
১. সংক্ষিপ্ত বিবরণ
অ্যালয়ডিবি (AlloyDB) ব্যবহার করে ফেসেটেড ফিল্টারিং এবং ভেক্টর সার্চের সমন্বয়ে একটি ডাইনামিক হাইব্রিড রিটেইল অভিজ্ঞতা তৈরির আমাদের যাত্রার কথা মনে আছে? সেই অ্যাপ্লিকেশনটি আধুনিক রিটেইলের চাহিদার একটি শক্তিশালী দৃষ্টান্ত ছিল, কিন্তু সেখানে পৌঁছানো এবং সেটিকে উন্নত করার জন্য উল্লেখযোগ্য পরিমাণ ডেভেলপমেন্ট প্রচেষ্টার প্রয়োজন হয়েছিল। ফুল-স্ট্যাক ডেভেলপারদের জন্য, কোড এডিটর এবং ডেটাবেস টুলের মধ্যে এই অবিরাম আসা-যাওয়া প্রায়শই একটি প্রতিবন্ধকতা হয়ে দাঁড়ায়, যা উদ্ভাবনকে ধীর করে দেয় এবং আপনার ডেটা বোঝার গুরুত্বপূর্ণ প্রক্রিয়াকে ব্যাহত করে।
সমাধান
ঠিক এখানেই ত্বরান্বিত অ্যাপ্লিকেশন ডেভেলপমেন্টের শক্তি তার আসল রূপ দেখায়, এবং একারণেই আমি আপনাদের সাথে শেয়ার করতে পেরে খুব আনন্দিত যে, কীভাবে সহজবোধ্য Gemini CLI-এর মাধ্যমে ব্যবহারযোগ্য MCP (মডার্ন ক্লাউড প্ল্যাটফর্ম) টুলবক্সটি আমার টুলকিটের একটি অপরিহার্য অংশ হয়ে উঠেছে। কল্পনা করুন, আপনি আপনার ইন্টিগ্রেটেড ডেভেলপমেন্ট এনভায়রনমেন্ট (IDE)-এর মধ্যেই নির্বিঘ্নে আপনার AlloyDB ইনস্ট্যান্সের সাথে ইন্টারঅ্যাক্ট করছেন, কোয়েরি লিখছেন এবং আপনার ডেটাসেট সম্পর্কে জানছেন। এটি কেবল সুবিধার বিষয় নয়; এটি ডেভেলপমেন্ট লাইফসাইকেলের বাধা-বিঘ্নকে মৌলিকভাবে কমিয়ে আনে, যা আপনাকে বাইরের টুল নিয়ে মাথা ঘামানোর পরিবর্তে উদ্ভাবনী ফিচার তৈরিতে মনোযোগ দিতে সাহায্য করে।
আমাদের রিটেইল ই-কমার্স অ্যাপের প্রেক্ষাপটে, যেখানে আমাদের দক্ষতার সাথে পণ্যের ডেটা কোয়েরি করা, জটিল ফিল্টারিং পরিচালনা করা এবং ভেক্টর সার্চের সূক্ষ্মতা কাজে লাগানোর প্রয়োজন ছিল, সেখানে ডাটাবেস ইন্টারঅ্যাকশনে দ্রুত পুনরাবৃত্তি করার ক্ষমতা অত্যন্ত গুরুত্বপূর্ণ ছিল। জেমিনি সিএলআই দ্বারা চালিত এমসিপি টুলবক্স এই কাজটিকে কেবল সহজই করে না, বরং গতিও বাড়ায়, যা আমাদের অ্যাপ্লিকেশনগুলোর ভিত্তি হিসেবে থাকা ডাটাবেস লজিক অন্বেষণ, পরীক্ষা এবং পরিমার্জন করার পদ্ধতিকে রূপান্তরিত করে। চলুন জেনে নেওয়া যাক, কীভাবে এই যুগান্তকারী সমন্বয় ফুল-স্ট্যাক ডেভেলপমেন্টকে আরও দ্রুত, স্মার্ট এবং আনন্দদায়ক করে তুলছে।
আপনি যা শিখবেন ও গড়ে তুলবেন
জেমিনি সিএলআই দ্বারা চালিত এবং আইডিই-এর মধ্যে থাকা এমসিপি টুলবক্স ব্যবহার করে একটি রিটেইল সার্চ অ্যাপ্লিকেশন । আমরা আলোচনা করব:
- নির্বিঘ্ন AlloyDB ইন্টারঅ্যাকশনের জন্য কীভাবে MCP টুলবক্স সরাসরি আপনার IDE-তে ইন্টিগ্রেট করবেন।
- আপনার রিটেইল ডেটার উপর SQL কোয়েরি লেখা ও কার্যকর করার জন্য Gemini CLI ব্যবহারের বাস্তব উদাহরণ।
- আমাদের রিটেইল ই-কমার্স ডেটাসেটের সাথে কাজ করতে জেমিনি সিএলআই (Gemini CLI) ব্যবহার করুন; এমন সব কোয়েরি লিখুন যার জন্য সাধারণত আলাদা টুলের প্রয়োজন হয়, এবং ফলাফল সঙ্গে সঙ্গে দেখুন।
- আমাদের IDE-এর পরিচিত কমান্ড-লাইন ইন্টারফেসের মাধ্যমেই ডেটা বিশ্লেষণ ও বোঝার নতুন উপায় আবিষ্কার করুন — টেবিলের কাঠামো পরীক্ষা করা থেকে শুরু করে ডেটার দ্রুত যৌক্তিকতা যাচাই পর্যন্ত।
- কীভাবে এই ত্বরান্বিত ডাটাবেস ওয়ার্কফ্লো সরাসরি ফুল-স্ট্যাক ডেভেলপমেন্ট চক্রকে দ্রুততর করতে সাহায্য করে, যা দ্রুত প্রোটোটাইপিং এবং পুনরাবৃত্তির সুযোগ করে দেয়।
টেকস্ট্যাক
আমরা ব্যবহার করছি:
- ডাটাবেসের জন্য অ্যালয়ডিবি
- অ্যাপ্লিকেশন থেকে ডেটাবেসের উন্নত জেনারেটিভ এবং এআই বৈশিষ্ট্যগুলোকে বিমূর্ত করার জন্য এমসিপি টুলবক্স
- সার্ভারবিহীন ডেপ্লয়মেন্টের জন্য ক্লাউড রান।
- রিটেইল ই-কমার্স অ্যাপ্লিকেশনের ডেটাসেট বোঝা ও বিশ্লেষণ করা এবং ডেটাবেস অংশ তৈরি করার জন্য জেমিনি সিএলআই ব্যবহার করা হয়।
প্রয়োজনীয়তা
- ক্রোম বা ফায়ারফক্সের মতো একটি ব্রাউজার
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট।
২. শুরু করার আগে
একটি প্রকল্প তৈরি করুন
- গুগল ক্লাউড কনসোলের প্রজেক্ট সিলেক্টর পেজে, একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন।
- আপনার ক্লাউড প্রোজেক্টের জন্য বিলিং চালু আছে কিনা তা নিশ্চিত করুন। কোনো প্রোজেক্টে বিলিং চালু আছে কিনা তা কীভাবে পরীক্ষা করবেন, তা জেনে নিন।
- আপনি ক্লাউড শেল ব্যবহার করবেন, যা গুগল ক্লাউডে চালিত একটি কমান্ড-লাইন পরিবেশ। গুগল ক্লাউড কনসোলের শীর্ষে থাকা ‘Activate Cloud Shell’-এ ক্লিক করুন।

- ক্লাউড শেলে সংযুক্ত হওয়ার পর, আপনি নিম্নলিখিত কমান্ডটি ব্যবহার করে যাচাই করে নিন যে আপনি ইতিমধ্যেই প্রমাণীকৃত এবং প্রজেক্টটি আপনার প্রজেক্ট আইডিতে সেট করা আছে:
gcloud auth list
- gcloud কমান্ডটি আপনার প্রজেক্ট সম্পর্কে অবগত আছে কিনা, তা নিশ্চিত করতে ক্লাউড শেলে নিম্নলিখিত কমান্ডটি চালান।
gcloud config list project
- আপনার প্রজেক্টটি সেট করা না থাকলে, এটি সেট করতে নিম্নলিখিত কমান্ডটি ব্যবহার করুন:
gcloud config set project <YOUR_PROJECT_ID>
- প্রয়োজনীয় এপিআইগুলো সক্রিয় করুন: লিঙ্কটি অনুসরণ করুন এবং এপিআইগুলো সক্রিয় করুন।
বিকল্পভাবে আপনি এর জন্য gcloud কমান্ড ব্যবহার করতে পারেন। gcloud কমান্ড এবং এর ব্যবহার সম্পর্কে জানতে ডকুমেন্টেশন দেখুন।
৩. ডাটাবেস সেটআপ
এই ল্যাবে আমরা ই-কমার্স ডেটার ডেটাবেস হিসেবে অ্যালয়ডিবি (AlloyDB) ব্যবহার করব। এটি ডেটাবেস এবং লগের মতো সমস্ত রিসোর্স ধারণ করার জন্য ক্লাস্টার ব্যবহার করে। প্রতিটি ক্লাস্টারে একটি প্রাইমারি ইনস্ট্যান্স থাকে যা ডেটাতে অ্যাক্সেস পয়েন্ট সরবরাহ করে। টেবিলগুলোতে প্রকৃত ডেটা থাকবে।
চলুন একটি AlloyDB ক্লাস্টার, ইনস্ট্যান্স এবং টেবিল তৈরি করি যেখানে ইকমার্স ডেটাসেটটি লোড করা হবে।
একটি ক্লাস্টার এবং ইনস্ট্যান্স তৈরি করুন
- ক্লাউড কনসোলে AlloyDB পেজটিতে যান। ক্লাউড কনসোলের বেশিরভাগ পেজ খুঁজে পাওয়ার একটি সহজ উপায় হলো কনসোলের সার্চ বার ব্যবহার করে সেগুলোর জন্য অনুসন্ধান করা।
- সেই পৃষ্ঠা থেকে CREATE CLUSTER নির্বাচন করুন:

- আপনি নীচেরটির মতো একটি স্ক্রিন দেখতে পাবেন। নিম্নলিখিত মানগুলি দিয়ে একটি ক্লাস্টার এবং ইনস্ট্যান্স তৈরি করুন (আপনি যদি রিপো থেকে অ্যাপ্লিকেশন কোড ক্লোন করেন তবে নিশ্চিত করুন যে মানগুলি মিলে যায়):
- ক্লাস্টার আইডি : "
vector-cluster" - পাসওয়ার্ড : "
alloydb" - PostgreSQL 15 / সর্বশেষ সংস্করণ সুপারিশ করা হচ্ছে
- অঞ্চল : "
us-central1" - নেটওয়ার্কিং : "
default"
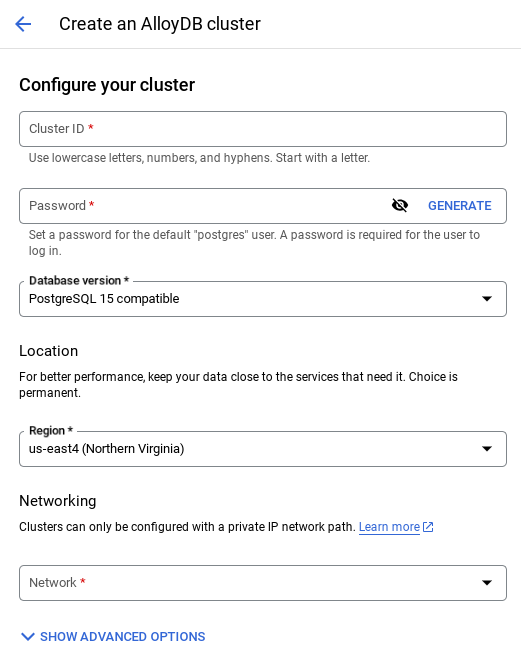
- আপনি যখন ডিফল্ট নেটওয়ার্ক নির্বাচন করবেন, তখন নিচের স্ক্রিনের মতো একটি স্ক্রিন দেখতে পাবেন।
সংযোগ স্থাপন নির্বাচন করুন।
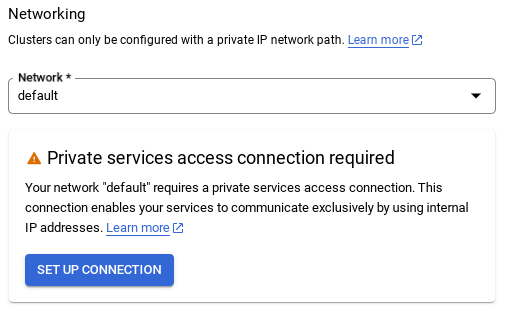
- সেখান থেকে, " Use an automatically allocated IP range " নির্বাচন করুন এবং Continue নির্বাচন করুন। তথ্য পর্যালোচনা করার পর, CREATE CONNECTION নির্বাচন করুন।
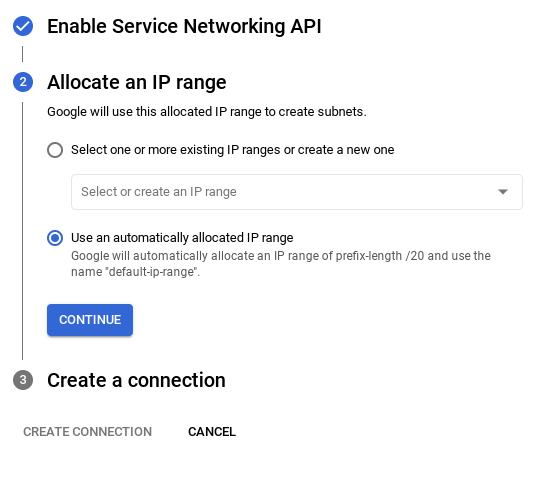
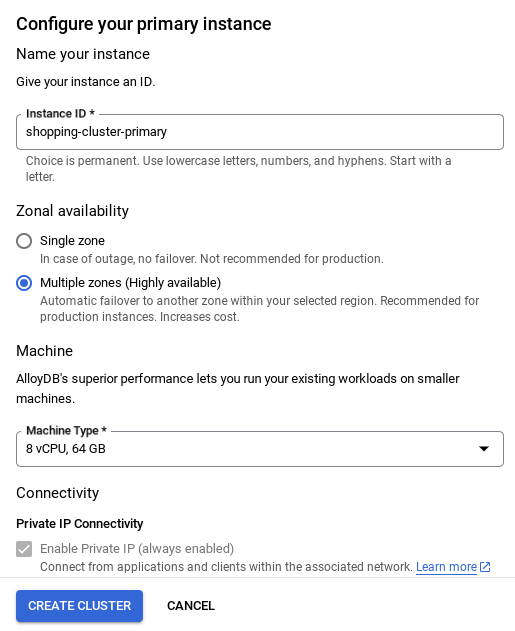
- আপনার নেটওয়ার্ক সেট আপ হয়ে গেলে, আপনি আপনার ক্লাস্টার তৈরি করা চালিয়ে যেতে পারেন। নিচে দেখানো অনুযায়ী ক্লাস্টার সেট আপ সম্পন্ন করতে CREATE CLUSTER-এ ক্লিক করুন:
গুরুত্বপূর্ণ দ্রষ্টব্য:
- ক্লাস্টার / ইনস্ট্যান্স কনফিগার করার সময় আপনি যে ইনস্ট্যান্স আইডিটি পাবেন, সেটি পরিবর্তন করে **
vector-instance** করতে ভুলবেন না। যদি আপনি এটি পরিবর্তন করতে না পারেন, তাহলে পরবর্তী সমস্ত রেফারেন্সে **আপনার ইনস্ট্যান্স আইডি** ব্যবহার করতে মনে রাখবেন। - মনে রাখবেন, ক্লাস্টার তৈরি হতে প্রায় ১০ মিনিট সময় লাগবে। এটি সফল হলে, আপনি আপনার তৈরি করা ক্লাস্টারের একটি সার্বিক চিত্র দেখতে পাবেন।
৪. ডেটা গ্রহণ
এখন স্টোর সম্পর্কিত ডেটা সহ একটি টেবিল যোগ করার সময় এসেছে। AlloyDB-তে যান, প্রাইমারি ক্লাস্টার নির্বাচন করুন এবং তারপর AlloyDB Studio-তে যান:
আপনার ইনস্ট্যান্সটি তৈরি হওয়া শেষ না হওয়া পর্যন্ত আপনাকে অপেক্ষা করতে হতে পারে। এটি তৈরি হয়ে গেলে, ক্লাস্টার তৈরির সময় আপনি যে ক্রেডেনশিয়ালগুলো তৈরি করেছিলেন, সেগুলো ব্যবহার করে AlloyDB-তে সাইন ইন করুন। PostgreSQL-এ প্রমাণীকরণের জন্য নিম্নলিখিত ডেটা ব্যবহার করুন:
- ব্যবহারকারীর নাম : "
postgres" - ডাটাবেস : "
postgres" - পাসওয়ার্ড : "
alloydb"
AlloyDB Studio-তে সফলভাবে প্রমাণীকরণের পর, এডিটর-এ SQL কমান্ডগুলো প্রবেশ করানো হয়। শেষ উইন্ডোটির ডানদিকে থাকা প্লাস চিহ্নটি ব্যবহার করে আপনি একাধিক এডিটর উইন্ডো যোগ করতে পারেন।
আপনি এডিটর উইন্ডোতে AlloyDB-এর জন্য কমান্ড লিখবেন এবং প্রয়োজন অনুযায়ী Run, Format ও Clear অপশনগুলো ব্যবহার করবেন।
এক্সটেনশনগুলি সক্ষম করুন
এই অ্যাপটি তৈরি করার জন্য, আমরা pgvector এবং google_ml_integration এক্সটেনশনগুলো ব্যবহার করব। pgvector এক্সটেনশনটি আপনাকে ভেক্টর এমবেডিং সংরক্ষণ এবং অনুসন্ধান করার সুযোগ দেয়। google_ml_integration এক্সটেনশনটি এমন সব ফাংশন সরবরাহ করে যা ব্যবহার করে আপনি Vertex AI প্রেডিকশন এন্ডপয়েন্টগুলো অ্যাক্সেস করে SQL-এ প্রেডিকশন পেতে পারেন। নিম্নলিখিত DDL-গুলো রান করে এই এক্সটেনশনগুলো সক্রিয় করুন :
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
আপনার ডাটাবেসে কোন এক্সটেনশনগুলো সক্রিয় করা হয়েছে তা পরীক্ষা করতে চাইলে, এই SQL কমান্ডটি চালান:
select extname, extversion from pg_extension;
একটি টেবিল তৈরি করুন
আপনি AlloyDB Studio-তে নিচের DDL স্টেটমেন্টটি ব্যবহার করে একটি টেবিল তৈরি করতে পারেন:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
এমবেডিং কলামটি টেক্সটের ভেক্টর মানগুলো সংরক্ষণের সুযোগ দেবে।
অনুমতি প্রদান করুন
'embedding' ফাংশনটিতে execute অনুমোদন দিতে নিচের স্টেটমেন্টটি চালান:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB পরিষেবা অ্যাকাউন্টে Vertex AI ব্যবহারকারীর ROLE প্রদান করুন।
Google Cloud IAM কনসোল থেকে, AlloyDB সার্ভিস অ্যাকাউন্টকে (যা দেখতে এইরকম: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) "Vertex AI User" রোলের অ্যাক্সেস দিন। PROJECT_NUMBER-এ আপনার প্রজেক্ট নম্বরটি থাকবে।
বিকল্পভাবে আপনি ক্লাউড শেল টার্মিনাল থেকে নিচের কমান্ডটি চালাতে পারেন:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
ডাটাবেসে ডেটা লোড করুন
- শীটে থাকা
insert scripts sqlথেকেinsertকোয়েরি স্টেটমেন্টগুলো উপরে উল্লিখিত এডিটরে কপি করুন। এই ব্যবহারের ক্ষেত্রটির একটি দ্রুত ডেমোর জন্য আপনি ১০-৫০টি ইনসার্ট স্টেটমেন্ট কপি করতে পারেন। এখানে 'Selected Inserts 25-30 rows' ট্যাবে ইনসার্টগুলোর একটি নির্বাচিত তালিকা রয়েছে । - রান-এ ক্লিক করুন। আপনার কোয়েরির ফলাফল রেজাল্টস টেবিলে প্রদর্শিত হবে।
গুরুত্বপূর্ণ দ্রষ্টব্য:
ইনসার্ট করার জন্য শুধু ২৫-৫০টি রেকর্ড কপি করুন এবং নিশ্চিত করুন যে সেগুলো ক্যাটাগরি, সাব-ক্যাটাগরি, রঙ ও লিঙ্গ ধরনের একটি নির্দিষ্ট পরিসর থেকে নেওয়া হয়েছে।
৫. ডেটার জন্য এমবেডিং তৈরি করুন
আধুনিক অনুসন্ধানের প্রকৃত উদ্ভাবন শুধু কীওয়ার্ড বোঝার মধ্যে নয়, বরং অর্থ অনুধাবন করার মধ্যে নিহিত। এখানেই এমবেডিং এবং ভেক্টর সার্চের ভূমিকা শুরু হয়।
আমরা প্রি-ট্রেইনড ল্যাঙ্গুয়েজ মডেল ব্যবহার করে পণ্যের বিবরণ এবং ব্যবহারকারীর কোয়েরিগুলোকে 'এম্বেডিংস' নামক উচ্চ-মাত্রিক সাংখ্যিক উপস্থাপনায় রূপান্তরিত করেছি। এই এম্বেডিংসগুলো শব্দার্থগত অর্থ ধারণ করে, যা আমাদেরকে শুধুমাত্র একই রকম শব্দ থাকার পরিবর্তে 'অর্থে সাদৃশ্যপূর্ণ' পণ্য খুঁজে পেতে সাহায্য করে। প্রাথমিকভাবে, আমরা একটি বেসলাইন স্থাপনের জন্য এই এম্বেডিংসগুলোর উপর সরাসরি ভেক্টর সিমিলারিটি সার্চ নিয়ে পরীক্ষা চালিয়েছি, যা পারফরম্যান্স অপটিমাইজেশনের আগেও শব্দার্থগত উপলব্ধির শক্তি প্রদর্শন করে।
'embedding' কলামটি পণ্যের বিবরণের টেক্সটের ভেক্টর মান সংরক্ষণের সুযোগ দেবে। 'img_embeddings' কলামটি ইমেজ এমবেডিং (মাল্টিমোডাল) সংরক্ষণের সুযোগ দেবে। এভাবে আপনি টেক্সট ও ইমেজের দূরত্বের ওপর ভিত্তি করে সার্চও করতে পারবেন। কিন্তু এই ল্যাবে আমরা শুধু টেক্সট এমবেডিং ব্যবহার করব।
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
এটি কোয়েরিতে থাকা নমুনা টেক্সটের জন্য এমবেডিংস ভেক্টরটি রিটার্ন করবে, যা ফ্লোট সংখ্যার একটি অ্যারের মতো দেখতে। এটি দেখতে এইরকম:
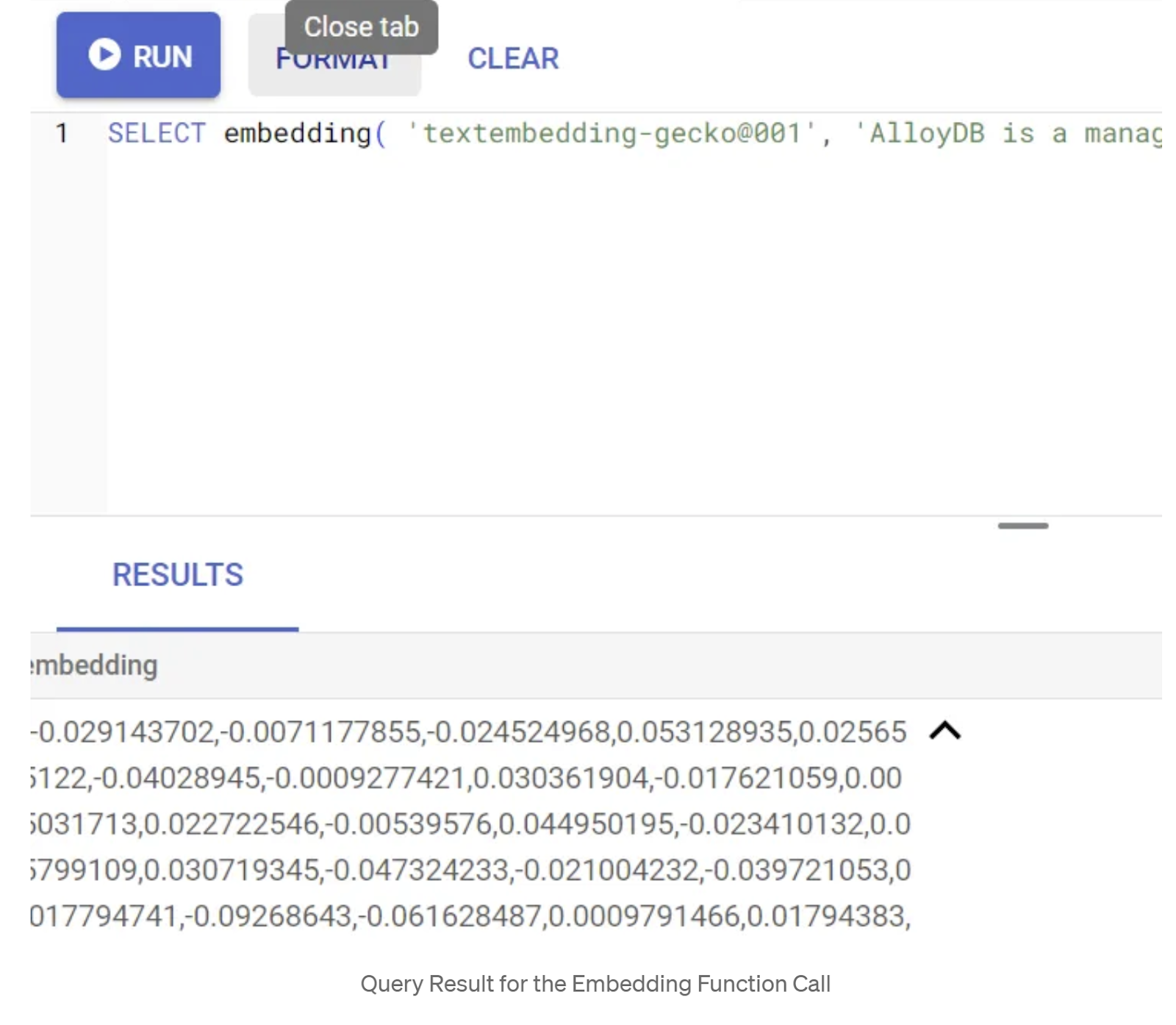
abstract_embeddings ভেক্টর ফিল্ডটি আপডেট করুন
টেবিলের বিষয়বস্তুর বিবরণ সংশ্লিষ্ট এমবেডিং দিয়ে আপডেট করতে নিচের DML-টি চালান:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
আপনি যদি গুগল ক্লাউডের জন্য একটি ট্রায়াল ক্রেডিট বিলিং অ্যাকাউন্ট ব্যবহার করেন, তাহলে কয়েকটি এমবেডিং (ধরুন সর্বোচ্চ ২০-২৫টি) তৈরি করতে আপনার সমস্যা হতে পারে। তাই ইনসার্ট স্ক্রিপ্টে সারির সংখ্যা সীমিত রাখুন।
আপনি যদি ইমেজ এমবেডিং তৈরি করতে চান (মাল্টিমোডাল কনটেক্সচুয়াল সার্চ করার জন্য), তাহলে নিচের আপডেটটিও চালান:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
৬. এমসিপি টুলবক্স ফর ডেটাবেস (অ্যালয়ডিবি)
নেপথ্যে, শক্তিশালী টুলিং এবং একটি সুগঠিত অ্যাপ্লিকেশন মসৃণ কার্যক্রম নিশ্চিত করে।
ডেটাবেসের জন্য এমসিপি (মডেল কনটেক্সট প্রোটোকল) টুলবক্স অ্যালয়ডিবি-র সাথে জেনারেটিভ এআই এবং এজেন্টিক টুলগুলির ইন্টিগ্রেশনকে সহজ করে তোলে। এটি একটি ওপেন-সোর্স সার্ভার হিসেবে কাজ করে যা কানেকশন পুলিং, অথেনটিকেশন এবং এআই এজেন্ট বা অন্যান্য অ্যাপ্লিকেশনের কাছে ডেটাবেসের কার্যকারিতাগুলির নিরাপদ প্রকাশকে সুবিন্যস্ত করে।
আমাদের অ্যাপ্লিকেশনে, আমরা সকল ইন্টেলিজেন্ট হাইব্রিড সার্চ কোয়েরির জন্য একটি অ্যাবস্ট্রাকশন লেয়ার হিসেবে MCP টুলবক্স ফর ডেটাবেস ব্যবহার করেছি।
আমাদের ব্যবহারের জন্য টুলবক্স সেট আপ ও স্থাপন করতে নিচের ধাপগুলো অনুসরণ করুন:
আপনি দেখতে পাচ্ছেন যে, MCP Toolbox for Databases দ্বারা সমর্থিত ডেটাবেসগুলোর মধ্যে AlloyDB অন্যতম এবং যেহেতু আমরা পূর্ববর্তী বিভাগে এটি ইতিমধ্যে প্রস্তুত করে ফেলেছি, চলুন এবার টুলবক্সটি সেট আপ করা যাক।
- আপনার ক্লাউড শেল টার্মিনালে যান এবং নিশ্চিত করুন যে আপনার প্রজেক্টটি নির্বাচিত আছে এবং টার্মিনালের প্রম্পটে প্রদর্শিত হচ্ছে। আপনার প্রজেক্ট ডিরেক্টরিতে প্রবেশ করতে ক্লাউড শেল টার্মিনাল থেকে নিচের কমান্ডটি চালান:
mkdir gemini-cli-project
cd gemini-cli-project
- আপনার নতুন ফোল্ডারে টুলবক্স ডাউনলোড ও ইনস্টল করতে নিচের কমান্ডটি চালান:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
এটি আপনার বর্তমান ডিরেক্টরিতে টুলবক্সটি তৈরি করবে। টুলবক্সটির পাথ কপি করুন।
- ক্লাউড শেল এডিটর (কোড এডিট মোডের জন্য) এ যান এবং প্রোজেক্ট রুট ফোল্ডার 'gemini-cli-project'-এ 'tools.yaml' নামে একটি ফাইল যোগ করুন।
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
চলুন tools.yaml ফাইলটি বুঝি:
সোর্স হলো আপনার বিভিন্ন ডেটা সোর্স, যেগুলোর সাথে একটি টুল ইন্টারঅ্যাক্ট করতে পারে। একটি সোর্স এমন একটি ডেটা সোর্সকে বোঝায় যার সাথে একটি টুল ইন্টারঅ্যাক্ট করতে পারে। আপনি আপনার tools.yaml ফাইলের sources সেকশনে সোর্সগুলোকে একটি ম্যাপ হিসেবে সংজ্ঞায়িত করতে পারেন। সাধারণত, একটি সোর্স কনফিগারেশনে ডাটাবেসের সাথে সংযোগ স্থাপন এবং ইন্টারঅ্যাক্ট করার জন্য প্রয়োজনীয় সমস্ত তথ্য থাকে।
টুলগুলো এজেন্টের বিভিন্ন কাজ নির্ধারণ করে – যেমন কোনো সোর্স থেকে ডেটা পড়া বা তাতে লেখা। একটি টুল আপনার এজেন্টের একটি কাজকে বোঝায়, যেমন একটি SQL স্টেটমেন্ট চালানো। আপনি আপনার tools.yaml ফাইলের tools সেকশনে টুলগুলোকে একটি ম্যাপ হিসেবে সংজ্ঞায়িত করতে পারেন। সাধারণত, কোনো টুলের কাজ করার জন্য একটি সোর্সের প্রয়োজন হয়।
আপনার tools.yaml কনফিগার করার বিষয়ে আরও বিস্তারিত জানতে এই ডকুমেন্টেশনটি দেখুন।
উপরে Tools.yaml ফাইলে যেমন দেখতে পাচ্ছেন, 'get-apparels' টুলটি ডাটাবেস থেকে সমস্ত পোশাকের বিবরণ তালিকাভুক্ত করে।
৭. জেমিনি সিএলআই সেট আপ করুন
ক্লাউড শেল এডিটর থেকে, gemini-cli-project ফোল্ডারের ভিতরে .gemini নামে একটি নতুন ফোল্ডার তৈরি করুন এবং এর ভিতরে settings.json নামে একটি নতুন ফাইল তৈরি করুন।
{
"mcpServers": {
"AlloyDBServer": {
"command": "/home/user/gemini-cli-project/toolbox",
"args": ["--tools-file", "tools.yaml", "--stdio"]
}
}
}
উপরের কোড স্নিপেটের কমান্ড সেকশনে, ' /home/user/gemini-cli-project/toolbox " এর জায়গায় আপনার টুলবক্সের পাথটি বসান।
Gemini CLI ইনস্টল করুন
অবশেষে ক্লাউড শেল টার্মিনাল থেকে, নিম্নলিখিত কমান্ডটি চালিয়ে gemini-cli-project নামক একই ডিরেক্টরিতে Gemini CLI ইনস্টল করুন:
sudo npm install -g @google/gemini-cli
আপনার প্রজেক্ট আইডি সেট করুন
নিশ্চিত করুন যে এনভায়রনমেন্টে সক্রিয় প্রজেক্ট আইডি সেট করা আছে:
export GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT_ID>>
Gemini CLI দিয়ে শুরু করুন
কমান্ড লাইন থেকে, এই কমান্ডটি প্রবেশ করান:
gemini
আপনি নীচের মতো একটি প্রতিক্রিয়া দেখতে পাবেন:
প্রমাণীকরণ করুন এবং পরবর্তী ধাপে এগিয়ে যান।
৮. জেমিনি সিএলআই-এর সাথে যোগাযোগ শুরু করুন।
কনফিগার করা এমসিপি সার্ভারগুলোর তালিকা দেখতে /mcp কমান্ডটি ব্যবহার করুন।
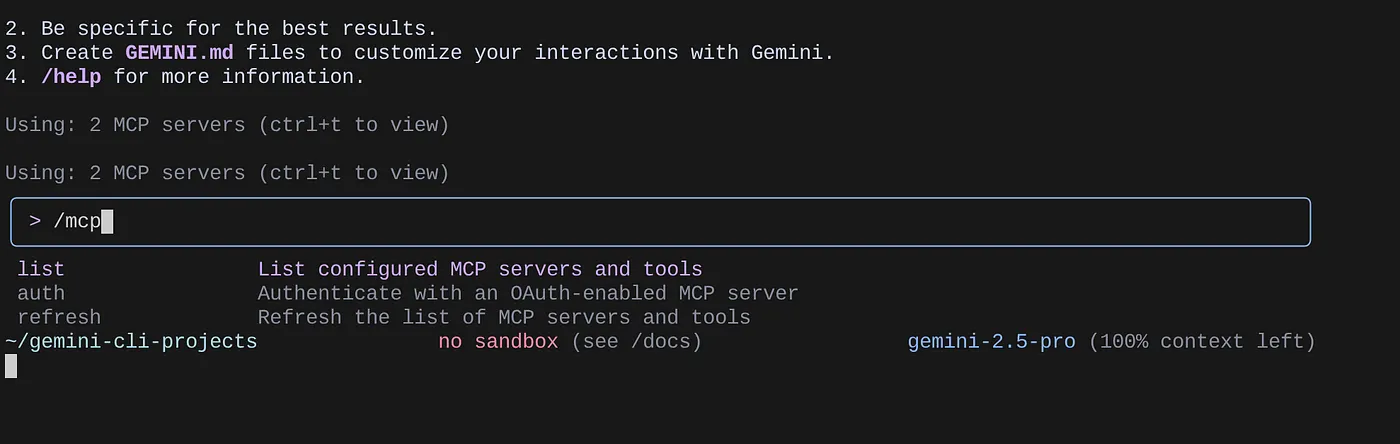
আপনি আমাদের কনফিগার করা দুটি এমসিপি সার্ভার—গিটহাব এবং এমসিপি টুলবক্স ফর ডেটাবেসেস—তাদের টুলগুলোসহ তালিকাভুক্ত দেখতে পাবেন।
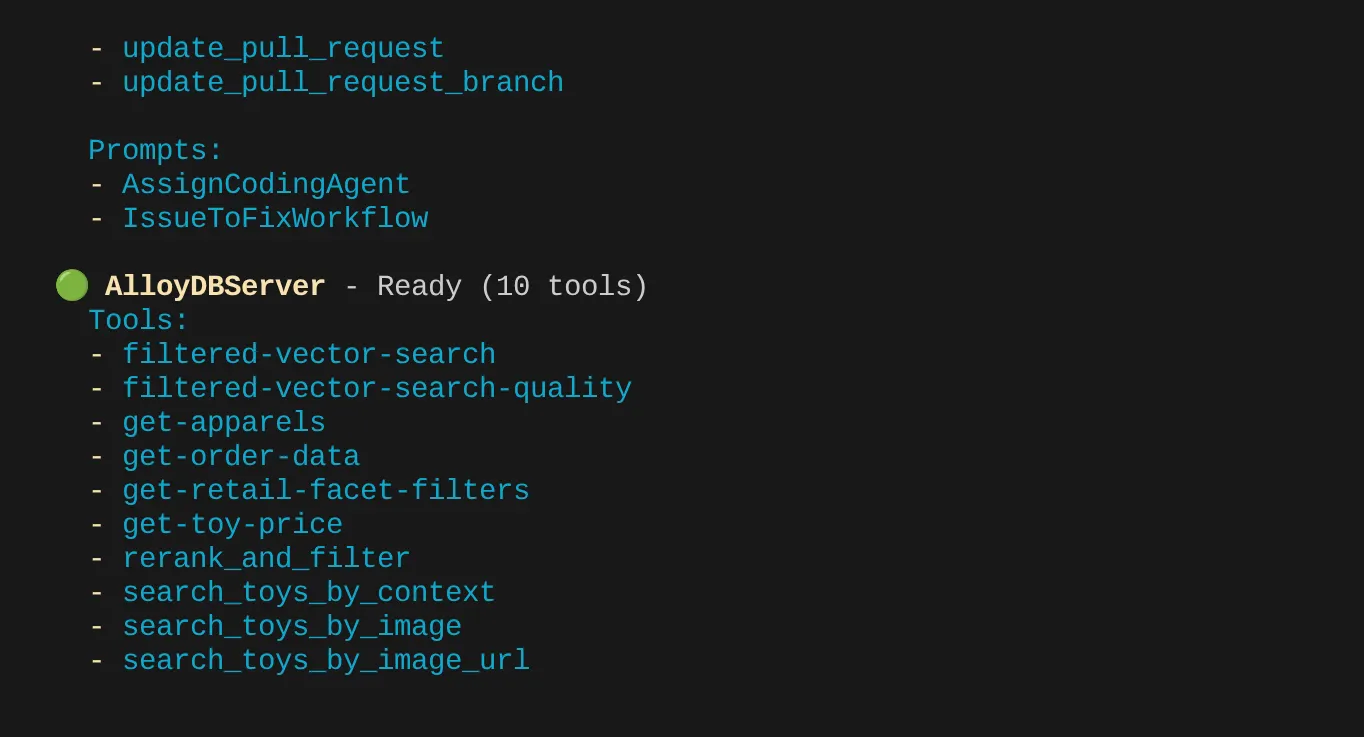
আমার ক্ষেত্রে আরও টুল আছে। তাই আপাতত এটা উপেক্ষা করুন। আপনি আপনার AlloyDB MCP সার্ভারে get-apparels টুলটি দেখতে পাবেন।
MCP টুলবক্সের মাধ্যমে ডাটাবেস কোয়েরি করা শুরু করুন।
এখন আমরা যে ডেটাসেটটি নিয়ে কাজ করছি, তার জন্য প্রতিক্রিয়া এবং কোয়েরি সংগ্রহ করতে স্বাভাবিক ভাষার প্রশ্ন জিজ্ঞাসা করার চেষ্টা করুন:
> How many types of genders the apparel dataset has?
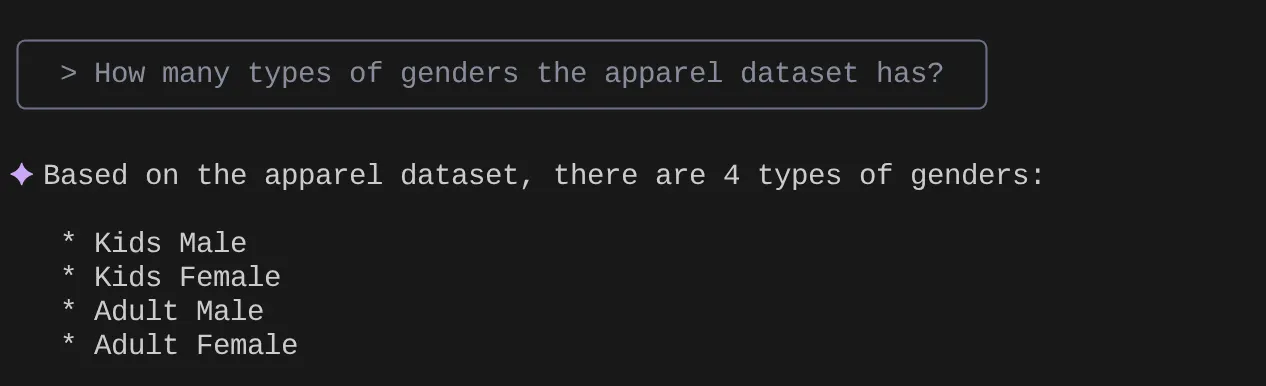
> Give me the SQL that I can use to find the number of apparels that are footwear
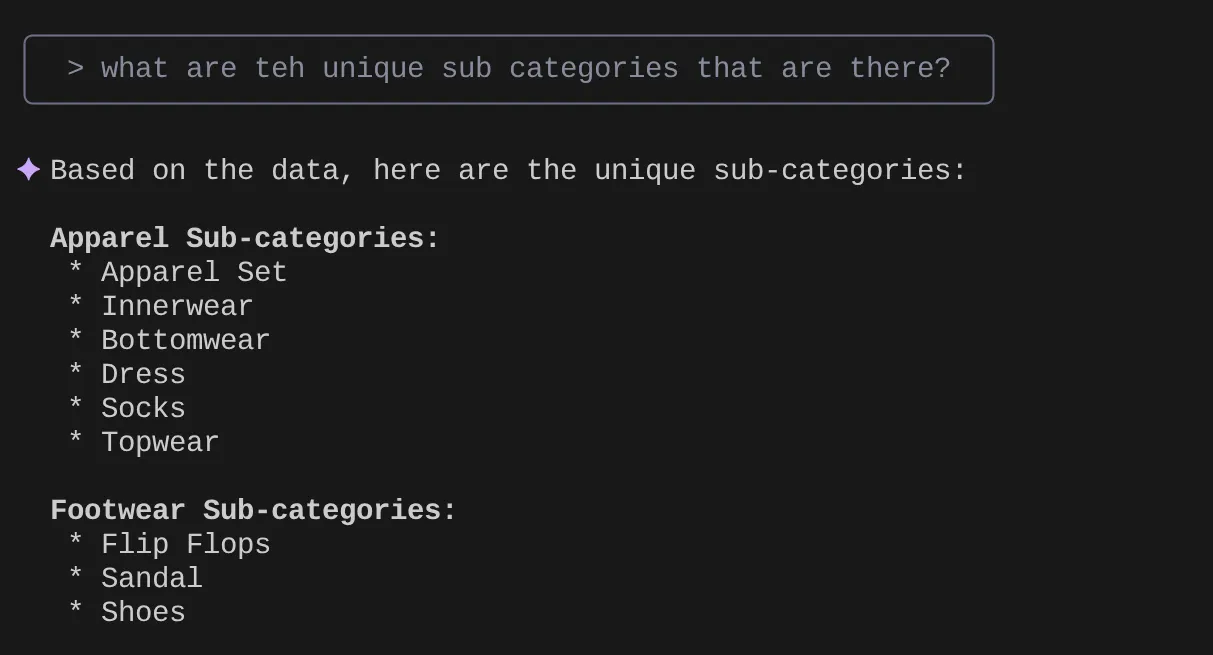
> What are the unique sub categories that are there?
that I can use to find the number of apparels that are footwear
এখন ধরা যাক, আমার পর্যবেক্ষণ এবং এই ধরনের অনেক কোয়েরির উপর ভিত্তি করে আমি একটি বিস্তারিত কোয়েরি তৈরি করেছি এবং সেটি পরীক্ষা করে দেখতে চাই। অথবা ধরা যাক, ডাটাবেস ইঞ্জিনিয়াররা ইতিমধ্যেই আপনার জন্য নিচের মতো Tools.yaml ফাইলটি তৈরি করে রেখেছেন:
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
filtered-vector-search:
kind: postgres-sql
source: alloydb
description: Get the list of facet filter values from the retail dataset.
parameters:
- name: categories
type: array
description: List of categories preferred by the user.
items:
name: category
type: string
description: Category value.
- name: subCategories
type: array
description: List of sub-categories preferred by the user.
items:
name: subCategory
type: string
description: Sub-Category value.
- name: colors
type: array
description: List of colors preferred by the user.
items:
name: color
type: string
description: Color value.
- name: genders
type: array
description: List of genders preferred by the user for apparel fitting.
items:
name: gender
type: string
description: Gender name.
- name: searchtext
type: string
description: Description of the product that the user wants to find database matches for.
statement: |
SELECT id, content, uri, category, sub_category,color,gender FROM apparels
where category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005',$5)::vector limit 10
এবার স্বাভাবিক ভাষায় অনুসন্ধান করে দেখা যাক:
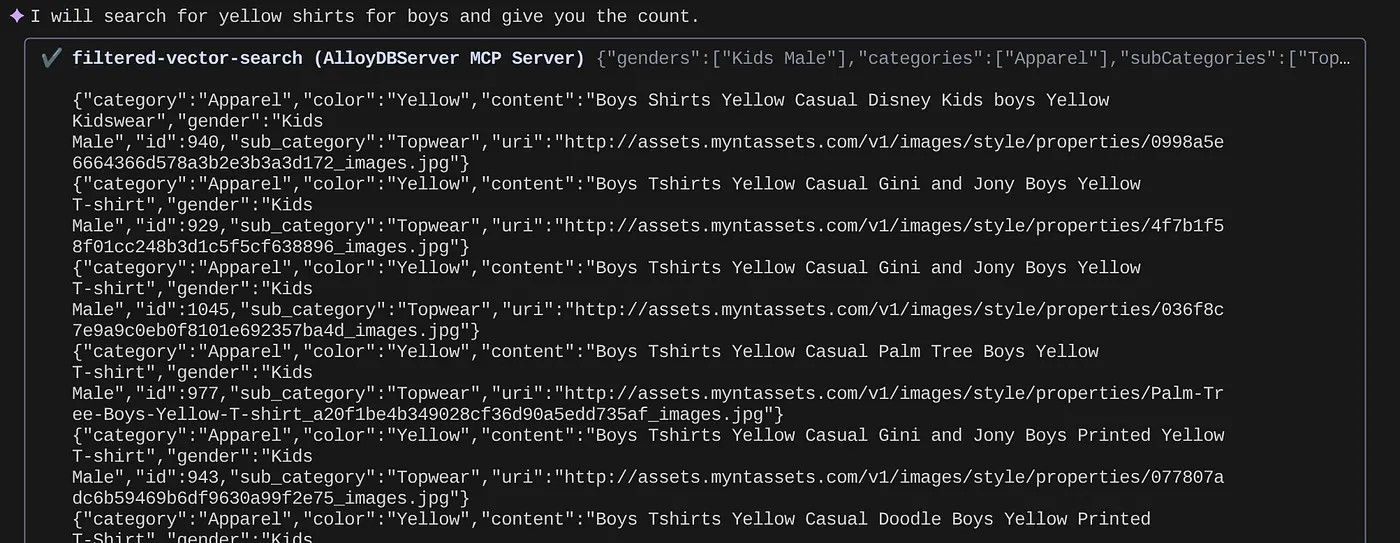
> How many yellow shirts are there for boys?

বেশ দারুণ, তাই না? এখন আমি আরও দ্রুত সময়ে আমার অ্যাপ্লিকেশনে নতুন কার্যকারিতা যোগ করার পাশাপাশি কোয়েরিগুলোর আরও উন্নতির জন্য YAML ফাইলটি ঠিক করতে পারব।
৯. দ্রুত অ্যাপ ডেভেলপমেন্ট
Gemini CLI এবং MCP টুলবক্সের মাধ্যমে সরাসরি আপনার IDE-তে ডাটাবেস সক্ষমতা নিয়ে আসার সুবিধাটি কেবল তাত্ত্বিক নয়। এটি বাস্তবিক এবং গতি-বর্ধক ওয়ার্কফ্লোতে রূপান্তরিত হয়, বিশেষ করে আমাদের হাইব্রিড রিটেইল অভিজ্ঞতার মতো একটি জটিল অ্যাপ্লিকেশনের ক্ষেত্রে। চলুন কয়েকটি পরিস্থিতি দেখা যাক:
১. পণ্য ফিল্টারিং লজিকের দ্রুত পুনরাবৃত্তি
ধরুন, আমরা এইমাত্র 'গ্রীষ্মকালীন অ্যাক্টিভ-ওয়্যার'-এর জন্য একটি নতুন প্রোমোশন চালু করেছি। আমরা পরীক্ষা করে দেখতে চাই যে আমাদের ফেসেটেড ফিল্টারগুলো (যেমন, ব্র্যান্ড, সাইজ, রঙ, মূল্যসীমা অনুযায়ী) এই নতুন ক্যাটাগরির সাথে কীভাবে কাজ করে।
IDE ইন্টিগ্রেশন ছাড়া:
সম্ভবত আমাকে একটি আলাদা SQL ক্লায়েন্টে যেতে হতো, আমার কোয়েরি লিখতে হতো, সেটি চালাতে হতো, ফলাফল বিশ্লেষণ করতে হতো, অ্যাপ্লিকেশন কোড ঠিক করার জন্য আমার IDE-তে ফিরে যেতে হতো, আবার ক্লায়েন্টে ফিরে আসতে হতো এবং এই প্রক্রিয়াটি পুনরাবৃত্তি করতে হতো। এই ঘন ঘন কাজের পরিবর্তন (কন্টেক্সট-সুইচিং) খুবই বিরক্তিকর।
জেমিনি সিএলআই এবং এমসিপি সহ:
আমি আমার IDE-তেই থাকতে পারি এবং আরও অনেক কিছু:
- কোয়েরি করা: আমি দ্রুত yaml-এ (কাল্পনিক ডেটাসেট) "SELECT DISTINCT brand FROM products WHERE category = 'activewear' AND season = 'summer'" কোয়েরিটি আপডেট করে সরাসরি আমার টার্মিনালে চেষ্টা করে দেখতে পারি।
- ডেটা অন্বেষণ: ফেরত আসা ব্র্যান্ডগুলো তাৎক্ষণিকভাবে দেখুন। যদি আমাকে কোনো নির্দিষ্ট ব্র্যান্ড এবং সাইজের পণ্যের প্রাপ্যতা দেখতে হয়, তাহলে আরেকটি দ্রুত কোয়েরিই যথেষ্ট: "SELECT COUNT(*) FROM products WHERE brand = 'SummitGear' AND size = 'M' AND category = 'activewear' AND season = 'summer'"
- কোড ইন্টিগ্রেশন: এর ফলে আমি IDE-এর মধ্যেই পাওয়া এই দ্রুত ডেটা তথ্যের উপর ভিত্তি করে তাৎক্ষণিকভাবে ফ্রন্ট-এন্ড ফিল্টারিং লজিক বা ব্যাকএন্ড API কলগুলো পরিবর্তন করতে পারি, যা ফিডব্যাক লুপকে উল্লেখযোগ্যভাবে কমিয়ে দেয়।
২. পণ্যের সুপারিশের জন্য ভেক্টর অনুসন্ধানের সূক্ষ্ম সমন্বয়
আমাদের হাইব্রিড সার্চ প্রাসঙ্গিক পণ্যের সুপারিশের জন্য ভেক্টর এমবেডিং-এর উপর নির্ভর করে। ধরা যাক, আমরা 'পুরুষদের দৌড়ানোর জুতো' সংক্রান্ত সুপারিশগুলোর ক্লিক-থ্রু রেটে একটি পতন দেখতে পাচ্ছি।
IDE ইন্টিগ্রেশন ছাড়া:
আমি সুপারিশকৃত জুতাগুলোর সাদৃশ্য স্কোর বিশ্লেষণ করতে, সেগুলোকে ব্যবহারকারীর ইন্টারঅ্যাকশন ডেটার সাথে তুলনা করতে এবং কোনো প্যাটার্নের মধ্যে সম্পর্ক খুঁজে বের করার চেষ্টা করতে একটি ডাটাবেস টুলে কাস্টম স্ক্রিপ্ট বা কোয়েরি চালাব।
জেমিনি সিএলআই এবং এমসিপি সহ:
- এমবেডিং বিশ্লেষণ: আমি সরাসরি পণ্যের এমবেডিং এবং এর সাথে সম্পর্কিত মেটাডেটা কোয়েরি করতে পারি: "SELECT product_id, name, vector_embedding FROM products WHERE category = 'running shoes' AND gender = 'male' LIMIT 10"
- ক্রস-রেফারেন্সিং: আমি সেখানেই একটি নির্বাচিত পণ্য এবং তার সুপারিশগুলোর মধ্যে প্রকৃত ভেক্টর সাদৃশ্য দ্রুত যাচাই করে নিতে পারি। উদাহরণস্বরূপ, যদি পণ্য A এমন ব্যবহারকারীদের কাছে সুপারিশ করা হয় যারা পণ্য B দেখেছেন, তাহলে আমি তাদের ভেক্টর এমবেডিংগুলো পুনরুদ্ধার এবং তুলনা করার জন্য একটি কোয়েরি চালাতে পারি।
- ডিবাগিং: এর মাধ্যমে দ্রুত ডিবাগিং এবং হাইপোথিসিস টেস্টিং করা যায়। এমবেডিং মডেলটি কি প্রত্যাশা অনুযায়ী কাজ করছে? ডেটাতে কি এমন কোনো অসঙ্গতি আছে যা সুপারিশের মানকে প্রভাবিত করে? আমি আমার কোডিং পরিবেশ থেকে বের না হয়েই প্রাথমিক উত্তরগুলো পেতে পারি।
৩. নতুন ফিচারের জন্য স্কিমা এবং ডেটা ডিস্ট্রিবিউশন বোঝা
ধরা যাক, আমরা একটি 'গ্রাহক পর্যালোচনা' ফিচার যোগ করার পরিকল্পনা করছি। ব্যাকএন্ড এপিআই লেখার আগে, আমাদের বিদ্যমান গ্রাহক ডেটা এবং পর্যালোচনাগুলো কীভাবে সাজানো থাকতে পারে, তা বুঝতে হবে।
IDE ইন্টিগ্রেশন ছাড়া:
সম্পর্ক এবং ডেটার ধরণ বোঝার জন্য আমাকে একটি ডাটাবেস ক্লায়েন্টের সাথে সংযোগ স্থাপন করতে হবে, customers এবং orders-এর মতো টেবিলগুলিতে DESCRIBE কমান্ড চালাতে হবে এবং তারপরে নমুনা ডেটার জন্য কোয়েরি করতে হবে।
জেমিনি সিএলআই এবং এমসিপি সহ:
- স্কিমা অন্বেষণ: আমি খুব সহজেই yaml ফাইলের টেবিলটি কোয়েরি করতে এবং সরাসরি টার্মিনালে তা চালাতে পারি।
- ডেটা স্যাম্পলিং: এরপর আমি গ্রাহকের জনসংখ্যাতাত্ত্বিক তথ্য এবং ক্রয়ের ইতিহাস বোঝার জন্য নমুনা ডেটা নিতে পারি: "SELECT customer_id, name, signup_date, total_orders FROM customers ORDER BY signup_date DESC LIMIT 5"
- পরিকল্পনা: স্কিমা এবং ডেটা ডিস্ট্রিবিউশনে এই দ্রুত অ্যাক্সেস আমাদের নতুন ফিচারটির জন্য এক লাইন অ্যাপ্লিকেশন কোড লেখার আগেই, নতুন রিভিউ টেবিলটি কীভাবে ডিজাইন করতে হবে, কী কী ফরেন কী স্থাপন করতে হবে এবং কীভাবে দক্ষতার সাথে রিভিউগুলোকে গ্রাহক ও পণ্যের সাথে লিঙ্ক করতে হবে, সে সম্পর্কে সুচিন্তিত সিদ্ধান্ত নিতে সাহায্য করে।
এগুলো মাত্র কয়েকটি উদাহরণ, কিন্তু এগুলো মূল সুবিধাটিকেই তুলে ধরে: বাধা কমানো এবং ডেভেলপারদের কাজের গতি বাড়ানো। AlloyDB-এর সাথে ইন্টারঅ্যাকশন সরাসরি IDE-তে নিয়ে আসার মাধ্যমে, Gemini CLI এবং MCP টুলবক্স আমাদেরকে আরও উন্নত ও দ্রুত রেসপন্সিভ অ্যাপ্লিকেশন তৈরি করতে সক্ষম করে।
১০. পরিষ্কার করুন
এই পোস্টে ব্যবহৃত রিসোর্সগুলোর জন্য আপনার গুগল ক্লাউড অ্যাকাউন্টে চার্জ হওয়া এড়াতে, এই ধাপগুলো অনুসরণ করুন:
- গুগল ক্লাউড কনসোলে, রিসোর্স ম্যানেজার পৃষ্ঠায় যান।
- প্রজেক্ট তালিকা থেকে, আপনি যে প্রজেক্টটি মুছতে চান সেটি নির্বাচন করুন এবং তারপর ডিলিট বোতামে ক্লিক করুন।
- ডায়ালগ বক্সে প্রজেক্ট আইডি টাইপ করুন এবং তারপর প্রজেক্টটি মুছে ফেলার জন্য 'শাট ডাউন'-এ ক্লিক করুন।
- বিকল্পভাবে, আপনি DELETE CLUSTER বোতামে ক্লিক করে এই প্রজেক্টের জন্য আমাদের তৈরি করা AlloyDB ক্লাস্টারটি মুছে ফেলতে পারেন (কনফিগারেশনের সময় ক্লাস্টারের জন্য us-central1 নির্বাচন না করে থাকলে এই হাইপারলিঙ্কে অবস্থান পরিবর্তন করুন)।
১১. অভিনন্দন
অভিনন্দন! আপনি নির্বিঘ্নে AlloyDB ব্যবহারের জন্য সফলভাবে MCP টুলবক্স সরাসরি আপনার IDE-তে ইন্টিগ্রেট করেছেন এবং আমাদের রিটেইল ই-কমার্স ডেটাসেটের সাথে কাজ করার জন্য Gemini CLI ব্যবহার করে এমন সব কোয়েরি লিখেছেন, যার জন্য সাধারণত আলাদা টুলের প্রয়োজন হতো। আপনি আমাদের IDE-র পরিচিত কমান্ড-লাইন ইন্টারফেসের মাধ্যমেই ডেটা পরীক্ষা ও বোঝার নতুন নতুন উপায় শিখেছেন — যেমন টেবিলের গঠন পরীক্ষা করা থেকে শুরু করে দ্রুত ডেটার যৌক্তিকতা যাচাই করা পর্যন্ত।
রেপোটি ক্লোন করে বিশ্লেষণ করুন এবং Gemini CLI ও MCP Toolbox for Databases ব্যবহার করে অ্যাপ্লিকেশনটি উন্নত করেছেন কিনা, তা আমাকে জানান।
Gemini CLI ও MCP দিয়ে তৈরি এবং সার্ভারলেস রানটাইমে ডেপ্লয় করা এই ধরনের আরও ডেটা-ড্রাইভেন অ্যাপ্লিকেশনের জন্য, আমাদের আসন্ন কোড বিপাসনা সিজনের জন্য রেজিস্টার করুন, যেখানে আপনি পাবেন প্রশিক্ষক-পরিচালিত হ্যান্ডস-অন সেশন এবং এই ধরনের আরও কোডল্যাব!!!