
১. সংক্ষিপ্ত বিবরণ
এই কোডল্যাবে, আপনি একটি স্কেলেবল নলেজ বেস সার্চ অ্যাপ্লিকেশন তৈরি করবেন। ভেক্টর এমবেডিং তৈরি করার জন্য পাইথন স্ক্রিপ্ট এবং লুপ ব্যবহার করে একটি জটিল ETL পাইপলাইন পরিচালনার পরিবর্তে, আপনি AlloyDB AI ব্যবহার করে একটিমাত্র SQL কমান্ডের মাধ্যমে ডাটাবেসের মধ্যেই এমবেডিং তৈরির কাজটি করবেন।
আপনি যা তৈরি করবেন
একটি উচ্চ কর্মক্ষমতা সম্পন্ন "অনুসন্ধানযোগ্য" জ্ঞানভান্ডার অ্যাপ্লিকেশন।
আপনি যা শিখবেন
আপনি শিখবেন কীভাবে:
- একটি AlloyDB ক্লাস্টার প্রস্তুত করুন এবং AI এক্সটেনশনগুলি সক্রিয় করুন।
- SQL ব্যবহার করে কৃত্রিম ডেটা (৫০,০০০+ সারি) তৈরি করুন।
- ব্যাচ প্রসেসিং ব্যবহার করে সম্পূর্ণ ডেটাসেটের জন্য ভেক্টর এমবেডিং ব্যাকফিল করুন।
- নতুন ডেটা স্বয়ংক্রিয়ভাবে যুক্ত করতে রিয়েল-টাইম ইনক্রিমেন্টাল ট্রিগার সেট আপ করুন।
- 'ফ্লেক্সিং কনটেক্সট'-এর জন্য হাইব্রিড সার্চ (ভেক্টর + এসকিউএল ফিল্টার) সম্পাদন করুন।
প্রয়োজনীয়তা
- একটি ব্রাউজার, যেমন ক্রোম বা ফায়ারফক্স ।
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট।
- SQL সম্পর্কে প্রাথমিক ধারণা।
২. শুরু করার আগে
একটি প্রকল্প তৈরি করুন
- গুগল ক্লাউড কনসোলের প্রজেক্ট সিলেক্টর পেজে, একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন।
- আপনার ক্লাউড প্রোজেক্টের জন্য বিলিং চালু আছে কিনা তা নিশ্চিত করুন। কোনো প্রোজেক্টে বিলিং চালু আছে কিনা তা কীভাবে পরীক্ষা করবেন, তা জেনে নিন ।
- আপনি ক্লাউড শেল ব্যবহার করবেন, যা গুগল ক্লাউডে চালিত একটি কমান্ড-লাইন পরিবেশ। গুগল ক্লাউড কনসোলের শীর্ষে থাকা ‘Activate Cloud Shell’-এ ক্লিক করুন।

- ক্লাউড শেলে সংযুক্ত হওয়ার পর, আপনি নিম্নলিখিত কমান্ডটি ব্যবহার করে যাচাই করে নিন যে আপনি ইতিমধ্যেই প্রমাণীকৃত এবং প্রজেক্টটি আপনার প্রজেক্ট আইডিতে সেট করা আছে:
gcloud auth list
- gcloud কমান্ডটি আপনার প্রজেক্ট সম্পর্কে অবগত আছে কিনা, তা নিশ্চিত করতে ক্লাউড শেলে নিম্নলিখিত কমান্ডটি চালান।
gcloud config list project
- আপনার প্রজেক্টটি সেট করা না থাকলে, এটি সেট করতে নিম্নলিখিত কমান্ডটি ব্যবহার করুন:
gcloud config set project <YOUR_PROJECT_ID>
- প্রয়োজনীয় এপিআইগুলো সক্রিয় করুন: লিঙ্কটি অনুসরণ করুন এবং এপিআইগুলো সক্রিয় করুন।
বিকল্পভাবে আপনি এর জন্য gcloud কমান্ড ব্যবহার করতে পারেন। gcloud কমান্ড এবং এর ব্যবহার সম্পর্কে জানতে ডকুমেন্টেশন দেখুন।
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
অপ্রত্যাশিত সমস্যা ও সমাধান
"ঘোস্ট প্রজেক্ট" সিন্ড্রোম | আপনি |
বিলিং ব্যারিকেড | আপনি প্রজেক্টটি চালু করেছেন, কিন্তু বিলিং অ্যাকাউন্টটি দিতে ভুলে গেছেন। AlloyDB একটি উচ্চ-ক্ষমতাসম্পন্ন ইঞ্জিন; এর 'গ্যাস ট্যাঙ্ক' (বিলিং) খালি থাকলে এটি চালু হবে না। |
এপিআই প্রচার বিলম্ব | আপনি "এপিআই সক্ষম করুন" এ ক্লিক করেছেন, কিন্তু কমান্ড লাইনে এখনও |
কোটা কোয়াগস | আপনি যদি একটি একেবারে নতুন ট্রায়াল অ্যাকাউন্ট ব্যবহার করেন, তাহলে AlloyDB ইনস্ট্যান্সের জন্য আপনার আঞ্চলিক কোটা শেষ হয়ে যেতে পারে। যদি |
"লুকানো" পরিষেবা এজেন্ট | কখনও কখনও AlloyDB সার্ভিস এজেন্টকে স্বয়ংক্রিয়ভাবে |
৩. ডাটাবেস সেটআপ
এই ল্যাবে আমরা পরীক্ষার ডেটার জন্য ডাটাবেস হিসেবে AlloyDB ব্যবহার করব। এটি ডাটাবেস এবং লগের মতো সমস্ত রিসোর্স ধারণ করার জন্য ক্লাস্টার ব্যবহার করে। প্রতিটি ক্লাস্টারে একটি প্রাইমারি ইনস্ট্যান্স থাকে যা ডেটাতে অ্যাক্সেস পয়েন্ট সরবরাহ করে। টেবিলগুলোতে আসল ডেটা থাকবে।
চলুন একটি AlloyDB ক্লাস্টার, ইনস্ট্যান্স এবং টেবিল তৈরি করি যেখানে টেস্ট ডেটাসেটটি লোড করা হবে।
- নিচের বোতামটিতে ক্লিক করুন অথবা লিঙ্কটি কপি করে আপনার ব্রাউজারে পেস্ট করুন, যেখানে গুগল ক্লাউড কনসোল ব্যবহারকারী লগ ইন করা আছেন।
- এই ধাপটি সম্পন্ন হলে রিপোটি আপনার লোকাল ক্লাউড শেল এডিটরে ক্লোন করা হবে এবং আপনি প্রজেক্ট ফোল্ডার থেকে নিচের কমান্ডটি চালাতে পারবেন (আপনাকে অবশ্যই প্রজেক্ট ডিরেক্টরিতে থাকতে হবে):
sh run.sh
- এখন UI ব্যবহার করুন (টার্মিনালে থাকা লিঙ্কে ক্লিক করে অথবা টার্মিনালে থাকা 'preview on web' লিঙ্কে ক্লিক করে)।
- শুরু করার জন্য আপনার প্রজেক্ট আইডি, ক্লাস্টার এবং ইনস্ট্যান্সের নামগুলোর বিবরণ লিখুন।
- লগগুলো স্ক্রল হতে হতে আপনি এক কাপ কফি নিয়ে আসুন এবং পর্দার আড়ালে এটি কীভাবে কাজ করছে তা এখানে পড়ে নিতে পারেন। এতে প্রায় ১০-১৫ মিনিট সময় লাগতে পারে।
অপ্রত্যাশিত সমস্যা ও সমাধান
"ধৈর্য" সমস্যা | ডাটাবেস ক্লাস্টার একটি ভারী অবকাঠামো। যদি আপনি পৃষ্ঠাটি রিফ্রেশ করেন বা ক্লাউড শেল সেশনটি "আটকে গেছে" ভেবে বন্ধ করে দেন, তাহলে এর ফলে একটি "ঘোস্ট" ইনস্ট্যান্স তৈরি হতে পারে যা আংশিকভাবে প্রোভিশন করা এবং ম্যানুয়াল হস্তক্ষেপ ছাড়া মুছে ফেলা অসম্ভব। |
অঞ্চলের অমিল | আপনি যদি |
জম্বি ক্লাস্টার | যদি আপনি আগে কোনো ক্লাস্টারের জন্য একই নাম ব্যবহার করে থাকেন এবং সেটি মুছে না ফেলেন, তাহলে স্ক্রিপ্টটি বলতে পারে যে ক্লাস্টারের নামটি ইতিমধ্যেই বিদ্যমান। একটি প্রোজেক্টের মধ্যে ক্লাস্টারের নাম অবশ্যই অনন্য হতে হবে। |
ক্লাউড শেল টাইমআউট | আপনার কফি বিরতি যদি ৩০ মিনিটের হয়, তাহলে ক্লাউড শেল স্লিপ মোডে চলে যেতে পারে এবং |
৪. স্কিমা প্রোভিশনিং
এই ধাপে আমরা নিম্নলিখিত বিষয়গুলো আলোচনা করব:
আপনার AlloyDB ক্লাস্টার এবং ইনস্ট্যান্স চালু হয়ে গেলে, AI এক্সটেনশনগুলি সক্রিয় করতে এবং স্কিমাটি প্রোভিশন করতে AlloyDB Studio SQL এডিটরে যান।
আপনার ইনস্ট্যান্সটি তৈরি হওয়া শেষ না হওয়া পর্যন্ত আপনাকে অপেক্ষা করতে হতে পারে। এটি তৈরি হয়ে গেলে, ক্লাস্টার তৈরির সময় আপনি যে ক্রেডেনশিয়ালগুলো তৈরি করেছিলেন, সেগুলো ব্যবহার করে AlloyDB-তে সাইন ইন করুন। PostgreSQL-এ প্রমাণীকরণের জন্য নিম্নলিখিত ডেটা ব্যবহার করুন:
- ব্যবহারকারীর নাম : "
postgres" - ডাটাবেস : "
postgres" - পাসওয়ার্ড : "
alloydb" (অথবা তৈরির সময় আপনি যা সেট করেছিলেন)
AlloyDB Studio-তে সফলভাবে প্রমাণীকরণের পর, এডিটর-এ SQL কমান্ডগুলো প্রবেশ করানো হয়। শেষ উইন্ডোটির ডানদিকে থাকা প্লাস চিহ্নটি ব্যবহার করে আপনি একাধিক এডিটর উইন্ডো যোগ করতে পারেন।
আপনি এডিটর উইন্ডোতে AlloyDB-এর জন্য কমান্ড লিখবেন এবং প্রয়োজন অনুযায়ী Run, Format ও Clear অপশনগুলো ব্যবহার করবেন।
এক্সটেনশনগুলি সক্ষম করুন
এই অ্যাপটি তৈরি করার জন্য, আমরা pgvector এবং google_ml_integration এক্সটেনশনগুলো ব্যবহার করব। pgvector এক্সটেনশনটি আপনাকে ভেক্টর এমবেডিং সংরক্ষণ এবং অনুসন্ধান করার সুযোগ দেয়। google_ml_integration এক্সটেনশনটি এমন সব ফাংশন সরবরাহ করে যা ব্যবহার করে আপনি Vertex AI প্রেডিকশন এন্ডপয়েন্টগুলো অ্যাক্সেস করে SQL-এ প্রেডিকশন পেতে পারেন। নিম্নলিখিত DDL-গুলো রান করে এই এক্সটেনশনগুলো সক্রিয় করুন :
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
একটি টেবিল তৈরি করুন
পরিধি প্রদর্শনের জন্য আমাদের একটি ডেটাসেট প্রয়োজন। CSV ইম্পোর্ট করার পরিবর্তে, আমরা SQL ব্যবহার করে তাৎক্ষণিকভাবে ৫০,০০০ সারি কৃত্রিম 'হেল্প আর্টিকেল' তৈরি করব।
আপনি AlloyDB Studio-তে নিচের DDL স্টেটমেন্টটি ব্যবহার করে একটি টেবিল তৈরি করতে পারেন:
-- 1. Create the table
CREATE TABLE help_articles (
id SERIAL PRIMARY KEY,
title TEXT,
category TEXT,
product_version TEXT,
content_body TEXT,
embedding vector(768) -- Dimension for text-embedding-005
);
-- 2. Generate 50,000 rows of synthetic data
INSERT INTO help_articles (title, category, product_version, content_body)
SELECT
'Help Article ' || i,
CASE
WHEN i % 3 = 0 THEN 'Billing'
WHEN i % 3 = 1 THEN 'Technical'
ELSE 'General'
END,
CASE
WHEN i % 2 = 0 THEN '2.0'
ELSE '1.0'
END,
'This article covers common issues regarding ' ||
CASE
WHEN i % 3 = 0 THEN 'payment failures, invoice disputes, and credit card updates.'
WHEN i % 3 = 1 THEN 'connection timeouts, latency issues, and API errors.'
ELSE 'account profile settings, password resets, and user roles.'
END
FROM generate_series(1, 50000) AS i;
item_vector কলামটি টেক্সটের ভেক্টর মানগুলো সংরক্ষণের সুযোগ দেবে।
ডেটা যাচাই করুন:
SELECT count(*) FROM help_articles;
-- Output: 50000
ডাটাবেস ফ্ল্যাগ সক্রিয় করুন
ইনস্ট্যান্স কনফিগারেশন কনসোলে যান, "এডিট প্রাইমারি"-তে ক্লিক করুন, অ্যাডভান্সড কনফিগারেশনে গিয়ে "অ্যাড ডেটাবেস ফ্ল্যাগস"-এ ক্লিক করুন।
অন্যথায়, ফ্ল্যাগস ড্রপডাউনে এটি প্রবেশ করিয়ে "ON" এ সেট করুন এবং ইনস্ট্যান্স আপডেট করুন।
- যাচাই করুন যে google_ml_integration.enable_faster_embedding_generation ফ্ল্যাগটি 'on' এ সেট করা আছে:
অন্যথায়, ফ্ল্যাগস ড্রপডাউনে এটি প্রবেশ করিয়ে "ON" এ সেট করুন এবং ইনস্ট্যান্স আপডেট করুন।
ডাটাবেস ফ্ল্যাগ কনফিগার করার ধাপসমূহ:
- গুগল ক্লাউড কনসোলে, ক্লাস্টার পৃষ্ঠায় যান।
- রিসোর্স নেম কলামে একটি ক্লাস্টারে ক্লিক করুন।
- ওভারভিউ পৃষ্ঠায়, আপনার ক্লাস্টারের ইনস্ট্যান্সগুলিতে যান, একটি ইনস্ট্যান্স নির্বাচন করুন এবং তারপরে সম্পাদনা (Edit ) ক্লিক করুন।
- আপনার ইনস্ট্যান্স থেকে একটি ডাটাবেস ফ্ল্যাগ যোগ, পরিবর্তন বা মুছে ফেলুন:
একটি পতাকা যোগ করুন
- আপনার ইনস্ট্যান্সে একটি ডাটাবেস ফ্ল্যাগ যোগ করতে, 'Add flag'-এ ক্লিক করুন।
- নতুন ডাটাবেস ফ্ল্যাগ তালিকা থেকে একটি ফ্ল্যাগ নির্বাচন করুন।
- ফ্ল্যাগটির জন্য একটি মান প্রদান করুন।
- সম্পন্ন ক্লিক করুন।
- ইনস্ট্যান্স আপডেট করুন-এ ক্লিক করুন।
- যাচাই করুন যে google_ml_integration এক্সটেনশনটির সংস্করণ 1.5.2 বা তার চেয়ে উচ্চতর:
নিম্নলিখিত কমান্ড ব্যবহার করে আপনার এক্সটেনশন সংস্করণ পরীক্ষা করুন:
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
এক্সটেনশনটি উচ্চতর সংস্করণে আপডেট করতে হলে, এই কমান্ডটি ব্যবহার করুন:
ALTER EXTENSION google_ml_integration UPDATE;
অনুমতি প্রদান করুন
