
1. はじめに
Google Antigravity は、エージェントの時代に開発を支援するために設計されたエージェント型開発プラットフォームです。Antigravity は AI エージェントの中央コマンド センターとして機能し、アクティビティの起動、モニタリング、オーケストレーションを行う統合プラットフォームを提供します。
この Codelab では、まず Agent Skills について学びます。Agent Skills は、専門知識とワークフローを使用して AI エージェントの機能を拡張するための軽量でオープンな形式です。エージェント スキルとは何か、そのメリット、構築方法について学習します。次に、Git フォーマッタ、テンプレート ジェネレータ、ツールコード スキャフォールディングなど、Antigravity 内で使用できる複数のエージェント スキルを構築します。
前提条件:
- Antigravity がインストールされ、構成されている。
- Google Antigravity の基本的な知識。Codelab: Google Antigravity を使ってみるを完了することをおすすめします。
2. スキルが必要な理由
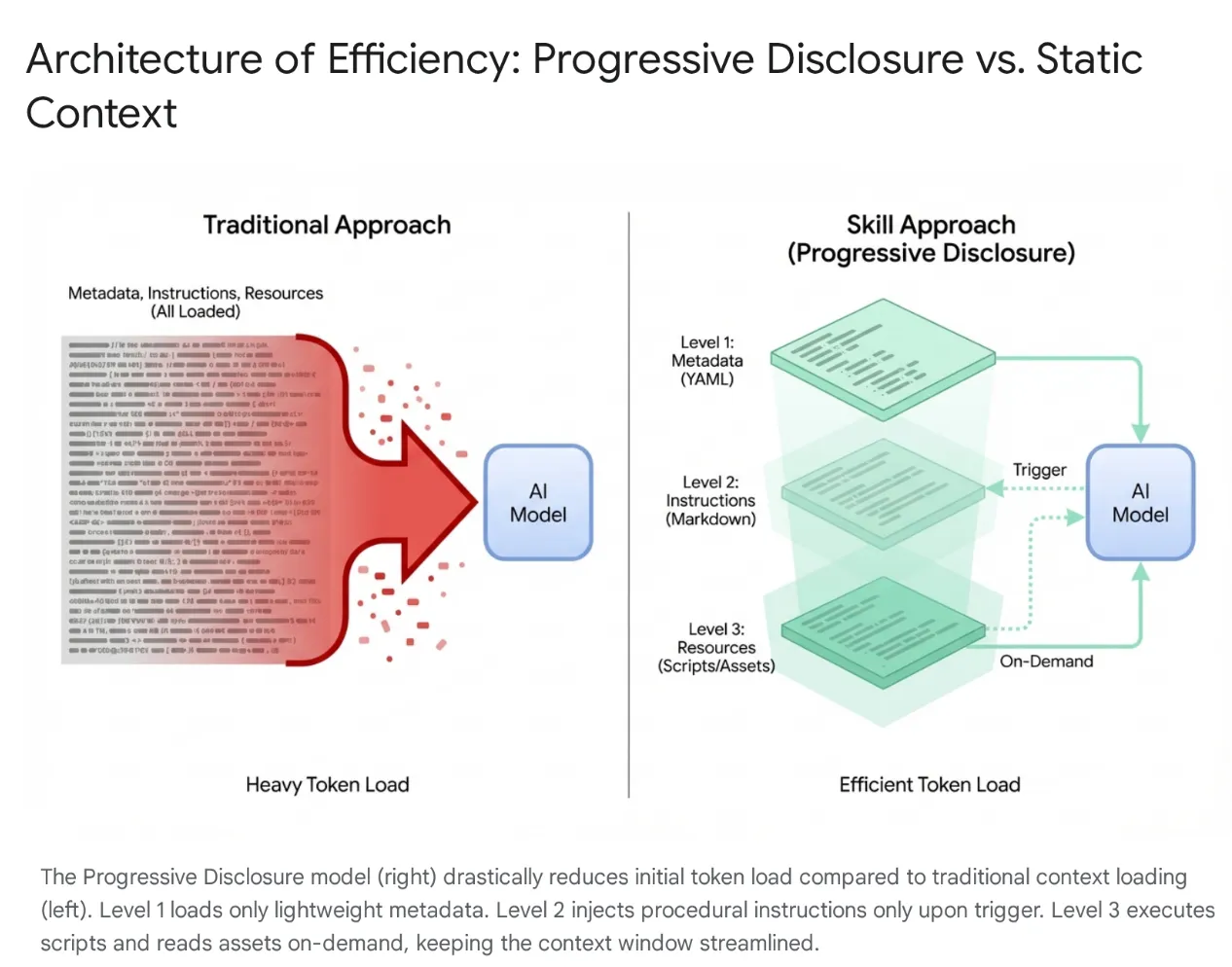
最新の AI エージェントは、単純なリスナーから、ローカル ファイル システムや外部ツール(MCP サーバー経由)と統合する複雑な推論エンジンへと進化しました。ただし、エージェントにコードベース全体と数百ものツールを無差別に読み込むと、コンテキストの飽和と「ツールの肥大化」が発生します。コンテキスト ウィンドウが大きい場合でも、未使用のツールの 4 ~ 5 万個のトークンをアクティブ メモリにダンプすると、レイテンシの増加、費用の無駄遣い、コンテキストの劣化(モデルが関連性のないデータによって混乱する状態)が発生します。
解決策: エージェントのスキル
この問題を解決するために、Anthropic は エージェント スキルを導入し、アーキテクチャをモノリシックなコンテキスト読み込みからプログレッシブ開示に移行しました。セッションの開始時に、モデルに特定のワークフロー(データベースの移行やセキュリティ監査など)をすべて「記憶」させるのではなく、これらの機能はモジュール式の検出可能なユニットにパッケージ化されています。
仕組み
モデルは、最初はメタデータの軽量な「メニュー」にのみ公開されます。ユーザーのインテントがスキルと明確に一致した場合にのみ、重い手続き型知識(指示とスクリプト)を読み込みます。これにより、認証ミドルウェアのリファクタリングをリクエストしたデベロッパーは、関連のない CSS パイプラインを読み込むことなくセキュリティ コンテキストを取得し、コンテキストを簡潔、高速、費用対効果の高い状態に保つことができます。
3. エージェントのスキルと Antigravity
Antigravity エコシステムでは、スキルは、汎用モデルと特定のコンテキストのギャップを埋める特殊なトレーニング モジュールとして機能します。これにより、エージェントは、関連するタスクがリクエストされた場合にのみ、定義された一連の手順とプロトコル(データベース移行標準やセキュリティ チェックなど)を「装備」できます。これらの実行プロトコルを動的に読み込むことで、スキルは AI を汎用プログラマーから、組織の成文化されたベスト プラクティスと安全基準を厳守するスペシャリストに効果的に変えます。
Antigravity のスキルとは
Google Antigravity のコンテキストでは、スキルは定義ファイル(SKILL.md)とオプションのサポート アセット(スクリプト、リファレンス、テンプレート)を含むディレクトリ ベースのパッケージです。
これは、オンデマンド機能拡張のメカニズムです。
- オンデマンド: システム プロンプト(常に読み込まれる)とは異なり、スキルは、エージェントがユーザーの現在のリクエストに関連すると判断した場合にのみ、エージェントのコンテキストに読み込まれます。これにより、コンテキスト ウィンドウが最適化され、エージェントが無関係な指示に気を取られるのを防ぐことができます。数十個のツールを使用する大規模なプロジェクトでは、この選択的読み込みがパフォーマンスと推論の精度に不可欠です。
- Capability Extension: スキルは指示するだけでなく、実行することもできます。Python スクリプトや Bash スクリプトをバンドルすることで、スキルはエージェントにローカルマシンや外部ネットワークで複雑な複数ステップのアクションを実行する機能を提供できます。ユーザーが手動でコマンドを実行する必要はありません。これにより、エージェントはテキスト生成ツールからツールユーザーに変わります。
スキルとエコシステム(ツール、ルール、ワークフロー)
Model Context Protocol(MCP)は、エージェントの「手」として機能し、GitHub や PostgreSQL などの外部システムへのヘビーデューティで永続的な接続を提供しますが、スキルはそれらを指示する「脳」として機能します。
MCP はステートフル インフラストラクチャを処理しますが、スキルはこれらのツールを使用するための方法論をパッケージ化した軽量で一時的なタスク定義です。このサーバーレス アプローチにより、エージェントは永続的なプロセスを実行する運用上のオーバーヘッドなしで、アドホック タスク(変更ログや移行の生成など)を実行できます。タスクがアクティブな場合にのみコンテキストを読み込み、タスクの完了直後にコンテキストを解放します。
スキルはエージェントによってトリガーされます。モデルはユーザーの意図を自動的に検出し、必要な特定の専門知識を動的に提供します。このアーキテクチャにより、強力なコンポーザビリティが可能になります。たとえば、グローバル ルールでデータベースの変更時に「Safe-Migration」スキルを使用するように強制したり、単一のワークフローで複数のスキルをオーケストレートして堅牢なデプロイ パイプラインを構築したりできます。
4. スキルを作成する
Antigravity でスキルを作成するには、特定のディレクトリ構造とファイル形式に従う必要があります。この標準化により、スキルがポータブルになり、エージェントがスキルを確実に解析して実行できるようになります。この設計は意図的にシンプルになっており、マークダウンや YAML などの広く理解されている形式に依存しているため、IDE の機能を拡張したいデベロッパーにとっての参入障壁が低くなっています。
ディレクトリ構造
一般的な Skill ディレクトリは次のようになります。
my-skill/
├── SKILL.md # The definition file
├── scripts/ # [Optional] Python, Bash, or Node scripts
├── run.py
└── util.sh
├── references/ # [Optional] Documentation or templates
└── api-docs.md
└── assets/ # [Optional] Static assets (images, logos)
この構造により、関心を効果的に分離できます。ロジック(scripts)は、命令(SKILL.md)と知識(references)から分離されており、標準的なソフトウェア エンジニアリング プラクティスを反映しています。
SKILL.md 定義ファイル
SKILL.md ファイルはスキルの頭脳です。スキルが何であるか、いつ使用するか、どのように実行するかをエージェントに伝えます。
次の 2 つの部分で構成されます。
- YAML フロントマター
- マークダウンの本文。
YAML フロントマター
これがメタデータ レイヤです。エージェントのハイレベル ルーターによってインデックス登録されるのは、スキルの一部のみです。ユーザーがプロンプトを送信すると、エージェントは利用可能なすべてのスキルの説明フィールドに対してプロンプトのセマンティック マッチングを行います。
---
name: database-inspector
description: Use this skill when the user asks to query the database, check table schemas, or inspect user data in the local PostgreSQL instance.
---
主なフィールド:
- name: 必須ではありません。スコープ内で一意である必要があります。小文字、ハイフン可(例:
postgres-query、pr-reviewer)。指定しない場合、デフォルトでディレクトリ名になります。 - description: 必須の最も重要なフィールドです。これは「トリガー フレーズ」として機能します。LLM がセマンティックな関連性を認識できる程度に説明的である必要があります。「データベース ツール」のような曖昧な説明では不十分です。「ローカル PostgreSQL データベースに対して読み取り専用の SQL クエリを実行して、ユーザーまたはトランザクション データを取得します。「Use this for debugging data states」を使用すると、スキルが正しく取得されます。
マークダウン本文
本文には手順が記載されています。これは、ファイルに保存された「プロンプト エンジニアリング」です。スキルが有効になると、このコンテンツがエージェントのコンテキスト ウィンドウに挿入されます。
本文には次の内容を含める必要があります。
- 目標: スキルで達成できることを明確に説明します。
- 手順: ステップごとのロジック。
- 例: モデルのパフォーマンスをガイドする入出力の少数ショットの例。
- 制約: 「しない」ルール(「DELETE クエリを実行しない」など)。
SKILL.md の本文の例:
Database Inspector
Goal
To safely query the local database and provide insights on the current data state.
Instructions
- Analyze the user's natural language request to understand the data need.
- Formulate a valid SQL query.
- CRITICAL: Only SELECT statements are allowed.
- Use the script scripts/query_runner.py to execute the SQL.
- Command: python scripts/query_runner.py "SELECT * FROM..."
- Present the results in a Markdown table.
Constraints
- Never output raw user passwords or API keys.
- If the query returns > 50 rows, summarize the data instead of listing it all.
スクリプトの統合
スキルの最も強力な機能の一つは、スクリプトへの実行の委任です。これにより、エージェントは LLM が直接行うことが難しい、または不可能なアクション(バイナリ実行、複雑な数学的計算、レガシー システムとのやり取りなど)を実行できます。
スクリプトは scripts/ サブディレクトリに配置されます。SKILL.md は相対パスでそれらを参照します。
5. 作成スキル
このセクションの目標は、Antigravity に統合されるスキルを構築し、リソースやスクリプトなどのさまざまな機能を段階的に表示することです。
スキルは、こちらの Github リポジトリ(https://github.com/rominirani/antigravity-skills)からダウンロードできます。
これらの各スキルがどのように構築されたかを理解する前に、それらを構成して Antigravity 製品スイート内で利用できるようにする方法を見てみましょう。以下のフォルダは、このラボの公開時点で適用されます。
Antigravity または Antigravity CLI を使用する
スキルは 2 つのスコープで定義できるため、プロジェクト固有のスキルとユーザー固有のスキル(グローバル スキル)の両方を定義できます。
- グローバル スコープ(
~/.gemini/config/skills/): すべての Antigravity プロダクト(Antigravity、Antigravity IDE、Antigravity CLI)とプロジェクトで使用できます。これらのスキルは、ユーザーのマシンのすべてのプロジェクトで使用できます。これは、「JSON のフォーマット」、「UUID の生成」、「コードスタイルのレビュー」などの一般的なユーティリティや、個人の生産性向上ツールとの統合に適しています。 - プロジェクト/ワークスペースのスコープ(
<project-root>/.agents/skills/): この設定にすると、スキルは特定のプロジェクト内でのみ利用可能になります。これは、特定の環境へのデプロイ、アプリのデータベース管理、独自のフレームワークのボイラープレート コードの生成など、プロジェクト固有のスクリプトに最適です。
Antigravity または Antigravity CLI でスキルをインストールする
このチュートリアルでは、次の手順を行うだけで済みます(独自の方法で行うこともできます)。
ステップ 1: https://github.com/rominirani/antigravity-skills の git clone を実行します。
ステップ 2: Antigravity または Antigravity CLI のどちらを使用しているかに応じて、antigravity-skills/skills_tutorial フォルダに移動します。
ステップ 3: スキルがそれぞれのフォルダにまとめられています。次の 4 つのフォルダをコピーします。
git-commit-formatterlicense-header-adderdatabase-schema-validatorjson-to-pydantic
(プロジェクト スコープまたはグローバル スコープ)の対象プロダクトのスキル フォルダに移動します。
ステップ 4: Antigravity または Antigravity CLI を使用している場合は、<project-root>/.agents/skills/(プロジェクト スコープ)にコピーします。
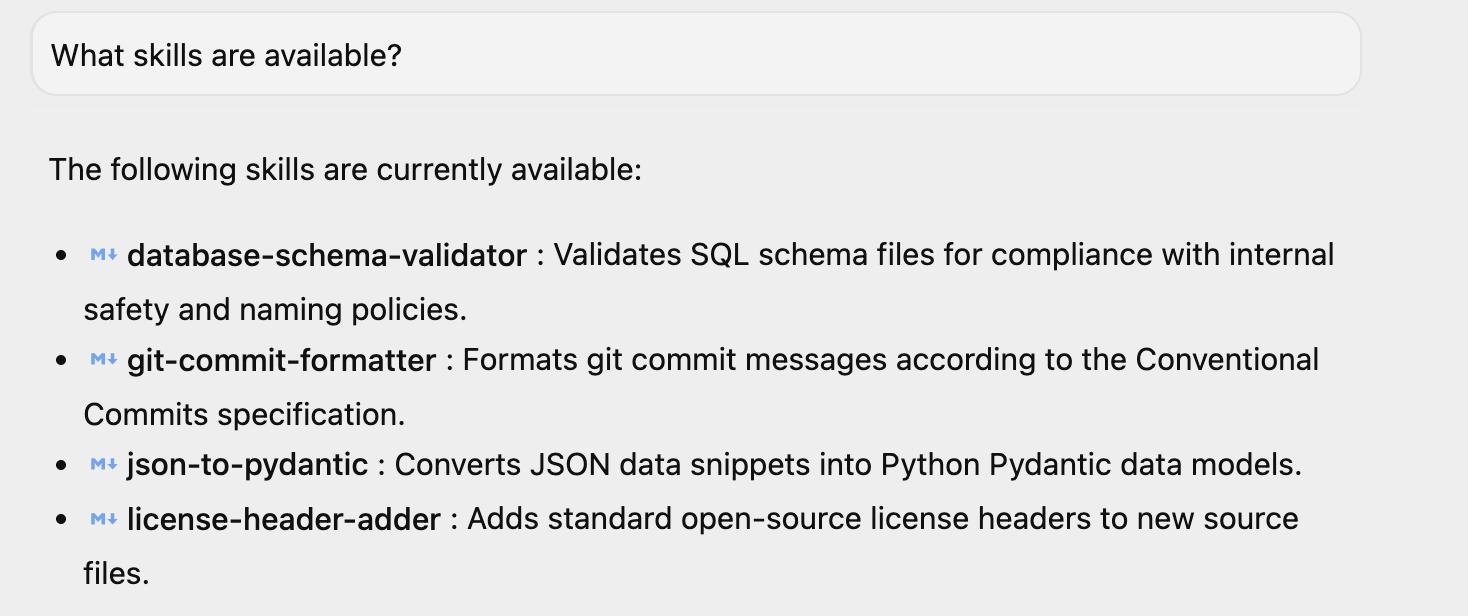
Antigravity を起動している場合は、「利用可能なスキルは何ですか?」という簡単な質問をすると、同じように回答が返ってきます。ここに 4 つのスキルが記載されています。環境にインストールしたスキルが他にもある可能性があります。
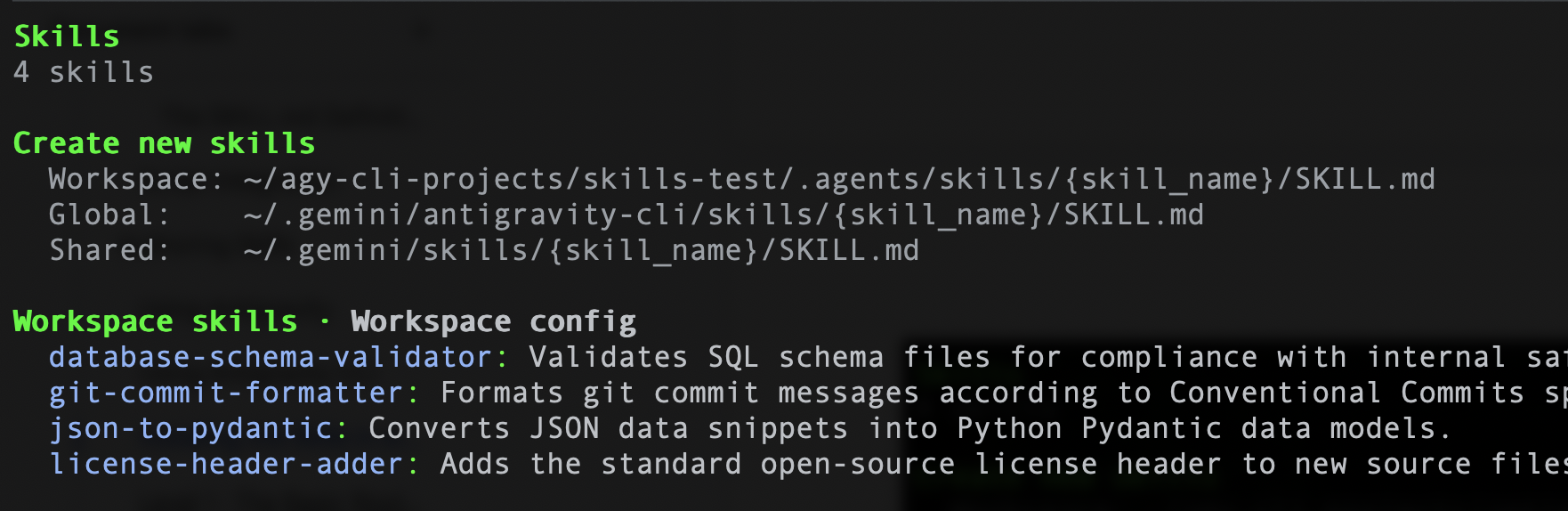
同様に、Antigravity CLI を使用している場合は、次のコマンド /skills を実行すると、4 つのスキルが一覧表示されます。サンプルを以下に示します。
スキルを設定する方法がわかったところで、各スキルについて、どのように構築されたのかを見ていきましょう。これらのテンプレートを使用して、独自のスキルを作成することもできます。
レベル 1 : 基本的なルーター(git-commit-formatter)
これをスキルの「Hello World」としましょう。
デベロッパーは「wip」、「fix bug」、「updates」などの怠惰なコミット メッセージを記述することがよくあります。「Conventional Commits」を手動で適用するのは面倒で、忘れられることがよくあります。Conventional Commits 仕様を適用する Skill を実装してみましょう。エージェントにルールを指示するだけで、エージェントが実施者として機能します。
git-commit-formatter/
└── SKILL.md (Instructions only)
SKILL.md ファイルは次のとおりです。
---
name: git-commit-formatter
description: Formats git commit messages according to Conventional Commits specification. Use this when the user asks to commit changes or write a commit message.
---
Git Commit Formatter Skill
When writing a git commit message, you MUST follow the Conventional Commits specification.
Format
`<type>[optional scope]: <description>`
Allowed Types
- **feat**: A new feature
- **fix**: A bug fix
- **docs**: Documentation only changes
- **style**: Changes that do not affect the meaning of the code (white-space, formatting, etc)
- **refactor**: A code change that neither fixes a bug nor adds a feature
- **perf**: A code change that improves performance
- **test**: Adding missing tests or correcting existing tests
- **chore**: Changes to the build process or auxiliary tools and libraries such as documentation generation
Instructions
1. Analyze the changes to determine the primary `type`.
2. Identify the `scope` if applicable (e.g., specific component or file).
3. Write a concise `description` in an imperative mood (e.g., "add feature" not "added feature").
4. If there are breaking changes, add a footer starting with `BREAKING CHANGE:`.
Example
`feat(auth): implement login with google`
Antigravity でこの例を実行する方法
以下の手順では、ローカルマシンで Git が使用可能で、正しく設定されていることを前提としています。
Antigravity または Antigravity CLI を起動したことを前提として、次の手順を行います。
ステップ 1: テスト Git リポジトリを設定する
エージェントに、Git オペレーションのテスト用にクリーンで分離されたディレクトリを設定するよう依頼します。
プロンプト:
Create a folder named git_test in the workspace, initialize a git repository inside it, and create an initial file auth.py with def login(): pass. Stage this file and make an initial commit.
エージェントは、ディレクトリの作成、リポジトリの初期化、ファイルのステージングを行い、「initial commit」のようなメッセージでコミットします。
ステップ 2: コードを変更する
エージェントに、commit する変更があるようにコードを変更するよう指示します。
プロンプト:
In the git_test folder, modify auth.py to add Google Login functionality.
エージェントはファイルを編集して新しい機能を追加し、コミット フェーズの準備をします。
ステップ 3: 変更をステージングしてコミットする
エージェントに変更をステージングして commit を作成するようリクエストして、git-commit-formatter スキルをトリガーします。
プロンプト:
Stage the changes in the git_test folder and commit them. Make sure to format the commit message using the Conventional Commits skill.
エージェントは git add auth.py を実行し、差分を分析して auth モジュールに新しい機能が追加されたことを確認し、git commit を実行する前に feat(auth): implement google login のような従来のコミット メッセージを作成します。
ステップ 4: Git ログを確認する
フォーマットされたコミットが正常に記録されたことを確認できるよう、担当者に git の履歴を取得してもらいます。
プロンプト:
Show me the git log in the git_test folder.
エージェントが git log -n 5 を実行し、フォーマットされたコミット メッセージを示す出力を返します。
レベル 2: アセットの利用率(license-header-adder)
これは「参照」パターンです。
企業プロジェクトのすべてのソースファイルに、特定の 20 行の Apache 2.0 ライセンス ヘッダーが必要になる場合があります。この静的テキストをプロンプト(または SKILL.md)に直接入れるのは無駄です。スキルがインデックスに登録されるたびにトークンが消費され、モデルが法的テキストの誤字脱字を「幻覚」する可能性があります。静的テキストは resources/ フォルダ内のプレーン テキスト ファイルにオフロードすることをおすすめします。スキルは、必要な場合にのみこのファイルを読み取るようエージェントに指示します。
ファイルは skills ディレクトリの license-header-adder フォルダにあります。
license-header-adder/
├── SKILL.md
└── resources/
└── HEADER_TEMPLATE.txt (The heavy text)
SKILL.md ファイルは次のとおりです。
---
name: license-header-adder
description: Adds the standard open-source license header to new source files. Use involves creating new code files that require copyright attribution.
---
# License Header Adder Skill
This skill ensures that all new source files have the correct copyright header.
## Instructions
1. **Read the Template**:
First, read the content of the header template file located at `resources/HEADER_TEMPLATE.txt`.
2. **Prepend to File**:
When creating a new file (e.g., `.py`, `.java`, `.js`, `.ts`, `.go`), prepend the `target_file` content with the template content.
3. **Modify Comment Syntax**:
- For C-style languages (Java, JS, TS, C++), keep the `/* ... */` block as is.
- For Python, Shell, or YAML, convert the block to use `#` comments.
- For HTML/XML, use `<!-- ... -->`.
Antigravity でこの例を実行する方法
Antigravity または Antigravity CLI を起動したことを前提として、次の手順を行います。
ステップ 1: サンプルコードを含む Python ファイルを作成する
プロンプト:
Create a new file my_script.py with the following python code:
def hello():
print("Hello, World!")
発生した事象(説明): エージェントは、ファイル書き込みツール(write_to_file)を呼び出して、アクティブなワークスペース ディレクトリに my_script.py という名前の新しいファイルを直接作成し、そこに基本的な Python 関数を書き込みました。また、このプロンプトによって license-header-adder スキルがトリガーされました。エージェントはライセンス テンプレート ファイル(HEADER_TEMPLATE.txt)を見つけて読み取り、コメント スタイルを C スタイルのブロック コメント(/* ... */)から Python スタイルのコメント(#)に変更し、replace_file_content ツールを使用してファイルの先頭に追加しました。
ステップ 2: ファイルの内容を確認する
my_script.py ファイルをご覧ください。上部にライセンス ヘッダーが含まれます。
レベル 3: 例による学習(json-to-pydantic)
「少数ショット」パターン。
緩いデータ(JSON API レスポンスなど)を厳密なコード(Pydantic モデルなど)に変換するには、数十もの決定が必要です。クラスにはどのような名前を付けるべきですか?Optional を使用すべきですか?snake_case または camelCase?これらの 50 個のルールを英語で記述するのは、面倒でエラーが発生しやすくなります。
LLM はパターン マッチング エンジンです。
スキルをゴールデン サンプル(Input -> Output)で作成する方が、詳細な手順よりも効果的な場合が多くあります。
以下のように、スキルファイルを含む json-to-pydantic/ フォルダに移動します。
json-to-pydantic/
├── SKILL.md
└── examples/
├── input_data.json (The Before State)
└── output_model.py (The After State)
SKILL.md ファイルは次のとおりです。
---
name: json-to-pydantic
description: Converts JSON data snippets into Python Pydantic data models.
---
# JSON to Pydantic Skill
This skill helps convert raw JSON data or API responses into structured, strongly-typed Python classes using Pydantic.
Instructions
1. **Analyze the Input**: Look at the JSON object provided by the user.
2. **Infer Types**:
- `string` -> `str`
- `number` -> `int` or `float`
- `boolean` -> `bool`
- `array` -> `List[Type]`
- `null` -> `Optional[Type]`
- Nested Objects -> Create a separate sub-class.
3. **Follow the Example**:
Review `examples/` to see how to structure the output code. notice how nested dictionaries like `preferences` are extracted into their own class.
- Input: `examples/input_data.json`
- Output: `examples/output_model.py`
Style Guidelines
- Use `PascalCase` for class names.
- Use type hints (`List`, `Optional`) from `typing` module.
- If a field can be missing or null, default it to `None`.
/examples フォルダには、JSON ファイルと出力ファイル(Python ファイル)があります。両方を以下に示します。
input_data.json
{
"user_id": 12345,
"username": "jdoe_88",
"is_active": true,
"preferences": {
"theme": "dark",
"notifications": [
"email",
"push"
]
},
"last_login": "2024-03-15T10:30:00Z",
"meta_tags": null
}
output_model.py
from pydantic import BaseModel, Field
from typing import List, Optional
class Preferences(BaseModel):
theme: str
notifications: List[str]
class User(BaseModel):
user_id: int
username: str
is_active: bool
preferences: Preferences
last_login: Optional[str] = None
meta_tags: Optional[List[str]] = None
Antigravity でこの例を実行する方法
Antigravity または Antigravity CLI を起動したことを前提として、次の手順を行います。
ステップ 1: サンプルデータを含む JSON ファイルを作成する
エージェントに、未加工の JSON ペイロードを含む新しいファイル product.json を作成するよう依頼します。
プロンプト:
Create a new file product.json with the following JSON:
{
"product": "Widget",
"cost": 10.99,
"stock": null
}
ステップ 2: JSON を Pydantic モデルに変換する
json-to-pydantic スキルをトリガーして、JSON データを構造化された Pydantic クラスに変換します。
プロンプト:
Convert the JSON in product.json to a Pydantic model and save it to product_model.py.
ステップ 3: 出力を確認する
product_model.py ファイルをご覧ください。これには、完成した Pydantic モデルが含まれます。
レベル 4: 手続き型ロジック(database-schema-validator)
これは「ツール使用」パターンです。
LLM に「このスキーマは安全ですか?」と尋ねると、SQL が正しく見えるという理由だけで、重要な主キーが欠落していても問題ないと回答する可能性があります。
このチェックを決定論的なスクリプトに委任しましょう。database-schema-validator スキルは、作成した Python スクリプトを実行するようにエージェントをルーティングします。スクリプトはバイナリ(True/False)の真理値を提供します。
database-schema-validator/
├── SKILL.md
└── scripts/
└── validate_schema.py (The Validator)
SKILL.md ファイルは次のとおりです。
---
name: database-schema-validator
description: Validates SQL schema files for compliance with internal safety and naming policies.
---
# Database Schema Validator Skill
This skill ensures that all SQL files provided by the user comply with our strict database standards.
Policies Enforced
1. **Safety**: No `DROP TABLE` statements.
2. **Naming**: All tables must use `snake_case`.
3. **Structure**: Every table must have an `id` column as PRIMARY KEY.
Instructions
1. **Do not read the file manually** to check for errors. The rules are complex and easily missed by eye.
2. **Run the Validation Script**:
Use the `run_command` tool to execute the python script provided in the `scripts/` folder against the user's file.
`python scripts/validate_schema.py <path_to_user_file>`
3. **Interpret Output**:
- If the script returns **exit code 0**: Tell the user the schema looks good.
- If the script returns **exit code 1**: Report the specific error messages printed by the script to the user and suggest fixes.
validate_schema.py ファイルは次のとおりです。
import sys
import re
def validate_schema(filename):
"""
Validates a SQL schema file against internal policy:
1. Table names must be snake_case.
2. Every table must have a primary key named 'id'.
3. No 'DROP TABLE' statements allowed (safety).
"""
try:
with open(filename, 'r') as f:
content = f.read()
lines = content.split('\n')
errors = []
# Check 1: No DROP TABLE
if re.search(r'DROP TABLE', content, re.IGNORECASE):
errors.append("ERROR: 'DROP TABLE' statements are forbidden.")
# Check 2 & 3: CREATE TABLE checks
table_defs = re.finditer(r'CREATE TABLE\s+(?P<name>\w+)\s*\((?P<body>.*?)\);', content, re.DOTALL | re.IGNORECASE)
for match in table_defs:
table_name = match.group('name')
body = match.group('body')
# Snake case check
if not re.match(r'^[a-z][a-z0-9_]*$', table_name):
errors.append(f"ERROR: Table '{table_name}' must be snake_case.")
# Primary key check
if not re.search(r'\bid\b.*PRIMARY KEY', body, re.IGNORECASE):
errors.append(f"ERROR: Table '{table_name}' is missing a primary key named 'id'.")
if errors:
for err in errors:
print(err)
sys.exit(1)
else:
print("Schema validation passed.")
sys.exit(0)
except FileNotFoundError:
print(f"Error: File '{filename}' not found.")
sys.exit(1)
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python validate_schema.py <schema_file>")
sys.exit(1)
validate_schema(sys.argv[1])
Antigravity でこの例を実行する方法
Antigravity または Antigravity CLI を起動したことを前提として、次の手順を行います。
ステップ 1: サンプルデータを含む JSON ファイルを作成する
エージェントに、複数のポリシー違反を含む新しいファイル bad_schema.sql を作成するよう依頼します。
プロンプト:
Create a new file bad_schema.sql with the following SQL:
DROP TABLE IF EXISTS legacy_users;
CREATE TABLE userProfile (
id INT PRIMARY KEY,
bio TEXT
);
CREATE TABLE posts (
title TEXT,
content TEXT,
created_at TIMESTAMP
);
CREATE TABLE comments (
id INT PRIMARY KEY,
post_id INT,
body TEXT
);
上記のスキーマ ファイルは、禁止されている DROP TABLE ステートメントを使用している、userProfile テーブル名に camelCase を使用している、posts テーブルで id 主キーを忘れているという 3 つのポリシーすべてに違反しています。
ステップ 2: SQL スキーマを検証する
database-schema-validator スキルをトリガーして、ファイルに対して Python バリデータ スクリプトを実行します。
プロンプト:
Validate bad_schema.sql using the database-schema-validator skill.
ステップ 3: 出力を確認する
エージェントは失敗を報告し、スクリプトによって検出された特定のエラーをチャットに直接表示します。出力例を次に示します。
Suggested Fixes:
Remove the line DROP TABLE IF EXISTS legacy_users; as dropping tables is forbidden by safety policy.
Rename the table userProfile to use snake_case (e.g., user_profile).
Add a primary key column named id to the posts table definition.
6. デベロッパー ツールキット(エージェント CLI スキル)
「アクションとライフサイクル」パターン。
AI エージェントの開発には、ボイラープレート ファイルのスキャフォールディング、ローカル ランタイム環境の構成、テスト プロンプトの実行、インタラクティブ プレイグラウンドの開始など、反復的なライフサイクル タスクが含まれます。
コーディング アシスタントにディレクトリ構造を推測させたり、ボイラープレート エージェント構成をゼロから記述させたりするのではなく、Agents CLI Skills はこのライフサイクルの専門知識を特定のエージェント スキルにパッケージ化します。
Agent CLI(コマンドライン インターフェース)スキルにより、デベロッパー中心の効率的な自動化をターミナル上で直接実行できるようになり、生のコードと自律実行のギャップを埋めることができます。Agent Development Kit(ADK)は、プログラムによるフレームワークに重点を置いており、AI エージェントの構築とオーケストレーションを行うための SDK、API、構造設計図を提供しますが、Agent CLI スキルは運用上の強みを提供します。これにより、デベロッパーはエージェントの足場を構築し、テストしてローカルにデプロイできます。フィードバック ループが高速で、重い UI オーバーヘッドを完全に回避できます。
必要に応じて、Google Cloud にマッピングすると、Agent CLI スキルはエンタープライズ グレードのインフラストラクチャへの直接パイプラインとして機能します。コンソールを操作する代わりに、CLI コマンドを使用して、エージェント ワークフローのパッケージ化、アクセス権限の管理、Google Cloud エコシステム(Vertex AI や Cloud Run など)へのデプロイを瞬時に行うことができます。これにより、以前は複雑だったクラウド アーキテクチャ タスクが、シンプルで再現可能なターミナル コマンドに変換され、自律エージェントを既存の CI/CD デプロイ パイプラインに簡単に統合できるようになります。
インストール方法
Python 3.11+、Node.js、uv パッケージ管理システムがインストールされていることを確認します。次に、ターミナルでセットアップ コマンドを実行します。
uvx google-agents-cli setup
このコマンドは、agents-cli バイナリをインストールし、コーディング アシスタントの環境内でスキャフォールディングと評価のための特殊なスキルを登録します。
注: スキルは ~/.agents/skills フォルダにインストールされます。このフォルダは Antigravity に表示されます。これらのスキルを Antigravity CLI で確認するには、~/.gemini/antigravity-cli/skills フォルダ(グローバル スコープ)に移動する必要があります。
スキルが Antigravity に読み込まれたかどうかは、利用可能なスキルについて質問するだけで確認できます。以下に、インストールしたばかりの Agent CLI スキルのレスポンスの例を示します。

ステップバイステップ チュートリアル
uvx google-agents-cli setup が完了すると、AI エージェントをローカルマシンでスピンアップ、操作、テストできます。
ステップ 1: 新しいエージェント プロジェクトをスキャフォールディングして初期化する
作成コマンドを実行して、標準化されたレイアウトをスキャフォールディングします。作成したら、実行タスクを実行する前にプロジェクトの依存関係をインストールする必要があります。
# 1. Create a lightweight prototype project structure
agents-cli create weather-assistant --prototype --yes
# 2. Move into the directory and install required ADK dependencies
cd weather-assistant
agents-cli install
バックグラウンドで実行される処理: app/agent.py(コアコード)、pyproject.toml(パッケージ メタデータ)、agents-cli-manifest.yaml(プロジェクト トラッカー)を含むクリーンなワークスペースが作成されます。
ステップ 2: ローカル テストクエリを実行する
エージェントに対して高速で直接的なコマンドライン テストを実行します。Google Cloud の ADC(アプリケーションのデフォルト認証情報)を使用していない場合は、ターミナルで GEMINI_API_KEY がエクスポートされていることを確認します。Gemini API キーはこちらから取得できます。鍵を取得したら、次のコマンドを使用してターミナルでエクスポートします。
export GEMINI_API_KEY="YOUR_GEMINI_API_KEY"
ターミナルで次のコマンドを実行します。
agents-cli run "How are you?"
舞台裏で実行される処理: CLI は、ターミナルのメモリ内で Agent Development Kit(ADK)のライフサイクル全体を初期化します。プロンプトはローカル認証情報を介して安全にルーティングされ、ライブ ストリーミングのレスポンスはコマンドラインに直接記録されます。
ステップ 3: インタラクティブ ウェブ プレイグラウンドを起動する
組み込みのローカル ウェブベースのプレイグラウンドを起動して、エージェントを視覚的に操作します。
agents-cli playground
バックグラウンドで実行される処理: CLI は ADK ウェブ UI サーバーを起動します。通常、このサーバーには http://localhost:8080 またはフォールバック http://127.0.0.1:8000 でアクセスでき、ホットリロードが完了しています。ウェブ インターフェースで、上部の [アプリを選択] プルダウンから [アプリ] を選択し、ウェブ アプリケーションの右側にある会話型インターフェースでエージェントとやり取りします。
7. npx skills を使用したエージェント スキルのインストール
npx skills は、Vercel Labs が開発したコマンドライン ツールで、AI エージェント(Antigravity、Claude Code、GitHub Copilot、Cursor、Cline など)のパッケージ マネージャーとして機能します。これは、オープン エージェント スキル エコシステムの CLI です。
npx skills パッケージを使用してエージェント スキルをダウンロードしてインストールする場合、スキルは ~/.agents/skills フォルダに配置されます。Antigravity などのツールがこのフォルダからスキルを取得すると記載されていますが、このドキュメントの作成時点では、Antigravity はこのフォルダからスキルを取得しますが、Antigravity CLI は取得しません。前述のように、~/.agents/skills フォルダにインストールされたこれらのスキルを、Antigravity CLI のスキルフォルダのプロジェクト スコープまたはグローバル スコープにコピーする必要があります。
- プロジェクトの範囲:
<project-root>/.agent/skills/にあります。 - グローバル スコープ:
~/.gemini/antigravity-cli/skills/にあります。
8. 完了
おめでとうございます!Google Antigravity を使用して最初のエージェント スキルを構築し、構成して、カスタム機能をスキルに追加できました。
また、プロジェクト スコープとグローバル スコープの両方でエージェント スキルを設定し、カスタマイズされたツールを有効にしました。
これで、Antigravity を使用して独自のプロジェクトで重い処理を行い、自由にコードを記述できるようになりました。
Kaggle 5-Day AI Agents バッジを獲得する
Kaggle の 5-Day AI Agents: Intensive Vibe Coding Course with Google の一環としてこのラボを完了しましたか?修了バッジを受け取る: 5 日間 AI エージェント バッジを取得します。
9. リファレンス ドキュメント
- Codelab : Google Antigravity を使ってみる
- 公式サイト : https://antigravity.google/
- ドキュメント: https://antigravity.google/docs
- ダウンロード : https://antigravity.google/download
- Antigravity Skills のドキュメント: https://antigravity.google/docs/skills