
1. परिचय
मॉडर्न रीटेल में, आपका डेटा एक बड़ा और अलग-अलग तरह का इकोसिस्टम होता है. आपके पास लेन-देन का सटीक डेटा (कीमत और इन्वेंट्री), अलग-अलग तरह के कैटलॉग (इलेक्ट्रॉनिक्स की खास बातें बनाम कपड़ों के साइज़) और पेटबाइट में व्यवहार से जुड़े लॉग हैं. इन सभी को एक ही मोनोलिथ में शामिल करने से, न सिर्फ़ तकनीकी समस्याएं बढ़ती हैं, बल्कि उपयोगकर्ता अनुभव भी खराब होता है.
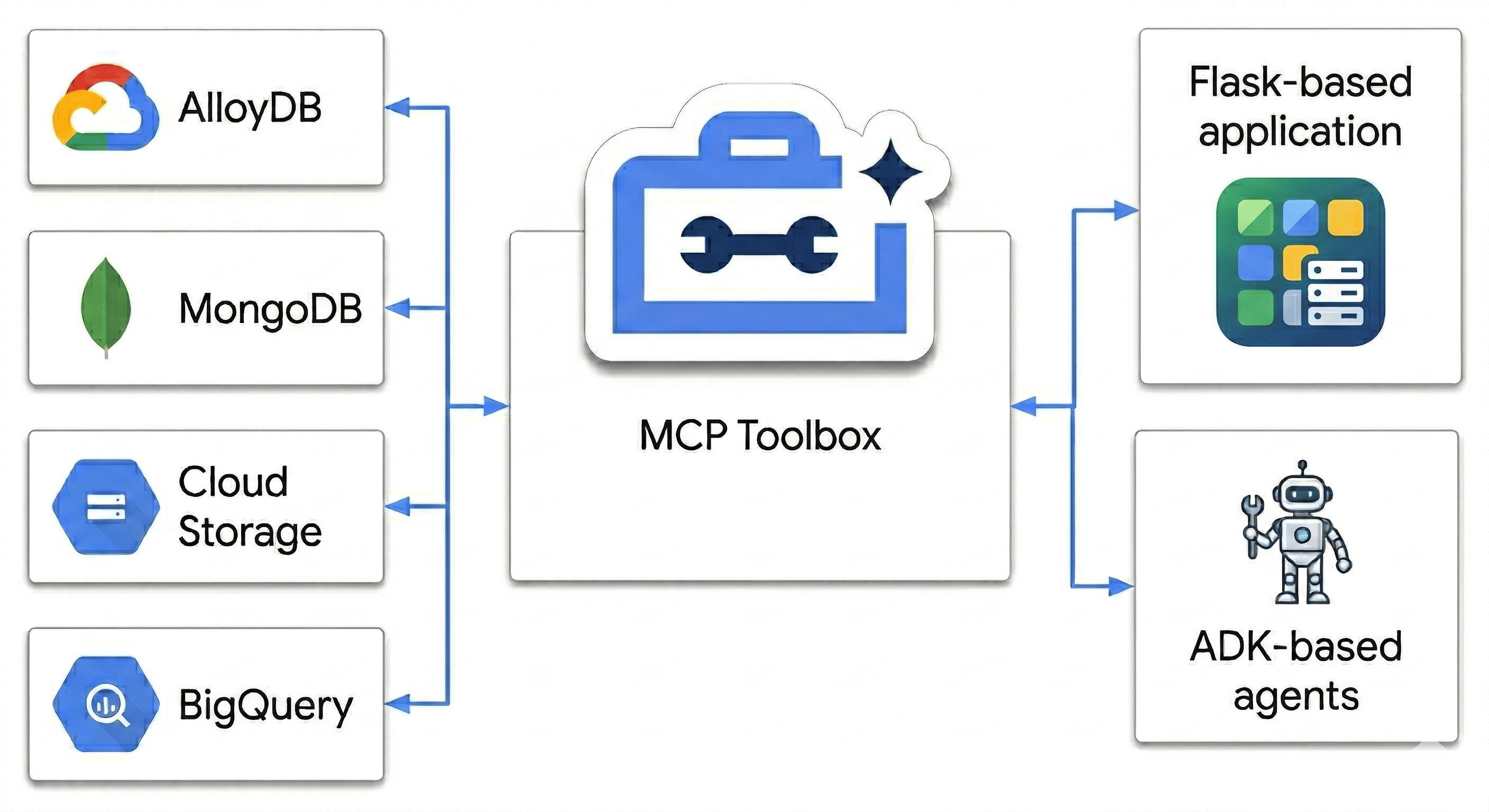
इस कोडलैब में, आपको एक ऐसा Polyglot Powerhouse बनाने के बारे में बताया जाएगा जो इन चीज़ों को एक साथ काम करने में मदद करता है:
- AlloyDB: यह तेज़ गति से काम करने वाला डेटाबेस है. इसमें इमेज एम्बेड करने की सुविधा भी मिलती है.
- Google Cloud पर MongoDB Atlas: यह आपकी कैटलॉग लेयर है, जिसमें स्कीमा की ज़रूरत नहीं होती और जिसे आसानी से बदला जा सकता है.
- Cloud Storage: यह रीयल-टाइम में रुझान का अनुमान लगाने के लिए, आपके दिमाग की तरह काम करता है.
- BigQuery: यह आपका हाई-रिज़ॉल्यूशन वाला डिजिटल वेयरहाउस है.
"सीक्रेट सॉस" क्या है? MCP Toolbox for Databases का इस्तेमाल करके, Cloud Run पर चल रहे डेटा सोर्स को बेहतर तरीके से व्यवस्थित और एक साथ किया जाएगा. इसके बाद, Agent Development Kit (ADK) का इस्तेमाल करके, मल्टी-एजेंट चैट ऐप्लिकेशन डिप्लॉय किया जाएगा. सिर्फ़ एक सर्च बार नहीं बनाया जा रहा है. इसके बजाय, एक ऐसा स्मार्ट सिस्टम बनाया जा रहा है जो खुदरा कारोबार के बारे में सोच-समझकर फ़ैसले ले सकता है. यह सिस्टम, कॉन्टेक्स्ट को समझता है, सीमाओं का पालन करता है, और रॉ डेटा और लोगों की ज़रूरतों के बीच के अंतर को कम करता है.
उपयोगकर्ता की ऐसी क्वेरी जिसका जवाब नहीं दिया जा सकता
स्टैंडर्ड ई-कॉमर्स एजेंट, कई तरह की वजहों से गहराई से विश्लेषण नहीं कर पाते. जैसे, नेगेटिव कंस्ट्रेंट, विज़ुअल समानता, और रीयल-टाइम इन्वेंट्री. उदाहरण के लिए, आम तौर पर मुझे इस तरह की खुदरा साइट से बात करनी होती है:
"मुझे ऊंचाई वाली जगह पर फ़ोटोग्राफ़ी के लिए जाना है. मुझे कुछ ऐसे बैकपैक दिखाओ जो पानी और मौसम के हिसाब से बने हों. ये ‘AeroGlow Pro' की तरह दिखते हों, लेकिन इनमें लेदर का इस्तेमाल न किया गया हो. इसके अलावा, मुझे यह भी बताएं कि क्या यह वाकई स्टॉक में है और क्या अन्य फ़ोटोग्राफ़र ने समीक्षाओं में, स्ट्रैप के टिकाऊपन के बारे में शिकायत की है."
इस क्वेरी को "द एजेंट किलर" क्यों कहा जाता है:
- विज़ुअल समानता (AlloyDB + Vector Search): "AeroGlow Pro की स्टाइल से मिलती-जुलती" क्वेरी के लिए, इमेज एम्बेडिंग की तुलना करना ज़रूरी है.
- नेगेटिव कंस्ट्रेंट (MongoDB): "बिना किसी लेदर के" के लिए, फ़्लेक्सिबल और नेस्ट किए गए एट्रिब्यूट के ज़रिए फ़िल्टर करने की ज़रूरत होती है. ये एट्रिब्यूट, आम तौर पर स्टैंडर्ड एसक्यूएल स्कीमा में नहीं होते.
- रीयल-टाइम इन्वेंट्री (AlloyDB): "असल में स्टॉक में है" के लिए, लाइव लेन-देन की जांच करना ज़रूरी है. इसके लिए, पुराने सर्च इंडेक्स का इस्तेमाल नहीं किया जा सकता.
- सिमैंटिक सिंथेसिस (BigQuery + मल्टी-एजेंट): "स्ट्रैप की मज़बूती" के बारे में समीक्षाओं का विश्लेषण करने के लिए, एजेंट को BigQuery से मिले अनस्ट्रक्चर्ड फ़ीडबैक की खास जानकारी तुरंत देनी होगी.
ज़्यादातर खुदरा बॉट को सिर्फ़ ‘बैकपैक' और ‘लेदर' दिखेगा. इसके बाद, वे लेदर के 10 बैकपैक दिखाएंगे. हम इसे कैसे रोक रहे हैं?
क्योंकि हम सिर्फ़ कीवर्ड मैच नहीं करते. हम MCP टूलबॉक्स का इस्तेमाल कर रहे हैं, ताकि हमारे एजेंट इन सभी सोर्स के साथ-साथ AlloyDB में लेन-देन से जुड़ी सटीक जानकारी और MongoDB में फ़्लेक्सिबल एट्रिब्यूट के बारे में ‘वजह' बता सकें. चलिए, इसे बनाते हैं.
