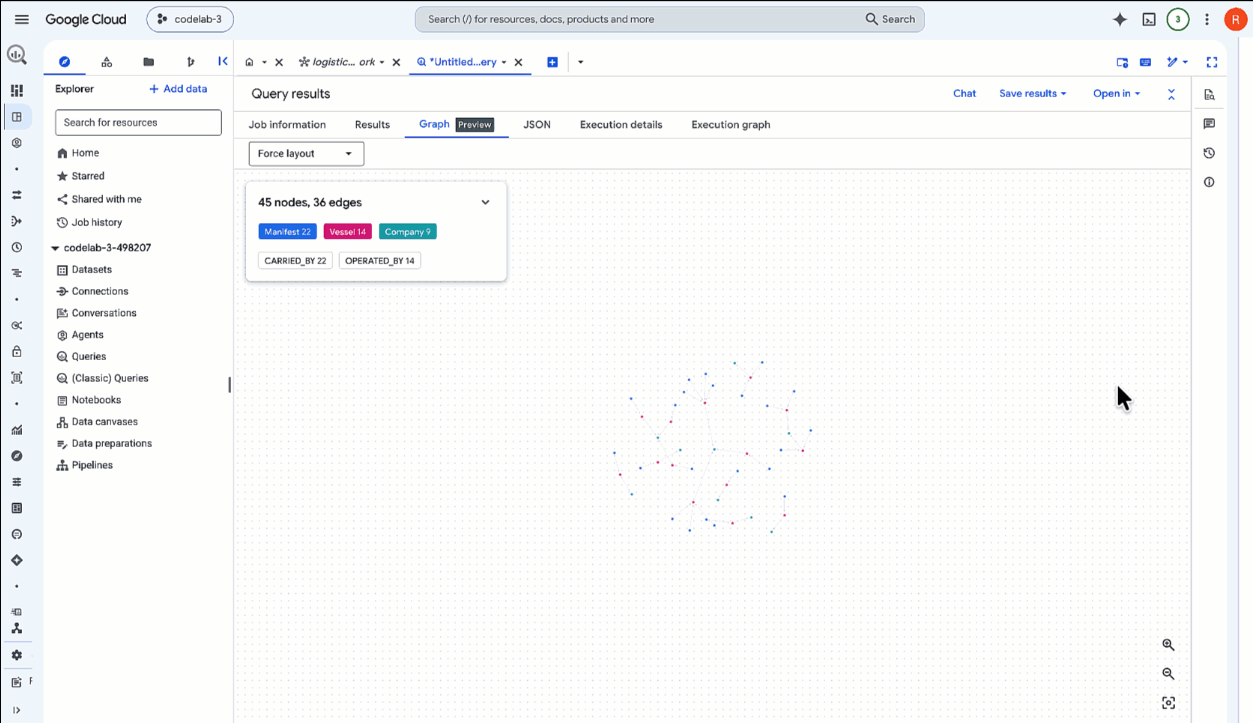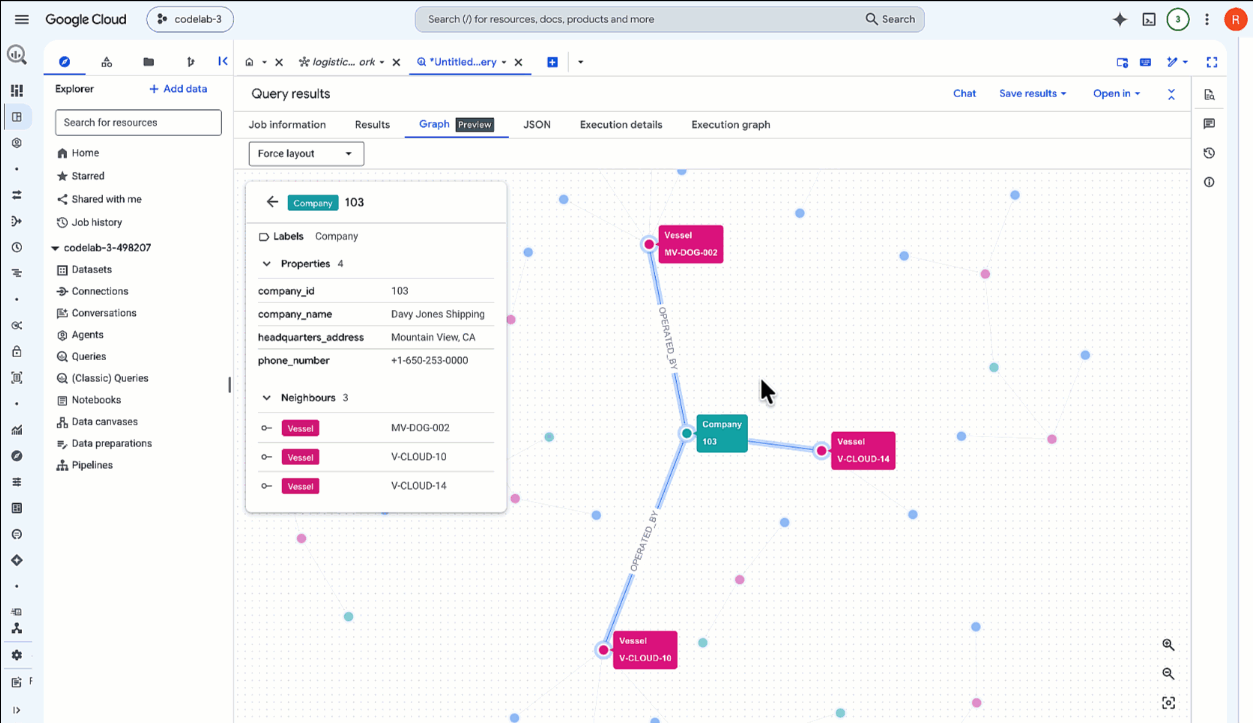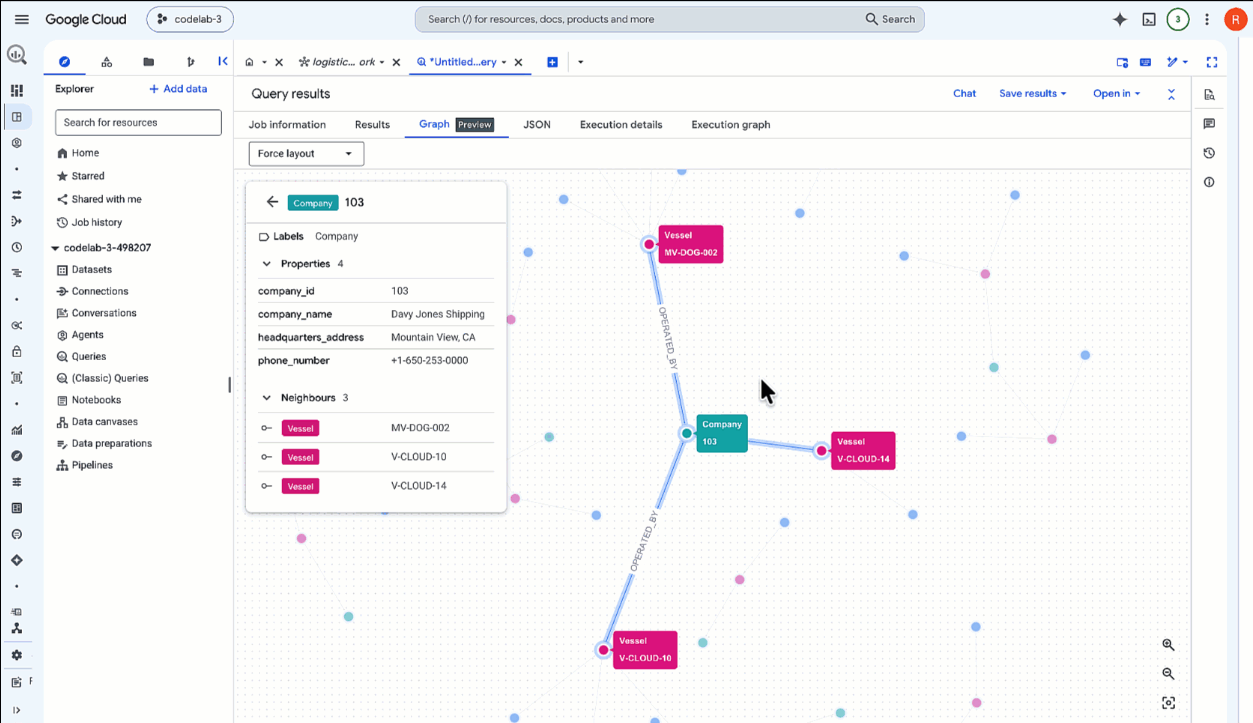
SELECT * FROM GRAPH_TABLE( `lost_cargo_dataset.logistics_network` MATCH p = (m:Manifest {shipment_id: 'MV-CAPYBARA-003'})-[:CARRIED_BY]->(v:Vessel)-[:OPERATED_BY]->(comp:Company) RETURN TO_JSON(p) AS path ); - Klicken Sie unter den Ergebnissen auf den Tab Diagramm.
- Im Viewer wird jetzt nur noch die aktive Route für
MV-CAPYBARA-003angezeigt. Zoomen Sie heran, um die Knoten und Verbindungen zu sehen:- Doppelklicken Sie auf den Knoten
Company, um den Eigenschaftenbereich zu öffnen. Unter Properties (Eigenschaften) sehen Sie den Operatorcompany_id:103(Davy Jones Shipping). Notieren Sie sich diese Unternehmens-ID. Sie benötigen sie später, um den Freigabecode aus dem Sicherheitsregister abzurufen. - Doppelklicken Sie auf den Knoten
Vessel, um zu prüfen, ob es sich um den KnotenFlying Dutchmanhandelt.
- Doppelklicken Sie auf den Knoten
6. Mit Ihrem Graph chatten – konversationelle Analyse
Nachdem Sie den Graph manuell abgefragt haben, um die Unternehmens-ID zu finden, verwenden wir jetzt die konversationelle Analyse, um direkt mit unserem Graph zu interagieren und herauszufinden, wohin unser Container unterwegs ist.
1. Conversational Analytics-Sitzung starten
- Rufen Sie in der Google Cloud Console die BigQuery Console auf und maximieren Sie den Ressourcenbereich, um Ihr Dataset zu finden (
lost_cargo_dataset). - Klicken Sie auf Ihre Property Graph-Ressource:
logistics_network. - Klicken Sie oben in der Symbolleiste des Detailbereichs auf die Schaltfläche Chat. Dadurch wird eine Sitzung für die konversationelle Analyse geöffnet, in der der Kontext Ihres Diagramms bereits geladen ist.
