
1. Übersicht
In verschiedenen Branchen ist die kontextbezogene Suche eine wichtige Funktion, die das Herzstück ihrer Anwendungen bildet. Retrieval Augmented Generation ist mit ihren auf generativer KI basierenden Abrufmechanismen seit einiger Zeit ein wichtiger Faktor für diese entscheidende technologische Entwicklung. Generative Modelle mit ihren großen Kontextfenstern und der beeindruckenden Ausgabequalität verändern die KI. RAG bietet eine systematische Möglichkeit, Kontext in KI-Anwendungen und ‑Agents einzufügen und sie in strukturierten Datenbanken oder Informationen aus verschiedenen Medien zu verankern. Diese Kontextdaten sind entscheidend für die Klarheit der Wahrheit und die Genauigkeit der Ausgabe. Wie genau sind diese Ergebnisse jedoch? Hängt Ihr Unternehmen größtenteils von der Genauigkeit dieser kontextbezogenen Übereinstimmungen und der Relevanz ab? Dann ist dieses Projekt genau das Richtige für dich!
Das eigentliche Problem bei der Vektorsuche ist nicht die Entwicklung, sondern die Frage, ob die Vektorübereinstimmungen tatsächlich gut sind. Das kennen wir alle: Man starrt auf eine Liste mit Ergebnissen und fragt sich: „Funktioniert das überhaupt?“ Sehen wir uns an, wie Sie die Qualität Ihrer Vektorabgleiche bewerten können. Was hat sich also bei RAG geändert? Alles! Jahrelang war Retrieval-Augmented Generation (RAG) ein vielversprechendes, aber schwer zu erreichendes Ziel. Jetzt haben wir endlich die Tools, um RAG-Anwendungen mit der Leistung und Zuverlässigkeit zu entwickeln, die für geschäftskritische Aufgaben erforderlich sind.
Wir haben jetzt bereits ein grundlegendes Verständnis von drei Dingen:
- Was die kontextbezogene Suche für Ihren Agenten bedeutet und wie Sie sie mithilfe der Vektorsuche umsetzen können.
- Wir haben uns auch intensiv mit der Vektorsuche im Rahmen Ihrer Daten beschäftigt, also in Ihrer Datenbank selbst. Alle Google Cloud-Datenbanken unterstützen das, falls Sie es noch nicht wussten.
- Wir sind einen Schritt weiter gegangen als der Rest der Welt und haben Ihnen gezeigt, wie Sie eine solche schlanke RAG-Funktion für die Vektorsuche mit hoher Leistung und Qualität mit der AlloyDB-Vektorsuche auf Basis des ScaNN-Index erreichen können.
Wenn Sie diese grundlegenden, fortgeschrittenen und etwas komplexeren RAG-Tests noch nicht durchgeführt haben, empfehlen wir Ihnen, die entsprechenden Artikel hier, hier und hier in der angegebenen Reihenfolge zu lesen.
Patent Search unterstützt den Nutzer bei der Suche nach kontextuell relevanten Patenten zu seinem Suchtext. Eine Version davon haben wir bereits in der Vergangenheit entwickelt. Jetzt erstellen wir sie mit neuen und erweiterten RAG-Funktionen, die eine kontextbezogene Suche mit Qualitätskontrolle für diese Anwendung ermöglichen. Sehen wir uns das genauer an.
Das Bild unten zeigt den allgemeinen Ablauf in dieser Anwendung.~ 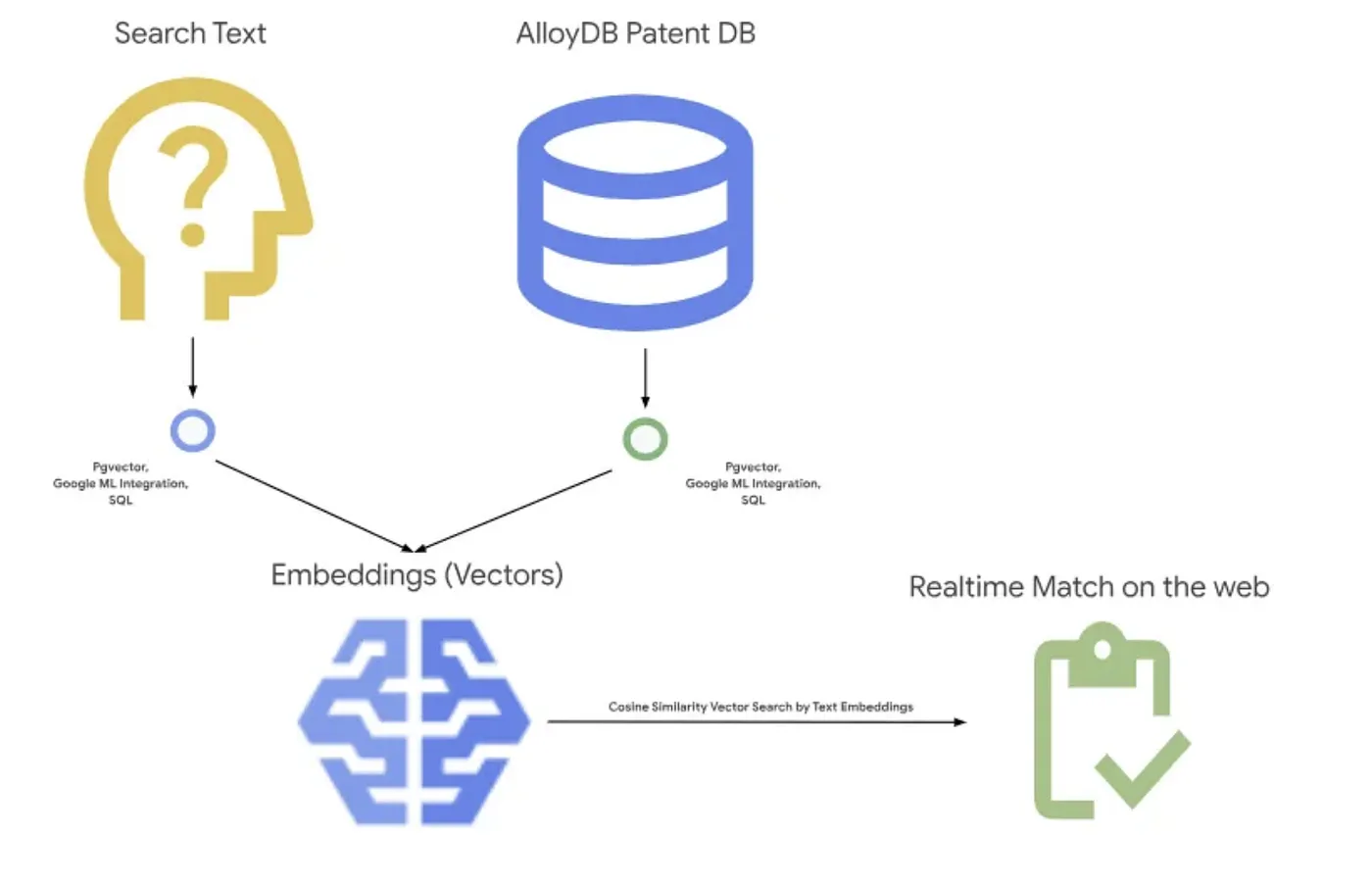
Ziel
Nutzer können anhand einer Textbeschreibung nach Patenten suchen. Die Leistung und Qualität wurden verbessert. Außerdem können sie die Qualität der generierten Übereinstimmungen mithilfe der neuesten RAG-Funktionen von AlloyDB bewerten.
Aufgaben
In diesem Lab haben Sie folgende Aufgaben:
- AlloyDB-Instanz erstellen und öffentliches Patent-Dataset laden
- Metadatenindex und ScaNN-Index erstellen
- Erweiterte Vektorsuche in AlloyDB mit der Inline-Filterungsmethode von ScaNN implementieren
- Funktion zur Recall-Bewertung implementieren
- Abfrageantwort bewerten
Voraussetzungen
2. Hinweis
Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist .
- Sie verwenden Cloud Shell, eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird. Klicken Sie oben in der Google Cloud Console auf „Cloud Shell aktivieren“.

- Sobald die Verbindung mit der Cloud Shell hergestellt ist, prüfen Sie mit dem folgenden Befehl, ob Sie bereits authentifiziert sind und für das Projekt schon Ihre Projekt-ID eingestellt ist:
gcloud auth list
- Führen Sie den folgenden Befehl in Cloud Shell aus, um zu bestätigen, dass der gcloud-Befehl Ihr Projekt kennt.
gcloud config list project
- Wenn Ihr Projekt nicht festgelegt ist, verwenden Sie den folgenden Befehl, um es festzulegen:
gcloud config set project <YOUR_PROJECT_ID>
- Aktivieren Sie die erforderlichen APIs. Sie können einen gcloud-Befehl im Cloud Shell-Terminal verwenden:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
Alternativ zum gcloud-Befehl können Sie in der Konsole nach den einzelnen Produkten suchen oder diesen Link verwenden.
Informationen zu gcloud-Befehlen und deren Verwendung finden Sie in der Dokumentation.
3. Datenbank einrichten
In diesem Lab verwenden wir AlloyDB als Datenbank für die Patentdaten. Darin werden Cluster verwendet, um alle Ressourcen wie Datenbanken und Logs zu speichern. Jeder Cluster hat eine primäre Instanz, die einen Zugriffspunkt auf die Daten bietet. Tabellen enthalten die tatsächlichen Daten.
Erstellen wir einen AlloyDB-Cluster, eine AlloyDB-Instanz und eine AlloyDB-Tabelle, in die das Patent-Dataset geladen wird.
Cluster und Instanz erstellen
- Rufen Sie in der Cloud Console die AlloyDB-Seite auf. Die meisten Seiten in der Cloud Console lassen sich ganz einfach über die Suchleiste der Console finden.
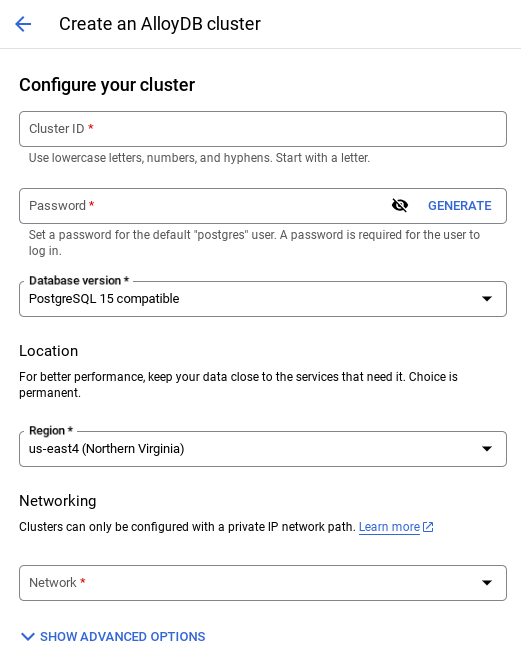
- Wählen Sie auf dieser Seite CLUSTER ERSTELLEN aus:

- Sie sehen einen Bildschirm wie den unten. Erstellen Sie einen Cluster und eine Instanz mit den folgenden Werten. Achten Sie darauf, dass die Werte übereinstimmen, wenn Sie den Anwendungscode aus dem Repository klonen:
- Cluster-ID: „
vector-cluster“ - password: "
alloydb" - PostgreSQL 15 / neueste empfohlene Version
- Region: "
us-central1" - Netzwerk: „
default“
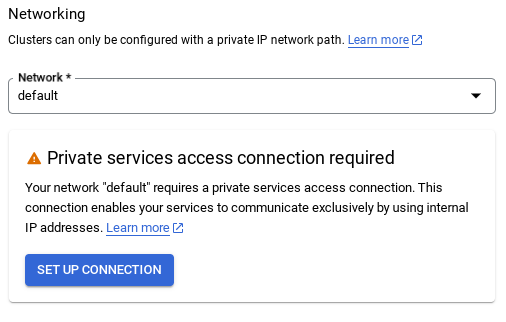
- Wenn Sie das Standardnetzwerk auswählen, wird ein Bildschirm wie der unten angezeigt.
Wählen Sie Verbindung einrichten aus.
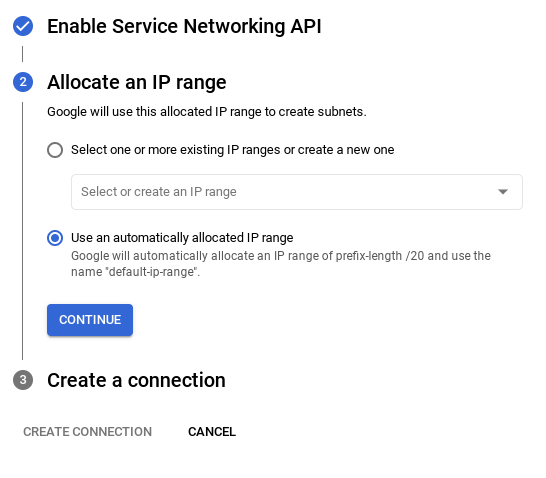
- Wählen Sie dort Automatisch zugewiesenen IP-Bereich verwenden aus und klicken Sie auf „Weiter“. Nachdem Sie die Informationen geprüft haben, wählen Sie „VERBINDUNG ERSTELLEN“ aus.
- Nachdem Sie Ihr Netzwerk eingerichtet haben, können Sie mit der Clustererstellung fortfahren. Klicken Sie auf CLUSTER ERSTELLEN, um die Einrichtung des Clusters abzuschließen (siehe unten):
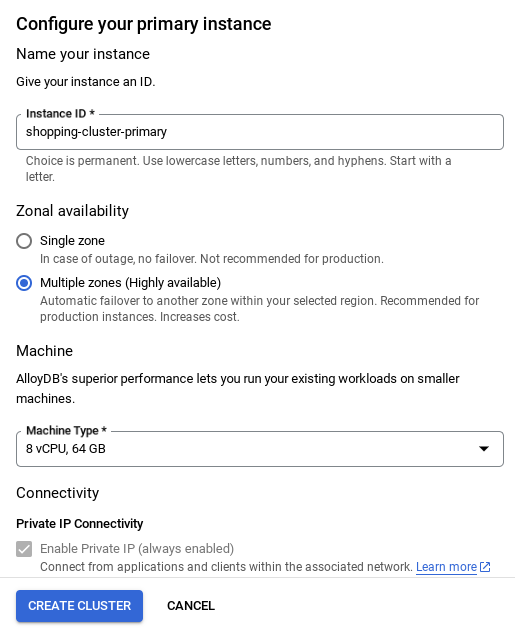
Achten Sie darauf, die Instanz-ID zu ändern (die Sie bei der Konfiguration des Clusters / der Instanz finden), in
vector-instance: Wenn Sie sie nicht ändern können, denken Sie daran, in allen nachfolgenden Verweisen Ihre Instanz-ID zu verwenden.
Die Clustererstellung dauert etwa 10 Minuten. Wenn die Einrichtung erfolgreich war, wird ein Bildschirm mit der Übersicht des gerade erstellten Clusters angezeigt.
4. Datenaufnahme
Jetzt ist es an der Zeit, eine Tabelle mit den Daten zum Geschäft hinzuzufügen. Rufen Sie AlloyDB auf, wählen Sie den primären Cluster und dann AlloyDB Studio aus:

Möglicherweise müssen Sie warten, bis die Instanz erstellt wurde. Melden Sie sich dann mit den Anmeldedaten in AlloyDB an, die Sie beim Erstellen des Clusters erstellt haben. Verwenden Sie die folgenden Daten für die Authentifizierung bei PostgreSQL:
- Nutzername: „
postgres“ - Datenbank: „
postgres“ - Passwort: „
alloydb“
Nachdem Sie sich erfolgreich in AlloyDB Studio authentifiziert haben, werden SQL-Befehle im Editor eingegeben. Sie können mehrere Editorfenster hinzufügen, indem Sie auf das Pluszeichen rechts neben dem letzten Fenster klicken.
Sie geben Befehle für AlloyDB in Editorfenstern ein und verwenden bei Bedarf die Optionen „Ausführen“, „Formatieren“ und „Löschen“.
Erweiterungen aktivieren
Für die Entwicklung dieser App verwenden wir die Erweiterungen pgvector und google_ml_integration. Mit der pgvector-Erweiterung können Sie Vektoreinbettungen speichern und durchsuchen. Die Erweiterung google_ml_integration bietet Funktionen, mit denen Sie auf Vertex AI-Vorhersageendpunkte zugreifen können, um Vorhersagen in SQL zu erhalten. Aktivieren Sie diese Erweiterungen, indem Sie die folgenden DDLs ausführen:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Wenn Sie prüfen möchten, welche Erweiterungen für Ihre Datenbank aktiviert wurden, führen Sie diesen SQL-Befehl aus:
select extname, extversion from pg_extension;
Tabelle erstellen
Sie können eine Tabelle mit der folgenden DDL-Anweisung in AlloyDB Studio erstellen:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
In der Spalte „abstract_embeddings“ können die Vektorwerte des Texts gespeichert werden.
Berechtigung gewähren
Führen Sie die folgende Anweisung aus, um die Ausführung der Funktion „embedding“ zu gewähren:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB-Dienstkonto die Rolle „Vertex AI User“ gewähren
Gewähren Sie in der Google Cloud IAM-Konsole dem AlloyDB-Dienstkonto (das so aussieht: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) Zugriff auf die Rolle „Vertex AI-Nutzer“. PROJECT_NUMBER enthält Ihre Projektnummer.
Alternativ können Sie den folgenden Befehl im Cloud Shell-Terminal ausführen:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Patentdaten in die Datenbank laden
Als Dataset verwenden wir die öffentlichen Google Patents-Datasets in BigQuery. Wir verwenden AlloyDB Studio, um unsere Abfragen auszuführen. Die Daten werden in diese Datei insert_scripts.sql aufgenommen und wir führen sie aus, um die Patentdaten zu laden.
- Öffnen Sie in der Google Cloud Console die Seite AlloyDB.
- Wählen Sie den neu erstellten Cluster aus und klicken Sie auf die Instanz.
- Klicken Sie im AlloyDB-Navigationsmenü auf AlloyDB Studio. Melden Sie sich mit Ihren Anmeldedaten an.
- Öffnen Sie einen neuen Tab, indem Sie rechts auf das Symbol Neuer Tab klicken.
- Kopieren Sie die
insert-Abfrageanweisung aus dem oben erwähnteninsert_scripts.sql-Skript in den Editor. Sie können 10 bis 50 INSERT-Anweisungen kopieren, um diesen Anwendungsfall schnell zu demonstrieren. - Klicken Sie auf Ausführen. Die Ergebnisse Ihrer Abfrage werden in der Tabelle Ergebnisse angezeigt.
Hinweis:Das Einfügeskript enthält möglicherweise viele Daten. Das liegt daran, dass wir Einbettungen in die Einfügeskripts aufgenommen haben. Klicken Sie auf „Rohdaten ansehen“, falls Sie Probleme beim Laden der Datei in GitHub haben. So vermeiden Sie, dass Sie in den nächsten Schritten mehr als einige wenige Einbettungen (maximal 20 bis 25) generieren müssen, wenn Sie ein Abrechnungskonto mit Testguthaben für Google Cloud verwenden.
5. Einbettungen für Patentdaten erstellen
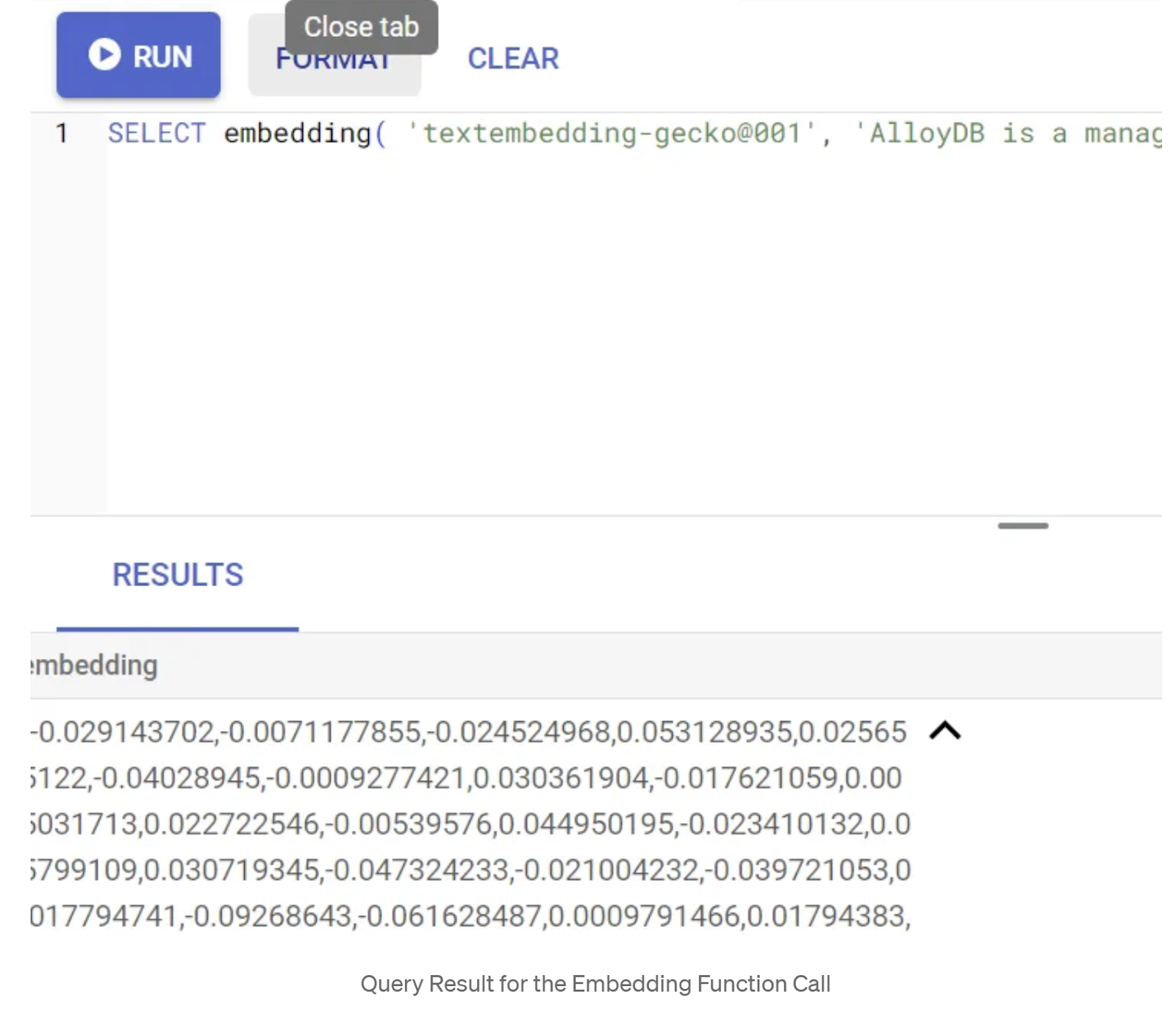
Testen wir zuerst die Einbettungsfunktion, indem wir die folgende Beispielabfrage ausführen:
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Dadurch sollte der Einbettungsvektor für den Beispieltext in der Anfrage zurückgegeben werden. Er sieht wie ein Array von Gleitkommazahlen aus. Sieht so aus:
Vektorfeld „abstract_embeddings“ aktualisieren
Führen Sie die folgende DML aus, um die Patentzusammenfassungen in der Tabelle mit den entsprechenden Einbettungen zu aktualisieren, nur wenn Sie die Daten für „abstract_embeddings“ nicht im Rahmen des Einfügeskripts eingefügt haben:
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
Wenn Sie ein Abrechnungskonto mit Testguthaben für Google Cloud verwenden, kann es sein, dass Sie Probleme haben, mehr als einige wenige Einbettungen (maximal 20 bis 25) zu generieren. Aus diesem Grund habe ich die Einbettungen bereits in die Einfügeskripts aufgenommen. Sie sollten also in Ihrer Tabelle vorhanden sein, wenn Sie den Schritt „Patentdaten in die Datenbank laden“ abgeschlossen haben.
6. Erweitertes RAG mit den neuen Funktionen von AlloyDB ausführen
Nachdem die Tabelle, die Daten und die Einbettungen bereit sind, führen wir die Echtzeit-Vektorsuche für den Suchtext des Nutzers durch. Sie können dies testen, indem Sie die folgende Abfrage ausführen:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
In dieser Abfrage
- Der vom Nutzer gesuchte Text lautet: „Sentiment Analysis“.
- Wir wandeln sie mit dem Modell „text-embedding-005“ in der Methode „embedding()“ in Einbettungen um.
- „<=>“ steht für die Verwendung der Distanzmethode „COSINE SIMILARITY“.
- Wir konvertieren das Ergebnis der Einbettungsmethode in den Vektortyp, damit es mit den in der Datenbank gespeicherten Vektoren kompatibel ist.
- LIMIT 10 bedeutet, dass die zehn am besten passenden Ergebnisse für den Suchtext ausgewählt werden.
AlloyDB bringt Vector Search RAG auf ein neues Niveau:
Es gibt eine Reihe von Neuerungen. Zwei davon sind:
- Inline-Filterung
- Recall Evaluator
Inline-Filterung
Bisher mussten Sie als Entwickler die Vector Search-Abfrage ausführen und sich um das Filtern und den Recall kümmern. Der AlloyDB-Abfrageoptimierer entscheidet, wie eine Abfrage mit Filtern ausgeführt wird. Die Inline-Filterung ist eine neue Technik zur Abfrageoptimierung, mit der der AlloyDB-Abfrageoptimierer sowohl die Metadatenfilterbedingungen als auch die Vektorsuche gleichzeitig auswerten kann. Dabei werden sowohl Vektorindexe als auch Indexe für die Metadatenspalten verwendet. Dadurch hat sich die Recall-Leistung erhöht, sodass Entwickler die Vorteile von AlloyDB sofort nutzen können.
Inline-Filter eignen sich am besten für Fälle mit mittlerer Selektivität. Wenn AlloyDB den Vektorindex durchsucht, werden Distanzen nur für Vektoren berechnet, die den Metadatenfilterbedingungen entsprechen (Ihre funktionalen Filter in einer Abfrage, die normalerweise in der WHERE-Klausel verarbeitet werden). Dadurch wird die Leistung dieser Abfragen erheblich verbessert, was die Vorteile von Post-Filter oder Pre-Filter ergänzt.
- pgvector-Erweiterung installieren oder aktualisieren
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
Wenn die pgvector-Erweiterung bereits installiert ist, führen Sie ein Upgrade der Vektorerweiterung auf Version 0.8.0.google-3 oder höher durch, um die Funktionen des Recall-Evaluators zu erhalten.
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
Dieser Schritt muss nur ausgeführt werden, wenn Ihre Vektorerweiterung <0.8.0.google-3> ist.
Wichtiger Hinweis:Wenn die Anzahl der Zeilen weniger als 100 beträgt, müssen Sie den ScaNN-Index nicht erstellen, da er für weniger Zeilen nicht gilt. Überspringen Sie in diesem Fall die folgenden Schritte.
- Wenn Sie ScaNN-Indizes erstellen möchten, müssen Sie die Erweiterung „alloydb_scann“ installieren.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
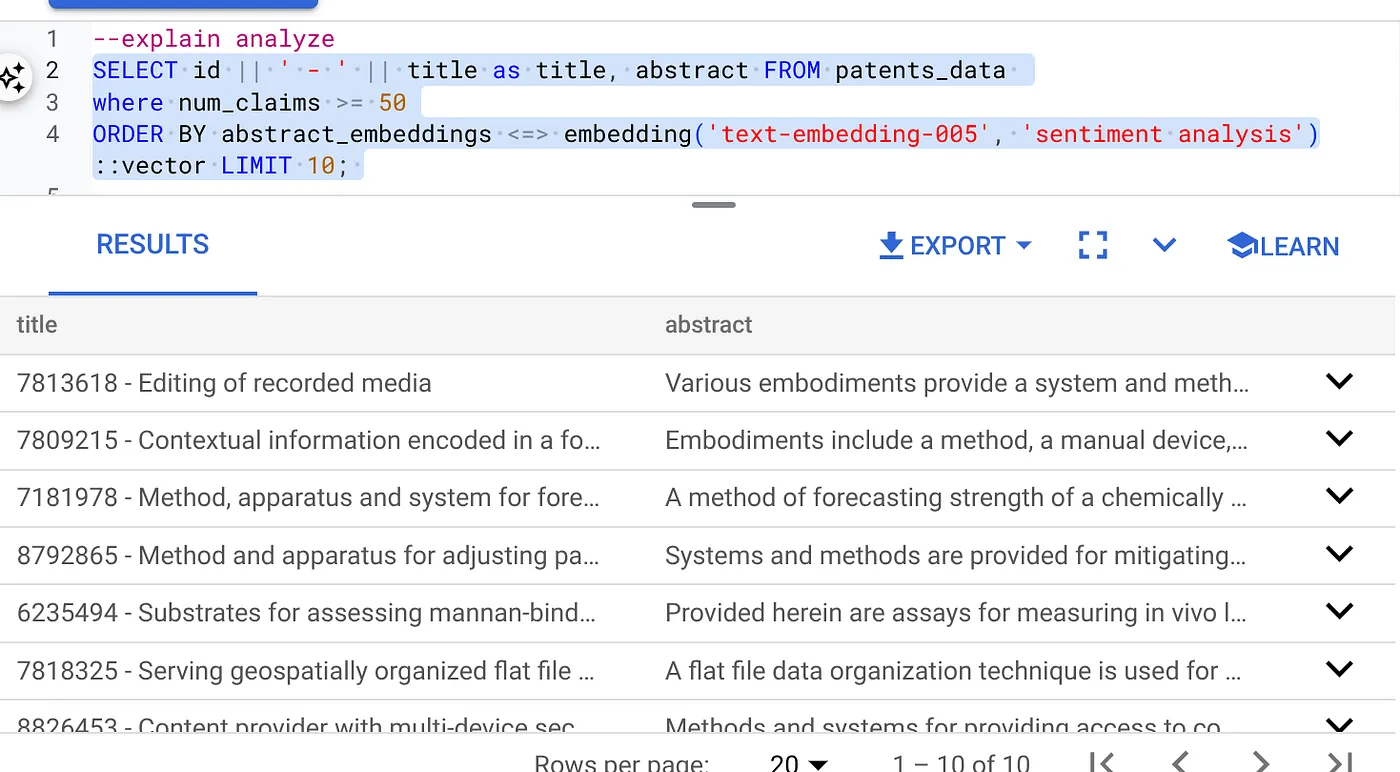
- Führen Sie zuerst die Vektorsuchanfrage ohne Index und ohne aktivierten Inline-Filter aus:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
Das Ergebnis sollte in etwa so aussehen:
- Führen Sie „Explain Analyze“ für den Text aus (ohne Index und Inline-Filterung):
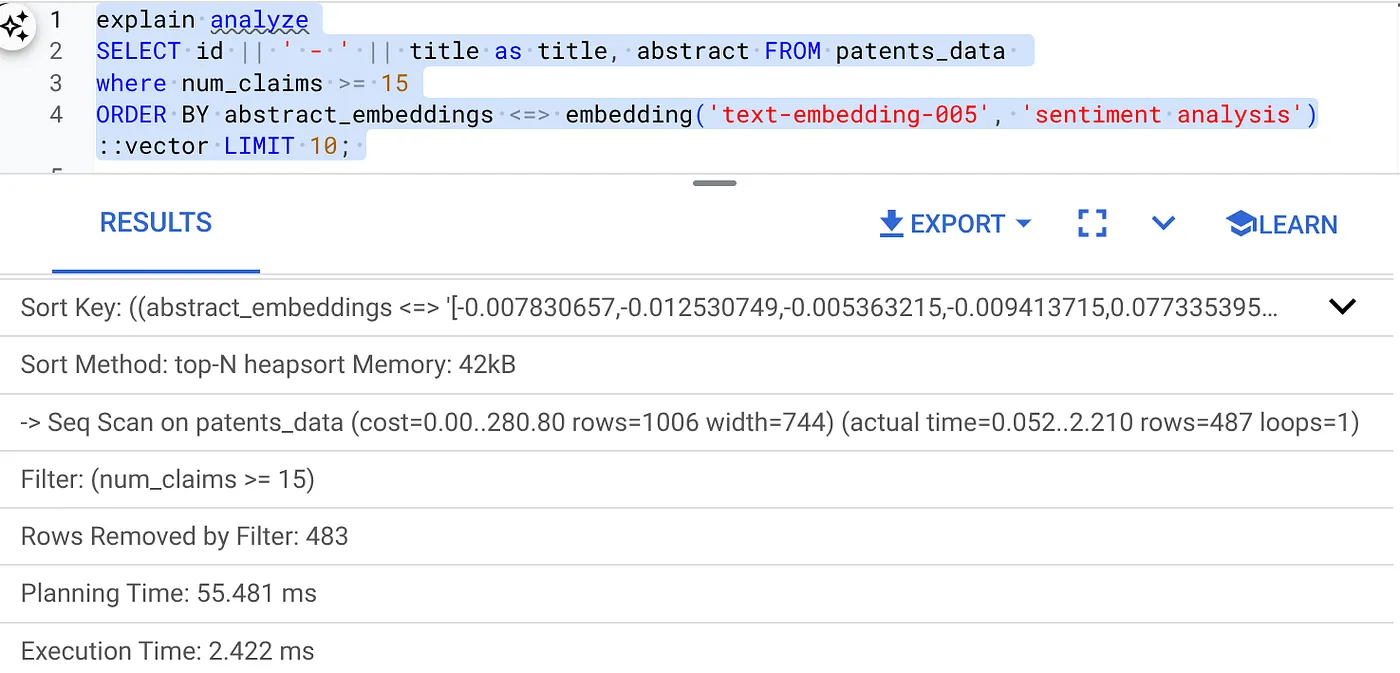
Die Ausführungszeit beträgt 2,4 ms.
- Erstellen wir einen regulären Index für das Feld „num_claims“, damit wir danach filtern können:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- Erstellen wir den ScaNN-Index für unsere Patent Search-Anwendung. Führen Sie Folgendes in AlloyDB Studio aus:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
Wichtiger Hinweis : (num_leaves=32) gilt für unseren gesamten Datensatz mit mehr als 1.000 Zeilen. Wenn die Anzahl der Zeilen weniger als 100 beträgt, müssen Sie keinen Index erstellen, da er für weniger Zeilen nicht gilt.
- Inline-Filterung für den ScaNN-Index aktivieren:
SET scann.enable_inline_filtering = on
- Führen Sie nun dieselbe Abfrage mit Filter und Vektorsuche aus:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
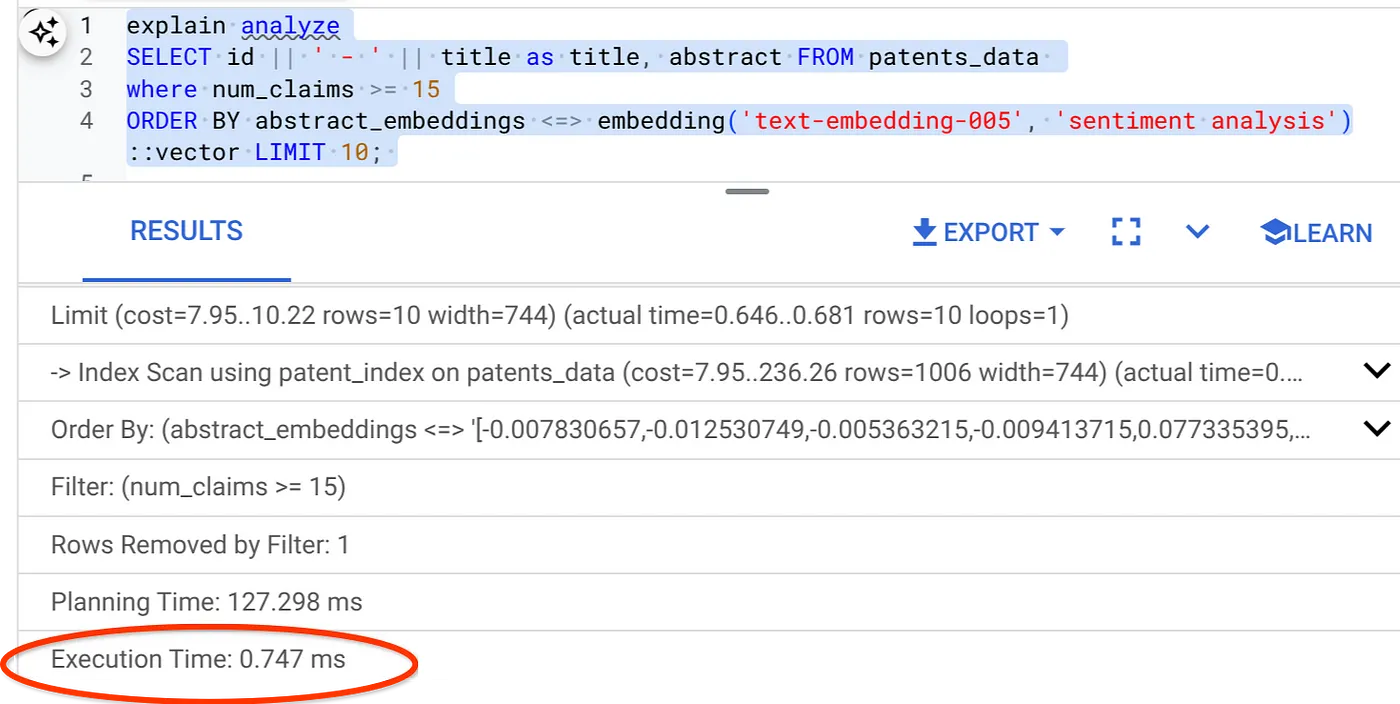
Wie Sie sehen, wird die Ausführungszeit für dieselbe Vektorsuche deutlich verkürzt. Der ScaNN-Index mit Inline-Filterung in der Vektorsuche hat dies ermöglicht.
Als Nächstes bewerten wir den Recall für diese ScaNN-basierte Vektorsuche.
Recall Evaluator
Der Recall bei der Ähnlichkeitssuche ist der Prozentsatz der relevanten Instanzen, die bei einer Suche abgerufen wurden, d.h. die Anzahl der korrekt positiven Ergebnisse. Dies ist der gängigste Messwert zur Messung der Suchqualität. Eine Quelle für den Verlust der Trefferquote ist der Unterschied zwischen der Suche nach dem ungefähren nächsten Nachbarn (Approximate Nearest Neighbor, aNN) und der Suche nach dem k (exakten) nächsten Nachbarn (k-Nearest Neighbor, kNN). Vektorindexe wie ScaNN von AlloyDB implementieren aNN-Algorithmen, mit denen Sie die Vektorsuche in großen Datasets beschleunigen können. Dabei wird ein geringfügiger Recall-Kompromiss eingegangen. Mit AlloyDB können Sie diesen Kompromiss jetzt direkt in der Datenbank für einzelne Abfragen messen und dafür sorgen, dass er im Zeitverlauf stabil bleibt. Sie können Abfrage- und Indexparameter auf Grundlage dieser Informationen aktualisieren, um bessere Ergebnisse und eine bessere Leistung zu erzielen.
Welche Logik steckt hinter dem Abrufen von Suchergebnissen?
Im Kontext der Vektorsuche bezieht sich der Recall bzw. die Trefferquote auf den Prozentsatz der Vektoren, die vom Index zurückgegeben werden und die tatsächlichen nächsten Nachbarn sind. Wenn z. B. eine Abfrage nach 20 nächsten Nachbarn 19 der „grundlegend echten“ nächsten Nachbarn zurückgibt, beträgt der Recall 19/20 × 100 = 95%. Recall ist der Messwert für die Suchqualität und wird als Prozentsatz der zurückgegebenen Ergebnisse definiert, die den Anfragevektoren objektiv am nächsten sind.
Mit der Funktion evaluate_query_recall können Sie den Recall für eine Vektoranfrage für einen Vektorindex für eine bestimmte Konfiguration ermitteln. Mit dieser Funktion können Sie Ihre Parameter so anpassen, dass Sie die gewünschten Recall-Ergebnisse für Vektorabfragen erzielen.
Wichtiger Hinweis:
Wenn Sie bei den folgenden Schritten einen Fehler vom Typ „Permission denied“ für den HNSW-Index erhalten, überspringen Sie diesen gesamten Abschnitt zur Recall-Auswertung vorerst. Das kann mit Zugriffsbeschränkungen zusammenhängen, da die Funktion zum Zeitpunkt der Dokumentation dieses Codelabs gerade erst veröffentlicht wurde.
- Legen Sie das Flag „Enable Index Scan“ für den ScaNN-Index und den HNSW-Index fest:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- Führen Sie die folgende Abfrage in AlloyDB Studio aus:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Die Funktion „evaluate_query_recall“ verwendet die Abfrage als Parameter und gibt den entsprechenden Recall zurück. Ich verwende dieselbe Abfrage, mit der ich die Leistung geprüft habe, als Funktionseingabeabfrage. Ich habe SCaNN als Indexmethode hinzugefügt. Weitere Parameteroptionen finden Sie in der Dokumentation.
Der Recall für diese Vektorsuche-Anfrage, die wir verwendet haben:
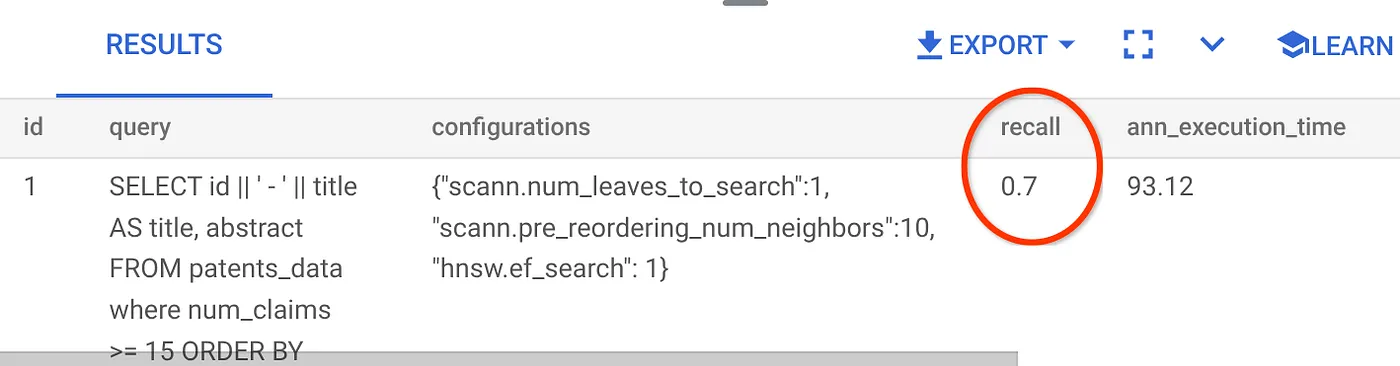
Der RECALL liegt bei 70%. Jetzt kann ich diese Informationen verwenden, um die Indexparameter, Methoden und Abfrageparameter zu ändern und die Erinnerung für diese Vektorsuche zu verbessern.
7. Mit geänderten Abfrage- und Indexparametern testen
Jetzt testen wir die Abfrage, indem wir die Abfrageparameter auf Grundlage des erhaltenen Rückrufs ändern.
- Ich habe die Anzahl der Zeilen im Ergebnis-Set auf 7 (zuvor 25) geändert und sehe einen verbesserten RECALL von 86%.
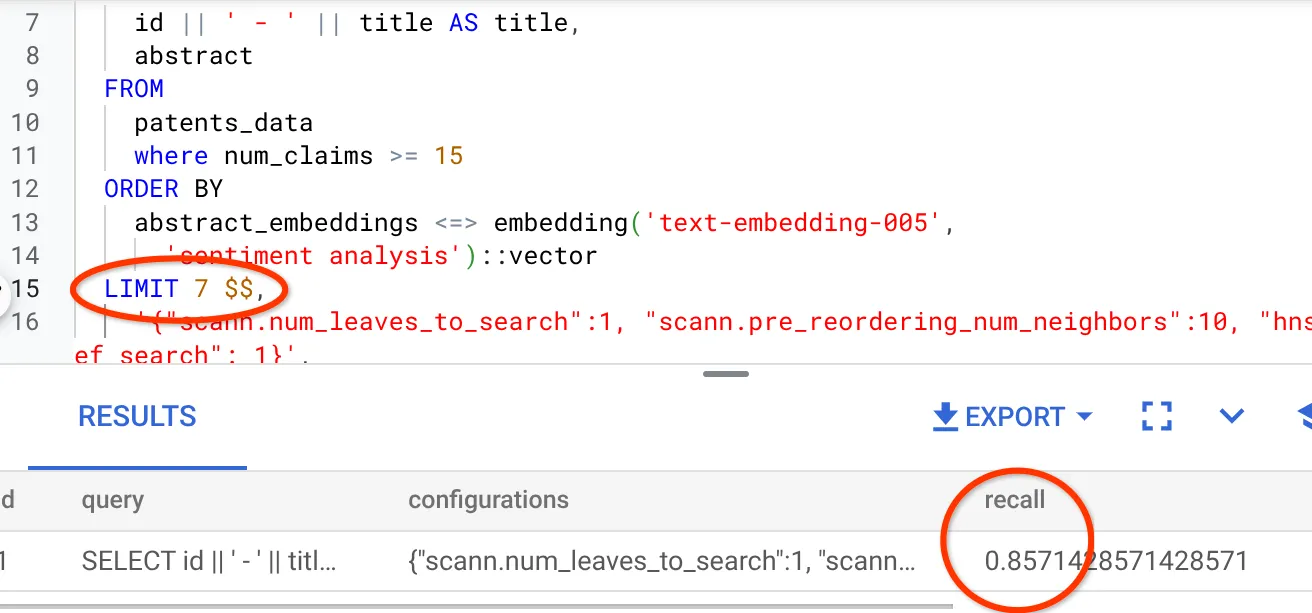
Das bedeutet, dass ich die Anzahl der Ergebnisse, die meine Nutzer sehen, in Echtzeit variieren kann, um die Relevanz der Ergebnisse entsprechend dem Suchkontext der Nutzer zu verbessern.
- Versuchen wir es noch einmal, indem wir die Indexparameter ändern:
Für diesen Test verwende ich die Distanzfunktion L2-Distanz anstelle von Kosinus. Außerdem ändere ich das Limit der Anfrage auf 10, um zu zeigen, ob sich die Qualität der Suchergebnisse auch bei einer erhöhten Anzahl von Suchergebnissen verbessert.
[BEFORE] Abfrage, in der die Kosinus-Ähnlichkeitsdistanzfunktion verwendet wird:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Sehr wichtiger Hinweis: „Woher wissen wir, dass in dieser Anfrage die KOSINUS-Ähnlichkeit verwendet wird?“, fragen Sie sich vielleicht. Die Distanzfunktion wird durch die Verwendung von „<=>“ zur Darstellung der Kosinusdistanz identifiziert.
Dokumentationslink für Distanzfunktionen der Vektorsuche.
Das Ergebnis der obigen Abfrage ist:
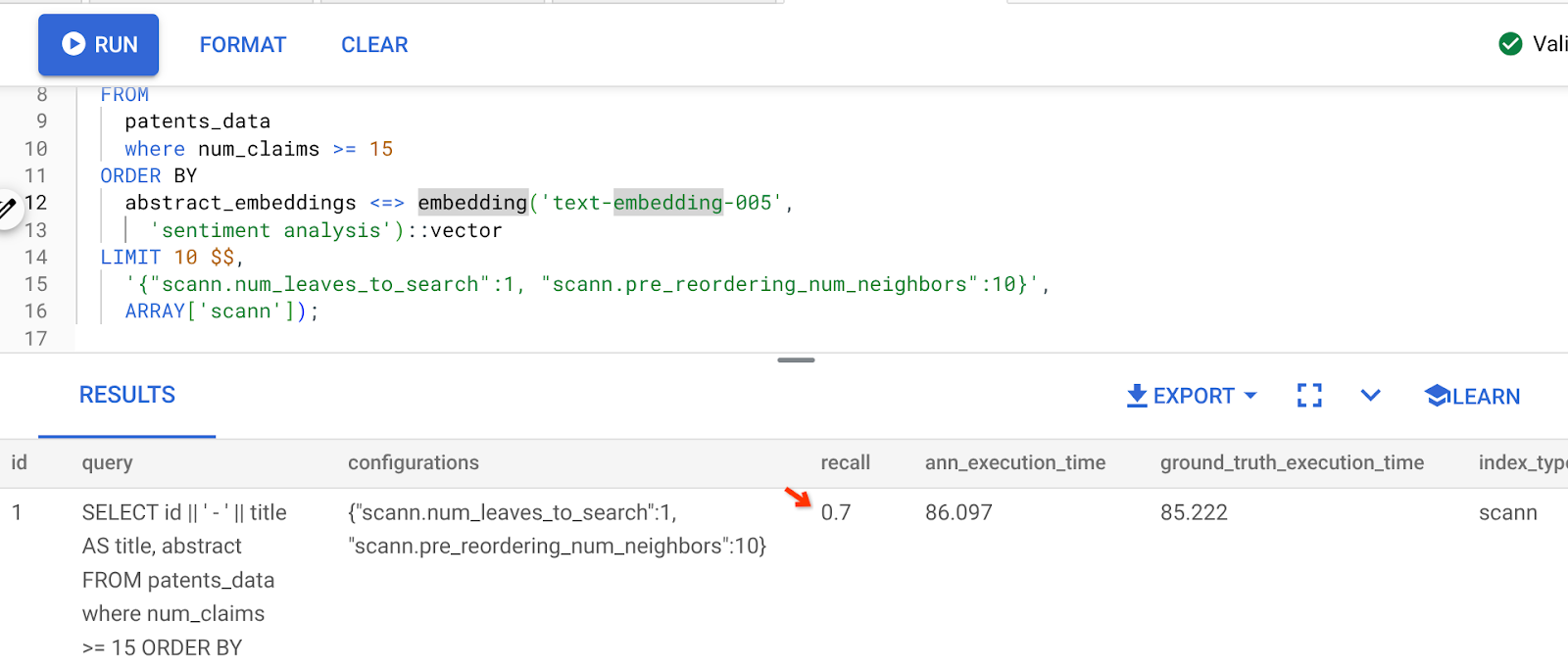
Wie Sie sehen, liegt der RECALL bei 70%, ohne dass sich etwas an unserer Indexlogik geändert hat. Erinnern Sie sich an den ScaNN-Index, den wir in Schritt 6 des Abschnitts „Inline-Filterung“ erstellt haben (patent_index)? Derselbe Index ist weiterhin aktiv, während wir die obige Abfrage ausgeführt haben.
Erstellen wir nun einen Index mit einer anderen Distanzfunktionsabfrage: L2-Distanz: <->
drop index patent_index;
CREATE INDEX patent_index_L2 ON patents_data
USING scann (abstract_embeddings L2)
WITH (num_leaves=32);
Die Anweisung „DROP INDEX“ dient nur dazu, sicherzustellen, dass kein unnötiger Index für die Tabelle vorhanden ist.
Jetzt kann ich die folgende Abfrage ausführen, um den RECALL nach dem Ändern der Distanzfunktion meiner Vektorsuchfunktion zu bewerten.
[AFTER]: Abfrage, in der die Distanzfunktion „Kosinus-Ähnlichkeit“ verwendet wird:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <-> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Das Ergebnis der obigen Abfrage ist:
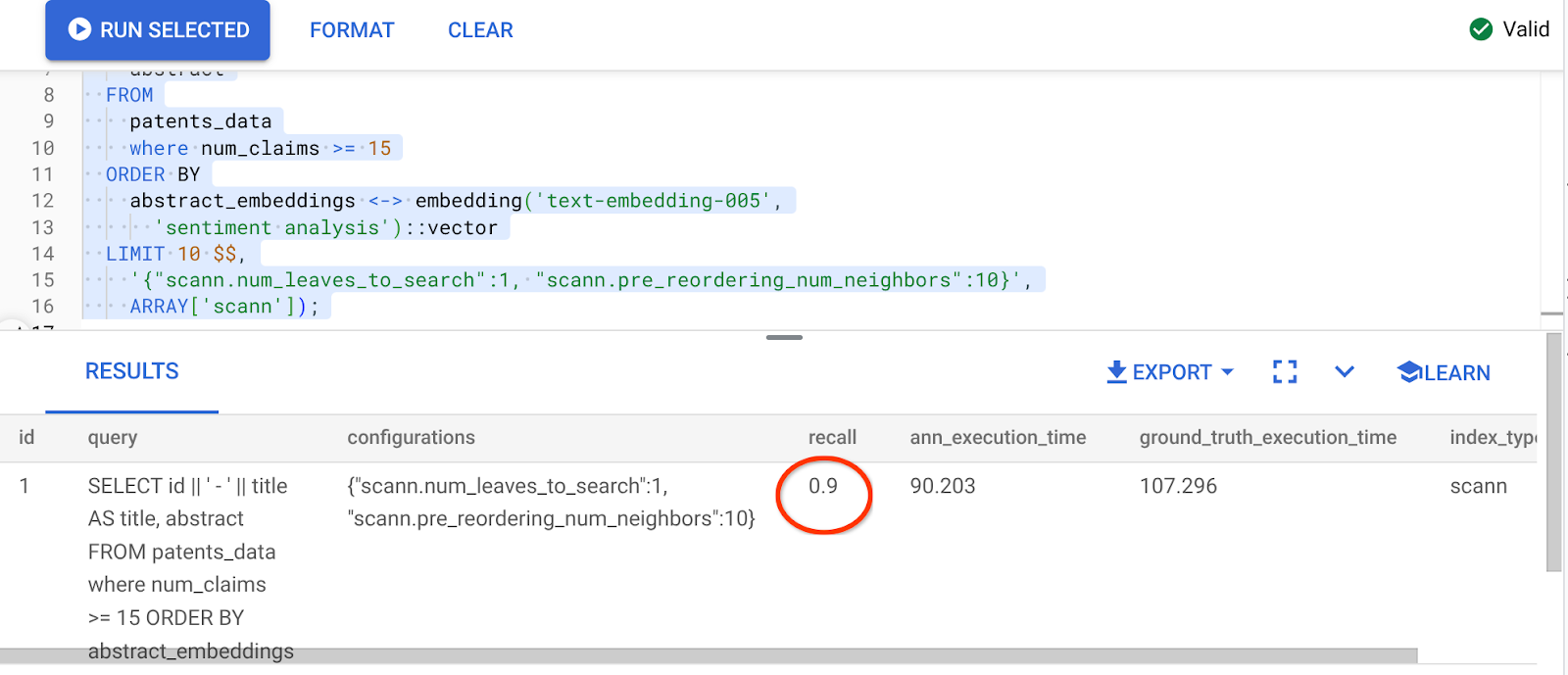
Was für eine Steigerung des Erinnerungswerts – 90%!!!
Es gibt weitere Parameter, die Sie im Index ändern können, z. B. „num_leaves“, basierend auf dem gewünschten Recall-Wert und dem Dataset, das von Ihrer Anwendung verwendet wird.
8. Bereinigen
So vermeiden Sie, dass Ihrem Google Cloud-Konto die in diesem Beitrag verwendeten Ressourcen in Rechnung gestellt werden:
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcenmanager.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Beenden, um das Projekt zu löschen.
- Alternativ können Sie einfach den AlloyDB-Cluster löschen, den wir gerade für dieses Projekt erstellt haben. Klicken Sie dazu auf die Schaltfläche „CLUSTER LÖSCHEN“. Wenn Sie bei der Konfiguration nicht „us-central1“ für den Cluster ausgewählt haben, ändern Sie den Speicherort in diesem Hyperlink.
9. Glückwunsch
Glückwunsch! Sie haben Ihre kontextbezogene Patent Search-Anfrage mit der erweiterten Vektorsuche von AlloyDB erstellt, um eine hohe Leistung zu erzielen und sie wirklich aussagekräftig zu machen. Ich habe eine qualitätskontrollierte, agentenbasierte Multi-Tool-Anwendung erstellt, die das ADK und alle hier besprochenen AlloyDB-Funktionen nutzt, um einen leistungsstarken und hochwertigen Patent Vector Search & Analyzer-Agenten zu erstellen. Sie können ihn sich hier ansehen: https://youtu.be/Y9fvVY0yZTY
Wenn Sie lernen möchten, wie Sie diesen Agent erstellen, sehen Sie sich dieses Codelab an.