
1. 简介
在现代零售业中,您的数据是一个多样化且庞大的生态系统。您拥有可靠的交易数据(价格和库存)、“杂乱”的多态目录(电子产品规格与服装尺码)以及 PB 级的行为日志。如果强行将这些内容整合到单个单体应用中,不仅会产生技术债务,还会严重影响用户体验。
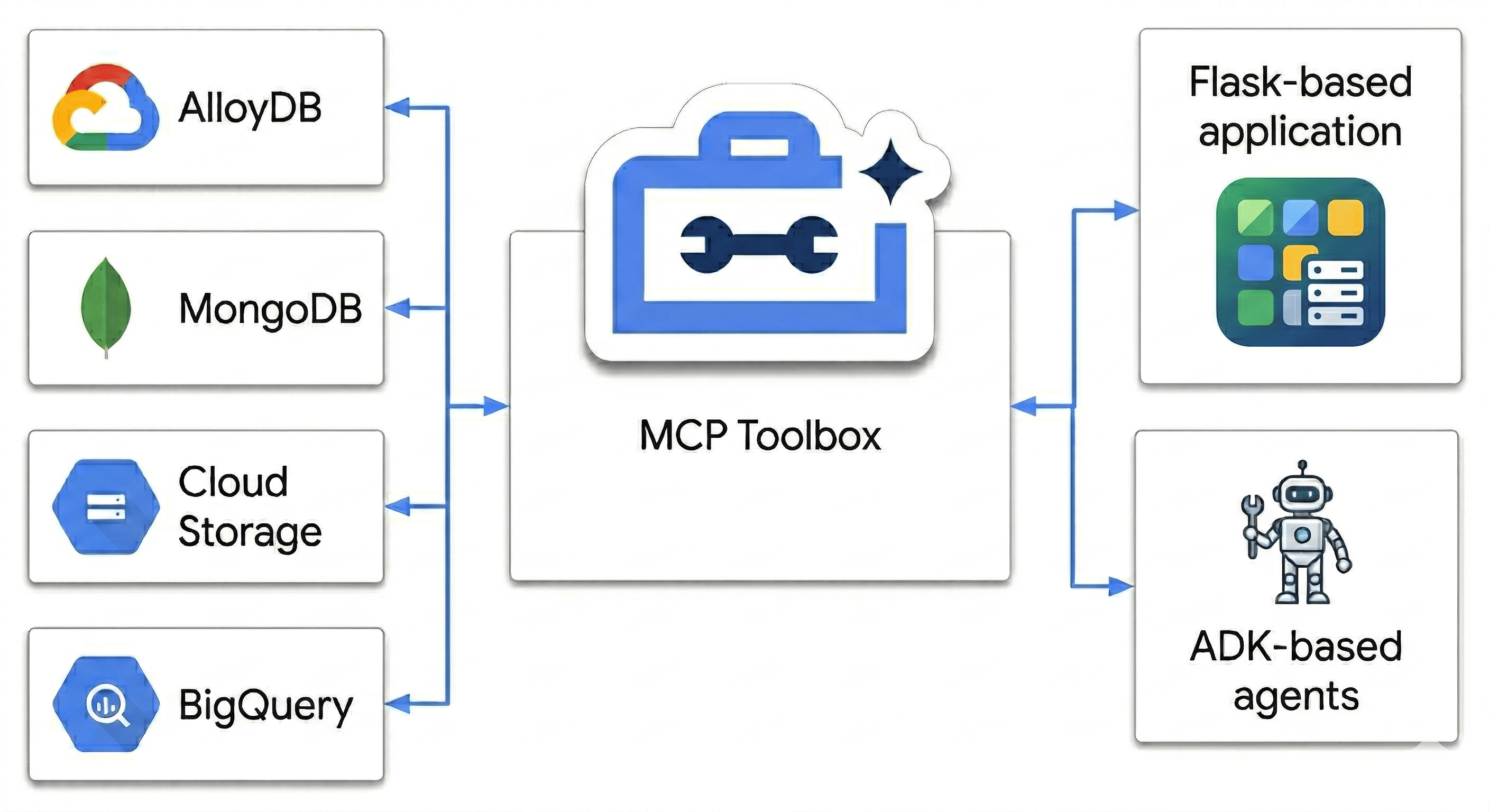
在此 Codelab 中,您将设计一个可协调以下各项的 Polyglot Powerhouse:
- AlloyDB:事务型主干,可实现高速一致性和图片嵌入。
- Google Cloud 上的 MongoDB Atlas:灵活且与架构无关的目录层。
- Cloud Storage:您的分析大脑,可用于实时预测趋势。
- BigQuery:高分辨率数字仓库。
“秘诀”是什么?您将使用 MCP Toolbox for Databases 智能编排和统一在 Cloud Run 上运行的数据源,将其作为语义桥梁,然后使用智能体开发套件 (ADK) 部署多智能体聊天应用。您不仅要构建一个搜索栏,还要构建一个智能零售大脑,它能理解上下文、遵守限制条件,并弥合原始数据与人类意图之间的差距。
不可能的用户查询
标准电子商务代理在多维度推理(结合负面限制、视觉相似性和实时库存)方面表现不佳。例如,我通常希望与这样的零售网站对话:
“嘿,我正在规划一次高海拔摄影之旅。请向我展示一些风格与“AeroGlow Pro”相似但不含任何皮革组件的耐候背包。另外,请告诉我这些商品是否实际有货,以及其他摄影师是否在评价中抱怨过背带的耐用性。”
为什么此查询是“代理杀手”:
- 视觉相似性(AlloyDB + 向量搜索):“风格与 AeroGlow Pro 相似”需要进行图片嵌入比较。
- 否定约束条件 (MongoDB):“不含任何皮革”需要通过灵活的嵌套属性进行过滤,而这些属性通常不在标准 SQL 架构中。
- 实时库存 (AlloyDB):“实际有货”需要进行实时事务性检查(而不是过时的搜索索引)。
- 语义合成(BigQuery + 多智能体):分析有关“表带耐用性”的评价时,智能体需要实时总结来自 BigQuery 的非结构化反馈。
大多数零售聊天机器人只会看到“背包”和“皮革”,然后显示 10 个皮革背包。我们如何阻止这种情况?
因为我们不仅仅是匹配关键字。我们使用 MCP Toolbox 让代理能够同时在所有这些来源(AlloyDB 中的事务性事实和 MongoDB 中的灵活属性)中进行“推理”。让我们来构建它。
您将执行的操作
- 为核心产品数据预配 AlloyDB 集群
- 配置 Google Cloud 上的 MongoDB Atlas 以存储半结构化商品详情
- 创建 Cloud Storage 存储分区以提供商品图片
- 将 MCP Toolbox for Databases 部署到 Cloud Run,以实现统一的数据访问
- 运行 ETL 流程,将数据推送到 BigQuery 以进行分析
- 使用自然语言与 AI 智能体进行对话。
前提条件
- 网络浏览器,例如 Chrome
- 启用了结算功能的 Google Cloud 项目
- 免费的 Google Cloud 上的 MongoDB Atlas 账号
2. 准备工作
创建 Google Cloud 项目
- 在 Google Cloud 控制台的项目选择器页面上,选择或创建一个 Google Cloud 项目。
- 确保您的 Cloud 项目已启用结算功能。了解如何检查项目是否已启用结算功能。
启动 Cloud Shell
Cloud Shell 是在 Google Cloud 中运行的命令行环境,预加载了必要的工具。
- 点击 Google Cloud 控制台顶部的激活 Cloud Shell。
- 连接到 Cloud Shell 后,验证您的身份验证:
gcloud auth list - 确认您的项目已配置:
gcloud config get project - 如果项目未按预期设置,请进行设置:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
启用必需的 API
运行以下命令可启用所有必需的 API:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
3. 设置 Cloud Storage
Cloud Storage 可作为非结构化媒体资产(例如产品图片)的海量存储空间。
- 在 Google Cloud 控制台中,前往 Cloud Storage,然后点击创建存储分区。
- 为存储分区指定一个全局唯一的名称(例如
ecommerce-app-images)。 - 点击创建。
- 如需允许演示应用在未经身份验证的情况下访问图片,请清除禁止公开访问此存储分区选项,然后点击确认。
- 前往权限标签页。
- 在权限中,点击授予访问权限。
- 在新主账号中,输入
allUsers。 - 在选择角色中,选择 Cloud Storage > Storage Object User。
- 点击保存,然后点击允许公开访问,确认要将资源设为公开。
上传占位图片
BRK2-149-multidb-ecommerce 使用占位图片来提供最佳视觉体验。
- 在 Cloud Shell 中,克隆
next-26-sessions代码库:git clone https://github.com/GoogleCloudPlatform/next-26-sessions.git - 转到
UploadImages文件夹:cd next-26-sessions/BRK2-149-multidb-ecommerce/UploadImages - 在 Google Cloud 控制台中,前往 Cloud Storage,然后点击存储分区。
- 点击您新创建的存储分区的名称。
- 依次点击上传 > 上传文件,选择下载的示例图片,然后点击打开。
4. 设置 AlloyDB
AlloyDB 可作为结构化、事务型关键数据(例如产品 ID、名称、SKU、价格和库存)的唯一可信来源。AlloyDB 还为 AI 智能体提供相似度搜索功能,以用于推荐和自然语言查询。
预配 AlloyDB 集群
- 在 Google Cloud 控制台中,前往 AlloyDB for PostgreSQL。
- 点击创建集群。
- 在集群 ID 部分,输入
ecommerce-cluster。 - 为
postgres用户设置安全系数高的密码。出于学习目的,您可以使用alloydb。 - 对于数据库版本,保留默认值。
- 对于区域,选择
us-central1(或您的首选区域)。
配置主实例
- 在实例 ID 部分,输入
ecommerce-cluster-primary。 - 在可用区级可用性中,选择单个可用区。
- 对于机器类型,选择小型机器类型(例如 N2、4 个 vCPU、32 GB RAM)。
- 在专用 IP 连接中,选择专用服务访问通道 (PSA),然后选择
default网络。如果尚未设置默认网络,请点击确认网络设置以创建一个。 - 在公共 IP 连接中,选中 Enable Public IP 复选框,以便 MCP 工具箱在此 Codelab 中正常连接。
- 在授权外部网络中,输入
0.0.0.0/0。选中我确认了解相关风险复选框,然后点击保存。 - 点击创建集群。
注意:请务必记下您的公共 IP 地址(它看起来类似于 34.124.240.26)。
初始化数据库
- 点击左侧导航菜单中的 AlloyDB Studio。
- 在数据库下拉菜单中,选择
postgres。 - 选择内置身份验证以登录数据库。
- 对于用户名,请使用
postgres用户。 - 在密码部分,输入您之前设置的密码。
- 点击身份验证。
- 在编辑器视图中,打开新的未命名查询标签页。
- 复制以下 DDL,然后点击运行:
CREATE TABLE products_core_table ( product_id UUID PRIMARY KEY, name VARCHAR(255) NOT NULL, sku VARCHAR(50) UNIQUE NOT NULL, price NUMERIC(10, 2) NOT NULL, stock INT NOT NULL ); - 在 Cloud Shell 中,前往
BRK2-149-multidb-ecommerce文件夹:cd next-26-sessions/BRK2-149-multidb-ecommerce - 在 Cloud Shell 中打开
alloydb_insert_queries.sql文件,然后复制插入查询。cat alloydb_insert_queries.sql - 在新的未命名查询标签页中,仅粘贴
INSERT语句,然后点击运行。 - 在新的“未命名的查询”标签页中,复制以下 DDL,然后点击运行以在
products_core_table表上创建索引:CREATE INDEX idx_products_core_sku ON products_core_table(sku);
为 AI 智能体创建图片嵌入,以便提取类似商品
AI 智能体集成使用图片嵌入来提取类似产品。嵌入是使用 multimodalembedding@001 模型生成的,并存储在 AlloyDB 数据库中。嵌入是 1408 维向量,存储在 img_embeddings 列中。
在生成嵌入之前,我们必须向 AlloyDB 服务账号授予访问 Cloud Storage 所需的角色。
向 AlloyDB 服务账号授予访问 Cloud Storage 的角色
我们向 AlloyDB 服务账号授予 Storage Object User 和 Storage Object Viewer 角色,以使其能够从 Cloud Storage 存储分区中读取对象。
- 前往 IAM 和管理。
- 点击授予访问权限。
- 在新的主账号字段中,输入 AlloyDB 服务账号。服务账号类似于
service-991742412753@gcp-sa-alloydb.iam.gserviceaccount.com。 - 点击选择角色。
- 找到并选择 Storage Object User 角色。
- 点击添加其他角色,然后选择 Storage Object Viewer 角色。
- 点击添加其他角色,然后选择 Vertex AI User 角色。
- 点击保存。
启用扩展程序
在构建此应用时,我们将使用扩展程序 pgvector 和 google_ml_integration。借助 pgvector 扩展程序,您可以存储和搜索向量嵌入。google_ml_integration 扩展程序提供了一些函数,您可以使用这些函数访问 Vertex AI 预测端点,以在 SQL 中获取预测结果。运行以下 DDL 以启用这些扩展程序:
- 在 Google Cloud 控制台中,前往 AlloyDB for PostgreSQL。
- 点击左侧导航菜单中的 AlloyDB Studio。
- 在编辑器视图中,打开新的未命名查询标签页。
- 复制以下 DDL,然后点击运行:
CREATE EXTENSION IF NOT EXISTS vector; CREATE EXTENSION IF NOT EXISTS google_ml_integration;
使用嵌入初始化数据库
- 将 img_embeddings 列添加到
products_core_table。ALTER TABLE products_core_table ADD COLUMN img_embeddings vector(1408); - 为图片生成嵌入向量,并将其存储在
img_embeddings列中。UPDATE products_core_table SET img_embeddings = google_ml.image_embedding( model_id => 'multimodalembedding@001', image => 'gs://<STORAGE_BUCKET_NAME>/' || sku || '.jpg', mimetype => 'image/jpeg') WHERE sku IN ( SELECT sku FROM products_core_table WHERE img_embeddings IS NULL AND sku IS NOT NULL LIMIT 10 ); - 至少重复运行上述查询 5 次,以生成整个数据集的图片嵌入内容,因为 Studio 有 5 分钟的限制。如果此查询超时,请将
LIMIT更改为5,然后重新运行查询 10 次。此步骤可能需要几分钟才能完成。
5. 在 Google Cloud 上设置 MongoDB Atlas
MongoDB 可存储丰富的半结构化商品详情和灵活的用户行为数据(例如点击和浏览)。\
创建 MongoDB 集群
- 前往 Google Cloud 上的 MongoDB Atlas,选择一个免费层级账号。
- 选择免费集群层级,然后输入集群的名称,例如
ecommerce-cluster。 - 选择 Google Cloud 作为提供方,并确保区域与您的 Google Cloud 区域(例如
us-central1)一致。 - 点击创建部署。
- 点击关闭。
配置网络访问权限
- 在 Atlas 控制台中,前往 Database & Network Access。
- 点击 IP 访问列表。
- 点击添加 IP 地址。
- 添加了
0.0.0.0/0,允许从任何位置进行访问。 - 点击确认。
创建数据库用户
- 在 Atlas 控制台中,前往 Database & Network Access。
- 点击数据库用户。
- 点击添加新的数据库用户。
- 选择密码作为身份验证方法。
- 输入用户名
store-user和密码storeuser。 - 点击 Add Built In Role,然后选择 Read and write to any database。
- 点击添加用户。
获取连接字符串
- 依次前往数据库 > 集群 > 连接。
- 在关联您的应用中,点击驱动程序。
- 复制将连接字符串添加到应用代码中中显示的连接字符串。该字符串大致如下所示:
mongodb+srv://store-user:<db_password>@ecommerce-cluster.g8vaekh.mongodb.net/?appName=ecommerce-clusterdb_password替换为您的 MongoDB 密码。在此 Codelab 中,该值为storeuser。
保存此连接字符串。您稍后将使用它来设置 MONGODB_CONNECTION_STRING 环境变量。
创建数据库和集合
- 在 Atlas 控制台中,依次前往数据库 > 集群 > 浏览集合。
- 点击创建数据库,然后输入以下详细信息:
- 数据库名称:
ecommerce_db - 集合名称:
product_details_collection
- 数据库名称:
- 点击创建数据库。
- 在数据探索器中,选择集合名称。
- 点击添加数据 (+) 图标,然后点击插入文档。
- 从 product_details_export.json 中复制 JSON 内容,并将其粘贴到插入文档编辑器对话框中。
- 点击 Insert 插入文档数组,并验证是否添加了 192 个文档。
- 在数据探索器中,点击
ecommerce_db数据库旁边的创建集合 (+)。 - 输入
user_interactions_collection作为集合名称,然后点击创建集合。 - 在数据探索器中,选择
user_interactions_collection集合。 - 点击添加数据 (+) 图标,然后点击插入文档。
- 从 user_interactions_export.json 中复制 JSON 内容,并将其粘贴到插入文档编辑器对话框中。
- 点击插入文档。
6. 设置 BigQuery
BigQuery 会汇总和分析历史用户行为,以生成智能报告和建议。
创建数据集
- 在 Google Cloud 控制台中,前往 BigQuery。
- 在“探索器”窗格中,点击项目 ID 旁边的三点状菜单,然后选择创建数据集。
- 在数据集 ID 部分,输入
ecommerce_analytics。 - 点击创建数据集。
创建 Analytics 表
- 在 BigQuery 工作区中打开新查询。
- 运行以下 SQL 语句以创建将用户与产品互动相关联的汇总表:
CREATE TABLE ecommerce_analytics.user_product_interactions (
user_id STRING DEFAULT 'any user',
product_id STRING,
interaction_score INT
);
向 MCP Toolbox 的 Compute 服务账号授予角色
我们会向用于工具箱的 Compute 服务账号授予角色。这样做是为了让 MCP Toolbox 能够访问 BigQuery、Secret Manager 和其他云服务。
如需授予角色,请完成以下步骤:
- 前往 IAM 和管理。
- 点击授予访问权限。
- 在新的主账号字段中,输入名为
YOUR_PROJECT_NUMBER-compute@developer.gserviceaccount.com的默认 Compute 服务账号。将YOUR_PROJECT_NUMBER替换为您的 Google Cloud 项目编号。 - 点击选择角色。
- 找到并选择 BigQuery Data Editor 角色。
- 点击添加其他角色,然后选择 BigQuery Job User 角色。
- 点击添加其他角色,然后选择 Secret Manager Secret Accessor 角色。
- 点击添加其他角色,然后选择编辑者角色。
- 点击保存。
7. 了解应用的端到端流程
为了解每个组件如何相互协作,我们将创建一个使用多个数据库和服务的简单电子商务应用。该应用采用 Python (Flask) 后端构建,并集成了多项 Google Cloud 服务和数据库。
了解目录结构
在下一部分中,您将克隆 BRK2-149-multidb-ecommerce 代码库并使用它在本地运行应用。在本地测试应用后,我们将 MCP Toolbox 和应用都部署到 Cloud Run。
探索此目录中的下载文件。存在以下高级别目录:
UploadImages:存储图片资源,主要用于电子商务产品目录的文档或视觉内容。static:存储应用的静态 Web 资源,例如用于设置用户界面样式和添加互动性的 CSS 和 JavaScript 文件(来源)。templates:存储 Python 应用使用的 HTML 模板(可能是 Flask 的 Jinja2),用于动态呈现电子商务目录的网页(来源)。toolbox-implementation:存储 Model Context Protocol (MCP) Toolbox 的配置和实现详细信息,以便使用预定义工具进行多数据库交互。
此代码库中的文件协同工作,以构建、配置和部署多数据库电子商务应用。app.py 等中心文件通过集成 SQL 和 JSON 文件中定义的不同数据源来编排后端,而配置文件则确保无缝部署到云环境:
app.py:用于编排 Flask 后端和多数据库集成。agentengine.py:用于初始化和配置 Vertex AI 智能体的核心逻辑。.env:存储数据库和存储连接的 Secret。tools.yaml:配置 MCP Toolbox 以进行多数据库操作。Dockerfile:定义容器映像和环境设置。requirements.txt:列出应用运行时所需的 Python 库。tools.yaml:MCP Toolbox 的配置。Procfile:指定部署的生产执行命令。alloydb_insert_queries.sql:包含关系数据的 SQL 查询。product_details_export.json和user_interactions_export.json:为 NoSQL 数据库提供示例 JSON 数据。README.md:指导设置、部署和项目理解。
应用的端到端流程
- AlloyDB 设置:预配高性能集群,并使用提供的 SQL 脚本创建包含图片嵌入向量列的 products_core_table。
- MongoDB Atlas 设置:在 Google Cloud 上部署集群,以在 product_details 中存储动态商品属性,并在 user_interactions 中记录实时点击流。
- BigQuery Analytics:创建一个数据集来汇总互动日志,从而实现复杂的分析查询,以识别数百万个事件中的“前 5 名”热门商品。
- Cloud Storage 代码库:创建一个公共存储分区来存放高分辨率商品图片,确保每个素材资源都可以通过签名网址或公共网址供前端访问。
- MCP Toolbox 部署:将 Toolbox 部署到 Cloud Run,将其确立为中央 RESTful 桥梁,用于将自然语言意图转换为多数据库查询。
- Tools.yaml 配置:定义您的“工具”,例如 get_product_core_data 或 get_top_5_views,将特定的 SQL 和 NoSQL 操作映射到简单且代理可读的名称。
- Flask 后端逻辑:实现与 MCP Toolbox 交互的 app.py 路由,处理数据检索的协调工作,并充当界面 API。
- 多智能体编排:在代码中配置 ADK 智能体,以推理用户意图,选择合适的“工具”来解决复杂的多来源零售查询。
- 前端集成:构建一个 index.html 界面,其中包含具有互动记录功能的产品目录、用于了解产品效果分析的“分析”标签页,以及一个使用 ADK 多智能体聊天功能的专用“智能体”标签页,以提供顺畅的对话式购物体验。
现在,我们来实现编排和部署。
8. 设置 MCP Toolbox 并部署到 Cloud Run
MCP Toolbox 可抽象出我们的多个数据源,让应用能够以统一的方式提取和写入数据。
在本地安装 MCP Toolbox
- 在 Cloud Shell 中,前往
toolbox-implementation文件夹:cd next-26-sessions/BRK2-149-multidb-ecommerce/toolbox-implementation - 下载 MCP Toolbox 二进制文件并使其可执行:
export VERSION=0.29.0 curl -L -o toolbox https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox chmod +x toolbox
配置 tools.yaml
您需要为 AlloyDB、MongoDB 和 BigQuery 定义抽象。tools.yaml 文件用于告知 MCP Toolbox 各个工具之间的交互方式。
- 使用嵌入式编辑器创建和修改文件
tools.yaml:cloudshell edit tools.yamltools.yaml文件可在 GitHub 代码库中找到。将其内容复制到新的tools.yaml文件中。 - 更新主机、用户、密码、项目 ID 和连接字符串,以与您在之前的步骤中预配的基础设施相匹配:
数据库
字段
示例值
AlloyDB/BigQuery
project_idYOUR_PROJECT_IDAlloyDB
regionus-central1AlloyDB
clusterecommerce-clusterAlloyDB
instanceecommerce-cluster-primaryAlloyDB
databasepostgresAlloyDB
passwordalloydbMongoDB
connection_stringmongodb+srv://store-user:storeuser@ecommerce-cluster.urcxr6q.mongodb.net
向 MCP Toolbox 的 Compute 服务账号授予角色
我们会向用于工具箱的 Compute 服务账号授予角色。这样做是为了让 MCP Toolbox 能够访问 AlloyDB。
- 前往 IAM 和管理。
- 点击授予访问权限。
- 在新的主账号字段中,输入名为
YOUR_PROJECT_NUMBER-compute@developer.gserviceaccount.com的默认 Compute 服务账号。将YOUR_PROJECT_NUMBER替换为您的 Google Cloud 项目编号。 - 点击选择角色。
- 找到并选择 BigQuery Data Editor 角色。
- 点击添加其他角色,然后选择 AlloyDB Client 角色。
- 点击添加其他角色,然后选择 Service Usage Consumer 角色。
- 点击添加其他角色,然后选择 Storage Object Viewer 角色。
- 点击保存。
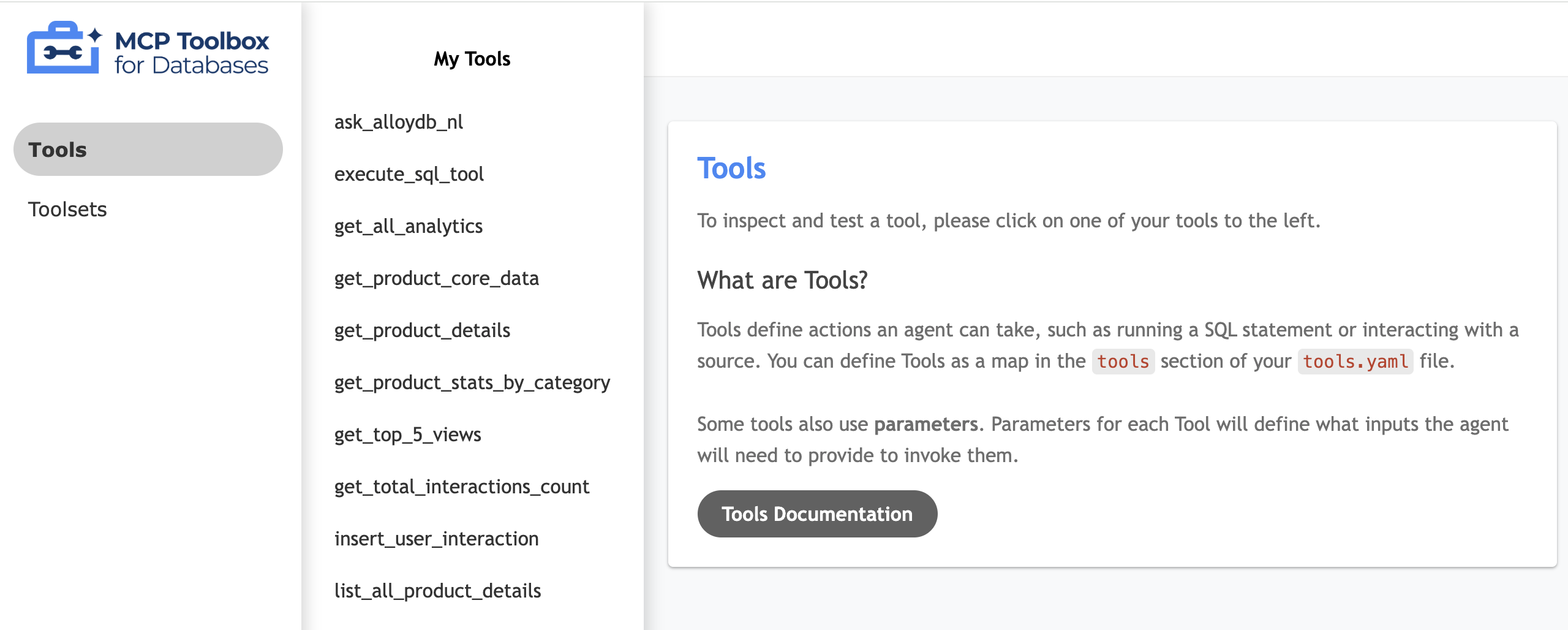
测试工具界面
- 在 Cloud Shell 终端中,在本地运行该工具箱以提供界面:
./toolbox --ui - 在 Cloud Shell 中打开端口 5000 上的网页预览,然后前往工具页面。例如,您可以访问以下网址来查看会话网址:
https://5000-cs-71152278760-default.cs-asia-southeast1-cash.cloudshell.dev/ui
系统会显示以下 MCP 工具箱界面:
部署到 Cloud Run
将 MCP Toolbox 部署到 Cloud Run,使其作为安全托管式服务供我们的应用用于查询数据库。我们将配置存储在 Secret Manager 中,以保护敏感的连接详细信息。
- 打开新的 Cloud Shell 会话。
- 转到
toolbox-implementation文件夹:cd next-26-sessions/BRK2-149-multidb-ecommerce/toolbox-implementation - 将
tools.yaml配置上传到 Google Secret Manager:gcloud secrets create tools --data-file=tools.yamlgcloud secrets versions add tools --data-file=tools.yaml - 使用公开的 MCP Toolbox 容器映像进行部署:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:0.29.0 export PROJECT_ID=$(gcloud config get-value project) gcloud run deploy toolbox \ --image $IMAGE \ --region us-central1 \ --service-account $(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")-compute@developer.gserviceaccount.com \ --set-secrets "/app/tools.yaml=tools:latest" \ --args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080","--ui" \ --allow-unauthenticated - 部署完成后,记下提供的 Cloud Run 服务网址。其格式应为
https://toolbox-*********-uc.a.run.app/ui。
9. 设置电子商务应用并将其部署到 Cloud Run
在数据库运行且 MCP Toolbox 抽象层部署完毕后,我们就可以运行 Flask Web 应用了!
为了提供产品目录,Flask 应用会通过执行以下步骤来处理数据:
- 提取核心数据:从 AlloyDB (
list_products_core) 中检索完整的产品列表。 - 提取扩展详情:从 MongoDB (
list_all_product_details) 中检索所有商品详情。 - 合并名单:将两个名单串联起来。
- 添加媒体内容:将 Cloud Storage 图片网址添加到每个商品中。
生成推理引擎应用路径
如需使用 Google Cloud 的 Vertex AI Reasoning Engine 初始化并注册 AI 智能体,请运行以下命令:
- 在 Cloud Shell 终端中,前往
BRK2-149-multidb-ecommerce文件夹。cd next-26-sessions/BRK2-149-multidb-ecommerce - 运行 requirements.txt 以安装依赖项
pip install -r requirements.txt - 运行
agentengine.py脚本以生成推理引擎应用路径:python agentengine.py
输出将如下所示:
projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856
配置环境变量
- 创建
.env文件并对其进行修改:cloudshell edit .env - 将这些值替换为您的特定数据库连接和新的 Cloud Run Toolbox 网址:
# 1. MongoDB Connection String MONGODB_CONNECTION_STRING="mongodb+srv://<db_user>:<db_password>@cluster0.mongodb.net" # 2. MCP Toolbox Server Location # Must match the address where you run the toolbox server MCP_TOOLBOX_SERVER_URL="https://toolbox-*********-uc.a.run.app" # 3. Google Cloud Storage Bucket Name GCS_PRODUCT_BUCKET="ecommerce-app-images" # 4. Fallback image URL FALLBACK_IMAGE_URL="https://storage.googleapis.com/ecommerce-media-bold-circuit-492711-n9/fallback.jpg" # 5. Google Gen AI Vertex AI flag GOOGLE_GENAI_USE_VERTEXAI=TRUE # 6. Project ID PROJECT_ID=codelab-project-491117 # 7. Google Cloud Location of AlloyDB, BigQuery databases GOOGLE_CLOUD_LOCATION=us-central1 # 8. Reasoning engine application path APP_NAME=projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856 # 9. Model ID MODEL=gemini-1.5-flash-lite
将前端部署到 Cloud Run
- 将 Web 应用部署到 Cloud Run 以完成架构:
gcloud run deploy polyglot --source . --platform managed \ --region us-central1 \ --allow-unauthenticated \ --set-env-vars \ MONGODB_CONNECTION_STRING="<MONGODB_CONNECTION_STRING>", \ MCP_TOOLBOX_SERVER_URL="<MCP_TOOLBOX_SERVER_URL>", \ GCS_PRODUCT_BUCKET="<GCS_PRODUCT_BUCKET>", \ FALLBACK_IMAGE_URL="<FALLBACK_IMAGE_URL>", \ GOOGLE_GENAI_USE_VERTEXAI=TRUE, \ PROJECT_ID="YOUR_PROJECT_ID", \ GOOGLE_CLOUD_LOCATION=us-central1, \ APP_NAME="<YOUR_REASONING_ENGINE_APP_PATH>", \ MODEL="gemini-1.5-flash-lite"YOUR_PROJECT_ID:您的 Google Cloud 项目 ID。YOUR_REASONING_ENGINE_APP_PATH:运行python agentengine.py的输出,例如projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856。MCP_TOOLBOX_SERVER_URL:MCP Toolbox 服务器的网址,例如https://toolbox-*********-uc.a.run.app。GCS_PRODUCT_BUCKET:Google Cloud Storage 存储分区的名称,例如ecommerce-app-images。MONGODB_CONNECTION_STRING:MongoDB 数据库的连接字符串,例如mongodb+srv://store-user:storeuser@ecommerce-cluster.g8vaekh.mongodb.netFALLBACK_IMAGE_URL:后备图片的网址,例如https://storage.googleapis.com/ecommerce-app-images/fallback.jpg
您的应用现已上线!打开 Cloud Run 提供的服务网址,查看 Multidb 电子商务目录。网址将类似于 https://polyglot-*********-uc.a.run.app/。
10. 探索应用
- 点击商品目录可查看所有商品。
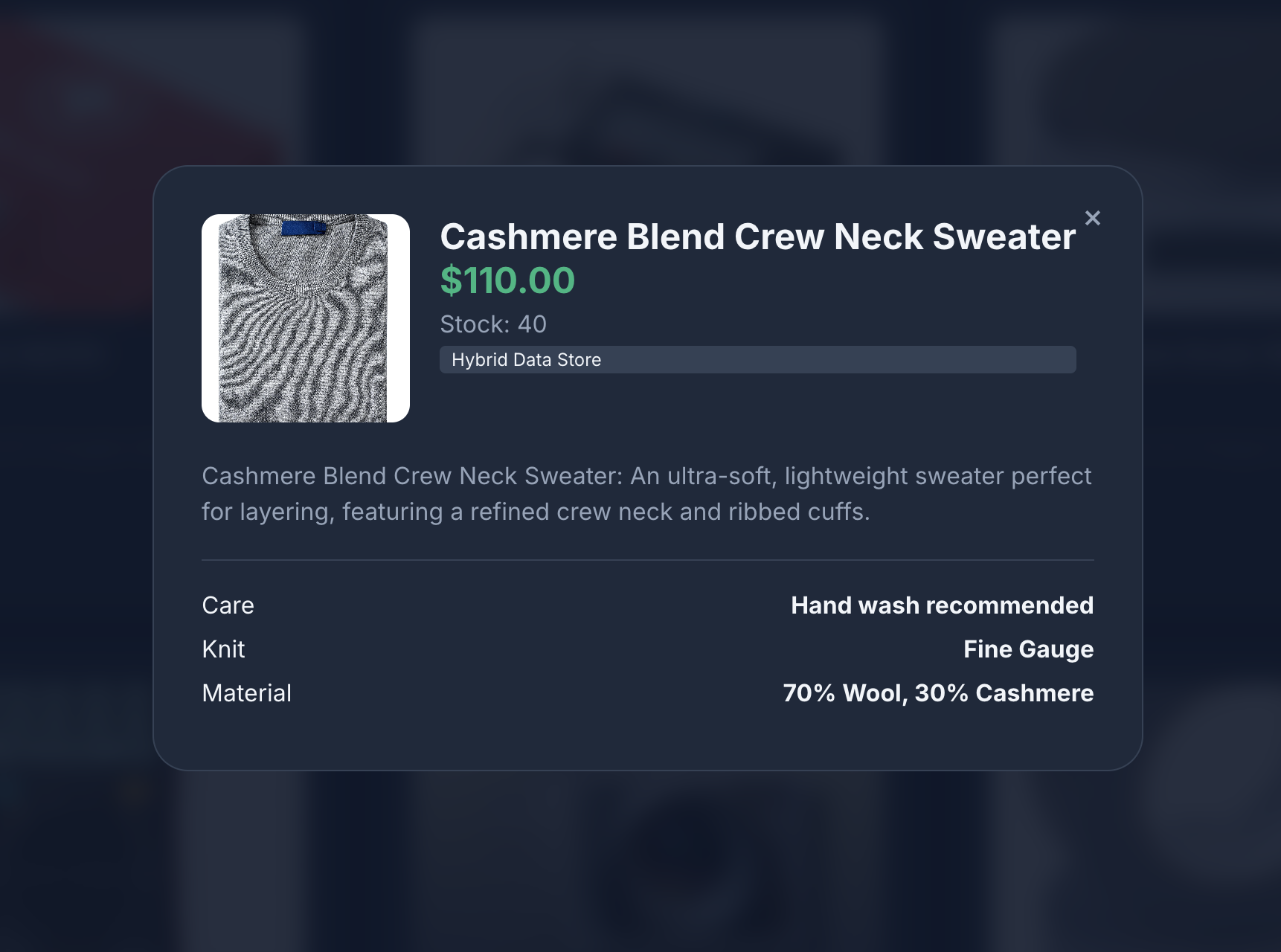
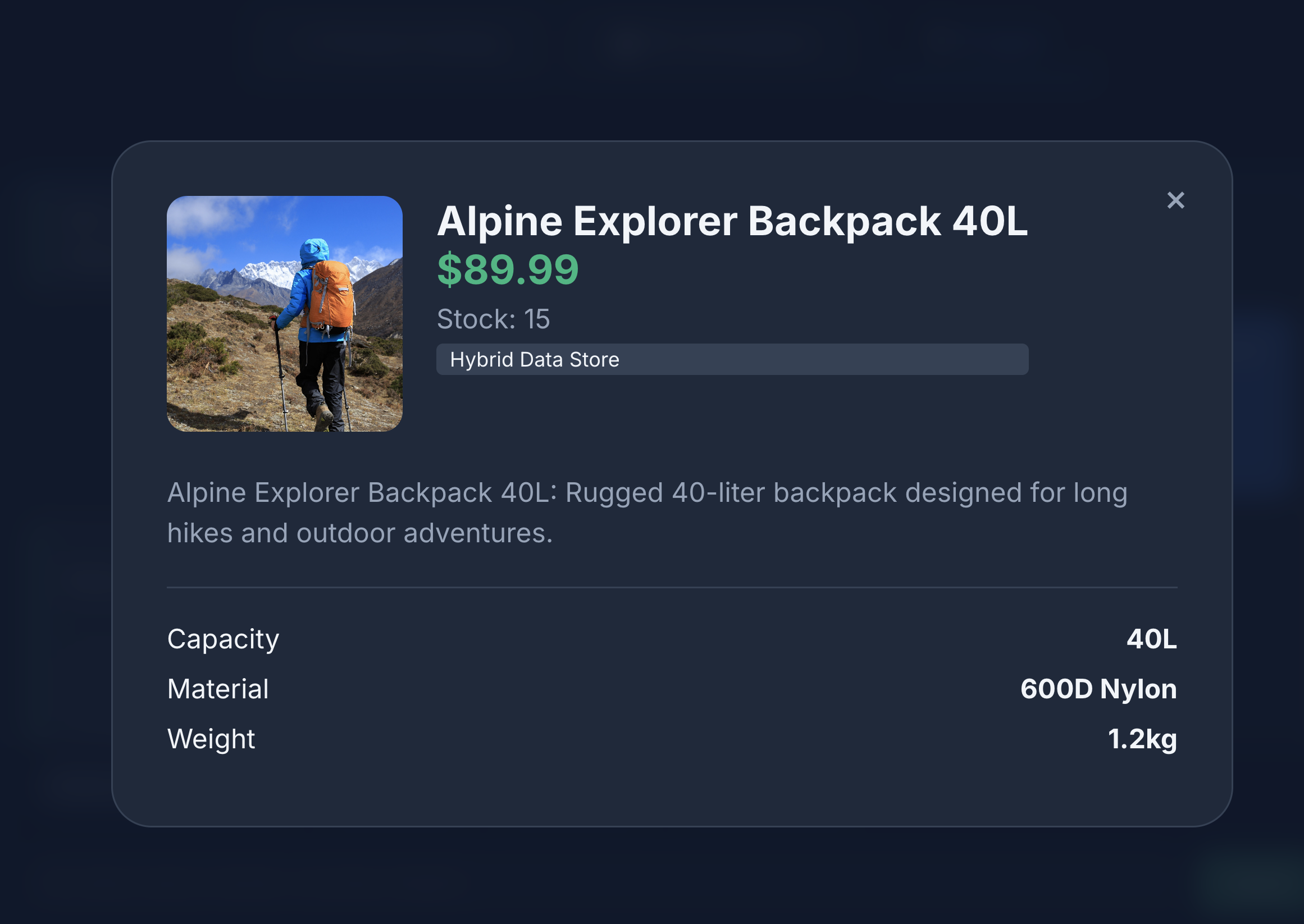
- 点击商品图标,查看商品详情。您会发现,图片来自 Cloud Storage,商品详情来自 MongoDB,商品目录来自 AlloyDB。
- 与商品目录互动,以生成发送到 MongoDB 的模拟观看和写入。
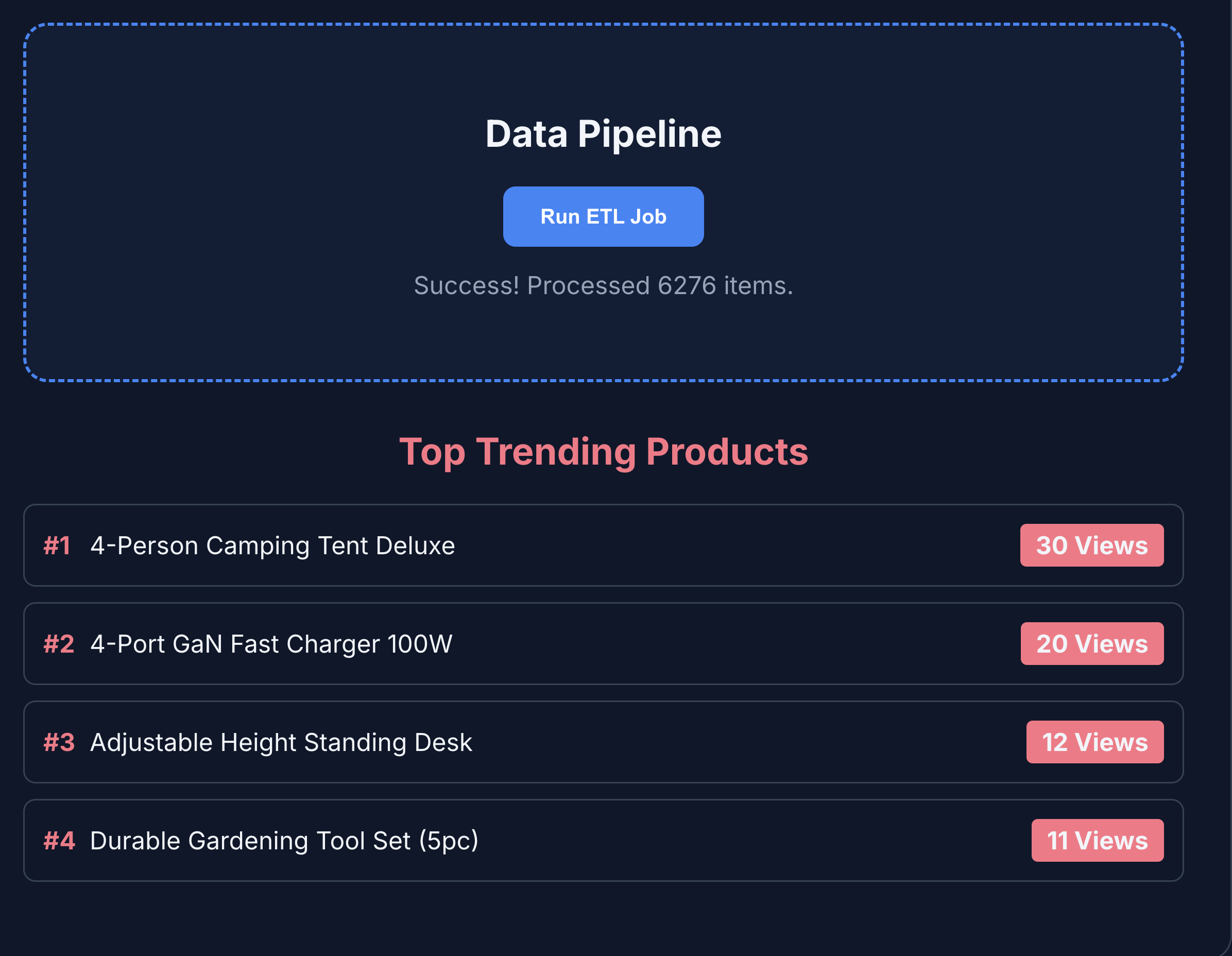
- 点击 ETL 和分析以查看产品分析。您会发现,产品分析是从 BigQuery 中提取的。
- 点击 AI 智能体标签页,与 AI 智能体互动。提出自然语言问题,例如:
I'm planning a high-altitude photography trip. Show me some weather-resistant backpacks similar in style to aero glow pro but without any leather components. Also, let me know if they are actually in stock and if other photographers have complained about the strap durability in the reviews.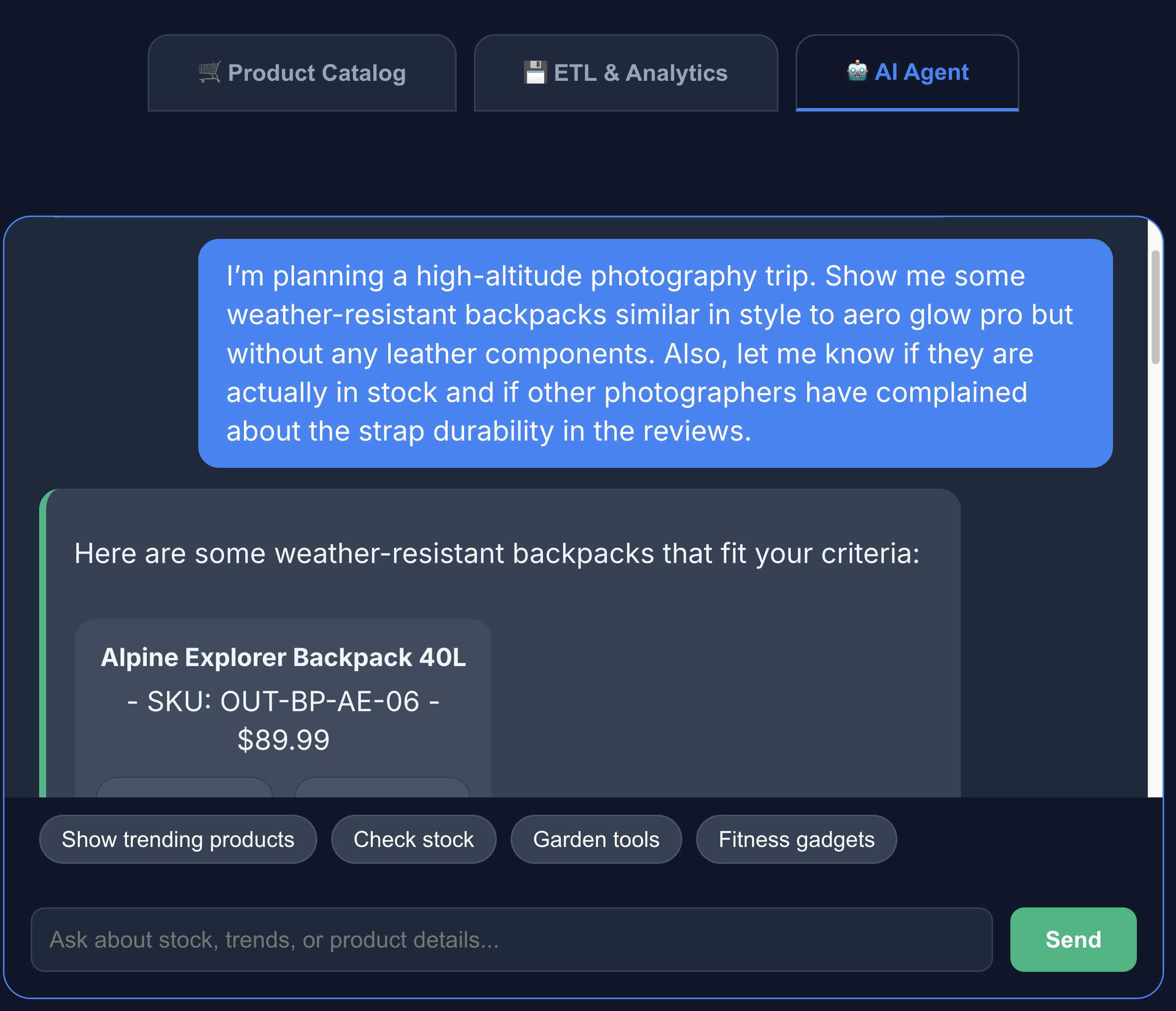
您可以看到,搜索结果完全符合我们的要求:不含皮革组件的背包,有货,且评价中没有关于肩带耐用性的投诉。
11. 清理
为避免系统向您的 Google Cloud 账号持续收取费用,请删除在此 Codelab 中创建的资源。
运行以下 Cloud Shell 命令:
gcloud run services delete toolbox --region us-central1 --quiet
gcloud run services delete multi-db-app --region us-central1 --quiet
bq rm -r -f -d $PROJECT_ID:ecommerce_analytics
gcloud storage rm --recursive gs://ecommerce-app-images
gcloud alloydb clusters delete ecommerce-cluster --region us-central1 --force --quiet
(可选)如需删除整个 Google Cloud 项目及其所有资源,请运行以下命令:
gcloud projects delete $PROJECT_ID
12. 恭喜
恭喜!您已成功构建跨云 Multidb 架构。
您演示了 MCP Toolbox 如何充当现代专业化应用的架构粘合剂。通过将合适的数据库与合适的工作相匹配,您实现了以下目标:
- 灵活的数据写入:适用于事件日志的 MongoDB。
- 事务一致性:AlloyDB 可确保核心完整性。
- 高性能分析:用于商业智能的 BigQuery。
- 统一开发:使用 MCP Toolbox 的单个 Python 后端可抽象出所有复杂性。
参考文档
详细了解相关 Google Cloud 产品,并探索以下 Codelab:
- AlloyDB AI:开始使用 AlloyDB AI 向量嵌入
- AlloyDB AI:AlloyDB 中的多模态嵌入
- MCP Toolbox:在 AlloyDB 上安装和设置 MCP Toolbox for Databases
如需详细了解本 Codelab 中使用的产品,请参阅: