
1. はじめに
この Codelab は、ガバナンス対応の GenAI エージェントを構築する方法を説明する 2 部構成のシリーズの一部です。
(このシリーズの第 1 部では、Knowledge Catalog のアスペクトを BigQuery テーブルに適用し、Gemini CLI を使用してルールをローカルでテストすることで、データ基盤を確立する方法について説明しています。👉 第 1 部を読む)
ただし、ローカル CLI でのテストは始まりにすぎません。会社全体にロールアウトするには、一元化されたセキュリティ、標準化された AI ツール接続、エージェントのロジックをオーケストレートして使い慣れたチャット インターフェースを提供する適切なアプリケーション フレームワークが必要です。
この第 2 部では、これらの課題を解決し、本番環境にスケーリングします。ガバナンス ルールを Cloud Run でホストされている中央の MCP サーバーにデプロイします。次に、Google の Agent Development Kit(ADK)を使用して実際のエージェント アプリケーションを構築し、プロフェッショナルなウェブ UI を備えた MCP ツールに接続します。
前提条件
- 課金を有効にした Google Cloud プロジェクト
- Cloud Run、IAM サービス アカウント、Python の基本的な知識。
- パート 1 で作成した BigQuery データセットと Knowledge Catalog アスペクト。(削除してしまっても問題ありません。再作成するための高速トラック スクリプトを以下に示します)。
学習内容
- Model Context Protocol(MCP)を使用して、AI エージェントが Google Cloud データとやり取りする方法を標準化する方法。
- 安全な MCP サーバーを Cloud Run にデプロイする方法。
- Agent Development Kit(ADK)を使用して AI エージェントを構築し、MCP バックエンドに接続する方法。
- ADK の組み込みデベロッパー UI を実行して、ガバナンス対象のエージェントを操作する方法。
必要なもの
- Google Cloud Shell へのアクセス
主なコンセプト
- Model Context Protocol(MCP): MCP は、AI エージェントの「ユニバーサル USB-C ケーブル」のようなものです。MCP は、個々の AI モデルごとにカスタム API 統合コードを作成するのではなく、AI がエンタープライズ データツール(Knowledge Catalog や BigQuery など)に安全に接続するための標準的な方法を提供します。
- Agent Development Kit(ADK): Google が設計した柔軟なオープンソース フレームワークで、AI エージェントのエンドツーエンドの開発を簡素化するように設計されています。ソフトウェア エンジニアリングの原則をエージェントの作成に適用することで、複雑なツールをオーケストレートし、状態を管理し、テストとデプロイ用の組み込みデベロッパー UI を簡単に起動できます。
2. 設定と要件
Cloud Shell の起動
Google Cloud はノートパソコンからリモートで操作できますが、この Codelab では、Google Cloud Shell(Cloud 上で動作するコマンドライン環境)を使用します。
Google Cloud コンソールで、右上のツールバーにある Cloud Shell アイコンをクリックします。
プロビジョニングと環境への接続にはそれほど時間はかかりません。完了すると、次のように表示されます。

この仮想マシンには、必要な開発ツールがすべて用意されています。永続的なホーム ディレクトリが 5 GB 用意されており、Google Cloud で稼働します。そのため、ネットワークのパフォーマンスと認証機能が大幅に向上しています。この Codelab での作業はすべて、ブラウザ内から実行できます。インストールは不要です。
環境を初期化する
Cloud Shell を開き、プロジェクト変数を設定して、すべてのコマンドが正しいインフラストラクチャをターゲットにしていることを確認します。
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export REGION="us-central1"
チェックポイント: 再開と再構築のどちらを選択すべきか?
これはパート 2 であるため、エージェントが機能するにはパート 1 の管理対象データが必要です。次のいずれかを選択してください。
パス A: パート 1 を完了したばかりで、リソースはまだ実行中です。
これで、作業ディレクトリに移動すると、続行できるようになります。
cd ~/devrel-demos/data-analytics/governance-context
パス B: パート 1 をスキップした、またはリソースを削除した(クリーンアップした)。
ご安心ください。以下に「Fast-Track」コマンド ブロックを示します。これにより、BigQuery データレイクが自動的に再構築され、パート 1 で行ったのとまったく同じように Knowledge Catalog ガバナンス メタデータが適用されます。
# 1. Clone the repo and navigate to the working directory
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set data-analytics/governance-context
cd data-analytics/governance-context
# 2. Rebuild the messy data lake with Terraform
cd terraform
terraform init
terraform apply -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
# 3. Generate and apply Knowledge Catalog Aspects (Governance rules)
cd ..
chmod +x ./generate_payloads.sh ./apply_governance.sh
./generate_payloads.sh
./apply_governance.sh
3. MCP でスケーリングする: データ コントロール プレーンの構築
これまでのところ、Gemini CLI を使用してガバナンス ロジックをテストすることに成功しています。これは迅速なプロトタイピングには最適ですが、個人のユーザー認証情報を使用してローカルで実行されます。
実際の企業環境では、一元化されたデータ コントロール プレーンが必要です。これを構築するには、Google の公式オープンソース プロジェクトである GenAI Toolbox for Databases を使用します。このツールボックスには、AI エージェントを Google Cloud データベースや Knowledge Catalog などのメタデータ サービスに安全に接続するように設計された、事前構築済みの MCP サーバーが用意されています。
このツールボックスを Cloud Run の MCP サーバーとしてデプロイすることで、次のことが実現します。
- 一元化された ID: エージェントは、個人のユーザー アカウントではなく、制限付きのサービス アカウントとして実行されます。
- 標準化: 標準の MCP プロトコルを使用して、任意のクライアント(ADK、Gemini、カスタムアプリ)をこのサーバーに「プラグイン」できます。
- 制御されたスコープ(最小権限): LLM に BigQuery への無制限のアクセス権を付与しません。Knowledge Catalog メタデータ カタログを最初にナビゲートするように強制します。
ツール定義を構成する(tools.yaml)
生成 AI ツールボックスには、宣言型構成ファイル tools.yaml が必要です。このファイルでは、sources(接続先)と tools(AI が実行できること)を定義します。
- サーバー ディレクトリに移動し、構成ファイルにプロジェクト ID を挿入します。
cd ~/devrel-demos/data-analytics/governance-context/mcp_server
envsubst < tools.yaml > tools.tmp && mv tools.tmp tools.yaml
cat tools.yaml
次のスニペットと同じになるはずです。プロジェクト フィールドが実際の Google Cloud プロジェクト ID と一致していることを確認します。
sources:
dataplex:
kind: dataplex
project: YOUR-PROJECT-ID
tools:
search_entries:
kind: dataplex-search-entries
source: dataplex
description: Search for entries in Knowledge Catalog.
lookup_entry:
kind: dataplex-lookup-entry
source: dataplex
description: Retrieve a specific entry from Knowledge Catalog.
search_aspect_types:
kind: dataplex-search-aspect-types
source: dataplex
description: Find aspect types relevant to a query.
toolsets:
dataplex-toolset:
- search_entries
- lookup_entry
- search_aspect_types
この 3 つのツールを定義することで、AI を「読み取り専用」かつ「ガバナンス優先」にすることができます。
構成を保護する(Secret Manager)
エンタープライズ アーキテクチャでは、構成ファイルをコンテナ イメージに直接組み込むことは避けるべきです。tools.yaml は Google Cloud Secret Manager に安全に保存します。
gcloud services enable secretmanager.googleapis.com
gcloud secrets create dataplex-tools-config --data-file=tools.yaml
最小権限(IAM)を実装する
次に、GenAI ツールボックス MCP サーバー専用のサービス アカウントを作成します。この ID には、Knowledge Catalog カタログの読み取りと BigQuery データへのアクセスに必要な権限のみが付与されます。
export MCP_SA=mcp-sa
gcloud iam service-accounts create ${MCP_SA} \
--display-name="Service Account for Knowledge Catalog MCP"
export MCP_SERVICE_ACCOUNT="${MCP_SA}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow the server to read its own config from Secret Manager
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/secretmanager.secretAccessor"
# Allow the server to read Knowledge Catalog Metadata and BigQuery Data
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/dataplex.catalogViewer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/bigquery.dataViewer"
MCP サーバーを Cloud Run にデプロイする
次に、生成 AI ツールボックスをデプロイします。Google のビルド済みコンテナ イメージ(database-toolbox/toolbox)を使用し、実行時に Secret Manager(--set-secrets)から構成をマウントします。
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
gcloud run deploy governance-mcp \
--image=$IMAGE \
--service-account $MCP_SERVICE_ACCOUNT \
--region=$REGION \
--no-allow-unauthenticated \
--set-secrets="/app/tools.yaml=dataplex-tools-config:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080"
これで、管理対象 API が確立されました。GenAI フロントエンドは、データベースに直接アクセスするのではなく、この Cloud Run URL に接続します。エージェントは、このツールボックスで許可されている内容のみを表示できます。
4. ADK を使用してエージェント バックエンドを構築する
Cloud Run で実行される安全で管理されたデータ コントロール プレーン(MCP)を確立しました。AI エージェントには、ユーザー入力の処理、MCP サーバーを呼び出すタイミングの決定、出力のフォーマットなどのロジックをオーケストレートするフレームワークが必要です。
このボイラープレート コードをすべてゼロから記述する代わりに、Google の Agent Development Kit(ADK)を使用します。ADK は、エージェント ロジックを FastAPI バックエンドに自動的にラップするコードファーストのフレームワークです。さらに、組み込みの開発者 UI が付属しているため、カスタム フロントエンドを最初に構築しなくても、エージェントの推論プロセスとツール呼び出しをすぐに可視化できます。
エージェントのロジック(agent.py)を調べる
インフラストラクチャを構成する前に、このアプリケーションのコアを見てみましょう。
ディレクトリに移動して、agent.py の内容を出力します。このファイルは ADK デプロイの「頭脳」です。
cd ~/devrel-demos/data-analytics/governance-context/mcp_server
cat agent.py
コード構造を見てみましょう。最小限のボイラープレートで 3 つの重要な関数を実行します。
- MCPToolset 統合: Knowledge Catalog ツールとやり取りするためにカスタム HTTP クライアントを記述する代わりに、ADK は
MCPToolset(server_url=mcp_url)を使用します。これにより、デプロイされた MCP サーバーからtools.yaml定義が動的に取得され、LLM のネイティブ関数呼び出しに変換されます。 - システム指示:
instructionsパラメータには、厳格なガバナンス ルール(CLIGEMINI.mdで使用したのと同じロジック)が含まれています。モデルに、フェーズ 1(メタデータのルックアップ)からフェーズ 2(データクエリ)の推論ループを実行するように明示的に指示します。 - エージェント オーケストレーション:
Agent(...)クラスは、Gemini モデル、システム プロンプト、MCP ツールを相互にバインドします。デプロイされると、ADK はこのオブジェクトをスケーラブルな FastAPI エンドポイントに自動的に変換します。
職務の分離: フロントエンド ID を構成する
このコードを安全に実行するには、MCP サーバーの場所をエージェントに伝える必要があります。URL を動的に構築し、ADK が実行時に読み取る .env ファイルに保存します。
また、このユーザー向けアプリケーション用に別の ID(dataplex-agent-sa)を作成します。このように役割を分離することで、フロントエンド エージェントとバックエンド ガバナンス サーバーの権限が異なるようになります。
次のコマンドを実行して、環境と ID を構成します。
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export MCP_SERVER_URL=https://governance-mcp-${PROJECT_NUMBER}.${REGION}.run.app/mcp
export AGENT_SA=knowledge-catalog-agent-sa
export AGENT_SERVICE_ACCOUNT="${AGENT_SA}@${PROJECT_ID}.iam.gserviceaccount.com"
gcloud iam service-accounts create ${AGENT_SA} \
--display-name="Service Account for Knowledge Catalog Agent "
ランタイム変数を構成する
ADK フレームワークは、環境変数を使用してコンテキストを理解します。プロジェクト ID とリージョンを明示的に設定し、Gemini Enterprise エージェント エンジンの使用を有効にする必要があります。これらは同じ .env ファイルに追加します。
echo MCP_SERVER_URL=$MCP_SERVER_URL > .env
echo GOOGLE_GENAI_USE_VERTEXAI=1 >> .env
echo GOOGLE_CLOUD_PROJECT=$PROJECT_ID >> .env
echo GOOGLE_CLOUD_LOCATION=$REGION >> .env
権限を付与する
エージェントはガバナンス チェックを MCP サーバーに委任しますが、動作するには基本的な権限が必要です。次の 2 つのロールを付与します。
- Gemini Enterprise Agent Engine ユーザー: 自然言語レスポンスを生成するために Gemini モデルを呼び出す。
- Cloud Run 起動元: MCP サーバー API を安全に呼び出すため。BigQuery や Knowledge Catalog に直接アクセスすることはありません。
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/aiplatform.user"
gcloud run services add-iam-policy-binding governance-mcp \
--region=$REGION \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/run.invoker"
Cloud Run へのデプロイ
最後に、フルスタックを Cloud Run にデプロイします。
uvx を使用して、依存関係を手動でインストールせずに ADK ツールを実行します。次のコマンドは、agent.py ロジックをパッケージ化し、コンテナ イメージをビルドし、サービス アカウントを挿入して、FastAPI サーバーを起動します。--with_ui フラグを追加すると、デバッグ用の ADK Web Playground もバンドルされます。
このコマンドはコンテナをビルドしてデプロイします。完了までに 1 ~ 3 分かかることがあります。
uvx --from google-adk \
adk deploy cloud_run \
--project=$PROJECT_ID \
--region=$REGION \
--service_name=knowledge-catalog-agent \
--with_ui \
. \
-- \
--service-account=$AGENT_SERVICE_ACCOUNT \
--allow-unauthenticated
このコマンドが完了すると、サービス URL(e.g., https://dataplex-agent-xyz.run.app)が出力されます。このリンクをクリックして、完全に管理された GenAI Chat Interface を開きます。
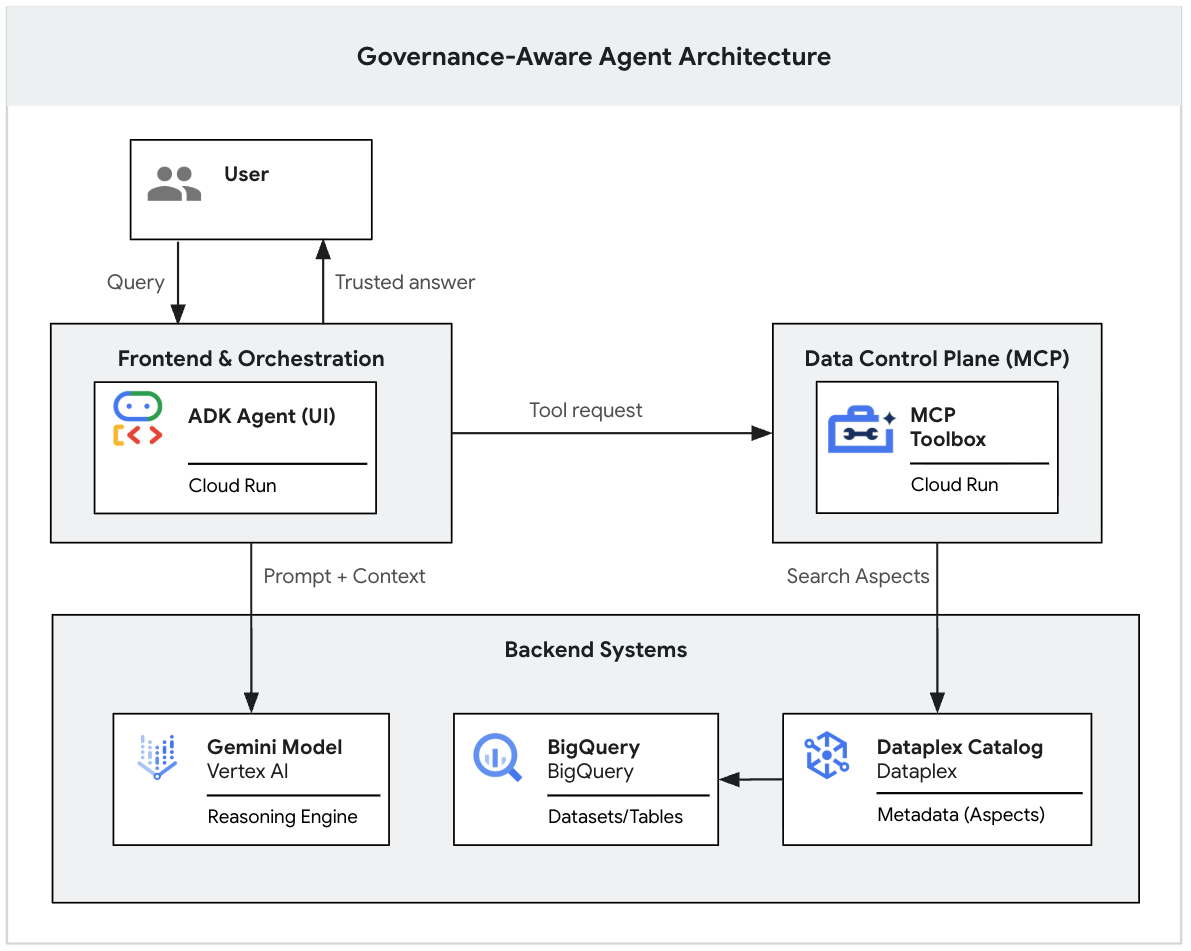
エンドツーエンドのアーキテクチャ フロー
これでシステムは完成しました。ユーザーが ADK UI を操作すると、次のシーケンスが発生します。
- ユーザーが ADK エージェント(開発 UI)でプロンプトを送信します。
- ADK エージェント(agent.py)は入力を処理し、Gemini モデルを呼び出します。
- Gemini はコンテキストが必要であると判断し、MCP サーバーに Knowledge Catalog ツールの実行をリクエストします。
- MCP サーバーは Knowledge Catalog ガバナンス ルールを適用し、メタデータを返します。
- Gemini は、メタデータに基づいて信頼できる回答を合成し、ユーザーに返します。
5. Enterprise Agent をテストする
エージェントが稼働したので、CLI でテストしたガバナンス シナリオをもう一度見てみましょう。ロジックは同じですが、内部状態とツールの実行を可視化するデプロイされた ADK Web Playground を操作します。
- オーケストレーション: ADK エージェント(Cloud Run で実行)がテキストを受け取ります。
- ツール ルーティング: Gemini は、質問にデータ コンテキストが必要であることを認識し、リクエストを MCP サーバーに転送します。
- ガバナンス チェック: MCP サーバー(別の Cloud Run インスタンスで実行)が、特定の Aspect Type について Knowledge Catalog にクエリを実行します。
- 合成: 関連するメタデータが Gemini に返され、最終的な回答が生成されます。
ガバナンス ロジックを確認する
前の手順(e.g., https://dataplex-agent-xyz.run.app)で生成したサービス URL をブラウザで開きます。次のプロンプトを貼り付けます。
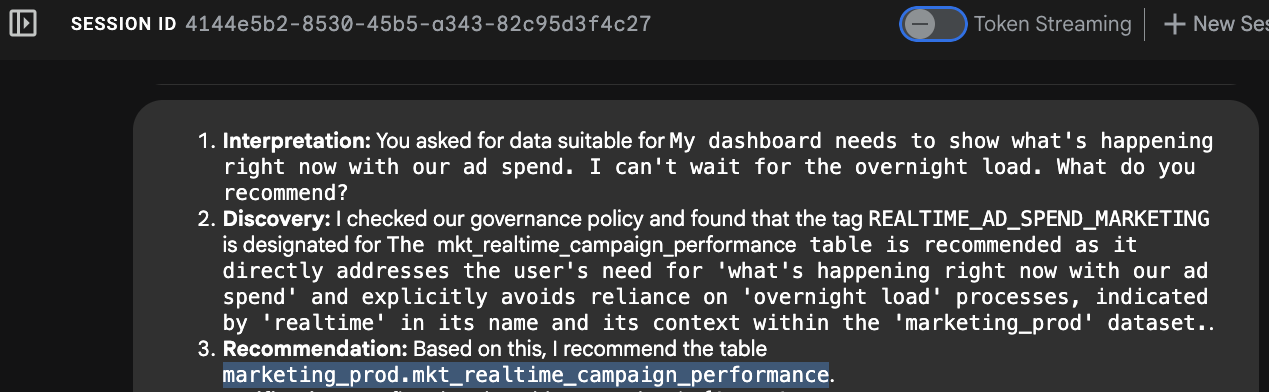
"My dashboard needs to show what's happening right now with our ad spend. I can't wait for the overnight load. What do you recommend?"
デベロッパー UI でエージェントの推論プロセスを確認します。
- インテント認識: エージェントが「今すぐ」と「一晩待てない」を解析します。
- メタデータのルックアップ: MCP ツール
search_aspect_typesを呼び出します。update_frequencyアスペクトが DAILY または MONTHLY ではなく、REALTIME または STREAMING に設定されているデータアセットを探します。 - 選択: テーブル
mkt_realtime_campaign_performanceがこれらの条件を満たしていることを特定します。一方、fin_monthly_closing_internalは高品質ですが、リクエストに対して遅すぎます。 - 回答: エージェントがリアルタイム テーブルを推奨します。
この機能が重要な理由:
このガバナンス メタデータがないと、LLM は「ad_spend」という名前の列があるという理由だけで fin_monthly_closing_internal テーブルを推奨する可能性が高く、データが 24 時間前のデータであるという事実を無視します。メタデータ コンテキストにより、ビジネス エラーが回避されました。
「Board Meeting」プロンプトをテストして、データ プロダクトの階層の側面に基づいてエージェントがさまざまなテーブルにピボットする方法を確認することもできます。
"We are preparing the deck for an internal Board of Directors meeting next week. I need the numbers to be absolutely finalized, trustworthy, and kept strictly confidential. Which table is safe to use?"
6. クリーンアップ
この Codelab で使用したリソースについて、Google Cloud アカウントに課金されないようにするには、次の手順でパート 1 とパート 2 で作成したすべてのインフラストラクチャを破棄します。
データレイクを破棄する(Terraform)
Terraform を使用して、BigQuery テーブル、データセット、Knowledge Catalog アスペクト定義を削除します。
cd ~/devrel-demos/data-analytics/governance-context/terraform
terraform destroy -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
Cloud Run サービスを削除する
コンピューティング リソースを削除して、実行中のコンテナに対するアクティブな課金を停止します。
gcloud run services delete governance-mcp --region=$REGION --quiet
gcloud run services delete knowledge-catalog-agent --region=$REGION --quiet
ビルド アーティファクトとステージング ストレージをクリーンアップする
uvx を使用して ADK エージェントをデプロイすると、システムは自動的にコンテナ イメージをビルドし、ソースコードを一時的な Cloud Storage バケットにアップロードしました。これらのアーティファクトは、Cloud Run サービスが削除された後も保持され、継続的なストレージ費用が発生します。
Artifact Registry リポジトリと Cloud Storage ステージング バケットを削除します。
# Delete the repository used for the agent build
gcloud artifacts repositories delete cloud-run-source-deploy \
--location=$REGION \
--quiet
# Delete the staging bucket created by Cloud Run source deploy
gcloud storage rm --recursive gs://run-sources-${PROJECT_ID}-${REGION}
ID、権限、シークレットを削除する
最初に IAM ポリシー バインディングを削除して、プロジェクトの IAM ページに「墓石」エントリ(孤立したレコード)が残らないようにします。次に、サービス アカウントと構成シークレットを削除します。
# Remove IAM roles granted to the MCP Service Account
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/secretmanager.secretAccessor" --quiet
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/dataplex.catalogViewer" --quiet
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/bigquery.dataViewer" --quiet
# Remove IAM roles granted to the Agent Service Account
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/aiplatform.user" --quiet
# Delete the Service Accounts
gcloud iam service-accounts delete $MCP_SERVICE_ACCOUNT --quiet
gcloud iam service-accounts delete $AGENT_SERVICE_ACCOUNT --quiet
# Delete the Secret Manager entry
gcloud secrets delete dataplex-tools-config --quiet
ローカル構成を削除する
最後に、Cloud Shell でローカル構成ファイルと環境変数をクリーンアップします。
# Uninstall the Gemini CLI extension (installed in Part 1)
gemini extensions uninstall dataplex
# Remove local repository files and unset variables
cd ~
rm -rf ~/devrel-demos
unset MCP_SERVER_URL
unset MCP_SERVICE_ACCOUNT
unset AGENT_SERVICE_ACCOUNT
7. 完了
エンドツーエンドのガバナンス対応の生成 AI エージェントを正常にデプロイしました。
この 2 部構成の Codelab では、単純なプロンプト エンジニアリングから一歩進んで、堅牢で本番環境に対応したアーキテクチャを実装しました。データガバナンスを GenAI の前提条件として扱うことで、モデルが未認証のデータやハルシネーション データを取得しないようにする体系的な方法を確立しました。
重要ポイント
- メタデータによる決定論的 AI: LLM が列名に基づいて正しいテーブルを推測するのではなく、GenAI データベース向けツールボックスを使用して厳密な推論ループを適用しました。3 つの Knowledge Catalog ツール(
search_aspect_types、search_entries、lookup_entry)のみを明示的に公開することで、モデルは回答を合成する前にデータ認証を確認するようになります。 - 分離されたアーキテクチャ(MCP): Cloud Run に Model Context Protocol(MCP)サーバーをデプロイすることで、データガバナンス ルールを集中化された標準化された API に抽象化しました。フロントエンド エージェントにデータベース ロジックを含める必要はなく、MCP 標準を介して通信するだけで済みます。つまり、将来の AI モデルやクライアントを同じ管理されたバックエンドに接続できます。
- 職務の分離: IAM ID を分離することで、最小権限の原則を適用しました。ユーザー向けの ADK エージェントは、モデル呼び出しと API ルーティングに制限された権限で動作し、バックエンド MCP サーバーは Knowledge Catalog クエリと BigQuery データ取得を安全に処理します。
- コードファーストのエージェント オーケストレーション: Google Agent Development Kit(ADK)を使用して、Python エージェント ロジックをスケーラブルな FastAPI バックエンドに瞬時にラップし、組み込みのデベロッパー UI を使用してエージェントの内部ツール実行を可視化してデバッグしました。
次のステップ
- Knowledge Catalog の基本的なガバナンスに関する Codelab: AI レイヤを追加する前に、Knowledge Catalog でデータ ガバナンスの基本を習得します。
- Knowledge Catalog ツールのドキュメント: このラボで使用する事前構築済みの Knowledge Catalog ツールと拡張機能の公式ドキュメントをご覧ください。
- Gemini CLI 拡張機能を使ってみる: 独自のカスタム拡張機能を構築して、GenAI エージェントにさらに多くの機能を追加する方法について説明します。
- MCP の詳細: 公式の MCP 仕様を確認して、社内エンタープライズ API 用のカスタム サーバーを構築する方法を理解します。