
1. 简介
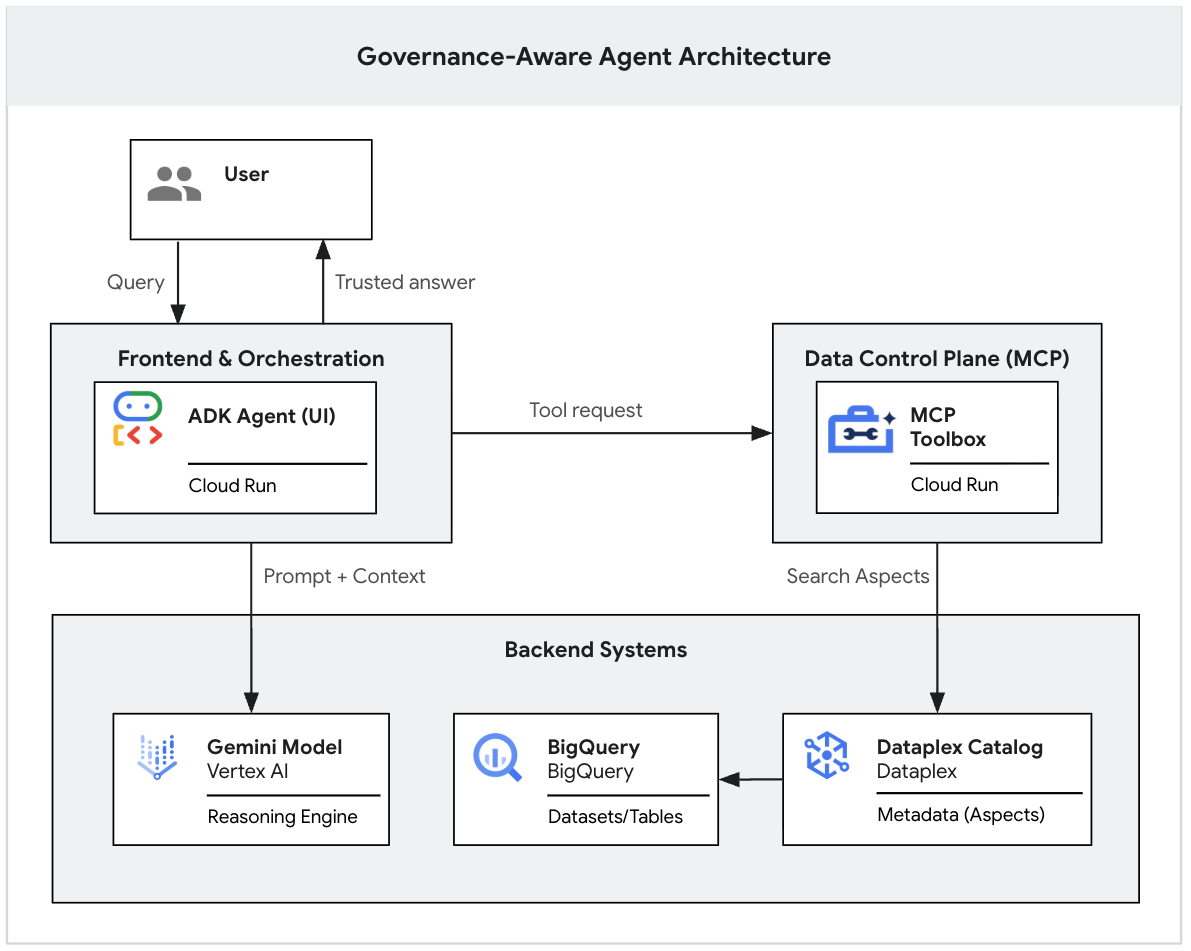
生成式 AI 模型是强大的推理工具,但缺乏机构背景信息。如果高管向 AI 智能体提出“我们第一季度的收入是多少?”这个问题,智能体可能会在数据湖中找到数十个名为“收入”的表格。有些是严谨的财务报告,有些是实时营销估算,还有许多可能是已弃用的沙盒。
如果没有明确的依据,AI 智能体 会根据简单的名称相似性来选择表格,从而导致根据未经验证的数据得出“令人信服的错误”答案。
本 Codelab 是一个分为两部分的系列教程,旨在探讨如何构建具有治理意识的 GenAI 代理。
在第一部分中,您将构建数据基础。您将在 BigQuery 中设置一个真实且“杂乱”的数据湖,应用严格的元数据标记(Knowledge Catalog Aspects)来区分有效数据和噪声,并使用 Gemini CLI 在本地测试大语言模型是否严格遵循您的治理规则。
(您可以阅读本系列的第二部分,了解如何使用 Model Context Protocol (MCP) 和 Cloud Run 将此本地原型部署到安全的企业级 Web 应用中。👉 阅读第 2 部分)
前提条件
- 启用了结算功能的 Google Cloud 项目。
- 对 BigQuery、Knowledge Catalog 通用目录和 Terraform 有基本的了解和熟悉程度。
- 能够访问 Google Cloud Shell。
学习内容
- 使用 Terraform 部署真实的多层数据湖。
- 在 Knowledge Catalog 中设计严格的元数据模板(切面类型),以区分正式数据产品与原始沙盒表。
- 在编写任何应用代码之前,请先使用 Gemini CLI 在本地验证治理规则。
所需条件
- Google Cloud Shell 访问权限
- Terraform(已预安装在 Cloud Shell 中)。
- Gemini CLI(已预安装在 Cloud Shell 中)。
主要概念
- Knowledge Catalog Universal Catalog:统一的元数据管理服务。我们使用它通过业务上下文(治理)来丰富技术元数据(架构)。
- 方面类型:一种结构化元数据模板。与自由文本标记不同,方面会强制执行强类型(枚举、布尔值),因此机器可以可靠地评估它们。
2. 设置和要求
启动 Cloud Shell
虽然可以通过笔记本电脑对 Google Cloud 进行远程操作,但在此 Codelab 中,您将使用 Google Cloud Shell,这是一个在云端运行的命令行环境。
在 Google Cloud 控制台 中,点击右上角工具栏中的 Cloud Shell 图标:
预配和连接到环境应该只需要片刻时间。完成后,您应该会看到如下内容:

这个虚拟机已加载了您需要的所有开发工具。它提供了一个持久的 5 GB 主目录,并且在 Google Cloud 中运行,大大增强了网络性能和身份验证功能。您在此 Codelab 中的所有工作都可以在浏览器中完成。您无需安装任何程序。
初始化环境
打开 Cloud Shell 并设置项目变量,以确保所有命令都指向正确的基础设施。
