
1. Genel Bakış
Bu codelab'de, ölçeklenebilir bir bilgi bankası arama uygulaması oluşturacaksınız. Vektör yerleştirmeleri oluşturmak için Python komut dosyaları ve döngülerle karmaşık bir ETL ardışık düzenini yönetmek yerine, tek bir SQL komutu kullanarak yerleştirme oluşturmayı veritabanında yerel olarak işlemek için AlloyDB AI'yı kullanacaksınız.
Ne oluşturacaksınız?
Yüksek performanslı, "aranabilir" bir bilgi bankası veritabanı uygulaması.
Neler öğreneceksiniz?
Bu kursta şunları öğreneceksiniz:
- AlloyDB kümesi sağlayın ve yapay zeka uzantılarını etkinleştirin.
- SQL kullanarak sentetik veriler (50.000'den fazla satır) oluşturun.
- Toplu İşleme'yi kullanarak veri kümesinin tamamı için vektör yerleştirmelerini doldurun.
- Yeni verileri otomatik olarak yerleştirmek için anlık artımlı tetikleyiciler ayarlayın.
- "Flexing Context" için Karma Arama (Vektör + SQL Filtreleri) gerçekleştirin.
Şartlar
2. Başlamadan önce
Proje oluşturma
- Google Cloud Console'daki proje seçici sayfasında bir Google Cloud projesi seçin veya oluşturun.
- Cloud projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Bir projede faturalandırmanın etkin olup olmadığını kontrol etmeyiöğrenin.
- Google Cloud'da çalışan bir komut satırı ortamı olan Cloud Shell'i kullanacaksınız. Google Cloud Console'un üst kısmında Cloud Shell'i etkinleştir'i tıklayın.

- Cloud Shell'e bağlandıktan sonra aşağıdaki komutu kullanarak kimliğinizin doğrulandığını ve projenin proje kimliğinize ayarlandığını kontrol edin:
gcloud auth list
- gcloud komutunun projeniz hakkında bilgi sahibi olduğunu onaylamak için Cloud Shell'de aşağıdaki komutu çalıştırın.
gcloud config list project
- Projeniz ayarlanmamışsa ayarlamak için aşağıdaki komutu kullanın:
gcloud config set project <YOUR_PROJECT_ID>
- Gerekli API'leri etkinleştirin: Bağlantıyı takip ederek API'leri etkinleştirin.
Alternatif olarak, bu işlem için gcloud komutunu kullanabilirsiniz. gcloud komutları ve kullanımı için belgelere bakın.
gcloud services enable \
alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Dikkat Edilmesi Gerekenler ve Sorun Giderme
"Hayalet Proje" Sendromu |
|
Faturalandırma Barikatı | Projeyi etkinleştirdiniz ancak faturalandırma hesabını unuttunuz. AlloyDB yüksek performanslı bir motordur. "Benzin deposu" (faturalandırma) boşsa çalışmaz. |
API Yayılımı Gecikmesi | "API'leri etkinleştir"i tıkladınız ancak komut satırında hâlâ |
Kota Quags | Yeni bir deneme hesabı kullanıyorsanız AlloyDB örnekleri için bölgesel kotaya ulaşabilirsiniz. |
"Gizli" Hizmet Aracısı | Bazen AlloyDB hizmet aracısına |
3. Veritabanı kurulumu
Bu laboratuvarda, test verileri için veritabanı olarak AlloyDB'yi kullanacağız. Veritabanları ve günlükler gibi tüm kaynakları tutmak için kümeler kullanılır. Her kümede, verilere erişim noktası sağlayan bir birincil örnek bulunur. Tablolar gerçek verileri içerir.
Test veri kümesinin yükleneceği bir AlloyDB kümesi, örneği ve tablosu oluşturalım.
- Google Cloud Console kullanıcısının oturumunun açık olduğu tarayıcınızda aşağıdaki bağlantıyı kopyalayın veya düğmeyi tıklayın.
- Bu adım tamamlandıktan sonra depo, yerel Cloud Shell düzenleyicinize klonlanır ve aşağıdaki komutu proje klasöründen çalıştırabilirsiniz (proje dizininde olduğunuzdan emin olmanız önemlidir):
sh run.sh
- Şimdi kullanıcı arayüzünü kullanın (terminaldeki bağlantıyı veya terminaldeki "web'de önizleme" bağlantısını tıklayarak).
- Başlamak için proje kimliği, küme ve örnek adlarıyla ilgili ayrıntılarınızı girin.
- Günlükler kayarken kahve almaya gidebilirsiniz. Bu işlemin perde arkasında nasıl yapıldığı hakkında bilgi edinmek için burayı ziyaret edebilirsiniz. Bu işlem yaklaşık 10-15 dakika sürebilir.
Dikkat Edilmesi Gerekenler ve Sorun Giderme
"Sabır" Sorunu | Veritabanı kümeleri ağır altyapılardır. Sayfayı yenilerseniz veya "takılmış gibi göründüğü" için Cloud Shell oturumunu sonlandırırsanız kısmen sağlanan ve manuel müdahale olmadan silinmesi mümkün olmayan bir "hayalet" örneğiyle karşılaşabilirsiniz. |
Bölge Uyuşmazlığı | API'lerinizi |
Zombi Kümeleri | Daha önce bir küme için aynı adı kullandıysanız ve bu adı silmediyseniz komut dosyası, küme adının zaten mevcut olduğunu söyleyebilir. Küme adları, proje içinde benzersiz olmalıdır. |
Cloud Shell Zaman Aşımı | Kahve molanız 30 dakika sürerse Cloud Shell uyku moduna geçebilir ve |
4. Şema Sağlama
Bu adımda şu konuları ele alacağız:
AlloyDB kümeniz ve örneğiniz çalıştıktan sonra, yapay zeka uzantılarını etkinleştirmek ve şemayı sağlamak için AlloyDB Studio SQL düzenleyicisine gidin.
Örneğinizin oluşturulmasının tamamlanmasını beklemeniz gerekebilir. Bu işlem tamamlandıktan sonra, kümeyi oluştururken oluşturduğunuz kimlik bilgilerini kullanarak AlloyDB'de oturum açın. PostgreSQL'de kimlik doğrulaması yapmak için aşağıdaki verileri kullanın:
- Kullanıcı adı : "
postgres" - Veritabanı : "
postgres" - Şifre : "
alloydb" (veya oluşturma sırasında ayarladığınız şifre)
AlloyDB Studio'da kimliğinizi başarıyla doğruladıktan sonra SQL komutları Düzenleyici'ye girilir. Son pencerenin sağındaki artı işaretini kullanarak birden fazla düzenleyici penceresi ekleyebilirsiniz.
AlloyDB ile ilgili komutları, gerektiğinde Çalıştır, Biçimlendir ve Temizle seçeneklerini kullanarak düzenleyici pencerelerine gireceksiniz.
Uzantıları etkinleştirme
Bu uygulamayı oluşturmak için pgvector ve google_ml_integration uzantılarını kullanacağız. pgvector uzantısı, vektör yerleştirmelerini depolamanıza ve aramanıza olanak tanır. google_ml_integration uzantısı, SQL'de tahmin almak için Vertex AI tahmin uç noktalarına erişmek üzere kullandığınız işlevleri sağlar. Aşağıdaki DDL'leri çalıştırarak bu uzantıları etkinleştirin:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Tablo oluşturma
Ölçeği göstermek için bir veri kümesine ihtiyacımız var. CSV dosyasını içe aktarmak yerine SQL kullanarak anında 50.000 satırlık yapay "Yardım Makalesi" oluşturacağız.
