
1. Pengantar
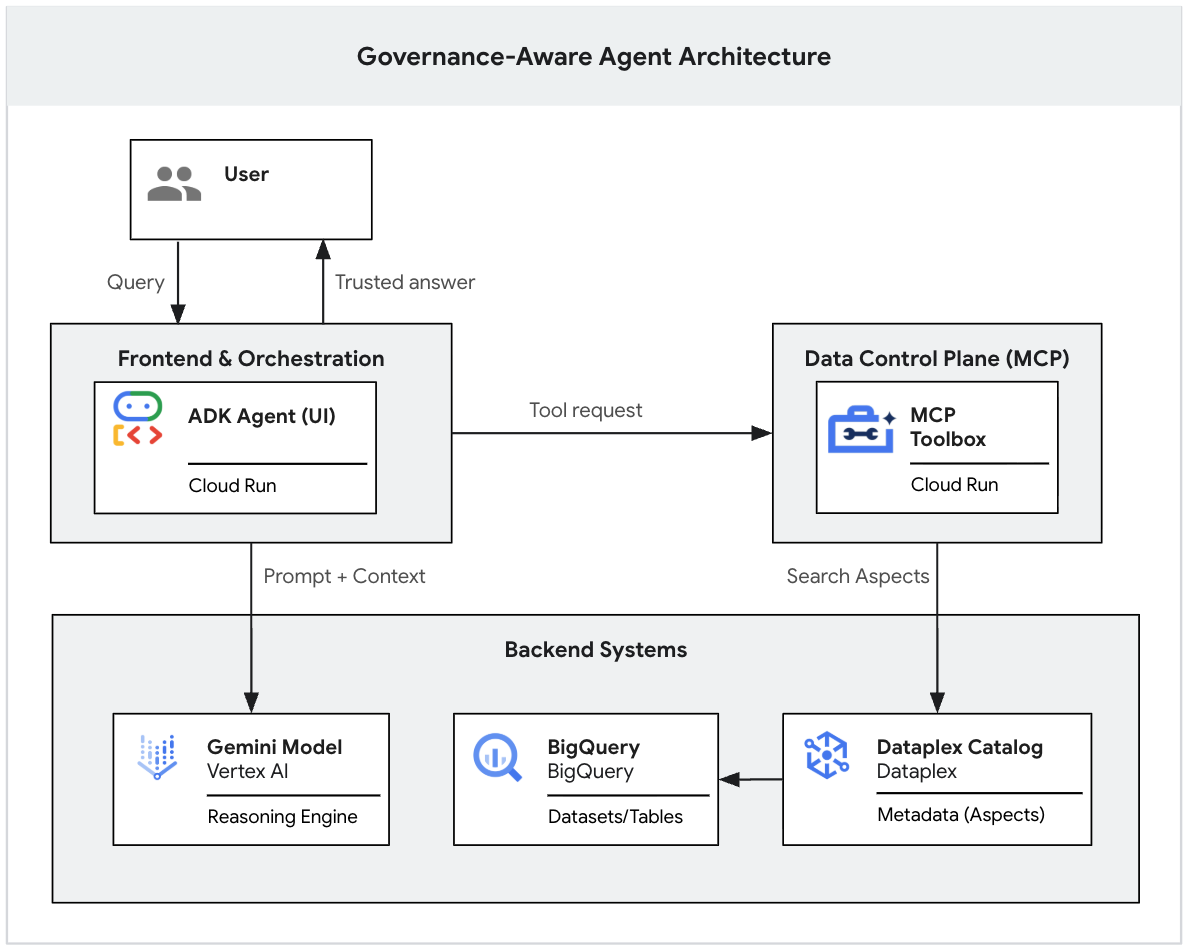
Model AI generatif adalah penalaran yang canggih, tetapi tidak memiliki konteks institusional. Jika seorang eksekutif bertanya kepada agen AI, "Berapa pendapatan Q1 kita?", agen tersebut mungkin menemukan lusinan tabel bernama "pendapatan" di seluruh data lake Anda. Beberapa di antaranya adalah laporan keuangan yang ketat, yang lain adalah perkiraan pemasaran real-time, dan banyak yang kemungkinan merupakan sandbox yang tidak digunakan lagi.
Tanpa dasar yang eksplisit, agen AI akan memilih tabel berdasarkan kesamaan nama sederhana, sehingga menghasilkan jawaban "sangat salah" yang berasal dari data yang tidak diverifikasi.
Codelab ini adalah bagian dari seri dua bagian yang membahas cara membangun Agen AI Generatif yang Memahami Tata Kelola.
Di bagian pertama ini, Anda akan membangun fondasi data. Anda akan menyiapkan data lake yang realistis dan "berantakan" di BigQuery, menerapkan tag metadata yang ketat (Aspek Knowledge Catalog) untuk membedakan data yang valid dari noise, dan menggunakan Gemini CLI untuk menguji secara lokal apakah LLM mengikuti aturan tata kelola Anda dengan ketat.
(Anda dapat membaca bagian kedua dari seri ini, yang membahas cara men-deploy prototipe lokal ini ke aplikasi web yang aman dan tingkat perusahaan menggunakan Model Context Protocol (MCP) dan Cloud Run. 👉 Baca Bagian 2)
Prasyarat
- Project Google Cloud yang mengaktifkan penagihan.
- Pemahaman dasar dan keakraban dengan BigQuery, Knowledge Catalog Universal Catalog, dan Terraform.
- Akses ke Google Cloud Shell.
Yang akan Anda pelajari
- Men-deploy data lake multi-tingkat yang realistis menggunakan Terraform.
- Mendesain template metadata yang ketat (Jenis Aspek) di Knowledge Catalog untuk membedakan produk data resmi dari tabel sandbox mentah.
- Memverifikasi aturan tata kelola secara lokal menggunakan Gemini CLI sebelum menulis kode aplikasi apa pun.
Yang akan Anda butuhkan
- Akses ke Google Cloud Shell
- Terraform (sudah terinstal di Cloud Shell).
- Gemini CLI (sudah terinstal di Cloud Shell).
Konsep utama
- Knowledge Catalog Universal Catalog: Layanan pengelolaan metadata terpadu. Kami menggunakannya untuk memperkaya metadata teknis (skema) dengan konteks bisnis (tata kelola).
- Jenis Aspek: Template metadata terstruktur. Tidak seperti tag teks bebas, Aspek menerapkan pengetikan yang kuat (enum, boolean), sehingga membuatnya dapat diandalkan untuk dievaluasi oleh mesin.
2. Penyiapan dan persyaratan
Mulai Cloud Shell
Meskipun Google Cloud dapat dioperasikan dari jarak jauh menggunakan laptop Anda, dalam codelab ini, Anda akan menggunakan Google Cloud Shell, lingkungan command line yang berjalan di Cloud.
Dari Konsol Google Cloud, klik ikon Cloud Shell di toolbar kanan atas:
Hanya perlu waktu beberapa saat untuk penyediaan dan terhubung ke lingkungan. Jika sudah selesai, Anda akan melihat tampilan seperti ini:

Mesin virtual ini berisi semua alat pengembangan yang Anda perlukan. Layanan ini menawarkan direktori beranda tetap sebesar 5 GB dan beroperasi di Google Cloud, sehingga sangat meningkatkan performa dan autentikasi jaringan. Semua pekerjaan Anda dalam codelab ini dapat dilakukan di browser. Anda tidak perlu menginstal apa pun.
Melakukan inisialisasi lingkungan
Buka Cloud Shell dan tetapkan variabel project Anda untuk memastikan semua perintah menargetkan infrastruktur yang benar.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export REGION="us-central1"
Mengaktifkan API
Aktifkan layanan Google Cloud yang diperlukan untuk menjalankan petunjuk berikut.
gcloud services enable \
artifactregistry.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
datacatalog.googleapis.com \
run.googleapis.com
Membuat clone repositori
Dapatkan kode infrastruktur dan skrip otomatisasi dari repositori GitHub. Untuk menghemat ruang disk di Cloud Shell, kita hanya akan mendownload folder tertentu yang diperlukan untuk lab ini.
# Perform a shallow clone to get only the latest repository structure without the full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Specify and download only the folder we need for this lab
git sparse-checkout set data-analytics/governance-context
cd data-analytics/governance-context
Membangun data lake yang "berantakan"
Lingkungan data dunia nyata jarang sekali bersih. Untuk mensimulasikan realitas, kita memerlukan campuran data mart "resmi" dan tabel "sandbox" yang tidak tepercaya.
Kita akan menggunakan Terraform untuk men-deploy lingkungan ini. Konfigurasi ini menangani dua tugas:
- Infrastruktur: Membuat Jenis Aspek Knowledge Catalog dan Set Data/Tabel BigQuery.
- Pemuatan Data: Menjalankan tugas BigQuery INSERT untuk mengisi tabel dengan data contoh segera setelah pembuatan.
- Buka direktori
terraformdan lakukan inisialisasi.
cd terraform
terraform init
- Terapkan konfigurasi. Proses ini mungkin memerlukan waktu hingga satu menit.
terraform apply -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
Checkpoint: Sekarang Anda memiliki data lake yang terisi penuh, tetapi sama sekali tidak diatur. Bagi AI, setiap tabel terlihat sama persis.
3. Menerapkan tata kelola
Ini adalah langkah engineering yang penting. Saat ini, tabel finance_mart.fin_monthly_closing_internal dan analyst_sandbox.tmp_data_dump_v2_final_real terlihat identik dengan LLM. Keduanya hanyalah objek dengan kolom.
Sebagai engineer tata kelola, Anda harus melampirkan Aspek (label metadata bersertifikat) ke tabel ini untuk membedakannya. Di perusahaan yang sebenarnya, Anda akan mengotomatiskan hal ini melalui pipeline CI/CD. Kita akan mensimulasikan otomatisasi tersebut dengan skrip.
Membuat payload tata kelola
Kunci Aspek Knowledge Catalog harus unik secara global (dengan awalan Project ID Anda). Skrip ./generate_payloads.sh akan membuat file metadata YAML secara dinamis.
cd ..
chmod +x ./generate_payloads.sh
./generate_payloads.sh
Output:
Tindakan ini akan membuat folder "./aspect_payloads" yang berisi 4 file YAML, yang menentukan skenario tata kelola (Emas/Internal, Emas/Publik, Perak/Realtime, Perunggu/Sandbox).
Menerapkan Aspek melalui CLI
Sebelum menjalankan skrip, mari kita lihat apa yang sebenarnya kita terapkan untuk menghilangkan keraguan dalam proses ini. Jalankan perintah berikut untuk melihat struktur payload keuangan internal:
cat aspect_payloads/fin_internal.yaml
Tindakan ini akan menampilkan konten berikut.
your-project-id.us-central1.official-data-product-spec:
data:
product_tier: GOLD_CRITICAL
data_domain: FINANCE
usage_scope: INTERNAL_ONLY
update_frequency: DAILY_BATCH
is_certified: true
Perhatikan bagaimana YAML ini secara eksplisit menentukan konteks bisnis, seperti menetapkan flag is_certified: true dan menetapkan tingkat GOLD_CRITICAL. Memberikan aturan yang jelas dan terstruktur kepada AI untuk dievaluasi, bukan hanya menebak berdasarkan nama tabel.
Sekarang, jalankan skrip aplikasi. Tindakan ini akan melakukan iterasi melalui tabel BigQuery dan menjalankan perintah gcloud dataplex entries update untuk melampirkan metadata yang ketat ini.
chmod +x ./apply_governance.sh
./apply_governance.sh
Verifikasi (Opsional)
Sebelum melanjutkan, pastikan metadata diterapkan dengan benar di konsol.
- Buka halaman Knowledge Catalog Universal Catalog di Konsol Google Cloud. Jika Anda tidak melihat "Knowledge Catalog Universal Catalog" di menu navigasi sebelah kiri, gunakan kotak Penelusuran di bagian atas jendela Konsol Google Cloud, ketik Knowledge Catalog, lalu pilih hasil di bagian "Hasil teratas" atau "Produk & Halaman".
- Telusuri
fin_monthly_closing_internal. Anda akan melihat tabel BigQuery yang tercantum dalam hasil. Klik nama tabel untuk membuka halaman detailnya.
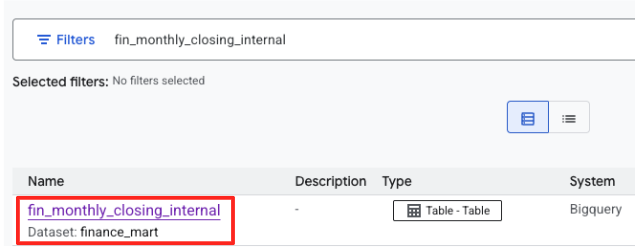
- Di halaman detail tabel, cari bagian "Tag dan aspek opsional" yang terletak di bagian bawah.
- Anda akan menemukan aspek
official-data-product-spec. Pastikan nilai tersebut cocok dengan skenario "Emas Internal" yang kita terapkan.
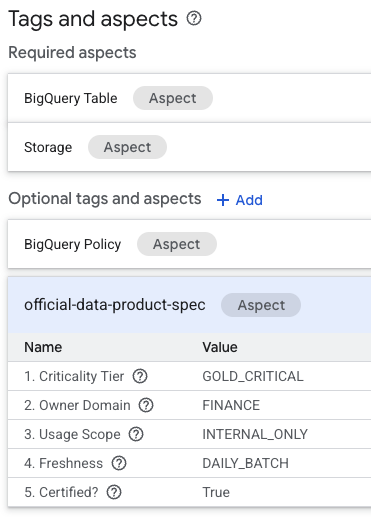
Sekarang Anda telah mengonfirmasi bahwa tabel BigQuery yang secara teknis identik (fin_monthly_closing_internal dan tmp_data_dump_v2_final_real) dibedakan secara logis oleh metadata yang dapat dibaca mesin.
4. Mengonfigurasi dan membuat prototipe agen
Sebelum membangun aplikasi web (yang akan kita lakukan di Bagian 2), kita akan memverifikasi logika tata kelola kita secara lokal. Kita perlu menginstal Ekstensi Knowledge Catalog dan mengonfigurasi perintah sistem.
Menginstal ekstensi
Di Cloud Shell, instal Ekstensi Knowledge Catalog. Sistem akan meminta konfirmasi dan detail penyiapan Anda.
export DATAPLEX_PROJECT="${PROJECT_ID}"
gemini extensions install https://github.com/gemini-cli-extensions/dataplex
(Ketik Y untuk menerima penginstalan, dan masukkan Project ID Anda saat diminta).
Menentukan file kebijakan
File GEMINI.md berisi logika yang menerjemahkan aturan manusia abstrak (misalnya, "Saya memerlukan data yang aman") ke dalam pencarian teknis yang ketat.
File ini saat ini bersifat umum. Agen perlu mengetahui project Google Cloud mana yang harus ditelusuri untuk mencegahnya berhalusinasi tabel dari internet publik atau konteks lainnya.
- Masukkan
PROJECT_IDAnda ke dalam file kebijakan.
envsubst < GEMINI.md > GEMINI.md.tmp && mv GEMINI.md.tmp GEMINI.md
- Periksa file untuk memahami algoritma yang kita ajarkan kepada AI.
cat GEMINI.md
Perhatikan dua hal dalam file ini:
- Cakupan Project: Periksa Fase 2. Pastikan projectid:
${PROJECT_ID}telah diganti dengan Project ID Anda yang sebenarnya(e.g., projectid:my-lab-project). Jika variabel ini tidak diganti, agen akan menelusuri setiap project yang dapat Anda akses, sehingga menghasilkan jawaban yang salah. - Algoritma: Perhatikan logika Fase 1 / Fase 2. Kita secara eksplisit menginstruksikan model untuk TIDAK menebak SQL. Model harus terlebih dahulu menelusuri definisi tag yang benar (Fase 1), lalu menelusuri data (Fase 2).
Memulai agen dan menguji skenario
Mulai sesi Gemini CLI, kali ini muat kebijakan tata kelola Anda sebagai konteks sistem.
gemini
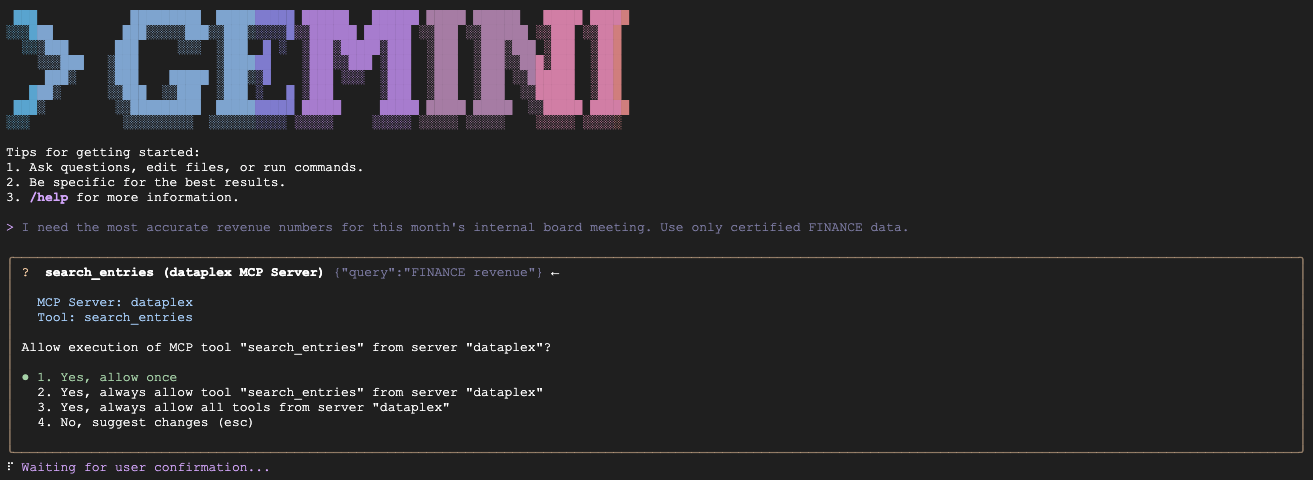
Catatan: Anda mungkin melihat beberapa file konteks dimuat (misalnya, GEMINI.md dan lainnya). Hal ini wajar. CLI memuat GEMINI.md lokal untuk aturan khusus project ini, ditambah petunjuk default untuk Ekstensi Knowledge Catalog itu sendiri.
Memverifikasi penginstalan
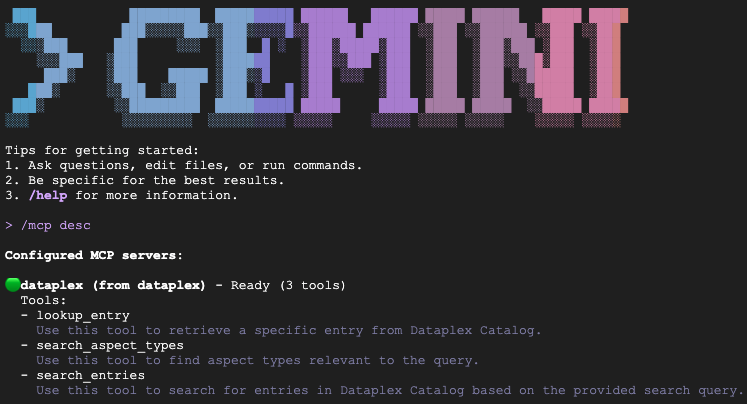
Ketik /mcp desc untuk mengonfirmasi bahwa Ekstensi Knowledge Catalog aktif. Anda akan melihat dataplex tercantum sebagai server MCP yang dikonfigurasi dengan alat yang tersedia.
Skenario pengujian (Pembuatan prototipe)
Tempel perintah berikut ke sesi agen yang berjalan satu per satu untuk memverifikasi bahwa agen tersebut mematuhi aturan Anda.
- Skenario A (Mensertifikasi data CFO):
"We are preparing the deck for an internal Board of Directors meeting next week. I need the numbers to be absolutely finalized, trustworthy, and kept strictly confidential. Which table is safe to use?"
Diharapkan: Kueri fin_monthly_closing_internal karena secara semantik cocok dengan GOLD_CRITICAL (akurat) dan INTERNAL_ONLY (rapat dewan) dalam Aspeknya.
- Skenario B (Pengungkapan publik):
"I need to share our quarterly financial summary with an external consulting firm. It is critical that we do not leak any raw or internal metrics. Which dataset is officially scrubbed and explicitly approved for external sharing?"
Diharapkan: Agen harus melewati tabel internal bulanan dan memilih fin_quarterly_public_report secara ketat karena merupakan satu-satunya aset yang diberi tag EXTERNAL_READY.
- Skenario C (Kebutuhan operasional):
"My dashboard needs to show what's happening right now with our ad spend. I can't wait for the overnight load. What do you recommend?"
Diharapkan: Agen memilih mkt_realtime_campaign_performance karena mengidentifikasi frekuensi update REALTIME_STREAMING, yang memprioritaskannya daripada tingkat GOLD_CRITICAL data keuangan.
- Skenario D (Eksperimen sandbox):
"I'm just playing around with some new ML models and need a lot of raw data. It doesn't need to be perfect, just a sandbox environment."
Diharapkan: Agen memilih tmp_data_dump_v2_final_real karena secara semantik cocok dengan BRONZE_ADHOC (data mentah) dan is_certified: false (lingkungan sandbox) dalam Aspeknya.
(Untuk keluar dari sesi Gemini, ketik /quit)
5. Selamat! Apa langkah selanjutnya?
Anda telah berhasil membangun fondasi data yang diatur dan membuktikan bahwa AI dapat mengikuti aturan metadata Anda dengan ketat menggunakan prototipe CLI lokal.
Sekarang, Anda telah mencapai checkpoint. Pilih langkah Anda berikutnya:
Opsi A: Saya ingin melanjutkan ke Bagian 2 sekarang juga!
Jika Anda siap mengubah prototipe lokal ini menjadi aplikasi web yang aman dan tingkat produksi menggunakan Model Context Protocol (MCP) dan Cloud Run:
Opsi B: Saya akan mengerjakan Bagian 2 nanti atau saya hanya ingin menyelesaikan Bagian 1.
Jika Anda ingin berhenti untuk hari ini dan menghindari biaya cloud, Anda harus membersihkan resource.
Jangan khawatir! Di Bagian 2, kami akan menyediakan "Skrip Jalur Cepat" yang akan membangun kembali lingkungan Bagian 1 ini sepenuhnya untuk Anda hanya dalam 2 menit sehingga Anda dapat melanjutkan tepat dari bagian yang Anda tinggalkan.
👉 Lanjutkan ke bagian Pembersihan.
6. Pembersihan (Hanya untuk opsi B)
Jika Anda berhenti di sini, hapus resource untuk menghindari timbulnya biaya.
Menghapus Datalake (Terraform)
Jika saat ini Anda berada di lingkungan Gemini CLI, keluar dari sesi dengan menekan Ctrl+C dua kali atau mengetik /quit. Kemudian, jalankan perintah berikut:
cd ~/devrel-demos/data-analytics/governance-context/terraform
terraform destroy -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
Meng-uninstal ekstensi Gemini CLI dan menghapus file lokal
gemini extensions uninstall dataplex
cd ~
rm -rf ~/devrel-demos