- কোনো ব্যবহারকারীকে স্বয়ংক্রিয় এমবেডিং তৈরি পরিচালনা করার সুযোগ দিতে, google_ml.embed_gen_progress এবং google_ml.embed_gen_settings টেবিলগুলিতে INSERT, UPDATE, এবং DELETE অনুমতি প্রদান করুন:
GRANT INSERT, UPDATE, DELETE ON google_ml.embed_gen_progress TO postgres;
'postgres' হলো সেই ব্যবহারকারীর নাম (USER_NAME) যার জন্য অনুমতিগুলো প্রদান করা হয়েছে।
- 'embedding' ফাংশনটিতে execute অনুমোদন দিতে নিচের স্টেটমেন্টটি চালান:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB পরিষেবা অ্যাকাউন্টে Vertex AI ব্যবহারকারীর ROLE প্রদান করুন।
Google Cloud IAM কনসোল থেকে, AlloyDB সার্ভিস অ্যাকাউন্টকে (যা দেখতে এইরকম: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) "Vertex AI User" রোলের অ্যাক্সেস দিন। PROJECT_NUMBER-এ আপনার প্রজেক্ট নম্বরটি থাকবে।
বিকল্পভাবে আপনি ক্লাউড শেল টার্মিনাল থেকে নিচের কমান্ডটি চালাতে পারেন:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
অপ্রত্যাশিত সমস্যা ও সমাধান
"পাসওয়ার্ড অ্যামনেসিয়া" লুপ | আপনি যদি "ওয়ান ক্লিক" সেটআপ ব্যবহার করে থাকেন এবং আপনার পাসওয়ার্ড মনে না থাকে, তাহলে কনসোলের ইনস্ট্যান্স বেসিক ইনফরমেশন পেজে গিয়ে |
"এক্সটেনশন খুঁজে পাওয়া যায়নি" ত্রুটি | যদি |
৫. ‘এক-শট’ ভেক্টর জেনারেশন
এটাই এই ল্যাবের মূল অংশ। এই ৫০,০০০ সারি প্রসেস করার জন্য পাইথন লুপ লেখার পরিবর্তে, আমরা ai.initialize_embeddings ফাংশনটি ব্যবহার করব।
এই একটিমাত্র কমান্ড দুটি কাজ করে:
- বিদ্যমান সমস্ত সারি পুনরায় পূরণ করে ।
- ভবিষ্যতের সারিগুলো স্বয়ংক্রিয়ভাবে যুক্ত করার জন্য একটি ট্রিগার তৈরি করে ।
AlloyDB কোয়েরি এডিটর থেকে নিচের SQL স্টেটমেন্টটি চালান।
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional'
);
এমবেডিংগুলি যাচাই করুন
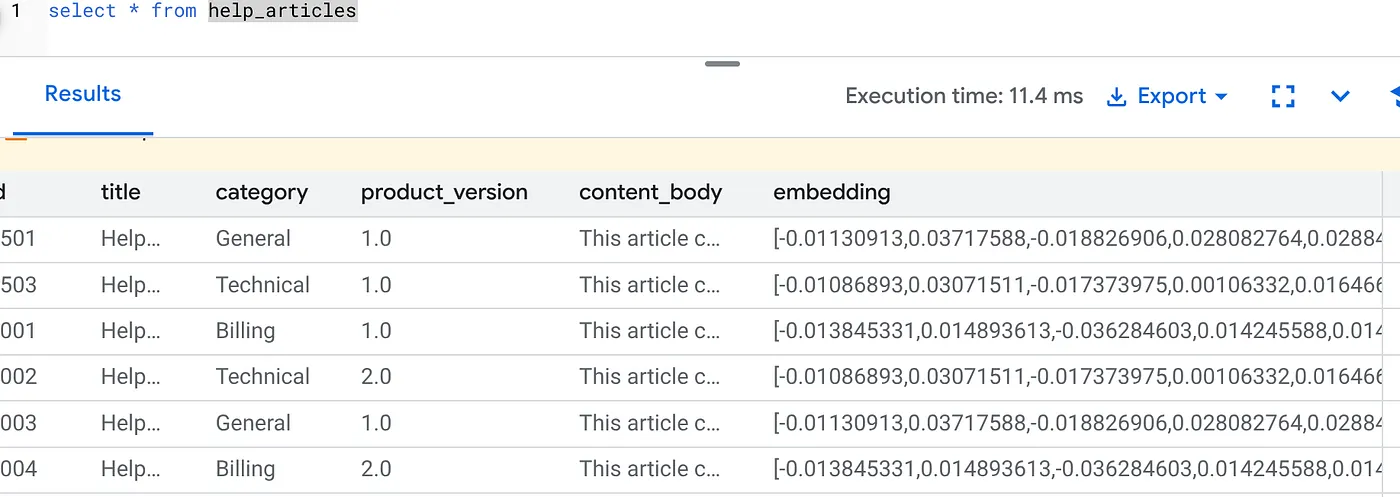
যাচাই করুন যে embedding কলামটি এখন পূরণ করা হয়েছে:
SELECT id, left(content_body, 30), substring(embedding::text, 1, 30) as vector_partial
FROM help_articles;
আপনি নীচের মতো একটি ফলাফল দেখতে পাবেন:
এইমাত্র কী ঘটল?
- বৃহৎ পরিসরে ব্যাকফিল: এটি স্বয়ংক্রিয়ভাবে আপনার বিদ্যমান ৫০,০০০ সারির মধ্য দিয়ে স্ক্যান করে এবং ভার্টেক্স এআই (Vertex AI)-এর মাধ্যমে এমবেডিং তৈরি করে।
- স্বয়ংক্রিয়করণ: incremental_refresh_mode => 'transactional' সেট করার মাধ্যমে, AlloyDB স্বয়ংক্রিয়ভাবে অভ্যন্তরীণ ট্রিগারগুলো সেট আপ করে। help_articles-এ যোগ করা যেকোনো নতুন সারির এমবেডিং তাৎক্ষণিকভাবে তৈরি হয়ে যাবে।
- আপনি চাইলে incremental_refresh_mode => 'None' সেট করতে পারেন, যাতে স্টেটমেন্টটি শুধু বাল্ক আপডেট করতে পারে এবং সমস্ত সারির এমবেডিং আপডেট করার জন্য ম্যানুয়ালি ai.refresh_embeddings() কল করা যায়।
আপনি মাত্র ৬ লাইনের SQL দিয়ে একটি কাফকা কিউ, একটি পাইথন ওয়ার্কার এবং একটি মাইগ্রেশন স্ক্রিপ্ট প্রতিস্থাপন করেছেন। এখানে সমস্ত অ্যাট্রিবিউটের বিস্তারিত অফিসিয়াল ডকুমেন্টেশন দেওয়া হলো।
রিয়েল-টাইম ট্রিগার পরীক্ষা
চলুন যাচাই করে দেখি যে "জিরো লুপ" অটোমেশনটি নতুন ডেটার জন্য কাজ করে কিনা।
- একটি নতুন সারি যোগ করুন:
INSERT INTO help_articles (title, category, product_version, content_body)
VALUES ('New Scaling Guide', 'Technical', '2.0', 'How to scale AlloyDB to millions of transactions.');
- অবিলম্বে যাচাই করুন:
SELECT embedding FROM help_articles WHERE title = 'New Scaling Guide';
ফলাফল:
কোনো বাহ্যিক স্ক্রিপ্ট না চালিয়েই আপনি তাৎক্ষণিকভাবে ভেক্টরটি তৈরি হতে দেখবেন।
টিউনিং ব্যাচ সাইজ
বর্তমানে AlloyDB ডিফল্টভাবে ব্যাচ সাইজ ৫০ সেট করে রাখে। যদিও ডিফল্ট সেটিংসগুলো স্বয়ংক্রিয়ভাবে চমৎকার কাজ করে, তবুও AlloyDB ব্যবহারকারীদের তাদের নিজস্ব মডেল এবং ডেটাসেটের জন্য নিখুঁত কনফিগারেশন তৈরি করার সুযোগ দেয়।
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional',
batch_size => 20
);
তবে ব্যবহারকারীদের কোটার সীমা সম্পর্কে সচেতন থাকতে হবে, যা পারফরম্যান্সকে সীমিত করতে পারে। প্রস্তাবিত AlloyDB কোটা পর্যালোচনা করতে, ডকুমেন্টেশনের "Before you begin" বিভাগটি দেখুন।
অপ্রত্যাশিত সমস্যা ও সমাধান
আইএএম প্রসারণ ব্যবধান | আপনি |
ভেক্টর মাত্রার অমিল | |
৬. প্রসঙ্গ অনুসন্ধানের নমনীয়তা
এখন আমরা একটি হাইব্রিড সার্চ পরিচালনা করব। আমরা শব্দার্থগত বোঝাপড়া (ভেক্টর) এবং ব্যবসায়িক যুক্তি (এসকিউএল ফিল্টার) একত্রিত করব।
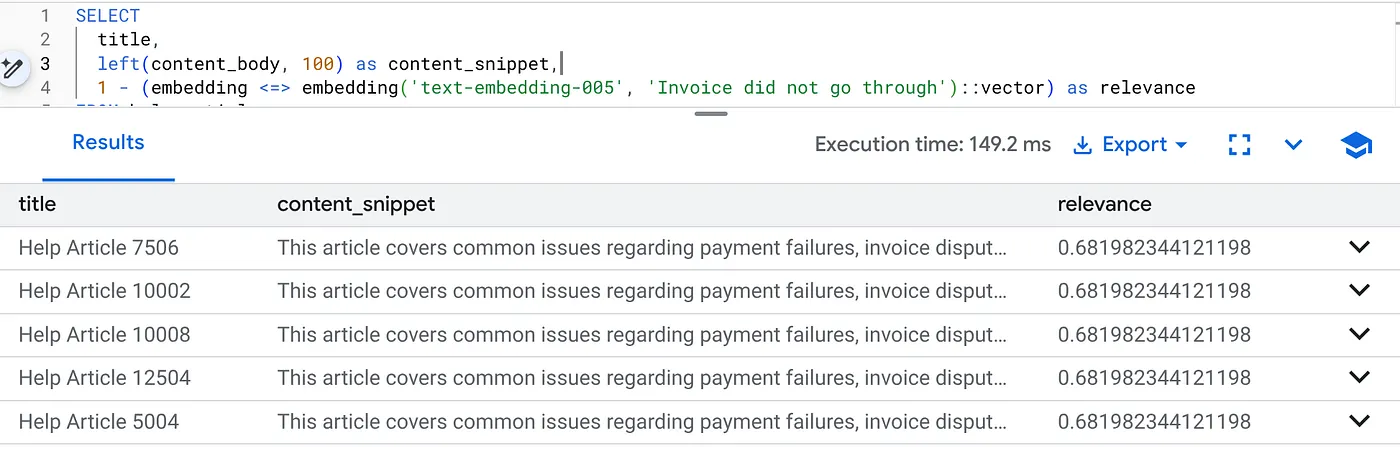
বিশেষভাবে প্রোডাক্ট ভার্সন ২.০-এর বিলিং সংক্রান্ত সমস্যা খুঁজে বের করতে এই কোয়েরিটি চালান:
SELECT
title,
left(content_body, 100) as content_snippet,
1 - (embedding <=> embedding('text-embedding-005', 'Invoice did not go through')::vector) as relevance
FROM help_articles
WHERE category = 'Billing' -- Hard SQL Filter
AND product_version = '2.0' -- Hard SQL Filter
ORDER BY relevance DESC
LIMIT 5;
এটাই ফ্লেক্সিং কনটেক্সট। কঠোর ব্যবসায়িক সীমাবদ্ধতাগুলো মেনে চলার পাশাপাশি, ব্যবহারকারীর অভিপ্রায় ("বিলিং সমস্যা") বোঝার জন্য সার্চটি নমনীয় হয় (ভার্সন ২.০)।
স্টার্টআপ এবং মাইগ্রেশনের জন্য এটি কেন লাভজনক
- অবকাঠামোগত বোঝা শূন্য: আপনি আলাদা কোনো ভেক্টর ডিবি (পাইনকোন/মিলভাস) তৈরি করেননি। আপনি আলাদা কোনো ইটিএল জব লেখেননি। এর সবকিছুই পোস্টগ্রেসে রয়েছে।
- রিয়েল-টাইম আপডেট: 'ট্রানজ্যাকশনাল' মোড ব্যবহার করার ফলে আপনার সার্চ ইনডেক্স কখনও পুরোনো বা অচল হয় না। ডেটা কমিট হওয়ার মুহূর্তেই তা ভেক্টর-রেডি হয়ে যায়।
- পরিধি: AlloyDB গুগলের পরিকাঠামোর উপর নির্মিত। এটি আপনার পাইথন স্ক্রিপ্টের চেয়েও দ্রুত লক্ষ লক্ষ ভেক্টর বিপুল পরিমাণে তৈরি করতে পারে।
অপ্রত্যাশিত সমস্যা ও সমাধান
প্রোডাকশন পারফরম্যান্স গটচা | সমস্যা: ৫০,০০০ সারির জন্য দ্রুত। যদি ক্যাটাগরি ফিল্টার যথেষ্ট সুনির্দিষ্ট না হয়, তবে ১০ লক্ষ সারির জন্য খুব ধীর হয়ে যায়। সমাধান: একটি ভেক্টর ইনডেক্স যোগ করুন: প্রোডাকশন স্কেলের জন্য, আপনাকে অবশ্যই একটি ইনডেক্স তৈরি করতে হবে: CREATE INDEX ON help_articles USING hnsw (vector_cosine_ops এমবেড করে); ইনডেক্স ব্যবহার যাচাই করুন: ডাটাবেস ইনডেক্স ব্যবহার করছে এবং কোনো সিকোয়েনশিয়াল স্ক্যান করছে না তা নিশ্চিত করতে |
"মডেল অমিল" বিপর্যয় | সমস্যা: আপনি CALL প্রসিডিউরে text-embedding-005 ব্যবহার করে কলামটি ইনিশিয়ালাইজ করেছেন। যদি আপনি ভুলবশত SELECT কোয়েরি ফাংশন embedding('model-name', ...)-এ একটি ভিন্ন মডেল (যেমন, text-embedding-004 বা একটি OSS মডেল) ব্যবহার করেন, তাহলে ডাইমেনশনগুলো মিলে যেতে পারে (768), কিন্তু ভেক্টর স্পেস সম্পূর্ণ ভিন্ন হবে। কোয়েরিটি ত্রুটি ছাড়াই চলে, কিন্তু ফলাফল সম্পূর্ণ অপ্রাসঙ্গিক (গার্বেজ রিলেভেন্স স্কোর)। সমস্যা সমাধান: নিশ্চিত করুন যে ai.initialize_embeddings-এর model_id আপনার SELECT কোয়েরির model_id-এর সাথে হুবহু মেলে। |
"নীরব শূন্য" ফলাফল (অতিরিক্ত ফিল্টারিং) | সমস্যা: হাইব্রিড সার্চ একটি "AND" অপারেশন। এর জন্য সিমান্টিক ম্যাচ এবং এসকিউএল ম্যাচ উভয়ই প্রয়োজন। যদি কোনো ব্যবহারকারী "বিলিং হেল্প" লিখে সার্চ করেন, কিন্তু
|
৪. অনুমতি/কোটা সংক্রান্ত ত্রুটি (৫০০ ত্রুটি) | সমস্যা:
|
৫. নাল এমবেডিং | সমস্যা: মডেলটি সম্পূর্ণরূপে ইনিশিয়ালাইজ হওয়ার আগে ডেটা ইনসার্ট করলে অথবা ব্যাকগ্রাউন্ড ওয়ার্কার ব্যর্থ হলে, কিছু সারির
|
৭. পরিষ্কার করুন
এই ল্যাবটি সম্পন্ন হয়ে গেলে, alloyDB ক্লাস্টার এবং ইনস্ট্যান্সটি ডিলিট করতে ভুলবেন না।
এটি ক্লাস্টারটিকে তার ইনস্ট্যান্স(গুলি) সহ পরিষ্কার করে দেবে।
৮. অভিনন্দন
আপনি সফলভাবে একটি স্কেলেবল নলেজ বেস সার্চ অ্যাপ্লিকেশন তৈরি করেছেন। ভেক্টর এমবেডিং তৈরি করার জন্য পাইথন স্ক্রিপ্ট এবং লুপ ব্যবহার করে একটি জটিল ETL পাইপলাইন পরিচালনার পরিবর্তে, আপনি একটিমাত্র SQL কমান্ড ব্যবহার করে ডাটাবেসের মধ্যেই নেটিভভাবে এমবেডিং তৈরির কাজটি করতে AlloyDB AI ব্যবহার করেছেন।
আমরা যা আলোচনা করেছি
- আমরা ডেটা প্রসেসিংয়ের জন্য 'পাইথন ফর-লুপ' ব্যবহার করা বন্ধ করে দিয়েছি।
- আমরা একটি SQL কমান্ডের মাধ্যমে ৫০,০০০ ভেক্টর তৈরি করেছি।
- আমরা ট্রিগারের মাধ্যমে ভবিষ্যৎ ভেক্টর তৈরি প্রক্রিয়াকে স্বয়ংক্রিয় করেছি।
- আমরা হাইব্রিড সার্চ পরিচালনা করেছি।
পরবর্তী পদক্ষেপ
- আপনার নিজের ডেটাসেট দিয়ে এটি চেষ্টা করে দেখুন।
- AlloyDB AI ডকুমেন্টেশন অন্বেষণ করুন।
- আরও কর্মশালার জন্য কোড বিপাসনা ওয়েবসাইটটি দেখুন।