
1. Introduction
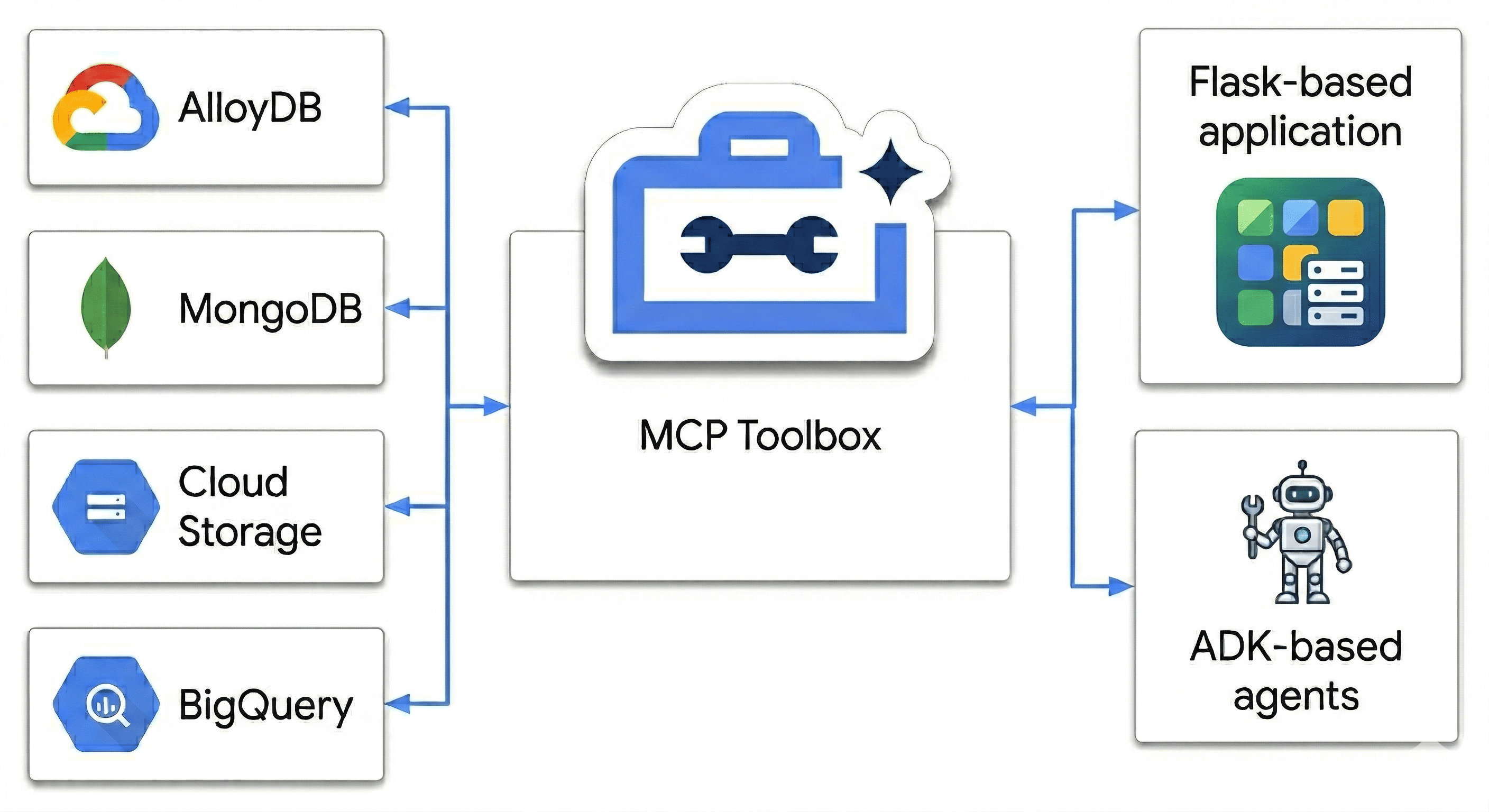
Dans le commerce moderne, vos données constituent un écosystème diversifié et tentaculaire. Vous disposez de données transactionnelles solides (prix et inventaire), de catalogues polymorphes "désordonnés" (spécifications électroniques vs tailles de vêtements) et de pétaoctets de journaux comportementaux. Forcer ces éléments dans un seul monolithe ne crée pas seulement une dette technique, mais détruit également l'expérience utilisateur.
Dans cet atelier de programmation, vous allez concevoir un Polyglot Powerhouse qui harmonise :
- AlloyDB : votre base de données transactionnelle pour une cohérence et des embeddings d'images à haute vitesse.
- MongoDB Atlas sur Google Cloud : votre couche de catalogue flexible et indépendante du schéma.
- Cloud Storage : votre cerveau analytique pour la prévision des tendances en temps réel.
- BigQuery : votre entrepôt numérique haute résolution.
L'ingrédient secret ? Vous utiliserez MCP Toolbox for Databases pour orchestrer et unifier intelligemment les sources de données s'exécutant sur Cloud Run en tant que pont sémantique, puis vous déploierez une application de chat multi-agents à l'aide d'Agent Development Kit (ADK). Vous ne créez pas seulement une barre de recherche, mais un cerveau retail intelligent qui comprend le contexte, respecte les contraintes et comble le fossé entre les données brutes et l'intention humaine.
Requête utilisateur impossible
Les agents d'e-commerce standards ne parviennent pas à effectuer un raisonnement multidimensionnel (combinaison de contraintes négatives, de similarité visuelle et d'inventaire en temps réel). Par exemple, je souhaite généralement parler à un site de vente au détail comme celui-ci :
"Hey, I'm planning a high-altitude photography trip. Montre-moi des sacs à dos résistants aux intempéries dont le style est similaire à celui de l'AeroGlow Pro, mais sans aucun composant en cuir. Indique-moi également s'ils sont réellement en stock et si d'autres photographes se sont plaints de la durabilité de la sangle dans les avis."
Pourquoi cette requête est-elle "The Agent Killer" ?
- Similarité visuelle (AlloyDB + Recherche vectorielle) : "Similaire au style AeroGlow Pro" nécessite une comparaison des embeddings d'images.
- Contrainte négative (MongoDB) : "Sans cuir" nécessite de filtrer des attributs flexibles et imbriqués qui ne figurent généralement pas dans un schéma SQL standard.
- Inventaire en temps réel (AlloyDB) : l'attribut "En stock" nécessite une vérification transactionnelle en direct (et non un index de recherche obsolète).
- Synthèse sémantique (BigQuery + multi-agents) : l'analyse des avis sur la "durabilité du bracelet" nécessite que l'agent résume les commentaires non structurés de BigQuery à la volée.
La plupart des robots commerciaux ne verraient que "sac à dos" et "cuir", et afficheraient 10 sacs à dos en cuir. Comment l'empêchons-nous ?
Parce que nous ne nous contentons pas de faire correspondre des mots clés. Nous utilisons MCP Toolbox pour permettre à nos agents de "raisonner" sur toutes ces sources, à savoir la vérité transactionnelle dans AlloyDB et les attributs flexibles dans MongoDB, simultanément. C'est parti !
Objectifs de l'atelier
- Provisionner un cluster AlloyDB pour les données produit principales
- Configurez MongoDB Atlas sur Google Cloud pour stocker les informations semi-structurées sur les produits.
- Créer un bucket Cloud Storage pour diffuser des images de produits
- Déployez MCP Toolbox for Databases sur Cloud Run pour un accès uniforme aux données.
- Exécuter des processus ETL pour transférer des données dans BigQuery à des fins d'analyse
- Discutez avec un agent d'IA en langage naturel.
Prérequis
- Un navigateur Web (par exemple, Chrome)
- Un projet Google Cloud avec facturation activée
- Un compte MongoDB Atlas sur Google Cloud sans frais
2. Avant de commencer
Créer un projet Google Cloud
- Dans la console Google Cloud, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
Démarrer Cloud Shell
Cloud Shell est un environnement de ligne de commande exécuté dans Google Cloud et fourni avec les outils nécessaires.
- Cliquez sur Activer Cloud Shell en haut de la console Google Cloud.
- Une fois connecté à Cloud Shell, vérifiez votre authentification :
gcloud auth list - Vérifiez que votre projet est configuré :
gcloud config get project - Si votre projet n'est pas défini comme prévu, définissez-le :
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Activer les API requises
Exécutez la commande suivante pour activer toutes les API requises :
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
3. Configurer Cloud Storage
Cloud Storage sert de vaste plate-forme de stockage pour les éléments multimédias non structurés, tels que les images de produits.
- Dans la console Google Cloud, accédez à Cloud Storage, puis cliquez sur Créer un bucket.
- Attribuez un nom unique au bucket (par exemple,
ecommerce-app-images). - Cliquez sur Créer.
- Pour permettre à l'application de démonstration d'accéder aux images sans authentification, décochez l'option Appliquer la protection contre l'accès public sur ce bucket, puis cliquez sur Confirmer.
- Accédez à l'onglet Autorisations.
- Dans Autorisations, cliquez sur Accorder l'accès.
- Dans Nouveaux comptes principaux, saisissez
allUsers. - Dans Sélectionnez un rôle, sélectionnez Cloud Storage > Utilisateur d'objets Storage.
- Cliquez sur Enregistrer, puis sur Autoriser l'accès public pour confirmer que vous rendez la ressource publique.
Importer des images de substitution
Le BRK2-149-multidb-ecommerce utilise des images de substitution pour une expérience visuelle optimale.
- Dans votre Cloud Shell, clonez le dépôt
next-26-sessions:git clone https://github.com/GoogleCloudPlatform/next-26-sessions.git - Accédez au dossier
UploadImages:cd next-26-sessions/BRK2-149-multidb-ecommerce/UploadImages - Dans la console Google Cloud, accédez à Cloud Storage, puis cliquez sur Buckets.
- Cliquez sur le nom du bucket que vous venez de créer.
- Cliquez sur Importer > Importer des fichiers, sélectionnez les exemples d'images téléchargés, puis cliquez sur Ouvrir.
4. Configurer AlloyDB
AlloyDB sert de source unique de vérité pour les données structurées, transactionnelles et critiques, comme les ID, les noms, les SKU, les prix et l'inventaire des produits. AlloyDB alimente également l'agent d'IA avec des fonctionnalités de recherche par similarité pour les recommandations et les requêtes en langage naturel.
Provisionner un cluster AlloyDB
- Dans la console Google Cloud, accédez à AlloyDB pour PostgreSQL.
- Cliquez sur Créer un cluster.
- Dans le champ ID de cluster, saisissez
ecommerce-cluster. - Définissez un mot de passe sécurisé pour l'utilisateur
postgres. Pour les besoins de ce tutoriel, vous pouvez utiliseralloydb. - Pour Version de la base de données, conservez la valeur par défaut.
- Pour Région, sélectionnez
us-central1(ou la région de votre choix).
Configurer l'instance principale
- Dans le champ ID d'instance, saisissez
ecommerce-cluster-primary. - Dans Disponibilité zonale, sélectionnez Zone unique.
- Pour Type de machine, choisissez un petit type de machine (par exemple, N2, 4 processeurs virtuels, 32 Go de RAM).
- Dans Connectivité IP privée, sélectionnez Accès aux services privés (PSA), puis sélectionnez le réseau
default.Si le réseau par défaut n'est pas encore défini, cliquez sur Confirmer la configuration du réseau pour en créer un. - Dans Connectivité IP publique, cochez la case Activer l'adresse IP publique pour que la boîte à outils MCP se connecte correctement dans cet atelier de programmation.
- Dans Réseaux externes autorisés, saisissez
0.0.0.0/0. Cochez la case Je reconnais les risques, puis cliquez sur Enregistrer. - Cliquez sur Créer un cluster.
Remarque : Assurez-vous de noter votre adresse IP publique (elle ressemble à 34.124.240.26).
Initialiser la base de données
- Cliquez sur AlloyDB Studio dans le menu de navigation de gauche.
- Dans le menu déroulant Base de données, sélectionnez
postgres. - Sélectionnez Authentification intégrée pour vous connecter à la base de données.
- Dans le champ Nom d'utilisateur, utilisez l'utilisateur
postgres. - Dans le champ Mot de passe, saisissez le mot de passe que vous avez défini précédemment.
- Cliquez sur Authentifier.
- Dans la vue de l'éditeur, ouvrez un nouvel onglet "Requête sans titre".
- Copiez le DDL suivant, puis cliquez sur Exécuter :
CREATE TABLE products_core_table ( product_id UUID PRIMARY KEY, name VARCHAR(255) NOT NULL, sku VARCHAR(50) UNIQUE NOT NULL, price NUMERIC(10, 2) NOT NULL, stock INT NOT NULL ); - Dans votre Cloud Shell, accédez au dossier
BRK2-149-multidb-ecommerce:cd next-26-sessions/BRK2-149-multidb-ecommerce - Ouvrez le fichier
alloydb_insert_queries.sqldans Cloud Shell et copiez les requêtes d'insertion.cat alloydb_insert_queries.sql - Dans un nouvel onglet de requête sans titre, collez uniquement les instructions
INSERT, puis cliquez sur Exécuter. - Dans un nouvel onglet de requête sans titre, copiez le LDD suivant et cliquez sur Exécuter pour créer un index sur la table
products_core_table:CREATE INDEX idx_products_core_sku ON products_core_table(sku);
Créer des embeddings d'images pour que l'agent d'IA puisse récupérer des produits similaires
L'intégration de l'agent d'IA utilise des embeddings d'images pour récupérer des produits similaires. Les embeddings sont générés à l'aide du modèle multimodalembedding@001 et stockés dans la base de données AlloyDB. Les embeddings sont des vecteurs de 1 408 dimensions et sont stockés dans la colonne img_embeddings.
Avant de pouvoir générer des embeddings, nous devons accorder les rôles requis au compte de service AlloyDB pour accéder à Cloud Storage.
Attribuer des rôles au compte de service AlloyDB pour accéder à Cloud Storage
Nous attribuons les rôles "Utilisateur d'objets de stockage" et "Lecteur des objets Storage" au compte de service AlloyDB pour lui permettre de lire les objets du bucket Cloud Storage.
- Accédez à IAM et administration.
- Cliquez sur Accorder l'accès.
- Dans le champ Nouveaux comptes principaux, saisissez le compte de service AlloyDB. Le compte de service ressemble à
service-991742412753@gcp-sa-alloydb.iam.gserviceaccount.com. - Cliquez sur Sélectionner un rôle.
- Recherchez et sélectionnez le rôle Utilisateur d'objets Storage.
- Cliquez sur Ajouter un autre rôle, puis sélectionnez le rôle Lecteur des objets Storage.
- Cliquez sur Ajouter un autre rôle, puis sélectionnez le rôle Utilisateur Vertex AI.
- Cliquez sur Enregistrer.
Activer les extensions
Pour créer cette application, nous allons utiliser les extensions pgvector et google_ml_integration. L'extension pgvector vous permet de stocker et de rechercher des embeddings vectoriels. L'extension google_ml_integration fournit les fonctions que vous utilisez pour accéder aux points de terminaison de prédiction Vertex AI afin d'obtenir des prédictions en SQL. Activez ces extensions en exécutant les LDD suivantes :
- Dans la console Google Cloud, accédez à AlloyDB pour PostgreSQL.
- Cliquez sur AlloyDB Studio dans le menu de navigation de gauche.
- Dans la vue de l'éditeur, ouvrez un nouvel onglet "Requête sans titre".
- Copiez le DDL suivant, puis cliquez sur Exécuter :
CREATE EXTENSION IF NOT EXISTS vector; CREATE EXTENSION IF NOT EXISTS google_ml_integration;
Initialiser la base de données avec des embeddings
- Ajoutez la colonne "img_embeddings" à
products_core_table.ALTER TABLE products_core_table ADD COLUMN img_embeddings vector(1408); - Générez des embeddings pour les images et stockez-les dans la colonne
img_embeddings.UPDATE products_core_table SET img_embeddings = google_ml.image_embedding( model_id => 'multimodalembedding@001', image => 'gs://<STORAGE_BUCKET_NAME>/' || sku || '.jpg', mimetype => 'image/jpeg') WHERE sku IN ( SELECT sku FROM products_core_table WHERE img_embeddings IS NULL AND sku IS NOT NULL LIMIT 10 ); - Répétez la requête précédente au moins cinq fois pour générer des embeddings d'image pour l'ensemble du jeu de données, car le Studio est limité à cinq minutes. Si cette requête expire, remplacez
LIMITpar5et exécutez la requête dix fois. Cette étape peut prendre quelques minutes.
5. Configurer MongoDB Atlas sur Google Cloud
MongoDB stocke des informations détaillées sur les produits, semi-structurées, ainsi que des données flexibles sur le comportement des utilisateurs (comme les clics et les vues).\
Créer un cluster MongoDB
- Accédez à MongoDB Atlas sur Google Cloud, puis sélectionnez un compte de niveau sans frais.
- Sélectionnez le niveau de cluster Free (Sans frais), puis saisissez un nom pour le cluster, par exemple
ecommerce-cluster. - Sélectionnez Google Cloud comme fournisseur et assurez-vous que la région correspond à votre région Google Cloud (par exemple,
us-central1). - Cliquez sur Créer un déploiement.
- Cliquez sur Fermer.
Configurer l'accès au réseau
- Dans la console Atlas, accédez à Database & Network Access (Accès aux bases de données et au réseau).
- Cliquez sur Liste d'accès aux adresses IP.
- Cliquez sur Ajouter une adresse IP.
- Ajoutez
0.0.0.0/0, qui permet d'accéder à l'application depuis n'importe où. - Cliquez sur Confirmer.
Créer un utilisateur de base de données
- Dans la console Atlas, accédez à Database & Network Access (Accès aux bases de données et au réseau).
- Cliquez sur Utilisateurs de la base de données.
- Cliquez sur Ajouter un utilisateur de base de données.
- Sélectionnez Mot de passe comme méthode d'authentification.
- Saisissez le nom d'utilisateur
store-useret le mot de passestoreuser. - Cliquez sur Add Built In Role (Ajouter un rôle intégré), puis sélectionnez Read and write to any database (Lire et écrire dans n'importe quelle base de données).
- Cliquez sur Ajouter un utilisateur.
Obtenir la chaîne de connexion
- Accédez à Base de données > Clusters > Se connecter.
- Dans Connect to your application (Se connecter à votre application), cliquez sur Drivers (Pilotes).
- Copiez la chaîne de connexion affichée dans Add your connection string into your application code (Ajouter votre chaîne de connexion dans le code de votre application). La chaîne ressemble à ceci :
mongodb+srv://store-user:<db_password>@ecommerce-cluster.g8vaekh.mongodb.net/?appName=ecommerce-clusterdb_passwordpar votre mot de passe MongoDB. Dans cet atelier de programmation, il s'agit destoreuser.
Enregistrez cette chaîne de connexion. Vous l'utiliserez plus tard pour la variable d'environnement MONGODB_CONNECTION_STRING.
Créer une base de données et une collection
- Dans la console Atlas, accédez à Database > Clusters > Browse Collections.
- Cliquez sur Créer une base de données et saisissez les informations suivantes :
- Nom de la base de données :
ecommerce_db - Nom de la collection :
product_details_collection
- Nom de la base de données :
- Cliquez sur Créer une base de données.
- Dans l'explorateur de données, sélectionnez le nom de la collection.
- Cliquez sur l'icône Ajouter des données (+), puis sur Insérer un document.
- Copiez le contenu JSON de product_details_export.json et collez-le dans la boîte de dialogue de l'éditeur Insérer un document.
- Cliquez sur Insérer pour insérer le tableau de documents et vérifiez que 192 documents ont été ajoutés.
- Dans l'explorateur de données, cliquez sur Créer une collection (+) à côté de la base de données
ecommerce_db. - Saisissez
user_interactions_collectioncomme nom de la collection, puis cliquez sur Créer une collection. - Dans l'explorateur de données, sélectionnez la collection
user_interactions_collection. - Cliquez sur l'icône Ajouter des données (+), puis sur Insérer un document.
- Copiez le contenu JSON de user_interactions_export.json et collez-le dans la boîte de dialogue de l'éditeur Insérer un document.
- Cliquez sur Insérer un document.
6. Configurer BigQuery
BigQuery agrège et analyse l'historique du comportement des utilisateurs pour générer des rapports et des recommandations intelligents.
Créer l'ensemble de données
- Dans la console Google Cloud, accédez à BigQuery.
- À côté de l'ID de votre projet dans le volet "Explorateur", cliquez sur le menu à trois points, puis sélectionnez Créer un ensemble de données.
- Saisissez
ecommerce_analyticspour l'ID de l'ensemble de données. - Cliquez sur Créer un ensemble de données.
Créer la table Analytics
- Ouvrez une requête dans l'espace de travail BigQuery.
- Exécutez l'instruction SQL suivante pour créer la table récapitulative associant les utilisateurs aux interactions avec les produits :
CREATE TABLE ecommerce_analytics.user_product_interactions (
user_id STRING DEFAULT 'any user',
product_id STRING,
interaction_score INT
);
Attribuer des rôles au compte de service Compute pour MCP Toolbox
Nous attribuons des rôles au compte de service Compute utilisé pour notre boîte à outils. Cela permet à MCP Toolbox d'accéder à BigQuery, Secret Manager et d'autres services cloud.
Pour attribuer des rôles, procédez comme suit :
- Accédez à IAM et administration.
- Cliquez sur Accorder l'accès.
- Dans le champ Nouveaux comptes principaux, saisissez le compte de service Compute par défaut nommé
YOUR_PROJECT_NUMBER-compute@developer.gserviceaccount.com. RemplacezYOUR_PROJECT_NUMBERpar votre numéro de projet Google Cloud. - Cliquez sur Sélectionner un rôle.
- Recherchez et sélectionnez le rôle Éditeur de données BigQuery.
- Cliquez sur Ajouter un autre rôle, puis sélectionnez le rôle Utilisateur de tâche BigQuery.
- Cliquez sur Ajouter un autre rôle, puis sélectionnez le rôle Accesseur de secrets Secret Manager.
- Cliquez sur Ajouter un autre rôle, puis sélectionnez le rôle Éditeur.
- Cliquez sur Enregistrer.
7. Comprendre l'application de bout en bout
Pour découvrir comment chaque composant fonctionne avec les autres, nous allons créer une application d'e-commerce simple qui utilise plusieurs bases de données et services. L'application est conçue avec un backend Python (Flask) et intègre plusieurs services et bases de données Google Cloud.
Comprendre la structure des répertoires
Dans la section suivante, vous allez cloner le dépôt BRK2-149-multidb-ecommerce et l'utiliser pour exécuter l'application en local. Une fois que nous aurons testé l'application en local, nous déploierons MCP Toolbox et l'application sur Cloud Run.
Explorez les fichiers téléchargés dans ce répertoire. Les répertoires généraux suivants sont présents :
UploadImages: stocke les composants d'image, principalement utilisés pour la documentation ou le contenu visuel du catalogue de produits d'e-commerce.static: stocke les éléments Web statiques de l'application, tels que les fichiers CSS et JavaScript, utilisés pour styliser l'interface utilisateur et y ajouter de l'interactivité ( source).templates: stocke les modèles HTML (probablement Jinja2 pour Flask) utilisés par l'application Python pour afficher dynamiquement les pages Web du catalogue d'e-commerce ( source).toolbox-implementation: stocke les détails de configuration et d'implémentation de MCP (Model Context Protocol) Toolbox, ce qui facilite les interactions avec plusieurs bases de données à l'aide d'outils prédéfinis.
Les fichiers de ce dépôt fonctionnent ensemble pour créer, configurer et déployer une application d'e-commerce multidb. Les fichiers centraux tels que app.py orchestrent le backend en intégrant diverses sources de données définies dans des fichiers SQL et JSON, tandis que les fichiers de configuration assurent un déploiement fluide dans les environnements cloud :
app.py: orchestre le backend Flask et les intégrations multidatabases.agentengine.py: logique de base pour initialiser et configurer les agents Vertex AI..env: stocke les secrets pour les connexions aux bases de données et au stockage.tools.yaml: configure MCP Toolbox pour les opérations de base de données multidb.Dockerfile: définit l'image de conteneur et la configuration de l'environnement.requirements.txt: liste les bibliothèques Python nécessaires à l'exécution de l'application.tools.yaml: configurations pour MCP Toolbox.Procfile: spécifie les commandes d'exécution de production pour le déploiement.alloydb_insert_queries.sql: contient des requêtes SQL pour les données relationnelles.product_details_export.jsonetuser_interactions_export.json: fournissent des exemples de données JSON pour la base de données NoSQL.README.md: guide la configuration, le déploiement et la compréhension du projet.
Flux de bout en bout de l'application
- Configuration d'AlloyDB : provisionnez un cluster hautes performances et utilisez les scripts SQL fournis pour créer la table products_core_table avec des colonnes vectorielles pour les embeddings d'images.
- Configuration de MongoDB Atlas : déployez un cluster sur Google Cloud pour stocker les attributs de produit fluides dans product_details et enregistrer les flux de clics en temps réel dans user_interactions.
- BigQuery Analytics : créez un ensemble de données pour agréger les journaux d'interaction. Vous pourrez ainsi exécuter des requêtes analytiques complexes qui identifient les cinq articles les plus tendances parmi des millions d'événements.
- Dépôt Cloud Storage : créez un bucket public pour héberger les images de produits en haute résolution. Assurez-vous que chaque élément est accessible via une URL signée ou publique pour le frontend.
- Déploiement de MCP Toolbox : déployez la boîte à outils sur Cloud Run, en l'établissant comme pont RESTful central qui traduit l'intention en langage naturel en requêtes multidatabases.
- Configuration Tools.yaml : définissez vos "outils" (par exemple, get_product_core_data ou get_top_5_views) en mappant des opérations SQL et NoSQL spécifiques à des noms simples et lisibles par l'agent.
- Logique de backend Flask : implémentez des routes app.py qui interagissent avec MCP Toolbox, en gérant la coordination de la récupération des données et en servant d'API pour l'UI.
- Orchestration multi-agents : configurez les agents ADK dans le code pour comprendre l'intention de l'utilisateur et sélectionner le bon "outil" pour résoudre des requêtes complexes et multisources dans le secteur du commerce.
- Intégration du frontend : créez une interface index.html présentant le catalogue de produits avec une fonctionnalité d'enregistrement des interactions, un onglet "Analytics" pour comprendre les performances des produits et un onglet "Agent" dédié qui utilise le chat multi-agent ADK pour offrir une expérience d'achat conversationnelle fluide.
Implémentons maintenant l'orchestration et les déploiements.
8. Configurer MCP Toolbox et déployer sur Cloud Run
MCP Toolbox fait abstraction de nos multiples sources de données, ce qui permet à notre application d'extraire et d'écrire des données de manière uniforme.
Installer MCP Toolbox en local
- Dans votre Cloud Shell, accédez au dossier
toolbox-implementation:cd next-26-sessions/BRK2-149-multidb-ecommerce/toolbox-implementation - Téléchargez le binaire MCP Toolbox et rendez-le exécutable :
export VERSION=0.29.0 curl -L -o toolbox https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox chmod +x toolbox
Configurer tools.yaml
Vous devez définir les abstractions pour AlloyDB, MongoDB et BigQuery. Le fichier tools.yaml indique à la boîte à outils MCP comment interagir les uns avec les autres.
- Créez et modifiez le fichier
tools.yamlà l'aide de l'éditeur intégré :cloudshell edit tools.yamltools.yamlcomplet est disponible dans le dépôt GitHub. Copiez son contenu dans votre nouveau fichiertools.yaml. - Mettez à jour l'hôte, l'utilisateur, les mots de passe, les ID de projet et les chaînes de connexion pour qu'ils correspondent à l'infrastructure que vous avez provisionnée lors des étapes précédentes :
Base de données
Champ
Exemple de valeur
AlloyDB/BigQuery
project_idYOUR_PROJECT_IDAlloyDB
regionus-central1AlloyDB
clusterecommerce-clusterAlloyDB
instanceecommerce-cluster-primaryAlloyDB
databasepostgresAlloyDB
passwordalloydbMongoDB
connection_stringmongodb+srv://store-user:storeuser@ecommerce-cluster.urcxr6q.mongodb.net
Attribuer des rôles au compte de service Compute pour MCP Toolbox
Nous attribuons des rôles au compte de service Compute utilisé pour notre boîte à outils. Cela permet à MCP Toolbox d'accéder à AlloyDB.
- Accédez à IAM et administration.
- Cliquez sur Accorder l'accès.
- Dans le champ Nouveaux comptes principaux, saisissez le compte de service Compute par défaut nommé
YOUR_PROJECT_NUMBER-compute@developer.gserviceaccount.com. RemplacezYOUR_PROJECT_NUMBERpar votre numéro de projet Google Cloud. - Cliquez sur Sélectionner un rôle.
- Recherchez et sélectionnez le rôle Éditeur de données BigQuery.
- Cliquez sur Ajouter un autre rôle, puis sélectionnez le rôle Client AlloyDB.
- Cliquez sur Ajouter un autre rôle, puis sélectionnez le rôle Consommateur Service Usage.
- Cliquez sur Ajouter un autre rôle, puis sélectionnez le rôle Lecteur des objets Storage.
- Cliquez sur Enregistrer.
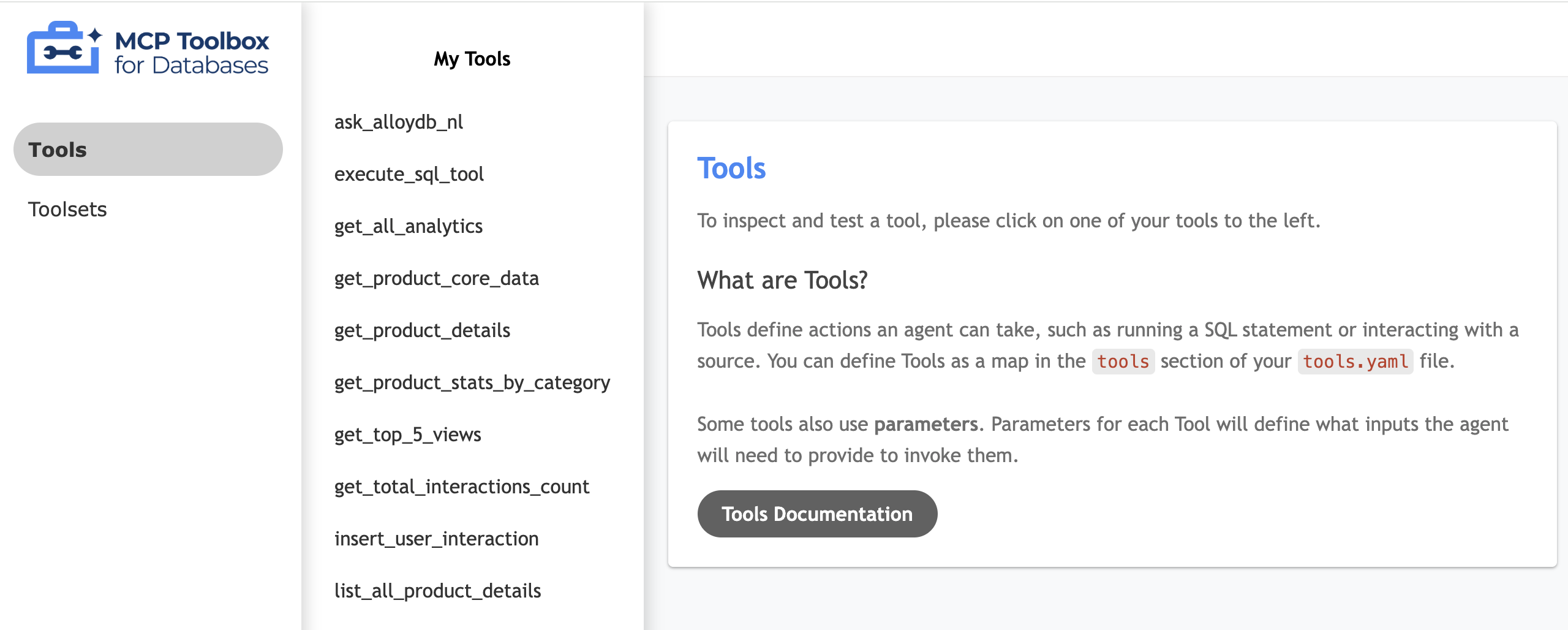
Tester l'UI de votre outil
- Dans votre terminal Cloud Shell, exécutez la boîte à outils en local pour diffuser l'UI :
./toolbox --ui - Ouvrez l'aperçu sur le Web dans Cloud Shell sur le port 5000 et accédez à la page des outils. Par exemple, selon l'URL de votre session, vous pouvez la consulter à l'adresse suivante :
https://5000-cs-71152278760-default.cs-asia-southeast1-cash.cloudshell.dev/ui.
L'interface utilisateur de MCP Toolbox suivante s'affiche :
Déployer dans Cloud Run
Déployez MCP Toolbox sur Cloud Run pour le rendre disponible en tant que service sécurisé et géré que notre application peut utiliser pour interroger les bases de données. Nous stockerons la configuration dans Secret Manager pour protéger les informations de connexion sensibles.
- Ouvrez une nouvelle session Cloud Shell.
- Accédez au dossier
toolbox-implementation:cd next-26-sessions/BRK2-149-multidb-ecommerce/toolbox-implementation - Importez la configuration
tools.yamldans Google Secret Manager :gcloud secrets create tools --data-file=tools.yamlgcloud secrets versions add tools --data-file=tools.yaml - Déployez à l'aide de l'image de conteneur MCP Toolbox publique :
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:0.29.0 export PROJECT_ID=$(gcloud config get-value project) gcloud run deploy toolbox \ --image $IMAGE \ --region us-central1 \ --service-account $(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")-compute@developer.gserviceaccount.com \ --set-secrets "/app/tools.yaml=tools:latest" \ --args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080","--ui" \ --allow-unauthenticated - Une fois le service déployé, notez l'URL du service Cloud Run fournie. Elle doit se présenter comme ceci :
https://toolbox-*********-uc.a.run.app/ui.
9. Configurer l'application d'e-commerce et la déployer sur Cloud Run
Maintenant que nos bases de données sont en cours d'exécution et que l'abstraction MCP Toolbox est déployée, nous pouvons exécuter l'application Web Flask.
Pour diffuser le catalogue de produits, l'application Flask traite les données en procédant comme suit :
- Récupérer les données de base : récupère la liste complète des produits depuis AlloyDB (
list_products_core). - Récupérer les informations détaillées : récupère toutes les informations sur le produit à partir de MongoDB (
list_all_product_details). - Combiner des listes : concatène les deux listes.
- Enrichir avec des éléments multimédias : ajoute l'URL de l'image Cloud Storage à chaque élément.
Générer le chemin d'accès à l'application Reasoning Engine
Pour initialiser et enregistrer un agent d'IA à l'aide du moteur de raisonnement Vertex AI de Google Cloud, exécutez la commande suivante :
- Dans le terminal Cloud Shell, accédez au dossier
BRK2-149-multidb-ecommerce.cd next-26-sessions/BRK2-149-multidb-ecommerce - Exécutez requirements.txt pour installer les dépendances.
pip install -r requirements.txt - Exécutez le script
agentengine.pypour générer le chemin d'accès à l'application du moteur de raisonnement :python agentengine.py
Le résultat doit ressembler à ce qui suit :
projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856
Configurer les variables d'environnement
- Créez et modifiez un fichier
.env:cloudshell edit .env - Remplacez les valeurs par vos connexions de base de données spécifiques et votre nouvelle URL Cloud Run Toolbox :
# 1. MongoDB Connection String MONGODB_CONNECTION_STRING="mongodb+srv://<db_user>:<db_password>@cluster0.mongodb.net" # 2. MCP Toolbox Server Location # Must match the address where you run the toolbox server MCP_TOOLBOX_SERVER_URL="https://toolbox-*********-uc.a.run.app" # 3. Google Cloud Storage Bucket Name GCS_PRODUCT_BUCKET="ecommerce-app-images" # 4. Fallback image URL FALLBACK_IMAGE_URL="https://storage.googleapis.com/ecommerce-media-bold-circuit-492711-n9/fallback.jpg" # 5. Google Gen AI Vertex AI flag GOOGLE_GENAI_USE_VERTEXAI=TRUE # 6. Project ID PROJECT_ID=codelab-project-491117 # 7. Google Cloud Location of AlloyDB, BigQuery databases GOOGLE_CLOUD_LOCATION=us-central1 # 8. Reasoning engine application path APP_NAME=projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856 # 9. Model ID MODEL=gemini-1.5-flash-lite
Déployer le frontend sur Cloud Run
- Déployez l'application Web sur Cloud Run pour finaliser l'architecture :
gcloud run deploy polyglot --source . --platform managed \ --region us-central1 \ --allow-unauthenticated \ --set-env-vars \ MONGODB_CONNECTION_STRING="<MONGODB_CONNECTION_STRING>", \ MCP_TOOLBOX_SERVER_URL="<MCP_TOOLBOX_SERVER_URL>", \ GCS_PRODUCT_BUCKET="<GCS_PRODUCT_BUCKET>", \ FALLBACK_IMAGE_URL="<FALLBACK_IMAGE_URL>", \ GOOGLE_GENAI_USE_VERTEXAI=TRUE, \ PROJECT_ID="YOUR_PROJECT_ID", \ GOOGLE_CLOUD_LOCATION=us-central1, \ APP_NAME="<YOUR_REASONING_ENGINE_APP_PATH>", \ MODEL="gemini-1.5-flash-lite"YOUR_PROJECT_ID: ID de votre projet Google Cloud.YOUR_REASONING_ENGINE_APP_PATH: résultat de l'exécution depython agentengine.py, par exempleprojects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856.MCP_TOOLBOX_SERVER_URL: URL de votre serveur MCP Toolbox, par exemplehttps://toolbox-*********-uc.a.run.app.GCS_PRODUCT_BUCKET: nom de votre bucket Google Cloud Storage (par exemple,ecommerce-app-images).MONGODB_CONNECTION_STRING: chaîne de connexion à votre base de données MongoDB, par exemplemongodb+srv://store-user:storeuser@ecommerce-cluster.g8vaekh.mongodb.netFALLBACK_IMAGE_URL: URL de l'image de remplacement, par exemplehttps://storage.googleapis.com/ecommerce-app-images/fallback.jpg
Votre application est désormais en ligne. Ouvrez l'URL du service fournie par Cloud Run pour afficher le catalogue Multidb Ecommerce. L'URL doit ressembler à ceci : https://polyglot-*********-uc.a.run.app/.
10. Explorer l'application
- Cliquez sur Catalogue de produits pour afficher tous les produits.
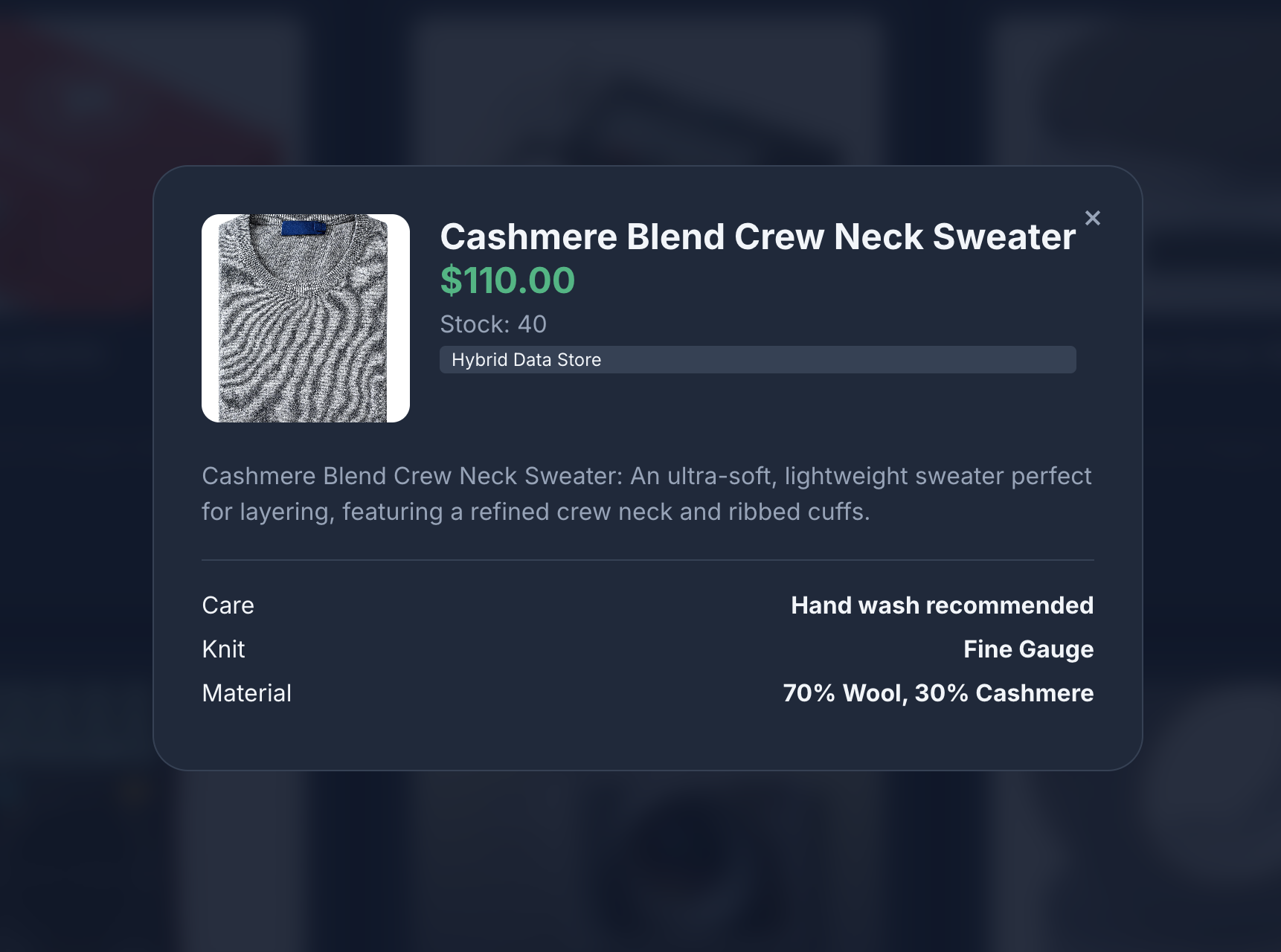
- Cliquez sur l'icône d'un produit pour afficher ses détails. Vous remarquerez que les images proviennent de Cloud Storage, les informations détaillées sur les produits sont extraites de MongoDB et l'inventaire des produits est extrait d'AlloyDB.
- Interagissez avec le catalogue de produits pour générer des vues et des écritures fictives envoyées à MongoDB.
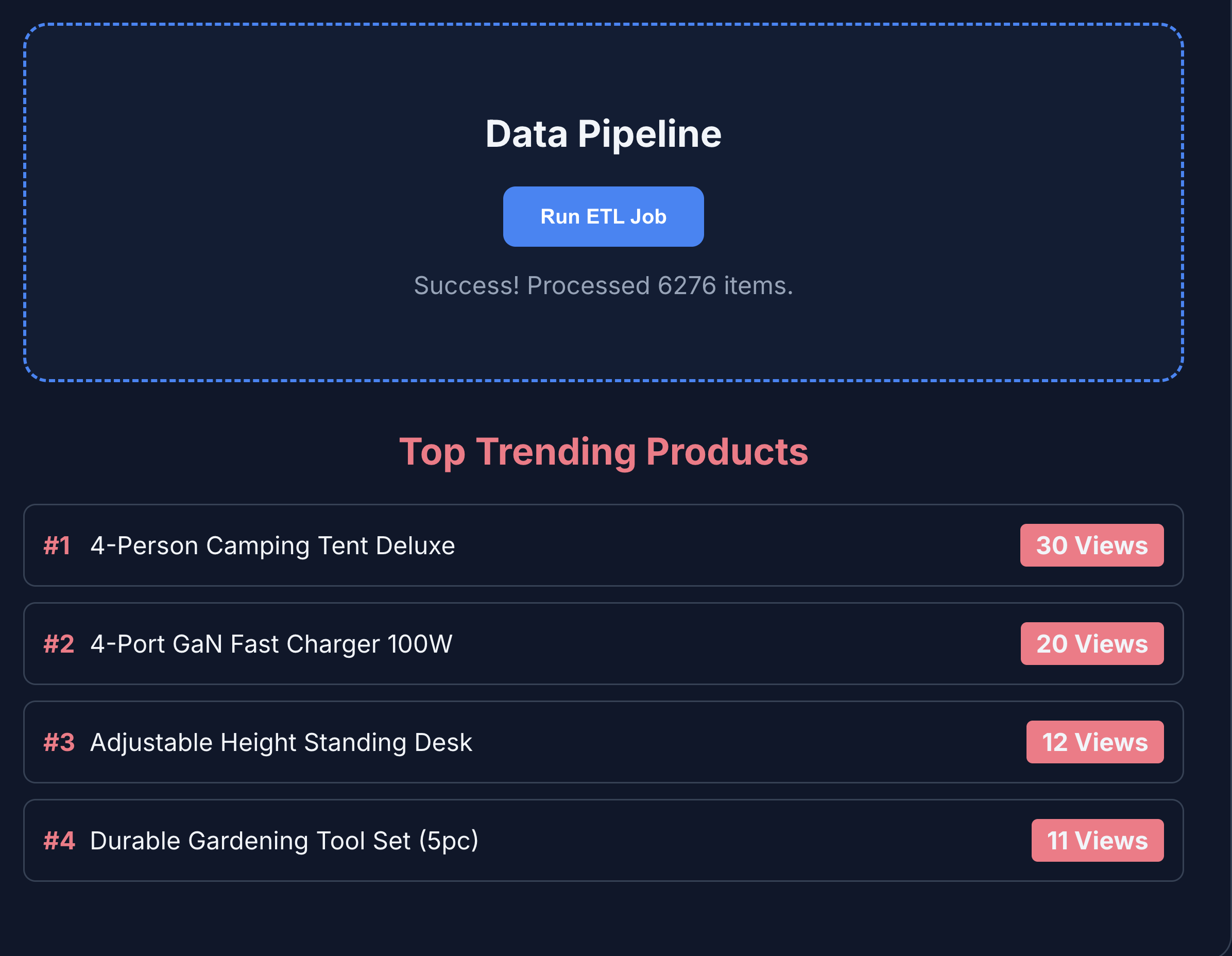
- Cliquez sur ETL et Analytics pour afficher les données analytiques sur le produit. Vous remarquerez que les données analytiques sur les produits sont extraites de BigQuery.
- Cliquez sur l'onglet Agent d'IA pour interagir avec l'agent d'IA. Posez des questions en langage naturel, par exemple :
I'm planning a high-altitude photography trip. Show me some weather-resistant backpacks similar in style to aero glow pro but without any leather components. Also, let me know if they are actually in stock and if other photographers have complained about the strap durability in the reviews.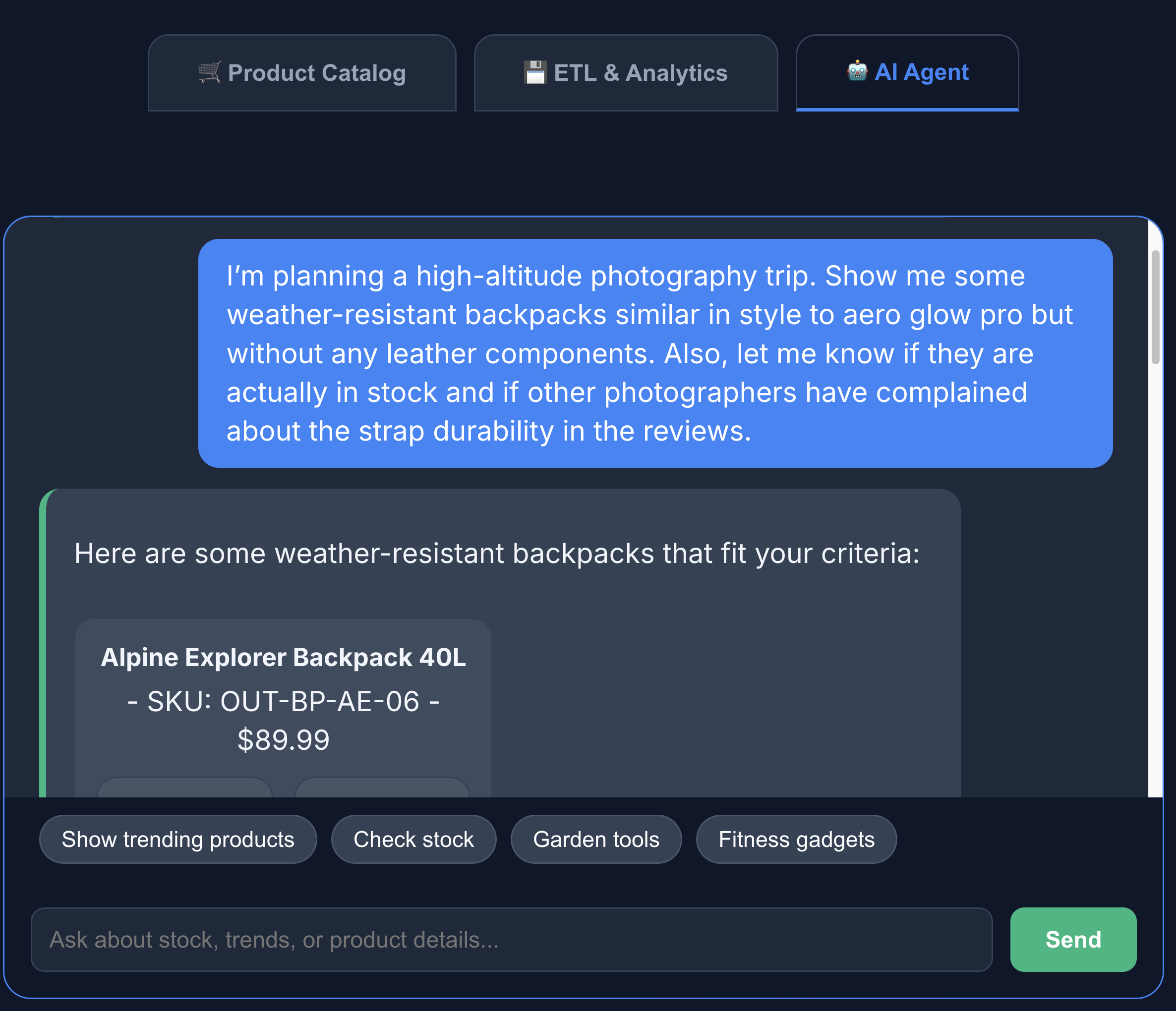
Vous pouvez constater que la recherche renvoie exactement ce que nous avons demandé : un sac à dos sans composants en cuir, en stock et sans aucune plainte concernant la durabilité des bretelles dans les avis.
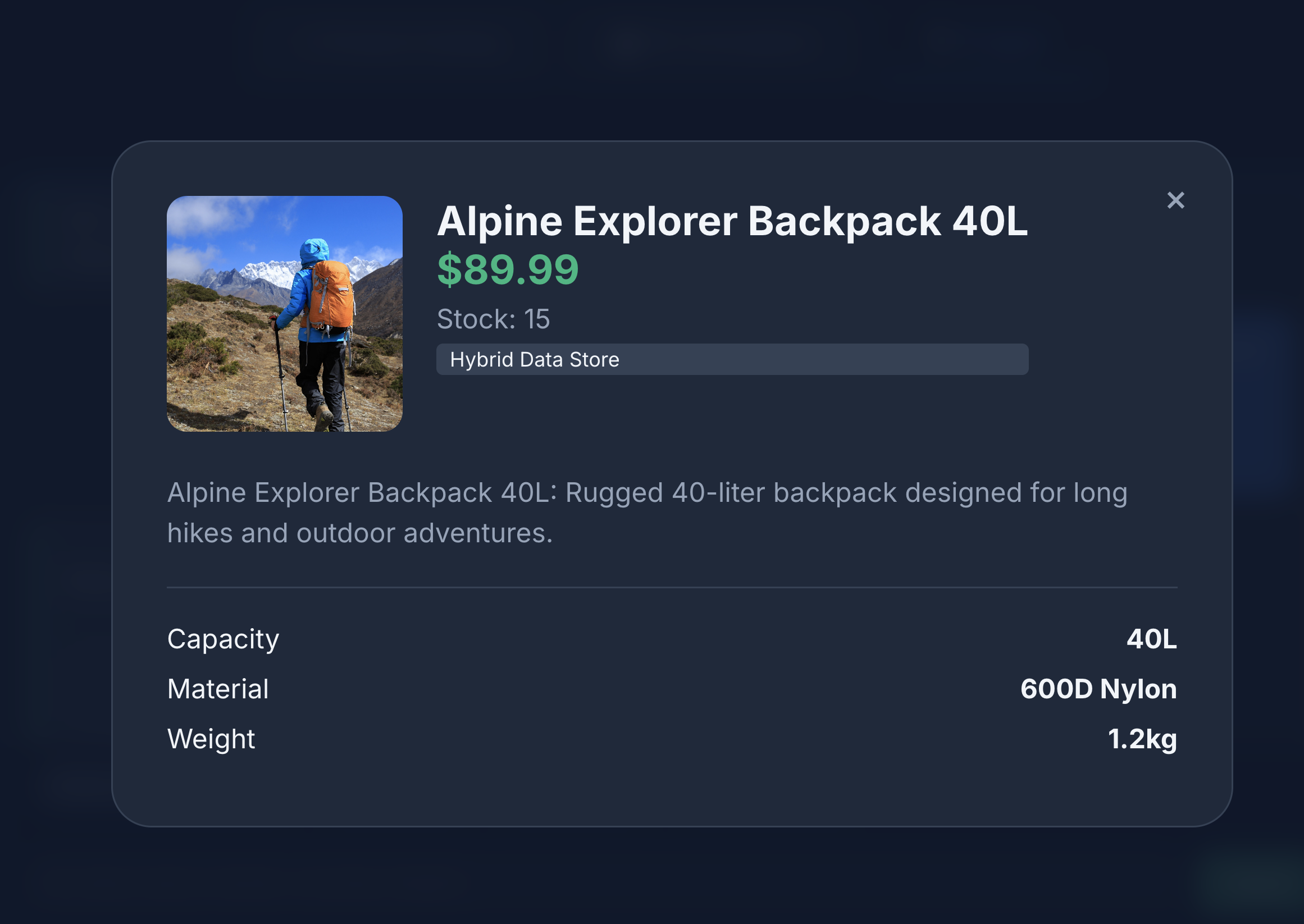
11. Effectuer un nettoyage
Pour éviter que les ressources créées lors de cet atelier de programmation ne soient facturées en permanence sur votre compte Google Cloud, supprimez-les.
Exécutez les commandes Cloud Shell suivantes :
gcloud run services delete toolbox --region us-central1 --quiet
gcloud run services delete multi-db-app --region us-central1 --quiet
bq rm -r -f -d $PROJECT_ID:ecommerce_analytics
gcloud storage rm --recursive gs://ecommerce-app-images
gcloud alloydb clusters delete ecommerce-cluster --region us-central1 --force --quiet
Vous pouvez également supprimer l'intégralité du projet Google Cloud et toutes ses ressources en exécutant la commande suivante :
gcloud projects delete $PROJECT_ID
12. Félicitations
Félicitations ! Vous avez créé une architecture multidb cross-cloud.
Vous avez montré comment MCP Toolbox sert de lien architectural pour une application moderne et spécialisée. En associant la bonne base de données à la bonne tâche, vous avez obtenu les résultats suivants :
- Écritures de données flexibles : MongoDB pour les journaux d'événements.
- Cohérence transactionnelle : AlloyDB pour l'intégrité du cœur.
- Analyses hautes performances : BigQuery pour l'informatique décisionnelle.
- Développement unifié : un seul backend Python abstrait toute la complexité à l'aide de MCP Toolbox.
Documents de référence
En savoir plus sur les produits Google Cloud associés et découvrir ces ateliers de programmation :
- AlloyDB AI : Premiers pas avec les embeddings vectoriels AlloyDB AI
- AlloyDB AI : embeddings multimodaux dans AlloyDB
- MCP Toolbox : Installer et configurer MCP Toolbox for Databases sur AlloyDB
Pour en savoir plus sur les produits utilisés dans cet atelier de programmation, consultez les ressources suivantes :