
1. Einführung
Im modernen Einzelhandel sind Ihre Daten ein vielfältiges, weitläufiges Ökosystem. Sie haben solide Transaktionsdaten (Preise und Inventar), „unsaubere“ polymorphe Kataloge (Elektronikspezifikationen im Vergleich zu Bekleidungsgrößen) und Petabyte an Verhaltensprotokollen. Wenn Sie diese in einen einzelnen Monolithen zwingen, entsteht nicht nur technische Schuld, sondern auch eine schlechte Nutzererfahrung.
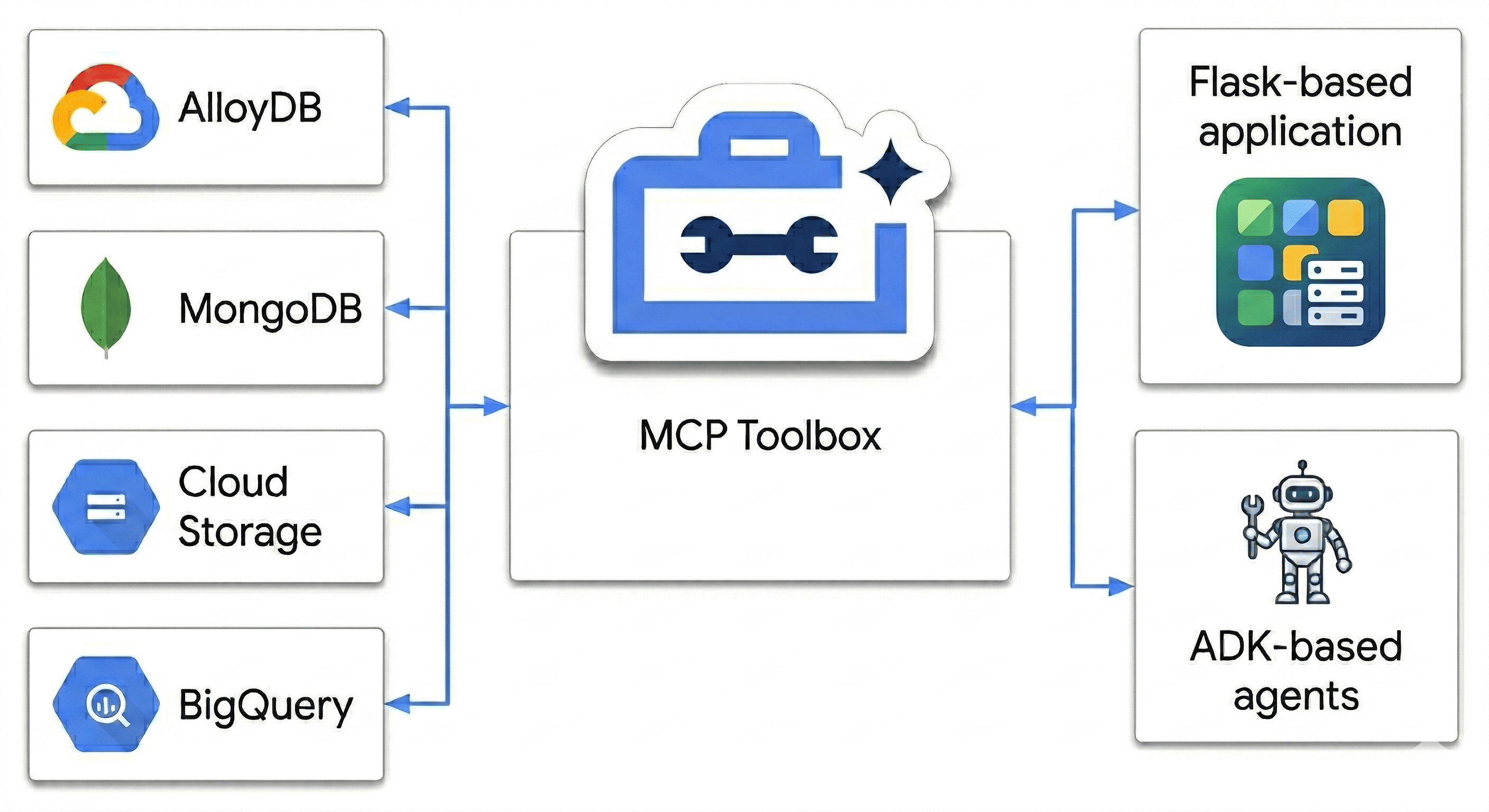
In diesem Codelab entwickeln Sie ein Polyglot Powerhouse, das Folgendes vereint:
- AlloyDB: Ihr transaktionales Rückgrat für schnelle Konsistenz und Bildeinbettungen.
- MongoDB Atlas in Google Cloud: Ihre flexible, schemaunabhängige Katalogsicht.
- Cloud Storage: Ihr analytisches Gehirn für Echtzeit-Trendprognosen.
- BigQuery: Ihr hochauflösendes digitales Data Warehouse.
Die „Geheimzutat“? Sie verwenden die MCP Toolbox for Databases, um die in Cloud Run ausgeführten Datenquellen intelligent zu orchestrieren und als semantische Brücke zu vereinheitlichen. Anschließend stellen Sie eine Chat-App mit mehreren Agenten mit dem Agent Development Kit (ADK) bereit. Sie entwickeln nicht nur eine Suchleiste, sondern ein intelligentes Einzelhandels-Gehirn, das den Kontext versteht, Einschränkungen berücksichtigt und die Lücke zwischen Rohdaten und menschlicher Absicht schließt.
Die unmögliche Nutzeranfrage
Standard-E-Commerce-Agents scheitern bei der mehrdimensionalen Argumentation (Kombination von negativen Einschränkungen, visueller Ähnlichkeit und Echtzeitinventar). Ich möchte beispielsweise in der Regel mit einer Einzelhandelswebsite so interagieren:
„Hey, ich plane eine Fotoreise in die Berge. Zeige mir einige wetterfeste Rucksäcke, die dem „AeroGlow Pro“ ähneln, aber keine Lederkomponenten haben. Sag mir bitte auch, ob sie tatsächlich auf Lager sind und ob sich andere Fotografen in den Rezensionen über die Haltbarkeit des Tragegurts beschwert haben.“
Warum diese Anfrage als „Agent Killer“ bezeichnet wird:
- Visuelle Ähnlichkeit (AlloyDB + Vektorsuche): „Ähnlich im Stil wie AeroGlow Pro“ erfordert einen Vergleich von Bildeinbettungen.
- Negative Einschränkung (MongoDB): „Ohne Leder“ erfordert das Filtern über flexible, verschachtelte Attribute, die normalerweise nicht in einem Standard-SQL-Schema enthalten sind.
- Echtzeitinventar (AlloyDB): Für „Tatsächlich auf Lager“ ist eine Live-Transaktionsprüfung erforderlich (kein veralteter Suchindex).
- Semantische Synthese (BigQuery + Multi-Agent): Um Rezensionen zur „Strapazierfähigkeit des Armbands“ zu analysieren, muss der Agent unstrukturiertes Feedback aus BigQuery spontan zusammenfassen.
Die meisten Einzelhandelsbots würden nur „Rucksack“ und „Leder“ sehen und 10 Lederrucksäcke anzeigen. Wie verhindern wir das?
Wir gleichen nicht nur Keywords ab. Wir verwenden die MCP Toolbox, damit unsere Agents gleichzeitig auf alle diese Quellen zugreifen können, um die transaktionale Wahrheit in AlloyDB und die flexiblen Attribute in MongoDB zu berücksichtigen. Lass uns das gemeinsam entwickeln.
Aufgaben
- AlloyDB-Cluster für Kernproduktdaten bereitstellen
- MongoDB Atlas in Google Cloud zum Speichern halbstrukturierter Produktdetails konfigurieren
- Cloud Storage-Bucket zum Bereitstellen von Produktbildern erstellen
- MCP Toolbox for Databases in Cloud Run für einheitlichen Datenzugriff bereitstellen
- ETL-Prozesse ausführen, um Daten zur Analyse in BigQuery zu übertragen
- Mit einem KI-Agenten in natürlicher Sprache kommunizieren
Vorbereitung
- Ein Webbrowser wie Chrome
- Ein Google Cloud-Projekt mit aktivierter Abrechnungsfunktion
- Ein kostenloses MongoDB Atlas in Google Cloud-Konto
2. Hinweis
Google Cloud-Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
Cloud Shell starten
Cloud Shell ist eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird und mit den erforderlichen Tools vorinstalliert ist.
- Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren.
- Prüfen Sie nach der Verbindung mit Cloud Shell Ihre Authentifizierung:
gcloud auth list - Prüfen Sie, ob Ihr Projekt konfiguriert ist:
gcloud config get project - Wenn Ihr Projekt nicht wie erwartet festgelegt ist, legen Sie es fest:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Erforderliche APIs aktivieren
Führen Sie diesen Befehl aus, um alle erforderlichen APIs zu aktivieren:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
3. Cloud Storage einrichten
Cloud Storage dient als umfassender Speicher für unstrukturierte Media-Assets wie Produktbilder.
- Rufen Sie in der Google Cloud Console Cloud Storage auf und klicken Sie auf Bucket erstellen.
- Geben Sie Ihrem Bucket einen global eindeutigen Namen, z.B.
ecommerce-app-images. - Klicken Sie auf Erstellen.
- Wenn Sie der Demoanwendung erlauben möchten, ohne Authentifizierung auf die Bilder zuzugreifen, deaktivieren Sie die Option Verhinderung des öffentlichen Zugriffs für diesen Bucket erzwingen und klicken Sie auf Bestätigen.
- Wechseln Sie zum Tab Berechtigungen.
- Klicken Sie unter Berechtigungen auf Zugriff gewähren.
- Geben Sie unter Neue Hauptkonten
allUsersein. - Wählen Sie unter Rolle auswählen die Option Cloud Storage > Storage Object User aus.
- Klicken Sie auf Speichern und dann auf Öffentlichen Zugriff erlauben, um zu bestätigen, dass Sie die Ressource öffentlich machen.
Platzhalterbilder hochladen
Im BRK2-149-multidb-ecommerce werden Platzhalterbilder verwendet, um eine optimale Darstellung zu gewährleisten.
- Klonen Sie in Cloud Shell das Repository
next-26-sessions:git clone https://github.com/GoogleCloudPlatform/next-26-sessions.git - Rufen Sie den
UploadImages-Ordner auf:cd next-26-sessions/BRK2-149-multidb-ecommerce/UploadImages - Rufen Sie in der Google Cloud Console Cloud Storage auf und klicken Sie auf Buckets.
- Klicken Sie auf den Namen des neu erstellten Buckets.
- Klicken Sie auf Hochladen > Dateien hochladen, wählen Sie die heruntergeladenen Beispielbilder aus und klicken Sie auf Öffnen.
4. AlloyDB einrichten
AlloyDB dient als Single Source of Truth für strukturierte, transaktionale und kritische Daten wie Produkt-IDs, Namen, Artikelnummern, Preise und Inventar. AlloyDB unterstützt den KI-Agenten auch mit Funktionen für die Ähnlichkeitssuche für Empfehlungen und Abfragen in natürlicher Sprache.
AlloyDB-Cluster bereitstellen
- Rufen Sie in der Google Cloud Console AlloyDB for PostgreSQL auf.
- Klicken Sie auf Cluster erstellen.
- Geben Sie als Cluster-ID
ecommerce-clusterein. - Legen Sie ein starkes Passwort für den Nutzer
postgresfest. Zu Lernzwecken können Siealloydbverwenden. - Behalten Sie für Datenbankversion die Standardeinstellung bei.
- Wählen Sie bei Region die Option
us-central1(oder Ihre bevorzugte Region) aus.
Primäre Instanz konfigurieren
- Geben Sie als Instanz-ID
ecommerce-cluster-primaryein. - Wählen Sie unter Zonale Verfügbarkeit die Option Einzelne Zone aus.
- Wählen Sie als Maschinentyp einen kleinen Maschinentyp aus, z.B. N2, 4 vCPUs, 32 GB RAM.
- Wählen Sie unter Private IP Connectivity (Private IP-Verbindung) die Option Private Services Access (PSA) (Zugriff auf private Dienste) und das
default-Netzwerk aus.Wenn das Standardnetzwerk noch nicht festgelegt ist, klicken Sie auf Confirm network setup (Netzwerkeinrichtung bestätigen), um eines zu erstellen. - Wählen Sie unter Öffentliche IP-Verbindung das Kästchen Öffentliche IP-Adresse aktivieren aus, damit die MCP-Toolbox in diesem Codelab richtig verbunden wird.
- Geben Sie unter Autorisierte externe Netzwerke den Wert
0.0.0.0/0ein. Klicken Sie das Kästchen Ich bin mir der Risiken bewusst an und klicken Sie auf Speichern. - Klicken Sie auf Cluster erstellen.
Hinweis: Notieren Sie sich Ihre öffentliche IP-Adresse (sie sieht ähnlich aus wie 34.124.240.26).
Datenbank initialisieren
- Klicken Sie im linken Navigationsmenü auf AlloyDB Studio.
- Wählen Sie im Drop-down-Menü Datenbank die Option
postgresaus. - Wählen Sie Integrierte Authentifizierung aus, um sich in der Datenbank anzumelden.
- Verwenden Sie für Nutzername den Nutzer
postgres. - Geben Sie unter Passwort das Passwort ein, das Sie zuvor festgelegt haben.
- Klicken Sie auf Authentifizieren.
- Öffnen Sie in der Editoransicht einen neuen Tab „Unbenannte Abfrage“.
- Kopieren Sie die folgende DDL und klicken Sie auf Ausführen:
CREATE TABLE products_core_table ( product_id UUID PRIMARY KEY, name VARCHAR(255) NOT NULL, sku VARCHAR(50) UNIQUE NOT NULL, price NUMERIC(10, 2) NOT NULL, stock INT NOT NULL ); - Wechseln Sie in Cloud Shell zum Ordner
BRK2-149-multidb-ecommerce:cd next-26-sessions/BRK2-149-multidb-ecommerce - Öffnen Sie die Datei
alloydb_insert_queries.sqlin Cloud Shell und kopieren Sie die Einfügeabfragen.cat alloydb_insert_queries.sql - Fügen Sie in einem neuen Tab mit einer unbenannten Abfrage nur die
INSERT-Anweisungen ein und klicken Sie auf Ausführen. - Kopieren Sie die folgende DDL auf einen neuen Tab für unbenannte Abfragen und klicken Sie auf Ausführen, um einen Index für die Tabelle
products_core_tablezu erstellen:CREATE INDEX idx_products_core_sku ON products_core_table(sku);
Bildeinbettungen für KI‑Agenten erstellen, damit ähnliche Produkte abgerufen werden können
Bei der Integration des KI‑Agents werden Bildeinbettungen verwendet, um ähnliche Produkte abzurufen. Die Einbettungen werden mit dem Modell multimodalembedding@001 generiert und in der AlloyDB-Datenbank gespeichert. Die Einbettungen sind 1408-dimensionale Vektoren und werden in der Spalte img_embeddings gespeichert.
Bevor wir Einbettungen generieren können, müssen wir dem AlloyDB-Dienstkonto die erforderlichen Rollen für den Zugriff auf Cloud Storage gewähren.
Rollen für das AlloyDB-Dienstkonto für den Zugriff auf Cloud Storage zuweisen
Wir weisen dem AlloyDB-Dienstkonto die Rolle „Storage Object User“ und „Storage Object Viewer“ zu, damit es Objekte aus dem Cloud Storage-Bucket lesen kann.
- Rufen Sie IAM und Verwaltung auf.
- Klicken Sie auf Zugriff erlauben.
- Geben Sie im Feld Neue Hauptkonten das Dienstkonto für die Suche nach AlloyDB ein. Das Dienstkonto sieht in etwa so aus:
service-991742412753@gcp-sa-alloydb.iam.gserviceaccount.com. - Klicken Sie auf Rolle auswählen.
- Suchen Sie die Rolle Storage Object User und wählen Sie sie aus.
- Klicken Sie auf Weitere Rolle hinzufügen und wählen Sie die Rolle Storage-Objekt-Betrachter aus.
- Klicken Sie auf Weitere Rolle hinzufügen und wählen Sie die Rolle Vertex AI User aus.
- Klicken Sie auf Speichern.
Erweiterungen aktivieren
Für die Entwicklung dieser App verwenden wir die Erweiterungen pgvector und google_ml_integration. Mit der pgvector-Erweiterung können Sie Vektoreinbettungen speichern und durchsuchen. Die google_ml_integration-Erweiterung bietet Funktionen, mit denen Sie auf Vertex AI-Vorhersageendpunkte zugreifen können, um Vorhersagen in SQL zu erhalten. Aktivieren Sie diese Erweiterungen, indem Sie die folgenden DDLs ausführen:
- Rufen Sie in der Google Cloud Console AlloyDB for PostgreSQL auf.
- Klicken Sie im linken Navigationsmenü auf AlloyDB Studio.
- Öffnen Sie in der Editoransicht einen neuen Tab „Unbenannte Abfrage“.
- Kopieren Sie die folgende DDL und klicken Sie auf Ausführen:
CREATE EXTENSION IF NOT EXISTS vector; CREATE EXTENSION IF NOT EXISTS google_ml_integration;
Datenbank mit Einbettungen initialisieren
- Fügen Sie der
products_core_tabledie Spalte „img_embeddings“ hinzu.ALTER TABLE products_core_table ADD COLUMN img_embeddings vector(1408); - Generieren Sie Einbettungen für die Bilder und speichern Sie sie in der Spalte
img_embeddings.UPDATE products_core_table SET img_embeddings = google_ml.image_embedding( model_id => 'multimodalembedding@001', image => 'gs://<STORAGE_BUCKET_NAME>/' || sku || '.jpg', mimetype => 'image/jpeg') WHERE sku IN ( SELECT sku FROM products_core_table WHERE img_embeddings IS NULL AND sku IS NOT NULL LIMIT 10 ); - Wiederholen Sie die vorherige Abfrage mindestens fünfmal, um Bild-Embeddings für das gesamte Set zu generieren, da Studio eine Beschränkung von fünf Minuten hat. Wenn das Zeitlimit für diese Abfrage überschritten wird, ändern Sie
LIMITin5und führen Sie die Abfrage zehnmal aus. Dieser Schritt kann einige Minuten dauern.
5. MongoDB Atlas in Google Cloud einrichten
In MongoDB werden umfangreiche, semistrukturierte Produktdetails und flexible Daten zum Nutzerverhalten (z. B. Klicks und Aufrufe) gespeichert.\
MongoDB-Cluster erstellen
- Rufen Sie MongoDB Atlas in Google Cloud auf und wählen Sie ein Konto für die kostenlose Stufe aus.
- Wählen Sie die Clusterstufe Kostenlos aus und geben Sie einen Namen für den Cluster ein, z. B.
ecommerce-cluster. - Wählen Sie Google Cloud als Anbieter aus und achten Sie darauf, dass die Region mit Ihrer Google Cloud-Region übereinstimmt (z.B.
us-central1). - Klicken Sie auf Deployment erstellen.
- Klicken Sie auf Schließen.
Netzwerkzugriff konfigurieren
- Rufen Sie in der Atlas-Konsole Database & Network Access (Datenbank- und Netzwerkzugriff) auf.
- Klicken Sie auf IP-Zugriffsliste.
- Klicken Sie auf IP-Adresse hinzufügen.
- Fügen Sie
0.0.0.0/0hinzu, um den Zugriff von überall aus zu ermöglichen. - Klicken Sie auf Bestätigen.
Datenbanknutzer erstellen
- Rufen Sie in der Atlas-Konsole Database & Network Access (Datenbank- und Netzwerkzugriff) auf.
- Klicken Sie auf Datenbanknutzer.
- Klicken Sie auf Neuen Datenbanknutzer hinzufügen.
- Wählen Sie Passwort als Authentifizierungsmethode aus.
- Geben Sie den Nutzernamen als
store-userund das Passwort alsstoreuserein. - Klicken Sie auf Integrierte Rolle hinzufügen und wählen Sie Lesen und Schreiben in beliebige Datenbanken aus.
- Klicken Sie auf Nutzer hinzufügen.
Verbindungsstring abrufen
- Klicken Sie auf Database > Clusters > Connect (Datenbank > Cluster > Verbinden).
- Klicken Sie unter Anwendung verbinden auf Treiber.
- Kopieren Sie den Verbindungsstring, der unter Verbindungsstring in den Anwendungscode einfügen angezeigt wird. Der String sieht in etwa so aus:
mongodb+srv://store-user:<db_password>@ecommerce-cluster.g8vaekh.mongodb.net/?appName=ecommerce-clusterdb_passworddurch Ihr MongoDB-Passwort. In diesem Codelab ist dasstoreuser.
Speichern Sie diese Verbindungszeichenfolge. Sie verwenden sie später für die Umgebungsvariable MONGODB_CONNECTION_STRING.
Datenbank und Sammlung erstellen
- Rufen Sie in der Atlas-Konsole Database > Clusters > Browse Collections auf.
- Klicken Sie auf Datenbank erstellen und geben Sie die Details ein:
- Datenbankname :
ecommerce_db - Name der Sammlung:
product_details_collection
- Datenbankname :
- Klicken Sie auf Datenbank erstellen.
- Wählen Sie im Data Explorer den Sammlungsnamen aus.
- Klicken Sie auf das Symbol Daten hinzufügen (+) und dann auf Dokument einfügen.
- Kopieren Sie den JSON-Inhalt aus product_details_export.json und fügen Sie ihn in den Editor des Dialogfelds Dokument einfügen ein.
- Klicken Sie auf Einfügen, um das Array von Dokumenten einzufügen, und prüfen Sie, ob 192 Dokumente hinzugefügt wurden.
- Klicken Sie im Data Explorer neben der Datenbank
ecommerce_dbauf Sammlung erstellen (+). - Geben Sie
user_interactions_collectionals Namen für die Sammlung ein und klicken Sie auf Sammlung erstellen. - Wählen Sie im Data Explorer die Sammlung
user_interactions_collectionaus. - Klicken Sie auf das Symbol Daten hinzufügen (+) und dann auf Dokument einfügen.
- Kopieren Sie den JSON-Inhalt aus user_interactions_export.json und fügen Sie ihn in das Dialogfeld Dokument einfügen ein.
- Klicken Sie auf Dokument einfügen.
6. BigQuery einrichten
BigQuery aggregiert und analysiert das bisherige Nutzerverhalten, um intelligente Berichte und Empfehlungen zu erstellen.
Dataset erstellen
- Rufen Sie in der Google Cloud Console BigQuery auf.
- Klicken Sie im Explorer-Bereich neben Ihrer Projekt-ID auf das Dreipunkt-Menü und wählen Sie Dataset erstellen aus.
- Geben Sie als Dataset-ID
ecommerce_analyticsein. - Klicken Sie auf Dataset erstellen.
Analytics-Tabelle erstellen
- Öffnen Sie eine neue Abfrage im BigQuery-Arbeitsbereich.
- Führen Sie die folgende SQL-Anweisung aus, um die Zusammenfassungstabelle zu erstellen, in der Nutzer mit Produktinteraktionen verknüpft werden:
CREATE TABLE ecommerce_analytics.user_product_interactions (
user_id STRING DEFAULT 'any user',
product_id STRING,
interaction_score INT
);
Compute-Dienstkonto für die MCP Toolbox Rollen zuweisen
Wir weisen dem für unsere Toolbox verwendeten Compute-Dienstkonto Rollen zu. Dies ist erforderlich, damit die MCP Toolbox auf BigQuery, Secret Manager und andere Cloud-Dienste zugreifen kann.
So weisen Sie Rollen zu:
- Rufen Sie IAM und Verwaltung auf.
- Klicken Sie auf Zugriff erlauben.
- Geben Sie im Feld Neue Hauptkonten das standardmäßige Compute-Dienstkonto mit dem Namen
YOUR_PROJECT_NUMBER-compute@developer.gserviceaccount.comein. Ersetzen SieYOUR_PROJECT_NUMBERdurch Ihre Google Cloud-Projektnummer. - Klicken Sie auf Rolle auswählen.
- Suchen Sie nach der Rolle BigQuery-Datenbearbeiter und wählen Sie sie aus.
- Klicken Sie auf Weitere Rolle hinzufügen und wählen Sie die Rolle BigQuery-Jobnutzer aus.
- Klicken Sie auf Weitere Rolle hinzufügen und wählen Sie die Rolle Secret Manager Secret Accessor aus.
- Klicken Sie auf Weitere Rolle hinzufügen und wählen Sie die Rolle Editor aus.
- Klicken Sie auf Speichern.
7. Anwendung von Anfang bis Ende verstehen
Um zu verstehen, wie die einzelnen Komponenten zusammenarbeiten, erstellen wir eine einfache E-Commerce-Anwendung, die mehrere Datenbanken und Dienste verwendet. Die Anwendung basiert auf einem Python-Backend (Flask) und umfasst mehrere Google Cloud-Dienste und ‑Datenbanken.
Verzeichnisstruktur
Im nächsten Abschnitt klonen Sie das Repository BRK2-149-multidb-ecommerce und verwenden es, um die Anwendung lokal auszuführen. Nachdem wir die Anwendung lokal getestet haben, stellen wir sowohl die MCP Toolbox als auch die Anwendung in Cloud Run bereit.
Sehen Sie sich die heruntergeladenen Dateien in diesem Verzeichnis an. Die folgenden Verzeichnisse sind vorhanden:
UploadImages: Hier werden Bild-Assets gespeichert, die hauptsächlich für die Dokumentation oder für visuelle Inhalte für den E-Commerce-Produktkatalog verwendet werden.static: Hier werden die statischen Web-Assets der Anwendung gespeichert, z. B. CSS- und JavaScript-Dateien, die zum Formatieren und Hinzufügen von Interaktivität zur Benutzeroberfläche verwendet werden ( Quelle).templates: Hier werden die HTML-Vorlagen (wahrscheinlich Jinja2 für Flask) gespeichert, die von der Python-Anwendung verwendet werden, um Webseiten für den E-Commerce-Katalog dynamisch zu rendern ( Quelle).toolbox-implementation: Speichert Konfigurations- und Implementierungsdetails für die MCP-Toolbox (Model Context Protocol) und ermöglicht Datenbankinteraktionen mit mehreren Datenbanken mithilfe vordefinierter Tools.
Die Dateien in diesem Repository arbeiten zusammen, um eine E-Commerce-Anwendung mit mehreren Datenbanken zu erstellen, zu konfigurieren und bereitzustellen. Zentrale Dateien wie app.py orchestrieren das Backend, indem sie verschiedene Datenquellen integrieren, die in SQL- und JSON-Dateien definiert sind. Konfigurationsdateien sorgen für eine nahtlose Bereitstellung in Cloud-Umgebungen:
app.py: Orchestriert das Flask-Backend und die Integrationen mehrerer Datenbanken.agentengine.py: Kernlogik zum Initialisieren und Konfigurieren von Vertex AI-Agents..env: Speichert Secrets für Datenbank- und Speicherverbindungen.tools.yaml: Konfiguriert die MCP Toolbox für Datenbankvorgänge mit mehreren Datenbanken.Dockerfile: Definiert das Container-Image und die Umgebungseinrichtung.requirements.txt: Listet die Python-Bibliotheken auf, die für die Ausführung der Anwendung erforderlich sind.tools.yaml: Konfigurationen für die MCP Toolbox.Procfile: Gibt Produktionsausführungsbefehle für das Deployment an.alloydb_insert_queries.sql: Enthält SQL-Abfragen für relationale Daten.product_details_export.jsonunduser_interactions_export.json: Hier finden Sie JSON-Beispieldaten für die NoSQL-Datenbank.README.md: bietet Unterstützung bei der Einrichtung, Bereitstellung und dem Verständnis des Projekts.
End-to-End-Ablauf der Anwendung
- AlloyDB-Einrichtung: Stellen Sie einen leistungsstarken Cluster bereit und verwenden Sie die bereitgestellten SQL-Scripts, um die Tabelle „products_core_table“ mit Vektorspalten für Bildeinbettungen zu erstellen.
- MongoDB Atlas einrichten: Stellen Sie einen Cluster in Google Cloud bereit, um dynamische Produktattribute in „product_details“ zu speichern und Clickstreams in Echtzeit in „user_interactions“ zu protokollieren.
- BigQuery Analytics: Erstellen Sie ein Dataset, um Interaktionsprotokolle zusammenzufassen. So können Sie komplexe Analyseabfragen ausführen, mit denen sich die fünf wichtigsten Trendartikel aus Millionen von Ereignissen ermitteln lassen.
- Cloud Storage-Repository: Erstellen Sie einen öffentlichen Bucket für hochauflösende Produktbilder. Jedes Asset muss über eine signierte oder öffentliche URL für das Frontend zugänglich sein.
- MCP Toolbox bereitstellen: Stellen Sie die Toolbox in Cloud Run bereit. Sie fungiert als zentrale RESTful-Brücke, die Intentionen in natürlicher Sprache in Datenbankabfragen übersetzt.
- Tools.yaml-Konfiguration: Definieren Sie Ihre Tools, z. B. „get_product_core_data“ oder „get_top_5_views“, und ordnen Sie bestimmte SQL- und NoSQL-Vorgänge einfachen, für den Agent lesbaren Namen zu.
- Flask-Backend-Logik: Implementieren Sie app.py-Routen, die mit der MCP Toolbox interagieren und die Koordination des Datenabrufs sowie die Bereitstellung als API für die Benutzeroberfläche übernehmen.
- Multi-Agent-Orchestrierung: Konfigurieren Sie die ADK-Agents im Code, um die Nutzerabsicht zu analysieren und das richtige „Tool“ auszuwählen, um komplexe, aus mehreren Quellen stammende Einzelhandelsanfragen zu beantworten.
- Frontend-Integration: Erstellen Sie eine index.html-Oberfläche mit dem Produktkatalog und einer Funktion zur Aufzeichnung von Interaktionen, einem Analytics-Tab, um die Produktleistung zu analysieren, und einem speziellen „Agent-Tab“, in dem der ADK-Chat mit mehreren Agenten verwendet wird, um ein nahtloses Shoppingerlebnis zu ermöglichen.
Jetzt implementieren wir die Orchestrierung und die Deployments.
8. MCP Toolbox einrichten und in Cloud Run bereitstellen
Die MCP Toolbox abstrahiert unsere verschiedenen Datenquellen, sodass unsere Anwendung Daten einheitlich abrufen und schreiben kann.
MCP Toolbox lokal installieren
- Wechseln Sie in Cloud Shell zum Ordner
toolbox-implementation:cd next-26-sessions/BRK2-149-multidb-ecommerce/toolbox-implementation - Laden Sie das MCP Toolbox-Binärprogramm herunter und machen Sie es ausführbar:
export VERSION=0.29.0 curl -L -o toolbox https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox chmod +x toolbox
tools.yaml konfigurieren
Sie müssen die Abstraktionen für AlloyDB, MongoDB und BigQuery definieren. Die Datei tools.yaml gibt an, wie die MCP-Toolbox-Komponenten miteinander interagieren.
- Erstellen und bearbeiten Sie die Datei
tools.yamlmit dem eingebetteten Editor:cloudshell edit tools.yamltools.yaml-Datei finden Sie im GitHub-Repository. Kopieren Sie den Inhalt in Ihre neuetools.yaml-Datei. - Aktualisieren Sie den Host, den Nutzer, die Passwörter, die Projekt-IDs und die Verbindungsstrings entsprechend der Infrastruktur, die Sie in den vorherigen Schritten bereitgestellt haben:
Datenbank
Feld
Beispielwert
AlloyDB/BigQuery
project_idYOUR_PROJECT_IDAlloyDB
regionus-central1AlloyDB
clusterecommerce-clusterAlloyDB
instanceecommerce-cluster-primaryAlloyDB
databasepostgresAlloyDB
passwordalloydbMongoDB
connection_stringmongodb+srv://store-user:storeuser@ecommerce-cluster.urcxr6q.mongodb.net
Compute-Dienstkonto für die MCP Toolbox Rollen zuweisen
Wir weisen dem für unsere Toolbox verwendeten Compute-Dienstkonto Rollen zu. Dies ist erforderlich, damit die MCP Toolbox auf AlloyDB zugreifen kann.
- Rufen Sie IAM und Verwaltung auf.
- Klicken Sie auf Zugriff erlauben.
- Geben Sie im Feld Neue Hauptkonten das standardmäßige Compute-Dienstkonto mit dem Namen
YOUR_PROJECT_NUMBER-compute@developer.gserviceaccount.comein. Ersetzen SieYOUR_PROJECT_NUMBERdurch Ihre Google Cloud-Projektnummer. - Klicken Sie auf Rolle auswählen.
- Suchen Sie nach der Rolle BigQuery-Datenbearbeiter und wählen Sie sie aus.
- Klicken Sie auf Weitere Rolle hinzufügen und wählen Sie die Rolle AlloyDB Client aus.
- Klicken Sie auf Weitere Rolle hinzufügen und wählen Sie die Rolle Service Usage Consumer aus.
- Klicken Sie auf Weitere Rolle hinzufügen und wählen Sie die Rolle Storage-Objekt-Betrachter aus.
- Klicken Sie auf Speichern.
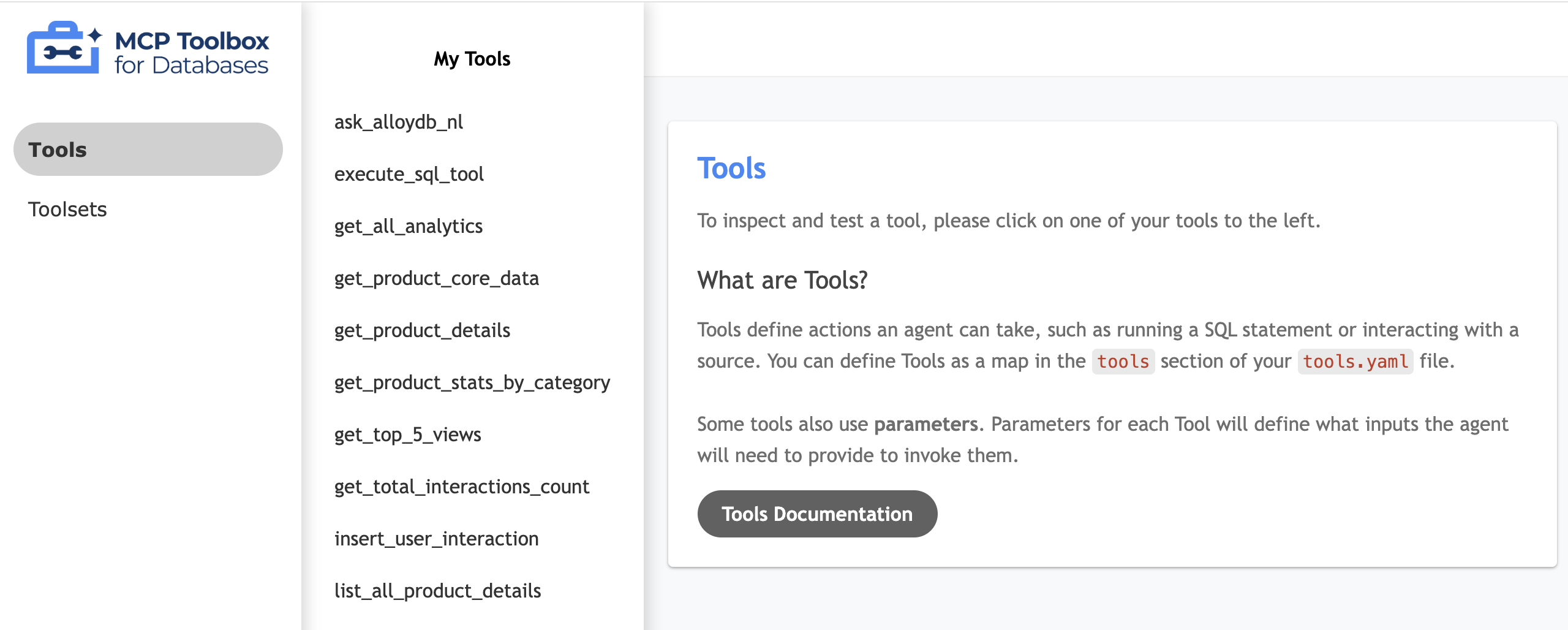
Tool-Benutzeroberfläche testen
- Führen Sie die Toolbox in Ihrem Cloud Shell-Terminal lokal aus, um die Benutzeroberfläche bereitzustellen:
./toolbox --ui - Öffnen Sie die Webvorschau in Cloud Shell auf Port 5000 und rufen Sie die Seite „Tools“ auf. Je nach Sitzungs-URL können Sie sie beispielsweise unter
https://5000-cs-71152278760-default.cs-asia-southeast1-cash.cloudshell.dev/uiaufrufen.
Die folgende Benutzeroberfläche der MCP Toolbox wird angezeigt:
In Cloud Run bereitstellen
Stellen Sie die MCP Toolbox in Cloud Run bereit, damit sie als sicherer, verwalteter Dienst verfügbar ist, mit dem unsere Anwendung die Datenbanken abfragen kann. Wir speichern die Konfiguration in Secret Manager, um sensible Verbindungsdetails zu schützen.
- Öffnen Sie eine neue Cloud Shell-Sitzung.
- Rufen Sie den
toolbox-implementation-Ordner auf:cd next-26-sessions/BRK2-149-multidb-ecommerce/toolbox-implementation - Laden Sie die
tools.yaml-Konfiguration in Google Secret Manager hoch:gcloud secrets create tools --data-file=tools.yamlgcloud secrets versions add tools --data-file=tools.yaml - Mit dem öffentlichen MCP Toolbox-Container-Image bereitstellen:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:0.29.0 export PROJECT_ID=$(gcloud config get-value project) gcloud run deploy toolbox \ --image $IMAGE \ --region us-central1 \ --service-account $(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")-compute@developer.gserviceaccount.com \ --set-secrets "/app/tools.yaml=tools:latest" \ --args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080","--ui" \ --allow-unauthenticated - Notieren Sie sich nach der Bereitstellung die bereitgestellte Cloud Run-Dienst-URL. Sie sollte etwa so
https://toolbox-*********-uc.a.run.app/uiaussehen:
9. E-Commerce-Anwendung einrichten und in Cloud Run bereitstellen
Nachdem unsere Datenbanken ausgeführt und die MCP Toolbox-Abstraktion bereitgestellt wurde, können wir die Flask-Webanwendung ausführen.
Zum Bereitstellen des Produktkatalogs verarbeitet die Flask-Anwendung Daten in den folgenden Schritten:
- Kerndaten abrufen: Ruft die vollständige Liste der Produkte aus AlloyDB (
list_products_core) ab. - Erweiterte Details abrufen: Ruft alle Produktdetails aus MongoDB (
list_all_product_details) ab. - Listen kombinieren: Die beiden Listen werden verkettet.
- Mit Media anreichern: Die Cloud Storage-Bild-URL wird jedem Element hinzugefügt.
Anwendungspfad für Reasoning Engine generieren
Führen Sie den folgenden Befehl aus, um einen KI-Agenten mit der Vertex AI Reasoning Engine von Google Cloud zu initialisieren und zu registrieren:
- Wechseln Sie im Cloud Shell-Terminal zum Ordner
BRK2-149-multidb-ecommerce.cd next-26-sessions/BRK2-149-multidb-ecommerce - Führen Sie „requirements.txt“ aus, um die Abhängigkeiten zu installieren.
pip install -r requirements.txt - Führen Sie das Skript
agentengine.pyaus, um den Anwendungspfad der Reasoning Engine zu generieren:python agentengine.py
Die Ausgabe sollte in etwa so aussehen:
projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856
Umgebungsvariablen konfigurieren
.env-Datei erstellen und bearbeiten:cloudshell edit .env- Ersetzen Sie die Werte durch Ihre spezifischen Datenbankverbindungen und Ihre neue Cloud Run Toolbox-URL:
# 1. MongoDB Connection String MONGODB_CONNECTION_STRING="mongodb+srv://<db_user>:<db_password>@cluster0.mongodb.net" # 2. MCP Toolbox Server Location # Must match the address where you run the toolbox server MCP_TOOLBOX_SERVER_URL="https://toolbox-*********-uc.a.run.app" # 3. Google Cloud Storage Bucket Name GCS_PRODUCT_BUCKET="ecommerce-app-images" # 4. Fallback image URL FALLBACK_IMAGE_URL="https://storage.googleapis.com/ecommerce-media-bold-circuit-492711-n9/fallback.jpg" # 5. Google Gen AI Vertex AI flag GOOGLE_GENAI_USE_VERTEXAI=TRUE # 6. Project ID PROJECT_ID=codelab-project-491117 # 7. Google Cloud Location of AlloyDB, BigQuery databases GOOGLE_CLOUD_LOCATION=us-central1 # 8. Reasoning engine application path APP_NAME=projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856 # 9. Model ID MODEL=gemini-1.5-flash-lite
Frontend in Cloud Run bereitstellen
- Stellen Sie die Webanwendung in Cloud Run bereit, um die Architektur zu vervollständigen:
gcloud run deploy polyglot --source . --platform managed \ --region us-central1 \ --allow-unauthenticated \ --set-env-vars \ MONGODB_CONNECTION_STRING="<MONGODB_CONNECTION_STRING>", \ MCP_TOOLBOX_SERVER_URL="<MCP_TOOLBOX_SERVER_URL>", \ GCS_PRODUCT_BUCKET="<GCS_PRODUCT_BUCKET>", \ FALLBACK_IMAGE_URL="<FALLBACK_IMAGE_URL>", \ GOOGLE_GENAI_USE_VERTEXAI=TRUE, \ PROJECT_ID="YOUR_PROJECT_ID", \ GOOGLE_CLOUD_LOCATION=us-central1, \ APP_NAME="<YOUR_REASONING_ENGINE_APP_PATH>", \ MODEL="gemini-1.5-flash-lite"YOUR_PROJECT_ID: Ihre Google Cloud-Projekt-ID.YOUR_REASONING_ENGINE_APP_PATH: Die Ausgabe nach Ausführung vonpython agentengine.py, z. B.projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856.MCP_TOOLBOX_SERVER_URL: Die URL Ihres MCP Toolbox-Servers, z. B.https://toolbox-*********-uc.a.run.app.GCS_PRODUCT_BUCKET: Der Name Ihres Google Cloud Storage-Buckets, z. B.ecommerce-app-images.MONGODB_CONNECTION_STRING: Der Verbindungsstring für Ihre MongoDB-Datenbank, z. B.mongodb+srv://store-user:storeuser@ecommerce-cluster.g8vaekh.mongodb.netFALLBACK_IMAGE_URL: Die URL des Fallback-Bildes, z. B.https://storage.googleapis.com/ecommerce-app-images/fallback.jpg
Ihre Anwendung ist jetzt live! Öffnen Sie die von Cloud Run bereitgestellte Dienst-URL, um den Multidb E-Commerce-Katalog aufzurufen. Die URL sieht in etwa so aus: https://polyglot-*********-uc.a.run.app/.
10. Anwendung ausprobieren
- Klicken Sie auf Produktkatalog, um alle Produkte aufzurufen.
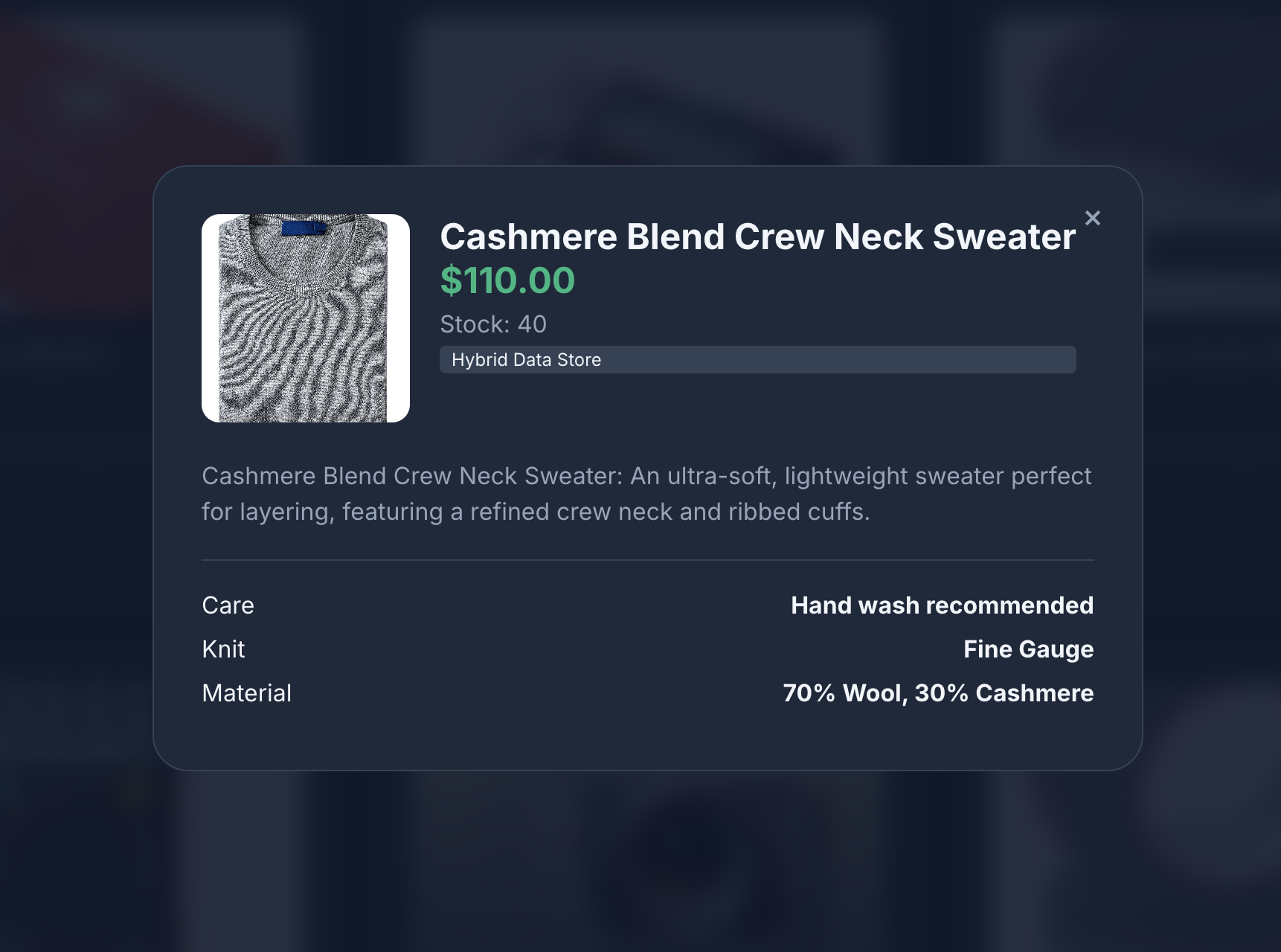
- Klicken Sie auf ein Produktsymbol, um die Produktdetails aufzurufen. Die Bilder stammen aus Cloud Storage, die Produktdetails werden aus MongoDB und der Produktbestand aus AlloyDB abgerufen.
- Interagieren Sie mit dem Produktkatalog, um Mock-Ansichten und ‑Schreibvorgänge zu generieren, die an MongoDB gesendet werden.
- Klicken Sie auf ETL & Analytics, um die Produktanalysen aufzurufen. Die Produktanalysen werden aus BigQuery abgerufen.
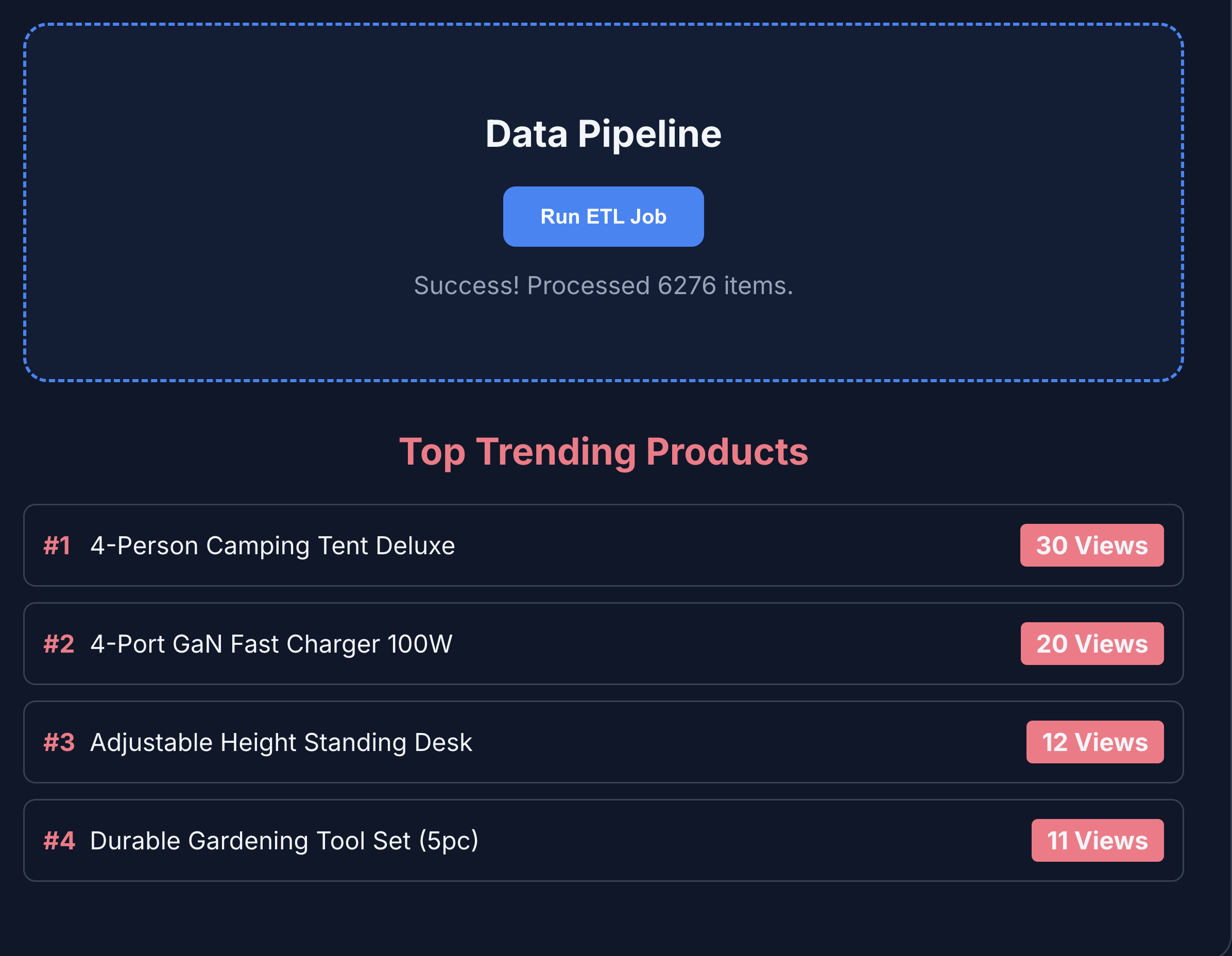
- Klicken Sie auf den Tab KI-Agent, um mit dem KI-Agenten zu interagieren. Stellen Sie Fragen in natürlicher Sprache, z. B.:
I'm planning a high-altitude photography trip. Show me some weather-resistant backpacks similar in style to aero glow pro but without any leather components. Also, let me know if they are actually in stock and if other photographers have complained about the strap durability in the reviews.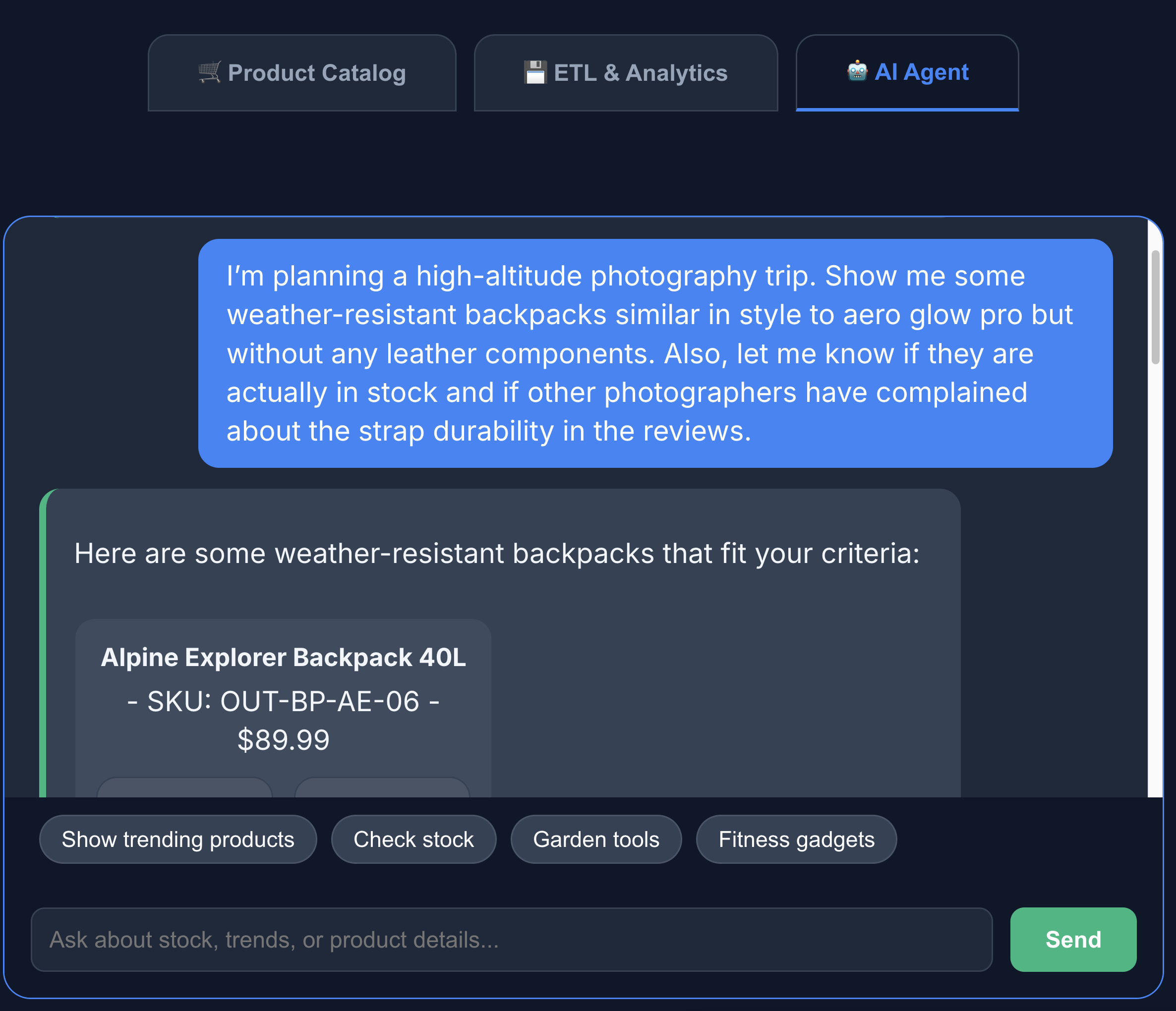
Die Suche liefert genau das, was wir gesucht haben: einen Rucksack ohne Lederbestandteile, der auf Lager ist und bei dem es in den Rezensionen keine Beschwerden über die Haltbarkeit der Tragegurte gibt.
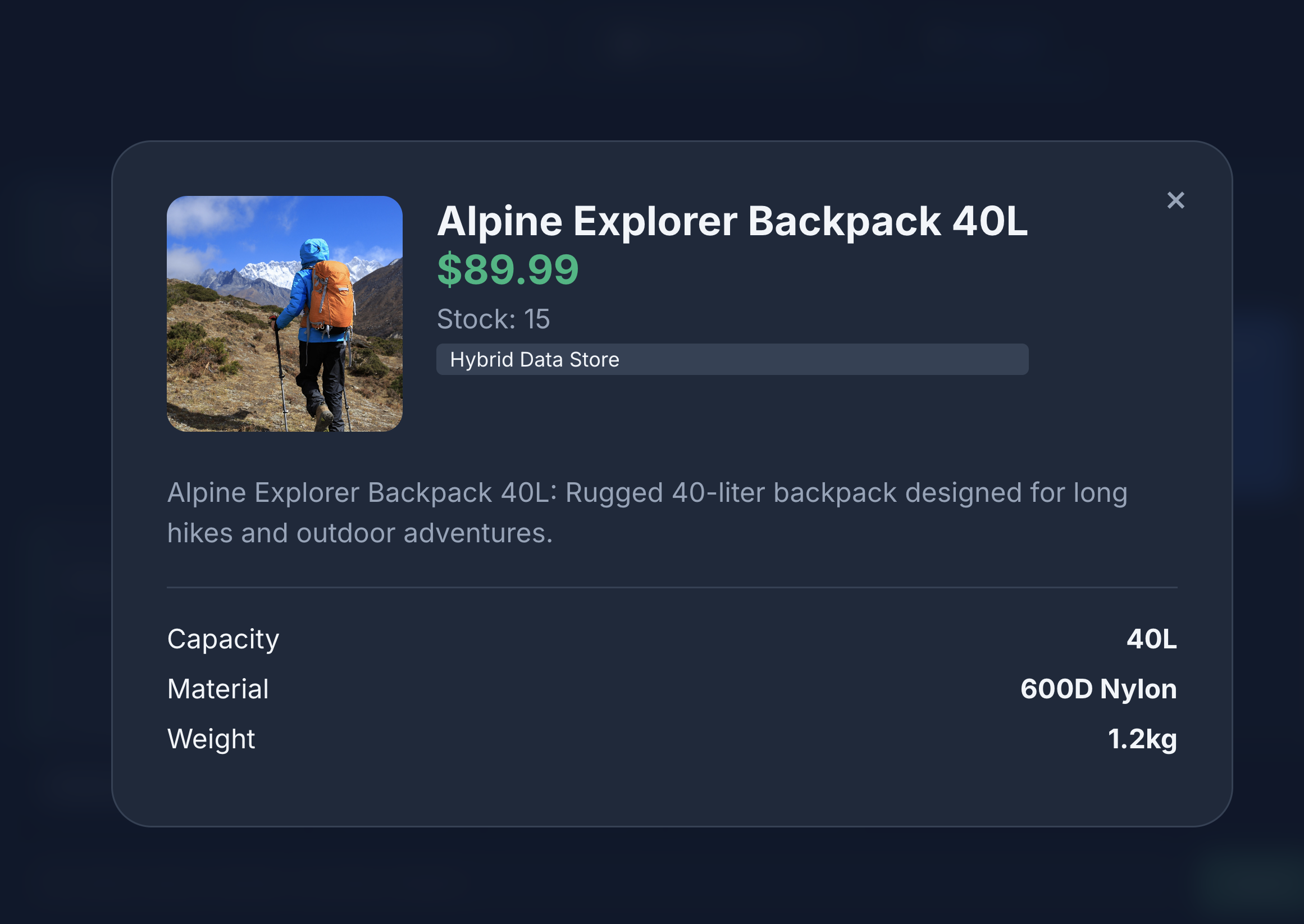
11. Bereinigen
Löschen Sie die in diesem Codelab erstellten Ressourcen, um laufende Gebühren für Ihr Google Cloud-Konto zu vermeiden.
Führen Sie die folgenden Cloud Shell-Befehle aus:
gcloud run services delete toolbox --region us-central1 --quiet
gcloud run services delete multi-db-app --region us-central1 --quiet
bq rm -r -f -d $PROJECT_ID:ecommerce_analytics
gcloud storage rm --recursive gs://ecommerce-app-images
gcloud alloydb clusters delete ecommerce-cluster --region us-central1 --force --quiet
Optional können Sie das gesamte Google Cloud-Projekt und alle zugehörigen Ressourcen mit dem folgenden Befehl löschen:
gcloud projects delete $PROJECT_ID
12. Glückwunsch
Das wars! Sie haben das Lab erfolgreich abgeschlossen. Sie haben erfolgreich eine cloudübergreifende Multidb-Architektur erstellt.
Sie haben gezeigt, wie die MCP Toolbox als architektonisches Bindeglied für eine moderne, spezialisierte Anwendung dient. Durch die Zuordnung der richtigen Datenbank zum richtigen Job haben Sie Folgendes erreicht:
- Flexible Data Writes: MongoDB für Ereignisprotokolle.
- Transaktionale Konsistenz: AlloyDB für die Kernintegrität.
- Leistungsstarke Analysen: BigQuery für Business Intelligence.
- Einheitliche Entwicklung: Ein einzelnes Python-Backend, das mithilfe der MCP Toolbox die gesamte Komplexität abstrahiert.
Referenzdokumente
Weitere Informationen zu den zugehörigen Google Cloud-Produkten und Codelabs:
- AlloyDB AI: Erste Schritte mit Vektoreinbettungen in AlloyDB AI
- AlloyDB AI: Multimodale Einbettungen in AlloyDB
- MCP Toolbox: Installation und Einrichtung der MCP Toolbox for Databases in AlloyDB
Weitere Informationen zu den in diesem Codelab verwendeten Produkten finden Sie unter: