
1. Einführung
Wenn Sie einem vorhandenen Agenten Funktionen hinzufügen – in der Regel eine neue datenbankgestützte Funktion –, müssen Sie Boilerplate-Code schreiben, Integrationen einrichten und dafür sorgen, dass alles mit den Mustern in der Codebasis übereinstimmt. Antigravity beschleunigt jede Phase dieses Prozesses: Es analysiert Ihre Codebasis, um den erforderlichen Kontext zu erstellen, erstellt strukturierte Spezifikationen und Implementierungspläne zur Überprüfung und führt die Codeänderungen aus. All dies wird durch Domänenwissen gesteuert, das Sie als wiederverwendbare Skills und eine Projektkonstitution erfassen können, die nicht verhandelbare Prinzipien durchsetzt. In diesem Codelab wird eine Möglichkeit vorgestellt, das Spec-driven Development-Paradigma von Antigravity zu optimieren, indem ein neuer Zyklus eingeführt wird, um die Spezifikationsdokumentation, die sich stark auf spec-kit bezieht, zu verbessern.
Aufgaben
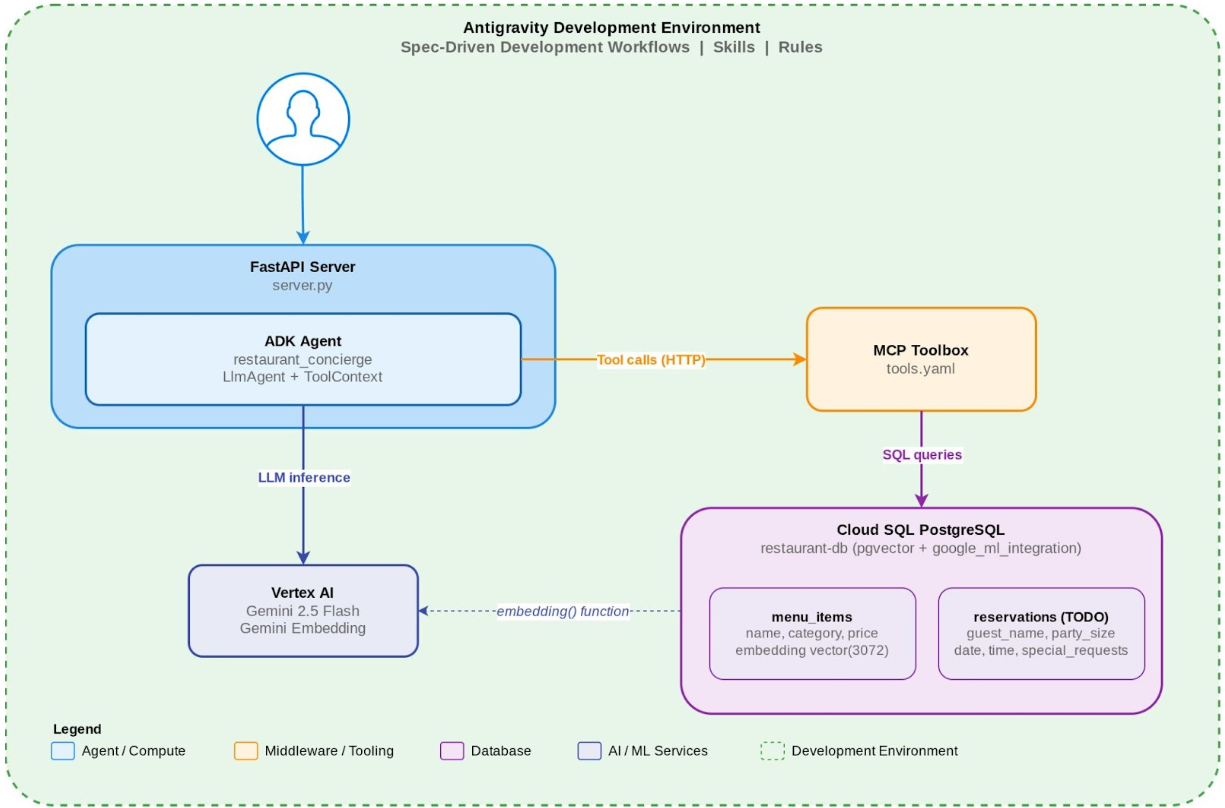
Eine lokal ausgeführte Restaurant-Concierge-Anwendung mit Reservierungsbuchung, die über einen vollständigen SDD-Zyklus hinzugefügt wurde:
- Reservierungsbuchung: Gäste buchen Tische und prüfen Reservierungen. Dies wird durch neue MCP Toolbox-Datenbanktools und eine Cloud SQL-Tabelle
reservationsunterstützt. - (Herausforderung): Entwickeln Sie eine eigene Benutzeroberfläche für den Agent.
- (Challenge): Mit dem Antigravity-Agent in Google Cloud bereitstellen
Der Startcode enthält einen funktionierenden ADK-Agenten mit Menüsuche (Keyword + semantisch über die MCP Toolbox) und Erfassung von Ernährungspräferenzen (über ToolContext). Sie können die Funktion erweitern, ohne Anwendungscode manuell schreiben zu müssen. Antigravity übernimmt die Implementierung basierend auf Ihren Spezifikationen.
Lerninhalte
- Projektkontext so booten, dass Antigravity eine vorhandene Codebasis versteht
- Antigravity-Skills erstellen und MCP konfigurieren, die Domänenwissen (z.B. ADK-Dokumente, Drittanbieter-Skills) zur Wiederverwendung verpacken
- So legen Sie eine Projektverfassung fest, anhand derer die SDD-Workflows während der Planung und Analyse validiert werden
- Spezifikationsbasierte Entwicklung (Spec-Driven Development, SDD) in Antigravity verwenden, um systematisch Funktionen hinzuzufügen
- ADK-Agenten mit neuen datenbankgestützten Tools über die MCP Toolbox erweitern
Vorbereitung
- Google Antigravity und
gitauf Ihrem lokalen Computer installiert - Ein Google Cloud-Konto mit einem aktivierten Abrechnungskonto
- Es ist hilfreich, wenn Sie die vier erforderlichen ADK-Codelabs bereits absolviert haben oder über entsprechende Kenntnisse verfügen, um den Kontext des Anwendungsfalls zu verstehen:
- KI-Agenten mit ADK erstellen: Grundlagen
- KI-Agenten mit ADK erstellen: Tools hinzufügen
- Persistente KI-Agenten mit ADK und Cloud SQL erstellen
- ADK-Agenten in Cloud Run bereitstellen, verwalten und beobachten
- Datenbank als Tool: agentische RAG mit ADK, MCP Toolbox und Cloud SQL
2. Umgebung einrichten
In diesem Schritt wird das Starter-Repository geklont, die Authentifizierung bei Google Cloud durchgeführt, eine Cloud SQL-Datenbank bereitgestellt und Ihre lokale Antigravity-Umgebung vorbereitet.
Erforderliche Komponenten installieren
Prüfen Sie, ob auf Ihrem System die folgende ausführbare CLI-Datei vorhanden ist:
Die Installationsanleitung variiert je nach Betriebssystem Ihres Computers.
Starter-Repository klonen
Öffnen Sie ein Terminal in Antigravity (oder das Systemterminal). Klonen Sie das zugehörige Repository und wechseln Sie in das Verzeichnis:
git clone https://github.com/alphinside/sdd-adk-antigravity-starter.git sdd-adk-agents-agy
cd sdd-adk-agents-agy
Öffnen Sie das geklonte Repository in Antigravity. Datei -> Ordner öffnen -> wählen Sie das geklonte Verzeichnis sdd-adk-agents-agy aus.
Entfernen Sie die Upstream-Fernbedienung. In den SDD-Workflows werden Git-Branches für Funktionsspezifikationen erstellt. Durch das Entfernen des Remote-Repository wird verhindert, dass versehentlich Push-Vorgänge in das Starter-Repository ausgeführt werden:
git remote remove origin
Mit Google Cloud authentifizieren
Führen Sie zwei Authentifizierungsbefehle aus. Beide öffnen einen Browser für OAuth:
gcloud auth login
gcloud auth application-default login
Da Sie lokal mit Antigravity arbeiten, authentifizieren Sie sich manuell. auth login authentifiziert die gcloud-Befehlszeile. application-default login authentifiziert Google Cloud SDKs, die von Ihrer Anwendung verwendet werden. Sowohl die Vertex AI-Aufrufe des ADK als auch der Cloud SQL-Python-Connector basieren auf Standardanmeldedaten für Anwendungen.
Google Cloud-Projekt einrichten
Schreiben Sie die Standortvariablen in .env, bevor Sie das Setupscript zur Projekteinrichtung ausführen:
echo "GOOGLE_CLOUD_LOCATION=global" > .env
echo "REGION=us-central1" >> .env
GOOGLE_CLOUD_LOCATION=globalwird für Vertex AI-/Gemini API-Aufrufe verwendet.REGION=us-central1wird für Cloud SQL und andere GCP-Infrastrukturen verwendet.
Laden Sie das Projekt-Setupskript herunter und führen Sie es aus. Damit wird ein Google Cloud-Projekt mit Testabrechnung erstellt oder validiert und die Projekt-ID in .env gespeichert. Anschließend wird die Quelle abgerufen:
curl -sL https://raw.githubusercontent.com/alphinside/cloud-trial-project-setup/main/setup_verify_trial_project.sh -o setup_verify_trial_project.sh
bash setup_verify_trial_project.sh && source .env
API wird aktiviert...
Aktivieren Sie die erforderlichen APIs:
gcloud services enable \
aiplatform.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com
Abhängigkeiten installieren
Wir verwenden uv als Python-Projektmanager. uv ist ein schneller Python-Paket- und Projektmanager, der in Rust geschrieben wurde ( Dokumentation ). In diesem Codelab wird er aus Gründen der Geschwindigkeit und Einfachheit verwendet. Installieren Sie die Python-Abhängigkeiten:
uv sync
Aktualisieren Sie dann die Datei .env des ADK-Agents mit Ihrer Projektkonfiguration:
cat > restaurant_concierge/.env <<EOF
GOOGLE_CLOUD_PROJECT=${GOOGLE_CLOUD_PROJECT}
GOOGLE_CLOUD_LOCATION=global
GOOGLE_GENAI_USE_VERTEXAI=True
EOF
Datenbankinfrastruktur und Daten vorbereiten
Legen Sie das Datenbankpasswort fest und fügen Sie es .env hinzu:
export DB_PASSWORD=codelabpassword
echo "DB_PASSWORD=${DB_PASSWORD}" >> .env
Führen Sie dann das scripts/setup_database.sh-Skript aus, um die erforderliche Infrastruktur vorzubereiten. Dabei wird Folgendes ausgeführt:
- Cloud SQL-Instanz erstellen
- Prüfen, ob die Instanz bereit ist
- Vertex AI-Berechtigungen erteilen
- Datenbank erstellen
- Seed-Datenbank
- MCP Toolbox-Dienst im Hintergrund ausführen
chmod +x scripts/setup_database.sh
./scripts/setup_database.sh > database_setup.log 2>&1 &
Mit diesem Befehl wird die Einrichtung im Hintergrund ausgeführt. Sie können die Ausgabe regelmäßig in der Datei database_setup.log prüfen.
Jetzt sollten wir alle erforderlichen ADK-Agent-Repos haben, mit denen wir arbeiten können. Im nächsten Abschnitt geht es um Antigravity und die spezifikationsgesteuerte Entwicklung.
3. Startercode ansehen und spezifikationsbasierte Entwicklung verstehen
In diesem Schritt wird die Struktur des Startcodes erläutert, die Spec-Driven Development-Methodik vorgestellt, die Datenbank mit Daten gefüllt und geprüft, ob der Basis-Agent funktioniert, bevor Sie ihn erweitern.
Projektstruktur
Öffnen Sie das geklonte Repository-Projekt im Antigravity-Editor und sehen Sie sich das Verzeichnislayout an:
sdd-adk-agents-agy/ ├── .agents/ │ ├── workflows/ # SDD slash commands (/speckit.*) – manual trigger │ │ ├── speckit.specify.md │ │ ├── speckit.clarify.md │ │ ├── speckit.plan.md │ │ ├── speckit.tasks.md │ │ ├── speckit.analyze.md │ │ ├── speckit.implement.md │ │ ├── speckit.checklist.md │ │ └── speckit.constitution.md │ ├── skills/ # Antigravity skills (loaded on demand, agent determined) │ │ ├── mcp-toolbox-postgres/ │ │ │ └── SKILL.md # MCP Toolbox config skill │ │ └── repo-research/ │ │ └── SKILL.md # Repo analysis skill │ └── rules/ # Always-active context ├── .specify/ # spec-kit SDD templates and memory │ ├── memory/constitution.md │ ├── templates/ │ └── scripts/ ├── restaurant_concierge/ # ADK agent package │ ├── __init__.py │ ├── agent.py # LlmAgent + ToolContext tools + Toolbox integration │ └── .env # Vertex AI configuration ├── server.py # FastAPI server wrapping the agent ├── tools.yaml # MCP Toolbox tool definitions ├── scripts/ # Setup scripts └── pyproject.toml
Schlüsseldateien
Dateien für die Agentenanwendung
restaurant_concierge/agent.py: Der Kern-Agent. EineLlmAgent, die Datenbanktools der MCP Toolbox mit derToolContext-basierten Erfassung von Ernährungspräferenzen kombiniert. Der Agent lädt alle Tools vom Toolbox-Server und fügt zwei Python-Funktionen (save_dietary_preference,get_dietary_preferences) hinzu, dieToolContextzum Verwalten des Status verwenden.tools.yaml– Definitionen von MCP-Toolbox-Tools. Es sind drei Menü-Suchoptionen definiert: die Stichwortsuche (search_menu), die semantische Suche überpgvector(semantic_search_menu) und der Kategoriefilter (get_menu_by_category). Es sind noch keine Reservierungstools vorhanden. Diese fügen Sie später hinzu.server.py: Ein minimaler FastAPI-Server, der zeigt, wie Sie als FastAPI-Objekt auf das ADK zugreifen können.get_fast_api_app()aus dem ADK bietet integrierte Endpunkte, darunter/run_ssefür SSE-Streaming und APIs für die Sitzungsverwaltung.
Antigravity-Dateien
.agents/skills/mcp-toolbox-postgres/SKILL.md: Ein Skill, der Antigravity anleitet, wie eine korrekte tools.yaml-Konfiguration für die MCP-Toolbox erstellt wird. In diesem Kurs lernen Sie die Konfigurationen fürsources,toolsundembeddingModelskennen , die für die Erstellung einer geeigneten RAG-Pipeline erforderlich sind. Dieser Skill wird erst aktiviert, wenn Sie die richtige YAML-Frontmatter hinzufügen, damit sie von Antigravity erkannt wird..agents/skills/repo-research/SKILL.md: Eine Funktion, mit der Antigravity lernt, ein Repository inkrementell zu analysieren und ein strukturiertes Projektkontextdokument zu erstellen. Dabei wird ein 4-Phasen-Ansatz verwendet: Oberflächenscan (nur Verzeichnisbaum), Konfigurations- und Metadatendateien, Einstiegspunkte und Datenmodelle sowie gezielte Analysen. In jeder Phase werden die Ergebnisse gespeichert, bevor mit der nächsten fortgefahren wird. Sie ist auch inaktiv, bis Sie später YAML-Frontmatter hinzufügen. Nach der Aktivierung können Sie das Tool aufrufen, um.agents/rules/project-context.mdzu generieren – ein umfassendes Onboarding-Dokument, das Architektur, Laufzeitabhängigkeiten, API-Oberfläche und Domänen-Glossar abdeckt.
Spezifikationsbasierte Entwicklung: von der integrierten Planung in Antigravity zur strukturierten spezifikationsbasierten Entwicklung
KI-Code-Assistenten erleichtern das Generieren von Code aus einem Prompt. Das Risiko: Sie beschreiben eine Funktion in einem Satz, der Assistent schreibt Hunderte von Zeilen und Sie akzeptieren das, weil es richtig aussieht. Das wird manchmal auch als „Vibe Coding“ bezeichnet. Sie steuern die KI dabei intuitiv und akzeptieren oder lehnen die Ausgabe ab, je nachdem, ob sie zu funktionieren scheint. Es ist schnell für Prototypen und Einwegskripts. Das funktioniert nicht mehr, wenn die Codebasis wächst, Funktionen interagieren oder Sie sich Wochen später Code ansehen und nicht mehr nachvollziehen können, warum eine Entscheidung getroffen wurde.
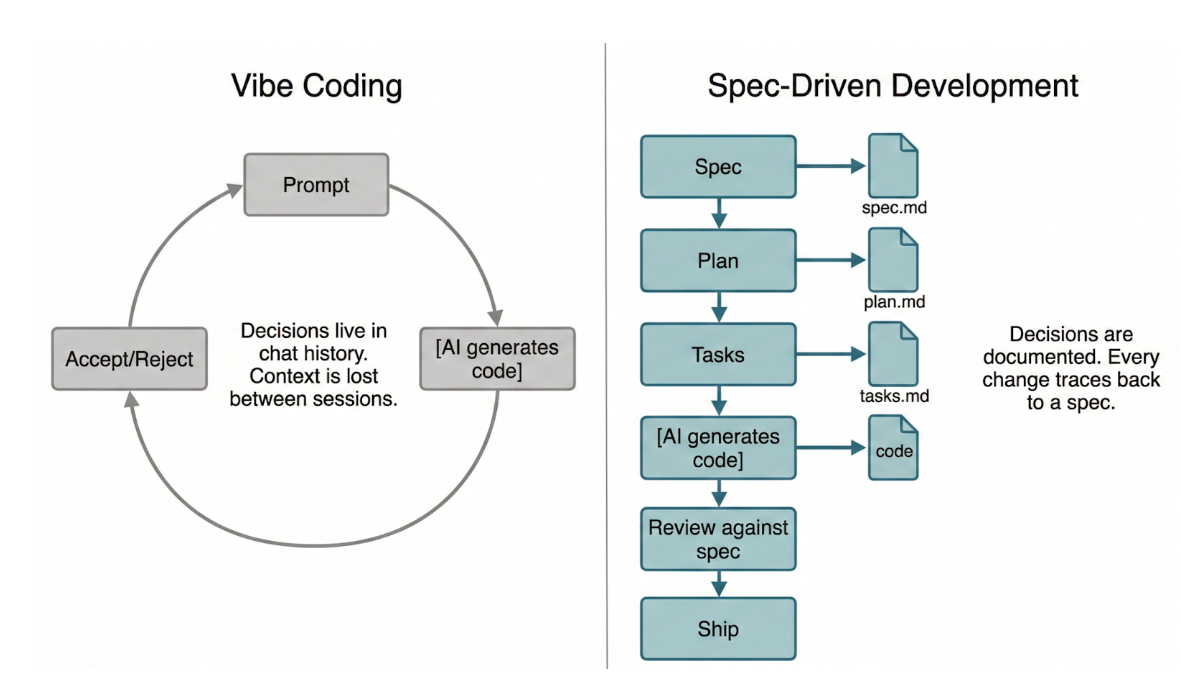
Spec-Driven Development (SDD) gibt diesem Zyklus eine Struktur. Bevor Code generiert wird, schreiben Sie eine Spezifikation: Was macht das Feature, für wen ist es gedacht und was sind die Erfolgskriterien? Der KI-Assistent arbeitet auf Grundlage dieser Spezifikation – und Sie auch, wenn Sie seine Ausgabe überprüfen. Die Spezifikation wird zur zentralen Informationsquelle für den Intent. Wenn der Code von der Spezifikation abweicht, wird dies bei der Überprüfung festgestellt. Wenn sich die Anforderungen ändern, aktualisieren Sie zuerst die Spezifikation und generieren Sie sie dann neu. Entscheidungen werden dokumentiert, nicht improvisiert.
Das ist ein echter Kompromiss: SDD ist pro Funktion langsamer als die Vibe-Codierung. Sie schreiben Dokumente, bevor Sie Code schreiben. Die Vorteile summieren sich jedoch: Jede zukünftige Änderung der Codebasis hat Kontext, jede KI-generierte Implementierung hat einen überprüfbaren Vertrag und Sie können Mitbearbeiter (menschlich oder KI) einarbeiten, indem Sie sie auf Spezifikationen verweisen, anstatt Entscheidungen aus dem Gedächtnis zu erklären.
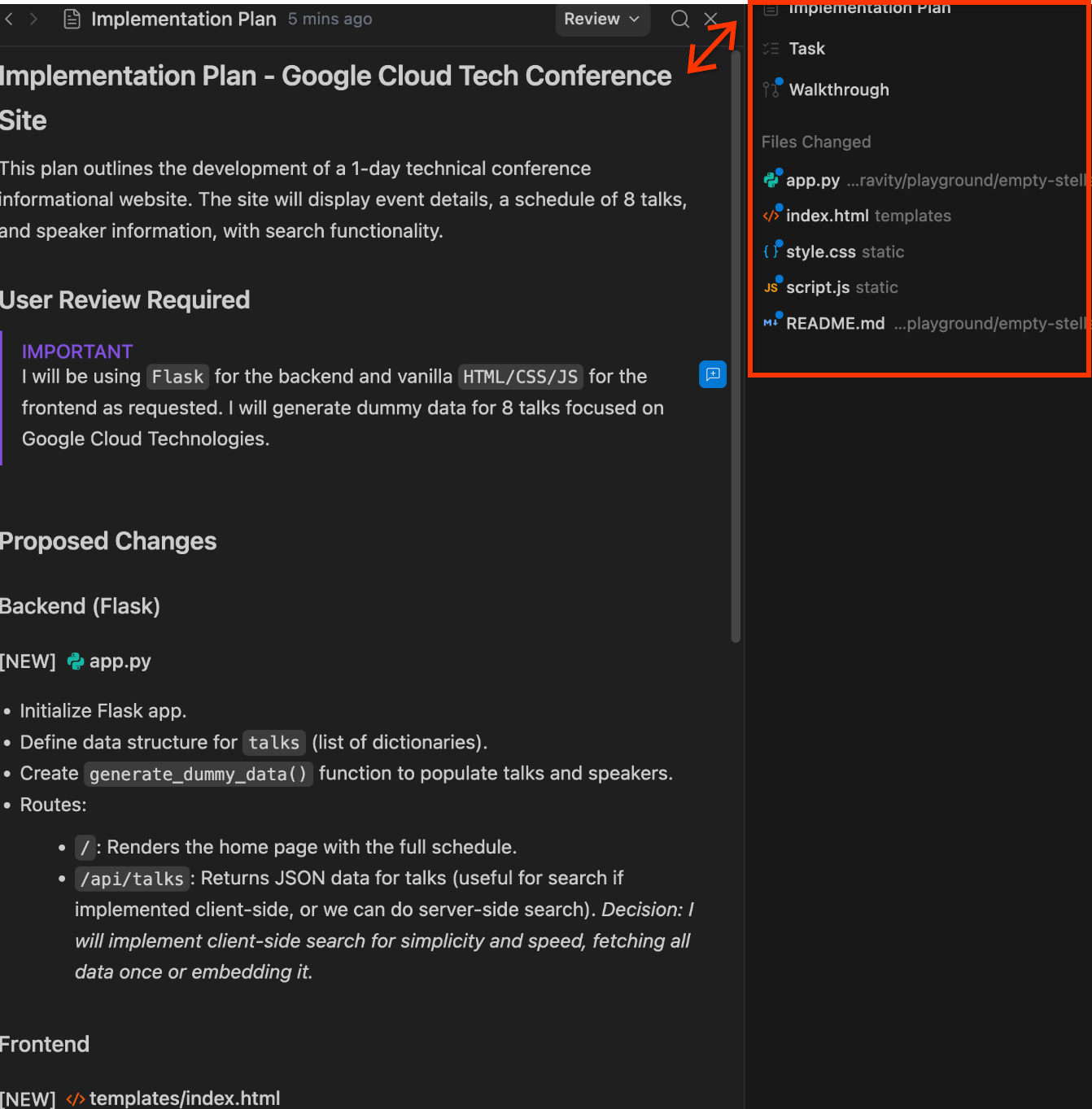
Antigravity folgt bereits den Prinzipien der spezifikationsbasierten Entwicklung. Wenn Sie den Agent in den Planungsmodus versetzen, werden zwei Artefakte erstellt, bevor Code geschrieben wird:
- Implementierungsplan: Eine Übersicht über den vorgeschlagenen technischen Ansatz, Dateiänderungen und Architektur-Entscheidungen
- Aufgabenliste: eine strukturierte Aufschlüsselung von Arbeitselementen
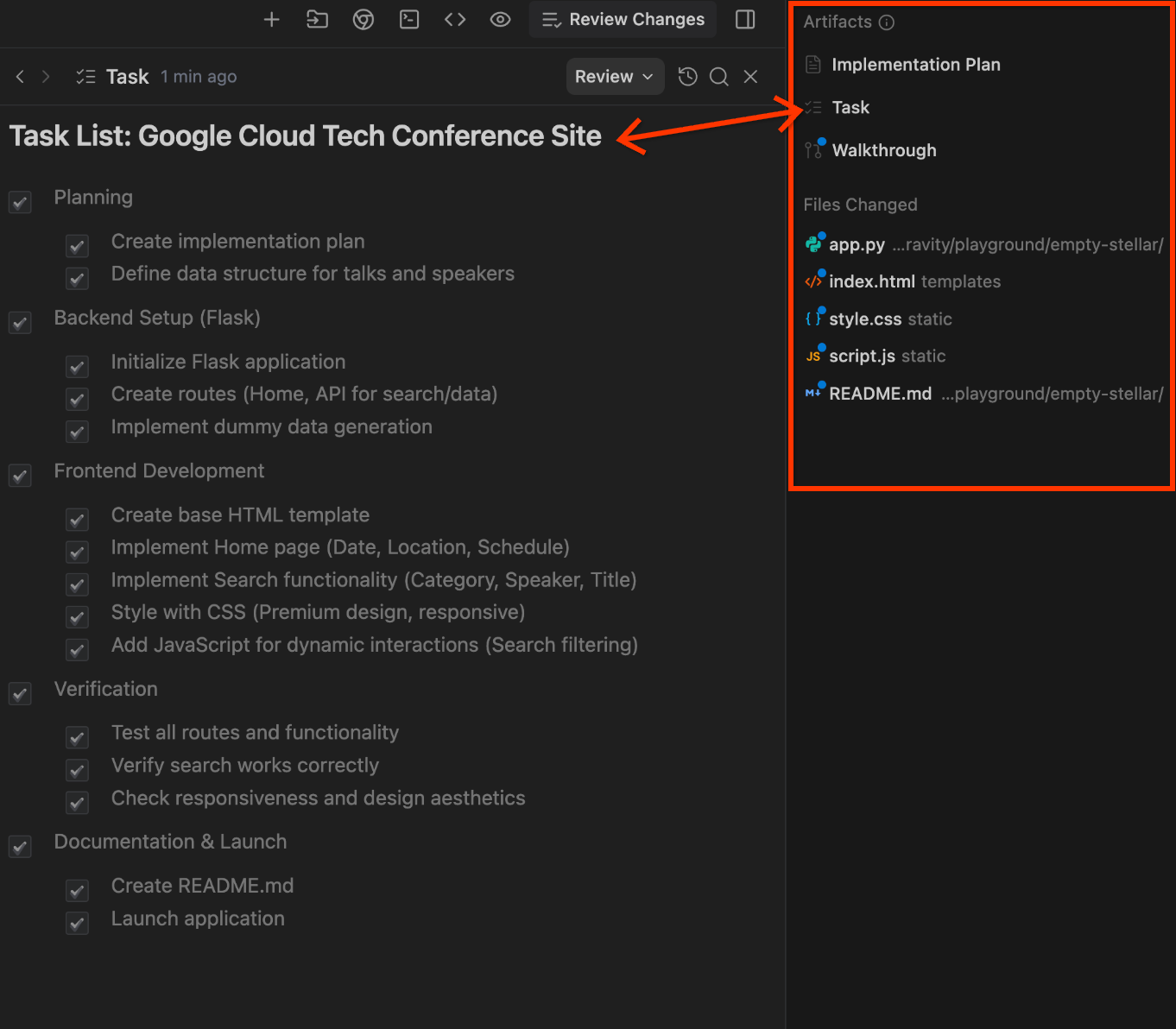
Antigravity fordert Sie auf, diese Artefakte vor der Ausführung zu überprüfen und zu genehmigen. Dieser Planungs- und Implementierungszyklus ist das Herzstück der spezifikationsgesteuerten Entwicklung: Spezifikationen leiten den Code und nicht umgekehrt.
In diesem Codelab wird diese Grundlage mit einem meinungsbasierten, versionskontrollierten Workflow auf Basis von spec-kit weiter ausgebaut – einem spezifikationsbasierten Entwicklungsframework von GitHub. Jedes Feature durchläuft eine sorgfältige Pipeline, in der jedes Artefakt ein eigenständiges Dokument ist, das Sie in git überprüfen, bearbeiten und nachverfolgen können. Die Pipeline umfasst zwei optionale Quality-Gate-Phasen („Klären“ und „Analysieren“), in denen Probleme erkannt werden, bevor sie zu Implementierungsproblemen werden:
Phase | Artefakt | Purpose |
|
| Definieren Sie, WAS entwickelt werden soll (nutzerorientiert, technologieunabhängig). |
| Aktualisiert: | Unterbestimmte Bereiche identifizieren, gezielte Fragen zur Klärung stellen, Antworten wieder in die Spezifikation aufnehmen |
|
| Entwerfen, WIE es erstellt werden soll (technischer Ansatz, Datenmodelle, Recherche) |
|
| Plan in geordnete, umsetzbare Schritte unterteilen |
| Analysebericht | Aufgaben vor der Implementierung auf Risiken, Lücken oder fehlende Grenzfälle prüfen |
| Codeänderungen | Führen Sie die Aufgaben aus und haken Sie jede ab. |
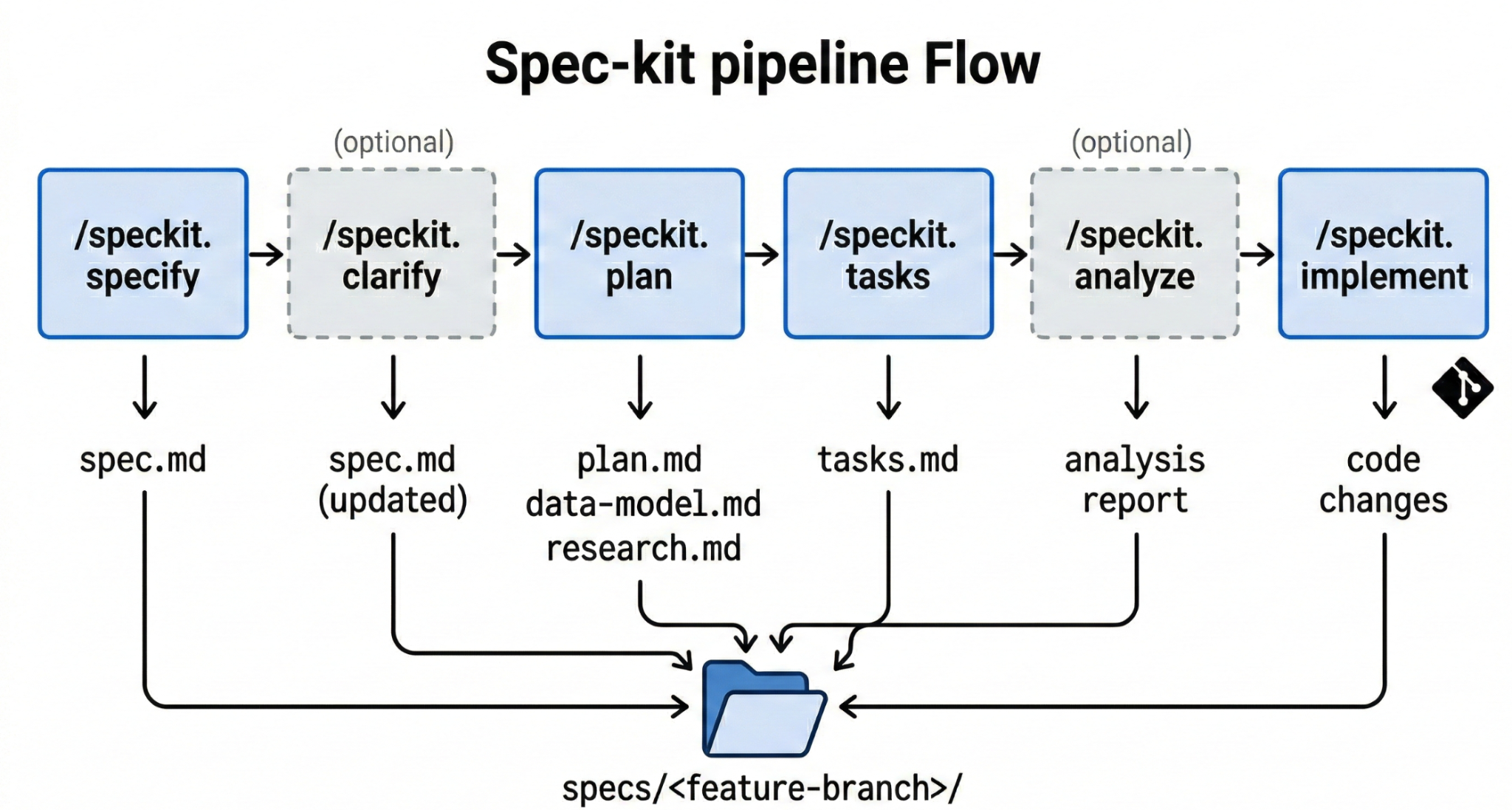
Jedes Artefakt wird als Datei in specs/<feature-branch>/ gespeichert, in Git versionsverwaltet und kann wiederverwendet werden. Wenn eine Unterhaltung unterbrochen wird oder Sie später noch einmal auf Entscheidungen zurückgreifen möchten, sind die Spezifikationsdokumente immer verfügbar und nicht in einem Chatverlauf verborgen.
Das Starter-Repository enthält diese SDD-Workflows in .agents/workflows/ und Vorlagen in .specify/templates/. Sie werden später verwendet, um dem Agent Funktionen hinzuzufügen.
4. Projektkontext mit Antigravity bootstrappen
Nun simulieren wir die Situation mit einer Bedingung, die unserem Arbeitsalltag „etwas näher“ kommt:
- Schlecht verwaltetes Repository
- README veraltet
- Dokumentationen werden nicht häufig aktualisiert
Als Erstes möchten wir in einer solchen Situation in der Regel eine Karte oder einen Kontext für das Projekt erstellen, an dem Antigravity arbeiten soll. In diesem Schritt wird ein Beispiel für einen Ansatz gezeigt, mit dem Antigravity ein umfassendes Verständnis einer vorhandenen Codebasis vermittelt werden kann. Dazu wird ein Skill erstellt, der das Repository analysiert und ein Projektkontextdokument generiert.
Außerdem wird die Projektverfassung eingerichtet – die nicht verhandelbaren Grundsätze, anhand derer die SDD-Workflows validiert werden. Zusammen liefern sie Antigravity den Kontext und die Einschränkungen, die für die SDD-Zyklen später erforderlich sind.
Die Antigravity-Kontexthierarchie
Antigravity verwendet drei Kontextebenen mit jeweils unterschiedlichem Umfang:
- Regeln (
.agents/rules/): Immer aktive Anweisungen. In jeder Unterhaltung in diesem Arbeitsbereich sind sie zu sehen ( sofern Sie sie aktiviert haben). Verwenden Sie Regeln für projektweiten Kontext wie Architektur-Entscheidungen, Codierungsstandards oder Informationen zum Technologie-Stack. - Kompetenzen (
.agents/skills/): On-Demand-Wissen. Antigravity lädt einen Skill nur, wenn die aktuelle Aufgabe mit dem Felddescriptiondes Skills übereinstimmt. Skills für fachbereichsspezifisches Referenzmaterial verwenden - Workflows (
.agents/workflows/): Gespeicherte Prompts, die mit/-Befehlen ausgelöst werden. Verwenden Sie Workflows für wiederholbare mehrstufige Prozesse wie die SDD-Pipeline.
Skills aktivieren
Das Starter-Repository enthält zwei vorgefertigte Skills in .agents/skills/. Sie enthalten detaillierte Anleitungen, beginnen aber mit TODO(codelab)-Kommentaren anstelle des erforderlichen YAML-Frontmatter. Ohne Frontmatter kann Antigravity sie nicht erkennen.
Für Antigravity-Skills ist oben in der Datei ein YAML-Frontmatter-Block mit zwei Feldern erforderlich:
name: Eine eindeutige Kennung für den Skill.description: Eine Zusammenfassung in natürlicher Sprache, die Antigravity abgleicht, um zu entscheiden, welcher Skill für eine bestimmte Anfrage geladen werden soll.
Öffnen Sie .agents/skills/mcp-toolbox-postgres/SKILL.md im Editor. Ersetzen Sie die Kommentarzeilen TODO(codelab) oben durch diesen Frontmatter:
---
name: mcp-toolbox-postgres
description: Configure MCP Toolbox for PostgreSQL — sources, tools, and embedding models
---
Öffnen Sie .agents/skills/repo-research/SKILL.md im Editor. Ersetzen Sie die Kommentarzeilen TODO(codelab) oben durch diesen Frontmatter:
---
name: repo-research
description: Analyze a repository's structure, technologies, and patterns to create or update a project context document. Use when asked to research, analyze, or understand a codebase.
---
Prüfen Sie, ob beide Skills gültige Frontmatter haben:
head -4 .agents/skills/mcp-toolbox-postgres/SKILL.md
head -4 .agents/skills/repo-research/SKILL.md
Jedes sollte ----Trennzeichen enthalten, die die Felder name: und description: umschließen. Wenn die Trennzeichen oder Felder fehlen, erkennt Antigravity den Skill nicht.
Beide Skills werden bei Bedarf geladen: Antigravity gleicht Ihre Anfrage mit dem Feld description ab und ruft die vollständigen Anweisungen nur bei Bedarf ab.
ADK Docs MCP konfigurieren
Damit unser Coding-Agent weiß, wie unser ADK-Agent entwickelt werden muss, benötigt er den entsprechenden Zugriff auf die ADK-Dokumentation. Wir können dies aktivieren, indem wir den ADK-Dokumentations-MCP-Server einrichten .
Suchen Sie zuerst im Antigravity-Editor rechts oben im Agent-Fenster nach dem Dreipunkt-Menü und klicken Sie darauf. Daraufhin werden Konfigurationsoptionen für den MCP und Anpassungen wie diese angezeigt. Klicken Sie auf das MCP.
 \
\
Klicken Sie als Nächstes auf die Schaltfläche Manage MCP servers.
Dadurch wird der Tab „MCP-Serverkonfigurationen“ geöffnet. Klicken Sie dann auf die Schaltfläche View Raw Config.

Dadurch wird die Datei mcp_config.json geöffnet. Kopieren Sie diese Konfiguration nun in die Datei.
{
"mcpServers": {
"adk-docs-mcp": {
"command": "uvx",
"args": [
"--from",
"mcpdoc",
"mcpdoc",
"--urls",
"AgentDevelopmentKit:https://adk.dev/llms.txt",
"--transport",
"stdio"
]
}
}
}
Mit dieser Einrichtung kann der Coding-Agent mithilfe eines MCP-Servers in der ADK-Dokumentation suchen und sie lesen.
Öffentlich verfügbare Skills installieren
Wir haben uns bereits Skills angesehen, die wir selbst erstellt haben ( die Skills repo-research und mcp-toolbox-postgres). Es gibt jedoch viele andere Fähigkeiten, die für die Softwareentwicklung nützlich sind und die sich problemlos in unseren Coding-Agenten integrieren lassen.
Höhlenmensch-Fähigkeiten
Eine der nützlichen Strategien zur Reduzierung der Token-Nutzung ist die Höhlenmensch-Strategie . Mit dieser Funktion kann das Ausgabetoken des Agents gekürzt werden. Das ist eine gute Kombination,wenn Sie eine vollständige spezifikationsgesteuerte Entwicklung wie in dieser Anleitung verwenden.
npx skills add JuliusBrussee/caveman
Wählen wir wie zuvor den Skill caveman aus.
Klicken Sie dann einfach auf Eingabe, um die Standardinstallation zu aktivieren und den Skill in Ihrem aktuellen Projekt zu installieren.
Jetzt sollten bereits vier Skills konfiguriert sein und wir können mit der SDD beginnen.
.agents/skills/ ├── caveman ├── mcp-toolbox-postgres └── repo-research
Projektkontext generieren
Prüfen Sie, ob das Verzeichnis „rules“ vorhanden ist:
mkdir -p .agents/rules
Starten Sie im Agent Manager/Chat-Feld von Antigravity (im Editormodus drücken Sie ctrl + L) eine neue Unterhaltung. Typ:
Research this repository and create a project context document, and communicate efficiently
Antigravity vergleicht Ihre Anfrage mit den Skills repo-research und caveman ( Befehl zur effizienten Kommunikation) und beginnt mit der systematischen Analyse der Codebasis. Es liest Konfigurationsdateien, Quellcode und Dokumentation und füllt dann die Vorlage für den Projektkontext mit den Ergebnissen.
Öffnen Sie .agents/rules/project-context.md nach Abschluss des Vorgangs im Editor. Es enthält konkrete Informationen zum Projekt: Technologiestack (Python 3.12, ADK, MCP-Toolbox, Cloud SQL), Projektstruktur, Datenmodell (Tabelle „menu_items“ mit pgvector) und externe Integrationen.
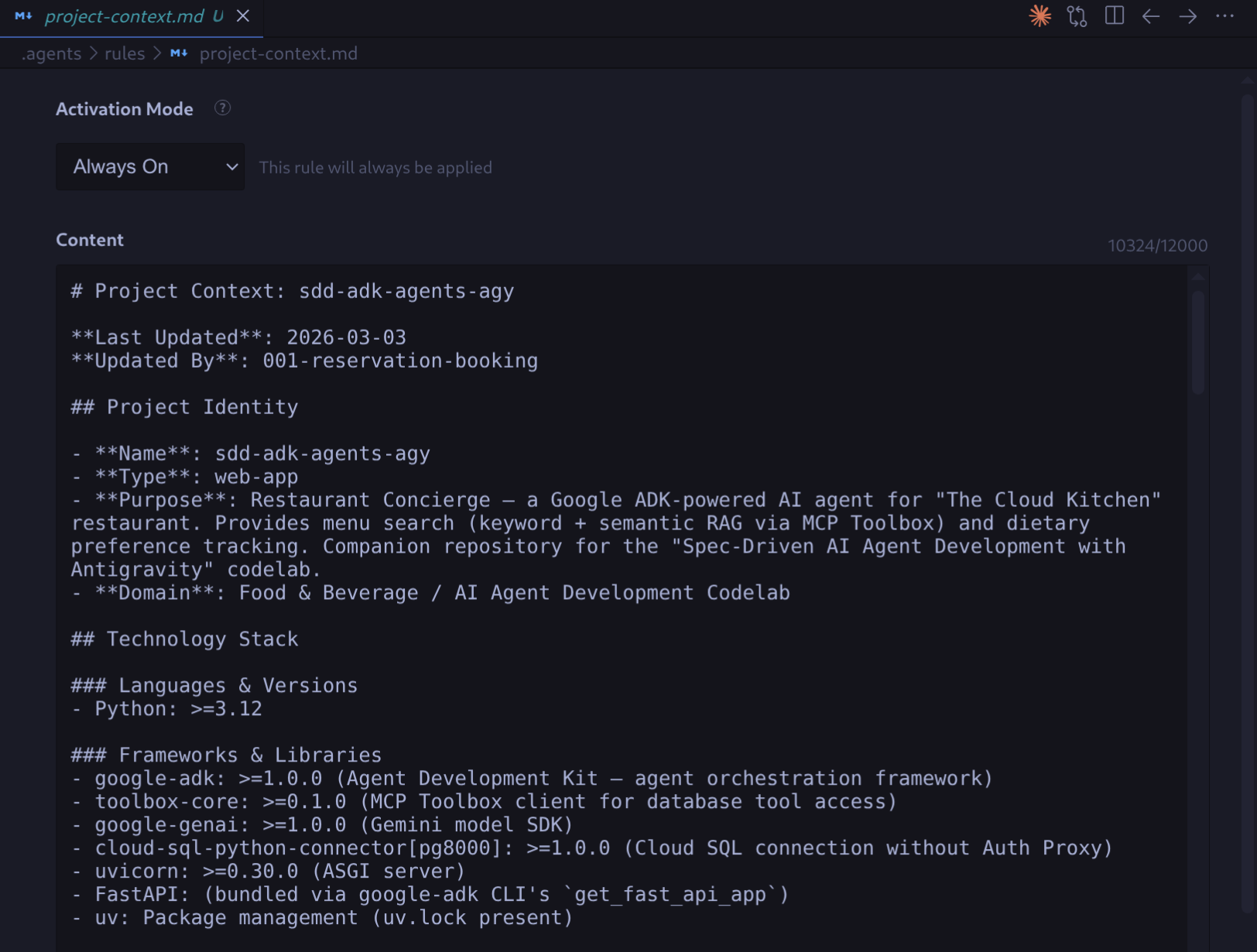
Projektkonstitution festlegen
In den SDD-Workflows wird während der Planung und Analyse auf eine Projektkonstitution unter .specify/memory/constitution.md verwiesen. Im /speckit.plan-Workflow wird eine „Constitution Check“-Prüfung durchgeführt und /speckit.analyze kennzeichnet Verstöße als CRITICAL. Wenn die Verfassung als leere Vorlage mit Platzhalter-Tokens belassen wird, gibt es nichts, woran diese Prüfungen vorgenommen werden können. Pläne und Analysen werden ohne Schutzmaßnahmen ausgeführt.
In der Verfassung werden nicht verhandelbare Projektgrundsätze definiert. Dies ist ein kleines Repository, das von einem einzelnen Entwickler verwaltet wird. Die Verfassung sollte dies widerspiegeln. Halten Sie die Dinge einfach und einheitlich und vermeiden Sie Over-Engineering.
Starten Sie im Agent Manager von Antigravity eine neue Unterhaltung. Führen Sie den Workflow für die Verfassung aus:
/speckit.constitution This is a small restaurant concierge ADK agent maintained by one developer. Set 3 principles: (1) All database operations go through MCP Toolbox tool definitions in tools.yaml — no raw SQL in Python code, no ORM. (2) Session state uses ADK ToolContext — no custom state management, no external state stores. (3) Keep it simple — follow existing file and naming conventions exactly.
Antigravity füllt die Verfassungsvorlage mit konkreten Grundsätzen, weist eine Version (1.0.0) zu und führt eine Konsistenzprüfung für die SDD-Vorlagen durch.
Sehen Sie sich die generierte Verfassung unter .specify/memory/constitution.md an. Prüfen Sie, ob die drei Grundsätze vorhanden und klar formuliert sind.
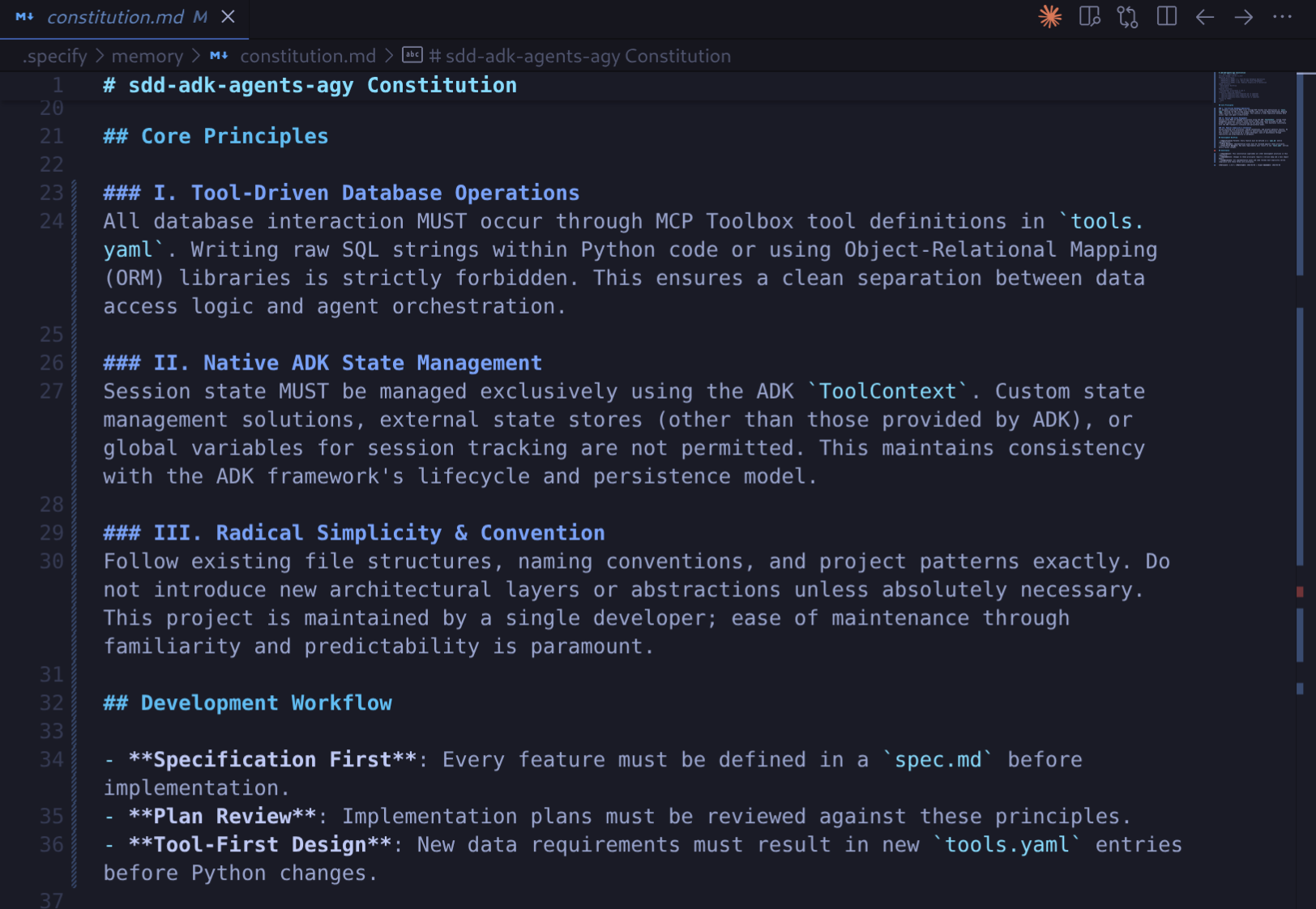
5. SDD-Zyklus – Reservierungsfunktion hinzufügen
In diesem Schritt wird ein vollständiger SDD-Zyklus durchlaufen, um dem Restaurant-Concierge-Agenten die Reservierungsbuchung hinzuzufügen. Sie führen Antigravity durch die einzelnen Phasen – Spezifizieren, Klären, Planen, Aufgaben, Analysieren, Implementieren – und beobachten, wie jedes Artefakt auf dem vorherigen aufbaut. Das ist der Kern des Codelabs.
Funktion angeben
Starten Sie im Agent Manager von Antigravity eine neue Unterhaltung. Geben Sie den /speckit.specify Workflow-Befehl mit einer Merkmalsbeschreibung ein:
/speckit.specify Add reservation booking capability to the restaurant concierge agent. Guests should be able to make a table reservation by providing their name, party size, date, and time. They should also be able to check existing reservations. The agent should confirm reservation details before booking and handle special requests (e.g., "window seat", "birthday celebration").
Antigravity erstellt einen Feature-Branch, generiert ein Spezifikationsdokument und führt eine Qualitätsvalidierung durch. Wenn Antigravity Klärungsfragen stellt, beantworten Sie diese anhand der obigen Merkmalsbeschreibung.
Die Spezifikation konzentriert sich auf WAS und WARUM, nicht auf WIE. Es wird die Nutzerfreundlichkeit beschrieben („Gäste können eine Reservierung vornehmen, indem sie ihren Namen, die Anzahl der Personen, das Datum und die Uhrzeit angeben“), ohne SQL-Tabellen, tools.yaml oder ADK-APIs zu erwähnen. Details zur Implementierung folgen in der Planungsphase.
Sehen Sie sich die generierte Spezifikation unter specs/<branch-name>/spec.md an. Prüfen Sie, ob die funktionalen Anforderungen und Erfolgskriterien berücksichtigt werden.
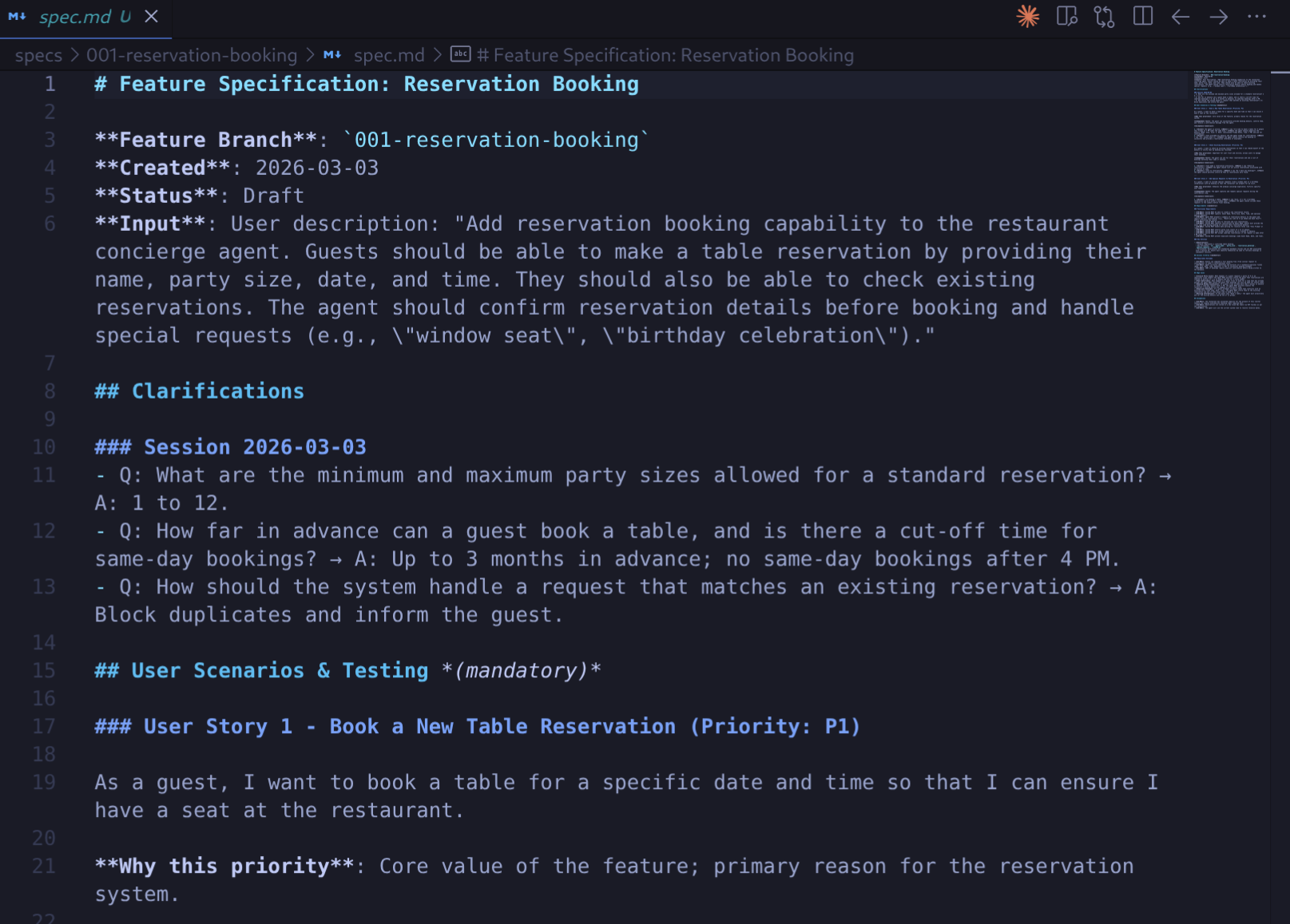
Spezifikation erläutern (optional)
Führen Sie den Workflow „Clarify“ aus, um unterbestimmte Bereiche in der Spezifikation zu identifizieren und zu beheben:
/speckit.clarify
Antigravity scannt die Spezifikation nach Unklarheiten, fehlenden Akzeptanzkriterien und unzureichend spezifizierten Anforderungen. Es werden gezielte Fragen zur Klärung gestellt, die jeweils mit einer kurzen Auswahl oder Formulierung beantwortet werden können. Ihre Antworten werden direkt in die Spezifikation codiert, wodurch sie präziser wird, bevor die Planung beginnt.
Implementierung planen
Planungsworkflow ausführen:
/speckit.plan Update the restaurant concierge agent to multi agent architecture which separate responsibilities for handling menu and reservations. Utilize your access to ADK Docs tools and MCP toolbox skill to implement it properly
Antigravity generiert einen technischen Plan in zwei Phasen:
- Recherchedurchführung: Unbekannte Aspekte der vorhandenen Codebasis werden ermittelt und
research.mdwird generiert. - Entwurfsphase: Erstellt
data-model.md(Definition der Reservierungseinheit) und aktualisiertproject-context.md.
Antigravity sollte bei der Planung die ADK-Dokumentation zu MCP-Tools und die Dokumentation zur MCP Toolbox verwenden. Prüfen Sie die wichtigsten Artefakte:
specs/<branch-name>/plan.md– der technische Ansatz: welche Dateien geändert werden müssen, welche Muster zu befolgen sindspecs/<branch-name>/data-model.md: die Entitätsdefinition für Reservierungen (Spalten, Typen, Beziehungen)specs/<branch-name>/research.md– getroffene Entscheidungen und Begründung
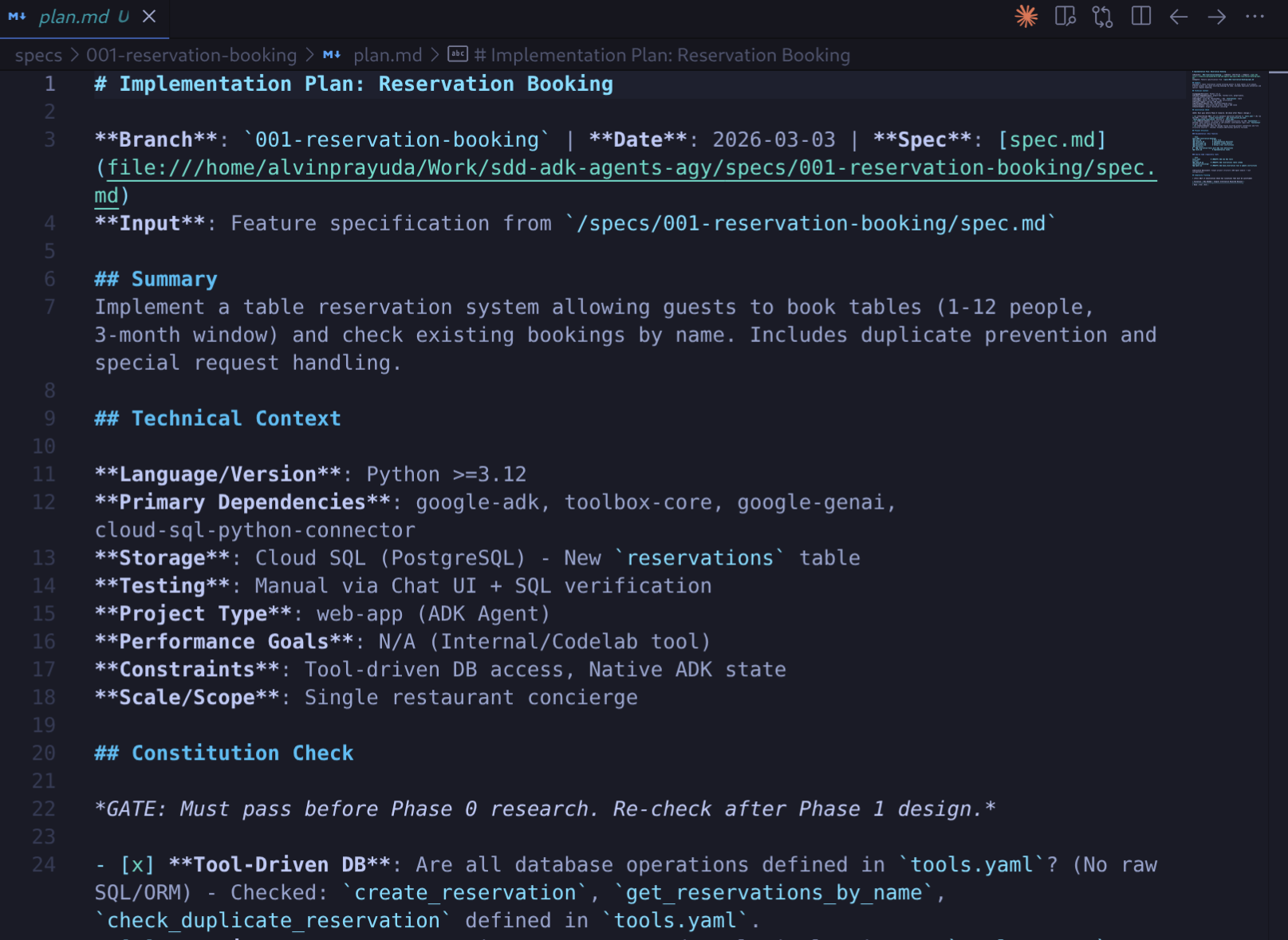
Aufgaben generieren
Workflow „Aufgaben“ ausführen
/speckit.tasks
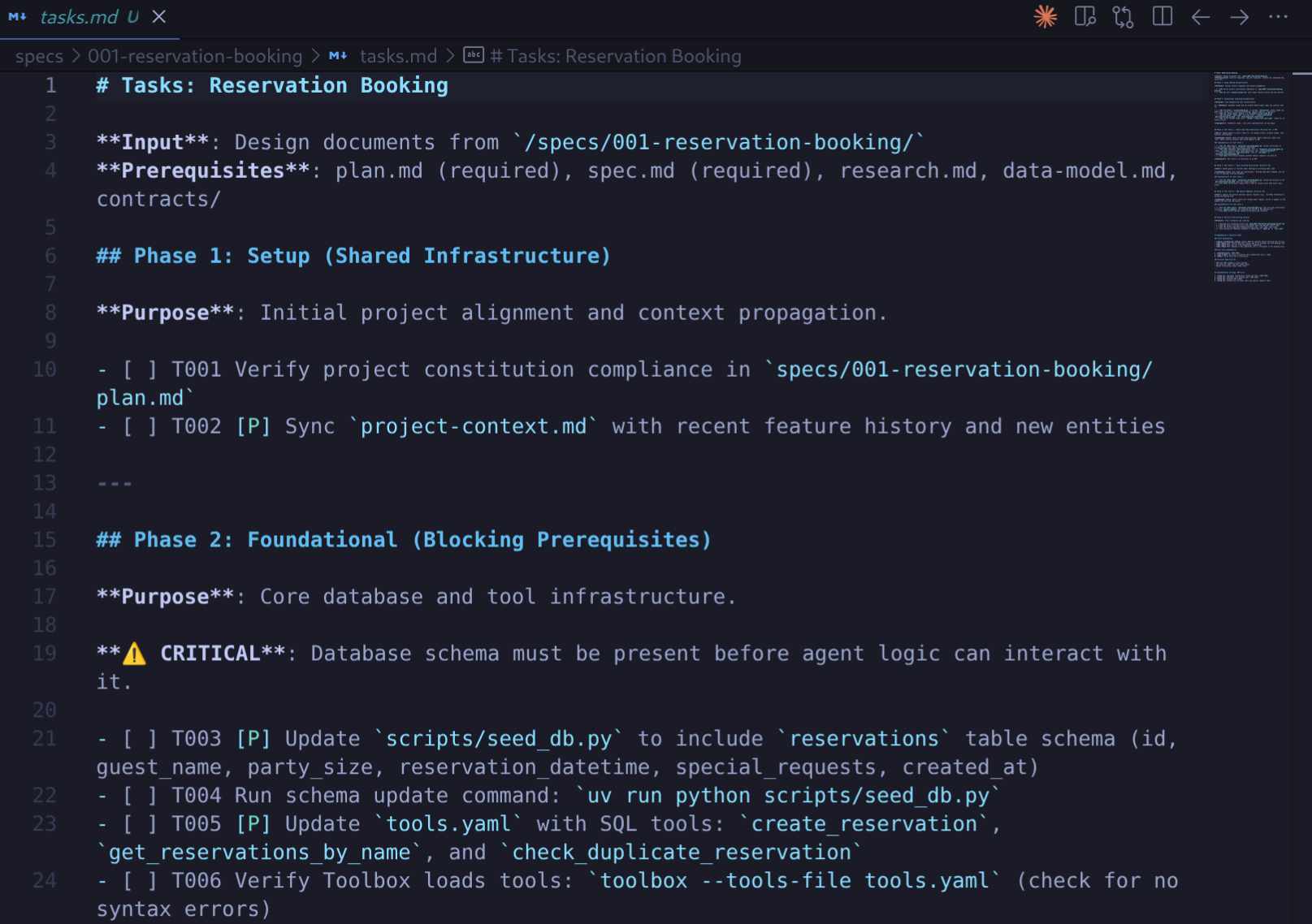
Antigravity unterteilt den Plan in eine geordnete Aufgabenliste in specs/<branch-name>/tasks.md. Aufgaben folgen einem strengen Checklistenformat mit IDs, Prioritätsmarkierungen und Dateipfaden, z. B.:
- [ ] [T001] [P] Create reservations table schema in scripts/seed_db.py - [ ] [T002] [P] Add create_reservation tool to tools.yaml - [ ] [T003] [P] Add list_reservations tool to tools.yaml - [ ] [T004] [P] Update agent instruction in restaurant_concierge/agent.py
Aufgaben sind in Phasen unterteilt: Einrichtung → Grundlagen → User-Storys → Optimierung. Sehen Sie sich die Aufgabenliste an, um zu verstehen, was erstellt und geändert wird.
Aufgaben analysieren (optional)
Führen Sie den Analyse-Workflow aus, um die Aufgaben auf Risiken und Lücken zu prüfen:
/speckit.analyze
Antigravity vergleicht die Aufgabenliste mit der Spezifikation und dem Plan und sucht nach fehlenden Grenzfalltests, Aufgaben, die in Konflikt stehen könnten, oder Lücken zwischen den Anforderungen der Spezifikation und der geplanten Arbeit. Beheben Sie kritische Probleme, bevor Sie die Implementierung vornehmen.
6. Implementieren
Führen Sie den Implementierungsworkflow aus:
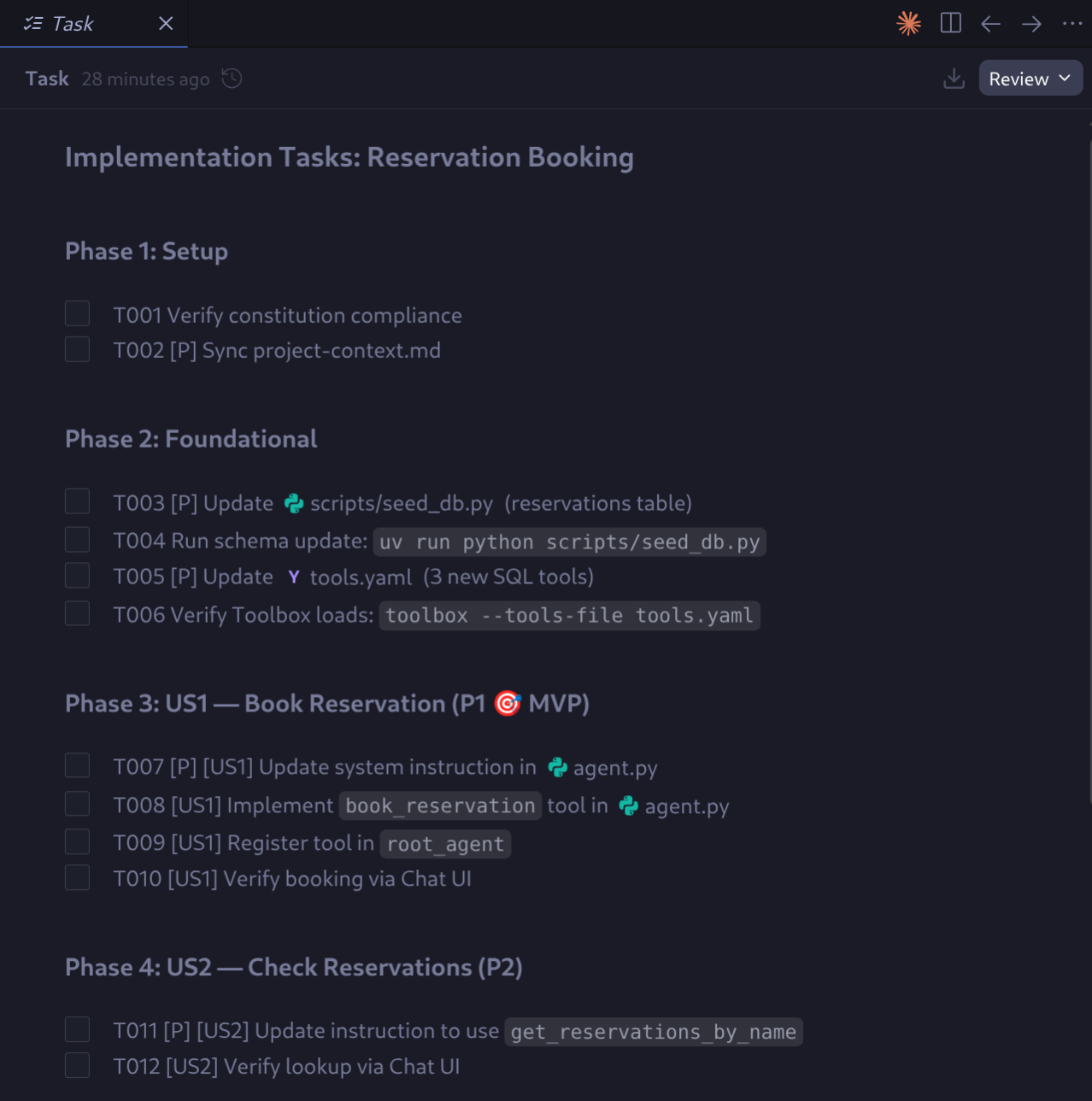
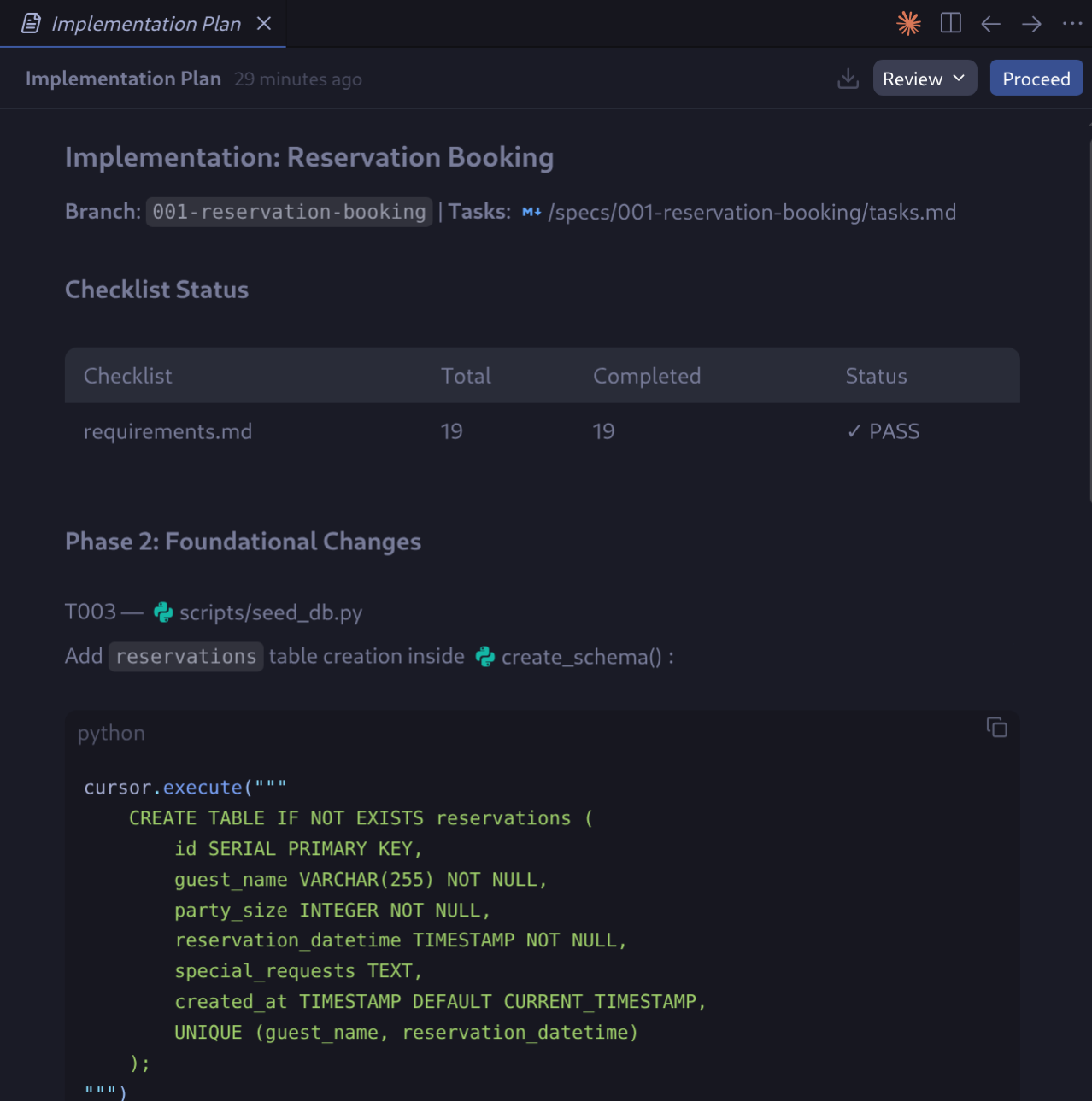
/speckit.implement
Antigravity präsentiert einen endgültigen Implementierungsplan und ein Aufgabenartefakt. Prüfen und genehmigen Sie sie, um fortzufahren.
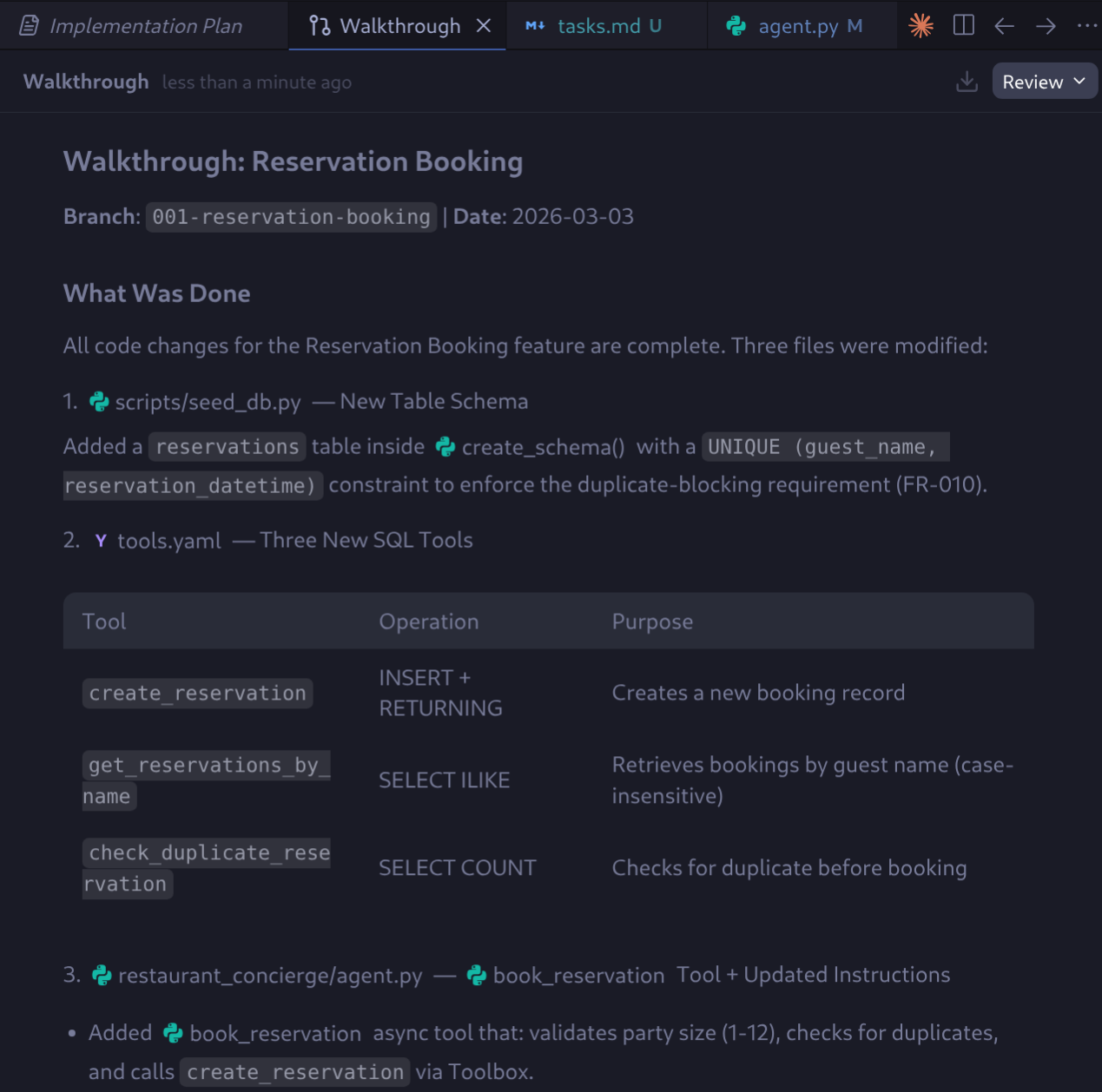
Antigravity führt die Aufgaben aus und hakt sie ab, sobald sie erledigt sind. Nach Abschluss wird der vollständige Walkthrough angezeigt.
Codeänderungen testen
Prüfen Sie nach Abschluss der Implementierung, ob die wichtigsten Änderungen vorgenommen wurden. Die genauen Dateinamen und Inhalte können variieren, aber diese Muster sollten wie in tools.yaml und agent.py vorhanden sein:
# Verify reservation tools were added to tools.yaml
grep -i "reservation" tools.yaml
Die Ausgabe sieht ungefähr so aus:
...
get_reservations_by_name:
Retrieve all reservations for a guest by their name. Uses case-insensitive
SELECT id, guest_name, party_size, reservation_datetime, special_requests, created_at
FROM reservations
ORDER BY reservation_datetime DESC
...
Und für agent.py
# Verify agent instruction was updated
grep -i "reservation" restaurant_concierge/agent.py
# Check what files changed
git diff --name-only
Vielleicht finden Sie Änderungen wie diese:
...
- **Table Reservations**: Help guests book a table or check their existing reservations.
## Reservation Booking Rules
When a guest wants to make a reservation, collect ALL of the following before confirming:
**IMPORTANT**: Before calling `book_reservation`, you MUST:
- Only call `book_reservation` after the guest says "yes" or "confirm"
## Checking Reservations
When a guest asks to check their reservations:
- Use `get_reservations_by_name` to find their bookings
book_reservation,
...
Die Änderungen sollten sich auf das Seed-Datenbankskript auswirken. Das aktualisierte Skript sollte die Tabelle reservations erstellen, falls sie noch nicht vorhanden ist. Sie sollten eine Ausgabe sehen, die bestätigt, dass die neue Tabelle erstellt wurde (die vorhandenen menu_items-Daten bleiben erhalten).
Wenn bis dahin alles gut läuft, können wir die Funktion in der Entwickler-UI des ADK-Agents testen. Wir führen die Datenbankmigration durch, um die neue Tabelle einzufügen, und starten die Toolbox neu, damit die neuen Tooldefinitionen in tools.yaml übernommen werden. Beenden Sie alle vorhandenen Toolbox-Prozesse und starten Sie einen neuen:
lsof -ti:5000 | xargs kill -9 2>/dev/null; echo "Done"
./scripts/setup_database.sh > database_setup.log 2>&1 &
Im Ausgabelog im database_setup.log können Sie prüfen, ob Antigravity korrekten Code und eine korrekte Konfiguration generiert. Wenn ein Fehler auftritt, versuchen Sie, ihn durch Interaktion mit dem Agent zu beheben.
Wenn alles gut geht, können wir die ADK-Entwickler-UI starten:
uv run adk web .
Öffnen Sie http://localhost:8000 in Ihrem Browser und testen Sie mit diesen Prompts:
I'd like to book a table for 4 people on Friday at 7pm under the name Timmy
Do I have any upcoming reservations?
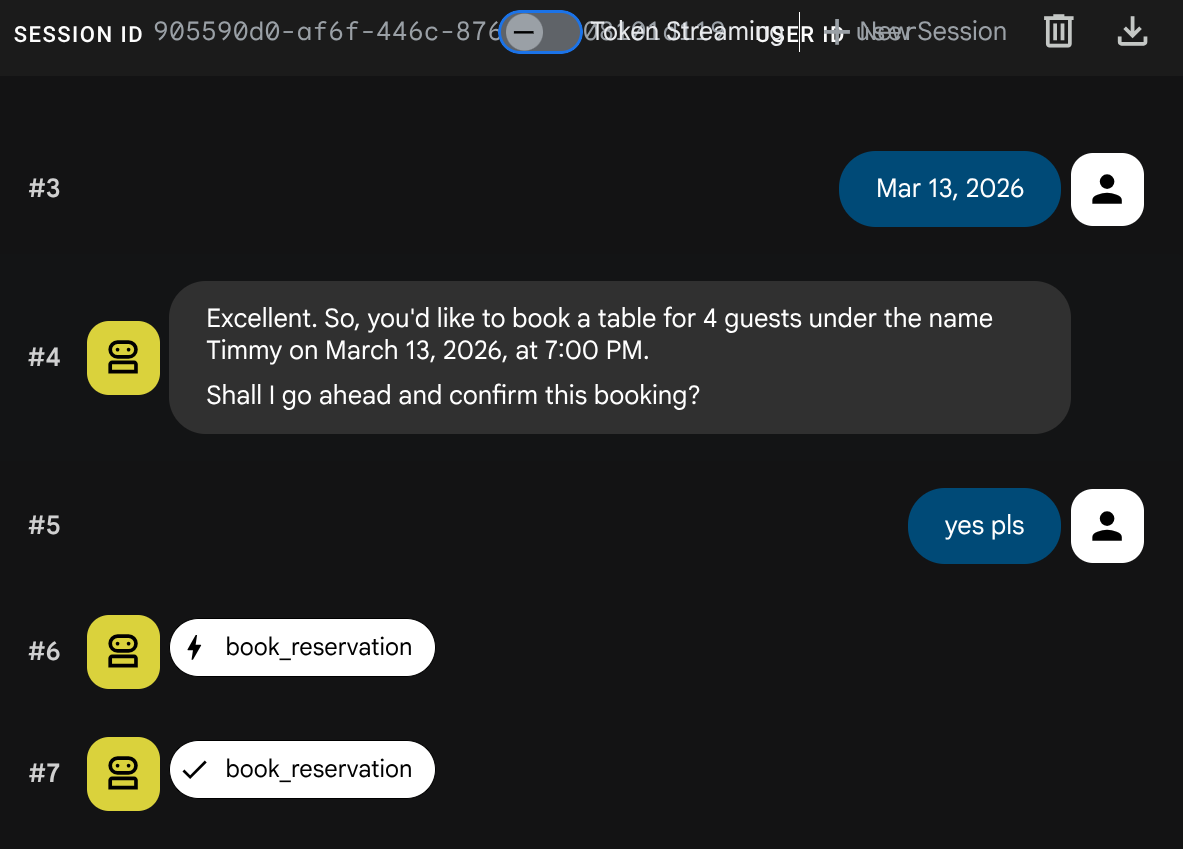
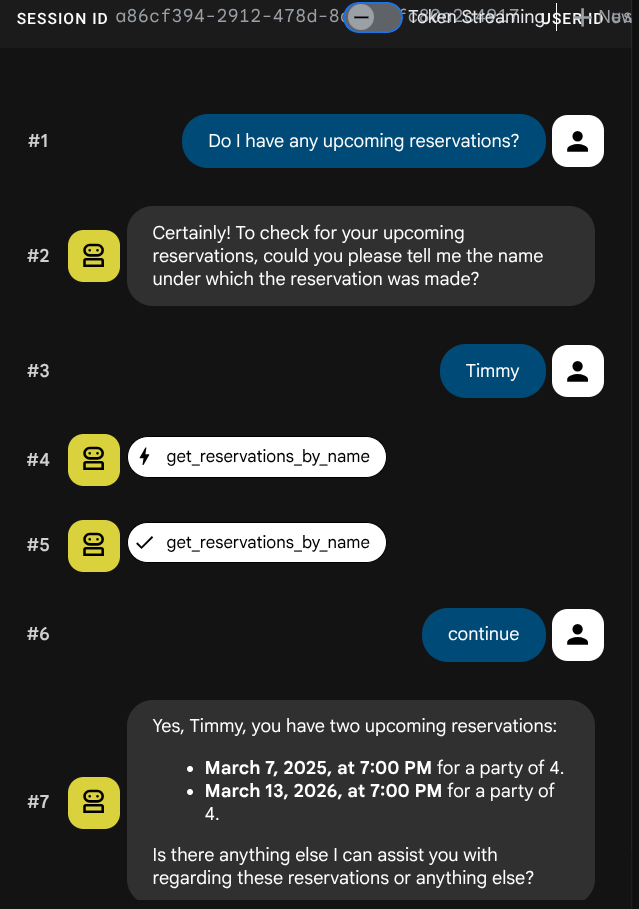
Beenden Sie nun die ADK-Entwicklungsoberfläche mit Ctrl+C (zweimal).
7. Herausforderungen (optional)
Sie kennen jetzt den gesamten SDD-Workflow. So testen Sie es:
- Führen Sie einen zweiten SDD-Zyklus aus, um eine Webchat-Oberfläche für den Restaurant-Concierge zu erstellen – diesmal ohne Schritt-für-Schritt-Anleitung.
- Agent für das Produktionsszenario in Cloud Run bereitstellen
Hinweise
- Das Projekt hat kein Frontend-Framework. Antigravity sollte reines HTML/CSS/JS vorschlagen. Wenn React oder Ähnliches vorgeschlagen wird, sollte es auf Einfachheit ausgerichtet werden (das Prinzip „Keep it simple“ Ihrer Verfassung sollte dies erkennen).
- Der ADK-Server stellt
/run_ssefür das Streaming und/apps/{app_name}/users/{user_id}/sessionsfür die Sitzungsverwaltung bereit. Antigravity ermittelt diese aus dem Projektkontext. - Starten Sie den Server nach der Implementierung mit
uv run uvicorn server:app --host 0.0.0.0 --port 8080(nichtadk web), damit die Bereitstellung statischer Dateien funktioniert. - Testen Sie unter
http://localhost:8080/static/index.html. - In den Referenz-Codelabs wird bereits gezeigt, wie ADK-Agenten bereitgestellt und beibehalten werden. Gib Antigravity-Referenzen dazu an.
8. Glückwunsch!
Sie haben einen ADK-Agenten für einen Restaurant-Concierge mit Reservierungsbuchung erweitert – vollständig über die SDD-Workflows von Antigravity, ohne Anwendungscode manuell zu schreiben.
Was Sie erstellt haben
- Ein ADK-Agent für Restaurant-Concierge mit Menüsuche, semantischer Suche, Erfassung von Ernährungspräferenzen und Reservierungsbuchung
- Eine Antigravity-Skill für die Repository-Recherche, die ein Projektkontextdokument generiert und verwaltet
- Eine Projektverfassung, die nicht verhandelbare Grundsätze während der Planung und Analyse durchsetzt
- Ein vollständiger SDD-Zyklus, der den Workflow „Spezifizieren → Klären → Planen → Aufgaben → Analysieren → Implementieren“ veranschaulicht
Das haben Sie gelernt
- Spezifikationsbasierte Entwicklungsworkflows in Antigravity verwenden, um einer vorhandenen Codebasis systematisch Funktionen hinzuzufügen
- Antigravity-Skills erstellen und MCP konfigurieren, die Domänenwissen für die Wiederverwendung in Konversationen bündeln
- So wird der Projektkontext so aufgebaut, dass Antigravity fundierte Entscheidungen zu Architektur, Mustern und Technologie treffen kann.
- Festlegen einer Projektverfassung, anhand derer die SDD-Workflows validiert werden
- ADK-Agenten mit neuen datenbankgestützten Tools über die MCP Toolbox erweitern
Bereinigen
Beenden Sie alle laufenden lokalen Prozesse (Toolbox):
lsof -ti:5000 | xargs kill -9 2>/dev/null
Löschen Sie die Cloud SQL-Instanz, um laufende Gebühren zu vermeiden:
gcloud sql instances delete restaurant-db --quiet
Optional: Gesamtes Projekt löschen:
gcloud projects delete $GOOGLE_CLOUD_PROJECT