
1. Wprowadzenie
Witamy na ostatnim etapie śledztwa w sprawie zaginionego ładunku. Po śledzeniu skradzionego kontenera z figurkami Androida z Londynu aż do Sydney ślad się urwał. Wyłączenie transpondera spowodowało automatyczne zablokowanie inteligentnego sejfu kontenera.
Aby odzyskać cenny ładunek, zanim zostanie na zawsze zamknięty, musisz odnaleźć ostateczną lokalizację kontenera i zdobyć ręczny kod dostępu, który pozwoli fizycznie otworzyć skarbiec.

Aby znaleźć zaginiony kontener i zabezpieczyć ładunek, utworzysz graf właściwości BigQuery, który pozwoli Ci prześledzić podróż przesyłki. Następnie za pomocą analityki konwersacyjnej będziesz wysyłać do tej sieci zapytania w języku naturalnym. Na koniec użyjesz Knowledge Catalog do przeprowadzenia wyszukiwania semantycznego w metadanych, aby znaleźć kody zastąpienia.
💡 Nie udało Ci się ukończyć modułu 1 lub modułu 2? Bez obaw, Ten moduł jest w pełni samodzielny. Kroki konfiguracji środowiska zapewnią wszystko, czego potrzebujesz, aby od razu zacząć i samodzielnie ukończyć projekt.
Jakie zadania wykonasz
- Sklonuj repozytorium i uruchom skrypt konfiguracji w Google Cloud Shell.
- Utwórz graf właściwości w BigQuery, który będzie łączyć dane o firmie, statku i manifeście.
- Użyj analityki konwersacyjnej, aby wysyłać do wykresu zapytania w języku naturalnym i śledzić podróż ładunku, aby zidentyfikować odpowiedzialnego operatora.
- Znajdź tabelę zawierającą ostateczne kody zastąpienia za pomocą Knowledge Catalog.
- Użyj kontroli dostępu na poziomie kolumn BigQuery, aby odkryć i ujawnić ostateczny kod.
Czego potrzebujesz
- przeglądarka, np. Chrome;
- projekt Google Cloud z włączonymi płatnościami;
- Dostęp do Google Cloud Shell
Te warsztaty są przeznaczone dla specjalistów ds. danych na wszystkich poziomach zaawansowania.
Zasoby utworzone w tym module powinny kosztować mniej niż 5 USD.
Szacowany czas trwania: ukończenie tego laboratorium zajmie około 45 minut.
2. Zanim zaczniesz
Tworzenie projektu Google Cloud
- W konsoli Google Cloud na stronie wyboru projektu wybierz lub utwórz projekt w chmurze Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności.
Uruchamianie Cloud Shell
Do pobrania kodu, uruchomienia skryptów konfiguracji i wdrożenia aplikacji użyjesz Google Cloud Shell.
- Na nowej karcie przeglądarki otwórz Cloud Shell:

- Po połączeniu ustaw identyfikator projektu i potwierdź środowisko:
gcloud config set project <<YOUR_PROJECT_ID>>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
Wyświetli się komunikat podobny do tego:
Your active configuration is: [cloudshell-####] Updated property [core/project]
Włącz wymagane interfejsy API
Aby włączyć wymagane interfejsy API, uruchom w Cloud Shell to polecenie:
gcloud services enable \
bigquery.googleapis.com \
aiplatform.googleapis.com \
datacatalog.googleapis.com \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com
Po pomyślnym wykonaniu powinien wyświetlić się komunikat podobny do tego:
Operation "operations/..." finished successfully.
3. Konfigurowanie środowiska
W poprzednich modułach z tej serii przygotowaliśmy podstawy do naszego dochodzenia.
1. Klonowanie repozytorium
Sklonuj repozytorium z ćwiczeniami do środowiska powłoki Cloud Shell:
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/bigquery-graph-analytics
git checkout main
cd codelabs/bigquery-graph-analytics/
2. Konfigurowanie tabel podstawowych i tagów zasad
Uruchom skrypt konfiguracji, aby wypełnić zbiór danych BigQuery i zastosować tagi zabezpieczeń na poziomie kolumn w celu ograniczenia dostępu do danych wrażliwych:
bash setup_lab.sh
Sprawdź, czy w terminalu wyświetla się komunikat o pomyślnej inicjalizacji:
🚀 Provisioning foundational tables and deploying Policy Tag security bindings... 🎯 Active Project: your-project-id ... 🎉 Success! Foundational tables initialized and Column-Level Policy Tags fully mapped out of the box!
Po skonfigurowaniu środowiska i wypełnieniu BigQuery danymi logistycznymi możesz teraz utworzyć wykres właściwości, aby połączyć tabele i śledzić podróż ładunku.
4. Łączenie danych za pomocą BigQuery Graph
Aby przeanalizować dane z naszego łańcucha dostaw, określimy, jak firmy, statki i manifesty są ze sobą powiązane. Utworzenie grafu właściwości umożliwia łatwe wysyłanie zapytań dotyczących tych połączeń.
1. Jak wykresy właściwości modelują relacje
Graf właściwości BigQuery modeluje sieci za pomocą:
- Węzły: elementy w sieci. W tym laboratorium węzły reprezentują firmy (które przechowują dane kontaktowe bezpośrednio), manifesty i statki.
- Krawędzie: relacje łączące węzły. Na przykład:
- Krawędź łączy Manifest z Vessel (za pomocą relacji w tabeli
manifests). - Krawędź łączy statek z firmą (za pomocą relacji w
vesselstabeli).
- Krawędź łączy Manifest z Vessel (za pomocą relacji w tabeli
- Właściwości: metadane przechowywane w węzłach lub krawędziach. Na przykład węzeł Firma ma kolumny takie jak
company_nameiphone_number, a węzeł Manifest ma kolumnęseal_integrity_statusi współrzędne (last_ping_lat,last_ping_long). - Etykiety: nazwy tagów przypisane do węzłów (np.
Company,Vessel,Manifest) i krawędzi (np.CARRIED_BY,OPERATED_BY), aby narzędzia do wykonywania zapytań mogły rozpoznawać typy węzłów i relacji.
2. Wdrażanie wykresu właściwości w BigQuery
Plik setup_graph.sql zawiera instrukcje SQL DDL do zdefiniowania i utworzenia wykresu właściwości, ale jest obecnie niekompletny. Zanim skompilujesz i wdrożysz ten plik schematu, musisz zdefiniować w nim etykiety krawędzi (relacje):
- Otworzyć edytor Cloud Shell

- Otwórz plik
setup_graph.sqlw edytorze Cloud Shell.

- Znajdź obiekty zastępcze etykiet krawędzi:
- Wiersz 22: zastąp
`EDGE_TABLE_PLACEHOLDER`odpowiednim tagiem, który określa, jak pliki manifestu są powiązane z statkami (np.CARRIED_BY). - Wiersz 27: zastąp
`EDGE_TABLE_PLACEHOLDER`tagiem reprezentującym powiązanie statków z firmami (np.OPERATED_BY).
- Wiersz 22: zastąp
- Zapisz plik.
Teraz wróć do terminala Cloud Shell i wdroż zaktualizowany wykres właściwości za pomocą ukończonego skryptu:
bq query --use_legacy_sql=false < setup_graph.sql
Powinny się wyświetlić dane wyjściowe wskazujące, że zadanie zostało ukończone:
Waiting on bqjob_r... ... (0s) Current status: DONE
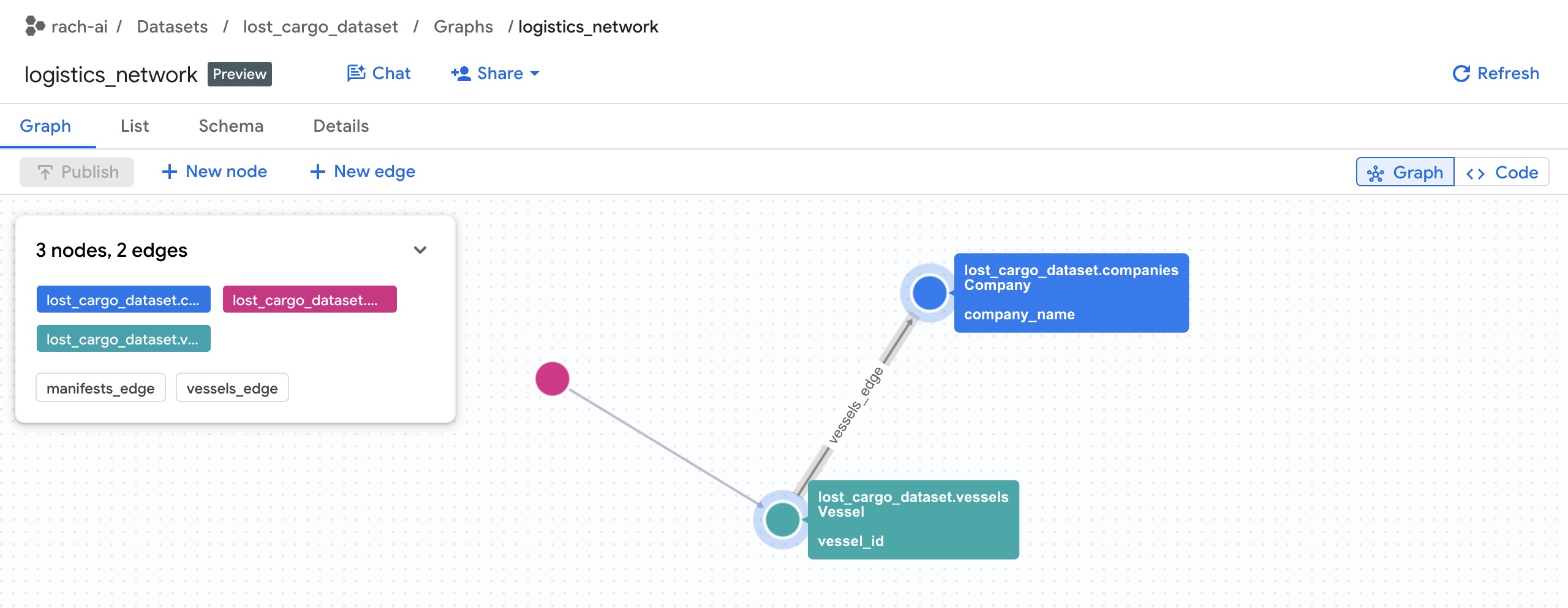
Szczegóły wykresu usługi możesz wyświetlić w konsoli BigQuery:
Znajdź zbiór danych lost_cargo_dataset i wybierz Wykresy:

Po pomyślnym skompilowaniu wykresu właściwości przejdźmy do BigQuery Studio, aby wysyłać zapytania dotyczące połączeń i je wizualizować.
5. Tworzenie zapytań do grafu
Możesz wysyłać zapytania i wizualnie eksplorować graf przy użyciu natywnego języka zapytań GQL (Graph Query Language) bezpośrednio w BigQuery Studio.
1. Wysyłanie zapytań do łańcucha kontener – statek – firma
Przyjrzyjmy się zapytaniom GQL, aby dowiedzieć się, kto obsługuje statki przewożące ładunki. Znalezienie operatora wymaga przejścia przez 3 osobne węzły podmiotów w naszej sieci logistycznej:

- Zacznij od węzła kontenera
Manifest. - Podążaj za krawędzią relacji
CARRIED_BY, aby znaleźćVessel. - Podążaj za krawędzią relacji
OPERATED_BYod tego statku do odpowiedzialnegoCompanyi pobierz jego identyfikator.
Najpierw uruchom zapytanie, aby wizualizować całą sieć (bez filtrów) i wyświetlić pełny wykres.
- Otwórz nową kartę w edytorze SQL BigQuery Studio, wklej to zapytanie GQL i kliknij Uruchom:
SELECT * FROM GRAPH_TABLE( `lost_cargo_dataset.logistics_network` MATCH p = (m:Manifest)-[:CARRIED_BY]->(v:Vessel)-[:OPERATED_BY]->(comp:Company) RETURN TO_JSON(p) AS path ); - Gdy zapytanie się zakończy, w panelu Wyniki zapytania u dołu kliknij kartę Wykres (znajdującą się obok karty Tabela wyników).
- BigQuery renderuje wyniki w postaci interaktywnego wykresu wizualnego. Powiększ, aby zobaczyć całą sieć połączonych kontenerów, statków i operatorów.
Anatomia zapytania GQL
Przyjrzyjmy się zapytaniu GQL, które właśnie zostało wykonane:
GRAPH_TABLE: nakazuje BigQuery wykonanie zapytania o wykres właściwości względemlogistics_networkwykresu.MATCH: deklaruje wzorzec przechodzenia przez wiele węzłów. Zaczynamy od węzłaManifest(m), dopasowujemy relację krawędzi:CARRIED_BYwskazującą na węzełVessel(v), a następnie dopasowujemy relację krawędzi:OPERATED_BYwskazującą na węzełCompany(comp).- GQL zastępuje złożoną logikę łączenia intuicyjnymi, czytelnymi strzałkami relacji w formie ASCII-artu
()->[]->(), co znacznie ułatwia pisanie i optymalizowanie zapytań wieloetapowych. RETURN: zwraca właściwości lub ścieżkę JSON z pasujących elementów.
2. Filtrowanie wyników zapytania GQL
Teraz przefiltrujmy zapytanie, aby wyświetlić tylko ścieżkę do naszego docelowego przejętego kontenera MV-CAPYBARA-003.
- Wklej poniższe zapytanie do edytora SQL i kliknij Uruchom:
SELECT * FROM GRAPH_TABLE( `lost_cargo_dataset.logistics_network` MATCH p = (m:Manifest {shipment_id: 'MV-CAPYBARA-003'})-[:CARRIED_BY]->(v:Vessel)-[:OPERATED_BY]->(comp:Company) RETURN TO_JSON(p) AS path ); - W sekcji wyników kliknij kartę Wykres.
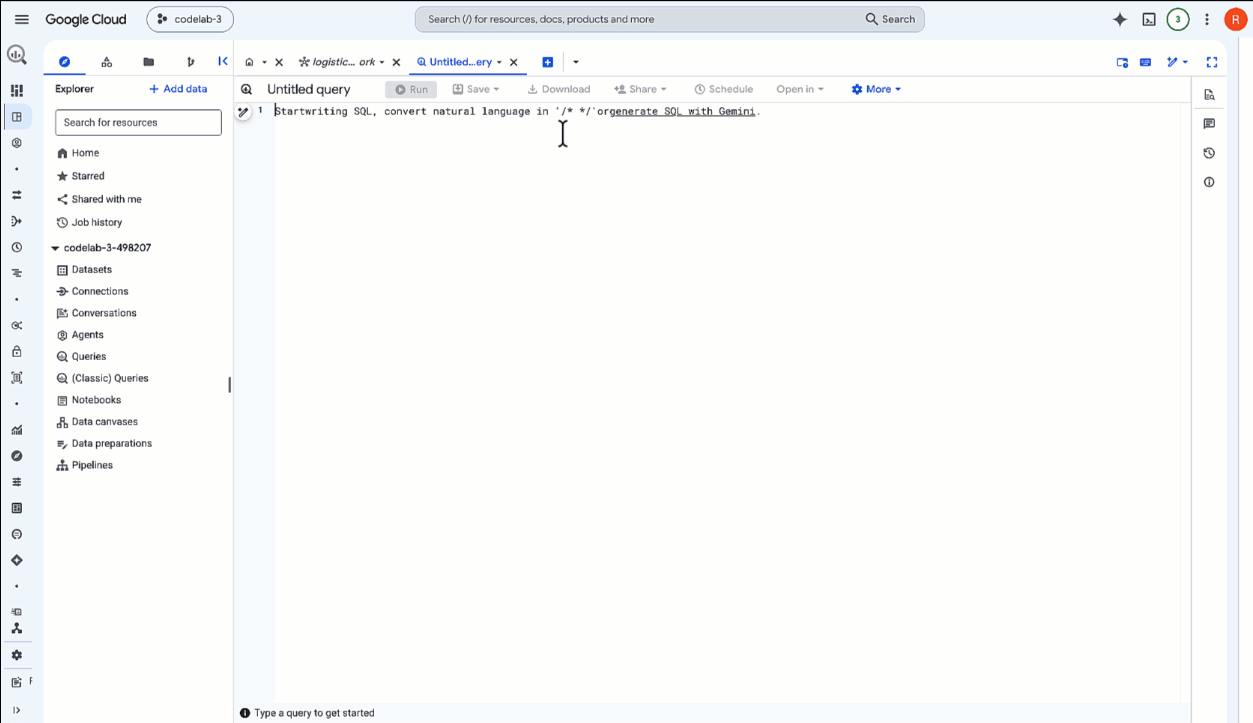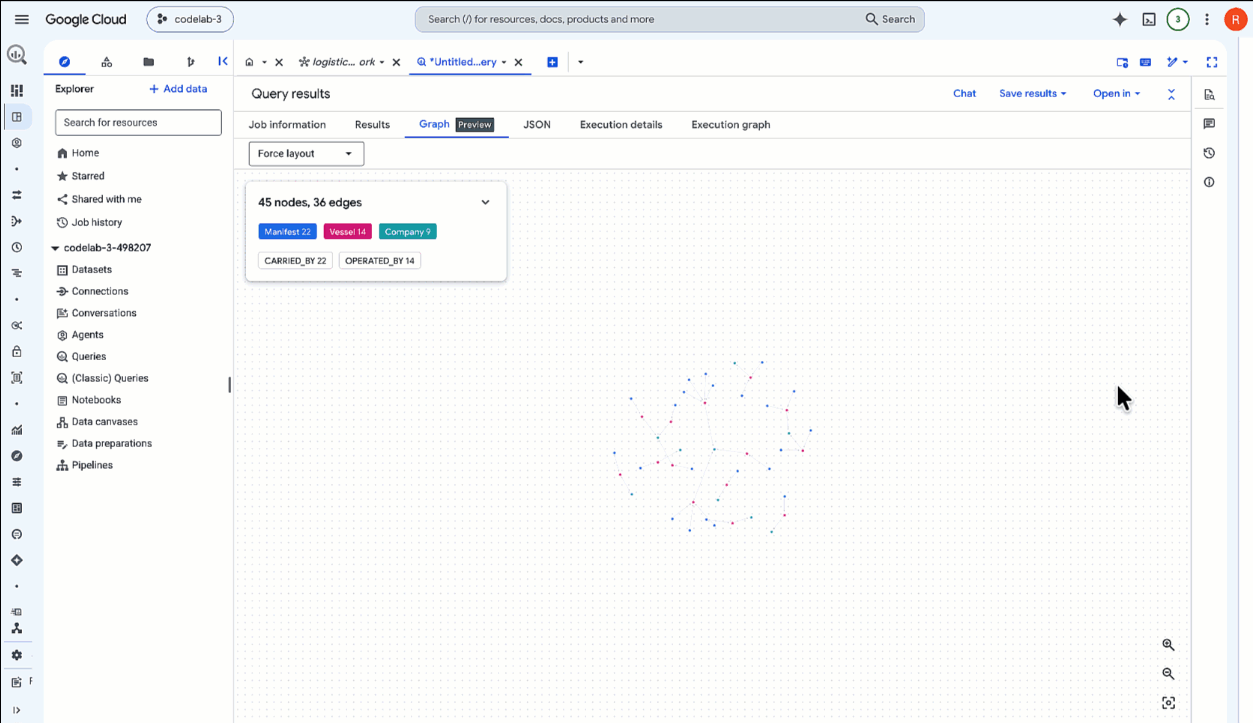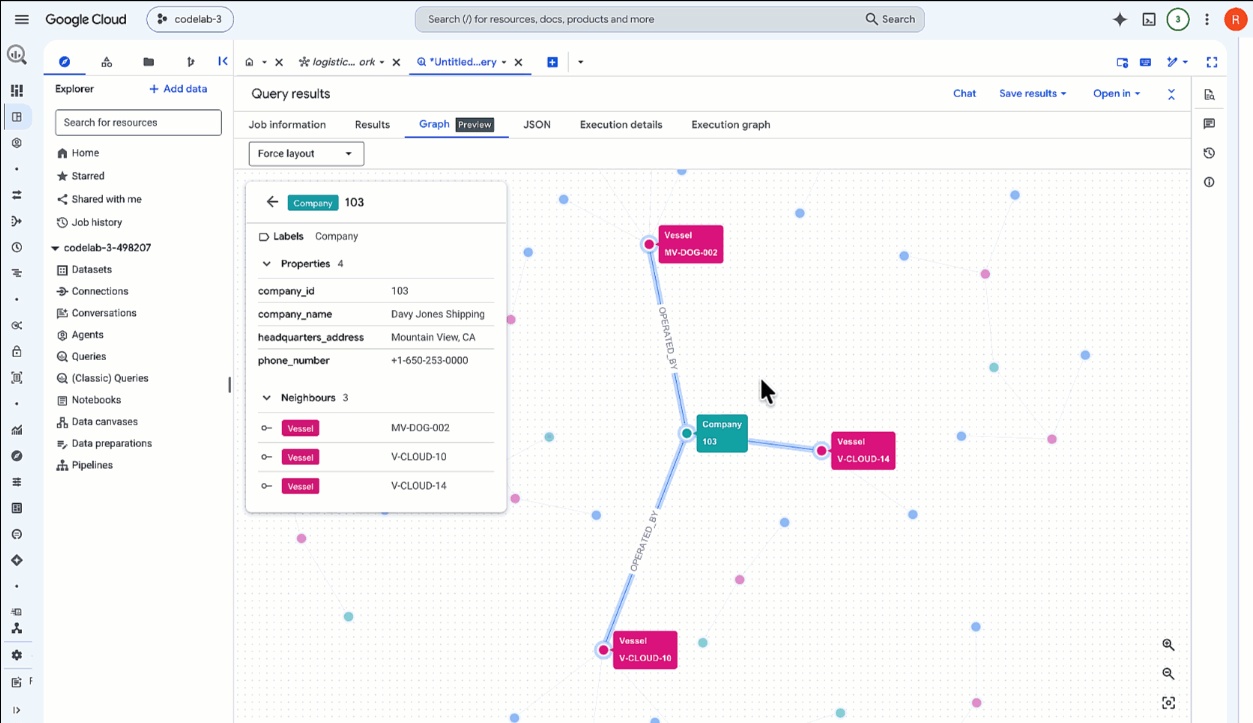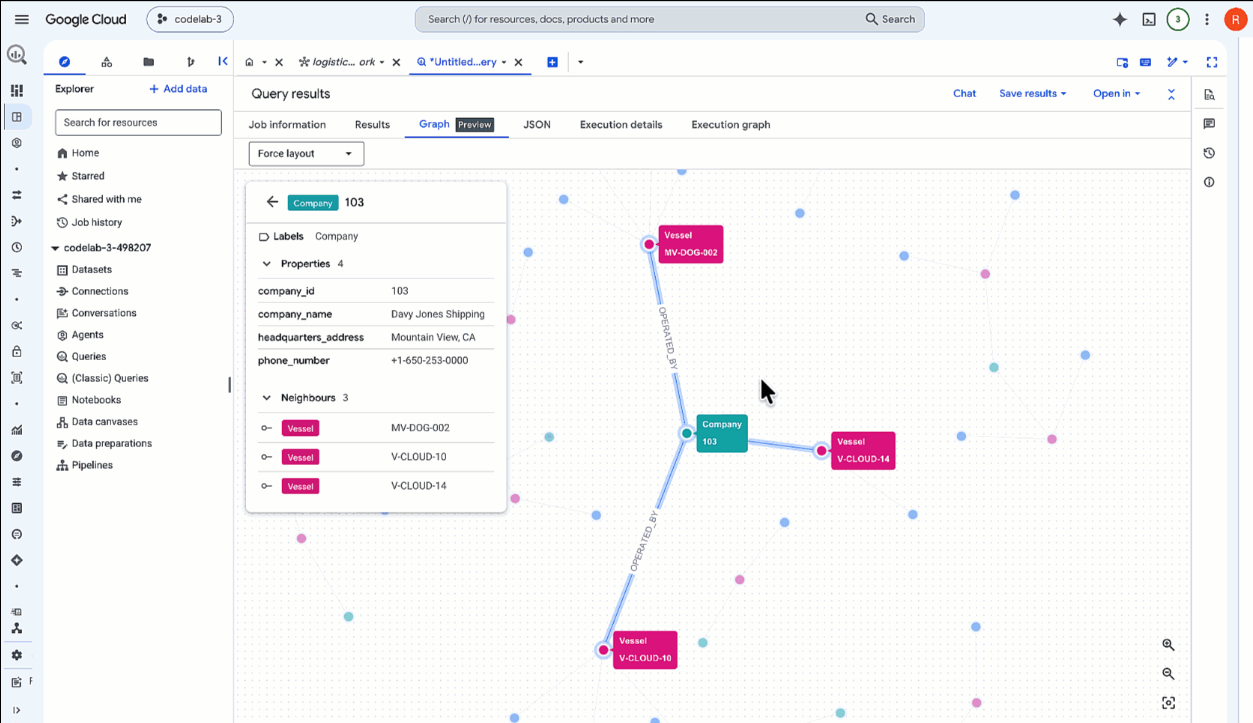
- W przeglądarce wyświetlana jest teraz tylko aktywna trasa przejścia dla
MV-CAPYBARA-003. Aby zobaczyć węzły i połączenia, powiększ widok:- Kliknij dwukrotnie węzeł
Company, aby otworzyć panel właściwości. W sekcji Właściwości zobaczysz operatoracompany_id:103(Davy Jones Shipping). Zanotuj ten identyfikator firmy – będzie Ci potrzebny później do pobrania kodu dostępu z rejestru zabezpieczeń. - Kliknij dwukrotnie węzeł
Vessel, aby sprawdzić, czy jest to węzełFlying Dutchman.
- Kliknij dwukrotnie węzeł
6. Czatowanie z wykresem za pomocą analityki konwersacyjnej
Po ręcznym wysłaniu zapytania do wykresu w celu znalezienia identyfikatora firmy użyjmy analityki konwersacyjnej, aby porozmawiać bezpośrednio z wykresem i określić, dokąd zmierza nasz kontener.
1. Rozpoczynanie sesji Conversational Analytics
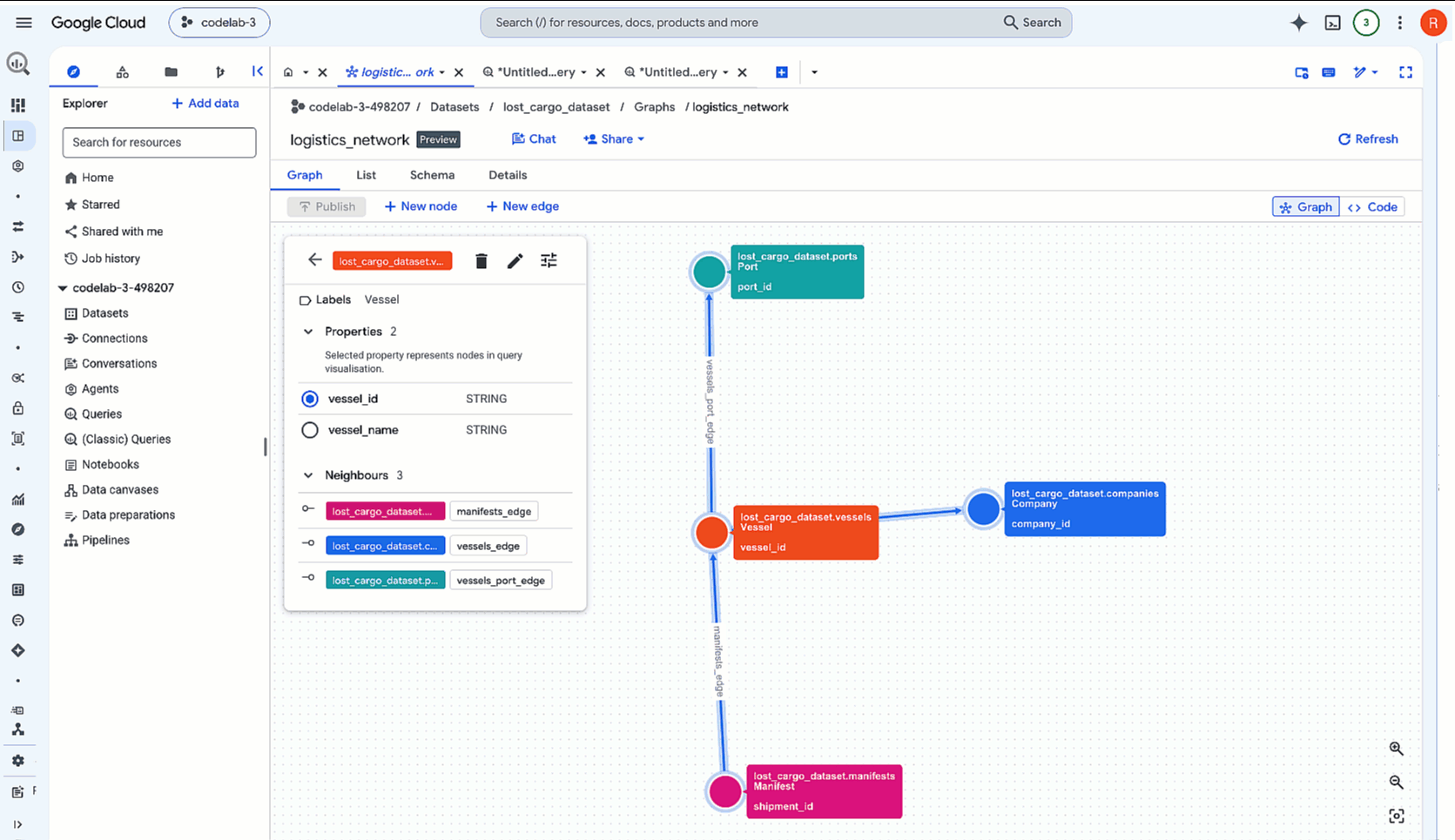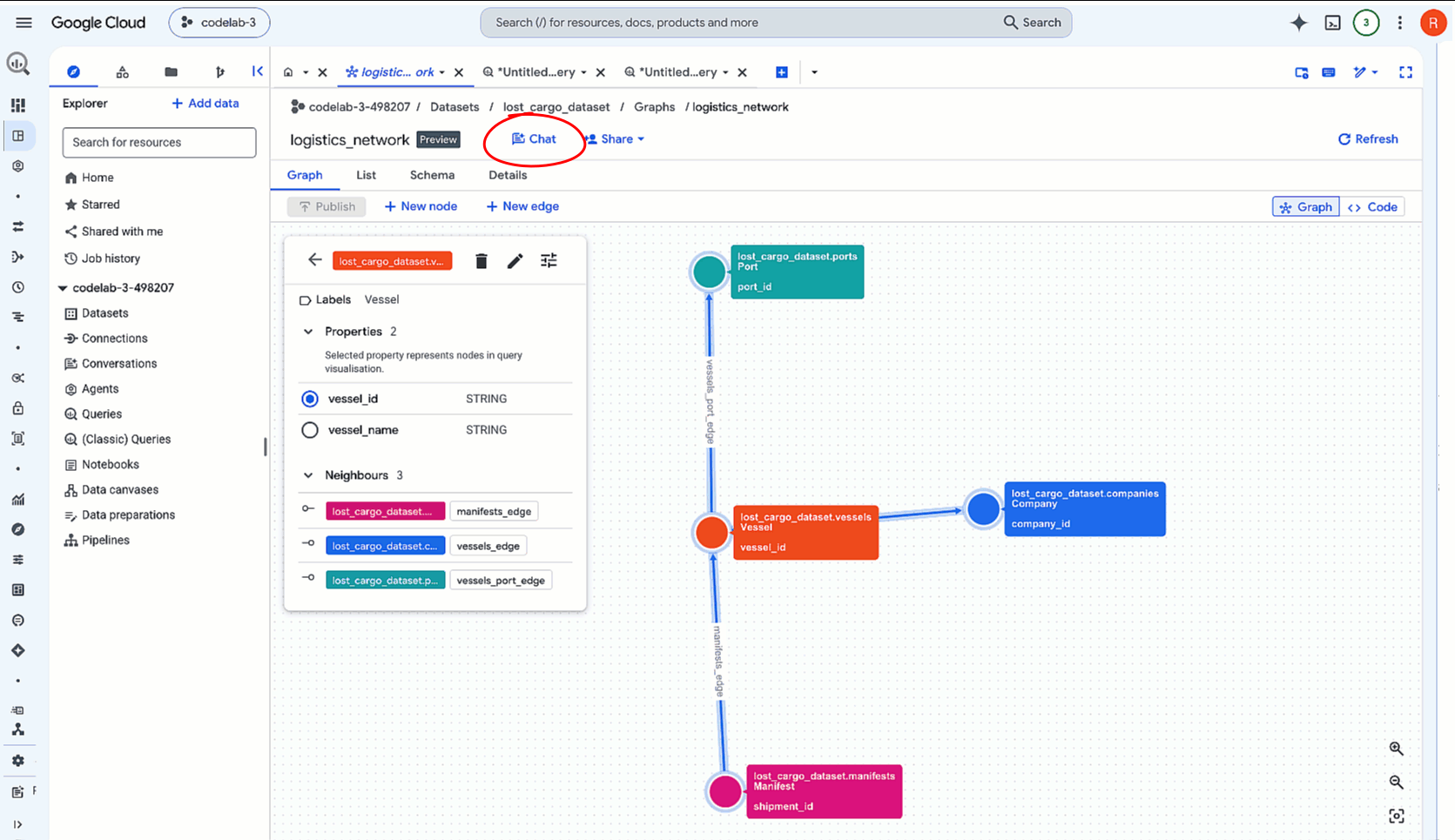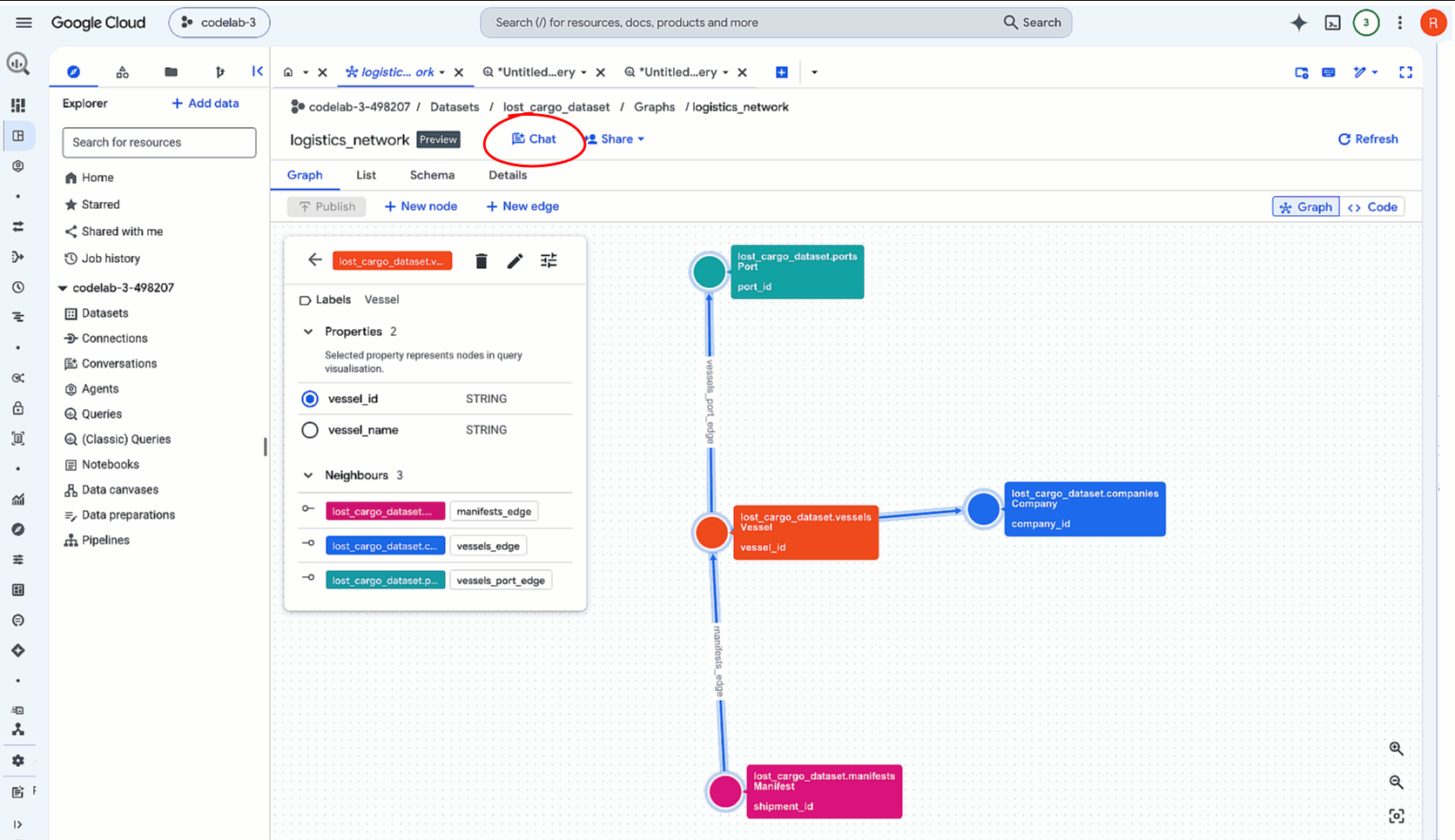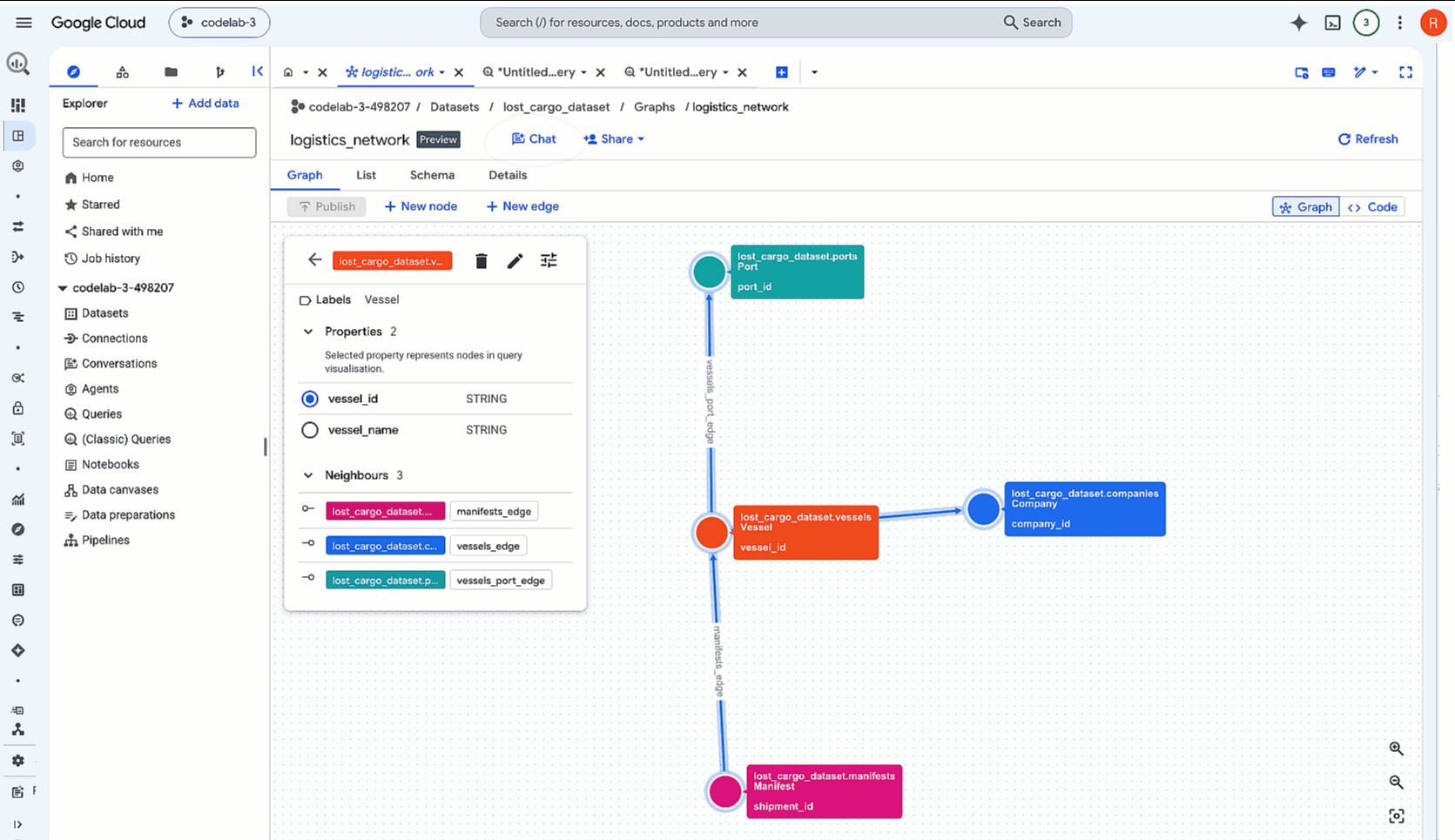
- W konsoli Google Cloud otwórz konsolę BigQuery i rozwiń panel zasobów, aby znaleźć zbiór danych (
lost_cargo_dataset). - Kliknij zasób Wykres właściwości:
logistics_network - Na pasku narzędzi panelu szczegółów u góry kliknij przycisk Czat. Spowoduje to otwarcie sesji Analytics konwersacyjnej wstępnie załadowanej kontekstem wykresu.
2. Wskaż najbliższy port dokowania porwanego kontenera.
Samolot patrolowy właśnie zauważył statek pasujący do opisu naszego frachtowca, który płynie poza zasięgiem sieci (z wyłączonym transponderem) na współrzędnych POINT(-122.48 37.55). Aby przechwycić ładunek, musimy znaleźć najbliższy port dokujący, w którym działa syndykat cieni Davy Jones Shipping.
Zamiast ręcznie przeszukiwać wszystkie porty na świecie, będziemy wysyłać zapytania do naszej sieci grafów, aby pobrać porty połączone z aktywną flotą syndykatu i określić, który z nich jest fizycznie najbliżej miejsca obserwacji.
- W polu czatu analityki konwersacyjnej wpisz ten prompt:
Find all ports associated with Davy Jones Shipping vessels. Which port is closest to coordinate POINT(-122.48 37.55), show the distance in km, and display it on a map.
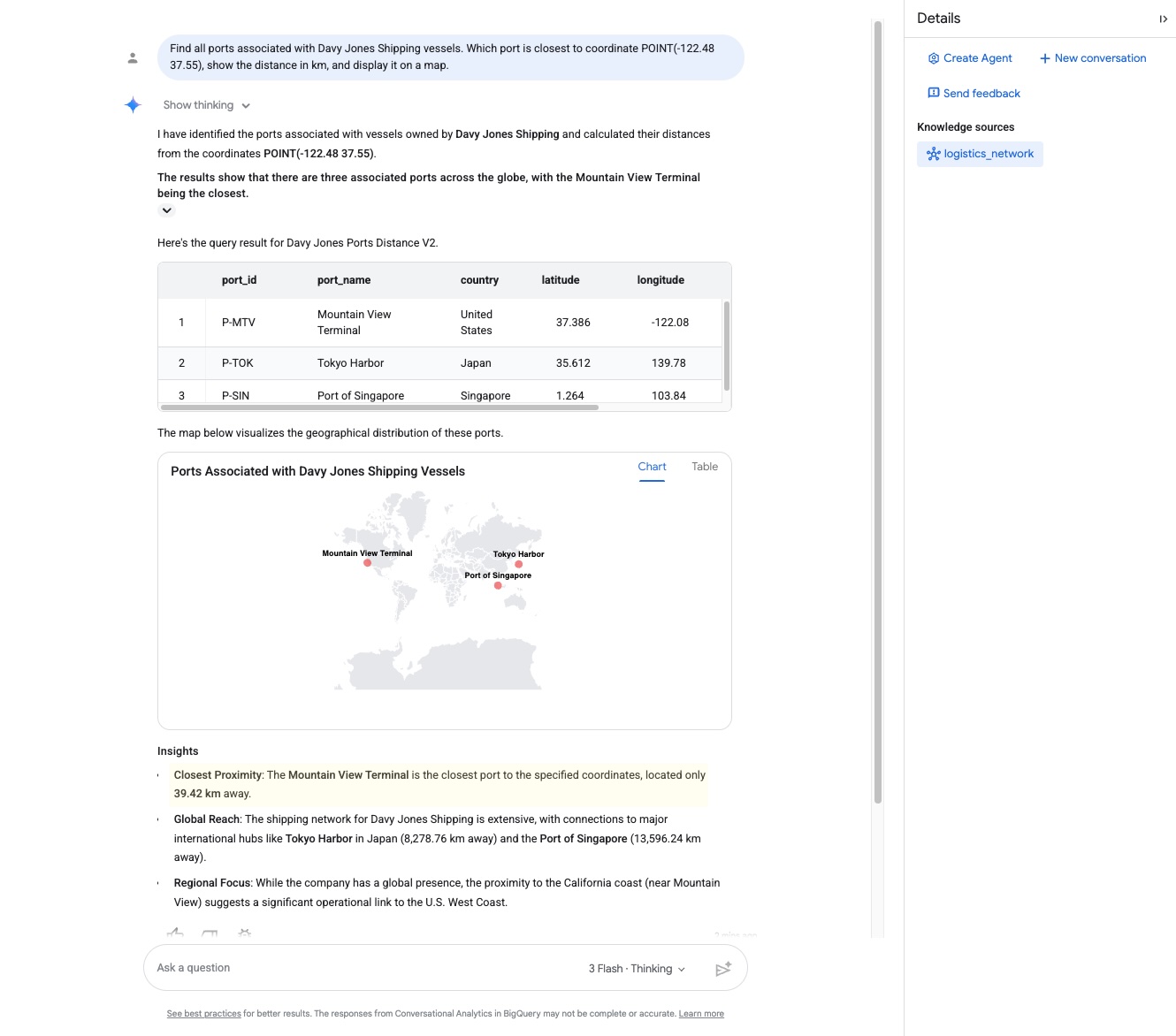
- Przyjrzyj się uważnie odpowiedzi. Agent przechodzi przez graf i zwraca najbliższy obiekt dokujący oraz jego odległość:
- Port dokowania:
Mountain View Terminal - Odległość:
39.42 kilometers
- Port dokowania:
- Analityka konwersacyjna korzysta z Gemini z natywną integracją z systemami informacji geograficznej (GIS), dzięki czemu może interpretować punkty współrzędnych geograficznych i wykorzystywać swoją wiedzę o świecie do weryfikowania lokalizacji:„Statek znajduje się w odległości około 39,42 km od terminalu Mountain View w Kalifornii, co oznacza, że zmierza tam, aby zacumować”.
Potwierdza to, że nasz ładunek zmierza bezpośrednio do Mountain View.
Pod maską: Graph Query Language (GQL) i geoprzestrzenne systemy informacji geograficznej
Za kulisami agent analizy konwersacyjnej dynamicznie skompilował i wykonał zapytanie, które łączy dopasowywanie ścieżki w grafie z obliczeniami odległości geoprzestrzennej. Jest to możliwe dzięki klauzuli COLUMNS w języku GQL, która oblicza odległość geodezyjną w ramach dopasowania do ścieżki w grafie:
SELECT port_id, port_name, country, latitude, longitude, distance_km
FROM GRAPH_TABLE(
`lost_cargo_dataset.logistics_network`
MATCH (c:Company)<-[]-(v:Vessel)-[]->(p:Port)
WHERE LOWER(c.company_name) = 'davy jones shipping'
COLUMNS (
p.port_id,
p.port_name,
p.country,
p.latitude,
p.longitude,
ROUND(ST_DISTANCE(ST_GEOGPOINT(p.longitude, p.latitude), ST_GEOGPOINT(-122.48, 37.55)) / 1000, 2) AS distance_km
)
)
ORDER BY distance_km ASC;
Dzięki połączeniu natywnych funkcji geoprzestrzennych (GIS) (ST_DISTANCE, ST_GEOGPOINT) z dopasowaniem wykresu właściwości GQL BigQuery dynamicznie określa obszar działalności syndykatu i oblicza rzeczywistą bliskość fizyczną w ramach jednego zapytania.
7. Znajdowanie brakujących danych za pomocą Knowledge Catalog
Wykres właściwości pokazuje relacje, ale nie zawiera tabeli, w której są przechowywane rzeczywiste kody zastąpienia.
W prawdziwym środowisku przedsiębiorstwa z setkami zbiorów danych i tabel znalezienie tych informacji może być trudne. Użyjemy Knowledge Catalog, aby przeprowadzić wyszukiwanie semantyczne i zlokalizować odpowiednią tabelę.
1. Wyszukiwanie semantyczne w Knowledge Catalog
- W konsoli Google Cloud wyszukaj i otwórz Knowledge Catalog ➔ Wyszukiwanie.
- Aby zawęzić wyniki, w kolumnie filtra wyszukiwania w sekcji Systemy zaznacz BigQuery.
- W polu wyszukiwania wpisz to zapytanie:
container override codes
- Kliknij zasób tabeli
maritime_security_registry, który pojawi się w wynikach wyszukiwania:
Po sprawdzeniu schematu metadanych zobaczysz, że tabela zawiera kolumny z danymi dotyczącymi bezpieczeństwa kontenera, takie jak firma koordynująca co_id, token depozytariusza cust_tok i najważniejsza kolumna z kodem dostępu do bezpiecznego kontenera: clc_ovr_cd.
Udało nam się zlokalizować zarówno stół, jak i dokładną kolumnę zabezpieczoną, której potrzebujemy, aby odzyskać ładunek.
🔓 Zarządzanie w rzeczywistym świecie: w środowisku produkcyjnym przedsiębiorstwa zespoły ds. zabezpieczeń i zarządzania korzystają też z:
- Aspekty i szablony tagów: umożliwiają dołączanie metadanych biznesowych (np. właściciela danych, okresu przechowywania lub klasyfikacji informacji umożliwiających identyfikację) do schematów tabel.
- Data Lineage: automatyczne generowanie wizualnych schematów blokowych przedstawiających sposób, w jaki tabele takie jak
maritime_security_registrysą wysyłane i wykorzystywane przez systemy podrzędne.
2. Sprawdzanie zabezpieczeń kolumn w BigQuery
- Wróć do konsoli BigQuery.
- Na karcie Eksplorator wybierz
lost_cargo_dataseti kliknij tabelęmaritime_security_registry. - Kliknij kartę Schemat.
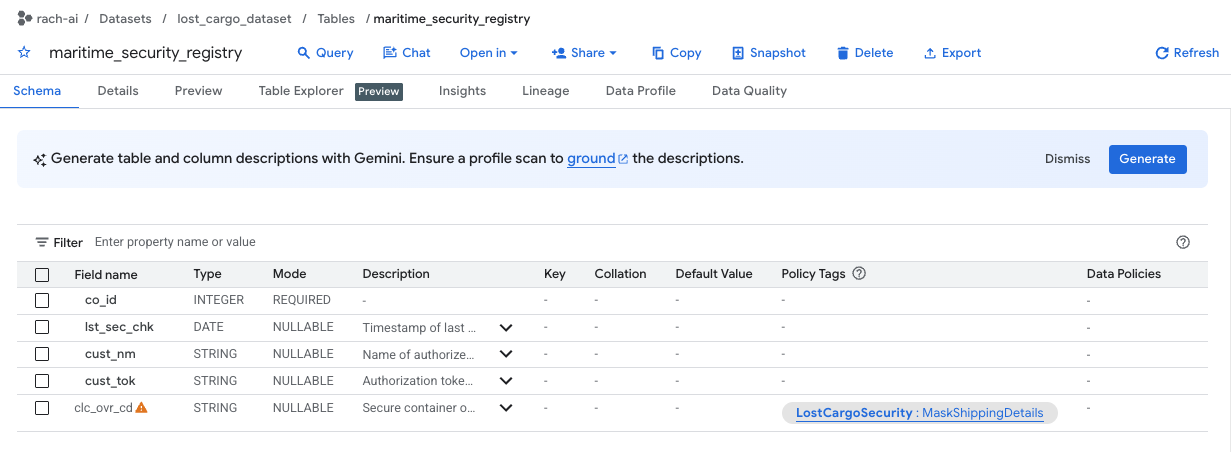
- Zwróć uwagę, że kolumna
clc_ovr_cdjest zabezpieczona tagiem zasad o nazwieMaskShippingDetails(wymienionym w kolumnie Tagi zasad). - Otwórz w BigQuery nową kartę edytora SQL i spróbuj wyświetlić kody zastąpienia rejestru, uruchamiając to zapytanie:
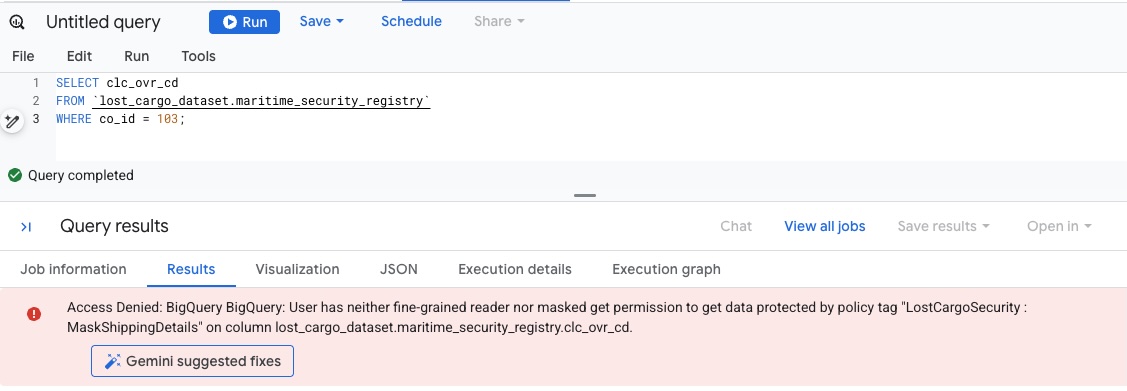
SELECT * FROM `lost_cargo_dataset.maritime_security_registry` WHERE co_id = 103; - Ponieważ Twoje konto nie ma jeszcze uprawnień do odczytywania kolumn oznaczonych tagiem
MaskShippingDetails, zapytanie natychmiast zakończy się niepowodzeniem z powodu błędu zabezpieczeń bazy danych Access Denied:
8. Łamanie zabezpieczeń kolumny w celu odzyskania kodu dostępu
Aby odczytać końcowy kod zastąpienia w formie zwykłego tekstu, musimy przyznać kontu użytkownika uprawnienia do odczytywania kolumn oznaczonych symbolem MaskShippingDetails.
1. Przyznawanie uprawnień do tagów zasad
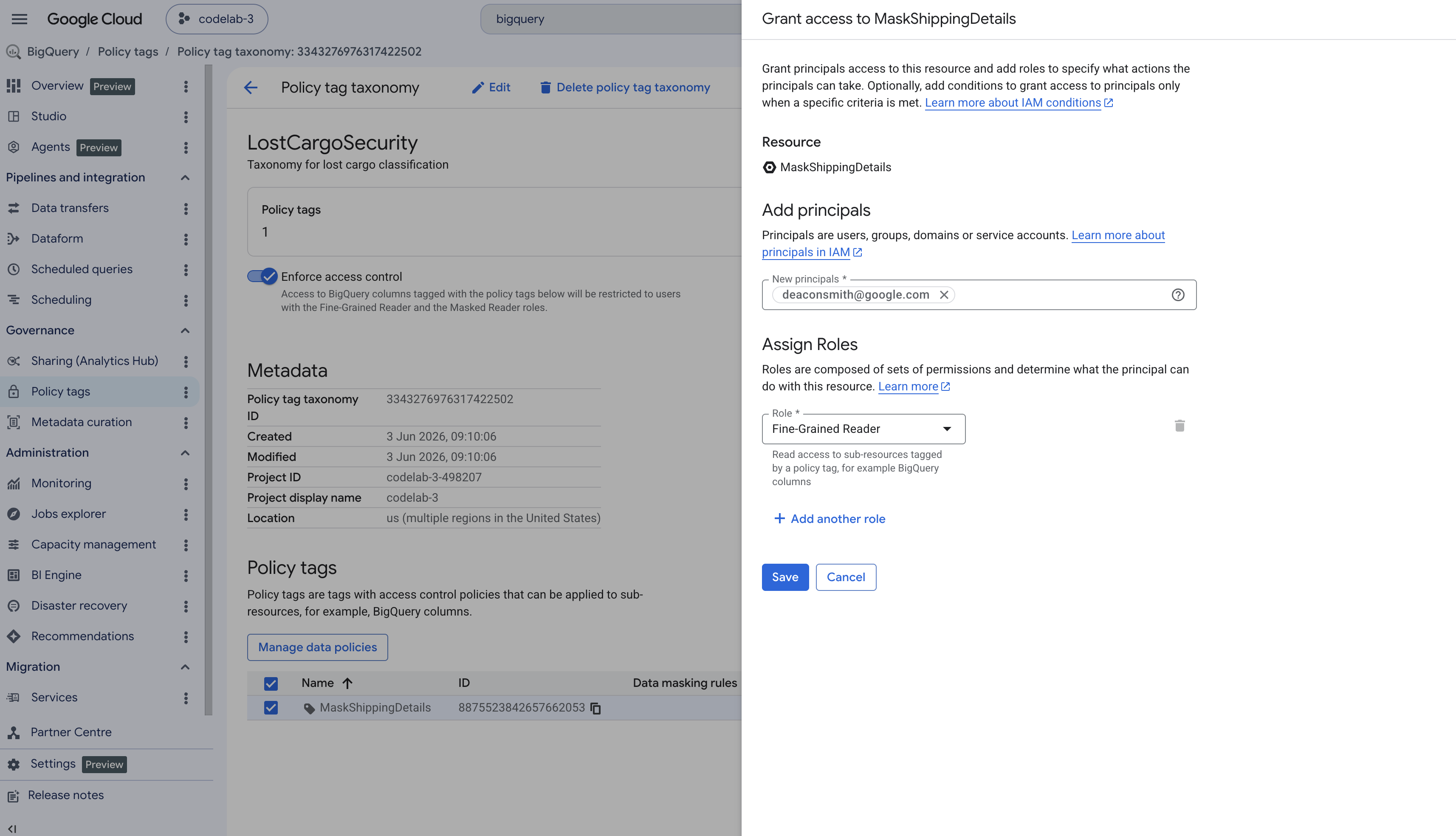
- W panelu nawigacji po lewej stronie konsoli BigQuery otwórz Tagi zasad.
- Wybierz taksonomię o nazwie
LostCargoSecurity_. - Na liście tagów kliknij
MaskShippingDetails. - W panelu informacyjnym po prawej stronie ekranu kliknij Dodaj podmiot zabezpieczeń. Jeśli panel jest ukryty, w prawym górnym rogu kliknij Pokaż panel informacyjny.
- W polu Nowe podmioty zabezpieczeń wpisz adres e-mail aktywnego użytkownika Google Cloud.
- W menu Wybierz rolę odszukaj i wybierz Czytelnik z precyzyjnym dostępem, a następnie kliknij Zapisz.
2. Zapytanie o kod zastąpienia
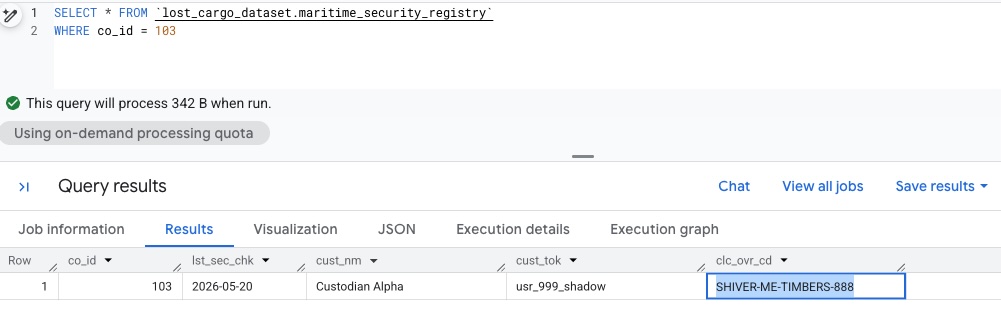
Wróć do edytora obszaru roboczego BigQuery. Teraz masz szczegółowy dostęp do odczytu, więc powinniśmy móc ponownie uruchomić zapytanie i wyświetlić dane bez maskowania:
SELECT * FROM `lost_cargo_dataset.maritime_security_registry`
WHERE co_id = 103;
🔓 Wynik
Zapytanie zwraca niezasłonięty kod zastąpienia:
SHIVER-ME-TIMBERS-888
9. Czyszczenie danych
Aby uniknąć opłat, zwalniaj miejsce w zasobach piaskownicy utworzonych podczas tego modułu.
Wróć do terminala Cloud Shell i usuń zbiór danych BigQuery zawierający tabele logistyczne:
bq rm -r -f -d lost_cargo_dataset
Usuń pliki sklonowanego repozytorium:
cd ..
rm -rf data-cloud-roadshow-26
10. Gratulacje
Udało Ci się zakończyć dochodzenie i uzyskać kod zastąpienia zezwolenia.
Czego się dowiedziałeś(-aś)
- Jak utworzyć w BigQuery graf właściwości, który będzie reprezentować złożone encje i relacje.
- Jak skonfigurować węzły, krawędzie, właściwości i etykiety, aby rejestrować połączenia danych.
- Jak wykonywać zapytania dotyczące wykresów właściwości przy użyciu języka naturalnego za pomocą analityki konwersacyjnej BigQuery.
- Jak są skonstruowane wyrażenia Graph Query Language (GQL), aby przechodzić ścieżki relacyjne.
- Jak wykrywać zabezpieczone zasoby za pomocą Knowledge Catalog i uzyskiwać dostęp do danych z ograniczeniami na poziomie kolumny za pomocą tagów zasad.