
۱. مقدمه
این آزمایشگاه کد بخشی از یک مجموعه دو قسمتی است که به بررسی چگونگی ساخت یک عامل GenAI آگاه از مدیریت میپردازد.
(میتوانید بخش اول این مجموعه را بخوانید که نحوه ایجاد پایه دادهها را با اعمال جنبههای کاتالوگ دانش به جداول BigQuery و آزمایش قوانین به صورت محلی از طریق Gemini CLI پوشش میدهد. 👉 بخش ۱ را بخوانید .)
با این حال، آزمایش در یک رابط خط فرمان محلی (CLI) فقط آغاز کار است. برای گسترش این قابلیت به کل شرکت خود، به امنیت متمرکز، اتصالات استاندارد ابزار هوش مصنوعی و یک چارچوب کاربردی مناسب برای هماهنگ کردن منطق عامل و ارائه یک رابط چت آشنا نیاز دارید.
در بخش دوم، شما این چالشها را حل کرده و به مقیاس تولید ارتقا میدهید. شما قوانین مدیریتی خود را در یک سرور مرکزی MCP که در Cloud Run میزبانی میشود، مستقر خواهید کرد. سپس، از کیت توسعه عامل گوگل (ADK) برای ساخت برنامه عامل واقعی و اتصال آن به ابزارهای MCP خود، به همراه یک رابط کاربری وب حرفهای، استفاده خواهید کرد.
پیشنیازها
- یک پروژه گوگل کلود با قابلیت پرداخت.
- آشنایی اولیه با Cloud Run، حسابهای سرویس IAM و پایتون.
- مجموعه دادههای BigQuery و جنبههای کاتالوگ دانش که در بخش ۱ ایجاد شدند. (اگر آنها را حذف کردهاید نگران نباشید؛ ما یک اسکریپت سریع برای ایجاد مجدد آنها در زیر ارائه میدهیم!)
آنچه یاد خواهید گرفت
- نحوه استفاده از پروتکل مدل زمینه (MCP) برای استانداردسازی نحوه تعامل عوامل هوش مصنوعی با دادههای Google Cloud.
- نحوه استقرار یک سرور امن MCP در Cloud Run.
- نحوه ساخت یک عامل هوش مصنوعی با استفاده از کیت توسعه عامل (ADK) و اتصال آن به بکاند MCP شما.
- نحوه اجرای رابط کاربری توسعهدهنده داخلی ADK برای تعامل با عامل تحت کنترل شما.
آنچه نیاز دارید
- دسترسی به پوسته ابری گوگل
مفاهیم کلیدی
- پروتکل زمینه مدل (MCP): MCP را به عنوان یک "کابل USB-C جهانی" برای عوامل هوش مصنوعی در نظر بگیرید. MCP به جای نوشتن کد یکپارچهسازی API سفارشی برای هر مدل هوش مصنوعی، یک روش استاندارد برای هوش مصنوعی فراهم میکند تا به طور ایمن به ابزارهای داده سازمانی شما (مانند کاتالوگ دانش و BigQuery) متصل شود.
- کیت توسعه عامل (ADK): یک چارچوب انعطافپذیر و متنباز توسط گوگل که برای سادهسازی توسعه عاملهای هوش مصنوعی از ابتدا تا انتها طراحی شده است. این کیت اصول مهندسی نرمافزار را در ایجاد عامل اعمال میکند و به شما امکان میدهد ابزارهای پیچیده را هماهنگ کنید، وضعیت را مدیریت کنید و به راحتی یک رابط کاربری توسعهدهنده داخلی را برای آزمایش و استقرار راهاندازی کنید.
۲. تنظیمات و الزامات
شروع پوسته ابری
اگرچه میتوان از راه دور و از طریق لپتاپ، گوگل کلود را مدیریت کرد، اما در این آزمایشگاه کد، از گوگل کلود شل ، یک محیط خط فرمان که در فضای ابری اجرا میشود، استفاده خواهید کرد.
