
১. সংক্ষিপ্ত বিবরণ
বিভিন্ন শিল্পে, প্রাসঙ্গিক অনুসন্ধান একটি অত্যন্ত গুরুত্বপূর্ণ কার্যকারিতা যা তাদের অ্যাপ্লিকেশনগুলির কেন্দ্রবিন্দু গঠন করে। রিট্রিভাল অগমেন্টেড জেনারেশন (RAG) তার জেনারেটিভ এআই চালিত পুনরুদ্ধার পদ্ধতির মাধ্যমে বেশ কিছুদিন ধরে এই গুরুত্বপূর্ণ প্রযুক্তিগত বিবর্তনের একটি প্রধান চালক হিসেবে কাজ করছে। জেনারেটিভ মডেলগুলি, তাদের বৃহৎ কনটেক্সট উইন্ডো এবং চিত্তাকর্ষক আউটপুট কোয়ালিটির মাধ্যমে, এআই-কে রূপান্তরিত করছে। RAG এআই অ্যাপ্লিকেশন এবং এজেন্টগুলিতে কনটেক্সট যুক্ত করার একটি পদ্ধতিগত উপায় প্রদান করে, যা সেগুলিকে কাঠামোগত ডেটাবেস বা বিভিন্ন মাধ্যম থেকে প্রাপ্ত তথ্যের উপর ভিত্তি করে প্রতিষ্ঠিত করে। এই প্রাসঙ্গিক ডেটা সত্যের স্বচ্ছতা এবং আউটপুটের নির্ভুলতার জন্য অত্যন্ত গুরুত্বপূর্ণ, কিন্তু সেই ফলাফলগুলি কতটা নির্ভুল? আপনার ব্যবসা কি এই প্রাসঙ্গিক মিল এবং প্রাসঙ্গিকতার নির্ভুলতার উপর অনেকাংশে নির্ভরশীল? তাহলে এই প্রকল্পটি আপনার মন জয় করে নেবে!
ভেক্টর সার্চের আসল রহস্য শুধু এটি তৈরি করাই নয়, বরং আপনার ভেক্টর ম্যাচগুলো আসলেই ভালো কি না, তা জানা। আমরা সবাই এই অভিজ্ঞতার সম্মুখীন হয়েছি, ফলাফলের তালিকার দিকে ফ্যালফ্যাল করে তাকিয়ে ভেবেছি, ‘এটা কি আদৌ কাজ করছে?!’ চলুন জেনে নেওয়া যাক, কীভাবে আপনার ভেক্টর ম্যাচগুলোর মান সঠিকভাবে মূল্যায়ন করা যায়। আপনি হয়তো জিজ্ঞেস করবেন, “তাহলে RAG-এ কী পরিবর্তন এসেছে?” সবকিছু! বছরের পর বছর ধরে, রিট্রিভাল অগমেন্টেড জেনারেশন (RAG)-কে একটি সম্ভাবনাময় কিন্তু অধরা লক্ষ্য বলে মনে হতো। এখন, অবশেষে, আমাদের কাছে এমন সব টুলস রয়েছে যা দিয়ে অত্যন্ত গুরুত্বপূর্ণ কাজগুলোর জন্য প্রয়োজনীয় পারফরম্যান্স এবং নির্ভরযোগ্যতাসহ RAG অ্যাপ্লিকেশন তৈরি করা যায়।
এখন আমাদের তিনটি বিষয় সম্পর্কে প্রাথমিক ধারণা রয়েছে:
- আপনার এজেন্টের জন্য কনটেক্সচুয়াল সার্চের অর্থ কী এবং ভেক্টর সার্চ ব্যবহার করে কীভাবে তা সম্পন্ন করা যায়।
- আমরা আপনার ডেটার পরিধির মধ্যে, অর্থাৎ আপনার ডেটাবেসের মধ্যেই ভেক্টর সার্চ অর্জনের বিষয়টি নিয়েও গভীরভাবে আলোচনা করেছি (যদি আপনি আগে থেকে না জেনে থাকেন, তবে বলে রাখি, গুগল ক্লাউডের সমস্ত ডেটাবেসই এটি সমর্থন করে!)।
- ScaNN ইনডেক্স দ্বারা চালিত AlloyDB ভেক্টর সার্চ ক্ষমতার মাধ্যমে কীভাবে উচ্চ পারফরম্যান্স ও গুণমান সহ এমন একটি হালকা ভেক্টর সার্চ RAG সক্ষমতা অর্জন করা যায়, তা আপনাদের জানাতে আমরা বিশ্বের বাকিদের চেয়ে এক ধাপ এগিয়ে গিয়েছি।
আপনি যদি সেই প্রাথমিক, মধ্যবর্তী এবং কিছুটা উন্নত RAG পরীক্ষাগুলো না করে থাকেন, তাহলে আমি আপনাকে এখানে , এখানে এবং এখানে তালিকাভুক্ত ক্রমানুসারে ওই তিনটি পড়ার জন্য উৎসাহিত করব।
পেটেন্ট সার্চ ব্যবহারকারীকে তার সার্চ টেক্সটের সাথে প্রাসঙ্গিকভাবে প্রাসঙ্গিক পেটেন্ট খুঁজে পেতে সহায়তা করে এবং আমরা অতীতে এর একটি সংস্করণ তৈরি করেছি। এখন আমরা এটিকে নতুন এবং উন্নত RAG বৈশিষ্ট্য সহ তৈরি করব যা সেই অ্যাপ্লিকেশনটির জন্য একটি মান নিয়ন্ত্রিত প্রাসঙ্গিক অনুসন্ধান সক্ষম করবে। চলুন শুরু করা যাক!
নিচের ছবিটি এই অ্যাপ্লিকেশনটিতে যা ঘটছে তার সার্বিক প্রবাহ দেখাচ্ছে। 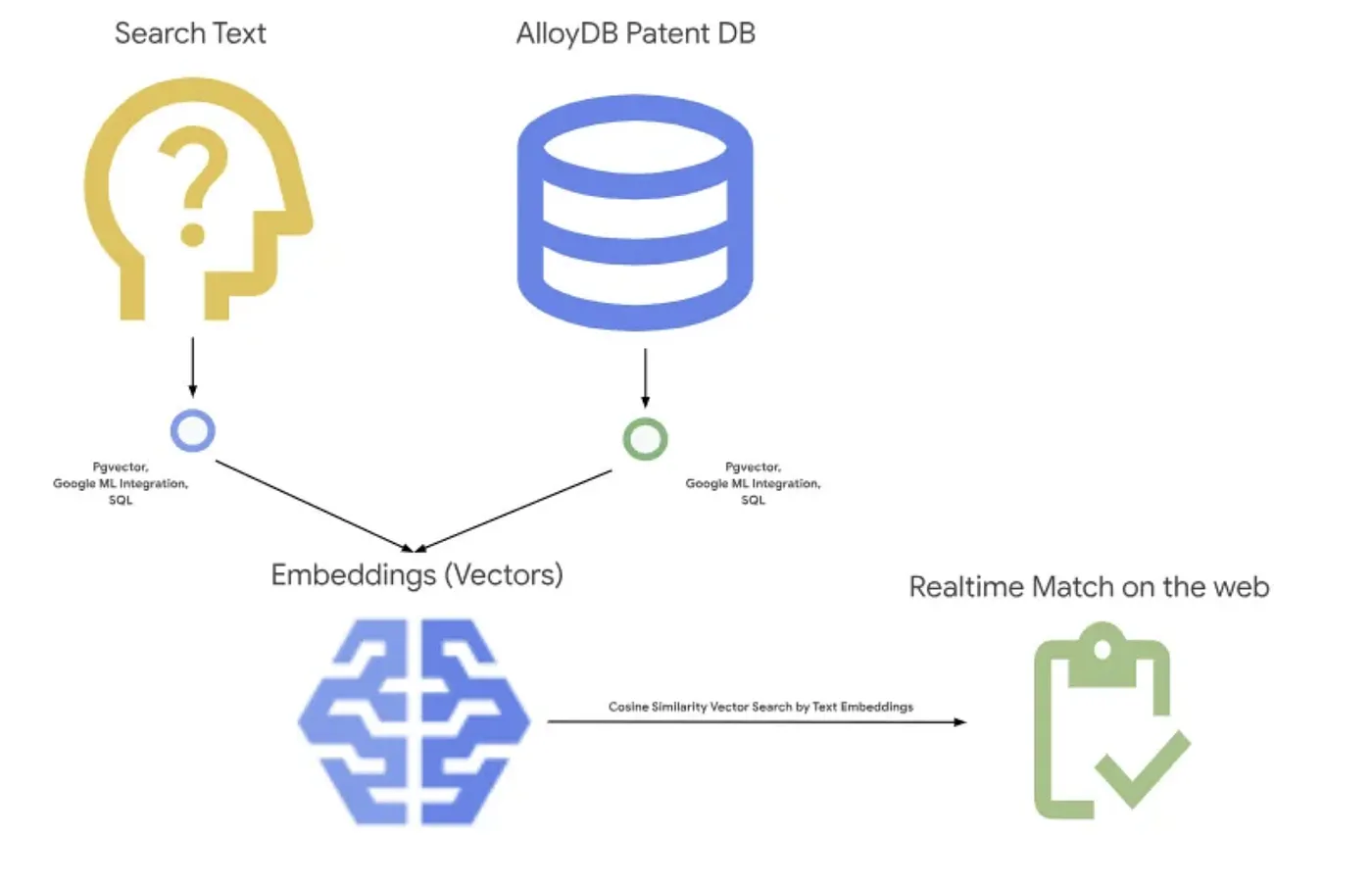
উদ্দেশ্য
ব্যবহারকারীকে উন্নত পারফরম্যান্স ও উন্নততর গুণমান সহ একটি পাঠ্য বিবরণের উপর ভিত্তি করে পেটেন্ট অনুসন্ধান করার সুযোগ দিন এবং একই সাথে AlloyDB-এর সর্বশেষ RAG বৈশিষ্ট্যগুলি ব্যবহার করে তৈরি হওয়া ফলাফলগুলির গুণমান মূল্যায়ন করার সুবিধা দিন।
আপনি যা তৈরি করবেন
এই ল্যাবের অংশ হিসেবে, আপনি যা করবেন:
- একটি AlloyDB ইনস্ট্যান্স তৈরি করুন এবং পেটেন্ট পাবলিক ডেটাসেট লোড করুন
- মেটাডেটা সূচক এবং স্ক্যান সূচক তৈরি করুন
- ScaNN-এর ইনলাইন ফিল্টারিং পদ্ধতি ব্যবহার করে AlloyDB-তে উন্নত ভেক্টর সার্চ বাস্তবায়ন করুন।
- রিকল ইভ্যাল বৈশিষ্ট্য বাস্তবায়ন করুন
- কোয়েরি প্রতিক্রিয়া মূল্যায়ন করুন
প্রয়োজনীয়তা
- ক্রোম বা ফায়ারফক্সের মতো একটি ব্রাউজার
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট।
২. শুরু করার আগে
একটি প্রকল্প তৈরি করুন
- গুগল ক্লাউড কনসোলের প্রজেক্ট সিলেক্টর পেজে, একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন।
- আপনার ক্লাউড প্রোজেক্টের জন্য বিলিং চালু আছে কিনা তা নিশ্চিত করুন। কোনো প্রোজেক্টে বিলিং চালু আছে কিনা তা কীভাবে পরীক্ষা করবেন, তা জেনে নিন।
- আপনি ক্লাউড শেল ব্যবহার করবেন, যা গুগল ক্লাউডে চালিত একটি কমান্ড-লাইন পরিবেশ। গুগল ক্লাউড কনসোলের শীর্ষে থাকা ‘Activate Cloud Shell’-এ ক্লিক করুন।

- ক্লাউড শেলে সংযুক্ত হওয়ার পর, আপনি নিম্নলিখিত কমান্ডটি ব্যবহার করে যাচাই করে নিন যে আপনি ইতিমধ্যেই প্রমাণীকৃত এবং প্রজেক্টটি আপনার প্রজেক্ট আইডিতে সেট করা আছে:
gcloud auth list
- gcloud কমান্ডটি আপনার প্রজেক্ট সম্পর্কে অবগত আছে কিনা, তা নিশ্চিত করতে ক্লাউড শেলে নিম্নলিখিত কমান্ডটি চালান।
gcloud config list project
- আপনার প্রজেক্টটি সেট করা না থাকলে, এটি সেট করতে নিম্নলিখিত কমান্ডটি ব্যবহার করুন:
gcloud config set project <YOUR_PROJECT_ID>
- প্রয়োজনীয় API-গুলো সক্রিয় করুন। আপনি ক্লাউড শেল টার্মিনালে gcloud কমান্ডটি ব্যবহার করতে পারেন:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
gcloud কমান্ডের বিকল্প হলো কনসোলের মাধ্যমে প্রতিটি পণ্য অনুসন্ধান করা অথবা এই লিঙ্কটি ব্যবহার করা।
gcloud কমান্ড এবং এর ব্যবহার সম্পর্কে জানতে ডকুমেন্টেশন দেখুন।
৩. ডাটাবেস সেটআপ
এই ল্যাবে আমরা পেটেন্ট ডেটার ডেটাবেস হিসেবে AlloyDB ব্যবহার করব। এটি ডেটাবেস এবং লগের মতো সমস্ত রিসোর্স ধারণ করার জন্য ক্লাস্টার ব্যবহার করে। প্রতিটি ক্লাস্টারে একটি প্রাইমারি ইনস্ট্যান্স থাকে যা ডেটাতে অ্যাক্সেস পয়েন্ট সরবরাহ করে। টেবিলগুলোতে প্রকৃত ডেটা থাকবে।
চলুন একটি AlloyDB ক্লাস্টার, ইনস্ট্যান্স এবং টেবিল তৈরি করি যেখানে পেটেন্ট ডেটাসেটটি লোড করা হবে।
একটি ক্লাস্টার এবং ইনস্ট্যান্স তৈরি করুন
- ক্লাউড কনসোলে AlloyDB পেজটিতে যান। ক্লাউড কনসোলের বেশিরভাগ পেজ খুঁজে পাওয়ার একটি সহজ উপায় হলো কনসোলের সার্চ বার ব্যবহার করে সেগুলোর জন্য অনুসন্ধান করা।
- সেই পৃষ্ঠা থেকে CREATE CLUSTER নির্বাচন করুন:

- আপনি নীচেরটির মতো একটি স্ক্রিন দেখতে পাবেন। নিম্নলিখিত মানগুলি দিয়ে একটি ক্লাস্টার এবং ইনস্ট্যান্স তৈরি করুন (আপনি যদি রিপো থেকে অ্যাপ্লিকেশন কোড ক্লোন করেন তবে নিশ্চিত করুন যে মানগুলি মিলে যায়):
- ক্লাস্টার আইডি : "
vector-cluster" - পাসওয়ার্ড : "
alloydb" - PostgreSQL 15 / সর্বশেষ সংস্করণ সুপারিশ করা হচ্ছে
- অঞ্চল : "
us-central1" - নেটওয়ার্কিং : "
default"
- আপনি যখন ডিফল্ট নেটওয়ার্ক নির্বাচন করবেন, তখন নিচের স্ক্রিনের মতো একটি স্ক্রিন দেখতে পাবেন।
সংযোগ স্থাপন নির্বাচন করুন।
- সেখান থেকে, " Use an automatically allocated IP range " নির্বাচন করুন এবং Continue নির্বাচন করুন। তথ্য পর্যালোচনা করার পর, CREATE CONNECTION নির্বাচন করুন।
- আপনার নেটওয়ার্ক সেট আপ হয়ে গেলে, আপনি আপনার ক্লাস্টার তৈরি করা চালিয়ে যেতে পারেন। নিচে দেখানো অনুযায়ী ক্লাস্টার সেট আপ সম্পন্ন করতে CREATE CLUSTER-এ ক্লিক করুন:
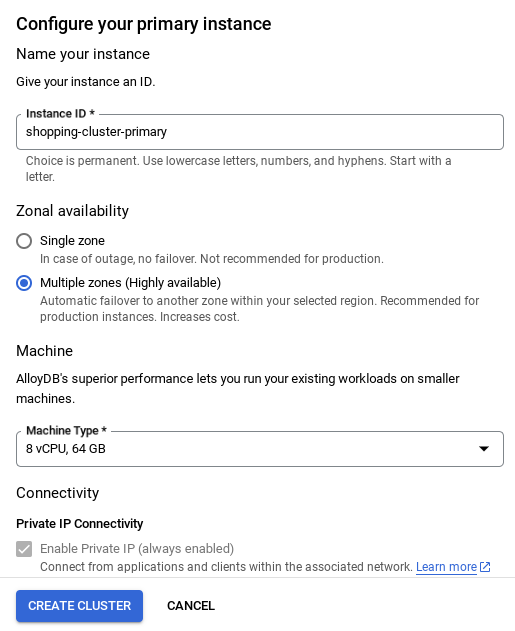
ইনস্ট্যান্স আইডিটি (যা আপনি ক্লাস্টার / ইনস্ট্যান্স কনফিগার করার সময় খুঁজে পাবেন) পরিবর্তন করে নিন ।
vector-instance । যদি আপনি এটি পরিবর্তন করতে না পারেন, তাহলে পরবর্তী সমস্ত রেফারেন্সে আপনার ইনস্ট্যান্স আইডি ব্যবহার করতে মনে রাখবেন।
মনে রাখবেন, ক্লাস্টার তৈরি হতে প্রায় ১০ মিনিট সময় লাগবে। এটি সফল হলে, আপনি আপনার তৈরি করা ক্লাস্টারের একটি সার্বিক চিত্র দেখতে পাবেন।
৪. ডেটা গ্রহণ
এখন স্টোর সম্পর্কিত ডেটা সহ একটি টেবিল যোগ করার সময় এসেছে। AlloyDB-তে যান, প্রাইমারি ক্লাস্টার নির্বাচন করুন এবং তারপর AlloyDB Studio-তে যান:
আপনার ইনস্ট্যান্সটি তৈরি হওয়া শেষ না হওয়া পর্যন্ত আপনাকে অপেক্ষা করতে হতে পারে। এটি তৈরি হয়ে গেলে, ক্লাস্টার তৈরির সময় আপনি যে ক্রেডেনশিয়ালগুলো তৈরি করেছিলেন, সেগুলো ব্যবহার করে AlloyDB-তে সাইন ইন করুন। PostgreSQL-এ প্রমাণীকরণের জন্য নিম্নলিখিত ডেটা ব্যবহার করুন:
- ব্যবহারকারীর নাম : "
postgres" - ডাটাবেস : "
postgres" - পাসওয়ার্ড : "
alloydb"
AlloyDB Studio-তে সফলভাবে প্রমাণীকরণের পর, এডিটর-এ SQL কমান্ডগুলো প্রবেশ করানো হয়। শেষ উইন্ডোটির ডানদিকে থাকা প্লাস চিহ্নটি ব্যবহার করে আপনি একাধিক এডিটর উইন্ডো যোগ করতে পারেন।
আপনি এডিটর উইন্ডোতে AlloyDB-এর জন্য কমান্ড লিখবেন এবং প্রয়োজন অনুযায়ী Run, Format ও Clear অপশনগুলো ব্যবহার করবেন।
এক্সটেনশনগুলি সক্ষম করুন
এই অ্যাপটি তৈরি করার জন্য, আমরা pgvector এবং google_ml_integration এক্সটেনশনগুলো ব্যবহার করব। pgvector এক্সটেনশনটি আপনাকে ভেক্টর এমবেডিং সংরক্ষণ এবং অনুসন্ধান করার সুযোগ দেয়। google_ml_integration এক্সটেনশনটি এমন সব ফাংশন সরবরাহ করে যা ব্যবহার করে আপনি Vertex AI প্রেডিকশন এন্ডপয়েন্টগুলো অ্যাক্সেস করে SQL-এ প্রেডিকশন পেতে পারেন। নিম্নলিখিত DDL-গুলো রান করে এই এক্সটেনশনগুলো সক্রিয় করুন :
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
আপনার ডাটাবেসে কোন এক্সটেনশনগুলো সক্রিয় করা হয়েছে তা পরীক্ষা করতে চাইলে, এই SQL কমান্ডটি চালান:
select extname, extversion from pg_extension;
একটি টেবিল তৈরি করুন
আপনি AlloyDB Studio-তে নিচের DDL স্টেটমেন্টটি ব্যবহার করে একটি টেবিল তৈরি করতে পারেন:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
abstract_embeddings কলামটি টেক্সটের ভেক্টর মানগুলো সংরক্ষণের সুযোগ দেবে।
অনুমতি প্রদান করুন
'embedding' ফাংশনটিতে execute অনুমোদন দিতে নিচের স্টেটমেন্টটি চালান:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB পরিষেবা অ্যাকাউন্টে Vertex AI ব্যবহারকারীর ROLE প্রদান করুন।
Google Cloud IAM কনসোল থেকে, AlloyDB সার্ভিস অ্যাকাউন্টকে (যা দেখতে এইরকম: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) "Vertex AI User" রোলের অ্যাক্সেস দিন। PROJECT_NUMBER-এ আপনার প্রজেক্ট নম্বরটি থাকবে।
বিকল্পভাবে আপনি ক্লাউড শেল টার্মিনাল থেকে নিচের কমান্ডটি চালাতে পারেন:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
ডেটাবেসে পেটেন্ট ডেটা লোড করুন
BigQuery-তে থাকা Google Patents Public Datasets আমাদের ডেটাসেট হিসেবে ব্যবহৃত হবে। আমরা আমাদের কোয়েরিগুলো চালানোর জন্য AlloyDB Studio ব্যবহার করব। ডেটা এই insert_scripts.sql ফাইলে সোর্স করা হয়েছে এবং পেটেন্ট ডেটা লোড করার জন্য আমরা এটি চালাব।
- গুগল ক্লাউড কনসোলে AlloyDB পেজটি খুলুন।
- আপনার নতুন তৈরি করা ক্লাস্টারটি নির্বাচন করুন এবং ইনস্ট্যান্সটিতে ক্লিক করুন।
- AlloyDB নেভিগেশন মেনুতে, AlloyDB Studio-তে ক্লিক করুন। আপনার ক্রেডেনশিয়াল দিয়ে সাইন ইন করুন।
- ডানদিকে থাকা নতুন ট্যাব আইকনে ক্লিক করে একটি নতুন ট্যাব খুলুন।
- উপরে উল্লিখিত
insert_scripts.sqlস্ক্রিপ্ট থেকেinsertকোয়েরি স্টেটমেন্টটি এডিটরে কপি করুন। এই ব্যবহারটির একটি দ্রুত ডেমোর জন্য আপনি ১০-৫০টি ইনসার্ট স্টেটমেন্ট কপি করতে পারেন। - রান-এ ক্লিক করুন। আপনার কোয়েরির ফলাফল রেজাল্টস টেবিলে প্রদর্শিত হবে।
দ্রষ্টব্য: আপনি হয়তো লক্ষ্য করবেন যে ইনসার্ট স্ক্রিপ্টটিতে প্রচুর ডেটা রয়েছে। এর কারণ হলো, আমরা ইনসার্ট স্ক্রিপ্টগুলোতে এমবেডিং অন্তর্ভুক্ত করেছি। গিটহাবে ফাইলটি লোড করতে সমস্যা হলে "ভিউ র" (View Raw) -এ ক্লিক করুন। আপনি যদি গুগল ক্লাউডের জন্য একটি ট্রায়াল ক্রেডিট বিলিং অ্যাকাউন্ট ব্যবহার করেন, তবে পরবর্তী ধাপগুলোতে কয়েকটি এমবেডিং (ধরা যাক সর্বোচ্চ ২০-২৫টি) তৈরি করার ঝামেলা থেকে আপনাকে বাঁচাতেই এটি করা হয়েছে।
৫. পেটেন্ট ডেটার জন্য এমবেডিং তৈরি করুন
প্রথমে নিচের নমুনা কোয়েরিটি চালিয়ে এমবেডিং ফাংশনটি পরীক্ষা করে নেওয়া যাক:
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
এটি কোয়েরিতে থাকা নমুনা টেক্সটের জন্য এমবেডিংস ভেক্টরটি রিটার্ন করবে, যা ফ্লোট সংখ্যার একটি অ্যারের মতো দেখতে। এটি দেখতে এইরকম:
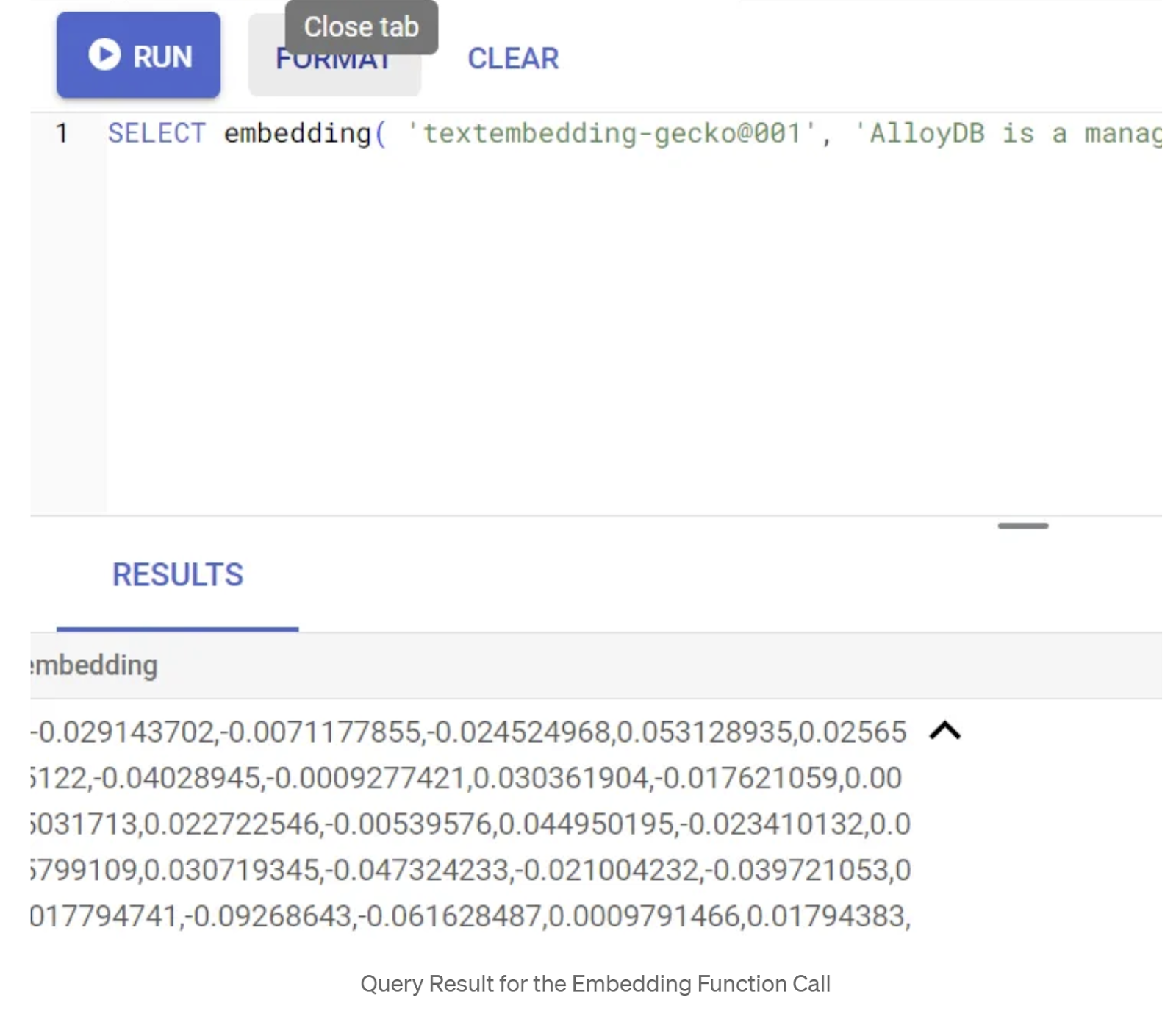
abstract_embeddings ভেক্টর ফিল্ডটি আপডেট করুন
যদি আপনি ইনসার্ট স্ক্রিপ্টের অংশ হিসেবে abstract_embeddings ডেটা সন্নিবেশ না করে থাকেন, তবেই টেবিলের পেটেন্ট অ্যাবস্ট্রাক্টগুলোকে সংশ্লিষ্ট এমবেডিং দিয়ে আপডেট করতে নিচের DML-টি চালান:
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
আপনি যদি গুগল ক্লাউডের জন্য একটি ট্রায়াল ক্রেডিট বিলিং অ্যাকাউন্ট ব্যবহার করেন, তাহলে কয়েকটি এমবেডিং (ধরা যাক সর্বোচ্চ ২০-২৫টি) তৈরি করতে আপনার সমস্যা হতে পারে। সেই কারণে, আমি ইনসার্ট স্ক্রিপ্টগুলিতে এমবেডিংগুলি আগেই অন্তর্ভুক্ত করে দিয়েছি এবং আপনি যদি "ডেটাবেসে পেটেন্ট ডেটা লোড করুন" ধাপটি সম্পন্ন করে থাকেন, তাহলে আপনার টেবিলে সেগুলি লোড হয়ে যাওয়ার কথা।
৬. AlloyDB-এর নতুন বৈশিষ্ট্যগুলির সাহায্যে উন্নত RAG সম্পাদন করুন
এখন যেহেতু টেবিল, ডেটা, এমবেডিং সবই প্রস্তুত, চলুন ব্যবহারকারীর সার্চ টেক্সটের জন্য রিয়েল টাইম ভেক্টর সার্চটি সম্পাদন করা যাক। নিচের কোয়েরিটি চালিয়ে আপনি এটি পরীক্ষা করতে পারেন:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
এই কোয়েরিতে,
- ব্যবহারকারী যে লেখাটি অনুসন্ধান করেছেন তা হলো: "Sentiment Analysis"।
- আমরা `text-embedding-005` মডেলটি ব্যবহার করে `embedding()` মেথডে এটিকে এমবেডিং-এ রূপান্তর করছি।
- "<=>" চিহ্নটি কোসাইন সিমিলারিটি দূরত্ব পদ্ধতির ব্যবহারকে নির্দেশ করে।
- ডাটাবেসে সংরক্ষিত ভেক্টরগুলোর সাথে সামঞ্জস্যপূর্ণ করার জন্য আমরা এমবেডিং মেথডের ফলাফলকে ভেক্টর টাইপে রূপান্তর করছি।
- LIMIT 10 এর অর্থ হলো, আমরা সার্চ টেক্সটের সবচেয়ে কাছাকাছি ১০টি মিল নির্বাচন করছি।
AlloyDB ভেক্টর সার্চ RAG-কে পরবর্তী স্তরে নিয়ে যায়:
এখানে বেশ কিছু নতুন জিনিস চালু করা হয়েছে। ডেভেলপারদের জন্য তৈরি করা দুটি বিষয় হলো:
- ইনলাইন ফিল্টারিং
- প্রত্যাহার মূল্যায়নকারী
ইনলাইন ফিল্টারিং
পূর্বে একজন ডেভেলপার হিসেবে, আপনাকে ভেক্টর সার্চ কোয়েরি চালাতে হতো এবং ফিল্টারিং ও রিকল নিয়ে কাজ করতে হতো। অ্যালয়ডিবি কোয়েরি অপটিমাইজার ফিল্টারসহ একটি কোয়েরি কীভাবে কার্যকর করা হবে, সেই সিদ্ধান্ত নেয়। ইনলাইন ফিল্টারিং হলো একটি নতুন কোয়েরি অপটিমাইজেশন কৌশল, যা অ্যালয়ডিবি কোয়েরি অপটিমাইজারকে মেটাডেটা ফিল্টারিং শর্তাবলী এবং ভেক্টর সার্চ উভয়কেই একসাথে মূল্যায়ন করার সুযোগ দেয় এবং এর জন্য ভেক্টর ইনডেক্স ও মেটাডেটা কলামের ইনডেক্স উভয়কেই কাজে লাগায়। এর ফলে রিকল পারফরম্যান্স বৃদ্ধি পেয়েছে, যা ডেভেলপারদের অ্যালয়ডিবির বিল্ট-ইন সুবিধাগুলো পুরোপুরি গ্রহণ করার সুযোগ করে দিয়েছে।
মাঝারি সিলেক্টিভিটির ক্ষেত্রে ইনলাইন ফিল্টারিং সবচেয়ে ভালো। AlloyDB যখন ভেক্টর ইনডেক্সে অনুসন্ধান করে, তখন এটি শুধুমাত্র সেইসব ভেক্টরের দূরত্ব গণনা করে যা মেটাডেটা ফিল্টারিং শর্তের সাথে মেলে (একটি কোয়েরিতে আপনার ফাংশনাল ফিল্টার, যা সাধারণত WHERE ক্লজে পরিচালনা করা হয়)। এটি পোস্ট-ফিল্টার বা প্রি-ফিল্টারের সুবিধার পরিপূরক হিসেবে এই কোয়েরিগুলির পারফরম্যান্স ব্যাপকভাবে উন্নত করে।
- pgvector এক্সটেনশনটি ইনস্টল বা আপডেট করুন
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
যদি pgvector এক্সটেনশনটি আগে থেকেই ইনস্টল করা থাকে, তাহলে রিকল ইভ্যালুয়েটর সুবিধাগুলো পেতে ভেক্টর এক্সটেনশনটিকে 0.8.0.google-3 বা তার পরবর্তী সংস্করণে আপগ্রেড করুন।
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
এই ধাপটি শুধুমাত্র তখনই সম্পাদন করতে হবে, যদি আপনার ভেক্টর এক্সটেনশন <0.8.0.google-3> হয়।
গুরুত্বপূর্ণ দ্রষ্টব্য: যদি আপনার সারির সংখ্যা ১০০-এর কম হয়, তাহলে আপনাকে শুরুতেই ScaNN ইনডেক্স তৈরি করতে হবে না, কারণ এটি কম সারির ক্ষেত্রে প্রযোজ্য হবে না। সেক্ষেত্রে অনুগ্রহ করে নিম্নলিখিত ধাপগুলো এড়িয়ে যান।
- ScaNN ইনডেক্স তৈরি করতে, alloydb_scann এক্সটেনশনটি ইনস্টল করুন।
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- প্রথমে ইনডেক্স এবং ইনলাইন ফিল্টার সক্রিয় না করে ভেক্টর সার্চ কোয়েরিটি চালান:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
ফলাফলটি নিম্নরূপ হওয়া উচিত:
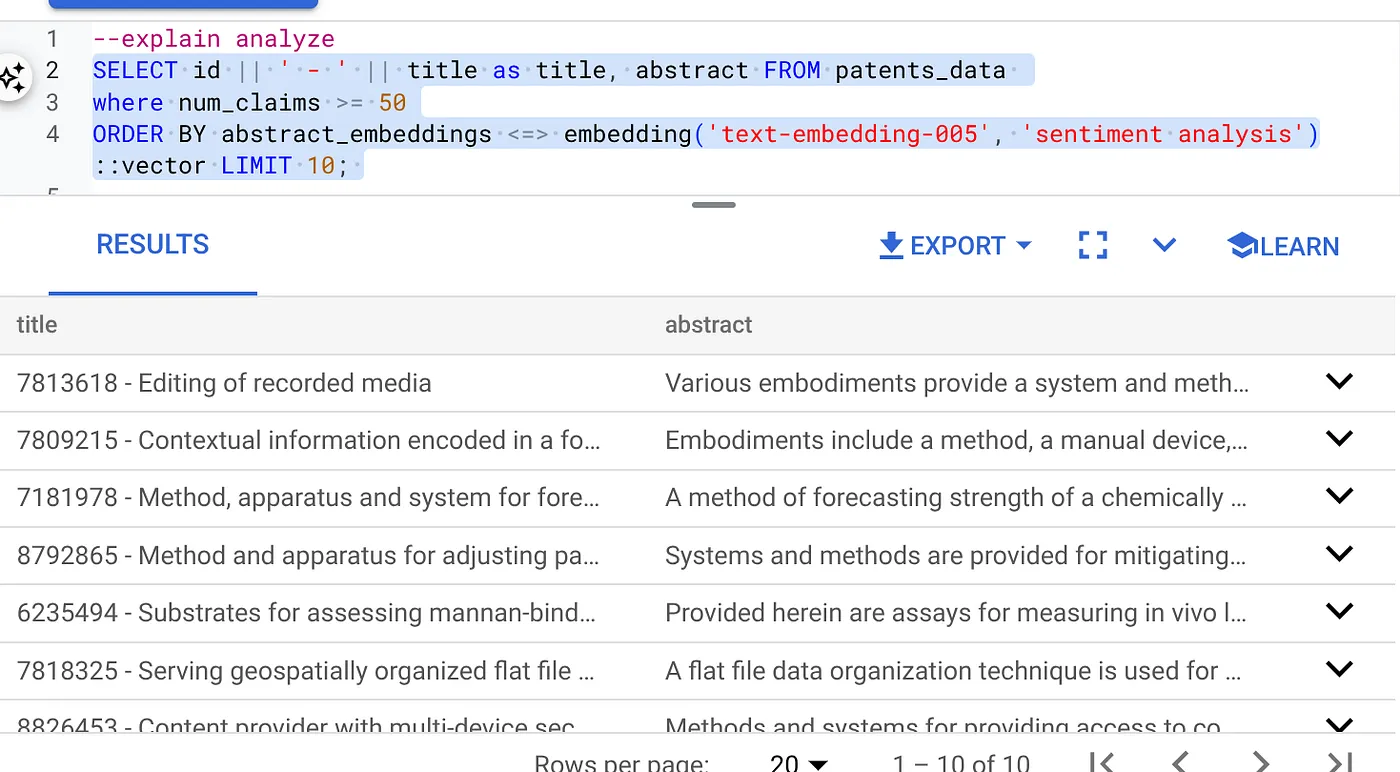
- এটির উপর এক্সপ্লেইন অ্যানালাইজ চালান: (কোনো ইনডেক্স বা ইনলাইন ফিল্টারিং ছাড়া)
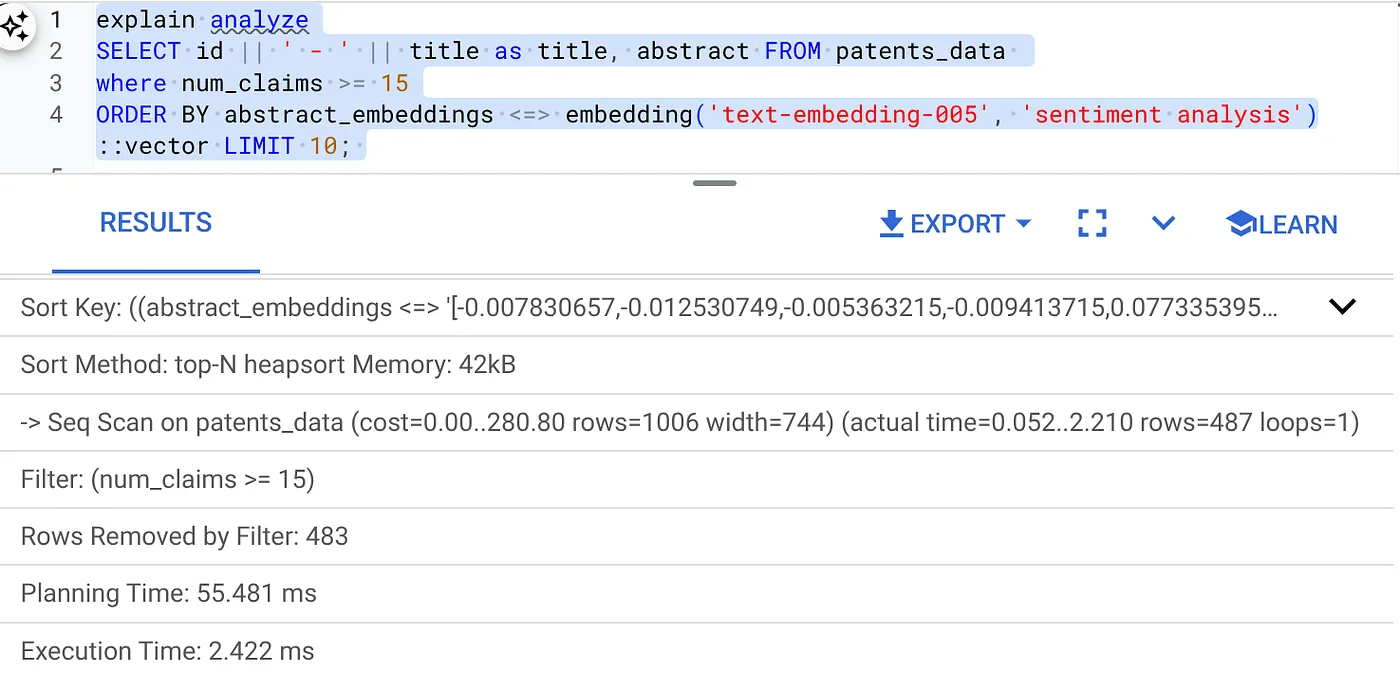
কার্য সম্পাদনের সময় ২.৪ মিলিসেকেন্ড।
- চলুন num_claims ফিল্ডটির উপর একটি সাধারণ ইনডেক্স তৈরি করি, যাতে আমরা এটি দিয়ে ফিল্টার করতে পারি:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- চলুন আমাদের পেটেন্ট সার্চ অ্যাপ্লিকেশনের জন্য ScaNN ইনডেক্স তৈরি করি। আপনার AlloyDB Studio থেকে নিম্নলিখিত কমান্ডটি চালান:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
গুরুত্বপূর্ণ দ্রষ্টব্য: (num_leaves=32) আমাদের ১০০০+ সারিযুক্ত সম্পূর্ণ ডেটাসেটের জন্য প্রযোজ্য। যদি আপনার সারির সংখ্যা ১০০-এর কম হয়, তাহলে আপনার শুরুতেই কোনো ইনডেক্স তৈরি করার প্রয়োজন হবে না, কারণ এটি কম সারির ক্ষেত্রে প্রযোজ্য হবে না।
- ScanN ইনডেক্সে ইনলাইন ফিল্টারিং সক্রিয় করুন:
SET scann.enable_inline_filtering = on
- এখন, ফিল্টার এবং ভেক্টর সার্চ সহ একই কোয়েরিটি চালানো যাক:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
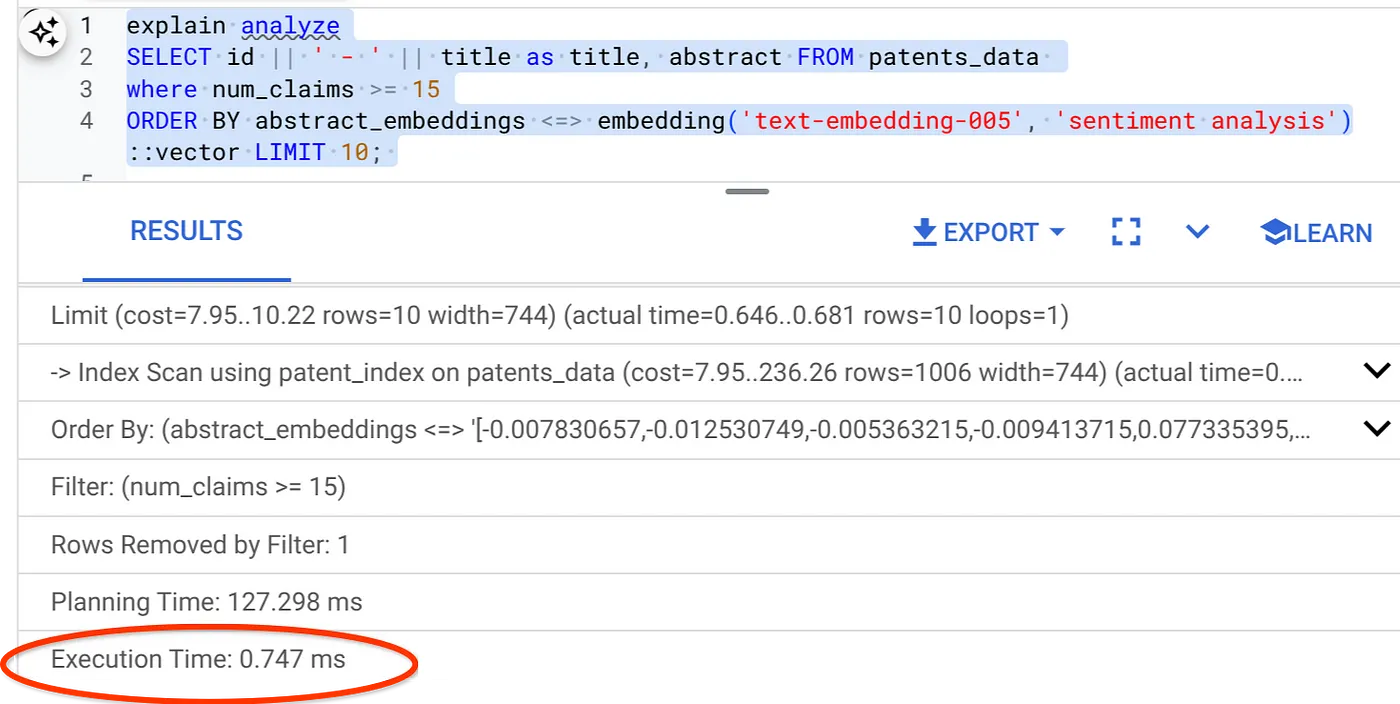
আপনি দেখতেই পাচ্ছেন, একই ভেক্টর সার্চের জন্য এক্সিকিউশন টাইম উল্লেখযোগ্যভাবে কমে গেছে। ভেক্টর সার্চে ইনলাইন ফিল্টারিং যুক্ত ScaNN ইনডেক্সই এটি সম্ভব করেছে!!!
এরপরে, এই ScaNN-সক্ষম ভেক্টর সার্চের রিকল মূল্যায়ন করা যাক।
প্রত্যাহার মূল্যায়নকারী
সিমিলারিটি সার্চে রিকল হলো একটি সার্চ থেকে প্রাপ্ত প্রাসঙ্গিক ইনস্ট্যান্সের শতাংশ, অর্থাৎ ট্রু পজিটিভের সংখ্যা। সার্চের মান পরিমাপের জন্য এটি সবচেয়ে প্রচলিত মেট্রিক। রিকল লসের একটি উৎস হলো অ্যাপ্রক্সিমেট নিয়ারেস্ট নেইবার সার্চ (aNN) এবং কে (এক্সাক্ট) নিয়ারেস্ট নেইবার সার্চ (kNN)-এর মধ্যকার পার্থক্য। AlloyDB-এর ScaNN-এর মতো ভেক্টর ইনডেক্সগুলো aNN অ্যালগরিদম প্রয়োগ করে, যা রিকলের সামান্য ঘাটতির বিনিময়ে আপনাকে বড় ডেটাসেটে ভেক্টর সার্চের গতি বাড়াতে সাহায্য করে। এখন, AlloyDB আপনাকে প্রতিটি কোয়েরির জন্য সরাসরি ডেটাবেসে এই ঘাটতি পরিমাপ করার এবং সময়ের সাথে সাথে এর স্থিতিশীলতা নিশ্চিত করার ক্ষমতা প্রদান করে। আরও ভালো ফলাফল এবং পারফরম্যান্স অর্জনের জন্য আপনি এই তথ্যের ভিত্তিতে কোয়েরি এবং ইনডেক্স প্যারামিটার আপডেট করতে পারেন।
অনুসন্ধানের ফলাফল মনে রাখার পেছনের যুক্তি কী?
ভেক্টর সার্চের ক্ষেত্রে, রিকল বলতে ইনডেক্স দ্বারা ফেরত দেওয়া ভেক্টরগুলোর মধ্যে প্রকৃত নিকটতম প্রতিবেশী ভেক্টরের শতাংশকে বোঝায়। উদাহরণস্বরূপ, যদি ২০টি নিকটতম প্রতিবেশীর জন্য করা একটি কোয়েরি গ্রাউন্ড ট্রুথ নিকটতম প্রতিবেশীদের মধ্যে ১৯টি ফেরত দেয়, তাহলে রিকল হবে ১৯/২০x১০০ = ৯৫%। রিকল হলো সার্চের গুণমান পরিমাপের জন্য ব্যবহৃত একটি মেট্রিক, এবং এটিকে ফেরত আসা ফলাফলগুলোর সেই শতাংশ হিসাবে সংজ্ঞায়িত করা হয় যা বস্তুনিষ্ঠভাবে কোয়েরি ভেক্টরগুলোর সবচেয়ে কাছাকাছি।
আপনি evaluate_query_recall ফাংশনটি ব্যবহার করে একটি নির্দিষ্ট কনফিগারেশনের জন্য ভেক্টর ইনডেক্সের উপর করা ভেক্টর কোয়েরির রিকল খুঁজে পেতে পারেন। এই ফাংশনটি আপনাকে আপনার কাঙ্ক্ষিত ভেক্টর কোয়েরি রিকলের ফলাফল অর্জনের জন্য প্যারামিটারগুলো টিউন করার সুযোগ দেয়।
গুরুত্বপূর্ণ দ্রষ্টব্য:
যদি আপনি নিম্নলিখিত ধাপগুলিতে HNSW ইনডেক্সে 'permission denied' ত্রুটির সম্মুখীন হন, তাহলে আপাতত এই সম্পূর্ণ রিকল ইভ্যালুয়েশন অংশটি এড়িয়ে যান। এই কোডল্যাবটি ডকুমেন্ট করার সময় এটি সদ্য প্রকাশিত হওয়ায়, এই মুহূর্তে এর কারণ অ্যাক্সেস সীমাবদ্ধতা হতে পারে।
- ScanN ইনডেক্স এবং HNSW ইনডেক্সে Enable Index Scan ফ্ল্যাগটি সেট করুন:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- AlloyDB Studio-তে নিম্নলিখিত কোয়েরিটি চালান:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
evaluate_query_recall ফাংশনটি প্যারামিটার হিসেবে কোয়েরি গ্রহণ করে এবং এর রিকল রিটার্ন করে। আমি পারফরম্যান্স পরীক্ষা করার জন্য যে কোয়েরিটি ব্যবহার করেছিলাম, সেটিই ফাংশনের ইনপুট কোয়েরি হিসেবে ব্যবহার করছি। আমি ইনডেক্স মেথড হিসেবে SCaNN যুক্ত করেছি। আরও প্যারামিটার অপশনের জন্য ডকুমেন্টেশন দেখুন।
আমরা যে ভেক্টর সার্চ কোয়েরিটি ব্যবহার করে আসছি তার রিকল হলো:
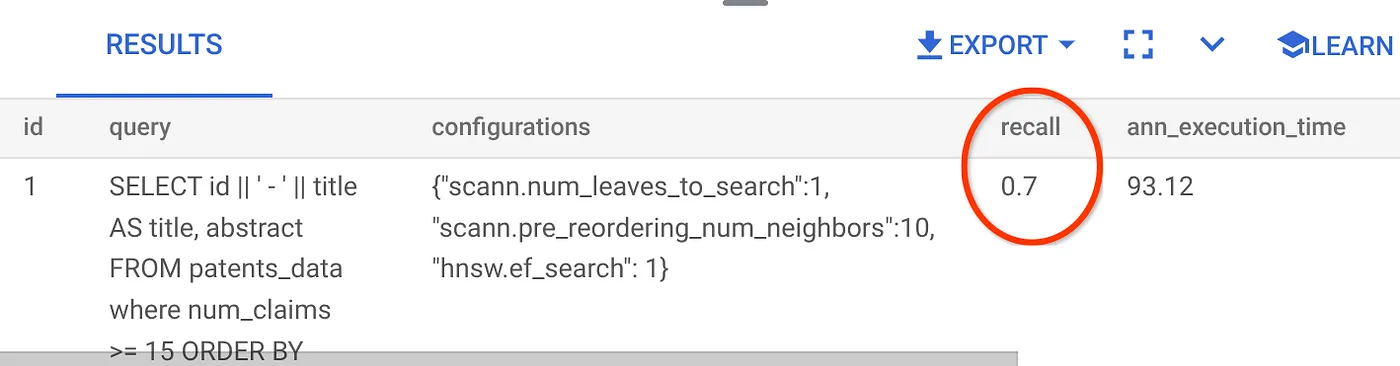
আমি দেখতে পাচ্ছি যে রিকল ৭০%। এখন আমি এই তথ্য ব্যবহার করে ইনডেক্স প্যারামিটার, মেথড এবং কোয়েরি প্যারামিটার পরিবর্তন করে এই ভেক্টর সার্চের জন্য আমার রিকল উন্নত করতে পারব!
৭. পরিবর্তিত কোয়েরি ও ইনডেক্স প্যারামিটার দিয়ে এটি পরীক্ষা করুন।
এখন প্রাপ্ত রিকলের উপর ভিত্তি করে কোয়েরি প্যারামিটারগুলো পরিবর্তন করে কোয়েরিটি পরীক্ষা করা যাক।
- আমি ফলাফল সেটের সারির সংখ্যা (আগের ২৫টি থেকে) পরিবর্তন করে ৭ করেছি এবং আমি রিকল-এর উন্নতি দেখতে পাচ্ছি, অর্থাৎ ৮৬%।
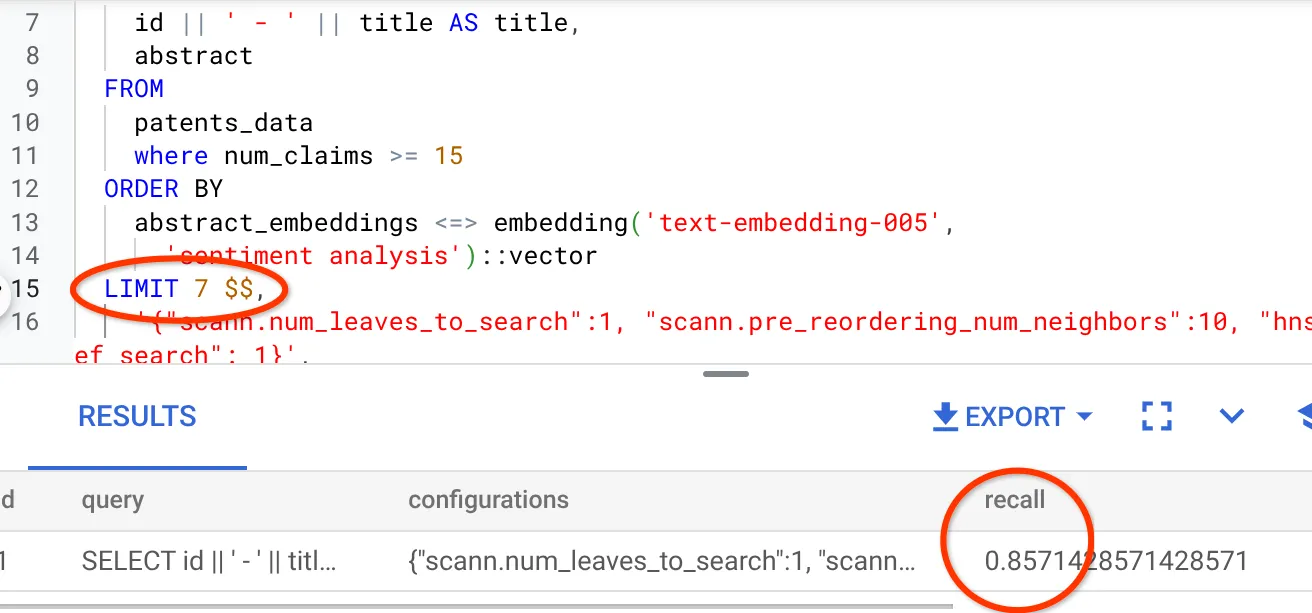
এর মানে হলো, ব্যবহারকারীর অনুসন্ধানের প্রেক্ষাপট অনুযায়ী ম্যাচগুলোর প্রাসঙ্গিকতা উন্নত করার জন্য আমি রিয়েল-টাইমে তাদের দেখানো ম্যাচের সংখ্যা পরিবর্তন করতে পারি।
- ইনডেক্স প্যারামিটারগুলো পরিবর্তন করে আবার চেষ্টা করা যাক:
এই পরীক্ষার জন্য, আমি 'কোসাইন' সিমিলারিটি ডিসট্যান্স ফাংশনের পরিবর্তে 'এল২ ডিসট্যান্স' ব্যবহার করব। সার্চ রেজাল্ট সেটের সংখ্যা বাড়লেও ফলাফলের মানের উন্নতি হয় কিনা, তা দেখানোর জন্য আমি কোয়েরির সীমাও ১০-এ পরিবর্তন করব।
[পূর্বে] যে কোয়েরিতে কোসাইন সিমিলারিটি ডিসটেন্স ফাংশন ব্যবহৃত হয়:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
অত্যন্ত গুরুত্বপূর্ণ দ্রষ্টব্য: আপনি জিজ্ঞাসা করতে পারেন, "আমরা কীভাবে জানব যে এই কোয়েরিটি কোসাইন সিমিলারিটি ব্যবহার করে?"। কোসাইন ডিসটেন্স বোঝাতে "<=>" চিহ্নের ব্যবহার দেখে আপনি ডিসটেন্স ফাংশনটি শনাক্ত করতে পারেন।
ভেক্টর সার্চ দূরত্ব ফাংশনগুলোর জন্য ডকুমেন্টেশন লিঙ্ক ।
উপরোক্ত কোয়েরির ফলাফল হলো:
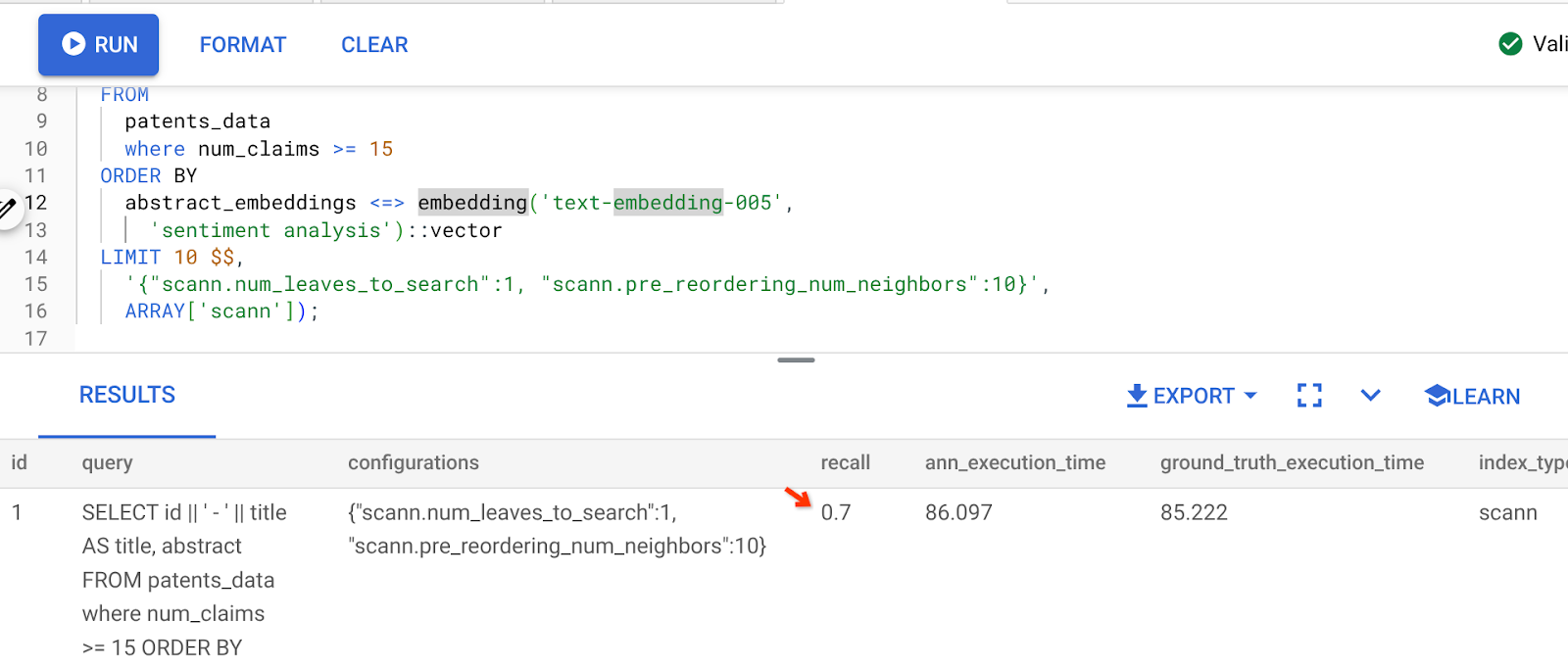
আপনি দেখতে পাচ্ছেন, আমাদের ইনডেক্স লজিকে কোনো পরিবর্তন না করেই রিকল (RECALL) ৭০% । ইনলাইন ফিল্টারিং অংশের ৬ নম্বর ধাপে আমরা যে ' patent_index ' নামের ScaNN ইনডেক্সটি তৈরি করেছিলাম, সেটি মনে আছে? উপরের কোয়েরিটি চালানোর সময়েও সেই একই ইনডেক্সটি কার্যকর ছিল।
এখন চলুন একটি ভিন্ন ডিস্ট্যান্স ফাংশন কোয়েরি দিয়ে একটি ইনডেক্স তৈরি করি: L2 ডিস্ট্যান্স: <->
drop index patent_index;
CREATE INDEX patent_index_L2 ON patents_data
USING scann (abstract_embeddings L2)
WITH (num_leaves=32);
টেবিলে কোনো অপ্রয়োজনীয় ইনডেক্স নেই, এটা নিশ্চিত করার জন্যই ড্রপ ইনডেক্স স্টেটমেন্টটি ব্যবহার করা হয়।
এখন, আমার ভেক্টর সার্চ ফাংশনালিটির ডিসট্যান্স ফাংশন পরিবর্তন করার পর RECALL মূল্যায়ন করতে আমি নিম্নলিখিত কোয়েরিটি চালাতে পারি।
[পরবর্তী] যে কোয়েরিতে কোসাইন সিমিলারিটি ডিসটেন্স ফাংশন ব্যবহার করা হয়েছে:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <-> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
উপরোক্ত কোয়েরির ফলাফল হলো:
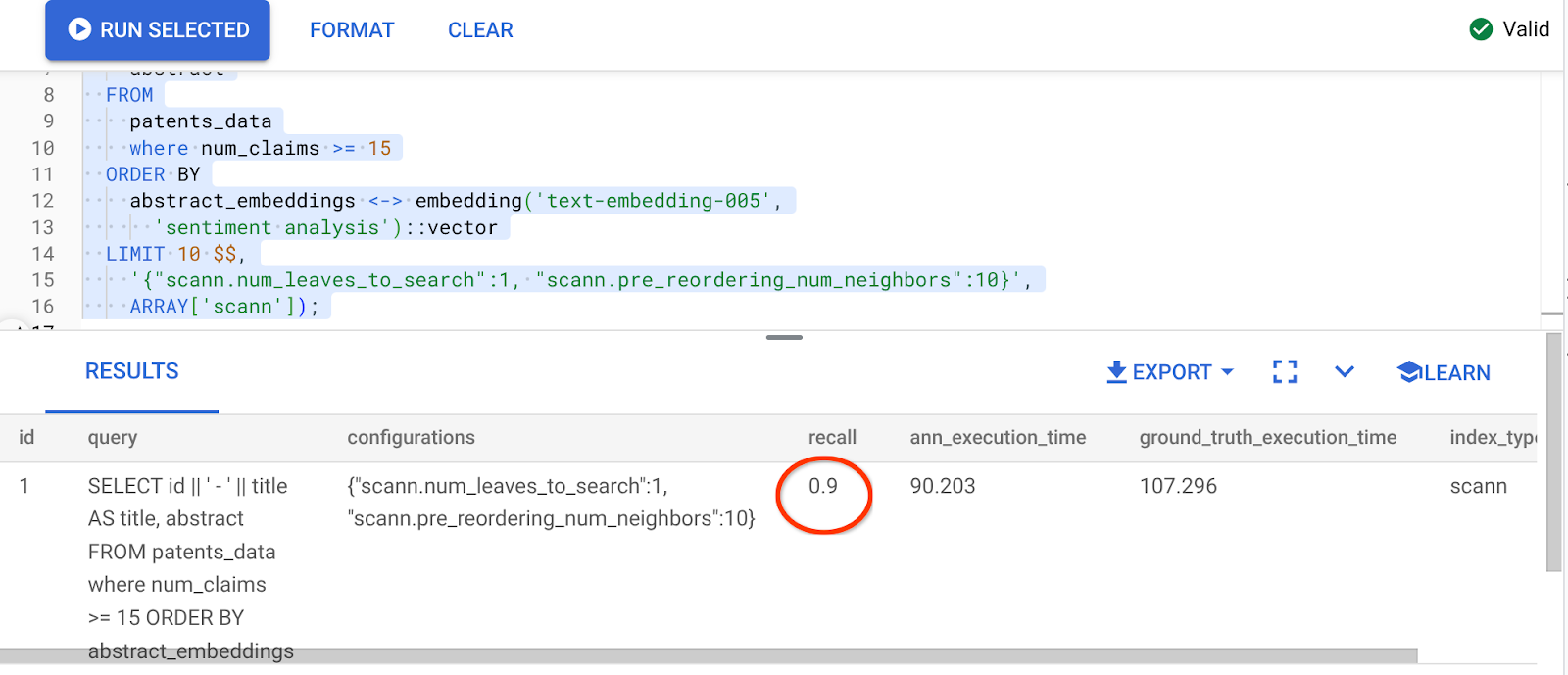
স্মরণশক্তির হারে কী অসাধারণ পরিবর্তন, ৯০%!!!
আপনার কাঙ্ক্ষিত রিকল ভ্যালু এবং আপনার অ্যাপ্লিকেশন যে ডেটাসেট ব্যবহার করে, তার উপর ভিত্তি করে ইনডেক্সে num_leaves ইত্যাদির মতো আরও অন্যান্য প্যারামিটার পরিবর্তন করা যায়।
৮. পরিষ্কার করুন
এই পোস্টে ব্যবহৃত রিসোর্সগুলোর জন্য আপনার গুগল ক্লাউড অ্যাকাউন্টে চার্জ হওয়া এড়াতে, এই ধাপগুলো অনুসরণ করুন:
- গুগল ক্লাউড কনসোলে, রিসোর্স ম্যানেজার পৃষ্ঠায় যান।
- প্রজেক্ট তালিকা থেকে, আপনি যে প্রজেক্টটি মুছতে চান সেটি নির্বাচন করুন এবং তারপর ডিলিট বোতামে ক্লিক করুন।
- ডায়ালগ বক্সে প্রজেক্ট আইডি টাইপ করুন এবং তারপর প্রজেক্টটি মুছে ফেলার জন্য 'শাট ডাউন'-এ ক্লিক করুন।
- বিকল্পভাবে, আপনি DELETE CLUSTER বোতামে ক্লিক করে এই প্রজেক্টের জন্য আমাদের তৈরি করা AlloyDB ক্লাস্টারটি মুছে ফেলতে পারেন (কনফিগারেশনের সময় ক্লাস্টারের জন্য us-central1 নির্বাচন না করে থাকলে এই হাইপারলিঙ্কে অবস্থান পরিবর্তন করুন)।
৯. অভিনন্দন
অভিনন্দন! আপনি উচ্চ কর্মক্ষমতা এবং প্রকৃত অর্থ-নির্ভর করার জন্য AlloyDB-এর উন্নত ভেক্টর সার্চ ব্যবহার করে সফলভাবে আপনার প্রাসঙ্গিক পেটেন্ট সার্চ কোয়েরি তৈরি করেছেন। আমি একটি মান-নিয়ন্ত্রিত মাল্টি-টুল এজেন্টিক অ্যাপ্লিকেশন তৈরি করেছি যা ADK এবং এখানে আলোচিত AlloyDB-এর সমস্ত উপাদান ব্যবহার করে একটি উচ্চ কর্মক্ষম ও উন্নত মানের পেটেন্ট ভেক্টর সার্চ ও অ্যানালাইজার এজেন্ট তৈরি করে, যা আপনি এখানে দেখতে পারেন: https://youtu.be/Y9fvVY0yZTY
আপনি যদি ওই এজেন্টটি তৈরি করতে শিখতে চান, তাহলে অনুগ্রহ করে এই কোডল্যাবটি দেখুন।