
1. はじめに
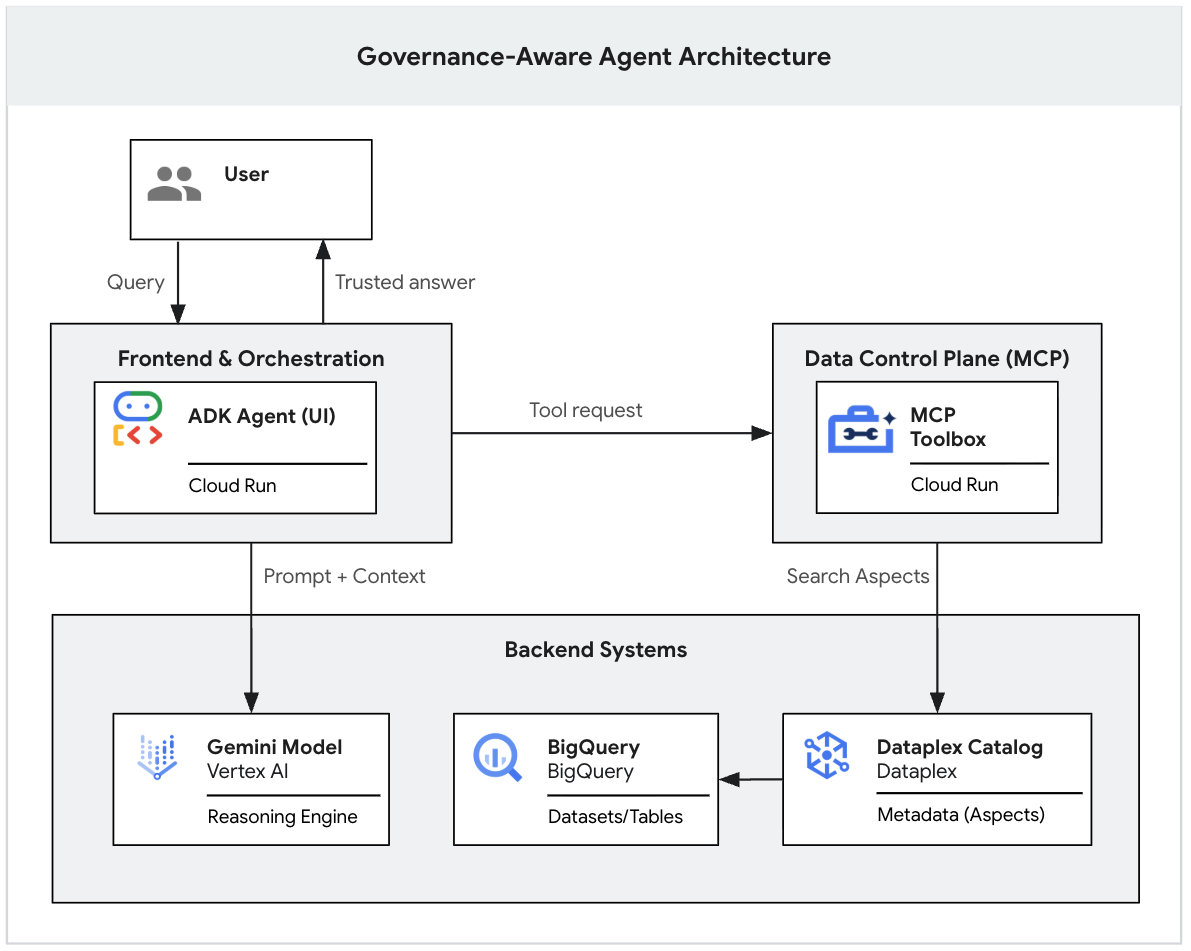
生成 AI モデルは強力な推論ツールですが、組織のコンテキストが欠けています。エグゼクティブが AI エージェントに「第 1 四半期の収益は?」と尋ねると、エージェントはデータレイク全体で「収益」という名前のテーブルを数十個見つける可能性があります。厳密な財務レポートもあれば、リアルタイムのマーケティング見積もりもあり、多くは非推奨のサンドボックスである可能性があります。
明示的なグラウンディングがない場合、AI エージェントは単純な名前の類似性に基づいてテーブルを選択するため、未確認のデータから「説得力のある誤った」回答が導き出されます。
この Codelab は、ガバナンス対応の GenAI エージェントを構築する方法を説明する 2 部構成のシリーズの一部です。
この最初のパートでは、データ基盤を構築します。BigQuery に現実的な「雑然とした」データレイクを設定し、厳格なメタデータタグ(Knowledge Catalog のアスペクト)を適用して有効なデータとノイズを区別します。また、Gemini CLI を使用して、LLM がガバナンス ルールを厳密に遵守しているかどうかをローカルでテストします。
(このシリーズの第 2 部では、Model Context Protocol(MCP)と Cloud Run を使用して、このローカル プロトタイプを安全なエンタープライズ グレードのウェブ アプリケーションにデプロイする方法について説明します。👉 パート 2 を読む)
前提条件
- 課金を有効にした Google Cloud プロジェクト
- BigQuery、Knowledge Catalog ユニバーサル カタログ、Terraform に関する基本的な知識と理解。
- Google Cloud Shell へのアクセス。
学習内容
- Terraform を使用して、現実的なマルチティア データレイクをデプロイします。
- Knowledge Catalog で厳格なメタデータ テンプレート(アスペクト タイプ)を設計して、公式のデータ プロダクトと未加工のサンドボックス テーブルを区別します。
- アプリケーション コードを記述する前に、Gemini CLI を使用してガバナンス ルールをローカルで検証します。
必要なもの
- Google Cloud Shell へのアクセス
- Terraform(Cloud Shell にプリインストールされています)。
- Gemini CLI(Cloud Shell にプリインストールされています)。
主なコンセプト
- Knowledge Catalog Universal Catalog: 統合メタデータ管理サービス。これを使用して、技術メタデータ(スキーマ)をビジネス コンテキスト(ガバナンス)で拡充します。
- アスペクト タイプ: 構造化メタデータ テンプレート。自由形式のタグとは異なり、アスペクトは強い型付けを適用する(列挙型、ブール値)ため、マシンが評価する際に信頼性が高くなります。
2. 設定と要件
Cloud Shell の起動
Google Cloud はノートパソコンからリモートで操作できますが、この Codelab では、Google Cloud Shell(Cloud 上で動作するコマンドライン環境)を使用します。
Google Cloud コンソールで、右上のツールバーにある Cloud Shell アイコンをクリックします。
プロビジョニングと環境への接続にはそれほど時間はかかりません。完了すると、次のように表示されます。

この仮想マシンには、必要な開発ツールがすべて用意されています。永続的なホーム ディレクトリが 5 GB 用意されており、Google Cloud で稼働します。そのため、ネットワークのパフォーマンスと認証機能が大幅に向上しています。この Codelab での作業はすべて、ブラウザ内から実行できます。インストールは不要です。
環境を初期化する
Cloud Shell を開き、プロジェクト変数を設定して、すべてのコマンドが正しいインフラストラクチャをターゲットにしていることを確認します。
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export REGION="us-central1"
API を有効にする
次の手順を実行するために必要な Google Cloud サービスを有効にします。
gcloud services enable \
artifactregistry.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
datacatalog.googleapis.com \
run.googleapis.com
リポジトリのクローンを作成します。
GitHub リポジトリからインフラストラクチャ コードと自動化スクリプトを取得します。Cloud Shell のディスク容量を節約するため、このラボに必要な特定のフォルダのみをダウンロードします。
# Perform a shallow clone to get only the latest repository structure without the full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Specify and download only the folder we need for this lab
git sparse-checkout set data-analytics/governance-context
cd data-analytics/governance-context
「雑然とした」データレイクを構築する
現実世界のデータ環境は、クリーンであることはほとんどありません。現実をシミュレートするには、「公式」データマートと信頼できない「サンドボックス」テーブルを混在させる必要があります。
この環境のデプロイには Terraform を使用します。この構成では、次の 2 つのタスクを処理します。
- インフラストラクチャ: Knowledge Catalog のアスペクト タイプと BigQuery データセット/テーブルを作成します。
- データ読み込み: BigQuery INSERT ジョブを実行して、作成直後にテーブルにサンプルデータを入力します。
terraformディレクトリに移動して初期化します。
cd terraform
terraform init
- 構成を適用します。これには 1 分ほどかかることがあります。
terraform apply -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
チェックポイント: データレイクが完全に作成されましたが、ガバナンスはまったく適用されていません。AI にとっては、すべてのテーブルが同じように見えます。
3. ガバナンスの適用
これは重要なエンジニアリング ステップです。現在、テーブル finance_mart.fin_monthly_closing_internal と analyst_sandbox.tmp_data_dump_v2_final_real は LLM にとって同じように見えます。これらは単に列を持つオブジェクトです。
ガバナンス エンジニアは、これらのテーブルを区別するために、アスペクト(認定メタデータ ラベル)をテーブルに付加する必要があります。実際の企業では、CI/CD パイプラインを使用してこれを自動化します。この自動化をスクリプトでシミュレートします。
ガバナンス ペイロードを生成する
Knowledge Catalog のアスペクトキーはグローバルに一意である必要があります(プロジェクト ID が接頭辞として付加されます)。./generate_payloads.sh スクリプトは、YAML メタデータ ファイルを動的に生成します。
cd ..
chmod +x ./generate_payloads.sh
./generate_payloads.sh
出力:
これにより、ガバナンス シナリオ(Gold/Internal、Gold/Public、Silver/Realtime、Bronze/Sandbox)を定義する 4 つの YAML ファイルを含む「./aspect_payloads」フォルダが作成されます。
CLI を使用してアスペクトを適用する
スクリプトを実行する前に、実際に適用する内容を確認して、プロセスを理解しましょう。次のコマンドを実行して、内部財務ペイロードの構造を確認します。
cat aspect_payloads/fin_internal.yaml
次の内容が表示されます。
your-project-id.us-central1.official-data-product-spec:
data:
product_tier: GOLD_CRITICAL
data_domain: FINANCE
usage_scope: INTERNAL_ONLY
update_frequency: DAILY_BATCH
is_certified: true
この YAML では、is_certified: true フラグを設定し、GOLD_CRITICAL 階層を割り当てるなど、ビジネス コンテキストが明示的に定義されています。AI には、テーブル名に基づいて推測するのではなく、評価するための明確で構造化されたルールが与えられます。
次に、アプリケーション スクリプトを実行します。これにより、BigQuery テーブルが反復処理され、gcloud dataplex entries update コマンドが実行されて、この固定メタデータが関連付けられます。
chmod +x ./apply_governance.sh
./apply_governance.sh
検証(省略可)
続行する前に、メタデータがコンソールで正しく適用されていることを確認します。
- Google Cloud コンソールで Knowledge Catalog ユニバーサル カタログ ページを開きます。左側のナビゲーション メニューに [Knowledge Catalog Universal Catalog] が表示されない場合は、Google Cloud コンソール ウィンドウの上部にある検索バーを使用して「Knowledge Catalog」と入力し、[上位の検索結果] または [プロダクトとページ] の結果を選択します。
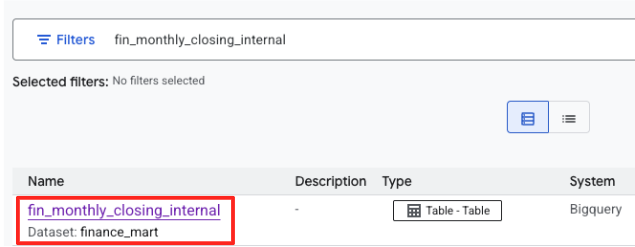
fin_monthly_closing_internalを検索します。結果に BigQuery テーブルが表示されます。テーブル名をクリックして、詳細ページに移動します。
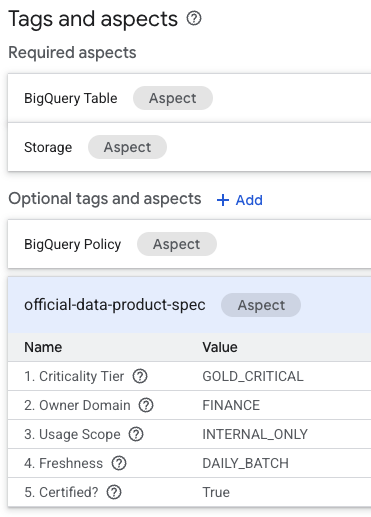
- テーブルの詳細ページで、下部にある [オプションのタグとアスペクト] セクションを探します。
official-data-product-specアスペクトが表示されます。値が、適用した「Gold Internal」シナリオと一致していることを確認します。
これで、技術的に同一の BigQuery テーブル(fin_monthly_closing_internal と tmp_data_dump_v2_final_real)が、マシンリーダブルなメタデータによって論理的に区別されていることを確認できました。
4. エージェントを構成してプロトタイプを作成する
ウェブ アプリケーションを構築する前に(パート 2 で実施)、ガバナンス ロジックをローカルで検証します。Knowledge Catalog 拡張機能をインストールし、システム プロンプトを構成する必要があります。
拡張機能をインストールする
Cloud Shell で、Knowledge Catalog 拡張機能をインストールします。確認と設定の詳細を求められます。
export DATAPLEX_PROJECT="${PROJECT_ID}"
gemini extensions install https://github.com/gemini-cli-extensions/dataplex
(インストールを承諾するには「Y」と入力し、プロンプトが表示されたらプロジェクト ID を入力します)。
ポリシー ファイルを定義する
GEMINI.md ファイルには、抽象的な人間によるルール(「安全なデータが必要」など)を厳密な技術的ルックアップに変換するロジックが含まれています。
このファイルは現在汎用的です。エージェントが公共のインターネットや他のコンテキストからテーブルを幻覚しないように、検索する Google Cloud プロジェクトを正確に把握する必要があります。
PROJECT_IDをポリシー ファイルに挿入します。
envsubst < GEMINI.md > GEMINI.md.tmp && mv GEMINI.md.tmp GEMINI.md
- ファイルを調べて、AI に教えるアルゴリズムを確認します。
cat GEMINI.md
このファイルには次の 2 つの点に注目してください。
- プロジェクトの範囲: フェーズ 2 を確認します。projectid:
${PROJECT_ID}が実際のプロジェクト ID(e.g., projectid:my-lab-project)に置き換えられていることを確認します。この変数を置き換えないと、アクセス可能なすべてのプロジェクトが検索され、誤った回答が返されます。 - アルゴリズム: フェーズ 1 / フェーズ 2 のロジックに注目してください。モデルに SQL を推測しないように明示的に指示します。まず正しいタグ定義を検索し(フェーズ 1)、その後でデータを検索する必要があります(フェーズ 2)。
エージェントを開始してシナリオをテストする
Gemini CLI セッションを開始します。今回は、ガバナンス ポリシーをシステム コンテキストとして読み込みます。
gemini
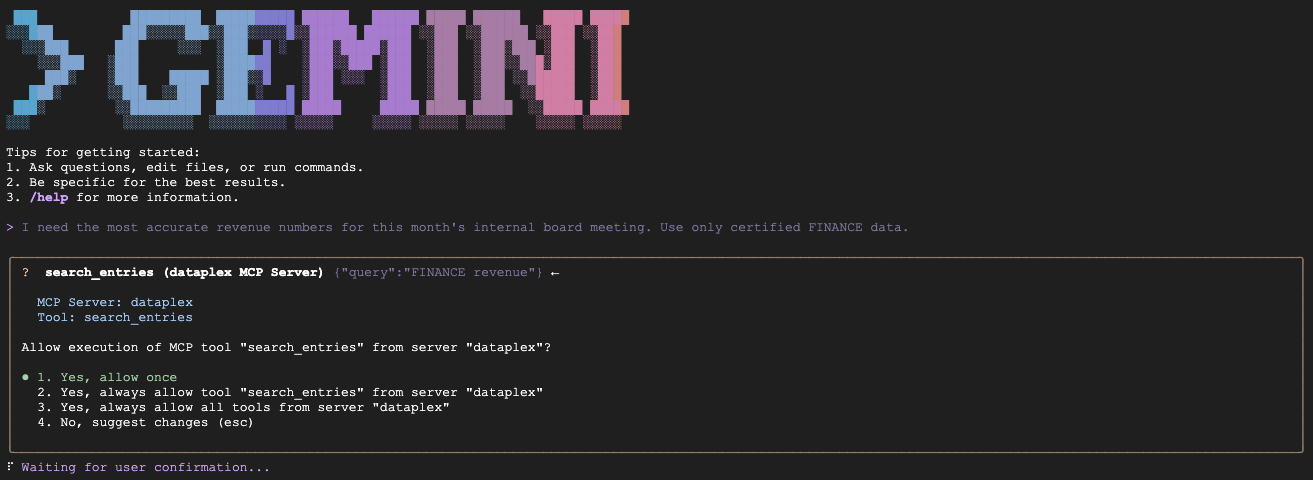
注: 複数のコンテキスト ファイル(GEMINI.md など)が読み込まれることがあります。これは正常な動作です。CLI は、このプロジェクトの特定のルール用のローカル GEMINI.md と、Knowledge Catalog Extension 自体のデフォルトの手順を読み込みます。
インストールを確認する
/mcp desc と入力して、Knowledge Catalog 拡張機能が有効になっていることを確認します。dataplex が、使用可能なツールを含む構成済みの MCP サーバーとして表示されます。
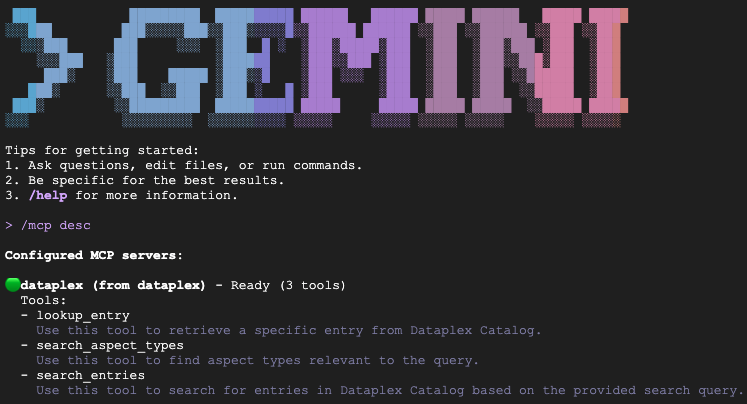
テスト シナリオ(プロトタイピング)
次のプロンプトを 1 つずつ実行中のエージェント セッションに貼り付けて、ルールに準拠していることを確認します。
- シナリオ A(CFO のデータを認証する):
"We are preparing the deck for an internal Board of Directors meeting next week. I need the numbers to be absolutely finalized, trustworthy, and kept strictly confidential. Which table is safe to use?"
期待される結果: アスペクトで GOLD_CRITICAL(正確)と INTERNAL_ONLY(取締役会)に意味的に一致するため、クエリ fin_monthly_closing_internal。
- シナリオ B(一般公開):
"I need to share our quarterly financial summary with an external consulting firm. It is critical that we do not leak any raw or internal metrics. Which dataset is officially scrubbed and explicitly approved for external sharing?"
想定される動作: エージェントは月次の内部テーブルをバイパスし、EXTERNAL_READY タグが付けられた唯一のアセットである fin_quarterly_public_report を厳密に選択する必要があります。
- シナリオ C(運用ニーズ):
"My dashboard needs to show what's happening right now with our ad spend. I can't wait for the overnight load. What do you recommend?"
期待される結果: エージェントは mkt_realtime_campaign_performance を選択します。これは、REALTIME_STREAMING の更新の頻度を特定し、財務データの GOLD_CRITICAL 階層よりも優先するためです。
- シナリオ D(サンドボックスでのテスト):
"I'm just playing around with some new ML models and need a lot of raw data. It doesn't need to be perfect, just a sandbox environment."
期待される結果: エージェントは、アスペクトで BRONZE_ADHOC(生データ)と is_certified: false(サンドボックス環境)に意味的に一致するため、tmp_data_dump_v2_final_real を選択します。
(Gemini セッションを終了するには、「/quit」と入力します)
5. おめでとうございます!次のステップ
管理されたデータ基盤を構築し、ローカル CLI プロトタイプを使用して AI がメタデータ ルールを厳密に遵守できることを実証できました。
チェックポイントに到達しました。次のステップを選択してください。
オプション A: 今すぐパート 2 に進みたい
Model Context Protocol(MCP)と Cloud Run を使用して、このローカル プロトタイプを安全な本番環境グレードのウェブ アプリケーションに変換する準備ができている場合は、次の操作を行います。
オプション B: パート 2 は後で実施する予定です。または、パート 1 のみを完了したいです。
ここで終了してクラウド費用を回避する場合は、リソースをクリーンアップする必要があります。
ご安心ください。パート 2 では、このパート 1 の環境を 2 分で完全に再構築し、中断したところから再開できる「ファスト トラック スクリプト」を提供します。
👉 [クリーンアップ] セクションに進みます。
6. クリーンアップ(オプション B のみ)
ここで停止する場合は、課金が発生しないようにリソースを破棄します。
データレイクを破棄する(Terraform)
現在 Gemini CLI 環境にいる場合は、Ctrl+C を 2 回押すか、/quit と入力してセッションを終了します。次のコマンドを実行します。
cd ~/devrel-demos/data-analytics/governance-context/terraform
terraform destroy -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
Gemini CLI 拡張機能をアンインストールしてローカル ファイルを削除する
gemini extensions uninstall dataplex
cd ~
rm -rf ~/devrel-demos