
1. Обзор
В различных отраслях патентные исследования являются важнейшим инструментом для понимания конкурентной среды, выявления потенциальных возможностей лицензирования или приобретения, а также предотвращения нарушения существующих патентов.
Поиск патентов – обширная и сложная задача. Просматривать бесчисленные технические аннотации в поисках релевантных инноваций – непростая задача. Традиционные поиски по ключевым словам часто неточны и отнимают много времени. Аннотации длинные и технические, что затрудняет быстрое понимание основной идеи. Это может привести к тому, что исследователи пропускают ключевые патенты или тратят время на нерелевантные результаты.
Секрет этой революции кроется в векторном поиске. Вместо простого сопоставления ключевых слов, векторный поиск преобразует текст в числовые представления (встраивания). Это позволяет нам искать на основе смысла запроса, а не только конкретных использованных слов. В мире поиска литературы это кардинально меняет ситуацию. Представьте, что вы нашли патент на «носимый пульсометр», даже если точная фраза не используется в документе.
Цель
В этом практическом занятии мы будем работать над тем, чтобы сделать процесс поиска патентов быстрее, интуитивнее и невероятно точным, используя AlloyDB, расширение pgvector и встроенные инструменты Gemini 1.5 Pro, Embeddings и Vector Search.
Что вы построите
В рамках этой лабораторной работы вы:
- Создайте экземпляр AlloyDB и загрузите данные из общедоступного набора данных о патентах.
- Включите расширения pgvector и генеративных моделей ИИ в AlloyDB.
- Сгенерируйте векторные представления на основе полученных данных.
- Выполняйте поиск сходства по косинусному закону в реальном времени для поискового запроса пользователя.
- Разверните решение в бессерверных облачных функциях.
Следующая диаграмма иллюстрирует поток данных и этапы реализации.

High level diagram representing the flow of the Patent Search Application with AlloyDB
Требования
2. Прежде чем начать
Создать проект
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud.
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
- Вы будете использовать Cloud Shell — среду командной строки, работающую в Google Cloud и поставляемую с предустановленным bq. Нажмите «Активировать Cloud Shell» в верхней части консоли Google Cloud.

- После подключения к Cloud Shell необходимо проверить, прошли ли вы аутентификацию и установлен ли идентификатор вашего проекта, используя следующую команду:
gcloud auth list
- Выполните следующую команду в Cloud Shell, чтобы убедиться, что команда gcloud знает о вашем проекте.
gcloud config list project
- Если ваш проект не задан, используйте следующую команду для его настройки:
gcloud config set project <YOUR_PROJECT_ID>
- Включите необходимые API. Вы можете использовать команду gcloud в терминале Cloud Shell:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
Альтернативой команде gcloud является поиск каждого продукта в консоли или использование этой ссылки .
Для получения информации о командах gcloud и их использовании обратитесь к документации .
3. Подготовьте базу данных AlloyDB.
Давайте создадим кластер AlloyDB, экземпляр и таблицу, куда будут загружены данные о патентах.
Создайте объекты AlloyDB.
Создайте кластер и экземпляр с идентификатором кластера " patent-cluster ", паролем " alloydb ", совместимостью с PostgreSQL 15 и регионом " us-central1 ", сетевыми настройками " default ". Установите идентификатор экземпляра на " patent-instance ". Нажмите "СОЗДАТЬ КЛАСТЕР". Подробная информация о создании кластера приведена по этой ссылке: https://cloud.google.com/alloydb/docs/cluster-create .
Создайте таблицу
В AlloyDB Studio можно создать таблицу, используя приведенный ниже оператор DDL:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT) ;
Включить расширения
Для создания приложения для поиска патентов мы будем использовать расширения pgvector и google_ml_integration. Расширение pgvector позволяет хранить и искать векторные представления. Расширение google_ml_integration предоставляет функции, которые вы используете для доступа к конечным точкам прогнозирования Vertex AI для получения прогнозов в формате SQL. Включите эти расширения, выполнив следующие DDL-скрипты:
CREATE EXTENSION vector;
CREATE EXTENSION google_ml_integration;
Предоставить разрешение
Выполните указанное ниже выражение, чтобы предоставить права на выполнение функции "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Предоставьте учетной записи службы AlloyDB роль пользователя Vertex AI.
В консоли Google Cloud IAM предоставьте учетной записи службы AlloyDB (которая выглядит следующим образом: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) доступ к роли "Пользователь Vertex AI". В поле PROJECT_NUMBER будет указан номер вашего проекта.
В качестве альтернативы вы также можете предоставить доступ с помощью команды gcloud:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Измените таблицу, добавив столбец «Вектор» для хранения векторных представлений.
Выполните приведенный ниже DDL-скрипт, чтобы добавить поле abstract_embeddings в только что созданную таблицу. Этот столбец позволит хранить векторные значения текста:
ALTER TABLE patents_data ADD column abstract_embeddings vector(3072);
4. Загрузите данные о патентах в базу данных.
В качестве набора данных мы будем использовать общедоступные наборы данных патентов Google на платформе BigQuery. Для выполнения запросов мы будем использовать AlloyDB Studio. В репозитории alloydb-pgvector содержится скрипт insert_into_patents_data.sql который мы будем запускать для загрузки данных о патентах.
- В консоли Google Cloud откройте страницу AlloyDB .
- Выберите созданный кластер и щелкните по его экземпляру.
- В меню навигации AlloyDB нажмите AlloyDB Studio . Войдите в систему, используя свои учетные данные.
- Откройте новую вкладку, нажав на значок «Новая вкладка» справа.
- Скопируйте в редактор оператор
insertиз скриптаinsert_into_patents_data.sql, упомянутого выше. Для быстрой демонстрации этого варианта использования можно скопировать от 50 до 100 операторов INSERT. - Нажмите кнопку «Выполнить» . Результаты вашего запроса отобразятся в таблице «Результаты» .
5. Создайте векторные представления данных о патентах.
Для начала протестируем функцию встраивания, выполнив следующий пример запроса:
SELECT embedding( 'gemini-embedding-001', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Эта функция должна вернуть вектор эмбеддингов, который выглядит как массив чисел с плавающей запятой, для примера текста в запросе. Выглядит это так:

Обновите поле Abstract_Embeddings Vector.
Выполните приведенный ниже DML-запрос, чтобы обновить аннотации патентов в таблице, добавив в них соответствующие векторные представления:
UPDATE patents_data set abstract_embeddings = embedding( 'gemini-embedding-001', abstract);
6. Выполните векторный поиск.
Теперь, когда таблица, данные и векторные представления готовы, давайте выполним векторный поиск в реальном времени для поискового запроса пользователя. Вы можете проверить это, выполнив запрос ниже:
SELECT id || ' - ' || title as literature FROM patents_data ORDER BY abstract_embeddings <=> embedding('gemini-embedding-001', 'A new Natural Language Processing related Machine Learning Model')::vector LIMIT 10;
В этом запросе,
- Поисковый запрос пользователя: «Новая модель машинного обучения, связанная с обработкой естественного языка».
- Мы преобразуем его в векторные представления в методе embedding(), используя модель gemini-embedding-001.
- Символ "<=>" обозначает использование метода расстояния косинусного сходства.
- Мы преобразуем результат метода встраивания в векторный тип, чтобы обеспечить его совместимость с векторами, хранящимися в базе данных.
- LIMIT 10 означает, что мы выбираем 10 наиболее близких совпадений с поисковым текстом.
Ниже приведён результат:

Как вы можете видеть в результатах, совпадения довольно близки к поисковому запросу.
7. Разместите приложение в интернете.
Готовы перенести это приложение в веб-браузер? Следуйте инструкциям ниже:
- Перейдите в редактор Cloud Shell и нажмите значок «Cloud Code — Войти» в левом нижнем углу (строка состояния) редактора. Выберите свой текущий проект Google Cloud, в котором включена оплата, и убедитесь, что вы также вошли в этот проект через Gemini (в правом углу строки состояния).
- Щелкните значок Cloud Code и дождитесь появления диалогового окна Cloud Code. Выберите «Новое приложение», а во всплывающем окне «Создать новое приложение» выберите приложение Cloud Functions:

На странице 2/2 всплывающего окна «Создать новое приложение» выберите Java: Hello World, введите имя вашего проекта как "alloydb-pgvector" в нужном месте и нажмите OK:

- В полученной структуре проекта найдите файл pom.xml и замените его содержимым из файла репозитория. В нем должны присутствовать следующие зависимости, а также еще несколько:

- Замените файл HelloWorld.java содержимым из файла репозитория .
Обратите внимание, что вам необходимо заменить приведенные ниже значения на ваши фактические данные:
String ALLOYDB_DB = "postgres";
String ALLOYDB_USER = "postgres";
String ALLOYDB_PASS = "*****";
String ALLOYDB_INSTANCE_NAME = "projects/<<YOUR_PROJECT_ID>>/locations/us-central1/clusters/<<YOUR_CLUSTER>>/instances/<<YOUR_INSTANCE>>";
//Replace YOUR_PROJECT_ID, YOUR_CLUSTER, YOUR_INSTANCE with your actual values
Обратите внимание, что функция ожидает в качестве входного параметра текст поиска с ключом "search", и в данной реализации мы возвращаем только одно наиболее близкое совпадение из базы данных:
// Get the request body as a JSON object.
JsonObject requestJson = new Gson().fromJson(request.getReader(), JsonObject.class);
String searchText = requestJson.get("search").getAsString();
//Sample searchText: "A new Natural Language Processing related Machine Learning Model";
BufferedWriter writer = response.getWriter();
String result = "";
HikariDataSource dataSource = AlloyDbJdbcConnector();
try (Connection connection = dataSource.getConnection()) {
//Retrieve Vector Search by text (converted to embeddings) using "Cosine Similarity" method
try (PreparedStatement statement = connection.prepareStatement("SELECT id || ' - ' || title as literature FROM patents_data ORDER BY abstract_embeddings <=> embedding('tgemini-embedding-001', '" + searchText + "' )::vector LIMIT 1")) {
ResultSet resultSet = statement.executeQuery();
resultSet.next();
String lit = resultSet.getString("literature");
result = result + lit + "\n";
System.out.println("Matching Literature: " + lit);
}
writer.write("Here is the closest match: " + result);
}
- Для развертывания только что созданной облачной функции выполните следующую команду в терминале Cloud Shell. Не забудьте сначала перейти в соответствующую папку проекта, используя команду:
cd alloydb-pgvector
Затем выполните команду:
gcloud functions deploy patent-search --gen2 --region=us-central1 --runtime=java11 --source=. --entry-point=cloudcode.helloworld.HelloWorld --trigger-http
ВАЖНЫЙ ШАГ:
После завершения развертывания вы сможете увидеть функции в консоли Google Cloud Run Functions . Найдите созданную функцию, откройте ее, отредактируйте конфигурацию и внесите следующие изменения:
- Перейдите в раздел «Среда выполнения», «Сборка», «Подключения» и «Параметры безопасности».
- Увеличьте время ожидания до 180 секунд.
- Перейдите на вкладку «СОЕДИНЕНИЯ»:

- В настройках входящего трафика убедитесь, что выбран параметр «Разрешить весь трафик».
- В настройках исходящего трафика щелкните раскрывающееся меню «Сеть» и выберите пункт «Добавить новый коннектор VPC», затем следуйте инструкциям в появившемся диалоговом окне:
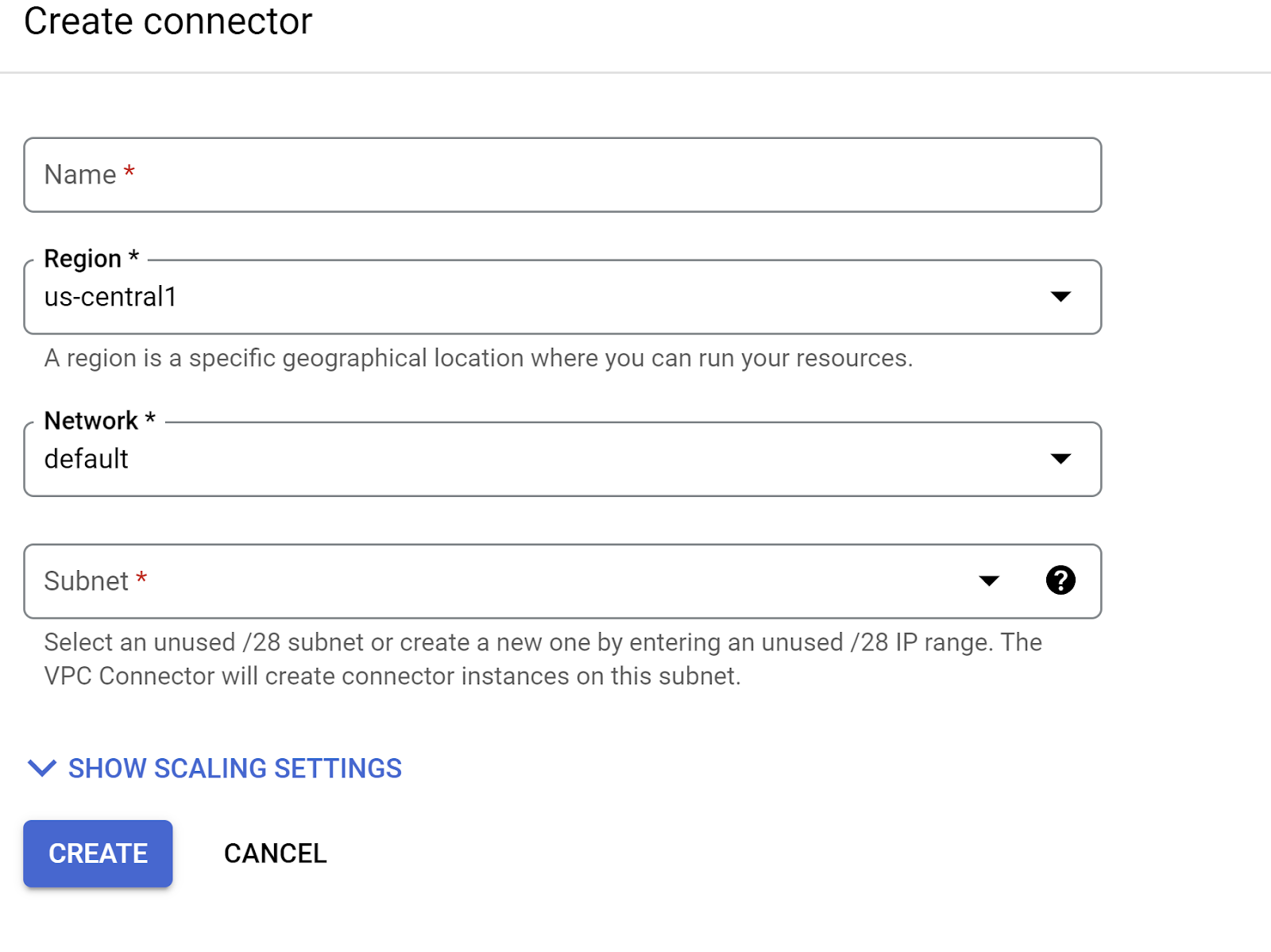
- Укажите имя для VPC-коннектора и убедитесь, что регион совпадает с регионом вашего экземпляра. Оставьте значение «Сеть» по умолчанию и установите подсеть как «Пользовательский диапазон IP-адресов» с диапазоном IP-адресов 10.8.0.0 или аналогичным доступным значением.
- Разверните раздел «ПОКАЗАТЬ НАСТРОЙКИ МАСШТАБИРОВАНИЯ» и убедитесь, что параметры конфигурации установлены точно следующим образом:

- Нажмите кнопку СОЗДАТЬ, и этот соединитель должен появиться в списке настроек исходящего трафика.
- Выберите только что созданный соединитель.
- Выберите вариант, при котором весь трафик будет направляться через этот VPC-коннектор.
8. Протестируйте приложение.
После развертывания вы должны увидеть конечную точку в следующем формате:
https://us-central1-YOUR_PROJECT_ID.cloudfunctions.net/patent-search
Вы можете проверить это в терминале Cloud Shell, выполнив следующую команду:
gcloud functions call patent-search --region=us-central1 --gen2 --data '{"search": "A new Natural Language Processing related Machine Learning Model"}'
Результат:

Вы также можете протестировать его из списка Cloud Functions . Выберите развернутую функцию и перейдите на вкладку «ТЕСТИРОВАНИЕ». В текстовом поле «Настройка события запуска для запроса JSON» введите следующее:
{"search": "A new Natural Language Processing related Machine Learning Model"}
Нажмите кнопку «ПРОВЕРИТЬ ФУНКЦИЮ», и вы увидите результат в правой части страницы:

Вот и всё! Выполнить поиск по вектору сходства с использованием модели Embeddings на данных AlloyDB очень просто.
9. Уборка
Чтобы избежать списания средств с вашего аккаунта Google Cloud за ресурсы, использованные в этой статье, выполните следующие действия:
- В консоли Google Cloud перейдите в раздел «Управление» .
- страница ресурсов .
- В списке проектов выберите проект, который хотите удалить, и нажмите кнопку «Удалить» .
- В диалоговом окне введите идентификатор проекта, а затем нажмите «Завершить» , чтобы удалить проект.
10. Поздравляем!
Поздравляем! Вы успешно выполнили поиск сходства с использованием AlloyDB, pgvector и Vector Search. Объединив возможности AlloyDB , Vertex AI и Vector Search , мы сделали огромный шаг вперед в обеспечении доступности, эффективности и подлинной информативности поиска литературы.