आपको क्या करना होगा
- कोर प्रॉडक्ट डेटा के लिए, AlloyDB क्लस्टर उपलब्ध कराएं
- प्रॉडक्ट की सेमी-स्ट्रक्चर्ड जानकारी सेव करने के लिए, Google Cloud पर MongoDB Atlas को कॉन्फ़िगर करें
- प्रॉडक्ट की इमेज दिखाने के लिए, Cloud Storage बकेट बनाएं
- डेटा को एक जैसा ऐक्सेस देने के लिए, डेटाबेस के लिए एमसीपी टूलबॉक्स को Cloud Run पर डिप्लॉय करें
- डेटा को BigQuery में पुश करने के लिए, ईटीएल प्रोसेस चलाएं, ताकि उसका विश्लेषण किया जा सके
- एआई एजेंट से आम बोलचाल की भाषा में बातचीत करें.
ज़रूरी शर्तें
- कोई वेब ब्राउज़र, जैसे कि Chrome
- बिलिंग की सुविधा वाला Google Cloud प्रोजेक्ट
- Google Cloud पर MongoDB Atlas का मुफ़्त खाता
2. शुरू करने से पहले
Google Cloud प्रोजेक्ट बनाना
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग की सुविधा चालू हो. किसी प्रोजेक्ट के लिए बिलिंग चालू है या नहीं, यह देखने का तरीका जानें.
Cloud Shell शुरू करना
Cloud Shell, Google Cloud में चलने वाला एक कमांड-लाइन एनवायरमेंट है. इसमें ज़रूरी टूल पहले से लोड होते हैं.
- Google Cloud कंसोल में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें.
- Cloud Shell से कनेक्ट होने के बाद, अपने क्रेडेंशियल की पुष्टि करें:
gcloud auth list - पुष्टि करें कि आपका प्रोजेक्ट कॉन्फ़िगर किया गया है:
gcloud config get project - अगर आपका प्रोजेक्ट उम्मीद के मुताबिक सेट नहीं है, तो इसे सेट करें:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
ज़रूरी एपीआई चालू करना
सभी ज़रूरी एपीआई चालू करने के लिए, यह निर्देश चलाएं:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
3. Cloud Storage सेट अप करना
Cloud Storage, बिना स्ट्रक्चर वाली मीडिया ऐसेट के लिए एक बड़े स्टोर के तौर पर काम करता है. जैसे, प्रॉडक्ट की इमेज.
- Google Cloud Console में, Cloud Storage पर जाएं. इसके बाद, बकेट बनाएं पर क्लिक करें.
- अपनी बकेट को ऐसा नाम दें जो दुनिया भर में यूनीक हो. उदाहरण के लिए,
ecommerce-app-images. - बनाएं पर क्लिक करें.
- डेमो ऐप्लिकेशन को बिना पुष्टि के इमेज ऐक्सेस करने की अनुमति देने के लिए, इस बकेट पर सार्वजनिक ऐक्सेस को रोकने की सुविधा लागू करें विकल्प से सही का निशान हटाएं. इसके बाद, पुष्टि करें पर क्लिक करें.
- अनुमतियां टैब पर जाएं.
- अनुमतियां में जाकर, ऐक्सेस करने की अनुमति दें पर क्लिक करें.
- नए मुख्य खातों में,
allUsersडालें. - भूमिका चुनें में जाकर, Cloud Storage > Storage Object User चुनें.
- सेव करें पर क्लिक करें. इसके बाद, सार्वजनिक ऐक्सेस की अनुमति दें पर क्लिक करके पुष्टि करें कि आपको संसाधन को सार्वजनिक करना है.
प्लेसहोल्डर वाली इमेज अपलोड करना
BRK2-149-multidb-ecommerce में, बेहतरीन विज़ुअल अनुभव के लिए प्लेसहोल्डर इमेज का इस्तेमाल किया जाता है.
- Cloud Shell में,
next-26-sessionsरिपॉज़िटरी को क्लोन करें:git clone https://github.com/GoogleCloudPlatform/next-26-sessions.git UploadImagesफ़ोल्डर पर जाएं:cd next-26-sessions/BRK2-149-multidb-ecommerce/UploadImages- Google Cloud Console में, Cloud Storage पर जाएं. इसके बाद, बकेट पर क्लिक करें.
- बनाए गए नए बकेट के नाम पर क्लिक करें.
- अपलोड करें > फ़ाइलें अपलोड करें पर क्लिक करें. इसके बाद, डाउनलोड की गई सैंपल इमेज चुनें और खोलें पर क्लिक करें.
4. AlloyDB सेट अप करना
AlloyDB, स्ट्रक्चर्ड, लेन-देन, और ज़रूरी डेटा के लिए एक ही सोर्स के तौर पर काम करता है. जैसे, प्रॉडक्ट आईडी, नाम, एसकेयू, कीमतें, और इन्वेंट्री. AlloyDB, एआई एजेंट को भी बेहतर बनाता है. इसमें मिलती-जुलती खोज की सुविधाएं होती हैं, ताकि सुझाव दिए जा सकें और नैचुरल लैंग्वेज में क्वेरी की जा सकें.
AlloyDB क्लस्टर प्रोविज़न करना
- Google Cloud Console में, PostgreSQL के लिए AlloyDB पर जाएं.
- क्लस्टर बनाएं पर क्लिक करें.
- क्लस्टर आईडी के लिए,
ecommerce-clusterडालें. postgresउपयोगकर्ता के लिए एक मज़बूत पासवर्ड सेट करें. सीखने के मकसद से,alloydbका इस्तेमाल किया जा सकता है.- डेटाबेस वर्शन के लिए, डिफ़ॉल्ट वैल्यू को बनाए रखें.
- क्षेत्र के लिए,
us-central1(या अपनी पसंद का क्षेत्र) चुनें.
प्राइमरी इंस्टेंस कॉन्फ़िगर करना
- इंस्टेंस आईडी के लिए,
ecommerce-cluster-primaryडालें. - ज़ोन के हिसाब से उपलब्धता में जाकर, सिंगल ज़ोन चुनें.
- मशीन टाइप के लिए, छोटा मशीन टाइप चुनें. जैसे, N2, 4 vCPU, 32 जीबी रैम.
- निजी आईपी कनेक्टिविटी में जाकर, प्राइवेट सर्विसेज़ ऐक्सेस (पीएसए) को चुनें. इसके बाद,
defaultनेटवर्क को चुनें. अगर डिफ़ॉल्ट नेटवर्क पहले से सेट नहीं है, तो उसे बनाने के लिए नेटवर्क सेटअप की पुष्टि करें पर क्लिक करें. - इस कोडलैब में MCP टूलबॉक्स को सही तरीके से कनेक्ट करने के लिए, सार्वजनिक आईपी कनेक्टिविटी में जाकर, सार्वजनिक आईपी चालू करें चेकबॉक्स को चुनें.
- अधिकृत बाहरी नेटवर्क में,
0.0.0.0/0डालें. मुझे जोखिमों के बारे में पता है चेकबॉक्स को चुनें और सेव करें पर क्लिक करें. - क्लस्टर बनाएं पर क्लिक करें.
ध्यान दें: पक्का करें कि आपने अपना सार्वजनिक आईपी पता लिख लिया हो. यह 34.124.240.26 जैसा दिखता है.
डेटाबेस शुरू करना
- बाईं ओर मौजूद नेविगेशन मेन्यू में, AlloyDB Studio पर क्लिक करें.
- डेटाबेस ड्रॉप-डाउन में,
postgresचुनें. - डेटाबेस में साइन इन करने के लिए, पहले से मौजूद पुष्टि करने की सुविधा को चुनें.
- Username के लिए,
postgresउपयोगकर्ता का इस्तेमाल करें. - पासवर्ड के लिए, वह पासवर्ड डालें जिसे आपने पहले सेट किया था.
- प्रमाणित करें पर क्लिक करें.
- एडिटर व्यू में, बिना शीर्षक वाली नई क्वेरी टैब खोलें.
- नीचे दिए गए DDL को कॉपी करें और चलाएं पर क्लिक करें:
CREATE TABLE products_core_table ( product_id UUID PRIMARY KEY, name VARCHAR(255) NOT NULL, sku VARCHAR(50) UNIQUE NOT NULL, price NUMERIC(10, 2) NOT NULL, stock INT NOT NULL ); - Cloud Shell में,
BRK2-149-multidb-ecommerceफ़ोल्डर पर जाएं:cd next-26-sessions/BRK2-149-multidb-ecommerce - Cloud Shell में
alloydb_insert_queries.sqlफ़ाइल खोलें और इंसर्ट क्वेरी कॉपी करें.cat alloydb_insert_queries.sql - बिना टाइटल वाले नए क्वेरी टैब में, सिर्फ़
INSERTस्टेटमेंट चिपकाएं. इसके बाद, चलाएं पर क्लिक करें. - बिना टाइटल वाले नए क्वेरी टैब में, इस डीडीएल को कॉपी करें. इसके बाद,
products_core_tableटेबल पर इंडेक्स बनाने के लिए, चलाएं पर क्लिक करें:CREATE INDEX idx_products_core_sku ON products_core_table(sku);
एआई एजेंट के लिए इमेज एम्बेडिंग बनाना, ताकि वह मिलते-जुलते प्रॉडक्ट खोज सके
एआई एजेंट इंटिग्रेशन, मिलते-जुलते प्रॉडक्ट खोजने के लिए इमेज एम्बेडिंग का इस्तेमाल करता है. एंबेडिंग, multimodalembedding@001 मॉडल का इस्तेमाल करके जनरेट की जाती हैं. इन्हें AlloyDB डेटाबेस में सेव किया जाता है. ये एम्बेडिंग, 1408 डाइमेंशनल वेक्टर हैं और इन्हें img_embeddings कॉलम में सेव किया जाता है.
एम्बेडिंग जनरेट करने से पहले, हमें Cloud Storage को ऐक्सेस करने के लिए, AlloyDB सेवा खाते को ज़रूरी भूमिकाएं देनी होंगी.
Cloud Storage को ऐक्सेस करने के लिए, AlloyDB सेवा खाते को भूमिकाएं असाइन करना
हम AlloyDB सेवा खाते को स्टोरेज ऑब्जेक्ट यूज़र और स्टोरेज ऑब्जेक्ट व्यूअर की भूमिका असाइन करते हैं, ताकि वह Cloud Storage बकेट से ऑब्जेक्ट पढ़ सके.
- IAM और एडमिन पर जाएं.
- ऐक्सेस दें पर क्लिक करें.
- नए मुख्य खाते फ़ील्ड में, AlloyDB के सेवा खाते को खोजें. सेवा खाता,
service-991742412753@gcp-sa-alloydb.iam.gserviceaccount.comसे मिलता-जुलता है. - कोई भूमिका चुनें पर क्लिक करें.
- Storage Object User भूमिका ढूंढें और चुनें.
- दूसरी भूमिका जोड़ें पर क्लिक करें और Storage Object Viewer भूमिका चुनें.
- दूसरी भूमिका जोड़ें पर क्लिक करें और Vertex AI उपयोगकर्ता की भूमिका चुनें.
- सेव करें पर क्लिक करें.
एक्सटेंशन चालू करना
इस ऐप्लिकेशन को बनाने के लिए, हम pgvector और google_ml_integration एक्सटेंशन का इस्तेमाल करेंगे. pgvector एक्सटेंशन की मदद से, वेक्टर एम्बेडिंग को सेव किया जा सकता है और उन्हें खोजा जा सकता है. google_ml_integration एक्सटेंशन, ऐसे फ़ंक्शन उपलब्ध कराता है जिनका इस्तेमाल करके, Vertex AI के अनुमान लगाने वाले एंडपॉइंट को ऐक्सेस किया जाता है. इससे एसक्यूएल में अनुमान पाए जा सकते हैं. इन एक्सटेंशन को चालू करने के लिए, यहां दिए गए DDL चलाएं:
- Google Cloud Console में, PostgreSQL के लिए AlloyDB पर जाएं.
- बाईं ओर मौजूद नेविगेशन मेन्यू में, AlloyDB Studio पर क्लिक करें.
- एडिटर व्यू में, बिना शीर्षक वाली नई क्वेरी टैब खोलें.
- नीचे दिए गए DDL को कॉपी करें और चलाएं पर क्लिक करें:
CREATE EXTENSION IF NOT EXISTS vector; CREATE EXTENSION IF NOT EXISTS google_ml_integration;
एम्बेडिंग के साथ डेटाबेस को शुरू करना
products_core_tableमें img_embeddings कॉलम जोड़ें.ALTER TABLE products_core_table ADD COLUMN img_embeddings vector(1408);- इमेज के लिए एम्बेडिंग जनरेट करें और उन्हें
img_embeddingsकॉलम में सेव करें.UPDATE products_core_table SET img_embeddings = google_ml.image_embedding( model_id => 'multimodalembedding@001', image => 'gs://<STORAGE_BUCKET_NAME>/' || sku || '.jpg', mimetype => 'image/jpeg') WHERE sku IN ( SELECT sku FROM products_core_table WHERE img_embeddings IS NULL AND sku IS NOT NULL LIMIT 10 ); - पूरे सेट के लिए इमेज एम्बेडिंग जनरेट करने के लिए, पिछली क्वेरी को कम से कम पांच बार दोहराएं. ऐसा इसलिए, क्योंकि Studio में पांच मिनट की सीमा होती है. अगर यह क्वेरी टाइम आउट हो जाती है, तो
LIMITको5में बदलें और क्वेरी को दस बार फिर से चलाएं. इस प्रोसेस को पूरा होने में कुछ मिनट लग सकते हैं.
5. Google Cloud पर MongoDB Atlas सेट अप करना
MongoDB, प्रॉडक्ट की ज़्यादा बेहतर और सेमी-स्ट्रक्चर्ड जानकारी सेव करता है. साथ ही, यह उपयोगकर्ता के व्यवहार से जुड़ा फ़्लेक्सिबल डेटा भी सेव करता है. जैसे, क्लिक और व्यू.\
MongoDB क्लस्टर बनाना
- Google Cloud पर MongoDB Atlas पर जाएं. इसके बाद, बिना शुल्क वाला टियर खाता चुनें.
- बिना शुल्क वाला क्लस्टर टियर चुनें. इसके बाद, क्लस्टर का नाम डालें. उदाहरण के लिए,
ecommerce-cluster. - सेवा देने वाली कंपनी के तौर पर Google Cloud को चुनें. साथ ही, पक्का करें कि क्षेत्र, आपके Google Cloud क्षेत्र (जैसे,
us-central1) के मुताबिक हो. - Create Deployment पर क्लिक करें.
- बंद करें पर क्लिक करें.
नेटवर्क ऐक्सेस कॉन्फ़िगर करना
- Atlas console में, Database & Network Access पर जाएं.
- आईपी ऐक्सेस लिस्ट पर क्लिक करें.
- आईपी पता जोड़ें पर क्लिक करें.
0.0.0.0/0जोड़ें. इससे कहीं से भी ऐक्सेस किया जा सकता है.- पुष्टि करें पर क्लिक करें.
डेटाबेस उपयोगकर्ता बनाना
- Atlas console में, Database & Network Access पर जाएं.
- डेटाबेस के उपयोगकर्ता पर क्लिक करें.
- Add New Database User पर क्लिक करें.
- पुष्टि करने के तरीके के तौर पर पासवर्ड चुनें.
- उपयोगकर्ता नाम के तौर पर
store-userऔर पासवर्ड के तौर परstoreuserडालें. - पहले से मौजूद भूमिका जोड़ें पर क्लिक करें. इसके बाद, किसी भी डेटाबेस में पढ़ने और लिखने की अनुमति चुनें.
- उपयोगकर्ता जोड़ें पर क्लिक करें.
कनेक्शन स्ट्रिंग पाना
- डेटाबेस > क्लस्टर > कनेक्ट करें पर जाएं.
- अपना ऐप्लिकेशन कनेक्ट करें में जाकर, ड्राइवर पर क्लिक करें.
- अपने ऐप्लिकेशन कोड में कनेक्शन स्ट्रिंग जोड़ें में दिखाई गई कनेक्शन स्ट्रिंग को कॉपी करें. स्ट्रिंग कुछ इस तरह दिखती है:
mongodb+srv://store-user:<db_password>@ecommerce-cluster.g8vaekh.mongodb.net/?appName=ecommerce-clusterdb_passwordकी जगह अपना MongoDB पासवर्ड डालें. इस कोडलैब में, यहstoreuserहै.
इस कनेक्शन स्ट्रिंग को सेव करें. इसका इस्तेमाल बाद में MONGODB_CONNECTION_STRING एनवायरमेंट वैरिएबल के लिए किया जाएगा.
डेटाबेस और कलेक्शन बनाना
- Atlas कंसोल में, Database > Clusters > Browse Collections पर जाएं.
- डेटाबेस बनाएं पर क्लिक करें और यह जानकारी डालें:
- डेटाबेस का नाम:
ecommerce_db - संग्रह का नाम:
product_details_collection
- डेटाबेस का नाम:
- डेटाबेस बनाएं पर क्लिक करें.
- डेटा एक्सप्लोरर में, कलेक्शन का नाम चुनें.
- डेटा जोड़ें (+) आइकॉन पर क्लिक करें. इसके बाद, दस्तावेज़ डालें पर क्लिक करें.
- product_details_export.json से JSON कॉन्टेंट कॉपी करें और उसे Insert Document एडिटर डायलॉग में चिपकाएं.
- दस्तावेज़ों का ऐरे डालने के लिए, डालें पर क्लिक करें. साथ ही, पुष्टि करें कि 192 दस्तावेज़ जोड़े गए हैं.
- डेटा एक्सप्लोरर में,
ecommerce_dbडेटाबेस के बगल में मौजूद, कलेक्शन बनाएं (+) पर क्लिक करें. - कलेक्शन के नाम के लिए
user_interactions_collectionडालें और कलेक्शन बनाएं पर क्लिक करें. - डेटा एक्सप्लोरर में,
user_interactions_collectionकलेक्शन चुनें. - डेटा जोड़ें (+) आइकॉन पर क्लिक करें. इसके बाद, दस्तावेज़ डालें पर क्लिक करें.
- user_interactions_export.json से JSON कॉन्टेंट कॉपी करें और उसे दस्तावेज़ डालें एडिटर डायलॉग में चिपकाएं.
- दस्तावेज़ शामिल करें पर क्लिक करें.
6. BigQuery सेट अप करना
BigQuery, उपयोगकर्ताओं के पुराने व्यवहार से जुड़े डेटा को इकट्ठा करता है और उसका विश्लेषण करता है. इससे, बेहतर रिपोर्टिंग और सुझाव जनरेट किए जाते हैं.
डेटासेट बनाना
- Google Cloud Console में, BigQuery पर जाएं.
- एक्सप्लोरर पैनल में, अपने प्रोजेक्ट आईडी के बगल में मौजूद तीन बिंदुओं वाले मेन्यू पर क्लिक करें. इसके बाद, डेटासेट बनाएं को चुनें.
- डेटासेट आईडी के लिए
ecommerce_analyticsडालें. - डेटासेट बनाएं पर क्लिक करें.
Analytics टेबल बनाना
- BigQuery वर्कस्पेस में नई क्वेरी खोलें.
- उपयोगकर्ताओं को प्रॉडक्ट इंटरैक्शन से लिंक करने वाली खास जानकारी वाली टेबल बनाने के लिए, यह एसक्यूएल स्टेटमेंट चलाएं:
CREATE TABLE ecommerce_analytics.user_product_interactions (
user_id STRING DEFAULT 'any user',
product_id STRING,
interaction_score INT
);
MCP Toolbox के लिए, Compute सेवा खाते को भूमिकाएं असाइन करना
हम अपने टूलबॉक्स के लिए इस्तेमाल किए जाने वाले Compute सेवा खाते को भूमिकाएं असाइन करते हैं. ऐसा इसलिए किया जाता है, ताकि एमसीपी टूलबॉक्स को BigQuery, Secret Manager, और अन्य क्लाउड सेवाओं को ऐक्सेस करने की अनुमति मिल सके.
भूमिकाएं असाइन करने के लिए, यह तरीका अपनाएं:
- IAM और एडमिन पर जाएं.
- ऐक्सेस दें पर क्लिक करें.
- नए प्रिंसिपल फ़ील्ड में, Compute सेवा खाते का डिफ़ॉल्ट नाम
YOUR_PROJECT_NUMBER-compute@developer.gserviceaccount.comडालें.YOUR_PROJECT_NUMBERकी जगह, Google Cloud का प्रोजेक्ट नंबर डालें. - कोई भूमिका चुनें पर क्लिक करें.
- BigQuery डेटा एडिटर की भूमिका ढूंढें और चुनें.
- दूसरी भूमिका जोड़ें पर क्लिक करें और BigQuery जॉब के उपयोगकर्ता की भूमिका चुनें.
- कोई दूसरी भूमिका जोड़ें पर क्लिक करें और Secret Manager Secret Accessor भूमिका चुनें.
- दूसरी भूमिका जोड़ें पर क्लिक करें और एडिटर की भूमिका चुनें.
- सेव करें पर क्लिक करें.
7. आवेदन की पूरी प्रोसेस के बारे में जानकारी
हर कॉम्पोनेंट एक-दूसरे के साथ कैसे काम करता है, यह जानने के लिए हम एक आसान ई-कॉमर्स ऐप्लिकेशन बनाएंगे. इसमें कई डेटाबेस और सेवाओं का इस्तेमाल किया जाएगा. इस ऐप्लिकेशन को Python (Flask) बैकएंड की मदद से बनाया गया है. इसमें Google Cloud की कई सेवाओं और डेटाबेस को इंटिग्रेट किया गया है.
डायरेक्ट्री स्ट्रक्चर को समझना
अगले सेक्शन में, BRK2-149-multidb-ecommerce रिपॉज़िटरी को क्लोन किया जाएगा. साथ ही, इसका इस्तेमाल ऐप्लिकेशन को स्थानीय तौर पर चलाने के लिए किया जाएगा. ऐप्लिकेशन की लोकल टेस्टिंग करने के बाद, हम MCP Toolbox और ऐप्लिकेशन, दोनों को Cloud Run पर डिप्लॉय करेंगे.
इस डायरेक्ट्री में डाउनलोड की गई फ़ाइलें एक्सप्लोर करें. ये टॉप लेवल डायरेक्ट्री मौजूद हैं:
UploadImages: यह कुकी, इमेज ऐसेट सेव करती है. इसका इस्तेमाल मुख्य रूप से दस्तावेज़ या ई-कॉमर्स प्रॉडक्ट कैटलॉग के लिए विज़ुअल कॉन्टेंट के लिए किया जाता है.static: यह ऐप्लिकेशन की स्टैटिक वेब ऐसेट को सेव करता है. जैसे, सीएसएस और JavaScript फ़ाइलें. इनका इस्तेमाल, यूज़र इंटरफ़ेस ( सोर्स) को स्टाइल करने और उसमें इंटरैक्टिविटी जोड़ने के लिए किया जाता है.templates: यह कुकी, एचटीएमएल टेंप्लेट सेव करती है. इनका इस्तेमाल Python ऐप्लिकेशन करता है. ये टेंप्लेट, ई-कॉमर्स कैटलॉग के वेब पेजों को डाइनैमिक तरीके से रेंडर करने के लिए इस्तेमाल किए जाते हैं. Flask के लिए, Jinja2 का इस्तेमाल किया जाता है (सोर्स).toolbox-implementation: यह कुकी, मॉडल कॉन्टेक्स्ट प्रोटोकॉल (MCP) टूलबॉक्स के कॉन्फ़िगरेशन और लागू करने की जानकारी सेव करती है. इससे पहले से तय किए गए टूल का इस्तेमाल करके, मल्टीडीबी डेटाबेस इंटरैक्शन को आसान बनाया जा सकता है.
इस रिपॉज़िटरी में मौजूद फ़ाइलें, एक साथ मिलकर मल्टीडेटाबेस ई-कॉमर्स ऐप्लिकेशन को बनाने, कॉन्फ़िगर करने, और डिप्लॉय करने का काम करती हैं. app.py जैसी सेंट्रल फ़ाइलें, SQL और JSON फ़ाइलों में तय किए गए अलग-अलग डेटा सोर्स को इंटिग्रेट करके बैकएंड को व्यवस्थित करती हैं. वहीं, कॉन्फ़िगरेशन फ़ाइलें यह पक्का करती हैं कि क्लाउड एनवायरमेंट में आसानी से डिप्लॉय किया जा सके:
app.py: यह Flask बैकएंड और मल्टी-डेटाबेस इंटिग्रेशन को व्यवस्थित करता है.agentengine.py: Vertex AI एजेंटों को शुरू करने और कॉन्फ़िगर करने के लिए मुख्य लॉजिक..env: यह डेटाबेस और स्टोरेज कनेक्शन के लिए सीक्रेट सेव करता है.tools.yaml: यह मल्टीडेटाबेस डेटाबेस ऑपरेशंस के लिए, एमसीपी टूलबॉक्स को कॉन्फ़िगर करता है.Dockerfile: कंटेनर इमेज और एनवायरमेंट सेटअप के बारे में बताता है.requirements.txt: इसमें ऐप्लिकेशन के रनटाइम के लिए ज़रूरी Python लाइब्रेरी की सूची होती है.tools.yaml: एमसीपी टूलबॉक्स के लिए कॉन्फ़िगरेशन.Procfile: इससे डिप्लॉयमेंट के लिए, प्रोडक्शन एक्ज़ीक्यूशन कमांड के बारे में पता चलता है.alloydb_insert_queries.sql: इसमें रिलेशनल डेटा के लिए एसक्यूएल क्वेरी होती हैं.product_details_export.jsonऔरuser_interactions_export.json: NoSQL डेटाबेस के लिए JSON डेटा का सैंपल उपलब्ध कराता है.README.md: यह सेटअप, डिप्लॉयमेंट, और प्रोजेक्ट को समझने में मदद करता है.
आवेदन करने की पूरी प्रोसेस
- AlloyDB सेटअप करना: ज़्यादा परफ़ॉर्मेंस वाला क्लस्टर उपलब्ध कराएं. साथ ही, दी गई एसक्यूएल स्क्रिप्ट का इस्तेमाल करके, इमेज एम्बेडिंग के लिए वेक्टर कॉलम वाली products_core_table बनाएं.
- MongoDB Atlas सेटअप करना: Google Cloud पर एक क्लस्टर डिप्लॉय करें, ताकि प्रॉडक्ट_डिटेल में प्रॉडक्ट के फ़्लूड एट्रिब्यूट सेव किए जा सकें. साथ ही, user_interactions में रीयल-टाइम क्लिकस्ट्रीम लॉग की जा सकें.
- BigQuery Analytics: इंटरैक्शन लॉग को इकट्ठा करने के लिए एक डेटासेट बनाएं. इससे जटिल विश्लेषण वाली क्वेरी की जा सकती हैं. ये क्वेरी, लाखों इवेंट में "टॉप 5" ट्रेंडिंग आइटम की पहचान करती हैं.
- Cloud Storage रिपॉज़िटरी: ज़्यादा रिज़ॉल्यूशन वाली प्रॉडक्ट इमेज को सेव करने के लिए, एक सार्वजनिक बकेट बनाएं. यह पक्का करें कि हर ऐसेट को फ़्रंटएंड के लिए, हस्ताक्षर किए गए या सार्वजनिक यूआरएल के ज़रिए ऐक्सेस किया जा सके.
- एमसीपी टूलबॉक्स डिप्लॉयमेंट: टूलबॉक्स को Cloud Run पर डिप्लॉय करें. इससे यह एक सेंट्रल RESTful ब्रिज के तौर पर काम करेगा. यह नैचुरल लैंग्वेज इंटेंट को कई डेटाबेस क्वेरी में बदलता है.
- Tools.yaml कॉन्फ़िगरेशन: "Tools" तय करें. जैसे, get_product_core_data या get_top_5_views. साथ ही, खास एसक्यूएल और NoSQL ऑपरेशन को एजेंट के लिए आसानी से पढ़े जा सकने वाले नामों के साथ मैप करें.
- Flask बैकएंड लॉजिक: app.py रास्तों को लागू करें. ये MCP टूलबॉक्स के साथ इंटरफ़ेस करते हैं. साथ ही, डेटा वापस पाने और यूज़र इंटरफ़ेस (यूआई) के लिए एपीआई के तौर पर काम करते हैं.
- मल्टी-एजेंट ऑर्केस्ट्रेशन: कोड में ADK एजेंट कॉन्फ़िगर करें, ताकि वे उपयोगकर्ता के इंटेंट के हिसाब से काम कर सकें. साथ ही, जटिल और अलग-अलग सोर्स से मिली खुदरा क्वेरी को हल करने के लिए, सही "टूल" चुन सकें.
- फ़्रंटएंड इंटिग्रेशन: index.html इंटरफ़ेस बनाएं. इसमें प्रॉडक्ट कैटलॉग, इंटरैक्शन रिकॉर्ड करने की सुविधा, और प्रॉडक्ट की परफ़ॉर्मेंस के आंकड़े समझने के लिए Analytics टैब शामिल हो. साथ ही, इसमें "एजेंट टैब" भी शामिल हो. यह ADK मल्टी-एजेंट चैट का इस्तेमाल करके, बातचीत के ज़रिए खरीदारी करने का बेहतर अनुभव देता है.
अब ऑर्केस्ट्रेशन और डिप्लॉयमेंट लागू करते हैं.
8. MCP Toolbox को सेटअप करना और Cloud Run पर डिप्लॉय करना
एमसीपी टूलबॉक्स, हमारे कई डेटा सोर्स को ऐब्स्ट्रैक्ट करता है. इससे हमारा ऐप्लिकेशन, डेटा को एक जैसा फ़ेच और राइट कर पाता है.
MCP टूलबॉक्स को स्थानीय तौर पर इंस्टॉल करना
- Cloud Shell में,
toolbox-implementationफ़ोल्डर पर जाएं:cd next-26-sessions/BRK2-149-multidb-ecommerce/toolbox-implementation - MCP टूलबॉक्स बाइनरी डाउनलोड करें और इसे एक्ज़ीक्यूटेबल बनाएं:
export VERSION=0.29.0 curl -L -o toolbox https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox chmod +x toolbox
tools.yaml फ़ाइल को कॉन्फ़िगर करना
आपको AlloyDB, MongoDB, और BigQuery के लिए ऐब्स्ट्रैक्शन तय करने होंगे. tools.yaml फ़ाइल से, एमसीपी टूलबॉक्स को एक-दूसरे के साथ इंटरैक्ट करने का तरीका पता चलता है.
- एम्बेड किए गए एडिटर का इस्तेमाल करके,
tools.yamlफ़ाइल बनाएं और उसमें बदलाव करें:cloudshell edit tools.yamltools.yamlफ़ाइल, GitHub रिपॉज़िटरी में देखी जा सकती है. इसके कॉन्टेंट को अपनी नईtools.yamlफ़ाइल में कॉपी करें. - होस्ट, उपयोगकर्ता, पासवर्ड, प्रोजेक्ट आईडी, और कनेक्शन स्ट्रिंग को अपडेट करें, ताकि वे उन बुनियादी ढांचे से मेल खाएं जिन्हें आपने पिछले चरणों में उपलब्ध कराया था:
डेटाबेस
फ़ील्ड
उदाहरण वैल्यू
AlloyDB/BigQuery
project_idYOUR_PROJECT_IDAlloyDB
regionus-central1AlloyDB
clusterecommerce-clusterAlloyDB
instanceecommerce-cluster-primaryAlloyDB
databasepostgresAlloyDB
passwordalloydbMongoDB
connection_stringmongodb+srv://store-user:storeuser@ecommerce-cluster.urcxr6q.mongodb.net
MCP Toolbox के लिए, Compute सेवा खाते को भूमिकाएं असाइन करना
हम अपने टूलबॉक्स के लिए इस्तेमाल किए जाने वाले Compute सेवा खाते को भूमिकाएं असाइन करते हैं. ऐसा इसलिए किया जाता है, ताकि एमसीपी टूलबॉक्स, AlloyDB को ऐक्सेस कर सके.
- IAM और एडमिन पर जाएं.
- ऐक्सेस दें पर क्लिक करें.
- नए प्रिंसिपल फ़ील्ड में, Compute सेवा खाते का डिफ़ॉल्ट नाम
YOUR_PROJECT_NUMBER-compute@developer.gserviceaccount.comडालें.YOUR_PROJECT_NUMBERकी जगह, Google Cloud का प्रोजेक्ट नंबर डालें. - कोई भूमिका चुनें पर क्लिक करें.
- BigQuery डेटा एडिटर की भूमिका ढूंढें और चुनें.
- दूसरी भूमिका जोड़ें पर क्लिक करें और AlloyDB Client भूमिका चुनें.
- कोई और भूमिका जोड़ें पर क्लिक करें और सेवा उपयोग उपभोक्ता की भूमिका चुनें.
- दूसरी भूमिका जोड़ें पर क्लिक करें और Storage Object Viewer भूमिका चुनें.
- सेव करें पर क्लिक करें.
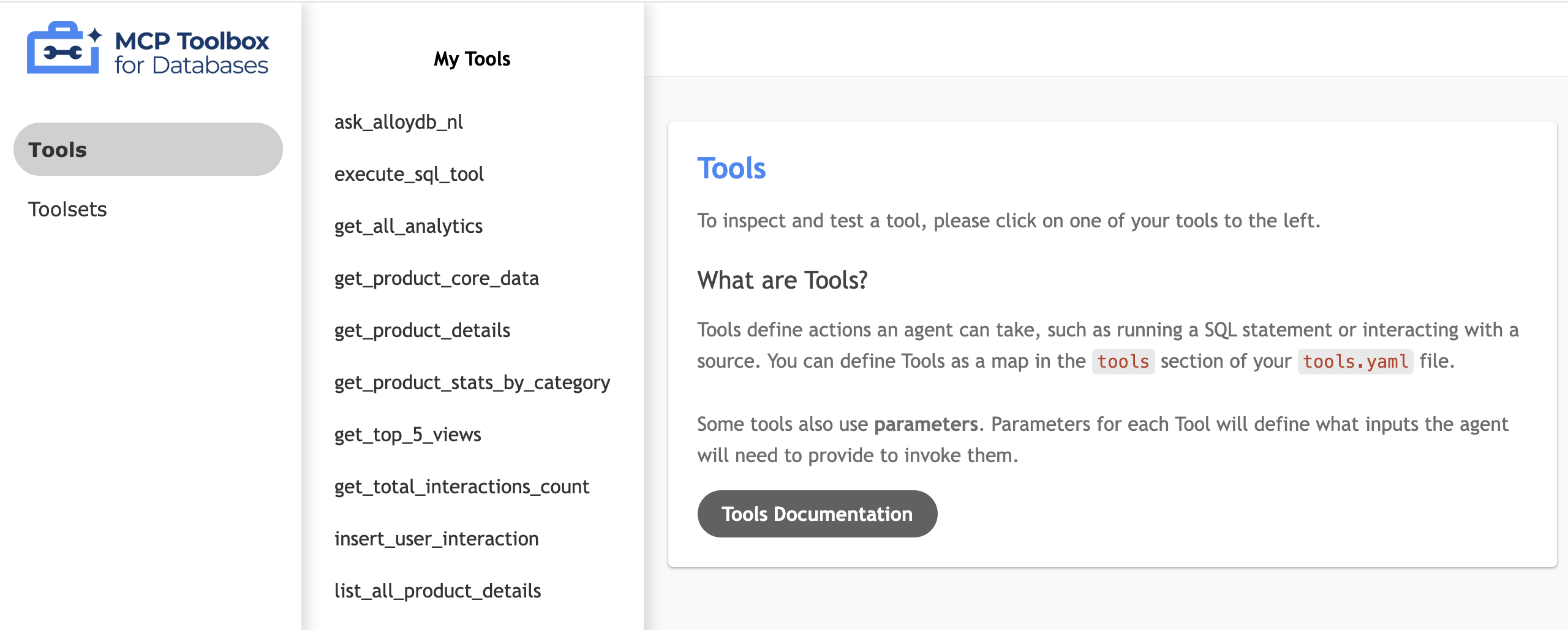
अपने टूल के यूज़र इंटरफ़ेस की जांच करना
- यूज़र इंटरफ़ेस (यूआई) दिखाने के लिए, अपने Cloud Shell टर्मिनल में टूलबॉक्स को स्थानीय तौर पर चलाएं:
./toolbox --ui - Cloud Shell में पोर्ट 5000 पर वेब प्रीव्यू खोलें और टूल पेज पर जाएं. उदाहरण के लिए, सेशन के यूआरएल के हिसाब से, इसे यहां देखा जा सकता है:
https://5000-cs-71152278760-default.cs-asia-southeast1-cash.cloudshell.dev/ui
एमसीपी टूलबॉक्स का यह यूज़र इंटरफ़ेस (यूआई) दिखता है:
Cloud Run पर डिप्लॉय करना
एमसीपी टूलबॉक्स को Cloud Run पर डिप्लॉय करें, ताकि यह एक सुरक्षित और मैनेज की गई सेवा के तौर पर उपलब्ध हो सके. हमारा ऐप्लिकेशन, इसका इस्तेमाल डेटाबेस को क्वेरी करने के लिए कर सकता है. हम कॉन्फ़िगरेशन को Secret Manager में सेव करेंगे, ताकि कनेक्शन की संवेदनशील जानकारी को सुरक्षित रखा जा सके.
- Cloud Shell का नया सेशन खोलें.
toolbox-implementationफ़ोल्डर पर जाएं:cd next-26-sessions/BRK2-149-multidb-ecommerce/toolbox-implementation- Google Secret Manager में
tools.yamlकॉन्फ़िगरेशन अपलोड करें:gcloud secrets create tools --data-file=tools.yamlgcloud secrets versions add tools --data-file=tools.yaml - पब्लिक एमसीपी टूलबॉक्स कंटेनर इमेज का इस्तेमाल करके डिप्लॉय करें:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:0.29.0 export PROJECT_ID=$(gcloud config get-value project) gcloud run deploy toolbox \ --image $IMAGE \ --region us-central1 \ --service-account $(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")-compute@developer.gserviceaccount.com \ --set-secrets "/app/tools.yaml=tools:latest" \ --args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080","--ui" \ --allow-unauthenticated - डिप्लॉय होने के बाद, Cloud Run सेवा का यूआरएल नोट कर लें. यह
https://toolbox-*********-uc.a.run.app/uiजैसा दिखना चाहिए.
9. ई-कॉमर्स ऐप्लिकेशन सेट अप करना और उसे Cloud Run पर डिप्लॉय करना
हमारे डेटाबेस चालू हैं और एमसीपी टूलबॉक्स अबस्ट्रैक्शन डिप्लॉय किया गया है. इसलिए, हम Flask वेब ऐप्लिकेशन चला सकते हैं!
प्रॉडक्ट कैटलॉग दिखाने के लिए, Flask ऐप्लिकेशन इन चरणों को पूरा करके डेटा प्रोसेस करता है:
- कोर डेटा फ़ेच करें: इससे AlloyDB (
list_products_core) से प्रॉडक्ट की पूरी सूची मिलती है. - ज़्यादा जानकारी फ़ेच करें: इससे MongoDB (
list_all_product_details) से प्रॉडक्ट की पूरी जानकारी मिलती है. - सूचियां जोड़ें: इससे दो सूचियां जुड़ जाती हैं.
- मीडिया जोड़ें: इससे हर आइटम में Cloud Storage इमेज का यूआरएल जुड़ जाता है.
रीज़निंग इंजन ऐप्लिकेशन का पाथ जनरेट करना
Google Cloud के Vertex AI Reasoning Engine का इस्तेमाल करके, एआई एजेंट को शुरू करने और रजिस्टर करने के लिए, यह कमांड चलाएं:
- Cloud Shell टर्मिनल में,
BRK2-149-multidb-ecommerceफ़ोल्डर पर जाएं.cd next-26-sessions/BRK2-149-multidb-ecommerce - डिपेंडेंसी इंस्टॉल करने के लिए, requirements.txt फ़ाइल चलाएं
pip install -r requirements.txt - रीज़निंग इंजन ऐप्लिकेशन पाथ जनरेट करने के लिए,
agentengine.pyस्क्रिप्ट चलाएं:python agentengine.py
आउटपुट इस तरह का होगा:
projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856
एनवायरमेंट वैरिएबल कॉन्फ़िगर करना
.envफ़ाइल बनाएं और उसमें बदलाव करें:cloudshell edit .env- वैल्यू को अपने डेटाबेस कनेक्शन और Cloud Run Toolbox के नए यूआरएल से बदलें:
# 1. MongoDB Connection String MONGODB_CONNECTION_STRING="mongodb+srv://<db_user>:<db_password>@cluster0.mongodb.net" # 2. MCP Toolbox Server Location # Must match the address where you run the toolbox server MCP_TOOLBOX_SERVER_URL="https://toolbox-*********-uc.a.run.app" # 3. Google Cloud Storage Bucket Name GCS_PRODUCT_BUCKET="ecommerce-app-images" # 4. Fallback image URL FALLBACK_IMAGE_URL="https://storage.googleapis.com/ecommerce-media-bold-circuit-492711-n9/fallback.jpg" # 5. Google Gen AI Vertex AI flag GOOGLE_GENAI_USE_VERTEXAI=TRUE # 6. Project ID PROJECT_ID=codelab-project-491117 # 7. Google Cloud Location of AlloyDB, BigQuery databases GOOGLE_CLOUD_LOCATION=us-central1 # 8. Reasoning engine application path APP_NAME=projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856 # 9. Model ID MODEL=gemini-1.5-flash-lite
फ़्रंटएंड को Cloud Run पर डिप्लॉय करना
- आर्किटेक्चर को पूरा करने के लिए, वेब ऐप्लिकेशन को Cloud Run पर डिप्लॉय करें:
gcloud run deploy polyglot --source . --platform managed \ --region us-central1 \ --allow-unauthenticated \ --set-env-vars \ MONGODB_CONNECTION_STRING="<MONGODB_CONNECTION_STRING>", \ MCP_TOOLBOX_SERVER_URL="<MCP_TOOLBOX_SERVER_URL>", \ GCS_PRODUCT_BUCKET="<GCS_PRODUCT_BUCKET>", \ FALLBACK_IMAGE_URL="<FALLBACK_IMAGE_URL>", \ GOOGLE_GENAI_USE_VERTEXAI=TRUE, \ PROJECT_ID="YOUR_PROJECT_ID", \ GOOGLE_CLOUD_LOCATION=us-central1, \ APP_NAME="<YOUR_REASONING_ENGINE_APP_PATH>", \ MODEL="gemini-1.5-flash-lite"YOUR_PROJECT_ID: यह आपका Google Cloud प्रोजेक्ट आईडी है.YOUR_REASONING_ENGINE_APP_PATH:python agentengine.pyको चलाने पर मिला आउटपुट. उदाहरण के लिए,projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856.MCP_TOOLBOX_SERVER_URL: यह आपके एमसीपी टूलबॉक्स सर्वर का यूआरएल होता है. उदाहरण के लिए,https://toolbox-*********-uc.a.run.app.GCS_PRODUCT_BUCKET: यह आपके Google Cloud Storage बकेट का नाम है. उदाहरण के लिए,ecommerce-app-images.MONGODB_CONNECTION_STRING: आपके MongoDB डेटाबेस के लिए कनेक्शन स्ट्रिंग. उदाहरण के लिए,mongodb+srv://store-user:storeuser@ecommerce-cluster.g8vaekh.mongodb.netFALLBACK_IMAGE_URL: फ़ॉलबैक इमेज का यूआरएल. उदाहरण के लिए,https://storage.googleapis.com/ecommerce-app-images/fallback.jpg
आपका आवेदन अब लाइव है! Cloud Run की ओर से दिए गए सेवा के यूआरएल को खोलें, ताकि Multidb Ecommerce कैटलॉग देखा जा सके. यूआरएल, https://polyglot-*********-uc.a.run.app/ जैसा होगा.
10. ऐप्लिकेशन के बारे में ज़्यादा जानें
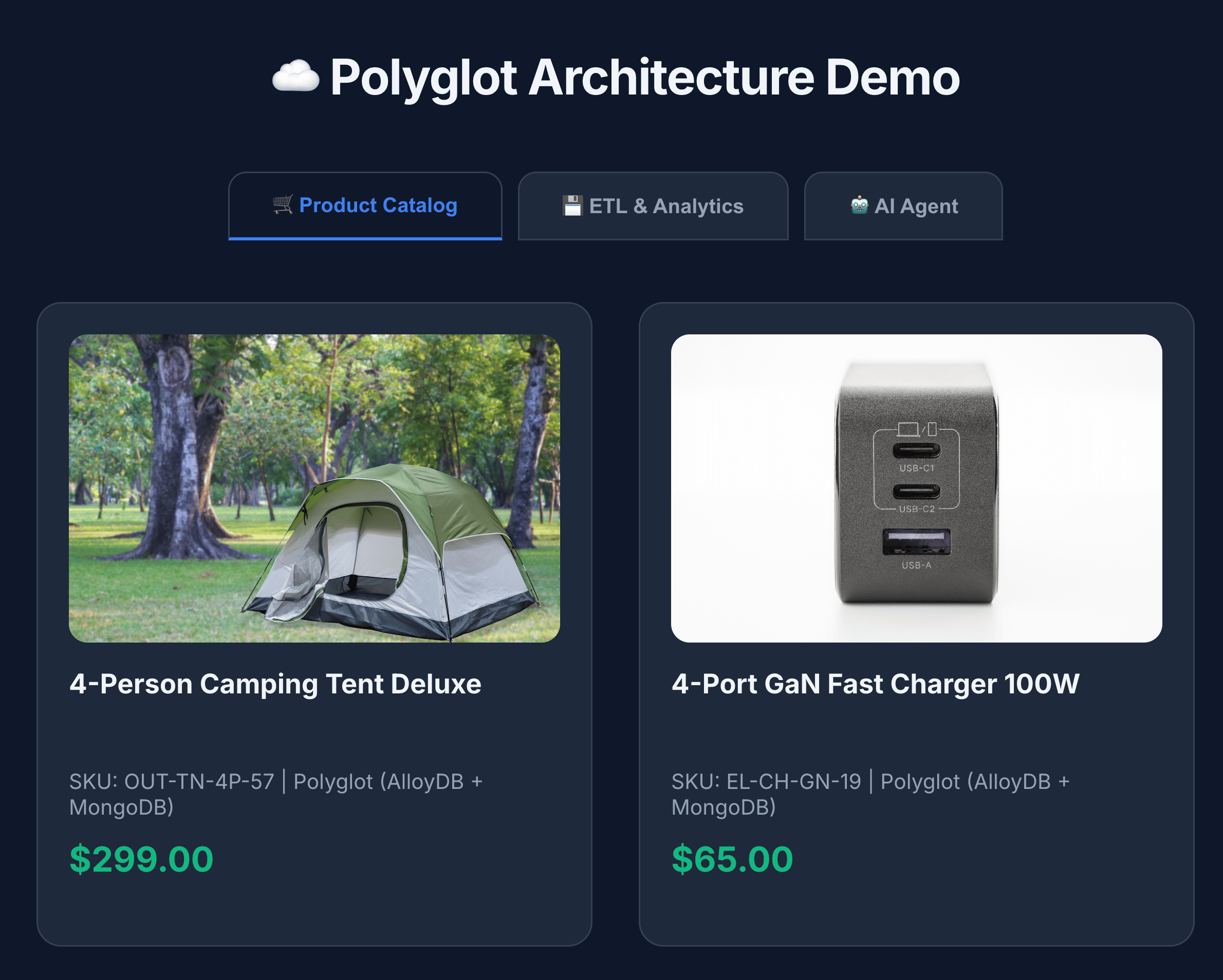
- सभी प्रॉडक्ट देखने के लिए, प्रॉडक्ट कैटलॉग पर क्लिक करें.
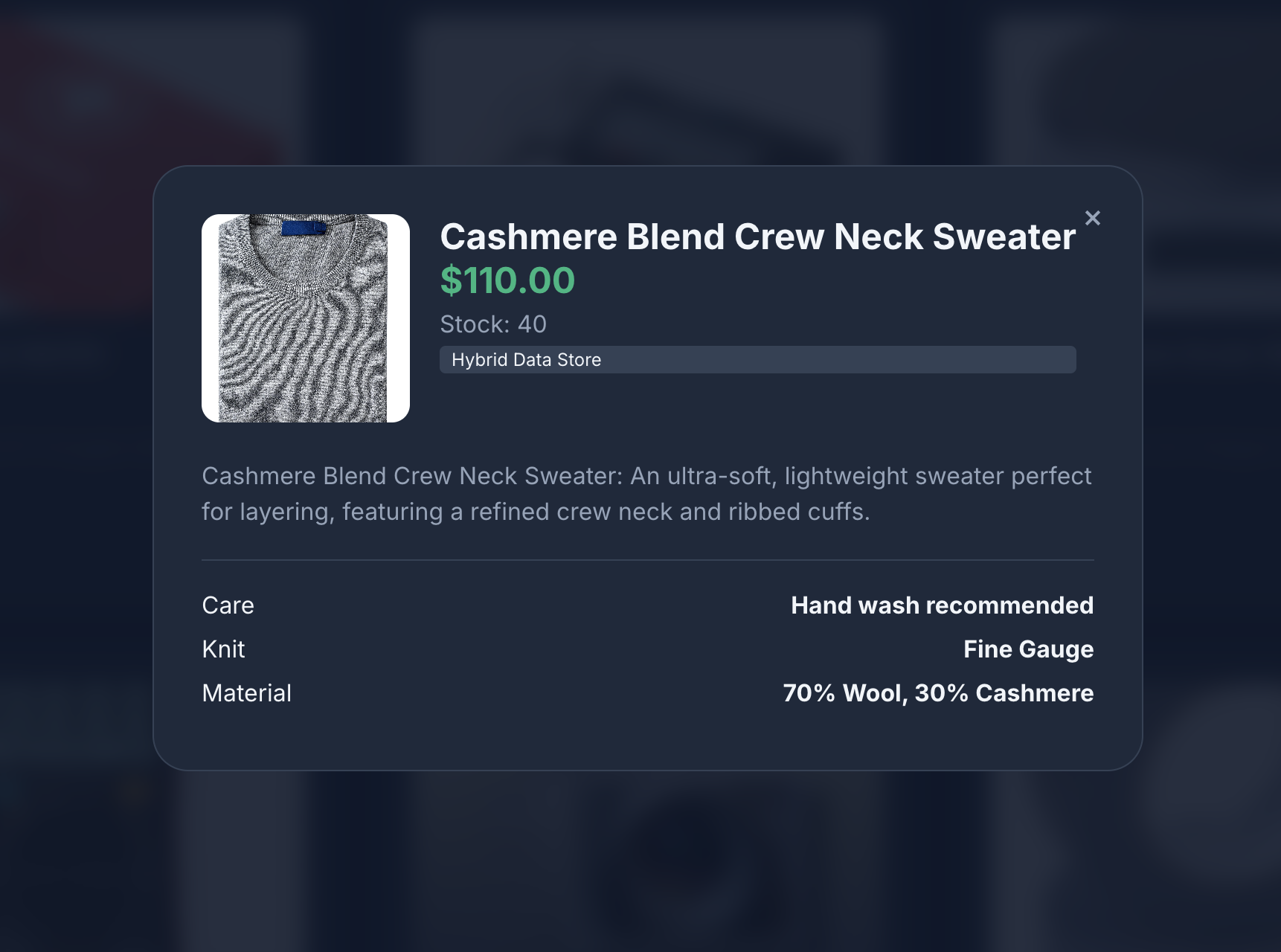
- प्रॉडक्ट की जानकारी देखने के लिए, प्रॉडक्ट आइकॉन पर क्लिक करें. आपको दिखेगा कि इमेज, Cloud Storage से ली गई हैं. प्रॉडक्ट के बारे में जानकारी, MongoDB से ली गई है. साथ ही, प्रॉडक्ट इन्वेंट्री, AlloyDB से ली गई है.
- MongoDB को भेजे गए मॉक व्यू और राइट जनरेट करने के लिए, प्रॉडक्ट कैटलॉग से इंटरैक्ट करें.
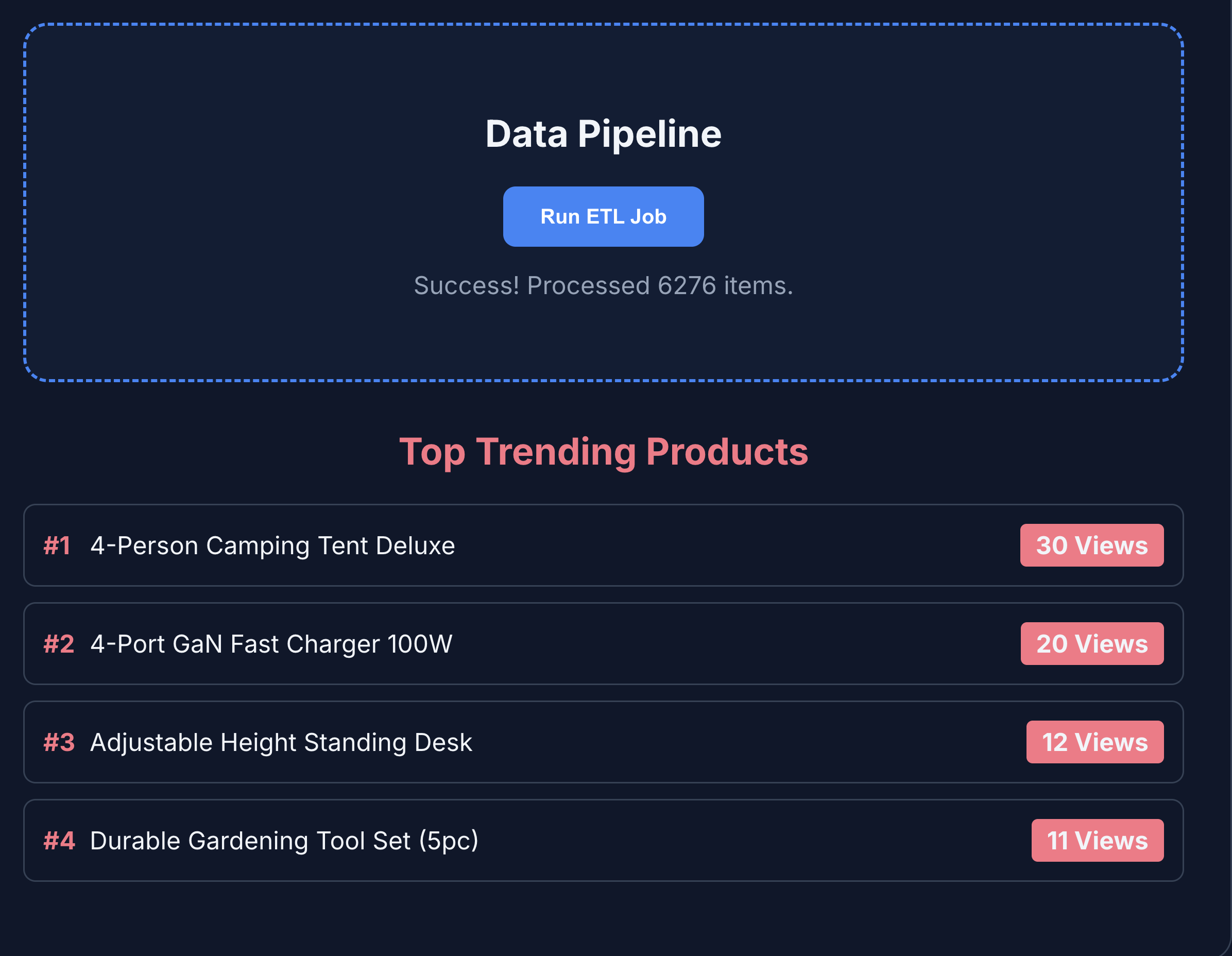
- प्रॉडक्ट के आंकड़े देखने के लिए, ETL और Analytics पर क्लिक करें. आपको दिखेगा कि प्रॉडक्ट के आंकड़े, BigQuery से फ़ेच किए गए हैं.
- एआई एजेंट से इंटरैक्ट करने के लिए, एआई एजेंट टैब पर क्लिक करें. नैचुरल लैंग्वेज में इस तरह के सवाल पूछें:
I'm planning a high-altitude photography trip. Show me some weather-resistant backpacks similar in style to aero glow pro but without any leather components. Also, let me know if they are actually in stock and if other photographers have complained about the strap durability in the reviews.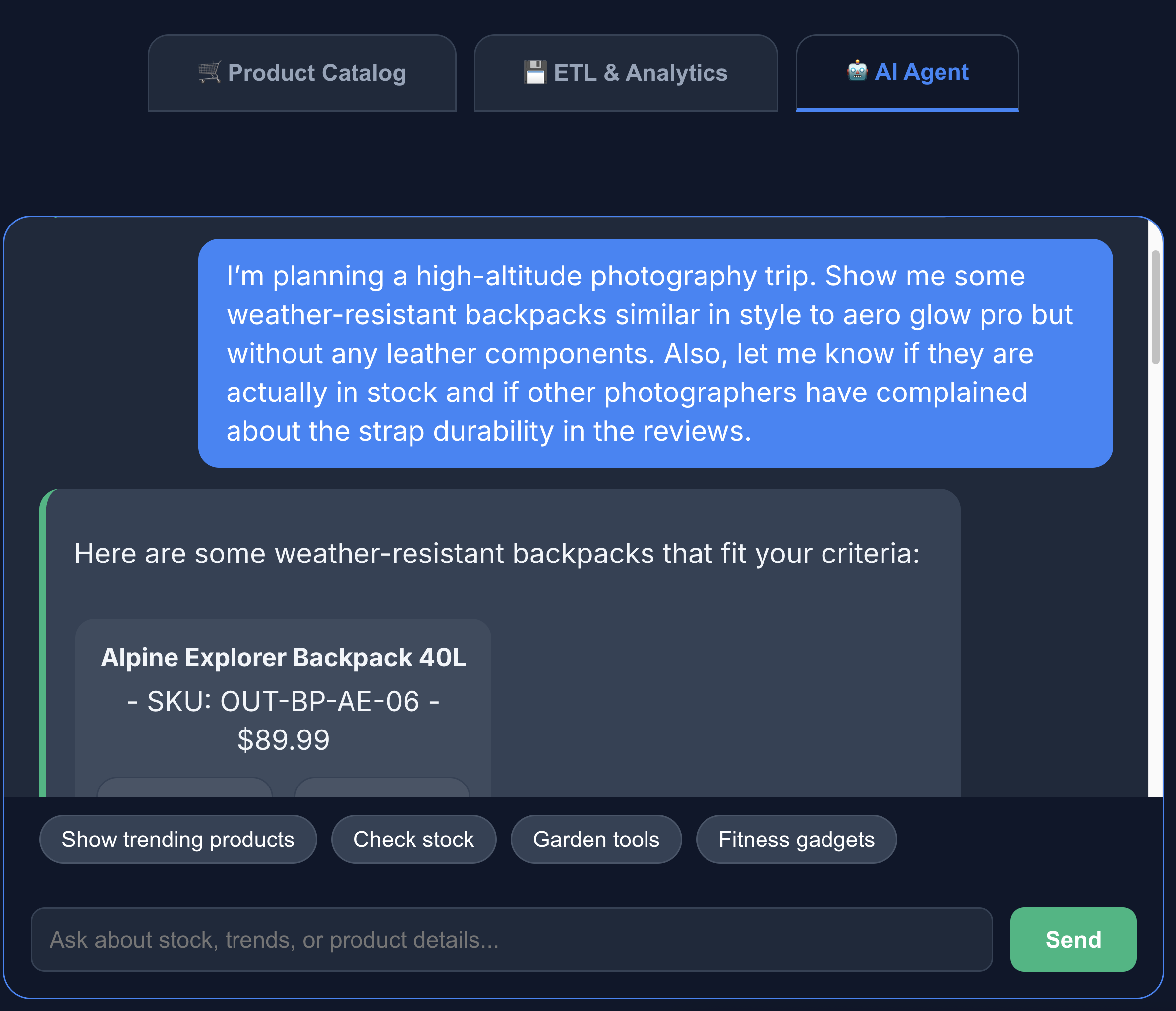
आपको दिख रहा होगा कि खोज के नतीजों में हमें ठीक वही जानकारी मिली है जो हमने मांगी थी. यानी, लेदर के कॉम्पोनेंट के बिना बना बैकपैक, स्टॉक में है, और समीक्षाओं में स्ट्रैप के टिकाऊपन के बारे में कोई शिकायत नहीं की गई है.
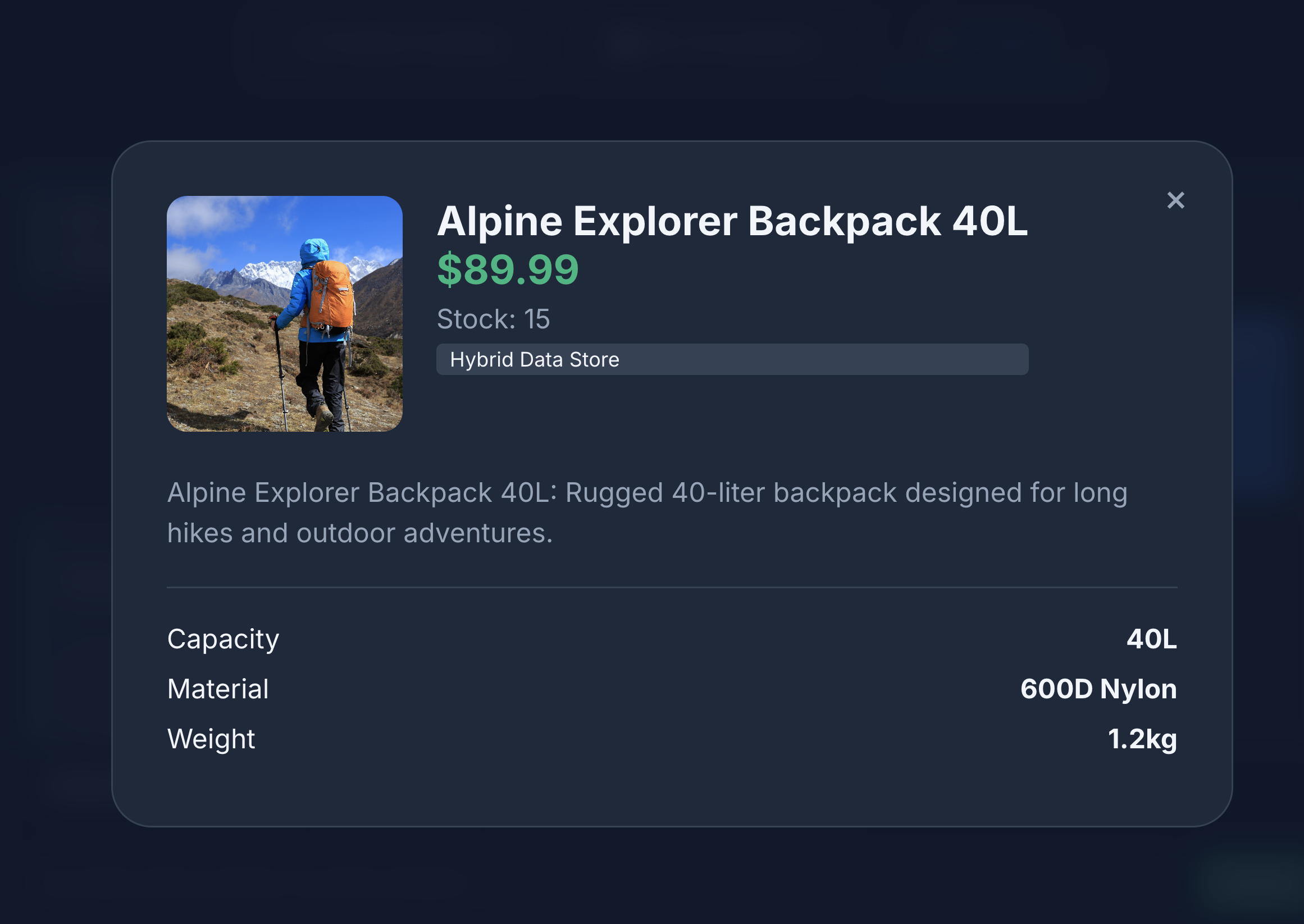
11. व्यवस्थित करें
अपने Google Cloud खाते से लगातार शुल्क लिए जाने से बचने के लिए, इस कोडलैब के दौरान बनाई गई संसाधन मिटाएं.
Cloud Shell में ये कमांड चलाएं:
gcloud run services delete toolbox --region us-central1 --quiet
gcloud run services delete multi-db-app --region us-central1 --quiet
bq rm -r -f -d $PROJECT_ID:ecommerce_analytics
gcloud storage rm --recursive gs://ecommerce-app-images
gcloud alloydb clusters delete ecommerce-cluster --region us-central1 --force --quiet
अगर आपको पूरा Google Cloud प्रोजेक्ट और उसके सभी संसाधन मिटाने हैं, तो यह कमांड चलाएं:
gcloud projects delete $PROJECT_ID
12. बधाई हो
बधाई हो! आपने अलग-अलग क्लाउड पर मौजूद कई डेटाबेस के साथ काम करने वाला आर्किटेक्चर बना लिया है.
आपने यह दिखाया कि MCP Toolbox, आधुनिक और खास ऐप्लिकेशन के लिए आर्किटेक्चरल ग्लू के तौर पर कैसे काम करता है. टास्क के हिसाब से सही डेटाबेस का इस्तेमाल करके, आपको ये फ़ायदे मिले:
- डेटा को आसानी से लिखना: इवेंट लॉग के लिए MongoDB.
- लेन-देन में डेटा को एक जैसा रखना: AlloyDB, डेटा को एक जैसा रखने के लिए.
- बेहतर परफ़ॉर्मेंस वाली Analytics: बिज़नेस इंटेलिजेंस के लिए BigQuery.
- यूनिफ़ाइड डेवलपमेंट: एक ही Python बैकएंड, MCP टूलबॉक्स का इस्तेमाल करके सभी जटिलताओं को कम करता है.
रेफ़रंस के लिए दस्तावेज़
Google Cloud के संबंधित प्रॉडक्ट के बारे में ज़्यादा जानें. साथ ही, इन कोडलैब को एक्सप्लोर करें:
- AlloyDB AI: AlloyDB AI की मदद से, वेक्टर एंबेडिंग का इस्तेमाल शुरू करने के बारे में जानकारी
- AlloyDB AI: AlloyDB में मल्टीमॉडल एम्बेडिंग
- एमसीपी टूलबॉक्स: AlloyDB पर डेटाबेस के लिए एमसीपी टूलबॉक्स को इंस्टॉल और सेट अप करना
इस कोडलैब में इस्तेमाल किए गए प्रॉडक्ट के बारे में ज़्यादा जानने के लिए, यहां जाएं: