
1. Introduzione
Nel retail moderno, i tuoi dati sono un ecosistema diversificato e in continua espansione. Hai dati transazionali solidi (prezzi e inventario), cataloghi polimorfici "disordinati" (specifiche di elettronica e taglie di abbigliamento) e petabyte di log comportamentali. Forzarli in un unico monolite non solo crea debito tecnico, ma rovina l'esperienza utente.
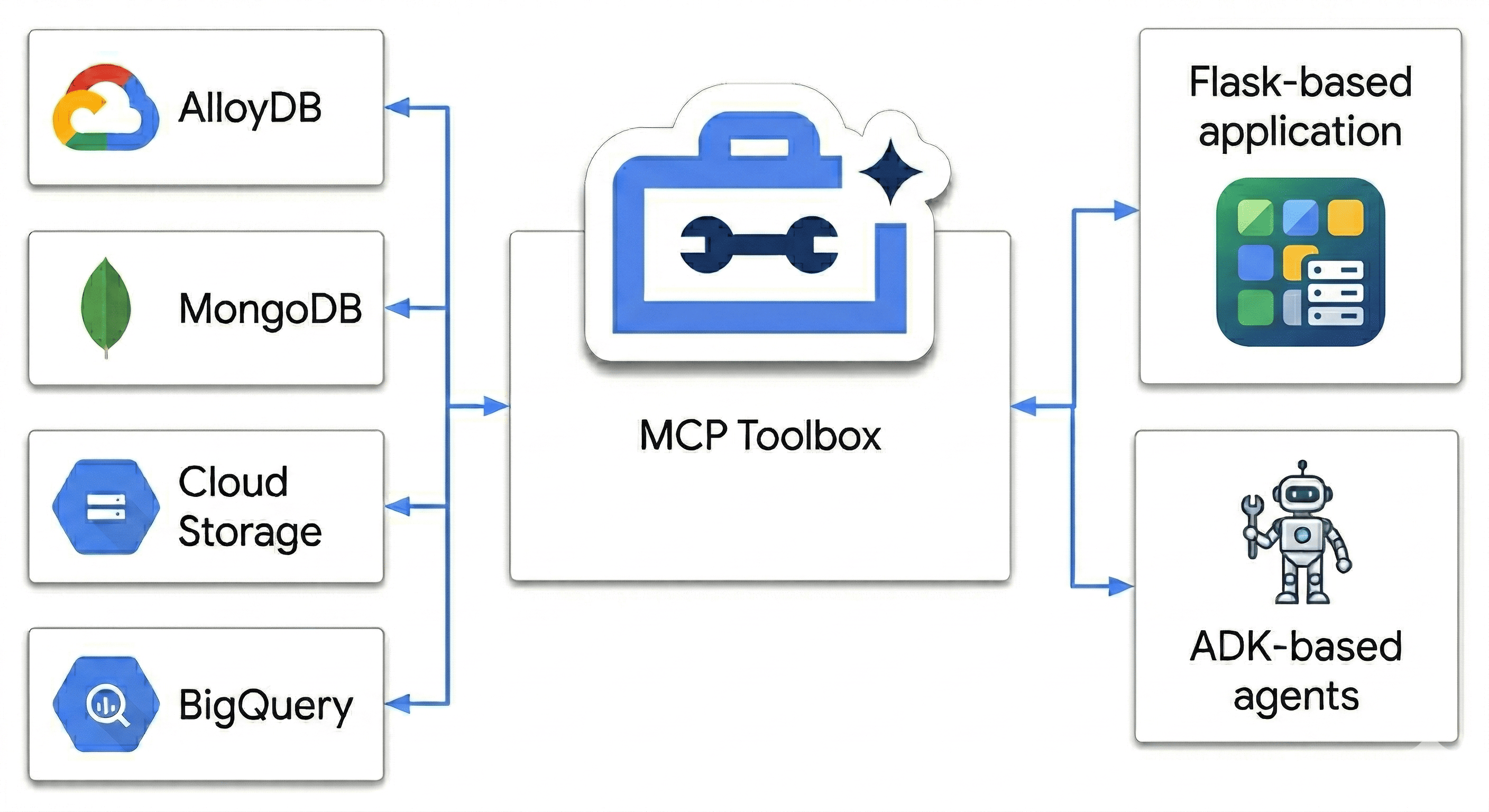
In questo codelab, progetterai un Polyglot Powerhouse che armonizzi:
- AlloyDB: la spina dorsale transazionale per coerenza e incorporamenti di immagini ad alta velocità.
- MongoDB Atlas su Google Cloud: il tuo livello di catalogo flessibile e indipendente dallo schema.
- Cloud Storage: il tuo cervello analitico per la previsione delle tendenze in tempo reale.
- BigQuery: il tuo magazzino digitale ad alta risoluzione.
L'ingrediente segreto? Utilizzerai MCP Toolbox for Databases per orchestrare e unificare in modo intelligente le origini dati in esecuzione su Cloud Run come ponte semantico, quindi eseguirai il deployment di un'app di chat multi-agente utilizzando Agent Development Kit (ADK). Non stai solo creando una barra di ricerca, ma un cervello intelligente per la vendita al dettaglio che comprende il contesto, rispetta i vincoli e colma il divario tra i dati non elaborati e l'intento umano.
La query utente impossibile
Gli agenti e-commerce standard non riescono nel ragionamento multidimensionale (combinando vincoli negativi, somiglianza visiva e inventario in tempo reale). Ad esempio, in genere voglio parlare con un sito di vendita al dettaglio come questo:
"Ehi, sto pianificando un viaggio per fare fotografie ad alta quota. Mostrami alcuni zaini resistenti alle intemperie con uno stile simile ad "AeroGlow Pro", ma senza componenti in pelle. Inoltre, fammi sapere se sono effettivamente disponibili e se altri fotografi si sono lamentati della durata della cinghia nelle recensioni".
Perché questa query è "The Agent Killer":
- Somiglianza visiva (AlloyDB + ricerca vettoriale): "Simile nello stile all'AeroGlow Pro" richiede il confronto dell'incorporamento delle immagini.
- Vincolo negativo (MongoDB): "Senza pelle" richiede il filtraggio tramite attributi flessibili e nidificati che di solito non si trovano in uno schema SQL standard.
- Inventario in tempo reale (AlloyDB): "Effettivamente disponibile" richiede un controllo transazionale in tempo reale (non un indice di ricerca obsoleto).
- Sintesi semantica (BigQuery + multi-agente): l'analisi delle recensioni relative alla "durabilità del cinturino" richiede all'agente di riassumere al volo i feedback non strutturati di BigQuery.
La maggior parte dei bot per la vendita al dettaglio vedrebbe solo "Zaino" e "Pelle" e mostrerebbe 10 zaini in pelle. Come lo stiamo impedendo?
Perché non ci limitiamo a trovare corrispondenze tra le parole chiave. Utilizziamo MCP Toolbox per consentire ai nostri agenti di "ragionare" contemporaneamente su tutte queste fonti, sulla verità transazionale in AlloyDB e sugli attributi flessibili in MongoDB. Creiamolo.
