
1. Introduction
Les modèles d'IA générative sont de puissants outils de raisonnement, mais ils manquent de contexte institutionnel. Si un dirigeant demande à un agent IA "Quels sont nos revenus du premier trimestre ?", l'agent peut trouver des dizaines de tableaux nommés "revenus" dans votre lac de données. Certains sont des rapports financiers rigoureux, d'autres des estimations marketing en temps réel, et beaucoup sont probablement des bacs à sable obsolètes.
Sans ancrage explicite, un agent d'IA sélectionnera une table en fonction d'une simple similitude de nom, ce qui entraînera des réponses convaincantes, mais incorrectes dérivées de données non vérifiées.
Cet atelier de programmation fait partie d'une série en deux parties qui explique comment créer un agent d'IA générative tenant compte de la gouvernance.
Dans cette première partie, vous allez créer la base de données. Vous allez configurer un lac de données réaliste et "désordonné" dans BigQuery, appliquer des tags de métadonnées rigides (aspects du Knowledge Catalog) pour différencier les données valides du bruit, et utiliser le Gemini CLI pour tester localement si le LLM respecte strictement vos règles de gouvernance.
(Vous pouvez lire la deuxième partie de cette série, qui explique comment déployer ce prototype local dans une application Web sécurisée de niveau entreprise à l'aide du protocole MCP (Model Context Protocol) et de Cloud Run. 👉 Lire la partie 2
Prérequis
- Un projet Google Cloud avec facturation activée.
- Connaissances de base sur BigQuery, le catalogue universel Knowledge Catalog et Terraform.
- un accès à Google Cloud Shell ;
Points abordés
- Déployez un lac de données réaliste à plusieurs niveaux à l'aide de Terraform.
- Concevez des modèles de métadonnées stricts (types d'aspects) dans Knowledge Catalog pour distinguer les produits de données officiels des tables sandbox brutes.
- Vérifiez les règles de gouvernance en local à l'aide de la Gemini CLI avant d'écrire du code d'application.
Prérequis
- Accès à Google Cloud Shell
- Terraform (préinstallé dans Cloud Shell)
- Gemini CLI (préinstallée dans Cloud Shell).
Concepts clés
- Knowledge Catalog Universal Catalog : service unifié de gestion des métadonnées. Nous l'utilisons pour enrichir les métadonnées techniques (schémas) avec un contexte métier (gouvernance).
- Type d'aspect : modèle de métadonnées structurées. Contrairement aux tags en texte libre, les aspects appliquent un typage fort (énumérations, booléens), ce qui les rend fiables pour l'évaluation par les machines.
2. Préparation
Démarrer Cloud Shell
Bien que Google Cloud puisse être utilisé à distance depuis votre ordinateur portable, nous allons nous servir de Google Cloud Shell pour cet atelier de programmation, un environnement de ligne de commande exécuté dans le cloud.
Dans la console Google Cloud, cliquez sur l'icône Cloud Shell dans la barre d'outils supérieure :
Le provisionnement et la connexion à l'environnement prennent quelques instants seulement. Une fois l'opération terminée, le résultat devrait ressembler à ceci :

Cette machine virtuelle contient tous les outils de développement nécessaires. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Vous pouvez effectuer toutes les tâches de cet atelier de programmation dans un navigateur. Vous n'avez rien à installer.
Initialiser l'environnement
Ouvrez Cloud Shell et définissez les variables de votre projet pour vous assurer que toutes les commandes ciblent la bonne infrastructure.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export REGION="us-central1"
Activer les API
Activez les services Google Cloud nécessaires pour exécuter l'instruction suivante.
gcloud services enable \
artifactregistry.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
datacatalog.googleapis.com \
run.googleapis.com
Cloner le dépôt
Récupérez le code d'infrastructure et les scripts d'automatisation à partir du dépôt GitHub. Pour économiser de l'espace disque dans Cloud Shell, nous ne téléchargerons que le dossier spécifique nécessaire à cet atelier.
# Perform a shallow clone to get only the latest repository structure without the full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Specify and download only the folder we need for this lab
git sparse-checkout set data-analytics/governance-context
cd data-analytics/governance-context
Créer le lac de données "brut"
Les environnements de données réels sont rarement propres. Pour simuler la réalité, nous avons besoin d'un mélange de data marts "officiels" et de tables "bac à sable" non fiables.
Nous allons utiliser Terraform pour déployer cet environnement. La configuration gère deux tâches :
- Infrastructure : crée des types d'aspect Knowledge Catalog et des ensembles de données/tables BigQuery.
- Chargement des données : exécute des tâches BigQuery INSERT pour remplir les tables avec des exemples de données immédiatement après leur création.
- Accédez au répertoire
terraformet initialisez-le.
cd terraform
terraform init
- Appliquez la configuration. Un délai d'une minute peut être nécessaire.
terraform apply -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
Point de contrôle : vous disposez désormais d'un lac de données entièrement rempli, mais totalement non gouverné. Pour une IA, chaque tableau se ressemble exactement.
3. Appliquer la gouvernance
Il s'agit de l'étape d'ingénierie critique. Actuellement, les tableaux finance_mart.fin_monthly_closing_internal et analyst_sandbox.tmp_data_dump_v2_final_real sont identiques pour un LLM. Il s'agit simplement d'objets avec des colonnes.
En tant qu'ingénieur en gouvernance, vous devez associer un aspect (un libellé de métadonnées certifié) à ces tables pour les différencier. Dans une véritable entreprise, vous automatiseriez cette opération à l'aide de pipelines CI/CD. Nous simulerons cette automatisation à l'aide de scripts.
Générer des charges utiles de gouvernance
Les clés d'aspect du Knowledge Catalog doivent être uniques au niveau mondial (avec le préfixe de votre ID du projet). Le script ./generate_payloads.sh génère dynamiquement les fichiers de métadonnées YAML.
cd ..
chmod +x ./generate_payloads.sh
./generate_payloads.sh
Résultat :
Cette commande crée un dossier "./aspect_payloads" contenant quatre fichiers YAML qui définissent les scénarios de gouvernance (Gold/Internal, Gold/Public, Silver/Realtime, Bronze/Sandbox).
Appliquer des aspects via la CLI
Avant d'exécuter le script, examinons ce que nous appliquons réellement pour démystifier le processus. Exécutez la commande suivante pour afficher la structure de la charge utile financière interne :
cat aspect_payloads/fin_internal.yaml
Les contenus suivants s'affichent.
your-project-id.us-central1.official-data-product-spec:
data:
product_tier: GOLD_CRITICAL
data_domain: FINANCE
usage_scope: INTERNAL_ONLY
update_frequency: DAILY_BATCH
is_certified: true
Remarquez comment ce code YAML définit explicitement le contexte métier, par exemple en définissant l'indicateur is_certified sur "true" et en attribuant le niveau GOLD_CRITICAL. L'IA dispose ainsi de règles claires et structurées pour évaluer les données au lieu de simplement deviner en fonction des noms de tables.
Exécutez maintenant le script d'application. Cette commande parcourt les tables BigQuery et exécute la commande gcloud dataplex entries update pour associer ces métadonnées rigides.
chmod +x ./apply_governance.sh
./apply_governance.sh
Validation (facultatif)
Avant de continuer, vérifiez que les métadonnées ont été correctement appliquées dans la console.
- Ouvrez la page Catalogue universel Knowledge Catalog dans la console Google Cloud. Si "Catalogue universel Knowledge Catalog" ne s'affiche pas dans le menu de navigation de gauche, utilisez la barre de recherche en haut de la fenêtre de la console Google Cloud, saisissez "Knowledge Catalog", puis sélectionnez le résultat sous "Meilleurs résultats" ou "Produits et pages".
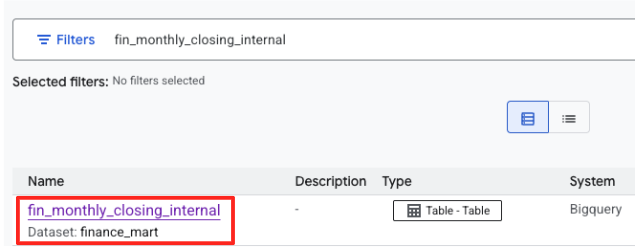
- Recherchez
fin_monthly_closing_internal. La table BigQuery devrait s'afficher dans les résultats. Cliquez sur le nom du tableau pour accéder à sa page d'informations.
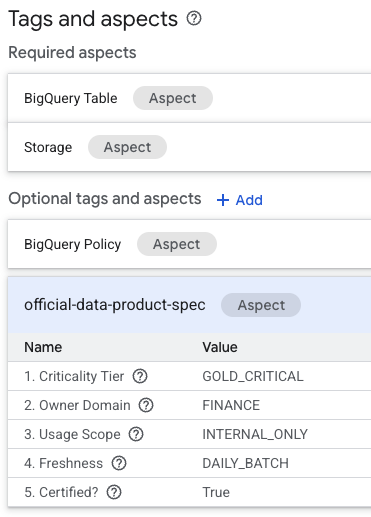
- Sur la page d'informations du tableau, recherchez la section Tags et aspects facultatifs en bas de la page.
- Vous trouverez l'aspect
official-data-product-spec. Vérifiez que les valeurs correspondent au scénario Gold Internal que nous avons appliqué.
Vous avez maintenant confirmé que les tables BigQuery techniquement identiques (fin_monthly_closing_internal et tmp_data_dump_v2_final_real) sont logiquement différenciées par des métadonnées lisibles par machine.
4. Configurer et prototyper l'agent
Avant de créer une application Web (ce que nous ferons dans la partie 2), nous allons vérifier notre logique de gouvernance en local. Nous devons installer l'extension Knowledge Catalog et configurer l'invite système.
Installer l'extension
Dans Cloud Shell, installez l'extension Knowledge Catalog. Il vous demandera de confirmer et de fournir les détails de votre configuration.
export DATAPLEX_PROJECT="${PROJECT_ID}"
gemini extensions install https://github.com/gemini-cli-extensions/dataplex
(Saisissez "Y" pour accepter l'installation et saisissez l'ID de votre projet lorsque vous y êtes invité.)
Définir le fichier de règles
Le fichier GEMINI.md contient la logique qui traduit les règles humaines abstraites (par exemple, "J'ai besoin de données sécurisées") en recherches techniques strictes.
Ce fichier est actuellement générique. L'agent doit savoir exactement quel projet Google Cloud interroger pour éviter de générer des tables à partir de l'Internet public ou d'autres contextes.
- Injectez votre
PROJECT_IDdans le fichier de stratégie.
envsubst < GEMINI.md > GEMINI.md.tmp && mv GEMINI.md.tmp GEMINI.md
- Examinez le fichier pour comprendre l'algorithme que nous enseignons à l'IA.
cat GEMINI.md
Notez deux choses dans ce fichier :
- Périmètre du projet : consultez la phase 2. Assurez-vous que projectid:
${PROJECT_ID}a été remplacé par l'ID de votre projet(e.g., projectid:my-lab-project). Si cette variable n'est pas remplacée, l'agent effectuera une recherche dans tous les projets auxquels vous avez accès, ce qui entraînera des réponses incorrectes. - L'algorithme : notez la logique de la phase 1 / phase 2. Nous demandons explicitement au modèle de NE PAS deviner le code SQL. Il doit d'abord rechercher la définition de balise appropriée (phase 1), puis rechercher les données (phase 2).
Démarrer l'agent et tester des scénarios
Démarrez la session Gemini CLI, cette fois en chargeant votre règlement en tant que contexte système.
gemini
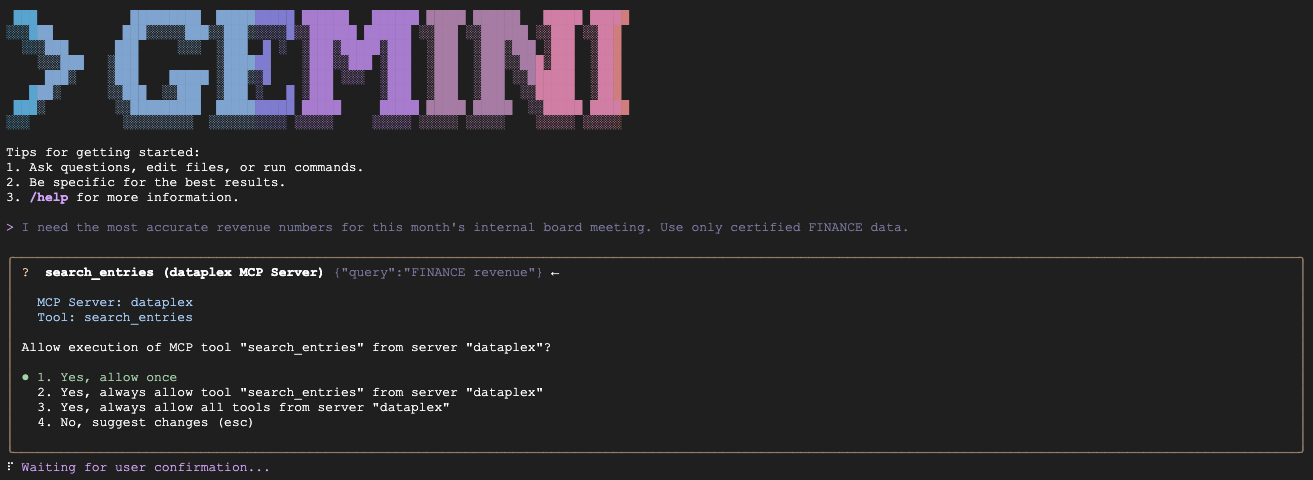
Remarque : Il est possible que plusieurs fichiers de contexte soient chargés (par exemple, GEMINI.md et d'autres). Ceci est normal. La CLI charge le fichier GEMINI.md local pour les règles spécifiques de ce projet, ainsi que les instructions par défaut pour l'extension Knowledge Catalog elle-même.