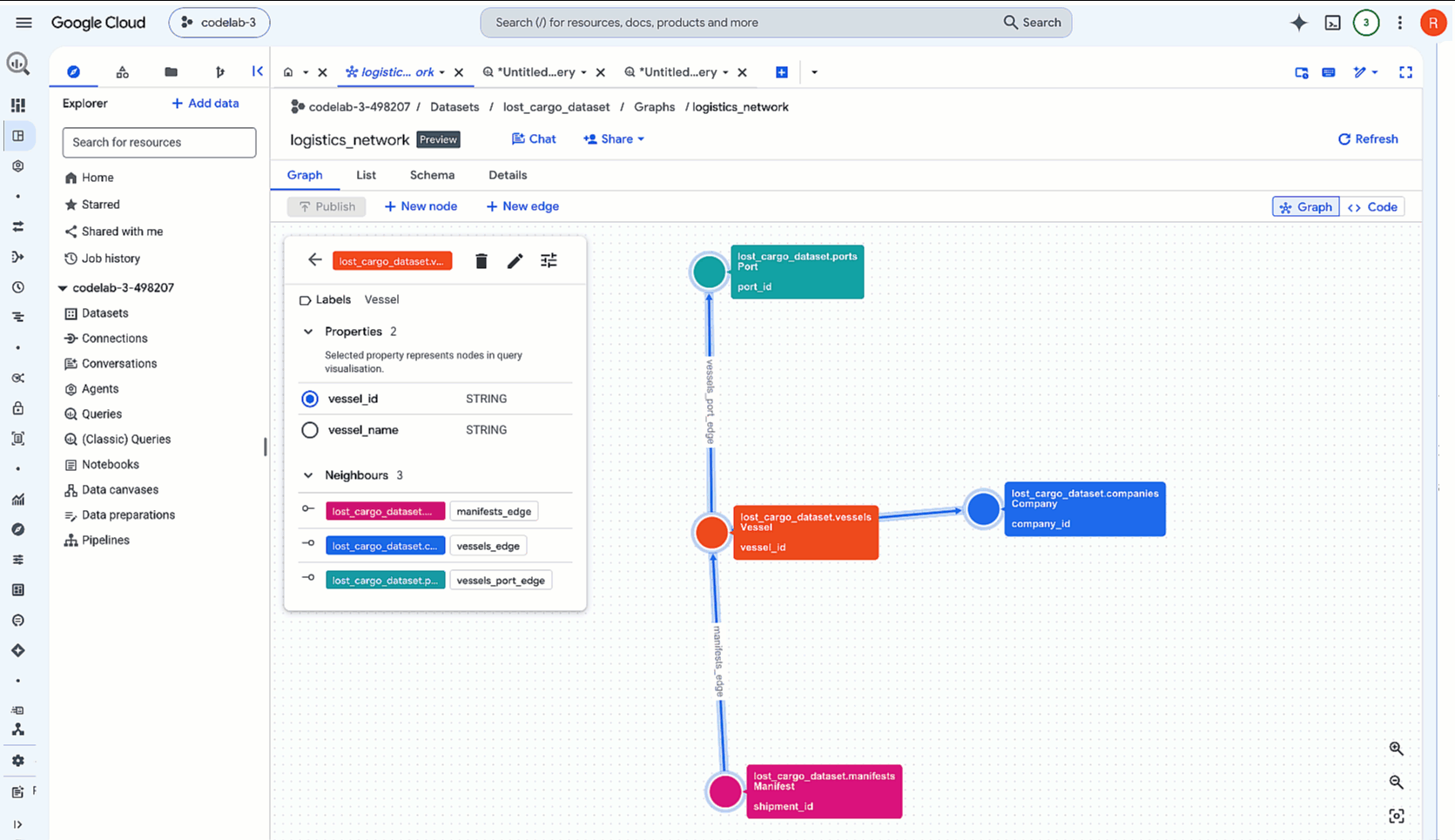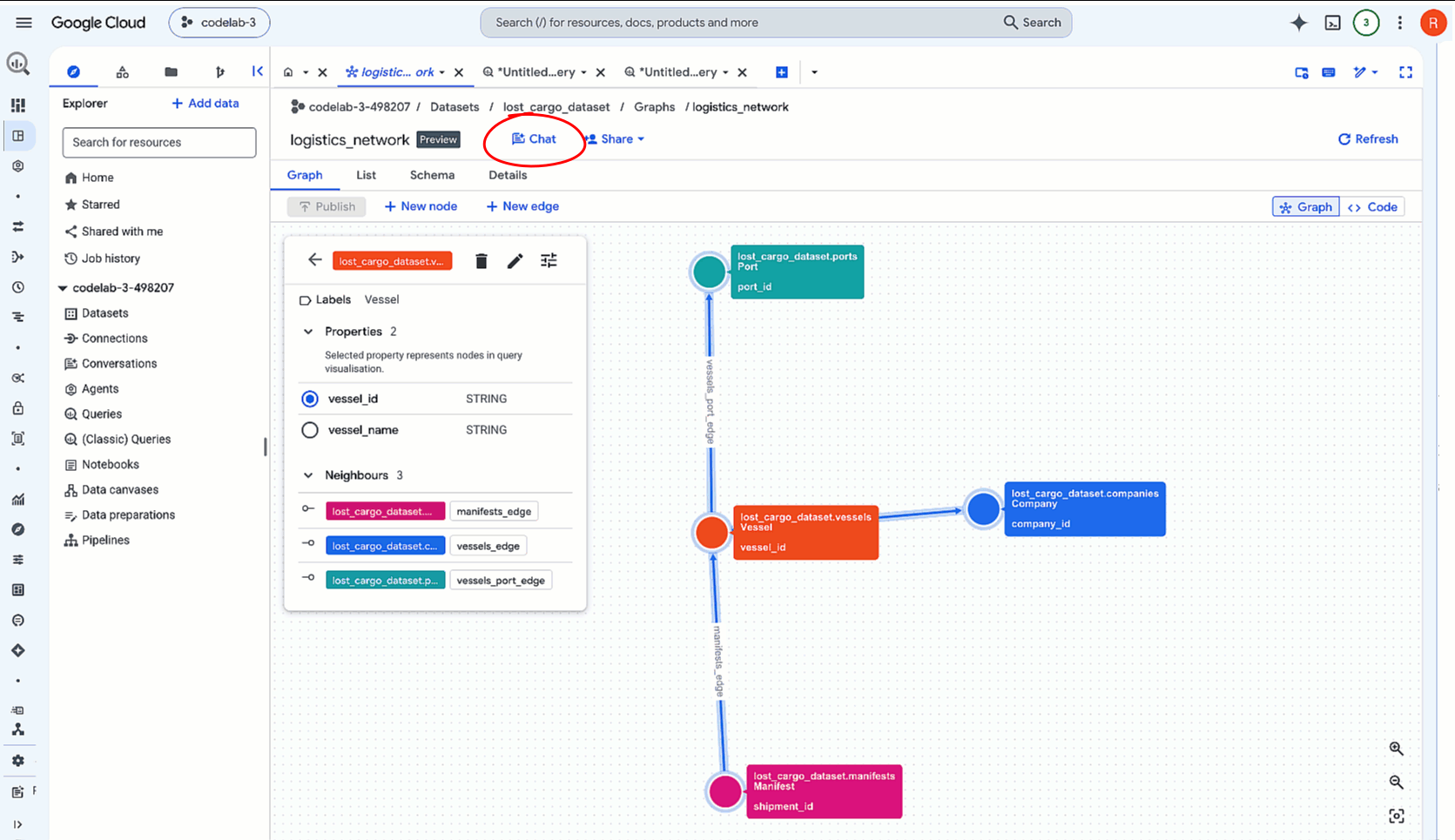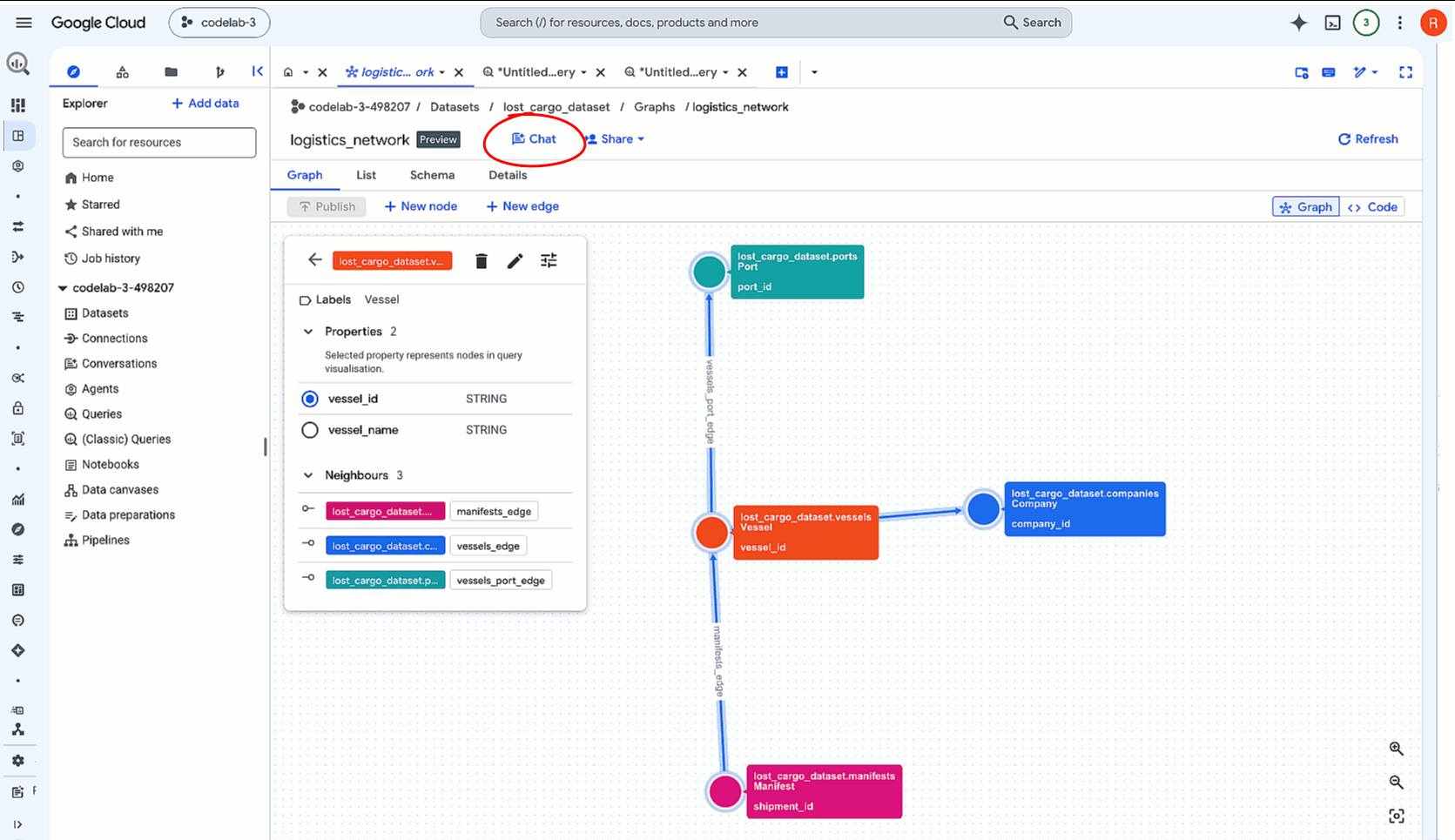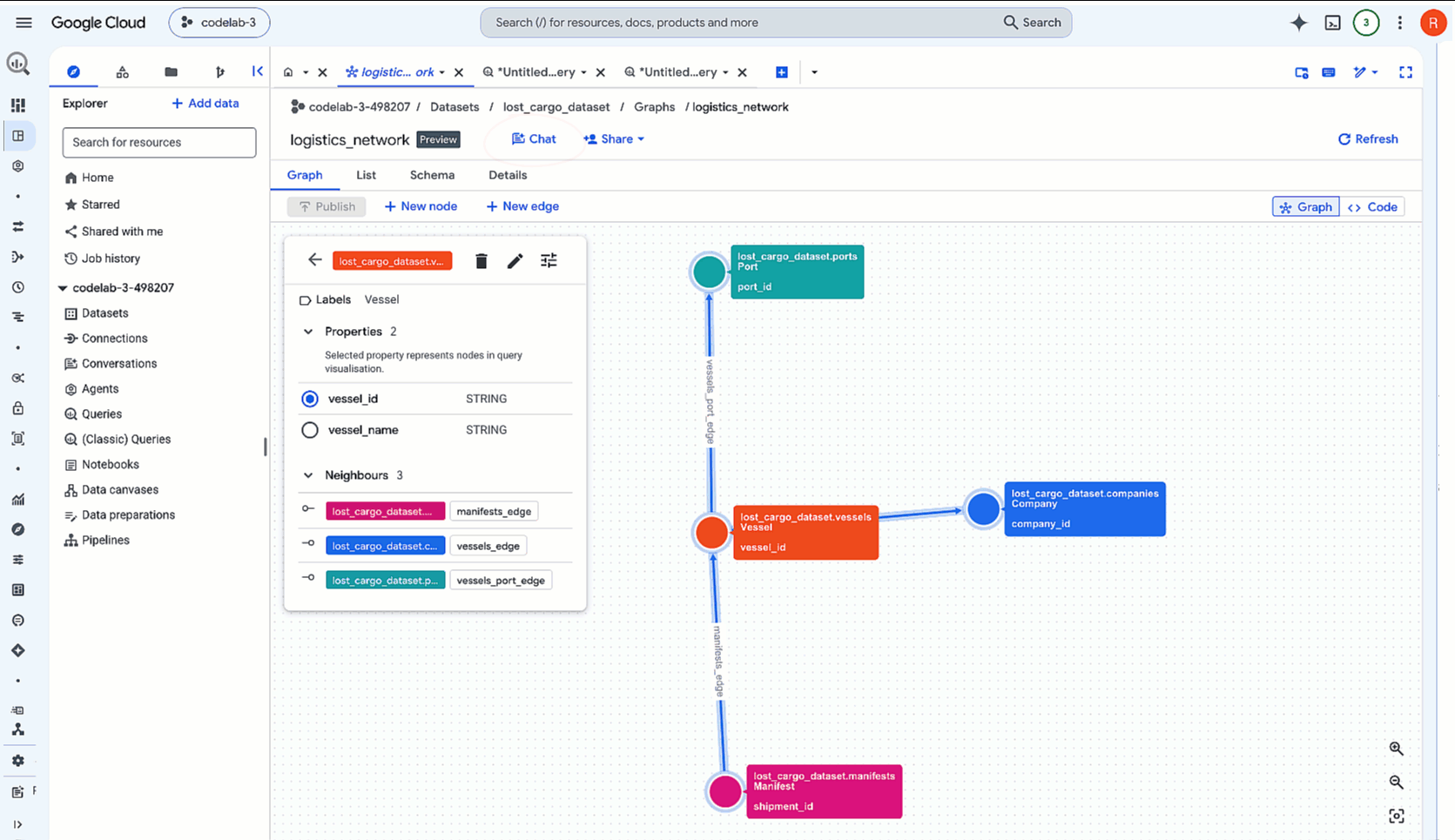
2. Den nächstgelegenen Andockpunkt für den entführten Container ermitteln
Ein Patrouillenflugzeug der Marine hat gerade ein Schiff gesichtet, das der Beschreibung unseres Frachtschiffs entspricht. Es fährt ohne Transponder bei den Koordinaten POINT(-122.48 37.55). Um die Fracht abzufangen, müssen wir den nächstgelegenen Dockingport finden, an dem die Schattenorganisation Davy Jones Shipping aktiv ist.
Anstatt alle globalen Häfen manuell zu durchsuchen, fragen wir unser Graph-Netzwerk ab, um die Häfen zu ermitteln, die mit der aktiven Flotte des Syndikats verbunden sind, und zu messen, welcher Hafen der Sichtung am nächsten ist.
- Geben Sie im Chatfeld „Konversationelle Analyse“ den folgenden Prompt ein:
Find all ports associated with Davy Jones Shipping vessels. Which port is closest to coordinate POINT(-122.48 37.55), show the distance in km, and display it on a map.
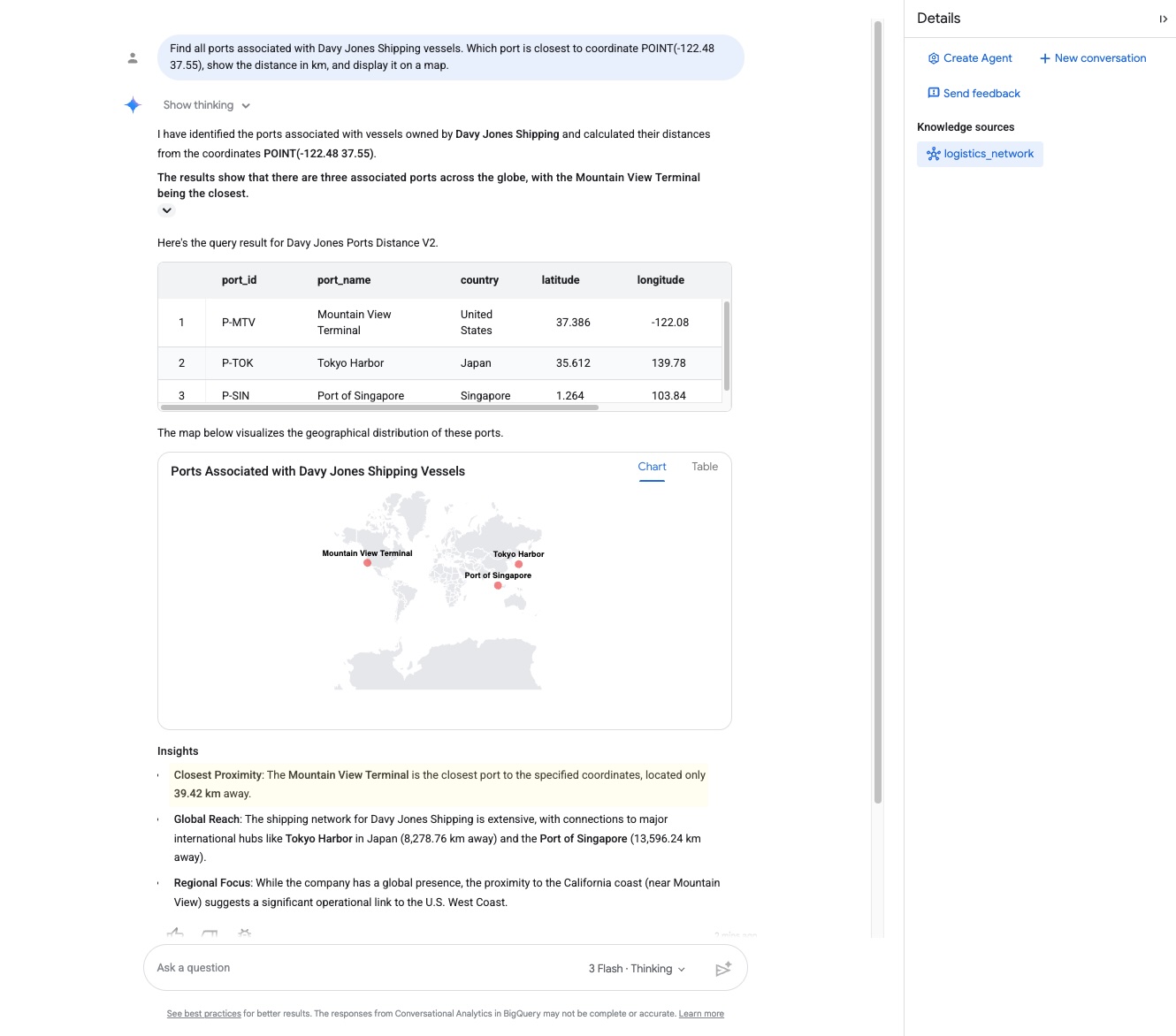
- Sehen Sie sich die Antwort genau an. Der Agent durchläuft den Graphen und gibt die nächstgelegene Andockstelle und ihre Entfernung zurück:
- Docking-Anschluss:
Mountain View Terminal - Distanz:
39.42 kilometers
- Docking-Anschluss:
- Da Conversational Analytics auf Gemini mit nativer GIS-Integration (Geographic Information System) basiert, können geografische Koordinatenpunkte interpretiert und das Weltwissen genutzt werden, um den Standort zu bestätigen:"Das Schiff ist etwa 39,42 Kilometer vom Mountain View Terminal in Kalifornien entfernt, was darauf hindeutet, dass es dorthin fährt, um anzulegen."
Das bestätigt, dass unsere Fracht direkt nach Mountain View unterwegs ist.
Im Hintergrund: Graph Query Language (GQL) und raumbezogenes GIS
Im Hintergrund hat der Conversational Analytics-Agent dynamisch eine Abfrage kompiliert und ausgeführt, die den Abgleich von Graphpfaden mit raumbezogenen Entfernungsberechnungen kombiniert. Dies wird durch eine native GQL-COLUMNS-Klausel erreicht, mit der die geodätische Distanz nativ im Graph-Traversal-Abgleich berechnet wird:
SELECT port_id, port_name, country, latitude, longitude, distance_km
FROM GRAPH_TABLE(
`lost_cargo_dataset.logistics_network`
MATCH (c:Company)<-[]-(v:Vessel)-[]->(p:Port)
WHERE LOWER(c.company_name) = 'davy jones shipping'
COLUMNS (
p.port_id,
p.port_name,
p.country,
p.latitude,
p.longitude,
ROUND(ST_DISTANCE(ST_GEOGPOINT(p.longitude, p.latitude), ST_GEOGPOINT(-122.48, 37.55)) / 1000, 2) AS distance_km
)
)
ORDER BY distance_km ASC;
Durch die Kombination von nativen Geospatial-Funktionen (GIS) (ST_DISTANCE, ST_GEOGPOINT) mit einem GQL-Eigenschaftsgraphenabgleich löst BigQuery den operativen Fußabdruck des Syndikats dynamisch auf und berechnet die physische Nähe in der realen Welt in einer einzigen Abfrage.
7. Fehlende Daten mit Knowledge Catalog finden
Im Property Graph werden Beziehungen dargestellt, er enthält aber nicht die Tabelle, in der die tatsächlichen Überschreibungscodes gespeichert sind.
In einer echten Unternehmensumgebung mit Hunderten von Datasets und Tabellen kann es schwierig sein, diese Informationen zu finden. Wir verwenden Knowledge Catalog, um eine semantische Suche durchzuführen und die richtige Tabelle zu finden.
1. Semantische Suche im Knowledge Catalog
- Suchen Sie in der Google Cloud Console nach Knowledge Catalog ➔ Search und rufen Sie die Seite auf.
- Aktivieren Sie in der Filterspalte „Suche“ unter Systeme die Option BigQuery, um die Ergebnisse einzugrenzen.
- Geben Sie die folgende Abfrage in das Suchfeld ein:
container override codes
- Klicken Sie in den Suchergebnissen auf die Tabellenressource
maritime_security_registry:
Wenn Sie das Metadatenschema prüfen, sehen Sie, dass die Tabelle Spalten für Container-Sicherheitsdaten enthält, z. B. das Koordinierungsunternehmen co_id, das Custodian-Token cust_tok und vor allem die Spalte für den sicheren Container-Überschreibungscode: clc_ovr_cd.
Wir haben sowohl die Tabelle als auch die genaue sichere Spalte gefunden, die wir zum Bergen unserer Ladung benötigen.
🔓 Governance in der Praxis: In einer Produktionsumgebung für Unternehmen nutzen Sicherheits- und Governance-Teams auch Folgendes:
- Aspekte und Tag-Vorlagen: Zum Anhängen von Geschäftsmetadaten wie Data Owner (Dateninhaber), Retention Period (Aufbewahrungszeitraum) oder PII Classification (Klassifizierung personenbezogener Daten) an Tabellenschemas.
- Datenherkunft: Damit automatisch Flussdiagramme generiert werden, die darstellen, wie Tabellen wie
maritime_security_registryvon Downstream-Systemen abgefragt und verwendet werden.
2. Spaltensicherheit in BigQuery prüfen
- Kehren Sie zur BigQuery Console zurück.
- Wählen Sie auf dem Tab Explorer die Option
lost_cargo_datasetund dann die Tabellemaritime_security_registryaus. - Klicken Sie auf den Tab Schema.
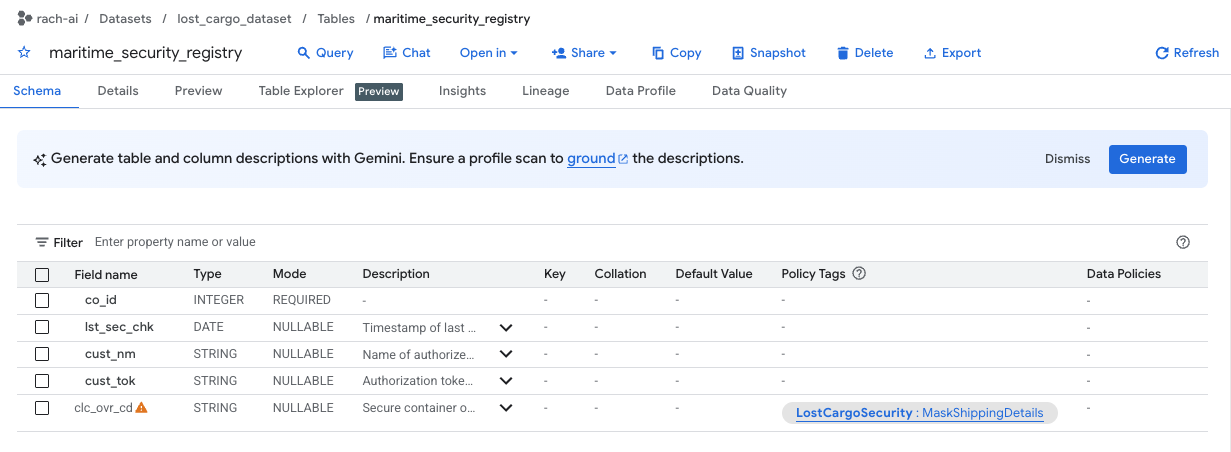
- Die Spalte
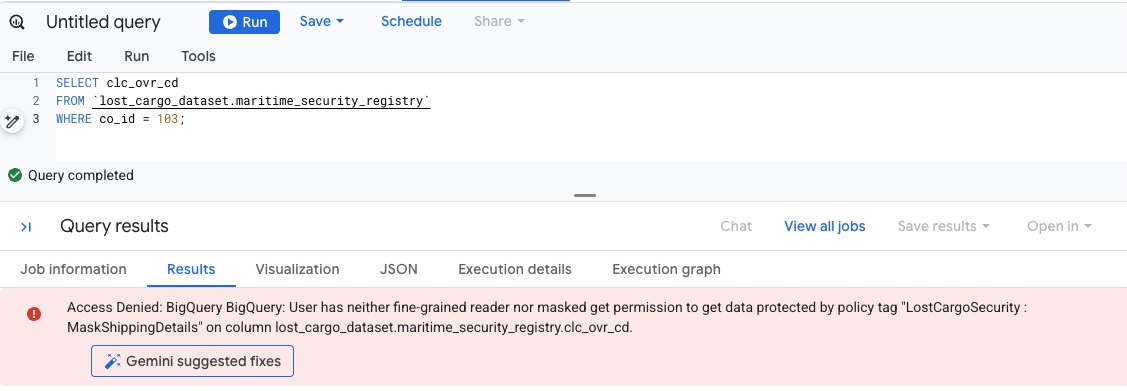
clc_ovr_cdist durch ein Richtlinien-Tag mit dem NamenMaskShippingDetailsgeschützt (in der Spalte „Richtlinien-Tags“ aufgeführt). - Öffnen Sie in BigQuery einen neuen Tab für den SQL-Editor und versuchen Sie, die Registrierungsüberschreibungscodes mit der folgenden Abfrage aufzurufen:
SELECT * FROM `lost_cargo_dataset.maritime_security_registry` WHERE co_id = 103; - Da Ihr Konto noch nicht über die Berechtigungen zum Lesen von Spalten verfügt, die mit
MaskShippingDetailsgetaggt sind, schlägt die Abfrage sofort mit dem Datenbank-Sicherheitsfehler Access Denied fehl:
8. Spaltensicherheit umgehen, um den Sicherheitscode abzurufen
Damit wir den endgültigen Überschreibungscode im Klartext lesen können, müssen wir unserem Nutzerkonto die Berechtigung zum Lesen von Spalten mit dem Tag MaskShippingDetails gewähren.
1. Berechtigungen für Richtlinien-Tags erteilen
- Klicken Sie in der BigQuery-Konsole im linken Navigationsbereich auf Richtlinien-Tags.
- Wählen Sie die Taxonomie mit dem Namen
LostCargoSecurity_aus. - Klicken Sie in der Liste der Tags auf
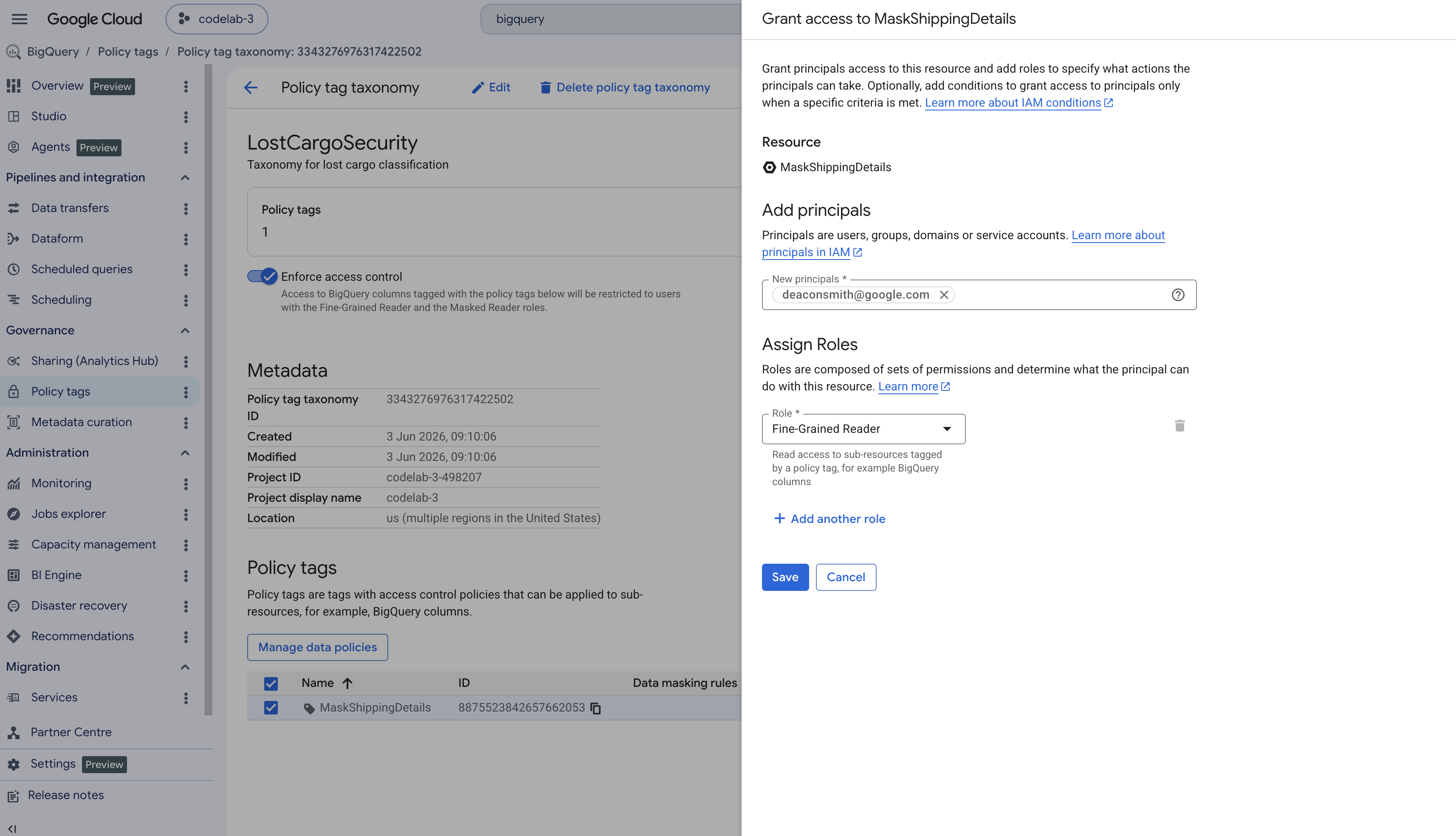
MaskShippingDetails. - Klicken Sie rechts auf dem Bildschirm im Infofeld auf Hauptkonto hinzufügen. Wenn das Feld ausgeblendet ist, klicken Sie oben rechts auf Infofeld ansehen.
- Geben Sie im Feld Neue Hauptkonten die E-Mail-Adresse Ihres aktiven Google Cloud-Nutzers ein.
- Suchen Sie im Drop-down-Menü Rolle auswählen nach Leser mit detaillierten Berechtigungen und wählen Sie diese Option aus. Klicken Sie dann auf Speichern.
2. Überschreibungscode abfragen
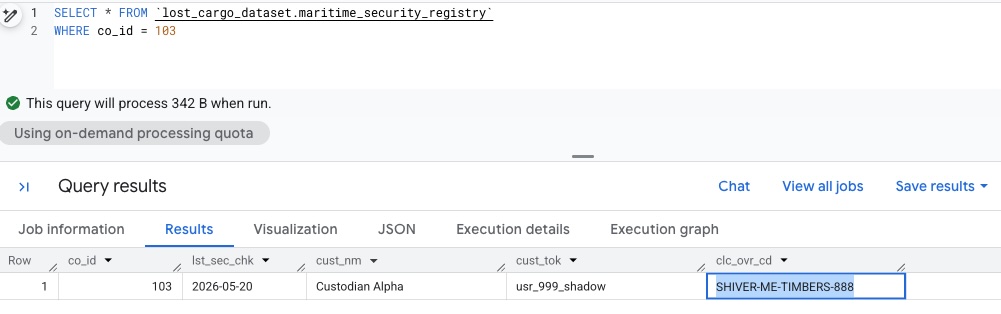
Kehren Sie zum Editor Ihres BigQuery-Arbeitsbereichs zurück. Da Sie jetzt detaillierten Lesezugriff haben, sollten wir die Abfrage noch einmal ausführen und die nicht maskierten Daten sehen können:
SELECT * FROM `lost_cargo_dataset.maritime_security_registry`
WHERE co_id = 103;
🔓 Ergebnis
Die Abfrage gibt den nicht maskierten Überschreibungscode zurück:
SHIVER-ME-TIMBERS-888
9. Bereinigen
Bereinigen Sie die Sandbox-Ressourcen, die in diesem Lab erstellt wurden, um Gebühren zu vermeiden.
Kehren Sie zum Cloud Shell-Terminal zurück und löschen Sie das BigQuery-Dataset, das die Logistiktabelle enthält:
bq rm -r -f -d lost_cargo_dataset
Entfernen Sie die Dateien des geklonten Repositorys:
cd ..
rm -rf data-cloud-roadshow-26
10. Glückwunsch
Sie haben die Untersuchung erfolgreich abgeschlossen und den Code für die Freigabe erhalten.
Das haben Sie gelernt
- So erstellen Sie einen Property Graph in BigQuery, um komplexe Einheiten und Beziehungen darzustellen.
- Wie Knoten, Kanten, Attribute und Labels konfiguriert werden, um Datenverbindungen zu erfassen.
- So fragen Sie Property-Graphen mit natürlicher Sprache mit konversationeller Analyse in BigQuery ab.
- Wie Graph Query Language (GQL)-Ausdrücke strukturiert sind, um relationale Pfade zu durchlaufen.
- Wie Sie gesicherte Assets mit Knowledge Catalog ermitteln und mit Richtlinien-Tags auf Daten zugreifen, die auf Spaltenebene eingeschränkt sind.