
1. Introdução
No varejo moderno, seus dados são um ecossistema diversificado e extenso. Você tem dados transacionais sólidos (preços e inventário), catálogos polimórficos "bagunçados" (especificações de eletrônicos x tamanhos de roupas) e petabytes de registros comportamentais. Forçar esses elementos em um único monólito não apenas cria dívida técnica, mas também prejudica a experiência do usuário.
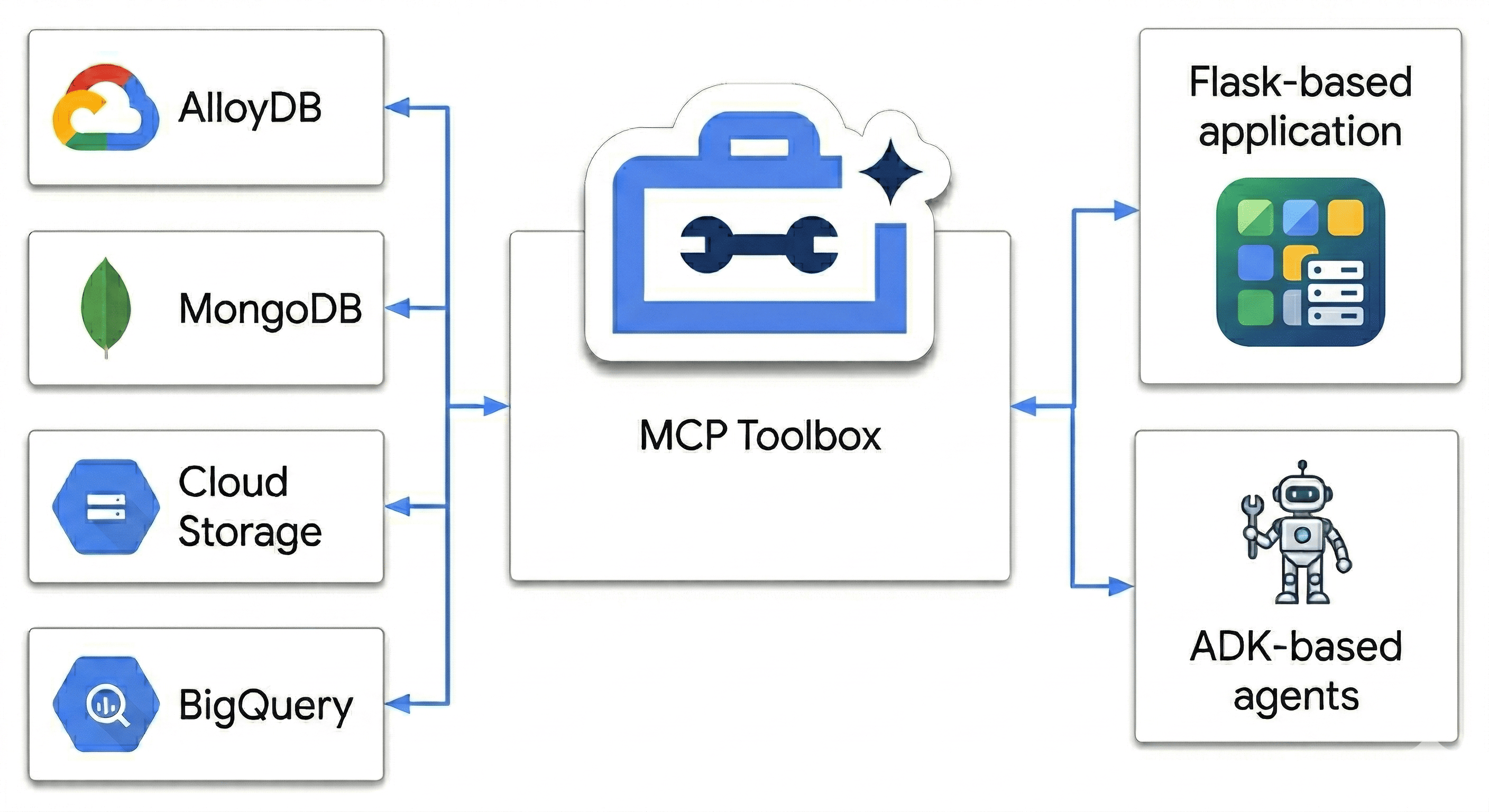
Neste codelab, você vai criar uma potência poliglota que harmoniza:
- AlloyDB: sua base transacional para consistência de alta velocidade e embeddings de imagem.
- MongoDB Atlas no Google Cloud: sua camada de catálogo flexível e independente de esquema.
- Cloud Storage: seu cérebro analítico para previsão de tendências em tempo real.
- BigQuery: seu data warehouse digital de alta resolução.
O "tempero secreto"? Você vai usar a MCP Toolbox for Databases para orquestrar e unificar de maneira inteligente as fontes de dados em execução no Cloud Run como uma ponte semântica e, em seguida, implantar um app de chat multiagente usando o Kit de Desenvolvimento de Agente (ADK). Você não está apenas criando uma barra de pesquisa, mas sim um cérebro de varejo inteligente que entende o contexto, respeita as restrições e preenche a lacuna entre dados brutos e intenção humana.
A consulta do usuário impossível
Os agentes de e-commerce padrão não conseguem fazer um raciocínio multidimensional (combinando restrições negativas, semelhança visual e inventário em tempo real). Por exemplo, normalmente quero falar com um site de varejo assim:
"Oi, estou planejando uma viagem para tirar fotos em alta altitude. Mostre algumas mochilas resistentes a água com estilo semelhante à "AeroGlow Pro", mas sem componentes de couro. Além disso, informe se eles estão em estoque e se outros fotógrafos reclamaram da durabilidade da alça nas avaliações".
Por que essa consulta é "The Agent Killer":
- Similaridade visual (AlloyDB + pesquisa vetorial): "Semelhante em estilo ao AeroGlow Pro" exige comparação de incorporação de imagens.
- Restrição negativa (MongoDB): "Sem couro" exige filtragem por atributos flexíveis e aninhados que geralmente não estão em um esquema SQL padrão.
- Inventário em tempo real (AlloyDB): "Em estoque" exige uma verificação transacional em tempo real, não um índice de pesquisa desatualizado.
- Síntese semântica (BigQuery + multiagente): para analisar avaliações sobre "durabilidade da pulseira", o agente precisa resumir o feedback não estruturado do BigQuery em tempo real.
A maioria dos bots de varejo só veria "Mochila" e "Couro" e mostraria 10 mochilas de couro. Como estamos impedindo isso?
Porque não estamos apenas fazendo a correspondência de palavras-chave. Estamos usando a MCP Toolbox para permitir que nossos agentes "raciocinem" em todas essas fontes: a verdade transacional no AlloyDB e os atributos flexíveis no MongoDB simultaneamente. Vamos criar.
Atividades deste laboratório
- Provisionar um cluster do AlloyDB para dados principais de produtos
- Configure o MongoDB Atlas no Google Cloud para armazenar detalhes de produtos semiestruturados
- Crie um bucket do Cloud Storage para veicular imagens de produtos
- Implante o MCP Toolbox for Databases no Cloud Run para ter acesso uniforme aos dados.
- Executar processos de ETL para enviar dados ao BigQuery para análise
- Conversar com um agente de IA em linguagem natural.
Pré-requisitos
- Um navegador da web, como o Chrome
- Tenha um projeto do Google Cloud com o faturamento ativado.
- Uma conta sem custo financeiro do MongoDB Atlas no Google Cloud
2. Antes de começar
Criar um projeto do Google Cloud
- No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto na nuvem do Google Cloud.
- Verifique se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto.
Iniciar o Cloud Shell
O Cloud Shell é um ambiente de linha de comando executado no Google Cloud que vem pré-carregado com as ferramentas necessárias.
- Clique em Ativar o Cloud Shell na parte de cima do console do Google Cloud.
- Depois de se conectar ao Cloud Shell, verifique sua autenticação:
gcloud auth list - Confirme se o projeto está configurado:
gcloud config get project - Se o projeto não estiver definido como esperado, faça o seguinte:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Ativar APIs obrigatórias
Execute este comando para ativar todas as APIs necessárias:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
3. Configurar o Cloud Storage
O Cloud Storage serve como um grande repositório de recursos de mídia não estruturados, como imagens de produtos.
- No console do Google Cloud, acesse Cloud Storage e clique em Criar bucket.
- Dê um nome globalmente exclusivo ao bucket (por exemplo,
ecommerce-app-images). - Clique em Criar.
- Para permitir que o aplicativo de demonstração acesse as imagens sem autenticação, desmarque a opção Aplicar a prevenção do acesso público neste bucket e clique em Confirmar.
- Acesse a guia Permissões.
- Em Permissões, clique em Conceder acesso.
- Em Novos principais, digite
allUsers. - Em Selecionar um papel, selecione Cloud Storage > Usuário de objetos do Storage.
- Clique em Salvar e em Permitir acesso público para confirmar que você está tornando o recurso público.
Fazer upload de imagens marcadoras de posição
O BRK2-149-multidb-ecommerce usa imagens de marcador de posição para oferecer a melhor experiência visual.
- No Cloud Shell, clone o repositório
next-26-sessions:git clone https://github.com/GoogleCloudPlatform/next-26-sessions.git - Navegue até a pasta
UploadImages:cd next-26-sessions/BRK2-149-multidb-ecommerce/UploadImages - No console do Google Cloud, acesse Cloud Storage e clique em Buckets.
- Clique no nome do bucket recém-criado.
- Clique em Fazer upload > Fazer upload de arquivos, selecione as imagens de amostra baixadas e clique em Abrir.
4. Configurar o AlloyDB
O AlloyDB serve como a única fonte de verdade para dados estruturados, transacionais e críticos, como IDs, nomes, SKUs, preços e inventário de produtos. O AlloyDB também alimenta o agente de IA com recursos de pesquisa por similaridade para recomendações e consultas em linguagem natural.
Provisionar um cluster do AlloyDB
- No console do Google Cloud, navegue até AlloyDB para PostgreSQL.
- Clique em Criar cluster.
- Em ID do cluster, digite
ecommerce-cluster. - Defina uma senha forte para o usuário
postgres. Para fins de aprendizado, usealloydb. - Em Versão do banco de dados, mantenha o padrão.
- Em Região, selecione
us-central1ou a região de sua preferência.
Configurar instância principal
- Em ID da instância, insira
ecommerce-cluster-primary. - Em Disponibilidade por zona, selecione Zona única.
- Em Tipo de máquina, escolha um tipo de máquina pequena (por exemplo, N2, 4 vCPUs, 32 GB de RAM).
- Em Conectividade de IP privado, selecione Acesso a serviços particulares (PSA) e a rede
default.Se a rede padrão ainda não estiver definida, clique em Confirmar configuração de rede para criar uma. - Em Conectividade de IP público, marque a caixa de seleção Ativar IP público para que a caixa de ferramentas do MCP se conecte corretamente neste codelab.
- Em Redes externas autorizadas, insira
0.0.0.0/0. Marque a caixa de seleção Aceito os riscos e clique em Salvar. - Clique em Criar cluster.
Observação: anote seu endereço IP público (parece 34.124.240.26).
Inicializar o banco de dados
- Clique em AlloyDB Studio no menu de navegação à esquerda.
- No menu suspenso Banco de dados, selecione
postgres. - Selecione Autenticação integrada para fazer login no banco de dados.
- Em Nome de usuário, use o usuário
postgres. - Em Senha, digite a senha que você definiu anteriormente.
- Clique em Autenticar.
- Na visualização do editor, abra uma nova guia de consulta sem título.
- Copie o seguinte DDL e clique em Executar:
CREATE TABLE products_core_table ( product_id UUID PRIMARY KEY, name VARCHAR(255) NOT NULL, sku VARCHAR(50) UNIQUE NOT NULL, price NUMERIC(10, 2) NOT NULL, stock INT NOT NULL ); - No Cloud Shell, navegue até a pasta
BRK2-149-multidb-ecommerce:cd next-26-sessions/BRK2-149-multidb-ecommerce - Abra o arquivo
alloydb_insert_queries.sqlno Cloud Shell e copie as consultas de inserção.cat alloydb_insert_queries.sql - Em uma nova guia de consulta sem título, cole apenas as instruções
INSERTe clique em Executar. - Em uma nova guia de consulta sem título, copie a DDL a seguir e clique em Executar para criar um índice na tabela
products_core_table:CREATE INDEX idx_products_core_sku ON products_core_table(sku);
Criar embeddings de imagem para o agente de IA buscar produtos semelhantes
A integração do agente de IA usa embeddings de imagens para buscar produtos semelhantes. Os embeddings são gerados usando o modelo multimodalembedding@001 e armazenados no banco de dados do AlloyDB. Os embeddings são vetores de 1.408 dimensões e são armazenados na coluna img_embeddings.
Antes de gerar incorporações, é preciso conceder à conta de serviço do AlloyDB os papéis necessários para acessar o Cloud Storage.
Conceder papéis à conta de serviço do AlloyDB para acessar o Cloud Storage
Concedemos o papel de usuário e leitor de objetos do Storage à conta de serviço do AlloyDB para permitir que ela leia objetos do bucket do Cloud Storage.
- Acesse IAM e administrador.
- Clique em Conceder acesso.
- No campo Novos principais, insira a pesquisa da conta de serviço do AlloyDB. A conta de serviço é semelhante a
service-991742412753@gcp-sa-alloydb.iam.gserviceaccount.com. - Clique em Selecionar papel.
- Encontre e selecione o papel Usuário de objetos do Storage.
- Clique em Adicionar outro papel e selecione Leitor de objetos do Storage.
- Clique em Adicionar outro papel e selecione o papel Usuário da Vertex AI.
- Clique em Salvar.
Ativar extensões
Para criar esse app, vamos usar as extensões pgvector e google_ml_integration. A extensão pgvector permite armazenar e pesquisar embeddings de vetor. A extensão google_ml_integration fornece funções que você usa para acessar endpoints de previsão da Vertex AI e receber previsões em SQL. Para ativar essas extensões, execute os seguintes DDLs:
- No console do Google Cloud, navegue até AlloyDB para PostgreSQL.
- Clique em AlloyDB Studio no menu de navegação à esquerda.
- Na visualização do editor, abra uma nova guia de consulta sem título.
- Copie o seguinte DDL e clique em Executar:
CREATE EXTENSION IF NOT EXISTS vector; CREATE EXTENSION IF NOT EXISTS google_ml_integration;
Inicializar o banco de dados com embeddings
- Adicione a coluna "img_embeddings" ao
products_core_table.ALTER TABLE products_core_table ADD COLUMN img_embeddings vector(1408); - Gere embeddings para as imagens e armazene-os na coluna
img_embeddings.UPDATE products_core_table SET img_embeddings = google_ml.image_embedding( model_id => 'multimodalembedding@001', image => 'gs://<STORAGE_BUCKET_NAME>/' || sku || '.jpg', mimetype => 'image/jpeg') WHERE sku IN ( SELECT sku FROM products_core_table WHERE img_embeddings IS NULL AND sku IS NOT NULL LIMIT 10 ); - Repita a consulta anterior pelo menos cinco vezes para gerar incorporações de imagens para todo o conjunto, já que o Studio tem uma limitação de cinco minutos. Se essa consulta expirar, mude
LIMITpara5e execute a consulta dez vezes. Essa etapa pode levar alguns minutos.
5. Configurar o MongoDB Atlas no Google Cloud
O MongoDB armazena detalhes de produtos avançados e semiestruturados e dados flexíveis de comportamento do usuário (como cliques e visualizações).\
Criar um cluster do MongoDB
- Acesse MongoDB Atlas no Google Cloud e selecione uma conta de nível sem custo financeiro.
- Selecione o nível de cluster Livre e insira um nome para o cluster, por exemplo,
ecommerce-cluster. - Selecione Google Cloud como o provedor e verifique se a região está alinhada com a sua região do Google Cloud (por exemplo,
us-central1). - Clique em Criar implantação.
- Clique em Fechar.
Configurar o acesso à rede
- No console do Atlas, acesse Acesso ao banco de dados e à rede.
- Clique em Lista de acesso por IP.
- Clique em Adicionar endereço IP.
- Adicione
0.0.0.0/0, que permite o acesso de qualquer lugar. - Clique em Confirmar.
Criar um usuário de banco de dados
- No console do Atlas, acesse Acesso ao banco de dados e à rede.
- Clique em Usuários do banco de dados.
- Clique em Adicionar novo usuário do banco de dados.
- Selecione Senha como o método de autenticação.
- Digite o nome de usuário como
store-usere a senha comostoreuser. - Clique em Adicionar função integrada e selecione Ler e gravar em qualquer banco de dados.
- Clique em Adicionar usuário.
Acessar a string de conexão
- Acesse Banco de dados > Clusters > Conectar.
- Em Conecte seu aplicativo, clique em Drivers.
- Copie a string de conexão mostrada em Adicionar a string de conexão ao código do aplicativo. A string vai ficar assim:
mongodb+srv://store-user:<db_password>@ecommerce-cluster.g8vaekh.mongodb.net/?appName=ecommerce-clusterdb_passwordpela sua senha do MongoDB. Neste codelab, éstoreuser.
Salve essa string de conexão. Você vai usá-lo mais tarde para a variável de ambiente MONGODB_CONNECTION_STRING.
Criar banco de dados e coleção
- No console do Atlas, acesse Database > Clusters > Browse Collections.
- Clique em Criar banco de dados e insira os detalhes:
- Nome do banco de dados :
ecommerce_db - Nome da coleção:
product_details_collection
- Nome do banco de dados :
- Clique em Criar banco de dados.
- No Data Explorer, selecione o nome da coleção.
- Clique no ícone Adicionar dados (+) e em Inserir documento.
- Copie o conteúdo JSON de product_details_export.json e cole na caixa de diálogo do editor Inserir documento.
- Clique em Inserir para inserir a matriz de documentos e verificar se 192 documentos foram adicionados.
- No Data Explorer, clique em Criar coleção (+) ao lado do banco de dados
ecommerce_db. - Digite
user_interactions_collectioncomo nome da coleção e clique em Criar coleção. - No Data Explorer, selecione a coleção
user_interactions_collection. - Clique no ícone Adicionar dados (+) e em Inserir documento.
- Copie o conteúdo JSON de user_interactions_export.json e cole na caixa de diálogo do editor Inserir documento.
- Clique em Inserir documento.
6. Configurar o BigQuery
O BigQuery agrega e analisa o comportamento histórico do usuário para gerar relatórios e recomendações inteligentes.
#create_the_data_set
- No console do Google Cloud, acesse o BigQuery.
- Ao lado do ID do projeto no painel "Explorer", clique no menu de três pontos e selecione Criar conjunto de dados.
- Insira
ecommerce_analyticsno campo ID do conjunto de dados. - Clique em Criar conjunto de dados.
Criar a tabela do Analytics
- Abra uma nova consulta no workspace do BigQuery.
- Execute a seguinte instrução SQL para criar a tabela de resumo que vincula usuários a interações com produtos:
CREATE TABLE ecommerce_analytics.user_product_interactions (
user_id STRING DEFAULT 'any user',
product_id STRING,
interaction_score INT
);
Conceder papéis à conta de serviço do Compute para a caixa de ferramentas do MCP
Concedemos papéis à conta de serviço do Compute usada para nossa caixa de ferramentas. Isso é feito para permitir que a MCP Toolbox acesse o BigQuery, o Secret Manager e outros serviços de nuvem.
Para conceder papéis, siga estas etapas:
- Acesse IAM e administrador.
- Clique em Conceder acesso.
- No campo Novos principais, insira a conta de serviço padrão do Compute Engine chamada
YOUR_PROJECT_NUMBER-compute@developer.gserviceaccount.com. SubstituaYOUR_PROJECT_NUMBERpelo número do projeto do Google Cloud. - Clique em Selecionar papel.
- Encontre e selecione a função Editor de dados do BigQuery.
- Clique em Adicionar outro papel e selecione Usuário de jobs do BigQuery.
- Clique em Adicionar outro papel e selecione o papel Acessador de secrets do Secret Manager.
- Clique em Adicionar outro papel e selecione Editor.
- Clique em Salvar.
7. Entenda o aplicativo de ponta a ponta
Para saber como cada componente funciona com os outros, vamos criar um aplicativo de e-commerce simples que usa vários bancos de dados e serviços. O aplicativo é criado com um back-end em Python (Flask) e integra vários serviços e bancos de dados do Google Cloud.
Entender a estrutura de diretórios
Na próxima seção, você vai clonar o repositório BRK2-149-multidb-ecommerce e usá-lo para executar o aplicativo localmente. Depois de testar o aplicativo localmente, vamos implantar a caixa de ferramentas do MCP e o aplicativo no Cloud Run.
Confira os arquivos baixados nesse diretório. Estes são os diretórios de alto nível:
UploadImages: armazena recursos de imagem, usados principalmente para documentação ou conteúdo visual do catálogo de produtos de e-commerce.static: armazena os recursos da Web estáticos do aplicativo, como arquivos CSS e JavaScript, usados para estilizar e adicionar interatividade à interface do usuário ( fonte).templates: armazena os modelos HTML (provavelmente Jinja2 para Flask) usados pelo aplicativo Python para renderizar dinamicamente páginas da Web para o catálogo de e-commerce ( fonte).toolbox-implementation: armazena detalhes de configuração e implementação da caixa de ferramentas do Protocolo de Contexto de Modelo (MCP), facilitando interações de banco de dados multidb usando ferramentas predefinidas.
Os arquivos neste repositório trabalham juntos para criar, configurar e implantar um aplicativo de e-commerce multidb. Arquivos centrais, como app.py, orquestram o back-end integrando diversas fontes de dados definidas em arquivos SQL e JSON, enquanto os arquivos de configuração garantem uma implantação perfeita em ambientes de nuvem:
app.py: orquestra o back-end do Flask e as integrações de vários bancos de dados.agentengine.py: lógica principal para inicializar e configurar agentes da Vertex AI..env: armazena segredos para conexões de banco de dados e armazenamento.tools.yaml: configura a MCP Toolbox para operações de banco de dados multidb.Dockerfile: define a imagem do contêiner e a configuração do ambiente.requirements.txt: lista as bibliotecas Python necessárias para a execução do aplicativo.tools.yaml: configurações da MCP Toolbox.Procfile: especifica comandos de execução de produção para implantação.alloydb_insert_queries.sql: contém consultas SQL para dados relacionais.product_details_export.jsoneuser_interactions_export.json: fornecem dados JSON de amostra para o banco de dados NoSQL.README.md: orienta a configuração, a implantação e a compreensão do projeto.
Fluxo de ponta a ponta do aplicativo
- Configuração do AlloyDB: provisione um cluster de alto desempenho e use os scripts SQL fornecidos para criar a products_core_table com colunas de vetor para embeddings de imagem.
- Configuração do MongoDB Atlas: implante um cluster no Google Cloud para armazenar atributos de produtos fluidos em product_details e registrar clickstreams em tempo real em user_interactions.
- BigQuery Analytics: crie um conjunto de dados para agregar registros de interação, permitindo consultas analíticas complexas que identificam os cinco principais itens em alta em milhões de eventos.
- Repositório do Cloud Storage: crie um bucket público para armazenar imagens de produtos em alta resolução, garantindo que cada recurso seja acessível por um URL assinado ou público para o front-end.
- Implantação da MCP Toolbox: implante a caixa de ferramentas no Cloud Run, estabelecendo-a como a ponte RESTful central que traduz a intenção de linguagem natural em consultas de vários bancos de dados.
- Configuração do Tools.yaml: defina suas "Ferramentas", como get_product_core_data ou get_top_5_views, mapeando operações específicas de SQL e NoSQL para nomes simples e legíveis para o agente.
- Lógica de back-end do Flask: implemente rotas app.py que interagem com o MCP Toolbox, processando a coordenação da recuperação de dados e servindo como a API da interface.
- Orquestração multiagente: configure os agentes do ADK no código para entender a intenção do usuário, selecionando a "Ferramenta" certa para resolver consultas complexas de varejo com várias fontes.
- Integração de front-end: crie uma interface index.html com o catálogo de produtos e o recurso de gravação de interações, a guia "Analytics" para entender a análise de performance do produto e uma "Guia do agente" dedicada que usa o chat multiagente do ADK para oferecer uma experiência de compra conversacional integrada.
Agora vamos implementar a orquestração e as implantações.
8. Configurar o MCP Toolbox e implantar no Cloud Run
A MCP Toolbox abstrai nossas várias fontes de dados, permitindo que o aplicativo busque e grave dados de maneira uniforme.
Instalar a MCP Toolbox localmente
- No Cloud Shell, navegue até a pasta
toolbox-implementation:cd next-26-sessions/BRK2-149-multidb-ecommerce/toolbox-implementation - Faça o download do binário da MCP Toolbox e torne-o executável:
export VERSION=0.29.0 curl -L -o toolbox https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox chmod +x toolbox
Configurar tools.yaml
Você precisa definir as abstrações para AlloyDB, MongoDB e BigQuery. O arquivo tools.yaml informa à MCP Toolbox como interagir.
- Crie e edite o arquivo
tools.yamlusando o editor incorporado:cloudshell edit tools.yamltools.yamlcompleto pode ser encontrado no repositório do GitHub. Copie o conteúdo dele para o novo arquivotools.yaml. - Atualize o host, o usuário, as senhas, os IDs do projeto e as strings de conexão para corresponder à infraestrutura provisionada nas etapas anteriores:
Banco de dados
Campo
Valor de exemplo
AlloyDB/BigQuery
project_idYOUR_PROJECT_IDAlloyDB
regionus-central1AlloyDB
clusterecommerce-clusterAlloyDB
instanceecommerce-cluster-primaryAlloyDB
databasepostgresAlloyDB
passwordalloydbMongoDB
connection_stringmongodb+srv://store-user:storeuser@ecommerce-cluster.urcxr6q.mongodb.net
Conceder papéis à conta de serviço do Compute para a caixa de ferramentas do MCP
Concedemos papéis à conta de serviço do Compute usada para nossa caixa de ferramentas. Isso é feito para permitir que o MCP Toolbox acesse o AlloyDB.
- Acesse IAM e administrador.
- Clique em Conceder acesso.
- No campo Novos principais, insira a conta de serviço padrão do Compute Engine chamada
YOUR_PROJECT_NUMBER-compute@developer.gserviceaccount.com. SubstituaYOUR_PROJECT_NUMBERpelo número do seu projeto do Google Cloud. - Clique em Selecionar papel.
- Encontre e selecione a função Editor de dados do BigQuery.
- Clique em Adicionar outro papel e selecione Cliente do AlloyDB.
- Clique em Adicionar outro papel e selecione Consumidor do Service Usage.
- Clique em Adicionar outro papel e selecione o papel Leitor de objetos do Storage.
- Clique em Salvar.
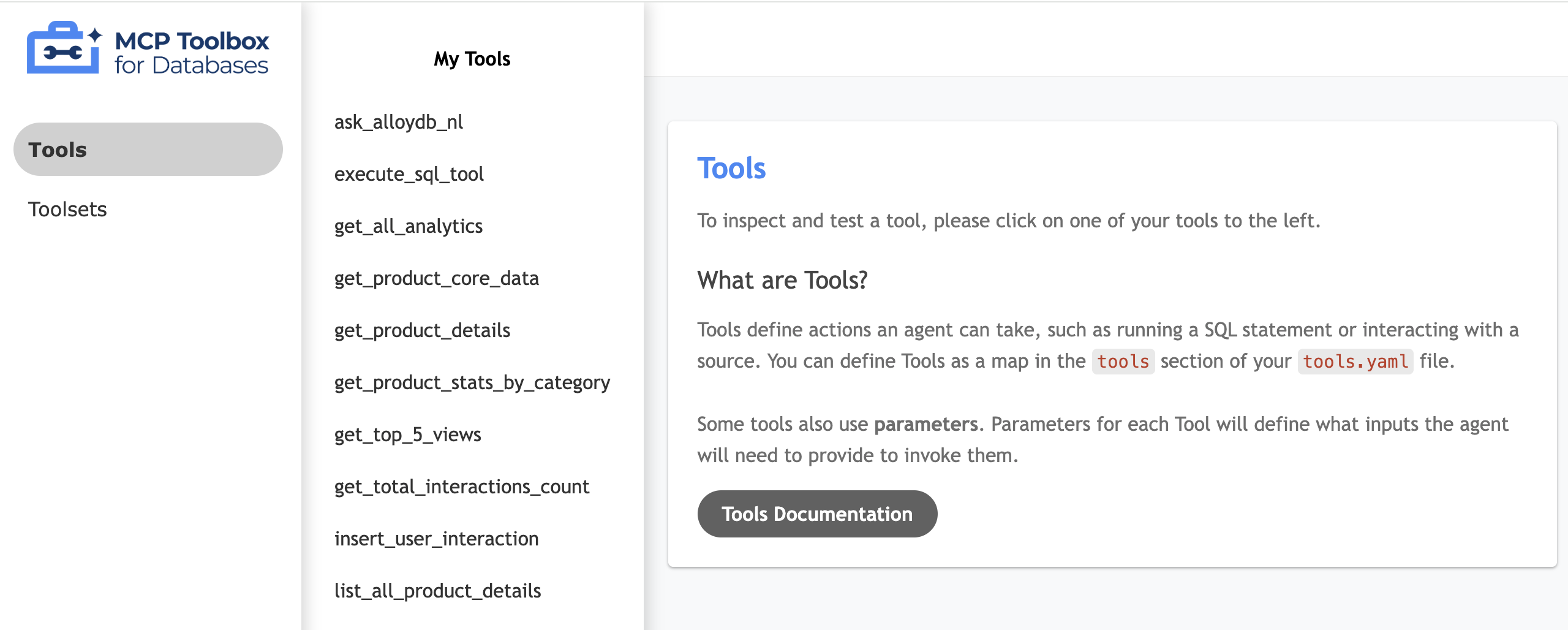
Testar a interface da ferramenta
- No terminal do Cloud Shell, execute a caixa de ferramentas localmente para veicular a interface:
./toolbox --ui - Abra a Visualização na Web no Cloud Shell na porta 5000 e navegue até a página de ferramentas. Por exemplo, dependendo do URL da sessão, você pode conferir em:
https://5000-cs-71152278760-default.cs-asia-southeast1-cash.cloudshell.dev/ui
A seguinte interface da caixa de ferramentas do MCP é exibida:
Implantar no Cloud Run
Implante o MCP Toolbox no Cloud Run para disponibilizá-lo como um serviço gerenciado e seguro que nosso aplicativo pode usar para consultar os bancos de dados. Vamos armazenar a configuração no Secret Manager para proteger detalhes de conexão sensíveis.
- Abra uma nova sessão do Cloud Shell.
- Navegue até a pasta
toolbox-implementation:cd next-26-sessions/BRK2-149-multidb-ecommerce/toolbox-implementation - Faça upload da configuração
tools.yamlpara o Google Secret Manager:gcloud secrets create tools --data-file=tools.yamlgcloud secrets versions add tools --data-file=tools.yaml - Implante usando a imagem pública do contêiner da MCP Toolbox:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:0.29.0 export PROJECT_ID=$(gcloud config get-value project) gcloud run deploy toolbox \ --image $IMAGE \ --region us-central1 \ --service-account $(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")-compute@developer.gserviceaccount.com \ --set-secrets "/app/tools.yaml=tools:latest" \ --args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080","--ui" \ --allow-unauthenticated - Depois da implantação, anote o URL do serviço do Cloud Run fornecido. Ele vai ficar assim:
https://toolbox-*********-uc.a.run.app/ui.
9. Configurar o aplicativo de e-commerce e implantar no Cloud Run
Com os bancos de dados em execução e a abstração da MCP Toolbox implantada, podemos executar o aplicativo da Web Flask.
Para disponibilizar o catálogo de produtos, o aplicativo Flask processa os dados seguindo estas etapas:
- Buscar dados principais: recupera a lista completa de produtos do AlloyDB (
list_products_core). - Buscar detalhes estendidos: recupera todos os detalhes do produto do MongoDB (
list_all_product_details). - Combinar listas: concatena as duas listas.
- Enriquecer com mídia: adiciona o URL da imagem do Cloud Storage a cada item.
Gerar o caminho do aplicativo do Reasoning Engine
Para inicializar e registrar um agente de IA usando o mecanismo de raciocínio da Vertex AI do Google Cloud, execute o seguinte comando:
- No terminal do Cloud Shell, navegue até a pasta
BRK2-149-multidb-ecommerce.cd next-26-sessions/BRK2-149-multidb-ecommerce - Execute o requirements.txt para instalar as dependências.
pip install -r requirements.txt - Execute o script
agentengine.pypara gerar o caminho do aplicativo do Reasoning Engine:python agentengine.py
A saída será semelhante a esta:
projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856
Configurar as variáveis de ambiente
- Crie e edite um arquivo
.env:cloudshell edit .env - Substitua os valores pelas suas conexões de banco de dados específicas e pelo novo URL da caixa de ferramentas do Cloud Run:
# 1. MongoDB Connection String MONGODB_CONNECTION_STRING="mongodb+srv://<db_user>:<db_password>@cluster0.mongodb.net" # 2. MCP Toolbox Server Location # Must match the address where you run the toolbox server MCP_TOOLBOX_SERVER_URL="https://toolbox-*********-uc.a.run.app" # 3. Google Cloud Storage Bucket Name GCS_PRODUCT_BUCKET="ecommerce-app-images" # 4. Fallback image URL FALLBACK_IMAGE_URL="https://storage.googleapis.com/ecommerce-media-bold-circuit-492711-n9/fallback.jpg" # 5. Google Gen AI Vertex AI flag GOOGLE_GENAI_USE_VERTEXAI=TRUE # 6. Project ID PROJECT_ID=codelab-project-491117 # 7. Google Cloud Location of AlloyDB, BigQuery databases GOOGLE_CLOUD_LOCATION=us-central1 # 8. Reasoning engine application path APP_NAME=projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856 # 9. Model ID MODEL=gemini-1.5-flash-lite
Implantar o front-end no Cloud Run
- Implante o aplicativo da Web no Cloud Run para concluir a arquitetura:
gcloud run deploy polyglot --source . --platform managed \ --region us-central1 \ --allow-unauthenticated \ --set-env-vars \ MONGODB_CONNECTION_STRING="<MONGODB_CONNECTION_STRING>", \ MCP_TOOLBOX_SERVER_URL="<MCP_TOOLBOX_SERVER_URL>", \ GCS_PRODUCT_BUCKET="<GCS_PRODUCT_BUCKET>", \ FALLBACK_IMAGE_URL="<FALLBACK_IMAGE_URL>", \ GOOGLE_GENAI_USE_VERTEXAI=TRUE, \ PROJECT_ID="YOUR_PROJECT_ID", \ GOOGLE_CLOUD_LOCATION=us-central1, \ APP_NAME="<YOUR_REASONING_ENGINE_APP_PATH>", \ MODEL="gemini-1.5-flash-lite"YOUR_PROJECT_ID: o ID do projeto do Google Cloud.YOUR_REASONING_ENGINE_APP_PATH: a saída da execução depython agentengine.py, por exemplo,projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856.MCP_TOOLBOX_SERVER_URL: o URL do servidor do MCP Toolbox, por exemplo,https://toolbox-*********-uc.a.run.app.GCS_PRODUCT_BUCKET: o nome do bucket do Google Cloud Storage, por exemplo,ecommerce-app-images.MONGODB_CONNECTION_STRING: a string de conexão do banco de dados do MongoDB, por exemplo,mongodb+srv://store-user:storeuser@ecommerce-cluster.g8vaekh.mongodb.netFALLBACK_IMAGE_URL: o URL da imagem substituta, por exemplo,https://storage.googleapis.com/ecommerce-app-images/fallback.jpg
Seu aplicativo agora está ao vivo. Abra o URL do serviço fornecido pelo Cloud Run para conferir o catálogo de e-commerce multidb. O URL será semelhante a https://polyglot-*********-uc.a.run.app/.
10. Conheça o aplicativo
- Clique em Catálogo de produtos para conferir todos os produtos.
- Clique no ícone de um produto para ver os detalhes dele. Você notará que as imagens são originadas do Cloud Storage, os detalhes do produto são buscados do MongoDB e o inventário de produtos é buscado do AlloyDB.
- Interaja com o catálogo de produtos para gerar visualizações e gravações simuladas enviadas ao MongoDB.
- Clique em ETL e Analytics para conferir a análise de produtos. Você vai notar que as análises de produtos são buscadas no BigQuery.
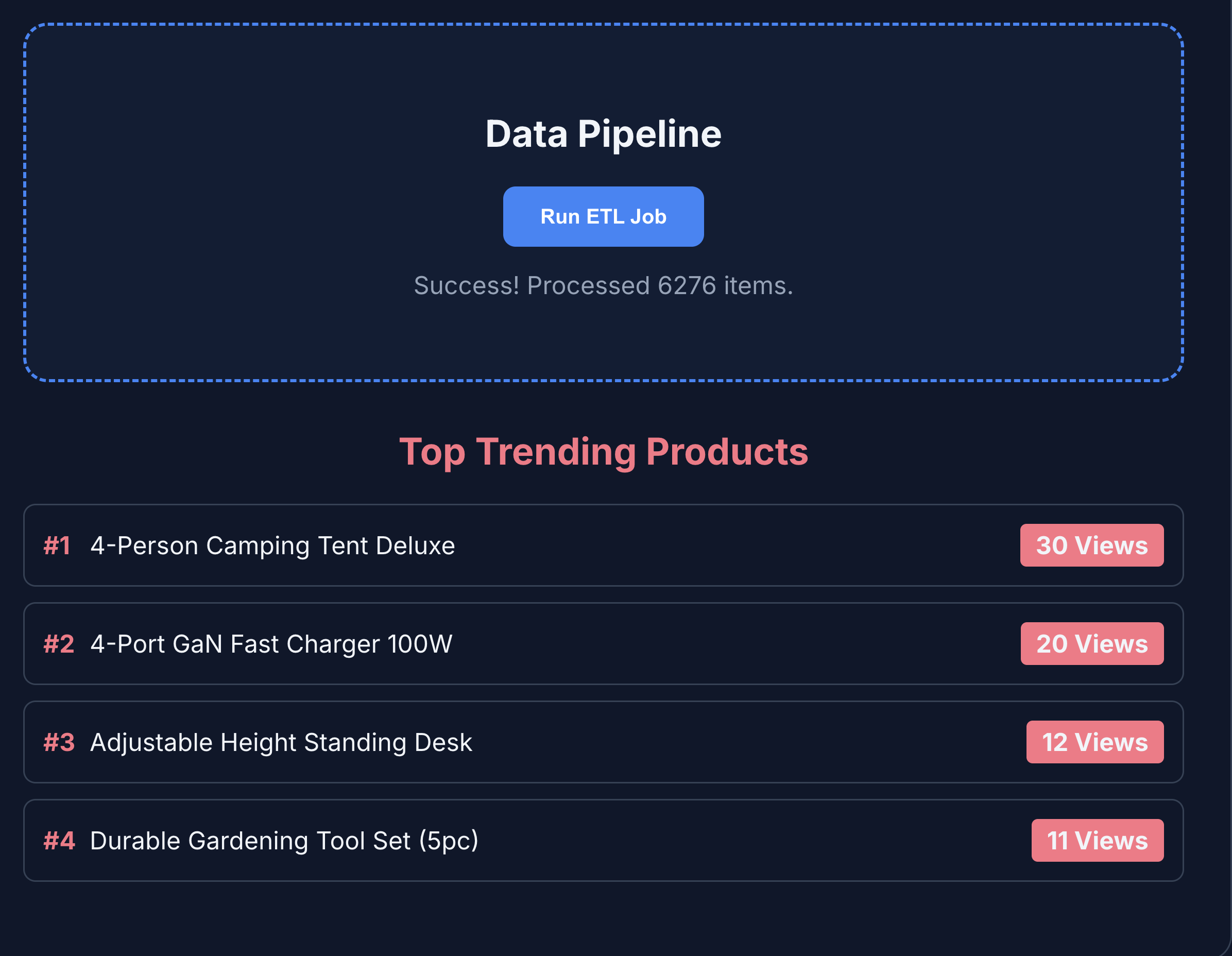
- Clique na guia Agente de IA para interagir com ele. Faça perguntas em linguagem natural, como:
I'm planning a high-altitude photography trip. Show me some weather-resistant backpacks similar in style to aero glow pro but without any leather components. Also, let me know if they are actually in stock and if other photographers have complained about the strap durability in the reviews.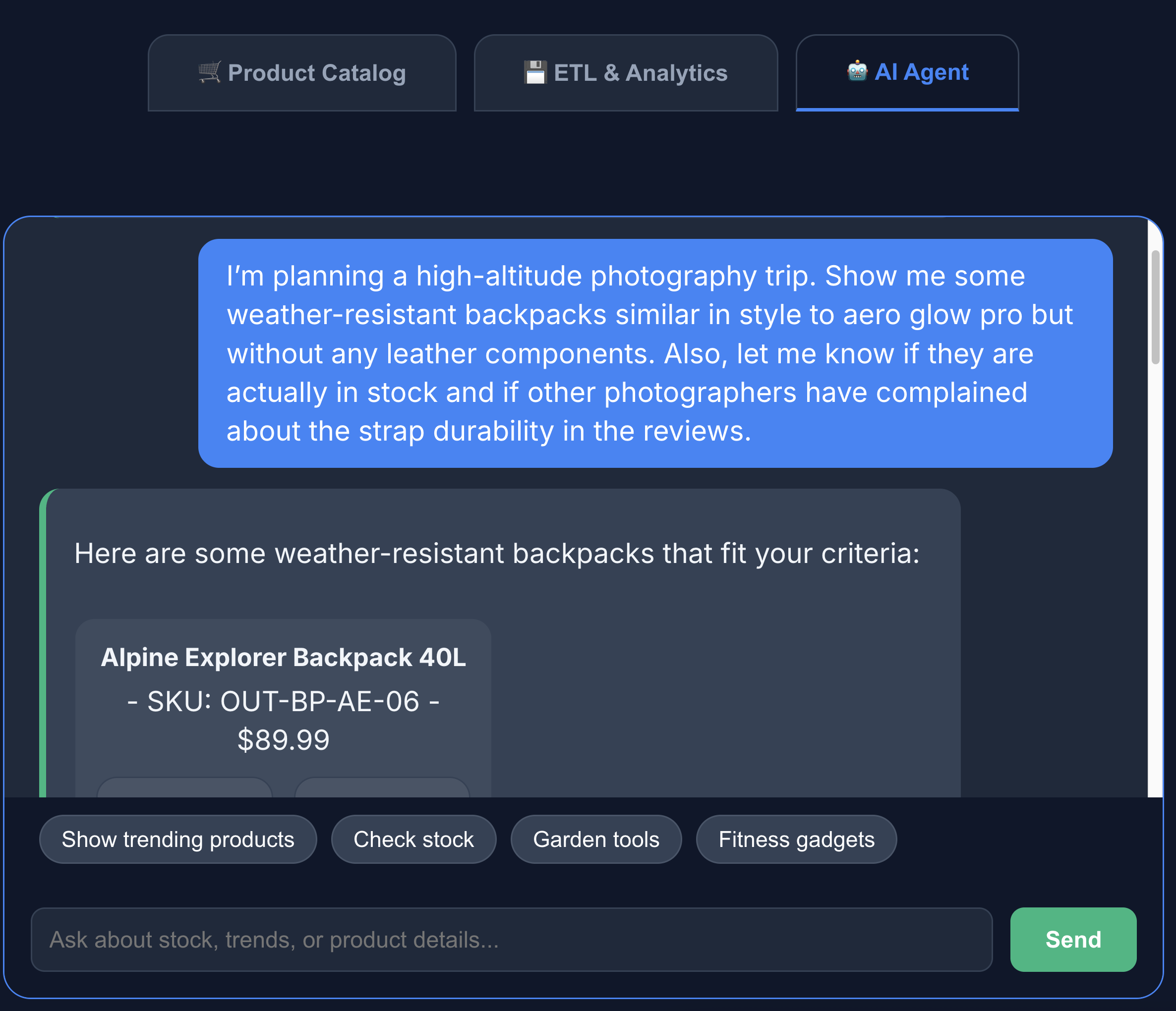
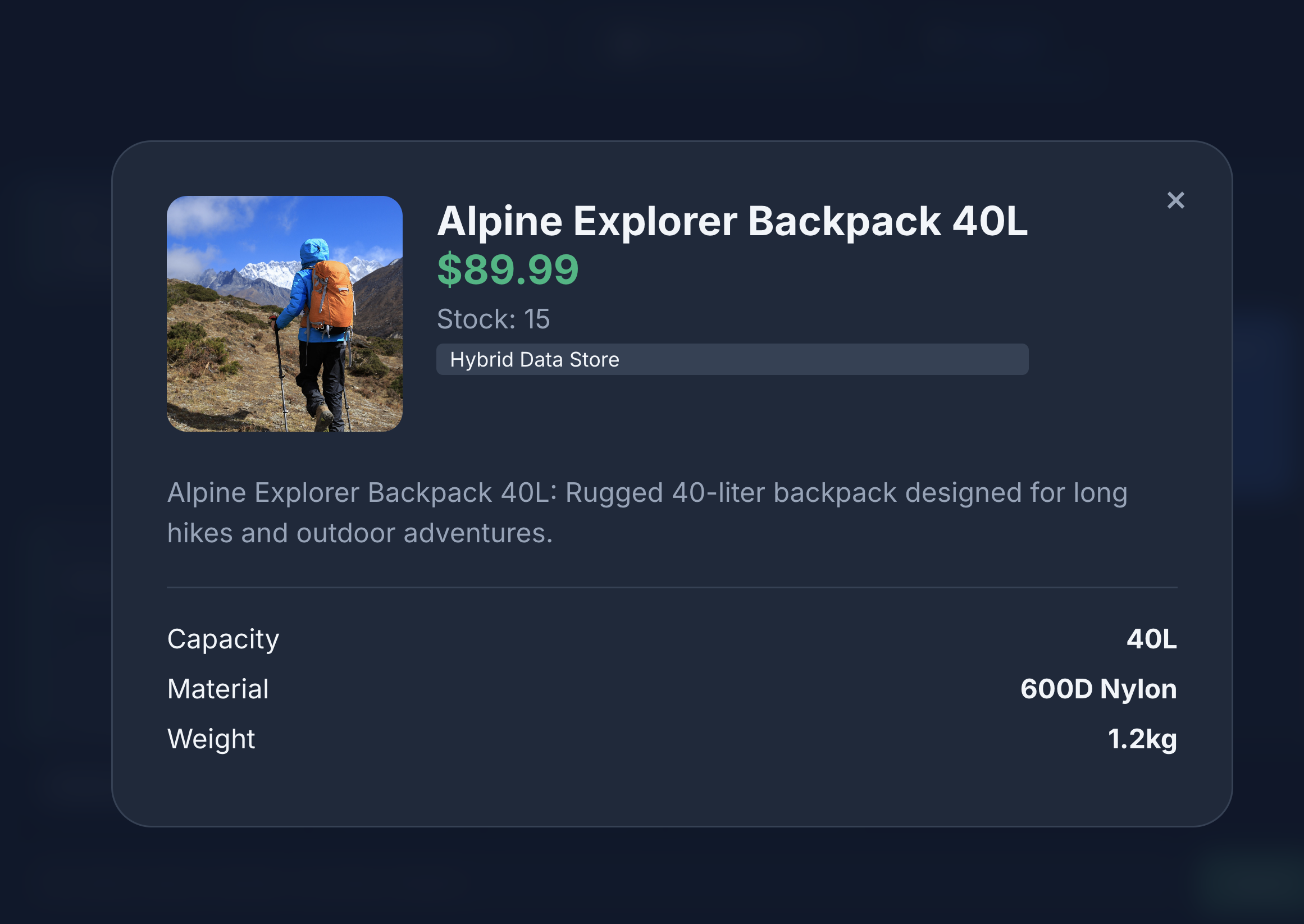
A pesquisa retorna exatamente o que pedimos: uma mochila sem componentes de couro, em estoque e sem reclamações sobre a durabilidade da alça nas avaliações.
11. Limpar
Para evitar cobranças contínuas na sua conta do Google Cloud, exclua os recursos criados durante este codelab.
Execute estes comandos do Cloud Shell:
gcloud run services delete toolbox --region us-central1 --quiet
gcloud run services delete multi-db-app --region us-central1 --quiet
bq rm -r -f -d $PROJECT_ID:ecommerce_analytics
gcloud storage rm --recursive gs://ecommerce-app-images
gcloud alloydb clusters delete ecommerce-cluster --region us-central1 --force --quiet
Opcionalmente, para excluir todo o projeto na nuvem do Google Cloud e todos os recursos dele, execute o seguinte comando:
gcloud projects delete $PROJECT_ID
12. Parabéns
Parabéns! Você criou uma arquitetura multidb entre nuvens.
Você demonstrou como a MCP Toolbox serve como a cola arquitetônica de um aplicativo moderno e especializado. Ao combinar o banco de dados certo com o trabalho certo, você conseguiu:
- Gravações de dados flexíveis: MongoDB para registros de eventos.
- Consistência transacional: AlloyDB para integridade principal.
- Análise de alta performance: BigQuery para business intelligence.
- Desenvolvimento unificado: um único back-end Python que abstrai toda a complexidade usando a caixa de ferramentas do MCP.
Documentos de referência
Saiba mais sobre os produtos relacionados do Google Cloud e confira estes codelabs:
- IA do AlloyDB: Introdução às embedding de vetor com a IA do AlloyDB
- AlloyDB AI: embeddings multimodais no AlloyDB
- MCP Toolbox: Instalar e configurar o MCP Toolbox for Databases no AlloyDB
Para mais informações sobre os produtos usados neste codelab, consulte: