
1. Einführung
Dieses Codelab ist Teil einer zweiteiligen Reihe, in der beschrieben wird, wie Sie einen Governance-konformen GenAI-Agenten erstellen.
Im ersten Teil dieser Reihe wird beschrieben, wie Sie die Datengrundlage schaffen, indem Sie Knowledge Catalog-Aspekte auf BigQuery-Tabellen anwenden und die Regeln lokal über die Gemini CLI testen. 👉 Teil 1 lesen)
Das Testen in einer lokalen CLI ist jedoch nur der Anfang. Wenn Sie diese Lösung für Ihr gesamtes Unternehmen einführen möchten, benötigen Sie eine zentrale Sicherheitslösung, standardisierte Verbindungen für KI-Tools und ein geeignetes Anwendungs-Framework, um die Logik des Agenten zu orchestrieren und eine vertraute Chat-Oberfläche bereitzustellen.
In diesem zweiten Teil werden Sie diese Herausforderungen meistern und die Lösung für die Produktion skalieren. Sie stellen Ihre Governance-Regeln auf einem zentralen MCP-Server bereit, der auf Cloud Run gehostet wird. Anschließend verwenden Sie das Agent Development Kit (ADK) von Google, um die eigentliche Agent-Anwendung zu erstellen und sie mit Ihren MCP-Tools zu verbinden. Die Anwendung wird mit einer professionellen Web-UI ausgeliefert.
Voraussetzungen
- Google Cloud-Projekt mit aktivierter Abrechnungsfunktion.
- Grundlegendes Verständnis von Cloud Run, IAM-Dienstkonten und Python.
- Die in Teil 1 erstellten BigQuery-Datasets und Knowledge Catalog-Aspekte (keine Sorge, wenn Sie sie gelöscht haben. Wir stellen unten ein Schnellstartskript zur Verfügung, mit dem Sie sie neu erstellen können.)
Lerninhalte
- Verwendung des Model Context Protocol (MCP) zur Standardisierung der Interaktion von KI-Agenten mit Google Cloud-Daten.
- So stellen Sie einen sicheren MCP-Server in Cloud Run bereit.
- Einen KI-Agenten mit dem Agent Development Kit (ADK) erstellen und mit Ihrem MCP-Backend verbinden
- So führen Sie die integrierte Entwickler-UI des ADK aus, um mit Ihrem geregelten Agenten zu interagieren.
Voraussetzungen
- Zugriff auf Google Cloud Shell
Wichtige Konzepte
- Model Context Protocol (MCP): MCP ist wie ein „universelles USB‑C-Kabel“ für KI‑Agents. Anstatt für jedes einzelne KI-Modell benutzerdefinierten API-Integrationscode zu schreiben, bietet MCP eine standardisierte Möglichkeit für KI, eine sichere Verbindung zu Ihren Unternehmensdatentools (wie Knowledge Catalog und BigQuery) herzustellen.
- Agent Development Kit (ADK): Ein flexibles Open-Source-Framework von Google, das die durchgängige Entwicklung von KI-Agenten vereinfachen soll. Es wendet Software-Engineering-Prinzipien auf die Agentenerstellung an, sodass Sie komplexe Tools orchestrieren, den Status verwalten und ganz einfach eine integrierte Entwickler-UI zum Testen und Bereitstellen starten können.
2. Einrichtung und Anforderungen
Cloud Shell starten
Während Sie Google Cloud von Ihrem Laptop aus per Fernzugriff nutzen können, wird in diesem Codelab Google Cloud Shell verwendet, eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird.
Klicken Sie in der Google Cloud Console rechts oben in der Symbolleiste auf das Cloud Shell-Symbol:
Die Bereitstellung und Verbindung mit der Umgebung sollte nur wenige Augenblicke dauern. Anschließend sehen Sie in etwa Folgendes:

Diese virtuelle Maschine verfügt über sämtliche Entwicklertools, die Sie benötigen. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud, was die Netzwerkleistung und Authentifizierung erheblich verbessert. Alle Aufgaben in diesem Codelab können in einem Browser ausgeführt werden. Sie müssen nichts installieren.
Umgebung initialisieren
Öffnen Sie Cloud Shell und legen Sie Ihre Projektvariablen fest, damit alle Befehle auf die richtige Infrastruktur ausgerichtet sind.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export REGION="us-central1"
Prüfpunkt: Fortsetzen oder neu erstellen?
Da dies Teil 2 ist, benötigt Ihr KI-Agent die geregelten Daten aus Teil 1, um zu funktionieren. Wählen Sie einen der folgenden Pfade aus:
Pfad A: Ich habe gerade Teil 1 abgeschlossen und meine Ressourcen werden noch ausgeführt.
Sehr gut! Wechseln Sie zum Arbeitsverzeichnis.
cd ~/devrel-demos/data-analytics/governance-context
Pfad B: Ich habe Teil 1 übersprungen ODER ich habe meine Ressourcen gelöscht (bereinigt).
Kein Problem! Unten finden Sie einen „Fast-Track“-Befehlsblock. Dadurch wird der BigQuery-Data Lake automatisch neu erstellt und die Governance-Metadaten des Knowledge Catalog werden genau wie in Teil 1 angewendet.
# 1. Clone the repo and navigate to the working directory
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set data-analytics/governance-context
cd data-analytics/governance-context
# 2. Rebuild the messy data lake with Terraform
cd terraform
terraform init
terraform apply -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
# 3. Generate and apply Knowledge Catalog Aspects (Governance rules)
cd ..
chmod +x ./generate_payloads.sh ./apply_governance.sh
./generate_payloads.sh
./apply_governance.sh
3. Mit MCP skalieren: Die Datensteuerungsebene erstellen
Bisher haben Sie Ihre Governance-Logik mit der Gemini CLI getestet. Das ist hervorragend für schnelles Prototyping geeignet, wird aber lokal mit Ihren persönlichen Nutzeranmeldedaten ausgeführt.
In einer echten Unternehmensumgebung benötigen Sie eine zentrale Steuerungsebene für Daten. Dazu verwenden wir die GenAI Toolbox for Databases, ein offizielles Open-Source-Projekt von Google. Diese Toolbox bietet einen vorkonfigurierten MCP-Server, der speziell dafür entwickelt wurde, KI-Agents sicher mit Google Cloud-Datenbanken und Metadatendiensten wie Knowledge Catalog zu verbinden.
Wenn wir diese Toolbox als unseren MCP-Server in Cloud Run bereitstellen, erreichen wir Folgendes:
- Zentrale Identität:Der Agent wird als eingeschränktes Dienstkonto und nicht als Ihr persönliches Nutzerkonto ausgeführt.
- Standardisierung:Jeder Client (ADK, Gemini, benutzerdefinierte Apps) kann sich über das Standard-MCP-Protokoll mit diesem Server verbinden.
- Kontrollierter Umfang (geringste Berechtigung): Das LLM hat keinen uneingeschränkten Zugriff auf BigQuery. Wir zwingen sie, zuerst den Metadatenkatalog von Knowledge Catalog zu durchsuchen.
Tool-Definition konfigurieren (tools.yaml)
Für die GenAI Toolbox ist eine deklarative Konfigurationsdatei, tools.yaml, erforderlich. In dieser Datei werden die sources (wo eine Verbindung hergestellt werden soll) und die tools (was die KI tun darf) definiert.
- Rufen Sie das Serververzeichnis auf und fügen Sie Ihre Projekt-ID in die Konfigurationsdatei ein:
cd ~/devrel-demos/data-analytics/governance-context/mcp_server
envsubst < tools.yaml > tools.tmp && mv tools.tmp tools.yaml
cat tools.yaml
Es sollte mit dem folgenden Snippet identisch sein. Prüfen Sie, ob das Projektfeld jetzt mit Ihrer tatsächlichen Google Cloud-Projekt-ID übereinstimmt.
sources:
dataplex:
kind: dataplex
project: YOUR-PROJECT-ID
tools:
search_entries:
kind: dataplex-search-entries
source: dataplex
description: Search for entries in Knowledge Catalog.
lookup_entry:
kind: dataplex-lookup-entry
source: dataplex
description: Retrieve a specific entry from Knowledge Catalog.
search_aspect_types:
kind: dataplex-search-aspect-types
source: dataplex
description: Find aspect types relevant to a query.
toolsets:
dataplex-toolset:
- search_entries
- lookup_entry
- search_aspect_types
Durch die Definition dieser drei Tools können wir die KI dazu zwingen, „schreibgeschützt“ und „Governance-first“ zu sein.
Konfiguration sichern (Secret Manager)
In der Unternehmensarchitektur sollten Sie Konfigurationsdateien niemals direkt in Container-Images einbinden. Wir speichern tools.yaml sicher in Google Cloud Secret Manager.
gcloud services enable secretmanager.googleapis.com
gcloud secrets create dataplex-tools-config --data-file=tools.yaml
Geringste Berechtigung implementieren (IAM)
Als Nächstes erstellen wir ein dediziertes Dienstkonto für den GenAI Toolbox MCP-Server. Diese Identität hat nur die Berechtigungen, die zum Lesen des Knowledge Catalog-Katalogs und zum Zugriff auf BigQuery-Daten erforderlich sind.
export MCP_SA=mcp-sa
gcloud iam service-accounts create ${MCP_SA} \
--display-name="Service Account for Knowledge Catalog MCP"
export MCP_SERVICE_ACCOUNT="${MCP_SA}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow the server to read its own config from Secret Manager
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/secretmanager.secretAccessor"
# Allow the server to read Knowledge Catalog Metadata and BigQuery Data
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/dataplex.catalogViewer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/bigquery.dataViewer"
MCP-Server in Cloud Run bereitstellen
Jetzt stellen wir die GenAI Toolbox bereit. Wir verwenden das vorgefertigte Container-Image von Google (database-toolbox/toolbox) und stellen unsere Konfiguration aus Secret Manager (--set-secrets) zur Laufzeit bereit.
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
gcloud run deploy governance-mcp \
--image=$IMAGE \
--service-account $MCP_SERVICE_ACCOUNT \
--region=$REGION \
--no-allow-unauthenticated \
--set-secrets="/app/tools.yaml=dataplex-tools-config:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080"
Sie haben jetzt eine verwaltete API eingerichtet. Anstatt Ihrem GenAI-Frontend direkten Datenbankzugriff zu gewähren, wird es eine Verbindung zu dieser Cloud Run-URL herstellen. Der Agent kann nur sehen, was diese Toolbox zulässt.
4. Agent-Backend mit ADK erstellen
Sie haben eine sichere, verwaltete Data Control Plane (MCP) eingerichtet, die in Cloud Run ausgeführt wird. Ihr KI-Agent benötigt nun ein Framework, um seine Logik zu orchestrieren, z. B. die Verarbeitung von Nutzereingaben, die Entscheidung, wann der MCP-Server aufgerufen werden soll, und die Formatierung der Ausgabe.
Anstatt diesen ganzen Boilerplate-Code von Grund auf neu zu schreiben, verwenden wir das Agent Development Kit (ADK) von Google. Das ADK ist ein Code-First-Framework, das Ihre Agentenlogik automatisch in ein FastAPI-Backend einbettet. Außerdem ist eine integrierte Entwickler-UI enthalten, mit der Sie den Entscheidungsprozess und die Tool-Aufrufe des Agenten sofort visualisieren können, ohne zuerst ein benutzerdefiniertes Frontend erstellen zu müssen.
Agent-Logik prüfen (agent.py)
Bevor wir die Infrastruktur konfigurieren, sehen wir uns den Kern dieser Anwendung an.
Wechseln Sie zum Verzeichnis und geben Sie den Inhalt von „agent.py“ aus. Diese Datei ist das „Gehirn“ Ihrer ADK-Bereitstellung.
cd ~/devrel-demos/data-analytics/governance-context/mcp_server
cat agent.py
Sehen Sie sich die Codestruktur an. Es führt drei wichtige Funktionen mit minimalem Boilerplate-Code aus:
- MCPToolset-Integration:Anstatt benutzerdefinierte HTTP-Clients zu schreiben, um mit Ihren Knowledge Catalog-Tools zu interagieren, verwendet das ADK
MCPToolset(server_url=mcp_url). Dadurch wird dietools.yaml-Definition dynamisch von Ihrem bereitgestellten MCP-Server abgerufen und in native Funktionsaufrufe für das LLM übersetzt. - Systemanweisungen:Der Parameter
instructionsenthält die strengen Governance-Regeln (dieselbe Logik wie in der CLIGEMINI.md). Er weist das Modell explizit an, den Reasoning-Loop von Phase 1 (Metadatensuche) bis Phase 2 (Datenabfrage) auszuführen. - Agent-Orchestrierung:Die Klasse
Agent(...)bindet das Gemini-Modell, den Systemprompt und die MCP-Tools zusammen. Bei der Bereitstellung wandelt ADK dieses Objekt automatisch in einen skalierbaren FastAPI-Endpunkt um.
Aufgabentrennung: Frontend-Identität konfigurieren
Damit dieser Code sicher ausgeführt werden kann, müssen wir dem KI-Agenten mitteilen, wo sich Ihr MCP-Server befindet. Wir erstellen die URL dynamisch und speichern sie in einer .env-Datei, die vom ADK zur Laufzeit gelesen wird.
Wir erstellen auch eine separate Identität (dataplex-agent-sa) für diese nutzerorientierte Anwendung. Durch diese Trennung der Aufgaben hat der Frontend-Agent andere Berechtigungen als der Backend-Governance-Server.
Führen Sie die folgenden Befehle aus, um die Umgebung und Identität zu konfigurieren:
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export MCP_SERVER_URL=https://governance-mcp-${PROJECT_NUMBER}.${REGION}.run.app/mcp
export AGENT_SA=knowledge-catalog-agent-sa
export AGENT_SERVICE_ACCOUNT="${AGENT_SA}@${PROJECT_ID}.iam.gserviceaccount.com"
gcloud iam service-accounts create ${AGENT_SA} \
--display-name="Service Account for Knowledge Catalog Agent "
Laufzeitvariablen konfigurieren
Das ADK-Framework stützt sich auf Umgebungsvariablen, um den Kontext zu verstehen. Wir müssen die Projekt-ID und die Region explizit festlegen und die Verwendung der Gemini Enterprise Agent Engine aktivieren. Wir hängen sie an dieselbe Datei .env an.
echo MCP_SERVER_URL=$MCP_SERVER_URL > .env
echo GOOGLE_GENAI_USE_VERTEXAI=1 >> .env
echo GOOGLE_CLOUD_PROJECT=$PROJECT_ID >> .env
echo GOOGLE_CLOUD_LOCATION=$REGION >> .env
Berechtigungen erteilen
Auch wenn der Agent Governance-Prüfungen an den MCP-Server delegiert, benötigt er grundlegende Berechtigungen, um zu funktionieren. Wir gewähren genau zwei Rollen:
- Gemini Enterprise Agent Engine-Nutzer:Zum Aufrufen des Gemini-Modells zum Generieren von Antworten in natürlicher Sprache.
- Cloud Run Invoker:Zum sicheren Aufrufen der MCP-Server-API. Es erhält keinen direkten Zugriff auf BigQuery oder Knowledge Catalog.
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/aiplatform.user"
gcloud run services add-iam-policy-binding governance-mcp \
--region=$REGION \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/run.invoker"
In Cloud Run bereitstellen
Schließlich stellen wir den gesamten Stack in Cloud Run bereit.
Wir verwenden uvx, um das ADK-Tool auszuführen, ohne Abhängigkeiten manuell installieren zu müssen. Mit dem folgenden Befehl wird Ihre agent.py-Logik verpackt, ein Container-Image erstellt, Ihr Dienstkonto eingefügt und ein FastAPI-Server gestartet. Durch Hinzufügen des Flags --with_ui wird auch das ADK Web Playground zum Debuggen gebündelt.
Mit diesem Befehl wird der Container erstellt und bereitgestellt. Das kann 1–3 Minuten dauern.
uvx --from google-adk \
adk deploy cloud_run \
--project=$PROJECT_ID \
--region=$REGION \
--service_name=knowledge-catalog-agent \
--with_ui \
. \
-- \
--service-account=$AGENT_SERVICE_ACCOUNT \
--allow-unauthenticated
Nachdem dieser Befehl ausgeführt wurde, wird eine Service-URL (e.g., https://dataplex-agent-xyz.run.app) ausgegeben. Klicken Sie auf diesen Link, um die vollständig verwaltete Chat-Oberfläche für generative KI zu öffnen.
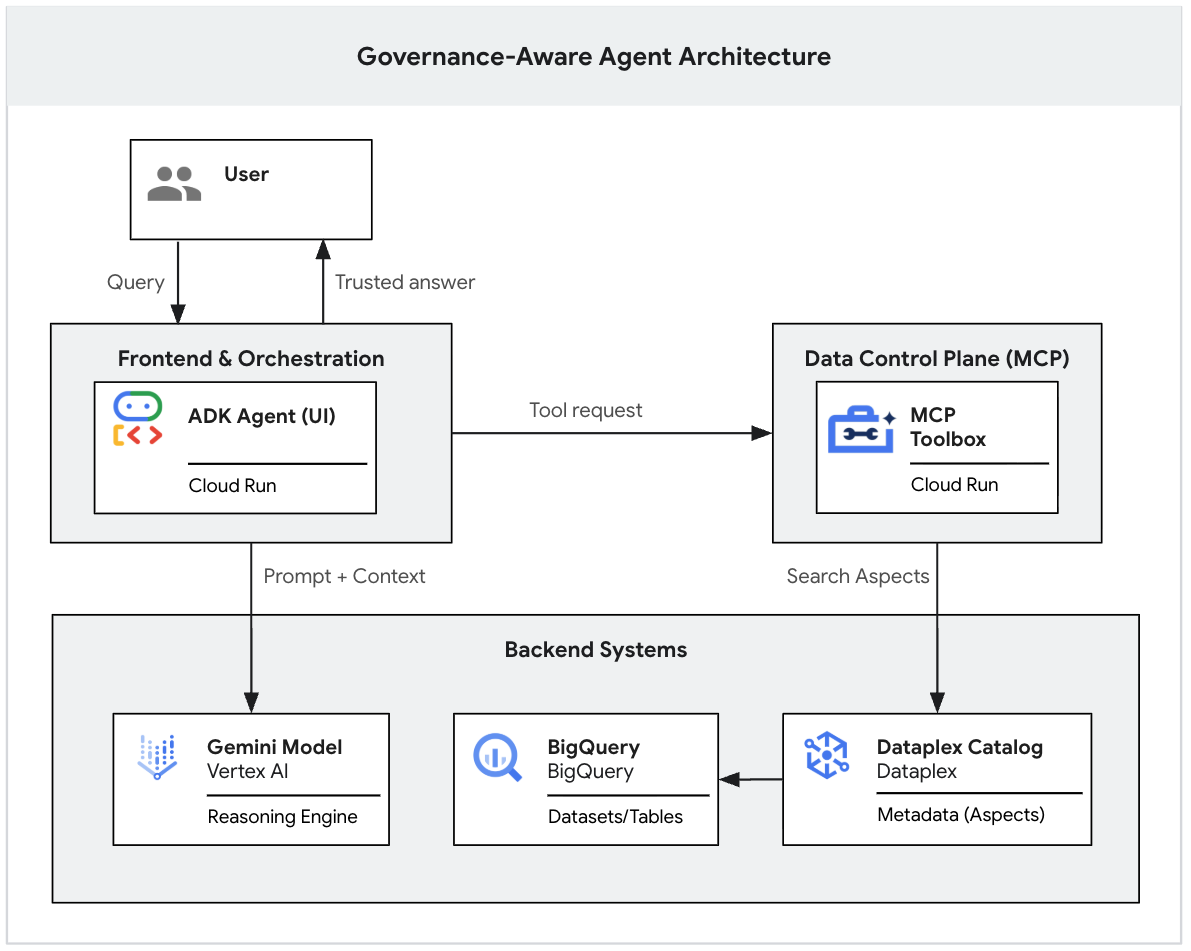
Umfassender Architekturablauf
Sie haben das System nun fertiggestellt. Wenn ein Nutzer mit der ADK-Benutzeroberfläche interagiert, passiert Folgendes:
- Der Nutzer sendet einen Prompt im ADK-Agenten (Entwicklungsoberfläche).
- Der ADK-Agent (agent.py) verarbeitet die Eingabe und ruft das Gemini-Modell auf.
- Gemini stellt fest, dass Kontext erforderlich ist, und fordert den MCP-Server auf, die Knowledge Catalog-Tools auszuführen.
- Der MCP-Server erzwingt Knowledge Catalog-Governance-Regeln und gibt die Metadaten zurück.
- Gemini fasst die vertrauenswürdige Antwort auf Grundlage der Metadaten zusammen und gibt sie an den Nutzer zurück.
5. Enterprise-Agent testen
Nachdem Ihr Agent jetzt aktiv ist, sehen wir uns die zuvor mit der CLI getesteten Governance-Szenarien noch einmal an. Die Logik bleibt dieselbe, aber Sie interagieren jetzt mit dem bereitgestellten ADK Web Playground, in dem der interne Status und die Tool-Ausführungen visualisiert werden.
- Orchestrierung:Der ADK-Agent (der in Cloud Run ausgeführt wird) empfängt Ihren Text.
- Tool-Routing:Gemini erkennt, dass für Ihre Frage Datenkontext erforderlich ist, und leitet die Anfrage an den MCP-Server weiter.
- Governance-Prüfung:Der MCP-Server (der auf einer separaten Cloud Run-Instanz ausgeführt wird) fragt Knowledge Catalog nach bestimmten Aspekttypen ab.
- Synthese:Die relevanten Metadaten werden an Gemini zurückgegeben, um die endgültige Antwort zu generieren.
Governance-Logik prüfen
Öffnen Sie die Dienst-URL, die Sie im vorherigen Schritt generiert haben (e.g., https://dataplex-agent-xyz.run.app), in Ihrem Browser. Fügen Sie den folgenden Prompt ein:
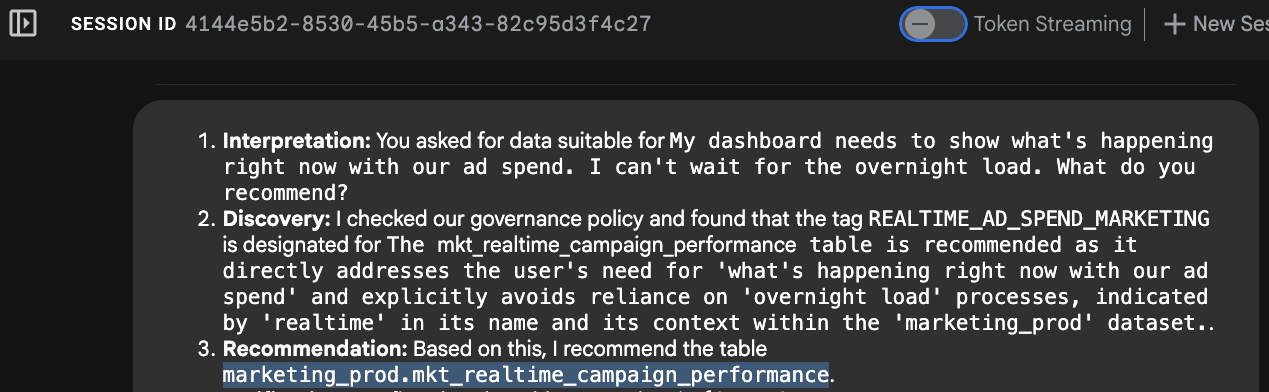
"My dashboard needs to show what's happening right now with our ad spend. I can't wait for the overnight load. What do you recommend?"
Reasoning-Prozess des KI-Agenten in der Entwickler-UI beobachten:
- Absichtserkennung:Der Agent analysiert „jetzt“ und „kann nicht bis morgen warten“.
- Metadatensuche:Das MCP-Tool
search_aspect_typeswird aufgerufen. Es wird nach Daten-Assets gesucht, bei denen derupdate_frequency-Aspekt auf REALTIME oder STREAMING und nicht auf DAILY oder MONTHLY festgelegt ist. - Auswahl:Die Tabelle
mkt_realtime_campaign_performanceerfüllt diese Kriterien, währendfin_monthly_closing_internal(obwohl sie von hoher Qualität ist) für Ihre Anfrage zu langsam ist. - Antwort:Der KI-Agent empfiehlt die Echtzeittabelle.
Warum das wichtig ist:
Ohne diese Governance-Metadaten würde ein LLM wahrscheinlich die Tabelle fin_monthly_closing_internal empfehlen, weil sie eine Spalte mit dem Namen „ad_spend“ enthält. Dabei würde ignoriert, dass die Daten 24 Stunden alt sind. Der Metadatenkontext hat einen geschäftlichen Fehler verhindert.
Sie können auch den Prompt „Board Meeting“ testen, um zu sehen, wie der Agent basierend auf der Data Product Tier-Ebene zu verschiedenen Tabellen wechselt:
"We are preparing the deck for an internal Board of Directors meeting next week. I need the numbers to be absolutely finalized, trustworthy, and kept strictly confidential. Which table is safe to use?"
6. Bereinigen
Mit den folgenden Schritten vermeiden Sie, dass Ihrem Google Cloud-Konto die in diesem Codelab verwendeten Ressourcen in Rechnung gestellt werden. Dazu müssen Sie die gesamte in Teil 1 und Teil 2 erstellte Infrastruktur löschen.
Datalake löschen (Terraform)
Verwenden Sie Terraform, um die BigQuery-Tabellen, ‑Datasets und Knowledge Catalog-Aspektdaten zu entfernen.
cd ~/devrel-demos/data-analytics/governance-context/terraform
terraform destroy -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
Cloud Run-Dienste löschen
Entfernen Sie die Computeressourcen, um die aktive Abrechnung für die ausgeführten Container zu beenden.
gcloud run services delete governance-mcp --region=$REGION --quiet
gcloud run services delete knowledge-catalog-agent --region=$REGION --quiet
Build-Artefakte und Staging-Speicherplatz bereinigen
Als Sie den ADK-Agenten mit uvx bereitgestellt haben, wurde automatisch ein Container-Image erstellt und Ihr Quellcode in einen temporären Cloud Storage-Bucket hochgeladen. Diese Artefakte bleiben auch nach dem Löschen des Cloud Run-Dienstes erhalten und verursachen laufende Speicherkosten.
Entfernen Sie das Artifact Registry-Repository und den Cloud Storage-Staging-Bucket:
# Delete the repository used for the agent build
gcloud artifacts repositories delete cloud-run-source-deploy \
--location=$REGION \
--quiet
# Delete the staging bucket created by Cloud Run source deploy
gcloud storage rm --recursive gs://run-sources-${PROJECT_ID}-${REGION}
Identität, Berechtigungen und Secrets löschen
Entfernen Sie zuerst die IAM-Richtlinienbindungen, damit keine „Tombstone“-Einträge (verwaiste Datensätze) auf der IAM-Seite Ihres Projekts verbleiben. Löschen Sie dann die Dienstkonten und Konfigurations-Secrets.
# Remove IAM roles granted to the MCP Service Account
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/secretmanager.secretAccessor" --quiet
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/dataplex.catalogViewer" --quiet
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/bigquery.dataViewer" --quiet
# Remove IAM roles granted to the Agent Service Account
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/aiplatform.user" --quiet
# Delete the Service Accounts
gcloud iam service-accounts delete $MCP_SERVICE_ACCOUNT --quiet
gcloud iam service-accounts delete $AGENT_SERVICE_ACCOUNT --quiet
# Delete the Secret Manager entry
gcloud secrets delete dataplex-tools-config --quiet
Lokale Konfiguration entfernen
Löschen Sie zum Schluss die lokalen Konfigurationsdateien und Umgebungsvariablen in Cloud Shell.
# Uninstall the Gemini CLI extension (installed in Part 1)
gemini extensions uninstall dataplex
# Remove local repository files and unset variables
cd ~
rm -rf ~/devrel-demos
unset MCP_SERVER_URL
unset MCP_SERVICE_ACCOUNT
unset AGENT_SERVICE_ACCOUNT
7. Glückwunsch!
Sie haben einen Governance-konformen GenAI-Agenten mit End-to-End-Funktionalität bereitgestellt.
In diesem zweiteiligen Codelab haben Sie eine robuste, produktionsreife Architektur implementiert, die über einfaches Prompt-Engineering hinausgeht. Indem Sie Data Governance als Voraussetzung für generative KI betrachtet haben, haben Sie eine systematische Methode entwickelt, um zu verhindern, dass das Modell nicht zertifizierte oder halluzinierte Daten abruft.
Zusammenfassung
- Deterministische KI durch Metadaten:Anstatt sich darauf zu verlassen, dass das LLM die richtige Tabelle anhand von Spaltennamen errät, haben Sie einen strengen Reasoning-Loop mit der GenAI-Toolbox für Datenbanken erzwungen. Indem Sie nur drei Knowledge Catalog-Tools (
search_aspect_types,search_entries,lookup_entry) explizit zur Verfügung gestellt haben, wurde das Modell gezwungen, Datenzertifizierungen zu überprüfen, bevor Antworten synthetisiert wurden. - Entkoppelte Architektur (MCP): Durch die Bereitstellung des MCP-Servers (Model Context Protocol) in Cloud Run haben Sie Ihre Regeln zur Datenverwaltung in einer zentralen, standardisierten API abstrahiert. Der Frontend-Agent muss keine Datenbanklogik enthalten, sondern nur über den MCP-Standard kommunizieren. Das bedeutet, dass Sie jedes zukünftige KI-Modell oder jeden zukünftigen Client in dasselbe verwaltete Backend einbinden können.
- Aufgabentrennung:Sie haben das Prinzip der geringsten Berechtigung angewendet, indem Sie IAM-Identitäten isoliert haben. Der ADK-Agent für Nutzer arbeitet mit Berechtigungen, die auf den Aufruf von Modellen und das API-Routing beschränkt sind. Der Backend-MCP-Server verarbeitet Knowledge Catalog-Abfragen und den Abruf von BigQuery-Daten sicher.
- Codeorientierte Agent-Orchestration:Sie haben das Google Agent Development Kit (ADK) verwendet, um Ihre Python-Agent-Logik sofort in ein skalierbares FastAPI-Backend zu verpacken. Mit der integrierten Entwickler-UI konnten Sie die internen Tool-Ausführungen des Agents visualisieren und debuggen.
Wie geht es weiter?
- Codelab zu den Grundlagen der Governance in Knowledge Catalog: Hier lernen Sie die Grundlagen der Data Governance in Knowledge Catalog kennen, bevor Sie die KI-Ebene hinzufügen.
- Dokumentation zu Knowledge Catalog-Tools: Hier finden Sie die offizielle Dokumentation zu den vorgefertigten Knowledge Catalog-Tools und ‑Erweiterungen, die in diesem Lab verwendet werden.
- Erste Schritte mit Gemini CLI-Erweiterungen: Hier erfahren Sie, wie Sie eigene benutzerdefinierte Erweiterungen erstellen, um Ihren GenAI-Agents noch mehr Funktionen zu geben.
- Detaillierte Informationen zu MCP: In der offiziellen MCP-Spezifikation erfahren Sie, wie Sie benutzerdefinierte Server für Ihre internen Unternehmens-APIs erstellen.