
1. Übersicht
Erinnern Sie sich an unser Projekt zur Entwicklung einer dynamischen hybriden Einzelhandelsanwendung mit AlloyDB, in der Facettenfilterung und Vektorsuche kombiniert werden? Diese Anwendung war ein eindrucksvolles Beispiel für die Anforderungen des modernen Einzelhandels. Die Entwicklung und Iteration war jedoch mit erheblichem Aufwand verbunden. Für Full-Stack-Entwickler kann das ständige Hin- und Herwechseln zwischen Code-Editoren und Datenbanktools oft ein Engpass sein, der Innovationen und den wichtigen Prozess des Verständnisses Ihrer Daten verlangsamt.
Lösung
Genau hier zeigt sich das Potenzial der beschleunigten Anwendungsentwicklung. Deshalb freue ich mich, Ihnen zu zeigen, wie die MCP (Modern Cloud Platform) Toolbox, auf die über die intuitive Gemini CLI zugegriffen werden kann, zu einem unverzichtbaren Bestandteil meiner Tools geworden ist. Stellen Sie sich vor, Sie könnten nahtlos mit Ihrer AlloyDB-Instanz interagieren, Abfragen schreiben und Ihr Dataset verstehen – alles direkt in Ihrer integrierten Entwicklungsumgebung (IDE). Es geht nicht nur um Komfort, sondern darum, die Reibung im Entwicklungszyklus grundlegend zu reduzieren, damit Sie sich auf die Entwicklung innovativer Funktionen konzentrieren können, anstatt sich mit externen Tools herumzuschlagen.
Im Kontext unserer E-Commerce-App für den Einzelhandel, in der wir Produktdaten effizient abfragen, komplexe Filterungen verarbeiten und die Nuancen der Vektorsuche nutzen mussten, war die Möglichkeit, Datenbankinteraktionen schnell zu wiederholen, von entscheidender Bedeutung. Die MCP Toolbox, die auf der Gemini CLI basiert, vereinfacht diesen Prozess nicht nur, sondern beschleunigt ihn auch. So können wir die Datenbanklogik, die unseren Anwendungen zugrunde liegt, auf ganz neue Weise untersuchen, testen und optimieren. Sehen wir uns an, wie diese bahnbrechende Kombination die Full-Stack-Entwicklung schneller, intelligenter und angenehmer macht.
Lerninhalte und Aufgaben
Eine Retail Search-Anwendung, die die MCP Toolbox in der IDE nutzt und von der Gemini CLI unterstützt wird. Die Informationen umfassen:
- So binden Sie die MCP Toolbox direkt in Ihre IDE ein, um nahtlos mit AlloyDB zu interagieren.
- Praktische Beispiele für die Verwendung der Gemini CLI zum Schreiben und Ausführen von SQL-Abfragen für Ihre Einzelhandelsdaten.
- Mit der Gemini CLI können Sie mit unserem E-Commerce-Dataset für den Einzelhandel interagieren und Abfragen schreiben, für die normalerweise separate Tools erforderlich wären. Die Ergebnisse werden sofort angezeigt.
- Entdecken Sie neue Möglichkeiten, Daten zu untersuchen und zu analysieren – von der Überprüfung von Tabellenstrukturen bis hin zur Durchführung schneller Datenintegritätsprüfungen – alles über vertraute Befehlszeilenschnittstellen in unserer IDE.
- Wie dieser beschleunigte Datenbankworkflow direkt zu schnelleren Full-Stack-Entwicklungszyklen beiträgt und so schnelles Prototyping und Iterieren ermöglicht.
Techstack
Wir verwenden:
- AlloyDB for PostgreSQL
- MCP Toolbox zum Abstrahieren erweiterter generativer und KI-Funktionen von Datenbanken aus der Anwendung
- Cloud Run für die serverlose Bereitstellung.
- Gemini CLI zum Analysieren des Datasets und zum Erstellen des Datenbankteils der E-Commerce-Anwendung für den Einzelhandel verwenden
Voraussetzungen
2. Hinweis
Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
- Sie verwenden Cloud Shell, eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird. Klicken Sie oben in der Google Cloud Console auf „Cloud Shell aktivieren“.

- Sobald die Verbindung mit der Cloud Shell hergestellt ist, prüfen Sie mit dem folgenden Befehl, ob Sie bereits authentifiziert sind und für das Projekt schon Ihre Projekt-ID eingestellt ist:
gcloud auth list
- Führen Sie den folgenden Befehl in Cloud Shell aus, um zu bestätigen, dass der gcloud-Befehl Ihr Projekt kennt.
gcloud config list project
- Wenn Ihr Projekt nicht festgelegt ist, verwenden Sie den folgenden Befehl, um es festzulegen:
gcloud config set project <YOUR_PROJECT_ID>
- Aktivieren Sie die erforderlichen APIs: Folgen Sie dem Link und aktivieren Sie die APIs.
Alternativ können Sie dazu den gcloud-Befehl verwenden. Informationen zu gcloud-Befehlen und deren Verwendung finden Sie in der Dokumentation.
3. Datenbank einrichten
In diesem Lab verwenden wir AlloyDB als Datenbank für die E-Commerce-Daten. Darin werden Cluster verwendet, um alle Ressourcen wie Datenbanken und Logs zu speichern. Jeder Cluster hat eine primäre Instanz, die einen Zugriffspunkt auf die Daten bietet. Tabellen enthalten die tatsächlichen Daten.
Wir erstellen jetzt einen AlloyDB-Cluster, eine AlloyDB-Instanz und eine AlloyDB-Tabelle, in die das E-Commerce-Dataset geladen wird.
Cluster und Instanz erstellen
- Rufen Sie in der Cloud Console die AlloyDB-Seite auf. Die meisten Seiten in der Cloud Console lassen sich ganz einfach über die Suchleiste der Console finden.
- Wählen Sie auf dieser Seite CLUSTER ERSTELLEN aus:

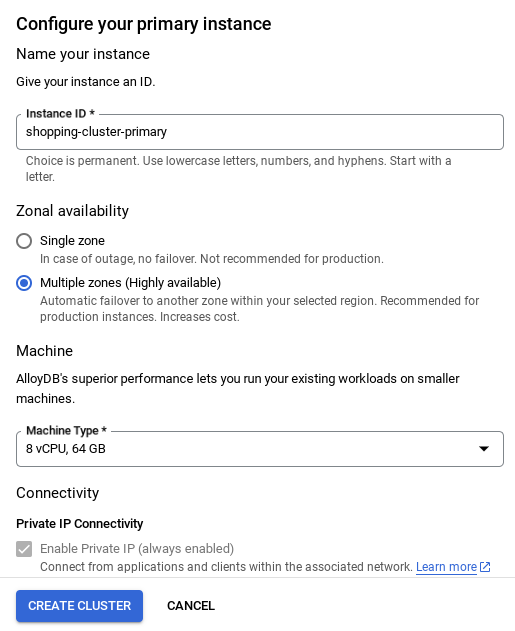
- Sie sehen dann einen Bildschirm wie den folgenden. Erstellen Sie einen Cluster und eine Instanz mit den folgenden Werten. Achten Sie darauf, dass die Werte übereinstimmen, wenn Sie den Anwendungscode aus dem Repository klonen:
- Cluster-ID: „
vector-cluster“ - password: "
alloydb" - PostgreSQL 15 / neueste empfohlene Version
- Region: "
us-central1" - Netzwerk: „
default“
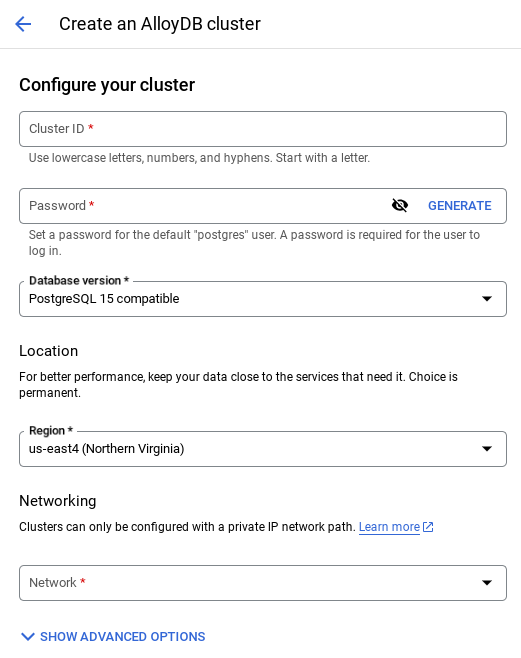
- Wenn Sie das Standardnetzwerk auswählen, wird ein Bildschirm wie der unten angezeigt.
Wählen Sie Verbindung einrichten aus.
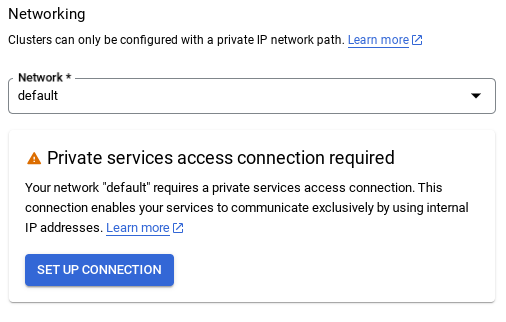
- Wählen Sie dort Automatisch zugewiesenen IP-Bereich verwenden aus und klicken Sie auf „Weiter“. Nachdem Sie die Informationen geprüft haben, wählen Sie „VERBINDUNG ERSTELLEN“ aus.
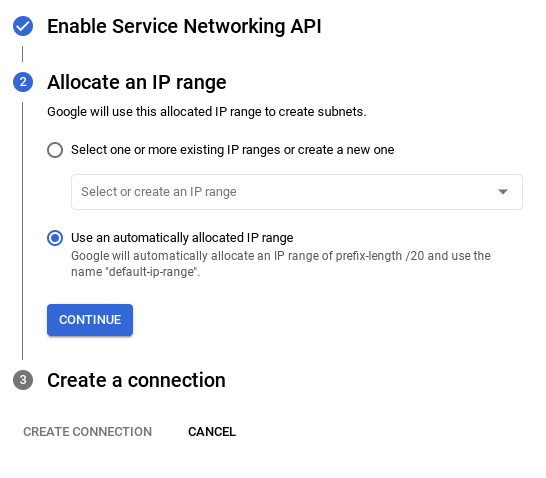
- Nachdem Sie Ihr Netzwerk eingerichtet haben, können Sie mit der Clustererstellung fortfahren. Klicken Sie auf CLUSTER ERSTELLEN, um die Einrichtung des Clusters abzuschließen (siehe unten):
WICHTIGER HINWEIS:
- Achten Sie darauf, die Instanz-ID zu ändern (die Sie bei der Konfiguration des Clusters / der Instanz finden) in**
vector-instance**. Wenn Sie sie nicht ändern können, denken Sie daran, **Ihre Instanz-ID** in allen nachfolgenden Referenzen zu verwenden. - Die Clustererstellung dauert etwa 10 Minuten. Nach erfolgreicher Ausführung sollte ein Bildschirm mit der Übersicht des gerade erstellten Clusters angezeigt werden.
4. Datenaufnahme
Jetzt ist es an der Zeit, eine Tabelle mit den Daten zum Geschäft hinzuzufügen. Rufen Sie AlloyDB auf, wählen Sie den primären Cluster und dann AlloyDB Studio aus:
Möglicherweise müssen Sie warten, bis die Instanz erstellt wurde. Melden Sie sich dann mit den Anmeldedaten in AlloyDB an, die Sie beim Erstellen des Clusters erstellt haben. Verwenden Sie die folgenden Daten für die Authentifizierung bei PostgreSQL:
- Nutzername: „
postgres“ - Datenbank: „
postgres“ - Passwort: „
alloydb“
Nachdem Sie sich erfolgreich in AlloyDB Studio authentifiziert haben, werden SQL-Befehle im Editor eingegeben. Sie können mehrere Editorfenster hinzufügen, indem Sie auf das Pluszeichen rechts neben dem letzten Fenster klicken.
Sie geben Befehle für AlloyDB in Editorfenstern ein und verwenden bei Bedarf die Optionen „Ausführen“, „Formatieren“ und „Löschen“.
