
1. نظرة عامة
هل تذكرون رحلتنا في إنشاء تجربة ديناميكية مختلطة للبيع بالتجزئة باستخدام AlloyDB، والجمع بين الفلترة المتعدّدة الأوجه والبحث المتّجه؟ كان هذا التطبيق مثالاً قويًا على احتياجات البيع بالتجزئة الحديثة، ولكن الوصول إلى هذا المستوى من الأداء وتكراره تطلّب جهدًا كبيرًا في التطوير. بالنسبة إلى مطوّري التطبيقات المتكاملة، يمكن أن يشكّل التنقّل المستمر بين أدوات تعديل الرموز البرمجية وأدوات قواعد البيانات عائقًا في كثير من الأحيان، ما يؤدي إلى إبطاء عملية الابتكار وعملية فهم بياناتك المهمة.
الحل
وهنا تبرز أهمية التطوير السريع للتطبيقات، ولهذا السبب أنا متحمّس جدًا لمشاركة كيف أصبحت مجموعة أدوات MCP (Modern Cloud Platform) Toolbox، التي يمكن الوصول إليها من خلال واجهة سطر الأوامر البديهية Gemini CLI، جزءًا لا غنى عنه من مجموعة أدواتي. تخيَّل التفاعل بسلاسة مع مثيل AlloyDB وكتابة الاستعلامات وفهم مجموعة البيانات، كل ذلك مباشرةً من داخل بيئة التطوير المتكاملة (IDE). لا يقتصر الأمر على توفير الراحة، بل يهدف إلى الحدّ بشكل أساسي من الصعوبات في مراحل نشاط التطوير، ما يتيح لك التركيز على إنشاء ميزات مبتكرة بدلاً من التعامل مع أدوات خارجية.
في سياق تطبيقنا للتجارة الإلكترونية في مجال البيع بالتجزئة، حيث كنّا بحاجة إلى الاستعلام بكفاءة عن بيانات المنتجات والتعامل مع الفلترة المعقّدة والاستفادة من الفروق الدقيقة في البحث المتّجه، كانت القدرة على تكرار تفاعلات قاعدة البيانات بسرعة أمرًا بالغ الأهمية. لا تعمل "مجموعة أدوات MCP" المستندة إلى Gemini CLI على تبسيط هذه العملية فحسب، بل تعمل أيضًا على تسريعها، ما يغيّر طريقة استكشافنا لمنطق قاعدة البيانات الذي تستند إليه تطبيقاتنا واختباره وتحسينه. لنتعرّف على كيف يساهم هذا المزيج المميّز في جعل عملية تطوير الحزمة الكاملة أسرع وأكثر ذكاءً ومتعةً.
ما ستتعلمه وتنشئه
تطبيق Retail Search يستخدم MCP Toolbox داخل بيئة التطوير المتكاملة (IDE)، وهو مزوّد بواجهة سطر الأوامر Gemini CLI. سنتناول:
- كيفية دمج MCP Toolbox مباشرةً في بيئة التطوير المتكاملة (IDE) للتفاعل بسلاسة مع AlloyDB
- أمثلة عملية على استخدام Gemini CLI لكتابة استعلامات SQL وتنفيذها على بيانات البيع بالتجزئة
- يمكنك الاستفادة من Gemini CLI للتفاعل مع مجموعة بيانات التجارة الإلكترونية الخاصة بقطاع البيع بالتجزئة، وكتابة طلبات بحث تتطلّب عادةً أدوات منفصلة، والاطّلاع على النتائج على الفور.
- استكشاف طرق جديدة لفحص البيانات وفهمها، بدءًا من التحقّق من بنى الجداول إلى إجراء عمليات تحقّق سريعة من صحة البيانات، كل ذلك من خلال واجهات سطر الأوامر المألوفة ضمن بيئة التطوير المتكاملة
- كيف يساهم سير عمل قاعدة البيانات السريع هذا بشكل مباشر في تسريع دورات تطوير التطبيقات المتكاملة، ما يسمح بإنشاء نماذج أولية وتكرار سريعَين
Techstack
نستخدم:
- AlloyDB لقاعدة البيانات
- MCP Toolbox لتجريد ميزات الذكاء الاصطناعي التوليدي والذكاء الاصطناعي المتقدّمة لقواعد البيانات من التطبيق
- Cloud Run للتفعيل بدون خادم
- Gemini CLI لفهم مجموعة البيانات وتحليلها وإنشاء جزء قاعدة البيانات من تطبيق التجارة الإلكترونية الخاص بالبيع بالتجزئة
المتطلبات
2. قبل البدء
إنشاء مشروع
- في Google Cloud Console، ضمن صفحة اختيار المشروع، اختَر أو أنشِئ مشروعًا على Google Cloud.
- تأكَّد من تفعيل الفوترة لمشروعك على السحابة الإلكترونية. تعرَّف على كيفية التحقّق مما إذا كانت الفوترة مفعَّلة في مشروع.
- ستستخدم Cloud Shell، وهي بيئة سطر أوامر تعمل في Google Cloud. انقر على "تفعيل Cloud Shell" في أعلى "وحدة تحكّم Google Cloud".

- بعد الاتصال بـ Cloud Shell، يمكنك التأكّد من أنّك قد أثبتّ هويتك وأنّ المشروع مضبوط على رقم تعريف مشروعك باستخدام الأمر التالي:
gcloud auth list
- نفِّذ الأمر التالي في Cloud Shell للتأكّد من أنّ أمر gcloud يعرف مشروعك.
gcloud config list project
- إذا لم يتم ضبط مشروعك، استخدِم الأمر التالي لضبطه:
gcloud config set project <YOUR_PROJECT_ID>
- فعِّل واجهات برمجة التطبيقات المطلوبة: اتّبِع الرابط وفعِّل واجهات برمجة التطبيقات.
يمكنك بدلاً من ذلك استخدام أمر gcloud لهذا الغرض. راجِع المستندات لمعرفة أوامر gcloud وطريقة استخدامها.
3- إعداد قاعدة البيانات
في هذا التمرين العملي، سنستخدم AlloyDB كقاعدة بيانات لبيانات التجارة الإلكترونية. يستخدم المجموعات للاحتفاظ بجميع الموارد، مثل قواعد البيانات والسجلات. تحتوي كل مجموعة على مثيل أساسي يوفّر نقطة وصول إلى البيانات. ستحتوي الجداول على البيانات الفعلية.
لننشئ مجموعة ومثيل وجدول AlloyDB حيث سيتم تحميل مجموعة بيانات التجارة الإلكترونية.
إنشاء مجموعة ومثيل
- انتقِل إلى صفحة AlloyDB في Cloud Console. تتمثّل إحدى الطرق السهلة للعثور على معظم الصفحات في Cloud Console في البحث عنها باستخدام شريط البحث في وحدة التحكّم.
- اختَر إنشاء مجموعة من تلك الصفحة:

- ستظهر لك شاشة مشابهة للشاشة أدناه. أنشئ مجموعة ومثيل بالقيم التالية (تأكَّد من تطابق القيم في حال استنساخ الرمز البرمجي للتطبيق من المستودع):
- معرّف المجموعة: "
vector-cluster" - كلمة المرور: "
alloydb" - PostgreSQL 15 / أحدث إصدار يُنصح به
- المنطقة: "
us-central1" - الشبكات: "
default"
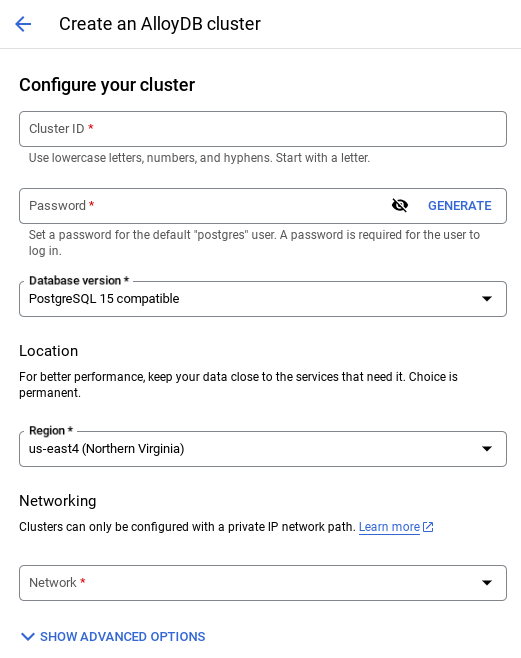
- عند اختيار الشبكة الافتراضية، ستظهر لك شاشة مثل الشاشة أدناه.
انقر على إعداد الاتصال.
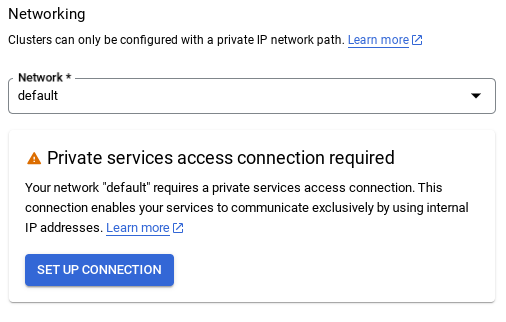
- من هناك، اختَر استخدام نطاق عناوين IP تم تخصيصه تلقائيًا وانقر على "متابعة". بعد مراجعة المعلومات، انقر على "إنشاء ربط".
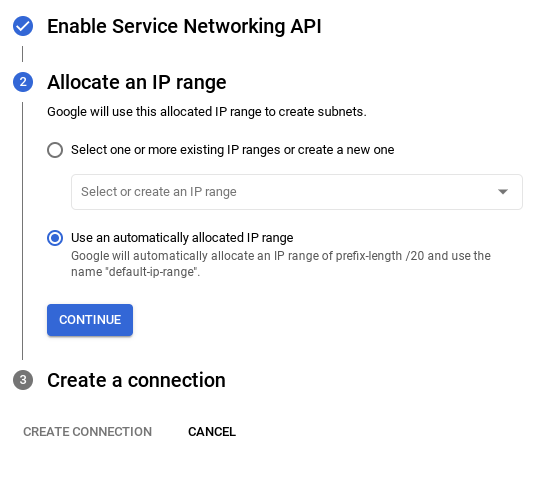
- بعد إعداد شبكتك، يمكنك مواصلة إنشاء مجموعتك. انقر على إنشاء مجموعة لإكمال عملية إعداد المجموعة كما هو موضّح أدناه:
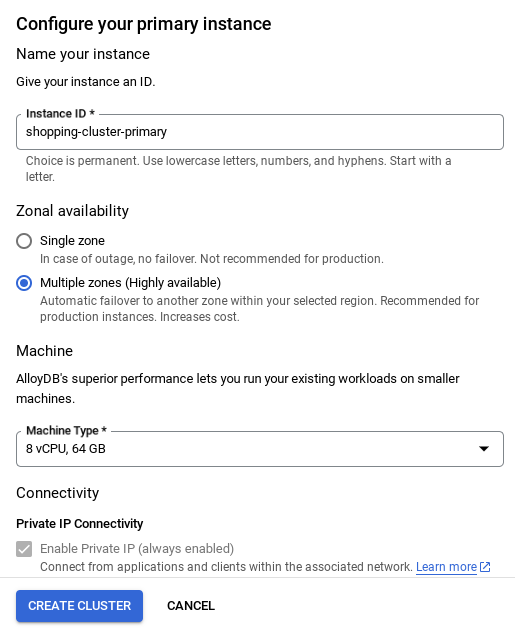
ملاحظة مهمة:
- احرص على تغيير معرّف المثيل (الذي يمكنك العثور عليه عند إعداد المجموعة أو المثيل) إلى **
vector-instance**. وإذا لم تتمكّن من تغييره، تذكَّر **استخدام معرّف المثيل** في جميع المراجع القادمة. - يُرجى العِلم أنّ إنشاء المجموعة سيستغرق حوالي 10 دقائق. بعد إتمام العملية بنجاح، من المفترض أن تظهر لك شاشة تعرض نظرة عامة على المجموعة التي أنشأتها للتو.
4. نقل البيانات
حان الوقت الآن لإضافة جدول يتضمّن بيانات حول المتجر. انتقِل إلى AlloyDB، واختَر المجموعة الأساسية، ثم AlloyDB Studio:
قد تحتاج إلى الانتظار إلى أن يكتمل إنشاء الجهاز الظاهري. بعد ذلك، سجِّل الدخول إلى AlloyDB باستخدام بيانات الاعتماد التي أنشأتها عند إنشاء المجموعة. استخدِم البيانات التالية للمصادقة على PostgreSQL:
- اسم المستخدم : "
postgres" - قاعدة البيانات : "
postgres" - كلمة المرور : "
alloydb"
بعد إكمال عملية المصادقة بنجاح في AlloyDB Studio، يتم إدخال أوامر SQL في "المحرّر". يمكنك إضافة نوافذ "المحرّر" متعددة باستخدام علامة الجمع على يسار النافذة الأخيرة.
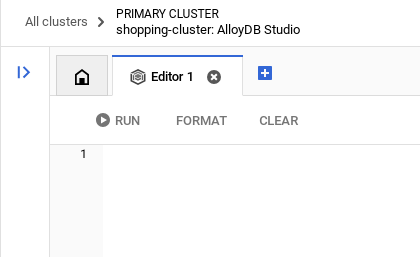
ستُدخل أوامر AlloyDB في نوافذ المحرّر، باستخدام الخيارات "تشغيل" و"تنسيق" و"محو" حسب الحاجة.
تفعيل الإضافات
لإنشاء هذا التطبيق، سنستخدم الإضافتين pgvector وgoogle_ml_integration. تتيح لك إضافة pgvector تخزين عمليات التضمين المتجهة والبحث عنها. توفّر إضافة google_ml_integration دوال يمكنك استخدامها للوصول إلى نقاط نهاية التوقّع في Vertex AI من أجل الحصول على توقّعات في SQL. فعِّل هذه الإضافات من خلال تنفيذ تعريفات البيانات التالية:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
إذا أردت التحقّق من الإضافات التي تم تفعيلها في قاعدة البيانات، نفِّذ أمر SQL التالي:
select extname, extversion from pg_extension;
إنشاء جدول
يمكنك إنشاء جدول باستخدام عبارة DDL أدناه في AlloyDB Studio:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
سيسمح عمود التضمين بتخزين قيم المتجهات للنص.
منح الإذن
نفِّذ العبارة أدناه لمنح إذن التنفيذ على الدالة "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
منح دور "مستخدم Vertex AI" لحساب خدمة AlloyDB
من وحدة تحكّم Google Cloud IAM، امنح حساب خدمة AlloyDB (الذي يبدو على النحو التالي: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) إذن الوصول إلى الدور "مستخدم Vertex AI". سيحتوي PROJECT_NUMBER على رقم مشروعك.
بدلاً من ذلك، يمكنك تنفيذ الأمر أدناه من "وحدة Cloud Shell الطرفية":
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
تحميل البيانات إلى قاعدة البيانات
- انسخ عبارات طلب البحث
insertمنinsert scripts sqlفي ورقة البيانات إلى المحرّر كما هو موضّح أعلاه. يمكنك نسخ 10 إلى 50 عبارة إدراج للحصول على عرض توضيحي سريع لحالة الاستخدام هذه. تتضمّن علامة التبويب"الإدخالات المحدّدة 25-30 صفًا" قائمة بالإدخالات المحدّدة. - انقر على تشغيل. تظهر نتائج طلب البحث في جدول النتائج.
ملاحظة مهمة:
احرص على نسخ 25 إلى 50 سجلاً فقط لإدراجها، وتأكَّد من أنّها من نطاق الفئة والفئة الفرعية واللون وأنواع الجنس.
5- إنشاء تضمينات للبيانات
يكمن الابتكار الحقيقي في محركات البحث الحديثة في فهم المعنى، وليس الكلمات الرئيسية فقط. وهنا يأتي دور التضمينات والبحث المتّجه.
حوّلنا أوصاف المنتجات وطلبات بحث المستخدمين إلى تمثيلات رقمية عالية الأبعاد تُعرف باسم "التضمينات" باستخدام نماذج لغوية مُدرَّبة مسبقًا. تتضمّن عمليات التضمين هذه المعنى الدلالي، ما يسمح لنا بالعثور على منتجات "متشابهة في المعنى" بدلاً من المنتجات التي تحتوي على كلمات متطابقة فقط. في البداية، أجرينا تجربة على البحث المباشر عن التشابه بين المتجهات في عمليات التضمين هذه لتحديد خط أساس، ما يوضّح قوة الفهم الدلالي حتى قبل تحسين الأداء.
سيتيح عمود التضمين تخزين قيم المتجهات لنص وصف المنتج. سيسمح عمود img_embeddings بتخزين تضمينات الصور (متعددة الوسائط). بهذه الطريقة، يمكنك أيضًا استخدام البحث المستند إلى المسافة بين النص والصورة. لكنّنا سنستخدم تضمينات نصية فقط في هذا الدرس التطبيقي.
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
من المفترض أن يعرض هذا الطلب متجه التضمينات، الذي يبدو كصفيف من الأرقام العشرية، للنص النموذجي في الطلب. يبدو على النحو التالي:
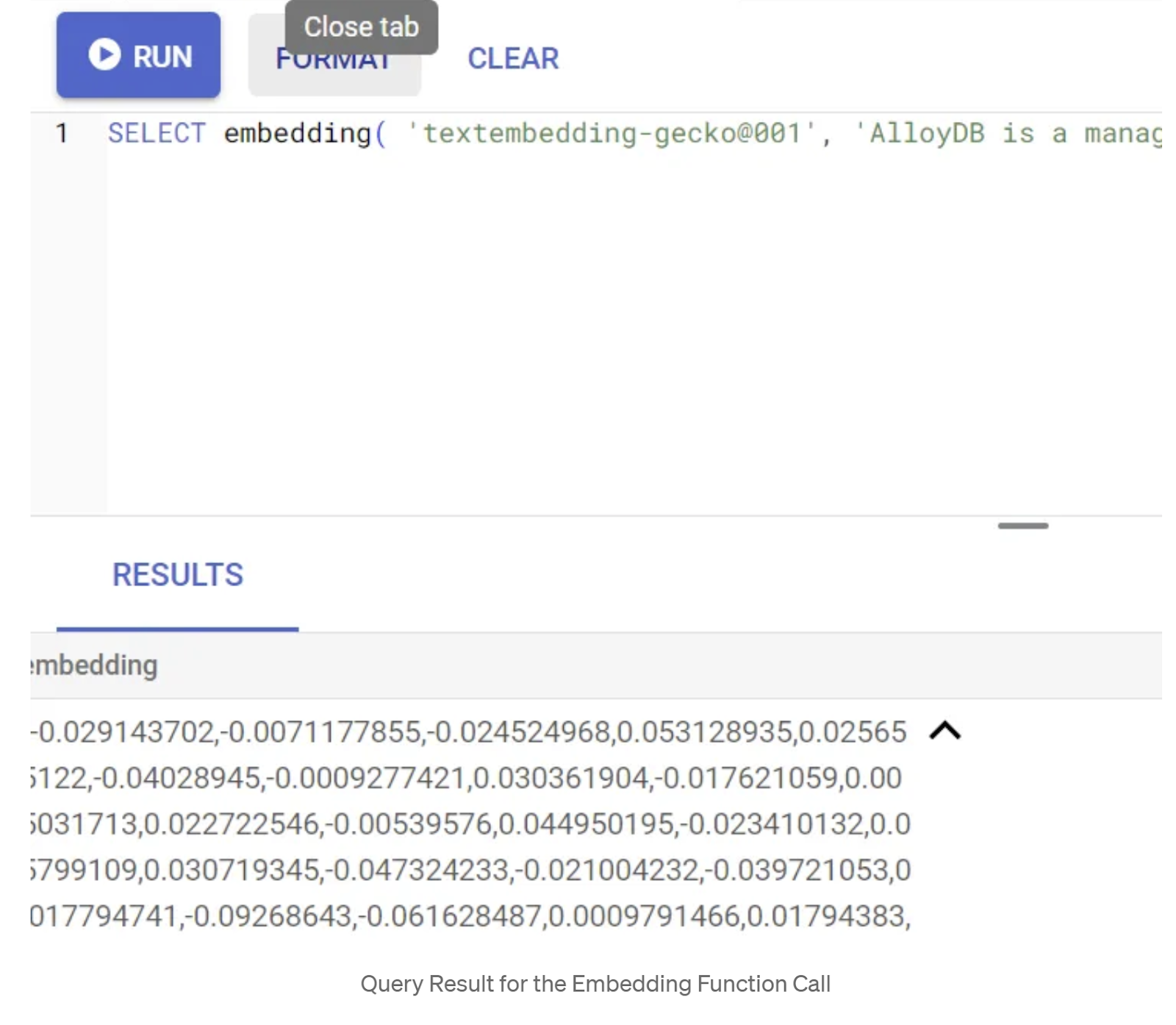
تعديل حقل المتّجه abstract_embeddings
نفِّذ عبارة DML أدناه لتعديل وصف المحتوى في الجدول باستخدام عمليات التضمين المقابلة:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
قد تواجه مشكلة في إنشاء أكثر من عدد قليل من التضمينات (20 إلى 25 كحد أقصى) إذا كنت تستخدم حساب فوترة برصيد تجريبي على Google Cloud. لذا، يجب الحدّ من عدد الصفوف في نص الإدراج.
إذا أردت إنشاء تضمينات صور (لإجراء بحث سياقي متعدد الوسائط)، نفِّذ التحديث أدناه أيضًا:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. MCP Toolbox for Databases (AlloyDB)
وراء الكواليس، تضمن الأدوات القوية والتطبيق المنظَّم جيدًا التشغيل السلس.
تُبسّط مجموعة أدوات MCP (بروتوكول سياق النموذج) لقواعد البيانات عملية دمج أدوات الذكاء الاصطناعي التوليدي والذكاء الاصطناعي الوكيل مع AlloyDB. وهو يعمل كخادم مفتوح المصدر يسهّل تجميع الاتصالات والمصادقة وعرض وظائف قاعدة البيانات بشكل آمن لوكلاء الذكاء الاصطناعي أو التطبيقات الأخرى.
في تطبيقنا، استخدمنا MCP Toolbox for Databases كطبقة تجريدية لجميع طلبات البحث الذكية المختلطة.
اتّبِع الخطوات التالية لإعداد "مجموعة الأدوات" ونشرها لحالة الاستخدام:
يمكنك ملاحظة أنّ إحدى قواعد البيانات المتوافقة مع MCP Toolbox for Databases هي AlloyDB، وبما أنّنا قد وفّرناها في القسم السابق، لننتقل إلى إعداد Toolbox.
- انتقِل إلى "وحدة Cloud Shell الطرفية" وتأكَّد من اختيار مشروعك وعرضه في موجّه الوحدة الطرفية. نفِّذ الأمر التالي من "وحدة Cloud Shell الطرفية" للانتقال إلى دليل مشروعك:
mkdir gemini-cli-project
cd gemini-cli-project
- نفِّذ الأمر أدناه لتنزيل مجموعة الأدوات وتثبيتها في مجلدك الجديد:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
من المفترض أن يؤدي ذلك إلى إنشاء مجموعة الأدوات في الدليل الحالي. انسخ المسار إلى صندوق الأدوات.
- انتقِل إلى "محرّر Cloud Shell" (لوضع تعديل الرمز) وفي مجلد جذر المشروع "gemini-cli-project"، أضِف ملفًا باسم "tools.yaml".
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
دعونا نتعرّف على ملف tools.yaml:
تمثّل المصادر مصادر البيانات المختلفة التي يمكن أن تتفاعل معها إحدى الأدوات. يمثّل المصدر مصدر بيانات يمكن أن تتفاعل معه إحدى الأدوات. يمكنك تعريف المصادر كخريطة في قسم المصادر ضمن ملف tools.yaml. عادةً، سيحتوي إعداد المصدر على أي معلومات مطلوبة للاتصال بقاعدة البيانات والتفاعل معها.
تحدِّد الأدوات الإجراءات التي يمكن أن يتّخذها الوكيل، مثل القراءة والكتابة إلى مصدر. تمثّل الأداة إجراءً يمكن أن يتّخذه الوكيل، مثل تنفيذ عبارة SQL. يمكنك تعريف "الأدوات" كخريطة في قسم الأدوات في ملف tools.yaml. عادةً، تتطلّب الأداة مصدرًا لتنفيذ الإجراءات.
لمزيد من التفاصيل حول ضبط ملف tools.yaml، يُرجى الرجوع إلى هذه المستندات.
كما هو موضّح في ملف Tools.yaml أعلاه، تعرض الأداة "get-apparels" جميع تفاصيل الملابس من قاعدة البيانات.
7. إعداد Gemini CLI
من Cloud Shell Editor، أنشئ مجلدًا جديدًا باسم .gemini داخل المجلد gemini-cli-project، ثم أنشئ ملفًا جديدًا باسم settings.json بداخله.
{
"mcpServers": {
"AlloyDBServer": {
"command": "/home/user/gemini-cli-project/toolbox",
"args": ["--tools-file", "tools.yaml", "--stdio"]
}
}
}
في قسم الأوامر في المقتطف أعلاه، استبدِل "/home/user/gemini-cli-project/toolbox" بمسار الأدوات.
تثبيت Gemini CLI
أخيرًا، من نافذة Cloud Shell، لنثبّت Gemini CLI في الدليل نفسه gemini-cli-project من خلال تنفيذ الأمر:
sudo npm install -g @google/gemini-cli
تحديد رقم تعريف المشروع
تأكَّد من ضبط رقم تعريف المشروع النشط في البيئة:
export GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT_ID>>
بدء استخدام Gemini CLI
من سطر الأوامر، أدخِل الأمر:
gemini
من المفترض أن يظهر لك ردّ مشابه لما يلي:
يجب إثبات ملكية الحساب والمتابعة إلى الخطوة التالية.
8. بدء التفاعل مع Gemini CLI
استخدِم الأمر /mcp لإدراج خوادم MCP التي تم ضبطها.
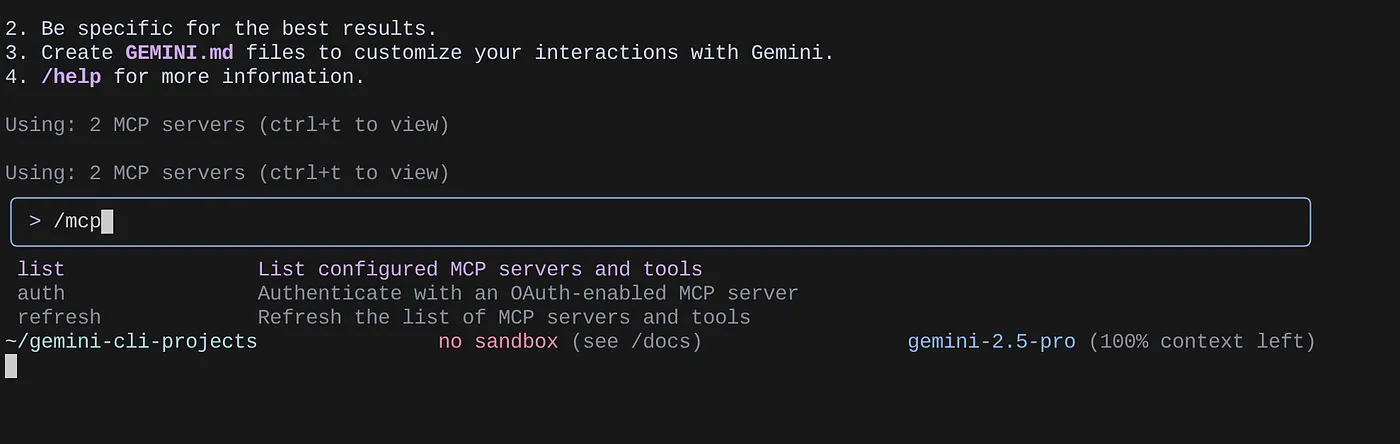
من المفترض أن تتمكّن من رؤية خادمي MCP اللذين أعددناهما: GitHub وMCP Toolbox for Databases المُدرَجان مع أدواتهما.
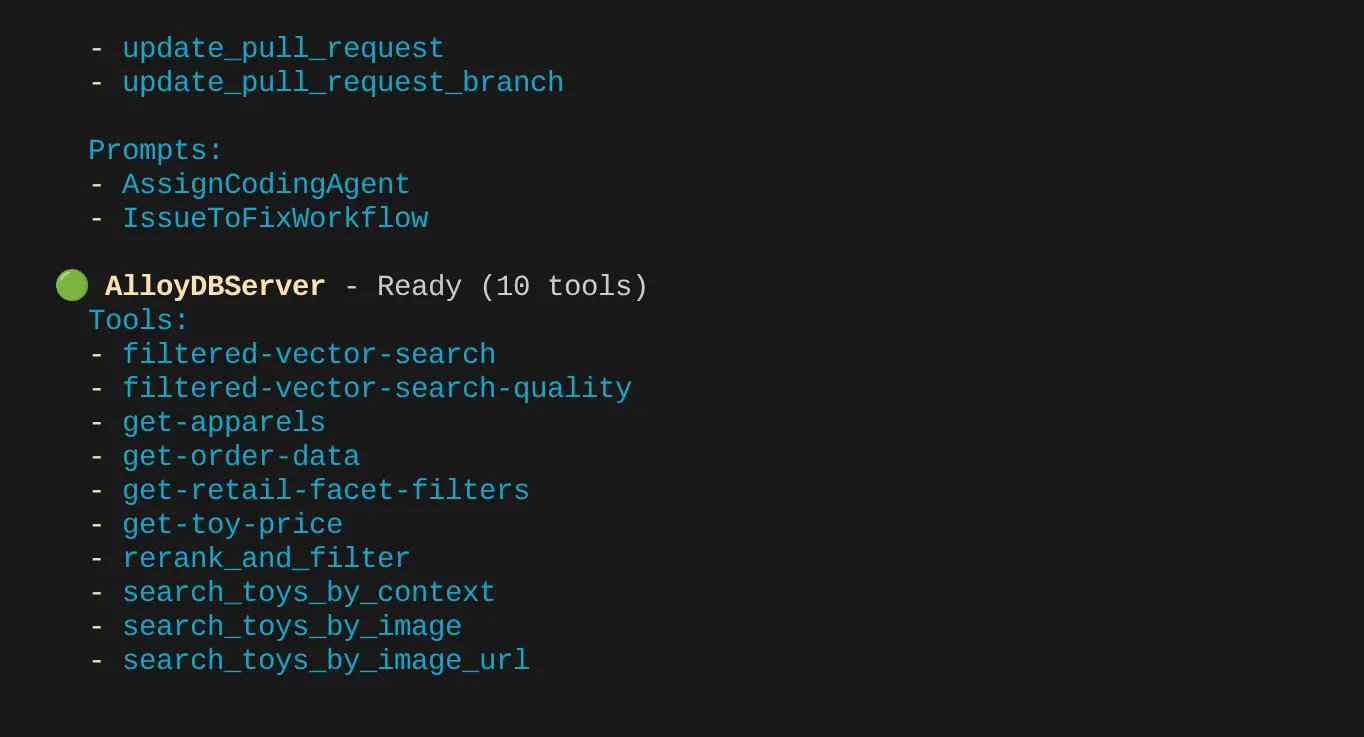
في حالتي، لديّ المزيد من الأدوات. لذا، تجاهِلها في الوقت الحالي. من المفترض أن تظهر أداة get-apparels في خادم AlloyDB MCP.
بدء طلب البحث من قاعدة البيانات من خلال MCP Toolbox
الآن، جرِّب طرح أسئلة بلغة طبيعية لجلب الردود والاستعلامات لمجموعة البيانات التي نعمل عليها:
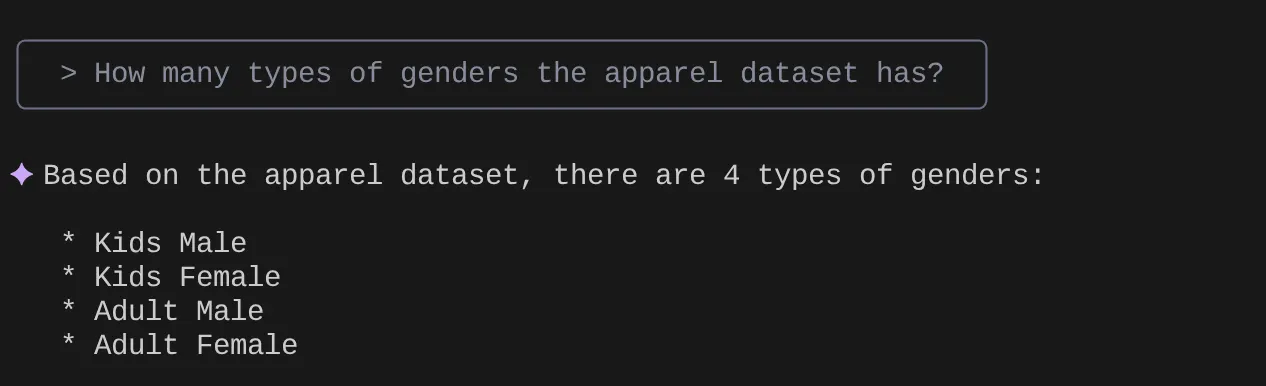
> How many types of genders the apparel dataset has?
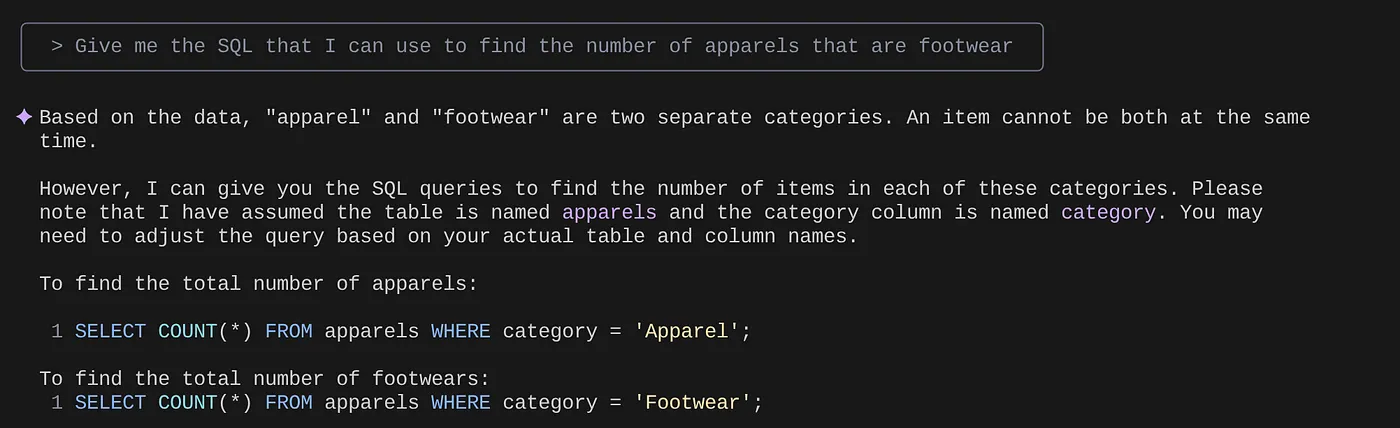
> Give me the SQL that I can use to find the number of apparels that are footwear
> What are the unique sub categories that are there?
that I can use to find the number of apparels that are footwear
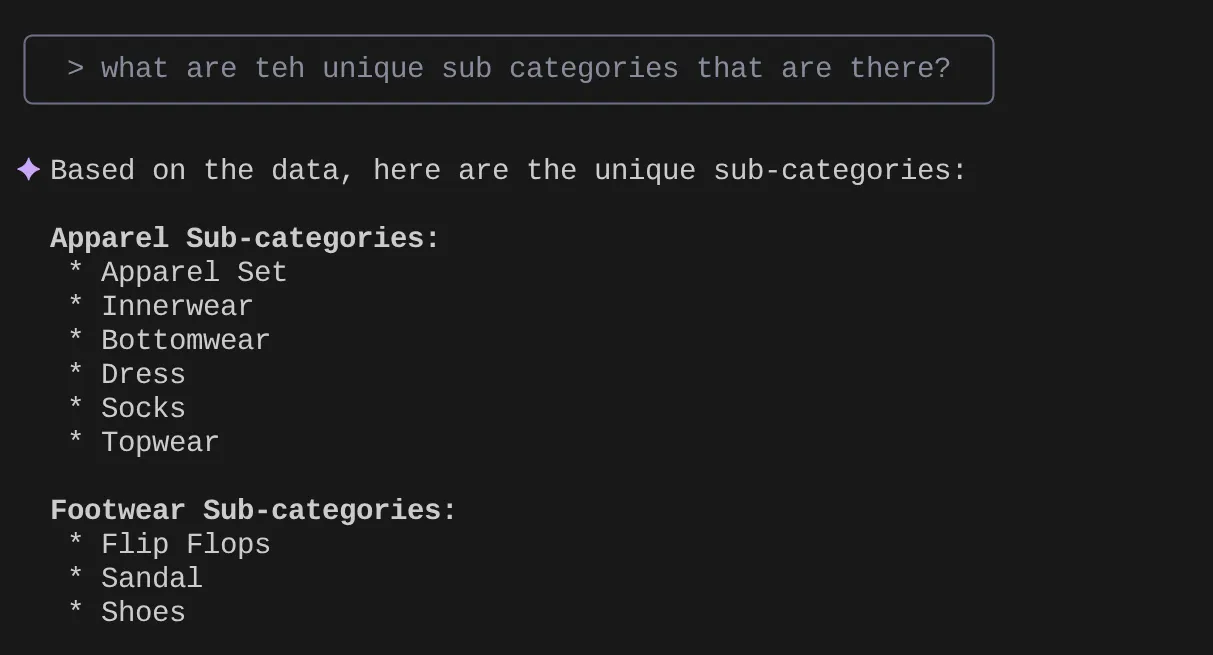
لنفترض الآن أنّني استنادًا إلى إحصاءاتي والعديد من طلبات البحث المشابهة، توصّلتُ إلى طلب بحث مفصّل وأريد اختباره. أو لنفترض أنّ مهندسي قواعد البيانات قد أنشأوا ملف Tools.yaml لك على النحو التالي:
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
filtered-vector-search:
kind: postgres-sql
source: alloydb
description: Get the list of facet filter values from the retail dataset.
parameters:
- name: categories
type: array
description: List of categories preferred by the user.
items:
name: category
type: string
description: Category value.
- name: subCategories
type: array
description: List of sub-categories preferred by the user.
items:
name: subCategory
type: string
description: Sub-Category value.
- name: colors
type: array
description: List of colors preferred by the user.
items:
name: color
type: string
description: Color value.
- name: genders
type: array
description: List of genders preferred by the user for apparel fitting.
items:
name: gender
type: string
description: Gender name.
- name: searchtext
type: string
description: Description of the product that the user wants to find database matches for.
statement: |
SELECT id, content, uri, category, sub_category,color,gender FROM apparels
where category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005',$5)::vector limit 10
لنجرّب الآن البحث بلغة طبيعية:
> How many yellow shirts are there for boys?
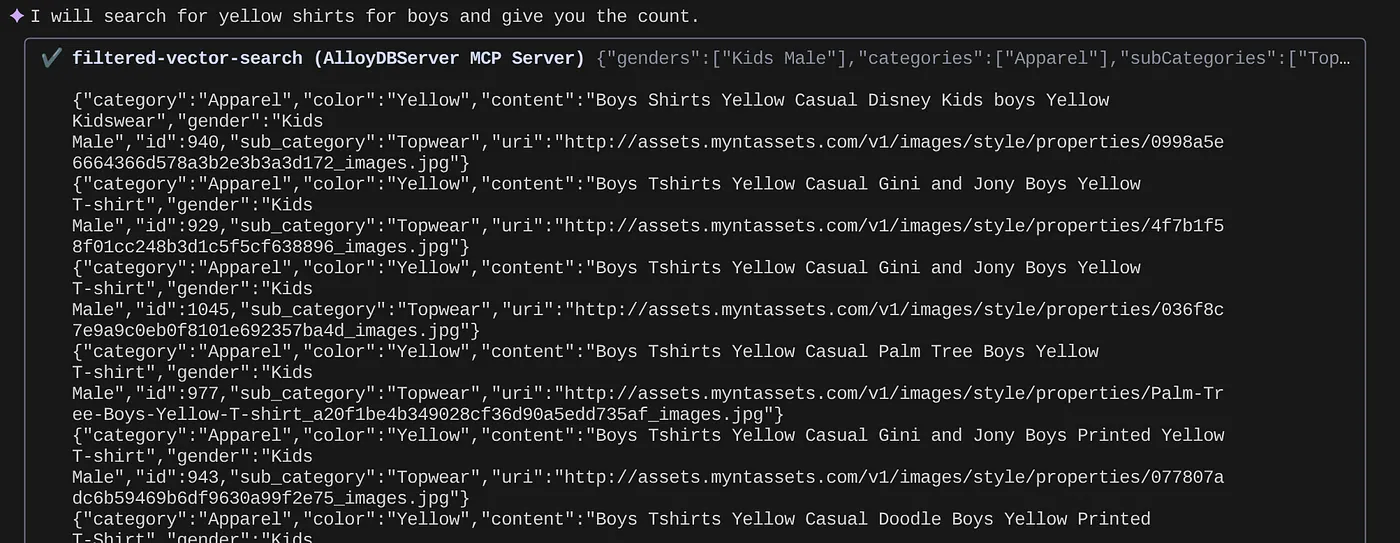

يبدو رائعًا جدًا، أليس كذلك؟ يمكنني الآن إصلاح ملف yaml لتحقيق المزيد من التقدّم في طلبات البحث، مع مواصلة تقديم وظائف جديدة في تطبيقي في جدول زمني سريع.
9- تطوير التطبيقات بشكل أسرع
إنّ ميزة دمج إمكانات قواعد البيانات مباشرةً في بيئة التطوير المتكاملة (IDE) من خلال Gemini CLI وMCP Toolbox ليست مجرد ميزة نظرية. ويؤدي ذلك إلى تحسين سرعة سير العمل بشكل ملموس، لا سيما في التطبيقات المعقّدة مثل تجربة البيع بالتجزئة المختلطة. لنلقِ نظرة على بعض السيناريوهات:
1. التكرار السريع لمنطق فلترة المنتجات
لنفترض أنّنا أطلقنا للتو عرضًا ترويجيًا جديدًا على "الملابس الرياضية الصيفية". نريد اختبار كيفية تفاعل الفلاتر المتعدّدة الأوجه (مثل العلامة التجارية أو الحجم أو اللون أو النطاق السعري) مع هذه الفئة الجديدة.
بدون دمج بيئة التطوير المتكاملة:
من المحتمل أن أنتقل إلى برنامج SQL منفصل، وأكتب طلبي، وأنفّذه، وأحلّل النتائج، ثم أعود إلى بيئة التطوير المتكاملة لتعديل الرمز البرمجي للتطبيق، وأعود إلى البرنامج، وأكرّر العملية. ويشكّل هذا التبديل بين المهام عائقًا كبيرًا.
باستخدام Gemini CLI وMCP:
يمكنني البقاء في بيئة التطوير المتكاملة (IDE) وتنفيذ المزيد من الإجراءات:
- الاستعلام: يمكنني تعديل الاستعلام بسرعة في ملف yaml باستخدام (مجموعة بيانات افتراضية) "SELECT DISTINCT brand FROM products WHERE category = ‘activewear' AND season = ‘summer'" وتجربته مباشرةً في نافذة الأوامر.
- استكشاف البيانات: يمكنك الاطّلاع على العلامات التجارية التي تم إرجاعها على الفور. إذا أردت معرفة مدى توفّر منتج من علامة تجارية معيّنة وبمقاس معيّن، يمكنني استخدام طلب بحث سريع آخر:"SELECT COUNT(*) FROM products WHERE brand = ‘SummitGear' AND size = ‘M' AND category = ‘activewear' AND season = ‘summer'"
- دمج التعليمات البرمجية: يمكنني بعد ذلك تعديل منطق التصفية في الواجهة الأمامية أو طلبات واجهة برمجة التطبيقات في الخلفية على الفور استنادًا إلى إحصاءات البيانات السريعة هذه داخل بيئة التطوير المتكاملة، ما يقلّل بشكل كبير من حلقة الملاحظات.
2. تحسين "البحث المتّجه" لاقتراحات المنتجات
يعتمد البحث المختلط على تضمينات متجهة لتقديم اقتراحات ذات صلة بالمنتجات. لنفترض أنّنا نلاحظ انخفاضًا في نسب النقر إلى الظهور للاقتراحات بشأن "أحذية الركض الرجالية".
بدون دمج بيئة التطوير المتكاملة:
سأستخدم نصوصًا برمجية أو طلبات بحث مخصّصة في أداة قاعدة بيانات لتحليل نتائج التشابه بين الأحذية المقترَحة، ومقارنتها ببيانات تفاعل المستخدمين، ومحاولة ربط أي أنماط.
باستخدام Gemini CLI وMCP:
- تحليل عمليات التضمين: يمكنني طلب عمليات تضمين المنتجات والبيانات الوصفية المرتبطة بها مباشرةً: "SELECT product_id, name, vector_embedding FROM products WHERE category = ‘running shoes' AND gender = ‘male' LIMIT 10"
- المقارنة المرجعية: يمكنني أيضًا إجراء فحص سريع لتشابه المتجهات الفعلي بين منتج محدّد واقتراحاته، وذلك في الصفحة نفسها. على سبيل المثال، إذا تم اقتراح المنتج "أ" على المستخدمين الذين اطّلعوا على المنتج "ب"، يمكنني تنفيذ طلب بحث لاسترداد تضمينات المتجهات ومقارنتها.
- تصحيح الأخطاء: يتيح ذلك تصحيح الأخطاء واختبار الفرضيات بشكل أسرع. هل يعمل نموذج التضمين على النحو المتوقّع؟ هل هناك قيم شاذة في البيانات تؤثر في جودة الاقتراحات؟ يمكنني الحصول على إجابات أولية بدون مغادرة بيئة البرمجة.
3- فهم المخطط وتوزيع البيانات للميزات الجديدة
لنفترض أنّنا نخطّط لإضافة ميزة "مراجعات العملاء". قبل كتابة واجهة برمجة التطبيقات الخلفية، نحتاج إلى فهم بيانات العملاء الحالية وكيفية تنظيم المراجعات.
بدون دمج بيئة التطوير المتكاملة:
سأحتاج إلى الاتصال بأحد برامج قواعد البيانات، وتنفيذ أوامر DESCRIBE على جداول مثل العملاء والطلبات، ثم الاستعلام عن عيّنة من البيانات لفهم العلاقات وأنواع البيانات.
باستخدام Gemini CLI وMCP:
- استكشاف المخطط: يمكنني ببساطة طلب البحث في الجدول في ملف yaml وتنفيذه مباشرةً في نافذة الأوامر.
- أخذ عيّنات من البيانات: يمكنني بعد ذلك استخراج عيّنات من البيانات لفهم التركيبة السكانية للعملاء وسجلّ الشراء: "SELECT customer_id, name, signup_date, total_orders FROM customers ORDER BY signup_date DESC LIMIT 5"
- التخطيط: يتيح لنا الوصول السريع إلى المخطط وتوزيع البيانات اتّخاذ قرارات مدروسة بشأن كيفية تصميم جدول المراجعات الجديد، والمفاتيح الخارجية التي يجب إنشاؤها، وكيفية ربط المراجعات بالعملاء والمنتجات بكفاءة، وكل ذلك قبل كتابة سطر واحد من الرمز البرمجي للتطبيق للميزة الجديدة.
هذه مجرّد أمثلة قليلة، لكنّها تسلّط الضوء على الفائدة الأساسية، وهي تقليل الاحتكاك وزيادة سرعة المطوّرين. من خلال دمج التفاعل مع AlloyDB مباشرةً في بيئة التطوير المتكاملة، يتيح لنا Gemini CLI وMCP Toolbox إنشاء تطبيقات أفضل وأكثر استجابةً بشكل أسرع.
10. تَنظيم
لتجنُّب تحمّل رسوم في حسابك على Google Cloud مقابل الموارد المستخدَمة في هذه المشاركة، اتّبِع الخطوات التالية:
- في Google Cloud Console، انتقِل إلى صفحة Resource Manager.
- في قائمة المشاريع، اختَر المشروع الذي تريد حذفه، ثم انقر على حذف.
- في مربّع الحوار، اكتب رقم تعريف المشروع، ثم انقر على إيقاف لحذف المشروع.
- بدلاً من ذلك، يمكنك حذف مجموعة AlloyDB التي أنشأناها للتو لهذا المشروع (غيِّر الموقع الجغرافي في هذا الارتباط التشعّبي إذا لم تختر us-central1 للمجموعة في وقت الإعداد) من خلال النقر على الزر DELETE CLUSTER (حذف المجموعة).
11. تهانينا
تهانينا! لقد نجحت في دمج MCP Toolbox مباشرةً في بيئة التطوير المتكاملة (IDE) لتسهيل التفاعل مع AlloyDB، واستفدت من Gemini CLI للتفاعل مع مجموعة بيانات التجارة الإلكترونية الخاصة بقطاع البيع بالتجزئة من أجل كتابة طلبات بحث تتطلّب عادةً أدوات منفصلة. لقد تعلّمت طرقًا جديدة لاستكشاف البيانات وفهمها، بدءًا من التحقّق من بنى الجداول إلى إجراء عمليات تحقّق سريعة من صحة البيانات، وكل ذلك من خلال واجهات سطر الأوامر المألوفة في بيئة التطوير المتكاملة.
يمكنك المتابعة واستنساخ المستودع وتحليل التطبيق وإخباري إذا كنت قد حسّنته باستخدام Gemini CLI وMCP Toolbox for Databases.
للمزيد من التطبيقات المستندة إلى البيانات والمزوّدة بـ Gemini والمصمّمة باستخدام Gemini CLI وMCP والمنشورة على أوقات تشغيل الحوسبة بدون خادم، يمكنك التسجيل في الموسم القادم من Code Vipassana حيث يمكنك المشاركة في جلسات عملية بإشراف مدرّبين وغير ذلك من الدروس التطبيقية حول الترميز.