
1. Introduzione

Nel lab precedente, hai aggregato i log di spedizione frammentati e hai tracciato il transponder del carico fino a New York. Tuttavia, i registri di arrivo mostrano che il container è stato immediatamente reindirizzato per evitare il rilevamento doganale. Il sentiero ti ha condotto al porto di Rio de Janeiro, un porto tentacolare con migliaia di container. Trovare il contenitore giusto tra migliaia di altri è un compito difficile.
In questo lab, utilizzerai le funzionalità di AI integrate di BigQuery per "leggere" le immagini non strutturate della sicurezza portuale e rilevare anomalie termiche nei dati dei sensori, il tutto utilizzando SQL standard. Quindi, esporterai gli incorporamenti vettoriali in AlloyDB ed eseguirai una ricerca vettoriale per trovare la corrispondenza tra un segnale di telemetria frammentato e il container mancante.
In questo lab proverai a:
- Scansiona le immagini di sicurezza del porto per identificare il container rubato utilizzando BigQuery AI
- Rilevare un'anomalia termica utilizzando BigQuery AI per confermare che il contenitore è stato rubato, non smarrito
- Genera vector embedding e caricali in AlloyDB per la ricerca in tempo reale
- Abbina un segnale beacon di telemetria frammentato per individuare il container rubato utilizzando la ricerca vettoriale
- Esplorare i dati delle indagini con il linguaggio naturale utilizzando l'analisi conversazionale
Che cosa ti serve
- Un browser web come Chrome
- Un progetto cloud Google Cloud con la fatturazione abilitata
- Familiarità di base con SQL e la console Google Cloud
Questo codelab è rivolto a sviluppatori di livello intermedio.
Le risorse create in questo codelab dovrebbero costare meno di 5 $.
2. Prima di iniziare
Avvia Cloud Shell
Utilizzerai Google Cloud Shell per scaricare il codice, eseguire gli script di configurazione e implementare l'applicazione.
- In una nuova scheda del browser, apri Cloud Shell: shell.cloud.google.com
- Una volta connesso, imposta l'ID progetto e conferma l'ambiente:
gcloud config set project <<YOUR_PROJECT_ID>>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
Dovresti visualizzare un messaggio simile al seguente:
Your active configuration is: [cloudshell-####] Updated property [core/project]
Clona il repository
Clona il repository del codelab nel tuo ambiente Cloud Shell:
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/bigquery-alloydb-insights
git checkout main
cd codelabs/bigquery-alloydb-insights/
Abilita API
Esegui questo comando in Cloud Shell per abilitare tutte le API richieste per questo lab:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com
Se l'esecuzione va a buon fine, dovresti visualizzare un messaggio simile a questo:
Operation "operations/..." finished successfully.
3. Configura l'ambiente
Prima di poter analizzare le immagini e i dati di telemetria, devi configurare l'infrastruttura per questo lab. Esegui due script: uno avvia il provisioning di AlloyDB in background e l'altro crea tutte le risorse BigQuery necessarie.
Passaggio 1: avvia il deployment di AlloyDB (in background)
Il provisioning del cluster AlloyDB richiede circa 10 minuti, quindi lo avvierai per primo e lo lascerai in esecuzione in background mentre lavori sulle sezioni di BigQuery. Lo script registra automaticamente le impostazioni del progetto attivo in un file .env locale, in modo che la configurazione venga salvata anche se il terminale Cloud Shell si chiude o si riavvia.
chmod +x scripts/setup_alloydb.sh
nohup ./scripts/setup_alloydb.sh > /dev/null 2>&1 &
echo "AlloyDB deployment started in background (PID: $!)"
Passaggio 2: esegui lo script di configurazione
Questo script crea il set di dati BigQuery, la connessione alle risorse Cloud, le concessioni IAM, il bucket GCS e carica tutti i dati dei sensori che analizzerai in questo lab. Legge e verifica anche le variabili di ambiente salvate nel file .env.
chmod +x scripts/setup_lab.sh
./scripts/setup_lab.sh
L'esecuzione dello script richiede circa un minuto. Al termine, vedrai un riepilogo di tutto ciò che è stato creato.
📝 Nota sui ripristini dell'ambiente: se la sessione Cloud Shell scade o viene riavviata in qualsiasi momento durante questo lab, puoi ripristinare immediatamente le variabili del terminale eseguendo:
source scripts/setenv.sh
Passaggio 3: avvia l'editor di Cloud Shell
Finora hai utilizzato il terminale Cloud Shell. Ora passa all'editor di Cloud Shell completo, che ti offre uno spazio di lavoro simile a VS Code con supporto BigQuery integrato.
- Nel riquadro del terminale di Cloud Shell nella parte inferiore dello schermo, fai clic sul pulsante Apri editor per avviare lo spazio di lavoro dell'editor di Cloud Shell.

Passaggio 4: installa l'estensione Data Agent Kit
L'estensione Google Cloud Data Agent Kit fornisce un'integrazione profonda con i servizi di dati Google Cloud direttamente nell'editor, consentendoti di interagire con BigQuery, AlloyDB, Cloud Storage e altro ancora senza cambiare contesto.
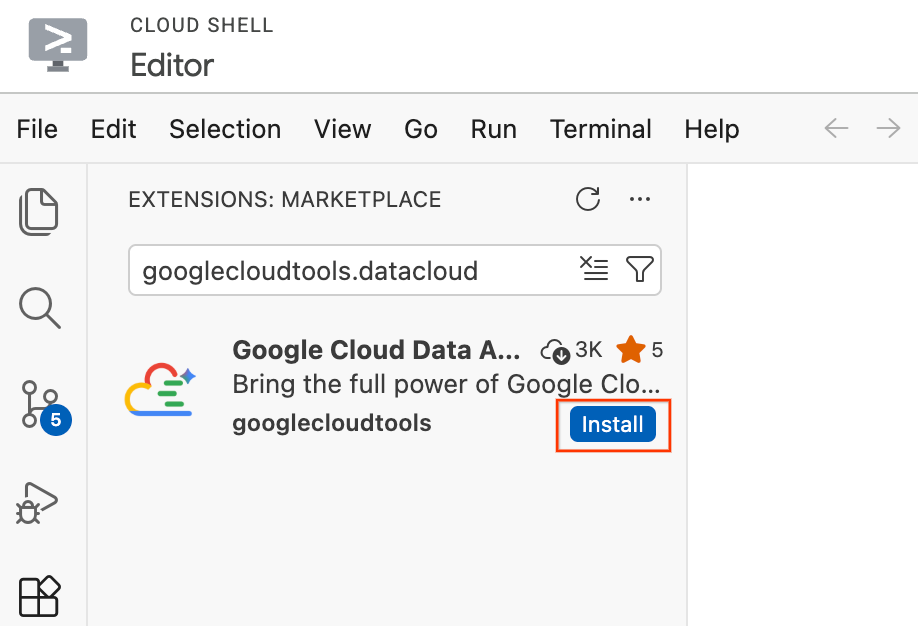
- Nell'editor di Cloud Shell, fai clic sull'icona Estensioni nella barra delle attività all'estrema sinistra dello schermo (ha l'aspetto di quattro quadrati).
- Nella barra di ricerca nella parte superiore del riquadro Estensioni, digita
googlecloudtools.datacloud. - Individua l'estensione denominata Google Cloud Data Agent Kit pubblicata da Google Cloud.
- Fai clic sul pulsante Installa.
- Viene visualizzato un messaggio che chiede: "Vuoi considerare attendibile l'editore "googlecloudtools" e le sue estensioni?". Fai clic su Considera attendibili gli editori e installa per procedere.
Passaggio 5: autentica e configura l'estensione
Dopo l'installazione, collega l'estensione al tuo progetto Google Cloud.
- Si aprirà automaticamente una pagina di onboarding intitolata "Google Cloud Data Agent Kit Onboarding". Fai clic su Accedi a Google Cloud. Segui le istruzioni del browser per consentire l'accesso.
- Viene visualizzata una finestra modale "Configurazione in corso". L'estensione verificherà automaticamente le dipendenze richieste, come Google Cloud CLI.
- Nella sezione Riepilogo configurazione, individua il campo del progetto. Fai clic sul menu a discesa e seleziona il tuo progetto Google Cloud. Imposta la tua regione su
us-central1. - Attendi il completamento dei controlli di configurazione. Quando vedi il messaggio "Configurazione completata", fai clic su Configura server MCP.
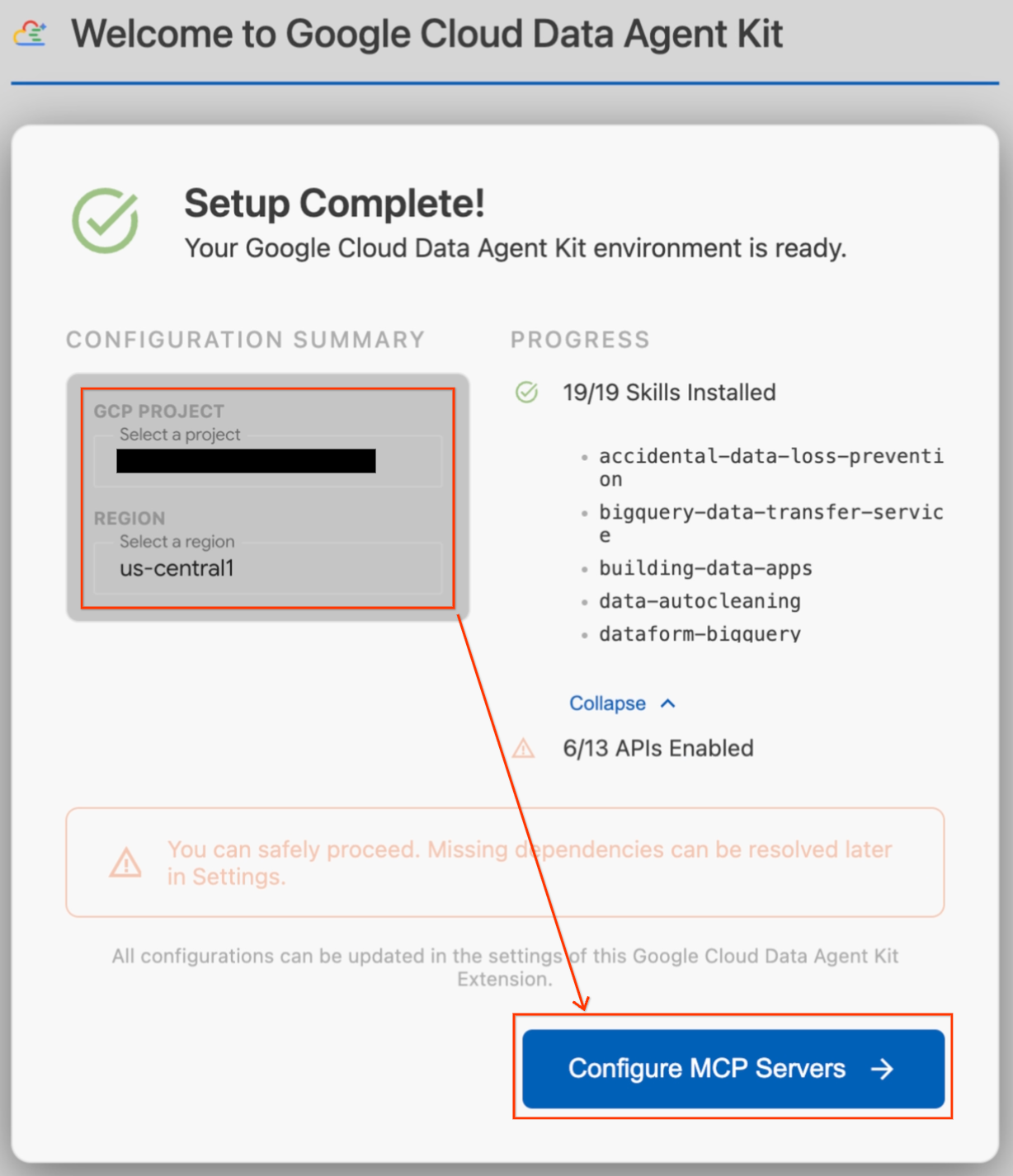
- Seleziona BigQuery e AlloyDB in Configurazione MCP e poi fai clic su Inizia.
Passaggio 6: esplora le opzioni di configurazione
Al termine della configurazione, verrà visualizzata la dashboard "Inizia a utilizzare Google Cloud Data Agent Kit".
- Nella sezione "Configurazione", fai clic su Inizia.
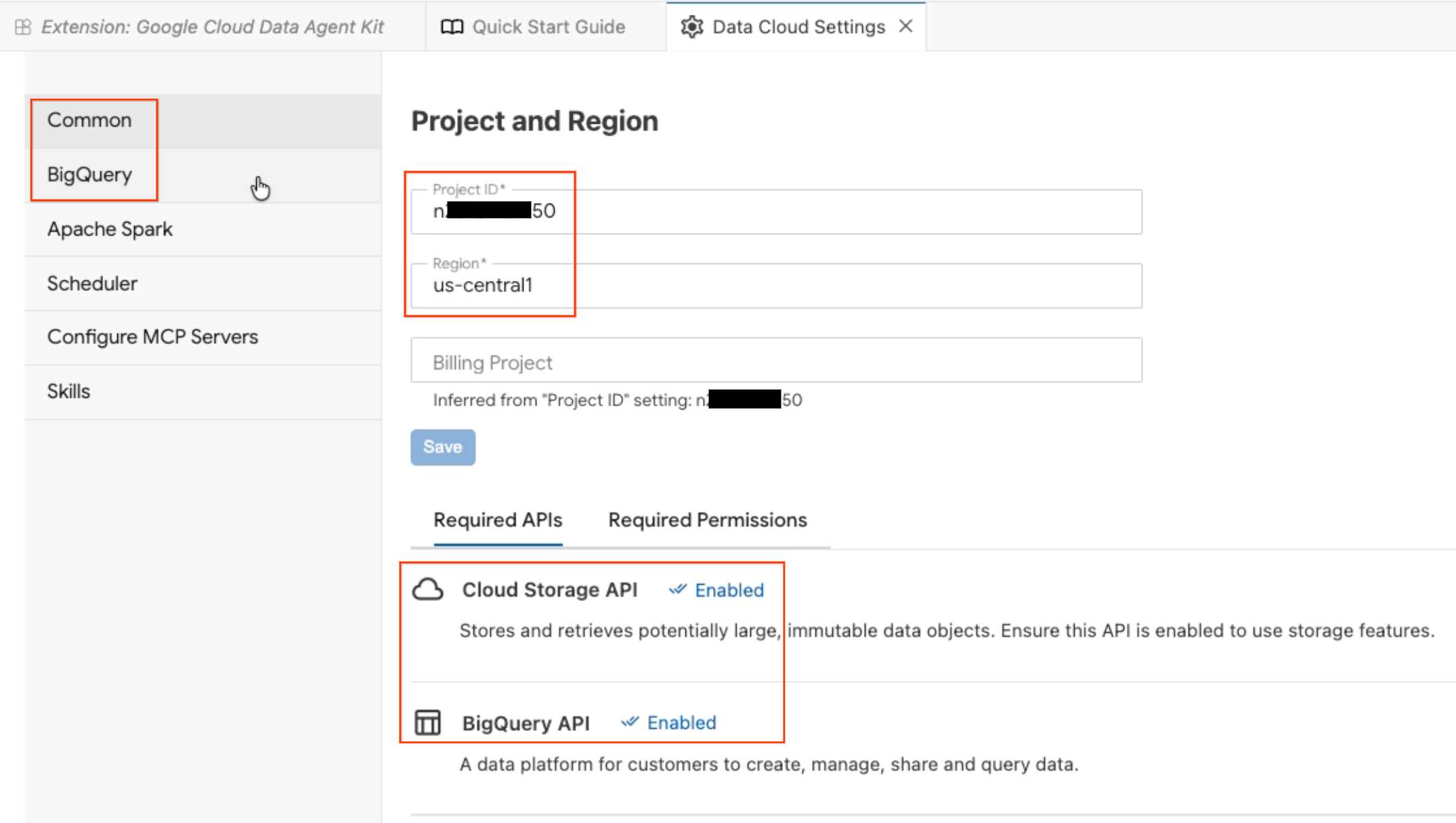
- Si apre il riquadro Configurazione agente dati. Esplora le schede:
- Progetto e regione:verifica l'ID progetto selezionato e controlla che le API richieste (API Cloud Storage, API BigQuery, API Catalog e API AlloyDB) siano attivate.
- BigQuery:configura la località predefinita per le query BigQuery. Utilizza la regione
us-central1. - Configura i server MCP:visualizza i server MCP abilitati (BigQuery, Notebook, AlloyDB e così via) che consentono agli agenti AI di interagire in modo sicuro con i tuoi dati.
- Competenze:esplora le competenze predefinite che forniscono agli agenti funzionalità specializzate per attività complesse sui dati.
Passaggio 7: verifica con BigQuery
Verifica che tutto funzioni eseguendo una query rapida su un set di dati pubblico.
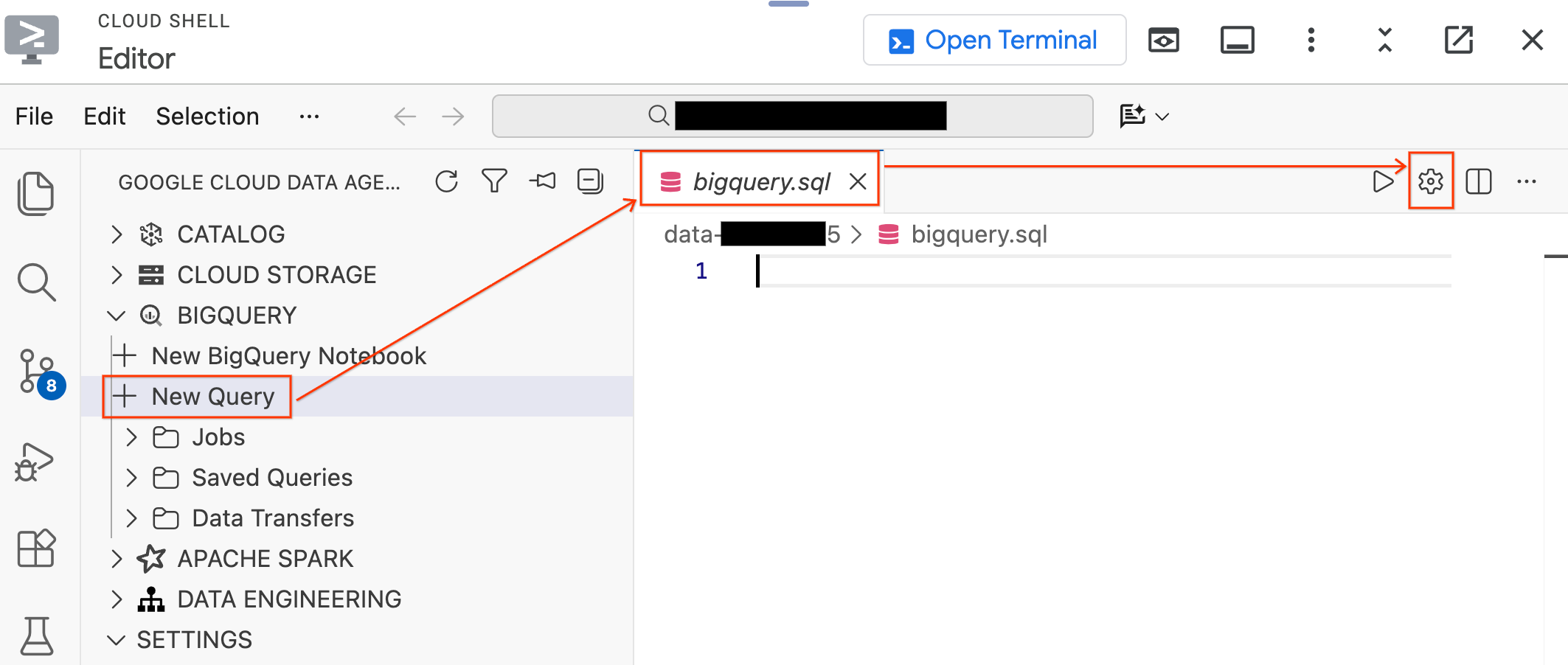
- Nel riquadro Data Agent Kit a sinistra, espandi la sezione BigQuery e fai clic su Nuova query per aprire una nuova scheda dell'editor di query.
- Salva il file premendo
Ctrl+S(Windows/Linux) oCmd+S(macOS) e chiamalobigquery. Questa scheda verrà utilizzata per tutte le operazioni BigQuery. - Fai clic su Impostazioni query con la scheda
bigquery.sqlattiva, seleziona BigQuery come origine dati e fai clic su Salva.
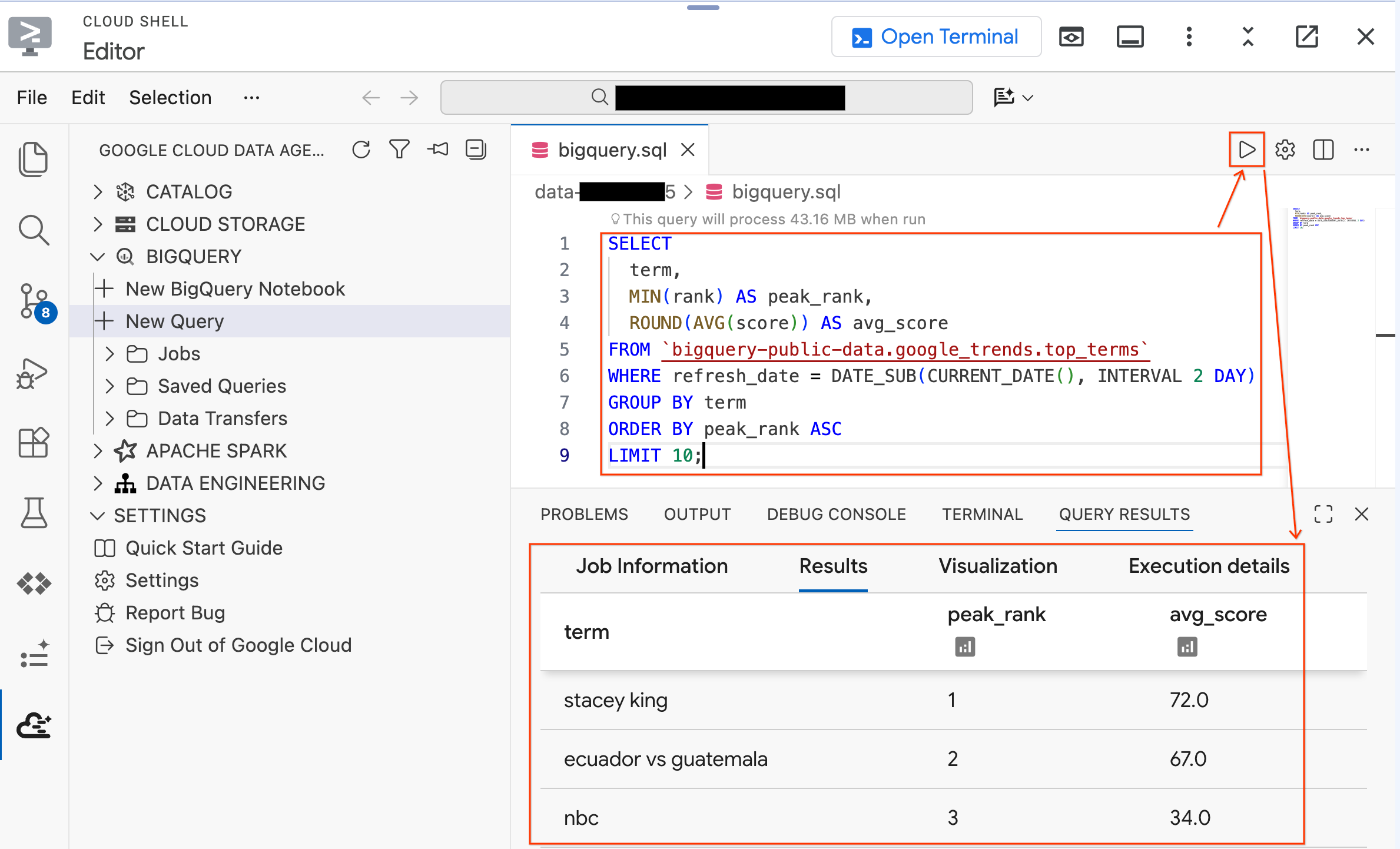
- Esegui la seguente query su un set di dati pubblico:
SELECT
term,
MIN(rank) AS peak_rank,
ROUND(AVG(score)) AS avg_score
FROM `bigquery-public-data.google_trends.top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 2 DAY)
GROUP BY term
ORDER BY peak_rank ASC
LIMIT 10;
- Dovresti visualizzare i 10 termini di ricerca di Google più popolari degli ultimi giorni. Se vengono visualizzati i risultati, l'estensione è connessa e pronta.
Ora prova una query sui dati del lab appena creati dallo script di configurazione. Sostituisci la query esistente con questa:
SELECT * FROM `lost_cargo_dataset.telemetry_data` LIMIT 5;
Dovresti visualizzare le voci di log di telemetria con le colonne shipment_id e telemetry_string. Questi sono i dati che analizzerai durante il lab.
Riepilogo della sezione:hai avviato il deployment di AlloyDB in background, eseguito lo script di configurazione e configurato Cloud Shell Editor con l'estensione Data Agent Kit.
4. Scansione dei filmati di sicurezza
Il team investigativo ha recuperato le riprese di sicurezza del porto di Rio de Janeiro che mostrano file di container marittimi. Dal laboratorio 1, sai che il container di destinazione è rosso. Ora devi identificare esattamente quale container rosso è.
Creerai una tabella degli oggetti che consente a BigQuery di "vedere" le immagini di sicurezza in Cloud Storage, quindi utilizzerai la funzione AI.GENERATE per chiedere a Gemini di estrarre dati strutturati da ogni immagine.
Passaggio 1: crea la tabella degli oggetti
Una tabella di oggetti è una tabella BigQuery speciale che funge da indice per i file non strutturati (immagini, PDF, audio) archiviati in Cloud Storage. Non copia i file in BigQuery, ma crea un riferimento su cui è possibile eseguire query in modo che le funzioni AI possano "vederli".
Nella scheda bigquery.sql dell'editor, esegui la seguente istruzione per creare la tabella degli oggetti che punta alle immagini di sicurezza delle porte nel bucket del progetto:
SET @@location = 'us-central1';
EXECUTE IMMEDIATE CONCAT("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.port_security_images`
WITH CONNECTION `us-central1.lost_cargo_conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://""", @@project_id, """-lab2/images/*']
);
""");
Dai un'occhiata rapida a ciò che BigQuery può vedere ora:
SELECT uri, content_type FROM `lost_cargo_dataset.port_security_images` LIMIT 5;
Ogni riga rappresenta un file immagine in Cloud Storage. BigQuery ora può passare queste immagini direttamente ai modelli di AI.
Passaggio 2: analizza le immagini di sicurezza
Ora utilizza la funzione AI.GENERATE di BigQuery per analizzare ogni immagine di sicurezza. Questa singola query SQL chiede a Gemini di esaminare ogni immagine e restituire dati strutturati:
SELECT
uri,
AI.GENERATE(
(
'Examine this port security image. Identify any shipping container IDs visible on the container and provide a one-word color of the container.',
ref
),
output_schema => 'detected_container_id STRING, color STRING'
).* EXCEPT (full_response, status)
FROM `lost_cargo_dataset.port_security_images`;
Passaggio 3: identifica il contenitore di destinazione
Esamina i risultati. Cerca la riga in cui la colonna color mostra "Rosso" (o una variante di rosso). Annota detected_container_id. Il tuo target è: MV-CAPYBARA-003.
Passaggio 4: verifica la corrispondenza visiva
Per visualizzare l'immagine effettivamente analizzata senza uscire dall'editor:
- Fai clic su Cloud Storage nel riquadro Data Agent Kit a sinistra.
- Espandi il bucket (
YOUR_PROJECT_ID-lab2/images/) e fai clic sul file immagine corrispondente al contenitore rosso per visualizzarlo direttamente nell'editor.
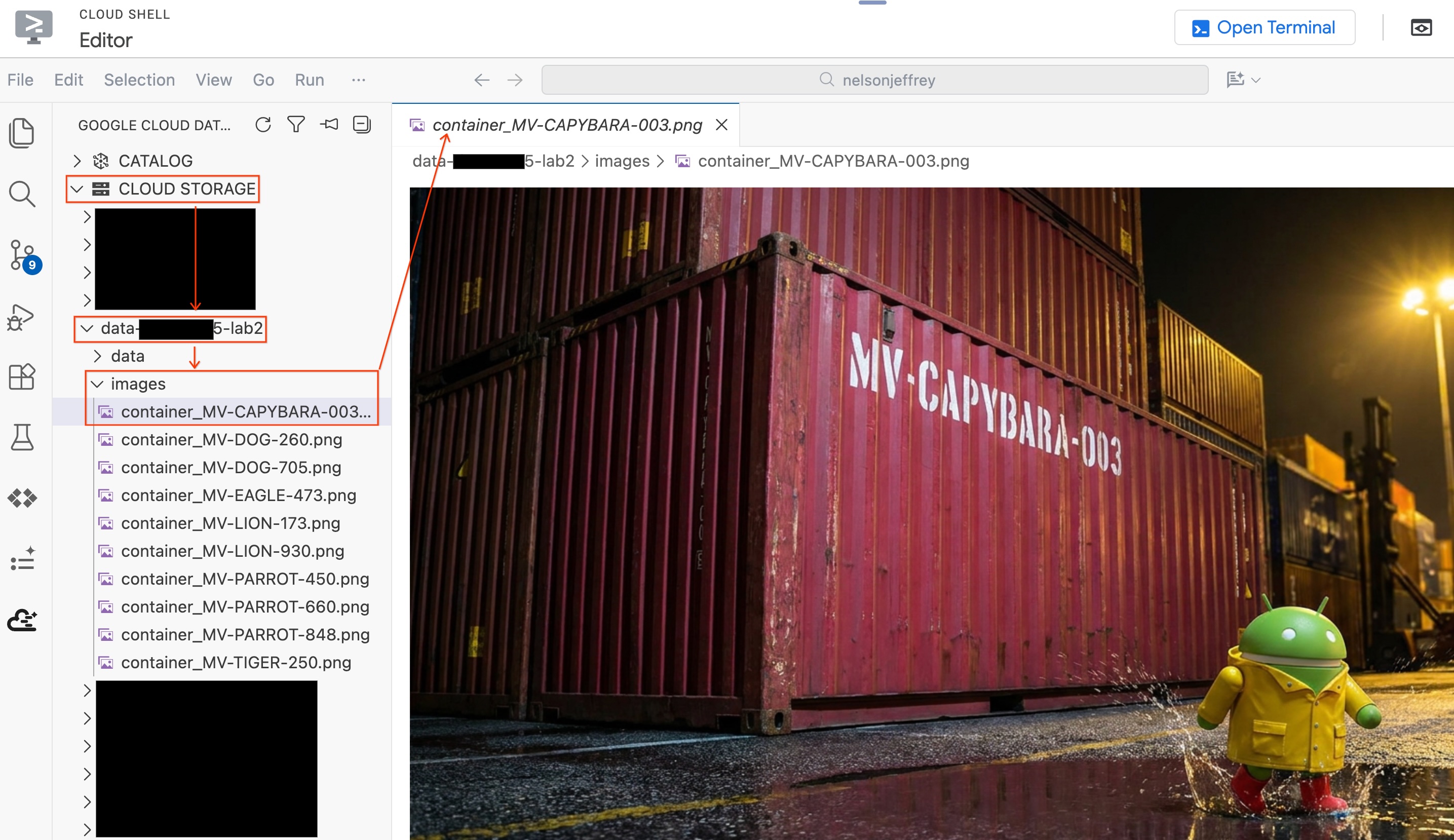
Riepilogo della sezione:hai creato una tabella degli oggetti per consentire a BigQuery di accedere alle immagini di sicurezza del porto, poi hai utilizzato AI.GENERATE per estrarre i dati strutturati dei container da ogni immagine. Il contenitore rosso è stato identificato come MV-CAPYBARA-003.
5. Conferma del furto
Hai identificato il container mancante come MV-CAPYBARA-003, ma è stato rubato o semplicemente smarrito? I log del manifest indicano che questo contenitore specifico è stato parcheggiato vicino al sensore ambientale SENS-99. Se i ladri hanno disattivato deliberatamente l'unità di refrigerazione integrata del container prima di spostarlo, SENS-99 potrebbe aver registrato un picco improvviso di scarico termico.
Utilizziamo il rilevamento di anomalie per dimostrare che il container è stato manomesso.
- Per prima cosa, esplora la base di riferimento storica. Si tratta delle letture normali di
SENS-99nelle ultime ore:
SELECT * FROM `lost_cargo_dataset.thermal_history`
ORDER BY reading_time DESC
LIMIT 50;
Nota che le temperature si mantengono in un intervallo ristretto intorno ai 24-26 °C. Questo è l'aspetto normale.
- Ora esamina il batch attuale di letture dello stesso sensore:
SELECT * FROM `lost_cargo_dataset.thermal_current`
ORDER BY thermal_reading DESC
LIMIT 50;
Vedi la lettura 64,7 °C vicino alla parte superiore? Tutto il resto sembra normale. Questo picco indicherebbe un guasto dell'unità di refrigerazione o una manomissione intenzionale. Scopriamolo.
- Esegui il rilevamento di anomalie.
AI.DETECT_ANOMALIESdi BigQuery utilizza il foundation model TimesFM preaddestrato per analizzare automaticamente i pattern delle serie temporali e segnalare i valori anomali, senza richiedere l'addestramento del modello:
SELECT *
FROM AI.DETECT_ANOMALIES(
TABLE `lost_cargo_dataset.thermal_history`,
TABLE `lost_cargo_dataset.thermal_current`,
data_col => 'thermal_reading',
timestamp_col => 'reading_time',
id_cols => ['sensor_id']
)
WHERE is_anomaly = TRUE;
- Esamina i risultati. La lettura di 64,7 °C deve essere contrassegnata come anomalia con un'alta probabilità di anomalia, a conferma che si è verificato qualcosa di insolito vicino all'area del contenitore.
Riepilogo della sezione:hai utilizzato la funzione AI.DETECT_ANOMALIES di BigQuery per sfruttare il modello TimesFM preaddestrato. Eseguendo una singola query SQL, hai identificato automaticamente gli outlier e isolato l'evento di manomissione anomalo senza scrivere codice di machine learning complesso o addestrare modelli da zero.
6. Preparazione del sistema di monitoraggio
È stato confermato il furto del container, che non si trova più a Rio de Janeiro. Ogni container del parco risorse trasmette segnali beacon di telemetria: letture dei sensori, frammenti GPS e log di stato. Se il beacon del container rubato trasmette ancora, puoi confrontarlo con le firme note per trovarlo.
BigQuery eccelle nel lavoro analitico che hai svolto finora, ma l'individuazione di un container in tempo reale richiede query operative a bassa latenza. AlloyDB, un database completamente gestito e compatibile con PostgreSQL, è progettato proprio per questo: query di ricerca vettoriale abbastanza veloci per un sistema di monitoraggio in tempo reale. Caricherai gli incorporamenti di telemetria in AlloyDB e li utilizzerai per trovare la corrispondenza con il segnale del beacon.
Il cluster AlloyDB che hai avviato in background in precedenza dovrebbe essere pronto. Configuriamolo direttamente dall'editor.
Passaggio 1: connettiti ad AlloyDB dall'editor
Anziché passare alla console Google Cloud, puoi connetterti direttamente ad AlloyDB utilizzando l'estensione Data Agent Kit.
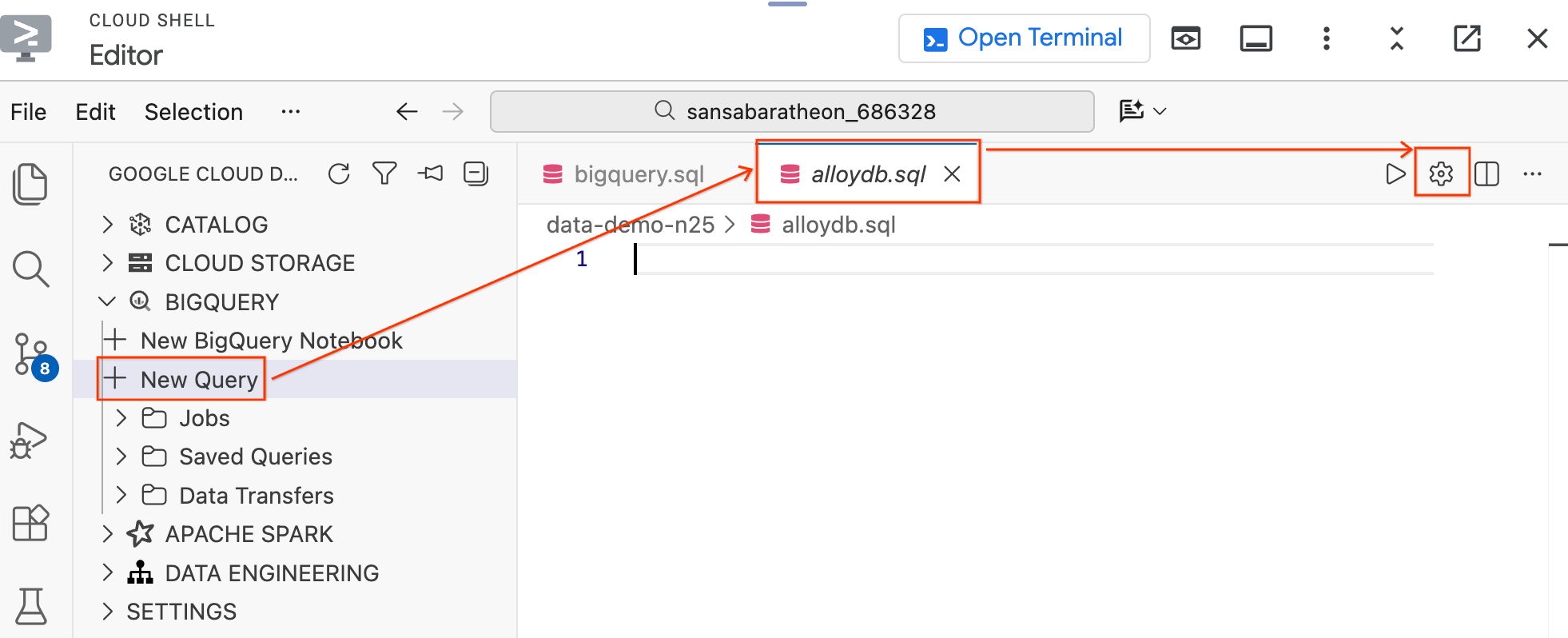
- Nel riquadro Data Agent Kit a sinistra, nella sezione BigQuery, fai clic su Nuova query per aprire una nuova scheda dell'editor di query.
- Salva il file premendo
Ctrl+S(Windows/Linux) oCmd+S(macOS) e chiamaloalloydb. Questa scheda verrà utilizzata per tutte le query AlloyDB. - Fai clic sull'icona a forma di ingranaggio per aprire la finestra modale Impostazioni query.
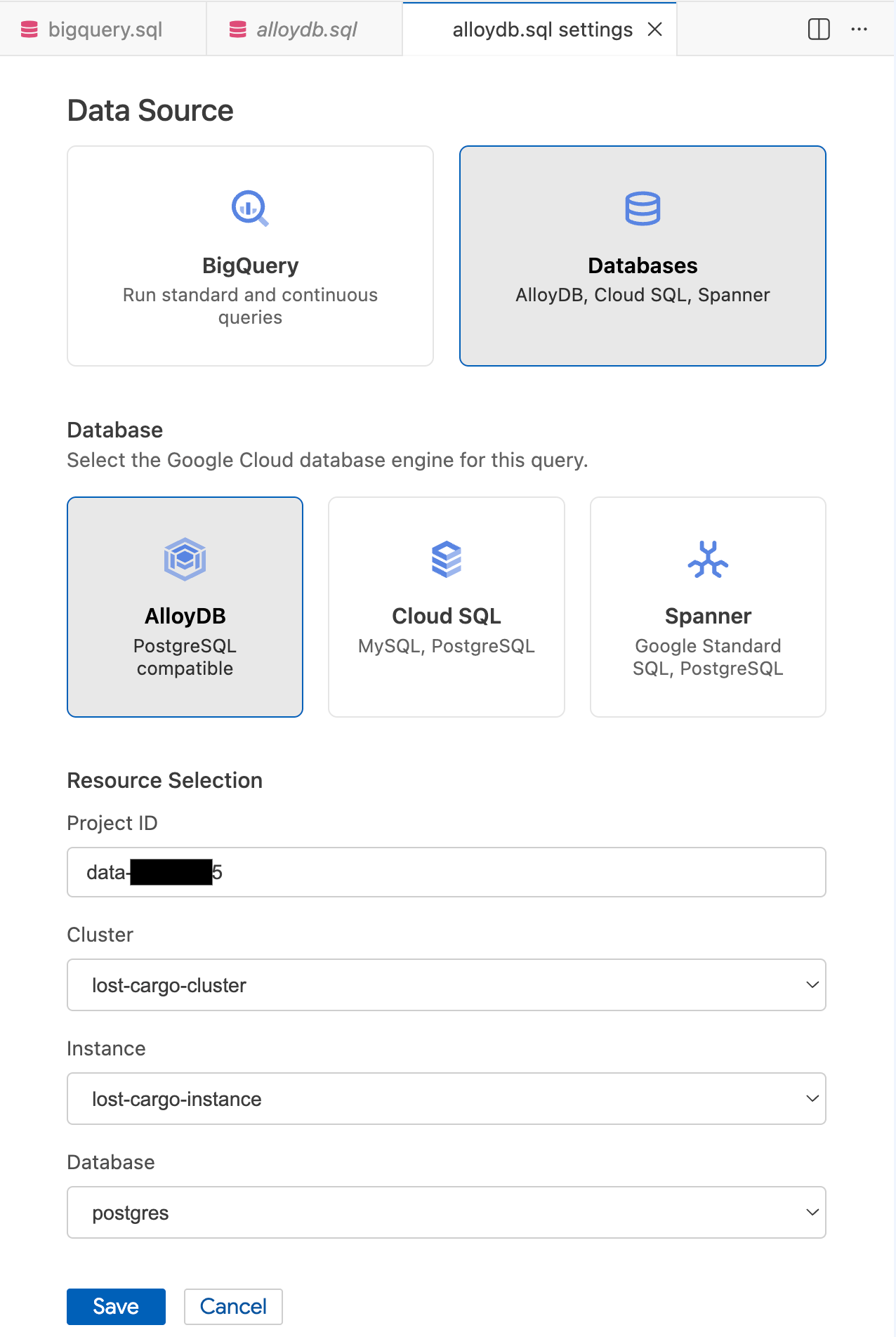
- Nella finestra modale Impostazioni query, seleziona Database in Origine dati.
- In Database, seleziona AlloyDB.
- Compila i dettagli della selezione delle risorse:
- ID progetto: inserisci l'ID progetto Google Cloud.
- Cluster: seleziona
lost-cargo-cluster. - Istanza: seleziona
lost-cargo-instance. - Database: seleziona
postgres.
- Fai clic su Salva.
Passaggio 2: attiva l'estensione vettoriale e crea la tabella
Ora che ti sei connesso ad AlloyDB, devi abilitare le estensioni AI necessarie e creare la tabella che riceverà i dati di telemetria incorporati.
- Nella scheda
.sqlattiva, incolla i seguenti comandi per abilitare le estensioni richieste:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
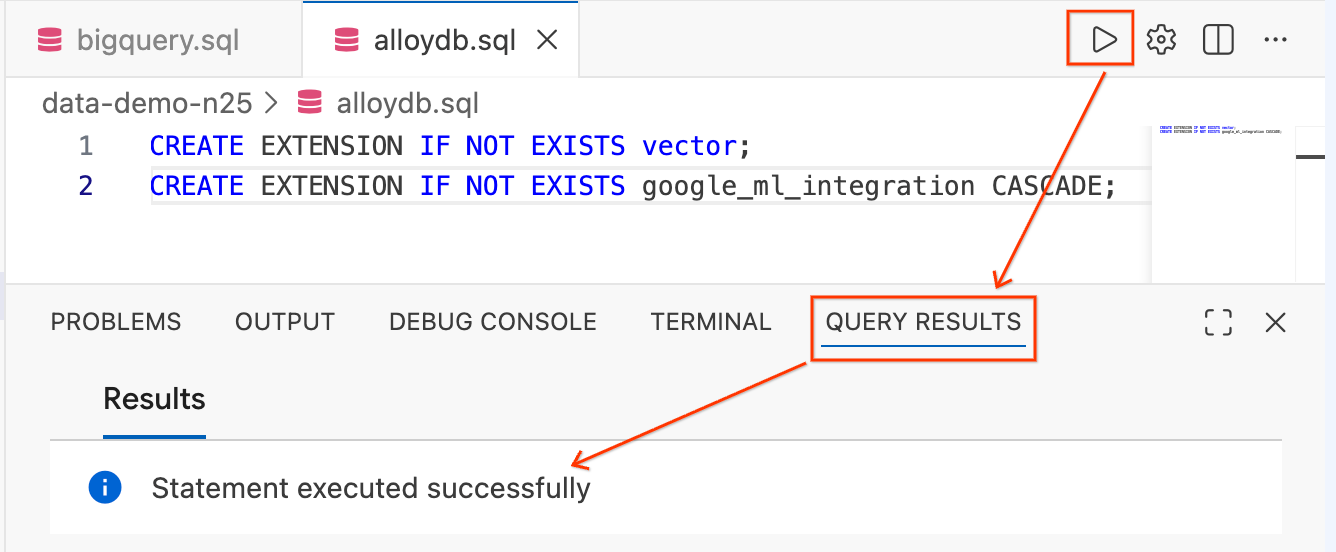
- Evidenzia il testo e fai clic sul pulsante Esegui query (l'icona di riproduzione) in alto a destra nell'editor.
- Controlla il pannello del terminale Risultati query nella parte inferiore dello schermo. Dovrebbe essere visualizzato il messaggio
Statement executed successfully.
- Successivamente, sostituisci il testo nell'editor con la seguente istruzione per creare la tabella di telemetria:
CREATE TABLE IF NOT EXISTS vessel_telemetry (
entry_id SERIAL PRIMARY KEY,
shipment_id VARCHAR(50),
telemetry_string TEXT,
embedding_vector vector(768)
);
- Esegui questa query come l'ultima. Verifica che l'esecuzione sia riuscita nel riquadro inferiore.
Il tipo vector(768) deriva dall'estensione pgvector che hai appena attivato. Le 768 dimensioni corrispondono all'output del modello text-embedding-005 di Google, che utilizzerai in BigQuery per generare gli incorporamenti.
Riepilogo della sezione:ti sei connesso ad AlloyDB direttamente da Cloud Shell Editor, hai attivato le estensioni pgvector e google_ml_integration e hai creato la tabella di destinazione. AlloyDB è ora pronto a fungere da backend operativo per la corrispondenza della telemetria in tempo reale.
7. Creazione dell'indice di ricerca
Ora devi inserire i dati di telemetria in AlloyDB in modo che possano supportare la corrispondenza dei beacon in tempo reale. I log di telemetria non elaborati sono disordinati e a lunghezza variabile, il che non è l'ideale per la ricerca di somiglianze. Utilizzerai le funzioni AI di BigQuery per riepilogare ogni log con Gemini e convertire ogni riepilogo in un embedding vettoriale a 768 dimensioni. Quindi, esporterai i dati arricchiti in Cloud Storage e li importerai in AlloyDB.
Passaggio 1: genera gli incorporamenti in BigQuery
Torna alla scheda dell'editor bigquery.sql (che rimane connessa a BigQuery).
Ora esegui la seguente query per riassumere ogni log di telemetria con Gemini e generare incorporamenti vettoriali:
CREATE OR REPLACE TABLE `lost_cargo_dataset.telemetry_embeddings_export` AS
WITH summarized_telemetry AS (
SELECT
shipment_id,
telemetry_string,
AI.GENERATE(
CONCAT('Summarize this telemetry log for vector search: ', telemetry_string)
).result AS summary
FROM `lost_cargo_dataset.telemetry_data`
),
telemetry_embeddings AS (
SELECT
shipment_id,
telemetry_string,
AI.EMBED(summary, endpoint => 'text-embedding-005').result AS embedding
FROM summarized_telemetry
)
SELECT
shipment_id,
telemetry_string,
TO_JSON_STRING(embedding) AS embedding_vector
FROM telemetry_embeddings;
Passaggio 2: visualizza l'anteprima dei dati arricchiti
Prima di esportare, dai un'occhiata a ciò che hai creato. Questa query mostra gli ID spedizione e i primi 80 caratteri di ogni riepilogo e incorporamento:
SELECT
shipment_id,
SUBSTR(telemetry_string, 1, 80) AS telemetry_preview,
SUBSTR(embedding_vector, 1, 80) AS embedding_preview
FROM `lost_cargo_dataset.telemetry_embeddings_export`
LIMIT 5;
Ogni riga ora contiene un ID spedizione, il log di telemetria originale e un vettore di incorporamento a 768 dimensioni. Questi sono i dati che inserirai in AlloyDB.
Passaggio 3: esporta gli incorporamenti in Cloud Storage
Utilizza l'istruzione EXPORT DATA di BigQuery per scrivere la tabella degli incorporamenti nel bucket GCS del lab come file CSV.
EXECUTE IMMEDIATE CONCAT("""
EXPORT DATA OPTIONS (
uri = 'gs://""", @@project_id, """-lab2/data/embeddings_export/*.csv',
format = 'CSV',
overwrite = true,
header = false
) AS
SELECT
shipment_id,
telemetry_string,
embedding_vector
FROM `lost_cargo_dataset.telemetry_embeddings_export`;
""");
Passaggio 4: importa in AlloyDB da Cloud Storage
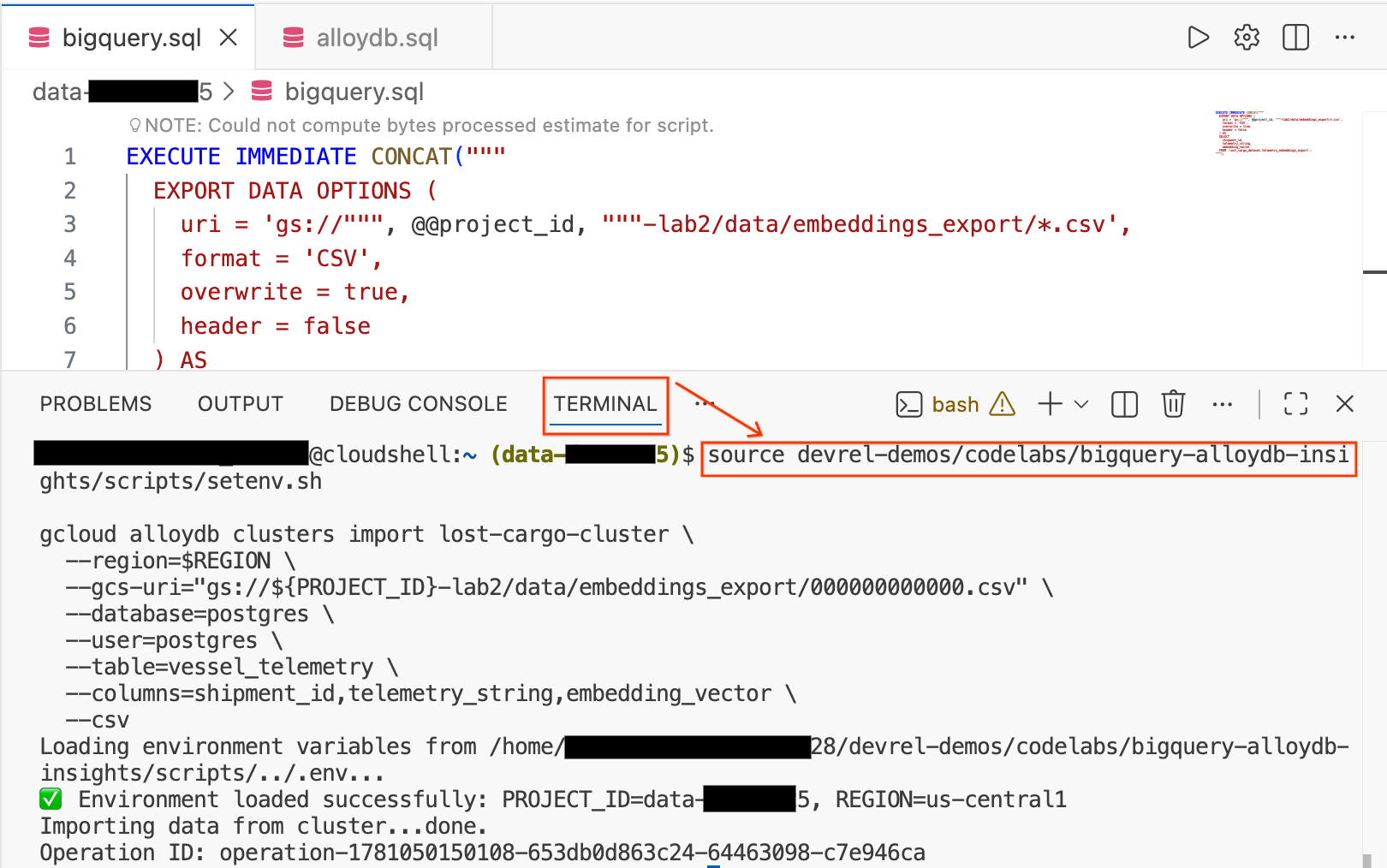
- Nell'editor di Cloud Shell, fai clic sulla scheda Terminale nella parte inferiore dello schermo per aprire una sessione del terminale.
- Esegui questi comandi per caricare l'ambiente e importare il file CSV direttamente nella tabella
vessel_telemetryin AlloyDB:
source devrel-demos/codelabs/bigquery-alloydb-insights/scripts/setenv.sh
gcloud alloydb clusters import lost-cargo-cluster \
--region=$REGION \
--gcs-uri="gs://${PROJECT_ID}-lab2/data/embeddings_export/000000000000.csv" \
--database=postgres \
--user=postgres \
--table=vessel_telemetry \
--columns=shipment_id,telemetry_string,embedding_vector \
--csv
Riepilogo della sezione:hai utilizzato le funzioni AI di BigQuery per riepilogare e incorporare i dati di telemetria, hai esportato i risultati in Cloud Storage come CSV e poi li hai importati in AlloyDB utilizzando gcloud. Il database di monitoraggio operativo è ora caricato e pronto.
8. Corrispondenza del segnale beacon
Un team sul campo vicino a Sydney ha intercettato un segnale frammentato di un beacon di telemetria. Il log parziale riporta:
"Unità di refrigerazione offline. Controllo manuale".
Se proviene dal contenitore rubato, la ricerca vettoriale di AlloyDB dovrebbe essere in grado di trovarlo anche se il segnale è incompleto. Questo è esattamente il tipo di query operativa in tempo reale per cui è stato creato AlloyDB.
Passaggio 1: verifica i dati importati
Torna alla scheda dell'editor alloydb.sql (che rimane connessa ad AlloyDB).
Verifica che i dati di telemetria siano stati caricati correttamente eseguendo:
SELECT shipment_id, LEFT(telemetry_string, 80) AS telemetry_preview
FROM vessel_telemetry
LIMIT 10;
Dovresti vedere righe con valori shipment_id e testo di telemetria. Queste sono le firme di telemetria della flotta, ora pronte per la corrispondenza in tempo reale.
Passaggio 2: cerca il contenitore mancante
Ora, utilizza l'estensione google_ml_integration di AlloyDB per cercare una corrispondenza utilizzando il frammento di segnale intercettato:
SELECT
shipment_id,
telemetry_string,
1 - (embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector) AS search_relevance_score
FROM vessel_telemetry
ORDER BY embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector
LIMIT 5;
La funzione embedding(), fornita dall'estensione google_ml_integration di AlloyDB, chiama Agent Platform direttamente da SQL per generare un vector embedding inline. L'operatore <=> calcola la distanza del coseno tra due vettori (più è vicino a 0, più i due vettori sono identici). Sottraiamo il risultato da 1 per esprimere i risultati come un punteggio di pertinenza in cui un valore più alto è migliore.
Passaggio 3: conferma la corrispondenza
Esamina i risultati. Il primo risultato dovrebbe essere MV-CAPYBARA-003, con il punteggio di pertinenza più alto.
Si tratta dello stesso contenitore che hai monitorato in ogni fase di questa indagine:
- 📷 Le riprese di sicurezza lo hanno identificato mentre lasciava il porto di Rio de Janeiro di notte.
- 🌡️ Il rilevamento di anomalie termiche ha confermato che l'unità di refrigerazione è stata disattivata intenzionalmente.
- 📡 Corrispondenza del segnale beacon ha appena individuato la sua firma di telemetria vicino a Sydney.
Tre prove indipendenti. Tre diverse funzionalità di AI Google Cloud. Un contenitore rubato.
🎯 Caso chiuso: MV-CAPYBARA-003 è stato trovato vicino a Sydney.

Riepilogo della sezione: hai utilizzato l'integrazione dell'AI integrata di AlloyDB per generare un incorporamento di ricerca ed eseguire una ricerca di similarità del coseno in una singola query SQL. La corrispondenza del beacon ha confermato la posizione del container rubato, completando l'indagine.
9. Esplorare le prove
Ora che hai identificato il contenitore tramite l'analisi multimodale delle immagini e la ricerca vettoriale, puoi utilizzare Conversational Analytics direttamente nell'editor per esplorare i dati dell'indagine utilizzando il linguaggio naturale, senza scrivere codice SQL.
Passaggio 1: individua i dati in Knowledge Catalog
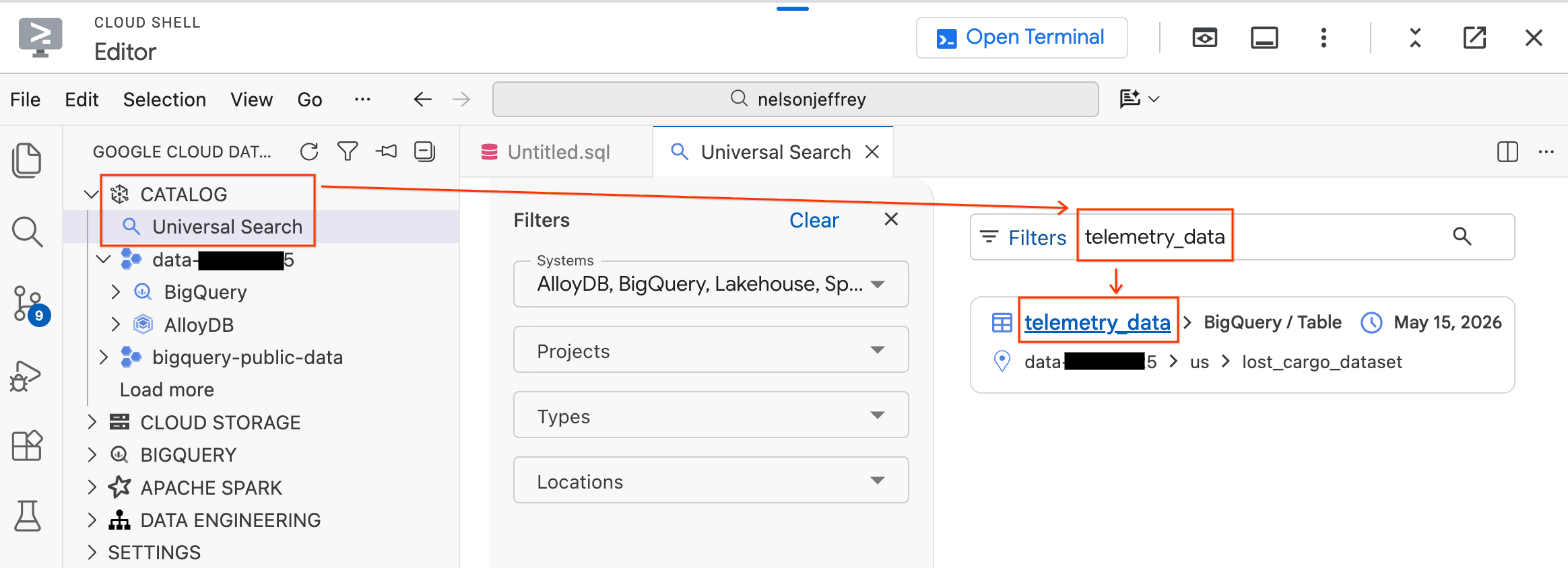
Data Agent Kit include una funzionalità dei risultati di ricerca universale che ti consente di trovare ed esplorare gli asset di dati nel tuo ambiente Google Cloud.
- Nel riquadro Data Agent Kit a sinistra, espandi la sezione Catalogo.
- Fai clic su Ricerca universale.
- Nella barra di ricerca, digita
telemetry_data. - Fai clic sulla tabella
telemetry_data(inlost_cargo_dataset) nei risultati di ricerca.
Passaggio 2: avvia l'analisi conversazionale
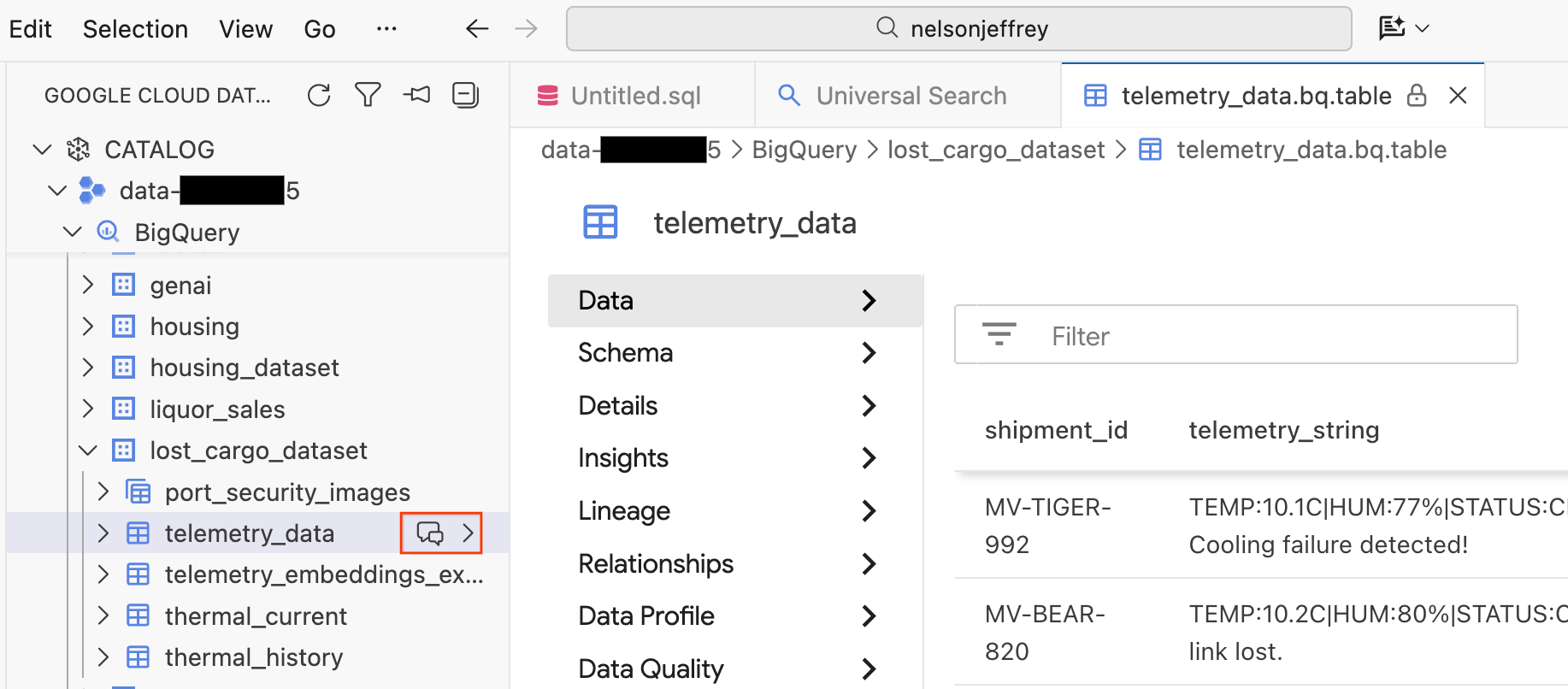
Se fai clic sul risultato di ricerca, si apre una scheda del visualizzatore di dati in cui puoi visualizzare l'anteprima dei dati non elaborati, visualizzare lo schema e controllare la qualità dei dati.
- Nel riquadro a sinistra sono visibili i set di dati e le tabelle BigQuery. Fai clic sul pulsante Chat per aprire una nuova finestra di chat.
Passaggio 3: fai domande in linguaggio naturale
Si apre una nuova scheda di chat "Ti diamo il benvenuto in Analisi conversazionale". L'agente ha informazioni sul contenuto e sullo schema della tabella.
- Nella finestra della chat, digita:"Show me the telemetry status and log for the Capybara shipment." (Mostrami lo stato e il log della telemetria per la spedizione di Capybara.)
- Premi Invio.
L'agente traduce la tua domanda in SQL BigQuery, esegue la query e restituisce i risultati, inclusi una tabella di dati e approfondimenti che riassumono i risultati. Puoi alternare la modalità Ragionamento (analisi più approfondita, più lenta) e la modalità Veloce (risposte più rapide) a seconda della complessità della domanda. Poiché si tratta di risposte create con l'AI, i risultati potrebbero essere leggermente diversi dagli screenshot riportati di seguito.
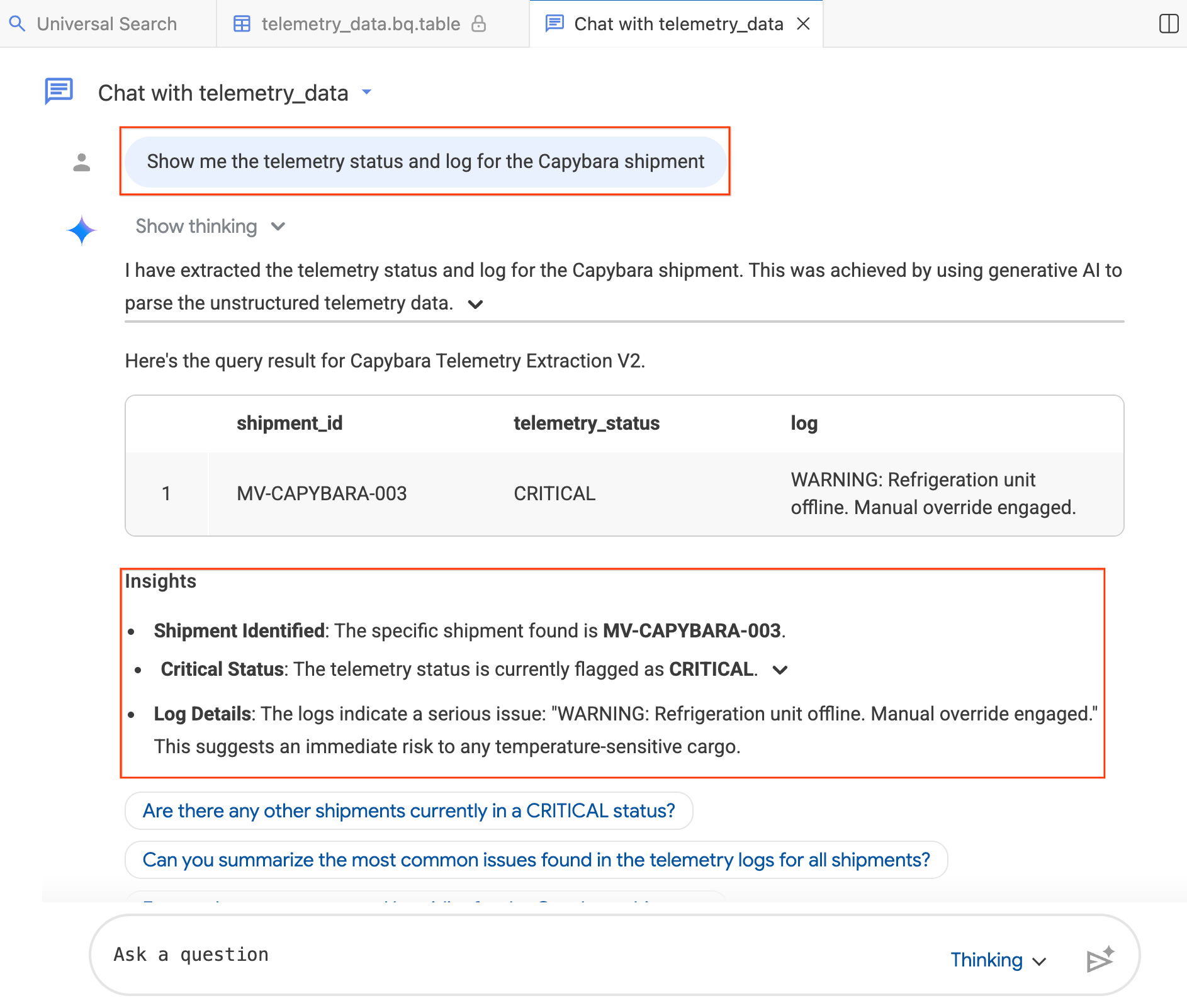
Passaggio 4: fai domande aggiuntive
L'agente ricorda il contesto della conversazione. Prova a fare una domanda aggiuntiva:
- "Quante spedizioni uniche sono presenti nei dati di telemetria?"
- "Quante altre spedizioni della flotta hanno attualmente lo stato CRITICO?"
Riepilogo della sezione:hai utilizzato la funzionalità di ricerca universale di Knowledge Catalog per individuare il tuo set di dati e hai avviato l'analisi conversazionale per eseguire query sui dati dell'indagine con un linguaggio naturale. L'agente AI ha tradotto le tue domande in SQL e ha fornito approfondimenti che hanno confermato i tuoi risultati.
10. Elimina
Per evitare che al tuo account Google Cloud vengano addebitati costi continui, elimina le risorse che hai creato in questo lab. Puoi eseguire questi comandi nel terminale integrato all'interno dell'editor di Cloud Shell (dove hai utilizzato Data Agent Kit) per liberare spazio nell'ambiente.
Innanzitutto, carica le variabili di ambiente:
source scripts/setenv.sh
- Elimina le risorse BigQuery (solo se non continui con il Lab 3):
Se prevedi di continuare con il lab 3, salta questo passaggio. Il lab 3 utilizza lo stesso set di dati e le stesse connessioni BigQuery per l'analisi dei grafici delle proprietà.
Per eliminare il set di dati e le connessioni BigQuery:
# Drop the dataset
bq rm -r -f $PROJECT_ID:lost_cargo_dataset
# Delete the connections
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_conn
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_alloydb_conn
- Elimina il bucket Cloud Storage:
gcloud storage rm --recursive gs://${PROJECT_ID}-lab2
- Elimina l'istanza e il cluster AlloyDB:
AlloyDB non viene utilizzato nel lab 3, quindi puoi eliminarlo in tutta sicurezza.
gcloud alloydb instances delete lost-cargo-instance \
--region=$REGION \
--cluster=lost-cargo-cluster \
--quiet
gcloud alloydb clusters delete lost-cargo-cluster \
--region=$REGION \
--force \
--quiet
- Elimina le impostazioni dell'ambiente locale:
Infine, libera spazio nel file delle impostazioni dell'ambiente locale dal tuo workspace:
rm -f .env
11. Complimenti!
Hai completato correttamente il lab 2: Analisi dei dati e approfondimenti multimodali. Hai seguito la pista da un porto pieno di migliaia di container a un furto confermato e a una posizione precisa.
Cosa hai realizzato
- Scanned the footage: hai utilizzato
AI.GENERATEdi BigQuery per analizzare le immagini di sicurezza del porto e identificare il container MV-CAPYBARA-003 di colore rosso cremisi. - Conferma del furto: hai esaminato i dati del sensore termico, hai notato un picco sospetto di 64, 7 °C e hai utilizzato
AI.DETECT_ANOMALIESper dimostrare che si trattava di una manomissione intenzionale. - Preparato il sistema di monitoraggio: hai configurato AlloyDB con pgvector e
google_ml_integrationper la corrispondenza dei beacon in tempo reale. - Creazione dell'indice di ricerca: hai utilizzato
AI.GENERATEeAI.EMBEDin BigQuery per creare incorporamenti, poi li hai esportati in Cloud Storage e importati in AlloyDB. - Corrispondenza con il segnale del beacon: hai utilizzato la ricerca vettoriale di AlloyDB per trovare una corrispondenza con un segnale di telemetria frammentato, individuando il container rubato vicino a Sydney.
- Esplorazione delle prove: hai utilizzato Analisi conversazionale direttamente dall'editor per eseguire query sui dati dell'indagine con il linguaggio naturale.

Passaggi successivi
Hai scoperto dove si trova il contenitore. Ora devi scoprire chi c'è dietro.
Nel Lab 3: Data Consumption & Agentic Workflows, creerai un grafico delle proprietà della rete logistica per mappare le relazioni tra le società schermo, utilizzare Conversational Analytics per interagire con il grafico e cercare nel Knowledge Catalog il codice di autorizzazione protetto necessario per recuperare il container.