AlloyDB Studio'da aşağıdaki DDL ifadesini kullanarak tablo oluşturabilirsiniz:
-- 1. Create the table
CREATE TABLE help_articles (
id SERIAL PRIMARY KEY,
title TEXT,
category TEXT,
product_version TEXT,
content_body TEXT,
embedding vector(768) -- Dimension for text-embedding-005
);
-- 2. Generate 50,000 rows of synthetic data
INSERT INTO help_articles (title, category, product_version, content_body)
SELECT
'Help Article ' || i,
CASE
WHEN i % 3 = 0 THEN 'Billing'
WHEN i % 3 = 1 THEN 'Technical'
ELSE 'General'
END,
CASE
WHEN i % 2 = 0 THEN '2.0'
ELSE '1.0'
END,
'This article covers common issues regarding ' ||
CASE
WHEN i % 3 = 0 THEN 'payment failures, invoice disputes, and credit card updates.'
WHEN i % 3 = 1 THEN 'connection timeouts, latency issues, and API errors.'
ELSE 'account profile settings, password resets, and user roles.'
END
FROM generate_series(1, 50000) AS i;
item_vector sütunu, metnin vektör değerlerinin depolanmasına olanak tanır.
Verileri doğrulayın:
SELECT count(*) FROM help_articles;
-- Output: 50000
Veritabanı İşaretlerini Etkinleştirme
Örnek yapılandırma konsoluna gidin, "Birincili Düzenle"yi tıklayın, Gelişmiş Yapılandırma'ya gidin ve "Veritabanı İşaretleri Ekle"yi tıklayın.
Aksi takdirde, flags açılır listesine girin, "ON" olarak ayarlayın ve örneği güncelleyin.
Aksi takdirde, flags açılır listesine girin, "ON" olarak ayarlayın ve örneği güncelleyin.
Veritabanı işaretlerini yapılandırma adımları:
- Google Cloud Console'da Kümeler sayfasına gidin.
- Kaynak Adı sütununda bir kümeyi tıklayın.
- Genel bakış sayfasında, kümenizdeki Örnekler'e gidin, bir örnek seçin ve Düzenle'yi tıklayın.
- Örneğinizden bir veritabanı işareti ekleme, değiştirme veya silme:
İşaret ekleme
- Örneğinize bir veritabanı işareti eklemek için İşaret ekle'yi tıklayın.
- Yeni veritabanı işareti listesinden bir işaret seçin.
- Bayrak için bir değer girin.
- Bitti'yi tıklayın.
- Örneği güncelle'yi tıklayın.
- google_ml_integration uzantısının 1.5.2 veya üzeri bir sürüm olduğunu doğrulayın:
Aşağıdaki komutla uzantı sürümünüzü kontrol edin:
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Uzantıyı daha yüksek bir sürüme güncellemeniz gerekiyorsa şu komutu kullanın:
ALTER EXTENSION google_ml_integration UPDATE;
İzin Ver
- Bir kullanıcının otomatik yerleştirme oluşturmayı yönetmesine izin vermek için google_ml.embed_gen_progress ve google_ml.embed_gen_settings tablolarında INSERT, UPDATE ve DELETE izinleri verin:
GRANT INSERT, UPDATE, DELETE ON google_ml.embed_gen_progress TO postgres;
"postgres", izinlerin verildiği USER_NAME'dir.
- "embedding" işlevinde yürütme izni vermek için aşağıdaki ifadeyi çalıştırın:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB hizmet hesabına Vertex AI Kullanıcısı ROLÜ'nü verme
Google Cloud IAM Console'dan AlloyDB hizmet hesabına (service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com şeklinde görünür) "Vertex AI Kullanıcısı" rolüne erişim izni verin. PROJECT_NUMBER, proje numaranızı içerir.
Alternatif olarak, aşağıdaki komutu Cloud Shell terminalinden çalıştırabilirsiniz:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Dikkat Edilmesi Gerekenler ve Sorun Giderme
"Parola Unutma" Döngüsü | "Tek Tıklama" kurulumunu kullandıysanız ve şifrenizi hatırlamıyorsanız konsoldaki örnek temel bilgileri sayfasına gidip "Düzenle"yi tıklayarak |
"Uzantı Bulunamadı" Hatası |
|
5. "Tek Atış" Vektör Oluşturma
Bu, laboratuvarın temelini oluşturur. Bu 50.000 satırı işlemek için Python döngüsü yazmak yerine ai.initialize_embeddings işlevini kullanacağız.
Bu tek komut iki işlem yapar:
- Mevcut tüm satırları doldurur.
- Gelecekteki satırları otomatik olarak yerleştirmek için Tetikleyici oluşturur.
AlloyDB sorgu düzenleyicisinden aşağıdaki SQL ifadesini çalıştırın.
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional'
);
Yerleştirilmiş öğeleri doğrulama
embedding sütununun artık doldurulduğunu kontrol edin:
SELECT id, left(content_body, 30), substring(embedding::text, 1, 30) as vector_partial
FROM help_articles;
Aşağıdakine benzer bir sonuç görmeniz gerekir:
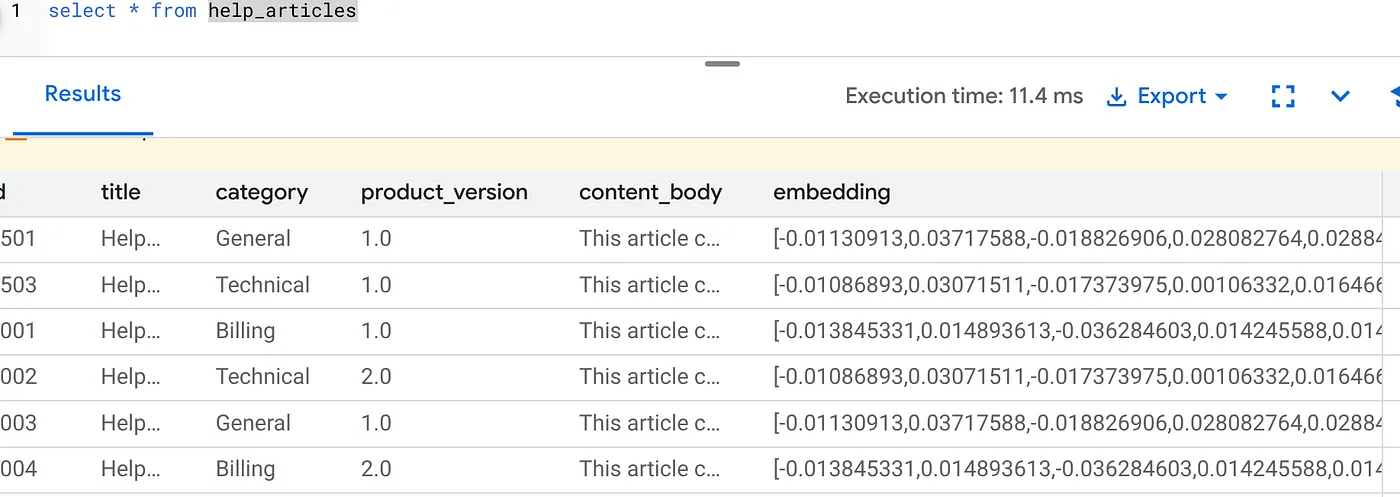
Ne oldu?
- Geniş Ölçekte Geri Doldurma: Mevcut 50.000 satırınızı otomatik olarak tarar ve Vertex AI aracılığıyla yerleştirmeler oluşturur.
- Otomasyon: incremental_refresh_mode => 'transactional' ayarını yaptığınızda AlloyDB, dahili tetikleyicileri otomatik olarak ayarlar. help_articles tablosuna eklenen her yeni satırın yerleştirme işlemi anında oluşturulur.
- İsterseniz incremental_refresh_mode => "None" değerini ayarlayabilirsiniz. Böylece, yalnızca toplu güncellemeler yapmak için ifadeyi alabilir ve tüm satır yerleştirmelerini güncellemek için ai.refresh_embeddings() işlevini manuel olarak çağırabilirsiniz.
Bir Kafka kuyruğunu, bir Python işçisini ve bir taşıma komut dosyasını 6 satırlık SQL ile değiştirdiniz. Tüm özelliklerle ilgili ayrıntılı resmi dokümanları burada bulabilirsiniz.
Anlık Tetikleyici Testi
"Sıfır Döngü" otomasyonunun yeni veriler için çalıştığını doğrulayalım.
- Yeni satır ekleme:
INSERT INTO help_articles (title, category, product_version, content_body)
VALUES ('New Scaling Guide', 'Technical', '2.0', 'How to scale AlloyDB to millions of transactions.');
- Hemen kontrol edin:
SELECT embedding FROM help_articles WHERE title = 'New Scaling Guide';
Sonuç:
Herhangi bir harici komut dosyası çalıştırmadan vektörün anında oluşturulduğunu görmelisiniz.
Ayarlama grubu boyutu
AlloyDB, varsayılan olarak grup boyutunu 50 olarak ayarlar. Varsayılan ayarlar kutudan çıktığı gibi mükemmel çalışsa da AlloyDB, kullanıcılara benzersiz modeliniz ve veri kümeniz için mükemmel yapılandırmayı ayarlama kontrolü verir.
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'help_articles',
content_column => 'content_body',
embedding_column => 'embedding',
incremental_refresh_mode => 'transactional',
batch_size => 20
);
Ancak kullanıcıların, performansı sınırlayabilecek kota sınırlarının farkında olması gerekir. Önerilen AlloyDB kotalarını incelemek için dokümanlardaki "Başlamadan önce" bölümüne bakın.
Dikkat Edilmesi Gerekenler ve Sorun Giderme
IAM Yayılma Boşluğu |
|
Vektör Boyutu Uyuşmazlığı |
|
6. Flexing Context Search
Şimdi karma arama yapıyoruz. Semantik anlayışı (Vektör) işletme mantığıyla (SQL filtreleri) birleştiririz.
Özellikle 2.0 ürün sürümüyle ilgili faturalandırma sorunlarını bulmak için bu sorguyu çalıştırın:
SELECT
title,
left(content_body, 100) as content_snippet,
1 - (embedding <=> embedding('text-embedding-005', 'Invoice did not go through')::vector) as relevance
FROM help_articles
WHERE category = 'Billing' -- Hard SQL Filter
AND product_version = '2.0' -- Hard SQL Filter
ORDER BY relevance DESC
LIMIT 5;
Bu, Flexing Context'tir. Arama, katı iş kısıtlamalarına (2.0 sürümü) uymaya devam ederken kullanıcının amacını ("fatura sorunları") anlamak için "esner".
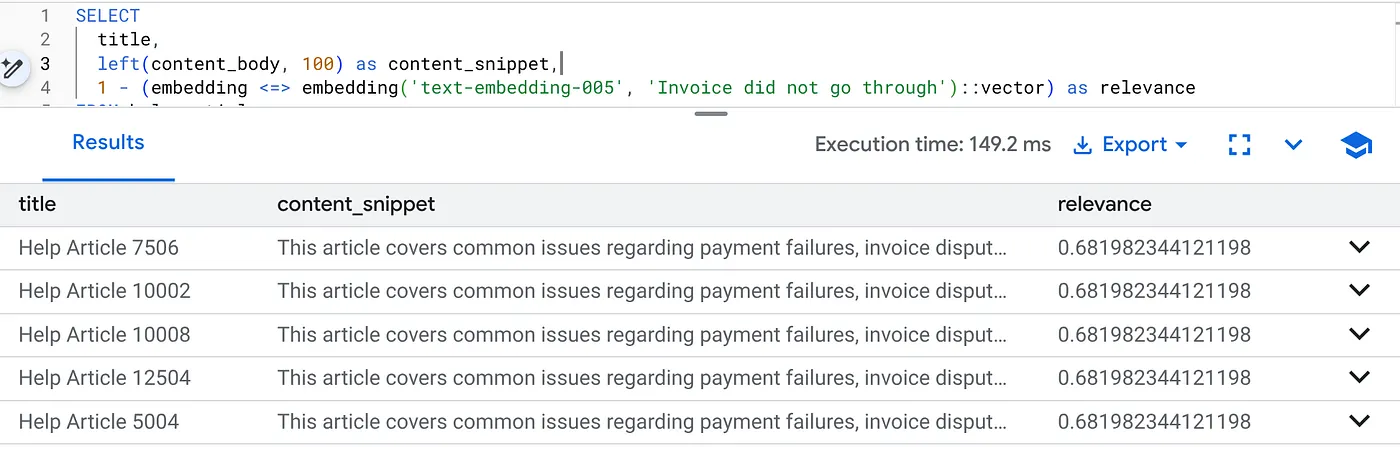
Bu özellik neden yeni başlayanlar ve taşıma işlemleri için avantajlıdır?
- Altyapı borcu yok: Ayrı bir vektör veritabanı (Pinecone/Milvus) oluşturmadınız. Ayrı bir ETL işi yazmadınız. Her şey Postgres'te.
- Anlık Güncellemeler: "İşlemsel" modu kullandığınızda arama dizininiz hiçbir zaman güncelliğini yitirmez. Veriler kaydedildiği anda vektör aramasına hazır olur.
- Ölçek: AlloyDB, Google'ın altyapısı üzerinde oluşturulmuştur. Milyonlarca vektörün toplu olarak oluşturulmasını Python komut dosyanızın yapabileceğinden daha hızlı bir şekilde işleyebilir.
Dikkat Edilmesi Gerekenler ve Sorun Giderme
Üretim Performansıyla İlgili Sorun | Sorun: 50.000 satır için hızlı. Kategori filtresi yeterince seçici değilse 1 milyon satır için çok yavaş.Çözüm:Vektör dizini ekleyin: Üretim ölçeğinde bir dizin oluşturmanız gerekir:CREATE INDEX ON help_articles USING hnsw (embedding vector_cosine_ops); Dizin kullanımını doğrulayın: Veritabanının dizini kullandığından ve sıralı tarama yapmadığından emin olmak için |
"Model Uyuşmazlığı" Felaketi | Sorun: Sütunu CALL prosedüründe text-embedding-005 kullanarak başlattınız. SELECT sorgu işlevinde embedding('model-name', ...) yanlışlıkla farklı bir model (ör. text-embedding-004 veya bir OSS modeli) kullanırsanız boyutlar eşleşebilir (768), ancak vektör alanı tamamen farklı olur. Sorgu hatasız çalışır ancak sonuçlar tamamen alakasızdır (alakasızlık puanları). Sorun giderme:ai.initialize_embeddings içindeki model_id'nin SELECT sorgunuzdaki model_id ile tam olarak eşleştiğinden emin olun. |
"Sessiz Boş" Sonuç (Aşırı Filtreleme) | Sorun: Karma arama bir "VE" işlemidir. Anlamsal Eşleşme VE SQL Eşleşmesi gerekir.Kullanıcı "Fatura yardımı" araması yaptığında
|
4. İzin/Kota Hataları (500 Hatası) | Sorun:
|
5. Boş yerleştirmeler | Sorun:Model tamamen başlatılmadan önce veri eklerseniz veya arka plan çalışanı başarısız olursa bazı satırların
|
7. Temizleme
Bu laboratuvar tamamlandıktan sonra AlloyDB kümesini ve örneğini silmeyi unutmayın.
Küme, örnekleriyle birlikte temizlenmelidir.
8. Tebrikler
Ölçeklenebilir bir bilgi bankası arama uygulamasını başarıyla oluşturdunuz. Vektör yerleştirmeleri oluşturmak için Python komut dosyaları ve döngülerle karmaşık bir ETL ardışık düzeni yönetmek yerine, tek bir SQL komutu kullanarak yerleştirme oluşturmayı veritabanında yerel olarak işlemek için AlloyDB AI'yı kullandınız.
İşlediğimiz konular
- Veri işleme için "Python For-Loop"u devre dışı bıraktık.
- Tek bir SQL komutuyla 50.000 vektör oluşturduk.
- Gelecekteki vektör oluşturma işlemlerini tetikleyicilerle otomatikleştiriyoruz.
- Karma arama yaptık.
Sonraki Adımlar
- Bunu kendi veri kümenizle deneyin.
- AlloyDB AI belgelerini inceleyin.
- Daha fazla atölye için Code Vipassana web sitesine göz atın.