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export REGION="us-central1"
启用 API
启用必要的 Google Cloud 服务,以执行以下说明。
gcloud services enable \
artifactregistry.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
datacatalog.googleapis.com \
run.googleapis.com
克隆代码库
从 GitHub 代码库获取基础架构代码和自动化脚本。为了节省 Cloud Shell 中的磁盘空间,我们只会下载本实验所需的特定文件夹。
# Perform a shallow clone to get only the latest repository structure without the full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Specify and download only the folder we need for this lab
git sparse-checkout set data-analytics/governance-context
cd data-analytics/governance-context
构建“杂乱”的数据湖
现实世界中的数据环境很少是干净的。为了模拟现实,我们需要混合使用“官方”数据集市和不可信的“沙盒”表。
我们将使用 Terraform 部署此环境。该配置可处理两项任务:
- 基础设施:创建 Knowledge Catalog 方面类型和 BigQuery 数据集/表。
- 数据加载:在创建表后立即运行 BigQuery INSERT 作业,以使用示例数据填充表。
- 前往
terraform目录并对其进行初始化。
cd terraform
terraform init
- 应用配置。 这最多可能需要 1 分钟的时间。
terraform apply -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
检查点:您现在拥有一个已完全填充但完全不受治理的数据湖。对于 AI 来说,每个表格看起来都完全一样。
3. 应用治理
这是关键的工程步骤。目前,表 finance_mart.fin_monthly_closing_internal 和 analyst_sandbox.tmp_data_dump_v2_final_real 在 LLM 看来是完全相同的。它们只是包含列的对象。
作为治理工程师,您必须将 Aspect(一种经过认证的元数据标签)附加到这些表中,以区分它们。在实际的企业环境中,您可以通过 CI/CD 流水线自动执行此操作。我们将使用脚本模拟该自动化流程。
生成治理载荷
Knowledge Catalog 方面键必须是全局唯一的(以您的项目 ID 为前缀)。./generate_payloads.sh 脚本将动态生成 YAML 元数据文件。
cd ..
chmod +x ./generate_payloads.sh
./generate_payloads.sh
输出:
这会创建一个“./aspect_payloads”文件夹,其中包含 4 个 YAML 文件,用于定义治理方案(Gold/Internal、Gold/Public、Silver/Realtime、Bronze/Sandbox)。
通过 CLI 应用方面
在运行脚本之前,我们先来看看实际应用的内容,以便揭秘该流程。运行以下命令可查看内部财务载荷的结构:
cat aspect_payloads/fin_internal.yaml
系统会显示以下内容。
your-project-id.us-central1.official-data-product-spec:
data:
product_tier: GOLD_CRITICAL
data_domain: FINANCE
usage_scope: INTERNAL_ONLY
update_frequency: DAILY_BATCH
is_certified: true
请注意,此 YAML 明确定义了业务情境,例如设置 is_certified: true 标志和分配 GOLD_CRITICAL 层级。为 AI 提供清晰的结构化规则以供评估,而不是仅根据表名称进行猜测。
现在,运行应用脚本。此脚本会遍历 BigQuery 表,并执行 gcloud dataplex entries update 命令来附加此刚性元数据。
chmod +x ./apply_governance.sh
./apply_governance.sh
验证(可选)
在继续操作之前,请验证元数据是否已在控制台中正确应用。
- 在 Google Cloud 控制台中打开 Knowledge Catalog Universal Catalog 页面。如果您在左侧导航菜单中看不到“Knowledge Catalog Universal Catalog”,请使用 Google Cloud 控制台窗口顶部的搜索栏,输入“Knowledge Catalog”,然后选择“热门结果”或“产品和页面”下的相应结果。
- 搜索
fin_monthly_closing_internal。 您应该会在结果中看到列出的 BigQuery 表。点击表名称以进入其详情页面。
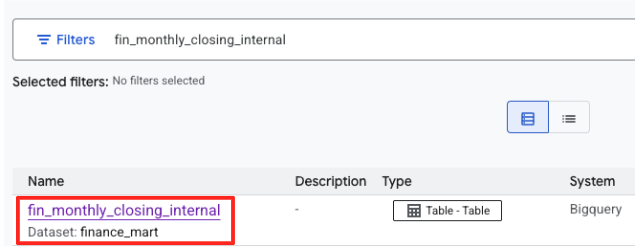
- 在表格的详情页面上,找到位于底部的“可选标记和方面”部分。
- 您会看到
official-data-product-spec方面。确认这些值与我们应用的“Gold Internal”方案相符。
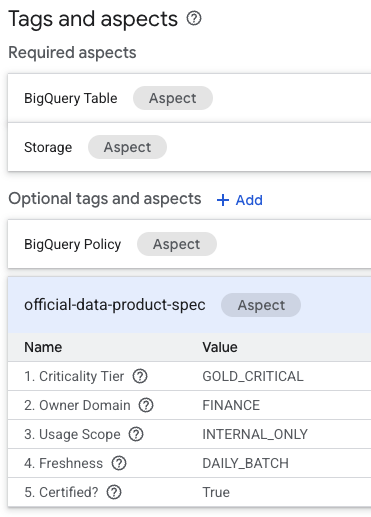
您现在已确认,在技术上相同的 BigQuery 表(fin_monthly_closing_internal 和 tmp_data_dump_v2_final_real)在逻辑上可通过机器可读的元数据进行区分。
4. 配置和原型设计代理
在构建 Web 应用(我们将在第 2 部分中完成此操作)之前,我们将在本地验证治理逻辑。我们需要安装 Knowledge Catalog 扩展程序并配置系统提示。
安装扩展程序
在 Cloud Shell 中,安装 Knowledge Catalog 扩展程序。系统会要求您确认并提供设置详细信息。
export DATAPLEX_PROJECT="${PROJECT_ID}"
gemini extensions install https://github.com/gemini-cli-extensions/dataplex
(输入 Y 接受安装,并在系统提示时输入您的项目 ID)。
定义政策文件
GEMINI.md 文件包含将抽象的人工规则(例如“我需要安全的数据”)转换为严格的技术查找的逻辑。
此文件目前是通用的。代理需要确切知道要搜索哪个 Google Cloud 云项目,以防止其从公共互联网或其他上下文中产生幻觉表。
- 将
PROJECT_ID注入到政策文件中。
envsubst < GEMINI.md > GEMINI.md.tmp && mv GEMINI.md.tmp GEMINI.md
- 检查该文件,了解我们教给 AI 的算法。
cat GEMINI.md
请注意此文件中的两点:
- 项目范围:检查第 2 阶段。确保 projectid:
${PROJECT_ID}已替换为您的实际项目 ID(e.g., projectid:my-lab-project)。如果未替换此变量,代理将搜索您有权访问的每个项目,从而导致回答不正确。 - 算法:请注意第 1 阶段 / 第 2 阶段的逻辑。我们明确指示模型不要猜测 SQL。它必须先搜索正确的标记定义(第 1 阶段),然后才能搜索数据(第 2 阶段)。
启动智能体并测试场景
启动 Gemini CLI 会话,这次将您的治理政策作为系统上下文加载。
gemini
注意:您可能会看到系统加载多个上下文文件(例如 GEMINI.md 和其他文件)。这种情况很正常。CLI 会加载此项目的本地 GEMINI.md 以获取特定规则,还会加载知识目录扩展程序的默认指令。
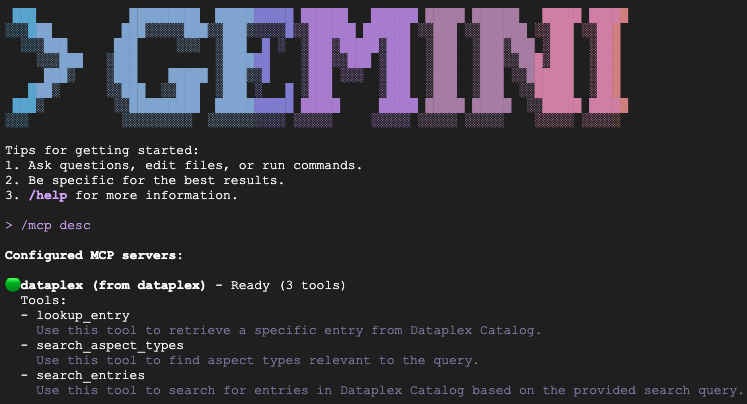
验证安装
输入 /mcp desc 以确认 Knowledge Catalog 扩展服务处于活跃状态。您应该会看到 dataplex 列为已配置的 MCP 服务器,并显示可用工具。
测试场景(原型设计)
将以下提示逐个粘贴到正在运行的代理会话中,以验证该代理是否遵守您的规则。
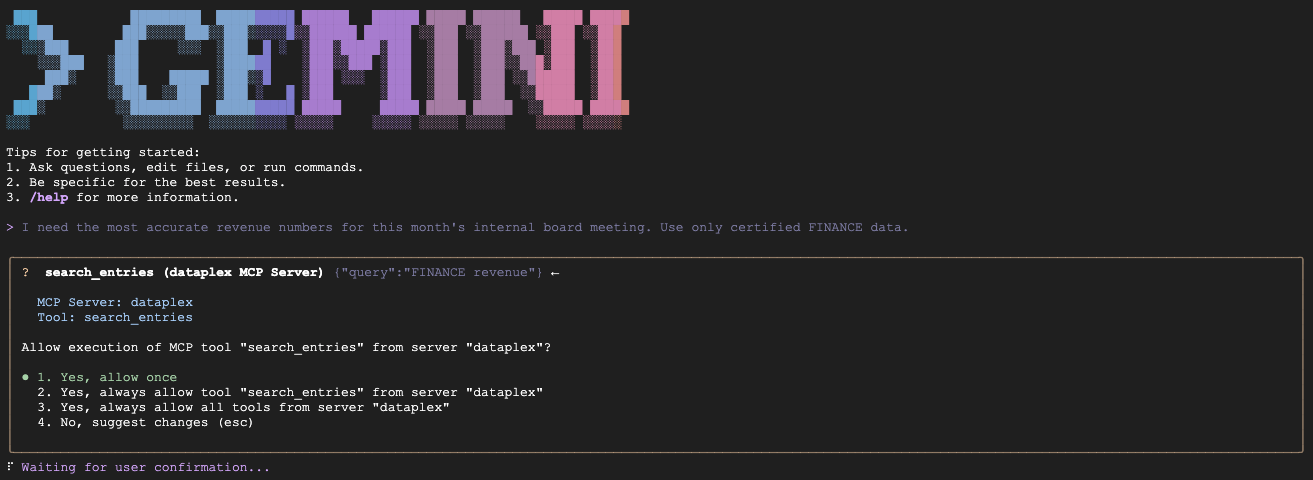
- 方案 A(证明 CFO 的数据):
"We are preparing the deck for an internal Board of Directors meeting next week. I need the numbers to be absolutely finalized, trustworthy, and kept strictly confidential. Which table is safe to use?"
预期:查询 fin_monthly_closing_internal,因为其方面在语义上与 GOLD_CRITICAL(准确)和 INTERNAL_ONLY(董事会会议)匹配。
- 场景 B(公开披露):
"I need to share our quarterly financial summary with an external consulting firm. It is critical that we do not leak any raw or internal metrics. Which dataset is officially scrubbed and explicitly approved for external sharing?"
预期:代理必须绕过每月内部表,并严格选择 fin_quarterly_public_report,因为它是唯一标记为 EXTERNAL_READY 的素材资源。
- 场景 C(运营需求):
"My dashboard needs to show what's happening right now with our ad spend. I can't wait for the overnight load. What do you recommend?"
预期:代理会选择 mkt_realtime_campaign_performance,因为它识别出 REALTIME_STREAMING 更新频率,并优先考虑该频率,而不是财务数据的 GOLD_CRITICAL 层级。
- 场景 D(沙盒实验):
"I'm just playing around with some new ML models and need a lot of raw data. It doesn't need to be perfect, just a sandbox environment."
预期:智能体选择 tmp_data_dump_v2_final_real,因为其 Aspect 在语义上与 BRONZE_ADHOC(原始数据)和 is_certified: false(沙盒环境)相匹配。
(如需退出 Gemini 会话,请输入 /quit)
5. 恭喜!接下来做什么?
您已成功构建受监管的数据基础,并使用本地 CLI 原型证明 AI 可以严格遵循您的元数据规则!
现在,您已到达检查点。请选择下一步:
选项 A:我想立即继续学习第 2 部分!
如果您已准备好使用 Model Context Protocol (MCP) 和 Cloud Run 将此本地原型转变为安全的生产级 Web 应用,请执行以下操作:
选项 B:我稍后会完成第 2 部分,或者我只想完成第 1 部分。
如果您想暂时停止操作并避免产生云费用,则应清理资源。
不用担心!在第 2 部分中,我们将提供一个“快速通道脚本”,该脚本只需 2 分钟即可完全重建第 1 部分的环境,以便您从上次中断的地方继续学习。
👉 前往“清理”部分。
6. 清理(仅适用于选项 B)
如果您要就此停止,请销毁资源,以免产生费用。
销毁数据湖 (Terraform)
如果您目前处于 Gemini CLI 环境中,请按两次 Ctrl+C 或输入 /quit 退出对话。然后,运行以下命令:
cd ~/devrel-demos/data-analytics/governance-context/terraform
terraform destroy -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
卸载 Gemini CLI 扩展程序并移除本地文件
gemini extensions uninstall dataplex
cd ~
rm -rf ~/devrel-demos