
1. Wprowadzenie
W nowoczesnym handlu detalicznym dane stanowią zróżnicowany, rozległy ekosystem. Masz solidne dane transakcyjne (ceny i asortyment), „nieuporządkowane” katalogi polimorficzne (specyfikacje elektroniki a rozmiary odzieży) i petabajty dzienników zachowań. Wymuszanie połączenia tych elementów w jeden monolit nie tylko generuje dług techniczny, ale też pogarsza wygodę użytkowników.
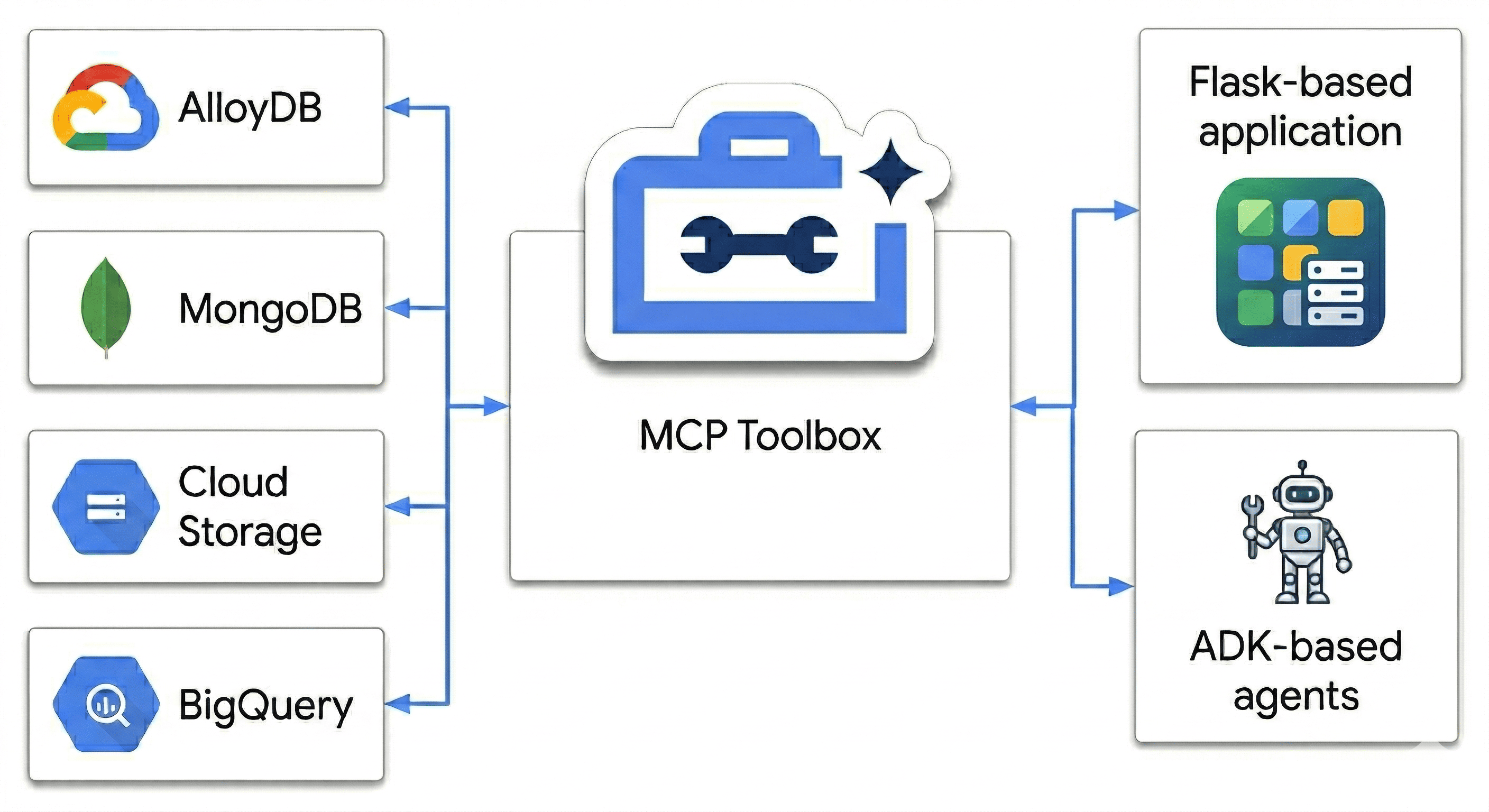
W tym ćwiczeniu zaprojektujesz wielojęzyczną platformę, która będzie harmonizować:
- AlloyDB baza danych transakcyjnych zapewniająca szybką spójność i osadzanie obrazów.
- MongoDB Atlas w Google Cloud: elastyczna warstwa katalogu niezależna od schematu.
- Cloud Storage: Twój analityczny umysł do prognozowania trendów w czasie rzeczywistym.
- BigQuery: hurtownia cyfrowa o wysokiej rozdzielczości.
„Tajemniczy składnik”? Użyjesz MCP Toolbox for Databases, aby inteligentnie aranżować i ujednolicać źródła danych działające w Cloud Run jako pomost semantyczny, a następnie wdrożyć aplikację do czatu z wieloma agentami przy użyciu pakietu Agent Development Kit (ADK). Nie tworzysz tylko paska wyszukiwania, ale inteligentny system, który rozumie kontekst, uwzględnia ograniczenia i łączy surowe dane z intencjami użytkowników.
Niemożliwe zapytanie użytkownika
Standardowe agenty e-commerce nie radzą sobie z wielowymiarowym rozumowaniem (łączeniem ograniczeń negatywnych, podobieństwa wizualnego i stanu magazynowego w czasie rzeczywistym). Na przykład zwykle chcę rozmawiać z witryną sklepu w ten sposób:
„Hej, planuję wyjazd, żeby robić zdjęcia na dużej wysokości. Pokaż mi plecaki odporne na warunki atmosferyczne, podobne stylem do „AeroGlow Pro”, ale bez elementów skórzanych. Daj mi też znać, czy są one dostępne w magazynie i czy inni fotografowie w swoich opiniach narzekali na trwałość paska”.
Dlaczego to zapytanie jest „zabójcą agentów”:
- Podobieństwo wizualne (AlloyDB + wyszukiwanie wektorowe): „Podobny stylem do AeroGlow Pro” wymaga porównania osadzania obrazów.
- Ograniczenie negatywne (MongoDB): „Bez skóry” wymaga filtrowania elastycznych, zagnieżdżonych atrybutów, które zwykle nie występują w standardowej wersji SQL.
- Asortyment w czasie rzeczywistym (AlloyDB): „Rzeczywiście w magazynie” wymaga sprawdzenia transakcji na żywo (nie nieaktualnego indeksu wyszukiwania).
- Synteza semantyczna (BigQuery + wielu agentów): analiza opinii dotyczących „trwałości paska” wymaga od agenta podsumowania na bieżąco nieustrukturyzowanych opinii z BigQuery.
Większość botów w sklepach zobaczy tylko „Plecak” i „Skóra” i wyświetli 10 plecaków skórzanych. Jak temu zapobiegamy?
Nie dopasowujemy tylko słów kluczowych. Używamy MCP Toolbox, aby umożliwić naszym agentom „rozumowanie” na podstawie wszystkich tych źródeł – prawdy transakcyjnej w AlloyDB i elastycznych atrybutów w MongoDB – jednocześnie. Zbudujmy go.
Jakie zadania wykonasz
- Aprowizuj klaster AlloyDB na potrzeby podstawowych danych o produktach.
- Skonfiguruj MongoDB Atlas w Google Cloud, aby przechowywać słabo ustrukturyzowane szczegóły produktu.
- Utwórz zasobnik Cloud Storage, w którym będą przechowywane obrazy produktów.
- Wdrażanie MCP Toolbox for Databases w Cloud Run w celu zapewnienia jednolitego dostępu do danych
- Uruchamiaj procesy ETL, aby przesyłać dane do BigQuery na potrzeby analizy.
- Rozmawiaj z agentem AI w języku naturalnym.
Wymagania wstępne
- przeglądarka, np. Chrome;
- projekt Google Cloud z włączonymi płatnościami;
- bezpłatne konto MongoDB Atlas w Google Cloud;
2. Zanim zaczniesz
Tworzenie projektu Google Cloud
- W konsoli Google Cloud na stronie wyboru projektu wybierz lub utwórz projekt w chmurze Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności.
Uruchamianie Cloud Shell
Cloud Shell to środowisko wiersza poleceń działające w Google Cloud, które zawiera niezbędne narzędzia.
- U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.
- Po połączeniu z Cloud Shell sprawdź uwierzytelnianie:
gcloud auth list - Sprawdź, czy projekt jest skonfigurowany:
gcloud config get project - Jeśli projekt nie jest ustawiony zgodnie z oczekiwaniami, ustaw go:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Włącz wymagane interfejsy API
Aby włączyć wszystkie wymagane interfejsy API, uruchom to polecenie:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
3. Konfigurowanie Cloud Storage
Cloud Storage to ogromny magazyn nieuporządkowanych zasobów multimedialnych, takich jak zdjęcia produktów.
- W konsoli Google Cloud otwórz Cloud Storage i kliknij Utwórz zasobnik.
- Nadaj zasobnikowi globalnie niepowtarzalną nazwę (np.
ecommerce-app-images). - Kliknij Utwórz.
- Aby umożliwić aplikacji demonstracyjnej dostęp do obrazów bez uwierzytelniania, odznacz opcję Wyegzekwuj blokadę dostępu publicznego do tego zasobnika i kliknij Potwierdź.
- Otwórz kartę Uprawnienia.
- W sekcji Uprawnienia kliknij Przyznaj dostęp.
- W polu Nowe podmioty zabezpieczeń wpisz
allUsers. - W sekcji Wybierz rolę kliknij Cloud Storage > Użytkownik obiektów w Cloud Storage.
- Kliknij Zapisz, a następnie Zezwól na dostęp publiczny, aby potwierdzić, że udostępniasz zasób publicznie.
Przesyłanie obrazów zastępczych
W BRK2-149-multidb-ecommerce używane są obrazy zastępcze, aby zapewnić jak najlepsze wrażenia wizualne.
- W Cloud Shell sklonuj repozytorium
next-26-sessions:git clone https://github.com/GoogleCloudPlatform/next-26-sessions.git - Przejdź do folderu
UploadImages:cd next-26-sessions/BRK2-149-multidb-ecommerce/UploadImages - W konsoli Google Cloud otwórz Cloud Storage i kliknij Zasobniki.
- Kliknij nazwę nowo utworzonego zasobnika.
- Kliknij Prześlij > Prześlij pliki, wybierz pobrane przykładowe obrazy i kliknij Otwórz.
4. Konfigurowanie AlloyDB
AlloyDB jest jedynym źródłem informacji o danych strukturalnych, transakcyjnych i krytycznych, takich jak identyfikatory produktów, nazwy, kody SKU, ceny i stan magazynowy. AlloyDB obsługuje też agenta AI, udostępniając mu funkcje wyszukiwania podobieństw na potrzeby rekomendacji i zapytań w języku naturalnym.
Udostępnianie klastra AlloyDB
- W konsoli Google Cloud otwórz AlloyDB for PostgreSQL.
- Kliknij Utwórz klaster.
- W polu Identyfikator klastra wpisz
ecommerce-cluster. - Ustaw silne hasło użytkownika
postgres. W celach szkoleniowych możesz użyć nazwyalloydb. - W polu Wersja bazy danych zachowaj wartość domyślną.
- W polu Region wybierz
us-central1(lub preferowany region).
Konfigurowanie instancji głównej
- W polu Identyfikator instancji wpisz
ecommerce-cluster-primary. - W sekcji Dostępność strefowa wybierz Jedna strefa.
- W sekcji Typ maszyny wybierz mały typ maszyny (np. N2, 4 procesory wirtualne, 32 GB pamięci RAM).
- W sekcji Prywatne środowisko IP wybierz Prywatny dostęp do usług (PSA) i wybierz sieć
default.Jeśli sieć domyślna nie jest jeszcze skonfigurowana, kliknij Potwierdź konfigurację sieci, aby ją utworzyć. - W sekcji Połączenia przy użyciu publicznego adresu IP zaznacz pole wyboru Włącz publiczny adres IP, aby skrzynka narzędziowa MCP mogła się prawidłowo połączyć w tym module.
- W polu Autoryzowane sieci zewnętrzne wpisz
0.0.0.0/0. Zaznacz pole wyboru I acknowledge the risks (Potwierdzam, że znam ryzyko) i kliknij Save (Zapisz). - Kliknij Utwórz klaster.
Uwaga: zanotuj swój publiczny adres IP (wygląda on podobnie do 34.124.240.26).
Inicjowanie bazy danych
- W menu nawigacyjnym po lewej stronie kliknij AlloyDB Studio.
- W menu Baza danych kliknij
postgres. - Aby zalogować się w bazie danych, wybierz Wbudowane uwierzytelnianie.
- W polu Nazwa użytkownika wpisz nazwę użytkownika
postgres. - W polu Hasło wpisz hasło ustawione wcześniej.
- Kliknij Uwierzytelnij.
- W widoku edytora otwórz nową kartę zapytania bez nazwy.
- Skopiuj ten kod DDL i kliknij Uruchom:
CREATE TABLE products_core_table ( product_id UUID PRIMARY KEY, name VARCHAR(255) NOT NULL, sku VARCHAR(50) UNIQUE NOT NULL, price NUMERIC(10, 2) NOT NULL, stock INT NOT NULL ); - W Cloud Shell przejdź do folderu
BRK2-149-multidb-ecommerce:cd next-26-sessions/BRK2-149-multidb-ecommerce - Otwórz plik
alloydb_insert_queries.sqlw Cloud Shell i skopiuj zapytania wstawiające.cat alloydb_insert_queries.sql - Na nowej karcie zapytania bez tytułu wklej tylko instrukcje
INSERTi kliknij Uruchom. - Na nowej karcie zapytania bez tytułu skopiuj ten język DDL i kliknij Uruchom, aby utworzyć indeks w tabeli
products_core_table:CREATE INDEX idx_products_core_sku ON products_core_table(sku);
Tworzenie osadzania obrazów, aby agent AI mógł pobierać podobne produkty
Integracja agenta AI wykorzystuje osadzanie obrazów do pobierania podobnych produktów. Wektory dystrybucyjne są generowane za pomocą modelu multimodalembedding@001 i przechowywane w bazie danych AlloyDB. Wektory dystrybucyjne to wektory 1408-wymiarowe, które są przechowywane w kolumnie img_embeddings.
Zanim będziemy mogli wygenerować wektory, musimy przyznać kontu usługi AlloyDB wymagane role, aby uzyskać dostęp do Cloud Storage.
Przyznawanie ról kontu usługi AlloyDB w celu uzyskania dostępu do Cloud Storage
Przypisujemy do konta usługi AlloyDB role użytkownika obiektów Cloud Storage i wyświetlającego obiekty Cloud Storage, aby umożliwić mu odczytywanie obiektów z zasobnika Cloud Storage.
- Otwórz Uprawnienia i administracja.
- Kliknij Przyznaj dostęp.
- W polu Nowe podmioty zabezpieczeń wpisz konto usługi wyszukiwania AlloyDB. Konto usługi wygląda podobnie do
service-991742412753@gcp-sa-alloydb.iam.gserviceaccount.com. - Kliknij Wybierz rolę.
- Znajdź i wybierz rolę Użytkownik obiektów Cloud Storage.
- Kliknij Dodaj kolejną rolę i wybierz rolę Wyświetlający obiekty Cloud Storage.
- Kliknij Dodaj kolejną rolę i wybierz rolę Użytkownik Vertex AI.
- Kliknij Zapisz.
Włączanie rozszerzeń
Do utworzenia tej aplikacji użyjemy rozszerzeń pgvector i google_ml_integration. Rozszerzenie pgvector umożliwia przechowywanie wektorów dystrybucyjnych i wyszukiwanie ich. Rozszerzenie google_ml_integration udostępnia funkcje, których możesz używać do uzyskiwania dostępu do punktów końcowych prognozowania Vertex AI w celu generowania prognoz w SQL. Włącz te rozszerzenia, uruchamiając te DDL:
- W konsoli Google Cloud otwórz AlloyDB for PostgreSQL.
- W menu nawigacyjnym po lewej stronie kliknij AlloyDB Studio.
- W widoku edytora otwórz nową kartę zapytania bez nazwy.
- Skopiuj ten kod DDL i kliknij Uruchom:
CREATE EXTENSION IF NOT EXISTS vector; CREATE EXTENSION IF NOT EXISTS google_ml_integration;
Inicjowanie bazy danych za pomocą wektorów
- Dodaj kolumnę img_embeddings do
products_core_table.ALTER TABLE products_core_table ADD COLUMN img_embeddings vector(1408); - Wygeneruj wektory dystrybucyjne dla obrazów i zapisz je w kolumnie
img_embeddings.UPDATE products_core_table SET img_embeddings = google_ml.image_embedding( model_id => 'multimodalembedding@001', image => 'gs://<STORAGE_BUCKET_NAME>/' || sku || '.jpg', mimetype => 'image/jpeg') WHERE sku IN ( SELECT sku FROM products_core_table WHERE img_embeddings IS NULL AND sku IS NOT NULL LIMIT 10 ); - Powtórz wcześniejsze zapytanie co najmniej 5 razy, aby wygenerować osadzanie obrazów dla całego zestawu, ponieważ Studio ma limit 5 minut. Jeśli to zapytanie przekroczy limit czasu, zmień
LIMITna5i uruchom je ponownie 10 razy. Wykonanie tego kroku może potrwać kilka minut.
5. Konfigurowanie MongoDB Atlas w Google Cloud
MongoDB przechowuje szczegółowe, częściowo ustrukturyzowane informacje o produktach i elastyczne dane o zachowaniach użytkowników (np. kliknięcia i wyświetlenia).
Tworzenie klastra MongoDB
- Otwórz MongoDB Atlas w Google Cloud i wybierz konto z poziomu bezpłatnego.
- Wybierz poziom klastra Bezpłatny i wpisz nazwę klastra, np.
ecommerce-cluster. - Wybierz Google Cloud jako dostawcę i upewnij się, że region jest zgodny z regionem Google Cloud (np.
us-central1). - Kliknij Utwórz wdrożenie.
- Kliknij Zamknij.
Konfigurowanie dostępu do sieci
- W konsoli Atlas otwórz Database & Network Access (Dostęp do bazy danych i sieci).
- Kliknij Lista dostępu IP.
- Kliknij Dodaj adres IP.
- Dodaj
0.0.0.0/0, który zezwala na dostęp z dowolnego miejsca. - Kliknij Potwierdź.
Tworzenie użytkownika bazy danych
- W konsoli Atlas otwórz Database & Network Access (Dostęp do bazy danych i sieci).
- Kliknij Użytkownicy bazy danych.
- Kliknij Dodaj nowego użytkownika bazy danych.
- Wybierz jako metodę uwierzytelniania Hasło.
- Wpisz nazwę użytkownika
store-useri hasłostoreuser. - Kliknij Dodaj rolę wbudowaną i wybierz Odczyt i zapis w dowolnej bazie danych.
- Kliknij Dodaj użytkownika.
Pobieranie ciągu znaków połączenia
- Otwórz Baza danych > Klastry > Połącz.
- W sekcji Połącz aplikację kliknij Sterowniki.
- Skopiuj ciąg połączenia widoczny w sekcji Dodaj ciąg połączenia do kodu aplikacji. Ciąg znaków wygląda mniej więcej tak:
mongodb+srv://store-user:<db_password>@ecommerce-cluster.g8vaekh.mongodb.net/?appName=ecommerce-clusterdb_passwordhasłem do MongoDB. W tym ćwiczeniu jest tostoreuser.
Zapisz ten ciąg połączenia. Będzie on potrzebny później w przypadku zmiennej środowiskowej MONGODB_CONNECTION_STRING.
Tworzenie bazy danych i kolekcji
- W konsoli Atlas kliknij Database > Clusters > Browse Collections (Baza danych > Klastry > Przeglądaj kolekcje).
- Kliknij Utwórz bazę danych i wpisz te informacje:
- Nazwa bazy danych:
ecommerce_db - Nazwa kolekcji:
product_details_collection
- Nazwa bazy danych:
- Kliknij Utwórz bazę danych.
- W Eksploratorze danych wybierz nazwę zbioru.
- Kliknij ikonę Dodaj dane (+), a potem Wstaw dokument.
- Skopiuj zawartość pliku JSON z pliku product_details_export.json i wklej ją w oknie edytora Wstaw dokument.
- Kliknij Wstaw, aby wstawić tablicę dokumentów, i sprawdź, czy dodano 192 dokumenty.
- W Eksploratorze danych kliknij Utwórz kolekcję (+) obok bazy danych
ecommerce_db. - Wpisz
user_interactions_collectionjako nazwę kolekcji i kliknij Utwórz kolekcję. - W Eksploratorze danych wybierz kolekcję
user_interactions_collection. - Kliknij ikonę Dodaj dane (+), a potem Wstaw dokument.
- Skopiuj zawartość pliku JSON z pliku user_interactions_export.json i wklej ją w oknie edytora Wstaw dokument.
- Kliknij Wstaw dokument.
6. Konfigurowanie BigQuery
BigQuery agreguje i analizuje historyczne zachowania użytkowników, aby generować inteligentne raporty i rekomendacje.
Tworzenie zbioru danych
- W konsoli Google Cloud otwórz BigQuery.
- Obok identyfikatora projektu w panelu Eksplorator kliknij menu z 3 kropkami i wybierz Utwórz zbiór danych.
- W polu Identyfikator zbioru danych wpisz
ecommerce_analytics. - Kliknij Utwórz zbiór danych.
Tworzenie tabeli Analytics
- Otwórz nowe zapytanie w obszarze roboczym BigQuery.
- Aby utworzyć tabelę podsumowującą, która łączy użytkowników z interakcjami z produktem, uruchom tę instrukcję SQL:
CREATE TABLE ecommerce_analytics.user_product_interactions (
user_id STRING DEFAULT 'any user',
product_id STRING,
interaction_score INT
);
Przypisywanie ról do konta usługi Compute na potrzeby MCP Toolbox
Przypisujemy role do konta usługi Compute używanego w naszym zestawie narzędzi. Jest to konieczne, aby umożliwić narzędziom MCP dostęp do BigQuery, Secret Manager i innych usług w chmurze.
Aby przyznać role, wykonaj te czynności:
- Otwórz Uprawnienia i administracja.
- Kliknij Przyznaj dostęp.
- W polu Nowe podmioty zabezpieczeń wpisz domyślne konto usługi Compute o nazwie
YOUR_PROJECT_NUMBER-compute@developer.gserviceaccount.com. ZastąpYOUR_PROJECT_NUMBERnumerem projektu Google Cloud. - Kliknij Wybierz rolę.
- Znajdź i wybierz rolę Edytujący dane BigQuery.
- Kliknij Dodaj kolejną rolę i wybierz rolę Użytkownik zadań BigQuery.
- Kliknij Dodaj kolejną rolę i wybierz rolę Dostęp do obiektu tajnego w Secret Managerze.
- Kliknij Dodaj kolejną rolę i wybierz rolę Edytujący.
- Kliknij Zapisz.
7. Zrozumienie działania aplikacji od początku do końca
Aby dowiedzieć się, jak poszczególne komponenty ze sobą współpracują, utworzymy prostą aplikację e-commerce, która korzysta z wielu baz danych i usług. Aplikacja ma backend w Pythonie (Flask) i integruje wiele usług i baz danych Google Cloud.
Struktura katalogu
W następnej sekcji sklonujesz repozytorium BRK2-149-multidb-ecommerce i użyjesz go do uruchomienia aplikacji lokalnie. Po przetestowaniu aplikacji lokalnie wdrożymy zarówno MCP Toolbox, jak i aplikację w Cloud Run.
Przejrzyj pobrane pliki w tym katalogu. Dostępne są te katalogi najwyższego poziomu:
UploadImages: przechowuje komponenty z obrazami, które są używane głównie w dokumentacji lub treściach wizualnych w katalogu produktów e-commerce.static: przechowuje statyczne komponenty internetowe aplikacji, takie jak pliki CSS i JavaScript, które służą do nadawania stylu interfejsowi użytkownika i dodawania do niego interaktywności ( źródło).templates: przechowuje szablony HTML (prawdopodobnie Jinja2 dla Flask), których aplikacja w języku Python używa do dynamicznego renderowania stron internetowych na potrzeby katalogu e-commerce ( źródło).toolbox-implementation: przechowuje szczegóły konfiguracji i wdrożenia zestawu narzędzi Model Context Protocol (MCP), ułatwiając interakcje z wieloma bazami danych za pomocą predefiniowanych narzędzi.
Pliki w tym repozytorium współpracują ze sobą, aby tworzyć, konfigurować i wdrażać aplikację e-commerce z wieloma bazami danych. Pliki centralne, takie jak app.py, koordynują backend, integrując różne źródła danych zdefiniowane w plikach SQL i JSON, a pliki konfiguracyjne zapewniają bezproblemowe wdrażanie w środowiskach chmurowych:
app.py: koordynuje integracje backendu Flask i wielu baz danych.agentengine.py: podstawowa logika inicjowania i konfigurowania agentów Vertex AI..env: przechowuje tajne klucze do połączeń z bazą danych i pamięcią masową.tools.yaml: konfiguruje MCP Toolbox do operacji na wielu bazach danych.Dockerfile: definiuje obraz kontenera i konfigurację środowiska.requirements.txt: zawiera listę bibliotek Pythona potrzebnych do działania aplikacji.tools.yaml: konfiguracje Zestawu narzędzi MCP.Procfile: określa polecenia wykonywania w środowisku produkcyjnym na potrzeby wdrożenia.alloydb_insert_queries.sql: zawiera zapytania SQL dotyczące danych relacyjnych.product_details_export.jsoniuser_interactions_export.json: przykładowe dane JSON dla bazy danych NoSQL.README.md: przewodniki po konfiguracji, wdrażaniu i rozumieniu projektu.
Cały proces aplikacji
- Konfiguracja AlloyDB: udostępnij klaster o wysokiej wydajności i użyj podanych skryptów SQL, aby utworzyć tabelę products_core_table z kolumnami wektorowymi dla wektorów dystrybucyjnych obrazów.
- Konfiguracja MongoDB Atlas: wdróż klaster w Google Cloud, aby przechowywać płynne atrybuty produktów w product_details i rejestrować strumienie kliknięć w czasie rzeczywistym w user_interactions.
- BigQuery Analytics: utwórz zbiór danych, aby agregować dzienniki interakcji, co umożliwi tworzenie złożonych zapytań analitycznych, które identyfikują 5 najpopularniejszych elementów w milionach zdarzeń.
- Repozytorium Cloud Storage: utwórz publiczny zasobnik, w którym będą przechowywane obrazy produktów w wysokiej rozdzielczości. Upewnij się, że każdy zasób jest dostępny za pomocą podpisanego lub publicznego adresu URL dla interfejsu.
- Wdrożenie MCP Toolbox: wdrożenie zestawu narzędzi w Cloud Run, aby utworzyć centralny mostek RESTful, który tłumaczy intencje wyrażone w języku naturalnym na zapytania do wielu baz danych.
- Konfiguracja pliku tools.yaml: zdefiniuj „narzędzia”, takie jak get_product_core_data lub get_top_5_views, przypisując konkretne operacje SQL i NoSQL do prostych, czytelnych dla agenta nazw.
- Logika backendu Flask: zaimplementuj trasy app.py, które współpracują z zestawem narzędzi MCP, koordynując pobieranie danych i pełniąc rolę interfejsu API dla interfejsu użytkownika.
- Orkiestracja wielu agentów: skonfiguruj agentów ADK w kodzie, aby analizować intencje użytkowników i wybierać odpowiednie „narzędzie” do rozwiązywania złożonych zapytań dotyczących sprzedaży detalicznej pochodzących z wielu źródeł.
- Integracja z interfejsem: utwórz interfejs index.html z katalogiem produktów z funkcją rejestrowania interakcji, kartą Analytics, która umożliwia analizowanie skuteczności produktów, oraz specjalną „kartą agenta”, która korzysta z czatu wieloagentowego ADK, aby zapewnić płynne zakupy konwersacyjne.
Teraz wdróżmy orkiestrację i wdrożenia.
8. Konfigurowanie MCP Toolbox i wdrażanie w Cloud Run
MCP Toolbox abstrahuje od naszych wielu źródeł danych, dzięki czemu nasza aplikacja może pobierać i zapisywać dane w jednolity sposób.
Instalowanie lokalnie MCP Toolbox
- W Cloud Shell przejdź do folderu
toolbox-implementation:cd next-26-sessions/BRK2-149-multidb-ecommerce/toolbox-implementation - Pobierz plik binarny narzędzi MCP i ustaw go jako wykonywalny:
export VERSION=0.29.0 curl -L -o toolbox https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox chmod +x toolbox
Konfigurowanie pliku tools.yaml
Musisz zdefiniować abstrakcje dla AlloyDB, MongoDB i BigQuery. Plik tools.yaml informuje zestaw narzędzi MCP, jak ze sobą współdziałać.
- Utwórz i edytuj plik
tools.yamlza pomocą wbudowanego edytora:cloudshell edit tools.yamltools.yamlznajdziesz w repozytorium GitHub. Skopiuj jego zawartość do nowego plikutools.yaml. - Zaktualizuj hosta, użytkownika, hasła, identyfikatory projektów i ciągi połączenia, aby pasowały do infrastruktury, którą udostępniono w poprzednich krokach:
Baza danych
Pole
Przykładowa wartość
AlloyDB/BigQuery
project_idYOUR_PROJECT_IDAlloyDB
regionus-central1AlloyDB
clusterecommerce-clusterAlloyDB
instanceecommerce-cluster-primaryAlloyDB
databasepostgresAlloyDB
passwordalloydbMongoDB
connection_stringmongodb+srv://store-user:storeuser@ecommerce-cluster.urcxr6q.mongodb.net
Przypisywanie ról do konta usługi Compute na potrzeby MCP Toolbox
Przypisujemy role do konta usługi Compute używanego w naszym zestawie narzędzi. Jest to konieczne, aby umożliwić zestawowi narzędzi MCP dostęp do AlloyDB.
- Otwórz Uprawnienia i administracja.
- Kliknij Przyznaj dostęp.
- W polu Nowe podmioty zabezpieczeń wpisz domyślne konto usługi Compute o nazwie
YOUR_PROJECT_NUMBER-compute@developer.gserviceaccount.com. ZastąpYOUR_PROJECT_NUMBERnumerem projektu Google Cloud. - Kliknij Wybierz rolę.
- Znajdź i wybierz rolę Edytujący dane BigQuery.
- Kliknij Dodaj kolejną rolę i wybierz rolę Klient AlloyDB.
- Kliknij Dodaj kolejną rolę i wybierz rolę konsument Wykorzystania usług.
- Kliknij Dodaj kolejną rolę i wybierz rolę Wyświetlający obiekty Cloud Storage.
- Kliknij Zapisz.
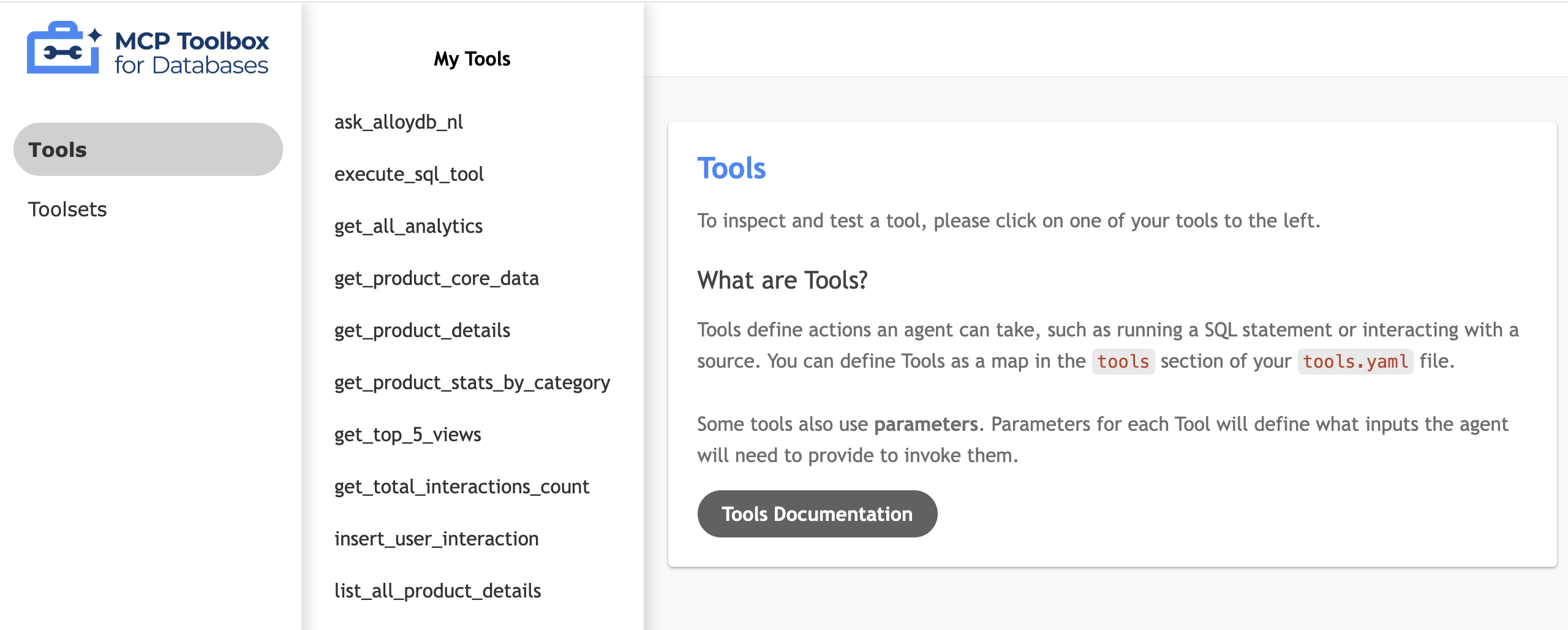
Testowanie interfejsu narzędzia
- W terminalu Cloud Shell uruchom lokalnie zestaw narzędzi, aby udostępnić interfejs:
./toolbox --ui - Otwórz podgląd w przeglądarce w Cloud Shell na porcie 5000 i przejdź na stronę narzędzi. W zależności od adresu URL sesji możesz ją wyświetlić np. pod adresem:
https://5000-cs-71152278760-default.cs-asia-southeast1-cash.cloudshell.dev/ui
Wyświetli się ten interfejs narzędzi MCP:
Wdrożenie w Cloud Run
Wdróż MCP Toolbox w Cloud Run, aby udostępnić go jako bezpieczną usługę zarządzaną, z której aplikacja może korzystać do wykonywania zapytań w bazach danych. Aby chronić poufne dane połączenia, będziemy przechowywać konfigurację w usłudze Secret Manager.
- Otwórz nową sesję Cloud Shell.
- Przejdź do folderu
toolbox-implementation:cd next-26-sessions/BRK2-149-multidb-ecommerce/toolbox-implementation - Prześlij konfigurację
tools.yamldo usługi Google Secret Manager:gcloud secrets create tools --data-file=tools.yamlgcloud secrets versions add tools --data-file=tools.yaml - Wdróż za pomocą publicznego obrazu kontenera MCP Toolbox:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:0.29.0 export PROJECT_ID=$(gcloud config get-value project) gcloud run deploy toolbox \ --image $IMAGE \ --region us-central1 \ --service-account $(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")-compute@developer.gserviceaccount.com \ --set-secrets "/app/tools.yaml=tools:latest" \ --args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080","--ui" \ --allow-unauthenticated - Po wdrożeniu zapisz podany adres URL usługi Cloud Run. Powinien on wyglądać tak:
https://toolbox-*********-uc.a.run.app/ui.
9. Konfigurowanie aplikacji e-commerce i wdrażanie jej w Cloud Run
Po uruchomieniu baz danych i wdrożeniu abstrakcji MCP Toolbox możemy uruchomić aplikację internetową Flask.
Aby udostępnić katalog produktów, aplikacja Flask przetwarza dane, wykonując te czynności:
- Pobierz podstawowe dane: pobiera pełną listę produktów z AlloyDB (
list_products_core). - Pobierz szczegółowe informacje: pobiera wszystkie szczegóły produktu z MongoDB (
list_all_product_details). - Połącz listy: łączy obie listy.
- Wzbogać o multimedia: dodaje adres URL obrazu z Cloud Storage do każdego produktu.
Generowanie ścieżki aplikacji silnika rozumowania
Aby zainicjować i zarejestrować agenta AI za pomocą silnika wnioskowania Vertex AI w Google Cloud, uruchom to polecenie:
- W terminalu Cloud Shell otwórz folder
BRK2-149-multidb-ecommerce.cd next-26-sessions/BRK2-149-multidb-ecommerce - Uruchom plik requirements.txt, aby zainstalować zależności.
pip install -r requirements.txt - Aby wygenerować ścieżkę aplikacji silnika rozumowania, uruchom skrypt
agentengine.py:python agentengine.py
Dane wyjściowe będą podobne do tych:
projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856
Konfigurowanie zmiennych środowiskowych
- Utwórz plik
.envi go edytuj:cloudshell edit .env - Zastąp wartości konkretnymi połączeniami z bazą danych i nowym adresem URL Cloud Run Toolbox:
# 1. MongoDB Connection String MONGODB_CONNECTION_STRING="mongodb+srv://<db_user>:<db_password>@cluster0.mongodb.net" # 2. MCP Toolbox Server Location # Must match the address where you run the toolbox server MCP_TOOLBOX_SERVER_URL="https://toolbox-*********-uc.a.run.app" # 3. Google Cloud Storage Bucket Name GCS_PRODUCT_BUCKET="ecommerce-app-images" # 4. Fallback image URL FALLBACK_IMAGE_URL="https://storage.googleapis.com/ecommerce-media-bold-circuit-492711-n9/fallback.jpg" # 5. Google Gen AI Vertex AI flag GOOGLE_GENAI_USE_VERTEXAI=TRUE # 6. Project ID PROJECT_ID=codelab-project-491117 # 7. Google Cloud Location of AlloyDB, BigQuery databases GOOGLE_CLOUD_LOCATION=us-central1 # 8. Reasoning engine application path APP_NAME=projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856 # 9. Model ID MODEL=gemini-1.5-flash-lite
Wdrażanie frontendu w Cloud Run
- Aby ukończyć architekturę, wdróż aplikację internetową w Cloud Run:
gcloud run deploy polyglot --source . --platform managed \ --region us-central1 \ --allow-unauthenticated \ --set-env-vars \ MONGODB_CONNECTION_STRING="<MONGODB_CONNECTION_STRING>", \ MCP_TOOLBOX_SERVER_URL="<MCP_TOOLBOX_SERVER_URL>", \ GCS_PRODUCT_BUCKET="<GCS_PRODUCT_BUCKET>", \ FALLBACK_IMAGE_URL="<FALLBACK_IMAGE_URL>", \ GOOGLE_GENAI_USE_VERTEXAI=TRUE, \ PROJECT_ID="YOUR_PROJECT_ID", \ GOOGLE_CLOUD_LOCATION=us-central1, \ APP_NAME="<YOUR_REASONING_ENGINE_APP_PATH>", \ MODEL="gemini-1.5-flash-lite"YOUR_PROJECT_ID: identyfikator Twojego projektu Google Cloud.YOUR_REASONING_ENGINE_APP_PATH: wynik uruchomienia poleceniapython agentengine.py, np.projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856.MCP_TOOLBOX_SERVER_URL: adres URL serwera MCP Toolbox, np.https://toolbox-*********-uc.a.run.app.GCS_PRODUCT_BUCKET: nazwa zasobnika Google Cloud Storage, np.ecommerce-app-images.MONGODB_CONNECTION_STRING: ciąg połączenia z bazą danych MongoDB, np.mongodb+srv://store-user:storeuser@ecommerce-cluster.g8vaekh.mongodb.netFALLBACK_IMAGE_URL: adres URL obrazu zastępczego, np.https://storage.googleapis.com/ecommerce-app-images/fallback.jpg
Twoja aplikacja jest już aktywna. Otwórz adres URL usługi podany przez Cloud Run, aby wyświetlić katalog Multidb Ecommerce. Adres URL będzie podobny do https://polyglot-*********-uc.a.run.app/.
10. Poznaj aplikację
- Kliknij Katalog produktów, aby wyświetlić wszystkie produkty.
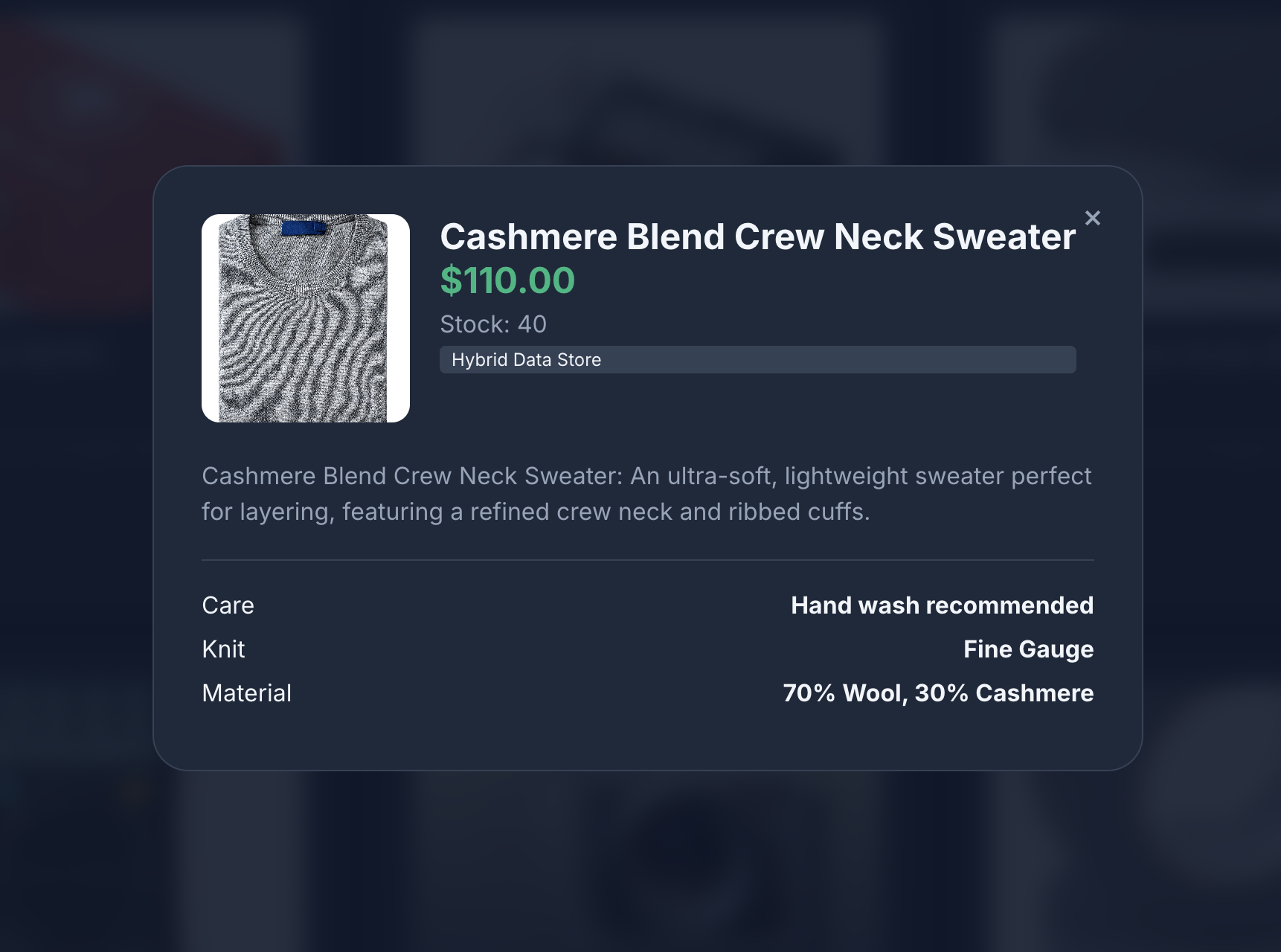
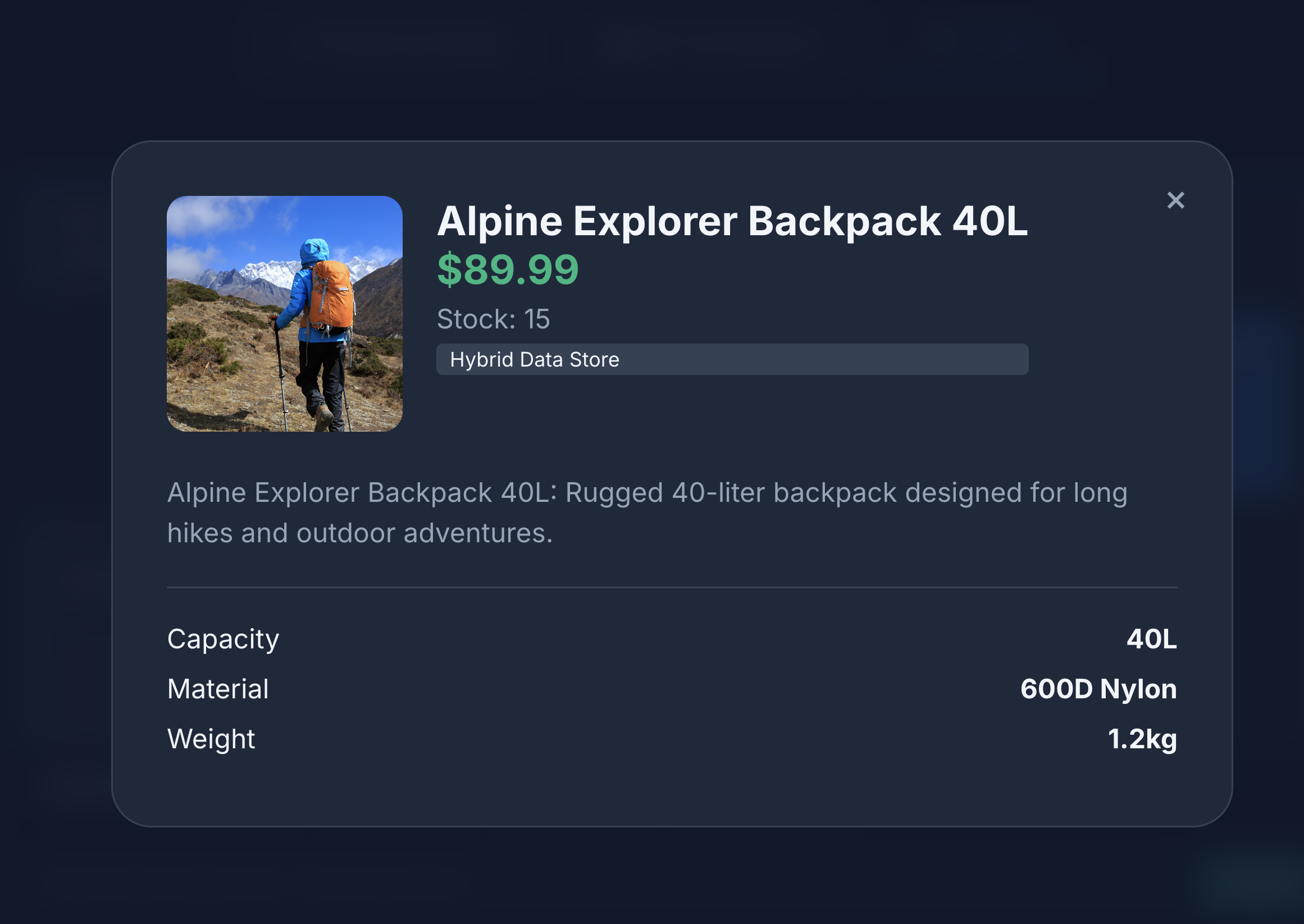
- Kliknij ikonę produktu, aby wyświetlić jego szczegóły. Zauważysz, że obrazy pochodzą z Cloud Storage, szczegóły produktu są pobierane z MongoDB, a asortyment produktów jest pobierany z AlloyDB.
- Interakcja z katalogiem produktów w celu generowania widoków próbnych i zapisów wysyłanych do MongoDB.
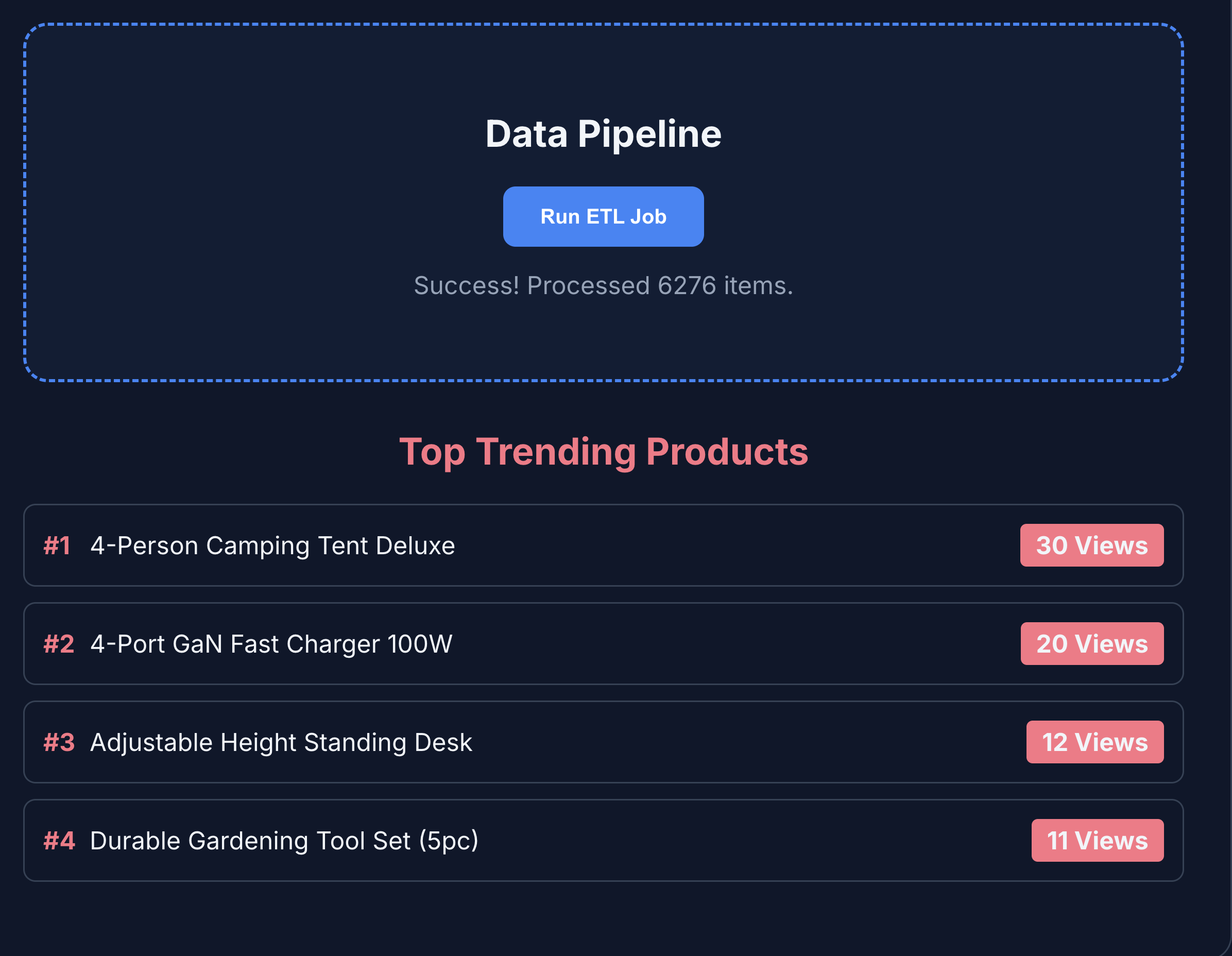
- Kliknij ETL i analityka, aby wyświetlić statystyki usługi. Zauważysz, że dane analityczne produktu są pobierane z BigQuery.
- Aby wejść w interakcję z agentem AI, kliknij kartę Agent AI. Zadawaj pytania w języku naturalnym, np.:
I'm planning a high-altitude photography trip. Show me some weather-resistant backpacks similar in style to aero glow pro but without any leather components. Also, let me know if they are actually in stock and if other photographers have complained about the strap durability in the reviews.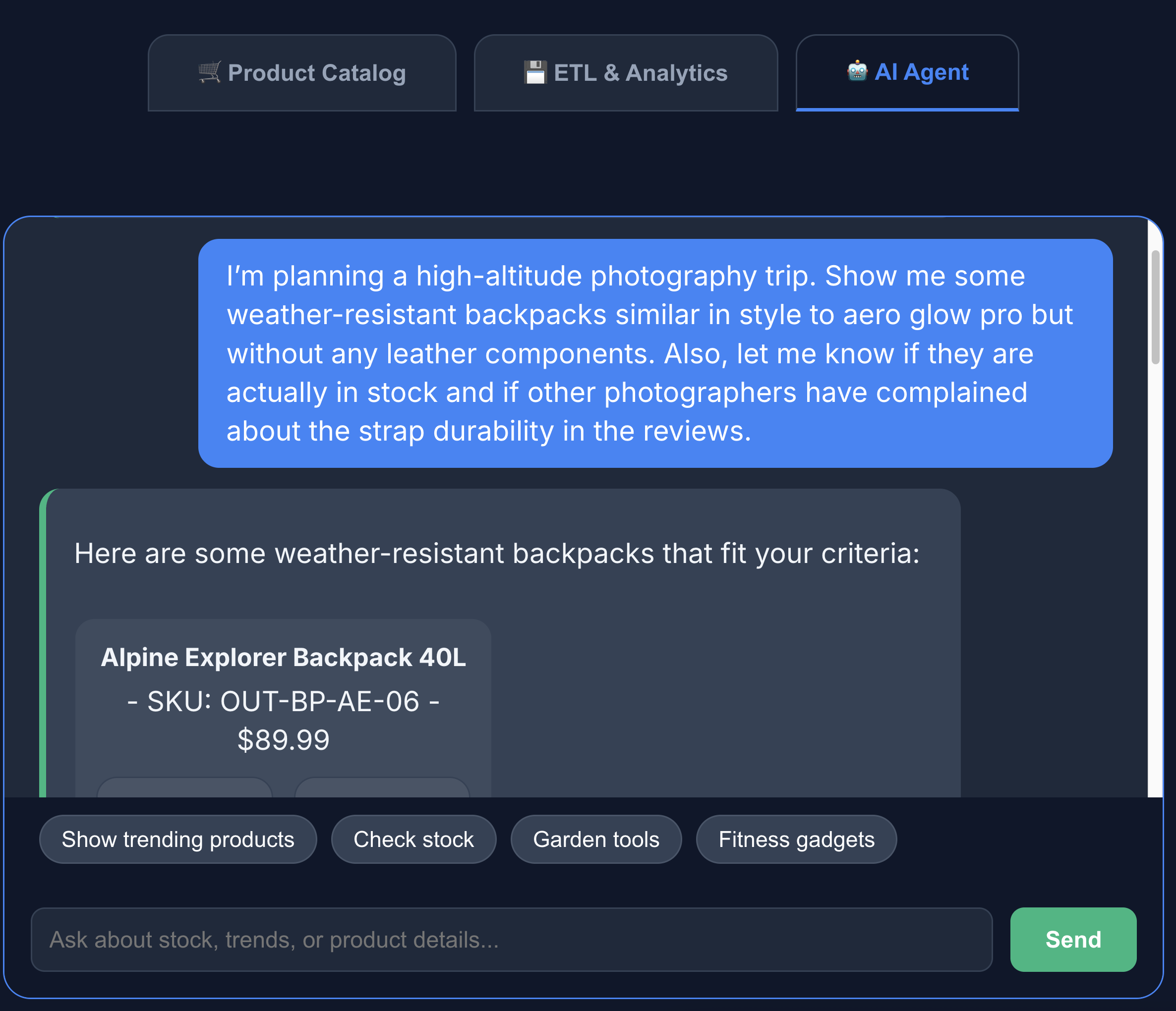
Widać, że wyszukiwarka zwraca dokładnie to, o co prosiliśmy – plecak bez elementów skórzanych, dostępny w magazynie i bez skarg na trwałość pasków w opiniach.
11. Czyszczenie danych
Aby uniknąć obciążenia konta Google Cloud bieżącymi opłatami, usuń zasoby utworzone podczas tego ćwiczenia.
Uruchom te polecenia Cloud Shell:
gcloud run services delete toolbox --region us-central1 --quiet
gcloud run services delete multi-db-app --region us-central1 --quiet
bq rm -r -f -d $PROJECT_ID:ecommerce_analytics
gcloud storage rm --recursive gs://ecommerce-app-images
gcloud alloydb clusters delete ecommerce-cluster --region us-central1 --force --quiet
Opcjonalnie, aby usunąć cały projekt w chmurze Google Cloud i wszystkie jego zasoby, uruchom to polecenie:
gcloud projects delete $PROJECT_ID
12. Gratulacje
Gratulacje! Udało Ci się utworzyć architekturę Multidb w wielu chmurach.
Pokazaliśmy, jak zestaw narzędzi MCP stanowi architektoniczny spoiwo nowoczesnej, specjalistycznej aplikacji. Dopasowując odpowiednią bazę danych do odpowiedniego zadania, udało Ci się:
- Elastyczny zapis danych: MongoDB do dzienników zdarzeń.
- Spójność transakcyjna: AlloyDB zapewnia integralność danych.
- Analytics o wysokiej wydajności: BigQuery do analizy biznesowej.
- Ujednolicone programowanie: pojedynczy backend w Pythonie, który za pomocą zestawu narzędzi MCP upraszcza wszystkie złożone procesy.
Dokumentacja
Dowiedz się więcej o powiązanych usługach Google Cloud i zapoznaj się z tymi samouczkami:
- AlloyDB AI: Wprowadzenie do wektorów dystrybucyjnych z pomocą AI w AlloyDB
- AlloyDB AI: multimodalne wektory dystrybucyjne w AlloyDB
- Zestaw narzędzi MCP: instalowanie i konfigurowanie zestawu narzędzi MCP dla baz danych w AlloyDB
Więcej informacji o usługach użytych w tym laboratorium znajdziesz w tych artykułach: