
1. Wprowadzenie

W poprzednim module udało Ci się zagregować pofragmentowane dzienniki wysyłki i wyśledzić transponder ładunku do Nowego Jorku. Jednak zapisy przybycia pokazują, że kontener został natychmiast przekierowany, aby uniknąć wykrycia przez służby celne. Szlak prowadzi teraz do portu w Rio de Janeiro, rozległego portu z tysiącami kontenerów. Znalezienie odpowiedniego kontenera spośród tysięcy innych jest trudnym zadaniem.
W tym module wykorzystasz wbudowane funkcje AI BigQuery, aby „odczytywać” nieustrukturyzowane obrazy zabezpieczeń portu i wykrywać anomalie termiczne w danych z czujników – wszystko to za pomocą standardowego języka SQL. Następnie wyeksportujesz wektory dystrybucyjne do AlloyDB i przeprowadzisz wyszukiwanie wektorowe, aby dopasować fragmentaryczny sygnał telemetryczny do brakującego kontenera.
Jakie zadania wykonasz
- Skanowanie zdjęć zabezpieczeń portu w celu zidentyfikowania skradzionego kontenera za pomocą BigQuery AI
- Wykrywanie anomalii termicznych za pomocą AI w BigQuery w celu potwierdzenia, że kontener został skradziony, a nie zgubiony
- Generowanie wektorów dystrybucyjnych i ładowanie ich do AlloyDB na potrzeby wyszukiwania w czasie rzeczywistym
- Dopasowywanie sygnału fragmentowanego beacona telemetrycznego w celu zlokalizowania skradzionego kontenera za pomocą wyszukiwania wektorowego
- Eksplorowanie danych z dochodzenia przy użyciu języka naturalnego w analityce konwersacyjnej
Czego potrzebujesz
- przeglądarka, np. Chrome;
- projekt Google Cloud z włączonymi płatnościami;
- Podstawowa znajomość SQL i konsoli Google Cloud
To ćwiczenie jest przeznaczone dla programistów na poziomie średnio zaawansowanym.
Zasoby utworzone w tym module powinny kosztować mniej niż 5 USD.
2. Zanim zaczniesz
Uruchamianie Cloud Shell
Do pobrania kodu, uruchomienia skryptów konfiguracji i wdrożenia aplikacji użyjesz Google Cloud Shell.
- Na nowej karcie przeglądarki otwórz Cloud Shell: shell.cloud.google.com
- Po połączeniu ustaw identyfikator projektu i potwierdź środowisko:
gcloud config set project <<YOUR_PROJECT_ID>>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
Wyświetli się komunikat podobny do tego:
Your active configuration is: [cloudshell-####] Updated property [core/project]
Klonowanie repozytorium
Sklonuj repozytorium z ćwiczeniami do środowiska powłoki Cloud Shell:
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/bigquery-alloydb-insights
git checkout main
cd codelabs/bigquery-alloydb-insights/
Włącz interfejsy API
Aby włączyć wszystkie interfejsy API wymagane w tym module, uruchom to polecenie w Cloud Shell:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com
Po pomyślnym wykonaniu powinien wyświetlić się komunikat podobny do tego:
Operation "operations/..." finished successfully.
3. Konfigurowanie środowiska
Zanim zaczniesz analizować obrazy i dane telemetryczne, musisz skonfigurować infrastrukturę na potrzeby tego modułu. Uruchomisz 2 skrypty: jeden rozpocznie w tle udostępnianie AlloyDB, a drugi utworzy wszystkie potrzebne zasoby BigQuery.
Krok 1. Rozpocznij wdrażanie AlloyDB (w tle)
Provisioning klastra AlloyDB trwa około 10 minut, więc najpierw uruchomisz ten proces i pozwolisz mu działać w tle, podczas gdy będziesz pracować nad sekcjami BigQuery. Skrypt automatycznie zapisze ustawienia aktywnego projektu w lokalnym pliku .env, dzięki czemu konfiguracja zostanie zapisana nawet wtedy, gdy terminal Cloud Shell zostanie zamknięty lub ponownie uruchomiony.
chmod +x scripts/setup_alloydb.sh
nohup ./scripts/setup_alloydb.sh > /dev/null 2>&1 &
echo "AlloyDB deployment started in background (PID: $!)"
Krok 2. Uruchom skrypt konfiguracji
Ten skrypt tworzy zbiór danych BigQuery, połączenie z zasobem Cloud, uprawnienia IAM i zasobnik GCS oraz wczytuje wszystkie dane z czujników, które będziesz analizować w tym module. Odczyta i zweryfikuje też zmienne środowiskowe zapisane w pliku .env.
chmod +x scripts/setup_lab.sh
./scripts/setup_lab.sh
Wykonanie skryptu zajmuje około minuty. Po zakończeniu zobaczysz podsumowanie wszystkich utworzonych elementów.
📝 Uwaga dotycząca resetowania środowiska: jeśli sesja Cloud Shell wygaśnie lub zostanie w dowolnym momencie tego modułu uruchomiona ponownie, możesz natychmiast przywrócić zmienne terminala, wykonując to polecenie:
source scripts/setenv.sh
Krok 3. Uruchom edytor Cloud Shell
Do tej pory używasz terminala Cloud Shell. Teraz przełącz się na pełną wersję edytora Cloud Shell, która zapewnia obszar roboczy podobny do VS Code ze zintegrowaną obsługą BigQuery.
- W panelu terminala Cloud Shell u dołu ekranu kliknij przycisk Otwórz edytor, aby uruchomić obszar roboczy edytora Cloud Shell.

Krok 4. Zainstaluj rozszerzenie Data Agent Kit
Rozszerzenie Google Cloud Data Agent Kit zapewnia głęboką integrację z usługami danych Google Cloud bezpośrednio w edytorze, dzięki czemu możesz korzystać z BigQuery, AlloyDB, Cloud Storage i innych usług bez przełączania kontekstu.
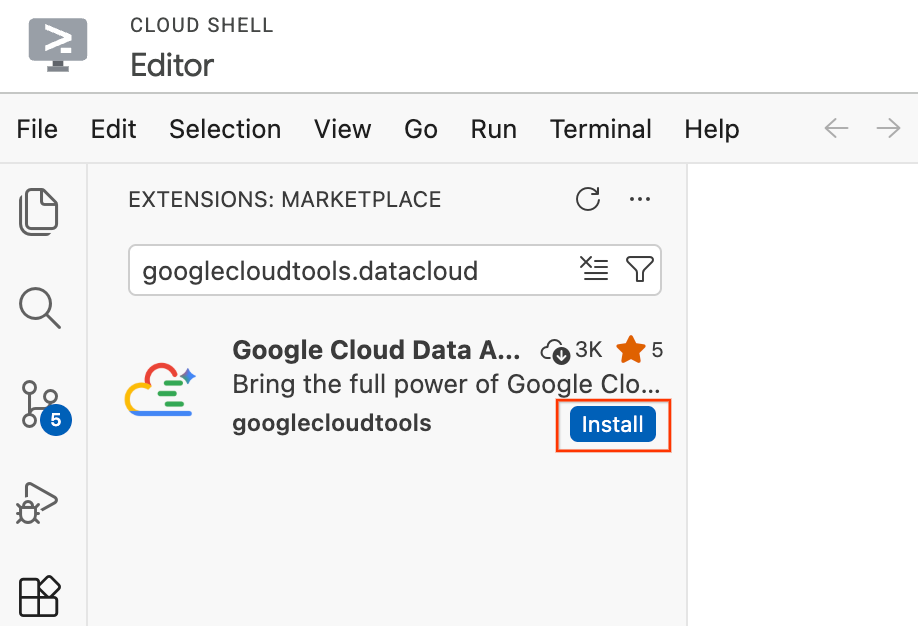
- W edytorze Cloud Shell kliknij ikonę Rozszerzenia na pasku działań po lewej stronie ekranu (wygląda jak 4 kwadraty).
- Na pasku wyszukiwania u góry panelu Rozszerzenia wpisz
googlecloudtools.datacloud. - Znajdź rozszerzenie o nazwie Google Cloud Data Agent Kit opublikowane przez Google Cloud.
- Kliknij przycisk Zainstaluj.
- Pojawi się pytanie: „Czy ufasz wydawcy „googlecloudtools” i jego rozszerzeniom?”. Aby kontynuować, kliknij Zaufaj wydawcom i zainstaluj.
Krok 5. Uwierzytelnianie i konfigurowanie rozszerzenia
Po zainstalowaniu połącz rozszerzenie z projektem Google Cloud.
- Strona wprowadzająca o nazwie „Google Cloud Data Agent Kit Onboarding” powinna otworzyć się automatycznie. Kliknij Zaloguj się w Google Cloud. Postępuj zgodnie z instrukcjami wyświetlanymi w przeglądarce, aby zezwolić na dostęp.
- Pojawi się okno „Konfiguracja w toku”. Rozszerzenie automatycznie sprawdzi wymagane zależności, takie jak Google Cloud CLI.
- W sekcji Podsumowanie konfiguracji znajdź pole projektu. Kliknij menu i wybierz projekt w chmurze Google Cloud. Ustaw region jako
us-central1. - Poczekaj, aż zakończą się testy konfiguracji. Gdy zobaczysz komunikat „Setup Complete!” (Konfiguracja zakończona!), kliknij Configure MCP Servers (Skonfiguruj serwery MCP).
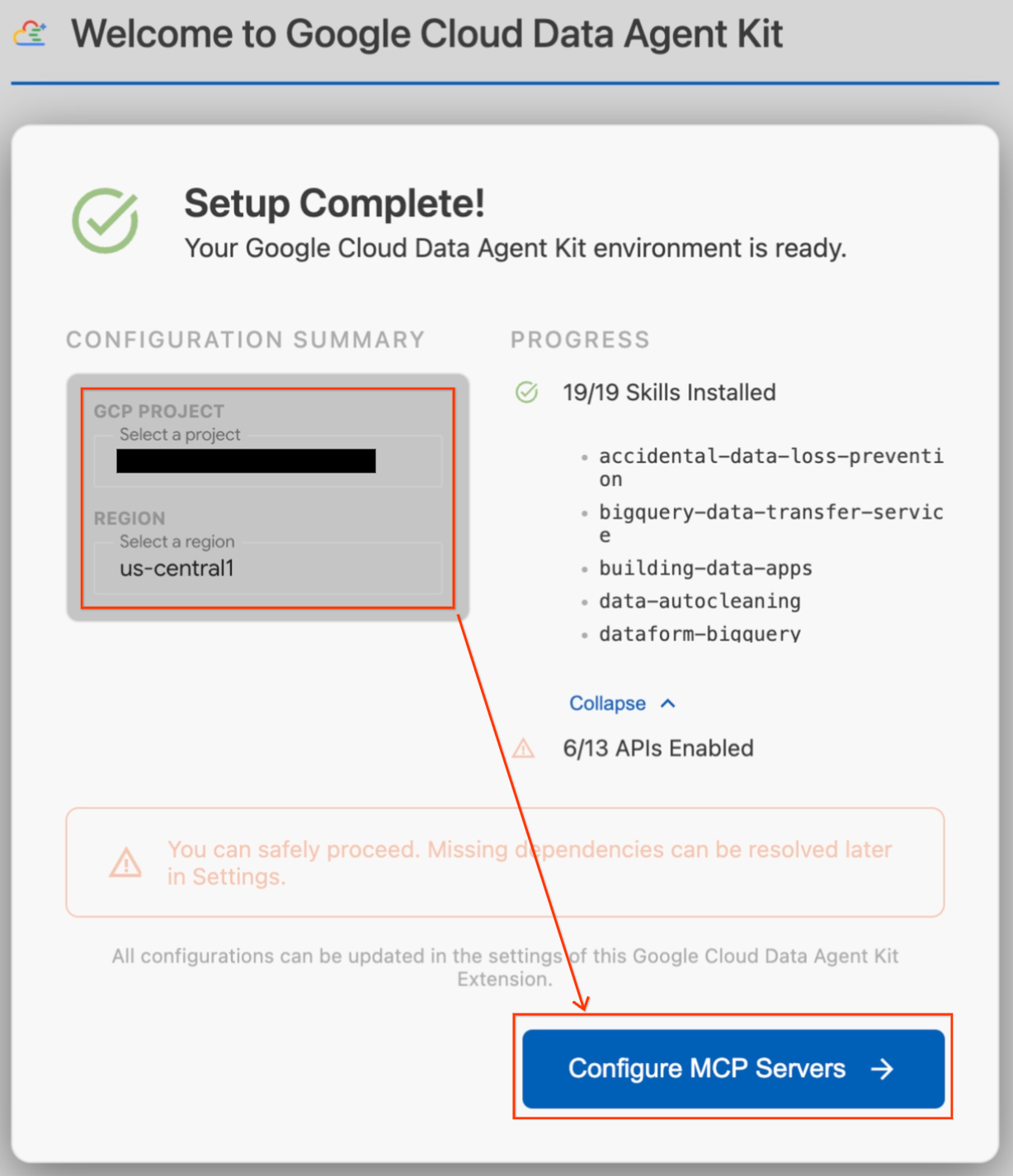
- W sekcji Konfiguracja MCP wybierz BigQuery i AlloyDB, a następnie kliknij Rozpocznij.
Krok 6. Zapoznaj się z opcjami konfiguracji
Po zakończeniu konfiguracji przejdziesz do panelu „Rozpocznij korzystanie z Google Cloud Data Agent Kit”.
- W sekcji „Konfiguracja” kliknij Rozpocznij.
- Otworzy się panel Konfiguracja agenta danych. Przeglądaj karty:
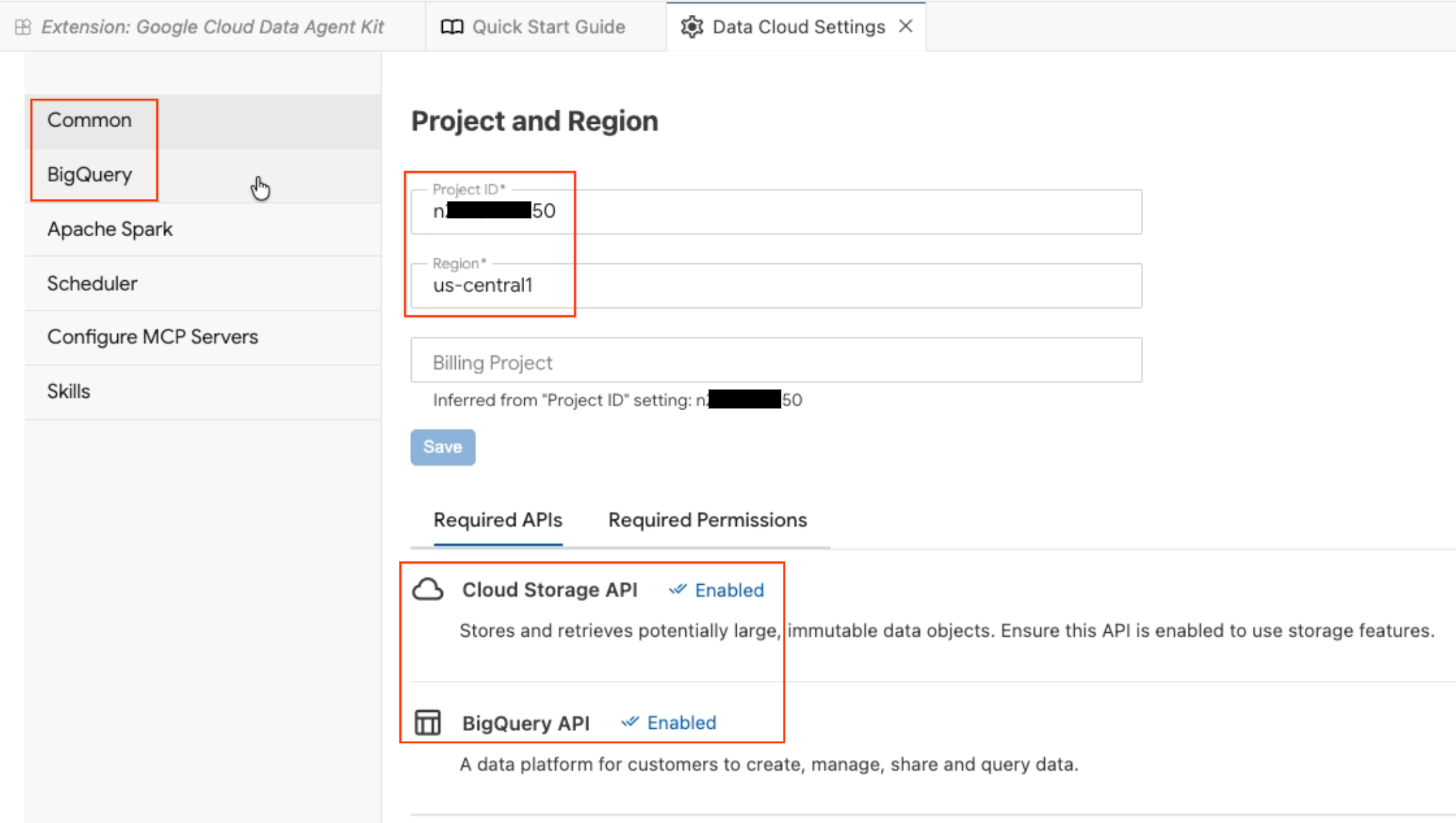
- Projekt i region: sprawdź wybrany identyfikator projektu i upewnij się, że wymagane interfejsy API (Cloud Storage API, BigQuery API, Catalog API i AlloyDB API) są włączone.
- BigQuery: skonfiguruj domyślną lokalizację zapytań BigQuery. Użyj regionu
us-central1. - Konfigurowanie serwerów MCP: wyświetl włączone serwery MCP (BigQuery, Notebooks, AlloyDB itp.), które umożliwiają agentom AI bezpieczną interakcję z Twoimi danymi.
- Umiejętności: poznaj gotowe umiejętności, które zapewniają agentom specjalistyczne możliwości wykonywania złożonych zadań związanych z danymi.
Krok 7. Weryfikacja za pomocą BigQuery
Sprawdź, czy wszystko działa, uruchamiając szybkie zapytanie dotyczące publicznego zbioru danych.
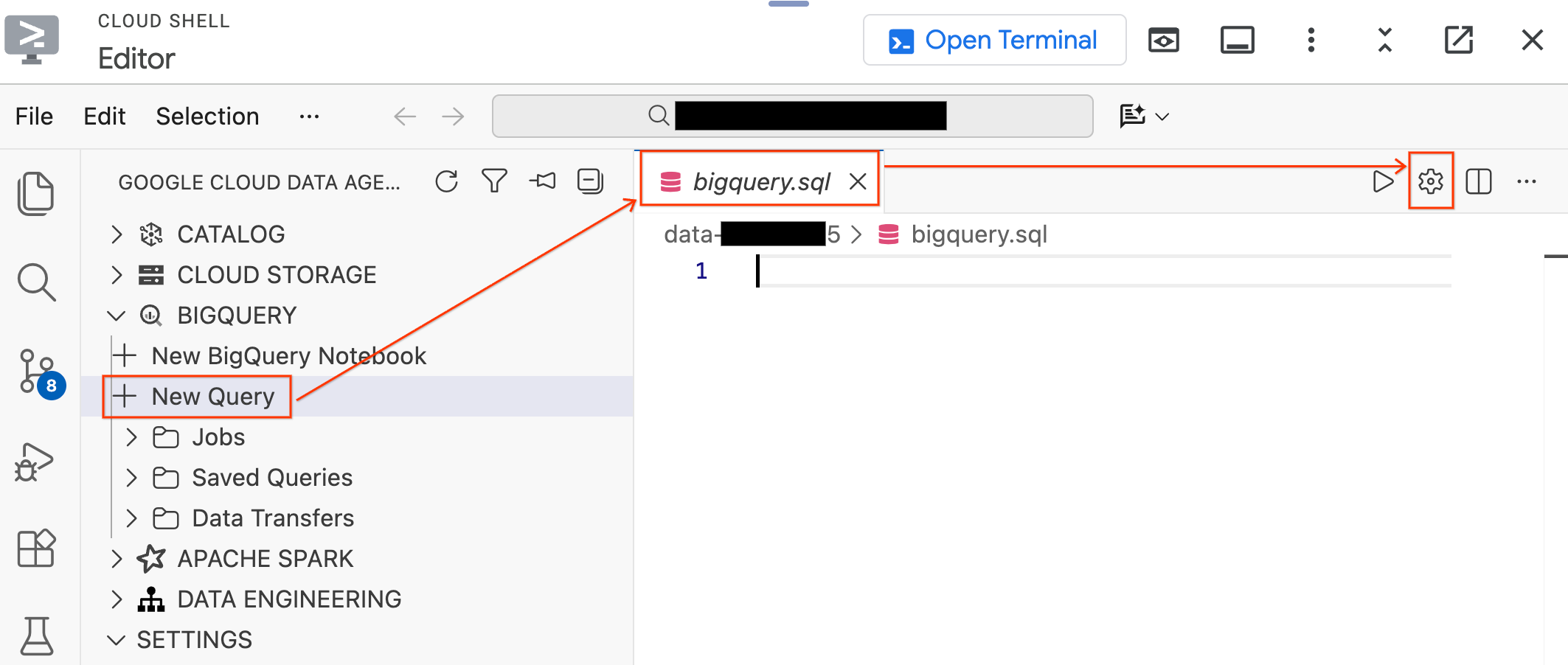
- W panelu Data Agent Kit po lewej stronie rozwiń sekcję BigQuery i kliknij Nowe zapytanie, aby otworzyć nową kartę edytora zapytań.
- Zapisz plik, naciskając
Ctrl+S(Windows/Linux) lubCmd+S(macOS), i nadaj mu nazwębigquery. Ta karta będzie używana do wszystkich operacji BigQuery. - Kliknij Ustawienia zapytania na aktywnej karcie
bigquery.sql, wybierz BigQuery jako źródło danych i kliknij Zapisz.
- Uruchom to zapytanie w publicznym zbiorze danych:
SELECT
term,
MIN(rank) AS peak_rank,
ROUND(AVG(score)) AS avg_score
FROM `bigquery-public-data.google_trends.top_terms`
WHERE refresh_date = DATE_SUB(CURRENT_DATE(), INTERVAL 2 DAY)
GROUP BY term
ORDER BY peak_rank ASC
LIMIT 10;
- Powinny się wyświetlić 10 najpopularniejszych haseł wyszukiwanych w Google w ciągu ostatnich kilku dni. Jeśli pojawią się wyniki, rozszerzenie jest połączone i gotowe do użycia.
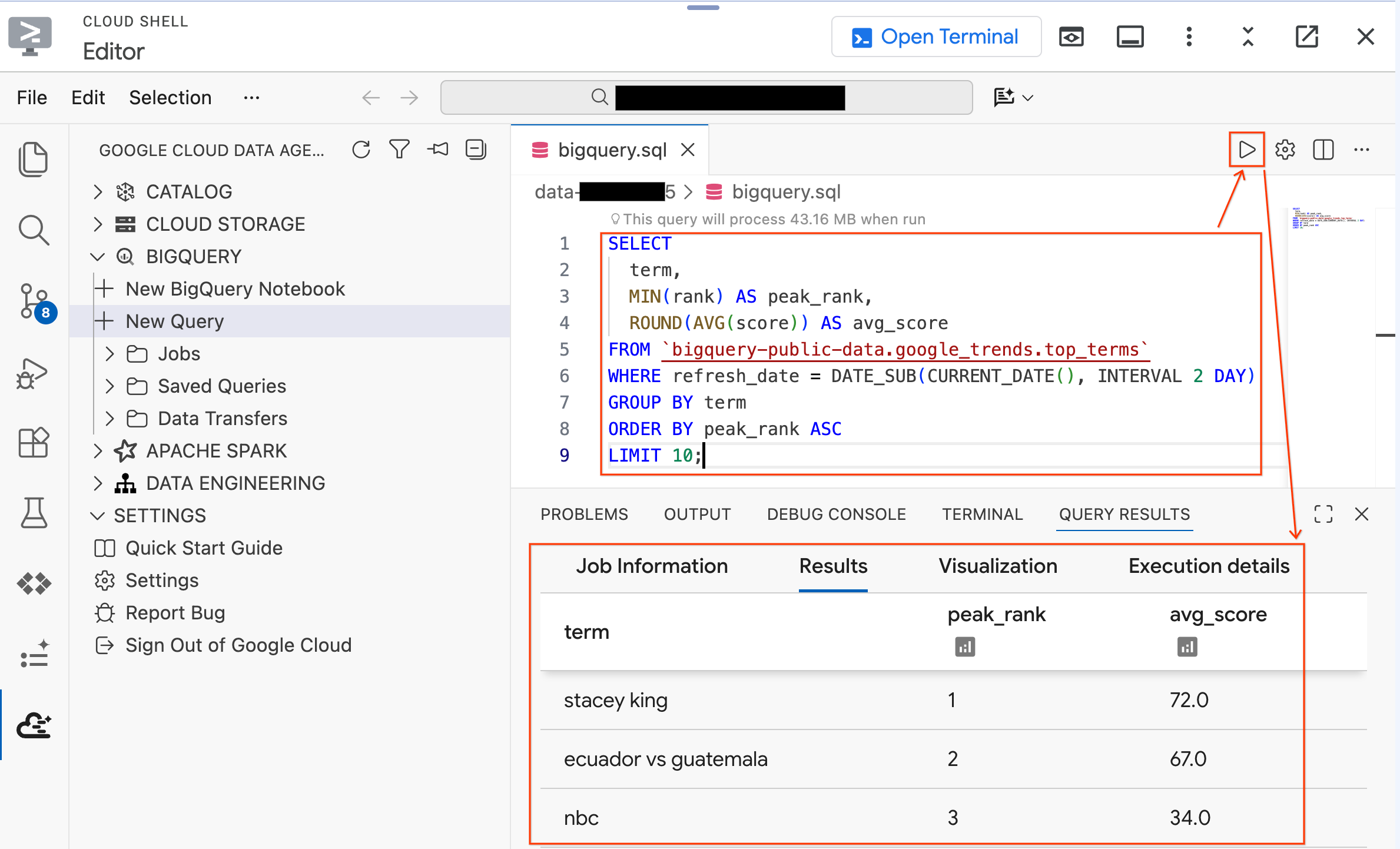
Teraz wypróbuj zapytanie dotyczące danych z modułu, które właśnie utworzył skrypt konfiguracji. Zastąp istniejące zapytanie tym:
SELECT * FROM `lost_cargo_dataset.telemetry_data` LIMIT 5;
Powinny pojawić się wpisy dziennika telemetrii z kolumnami shipment_id i telemetry_string. Są to dane, które będziesz analizować w tym module.
Podsumowanie sekcji: w tle rozpoczęto wdrażanie AlloyDB, uruchomiono skrypt konfiguracji i skonfigurowano edytor Cloud Shell za pomocą rozszerzenia Data Agent Kit.
4. Skanowanie nagrań z monitoringu
Zespół śledczy odzyskał nagranie z monitoringu z portu w Rio de Janeiro, na którym widać rzędy kontenerów. Z Laboratorium 1 wiesz, że kontener docelowy jest czerwony. Musisz teraz dokładnie określić, który to czerwony kontener.
Utworzysz tabelę obiektów, która umożliwi BigQuery „widzenie” obrazów zabezpieczeń w Cloud Storage, a następnie użyjesz funkcji AI.GENERATE, aby poprosić Gemini o wyodrębnienie danych strukturalnych z każdego obrazu.
Krok 1. Utwórz tabelę obiektów
Tabela obiektów to specjalna tabela BigQuery, która działa jako indeks nieustrukturyzowanych plików (obrazów, plików PDF, plików audio) przechowywanych w Cloud Storage. Nie kopiuje plików do BigQuery, ale tworzy odwołanie, na którym można wykonywać zapytania, dzięki czemu funkcje AI mogą je „widzieć”.
Na karcie bigquery.sql w edytorze uruchom to polecenie, aby utworzyć tabelę obiektów wskazującą obrazy zabezpieczeń portu w zasobniku projektu:
SET @@location = 'us-central1';
EXECUTE IMMEDIATE CONCAT("""
CREATE OR REPLACE EXTERNAL TABLE `lost_cargo_dataset.port_security_images`
WITH CONNECTION `us-central1.lost_cargo_conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://""", @@project_id, """-lab2/images/*']
);
""");
Sprawdź, co BigQuery może teraz zobaczyć:
SELECT uri, content_type FROM `lost_cargo_dataset.port_security_images` LIMIT 5;
Każdy wiersz reprezentuje 1 plik obrazu w Cloud Storage. BigQuery może teraz przekazywać te obrazy bezpośrednio do modeli AI.
Krok 2. Przeanalizuj obrazy zabezpieczeń
Teraz użyj funkcji AI.GENERATE BigQuery, aby przeanalizować każdy obraz zabezpieczający. To pojedyncze zapytanie SQL powoduje, że Gemini analizuje każdy obraz i zwraca dane strukturalne:
SELECT
uri,
AI.GENERATE(
(
'Examine this port security image. Identify any shipping container IDs visible on the container and provide a one-word color of the container.',
ref
),
output_schema => 'detected_container_id STRING, color STRING'
).* EXCEPT (full_response, status)
FROM `lost_cargo_dataset.port_security_images`;
Krok 3. Określ kontener docelowy
Przyjrzyj się wynikom. Znajdź wiersz, w którym w kolumnie color widnieje wartość „Czerwony” (lub inny odcień czerwieni). Zapisz detected_container_id. To jest Twój cel: MV-CAPYBARA-003.
Krok 4. Sprawdź podobieństwo wizualne
Aby zobaczyć przeanalizowany obraz bez opuszczania edytora:
- W panelu Data Agent Kit po lewej stronie kliknij Cloud Storage.
- Rozwiń zasobnik (
YOUR_PROJECT_ID-lab2/images/) i kliknij plik obrazu odpowiadający czerwonemu kontenerowi, aby wyświetlić go bezpośrednio w edytorze.
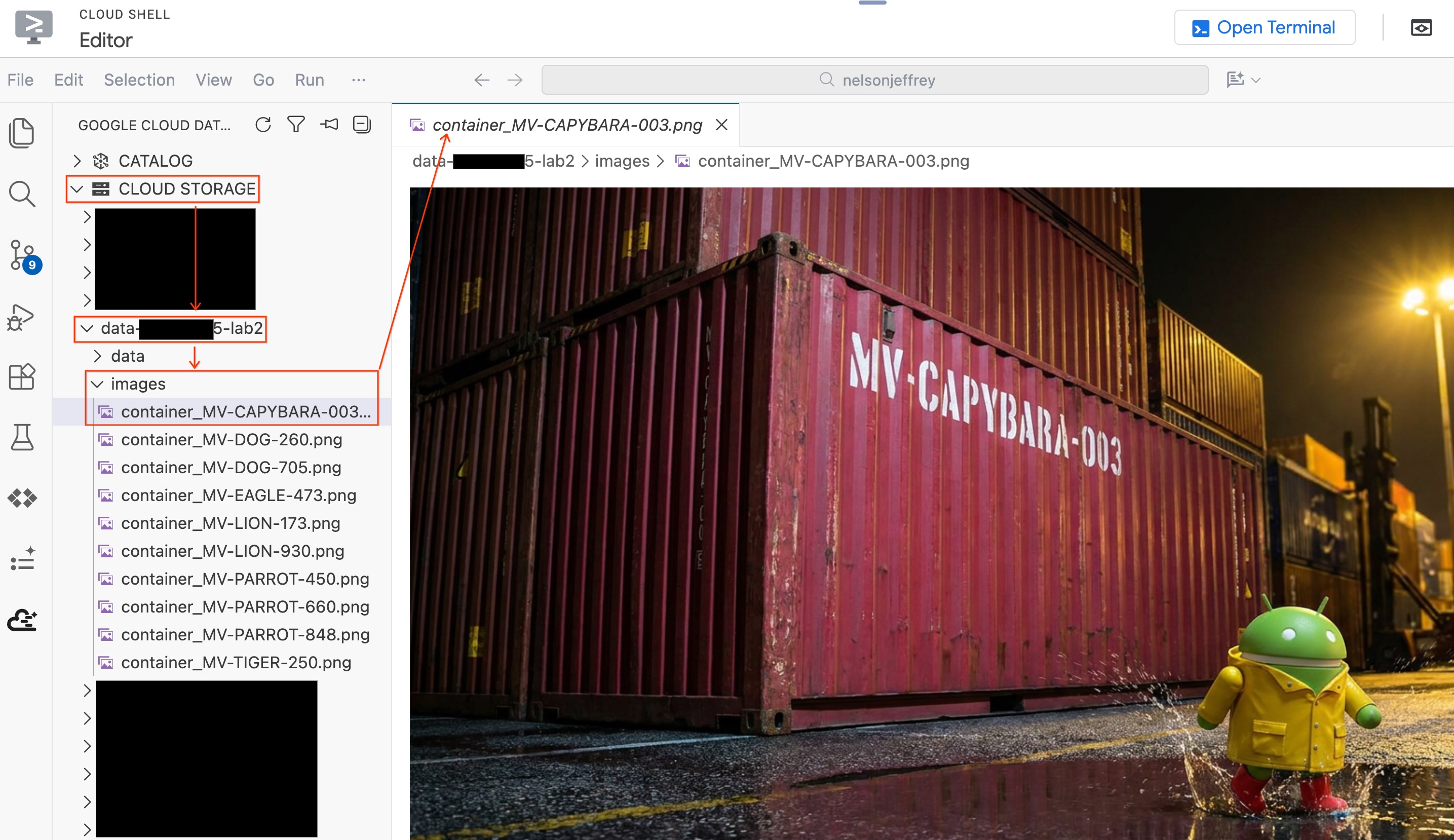
Podsumowanie sekcji: utworzono tabelę obiektów, aby umożliwić BigQuery dostęp do zdjęć zabezpieczeń portu, a następnie użyto funkcji AI.GENERATE do wyodrębnienia z każdego zdjęcia uporządkowanych danych kontenera. Czerwony kontener został oznaczony jako MV-CAPYBARA-003.
5. Potwierdzenie kradzieży
Zidentyfikowano brakujący kontener jako MV-CAPYBARA-003, ale czy został skradziony, czy po prostu zgubiony? Dzienniki manifestu wskazują, że ten konkretny kontener był zaparkowany obok czujnika środowiskowego SENS-99. Jeśli złodzieje celowo wyłączyli wbudowaną chłodnię kontenera przed jego przeniesieniem, SENS-99 mogło zarejestrować nagły wzrost emisji ciepła.
Użyjemy wykrywania anomalii, aby udowodnić, że kontener został zmodyfikowany.
- Najpierw zapoznaj się z historyczną wartością bazową. Oto normalne odczyty z urządzenia
SENS-99z ostatnich kilku godzin:
SELECT * FROM `lost_cargo_dataset.thermal_history`
ORDER BY reading_time DESC
LIMIT 50;
Zwróć uwagę, że temperatury utrzymują się w wąskim zakresie około 24–26°C. Tak wygląda normalny stan.
- Teraz sprawdź bieżącą partię odczytów z tego samego czujnika:
SELECT * FROM `lost_cargo_dataset.thermal_current`
ORDER BY thermal_reading DESC
LIMIT 50;
Widzisz odczyt 148,4°F u góry? Wszystko inne wygląda normalnie. Ten nagły wzrost może wskazywać na awarię urządzenia chłodniczego lub celowe manipulowanie nim. Zaraz się dowiemy.
- Uruchom wykrywanie anomalii.
AI.DETECT_ANOMALIESBigQuery używa wstępnie wytrenowanego modelu podstawowego TimesFM do analizowania wzorców w ciągach czasowych i automatycznego oznaczania wartości odstających bez konieczności trenowania modelu:
SELECT *
FROM AI.DETECT_ANOMALIES(
TABLE `lost_cargo_dataset.thermal_history`,
TABLE `lost_cargo_dataset.thermal_current`,
data_col => 'thermal_reading',
timestamp_col => 'reading_time',
id_cols => ['sensor_id']
)
WHERE is_anomaly = TRUE;
- Przyjrzyj się wynikom. Odczyt 64,7°C powinien być oznaczony jako anomalia o wysokim prawdopodobieństwie, co potwierdza, że w pobliżu kontenera wydarzyło się coś nietypowego.
Podsumowanie sekcji: za pomocą funkcji AI.DETECT_ANOMALIES w BigQuery wykorzystano wytrenowany już model TimesFM. Uruchamiając jedno zapytanie SQL, automatycznie wykryto wartości odstające i wyizolowano anomalne zdarzenie manipulacji bez pisania złożonego kodu uczenia maszynowego ani trenowania modeli od zera.
6. Przygotowanie systemu śledzenia
Kontener został potwierdzony jako skradziony i nie znajduje się już w Rio de Janeiro. Każdy kontener w flocie wysyła sygnały telemetryczne: odczyty czujników, fragmenty danych GPS i dzienniki stanu. Jeśli lokalizator skradzionego kontenera nadal wysyła sygnał, możesz go dopasować do znanych sygnatur, aby go znaleźć.
BigQuery doskonale sprawdza się w przypadku analiz, które zostały już przez Ciebie wykonane, ale lokalizowanie kontenera w czasie rzeczywistym wymaga zapytań operacyjnych o krótkim czasie oczekiwania. AlloyDB to w pełni zarządzana baza danych zgodna z PostgreSQL, która została stworzona właśnie w tym celu: do wykonywania zapytań o wyszukiwanie wektorowe wystarczająco szybko, aby można było używać jej w systemie śledzenia na żywo. Załadujesz do niej osadzenia telemetryczne i użyjesz ich do dopasowania sygnału lokalizatora.
Klaster AlloyDB, który został uruchomiony w tle, powinien być już gotowy. Skonfigurujmy go bezpośrednio w edytorze.
Krok 1. Połącz się z AlloyDB z poziomu edytora
Zamiast przełączać się na konsolę Cloud, możesz połączyć się z AlloyDB bezpośrednio za pomocą rozszerzenia Data Agent Kit.
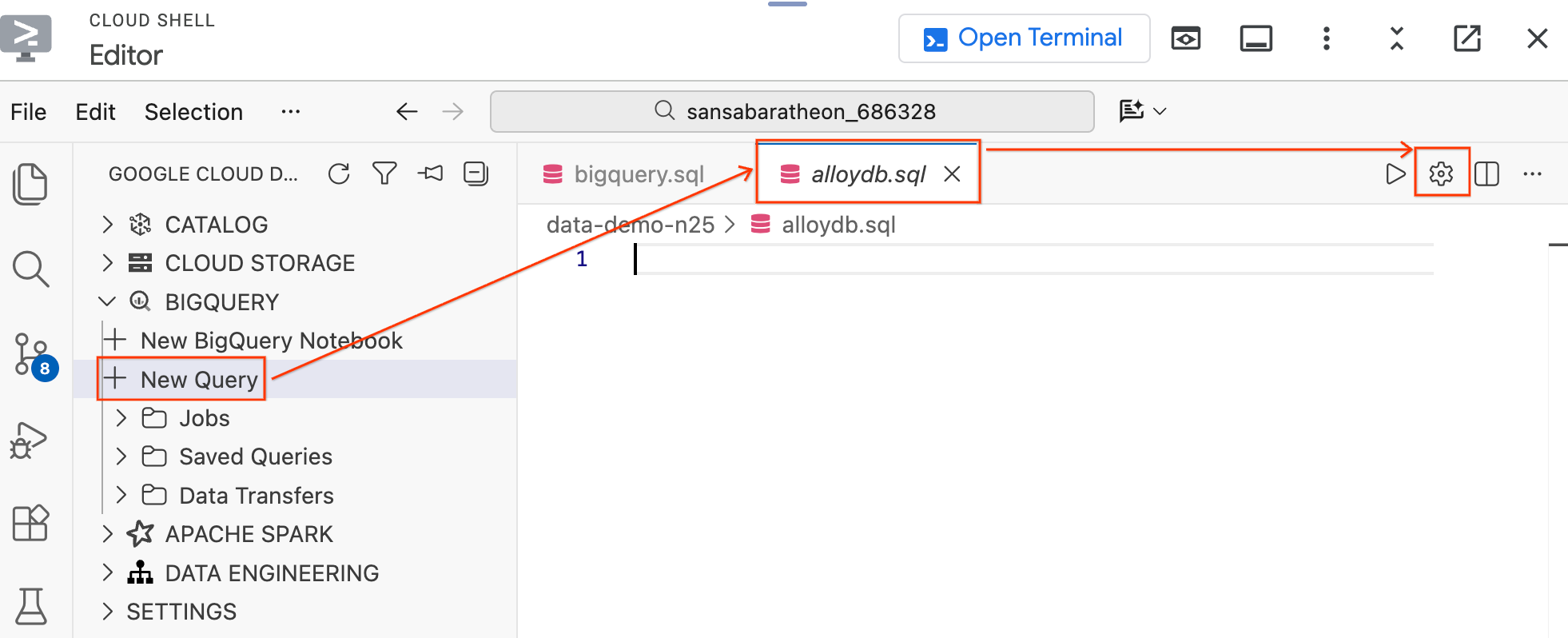
- W panelu Data Agent Kit po lewej stronie w sekcji BigQuery kliknij Nowe zapytanie, aby otworzyć nową kartę edytora zapytań.
- Zapisz plik, naciskając
Ctrl+S(Windows/Linux) lubCmd+S(macOS), i nadaj mu nazwęalloydb. Ta karta będzie używana w przypadku wszystkich zapytań AlloyDB. - Kliknij ikonę koła zębatego, aby otworzyć okno Ustawienia zapytania.
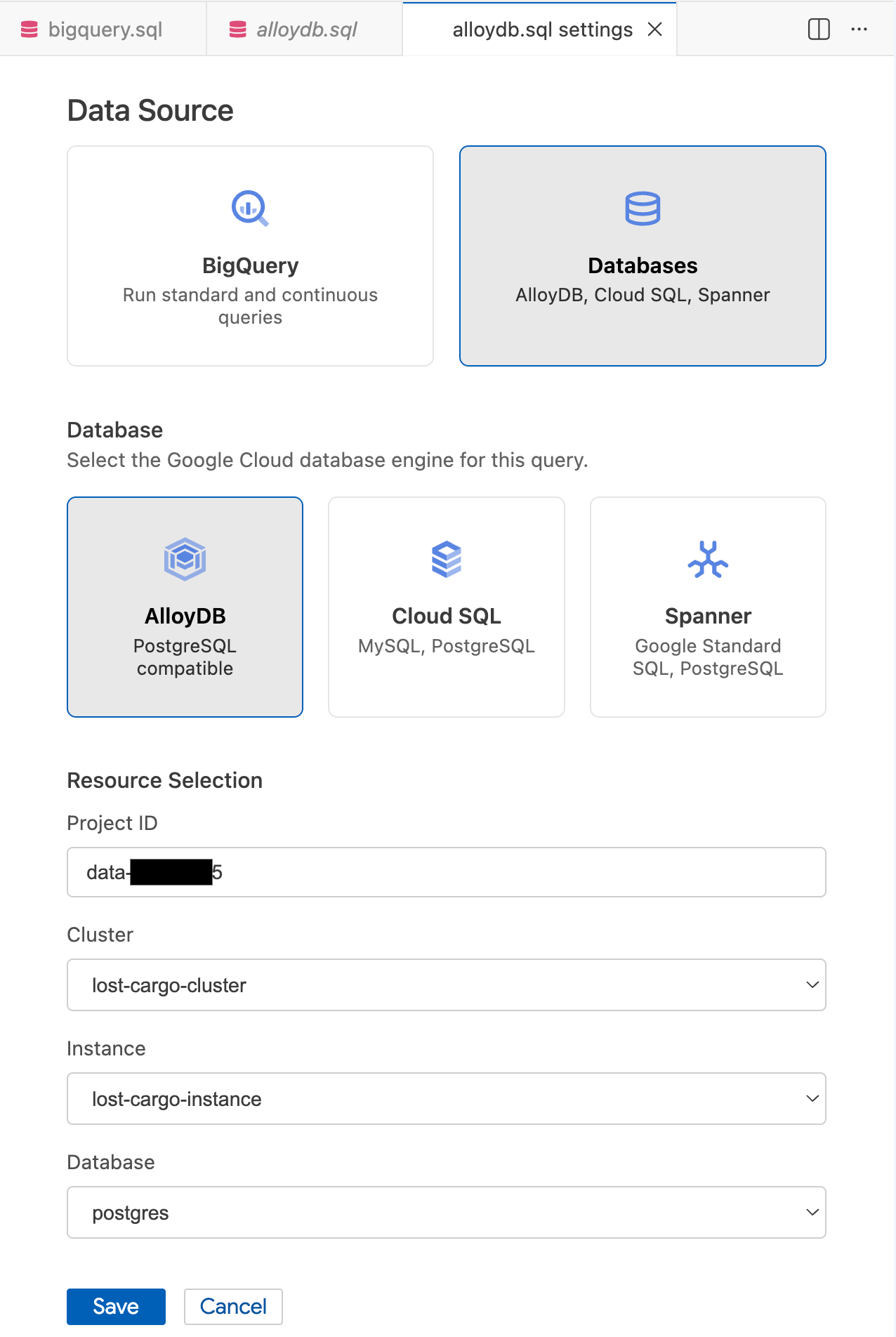
- W oknie Ustawienia zapytania w sekcji Źródło danych kliknij Bazy danych.
- W sekcji Baza danych wybierz AlloyDB.
- Wypełnij szczegóły wyboru zasobów:
- Identyfikator projektu: wpisz identyfikator projektu Google Cloud.
- Klaster: kliknij
lost-cargo-cluster. - Instancja: wybierz
lost-cargo-instance. - Baza danych: wybierz
postgres.
- Kliknij Zapisz.
Krok 2. Włącz rozszerzenie wektorowe i utwórz tabelę
Po połączeniu się z AlloyDB musisz włączyć niezbędne rozszerzenia AI i utworzyć tabelę, która będzie otrzymywać osadzone dane telemetryczne.
- Na aktywnej karcie
.sqlwklej te polecenia, aby włączyć wymagane rozszerzenia:
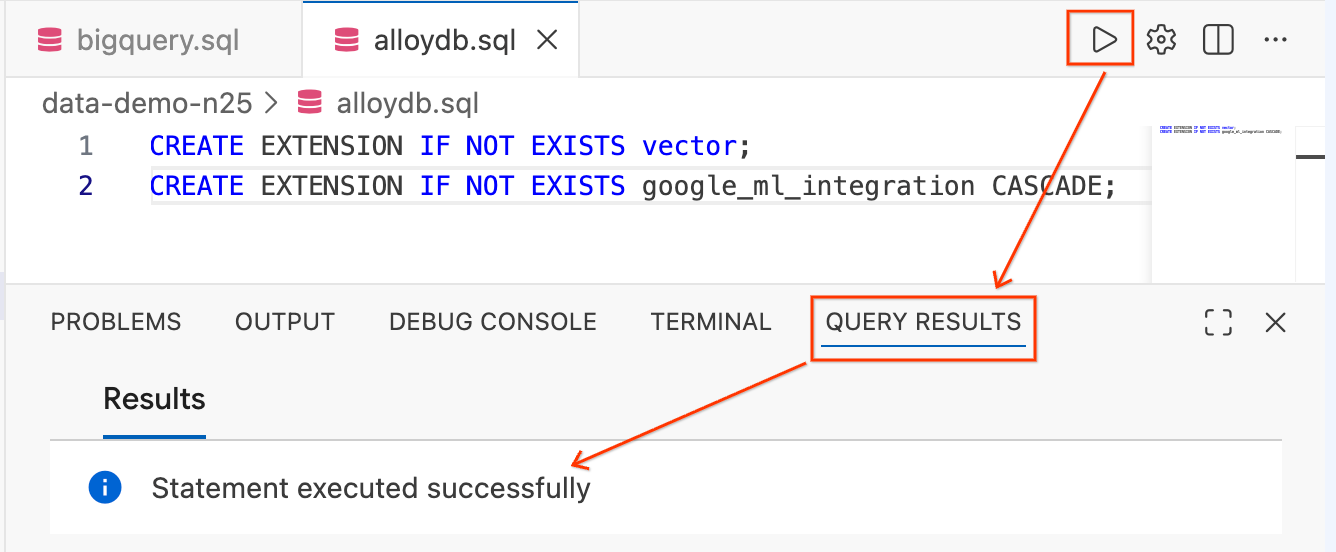
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
- Zaznacz tekst i w prawym górnym rogu edytora kliknij przycisk Uruchom zapytanie (ikonę odtwarzania).
- Sprawdź panel terminala Wyniki zapytania u dołu ekranu. Powinien wyświetlać komunikat
Statement executed successfully.
- Następnie zastąp tekst w edytorze tym stwierdzeniem, aby utworzyć tabelę telemetrii:
CREATE TABLE IF NOT EXISTS vessel_telemetry (
entry_id SERIAL PRIMARY KEY,
shipment_id VARCHAR(50),
telemetry_string TEXT,
embedding_vector vector(768)
);
- Uruchom to zapytanie tak samo jak poprzednie. Sprawdź, czy w dolnym panelu pojawi się komunikat o powodzeniu.
Typ vector(768) pochodzi z rozszerzenia pgvector, które zostało właśnie włączone. 768 wymiarów odpowiada danym wyjściowym modelu text-embedding-005 od Google, który będzie używany w BigQuery do generowania osadzania.
Podsumowanie sekcji: połączono się z AlloyDB bezpośrednio z edytora Cloud Shell, włączono rozszerzenia pgvector i google_ml_integration oraz utworzono tabelę docelową. AlloyDB jest teraz gotowa do pełnienia funkcji operacyjnego backendu do dopasowywania danych telemetrycznych w czasie rzeczywistym.
7. Tworzenie indeksu wyszukiwania
Teraz musisz przenieść dane telemetryczne do AlloyDB, aby umożliwić dopasowywanie sygnałów w czasie rzeczywistym. Surowe dzienniki telemetrii są nieuporządkowane i mają zmienną długość, co nie jest idealne w przypadku wyszukiwania podobieństw. Użyjesz funkcji AI BigQuery, aby podsumować każdy dziennik za pomocą Gemini i przekształcić każde podsumowanie w 768-wymiarowy wektor dystrybucyjny. Następnie wyeksportujesz wzbogacone dane do Cloud Storage i zaimportujesz je do AlloyDB.
Krok 1. Generowanie wektorów dystrybucyjnych w BigQuery
Wróć na kartę edytora bigquery.sql (która pozostaje połączona z BigQuery).
Teraz uruchom to zapytanie, aby podsumować każdy dziennik telemetrii za pomocą Gemini i wygenerować osadzenia wektorowe:
CREATE OR REPLACE TABLE `lost_cargo_dataset.telemetry_embeddings_export` AS
WITH summarized_telemetry AS (
SELECT
shipment_id,
telemetry_string,
AI.GENERATE(
CONCAT('Summarize this telemetry log for vector search: ', telemetry_string)
).result AS summary
FROM `lost_cargo_dataset.telemetry_data`
),
telemetry_embeddings AS (
SELECT
shipment_id,
telemetry_string,
AI.EMBED(summary, endpoint => 'text-embedding-005').result AS embedding
FROM summarized_telemetry
)
SELECT
shipment_id,
telemetry_string,
TO_JSON_STRING(embedding) AS embedding_vector
FROM telemetry_embeddings;
Krok 2. Wyświetl podgląd danych wzbogaconych
Przed wyeksportowaniem sprawdź, co zostało utworzone. To zapytanie pokazuje identyfikatory przesyłek oraz pierwsze 80 znaków każdego podsumowania i osadzenia:
SELECT
shipment_id,
SUBSTR(telemetry_string, 1, 80) AS telemetry_preview,
SUBSTR(embedding_vector, 1, 80) AS embedding_preview
FROM `lost_cargo_dataset.telemetry_embeddings_export`
LIMIT 5;
Każdy wiersz zawiera teraz identyfikator przesyłki, oryginalny dziennik telemetrii i 768-wymiarowy wektor osadzania. To dane, które zostaną przesłane do AlloyDB.
Krok 3. Eksportowanie osadzania do Cloud Storage
Użyj instrukcji EXPORT DATA BigQuery, aby zapisać tabelę z wektorami w zasobniku GCS laboratorium jako plik CSV.
EXECUTE IMMEDIATE CONCAT("""
EXPORT DATA OPTIONS (
uri = 'gs://""", @@project_id, """-lab2/data/embeddings_export/*.csv',
format = 'CSV',
overwrite = true,
header = false
) AS
SELECT
shipment_id,
telemetry_string,
embedding_vector
FROM `lost_cargo_dataset.telemetry_embeddings_export`;
""");
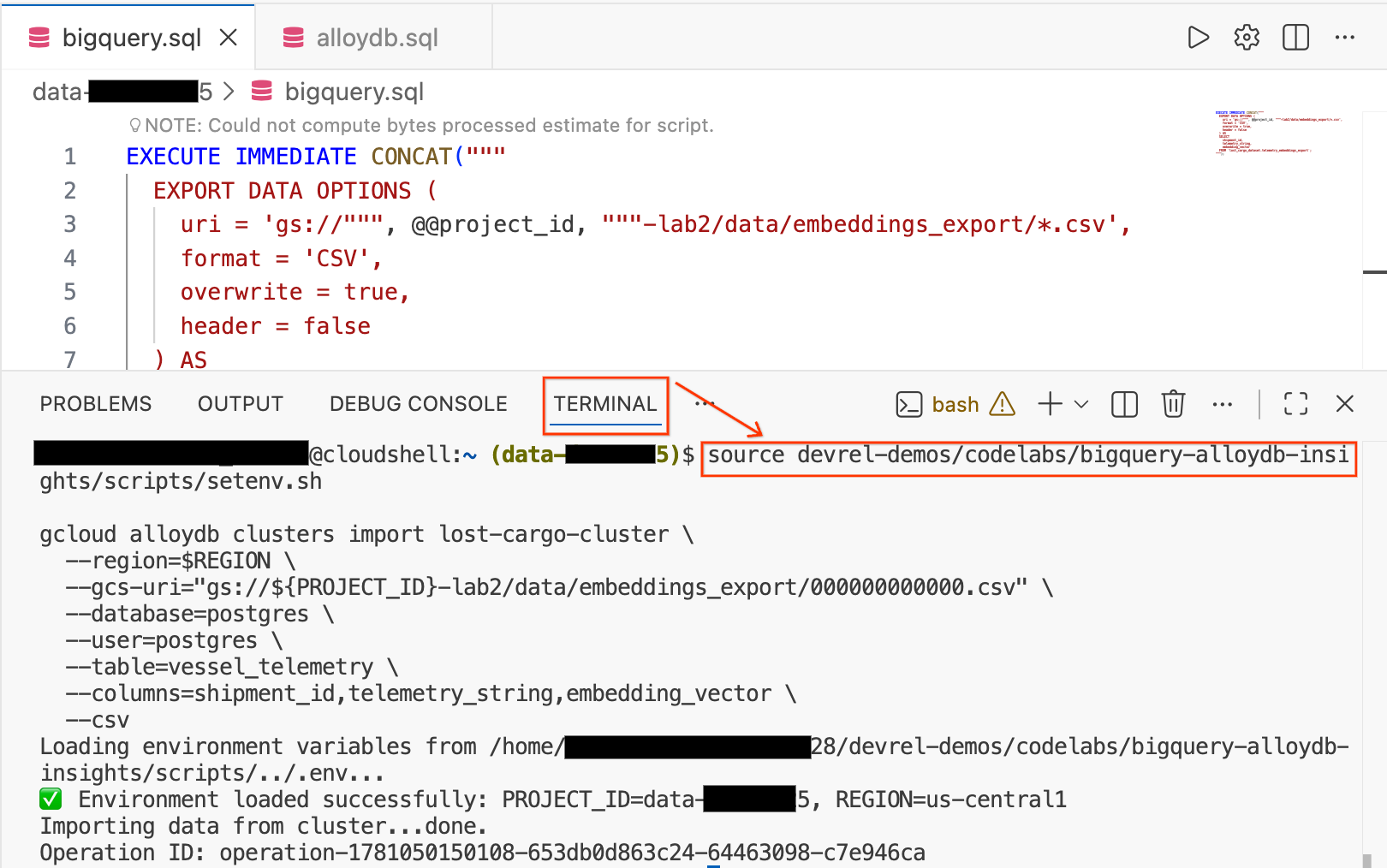
Krok 4. Importowanie do AlloyDB z Cloud Storage
- W edytorze Cloud Shell kliknij kartę Terminal u dołu ekranu, aby otworzyć sesję terminala.
- Uruchom te polecenia, aby załadować środowisko i zaimportować plik CSV bezpośrednio do tabeli
vessel_telemetryw AlloyDB:
source devrel-demos/codelabs/bigquery-alloydb-insights/scripts/setenv.sh
gcloud alloydb clusters import lost-cargo-cluster \
--region=$REGION \
--gcs-uri="gs://${PROJECT_ID}-lab2/data/embeddings_export/000000000000.csv" \
--database=postgres \
--user=postgres \
--table=vessel_telemetry \
--columns=shipment_id,telemetry_string,embedding_vector \
--csv
Podsumowanie sekcji: za pomocą funkcji AI w BigQuery podsumowano i osadzono dane telemetryczne, wyeksportowano wyniki do Cloud Storage w formacie CSV, a następnie zaimportowano je do AlloyDB za pomocą gcloud. Baza danych śledzenia operacyjnego została wczytana i jest gotowa.
8. Dopasowywanie sygnału beacon
Zespół terenowy w pobliżu Sydney przechwycił sygnał telemetryczny z fragmentami danych. Częściowy dziennik odczytu:
„Urządzenie chłodnicze offline. Ręczne zastąpienie”.
Jeśli pochodzi z ukradzionego kontenera, wyszukiwanie wektorowe AlloyDB powinno być w stanie dopasować go nawet wtedy, gdy sygnał jest niekompletny. Jest to dokładnie ten rodzaj zapytań operacyjnych w czasie rzeczywistym, do których AlloyDB jest przeznaczony.
Krok 1. Sprawdź zaimportowane dane
Przełącz kartę edytora z powrotem na alloydb.sql (która pozostaje połączona z AlloyDB).
Aby sprawdzić, czy dane telemetryczne zostały wczytane poprawnie, uruchom to polecenie:
SELECT shipment_id, LEFT(telemetry_string, 80) AS telemetry_preview
FROM vessel_telemetry
LIMIT 10;
Powinny pojawić się wiersze z wartościami shipment_id i tekstem telemetrycznym. Są to sygnatury telemetryczne floty, które są teraz gotowe do dopasowywania w czasie rzeczywistym.
Krok 2. Wyszukaj brakujący kontener
Teraz użyj rozszerzenia google_ml_integration AlloyDB, aby wyszukać dopasowanie za pomocą przechwyconego fragmentu sygnału:
SELECT
shipment_id,
telemetry_string,
1 - (embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector) AS search_relevance_score
FROM vessel_telemetry
ORDER BY embedding_vector <=> embedding('text-embedding-005', 'Refrigeration unit offline. Manual override.')::vector
LIMIT 5;
Funkcja embedding(), udostępniana przez rozszerzenie google_ml_integration AlloyDB, wywołuje platformę agentów bezpośrednio z SQL, aby generować wektorowe osadzanie w linii. Operator <=> oblicza odległość kosinusową między dwoma wektorami (im bliżej zera, tym bardziej są one identyczne). Od 1 odejmujemy wynik, aby wyrazić go jako wynik trafności, w którym wyższa wartość oznacza lepsze dopasowanie.
Krok 3. Potwierdź dopasowanie
Przyjrzyj się wynikom. Najlepszy wynik powinien mieć identyfikator MV-CAPYBARA-003 i najwyższy wynik trafności.
To ten sam kontener, który śledzisz na każdym etapie tego procesu:
- 📷 Nagranie z monitoringu pokazało, że opuścił on port w Rio de Janeiro w nocy.
- 🌡️ Wykrywanie anomalii termicznych potwierdziło, że urządzenie chłodnicze zostało celowo wyłączone.
- 📡 Dopasowanie sygnału beacon właśnie wskazało jego sygnaturę telemetryczną w pobliżu Sydney.
3 niezależne linie dowodowe. 3 różne funkcje AI w Google Cloud. Jeden skradziony kontener.
🎯 Sprawa zamknięta: MV-CAPYBARA-003 została zlokalizowana w pobliżu Sydney!

Podsumowanie sekcji: za pomocą wbudowanej integracji AI AlloyDB wygenerowano wektor dystrybucyjny wyszukiwania i wykonano wyszukiwanie podobieństwa kosinusowego w jednym zapytaniu SQL. Sygnał z lokalizatora potwierdził lokalizację skradzionego kontenera, co zakończyło dochodzenie.
9. Analiza dowodów
Po zidentyfikowaniu kontenera za pomocą wielomodalnej analizy obrazu i wyszukiwania wektorowego możesz użyć analityki konwersacyjnej bezpośrednio w edytorze, aby eksplorować dane dochodzenia za pomocą języka naturalnego bez pisania kodu SQL.
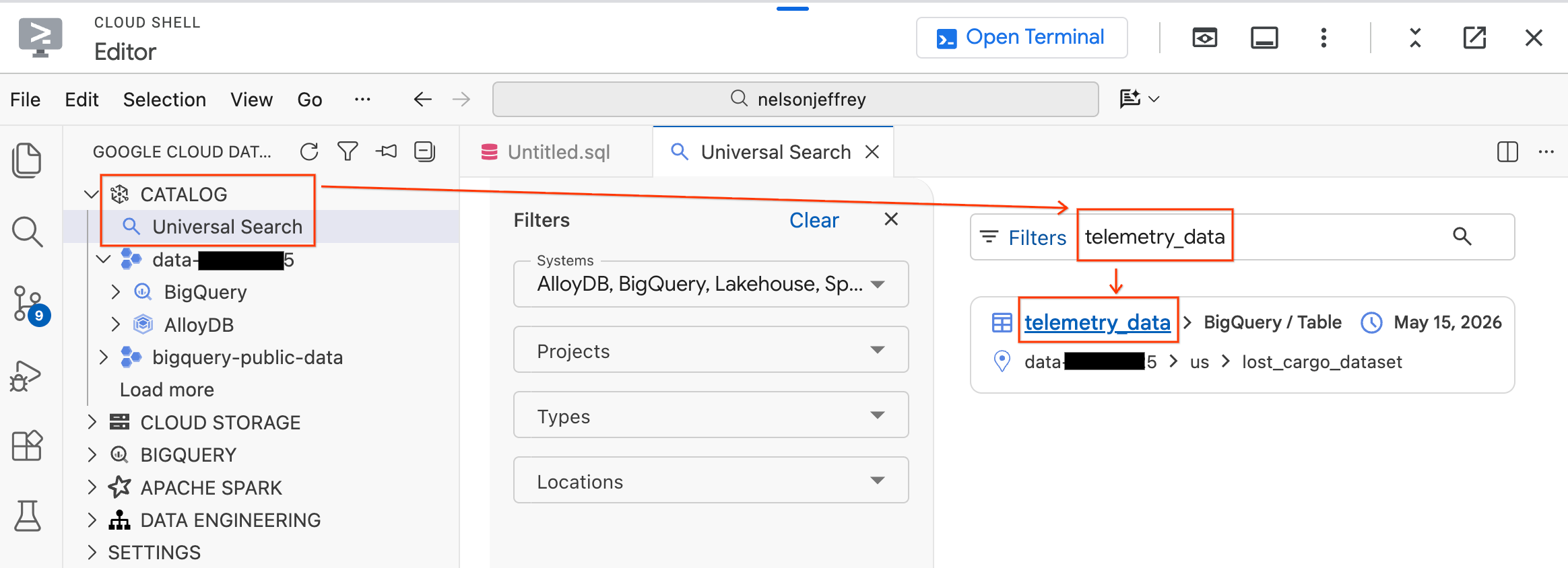
Krok 1. Znajdź dane w Knowledge Catalog
Zestaw Data Agent Kit zawiera funkcję wyszukiwania uniwersalnego, która umożliwia znajdowanie i przeglądanie zasobów danych w środowisku Google Cloud.
- W panelu Data Agent Kit po lewej stronie rozwiń sekcję Katalog.
- Kliknij Wyszukiwanie uniwersalne.
- Na pasku wyszukiwania wpisz
telemetry_data. - W wynikach wyszukiwania kliknij tabelę
telemetry_data(w sekcjilost_cargo_dataset).
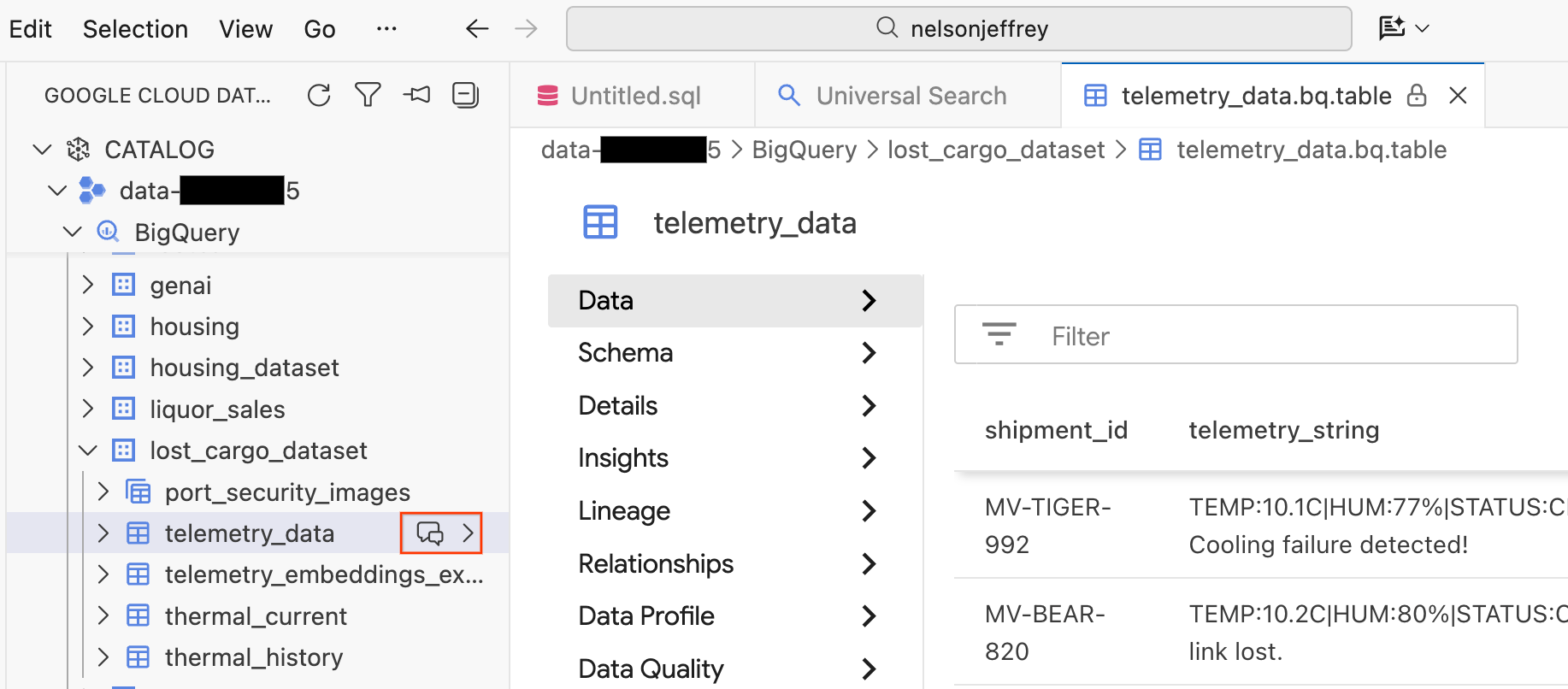
Krok 2. Uruchom analitykę konwersacyjną
Kliknięcie wyniku wyszukiwania powoduje otwarcie karty przeglądarki danych, na której możesz wyświetlić podgląd surowych danych, schemat i sprawdzić jakość danych.
- W panelu po lewej stronie widoczne są zbiory danych i tabele BigQuery. Kliknij przycisk Czat, aby otworzyć nowe okno czatu.
Krok 3. Zadawanie pytań w języku naturalnym
Otworzy się nowa karta czatu „Witamy w analityce konwersacyjnej!”. Agent ma kontekst dotyczący schematu i zawartości tabeli.
- W oknie czatu wpisz:„Pokaż mi stan telemetrii i dziennik przesyłki kapibary”.
- Naciśnij Enter.
Agent tłumaczy Twoje pytanie na język SQL BigQuery, wykonuje zapytanie i zwraca wyniki, w tym tabelę danych i statystyki podsumowujące wyniki. W zależności od złożoności pytania możesz przełączać się między trybami Myślący (dokładniejsza analiza, wolniejszy) i Szybki (szybsze odpowiedzi). Odpowiedzi są generowane przez AI, więc wyniki mogą się nieco różnić od tych widocznych na zrzutach ekranu poniżej.
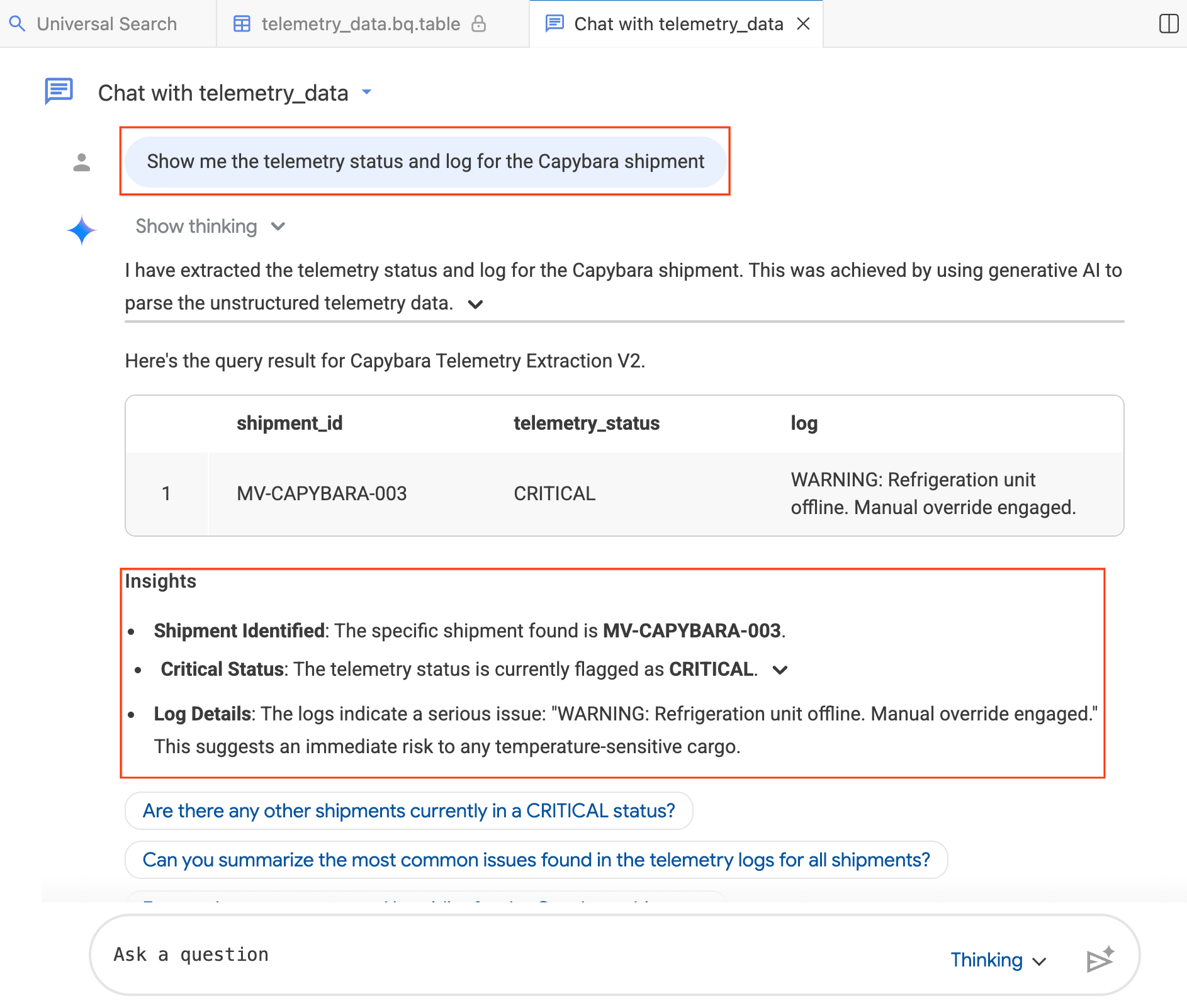
Krok 4. Zadawaj pytania dodatkowe
Agent zapamiętuje kontekst rozmowy. Zadaj kolejne pytanie:
- „Ile unikalnych przesyłek znajduje się w danych telemetrycznych?”
- „Ile innych przesyłek we flocie ma obecnie stan KRYTYCZNY?”
Podsumowanie sekcji: za pomocą funkcji wyszukiwania uniwersalnego w Knowledge Catalog udało Ci się znaleźć zbiór danych. Następnie uruchomiłeś(-aś) analitykę konwersacyjną, aby za pomocą języka naturalnego wysyłać zapytania o dane z dochodzenia. Agent AI przetłumaczył Twoje pytania na SQL i przedstawił statystyki, które potwierdziły Twoje ustalenia.
10. Czyszczenie
Aby uniknąć obciążenia konta Google Cloud bieżącymi opłatami, usuń zasoby utworzone w tym ćwiczeniu. Aby zwolnić miejsce w środowisku, możesz uruchomić te polecenia w zintegrowanym terminalu w edytorze Cloud Shell (w którym używasz zestawu Data Agent Kit).
Najpierw wczytaj zmienne środowiskowe:
source scripts/setenv.sh
- Usuń zasoby BigQuery (tylko jeśli nie kontynuujesz modułu 3):
Jeśli planujesz przejść do ćwiczenia 3, pomiń ten krok. Ćwiczenie 3 wykorzystuje ten sam zbiór danych BigQuery i połączenia do analizy wykresu właściwości.
Aby usunąć zbiór danych BigQuery i połączenia:
# Drop the dataset
bq rm -r -f $PROJECT_ID:lost_cargo_dataset
# Delete the connections
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_conn
bq rm --connection --location=us-central1 $PROJECT_ID.us-central1.lost_cargo_alloydb_conn
- Usuń zasobnik Cloud Storage:
gcloud storage rm --recursive gs://${PROJECT_ID}-lab2
- Usuń instancję i klaster AlloyDB:
AlloyDB nie jest używana w laboratorium 3, więc możesz ją teraz bezpiecznie usunąć.
gcloud alloydb instances delete lost-cargo-instance \
--region=$REGION \
--cluster=lost-cargo-cluster \
--quiet
gcloud alloydb clusters delete lost-cargo-cluster \
--region=$REGION \
--force \
--quiet
- Usuń ustawienia środowiska lokalnego:
Na koniec zwalniaj miejsce w pliku ustawień środowiska lokalnego z obszaru roboczego:
rm -f .env
11. Gratulacje!
Udało Ci się ukończyć moduł 2: analiza danych i wielomodowe statystyki. Przeanalizowano ślady prowadzące od portu pełnego tysięcy kontenerów do potwierdzonej kradzieży i dokładnej lokalizacji.
Co udało Ci się osiągnąć
- Skanowanie nagrań: za pomocą funkcji
AI.GENERATEBigQuery przeprowadzono analizę obrazów z monitoringu portu i zidentyfikowano kontener MV-CAPYBARA-003 w kolorze karmazynowej czerwieni. - Potwierdzenie kradzieży: po przeanalizowaniu danych z czujnika termicznego zauważasz podejrzany skok temperatury do 64, 7°C i za pomocą
AI.DETECT_ANOMALIESudowadniasz, że było to celowe działanie. - Przygotowano system śledzenia: skonfigurowano AlloyDB z rozszerzeniem pgvector i
google_ml_integrationna potrzeby dopasowywania sygnałów w czasie rzeczywistym. - Utworzono indeks wyszukiwania: w BigQuery użyto funkcji
AI.GENERATEiAI.EMBEDdo utworzenia wektorów, a następnie wyeksportowano je do Cloud Storage i zaimportowano do AlloyDB. - Dopasowano sygnał z lokalizatora: za pomocą wyszukiwania wektorowego w AlloyDB dopasowano podzielony sygnał telemetryczny, który pozwolił zlokalizować skradziony kontener w pobliżu Sydney.
- Sprawdzono dowody: do wysyłania zapytań o dane dotyczące dochodzenia w języku naturalnym użyto analityki konwersacyjnej bezpośrednio w edytorze.

Następne kroki
Wiesz już, gdzie znajduje się kontener. Teraz musisz dowiedzieć się, kto za nim stoi.
W laboratorium 3. Wykorzystywanie danych i przepływy pracy oparte na agentach utworzysz wykres właściwości sieci logistycznej, aby mapować relacje między spółkami fasadowymi, użyjesz analityki konwersacyjnej do rozmowy z wykresem i przeszukasz katalog wiedzy, aby znaleźć zabezpieczony kod dostępu potrzebny do odzyskania kontenera.