Erweiterungen aktivieren
Für die Entwicklung dieser App verwenden wir die Erweiterungen pgvector und google_ml_integration. Mit der pgvector-Erweiterung können Sie Vektoreinbettungen speichern und durchsuchen. Die Erweiterung google_ml_integration bietet Funktionen, mit denen Sie auf Vertex AI-Vorhersageendpunkte zugreifen können, um Vorhersagen in SQL zu erhalten. Aktivieren Sie diese Erweiterungen, indem Sie die folgenden DDLs ausführen:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Wenn Sie prüfen möchten, welche Erweiterungen für Ihre Datenbank aktiviert wurden, führen Sie diesen SQL-Befehl aus:
select extname, extversion from pg_extension;
Tabelle erstellen
Sie können eine Tabelle mit der folgenden DDL-Anweisung in AlloyDB Studio erstellen:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
In der Einbettungsspalte können die Vektorwerte des Texts gespeichert werden.
Berechtigung gewähren
Führen Sie die folgende Anweisung aus, um die Ausführung der Funktion „embedding“ zu gewähren:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB-Dienstkonto die Rolle „Vertex AI User“ gewähren
Gewähren Sie in der Google Cloud IAM-Konsole dem AlloyDB-Dienstkonto (das so aussieht: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) Zugriff auf die Rolle „Vertex AI-Nutzer“. PROJECT_NUMBER enthält Ihre Projektnummer.
Alternativ können Sie den folgenden Befehl im Cloud Shell-Terminal ausführen:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Daten in die Datenbank laden
- Kopieren Sie die
insert-Abfrageanweisungen aus deminsert scripts sqlim Tabellenblatt in den Editor. Sie können 10 bis 50 INSERT-Anweisungen kopieren, um diesen Anwendungsfall schnell zu demonstrieren. Eine ausgewählte Liste mit Einfügungen finden Sie auf dem Tab „Ausgewählte Einfügungen (25–30 Zeilen)“. - Klicken Sie auf Ausführen. Die Ergebnisse Ihrer Abfrage werden in der Tabelle Ergebnisse angezeigt.
WICHTIGER HINWEIS:
Kopieren Sie nur 25 bis 50 Datensätze zum Einfügen und achten Sie darauf, dass sie aus einem Bereich von Kategorie-, Unterkategorie-, Farb- und Geschlechtstypen stammen.
5. Einbettungen für die Daten erstellen
Die eigentliche Innovation bei der modernen Suche liegt darin, die Bedeutung zu verstehen, nicht nur die Keywords. Hier kommen Einbettungen und die Vektorsuche ins Spiel.
Wir haben Produktbeschreibungen und Nutzeranfragen mithilfe vortrainierter Sprachmodelle in hochdimensionale numerische Darstellungen, sogenannte „Embeddings“, umgewandelt. Diese Einbettungen erfassen die semantische Bedeutung, sodass wir Produkte finden können, die „ähnlich in der Bedeutung“ sind, anstatt nur Produkte mit übereinstimmenden Wörtern. Zuerst haben wir mit der direkten Suche nach Vektorähnlichkeiten für diese Einbettungen experimentiert, um eine Baseline zu erstellen. So konnten wir die Leistungsfähigkeit des semantischen Verständnisses schon vor Leistungsoptimierungen demonstrieren.
In der Einbettungsspalte können die Vektorwerte des Produktbeschreibungstexts gespeichert werden. In der Spalte „img_embeddings“ können Bildeinbettungen (multimodal) gespeichert werden. So können Sie auch die Suche auf Grundlage der Distanz zwischen Text und Bild verwenden. In diesem Lab verwenden wir jedoch nur Texteinbettungen.
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Dadurch sollte der Einbettungsvektor für den Beispieltext in der Anfrage zurückgegeben werden. Er sieht wie ein Array von Gleitkommazahlen aus. Sieht so aus:
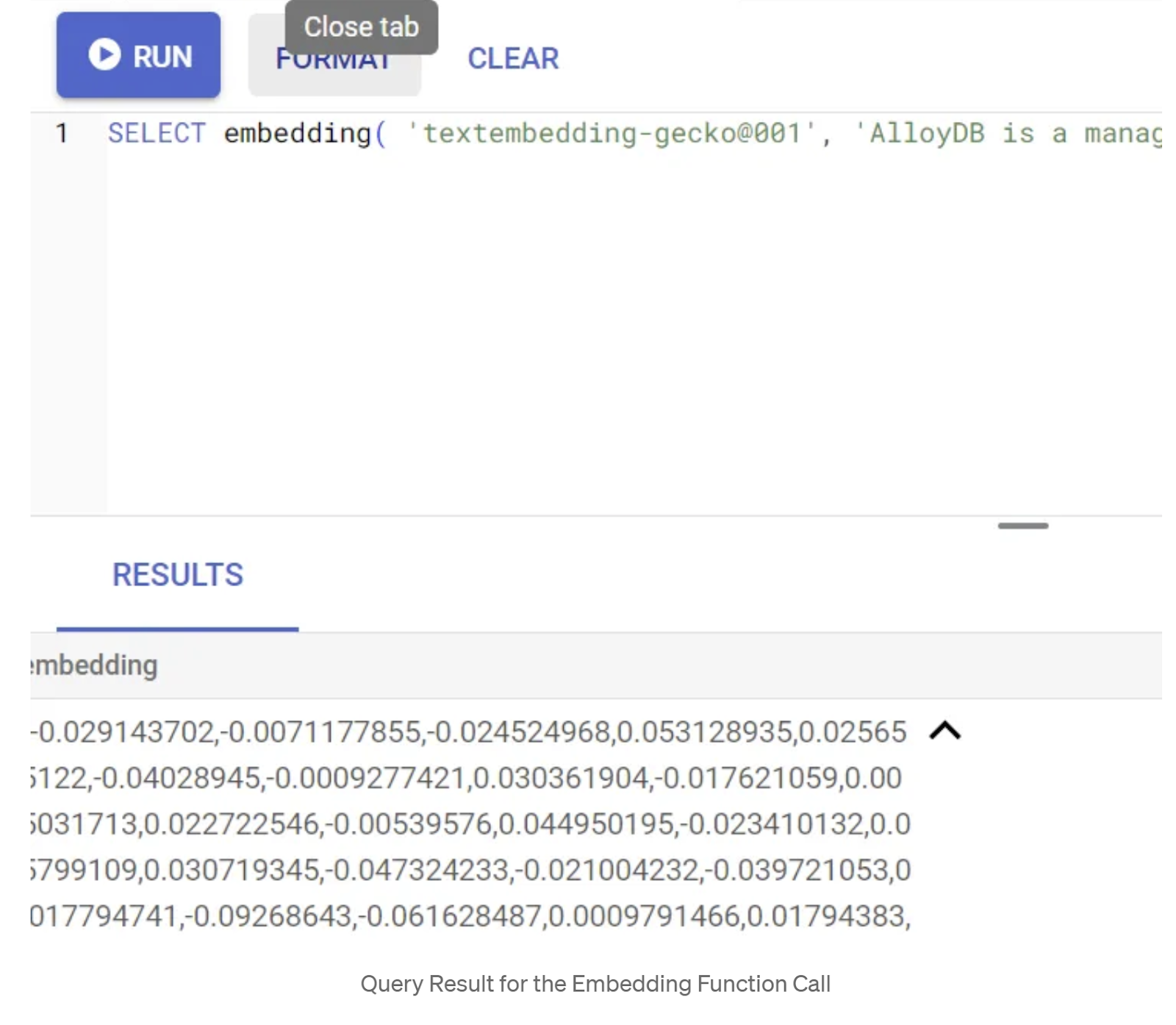
Vektorfeld „abstract_embeddings“ aktualisieren
Führen Sie die folgende DML aus, um die Inhaltsbeschreibung in der Tabelle mit den entsprechenden Einbettungen zu aktualisieren:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
