
1. ภาพรวม
การค้นหาตามบริบทเป็นฟังก์ชันที่สำคัญซึ่งเป็นหัวใจหลักของแอปพลิเคชันในอุตสาหกรรมต่างๆ การสร้างแบบดึงข้อมูลเสริมเป็นตัวขับเคลื่อนหลักของการพัฒนาเทคโนโลยีที่สำคัญนี้มาสักระยะแล้วด้วยกลไกการดึงข้อมูลที่ทำงานด้วยระบบ Generative AI โมเดล Generative ที่มีหน้าต่างบริบทขนาดใหญ่และคุณภาพเอาต์พุตที่น่าประทับใจกำลังเปลี่ยนโฉมหน้า AI RAG เป็นวิธีที่เป็นระบบในการแทรกบริบทลงในแอปพลิเคชันและเอเจนต์ AI โดยอิงตามฐานข้อมูลที่มีโครงสร้างหรือข้อมูลจากสื่อต่างๆ ข้อมูลตามบริบทนี้มีความสำคัญอย่างยิ่งต่อความชัดเจนของความจริงและความถูกต้องของเอาต์พุต แต่ผลลัพธ์เหล่านั้นมีความถูกต้องเพียงใด ธุรกิจของคุณขึ้นอยู่กับความแม่นยำและความเกี่ยวข้องของการจับคู่ตามบริบทเหล่านี้เป็นส่วนใหญ่ใช่ไหม โปรเจ็กต์นี้จะทำให้คุณหัวเราะได้แน่นอน
เคล็ดลับที่ซ่อนอยู่ของการค้นหาเวกเตอร์ไม่ได้อยู่ที่การสร้างเท่านั้น แต่อยู่ที่การรู้ว่าการจับคู่เวกเตอร์นั้นดีจริงหรือไม่ เราทุกคนเคยเจอสถานการณ์ที่จ้องมองรายการผลการค้นหาอย่างว่างเปล่าและสงสัยว่า "นี่มันใช้ได้จริงหรือเปล่า" มาเจาะลึกวิธีประเมินคุณภาพของการจับคู่เวกเตอร์กัน คุณอาจสงสัยว่า "แล้ว RAG มีอะไรเปลี่ยนแปลงบ้าง" ทุกอย่าง เป็นเวลาหลายปีที่ Retrieval Augmented Generation (RAG) ดูเหมือนจะเป็นเป้าหมายที่น่าสนใจแต่ก็เข้าถึงได้ยาก ในที่สุด เราก็มีเครื่องมือในการสร้างแอปพลิเคชัน RAG ที่มีประสิทธิภาพและความน่าเชื่อถือที่จำเป็นสำหรับงานที่สำคัญต่อภารกิจ
ตอนนี้เรามีความเข้าใจพื้นฐานเกี่ยวกับ 3 สิ่งต่อไปนี้แล้ว
- ความหมายของการค้นหาตามบริบทสำหรับ Agent และวิธีดำเนินการโดยใช้การค้นหาเวกเตอร์
- นอกจากนี้ เรายังเจาะลึกถึงการใช้การค้นหาเวกเตอร์ภายในขอบเขตของข้อมูลของคุณ ซึ่งก็คือภายในฐานข้อมูลของคุณเอง (ฐานข้อมูลทั้งหมดของ Google Cloud รองรับการค้นหาเวกเตอร์ หากคุณยังไม่ทราบ)
- เราก้าวไปอีกขั้นเหนือกว่าที่อื่นๆ ในโลกด้วยการบอกวิธีสร้างความสามารถ RAG ของ Vector Search ที่มีน้ำหนักเบาเช่นนี้ด้วยประสิทธิภาพและคุณภาพสูงด้วยความสามารถ Vector Search ของ AlloyDB ที่ขับเคลื่อนโดยดัชนี ScaNN
หากคุณยังไม่ได้ลองใช้การทดลอง RAG ขั้นพื้นฐาน ระดับกลาง และขั้นสูงเล็กน้อย ขอแนะนำให้อ่าน 3 บทความที่นี่ ที่นี่ และที่นี่ตามลำดับ
การค้นหาสิทธิบัตรช่วยให้ผู้ใช้ค้นหาสิทธิบัตรที่เกี่ยวข้องตามบริบทกับข้อความค้นหา และเราได้สร้างเวอร์ชันนี้ไปแล้วในอดีต ตอนนี้เราจะสร้างโดยใช้ฟีเจอร์ RAG ใหม่และขั้นสูงที่ช่วยให้การค้นหาตามบริบทที่ควบคุมคุณภาพสำหรับแอปพลิเคชันนั้น มาดูกันเลย
รูปภาพด้านล่างแสดงโฟลว์โดยรวมของสิ่งที่เกิดขึ้นในแอปพลิเคชันนี้~ 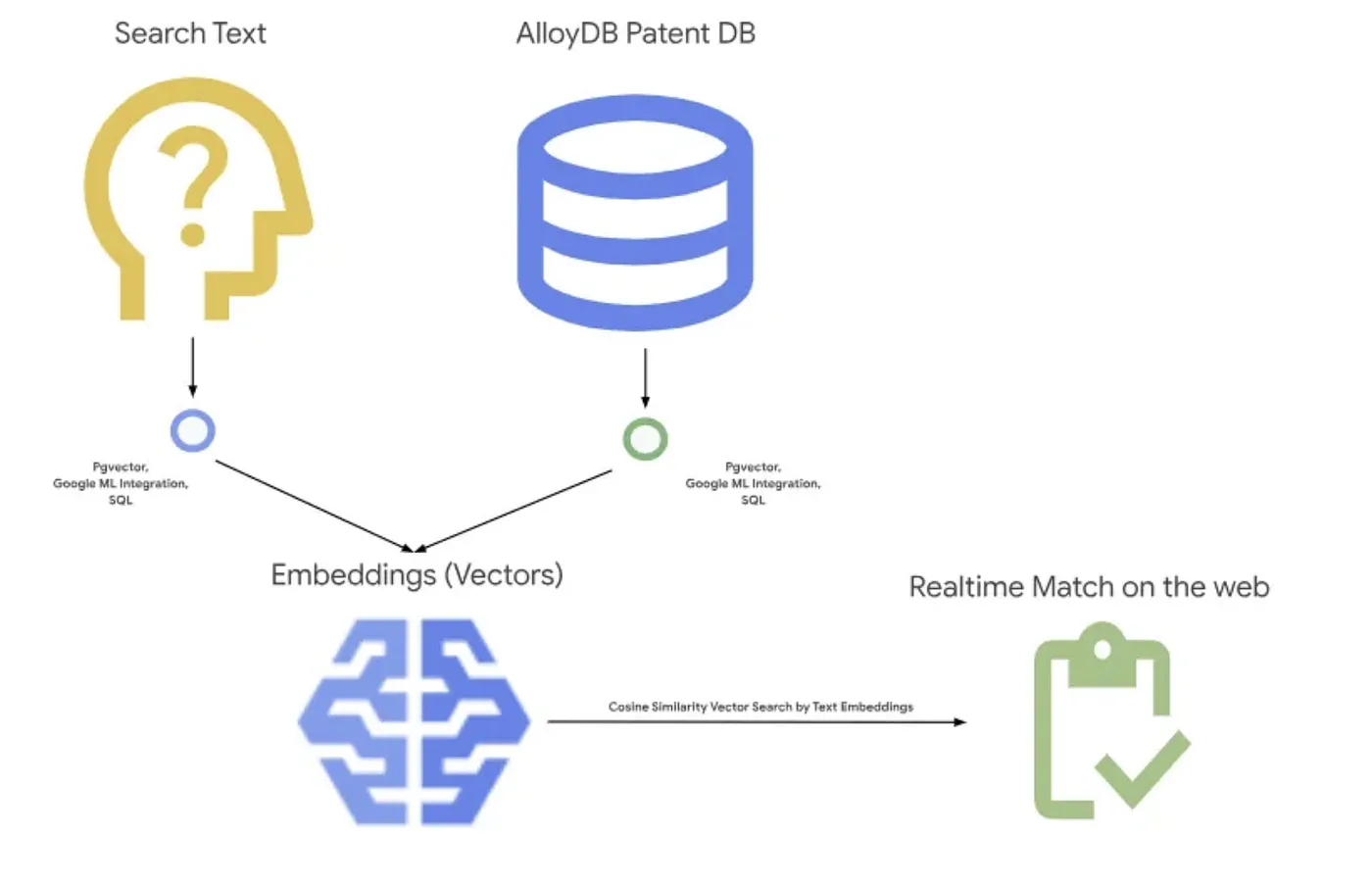
วัตถุประสงค์
อนุญาตให้ผู้ใช้ค้นหาสิทธิบัตรตามคำอธิบายที่เป็นข้อความโดยมีประสิทธิภาพที่ดีขึ้นและคุณภาพที่ดียิ่งขึ้น พร้อมทั้งสามารถประเมินคุณภาพของการจับคู่ที่สร้างขึ้นโดยใช้ฟีเจอร์ RAG ล่าสุดของ AlloyDB
สิ่งที่คุณจะสร้าง
ในห้องทดลองนี้ คุณจะทำสิ่งต่อไปนี้
- สร้างอินสแตนซ์ AlloyDB และโหลดชุดข้อมูลสาธารณะของสิทธิบัตร
- สร้างดัชนีข้อมูลเมตาและดัชนี ScaNN
- ใช้ Vector Search ขั้นสูงใน AlloyDB โดยใช้วิธีการกรองแบบอินไลน์ของ ScaNN
- ใช้ฟีเจอร์การประเมินการเรียกคืน
- ประเมินคำตอบของคำค้นหา
ข้อกำหนด
2. ก่อนเริ่มต้น
สร้างโปรเจ็กต์
- ในคอนโซล Google Cloud ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud ในหน้าตัวเลือกโปรเจ็กต์
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ Cloud แล้ว ดูวิธีตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินในโปรเจ็กต์แล้วหรือไม่
- คุณจะใช้ Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานใน Google Cloud คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud

- เมื่อเชื่อมต่อกับ Cloud Shell แล้ว ให้ตรวจสอบว่าคุณได้รับการตรวจสอบสิทธิ์แล้วและตั้งค่าโปรเจ็กต์เป็นรหัสโปรเจ็กต์โดยใช้คำสั่งต่อไปนี้
gcloud auth list
- เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อยืนยันว่าคำสั่ง gcloud รู้จักโปรเจ็กต์ของคุณ
gcloud config list project
- หากไม่ได้ตั้งค่าโปรเจ็กต์ ให้ใช้คำสั่งต่อไปนี้เพื่อตั้งค่า
gcloud config set project <YOUR_PROJECT_ID>
- เปิดใช้ API ที่จำเป็น คุณใช้คำสั่ง gcloud ในเทอร์มินัล Cloud Shell ได้โดยทำดังนี้
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
คุณสามารถใช้คอนโซลแทนคำสั่ง gcloud ได้โดยค้นหาแต่ละผลิตภัณฑ์หรือใช้ลิงก์นี้
โปรดดูคำสั่งและการใช้งาน gcloud ในเอกสารประกอบ
3. การตั้งค่าฐานข้อมูล
ในแล็บนี้ เราจะใช้ AlloyDB เป็นฐานข้อมูลสำหรับข้อมูลสิทธิบัตร โดยจะใช้คลัสเตอร์เพื่อจัดเก็บทรัพยากรทั้งหมด เช่น ฐานข้อมูลและบันทึก แต่ละคลัสเตอร์มีอินสแตนซ์หลักที่ให้จุดเข้าใช้งานข้อมูล ตารางจะเก็บข้อมูลจริง
มาสร้างคลัสเตอร์ อินสแตนซ์ และตาราง AlloyDB ที่จะโหลดชุดข้อมูลสิทธิบัตรกัน
สร้างคลัสเตอร์และอินสแตนซ์
- ไปที่หน้า AlloyDB ใน Cloud Console วิธีง่ายๆ ในการค้นหาหน้าส่วนใหญ่ใน Cloud Console คือการค้นหาโดยใช้แถบค้นหาของคอนโซล
- เลือกสร้างคลัสเตอร์จากหน้านั้น

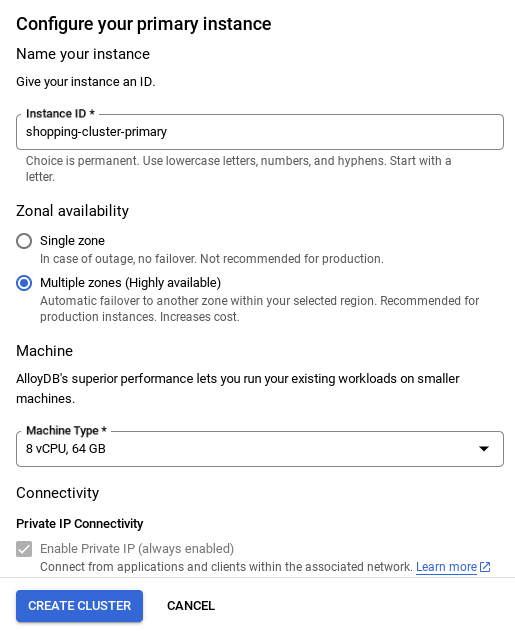
- คุณจะเห็นหน้าจอคล้ายกับหน้าจอด้านล่าง สร้างคลัสเตอร์และอินสแตนซ์ด้วยค่าต่อไปนี้ (ตรวจสอบว่าค่าตรงกันในกรณีที่คุณโคลนโค้ดของแอปพลิเคชันจากที่เก็บ)
- รหัสคลัสเตอร์: "
vector-cluster" - รหัสผ่าน: "
alloydb" - PostgreSQL 15 / ล่าสุดที่แนะนำ
- ภูมิภาค: "
us-central1" - เครือข่าย: "
default"
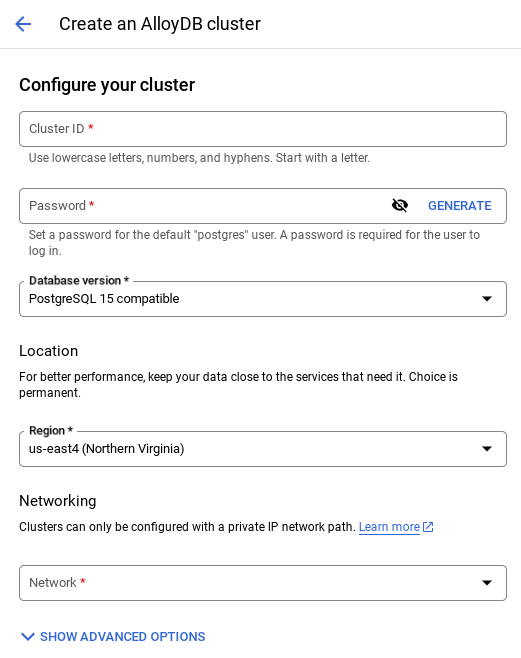
- เมื่อเลือกเครือข่ายเริ่มต้น คุณจะเห็นหน้าจอคล้ายกับหน้าจอด้านล่าง
เลือกตั้งค่าการเชื่อมต่อ
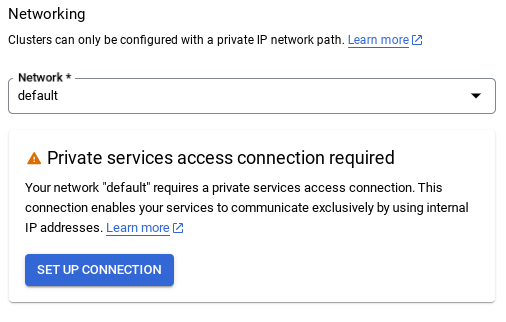
- จากนั้นเลือก "ใช้ช่วง IP ที่มีการจัดสรรโดยอัตโนมัติ" แล้วคลิก "ต่อไป" หลังจากตรวจสอบข้อมูลแล้ว ให้เลือกสร้างการเชื่อมต่อ
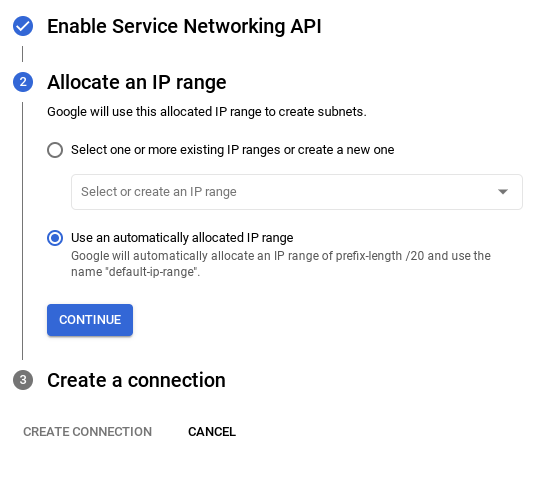
- เมื่อตั้งค่าเครือข่ายแล้ว คุณจะสร้างคลัสเตอร์ต่อไปได้ คลิกสร้างคลัสเตอร์เพื่อตั้งค่าคลัสเตอร์ให้เสร็จสมบูรณ์ตามที่แสดงด้านล่าง
อย่าลืมเปลี่ยนรหัสอินสแตนซ์ (ซึ่งคุณดูได้ในขณะที่กำหนดค่าคลัสเตอร์ / อินสแตนซ์) เป็น
vector-instance หากเปลี่ยนไม่ได้ โปรดใช้รหัสอินสแตนซ์ในการอ้างอิงที่จะเกิดขึ้นทั้งหมด
โปรดทราบว่าการสร้างคลัสเตอร์จะใช้เวลาประมาณ 10 นาที เมื่อดำเนินการสำเร็จแล้ว คุณควรเห็นหน้าจอที่แสดงภาพรวมของคลัสเตอร์ที่เพิ่งสร้าง
4. การนำเข้าข้อมูล
ตอนนี้ได้เวลาเพิ่มตารางที่มีข้อมูลเกี่ยวกับร้านค้าแล้ว ไปที่ AlloyDB เลือกคลัสเตอร์หลัก แล้วเลือก AlloyDB Studio โดยทำดังนี้
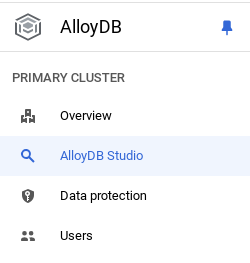
คุณอาจต้องรอให้อินสแตนซ์สร้างเสร็จ เมื่อพร้อมแล้ว ให้ลงชื่อเข้าใช้ AlloyDB โดยใช้ข้อมูลเข้าสู่ระบบที่คุณสร้างขึ้นเมื่อสร้างคลัสเตอร์ ใช้ข้อมูลต่อไปนี้เพื่อตรวจสอบสิทธิ์ใน PostgreSQL
- ชื่อผู้ใช้ : "
postgres" - ฐานข้อมูล : "
postgres" - รหัสผ่าน : "
alloydb"
เมื่อตรวจสอบสิทธิ์ใน AlloyDB Studio สำเร็จแล้ว ให้ป้อนคำสั่ง SQL ในเอดิเตอร์ คุณเพิ่มหน้าต่างเอดิเตอร์หลายหน้าต่างได้โดยใช้เครื่องหมายบวกทางด้านขวาของหน้าต่างสุดท้าย
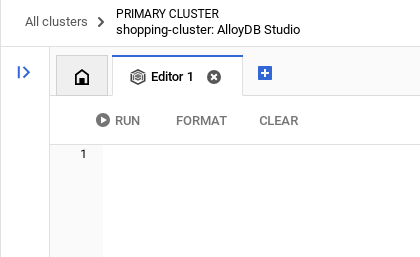
คุณจะป้อนคำสั่งสำหรับ AlloyDB ในหน้าต่างเอดิเตอร์ โดยใช้ตัวเลือกเรียกใช้ จัดรูปแบบ และล้างตามที่จำเป็น
เปิดใช้ส่วนขยาย
ในการสร้างแอปนี้ เราจะใช้ส่วนขยาย pgvector และ google_ml_integration ส่วนขยาย pgvector ช่วยให้คุณจัดเก็บและค้นหาการฝังเวกเตอร์ได้ ส่วนขยาย google_ml_integration มีฟังก์ชันที่คุณใช้เพื่อเข้าถึงปลายทางการคาดการณ์ของ Vertex AI เพื่อรับการคาดการณ์ใน SQL เปิดใช้ส่วนขยายเหล่านี้โดยเรียกใช้ DDL ต่อไปนี้
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
หากต้องการตรวจสอบส่วนขยายที่เปิดใช้ในฐานข้อมูล ให้เรียกใช้คำสั่ง SQL นี้
select extname, extversion from pg_extension;
สร้างตาราง
คุณสร้างตารางได้โดยใช้คำสั่ง DDL ด้านล่างใน AlloyDB Studio
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
คอลัมน์ abstract_embeddings จะอนุญาตให้จัดเก็บค่าเวกเตอร์ของข้อความ
ให้สิทธิ์
เรียกใช้คำสั่งด้านล่างเพื่อให้สิทธิ์ดำเนินการในฟังก์ชัน "ฝัง"
GRANT EXECUTE ON FUNCTION embedding TO postgres;
มอบบทบาทผู้ใช้ Vertex AI ให้กับบัญชีบริการ AlloyDB
จากคอนโซล Google Cloud IAM ให้สิทธิ์เข้าถึงบทบาท "ผู้ใช้ Vertex AI" แก่บัญชีบริการ AlloyDB (ซึ่งมีลักษณะดังนี้ service-<<PROJECT_NUMBER >>@gcp-sa-alloydb.iam.gserviceaccount.com) PROJECT_NUMBER จะมีหมายเลขโปรเจ็กต์ของคุณ
หรือคุณอาจเรียกใช้คำสั่งด้านล่างจากเทอร์มินัล Cloud Shell ก็ได้
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
โหลดข้อมูลสิทธิบัตรลงในฐานข้อมูล
เราจะใช้ชุดข้อมูลสาธารณะของ Google Patents ใน BigQuery เป็นชุดข้อมูล เราจะใช้ AlloyDB Studio เพื่อเรียกใช้การค้นหา ระบบจะดึงข้อมูลลงในไฟล์ insert_scripts.sql นี้ และเราจะเรียกใช้ไฟล์นี้เพื่อโหลดข้อมูลสิทธิบัตร
- เปิดหน้า AlloyDB ในคอนโซล Google Cloud
- เลือกคลัสเตอร์ที่สร้างขึ้นใหม่ แล้วคลิกอินสแตนซ์
- ในเมนูการนำทางของ AlloyDB ให้คลิก AlloyDB Studio ลงชื่อเข้าใช้ด้วยข้อมูลเข้าสู่ระบบ
- เปิดแท็บใหม่โดยคลิกไอคอนแท็บใหม่ทางด้านขวา
- คัดลอก
insertคำสั่งค้นหาจากสคริปต์insert_scripts.sqlที่กล่าวถึงข้างต้นไปยังเครื่องมือแก้ไข คุณสามารถคัดลอกคำสั่งแทรก 10-50 รายการเพื่อสาธิตกรณีการใช้งานนี้อย่างรวดเร็ว - คลิกเรียกใช้ ผลลัพธ์ของคำค้นหาจะปรากฏในตารางผลลัพธ์
หมายเหตุ: คุณอาจสังเกตเห็นว่าสคริปต์การแทรกมีข้อมูลจำนวนมาก เนื่องจากเราได้รวมการฝังไว้ในสคริปต์การแทรก คลิก "ดูไฟล์ข้อมูล RAW" ในกรณีที่คุณพบปัญหาในการโหลดไฟล์ใน GitHub เราทำเช่นนี้เพื่อช่วยให้คุณไม่ต้องเสียเวลา (ในขั้นตอนถัดไป) ในการสร้างการฝังมากกว่า 2-3 รายการ (เช่น สูงสุด 20-25 รายการ) ในกรณีที่คุณใช้บัญชีสำหรับการเรียกเก็บเงินตามเครดิตทดลองใช้สำหรับ Google Cloud
5. สร้างการฝังสำหรับข้อมูลสิทธิบัตร
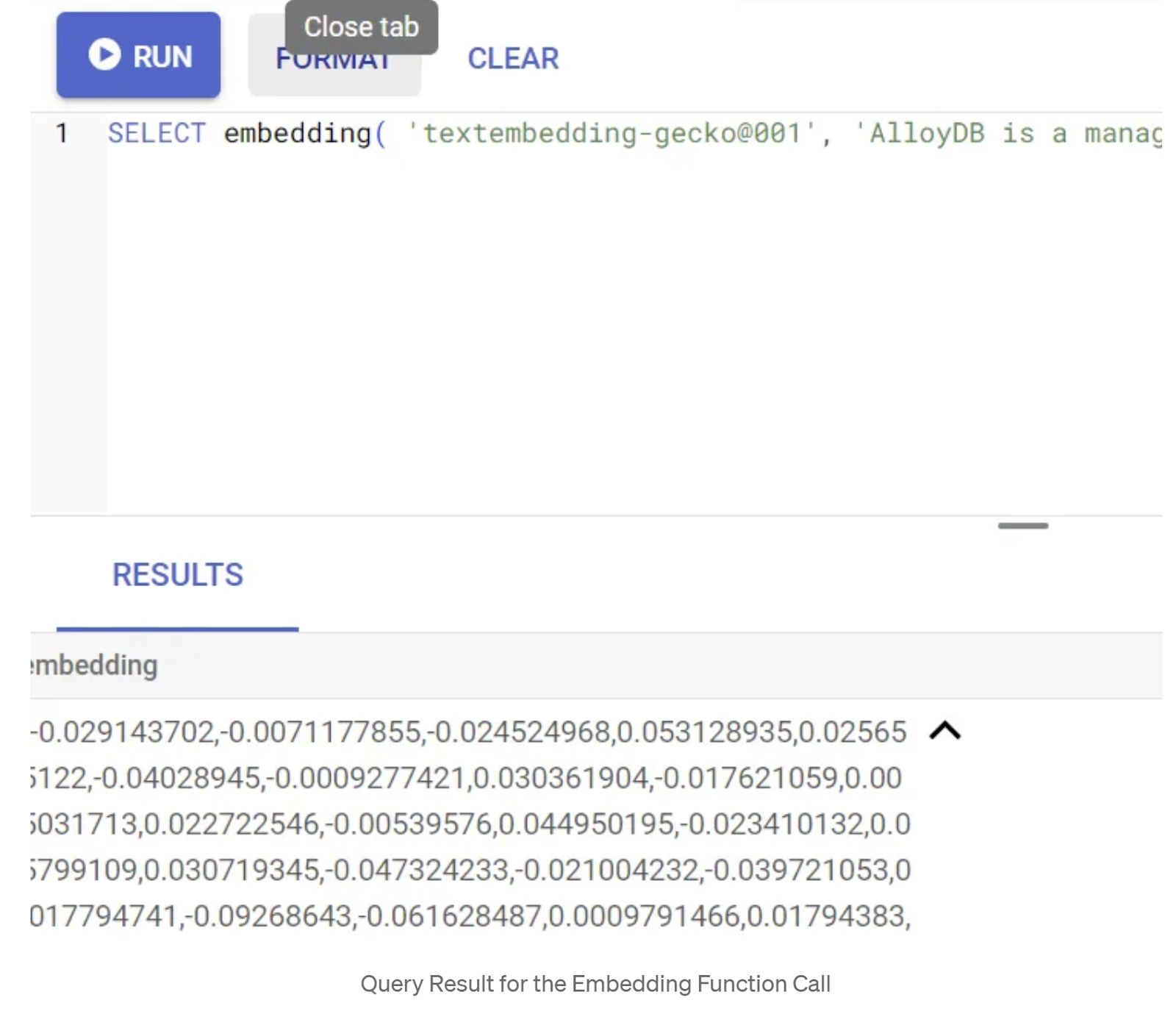
ก่อนอื่น มาทดสอบฟังก์ชันการฝังโดยเรียกใช้การสืบค้นตัวอย่างต่อไปนี้
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
ซึ่งควรแสดงผลเวกเตอร์การฝังที่มีลักษณะคล้ายอาร์เรย์ของจำนวนทศนิยมสำหรับข้อความตัวอย่างในการค้นหา มีลักษณะดังนี้
อัปเดตฟิลด์เวกเตอร์ abstract_embeddings
เรียกใช้ DML ด้านล่างเพื่ออัปเดตบทคัดย่อสิทธิบัตรในตารางด้วยการฝังที่เกี่ยวข้องเฉพาะในกรณีที่คุณไม่ได้แทรกข้อมูล abstract_embeddings เป็นส่วนหนึ่งของสคริปต์การแทรก
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
คุณอาจพบปัญหาในการสร้าง Embedding มากกว่า 2-3 รายการ (เช่น สูงสุด 20-25 รายการ) หากใช้บัญชีสำหรับการเรียกเก็บเงินเครดิตทดลองใช้สำหรับ Google Cloud ด้วยเหตุนี้ ฉันจึงรวมการฝังไว้ในสคริปต์การแทรกแล้ว และคุณควรมีการฝังในตารางที่โหลดแล้วหากทำขั้นตอน "โหลดข้อมูลสิทธิบัตรลงในฐานข้อมูล" เสร็จสมบูรณ์
6. ใช้ RAG ขั้นสูงด้วยฟีเจอร์ใหม่ของ AlloyDB
ตอนนี้ตาราง ข้อมูล และการฝังพร้อมใช้งานแล้ว มาทำการค้นหาเวกเตอร์แบบเรียลไทม์สำหรับข้อความค้นหาของผู้ใช้กัน คุณทดสอบได้โดยเรียกใช้คำค้นหาด้านล่าง
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
ในคำค้นหานี้
- ข้อความที่ผู้ใช้ค้นหาคือ "การวิเคราะห์ความเห็น"
- เราจะแปลงเป็น Embedding ในเมธอด embedding() โดยใช้โมเดล text-embedding-005
- "<=>" แสดงถึงการใช้วิธีการวัดระยะทาง COSINE SIMILARITY
- เราจะแปลงผลลัพธ์ของวิธีการฝังเป็นประเภทเวกเตอร์เพื่อให้เข้ากันได้กับเวกเตอร์ที่จัดเก็บไว้ในฐานข้อมูล
- LIMIT 10 หมายความว่าเราจะเลือกข้อความค้นหาที่ตรงกันมากที่สุด 10 รายการ
AlloyDB ยกระดับ RAG ของ Vector Search ไปอีกขั้น
เราได้เปิดตัวฟีเจอร์ใหม่ๆ มากมาย โดยมี 2 รายการที่มุ่งเน้นนักพัฒนาแอปโดยเฉพาะ ดังนี้
- การกรองแบบอินไลน์
- ผู้ประเมินฟีเจอร์ความทรงจำ
การกรองแบบอินไลน์
ก่อนหน้านี้ในฐานะนักพัฒนาซอฟต์แวร์ คุณจะต้องทำการค้นหาเวกเตอร์และต้องจัดการกับการกรองและการเรียกคืน ตัวเพิ่มประสิทธิภาพการค้นหาของ AlloyDB จะเลือกวิธีดำเนินการค้นหาด้วยตัวกรอง การกรองในบรรทัดเป็นเทคนิคการเพิ่มประสิทธิภาพการค้นหาแบบใหม่ที่ช่วยให้เครื่องมือเพิ่มประสิทธิภาพการค้นหาของ AlloyDB ประเมินทั้งเงื่อนไขการกรองข้อมูลเมตาและการค้นหาเวกเตอร์ควบคู่กันไป โดยใช้ทั้งดัชนีเวกเตอร์และดัชนีในคอลัมน์ข้อมูลเมตา ซึ่งช่วยเพิ่มประสิทธิภาพการเรียกคืนข้อมูล ทำให้นักพัฒนาแอปใช้ประโยชน์จากสิ่งที่ AlloyDB มีให้ได้ทันที
การกรองในบรรทัดเหมาะที่สุดสำหรับกรณีที่มีการเลือกปานกลาง ขณะที่ AlloyDB ค้นหาผ่านดัชนีเวกเตอร์ ระบบจะคำนวณระยะทางสำหรับเวกเตอร์ที่ตรงกับเงื่อนไขการกรองข้อมูลเมตาเท่านั้น (ตัวกรองฟังก์ชันการทำงานในคำค้นหาซึ่งมักจะจัดการในอนุประโยค WHERE) ซึ่งจะช่วยปรับปรุงประสิทธิภาพการค้นหาเหล่านี้ได้อย่างมาก โดยเสริมข้อดีของการกรองหลังการค้นหาหรือการกรองก่อนการค้นหา
- ติดตั้งหรืออัปเดตส่วนขยาย pgvector
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
หากติดตั้งส่วนขยาย pgvector ไว้แล้ว ให้อัปเกรดส่วนขยายเวกเตอร์เป็นเวอร์ชัน 0.8.0.google-3 ขึ้นไปเพื่อรับความสามารถของเครื่องมือประเมินการเรียกคืน
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
ขั้นตอนนี้ต้องดำเนินการก็ต่อเมื่อส่วนขยายเวกเตอร์ของคุณเป็น <0.8.0.google-3> เท่านั้น
หมายเหตุสำคัญ: หากจำนวนแถวน้อยกว่า 100 คุณไม่จำเป็นต้องสร้างดัชนี ScaNN ตั้งแต่แรก เนื่องจากดัชนีนี้จะใช้ไม่ได้กับแถวที่น้อยกว่า ในกรณีนี้ โปรดข้ามขั้นตอนต่อไปนี้
- หากต้องการสร้างดัชนี ScaNN ให้ติดตั้งส่วนขยาย alloydb_scann
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- ก่อนอื่น ให้เรียกใช้การค้นหาเวกเตอร์โดยไม่มีดัชนีและโดยไม่มีการเปิดใช้ตัวกรองแบบอินไลน์
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
ผลลัพธ์ควรมีลักษณะดังนี้
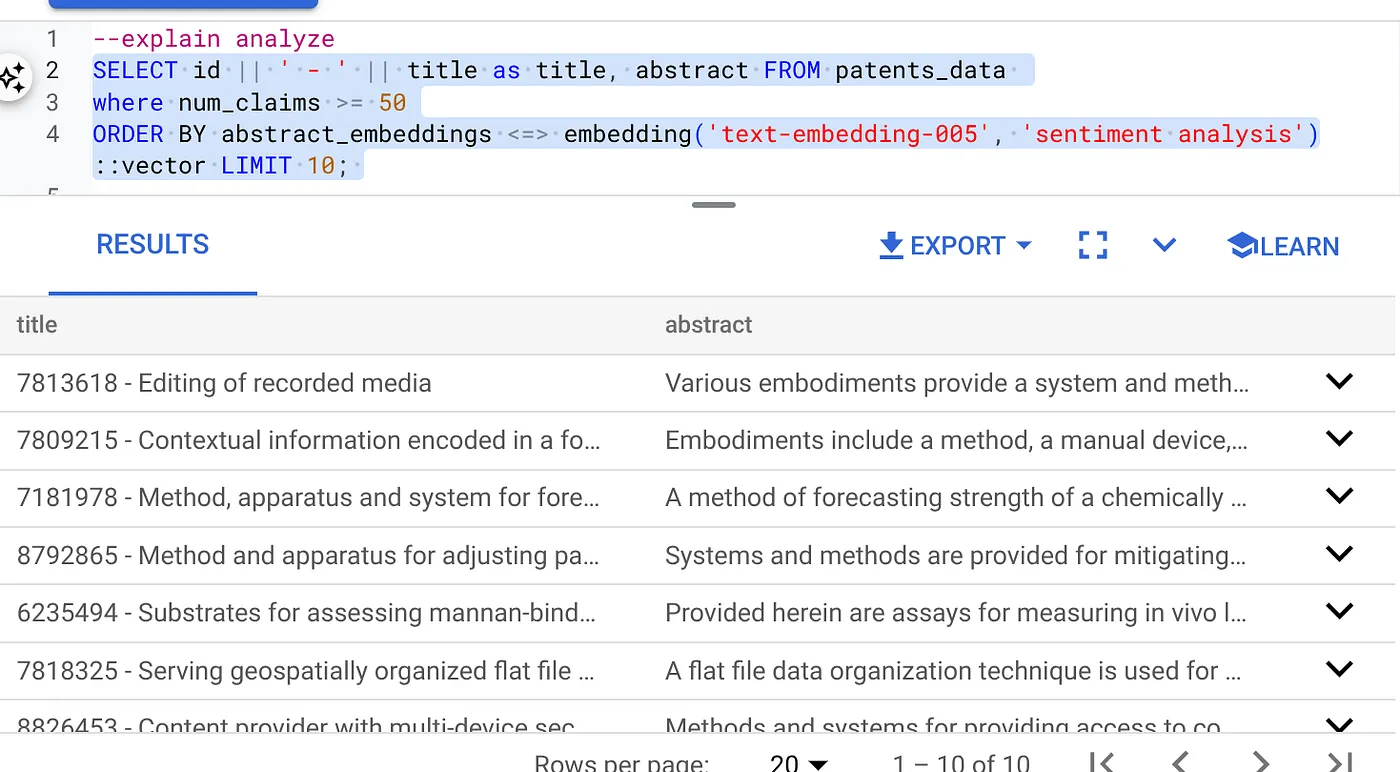
- เรียกใช้ Explain Analyze ในตาราง (ไม่มีดัชนีหรือการกรองในบรรทัด)
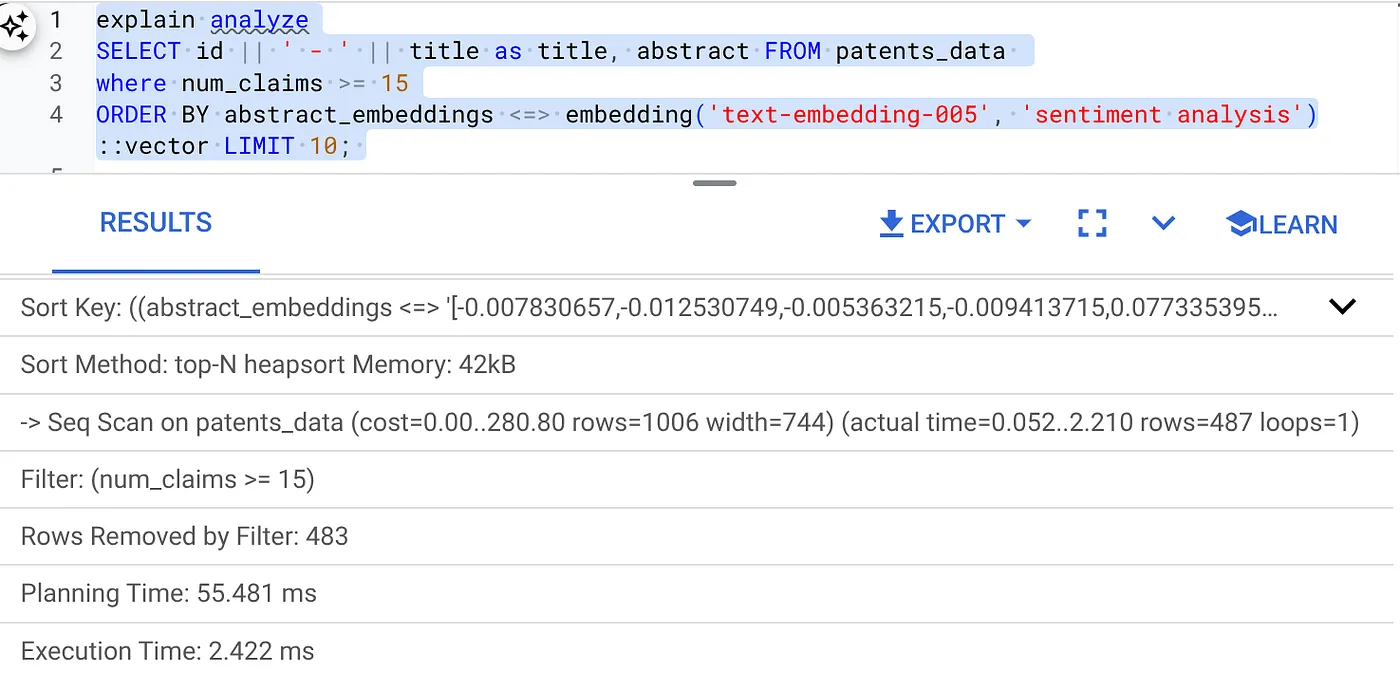
เวลาดำเนินการคือ 2.4 มิลลิวินาที
- มาสร้างดัชนีปกติในฟิลด์ num_claims เพื่อให้เรากรองตามฟิลด์นี้ได้
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- มาสร้างดัชนี ScaNN สำหรับแอปพลิเคชันการค้นหาสิทธิบัตรกัน เรียกใช้คำสั่งต่อไปนี้จาก AlloyDB Studio
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
หมายเหตุสำคัญ: (num_leaves=32) ใช้กับชุดข้อมูลทั้งหมดของเราที่มีมากกว่า 1,000 แถว หากจำนวนแถวน้อยกว่า 100 คุณไม่จำเป็นต้องสร้างดัชนีตั้งแต่แรกเนื่องจากดัชนีจะไม่มีผลกับแถวที่น้อยกว่า
- ตั้งค่าการกรองในบรรทัดที่เปิดใช้ในดัชนี ScaNN ดังนี้
SET scann.enable_inline_filtering = on
- ตอนนี้มาเรียกใช้การค้นหาเดียวกันโดยมีตัวกรองและการค้นหาเวกเตอร์กัน
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
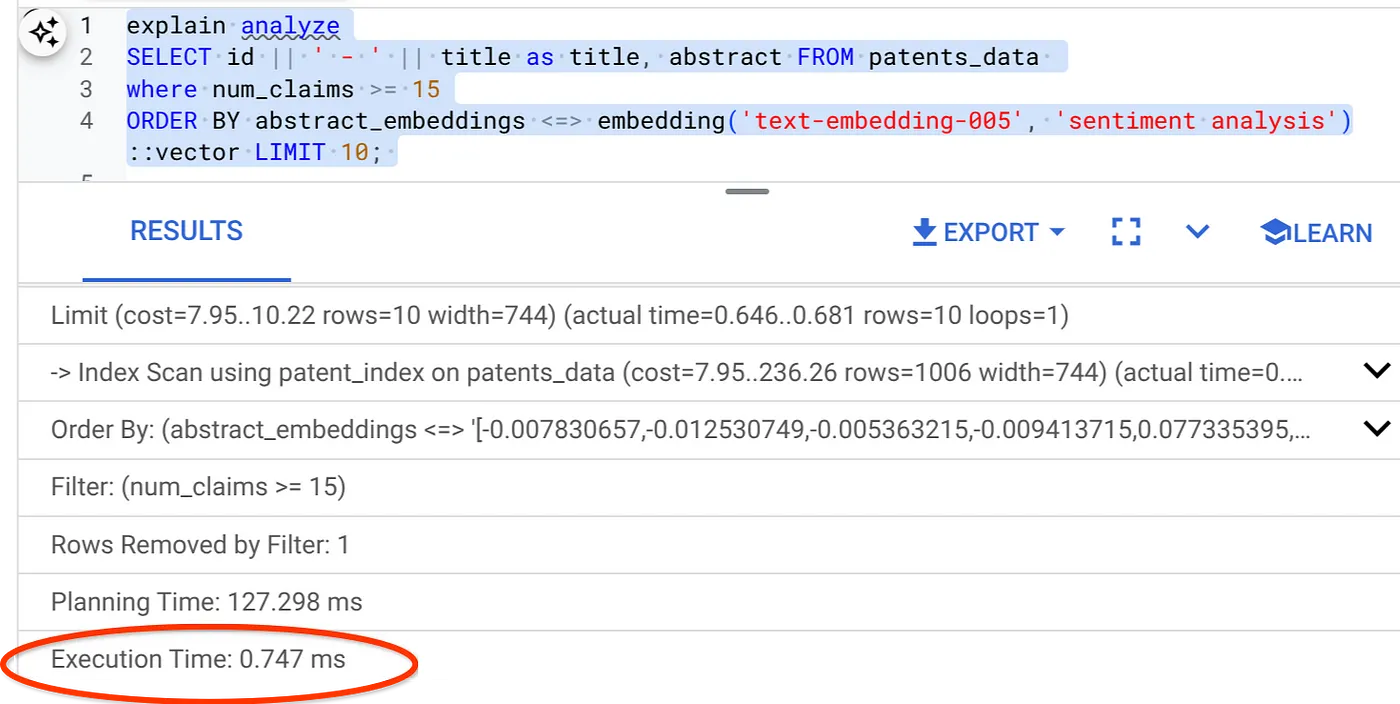
ดังที่เห็นได้ว่าเวลาในการดำเนินการลดลงอย่างมากสำหรับการค้นหาเวกเตอร์เดียวกัน ดัชนี ScaNN ที่มีการกรองในบรรทัดใน Vector Search ช่วยให้ทำเช่นนี้ได้!!!
ต่อไป เราจะประเมินการเรียกคืนสำหรับการค้นหาเวกเตอร์ที่เปิดใช้ ScaNN นี้
ผู้ประเมินฟีเจอร์ความทรงจำ
การเรียกคืนในการค้นหาที่คล้ายกันคือเปอร์เซ็นต์ของอินสแตนซ์ที่เกี่ยวข้องซึ่งดึงมาจากการค้นหา นั่นคือจำนวนผลบวกจริง นี่คือเมตริกที่ใช้กันโดยทั่วไปในการวัดคุณภาพการค้นหา แหล่งที่มาหนึ่งของการสูญเสียการเรียกคืนเกิดจากความแตกต่างระหว่างการค้นหาเพื่อนบ้านที่ใกล้ที่สุดโดยประมาณ หรือ aNN กับการค้นหาเพื่อนบ้านที่ใกล้ที่สุด k (แน่นอน) หรือ kNN ดัชนีเวกเตอร์ เช่น ScaNN ของ AlloyDB จะใช้อัลกอริทึม aNN ซึ่งช่วยให้คุณค้นหาเวกเตอร์ในชุดข้อมูลขนาดใหญ่ได้เร็วขึ้นโดยแลกกับการลดความสามารถในการเรียกคืนลงเล็กน้อย ตอนนี้ AlloyDB ช่วยให้คุณวัดการแลกเปลี่ยนนี้ได้โดยตรงในฐานข้อมูลสำหรับคำค้นหาแต่ละรายการ และมั่นใจได้ว่าการแลกเปลี่ยนนี้จะคงที่เมื่อเวลาผ่านไป คุณสามารถอัปเดตพารามิเตอร์การค้นหาและดัชนีเพื่อตอบสนองต่อข้อมูลนี้เพื่อให้ได้ผลลัพธ์และประสิทธิภาพที่ดีขึ้น
ตรรกะเบื้องหลังการเรียกคืนผลการค้นหาคืออะไร
ในบริบทของการค้นหาเวกเตอร์ การเรียกคืนหมายถึงเปอร์เซ็นต์ของเวกเตอร์ที่ดัชนีแสดงผลซึ่งเป็นจุดข้อมูลข้างเคียงที่ใกล้ที่สุดจริง ตัวอย่างเช่น หากการค้นหาเพื่อนบ้านที่ใกล้ที่สุดสำหรับเพื่อนบ้านที่ใกล้ที่สุด 20 รายการแสดงผลเพื่อนบ้านที่ใกล้ที่สุดที่เป็นข้อมูลที่เป็นความจริง 19 รายการ ความสามารถในการเรียกคืนจะเป็น 19/20x100 = 95% การเรียกคืนคือเมตริกที่ใช้สำหรับคุณภาพการค้นหา และกำหนดเป็นเปอร์เซ็นต์ของผลลัพธ์ที่แสดงซึ่งใกล้เคียงกับเวกเตอร์การค้นหามากที่สุดตามวัตถุประสงค์
คุณดูการเรียกคืนสำหรับการค้นหาเวกเตอร์ในดัชนีเวกเตอร์สำหรับการกำหนดค่าที่ระบุได้โดยใช้ฟังก์ชัน evaluate_query_recall ฟังก์ชันนี้ช่วยให้คุณปรับแต่งพารามิเตอร์เพื่อให้ได้ผลลัพธ์การเรียกคืนการค้นหาเวกเตอร์ที่ต้องการ
หมายเหตุสำคัญ:
หากคุณพบข้อผิดพลาด "ปฏิเสธการเข้าถึง" ในดัชนี HNSW ในขั้นตอนต่อไปนี้ ให้ข้ามส่วนการประเมินการเรียกคืนทั้งหมดนี้ไปก่อน อาจเกี่ยวข้องกับข้อจำกัดในการเข้าถึงในตอนนี้ เนื่องจากเพิ่งเปิดตัวในขณะที่บันทึก Codelab นี้
- ตั้งค่าสถานะเปิดใช้การสแกนดัชนีในดัชนี ScaNN และดัชนี HNSW
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- เรียกใช้การค้นหาต่อไปนี้ใน AlloyDB Studio
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
ฟังก์ชัน evaluate_query_recall จะรับการค้นหาเป็นพารามิเตอร์และแสดงผลการเรียกคืน ฉันใช้การค้นหาเดียวกันกับที่ใช้ตรวจสอบประสิทธิภาพเป็นการค้นหาอินพุตของฟังก์ชัน ฉันได้เพิ่ม SCaNN เป็นวิธีการจัดทำดัชนี ดูตัวเลือกพารามิเตอร์เพิ่มเติมได้ในเอกสารประกอบ
การเรียกคืนสำหรับคำค้นหา Vector Search ที่เราใช้มีดังนี้
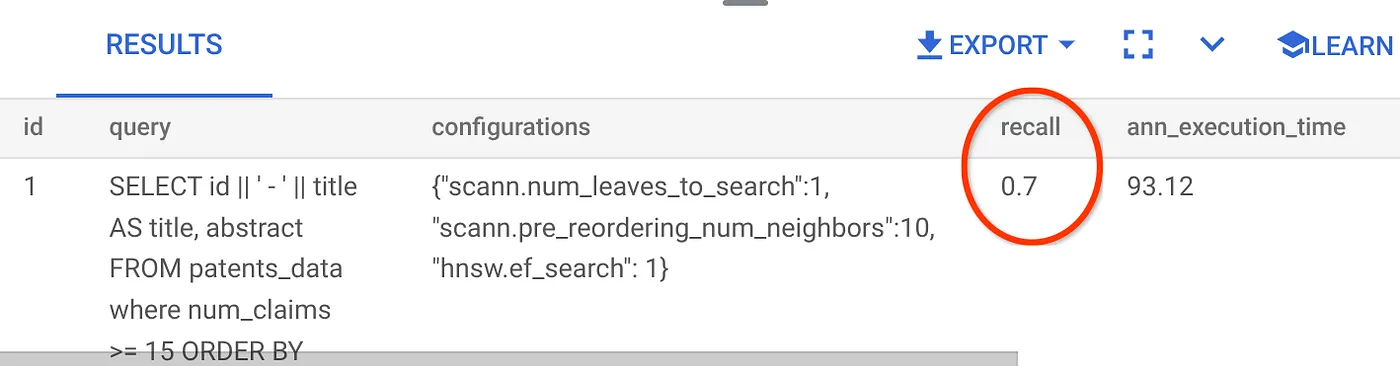
เราเห็นว่าการเรียกคืนอยู่ที่ 70% ตอนนี้ฉันสามารถใช้ข้อมูลนี้เพื่อเปลี่ยนพารามิเตอร์ดัชนี วิธีการ และพารามิเตอร์การค้นหา รวมถึงปรับปรุงการเรียกคืนสำหรับการค้นหาเวกเตอร์นี้ได้แล้ว
7. ทดสอบด้วยพารามิเตอร์การค้นหาและดัชนีที่แก้ไขแล้ว
ตอนนี้มาทดสอบการค้นหาโดยการแก้ไขพารามิเตอร์การค้นหาตามการเรียกคืนที่ได้รับ
- เราได้แก้ไขจำนวนแถวในชุดผลลัพธ์เป็น 7 (จากเดิม 25) และเห็นว่า RECALL ดีขึ้นเป็น 86%
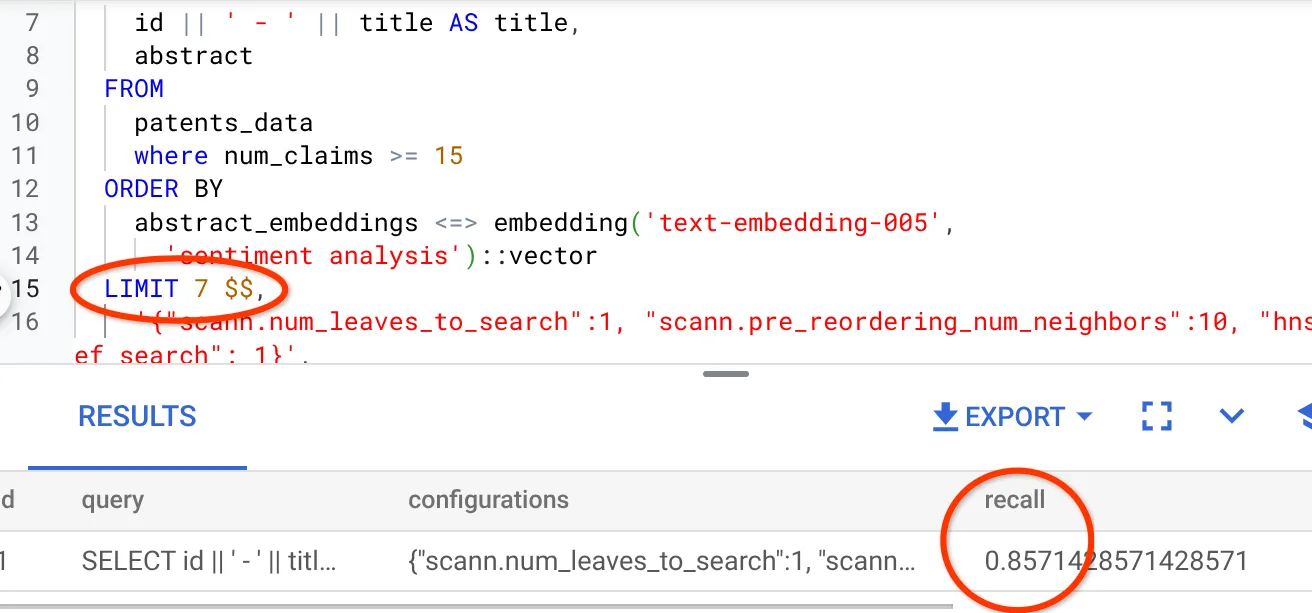
ซึ่งหมายความว่าฉันสามารถปรับเปลี่ยนจำนวนการจับคู่ที่ผู้ใช้เห็นได้แบบเรียลไทม์เพื่อปรับปรุงความเกี่ยวข้องของการจับคู่ให้สอดคล้องกับบริบทการค้นหาของผู้ใช้
- มาลองอีกครั้งโดยแก้ไขพารามิเตอร์ดัชนี
สำหรับการทดสอบนี้ ฉันจะใช้ฟังก์ชันระยะทางความคล้ายคลึงกันของ "L2 Distance" แทนฟังก์ชัน "Cosine" นอกจากนี้ ฉันจะเปลี่ยนขีดจำกัดของคำค้นหาเป็น 10 เพื่อแสดงให้เห็นว่าคุณภาพของผลการค้นหามีการปรับปรุงหรือไม่ แม้ว่าจำนวนชุดผลการค้นหาจะเพิ่มขึ้นก็ตาม
[ก่อน] คำค้นหาที่ใช้ฟังก์ชันระยะทางความคล้ายโคไซน์
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
หมายเหตุที่สำคัญมาก: คุณอาจสงสัยว่า "เราจะรู้ได้อย่างไรว่าคำค้นหานี้ใช้ความคล้ายคลึงแบบโคไซน์" คุณระบุฟังก์ชันระยะทางได้โดยใช้ "<=>" เพื่อแสดงระยะทางโคไซน์
ลิงก์เอกสารสำหรับฟังก์ชันระยะทางของ Vector Search
ผลลัพธ์ของคำค้นหาข้างต้นคือ
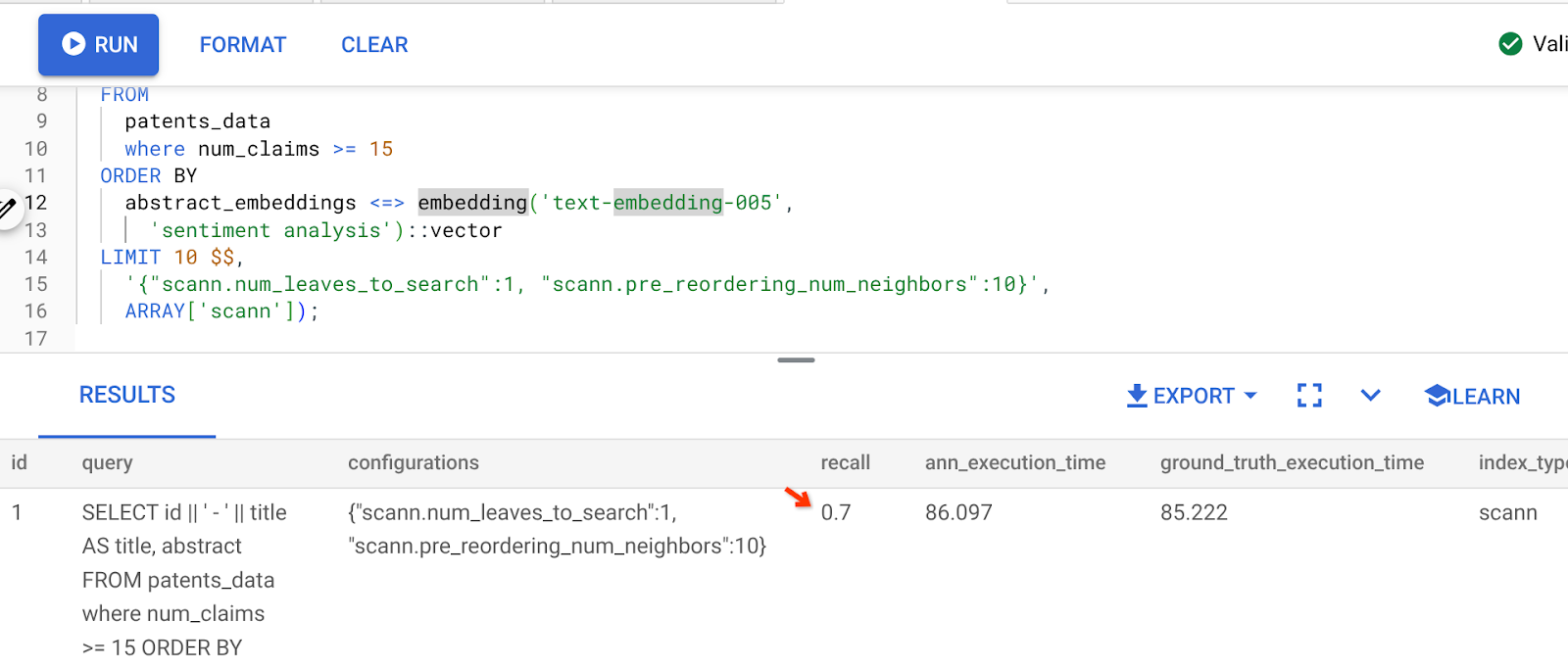
ดังที่คุณเห็น RECALL คือ 70% โดยไม่มีการเปลี่ยนแปลงตรรกะดัชนี โปรดจำดัชนี ScaNN ที่เราสร้างขึ้นในขั้นตอนที่ 6 ของส่วนการกรองในบรรทัด "patent_index " ดัชนีเดียวกันนี้ยังคงมีผลในขณะที่เราเรียกใช้การค้นหาข้างต้น
ตอนนี้มาสร้างดัชนีด้วยการค้นหาฟังก์ชันระยะทางอื่นกัน ระยะทาง L2: <->
drop index patent_index;
CREATE INDEX patent_index_L2 ON patents_data
USING scann (abstract_embeddings L2)
WITH (num_leaves=32);
คำสั่ง DROP INDEX มีไว้เพื่อให้แน่ใจว่าไม่มีดัชนีที่ไม่จำเป็นในตาราง
ตอนนี้ฉันสามารถเรียกใช้การค้นหาต่อไปนี้เพื่อประเมินการเรียกคืนหลังจากเปลี่ยนฟังก์ชันระยะทางของฟังก์ชันการค้นหาเวกเตอร์
[AFTER] คำค้นหาที่ใช้ฟังก์ชันระยะทางความคล้ายโคไซน์
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <-> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
ผลลัพธ์ของคำค้นหาข้างต้นคือ
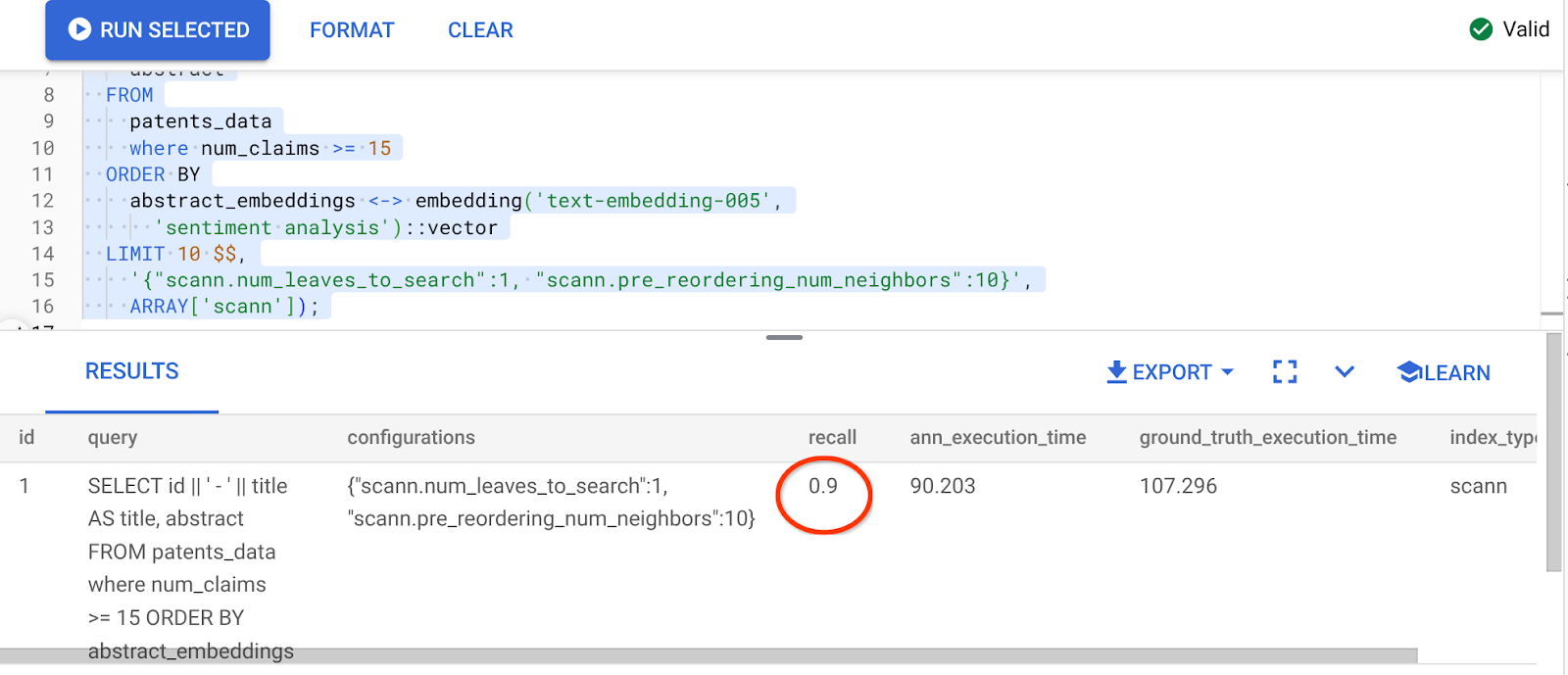
การเปลี่ยนแปลงในมูลค่าการเรียกคืนที่ 90%!!!
นอกจากนี้ ยังมีพารามิเตอร์อื่นๆ ที่คุณเปลี่ยนได้ในดัชนี เช่น num_leaves เป็นต้น โดยอิงตามค่าการเรียกคืนที่ต้องการและชุดข้อมูลที่แอปพลิเคชันของคุณใช้
8. ล้างข้อมูล
โปรดทำตามขั้นตอนต่อไปนี้เพื่อเลี่ยงไม่ให้เกิดการเรียกเก็บเงินกับบัญชี Google Cloud สำหรับทรัพยากรที่ใช้ในโพสต์นี้
- ในคอนโซล Google Cloud ให้ไปที่หน้าResource Manager
- ในรายการโปรเจ็กต์ ให้เลือกโปรเจ็กต์ที่ต้องการลบ แล้วคลิกลบ
- ในกล่องโต้ตอบ ให้พิมพ์รหัสโปรเจ็กต์ แล้วคลิกปิดเพื่อลบโปรเจ็กต์
- หรือคุณจะลบคลัสเตอร์ AlloyDB ที่เราเพิ่งสร้างขึ้นสำหรับโปรเจ็กต์นี้ก็ได้ (เปลี่ยนตำแหน่งในไฮเปอร์ลิงก์นี้หากคุณไม่ได้เลือก us-central1 สำหรับคลัสเตอร์ในขณะที่กำหนดค่า) โดยคลิกปุ่มลบคลัสเตอร์
9. ขอแสดงความยินดี
ยินดีด้วย คุณสร้างคำค้นหาสิทธิบัตรตามบริบทได้สำเร็จแล้วด้วย Vector Search ขั้นสูงของ AlloyDB เพื่อให้มีประสิทธิภาพสูงและขับเคลื่อนด้วยความหมายอย่างแท้จริง ผมได้รวบรวมแอปพลิเคชันแบบหลายเครื่องมือที่เป็น Agent ซึ่งควบคุมคุณภาพโดยใช้ ADK และทุกอย่างของ AlloyDB ที่เราพูดถึงกันที่นี่เพื่อสร้าง Agent ค้นหาและวิเคราะห์เวกเตอร์สิทธิบัตรที่มีประสิทธิภาพสูงและมีคุณภาพ ซึ่งคุณสามารถดูได้ที่ https://youtu.be/Y9fvVY0yZTY
หากต้องการเรียนรู้วิธีสร้าง Agent ดังกล่าว โปรดดู Codelab นี้