
1. Introduction
Cet atelier de programmation fait partie d'une série en deux parties qui explique comment créer un agent d'IA générative respectueux de la gouvernance.
(Vous pouvez lire la première partie de cette série, qui explique comment établir les bases des données en appliquant des aspects Knowledge Catalog aux tables BigQuery et en testant les règles localement via la CLI Gemini. 👉 Lire la partie 1)
Toutefois, les tests dans une CLI locale ne sont qu'un début. Pour déployer cette solution dans toute votre entreprise, vous avez besoin d'une sécurité centralisée, de connexions standardisées aux outils d'IA et d'un framework d'application approprié pour orchestrer la logique de l'agent et fournir une interface de chat familière.
Dans cette deuxième partie, vous allez résoudre ces défis et passer à la production. Vous allez déployer vos règles de gouvernance dans un serveur MCP central hébergé sur Cloud Run. Ensuite, vous utiliserez Agent Development Kit (ADK) de Google pour créer l'application d'agent proprement dite et la connecter à vos outils MCP, avec une interface utilisateur Web professionnelle.
Prérequis
- Un projet Google Cloud avec facturation activée.
- Connaissances de base de Cloud Run, des comptes de service IAM et de Python.
- Les ensembles de données BigQuery et les aspects Knowledge Catalog créés dans la partie 1. (Ne vous inquiétez pas si vous les avez supprimés. Nous fournissons un script ci-dessous pour les recréer rapidement.)
Points abordés
- Utiliser le protocole MCP (Model Context Protocol) pour standardiser la façon dont les agents IA interagissent avec les données Google Cloud.
- Déployer un serveur MCP sécurisé sur Cloud Run.
- Créer un agent IA à l'aide d'Agent Development Kit (ADK) et le connecter à votre backend MCP.
- Exécuter l'interface utilisateur de développement intégrée d'ADK pour interagir avec votre agent géré.
Prérequis
- Accès à Google Cloud Shell
Concepts clés
- Protocole MCP (Model Context Protocol) : considérez le protocole MCP comme un "câble USB-C universel" pour les agents IA. Au lieu d'écrire du code d'intégration d'API personnalisé pour chaque modèle d'IA, le protocole MCP fournit un moyen standard pour que l'IA se connecte de manière sécurisée à vos outils de données d'entreprise (comme Knowledge Catalog et BigQuery).
- Agent Development Kit (ADK) : framework Open Source flexible de Google conçu pour simplifier le développement de bout en bout des agents IA. Il applique les principes d'ingénierie logicielle à la création d'agents, ce qui vous permet d'orchestrer des outils complexes, de gérer l'état et de lancer facilement une interface utilisateur de développement intégrée pour les tests et le déploiement.
2. Préparation
Démarrer Cloud Shell
Bien que Google Cloud puisse être utilisé à distance depuis votre ordinateur portable, nous allons nous servir de Google Cloud Shell pour cet atelier de programmation, un environnement de ligne de commande exécuté dans le cloud.
Dans la console Google Cloud, cliquez sur l'icône Cloud Shell dans la barre d'outils supérieure :
Le provisionnement et la connexion à l'environnement prennent quelques instants seulement. Une fois l'opération terminée, le résultat devrait ressembler à ceci :

Cette machine virtuelle contient tous les outils de développement nécessaires. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Vous pouvez effectuer toutes les tâches de cet atelier de programmation dans un navigateur. Vous n'avez rien à installer.
Initialiser l'environnement
Ouvrez Cloud Shell et définissez les variables de votre projet pour vous assurer que toutes les commandes ciblent l'infrastructure appropriée.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export REGION="us-central1"
Point de contrôle : reprendre ou reconstruire ?
Comme il s'agit de la partie 2, votre agent a besoin des données gérées de la partie 1 pour fonctionner. Veuillez choisir votre chemin :
Chemin A : Je viens de terminer la partie 1 et mes ressources sont toujours en cours d'exécution.
Parfait ! Accédez au répertoire de travail et vous êtes prêt à continuer.
cd ~/devrel-demos/data-analytics/governance-context
Chemin B : J'ai ignoré la partie 1 OU j'ai supprimé mes ressources (nettoyage).
Aucun problème. Nous avons fourni un bloc de commandes "Fast-Track" ci-dessous. Cela reconstruira automatiquement le lac de données BigQuery et appliquera les métadonnées de gouvernance Knowledge Catalog exactement comme nous l'avons fait dans la partie 1.
# 1. Clone the repo and navigate to the working directory
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set data-analytics/governance-context
cd data-analytics/governance-context
# 2. Rebuild the messy data lake with Terraform
cd terraform
terraform init
terraform apply -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
# 3. Generate and apply Knowledge Catalog Aspects (Governance rules)
cd ..
chmod +x ./generate_payloads.sh ./apply_governance.sh
./generate_payloads.sh
./apply_governance.sh
3. Mettre à l'échelle avec MCP : créer le plan de contrôle des données
Jusqu'à présent, vous avez testé votre logique de gouvernance à l'aide de la CLI Gemini. C'est excellent pour le prototypage rapide, mais cela s'exécute localement à l'aide de vos identifiants utilisateur personnels.
Dans un environnement d'entreprise réel, vous avez besoin d'un plan de contrôle des données centralisé. Pour ce faire, nous allons utiliser le GenAI Toolbox for Databases, un projet Open Source officiel de Google. Cette boîte à outils fournit un serveur MCP prédéfini conçu spécifiquement pour connecter les agents IA de manière sécurisée aux bases de données Google Cloud et aux services de métadonnées tels que Knowledge Catalog.
En déployant cette boîte à outils en tant que serveur MCP sur Cloud Run, nous obtenons les résultats suivants :
- Identité centralisée : l'agent s'exécute en tant que compte de service limité, et non en tant que compte utilisateur personnel.
- Standardisation : n'importe quel client (ADK, Gemini, applications personnalisées) peut se connecter à ce serveur à l'aide du protocole MCP standard.
- Champ d'application contrôlé (principe du moindre privilège) : nous n'accordons pas au LLM un accès illimité à BigQuery. Nous l'obligeons à parcourir d'abord le catalogue de métadonnées Knowledge Catalog.
Configurer la définition de l'outil (tools.yaml)
GenAI Toolbox nécessite un fichier de configuration déclaratif, tools.yaml. Ce fichier définit les sources (où se connecter) et les tools (ce que l'IA est autorisée à faire).
- Accédez au répertoire du serveur et injectez votre ID de projet dans le fichier de configuration :
cd ~/devrel-demos/data-analytics/governance-context/mcp_server
envsubst < tools.yaml > tools.tmp && mv tools.tmp tools.yaml
cat tools.yaml
Le résultat doit être identique à l'extrait suivant. Vérifiez que le champ du projet correspond désormais à votre ID de projet Google Cloud.
sources:
dataplex:
kind: dataplex
project: YOUR-PROJECT-ID
tools:
search_entries:
kind: dataplex-search-entries
source: dataplex
description: Search for entries in Knowledge Catalog.
lookup_entry:
kind: dataplex-lookup-entry
source: dataplex
description: Retrieve a specific entry from Knowledge Catalog.
search_aspect_types:
kind: dataplex-search-aspect-types
source: dataplex
description: Find aspect types relevant to a query.
toolsets:
dataplex-toolset:
- search_entries
- lookup_entry
- search_aspect_types
En définissant ces trois outils, nous pouvons forcer l'IA à être "en lecture seule" et "axée sur la gouvernance".
Sécuriser la configuration (Secret Manager)
Dans l'architecture d'entreprise, vous ne devez jamais intégrer directement des fichiers de configuration dans des images de conteneurs. Nous allons stocker tools.yaml de manière sécurisée dans Google Cloud Secret Manager.
gcloud services enable secretmanager.googleapis.com
gcloud secrets create dataplex-tools-config --data-file=tools.yaml
Implémenter le principe du moindre privilège (IAM)
Ensuite, nous allons créer un compte de service dédié pour le serveur MCP GenAI Toolbox. Cette identité ne disposera que des autorisations exactes requises pour lire le catalogue Knowledge Catalog et accéder aux données BigQuery.
export MCP_SA=mcp-sa
gcloud iam service-accounts create ${MCP_SA} \
--display-name="Service Account for Knowledge Catalog MCP"
export MCP_SERVICE_ACCOUNT="${MCP_SA}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow the server to read its own config from Secret Manager
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/secretmanager.secretAccessor"
# Allow the server to read Knowledge Catalog Metadata and BigQuery Data
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/dataplex.catalogViewer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/bigquery.dataViewer"
Déployer le serveur MCP sur Cloud Run
Nous allons maintenant déployer GenAI Toolbox. Nous allons utiliser l'image de conteneur prédéfinie de Google (database-toolbox/toolbox) et installer notre configuration à partir de Secret Manager (--set-secrets) au moment de l'exécution.
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
gcloud run deploy governance-mcp \
--image=$IMAGE \
--service-account $MCP_SERVICE_ACCOUNT \
--region=$REGION \
--no-allow-unauthenticated \
--set-secrets="/app/tools.yaml=dataplex-tools-config:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080"
Vous avez maintenant établi une API gérée. Au lieu de donner à votre frontend GenAI un accès direct à la base de données, il se connectera à cette URL Cloud Run. L'agent ne peut voir que ce que cette boîte à outils lui permet de voir.
4. Créer le backend de l'agent avec ADK
Vous avez établi un plan de contrôle des données (MCP) sécurisé et géré qui s'exécute sur Cloud Run. Votre agent IA a maintenant besoin d'un framework pour orchestrer sa logique, par exemple pour traiter les entrées utilisateur, décider quand appeler le serveur MCP et mettre en forme la sortie.
Au lieu d'écrire tout ce code récurrent à partir de zéro, nous allons utiliser Agent Development Kit (ADK) de Google. ADK est un framework "code-first" qui encapsule automatiquement la logique de votre agent dans un backend FastAPI. De plus, il est fourni avec une interface utilisateur de développement intégrée, ce qui vous permet de visualiser instantanément le processus de raisonnement de l'agent et les appels d'outils sans avoir à créer d'abord un frontend personnalisé.
Inspecter la logique de l'agent (agent.py)
Avant de configurer l'infrastructure, examinons le cœur de cette application.
Accédez au répertoire et affichez le contenu d'agent.py. Ce fichier est le "cerveau" de votre déploiement ADK.
cd ~/devrel-demos/data-analytics/governance-context/mcp_server
cat agent.py
Examinez la structure du code. Il remplit trois fonctions essentielles avec un minimum de code récurrent :
- Intégration de MCPToolset : au lieu d'écrire des clients HTTP personnalisés pour interagir avec vos outils Knowledge Catalog, l'ADK utilise
MCPToolset(server_url=mcp_url). Cela récupère dynamiquement la définitiontools.yamlde votre serveur MCP déployé et la traduit en appels de fonction natifs pour le LLM. - Instructions système : le paramètre
instructionscontient les règles de gouvernance strictes (la même logique que celle que nous avons utilisée dans la CLIGEMINI.md). Il ordonne explicitement au modèle d'exécuter la boucle de raisonnement de la phase 1 (recherche de métadonnées) à la phase 2 (requête de données). - Orchestration de l'agent : la classe
Agent(...)lie le modèle Gemini, le prompt système et les outils MCP. Une fois déployé, ADK convertit automatiquement cet objet en un point de terminaison FastAPI évolutif.
Séparation des tâches : configurer l'identité du frontend
Pour exécuter ce code de manière sécurisée, nous devons indiquer à l'agent où se trouve votre serveur MCP. Nous allons construire l'URL de manière dynamique et l'enregistrer dans un fichier .env que l'ADK lira au moment de l'exécution.
Nous allons également créer une identité distincte (dataplex-agent-sa) pour cette application destinée aux utilisateurs. Cette séparation des tâches garantit que l'agent frontend dispose d'autorisations différentes de celles du serveur de gouvernance backend.
Exécutez les commandes suivantes pour configurer l'environnement et l'identité :
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export MCP_SERVER_URL=https://governance-mcp-${PROJECT_NUMBER}.${REGION}.run.app/mcp
export AGENT_SA=knowledge-catalog-agent-sa
export AGENT_SERVICE_ACCOUNT="${AGENT_SA}@${PROJECT_ID}.iam.gserviceaccount.com"
gcloud iam service-accounts create ${AGENT_SA} \
--display-name="Service Account for Knowledge Catalog Agent "
Configurer les variables d'exécution
Le framework ADK s'appuie sur des variables d'environnement pour comprendre son contexte. Nous devons définir explicitement l'ID du projet, la région et activer l'utilisation de Gemini Enterprise Agent Engine. Nous allons ajouter ces éléments au même fichier .env.
echo MCP_SERVER_URL=$MCP_SERVER_URL > .env
echo GOOGLE_GENAI_USE_VERTEXAI=1 >> .env
echo GOOGLE_CLOUD_PROJECT=$PROJECT_ID >> .env
echo GOOGLE_CLOUD_LOCATION=$REGION >> .env
Octroyer des autorisations
Même si l'agent délègue les vérifications de gouvernance au serveur MCP, il a toujours besoin d'autorisations de base pour fonctionner. Nous allons attribuer exactement deux rôles :
- Utilisateur de Gemini Enterprise Agent Engine : pour appeler le modèle Gemini afin de générer des réponses en langage naturel.
- Demandeur Cloud Run : pour appeler de manière sécurisée l'API de votre serveur MCP. Il n'obtient pas d'accès direct à BigQuery ni à Knowledge Catalog.
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/aiplatform.user"
gcloud run services add-iam-policy-binding governance-mcp \
--region=$REGION \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/run.invoker"
Déployer une application sur Cloud Run
Enfin, nous allons déployer la pile complète sur Cloud Run.
Nous allons utiliser uvx pour exécuter l'outil ADK sans installer manuellement les dépendances. La commande ci-dessous crée un package à partir de la logique de votre agent.py, génère une image de conteneur, injecte votre compte de service et lance un serveur FastAPI. En ajoutant l'indicateur --with_ui, elle regroupe également le bac à sable Web ADK pour le débogage.
Cette commande crée le conteneur et le déploie. Cette opération peut prendre 1 à 3 minutes.
uvx --from google-adk \
adk deploy cloud_run \
--project=$PROJECT_ID \
--region=$REGION \
--service_name=knowledge-catalog-agent \
--with_ui \
. \
-- \
--service-account=$AGENT_SERVICE_ACCOUNT \
--allow-unauthenticated
Une fois cette commande terminée, elle génère une URL de service (e.g., https://dataplex-agent-xyz.run.app). Cliquez sur ce lien pour ouvrir votre interface de chat GenAI entièrement gérée.
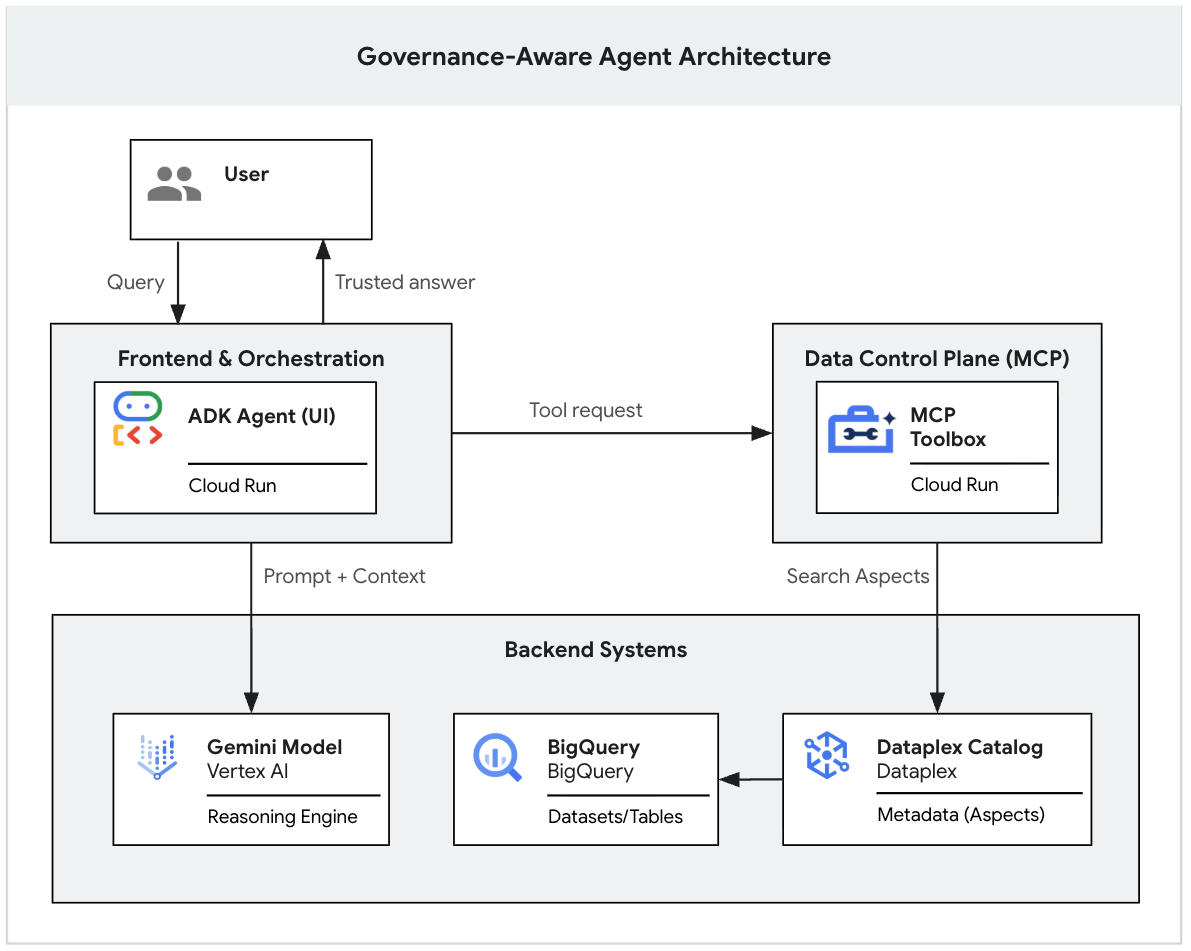
Flux architectural de bout en bout
Vous avez terminé le système. Lorsqu'un utilisateur interagit avec l'interface utilisateur ADK, la séquence suivante se produit :
- L'utilisateur envoie un prompt dans l'agent ADK (interface utilisateur de développement).
- L'agent ADK (agent.py) traite l'entrée et appelle le modèle Gemini.
- Gemini détermine qu'il a besoin de contexte et demande au serveur MCP d'exécuter les outils Knowledge Catalog.
- Le serveur MCP applique les règles de gouvernance Knowledge Catalog et renvoie les métadonnées.
- Gemini synthétise la réponse fiable en fonction des métadonnées et la renvoie à l'utilisateur.
5. Tester l'agent d'entreprise
Maintenant que votre agent est en ligne, revenons aux scénarios de gouvernance testés précédemment avec la CLI. La logique reste la même, mais vous interagissez désormais avec le bac à sable Web ADK déployé, qui visualise l'état interne et les exécutions d'outils.
- Orchestration : l'agent ADK (exécuté sur Cloud Run) reçoit votre texte.
- Routage des outils : Gemini reconnaît que votre question nécessite un contexte de données et transfère la requête au serveur MCP.
- Vérification de la gouvernance : le serveur MCP (exécuté sur une instance Cloud Run distincte) interroge Knowledge Catalog pour des types d'aspects spécifiques.
- Synthèse : les métadonnées pertinentes sont renvoyées à Gemini pour générer la réponse finale.
Vérifier la logique de gouvernance
Ouvrez l'URL de service que vous avez générée à l'étape précédente (e.g., https://dataplex-agent-xyz.run.app) dans votre navigateur. Collez le prompt suivant :
"My dashboard needs to show what's happening right now with our ad spend. I can't wait for the overnight load. What do you recommend?"
Observez le processus de raisonnement de l'agent dans l'interface utilisateur de développement :
- Reconnaissance de l'intention : l'agent analyse "tout de suite" et "ne peut pas attendre la nuit".
- Recherche de métadonnées : il appelle l'outil MCP
search_aspect_types. Il recherche des éléments de données où l'aspectupdate_frequencyest défini sur REALTIME ou STREAMING, plutôt que sur DAILY ou MONTHLY. - Sélection : il identifie que la table
mkt_realtime_campaign_performancerépond à ces critères, tandis quefin_monthly_closing_internal(bien qu'elle soit de haute qualité) est trop lente pour votre requête. - Réponse : l'agent recommande la table en temps réel.
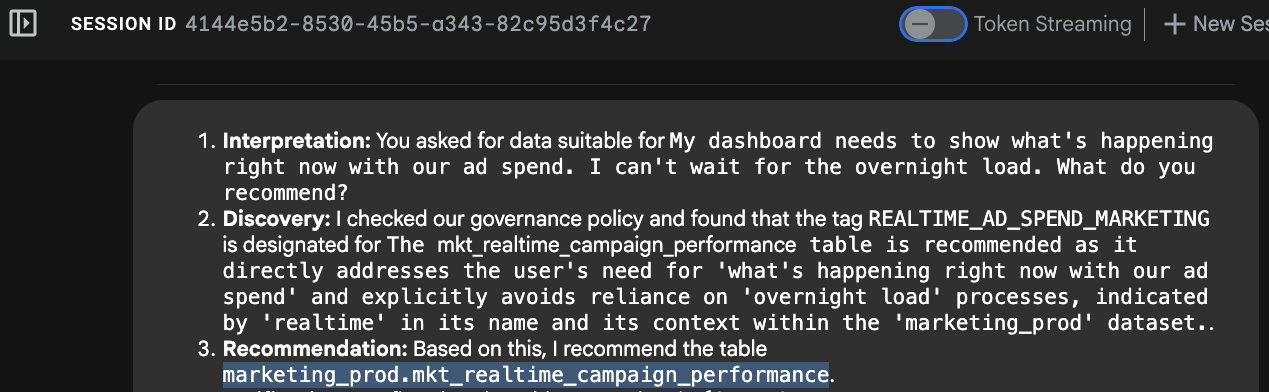
Explication :
Sans ces métadonnées de gouvernance, un LLM recommanderait probablement la table fin_monthly_closing_internal simplement parce qu'elle comporte une colonne nommée "ad_spend", sans tenir compte du fait que les données datent de 24 heures. Votre contexte de métadonnées a empêché une erreur commerciale.
Vous pouvez également tester le prompt "Board Meeting" pour voir comment l'agent passe à différentes tables en fonction de l'aspect Niveau du produit de données :
"We are preparing the deck for an internal Board of Directors meeting next week. I need the numbers to be absolutely finalized, trustworthy, and kept strictly confidential. Which table is safe to use?"
6. Libérer de l'espace
Pour éviter que les ressources utilisées dans cet atelier de programmation ne soient facturées sur votre compte Google Cloud, suivez ces étapes pour détruire toute l'infrastructure créée dans les parties 1 et 2.
Détruire le lac de données (Terraform)
Utilisez Terraform pour supprimer les tables, les ensembles de données et les définitions d'aspects Knowledge Catalog BigQuery.
cd ~/devrel-demos/data-analytics/governance-context/terraform
terraform destroy -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
Supprimer les services Cloud Run
Supprimez les ressources de calcul pour arrêter toute facturation active pour les conteneurs en cours d'exécution.
gcloud run services delete governance-mcp --region=$REGION --quiet
gcloud run services delete knowledge-catalog-agent --region=$REGION --quiet
Libérer de l'espace utilisé par les artefacts de compilation et le stockage intermédiaire
Lorsque vous avez déployé l'agent ADK à l'aide de uvx, le système a automatiquement créé une image de conteneur et importé votre code source dans un bucket Cloud Storage temporaire. Ces artefacts persistent même après la suppression du service Cloud Run et entraînent des coûts de stockage continus.
Supprimez le dépôt Artifact Registry et le bucket intermédiaire Cloud Storage :
# Delete the repository used for the agent build
gcloud artifacts repositories delete cloud-run-source-deploy \
--location=$REGION \
--quiet
# Delete the staging bucket created by Cloud Run source deploy
gcloud storage rm --recursive gs://run-sources-${PROJECT_ID}-${REGION}
Supprimer l'identité, les autorisations et les secrets
Supprimez d'abord les liaisons de stratégie IAM pour éviter que des entrées "tombstone" (enregistrements orphelins) ne restent sur la page IAM de votre projet. Supprimez ensuite les comptes de service et les secrets de configuration.
# Remove IAM roles granted to the MCP Service Account
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/secretmanager.secretAccessor" --quiet
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/dataplex.catalogViewer" --quiet
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/bigquery.dataViewer" --quiet
# Remove IAM roles granted to the Agent Service Account
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/aiplatform.user" --quiet
# Delete the Service Accounts
gcloud iam service-accounts delete $MCP_SERVICE_ACCOUNT --quiet
gcloud iam service-accounts delete $AGENT_SERVICE_ACCOUNT --quiet
# Delete the Secret Manager entry
gcloud secrets delete dataplex-tools-config --quiet
Supprimer la configuration locale
Enfin, nettoyez les fichiers de configuration locaux et les variables d'environnement dans Cloud Shell.
# Uninstall the Gemini CLI extension (installed in Part 1)
gemini extensions uninstall dataplex
# Remove local repository files and unset variables
cd ~
rm -rf ~/devrel-demos
unset MCP_SERVER_URL
unset MCP_SERVICE_ACCOUNT
unset AGENT_SERVICE_ACCOUNT
7. Félicitations !
Vous avez déployé un agent d'IA générative de bout en bout respectueux de la gouvernance.
Dans cet atelier de programmation en deux parties, vous avez dépassé la simple ingénierie de prompts pour implémenter une architecture robuste et prête pour la production. En traitant la gouvernance des données comme une condition préalable à l'IA générative, vous avez établi une méthode systématique pour empêcher le modèle de récupérer des données non certifiées ou hallucinées.
Points clés à retenir
- IA déterministe via les métadonnées : au lieu de laisser le LLM deviner la table correcte en fonction des noms de colonnes, vous avez appliqué une boucle de raisonnement stricte à l'aide de GenAI Toolbox for Databases. En exposant explicitement seulement trois outils Knowledge Catalog (
search_aspect_types,search_entries,lookup_entry), vous avez forcé le modèle à vérifier les certifications de données avant de synthétiser les réponses. - Architecture découplée (MCP) : en déployant le serveur MCP (Model Context Protocol) sur Cloud Run, vous avez abstrait vos règles de gouvernance des données dans une API centralisée et standardisée. L'agent frontend n'a pas besoin de contenir de logique de base de données. Il n'a besoin de communiquer que via la norme MCP. Cela signifie que vous pouvez connecter n'importe quel futur modèle ou client d'IA au même backend géré.
- Séparation des tâches : vous avez appliqué le principe du moindre privilège en isolant les identités IAM. L'agent ADK destiné aux utilisateurs fonctionne avec des autorisations limitées à l'appel de modèle et au routage d'API, tandis que le serveur MCP backend gère de manière sécurisée les requêtes Knowledge Catalog et la récupération des données BigQuery.
- Orchestration d'agents "code-first" : vous avez utilisé Google Agent Development Kit (ADK) pour encapsuler instantanément la logique de votre agent Python dans un backend FastAPI évolutif, en utilisant son interface utilisateur de développement intégrée pour visualiser et déboguer les exécutions d'outils internes de l'agent.
Et ensuite ?
- Atelier de programmation sur les bases de la gouvernance dans Knowledge Catalog : maîtrisez les principes fondamentaux de la gouvernance des données dans Knowledge Catalog avant d'ajouter la couche d'IA.
- Documentation sur les outils Knowledge Catalog : explorez la documentation officielle des outils et extensions Knowledge Catalog prédéfinis utilisés dans cet atelier.
- Premiers pas avec les extensions Gemini CLI : découvrez comment créer vos propres extensions personnalisées pour offrir encore plus de fonctionnalités à vos agents d'IA générative.
- Présentation détaillée du protocole MCP : consultez la spécification officielle du protocole MCP pour comprendre comment créer des serveurs personnalisés pour vos API d'entreprise internes.