Wenn Sie ein Abrechnungskonto mit Testguthaben für Google Cloud verwenden, kann es sein, dass Sie Probleme haben, mehr als einige wenige Einbettungen (maximal 20 bis 25) zu generieren. Begrenzen Sie daher die Anzahl der Zeilen im Einfügeskript.
Wenn Sie Image-Einbettungen generieren möchten (um eine multimodale kontextbezogene Suche durchzuführen), führen Sie auch das folgende Update aus:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. MCP Toolbox for Databases (AlloyDB)
Hinter den Kulissen sorgen robuste Tools und eine gut strukturierte Anwendung für einen reibungslosen Betrieb.
Die Toolbox für Datenbanken für das MCP (Model Context Protocol) vereinfacht die Integration von generativer KI und agentischen Tools in AlloyDB. Er fungiert als Open-Source-Server, der die Verbindungspooling, die Authentifizierung und die sichere Bereitstellung von Datenbankfunktionen für KI-Agents oder andere Anwendungen optimiert.
In unserer Anwendung haben wir die MCP Toolbox for Databases als Abstraktionsebene für alle unsere intelligenten Hybrid-Suchanfragen verwendet.
Gehen Sie so vor, um Toolbox für unseren Anwendungsfall einzurichten und bereitzustellen:
Eine der von der MCP Toolbox für Datenbanken unterstützten Datenbanken ist AlloyDB. Da wir diese bereits im vorherigen Abschnitt bereitgestellt haben, können wir jetzt die Toolbox einrichten.
- Rufen Sie Ihr Cloud Shell-Terminal auf und prüfen Sie, ob Ihr Projekt ausgewählt ist und im Prompt des Terminals angezeigt wird. Führen Sie den folgenden Befehl im Cloud Shell-Terminal aus, um das Projektverzeichnis zu öffnen:
mkdir gemini-cli-project
cd gemini-cli-project
- Führen Sie den folgenden Befehl aus, um die Toolbox in Ihren neuen Ordner herunterzuladen und zu installieren:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
Dadurch sollte die Toolbox in Ihrem aktuellen Verzeichnis erstellt werden. Pfad zur Toolbox kopieren
- Rufen Sie den Cloud Shell-Editor (für den Codebearbeitungsmodus) auf und fügen Sie im Projektstammordner „gemini-cli-project“ eine Datei mit dem Namen „tools.yaml“ hinzu.
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
Informationen zu „tools.yaml“:
Quellen stellen die verschiedenen Datenquellen dar, mit denen ein Tool interagieren kann. Eine Quelle ist eine Datenquelle, mit der ein Tool interagieren kann. Sie können Quellen als Map im Abschnitt „sources“ Ihrer tools.yaml-Datei definieren. Normalerweise enthält eine Quellkonfiguration alle Informationen, die für die Verbindung mit der Datenbank und die Interaktion mit ihr erforderlich sind.
Tools definieren Aktionen, die ein Agent ausführen kann, z. B. das Lesen und Schreiben in einer Quelle. Ein Tool stellt eine Aktion dar, die Ihr Agent ausführen kann, z. B. das Ausführen einer SQL-Anweisung. Sie können Tools als Map im Abschnitt „tools“ Ihrer Datei „tools.yaml“ definieren. Normalerweise benötigt ein Tool eine Quelle, auf die es sich beziehen kann.
Weitere Informationen zum Konfigurieren von „tools.yaml“ finden Sie in dieser Dokumentation.
Wie Sie in der Datei „Tools.yaml“ oben sehen können, werden mit dem Tool „get-apparels“ alle Details der Kleidungsstücke aus der Datenbank aufgelistet.
7. Gemini CLI einrichten
Erstellen Sie im Cloud Shell-Editor im Ordner gemini-cli-project einen neuen Ordner namens .gemini und darin eine neue Datei namens settings.json.
{
"mcpServers": {
"AlloyDBServer": {
"command": "/home/user/gemini-cli-project/toolbox",
"args": ["--tools-file", "tools.yaml", "--stdio"]
}
}
}
Ersetzen Sie im Befehlsabschnitt des Snippets oben „/home/user/gemini-cli-project/toolbox“ durch den Pfad zu „toolbox“.
