
۱. مقدمه
مدلهای هوش مصنوعی مولد، استدلالکنندگان قدرتمندی هستند، اما فاقد زمینه نهادی هستند. اگر یک مدیر اجرایی از یک عامل هوش مصنوعی بپرسد: «درآمد سهماهه اول ما چقدر است؟»، آن عامل ممکن است دهها جدول با نام «درآمد» در سراسر دریاچه داده شما پیدا کند. برخی گزارشهای مالی دقیق هستند، برخی دیگر تخمینهای بازاریابی در زمان واقعی هستند و بسیاری احتمالاً سندباکسهای منسوخشدهای هستند.
بدون زمینهسازی صریح، یک عامل هوش مصنوعی جدولی را بر اساس شباهت نام ساده انتخاب میکند که منجر به پاسخهای « بهطور متقاعدکنندهای اشتباه » حاصل از دادههای تأییدنشده میشود.
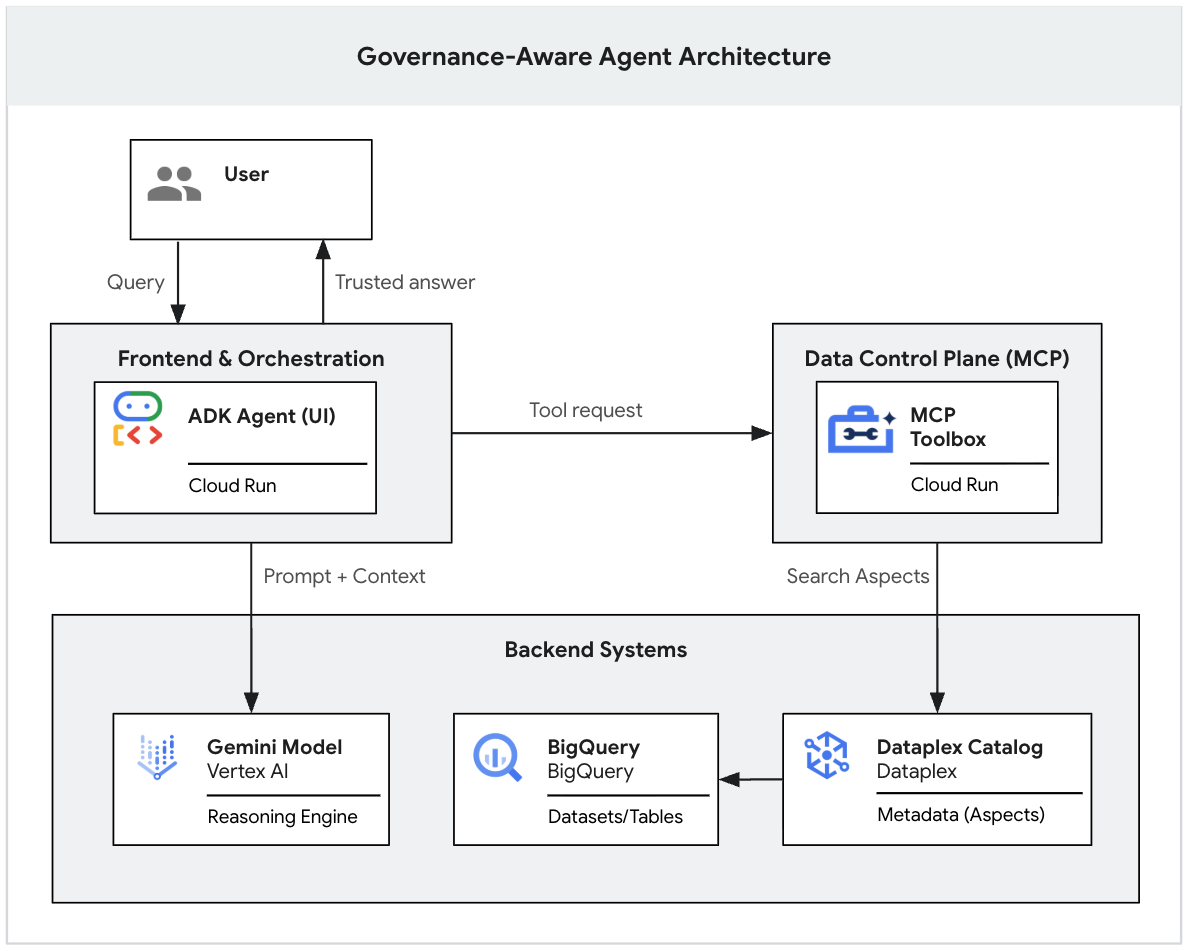
این آزمایشگاه کد بخشی از یک مجموعه دو قسمتی است که به بررسی چگونگی ساخت یک عامل GenAI آگاه از مدیریت میپردازد.
در بخش اول، شما پایه و اساس دادهها را خواهید ساخت. شما یک دریاچه داده واقعگرایانه و "نامرتب" را در BigQuery راهاندازی خواهید کرد، برچسبهای متادیتای سفت و سخت (جنبههای کاتالوگ دانش) را برای تمایز دادههای معتبر از دادههای نویز اعمال خواهید کرد و از رابط خط فرمان Gemini برای آزمایش محلی اینکه آیا LLM به طور دقیق از قوانین مدیریتی شما پیروی میکند یا خیر، استفاده خواهید کرد.
(شما میتوانید بخش دوم این مجموعه را بخوانید که نحوهی استقرار این نمونهی اولیهی محلی در یک برنامهی وب امن و در سطح سازمانی را با استفاده از پروتکل Model Context (MCP) و Cloud Run پوشش میدهد. 👉 بخش ۲ را بخوانید .)
پیشنیازها
- یک پروژه گوگل کلود با قابلیت پرداخت.
- آشنایی و درک اولیه با BigQuery ، Knowledge Catalog Universal Catalog و Terraform .
- دسترسی به پوسته ابری گوگل.
آنچه یاد خواهید گرفت
- با استفاده از Terraform، یک دریاچه داده واقعگرایانه و چندلایه مستقر کنید.
- قالبهای فرادادهای دقیق (انواع جنبهها) را در کاتالوگ دانش طراحی کنید تا محصولات دادهای رسمی را از جداول خام جعبه شنی متمایز کنید.
- قبل از نوشتن هرگونه کد برنامه، قوانین مدیریتی را به صورت محلی با استفاده از Gemini CLI تأیید کنید.
آنچه نیاز دارید
- دسترسی به پوسته ابری گوگل
- Terraform (از پیش نصب شده در Cloud Shell).
- رابط خط فرمان Gemini (از پیش نصب شده در Cloud Shell).
مفاهیم کلیدی
- کاتالوگ دانش جهانی: سرویس مدیریت یکپارچه فراداده. ما از آن برای غنیسازی فرادادههای فنی (طرحوارهها) با زمینه کسبوکار (مدیریت) استفاده میکنیم.
- نوع جنبه: یک الگوی فراداده ساختاریافته. برخلاف برچسبهای متن آزاد، جنبهها تایپ قوی (enums، booleans) را اعمال میکنند و ارزیابی آنها را برای ماشینها قابل اعتماد میکنند.
۲. تنظیمات و الزامات
شروع پوسته ابری
اگرچه میتوان از راه دور و از طریق لپتاپ، گوگل کلود را مدیریت کرد، اما در این آزمایشگاه کد، از گوگل کلود شل ، یک محیط خط فرمان که در فضای ابری اجرا میشود، استفاده خواهید کرد.
از کنسول گوگل کلود ، روی آیکون Cloud Shell در نوار ابزار بالا سمت راست کلیک کنید:
آمادهسازی و اتصال به محیط فقط چند لحظه طول میکشد. وقتی تمام شد، باید چیزی شبیه به این را ببینید:

این ماشین مجازی با تمام ابزارهای توسعهای که نیاز دارید، مجهز شده است. این ماشین مجازی یک دایرکتوری خانگی پایدار ۵ گیگابایتی ارائه میدهد و روی فضای ابری گوگل اجرا میشود که عملکرد شبکه و احراز هویت را تا حد زیادی بهبود میبخشد. تمام کارهای شما در این آزمایشگاه کد را میتوان در یک مرورگر انجام داد. نیازی به نصب چیزی ندارید.
مقداردهی اولیه محیط
Cloud Shell را باز کنید و متغیرهای پروژه خود را تنظیم کنید تا مطمئن شوید که همه دستورات زیرساخت صحیح را هدف قرار میدهند.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export REGION="us-central1"
فعال کردن APIها
برای اجرای دستورالعمل زیر، سرویسهای ابری گوگل مورد نیاز را فعال کنید.
gcloud services enable \
artifactregistry.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
datacatalog.googleapis.com \
run.googleapis.com
مخزن را کلون کنید
کد زیرساخت و اسکریپتهای اتوماسیون را از مخزن گیتهاب دریافت کنید. برای صرفهجویی در فضای دیسک در Cloud Shell، فقط پوشهی مورد نیاز برای این آزمایش را دانلود خواهیم کرد.
# Perform a shallow clone to get only the latest repository structure without the full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Specify and download only the folder we need for this lab
git sparse-checkout set data-analytics/governance-context
cd data-analytics/governance-context
دریاچه داده «نامرتب» را بسازید
محیطهای داده دنیای واقعی به ندرت تمیز هستند. برای شبیهسازی واقعیت، به ترکیبی از پایگاههای داده «رسمی» و جداول «جعبه شنی» غیرقابل اعتماد نیاز داریم.
ما از Terraform برای استقرار این محیط استفاده خواهیم کرد. این پیکربندی دو وظیفه را انجام میدهد:
- زیرساخت: انواع جنبههای کاتالوگ دانش و مجموعه دادهها/جداول BigQuery را ایجاد میکند.
- بارگذاری دادهها: دستورات BigQuery INSERT را اجرا میکند تا جداول را بلافاصله پس از ایجاد با دادههای نمونه پر کند.
- به پوشهی
terraformبروید و آن را مقداردهی اولیه کنید.
cd terraform
terraform init
- پیکربندی را اعمال کنید. این ممکن است تا یک دقیقه طول بکشد.
terraform apply -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
نقطه بازرسی : اکنون شما یک دریاچه داده کاملاً پرجمعیت اما کاملاً بدون مدیریت دارید. برای یک هوش مصنوعی، هر جدول دقیقاً یکسان به نظر میرسد.
۳. اعمال حاکمیت
این مرحله مهندسی حیاتی است. در حال حاضر، جدول finance_mart.fin_monthly_closing_internal و analyst_sandbox.tmp_data_dump_v2_final_real کاملاً مشابه یک LLM به نظر میرسند. آنها فقط اشیاء با ستون هستند.
به عنوان یک مهندس مدیریت، شما باید یک Aspect (یک برچسب ابرداده گواهیشده) را به این جداول الصاق کنید تا آنها را از هم متمایز کنید. در یک سازمان واقعی، شما این کار را از طریق خطوط لوله CI/CD خودکار میکنید. ما این خودکارسازی را با اسکریپتها شبیهسازی خواهیم کرد.
ایجاد پیلودهای مدیریتی
کلیدهای جنبههای کاتالوگ دانش باید به صورت جهانی منحصر به فرد باشند (با پیشوند شناسه پروژه شما). اسکریپت ./generate_payloads.sh به صورت پویا فایلهای فراداده YAML را تولید میکند.
cd ..
chmod +x ./generate_payloads.sh
./generate_payloads.sh
خروجی:
این یک پوشه "./aspect_payloads" ایجاد میکند که شامل ۴ فایل YAML است و سناریوهای مدیریتی (طلایی/داخلی، طلایی/عمومی، نقرهای/بلادرنگ، برنزی/سندباکس) را تعریف میکند.
اعمال جنبهها از طریق CLI
قبل از اجرای اسکریپت، بیایید نگاهی به آنچه که در واقع برای رفع ابهام از فرآیند اعمال میکنیم، بیندازیم. دستور زیر را اجرا کنید تا ساختار بار داده داخلی امور مالی را مشاهده کنید:
cat aspect_payloads/fin_internal.yaml
محتویات زیر را به شما نشان میدهد.
your-project-id.us-central1.official-data-product-spec:
data:
product_tier: GOLD_CRITICAL
data_domain: FINANCE
usage_scope: INTERNAL_ONLY
update_frequency: DAILY_BATCH
is_certified: true
توجه کنید که چگونه این YAML به صراحت زمینه کسب و کار را تعریف میکند، مانند تنظیم پرچم is_certified : true و اختصاص سطح GOLD_CRITICAL . به جای حدس زدن بر اساس نام جداول، به هوش مصنوعی قوانین واضح و ساختاریافتهای برای ارزیابی میدهد.
حالا، اسکریپت برنامه را اجرا کنید. این اسکریپت در جداول BigQuery تکرار میشود و دستور gcloud dataplex entries update را برای اتصال این فرادادههای صلب اجرا میکند.
chmod +x ./apply_governance.sh
./apply_governance.sh
تأیید (اختیاری)
قبل از ادامه، بررسی کنید که متادیتا به درستی در کنسول اعمال شده باشد.
- صفحه « کاتالوگ جهانی کاتالوگ دانش » را در کنسول گوگل کلود باز کنید. اگر «کاتالوگ جهانی کاتالوگ دانش» را در منوی ناوبری سمت چپ نمیبینید، از نوار جستجو در بالای پنجره کنسول گوگل کلود استفاده کنید، عبارت «کاتالوگ دانش» را تایپ کنید و نتیجه را در قسمت «نتایج برتر» یا «محصولات و صفحات» انتخاب کنید.
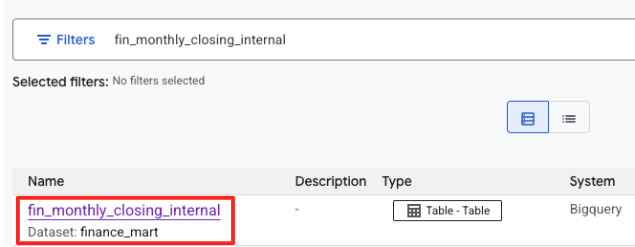
- عبارت
fin_monthly_closing_internalرا جستجو کنید. باید جدول BigQuery را در نتایج مشاهده کنید. برای ورود به صفحه جزئیات آن، روی نام جدول کلیک کنید.
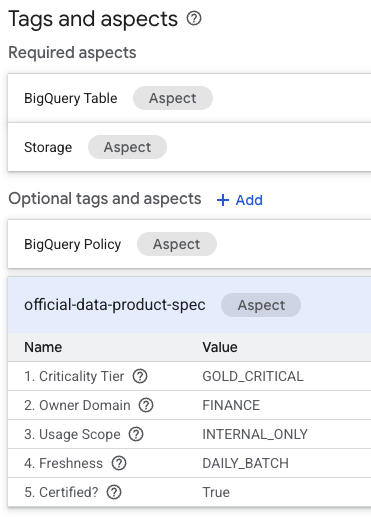
- در صفحه جزئیات جدول، به دنبال بخش « برچسبها و جنبههای اختیاری » که در پایین قرار دارد، بگردید.
- شما جنبه
official-data-product-specرا خواهید یافت. تأیید کنید که مقادیر با سناریوی « طلایی داخلی » که اعمال کردهایم، مطابقت دارند.
اکنون تأیید کردهاید که جداول BigQuery که از نظر فنی یکسان هستند ( fin_monthly_closing_internal و tmp_data_dump_v2_final_real ) منطقاً توسط فرادادههای قابل خواندن توسط ماشین از هم متمایز میشوند.
۴. پیکربندی و نمونهسازی اولیه عامل
قبل از ساخت یک برنامه وب (که در بخش ۲ انجام خواهیم داد)، منطق مدیریت خود را به صورت محلی تأیید خواهیم کرد. باید افزونه کاتالوگ دانش را نصب کرده و اعلان سیستم را پیکربندی کنیم.
افزونه را نصب کنید
در Cloud Shell، افزونه Knowledge Catalog Extension را نصب کنید. از شما تاییدیه و جزئیات تنظیمات را میپرسد.
export DATAPLEX_PROJECT="${PROJECT_ID}"
gemini extensions install https://github.com/gemini-cli-extensions/dataplex
(برای پذیرش نصب، Y را تایپ کنید و در صورت درخواست، شناسه پروژه خود را وارد کنید).
تعریف فایل سیاست
فایل GEMINI.md شامل منطقی است که قوانین انتزاعی انسانی (مثلاً «من به دادههای ایمن نیاز دارم») را به جستجوهای فنی دقیق تبدیل میکند.
این فایل در حال حاضر عمومی است. عامل باید دقیقاً بداند کدام پروژه Google Cloud را جستجو کند تا از توهم جداول از اینترنت عمومی یا سایر زمینهها جلوگیری کند.
-
PROJECT_IDخود را به فایل پالیسی تزریق کنید.
envsubst < GEMINI.md > GEMINI.md.tmp && mv GEMINI.md.tmp GEMINI.md
- برای درک الگوریتمی که به هوش مصنوعی آموزش میدهیم، فایل را بررسی کنید.
cat GEMINI.md
به دو نکته در این فایل توجه کنید:
- محدوده پروژه: مرحله ۲ را بررسی کنید. مطمئن شوید که projectid:
${PROJECT_ID}با شناسه پروژه واقعی شما جایگزین شده است(eg, projectid:my-lab-project). اگر این متغیر جایگزین نشود، عامل در هر پروژهای که به آن دسترسی دارید جستجو میکند و منجر به پاسخهای نادرست میشود. - الگوریتم: به منطق فاز ۱ / فاز ۲ توجه کنید. ما به صراحت به مدل دستور میدهیم که SQL را حدس نزند. ابتدا باید تعریف صحیح تگ را جستجو کند (فاز ۱) و تنها پس از آن به دنبال دادهها بگردد (فاز ۲).
شروع به کار عامل و آزمایش سناریوها
جلسه Gemini CLI را شروع کنید، این بار سیاست حاکمیتی خود را به عنوان زمینه سیستم بارگذاری کنید.
gemini
توجه: ممکن است چندین فایل زمینه (مثلاً GEMINI.md و موارد دیگر) در حال بارگیری باشند. این طبیعی است. رابط خط فرمان، فایل محلی GEMINI.md را برای قوانین خاص این پروژه، به علاوه دستورالعملهای پیشفرض برای خود افزونه کاتالوگ دانش، بارگیری میکند.
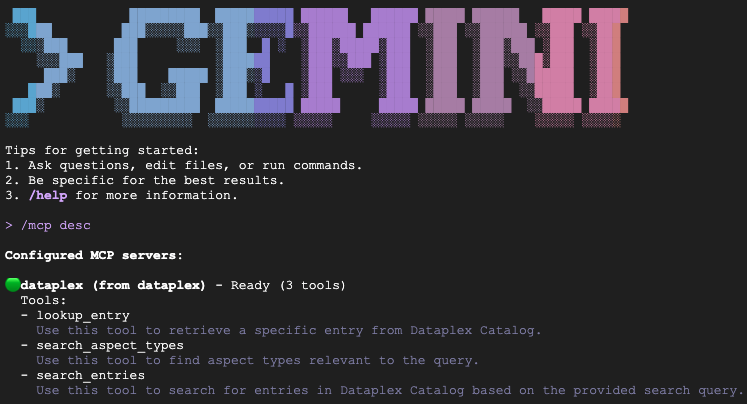
تأیید نصب
برای تأیید فعال بودن افزونه کاتالوگ دانش، عبارت /mcp desc تایپ کنید. باید dataplex به عنوان یک سرور MCP پیکربندی شده با ابزارهای موجود مشاهده کنید.
سناریوهای آزمایشی (نمونهسازی اولیه)
دستورات زیر را یکی یکی در جلسه عامل در حال اجرا قرار دهید تا تأیید کنید که از قوانین شما پیروی میکند.
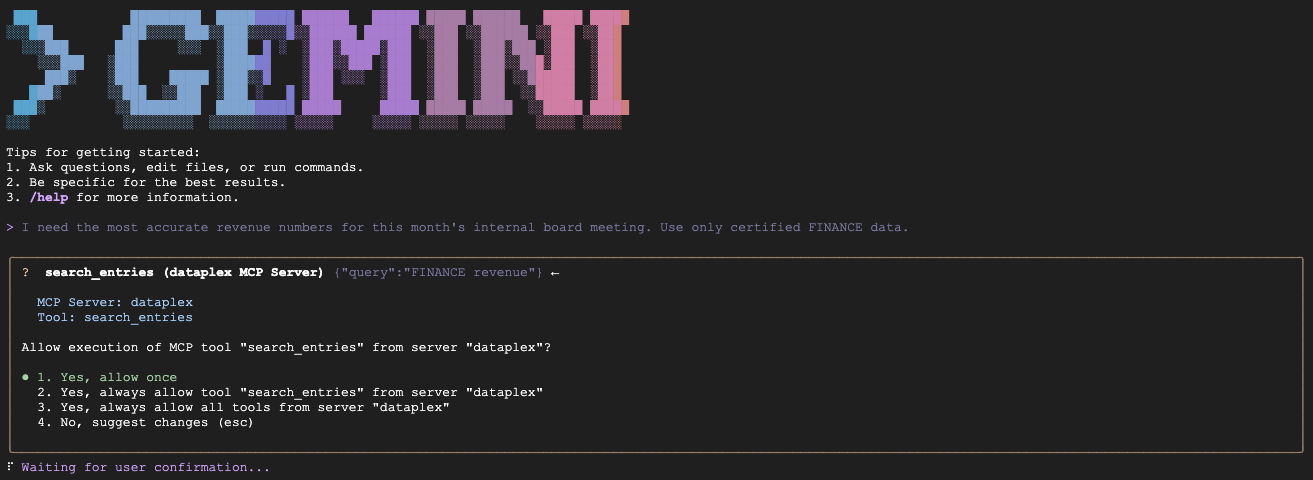
- سناریوی الف (تایید دادههای مدیر مالی):
"We are preparing the deck for an internal Board of Directors meeting next week. I need the numbers to be absolutely finalized, trustworthy, and kept strictly confidential. Which table is safe to use?"
مورد انتظار: عبارت fin_monthly_closing_internal را جستجو میکند زیرا از نظر معنایی با GOLD_CRITICAL (دقیق) و INTERNAL_ONLY (جلسه هیئت مدیره) در جنبه خود مطابقت دارد.
- سناریوی ب (افشای عمومی):
"I need to share our quarterly financial summary with an external consulting firm. It is critical that we do not leak any raw or internal metrics. Which dataset is officially scrubbed and explicitly approved for external sharing?"
مورد انتظار: نماینده باید جدول داخلی ماهانه را نادیده بگیرد و صرفاً fin_quarterly_public_report را انتخاب کند زیرا تنها دارایی با برچسب EXTERNAL_READY است.
- سناریوی ج (نیازهای عملیاتی):
"My dashboard needs to show what's happening right now with our ad spend. I can't wait for the overnight load. What do you recommend?"
مورد انتظار: عامل mkt_realtime_campaign_performance را انتخاب میکند زیرا فرکانس بهروزرسانی REALTIME_STREAMING را شناسایی میکند و آن را بر لایه GOLD_CRITICAL دادههای مالی اولویت میدهد.
- سناریوی D (آزمایش در محیط سندباکس):
"I'm just playing around with some new ML models and need a lot of raw data. It doesn't need to be perfect, just a sandbox environment."
مورد انتظار: عامل tmp_data_dump_v2_final_real انتخاب میکند زیرا از نظر معنایی با BRONZE_ADHOC (دادههای خام) مطابقت دارد و در جنبه (Aspect) خود is_certified: false (محیط sandbox) مطابقت دارد.
(برای خروج از جلسه Gemini، دستور /quit را تایپ کنید)
۵. تبریک میگویم! قدم بعدی چیست؟
شما با موفقیت یک پایه دادهی تحت کنترل ایجاد کردهاید و ثابت کردهاید که یک هوش مصنوعی میتواند با استفاده از یک نمونهی اولیهی رابط خط فرمان محلی، قوانین فرادادهی شما را به طور دقیق دنبال کند!
حالا به یک نقطهی بازرسی رسیدهاید. لطفاً مرحلهی بعدی خود را انتخاب کنید:
گزینه الف: میخواهم همین الان به بخش دوم بروم!
اگر آمادهاید که این نمونه اولیه محلی را با استفاده از پروتکل Model Context (MCP) و Cloud Run به یک برنامه وب امن و در سطح تولید تبدیل کنید:
گزینه ب: بخش دوم را بعداً انجام میدهم یا فقط میخواستم بخش اول را تمام کنم.
اگر میخواهید همین امروز دست از کار بکشید و از هزینههای ابری جلوگیری کنید، باید منابع خود را پاکسازی کنید.
نگران نباشید! در بخش دوم، ما یک «اسکریپت سریع» ارائه خواهیم داد که محیط بخش اول را تنها در عرض ۲ دقیقه به طور کامل برای شما بازسازی میکند تا بتوانید دقیقاً از همان جایی که متوقف شده بودید، ادامه دهید.
👉 به بخش پاکسازی بروید.
۶. تمیزکاری (فقط برای گزینه ب)
اگر اینجا توقف میکنید، منابع را از بین ببرید تا از پرداخت هزینهها جلوگیری کنید.
نابود کردن دیتالیک (ترافرم)
اگر در حال حاضر در محیط Gemini CLI هستید، با دو بار فشردن Ctrl+C یا تایپ کردن /quit از جلسه خارج شوید. سپس، دستورات زیر را اجرا کنید:
cd ~/devrel-demos/data-analytics/governance-context/terraform
terraform destroy -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
افزونهی Gemini CLI را حذف نصب کنید و فایلهای محلی را نیز حذف کنید.
gemini extensions uninstall dataplex
cd ~
rm -rf ~/devrel-demos