In questo lab proverai a:
- Esegui il provisioning di un cluster AlloyDB per i dati di prodotto principali
- Configura MongoDB Atlas su Google Cloud per archiviare i dettagli dei prodotti semistrutturati
- Crea un bucket Cloud Storage per pubblicare le immagini dei prodotti
- Esegui il deployment di MCP Toolbox for Databases in Cloud Run per un accesso uniforme ai dati
- Esegui processi ETL per inserire i dati in BigQuery per l'analisi
- Conversare con un agente AI in linguaggio naturale.
Prerequisiti
- Un browser web come Chrome
- Un progetto cloud Google Cloud con la fatturazione abilitata
- Un account MongoDB Atlas su Google Cloud senza costi
2. Prima di iniziare
Crea un progetto Google Cloud
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto.
Avvia Cloud Shell
Cloud Shell è un ambiente a riga di comando in esecuzione in Google Cloud che viene precaricato con gli strumenti necessari.
- Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud.
- Una volta connesso a Cloud Shell, verifica l'autenticazione:
gcloud auth list - Verifica che il progetto sia configurato:
gcloud config get project - Se il progetto non è impostato come previsto, impostalo:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Abilita le API richieste
Esegui questo comando per abilitare tutte le API richieste:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
3. Configura Cloud Storage
Cloud Storage funge da archivio di grandi dimensioni per asset multimediali non strutturati, come le immagini dei prodotti.
- Nella console Google Cloud, vai a Cloud Storage e fai clic su Crea bucket.
- Assegna al bucket un nome univoco globale (ad es.
ecommerce-app-images). - Fai clic su Crea.
- Per consentire all'applicazione demo di accedere alle immagini senza autenticazione, deseleziona l'opzione Applica la prevenzione dell'accesso pubblico in questo bucket e fai clic su Conferma.
- Vai alla scheda Autorizzazioni.
- In Autorizzazioni, fai clic su Concedi l'accesso.
- In Nuove entità, inserisci
allUsers. - In Seleziona un ruolo, seleziona Cloud Storage > Utente oggetti Storage.
- Fai clic su Salva, quindi su Consenti accesso pubblico per confermare che stai rendendo pubblica la risorsa.
Caricare immagini segnaposto
BRK2-149-multidb-ecommerce utilizza immagini segnaposto per un'esperienza visiva ottimale.
- In Cloud Shell, clona il repository
next-26-sessions:git clone https://github.com/GoogleCloudPlatform/next-26-sessions.git - Vai alla cartella
UploadImages:cd next-26-sessions/BRK2-149-multidb-ecommerce/UploadImages - Nella console Google Cloud, vai a Cloud Storage e fai clic su Bucket.
- Fai clic sul nome del bucket appena creato.
- Fai clic su Carica > Carica file, seleziona le immagini di esempio scaricate e fai clic su Apri.
4. Configura AlloyDB
AlloyDB funge da unica fonte attendibile per dati strutturati, transazionali e critici come ID prodotto, nomi, SKU, prezzi e inventario. AlloyDB alimenta anche l'agente AI con funzionalità di ricerca per similarità per consigli e query in linguaggio naturale.
Esegui il provisioning di un cluster AlloyDB
- Nella console Google Cloud, vai ad AlloyDB per PostgreSQL.
- Fai clic su Crea cluster.
- In ID cluster, inserisci
ecommerce-cluster. - Imposta una password efficace per l'utente
postgres. Per scopi di apprendimento, puoi utilizzarealloydb. - Per Versione database, mantieni il valore predefinito.
- In Regione, seleziona
us-central1(o la regione che preferisci).
Configura istanza principale
- In ID istanza, inserisci
ecommerce-cluster-primary. - In Disponibilità a livello di zona, seleziona Zona singola.
- Per Tipo di macchina, scegli un tipo di macchina piccolo (ad es. N2, 4 vCPU, 32 GB di RAM).
- In Connettività IP privato, seleziona Accesso privato ai servizi (PSA) e seleziona la rete
default.Se la rete predefinita non è ancora impostata, fai clic su Conferma configurazione di rete per crearne una. - In Connettività IP pubblico, seleziona la casella di controllo Abilita IP pubblico per consentire alla casella degli strumenti MCP di connettersi correttamente in questo codelab.
- In Reti esterne autorizzate, inserisci
0.0.0.0/0. Seleziona la casella di controllo Sono consapevole dei rischi e fai clic su Salva. - Fai clic su Crea cluster.
Nota: annota il tuo indirizzo IP pubblico (simile a 34.124.240.26).
Inizializza il database
- Fai clic su AlloyDB Studio nel menu di navigazione a sinistra.
- Nel menu a discesa Database, seleziona
postgres. - Seleziona Autenticazione integrata per accedere al database.
- Per Nome utente, utilizza l'utente
postgres. - In Password, inserisci la password che hai impostato in precedenza.
- Fai clic su Authenticate (Autentica).
- Nella visualizzazione dell'editor, apri una nuova scheda della query senza titolo.
- Copia il seguente DDL e fai clic su Esegui:
CREATE TABLE products_core_table ( product_id UUID PRIMARY KEY, name VARCHAR(255) NOT NULL, sku VARCHAR(50) UNIQUE NOT NULL, price NUMERIC(10, 2) NOT NULL, stock INT NOT NULL ); - In Cloud Shell, vai alla cartella
BRK2-149-multidb-ecommerce:cd next-26-sessions/BRK2-149-multidb-ecommerce - Apri il file
alloydb_insert_queries.sqlin Cloud Shell e copia le query di inserimento.cat alloydb_insert_queries.sql - In una nuova scheda della query senza titolo, incolla solo le istruzioni
INSERTe fai clic su Esegui. - In una nuova scheda di query senza titolo, copia il seguente DDL e fai clic su Esegui per creare un indice nella tabella
products_core_table:CREATE INDEX idx_products_core_sku ON products_core_table(sku);
Crea incorporamenti delle immagini per consentire all'agente AI di recuperare prodotti simili
L'integrazione dell'agente AI utilizza le rappresentazioni distribuite delle immagini per recuperare prodotti simili. Gli embedding vengono generati utilizzando il modello multimodalembedding@001 e archiviati nel database AlloyDB. Gli incorporamenti sono vettori a 1408 dimensioni e vengono archiviati nella colonna img_embeddings.
Prima di poter generare incorporamenti, dobbiamo concedere i ruoli richiesti al service account AlloyDB per accedere a Cloud Storage.
Concedi ruoli al service account AlloyDB per accedere a Cloud Storage
Concediamo i ruoli Storage Object User e Storage Object Viewer al service account AlloyDB per consentirgli di leggere gli oggetti dal bucket Cloud Storage.
- Vai a IAM e amministrazione.
- Fai clic su Concedi l'accesso.
- Nel campo Nuove entità, inserisci la ricerca dell'account di servizio AlloyDB. Il service account è simile a
service-991742412753@gcp-sa-alloydb.iam.gserviceaccount.com. - Fai clic su Seleziona un ruolo.
- Trova e seleziona il ruolo Storage Object User.
- Fai clic su Aggiungi un altro ruolo e seleziona il ruolo Visualizzatore oggetti Storage.
- Fai clic su Aggiungi un altro ruolo e seleziona il ruolo Utente Vertex AI.
- Fai clic su Salva.
Attivare le estensioni
Per creare questa app, utilizzeremo le estensioni pgvector e google_ml_integration. L'estensione pgvector ti consente di archiviare e cercare vector embedding. L'estensione google_ml_integration fornisce funzioni che utilizzi per accedere agli endpoint di previsione Vertex AI per ottenere previsioni in SQL. Abilita queste estensioni eseguendo i seguenti DDL:
- Nella console Google Cloud, vai ad AlloyDB per PostgreSQL.
- Fai clic su AlloyDB Studio nel menu di navigazione a sinistra.
- Nella visualizzazione dell'editor, apri una nuova scheda della query senza titolo.
- Copia il seguente DDL e fai clic su Esegui:
CREATE EXTENSION IF NOT EXISTS vector; CREATE EXTENSION IF NOT EXISTS google_ml_integration;
Inizializzare il database con gli incorporamenti
- Aggiungi la colonna img_embeddings a
products_core_table.ALTER TABLE products_core_table ADD COLUMN img_embeddings vector(1408); - Genera gli incorporamenti per le immagini e archiviali nella colonna
img_embeddings.UPDATE products_core_table SET img_embeddings = google_ml.image_embedding( model_id => 'multimodalembedding@001', image => 'gs://<STORAGE_BUCKET_NAME>/' || sku || '.jpg', mimetype => 'image/jpeg') WHERE sku IN ( SELECT sku FROM products_core_table WHERE img_embeddings IS NULL AND sku IS NOT NULL LIMIT 10 ); - Ripeti la query precedente almeno 5 volte per generare incorporamenti di immagini per l'intero set, poiché Studio ha un limite di 5 minuti. Se questa query scade, modifica
LIMITin5ed esegui di nuovo la query dieci volte. Il completamento di questo passaggio potrebbe richiedere un paio di minuti.
5. Configurare MongoDB Atlas su Google Cloud
MongoDB archivia dettagli dei prodotti semistrutturati e dati flessibili sul comportamento degli utenti (come clic e visualizzazioni).\
Crea il cluster MongoDB
- Vai a MongoDB Atlas su Google Cloud e seleziona un account di livello senza costi.
- Seleziona il livello del cluster Senza costi e inserisci un nome per il cluster, ad esempio
ecommerce-cluster. - Seleziona Google Cloud come provider e assicurati che la regione sia allineata alla tua regione Google Cloud (ad es.
us-central1). - Fai clic su Crea deployment.
- Fai clic su Chiudi.
Configurare l'accesso alla rete
- Nella console Atlas, vai ad Accesso al database e alla rete.
- Fai clic su Elenco di accesso IP.
- Fai clic su Aggiungi indirizzo IP.
- Aggiungi
0.0.0.0/0, che consente l'accesso da qualsiasi luogo. - Fai clic su Conferma.
Crea un utente del database
- Nella console Atlas, vai ad Accesso al database e alla rete.
- Fai clic su Utenti del database.
- Fai clic su Aggiungi nuovo utente del database.
- Seleziona Password come metodo di autenticazione.
- Inserisci il nome utente
store-usere la passwordstoreuser. - Fai clic su Aggiungi ruolo integrato e seleziona Lettura e scrittura in qualsiasi database.
- Fai clic su Aggiungi utente.
Recuperare la stringa di connessione
- Vai a Database > Cluster > Connetti.
- In Connetti la tua applicazione, fai clic su Driver.
- Copia la stringa di connessione mostrata in Aggiungi la stringa di connessione al codice dell'applicazione. La stringa è simile alla seguente:
mongodb+srv://store-user:<db_password>@ecommerce-cluster.g8vaekh.mongodb.net/?appName=ecommerce-clusterdb_passwordcon la password di MongoDB. In questo codelab, èstoreuser.
Salva questa stringa di connessione. Lo utilizzerai in un secondo momento per la variabile di ambiente MONGODB_CONNECTION_STRING.
Crea database e raccolta
- Nella console Atlas, vai a Database > Clusters > Browse Collections.
- Fai clic su Crea database e inserisci i dettagli:
- Nome database:
ecommerce_db - Nome raccolta:
product_details_collection
- Nome database:
- Fai clic su Crea database.
- In Esplora dati, seleziona il nome della raccolta.
- Fai clic sull'icona Aggiungi dati (+), quindi su Inserisci documento.
- Copia i contenuti JSON da product_details_export.json e incollali nella finestra di dialogo dell'editor Inserisci documento.
- Fai clic su Inserisci per inserire l'array di documenti e verifica che siano stati aggiunti 192 documenti.
- In Data Explorer, fai clic su Crea raccolta (+) accanto al database
ecommerce_db. - Inserisci
user_interactions_collectioncome nome della raccolta e fai clic su Crea raccolta. - In Esplora dati, seleziona la raccolta
user_interactions_collection. - Fai clic sull'icona Aggiungi dati (+), quindi su Inserisci documento.
- Copia i contenuti JSON da user_interactions_export.json e incollali nella finestra di dialogo dell'editor Inserisci documento.
- Fai clic su Inserisci documento.
6. Configurare BigQuery
BigQuery aggrega e analizza il comportamento storico degli utenti per generare report e consigli intelligenti.
Crea il set di dati
- Nella console Google Cloud, vai a BigQuery.
- Accanto all'ID progetto nel riquadro Explorer, fai clic sul menu con tre puntini e seleziona Crea set di dati.
- Inserisci
ecommerce_analyticsper l'ID set di dati. - Fai clic su Crea set di dati.
Crea la tabella Analytics
- Apri una nuova query nello spazio di lavoro BigQuery.
- Esegui la seguente istruzione SQL per creare la tabella riepilogativa che collega gli utenti alle interazioni con i prodotti:
CREATE TABLE ecommerce_analytics.user_product_interactions (
user_id STRING DEFAULT 'any user',
product_id STRING,
interaction_score INT
);
Concedi ruoli al service account Compute per MCP Toolbox
Concediamo ruoli all'account di servizio Compute utilizzato per la nostra casella degli strumenti. Questa operazione viene eseguita per consentire a MCP Toolbox di accedere a BigQuery, Secret Manager e ad altri servizi cloud.
Per concedere i ruoli, completa i seguenti passaggi:
- Vai a IAM e amministrazione.
- Fai clic su Concedi l'accesso.
- Nel campo Nuove entità, inserisci il service account Compute predefinito denominato
YOUR_PROJECT_NUMBER-compute@developer.gserviceaccount.com. SostituisciYOUR_PROJECT_NUMBERcon il numero del tuo progetto Google Cloud. - Fai clic su Seleziona un ruolo.
- Trova e seleziona il ruolo Editor dati BigQuery.
- Fai clic su Aggiungi un altro ruolo e seleziona il ruolo Utente job BigQuery.
- Fai clic su Aggiungi un altro ruolo e seleziona il ruolo Secret Manager Secret Accessor.
- Fai clic su Aggiungi un altro ruolo e seleziona il ruolo Editor.
- Fai clic su Salva.
7. Comprendere l'applicazione end-to-end
Per scoprire come interagiscono i componenti, creeremo una semplice applicazione di e-commerce che utilizza più database e servizi. L'applicazione è creata con un backend Python (Flask) e integra più servizi e database Google Cloud.
Comprendere la struttura delle directory
Nella sezione successiva clonerai il repository BRK2-149-multidb-ecommerce e lo utilizzerai per eseguire l'applicazione in locale. Dopo aver testato l'applicazione localmente, eseguiremo il deployment di MCP Toolbox e dell'applicazione su Cloud Run.
Esplora i file scaricati in questa directory. Sono presenti le seguenti directory di primo livello:
UploadImages: memorizza gli asset immagine, utilizzati principalmente per la documentazione o i contenuti visivi per il catalogo dei prodotti di e-commerce.static: memorizza gli asset web statici dell'applicazione, come i file CSS e JavaScript, utilizzati per definire lo stile e aggiungere interattività all'interfaccia utente ( origine).templates: memorizza i modelli HTML (probabilmente Jinja2 per Flask) utilizzati dall'applicazione Python per eseguire il rendering dinamico delle pagine web per il catalogo e-commerce ( origine).toolbox-implementation: memorizza i dettagli di configurazione e implementazione di Model Context Protocol (MCP) Toolbox, facilitando le interazioni con database multidb utilizzando strumenti predefiniti.
I file in questo repository funzionano insieme per creare, configurare e implementare un'applicazione di e-commerce multidatabase. I file centrali come app.py orchestrano il backend integrando diverse origini dati definite in file SQL e JSON, mentre i file di configurazione garantiscono un deployment senza problemi negli ambienti cloud:
app.py: coordina il backend Flask e le integrazioni di più database.agentengine.py: logica di base per l'inizializzazione e la configurazione degli agenti Vertex AI..env: archivia i secret per le connessioni a database e spazio di archiviazione.tools.yaml: configura MCP Toolbox per le operazioni di database multidb.Dockerfile: definisce l'immagine container e la configurazione dell'ambiente.requirements.txt: elenca le librerie Python necessarie per il runtime dell'applicazione.tools.yaml: configurazioni per MCP Toolbox.Procfile: specifica i comandi di esecuzione della produzione per il deployment.alloydb_insert_queries.sql: contiene query SQL per i dati relazionali.product_details_export.jsoneuser_interactions_export.json: fornisce dati JSON di esempio per il database NoSQL.README.md: guide alla configurazione, all'implementazione e alla comprensione del progetto.
Flusso end-to-end dell'applicazione
- Configurazione di AlloyDB: esegui il provisioning di un cluster ad alte prestazioni e utilizza gli script SQL forniti per creare la tabella products_core_table con colonne vettoriali per gli incorporamenti di immagini.
- Configurazione di MongoDB Atlas: esegui il deployment di un cluster su Google Cloud per archiviare gli attributi dei prodotti fluidi in product_details e registra i clickstream in tempo reale in user_interactions.
- BigQuery Analytics: crea un set di dati per aggregare i log delle interazioni, consentendo query analitiche complesse che identificano i primi 5 elementi di tendenza in milioni di eventi.
- Repository Cloud Storage: crea un bucket pubblico per ospitare le immagini dei prodotti ad alta risoluzione, assicurandoti che ogni asset sia accessibile tramite un URL firmato o pubblico per il frontend.
- Deployment di MCP Toolbox: esegui il deployment di Toolbox su Cloud Run, stabilendolo come bridge RESTful centrale che traduce l'intento in linguaggio naturale in query multi-database.
- Configurazione di Tools.yaml: definisci i tuoi "strumenti", ad esempio get_product_core_data o get_top_5_views, mappando operazioni SQL e NoSQL specifiche a nomi semplici e leggibili dall'agente.
- Logica di backend Flask: implementa le route app.py che interagiscono con MCP Toolbox, gestendo il coordinamento del recupero dei dati e fungendo da API per la UI.
- Orchestrazione multi-agente: configura gli agenti ADK all'interno del codice per ragionare sull'intent dell'utente, selezionando lo "strumento" giusto per risolvere query complesse e multiorigine per la vendita al dettaglio.
- Integrazione frontend: crea un'interfaccia index.html con il catalogo dei prodotti con funzionalità di registrazione delle interazioni, una scheda Analytics per comprendere l'analisi del rendimento dei prodotti e una "scheda Agente" dedicata che utilizza la chat multi-agente ADK per offrire un'esperienza di shopping conversazionale senza interruzioni.
Ora implementiamo l'orchestrazione e i deployment.
8. Configura MCP Toolbox ed esegui il deployment in Cloud Run
MCP Toolbox astrae le nostre molteplici origini dati, consentendo alla nostra applicazione di recuperare e scrivere i dati in modo uniforme.
Installa MCP Toolbox in locale
- In Cloud Shell, vai alla cartella
toolbox-implementation:cd next-26-sessions/BRK2-149-multidb-ecommerce/toolbox-implementation - Scarica il file binario di MCP Toolbox e rendilo eseguibile:
export VERSION=0.29.0 curl -L -o toolbox https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox chmod +x toolbox
Configura tools.yaml
Devi definire le astrazioni per AlloyDB, MongoDB e BigQuery. Il file tools.yaml indica alla toolbox MCP come interagire tra loro.
- Crea e modifica il file
tools.yamlutilizzando l'editor incorporato:cloudshell edit tools.yamltools.yamlcompleto è disponibile nel repository GitHub. Copiane i contenuti nel nuovo filetools.yaml. - Aggiorna l'host, l'utente, le password, gli ID progetto e le stringhe di connessione in modo che corrispondano all'infrastruttura di cui hai eseguito il provisioning nei passaggi precedenti:
Database
Campo
Valore di esempio
AlloyDB/BigQuery
project_idYOUR_PROJECT_IDAlloyDB
regionus-central1AlloyDB
clusterecommerce-clusterAlloyDB
instanceecommerce-cluster-primaryAlloyDB
databasepostgresAlloyDB
passwordalloydbMongoDB
connection_stringmongodb+srv://store-user:storeuser@ecommerce-cluster.urcxr6q.mongodb.net
Concedi ruoli al service account Compute per MCP Toolbox
Concediamo ruoli all'account di servizio Compute utilizzato per la nostra casella degli strumenti. Questa operazione viene eseguita per consentire a MCP Toolbox di accedere ad AlloyDB.
- Vai a IAM e amministrazione.
- Fai clic su Concedi l'accesso.
- Nel campo Nuove entità, inserisci il service account Compute predefinito denominato
YOUR_PROJECT_NUMBER-compute@developer.gserviceaccount.com. SostituisciYOUR_PROJECT_NUMBERcon il numero del tuo progetto Google Cloud. - Fai clic su Seleziona un ruolo.
- Trova e seleziona il ruolo Editor dati BigQuery.
- Fai clic su Aggiungi un altro ruolo e seleziona il ruolo Client AlloyDB.
- Fai clic su Aggiungi un altro ruolo e seleziona il ruolo Service Usage Consumer.
- Fai clic su Aggiungi un altro ruolo e seleziona il ruolo Visualizzatore oggetti Storage.
- Fai clic su Salva.
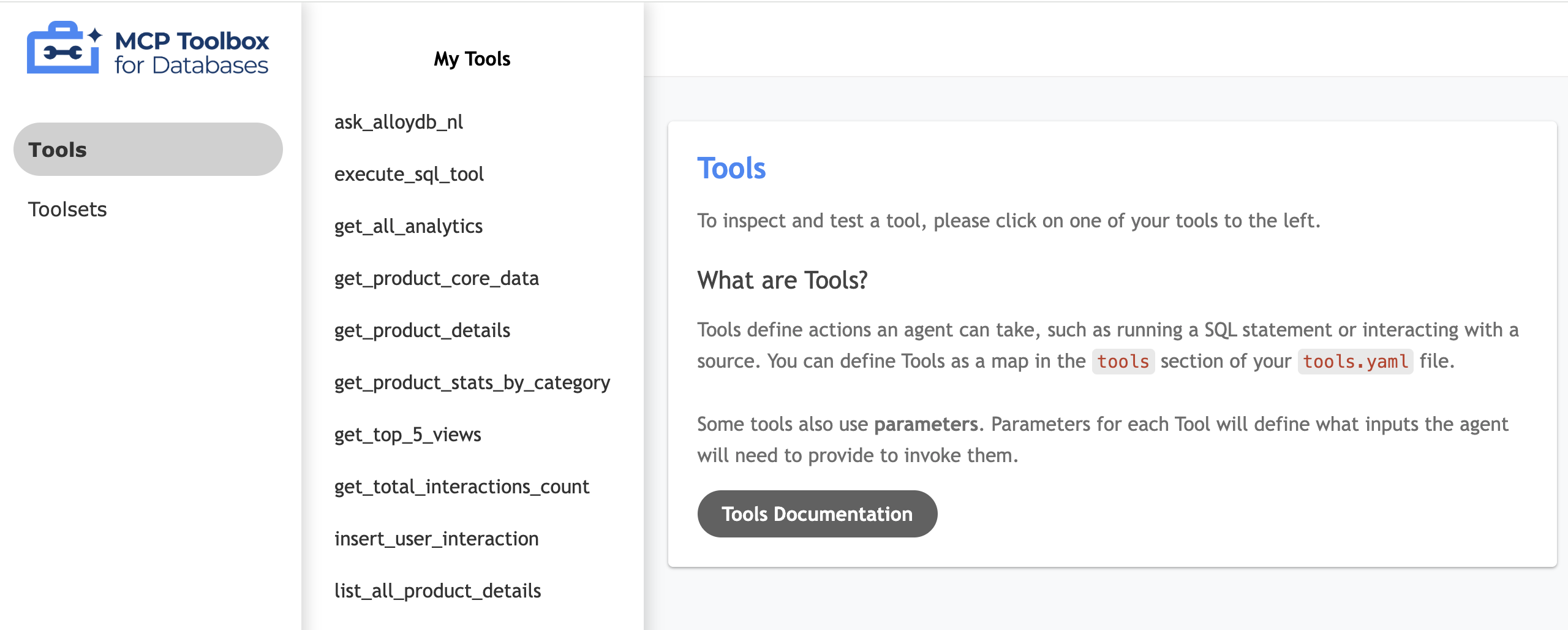
Testare la UI dello strumento
- Nel terminale Cloud Shell, esegui localmente la casella degli strumenti per pubblicare la UI:
./toolbox --ui - Apri l'anteprima web in Cloud Shell sulla porta 5000 e vai alla pagina degli strumenti. Ad esempio, a seconda dell'URL della sessione, puoi visualizzarlo all'indirizzo:
https://5000-cs-71152278760-default.cs-asia-southeast1-cash.cloudshell.dev/ui
Viene visualizzata la seguente UI di MCP Toolbox:
Esegui il deployment in Cloud Run
Esegui il deployment di MCP Toolbox su Cloud Run per renderlo disponibile come servizio gestito e sicuro che la nostra applicazione può utilizzare per eseguire query sui database. Memorizzeremo la configurazione in Secret Manager per proteggere i dettagli di connessione sensibili.
- Apri una nuova sessione di Cloud Shell.
- Vai alla cartella
toolbox-implementation:cd next-26-sessions/BRK2-149-multidb-ecommerce/toolbox-implementation - Carica la configurazione
tools.yamlin Google Secret Manager:gcloud secrets create tools --data-file=tools.yamlgcloud secrets versions add tools --data-file=tools.yaml - Esegui il deployment utilizzando l'immagine container pubblica di MCP Toolbox:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:0.29.0 export PROJECT_ID=$(gcloud config get-value project) gcloud run deploy toolbox \ --image $IMAGE \ --region us-central1 \ --service-account $(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")-compute@developer.gserviceaccount.com \ --set-secrets "/app/tools.yaml=tools:latest" \ --args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080","--ui" \ --allow-unauthenticated - Una volta eseguito il deployment, annota l'URL del servizio Cloud Run fornito. Dovrebbe avere un aspetto simile a questo:
https://toolbox-*********-uc.a.run.app/ui.
9. Configura l'applicazione di e-commerce ed esegui il deployment in Cloud Run
Con i nostri database in esecuzione e l'astrazione di MCP Toolbox implementata, possiamo eseguire l'applicazione web Flask.
Per pubblicare il catalogo prodotti, l'applicazione Flask elabora i dati svolgendo i seguenti passaggi:
- Recupera dati principali: recupera l'elenco completo dei prodotti da AlloyDB (
list_products_core). - Recupera dettagli estesi: recupera tutti i dettagli del prodotto da MongoDB (
list_all_product_details). - Combina elenchi: concatena i due elenchi.
- Arricchisci con contenuti multimediali: aggiunge l'URL dell'immagine di Cloud Storage a ogni elemento.
Genera il percorso dell'applicazione del motore di ragionamento
Per inizializzare e registrare un agente AI utilizzando Vertex AI Reasoning Engine di Google Cloud, esegui questo comando:
- Nel terminale Cloud Shell, vai alla cartella
BRK2-149-multidb-ecommerce.cd next-26-sessions/BRK2-149-multidb-ecommerce - Esegui requirements.txt per installare le dipendenze
pip install -r requirements.txt - Esegui lo script
agentengine.pyper generare il percorso dell'applicazione del motore di ragionamento:python agentengine.py
L'output sarà simile al seguente:
projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856
Configura le variabili di ambiente
- Crea un file
.enve modificalo:cloudshell edit .env - Sostituisci i valori con le connessioni al database specifiche e il nuovo URL di Cloud Run Toolbox:
# 1. MongoDB Connection String MONGODB_CONNECTION_STRING="mongodb+srv://<db_user>:<db_password>@cluster0.mongodb.net" # 2. MCP Toolbox Server Location # Must match the address where you run the toolbox server MCP_TOOLBOX_SERVER_URL="https://toolbox-*********-uc.a.run.app" # 3. Google Cloud Storage Bucket Name GCS_PRODUCT_BUCKET="ecommerce-app-images" # 4. Fallback image URL FALLBACK_IMAGE_URL="https://storage.googleapis.com/ecommerce-media-bold-circuit-492711-n9/fallback.jpg" # 5. Google Gen AI Vertex AI flag GOOGLE_GENAI_USE_VERTEXAI=TRUE # 6. Project ID PROJECT_ID=codelab-project-491117 # 7. Google Cloud Location of AlloyDB, BigQuery databases GOOGLE_CLOUD_LOCATION=us-central1 # 8. Reasoning engine application path APP_NAME=projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856 # 9. Model ID MODEL=gemini-1.5-flash-lite
Esegui il deployment del frontend in Cloud Run
- Esegui il deployment dell'applicazione web in Cloud Run per completare l'architettura:
gcloud run deploy polyglot --source . --platform managed \ --region us-central1 \ --allow-unauthenticated \ --set-env-vars \ MONGODB_CONNECTION_STRING="<MONGODB_CONNECTION_STRING>", \ MCP_TOOLBOX_SERVER_URL="<MCP_TOOLBOX_SERVER_URL>", \ GCS_PRODUCT_BUCKET="<GCS_PRODUCT_BUCKET>", \ FALLBACK_IMAGE_URL="<FALLBACK_IMAGE_URL>", \ GOOGLE_GENAI_USE_VERTEXAI=TRUE, \ PROJECT_ID="YOUR_PROJECT_ID", \ GOOGLE_CLOUD_LOCATION=us-central1, \ APP_NAME="<YOUR_REASONING_ENGINE_APP_PATH>", \ MODEL="gemini-1.5-flash-lite"YOUR_PROJECT_ID: l'ID progetto del tuo progetto Google Cloud.YOUR_REASONING_ENGINE_APP_PATH: l'output dell'esecuzione dipython agentengine.py, ad esempioprojects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856.MCP_TOOLBOX_SERVER_URL: l'URL del server MCP Toolbox, ad esempiohttps://toolbox-*********-uc.a.run.app.GCS_PRODUCT_BUCKET: il nome del bucket Google Cloud Storage, ad esempioecommerce-app-images.MONGODB_CONNECTION_STRING: la stringa di connessione per il database MongoDB, ad esempiomongodb+srv://store-user:storeuser@ecommerce-cluster.g8vaekh.mongodb.netFALLBACK_IMAGE_URL: l'URL dell'immagine di riserva, ad esempiohttps://storage.googleapis.com/ecommerce-app-images/fallback.jpg
La tua applicazione è ora disponibile. Apri l'URL del servizio fornito da Cloud Run per visualizzare il catalogo di e-commerce Multidb. L'URL sarà simile a https://polyglot-*********-uc.a.run.app/.
10. Esplora l'applicazione
- Fai clic su Catalogo prodotti per visualizzare tutti i prodotti.
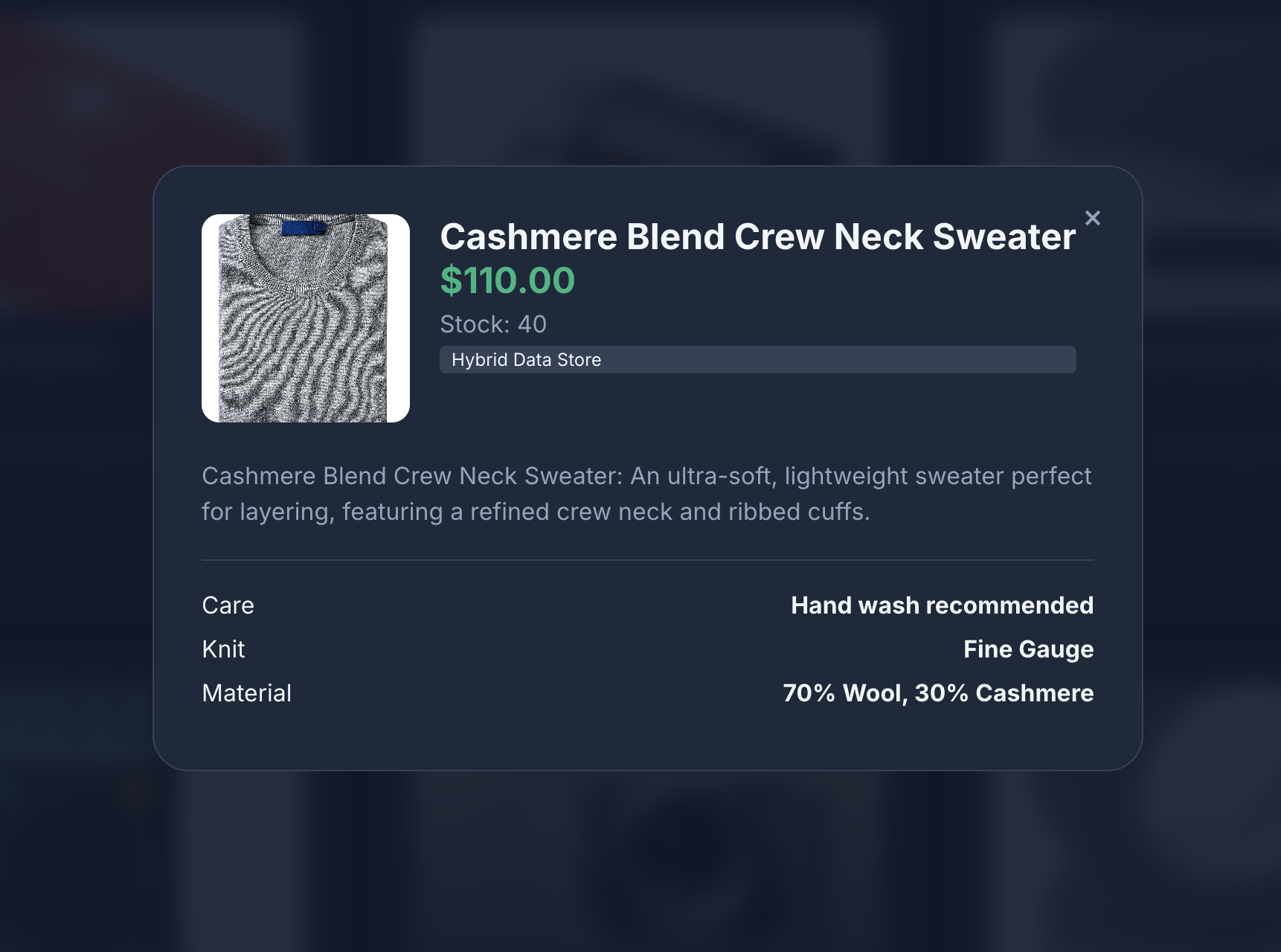
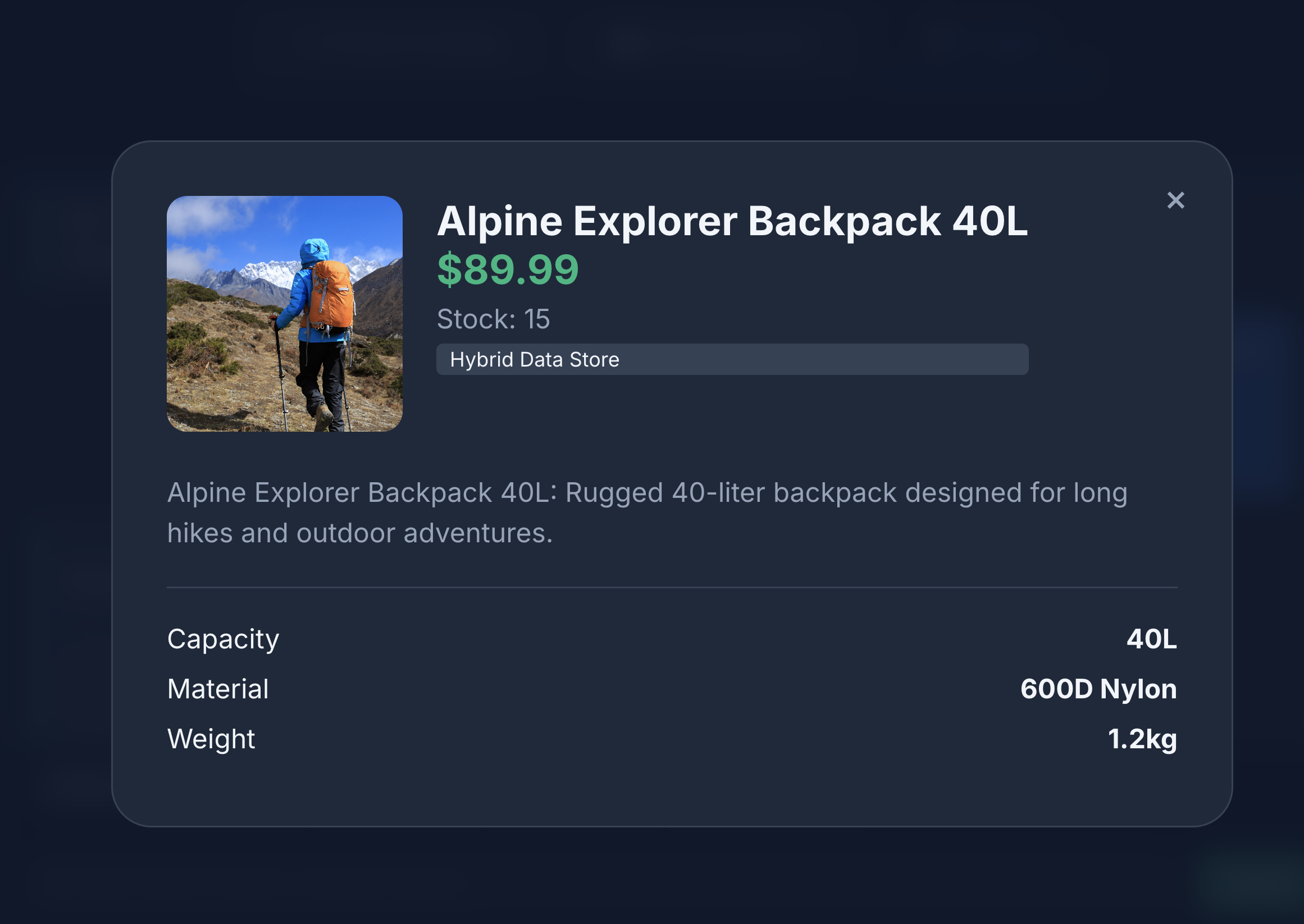
- Fai clic sull'icona di un prodotto per visualizzarne i dettagli. Noterai che le immagini provengono da Cloud Storage, i dettagli del prodotto vengono recuperati da MongoDB e l'inventario dei prodotti viene recuperato da AlloyDB.
- Interagisci con il catalogo dei prodotti per generare visualizzazioni e scritture simulate inviate a MongoDB.
- Fai clic su ETL e analisi per visualizzare le analisi del prodotto. Noterai che l'analisi del prodotto viene recuperata da BigQuery.
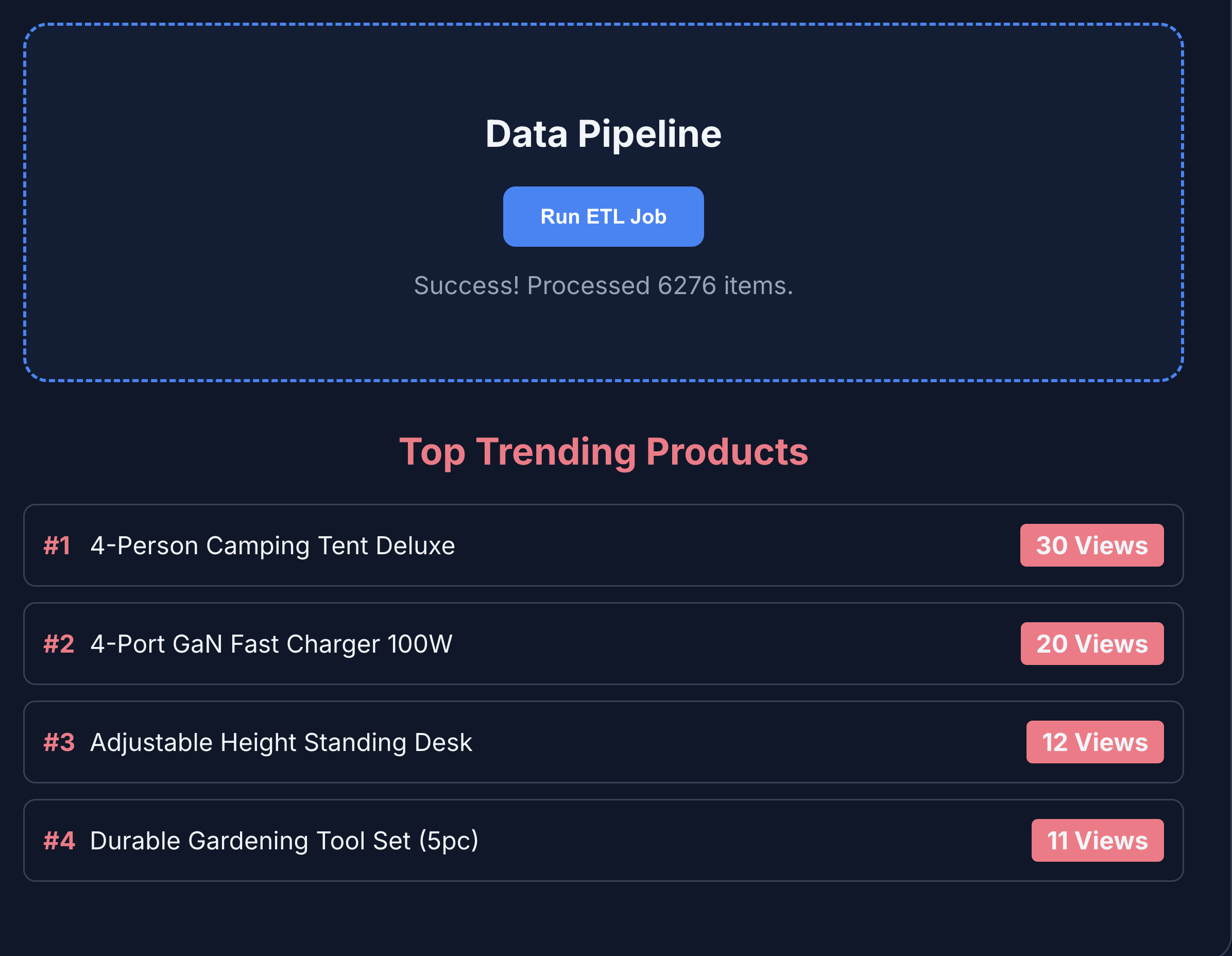
- Fai clic sulla scheda Agente AI per interagire con l'agente AI. Poni domande in linguaggio naturale come le seguenti:
I'm planning a high-altitude photography trip. Show me some weather-resistant backpacks similar in style to aero glow pro but without any leather components. Also, let me know if they are actually in stock and if other photographers have complained about the strap durability in the reviews.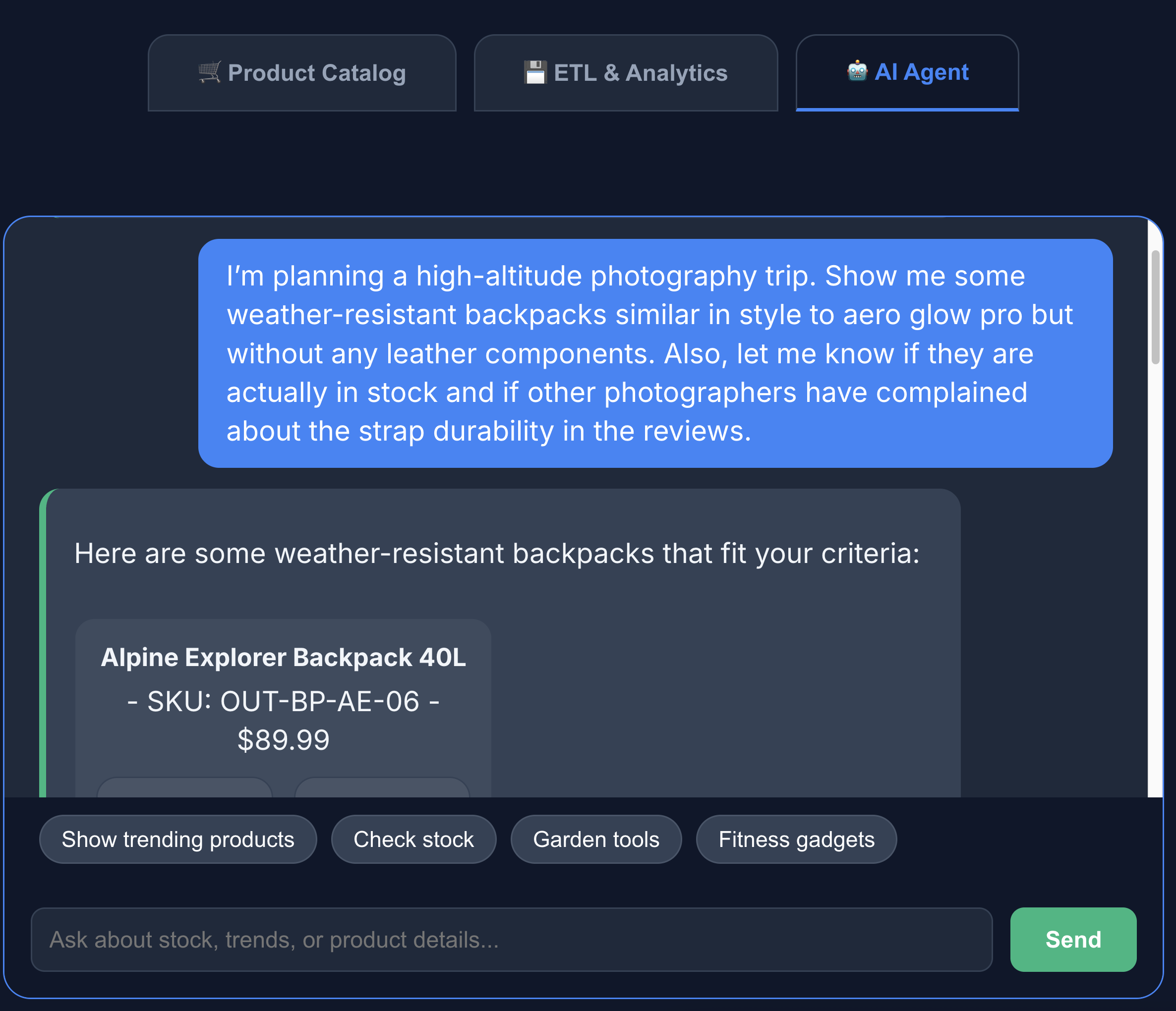
Puoi vedere che la ricerca restituisce esattamente ciò che abbiamo chiesto: uno zaino senza componenti in pelle, disponibile e senza reclami sulla durata degli spallacci nelle recensioni.
11. Esegui la pulizia
Per evitare addebiti continui al tuo account Google Cloud, elimina le risorse create durante questo codelab.
Esegui questi comandi di Cloud Shell:
gcloud run services delete toolbox --region us-central1 --quiet
gcloud run services delete multi-db-app --region us-central1 --quiet
bq rm -r -f -d $PROJECT_ID:ecommerce_analytics
gcloud storage rm --recursive gs://ecommerce-app-images
gcloud alloydb clusters delete ecommerce-cluster --region us-central1 --force --quiet
(Facoltativo) Per eliminare l'intero progetto Google Cloud e tutte le relative risorse, esegui questo comando:
gcloud projects delete $PROJECT_ID
12. Complimenti
Complimenti! Hai creato un'architettura Multidb cross-cloud.
Hai dimostrato come MCP Toolbox funge da collante architetturale per un'applicazione moderna e specializzata. Abbinando il database giusto al lavoro giusto, hai ottenuto:
- Scritture flessibili di dati: MongoDB per i log eventi.
- Coerenza transazionale: AlloyDB per l'integrità del core.
- Analisi ad alto rendimento: BigQuery per la business intelligence.
- Sviluppo unificato: un unico backend Python che astrae tutta la complessità utilizzando MCP Toolbox.
Documenti di riferimento
Scopri di più sui prodotti Google Cloud correlati ed esplora questi codelab:
- AlloyDB AI: Iniziare a utilizzare il vector embedding con l'AI di AlloyDB
- AlloyDB AI: embedding multimodali in AlloyDB
- MCP Toolbox: installazione e configurazione di MCP Toolbox for Databases su AlloyDB
Per ulteriori informazioni sui prodotti utilizzati in questo codelab, consulta: