
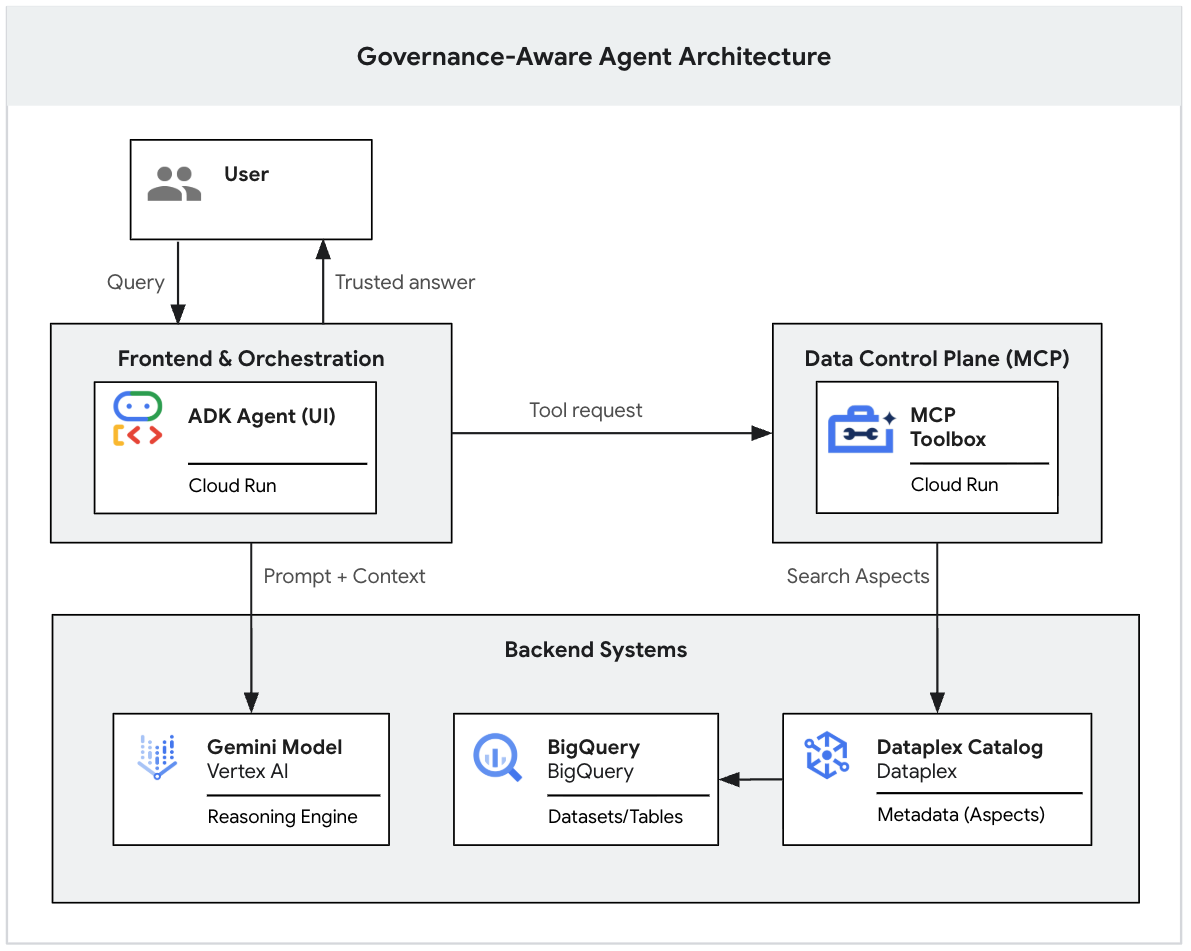
1. Einführung
Modelle, die auf generativer KI basieren, sind zwar leistungsstarke Argumentationswerkzeuge, aber ihnen fehlt der institutionelle Kontext. Wenn eine Führungskraft einen KI-Agenten fragt: „Wie hoch ist unser Umsatz im ersten Quartal?“, findet der Agent möglicherweise Dutzende von Tabellen mit dem Namen „Umsatz“ in Ihrem Data Lake. Einige sind detaillierte Finanzberichte, andere sind Marketing-Schätzungen in Echtzeit und viele sind wahrscheinlich veraltete Sandboxes.
Ohne explizite Fundierung wählt ein KI-Agent eine Tabelle basierend auf einer einfachen Namensähnlichkeit aus, was zu "überzeugend falschen" Antworten führt, die aus nicht überprüften Daten abgeleitet wurden.
Dieses Codelab ist Teil einer zweiteiligen Reihe, in der Sie erfahren, wie Sie einen Governance-basierten GenAI-Agenten erstellen.
In diesem ersten Teil erstellen Sie die Datengrundlage. Sie richten einen realistischen, „unordentlichen“ Data Lake in BigQuery ein, wenden starre Metadaten-Tags (Knowledge Catalog-Aspekte) an, um gültige Daten von Rauschen zu unterscheiden, und verwenden die Gemini CLI, um lokal zu testen, ob das LLM Ihre Governance-Regeln strikt einhält.
Im zweiten Teil dieser Reihe erfahren Sie, wie Sie diesen lokalen Prototyp mithilfe des Model Context Protocol (MCP) und Cloud Run in einer sicheren Webanwendung auf Enterprise-Niveau bereitstellen. 👉 Teil 2 lesen)
Voraussetzungen
- Google Cloud-Projekt mit aktivierter Abrechnungsfunktion.
- Grundlegende Kenntnisse und Vertrautheit mit BigQuery, Knowledge Catalog Universal Catalog und Terraform.
- Zugriff auf Google Cloud Shell.
Lerninhalte
- Mit Terraform einen realistischen, mehrstufigen Data Lake bereitstellen.
- Starre Metadatenvorlagen (Aspekttypen) in Knowledge Catalog entwerfen, um offizielle Datenprodukte von rohen Sandbox-Tabellen zu unterscheiden.
- Governance-Regeln lokal mit der Gemini CLI überprüfen, bevor Sie Anwendungscode schreiben.
Voraussetzungen
- Zugriff auf Google Cloud Shell
- Terraform (in Cloud Shell vorinstalliert).
- Gemini CLI (in Cloud Shell vorinstalliert).
Wichtige Konzepte
- Knowledge Catalog Universal Catalog:Der einheitliche Dienst zur Metadatenverwaltung. Wir verwenden ihn, um technische Metadaten (Schemas) mit geschäftlichem Kontext (Governance) anzureichern.
- Aspekttyp:Eine strukturierte Metadatenvorlage. Im Gegensatz zu Tags mit Freitext erzwingen Aspekte eine starke Typisierung (Aufzählungen, boolesche Werte), wodurch sie für Maschinen zuverlässig auswertbar sind.
2. Einrichtung und Anforderungen
Cloud Shell starten
Während Sie Google Cloud von Ihrem Laptop aus per Fernzugriff nutzen können, verwenden Sie in diesem Codelab Google Cloud Shell, eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird.
Klicken Sie in der Google Cloud Console rechts oben in der Symbolleiste auf das Cloud Shell-Symbol:
Die Bereitstellung und Verbindung mit der Umgebung sollte nur wenige Augenblicke dauern. Wenn der Vorgang abgeschlossen ist, sollte etwa Folgendes angezeigt werden:

Diese virtuelle Maschine verfügt über sämtliche Entwicklertools, die Sie benötigen. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud, was die Netzwerkleistung und Authentifizierung erheblich verbessert. Alle Aufgaben in diesem Codelab können in einem Browser ausgeführt werden. Sie müssen nichts installieren.
Umgebung initialisieren
Öffnen Sie Cloud Shell und legen Sie Ihre Projektvariablen fest, damit alle Befehle auf die richtige Infrastruktur ausgerichtet sind.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export REGION="us-central1"
APIs aktivieren
Aktivieren Sie die erforderlichen Google Cloud-Dienste, um die folgende Anleitung auszuführen.
gcloud services enable \
artifactregistry.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
datacatalog.googleapis.com \
run.googleapis.com
Repository klonen
Rufen Sie den Infrastrukturcode und die Automatisierungsskripts aus dem GitHub-Repository ab. Um Speicherplatz in Cloud Shell zu sparen, laden wir nur den für dieses Lab erforderlichen Ordner herunter.
# Perform a shallow clone to get only the latest repository structure without the full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Specify and download only the folder we need for this lab
git sparse-checkout set data-analytics/governance-context
cd data-analytics/governance-context
„Unordentlichen“ Data Lake erstellen
Datenumgebungen in der Praxis sind selten sauber. Um die Realität zu simulieren, benötigen wir eine Mischung aus „offiziellen“ Data Marts und nicht vertrauenswürdigen „Sandbox“-Tabellen.
Wir verwenden Terraform, um diese Umgebung bereitzustellen. Die Konfiguration umfasst zwei Aufgaben:
- Infrastruktur:Erstellt Knowledge Catalog-Aspekttypen und BigQuery-Datasets/Tabellen.
- Daten laden:Führt BigQuery-INSERT-Jobs aus, um die Tabellen unmittelbar nach der Erstellung mit Beispieldaten zu füllen.
- Wechseln Sie zum Verzeichnis
terraformund initialisieren Sie es.
cd terraform
terraform init
- Wenden Sie die Konfiguration an. Dieser Vorgang kann bis zu einer Minute dauern.
terraform apply -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
Prüfpunkt: Sie haben jetzt einen vollständig gefüllten, aber völlig unkontrollierten Data Lake. Für eine KI sieht jede Tabelle genau gleich aus.
3. Governance anwenden
Dies ist der entscheidende technische Schritt. Derzeit sehen die Tabelle finance_mart.fin_monthly_closing_internal und analyst_sandbox.tmp_data_dump_v2_final_real für ein LLM identisch aus. Sie sind nur Objekte mit Spalten.
Als Governance-Engineer müssen Sie diesen Tabellen einen Aspekt (ein zertifiziertes Metadatenlabel) zuweisen, um sie zu unterscheiden. In einem echten Unternehmen würden Sie dies über CI/CD-Pipelines automatisieren. Wir simulieren diese Automatisierung mit Skripts.
Governance-Nutzlasten generieren
Knowledge Catalog-Aspektschlüssel müssen global eindeutig sein (mit Ihrer Projekt-ID als Präfix). Mit dem Skript ./generate_payloads.sh werden die YAML-Metadatendateien dynamisch generiert.
cd ..
chmod +x ./generate_payloads.sh
./generate_payloads.sh
Ausgabe:
Dadurch wird ein Ordner „./aspect_payloads“ mit vier YAML-Dateien erstellt, in denen die Governance-Szenarien definiert sind (Gold/Internal, Gold/Public, Silver/Realtime, Bronze/Sandbox).
Aspekte über die Befehlszeile anwenden
Bevor wir das Skript ausführen, sehen wir uns an, was wir tatsächlich anwenden, um den Prozess zu entmystifizieren. Führen Sie den folgenden Befehl aus, um die Struktur der internen Finanznutzlast zu sehen:
cat aspect_payloads/fin_internal.yaml
Folgender Inhalt wird angezeigt.
your-project-id.us-central1.official-data-product-spec:
data:
product_tier: GOLD_CRITICAL
data_domain: FINANCE
usage_scope: INTERNAL_ONLY
update_frequency: DAILY_BATCH
is_certified: true
Beachten Sie, dass in diesem YAML-Code der geschäftliche Kontext explizit definiert ist, z. B. durch Festlegen des Flags is_certified: true und Zuweisen der Stufe GOLD_CRITICAL. So erhält die KI klare, strukturierte Regeln für die Auswertung, anstatt nur anhand von Tabellennamen zu raten.
Führen Sie nun das Anwendungsskript aus. Dabei werden die BigQuery-Tabellen durchlaufen und der Befehl gcloud dataplex entries update ausgeführt, um diese starren Metadaten anzuhängen.
chmod +x ./apply_governance.sh
./apply_governance.sh
Überprüfung (optional)
Prüfen Sie, bevor Sie fortfahren, ob die Metadaten in der Console korrekt angewendet wurden.
- Öffnen Sie in der Google Cloud Console die Seite Knowledge Catalog Universal Catalog. Wenn Sie „Knowledge Catalog Universal Catalog“ im Navigationsmenü auf der linken Seite nicht sehen, verwenden Sie die Suchleiste oben im Google Cloud Console-Fenster, geben Sie „Knowledge Catalog“ ein und wählen Sie das Ergebnis unter „Top-Ergebnisse“ oder „Produkte und Seiten“ aus.
- Suchen Sie nach
fin_monthly_closing_internal. Die BigQuery-Tabelle sollte in den Ergebnissen aufgeführt sein. Klicken Sie auf den Tabellennamen, um die Detailseite aufzurufen.
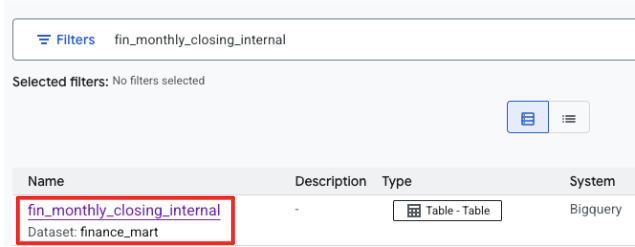
- Suchen Sie auf der Detailseite der Tabelle unten nach dem Abschnitt Optionale Tags und Aspekte.
- Dort finden Sie den Aspekt
official-data-product-spec. Prüfen Sie, ob die Werte mit dem angewendeten Szenario "Gold Internal" übereinstimmen.
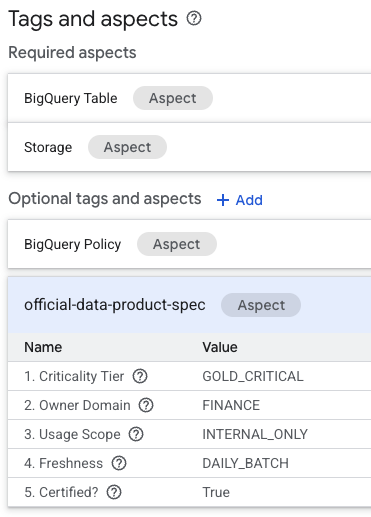
Sie haben jetzt bestätigt, dass technisch identische BigQuery-Tabellen (fin_monthly_closing_internal und tmp_data_dump_v2_final_real) durch maschinenlesbare Metadaten logisch unterschieden werden.
4. Agent konfigurieren und Prototyp erstellen
Bevor wir eine Webanwendung erstellen (was wir in Teil 2 tun werden), überprüfen wir unsere Governance-Logik lokal. Wir müssen die Knowledge Catalog-Erweiterung installieren und den System-Prompt konfigurieren.
Erweiterung installieren
Installieren Sie in Cloud Shell die Knowledge Catalog-Erweiterung. Sie werden zur Bestätigung und zur Eingabe Ihrer Einrichtungsinformationen aufgefordert.
export DATAPLEX_PROJECT="${PROJECT_ID}"
gemini extensions install https://github.com/gemini-cli-extensions/dataplex
(Geben Sie „Y“ ein, um die Installation zu akzeptieren, und geben Sie bei Aufforderung Ihre Projekt-ID ein).
Richtliniendatei definieren
Die Datei GEMINI.md enthält die Logik, die abstrakte menschliche Regeln (z.B. „Ich brauche sichere Daten“) in starre technische Suchvorgänge übersetzt.
Diese Datei ist derzeit generisch. Der Agent muss genau wissen, in welchem Google Cloud-Projekt er suchen soll, damit er keine Tabellen aus dem öffentlichen Internet oder anderen Kontexten halluziniert.
- Schleusen Sie Ihre
PROJECT_IDin die Richtliniendatei ein.
envsubst < GEMINI.md > GEMINI.md.tmp && mv GEMINI.md.tmp GEMINI.md
- Sehen Sie sich die Datei an, um den Algorithmus zu verstehen, den wir der KI beibringen.
cat GEMINI.md
Beachten Sie in dieser Datei zwei Dinge:
- Projektbereich:Prüfen Sie Phase 2. Achten Sie darauf, dass „projectid:
${PROJECT_ID}“ durch Ihre tatsächliche Projekt-ID ersetzt wurde(e.g., projectid:my-lab-project). Wenn diese Variable nicht ersetzt wird, sucht der Agent in allen Projekten, auf die Sie Zugriff haben, was zu falschen Antworten führt. - Der Algorithmus:Beachten Sie die Logik für Phase 1 und Phase 2. Wir weisen das Modell explizit an, SQL NICHT zu erraten. Es muss zuerst nach der richtigen Tag-Definition suchen (Phase 1) und erst dann nach Daten (Phase 2).
Agent starten und Szenarien testen
Starten Sie die Gemini CLI-Sitzung und laden Sie diesmal Ihre Governance-Richtlinie als Systemkontext.
gemini
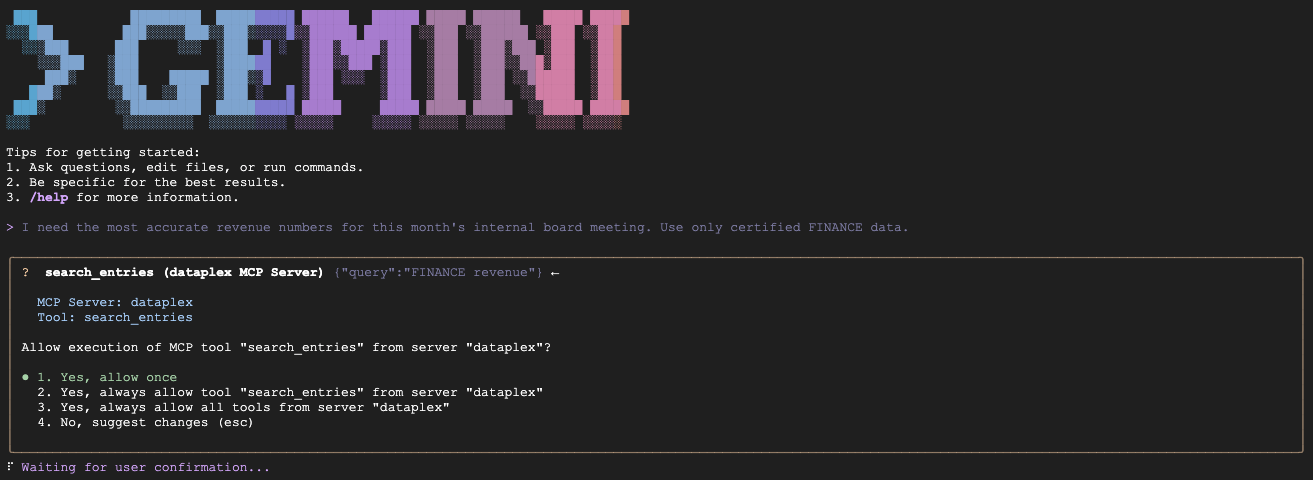
Hinweis: Möglicherweise werden mehrere Kontextdateien geladen (z.B. GEMINI.md und andere). Das ist normal. Die CLI lädt die lokale GEMINI.md-Datei für die spezifischen Regeln dieses Projekts sowie die Standardanweisungen für die Knowledge Catalog-Erweiterung selbst.
Installation überprüfen
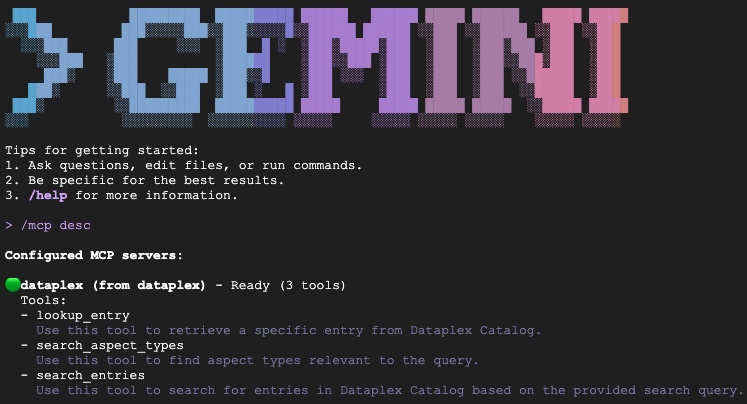
Geben Sie /mcp desc ein, um zu bestätigen, dass die Knowledge Catalog-Erweiterung aktiv ist. dataplex sollte als konfigurierter MCP-Server mit verfügbaren Tools aufgeführt sein.
Testszenarien (Prototyping)
Fügen Sie die folgenden Prompts einzeln in die laufende Agentensitzung ein, um zu prüfen, ob sie Ihren Regeln entspricht.
- Szenario A (Daten des CFO zertifizieren):
"We are preparing the deck for an internal Board of Directors meeting next week. I need the numbers to be absolutely finalized, trustworthy, and kept strictly confidential. Which table is safe to use?"
Erwartet:Fragt fin_monthly_closing_internal ab, da es semantisch mit GOLD_CRITICAL (genau) und INTERNAL_ONLY (Vorstandssitzung) in seinem Aspekt übereinstimmt.
- Szenario B (Öffentliche Offenlegung):
"I need to share our quarterly financial summary with an external consulting firm. It is critical that we do not leak any raw or internal metrics. Which dataset is officially scrubbed and explicitly approved for external sharing?"
Erwartet:Der Agent muss die monatliche interne Tabelle umgehen und unbedingt fin_quarterly_public_report auswählen, da dies das einzige Asset ist, das mit EXTERNAL_READY getaggt ist.
- Szenario C (Betriebliche Anforderungen):
"My dashboard needs to show what's happening right now with our ad spend. I can't wait for the overnight load. What do you recommend?"
Erwartet:Der Agent wählt mkt_realtime_campaign_performance aus, da er die Updatehäufigkeit REALTIME_STREAMING erkennt und diese gegenüber der Stufe GOLD_CRITICAL der Finanzdaten priorisiert.
- Szenario D (Sandbox-Experiment):
"I'm just playing around with some new ML models and need a lot of raw data. It doesn't need to be perfect, just a sandbox environment."
Erwartet:Der Agent wählt tmp_data_dump_v2_final_real aus, da es semantisch mit BRONZE_ADHOC (Rohdaten) und is_certified: false (Sandbox-Umgebung) in seinem Aspekt übereinstimmt.
(Geben Sie „/quit“ ein, um die Gemini-Sitzung zu beenden).
5. Glückwunsch! Nächste Schritte
Sie haben erfolgreich eine kontrollierte Datengrundlage erstellt und bewiesen, dass eine KI Ihre Metadatenregeln mithilfe eines lokalen CLI-Prototyps strikt einhalten kann.
Sie haben jetzt einen Prüfpunkt erreicht. Wählen Sie den nächsten Schritt aus:
Option A: Ich möchte jetzt mit Teil 2 fortfahren!
Wenn Sie bereit sind, diesen lokalen Prototyp mithilfe des Model Context Protocol (MCP) und Cloud Run in eine sichere Webanwendung auf Produktionsniveau umzuwandeln:
Option B: Ich werde Teil 2 später bearbeiten oder wollte nur Teil 1 abschließen.
Wenn Sie für heute aufhören und Cloud-Kosten vermeiden möchten, sollten Sie Ihre Ressourcen bereinigen.
Keine Sorge, in Teil 2 stellen wir ein „Fast-Track-Skript“ zur Verfügung, mit dem diese Umgebung aus Teil 1 in nur zwei Minuten vollständig neu erstellt wird, sodass Sie genau dort weitermachen können, wo Sie aufgehört haben.
👉 Weiter zum Abschnitt Bereinigen
6. Bereinigen (nur für Option B)
Wenn Sie hier aufhören, löschen Sie die Ressourcen, um Gebühren zu vermeiden.
Data Lake löschen (Terraform)
Wenn Sie sich derzeit in der Gemini CLI-Umgebung befinden, beenden Sie die Sitzung, indem Sie Ctrl+C zweimal drücken oder /quit eingeben. Führen Sie dann die folgenden Befehle aus:
cd ~/devrel-demos/data-analytics/governance-context/terraform
terraform destroy -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
Gemini CLI-Erweiterung deinstallieren und lokale Dateien entfernen
gemini extensions uninstall dataplex
cd ~
rm -rf ~/devrel-demos