از کنسول گوگل کلود ، روی آیکون Cloud Shell در نوار ابزار بالا سمت راست کلیک کنید:
آمادهسازی و اتصال به محیط فقط چند لحظه طول میکشد. وقتی تمام شد، باید چیزی شبیه به این را ببینید:

این ماشین مجازی با تمام ابزارهای توسعهای که نیاز دارید، مجهز شده است. این ماشین مجازی یک دایرکتوری خانگی پایدار ۵ گیگابایتی ارائه میدهد و روی فضای ابری گوگل اجرا میشود که عملکرد شبکه و احراز هویت را تا حد زیادی بهبود میبخشد. تمام کارهای شما در این آزمایشگاه کد را میتوان در یک مرورگر انجام داد. نیازی به نصب چیزی ندارید.
مقداردهی اولیه محیط
Cloud Shell را باز کنید و متغیرهای پروژه خود را تنظیم کنید تا مطمئن شوید که همه دستورات زیرساخت صحیح را هدف قرار میدهند.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export REGION="us-central1"
ایست بازرسی: از سرگیری یا بازسازی؟
از آنجایی که این بخش ۲ است، نماینده شما برای عملکرد خود به دادههای مدیریتشده از بخش ۱ نیاز دارد. لطفاً مسیر خود را انتخاب کنید:
مسیر الف: من تازه بخش اول را تمام کردم و منابعم هنوز در حال استفاده هستند.
عالی! به دایرکتوری کاری بروید و آماده ادامه هستید.
cd ~/devrel-demos/data-analytics/governance-context
مسیر ب: از بخش ۱ صرف نظر کردم یا منابعم را حذف کردم (پاکسازی کردم).
مشکلی نیست! ما یک بلوک فرمان "Fast-Track" در زیر ارائه دادهایم. این بلوک به طور خودکار دریاچه داده BigQuery را بازسازی میکند و فراداده مدیریت کاتالوگ دانش را دقیقاً همانطور که در بخش 1 انجام دادیم، اعمال میکند.
# 1. Clone the repo and navigate to the working directory
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set data-analytics/governance-context
cd data-analytics/governance-context
# 2. Rebuild the messy data lake with Terraform
cd terraform
terraform init
terraform apply -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
# 3. Generate and apply Knowledge Catalog Aspects (Governance rules)
cd ..
chmod +x ./generate_payloads.sh ./apply_governance.sh
./generate_payloads.sh
./apply_governance.sh
۳. مقیاسبندی با MCP: ساخت صفحه کنترل داده
تاکنون، شما با موفقیت منطق مدیریتی خود را با استفاده از رابط خط فرمان Gemini آزمایش کردهاید. این رابط برای نمونهسازی سریع عالی است، اما به صورت محلی با استفاده از اعتبارنامههای کاربری شخصی شما اجرا میشود.
در یک محیط سازمانی واقعی، به یک صفحه کنترل داده متمرکز نیاز دارید. برای ساخت این، ما از جعبه ابزار GenAI برای پایگاههای داده ، یک پروژه متنباز رسمی توسط گوگل، استفاده خواهیم کرد. این جعبه ابزار یک سرور MCP از پیش ساخته شده را ارائه میدهد که به طور خاص برای اتصال ایمن عاملهای هوش مصنوعی به پایگاههای داده و سرویسهای فراداده Google Cloud مانند Knowledge Catalog طراحی شده است.
با استقرار این جعبه ابزار به عنوان سرور MCP ما در Cloud Run، به موارد زیر دست مییابیم:
- هویت متمرکز: عامل به عنوان یک حساب سرویس محدود اجرا میشود، نه به عنوان حساب کاربری شخصی شما.
- استانداردسازی: هر کلاینتی (ADK، Gemini، برنامههای سفارشی) میتواند با استفاده از پروتکل استاندارد MCP به این سرور "متصل" شود.
- دامنه کنترلشده (حداقل امتیاز): ما به LLM دسترسی نامحدود به BigQuery نمیدهیم. ما آن را مجبور میکنیم که ابتدا از طریق کاتالوگ فراداده Knowledge Catalog حرکت کند.
تعریف ابزار ( tools.yaml ) را پیکربندی کنید
جعبه ابزار GenAI به یک فایل پیکربندی اعلانی، tools.yaml ، نیاز دارد. این فایل sources (محل اتصال) و tools (آنچه هوش مصنوعی مجاز به انجام آن است) را تعریف میکند.
- به دایرکتوری سرور بروید و شناسه پروژه خود را در فایل پیکربندی تزریق کنید:
cd ~/devrel-demos/data-analytics/governance-context/mcp_server
envsubst < tools.yaml > tools.tmp && mv tools.tmp tools.yaml
cat tools.yaml
باید مشابه قطعه کد زیر باشد. تأیید کنید که فیلد پروژه اکنون با شناسه پروژه Google Cloud واقعی شما مطابقت دارد.
sources:
dataplex:
kind: dataplex
project: YOUR-PROJECT-ID
tools:
search_entries:
kind: dataplex-search-entries
source: dataplex
description: Search for entries in Knowledge Catalog.
lookup_entry:
kind: dataplex-lookup-entry
source: dataplex
description: Retrieve a specific entry from Knowledge Catalog.
search_aspect_types:
kind: dataplex-search-aspect-types
source: dataplex
description: Find aspect types relevant to a query.
toolsets:
dataplex-toolset:
- search_entries
- lookup_entry
- search_aspect_types
با تعریف این سه ابزار، میتوانیم هوش مصنوعی را مجبور کنیم که «فقط خواندنی» و «در اولویت مدیریت» باشد.
پیکربندی را ایمن کنید (مدیر مخفی)
در معماری سازمانی، هرگز نباید فایلهای پیکربندی را مستقیماً در تصاویر کانتینر ذخیره کنید. ما tools.yaml به طور ایمن در Google Cloud Secret Manager ذخیره خواهیم کرد.
gcloud services enable secretmanager.googleapis.com
gcloud secrets create dataplex-tools-config --data-file=tools.yaml
پیادهسازی حداقل امتیاز (IAM)
در مرحله بعد، یک حساب کاربری سرویس اختصاصی برای سرور GenAI Toolbox MCP ایجاد میکنیم. این هویت فقط مجوزهای دقیق مورد نیاز برای خواندن کاتالوگ دانش و دسترسی به دادههای BigQuery را خواهد داشت.
export MCP_SA=mcp-sa
gcloud iam service-accounts create ${MCP_SA} \
--display-name="Service Account for Knowledge Catalog MCP"
export MCP_SERVICE_ACCOUNT="${MCP_SA}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow the server to read its own config from Secret Manager
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/secretmanager.secretAccessor"
# Allow the server to read Knowledge Catalog Metadata and BigQuery Data
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/dataplex.catalogViewer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/bigquery.dataViewer"
سرور MCP را روی Cloud Run مستقر کنید
اکنون، ما GenAI Toolbox را مستقر میکنیم. ما از تصویر کانتینر از پیش ساخته شده گوگل ( database-toolbox/toolbox ) استفاده میکنیم و پیکربندی خود را از Secret Manager ( --set-secrets ) در زمان اجرا، mount میکنیم.
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
gcloud run deploy governance-mcp \
--image=$IMAGE \
--service-account $MCP_SERVICE_ACCOUNT \
--region=$REGION \
--no-allow-unauthenticated \
--set-secrets="/app/tools.yaml=dataplex-tools-config:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080"
شما اکنون یک API مدیریتشده ایجاد کردهاید! به جای اینکه به رابط کاربری GenAI خود دسترسی مستقیم به پایگاه داده بدهید، به این URL Cloud Run متصل میشود. عامل فقط میتواند مواردی را که این جعبه ابزار به او اجازه میدهد، ببیند.
۴. ساخت بکاند عامل با ADK
شما یک صفحه کنترل داده (MCP) امن و مدیریتشده ایجاد کردهاید که روی Cloud Run اجرا میشود. اکنون عامل هوش مصنوعی شما به چارچوبی نیاز دارد تا منطق خود را تنظیم کند، مانند پردازش ورودیهای کاربر، تصمیمگیری در مورد زمان فراخوانی سرور MCP و قالببندی خروجی.
به جای نوشتن تمام این کدهای تکراری از ابتدا، ما از کیت توسعه عامل (ADK) گوگل استفاده خواهیم کرد. ADK یک چارچوب کد-اول است که به طور خودکار منطق عامل شما را در یک بکاند FastAPI قرار میدهد. علاوه بر این، دارای یک رابط کاربری توسعهدهنده داخلی است که به شما امکان میدهد فرآیند استدلال عامل و فراخوانیهای ابزار را فوراً و بدون نیاز به ساخت یک فرانتاند سفارشی، تجسم کنید.
بررسی منطق عامل (agent.py)
قبل از پیکربندی زیرساخت، بیایید نگاهی به هسته این برنامه بیندازیم.
به دایرکتوری بروید و محتویات agent.py را خروجی دهید. این فایل "مغز" استقرار ADK شماست.
cd ~/devrel-demos/data-analytics/governance-context/mcp_server
cat agent.py
به ساختار کد نگاه کنید. سه عملکرد حیاتی را با حداقل کدهای تکراری انجام میدهد:
- ادغام MCPToolset: ADK به جای نوشتن کلاینتهای HTTP سفارشی برای تعامل با ابزارهای کاتالوگ دانش شما، از
MCPToolset(server_url=mcp_url)استفاده میکند. این به صورت پویا تعریفtools.yamlرا از سرور MCP مستقر شما دریافت کرده و آنها را به فراخوانیهای تابع بومی برای LLM ترجمه میکند. - دستورالعملهای سیستم: پارامتر
instructionsشامل قوانین سختگیرانهی مدیریت است (همان منطقی که در CLIGEMINI.mdاستفاده کردیم). این پارامتر به صراحت به مدل دستور میدهد تا حلقه استدلال فاز ۱ (جستجوی فراداده) تا فاز ۲ (جستجوی داده) را اجرا کند. - هماهنگسازی عامل: کلاس
Agent(...)مدل Gemini، اعلان سیستم و ابزارهای MCP را به هم متصل میکند. ADK پس از استقرار، به طور خودکار این شیء را به یک نقطه پایانی FastAPI مقیاسپذیر تبدیل میکند.
تفکیک وظایف: پیکربندی هویت frontend
برای اجرای امن این کد، باید به عامل بگوییم که سرور MCP شما کجا قرار دارد. ما URL را به صورت پویا میسازیم و آن را در یک فایل .env ذخیره میکنیم که ADK در زمان اجرا آن را میخواند.
ما همچنین یک هویت جداگانه ( dataplex-agent-sa ) برای این برنامه کاربر-محور ایجاد خواهیم کرد. این تفکیک وظایف تضمین میکند که عامل frontend مجوزهای متفاوتی نسبت به سرور مدیریت backend داشته باشد.
برای پیکربندی محیط و هویت، دستورات زیر را اجرا کنید:
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export MCP_SERVER_URL=https://governance-mcp-${PROJECT_NUMBER}.${REGION}.run.app/mcp
export AGENT_SA=knowledge-catalog-agent-sa
export AGENT_SERVICE_ACCOUNT="${AGENT_SA}@${PROJECT_ID}.iam.gserviceaccount.com"
gcloud iam service-accounts create ${AGENT_SA} \
--display-name="Service Account for Knowledge Catalog Agent "
پیکربندی متغیرهای زمان اجرا
چارچوب ADK برای درک زمینه خود به متغیرهای محیطی متکی است. ما باید شناسه پروژه، منطقه و استفاده از موتور Gemini Enterprise Agent را به طور صریح تنظیم کنیم. ما این موارد را به همان فایل .env اضافه میکنیم.
echo MCP_SERVER_URL=$MCP_SERVER_URL > .env
echo GOOGLE_GENAI_USE_VERTEXAI=1 >> .env
echo GOOGLE_CLOUD_PROJECT=$PROJECT_ID >> .env
echo GOOGLE_CLOUD_LOCATION=$REGION >> .env
اعطای مجوزها
اگرچه عامل، بررسیهای مدیریتی را به سرور MCP واگذار میکند، اما همچنان برای فعالیت به مجوزهای اولیه نیاز دارد. ما دقیقاً دو نقش اعطا میکنیم:
- کاربر موتور عامل سازمانی Gemini: برای فراخوانی مدل Gemini برای تولید پاسخهای زبان طبیعی.
- فراخوانیکنندهی اجرای ابری: برای فراخوانی امن API سرور MCP شما. این فراخوانیکننده مستقیماً به BigQuery یا Knowledge Catalog دسترسی ندارد!
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/aiplatform.user"
gcloud run services add-iam-policy-binding governance-mcp \
--region=$REGION \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/run.invoker"
استقرار در Cloud Run
در نهایت، کل پشته را روی Cloud Run مستقر میکنیم.
ما uvx برای اجرای ابزار ADK بدون نصب دستی وابستگیها استفاده میکنیم. دستور زیر منطق agent.py شما را بستهبندی میکند، یک تصویر کانتینر میسازد، حساب سرویس شما را تزریق میکند و یک سرور FastAPI را راهاندازی میکند. با اضافه کردن پرچم --with_ui ، ADK Web Playground را نیز برای اشکالزدایی بستهبندی میکند.
این دستور کانتینر را میسازد و آن را مستقر میکند. تکمیل آن ممکن است ۱ تا ۳ دقیقه طول بکشد.
uvx --from google-adk \
adk deploy cloud_run \
--project=$PROJECT_ID \
--region=$REGION \
--service_name=knowledge-catalog-agent \
--with_ui \
. \
-- \
--service-account=$AGENT_SERVICE_ACCOUNT \
--allow-unauthenticated
پس از اتمام این دستور، یک URL سرویس ( eg, https://dataplex-agent-xyz.run.app ) نمایش داده میشود. برای باز کردن رابط چت GenAI کاملاً مدیریتشده، روی آن لینک کلیک کنید.
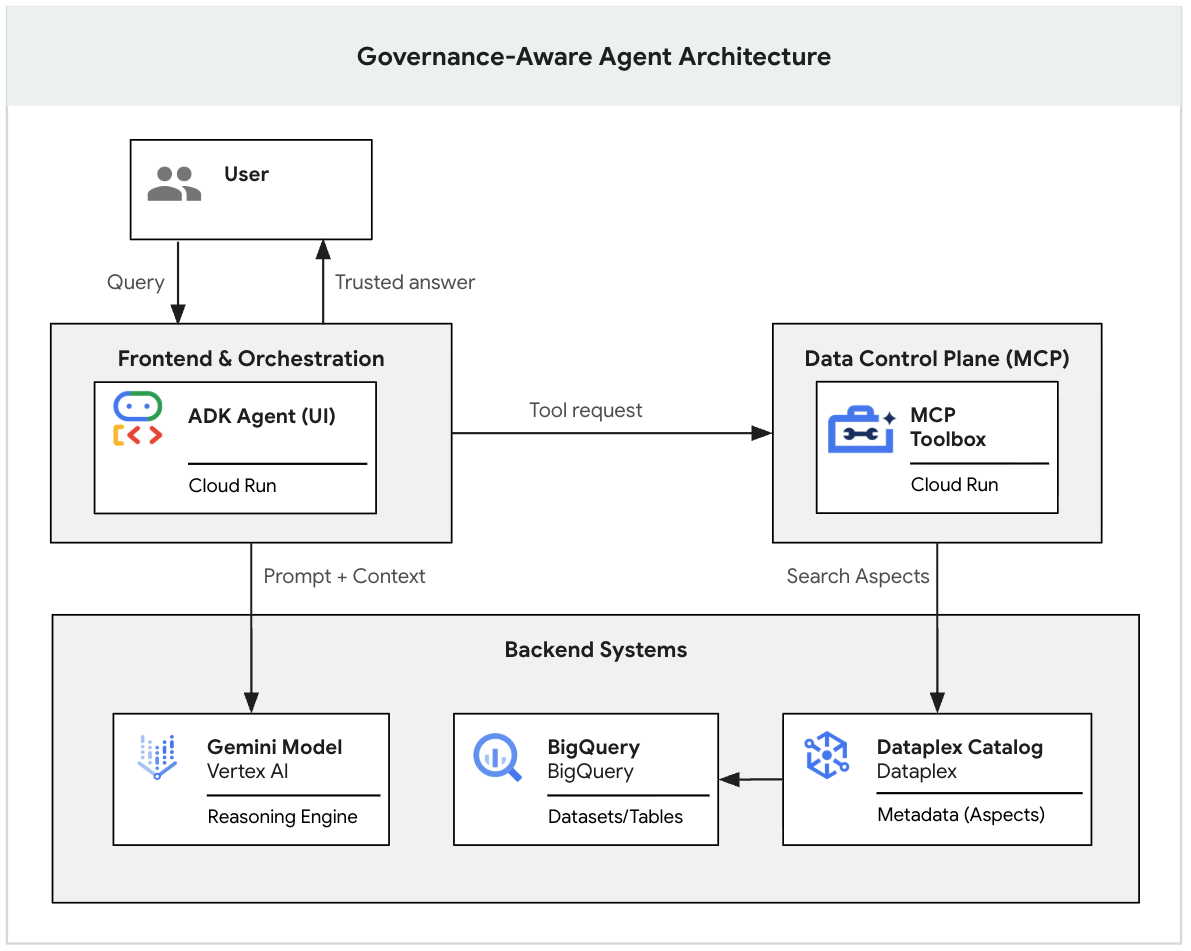
جریان معماری سرتاسری
اکنون سیستم را تکمیل کردهاید. وقتی کاربر با رابط کاربری ADK تعامل میکند، توالی زیر رخ میدهد:
- کاربر درخواستی را در ADK Agent (Dev UI) ارسال میکند.
- عامل ADK (agent.py) ورودی را پردازش کرده و مدل Gemini را فراخوانی میکند.
- Gemini تشخیص میدهد که به زمینه نیاز دارد و از سرور MCP میخواهد که ابزارهای کاتالوگ دانش را اجرا کند.
- سرور MCP قوانین مدیریت کاتالوگ دانش را اعمال کرده و فراداده را برمیگرداند.
- جمینی پاسخ مورد اعتماد را بر اساس فراداده ترکیب کرده و به کاربر بازمیگرداند.
۵. عامل سازمانی را آزمایش کنید
حالا که عامل شما فعال است، بیایید سناریوهای مدیریتی که قبلاً با رابط خط فرمان (CLI) آزمایش شدهاند را دوباره بررسی کنیم. منطق کار یکسان است، اما اکنون شما با ADK Web Playground مستقر شده در تعامل هستید که وضعیت داخلی و اجرای ابزارها را تجسم میکند.
- ارکستراسیون: ADK Agent (که روی Cloud Run اجرا میشود) متن شما را دریافت میکند.
- مسیریابی ابزار: جمینی تشخیص میدهد که سوال شما نیاز به زمینه داده دارد و درخواست را به سرور MCP ارسال میکند.
- بررسی مدیریت: سرور MCP (که روی یک نمونه Cloud Run جداگانه اجرا میشود) کاتالوگ دانش را برای انواع جنبههای خاص جستجو میکند.
- سنتز: فرادادههای مربوطه برای تولید پاسخ نهایی به Gemini بازگردانده میشوند.
منطق مدیریت را تأیید کنید
URL سرویسی که در مرحله قبل ایجاد کردید ( eg, https://dataplex-agent-xyz.run.app ) را در مرورگر خود باز کنید. عبارت زیر را در آن جایگذاری کنید:
"My dashboard needs to show what's happening right now with our ad spend. I can't wait for the overnight load. What do you recommend?"
فرآیند استدلال عامل را در رابط کاربری توسعهدهنده مشاهده کنید:
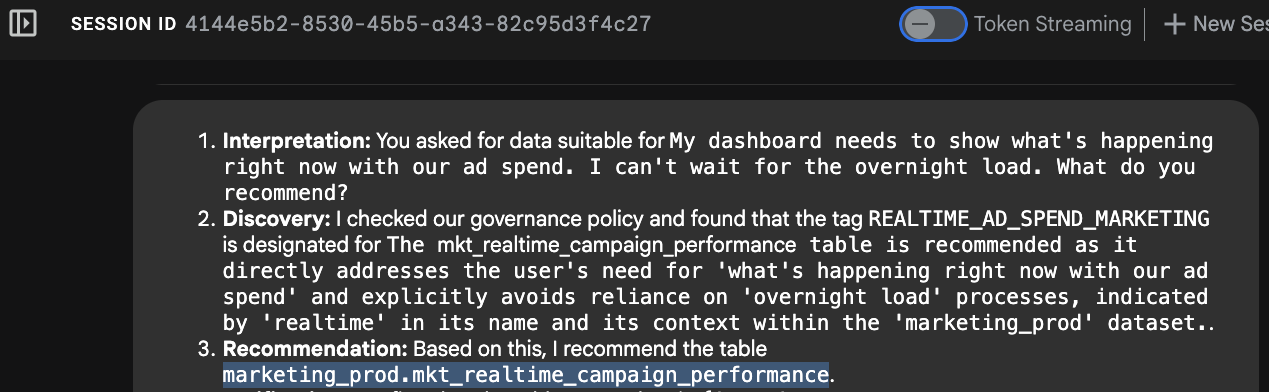
- تشخیص قصد: عامل «همین الان» و «بیصبرانه منتظر یک شبه هستم» را تجزیه و تحلیل میکند.
- جستجوی فراداده: این ابزار MCP را با نام
search_aspect_typesفراخوانی میکند. این ابزار به دنبال دادههایی میگردد که در آنها، مقدارupdate_frequencyAspect به جای DAILY یا MONTHLY، روی REALTIME یا STREAMING تنظیم شده باشد. - انتخاب: مشخص میکند که جدول
mkt_realtime_campaign_performanceاین معیارها را برآورده میکند، در حالی کهfin_monthly_closing_internal(با وجود کیفیت بالا) برای درخواست شما خیلی کند است. - پاسخ: نماینده، میز زمان واقعی را توصیه میکند.
چرا این مهم است:
بدون این فراداده مدیریتی، یک LLM احتمالاً جدول fin_monthly_closing_internal را صرفاً به این دلیل که ستونی به نام "ad_spend" دارد، توصیه میکند، بدون توجه به این واقعیت که دادهها ۲۴ ساعت قدمت دارند. زمینه فراداده شما از یک خطای تجاری جلوگیری کرد.
همچنین میتوانید اعلان «جلسه هیئت مدیره» را آزمایش کنید تا ببینید که چگونه عامل بر اساس جنبه Data Product Tier به جداول مختلف منتقل میشود:
"We are preparing the deck for an internal Board of Directors meeting next week. I need the numbers to be absolutely finalized, trustworthy, and kept strictly confidential. Which table is safe to use?"
۶. تمیز کردن
برای جلوگیری از تحمیل هزینه به حساب Google Cloud خود برای منابع مورد استفاده در این آزمایشگاه کد، این مراحل را دنبال کنید تا تمام زیرساختهای ایجاد شده در قسمت ۱ و قسمت ۲ را از بین ببرید.
نابود کردن دیتالیک (ترافرم)
از Terraform برای تجزیه و تحلیل جداول، مجموعه دادهها و تعاریف جنبههای کاتالوگ دانش در BigQuery استفاده کنید.
cd ~/devrel-demos/data-analytics/governance-context/terraform
terraform destroy -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
سرویسهای Cloud Run را حذف کنید
منابع محاسباتی را حذف کنید تا هرگونه صورتحساب فعال برای کانتینرهای در حال اجرا متوقف شود.
gcloud run services delete governance-mcp --region=$REGION --quiet
gcloud run services delete knowledge-catalog-agent --region=$REGION --quiet
پاکسازی مصنوعات ساخت و ذخیرهسازی مرحلهای
وقتی عامل ADK را با استفاده از uvx مستقر کردید، سیستم به طور خودکار یک تصویر کانتینر ساخت و کد منبع شما را در یک سطل ذخیرهسازی ابری موقت آپلود کرد. این مصنوعات حتی پس از حذف سرویس Cloud Run نیز باقی میمانند و هزینههای ذخیرهسازی مداوم را متحمل میشوند.
مخزن رجیستری Artifact و سطل مرحلهبندی Cloud Storage را حذف کنید:
# Delete the repository used for the agent build
gcloud artifacts repositories delete cloud-run-source-deploy \
--location=$REGION \
--quiet
# Delete the staging bucket created by Cloud Run source deploy
gcloud storage rm --recursive gs://run-sources-${PROJECT_ID}-${REGION}
حذف هویت، مجوزها و اطلاعات محرمانه
ابتدا اتصالات سیاست IAM را حذف کنید تا از باقی ماندن ورودیهای "tombstone" (رکوردهای یتیم) در صفحه IAM پروژه خود جلوگیری کنید. سپس، حسابهای سرویس و اسرار پیکربندی را حذف کنید.
# Remove IAM roles granted to the MCP Service Account
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/secretmanager.secretAccessor" --quiet
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/dataplex.catalogViewer" --quiet
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/bigquery.dataViewer" --quiet
# Remove IAM roles granted to the Agent Service Account
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/aiplatform.user" --quiet
# Delete the Service Accounts
gcloud iam service-accounts delete $MCP_SERVICE_ACCOUNT --quiet
gcloud iam service-accounts delete $AGENT_SERVICE_ACCOUNT --quiet
# Delete the Secret Manager entry
gcloud secrets delete dataplex-tools-config --quiet
پیکربندی محلی را حذف کنید
در نهایت، فایلهای پیکربندی محلی و متغیرهای محیطی را در Cloud Shell پاکسازی کنید.
# Uninstall the Gemini CLI extension (installed in Part 1)
gemini extensions uninstall dataplex
# Remove local repository files and unset variables
cd ~
rm -rf ~/devrel-demos
unset MCP_SERVER_URL
unset MCP_SERVICE_ACCOUNT
unset AGENT_SERVICE_ACCOUNT
۷. تبریک میگویم!
شما با موفقیت یک عامل GenAI آگاه از مدیریت و از ابتدا تا انتها را مستقر کردهاید.
در این آزمایشگاه کد دو بخشی، شما فراتر از مهندسی سریع ساده، به سمت پیادهسازی یک معماری قوی و آماده برای تولید حرکت کردید. با در نظر گرفتن مدیریت دادهها به عنوان پیشنیاز GenAI، شما یک روش سیستماتیک برای جلوگیری از بازیابی دادههای نامشخص یا توهمزا توسط مدل ایجاد کردید.
نکات کلیدی
- هوش مصنوعی قطعی از طریق فراداده: به جای تکیه بر LLM برای حدس زدن جدول صحیح بر اساس نام ستونها، شما یک حلقه استدلال دقیق را با استفاده از جعبه ابزار GenAI برای پایگاههای داده اعمال کردید. با افشای صریح تنها سه ابزار کاتالوگ دانش (
search_aspect_types،search_entries،lookup_entry)، مدل را مجبور کردید قبل از ترکیب پاسخها، گواهینامههای دادهها را تأیید کند. - معماری جدا شده (MCP): با استقرار سرور پروتکل زمینه مدل (MCP) در Cloud Run، شما قوانین مدیریت دادههای خود را در یک API متمرکز و استاندارد خلاصه میکنید. عامل frontend نیازی به منطق پایگاه داده ندارد؛ فقط باید از طریق استاندارد MCP ارتباط برقرار کند. این بدان معناست که میتوانید هر مدل یا کلاینت هوش مصنوعی آینده را به همان backend مدیریت شده متصل کنید.
- تفکیک وظایف: شما با جداسازی هویتهای IAM، اصل حداقل امتیاز را اعمال کردهاید. عامل ADK که با کاربر در ارتباط است، با مجوزهایی محدود به فراخوانی مدل و مسیریابی API عمل میکند، در حالی که سرور MCP در بکاند، به طور ایمن پرسوجوهای کاتالوگ دانش و بازیابی دادههای BigQuery را مدیریت میکند.
- هماهنگسازی عامل با کدنویسی: شما از کیت توسعه عامل گوگل (ADK) برای قرار دادن فوری منطق عامل پایتون خود در یک بکاند FastAPI مقیاسپذیر استفاده کردید و از رابط کاربری توسعهدهنده داخلی آن برای تجسم و اشکالزدایی اجراهای ابزار داخلی عامل استفاده کردید.
قدم بعدی چیست؟
- مدیریت بنیادی کاتالوگ دانش Codelab : قبل از اضافه کردن لایه هوش مصنوعی، بر اصول مدیریت دادهها در کاتالوگ دانش تسلط پیدا کنید.
- مستندات ابزارهای کاتالوگ دانش : مستندات رسمی مربوط به ابزارها و افزونههای از پیش ساخته شده کاتالوگ دانش مورد استفاده در این آزمایشگاه را بررسی کنید.
- شروع کار با افزونههای Gemini CLI : یاد بگیرید که چگونه افزونههای سفارشی خود را بسازید تا به عاملهای GenAI خود قابلیتهای بیشتری بدهید.
- نگاهی عمیق به MCP : برای درک نحوه ساخت سرورهای سفارشی برای APIهای داخلی سازمان خود، مشخصات رسمی MCP را بررسی کنید.