
1. Übersicht
In verschiedenen Branchen ist die Patentrecherche ein wichtiges Instrument, um die Wettbewerbssituation zu verstehen, potenzielle Lizenzierungs- oder Akquisitionsmöglichkeiten zu erkennen und die Verletzung bestehender Patente zu vermeiden.
Die Patentrecherche ist umfangreich und komplex. Das Durchsuchen unzähliger technischer Zusammenfassungen, um relevante Innovationen zu finden, ist eine entmutigende Aufgabe. Herkömmliche stichwortbasierte Suchanfragen sind oft ungenau und zeitaufwendig. Die Zusammenfassungen sind lang und technisch, sodass es schwierig ist, die Kernidee schnell zu erfassen. Das kann dazu führen, dass Forschende wichtige Patente übersehen oder Zeit mit irrelevanten Ergebnissen verschwenden.
Die Geheimzutat hinter dieser Revolution ist die Vektorsuche. Bei der Vektorsuche wird Text nicht nur anhand von einfachen Stichwortübereinstimmungen, sondern auch anhand von numerischen Darstellungen (Einbettungen) analysiert. So können wir anhand der Bedeutung der Anfrage suchen, nicht nur anhand der verwendeten Wörter. In der Welt der Literatursuche ist das ein Gamechanger. Stellen Sie sich vor, Sie finden ein Patent für einen „tragbaren Herzfrequenzmesser“, auch wenn der genaue Begriff im Dokument nicht verwendet wird.
Ziel
In diesem Codelab werden wir den Prozess der Patentsuche schneller, intuitiver und unglaublich präzise gestalten, indem wir AlloyDB, die pgvector-Erweiterung und Gemini 1.5 Pro, Embeddings und die Vektorsuche nutzen.
Aufgaben
In diesem Lab haben Sie folgende Aufgaben:
- AlloyDB-Instanz erstellen und Daten aus dem öffentlichen Patent-Dataset laden
- pgvector- und generative KI-Modellerweiterungen in AlloyDB aktivieren
- Einbettungen aus den Statistiken generieren
- Echtzeit-Suche nach Kosinusähnlichkeit für den Suchtext des Nutzers durchführen
- Lösung in serverlosen Cloud Functions bereitstellen
Das folgende Diagramm zeigt den Datenfluss und die Schritte, die für die Implementierung erforderlich sind.

High level diagram representing the flow of the Patent Search Application with AlloyDB
Voraussetzungen
2. Hinweis
Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist .
- Sie verwenden Cloud Shell, eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird und in der bq vorinstalliert ist. Klicken Sie oben in der Google Cloud Console auf „Cloud Shell aktivieren“.

- Sobald die Verbindung mit der Cloud Shell hergestellt ist, prüfen Sie mit dem folgenden Befehl, ob Sie bereits authentifiziert sind und für das Projekt schon Ihre Projekt-ID eingestellt ist:
gcloud auth list
- Führen Sie den folgenden Befehl in Cloud Shell aus, um zu bestätigen, dass der gcloud-Befehl Ihr Projekt kennt.
gcloud config list project
- Wenn Ihr Projekt nicht festgelegt ist, verwenden Sie den folgenden Befehl, um es festzulegen:
gcloud config set project <YOUR_PROJECT_ID>
- Aktivieren Sie die erforderlichen APIs. Sie können einen gcloud-Befehl im Cloud Shell-Terminal verwenden:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
Alternativ zum gcloud-Befehl können Sie in der Konsole nach den einzelnen Produkten suchen oder diesen Link verwenden.
Informationen zu gcloud-Befehlen und deren Verwendung finden Sie in der Dokumentation.
3. AlloyDB-Datenbank vorbereiten
Erstellen wir einen AlloyDB-Cluster, eine AlloyDB-Instanz und eine AlloyDB-Tabelle, in die das Patent-Dataset geladen wird.
AlloyDB-Objekte erstellen
Erstellen Sie einen Cluster und eine Instanz mit der Cluster-ID „patent-cluster“, dem Passwort „alloydb“, PostgreSQL 15-kompatibel und der Region „us-central1“ sowie dem Netzwerk „default“. Legen Sie die Instanz-ID auf „patent-instance“ fest. Klicken Sie auf „CLUSTER ERSTELLEN“. Details zum Erstellen eines Clusters finden Sie unter https://cloud.google.com/alloydb/docs/cluster-create.
Tabelle erstellen
Sie können eine Tabelle mit der folgenden DDL-Anweisung in AlloyDB Studio erstellen:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT) ;
Erweiterungen aktivieren
Für die Entwicklung der Patent Search App verwenden wir die Erweiterungen „pgvector“ und „google_ml_integration“. Mit der pgvector-Erweiterung können Sie Vektoreinbettungen speichern und durchsuchen. Die Erweiterung google_ml_integration bietet Funktionen, mit denen Sie auf Vertex AI-Vorhersageendpunkte zugreifen können, um Vorhersagen in SQL zu erhalten. Aktivieren Sie diese Erweiterungen, indem Sie die folgenden DDLs ausführen:
CREATE EXTENSION vector;
CREATE EXTENSION google_ml_integration;
Berechtigung gewähren
Führen Sie die folgende Anweisung aus, um die Ausführung der Funktion „embedding“ zu gewähren:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB-Dienstkonto die Rolle „Vertex AI User“ gewähren
Gewähren Sie in der Google Cloud IAM-Konsole dem AlloyDB-Dienstkonto (das so aussieht: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) Zugriff auf die Rolle „Vertex AI-Nutzer“. PROJECT_NUMBER enthält Ihre Projektnummer.
Alternativ können Sie den Zugriff auch mit dem gcloud-Befehl gewähren:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Tabelle ändern, um eine Vektorspalte zum Speichern der Einbettungen hinzuzufügen
Führen Sie die folgende DDL aus, um der gerade erstellten Tabelle das Feld „abstract_embeddings“ hinzuzufügen. In dieser Spalte können die Vektorwerte des Texts gespeichert werden:
ALTER TABLE patents_data ADD column abstract_embeddings vector(3072);
4. Patentdaten in die Datenbank laden
Als Dataset verwenden wir die öffentlichen Google Patents-Datasets in BigQuery. Wir verwenden AlloyDB Studio, um unsere Abfragen auszuführen. Das Repository alloydb-pgvector enthält das Skript insert_into_patents_data.sql, das wir zum Laden der Patentdaten ausführen.
- Öffnen Sie in der Google Cloud Console die Seite AlloyDB.
- Wählen Sie den neu erstellten Cluster aus und klicken Sie auf die Instanz.
- Klicken Sie im AlloyDB-Navigationsmenü auf AlloyDB Studio. Melden Sie sich mit Ihren Anmeldedaten an.
- Öffnen Sie einen neuen Tab, indem Sie rechts auf das Symbol Neuer Tab klicken.
- Kopieren Sie die
insert-Abfrageanweisung aus dem oben erwähnteninsert_into_patents_data.sql-Skript in den Editor. Sie können 50 bis 100 INSERT-Anweisungen kopieren, um diesen Anwendungsfall schnell zu demonstrieren. - Klicken Sie auf Ausführen. Die Ergebnisse Ihrer Abfrage werden in der Tabelle Ergebnisse angezeigt.
5. Einbettungen für Patentdaten erstellen
Testen wir zuerst die Einbettungsfunktion, indem wir die folgende Beispielabfrage ausführen:
SELECT embedding( 'gemini-embedding-001', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Dadurch sollte der Einbettungsvektor für den Beispieltext in der Anfrage zurückgegeben werden. Er sieht wie ein Array von Gleitkommazahlen aus. Sieht so aus:

Vektorfeld „abstract_embeddings“ aktualisieren
Führen Sie die folgende DML aus, um die Patentzusammenfassungen in der Tabelle mit den entsprechenden Einbettungen zu aktualisieren:
UPDATE patents_data set abstract_embeddings = embedding( 'gemini-embedding-001', abstract);
6. Vektorsuche durchführen
Nachdem die Tabelle, die Daten und die Einbettungen bereit sind, führen wir die Echtzeit-Vektorsuche für den Suchtext des Nutzers durch. Sie können dies testen, indem Sie die folgende Abfrage ausführen:
SELECT id || ' - ' || title as literature FROM patents_data ORDER BY abstract_embeddings <=> embedding('gemini-embedding-001', 'A new Natural Language Processing related Machine Learning Model')::vector LIMIT 10;
In dieser Abfrage
- Der Suchtext des Nutzers lautet: „A new Natural Language Processing related Machine Learning Model“.
- Wir konvertieren sie mit dem Modell „gemini-embedding-001“ in der Methode „embedding()“ in Einbettungen.
- „<=>“ steht für die Verwendung der Distanzmethode „COSINE SIMILARITY“.
- Wir konvertieren das Ergebnis der Einbettungsmethode in den Vektortyp, damit es mit den in der Datenbank gespeicherten Vektoren kompatibel ist.
- LIMIT 10 bedeutet, dass die zehn am besten passenden Ergebnisse für den Suchtext ausgewählt werden.
Das Ergebnis lautet:

Wie Sie in den Ergebnissen sehen können, sind die Übereinstimmungen sehr nah am Suchtext.
7. Anwendung ins Web bringen
Sind Sie bereit, diese App im Web zu nutzen? Gehen Sie dazu so vor:
- Rufen Sie den Cloud Shell-Editor auf und klicken Sie unten links im Editor (Statusleiste) auf das Symbol „Cloud Code – Anmelden“. Wählen Sie Ihr aktuelles Google Cloud-Projekt aus, für das die Abrechnung aktiviert ist, und achten Sie darauf, dass Sie auch in Gemini in diesem Projekt angemeldet sind (in der rechten Ecke der Statusleiste).
- Klicken Sie auf das Cloud Code-Symbol und warten Sie, bis das Cloud Code-Dialogfeld angezeigt wird. Wählen Sie „Neue Anwendung“ aus und wählen Sie im Pop-up-Fenster „Neue Anwendung erstellen“ die Option „Cloud Functions-Anwendung“ aus:

Wählen Sie auf Seite 2/2 des Pop-ups „Neue Anwendung erstellen“ die Option „Java: Hello World“ aus, geben Sie den Namen Ihres Projekts als „alloydb-pgvector“ an Ihrem bevorzugten Speicherort ein und klicken Sie auf „OK“:

- Suchen Sie in der resultierenden Projektstruktur nach pom.xml und ersetzen Sie die Datei durch den Inhalt der Repository-Datei. Es sollte zusätzlich zu den folgenden Abhängigkeiten noch einige weitere haben:

- Ersetzen Sie die Datei „HelloWorld.java“ durch den Inhalt der Datei repo.
Ersetzen Sie die folgenden Werte durch Ihre tatsächlichen Werte:
String ALLOYDB_DB = "postgres";
String ALLOYDB_USER = "postgres";
String ALLOYDB_PASS = "*****";
String ALLOYDB_INSTANCE_NAME = "projects/<<YOUR_PROJECT_ID>>/locations/us-central1/clusters/<<YOUR_CLUSTER>>/instances/<<YOUR_INSTANCE>>";
//Replace YOUR_PROJECT_ID, YOUR_CLUSTER, YOUR_INSTANCE with your actual values
Die Funktion erwartet den Suchtext als Eingabeparameter mit dem Schlüssel „search“. In dieser Implementierung wird nur die beste Übereinstimmung aus der Datenbank zurückgegeben:
// Get the request body as a JSON object.
JsonObject requestJson = new Gson().fromJson(request.getReader(), JsonObject.class);
String searchText = requestJson.get("search").getAsString();
//Sample searchText: "A new Natural Language Processing related Machine Learning Model";
BufferedWriter writer = response.getWriter();
String result = "";
HikariDataSource dataSource = AlloyDbJdbcConnector();
try (Connection connection = dataSource.getConnection()) {
//Retrieve Vector Search by text (converted to embeddings) using "Cosine Similarity" method
try (PreparedStatement statement = connection.prepareStatement("SELECT id || ' - ' || title as literature FROM patents_data ORDER BY abstract_embeddings <=> embedding('tgemini-embedding-001', '" + searchText + "' )::vector LIMIT 1")) {
ResultSet resultSet = statement.executeQuery();
resultSet.next();
String lit = resultSet.getString("literature");
result = result + lit + "\n";
System.out.println("Matching Literature: " + lit);
}
writer.write("Here is the closest match: " + result);
}
- Führen Sie den folgenden Befehl im Cloud Shell-Terminal aus, um die gerade erstellte Cloud-Funktion bereitzustellen. Denken Sie daran, zuerst mit dem folgenden Befehl in den entsprechenden Projektordner zu wechseln:
cd alloydb-pgvector
Führen Sie dann den folgenden Befehl aus:
gcloud functions deploy patent-search --gen2 --region=us-central1 --runtime=java11 --source=. --entry-point=cloudcode.helloworld.HelloWorld --trigger-http
WICHTIGER SCHRITT:
Sobald Sie die Bereitstellung gestartet haben, sollten Sie die Funktionen in der Cloud Run Functions-Konsole sehen können. Suchen Sie nach der neu erstellten Funktion und öffnen Sie sie. Bearbeiten Sie die Konfigurationen und ändern Sie Folgendes:
- Zu den Laufzeit-, Build-, Verbindungs- und Sicherheitseinstellungen
- Zeitlimit auf 180 Sekunden erhöhen
- Rufen Sie den Tab „VERBINDUNGEN“ auf:

- Achten Sie darauf, dass unter den Ingress-Einstellungen die Option „Gesamten Traffic zulassen“ ausgewählt ist.
- Klicken Sie unter „Einstellungen für ausgehenden Traffic“ auf das Drop-down-Menü „Netzwerk“, wählen Sie die Option „Neuen VPC-Connector hinzufügen“ aus und folgen Sie der Anleitung im Pop-up-Dialogfeld:

- Geben Sie einen Namen für den VPC-Connector an und achten Sie darauf, dass die Region mit der Ihrer Instanz übereinstimmt. Lassen Sie den Netzwerk-Wert auf dem Standardwert und legen Sie das Subnetz als benutzerdefinierten IP-Bereich mit dem IP-Bereich 10.8.0.0 oder einem ähnlichen verfügbaren Bereich fest.
- Klicken Sie auf „SHOW SCALING SETTINGS“ (Skalierungseinstellungen anzeigen) und prüfen Sie, ob die Konfiguration genau wie unten angegeben ist:

- Klicken Sie auf „ERSTELLEN“. Der Connector sollte jetzt in den Einstellungen für ausgehenden Traffic aufgeführt sein.
- Wählen Sie den neu erstellten Connector aus.
- Wählen Sie aus, dass der gesamte Traffic über diesen VPC-Connector weitergeleitet werden soll.
8. Anwendung testen
Nach der Bereitstellung sollte der Endpunkt im folgenden Format angezeigt werden:
https://us-central1-YOUR_PROJECT_ID.cloudfunctions.net/patent-search
Sie können es über das Cloud Shell-Terminal testen, indem Sie den folgenden Befehl ausführen:
gcloud functions call patent-search --region=us-central1 --gen2 --data '{"search": "A new Natural Language Processing related Machine Learning Model"}'
Ergebnis:
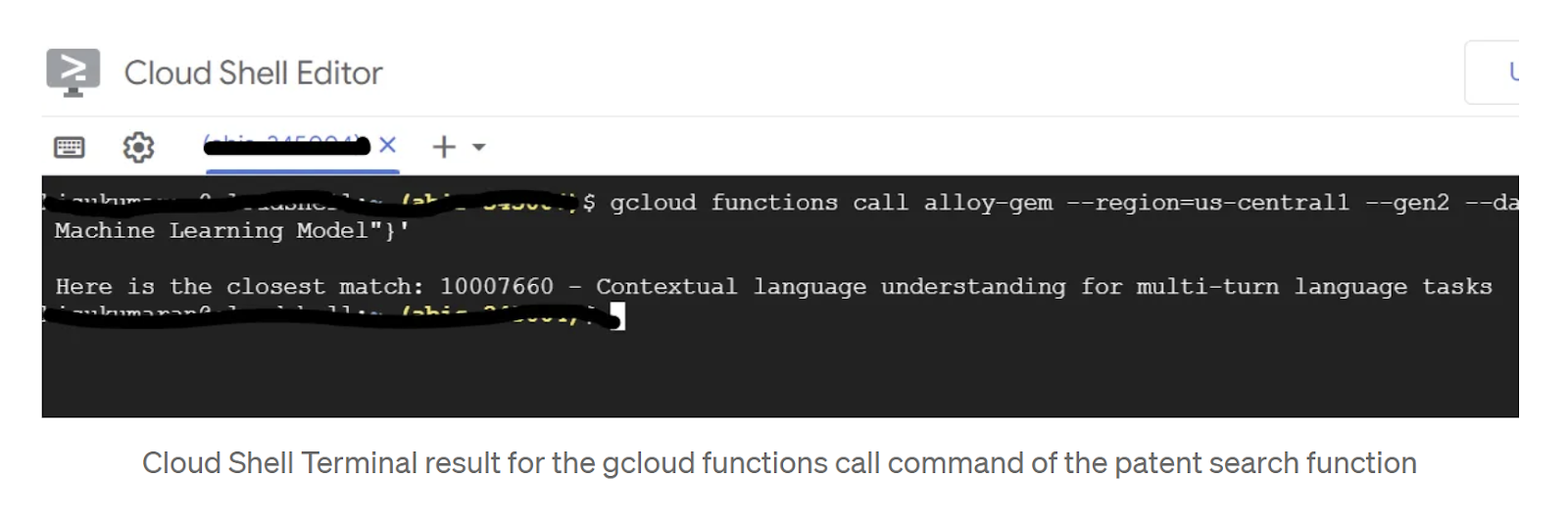
Sie können die Funktion auch über die Liste Cloud Functions testen. Wählen Sie die bereitgestellte Funktion aus und rufen Sie den Tab „TESTING“ auf. Geben Sie im Textfeld für die JSON-Anfrage im Abschnitt „Auslösendes Ereignis konfigurieren“ Folgendes ein:
{"search": "A new Natural Language Processing related Machine Learning Model"}
Klicken Sie auf die Schaltfläche „FUNKTION TESTEN“. Das Ergebnis wird rechts auf der Seite angezeigt:

Geschafft! So einfach ist es, mit dem Einbettungsmodell für AlloyDB-Daten eine Suche nach ähnlichen Vektoren durchzuführen.
9. Bereinigen
So vermeiden Sie, dass Ihrem Google Cloud-Konto die in diesem Beitrag verwendeten Ressourcen in Rechnung gestellt werden:
- Wechseln Sie in der Google Cloud Console zu Verwalten .
- Ressourcenseite
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Beenden, um das Projekt zu löschen.
10. Glückwunsch
Glückwunsch! Sie haben erfolgreich eine Ähnlichkeitssuche mit AlloyDB, pgvector und der Vektorsuche durchgeführt. Durch die Kombination der Funktionen von AlloyDB, Vertex AI und Vector Search haben wir einen großen Schritt nach vorn gemacht, um die Literatursuche zugänglich, effizient und wirklich aussagekräftig zu gestalten.