Vérifier l'installation
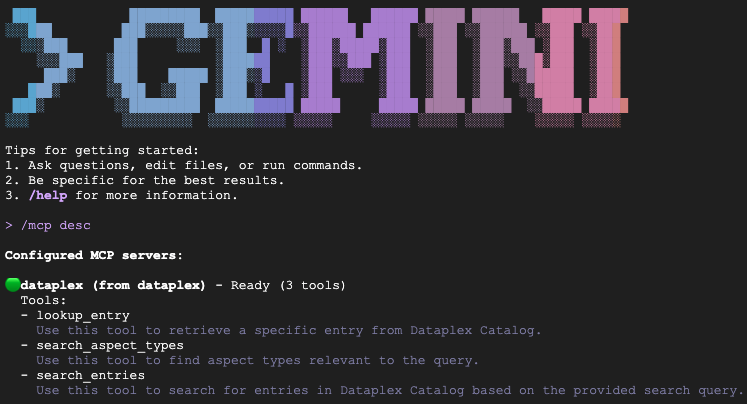
Saisissez /mcp desc pour confirmer que l'extension Knowledge Catalog est active. dataplex doit être listé en tant que serveur MCP configuré avec des outils disponibles.
Scénarios de test (prototypage)
Collez les requêtes suivantes dans la session de l'agent en cours d'exécution, une par une, pour vérifier qu'il respecte vos règles.
- Scénario A (certifier les données du DAF) :
"We are preparing the deck for an internal Board of Directors meeting next week. I need the numbers to be absolutely finalized, trustworthy, and kept strictly confidential. Which table is safe to use?"
Résultat attendu : la requête fin_monthly_closing_internal, car elle correspond sémantiquement à GOLD_CRITICAL (précis) et INTERNAL_ONLY (réunion du conseil d'administration) dans son aspect.
- Scénario B (divulgation publique) :
"I need to share our quarterly financial summary with an external consulting firm. It is critical that we do not leak any raw or internal metrics. Which dataset is officially scrubbed and explicitly approved for external sharing?"
Résultat attendu : l'agent doit ignorer le tableau interne mensuel et sélectionner strictement fin_quarterly_public_report, car il s'agit du seul composant tagué EXTERNAL_READY.
- Scénario C (besoins opérationnels) :
"My dashboard needs to show what's happening right now with our ad spend. I can't wait for the overnight load. What do you recommend?"
Résultat attendu : l'agent sélectionne mkt_realtime_campaign_performance, car il identifie la fréquence de mise à jour REALTIME_STREAMING, en la privilégiant par rapport au niveau GOLD_CRITICAL des données financières.
- Scénario D (expérimentation dans le bac à sable) :
"I'm just playing around with some new ML models and need a lot of raw data. It doesn't need to be perfect, just a sandbox environment."
Résultat attendu : l'agent sélectionne tmp_data_dump_v2_final_real, car il correspond sémantiquement à BRONZE_ADHOC (données brutes) et is_certified: false (environnement de bac à sable) dans son aspect.
(Pour quitter la session Gemini, saisissez /quit)
5. Félicitations ! Étape suivante
Vous avez créé une base de données régie et prouvé qu'une IA peut suivre strictement vos règles de métadonnées à l'aide d'un prototype de CLI locale.
Vous avez atteint un point de contrôle. Veuillez choisir une étape suivante :
Option A : Je souhaite passer à la partie 2 tout de suite !
Si vous êtes prêt à transformer ce prototype local en application Web sécurisée et de qualité professionnelle à l'aide du protocole MCP (Model Context Protocol) et de Cloud Run :
👉 Lien vers l'atelier de programmation de la partie 2
Option B : Je ferai la partie 2 plus tard ou je ne voulais faire que la partie 1.
Si vous souhaitez arrêter pour aujourd'hui et éviter les coûts liés au cloud, vous devez nettoyer vos ressources.
Pas de panique ! Dans la partie 2, nous vous fournirons un "script accéléré" qui reconstruira complètement cet environnement de la partie 1 en seulement deux minutes, afin que vous puissiez reprendre exactement là où vous vous êtes arrêté.
👉 Passez à la section "Nettoyage".
6. Libérer de l'espace (pour l'option B uniquement)
Si vous vous arrêtez ici, détruisez les ressources pour éviter que des frais ne vous soient facturés.
Détruire le lac de données (Terraform)
Si vous êtes actuellement dans l'environnement Gemini CLI, quittez la session en appuyant deux fois sur Ctrl+C ou en saisissant /quit. Exécutez ensuite les commandes suivantes :
cd ~/devrel-demos/data-analytics/governance-context/terraform
terraform destroy -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
Désinstaller l'extension Gemini CLI et supprimer les fichiers locaux
gemini extensions uninstall dataplex
cd ~
rm -rf ~/devrel-demos