
1. Обзор
В различных отраслях контекстный поиск является критически важной функцией, составляющей основу их приложений. Технология дополненной генерации поиска (Retrieval Augmented Generation, RAG) уже довольно давно является ключевым двигателем этой важной технологической эволюции благодаря своим механизмам поиска на основе генеративного ИИ. Генеративные модели с их большими контекстными окнами и впечатляющим качеством выходных данных трансформируют ИИ. RAG предоставляет систематический способ внедрения контекста в приложения и агентов ИИ, основываясь на структурированных базах данных или информации из различных источников. Эти контекстные данные имеют решающее значение для ясности истины и точности выходных данных, но насколько точны эти результаты? Зависит ли ваш бизнес в значительной степени от точности этих контекстных совпадений и релевантности? Тогда этот проект вас заинтересует!
Секрет векторного поиска не только в его создании, но и в оценке качества векторных совпадений. Все мы оказывались в такой ситуации: тупо смотрели на список результатов и задавались вопросом: «А работает ли это вообще?!» Давайте разберемся, как на самом деле оценить качество векторных совпадений. «Что же изменилось в RAG?», спросите вы? Всё! Долгие годы генерация с дополненной реальностью (RAG) казалась многообещающей, но труднодостижимой целью. Теперь, наконец, у нас есть инструменты для создания RAG-приложений с производительностью и надежностью, необходимыми для решения критически важных задач.
Теперь у нас уже есть базовое понимание трех вещей:
- Что означает контекстный поиск для вашего агента и как его реализовать с помощью векторного поиска.
- Мы также подробно рассмотрели возможность реализации векторного поиска в рамках ваших данных, то есть в самой базе данных (все облачные базы данных Google поддерживают эту функцию, если вы еще не знали!).
- Мы пошли на шаг дальше, чем остальной мир, рассказав вам, как реализовать столь легковесный векторный поиск RAG с высокой производительностью и качеством, используя возможности векторного поиска AlloyDB на основе индекса ScaNN.
Если вы еще не ознакомились с базовыми, промежуточными и немного более сложными экспериментами RAG, я бы посоветовал вам прочитать их здесь , здесь и здесь в указанном порядке.
Поиск патентов помогает пользователю находить патенты, имеющие отношение к его поисковому запросу, и мы уже создавали подобную функцию ранее . Теперь мы добавим в нее новые и расширенные функции RAG, которые позволят проводить качественный контекстный поиск по данному приложению. Давайте начнем!
На рисунке ниже показана общая схема работы этого приложения. 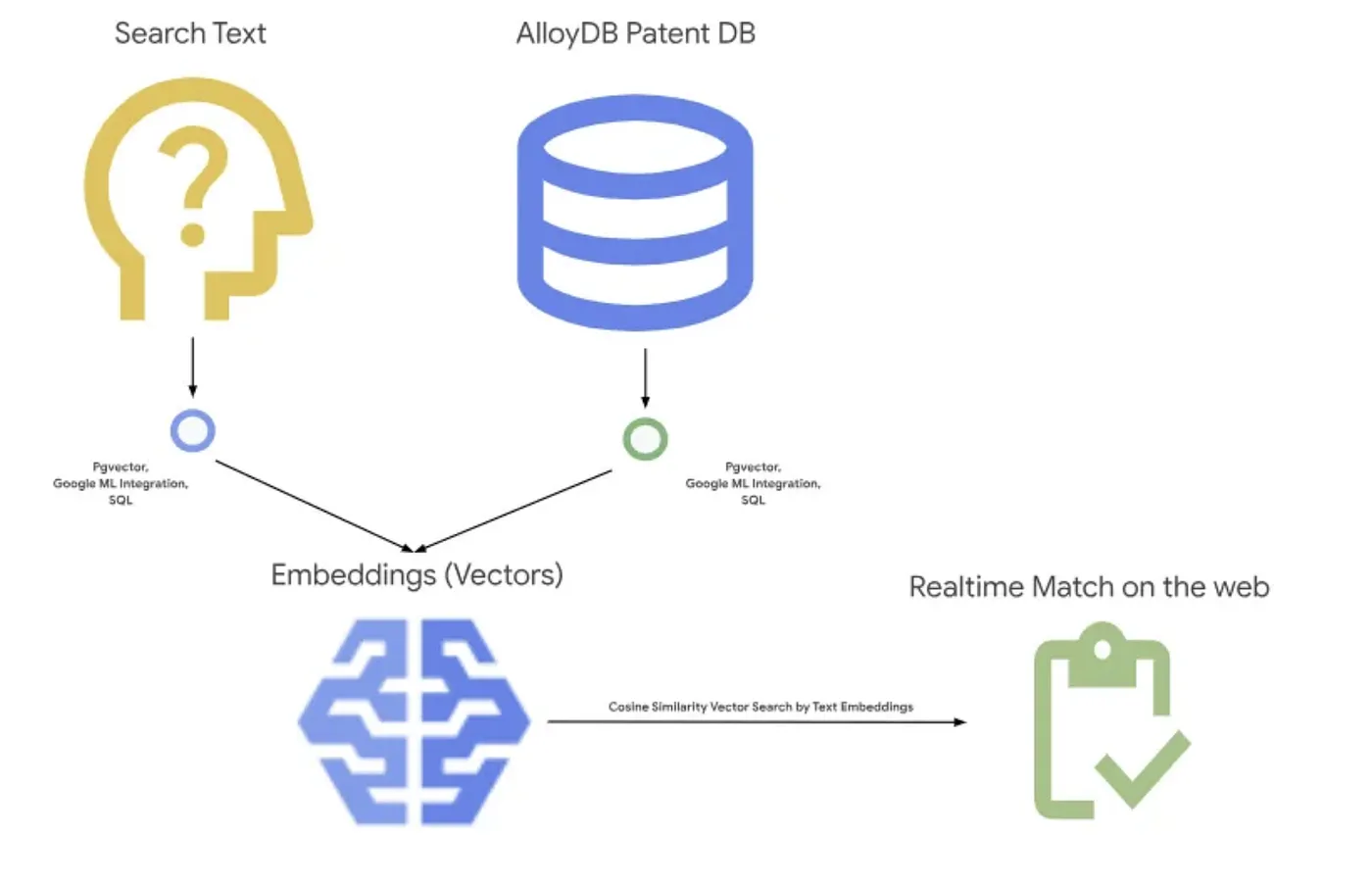
Цель
Предоставьте пользователю возможность поиска патентов на основе текстового описания с улучшенной производительностью и более высоким качеством, а также возможность оценивать качество сгенерированных совпадений, используя новейшие функции RAG от AlloyDB.
Что вы построите
В рамках этой лабораторной работы вы:
- Создайте экземпляр AlloyDB и загрузите общедоступный набор данных о патентах.
- Создайте индекс метаданных и индекс ScaNN.
- Реализуйте расширенный векторный поиск в AlloyDB, используя метод встроенной фильтрации ScaNN.
- Внедрить функцию оценки полноты.
- Оценить ответ на запрос
Требования
2. Прежде чем начать
Создать проект
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud.
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
- Вы будете использовать Cloud Shell — среду командной строки, работающую в Google Cloud. Нажмите «Активировать Cloud Shell» в верхней части консоли Google Cloud.

- После подключения к Cloud Shell необходимо проверить, прошли ли вы аутентификацию и установлен ли идентификатор вашего проекта, используя следующую команду:
gcloud auth list
- Выполните следующую команду в Cloud Shell, чтобы убедиться, что команда gcloud знает о вашем проекте.
gcloud config list project
- Если ваш проект не задан, используйте следующую команду для его установки:
gcloud config set project <YOUR_PROJECT_ID>
- Включите необходимые API. Вы можете использовать команду gcloud в терминале Cloud Shell:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
Альтернативой команде gcloud является поиск каждого продукта в консоли или использование этой ссылки .
Для получения информации о командах gcloud и их использовании обратитесь к документации .
3. Настройка базы данных
В этой лабораторной работе мы будем использовать AlloyDB в качестве базы данных для патентных данных. Она использует кластеры для хранения всех ресурсов, таких как базы данных и журналы. Каждый кластер имеет основной экземпляр , который обеспечивает точку доступа к данным. Таблицы будут содержать сами данные.
Давайте создадим кластер AlloyDB, экземпляр и таблицу, куда будут загружены данные о патентах.
Создайте кластер и экземпляр.
- Перейдите на страницу AlloyDB в Cloud Console. Большинство страниц в Cloud Console легко найти, используя строку поиска консоли.
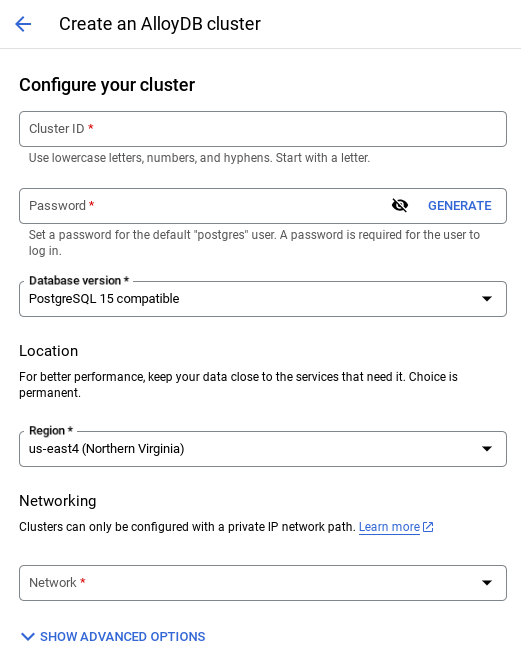
- На этой странице выберите пункт «СОЗДАТЬ КЛАСТЕР» :

- Вы увидите экран, похожий на тот, что показан ниже. Создайте кластер и экземпляр со следующими значениями (убедитесь, что значения совпадают, если вы клонируете код приложения из репозитория):
- идентификатор кластера : "
vector-cluster" - пароль : "
alloydb" - Рекомендуемая последняя версия PostgreSQL 15.
- Регион : "
us-central1" - Сетевые настройки : "
default"
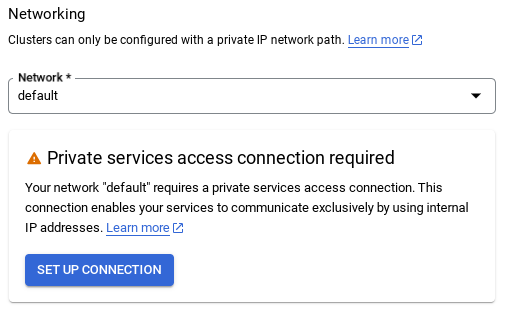
- При выборе сети по умолчанию вы увидите экран, похожий на тот, что показан ниже.
Выберите «НАСТРОЙКА СОЕДИНЕНИЯ» .
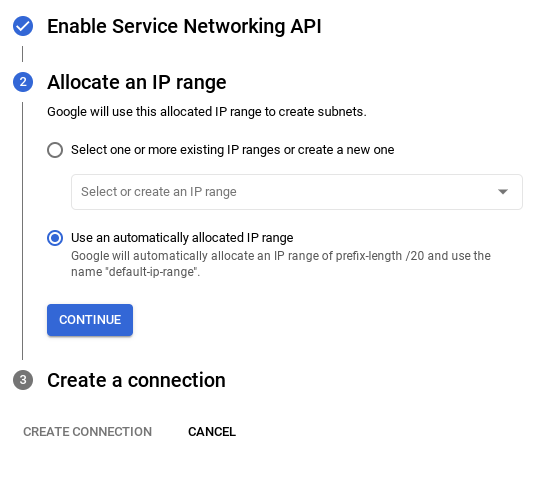
- Затем выберите « Использовать автоматически выделенный диапазон IP-адресов » и продолжите. После проверки информации выберите «СОЗДАТЬ СОЕДИНЕНИЕ».
- После настройки сети вы можете продолжить создание кластера. Нажмите кнопку «СОЗДАТЬ КЛАСТЕР» , чтобы завершить настройку кластера, как показано ниже:
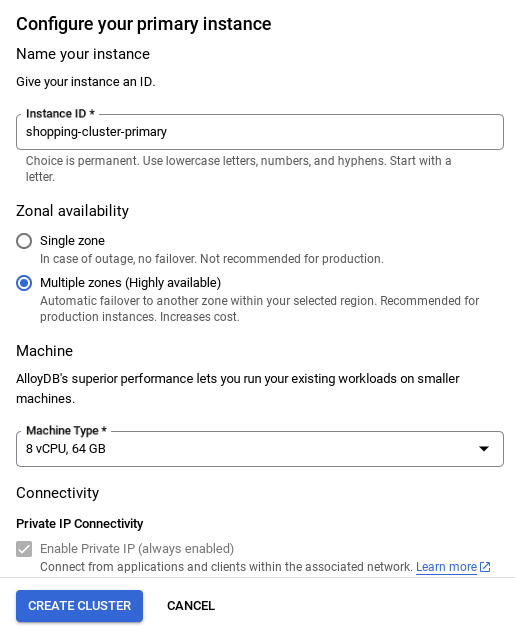
Обязательно измените идентификатор экземпляра (который можно найти во время настройки кластера/экземпляра) на
vector-instance . Если вы не можете его изменить, не забудьте использовать свой идентификатор экземпляра во всех последующих ссылках.
Обратите внимание, что создание кластера займет около 10 минут. После успешного завершения процесса вы увидите экран с обзором только что созданного кластера.
4. Ввод данных
Теперь пришло время добавить таблицу с данными о магазине. Перейдите в AlloyDB, выберите основной кластер, а затем AlloyDB Studio:
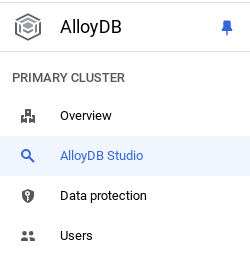
Возможно, вам потребуется дождаться завершения создания экземпляра. После этого войдите в AlloyDB, используя учетные данные, которые вы создали при создании кластера. Для аутентификации в PostgreSQL используйте следующие данные:
- Имя пользователя: "
postgres" - База данных: "
postgres" - Пароль: "
alloydb"
После успешной аутентификации в AlloyDB Studio команды SQL вводятся в редакторе. Вы можете добавить несколько окон редактора, используя значок плюса справа от последнего окна.
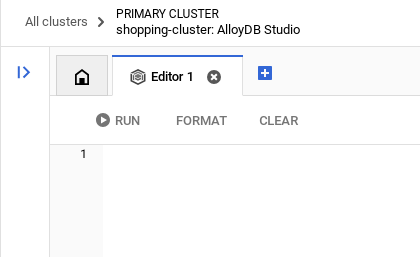
Команды для AlloyDB будут вводиться в окнах редактора, используя при необходимости параметры «Выполнить», «Форматировать» и «Очистить».
Включить расширения
Для создания этого приложения мы будем использовать расширения pgvector и google_ml_integration . Расширение pgvector позволяет хранить и искать векторные представления. Расширение google_ml_integration предоставляет функции, которые вы используете для доступа к конечным точкам прогнозирования Vertex AI и получения прогнозов в формате SQL. Включите эти расширения, выполнив следующие DDL-скрипты:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Чтобы проверить, какие расширения включены в вашей базе данных, выполните следующую SQL-команду:
select extname, extversion from pg_extension;
Создайте таблицу
В AlloyDB Studio можно создать таблицу, используя приведенный ниже оператор DDL:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
Столбец abstract_embeddings позволит хранить векторные значения текста.
Предоставить разрешение
Выполните указанное ниже выражение, чтобы предоставить права на выполнение функции "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Предоставьте учетной записи службы AlloyDB роль пользователя Vertex AI.
В консоли Google Cloud IAM предоставьте учетной записи службы AlloyDB (которая выглядит следующим образом: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) доступ к роли "Пользователь Vertex AI". В поле PROJECT_NUMBER будет указан номер вашего проекта.
В качестве альтернативы вы можете выполнить следующую команду в терминале Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Загрузите данные о патентах в базу данных.
В качестве набора данных мы будем использовать общедоступные наборы данных патентов Google в BigQuery. Для выполнения запросов мы будем использовать AlloyDB Studio. Данные записываются в файл insert_scripts.sql , который мы будем запускать для загрузки данных о патентах.
- В консоли Google Cloud откройте страницу AlloyDB .
- Выберите созданный кластер и щелкните по его экземпляру.
- В меню навигации AlloyDB нажмите AlloyDB Studio . Войдите в систему, используя свои учетные данные.
- Откройте новую вкладку, нажав на значок «Новая вкладка» справа.
- Скопируйте оператор запроса
insertиз указанного выше скриптаinsert_scripts.sqlв редактор. Для быстрой демонстрации этого варианта использования можно скопировать от 10 до 50 операторов на вставку. - Нажмите кнопку «Выполнить» . Результаты вашего запроса отобразятся в таблице «Результаты» .
Примечание: Вы можете заметить, что скрипт вставки содержит много данных. Это связано с тем, что мы включили в скрипты встраивания. Нажмите «Просмотреть исходный код», если у вас возникнут проблемы с загрузкой файла на GitHub. Это сделано для того, чтобы избавить вас (на следующих шагах) от необходимости генерировать более нескольких встраиваний (например, максимум 20-25), если вы используете пробный аккаунт Google Cloud с оплатой кредитной картой.
5. Создайте векторные представления данных о патентах.
Для начала протестируем функцию встраивания, выполнив следующий пример запроса:
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Эта функция должна вернуть вектор эмбеддингов, который выглядит как массив чисел с плавающей запятой, для примера текста в запросе. Выглядит это так:
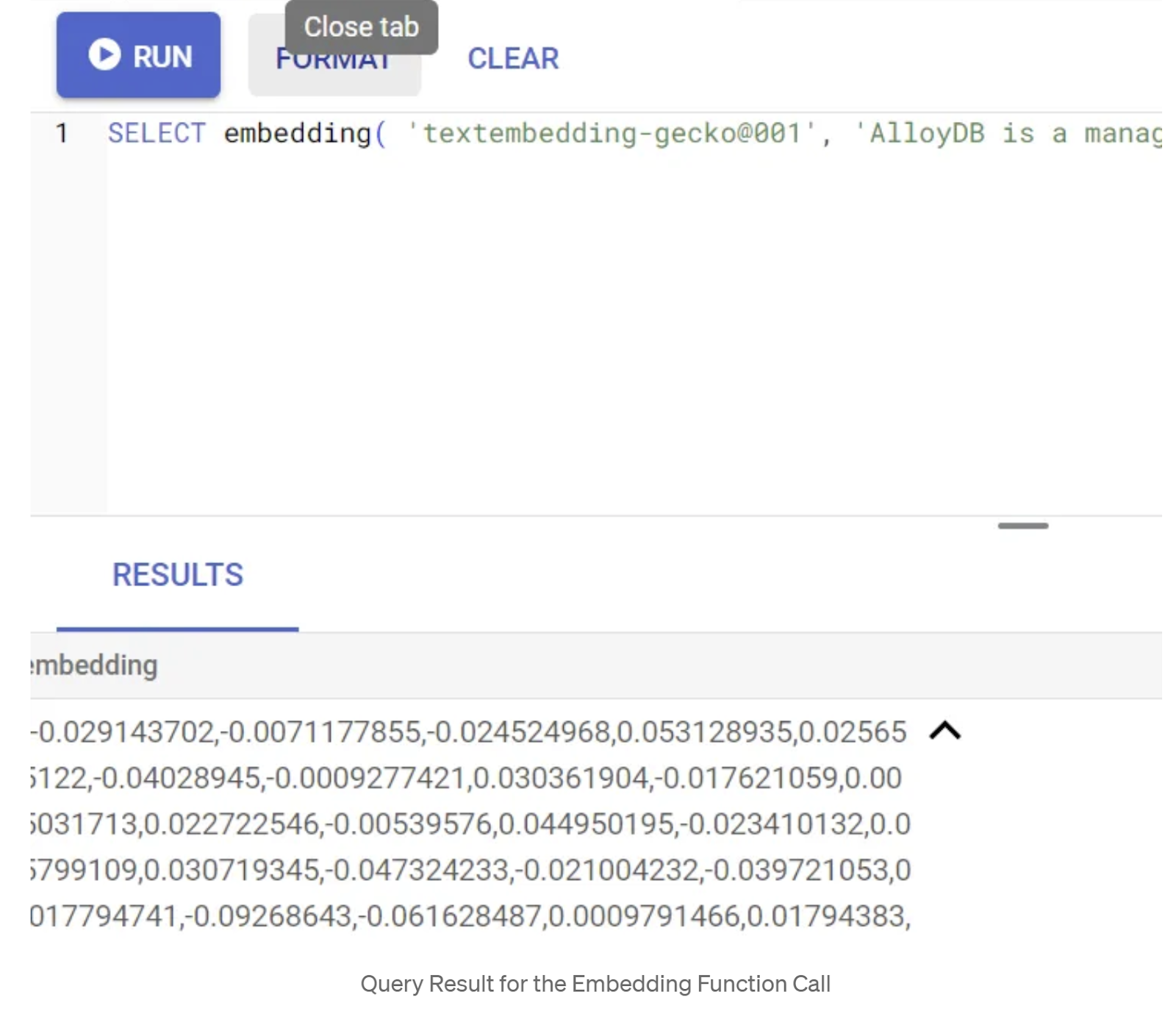
Обновите поле Abstract_Embeddings Vector.
Выполните приведенный ниже DML-запрос для обновления аннотаций патентов в таблице соответствующими векторными представлениями, только если вы не добавили данные abstract_embeddings в рамках скрипта вставки:
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
Если вы используете пробный аккаунт Google Cloud с оплатой за использование кредитов, у вас могут возникнуть проблемы с генерацией более чем нескольких векторных представлений (скажем, максимум 20-25). Поэтому я уже включил векторные представления в скрипты вставки, и они должны быть загружены в вашу таблицу, если вы выполнили шаг «загрузка данных патентов в базу данных».
6. Выполняйте расширенные операции RAG с помощью новых функций AlloyDB.
Теперь, когда таблица, данные и векторные представления готовы, давайте выполним векторный поиск в реальном времени для поискового запроса пользователя. Вы можете проверить это, выполнив запрос ниже:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
В этом запросе,
- Поисковый запрос пользователя: "Анализ настроений".
- Мы преобразуем его в векторные представления в методе embedding(), используя модель: text-embedding-005.
- Символ "<=>" обозначает использование метода расстояния косинусного сходства.
- Мы преобразуем результат метода встраивания в векторный тип, чтобы обеспечить его совместимость с векторами, хранящимися в базе данных.
- LIMIT 10 означает, что мы выбираем 10 наиболее близких совпадений с поисковым текстом.
AlloyDB выводит векторный поиск RAG на новый уровень:
Представлено немало нововведений. Два из них, ориентированные на разработчиков, следующие:
- Встроенная фильтрация
- Оценщик воспоминаний
Встроенная фильтрация
Раньше разработчикам приходилось выполнять векторный поиск и заниматься фильтрацией и полнотой запросов. Оптимизатор запросов AlloyDB сам выбирает способ выполнения запроса с фильтрами. Встроенная фильтрация — это новая техника оптимизации запросов, которая позволяет оптимизатору запросов AlloyDB оценивать как условия фильтрации метаданных, так и векторный поиск, используя как векторные индексы, так и индексы на столбцах метаданных. Это повысило производительность полноты запросов, позволяя разработчикам использовать все преимущества AlloyDB «из коробки».
Встроенная фильтрация лучше всего подходит для случаев со средней избирательностью. При поиске по векторному индексу AlloyDB вычисляет расстояния только для тех векторов, которые соответствуют условиям фильтрации метаданных (ваши функциональные фильтры в запросе, обычно обрабатываемые в предложении WHERE). Это значительно повышает производительность таких запросов, дополняя преимущества пост-фильтрации или пре-фильтрации .
- Установите или обновите расширение pgvector.
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
Если расширение pgvector уже установлено, обновите его до версии 0.8.0.google-3 или более поздней, чтобы получить возможности оценки отзыва.
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
Этот шаг необходимо выполнить только в том случае, если расширение вашего вектора — <0.8.0.google-3>.
Важное замечание: если количество строк меньше 100, вам вообще не нужно создавать индекс ScaNN, так как он не будет применяться к меньшему количеству строк. В этом случае пропустите следующие шаги.
- Для создания индексов ScaNN установите расширение alloydb_scann.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- Сначала выполните запрос векторного поиска без индекса и без включенного встроенного фильтра:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
Результат должен быть примерно таким:
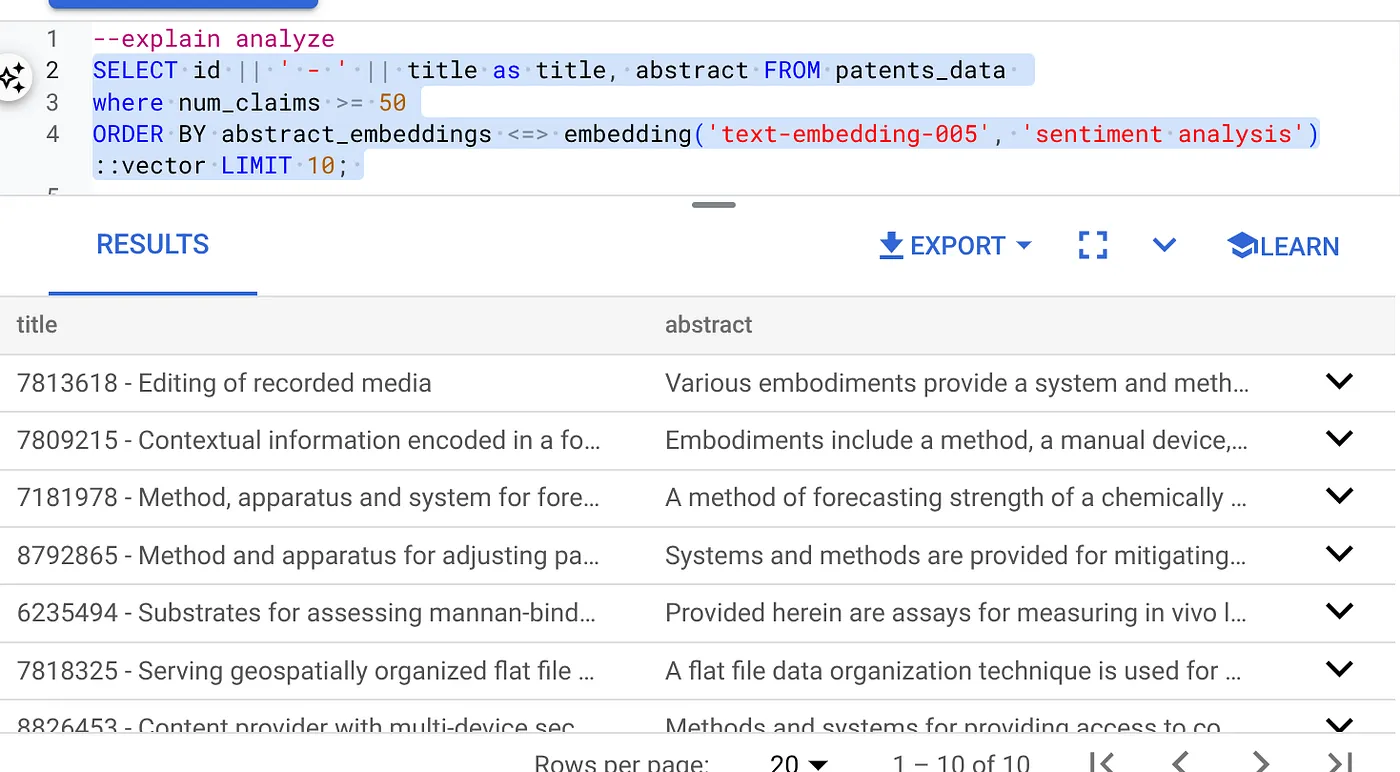
- Запустите на нем Explain Analyze (без индексации и встроенной фильтрации).
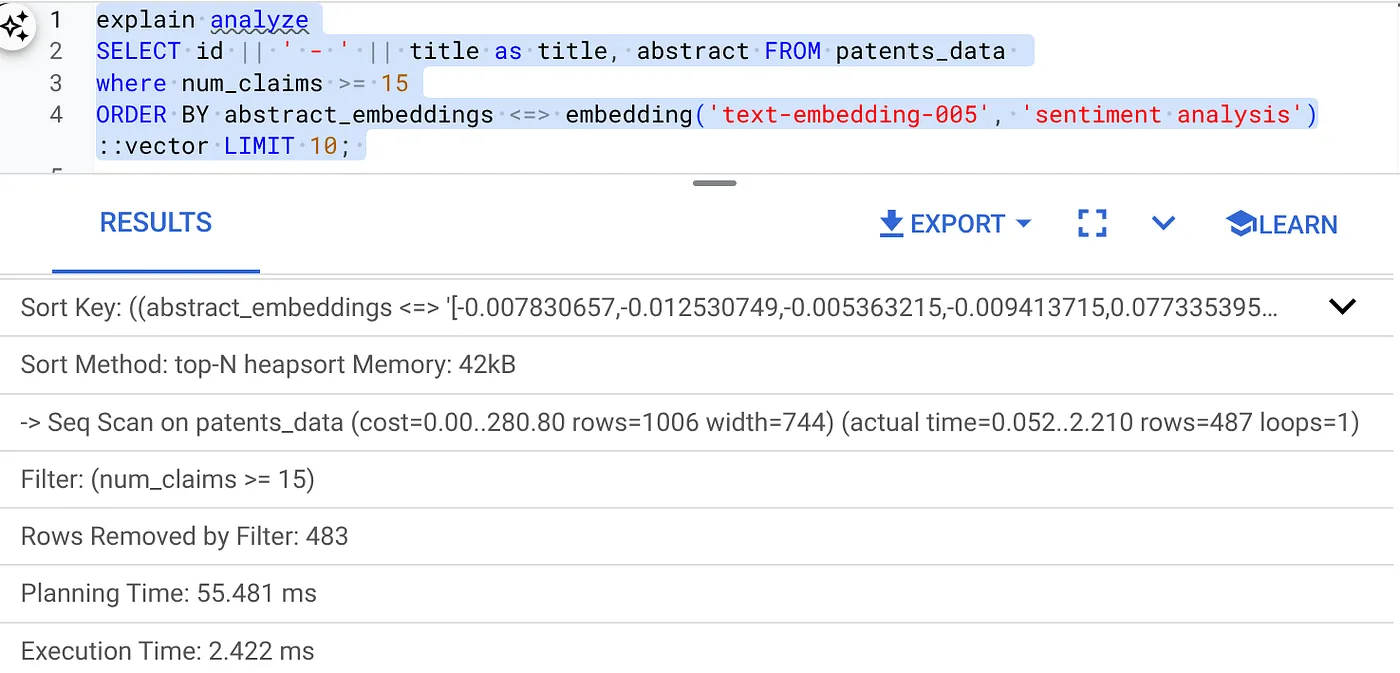
Время выполнения составляет 2,4 мс.
- Давайте создадим обычный индекс по полю num_claims, чтобы можно было фильтровать данные по нему:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- Давайте создадим индекс ScaNN для нашего приложения поиска патентов. Выполните следующие действия в AlloyDB Studio:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
Важное замечание: (num_leaves=32) применяется ко всему нашему набору данных, содержащему более 1000 строк. Если количество строк меньше 100, вам не нужно создавать индекс, так как он не будет применяться для меньшего количества строк.
- Включите встроенную фильтрацию для индекса ScaNN:
SET scann.enable_inline_filtering = on
- Теперь выполним тот же запрос, добавив фильтр и векторный поиск:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
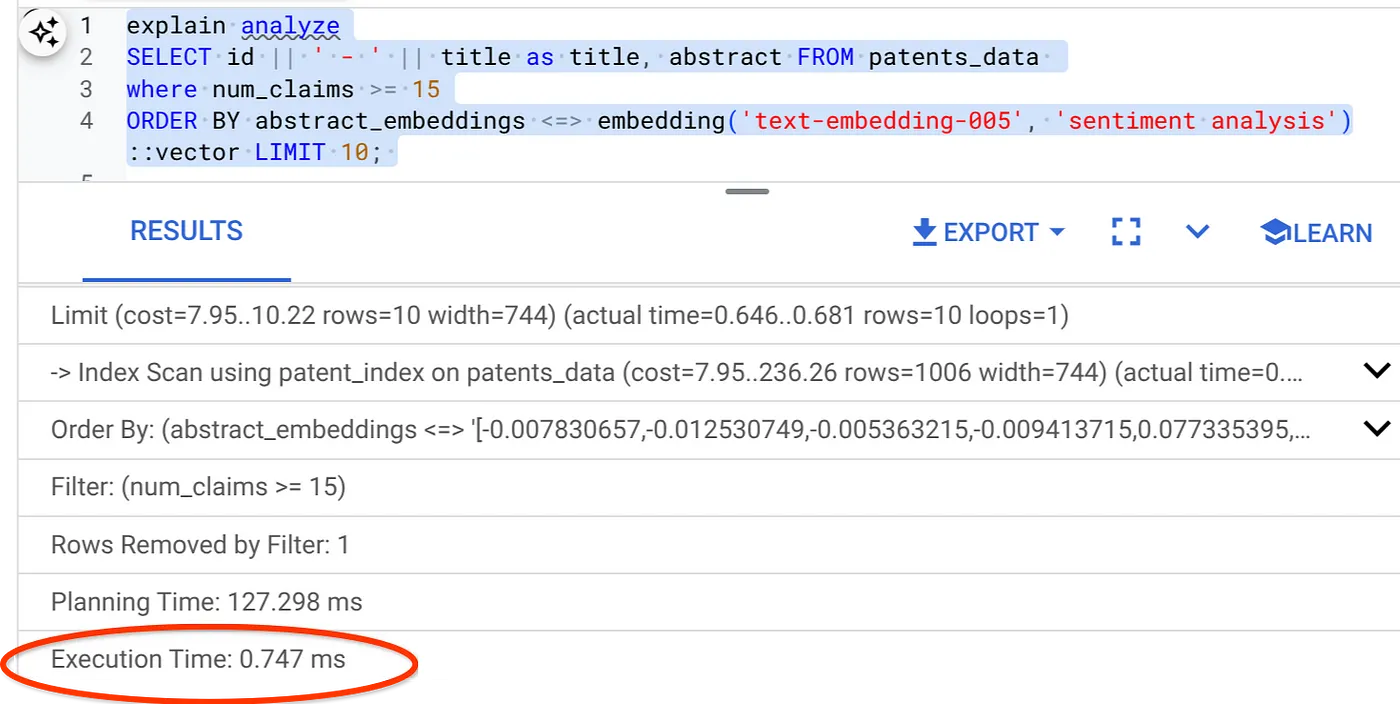
Как видите, время выполнения значительно сократилось для того же алгоритма векторного поиска. Это стало возможным благодаря встроенной фильтрации с использованием индекса ScaNN в алгоритме векторного поиска!
Далее оценим показатель полноты (recall) для этого векторного поиска с использованием ScaNN.
Оценщик воспоминаний
Показатель полноты (recall) в поиске по сходству — это процент релевантных результатов, полученных в ходе поиска, то есть количество истинных положительных результатов. Это наиболее распространенная метрика, используемая для измерения качества поиска. Одна из причин потери полноты связана с разницей между приблизительным поиском ближайшего соседа (aNN) и поиском k (точных) ближайших соседей (kNN). Векторные индексы, такие как ScaNN в AlloyDB, реализуют алгоритмы aNN, позволяя ускорить векторный поиск на больших наборах данных за счет небольшого снижения полноты. Теперь AlloyDB предоставляет возможность измерять этот компромисс непосредственно в базе данных для отдельных запросов и гарантировать его стабильность во времени. Вы можете обновлять параметры запроса и индекса в ответ на эту информацию для достижения лучших результатов и производительности.
Какова логика запоминания результатов поиска?
В контексте векторного поиска показатель полноты (recall) относится к проценту векторов, возвращаемых индексом, которые являются истинными ближайшими соседями. Например, если запрос на поиск ближайших соседей для 20 ближайших соседей возвращает 19 из истинных ближайших соседей, то показатель полноты составляет 19/20x100 = 95%. Полнота — это метрика, используемая для оценки качества поиска, и определяется как процент возвращаемых результатов, которые объективно наиболее близки к векторам запроса.
Для расчета полноты запроса к векторному индексу для заданной конфигурации можно использовать функцию evaluate_query_recall . Эта функция позволяет настраивать параметры для достижения желаемых результатов полноты запроса к векторному индексу.
Важное примечание:
Если на следующих шагах вы сталкиваетесь с ошибкой "Доступ запрещен" при работе с индексом HNSW, пропустите пока весь раздел оценки восстановления . Возможно, это связано с ограничениями доступа, поскольку на момент написания этого руководства это было только что выпущено.
- Установите флаг Enable Index Scan для индексов ScaNN и HNSW:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- Выполните следующий запрос в AlloyDB Studio:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Функция evaluate_query_recall принимает запрос в качестве параметра и возвращает его значение recall. В качестве входного запроса для функции я использую тот же запрос, что и для проверки производительности. В качестве метода индексации я добавил SCaNN. Дополнительные параметры см. в документации .
Для данного запроса векторного поиска мы использовали показатель полноты:
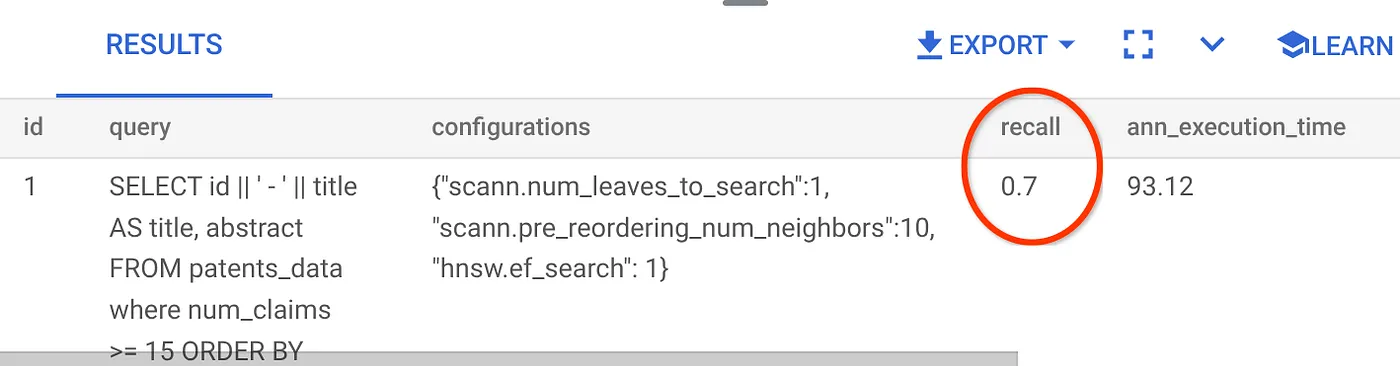
Я вижу, что показатель полноты (RECALL) составляет 70%. Теперь я могу использовать эту информацию для изменения параметров индекса, методов и параметров запроса, чтобы улучшить показатель полноты для этого векторного поиска!
7. Протестируйте с измененными параметрами запроса и индекса.
Теперь давайте протестируем запрос, изменив параметры запроса на основе полученного значения отзыва.
- Я изменил количество строк в результирующем наборе до 7 (с 25 ранее) и вижу улучшение показателя RECALL, а именно 86%.
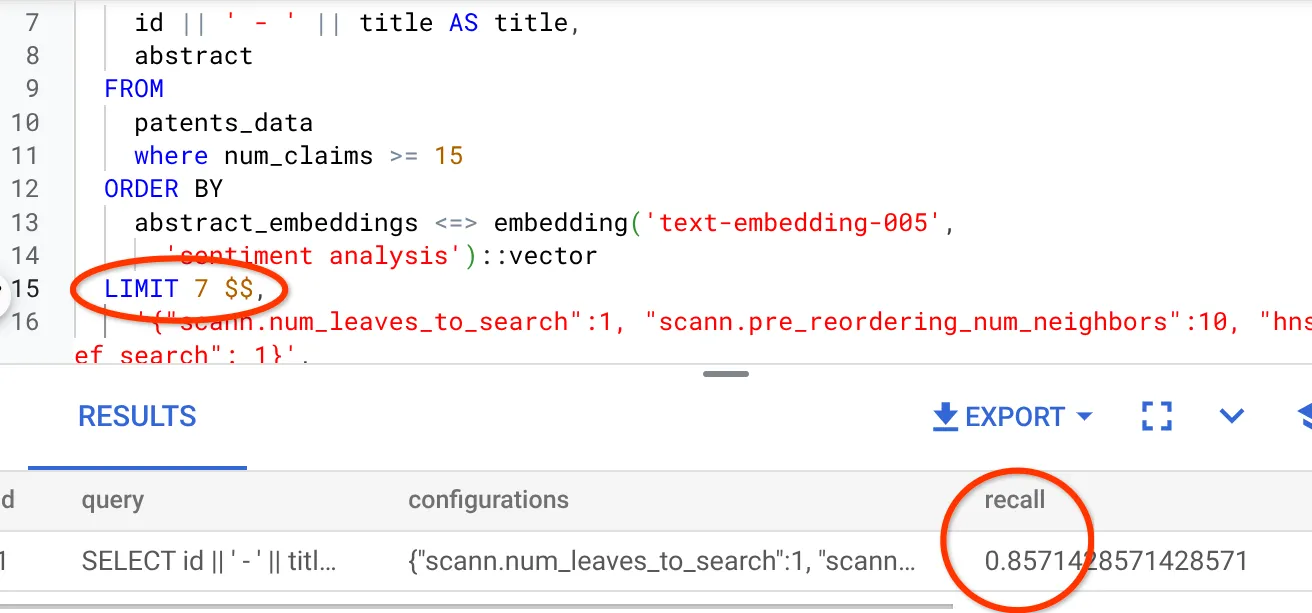
Это означает, что в режиме реального времени я могу изменять количество совпадений, которые видят мои пользователи, чтобы повысить релевантность результатов поиска в соответствии с контекстом поиска пользователей.
- Давайте попробуем еще раз, изменив параметры индекса:
Для этого теста я буду использовать "L2-расстояние" вместо функции расстояния сходства "Косинус" . Я также изменю ограничение запроса на 10, чтобы показать, улучшается ли качество результатов поиска даже при увеличении количества результатов поиска.
[ДО] Запрос, использующий функцию расстояния косинусного сходства:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Очень важное замечание: «Как узнать, что в этом запросе используется косинусное сходство?» — спросите вы. Функцию расстояния можно определить по использованию символа «<=>», обозначающего косинусное расстояние.
Ссылка на документацию по функциям поиска векторного расстояния.
Результатом вышеуказанного запроса является:
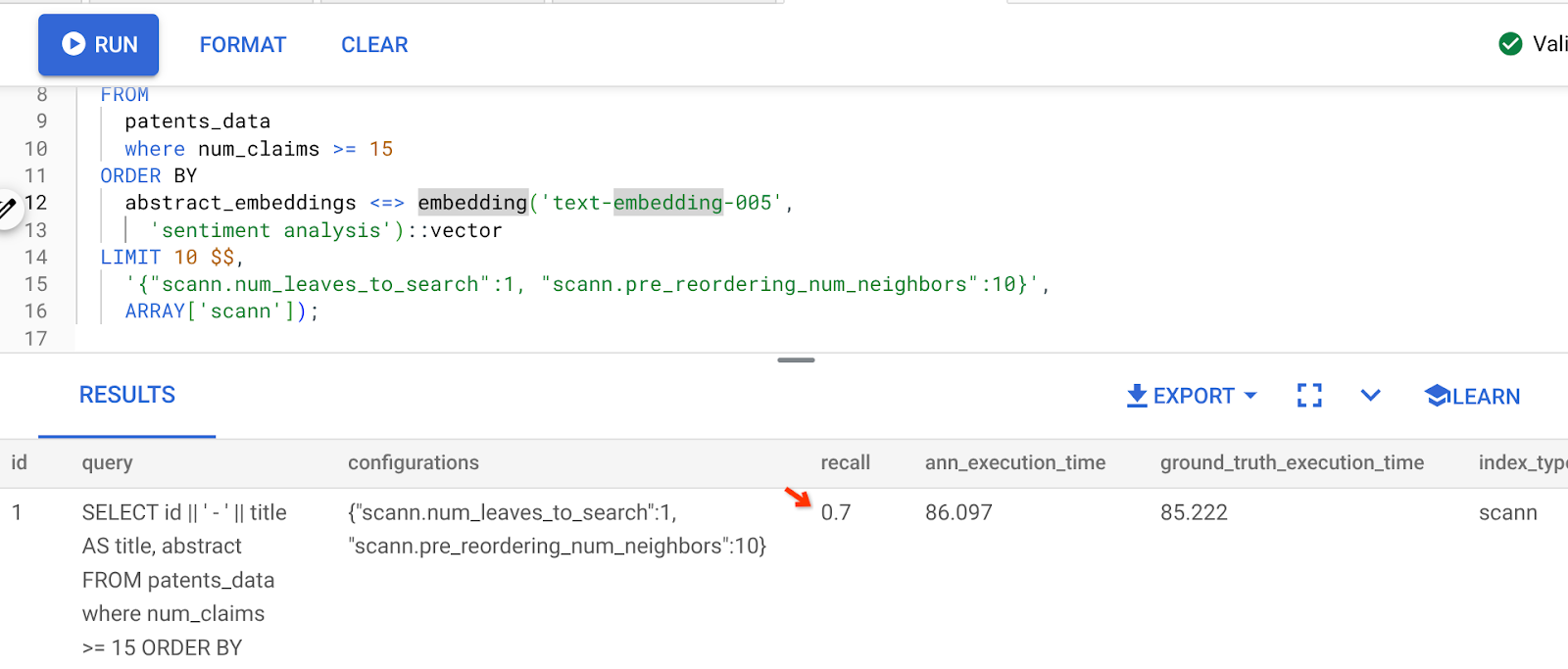
Как видите, показатель RECALL составляет 70% без каких-либо изменений в логике индексирования. Помните индекс ScaNN, который мы создали на шаге 6 раздела «Встроенная фильтрация», « patent_index »? Этот же индекс по-прежнему эффективен при выполнении приведенного выше запроса.
Теперь давайте создадим индекс с другим запросом функции расстояния: Расстояние L2: <->
drop index patent_index;
CREATE INDEX patent_index_L2 ON patents_data
USING scann (abstract_embeddings L2)
WITH (num_leaves=32);
Оператор drop index используется лишь для того, чтобы исключить наличие ненужных индексов в таблице.
Теперь я могу выполнить следующий запрос для оценки полноты (RECALL) после изменения функции расстояния в моей функции векторного поиска.
[ПОСЛЕ] Запрос, использующий функцию расстояния косинусного сходства:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <-> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Результатом вышеуказанного запроса является:
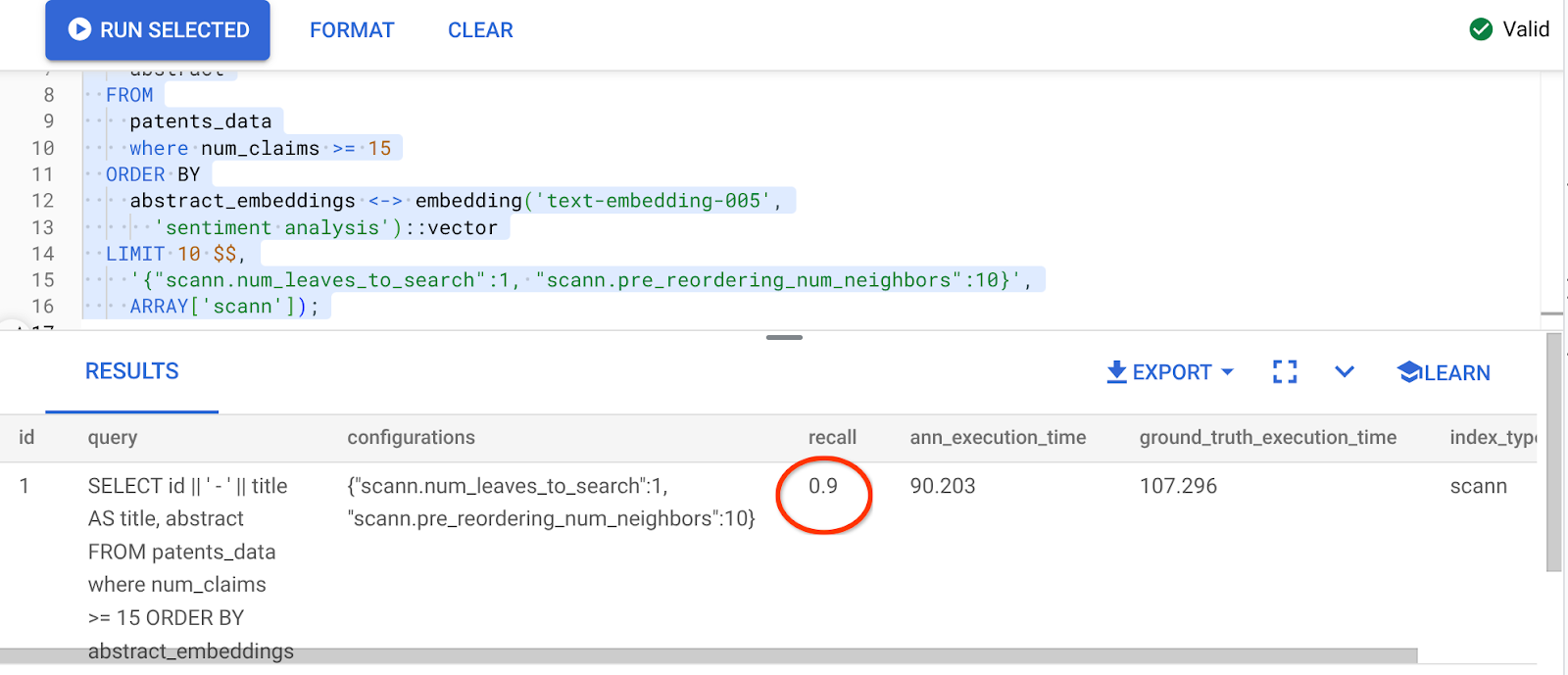
Какое невероятное изменение показателя запоминаемости — 90%!!!
В индексе можно изменять и другие параметры, например, num_leaves и т.д., в зависимости от желаемого значения полноты и набора данных, используемого вашим приложением.
8. Уборка
Чтобы избежать списания средств с вашего аккаунта Google Cloud за ресурсы, использованные в этой статье, выполните следующие действия:
- В консоли Google Cloud перейдите на страницу управления ресурсами .
- В списке проектов выберите проект, который хотите удалить, и нажмите кнопку «Удалить» .
- В диалоговом окне введите идентификатор проекта, а затем нажмите «Завершить» , чтобы удалить проект.
- В качестве альтернативы вы можете просто удалить кластер AlloyDB (измените местоположение по этой гиперссылке, если вы не выбрали us-central1 для кластера во время настройки), который мы только что создали для этого проекта, нажав кнопку «УДАЛИТЬ КЛАСТЕР».
9. Поздравляем!
Поздравляем! Вы успешно создали контекстный поисковый запрос для патентов с помощью расширенного векторного поиска AlloyDB, обеспечивающего высокую производительность и действительно содержательный поиск. Я подготовил высококачественное многофункциональное агентное приложение, использующее ADK и все возможности AlloyDB, которые мы здесь обсуждали, для создания высокопроизводительного и качественного агента векторного поиска и анализа патентов. Вы можете посмотреть его здесь: https://youtu.be/Y9fvVY0yZTY
Если вы хотите научиться создавать такого агента, пожалуйста, обратитесь к этому руководству .