Gemini CLI installieren
Installieren Sie die Gemini CLI im Cloud Shell-Terminal im selben Verzeichnis gemini-cli-project, indem Sie den folgenden Befehl ausführen:
sudo npm install -g @google/gemini-cli
Projekt-ID festlegen
Prüfen Sie, ob die aktive Projekt-ID in der Umgebung festgelegt ist:
export GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT_ID>>
Erste Schritte mit der Gemini CLI
Geben Sie in der Befehlszeile den folgenden Befehl ein:
gemini
Sie sollten eine Antwort ähnlich der folgenden sehen:
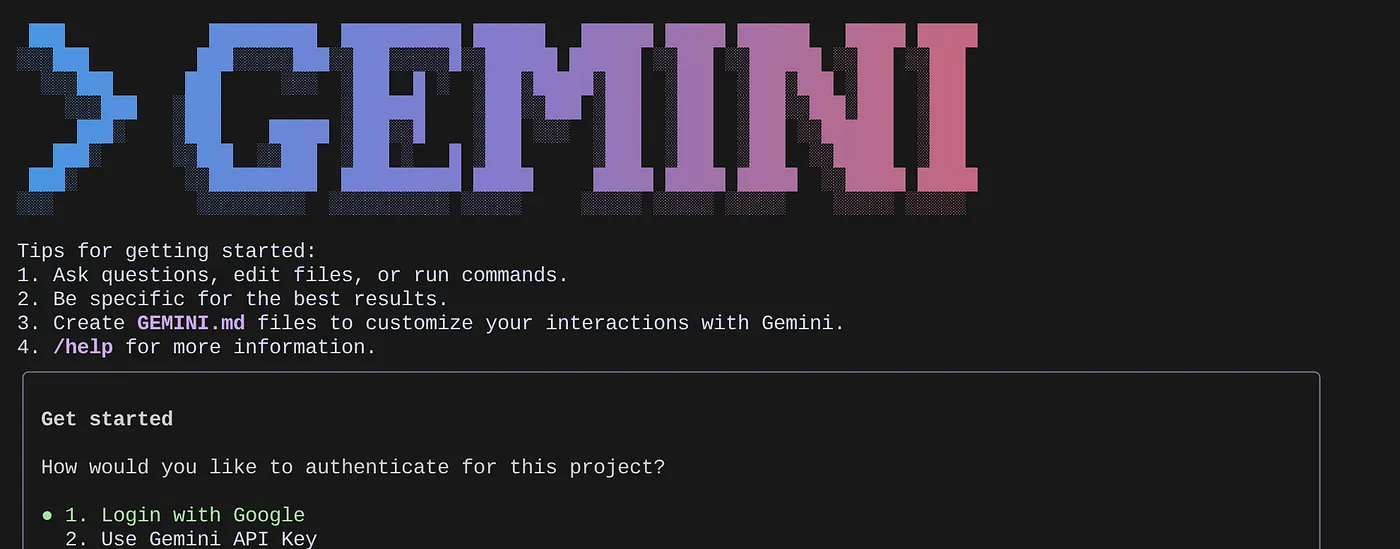
Authentifizieren Sie sich und fahren Sie mit dem nächsten Schritt fort.
8. Mit der Gemini CLI interagieren
Verwenden Sie den Befehl /mcp, um die konfigurierten MCP-Server aufzulisten.
Sie sollten die beiden konfigurierten MCP-Server sehen: GitHub und MCP Toolbox for Databases, zusammen mit den zugehörigen Tools.
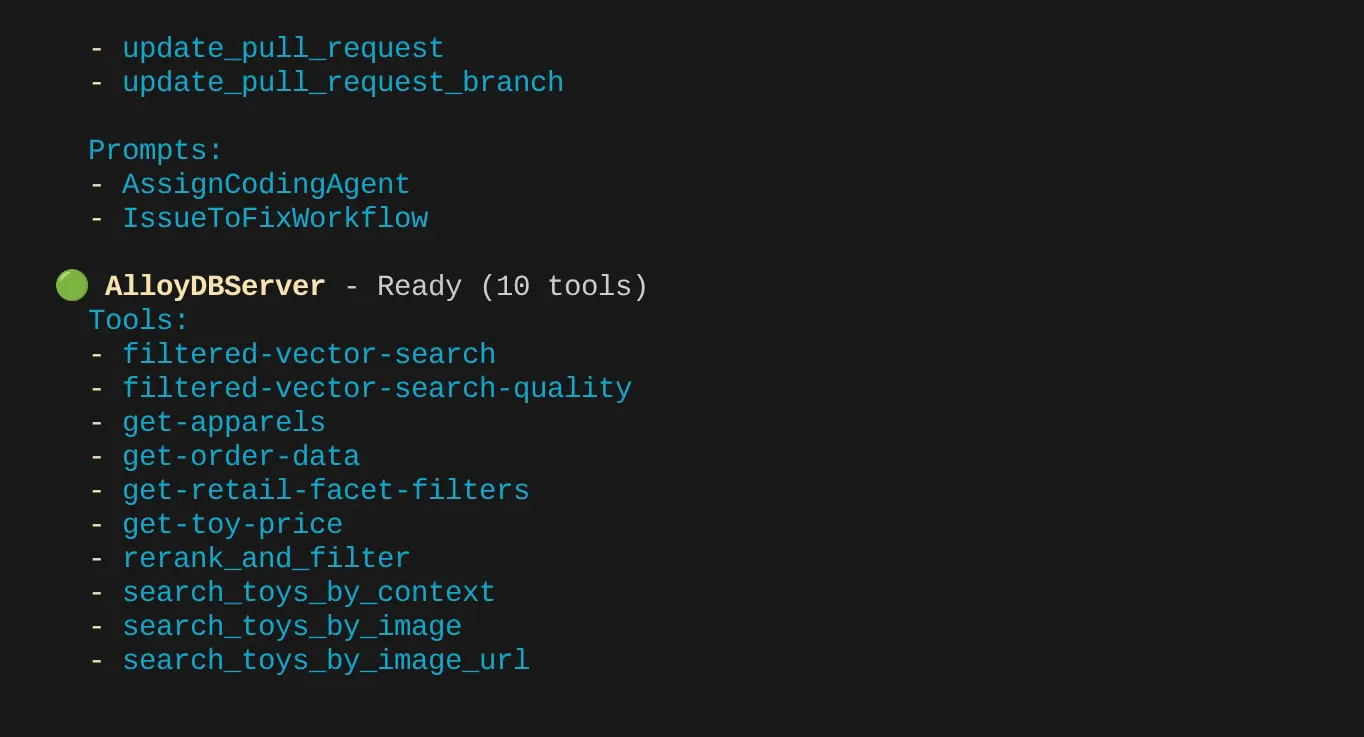
In meinem Fall habe ich mehr Tools. Ignorieren Sie sie also vorerst. Das Tool „get-apparels“ sollte auf Ihrem AlloyDB-MCP-Server angezeigt werden.
Datenbank über die MCP Toolbox abfragen
Stellen Sie jetzt Fragen in natürlicher Sprache, um Antworten und Abfragen für das Dataset abzurufen, mit dem wir arbeiten:
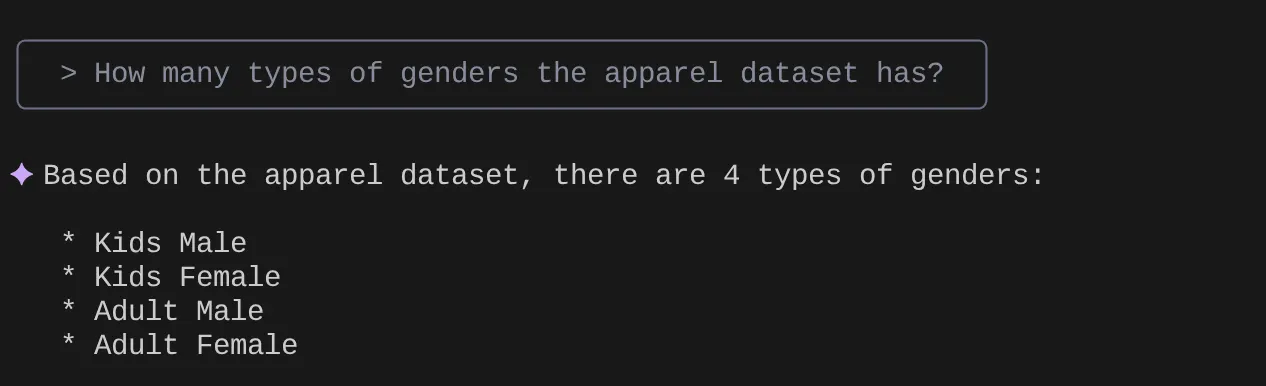
> How many types of genders the apparel dataset has?
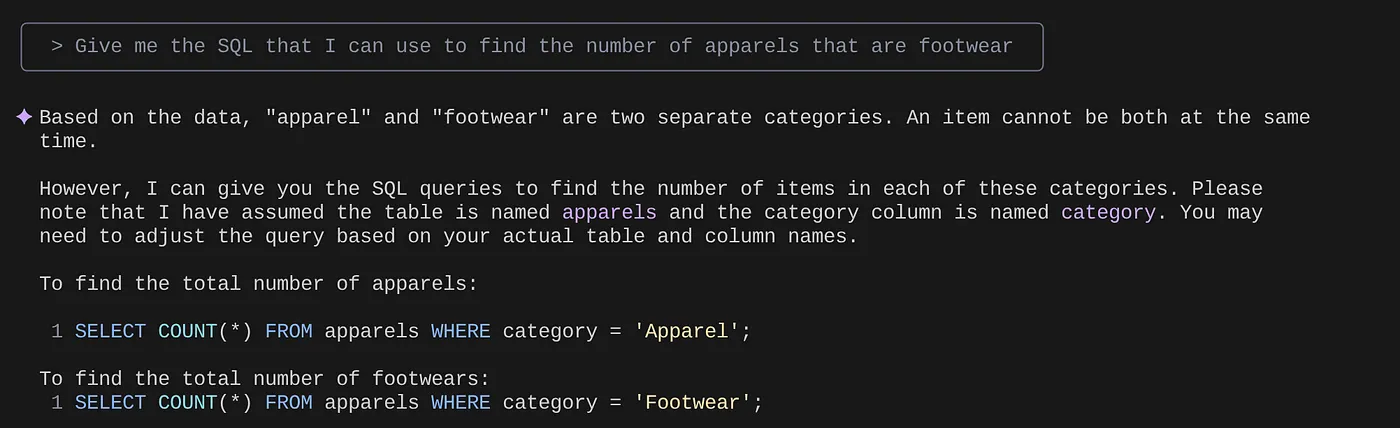
> Give me the SQL that I can use to find the number of apparels that are footwear
> What are the unique sub categories that are there?
that I can use to find the number of apparels that are footwear
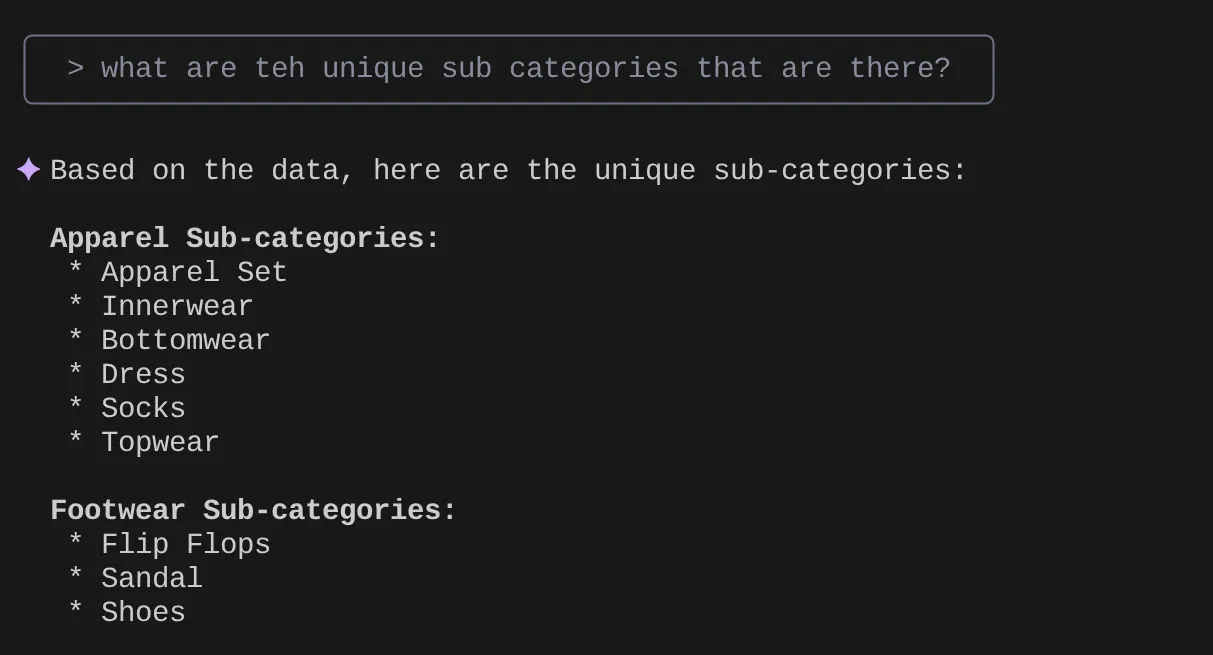
Angenommen, ich habe auf Grundlage meiner Statistiken und vieler solcher Anfragen eine detaillierte Anfrage erstellt und möchte sie testen. Angenommen, die Datenbankentwickler haben die Datei „Tools.yaml“ bereits für Sie erstellt, wie unten dargestellt:
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
filtered-vector-search:
kind: postgres-sql
source: alloydb
description: Get the list of facet filter values from the retail dataset.
parameters:
- name: categories
type: array
description: List of categories preferred by the user.
items:
name: category
type: string
description: Category value.
- name: subCategories
type: array
description: List of sub-categories preferred by the user.
items:
name: subCategory
type: string
description: Sub-Category value.
- name: colors
type: array
description: List of colors preferred by the user.
items:
name: color
type: string
description: Color value.
- name: genders
type: array
description: List of genders preferred by the user for apparel fitting.
items:
name: gender
type: string
description: Gender name.
- name: searchtext
type: string
description: Description of the product that the user wants to find database matches for.
statement: |
SELECT id, content, uri, category, sub_category,color,gender FROM apparels
where category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005',$5)::vector limit 10
Jetzt probieren wir eine Suche in natürlicher Sprache aus:
> How many yellow shirts are there for boys?
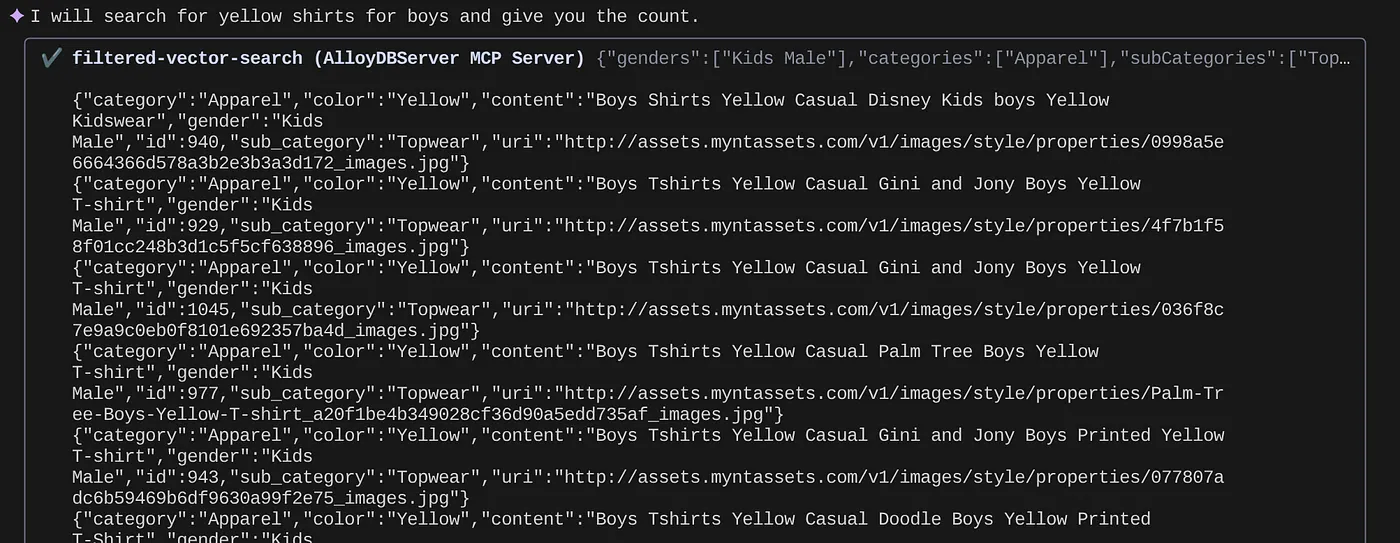

Ziemlich cool, oder? Jetzt kann ich die YAML-Datei korrigieren, um die Abfragen weiter zu optimieren, während ich weiterhin neue Funktionen in meiner Anwendung bereitstelle.
9. Schnellere App-Entwicklung
Die Vorteile, Datenbankfunktionen über die Gemini CLI und die MCP-Toolbox direkt in Ihre IDE zu integrieren, sind nicht nur theoretischer Natur. Das führt zu konkreten, geschwindigkeitssteigernden Workflows, insbesondere für eine komplexe Anwendung wie unsere hybride Einzelhandelsplattform. Sehen wir uns einige Szenarien an:
1. Schnelle Iteration der Logik für Produktfilter
Angenommen, wir haben gerade eine neue Werbeaktion für „Sommer-Sportbekleidung“ gestartet. Wir möchten testen, wie unsere Facettenfilter (z.B. nach Marke, Größe, Farbe, Preisspanne) mit dieser neuen Kategorie interagieren.
Ohne IDE-Integration:
Ich würde wahrscheinlich zu einem separaten SQL-Client wechseln, meine Abfrage schreiben, sie ausführen, die Ergebnisse analysieren, zur IDE zurückkehren, um den Anwendungscode anzupassen, wieder zum Client wechseln und das Ganze wiederholen. Dieser Kontextwechsel ist ein großer Nachteil.
Mit der Gemini CLI und MCP:
Ich kann in meiner IDE bleiben und mehr:
- Abfragen: Ich kann die Abfrage in der YAML-Datei schnell mit dem (hypothetischen Dataset) „SELECT DISTINCT brand FROM products WHERE category = ‚activewear‘ AND season = ‚summer‘“ aktualisieren und direkt im Terminal ausprobieren.
- Datenanalyse: Die zurückgegebenen Marken werden sofort angezeigt. Wenn ich die Produktverfügbarkeit für eine bestimmte Marke und Größe sehen möchte, ist das eine weitere schnelle Anfrage: „SELECT COUNT(*) FROM products WHERE brand = ‚SummitGear‘ AND size = ‚M‘ AND category = ‚activewear‘ AND season = ‚summer‘“
- Code-Integration: Ich kann dann sofort die Front-End-Filterlogik oder Backend-API-Aufrufe auf Grundlage dieser schnellen Datenstatistiken in der IDE anpassen, was den Feedbackzyklus erheblich verkürzt.
2. Vektorsuche für Produktempfehlungen optimieren
Bei der Hybridsuche werden Vektoreinbettungen für relevante Produktempfehlungen verwendet. Angenommen, die Klickraten für Empfehlungen für „Herrenlaufschuhe“ sind gesunken.
Ohne IDE-Integration:
Ich würde benutzerdefinierte Skripts oder Abfragen in einem Datenbanktool ausführen, um die Ähnlichkeitswerte der empfohlenen Schuhe zu analysieren, sie mit Nutzerinteraktionsdaten zu vergleichen und versuchen, Muster zu finden.
Mit der Gemini CLI und MCP:
- Embeddings analysieren:Ich kann direkt Produkt-Embeddings und die zugehörigen Metadaten abfragen: „SELECT product_id, name, vector_embedding FROM products WHERE category = ‚running shoes‘ AND gender = ‚male‘ LIMIT 10“
- Querverweise: Ich kann auch direkt die tatsächliche Vektorähnlichkeit zwischen einem ausgewählten Produkt und seinen Empfehlungen prüfen. Wenn beispielsweise Produkt A Nutzern empfohlen wird, die sich Produkt B angesehen haben, kann ich eine Abfrage ausführen, um die Vektoreinbettungen abzurufen und zu vergleichen.
- Debugging:Dies ermöglicht ein schnelleres Debugging und Testen von Hypothesen. Verhält sich das Einbettungsmodell erwartungsgemäß? Gibt es Anomalien in den Daten, die sich auf die Qualität der Empfehlungen auswirken? Ich kann erste Antworten erhalten, ohne meine Entwicklungsumgebung zu verlassen.
3. Schema und Datenverteilung für neue Funktionen
Angenommen, wir planen, eine Funktion für Kundenrezensionen hinzuzufügen. Bevor wir die Backend-API schreiben, müssen wir die vorhandenen Kundendaten und die Struktur von Rezensionen verstehen.
Ohne IDE-Integration:
Ich müsste eine Verbindung zu einem Datenbankclient herstellen, DESCRIBE-Befehle für Tabellen wie „customers“ und „orders“ ausführen und dann Beispieldaten abfragen, um Beziehungen und Datentypen zu verstehen.
Mit der Gemini CLI und MCP:
- Schema-Exploration:Ich kann die Tabelle in der YAML-Datei einfach abfragen und direkt im Terminal ausführen.
- Stichprobenerhebung:Ich kann dann Stichprobendaten abrufen, um die demografischen Merkmale von Kunden und die bisherigen Käufe zu analysieren: „SELECT customer_id, name, signup_date, total_orders FROM customers ORDER BY signup_date DESC LIMIT 5“
- Planung:Durch den schnellen Zugriff auf Schema und Datenverteilung können wir fundierte Entscheidungen darüber treffen, wie die neue Rezensionstabelle gestaltet werden soll, welche Fremdschlüssel eingerichtet werden müssen und wie Rezensionen effizient mit Kunden und Produkten verknüpft werden können – alles, bevor wir eine einzige Zeile Anwendungscode für die neue Funktion schreiben.
Das sind nur einige Beispiele, die den Hauptvorteil verdeutlichen: Reibungsverluste verringern und die Entwicklergeschwindigkeit erhöhen. Durch die direkte Einbindung der AlloyDB-Interaktion in die IDE können wir mit der Gemini CLI und der MCP Toolbox bessere und reaktionsfähigere Anwendungen schneller entwickeln.
10. Bereinigen
So vermeiden Sie, dass Ihrem Google Cloud-Konto die in diesem Beitrag verwendeten Ressourcen in Rechnung gestellt werden:
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcenmanager.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Herunterfahren, um das Projekt zu löschen.
- Alternativ können Sie einfach den AlloyDB-Cluster löschen, den wir gerade für dieses Projekt erstellt haben. Klicken Sie dazu auf die Schaltfläche „CLUSTER LÖSCHEN“. Wenn Sie bei der Konfiguration nicht „us-central1“ für den Cluster ausgewählt haben, ändern Sie den Speicherort in diesem Hyperlink.
11. Glückwunsch
Glückwunsch! Sie haben die MCP Toolbox erfolgreich direkt in Ihre IDE eingebunden, um nahtlos mit AlloyDB zu interagieren. Außerdem haben Sie die Gemini CLI verwendet, um mit unserem Einzelhandels-E-Commerce-Dataset zu interagieren und Abfragen zu schreiben, für die normalerweise separate Tools erforderlich wären. Sie haben neue Möglichkeiten kennengelernt, die Daten zu untersuchen und zu verstehen – von der Überprüfung der Tabellenstrukturen bis hin zur Durchführung schneller Datenintegritätsprüfungen – alles über vertraute Befehlszeilenschnittstellen in unserer IDE.
Klonen Sie das Repository, analysieren Sie es und teilen Sie mir mit, ob Sie die Anwendung mit der Gemini CLI und der MCP Toolbox für Datenbanken verbessert haben.
Wenn Sie weitere datengesteuerte Anwendungen kennenlernen möchten, die basierend auf Gemini CLI und MCP erstellt und in serverlosen Laufzeiten bereitgestellt wurden, registrieren Sie sich für die nächste Staffel von Code Vipassana. Dort finden Sie von Kursleitern geführte praktische Übungen und weitere Codelabs.