
1. Descripción general
¿Recuerdas nuestro recorrido para crear una experiencia híbrida dinámica de venta minorista con AlloyDB, que combina el filtrado por facetas y la búsqueda de vectores? Esa aplicación fue una poderosa demostración de las necesidades del comercio minorista moderno, pero llegar a ese punto y realizar iteraciones requirió un esfuerzo de desarrollo significativo. Para los desarrolladores full-stack, el constante ir y venir entre los editores de código y las herramientas de bases de datos a menudo puede ser un cuello de botella que ralentiza la innovación y el proceso crucial de comprender tus datos.
Solución
Es precisamente en este punto donde el poder del desarrollo acelerado de aplicaciones se destaca, y es por eso que me entusiasma tanto compartir cómo la caja de herramientas de MCP (Modern Cloud Platform), a la que se puede acceder a través de la intuitiva CLI de Gemini, se convirtió en una parte indispensable de mi caja de herramientas. Imagina interactuar sin problemas con tu instancia de AlloyDB, escribir consultas y comprender tu conjunto de datos, todo directamente desde tu entorno de desarrollo integrado (IDE). No se trata solo de comodidad, sino de reducir fundamentalmente la fricción en el ciclo de vida del desarrollo, lo que te permite enfocarte en crear funciones innovadoras en lugar de luchar con herramientas externas.
En el contexto de nuestra app de comercio electrónico minorista, en la que necesitábamos consultar de manera eficiente los datos de productos, controlar el filtrado complejo y aprovechar los matices de la búsqueda vectorial, la capacidad de iterar rápidamente en las interacciones de la base de datos era fundamental. La caja de herramientas de MCP, potenciada por la CLI de Gemini, no solo simplifica este proceso, sino que también lo acelera y transforma la forma en que podemos explorar, probar y perfeccionar la lógica de la base de datos que sustenta nuestras aplicaciones. Analicemos cómo esta combinación revolucionaria hace que el desarrollo full-stack sea más rápido, inteligente y agradable.
Qué aprenderás y crearás
Una aplicación de Retail Search que utiliza la caja de herramientas de MCP dentro del IDE, potenciada por la CLI de Gemini. Temas que trataremos:
- Cómo integrar MCP Toolbox directamente en tu IDE para una interacción fluida con AlloyDB
- Ejemplos prácticos del uso de la CLI de Gemini para escribir y ejecutar consultas en SQL en tus datos de venta minorista.
- Aprovecha la CLI de Gemini para interactuar con nuestro conjunto de datos de comercio electrónico minorista, escribir consultas que normalmente requerirían herramientas separadas y ver los resultados al instante.
- Descubre nuevas formas de explorar y comprender los datos, desde verificar las estructuras de las tablas hasta realizar verificaciones rápidas de la integridad de los datos, todo a través de interfaces de línea de comandos conocidas dentro de nuestro IDE.
- Cómo este flujo de trabajo de base de datos acelerado contribuye directamente a ciclos de desarrollo de pila completa más rápidos, lo que permite la creación rápida de prototipos y la iteración.
Pila tecnológica
Usamos lo siguiente:
- AlloyDB para bases de datos
- MCP Toolbox para abstraer funciones avanzadas de IA y generativas de bases de datos de la aplicación
- Cloud Run para la implementación sin servidores
- Gemini CLI para comprender y analizar el conjunto de datos, y compilar la parte de la base de datos de la aplicación de comercio electrónico minorista
Requisitos
2. Antes de comenzar
Crea un proyecto
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información sobre cómo verificar si la facturación está habilitada en un proyecto.
- Usarás Cloud Shell, un entorno de línea de comandos que se ejecuta en Google Cloud. Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.

- Una vez que te conectes a Cloud Shell, verifica que ya te autenticaste y que el proyecto se configuró con tu ID del proyecto con el siguiente comando:
gcloud auth list
- En Cloud Shell, ejecuta el siguiente comando para confirmar que el comando gcloud conoce tu proyecto.
gcloud config list project
- Si tu proyecto no está configurado, usa el siguiente comando para hacerlo:
gcloud config set project <YOUR_PROJECT_ID>
- Habilita las APIs necesarias: Sigue el vínculo y habilita las APIs.
Como alternativa, puedes usar el comando de gcloud para esto. Consulta la documentación para ver los comandos y el uso de gcloud.
3. Configuración de la base de datos
En este lab, usaremos AlloyDB como la base de datos para los datos de comercio electrónico. Utiliza clústeres para contener todos los recursos, como bases de datos y registros. Cada clúster tiene una instancia principal que proporciona un punto de acceso a los datos. Las tablas contendrán los datos reales.
Creemos un clúster, una instancia y una tabla de AlloyDB en los que se cargará el conjunto de datos de comercio electrónico.
Crea un clúster y una instancia
- Navega por la página de AlloyDB en Cloud Console. Una forma sencilla de encontrar la mayoría de las páginas en la consola de Cloud es buscarlas con la barra de búsqueda de la consola.
- Selecciona CREATE CLUSTER en esa página:

- Verás una pantalla como la que se muestra a continuación. Crea un clúster y una instancia con los siguientes valores (asegúrate de que los valores coincidan si clonas el código de la aplicación desde el repo):
- ID del clúster: "
vector-cluster" - contraseña: "
alloydb" - PostgreSQL 15 o la versión recomendada más reciente
- Región: "
us-central1" - Networking: "
default"
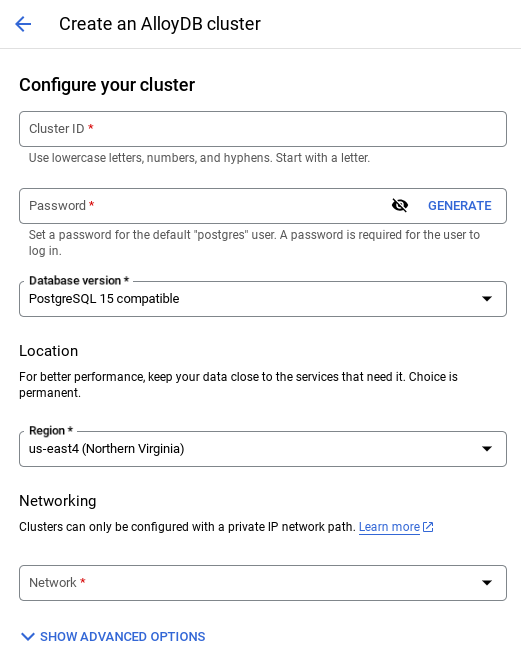
- Cuando selecciones la red predeterminada, verás una pantalla como la que se muestra a continuación.
Selecciona CONFIGURAR CONEXIÓN.
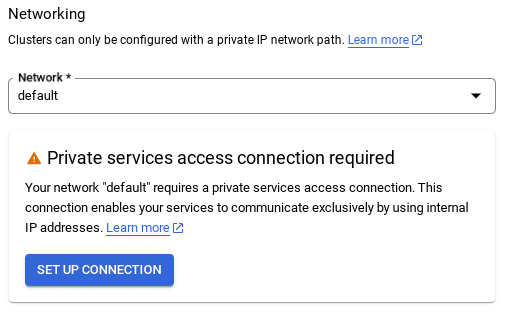
- Allí, selecciona "Usar un rango de IP asignado automáticamente" y haz clic en Continuar. Después de revisar la información, selecciona CREAR CONEXIÓN.
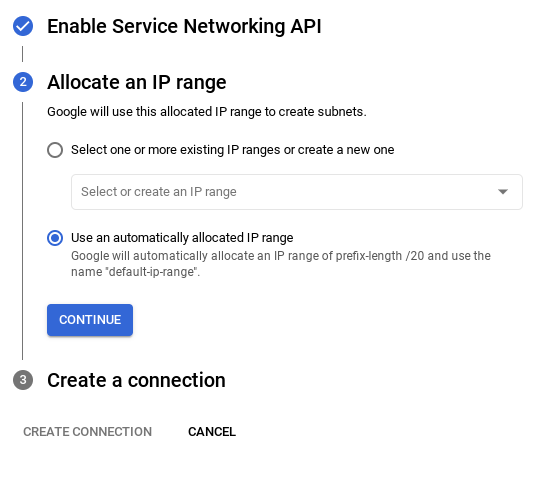
- Una vez que configures tu red, podrás continuar con la creación del clúster. Haz clic en CREATE CLUSTER para completar la configuración del clúster, como se muestra a continuación:
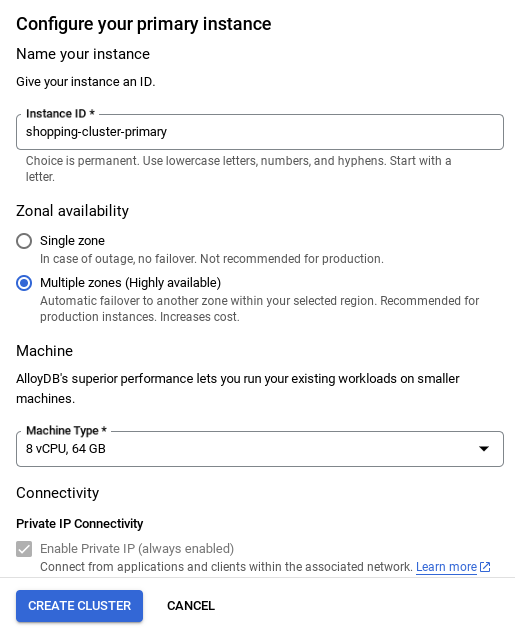
NOTA IMPORTANTE:
- Asegúrate de cambiar el ID de la instancia (que puedes encontrar en el momento de configurar el clúster o la instancia) a **
vector-instance**. Si no puedes cambiarlo, recuerda **usar tu ID de instancia** en todas las referencias futuras. - Ten en cuenta que la creación del clúster tardará alrededor de 10 minutos. Una vez que se complete correctamente, deberías ver una pantalla que muestra el resumen del clúster que acabas de crear.
4. Transferencia de datos
Ahora es el momento de agregar una tabla con los datos del almacén. Navega a AlloyDB, selecciona el clúster principal y, luego, AlloyDB Studio:
Es posible que debas esperar a que termine de crearse la instancia. Una vez que lo hagas, accede a AlloyDB con las credenciales que creaste cuando creaste el clúster. Usa los siguientes datos para autenticarte en PostgreSQL:
- Nombre de usuario : "
postgres" - Base de datos : "
postgres" - Contraseña : "
alloydb"
Una vez que te autentiques correctamente en AlloyDB Studio, ingresa los comandos SQL en el editor. Puedes agregar varias ventanas del editor con el signo más que se encuentra a la derecha de la última ventana.
Ingresarás comandos para AlloyDB en ventanas del editor, y usarás las opciones Ejecutar, Formatear y Borrar según sea necesario.
Habilitar extensiones
Para compilar esta app, usaremos las extensiones pgvector y google_ml_integration. La extensión pgvector te permite almacenar y buscar embeddings de vectores. La extensión google_ml_integration proporciona funciones que usas para acceder a los extremos de predicción de Vertex AI y obtener predicciones en SQL. Habilita estas extensiones ejecutando los siguientes DDL:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Si quieres verificar las extensiones que se habilitaron en tu base de datos, ejecuta este comando de SQL:
select extname, extversion from pg_extension;
Crea una tabla
Puedes crear una tabla con la siguiente instrucción DDL en AlloyDB Studio:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
La columna de incorporación permitirá el almacenamiento de los valores vectoriales del texto.
Otorgar permiso
Ejecuta la siguiente sentencia para otorgar permiso de ejecución en la función "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Otorga el rol de usuario de Vertex AI a la cuenta de servicio de AlloyDB
En la consola de IAM de Google Cloud, otorga a la cuenta de servicio de AlloyDB (que se ve así: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) acceso al rol "Usuario de Vertex AI". PROJECT_NUMBER tendrá tu número de proyecto.
Como alternativa, puedes ejecutar el siguiente comando desde la terminal de Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Carga datos en la base de datos
- Copia las instrucciones de la consulta
insertdeinsert scripts sqlen la hoja al editor mencionado anteriormente. Puedes copiar entre 10 y 50 instrucciones de inserción para una demostración rápida de este caso de uso. Aquí hay una lista seleccionada de inserciones en la pestaña"Selected Inserts 25-30 rows". - Haz clic en Ejecutar. Los resultados de tu consulta aparecen en la tabla Resultados.
NOTA IMPORTANTE:
Asegúrate de copiar solo entre 25 y 50 registros para insertar, y de que provengan de un rango de tipos de categoría, subcategoría, color y género.
5. Crea embeddings para los datos
La verdadera innovación en la búsqueda moderna radica en comprender el significado, no solo las palabras clave. Aquí es donde entran en juego los embeddings y la búsqueda de vectores.
Transformamos las descripciones de los productos y las búsquedas de los usuarios en representaciones numéricas de alta dimensión llamadas "embeddings" con modelos de lenguaje previamente entrenados. Estos embeddings capturan el significado semántico, lo que nos permite encontrar productos que son "similares en significado" en lugar de solo contener palabras coincidentes. Inicialmente, experimentamos con la búsqueda directa de similitud de vectores en estas incorporaciones para establecer un valor de referencia, lo que demostró el poder de la comprensión semántica incluso antes de las optimizaciones del rendimiento.
La columna de embedding permitirá almacenar los valores vectoriales del texto de la descripción del producto. La columna img_embeddings permitirá almacenar incorporaciones de imágenes (multimodales). De esta manera, también puedes usar la búsqueda basada en la distancia entre texto e imagen. Sin embargo, en este lab, solo usaremos las embeddings de texto.
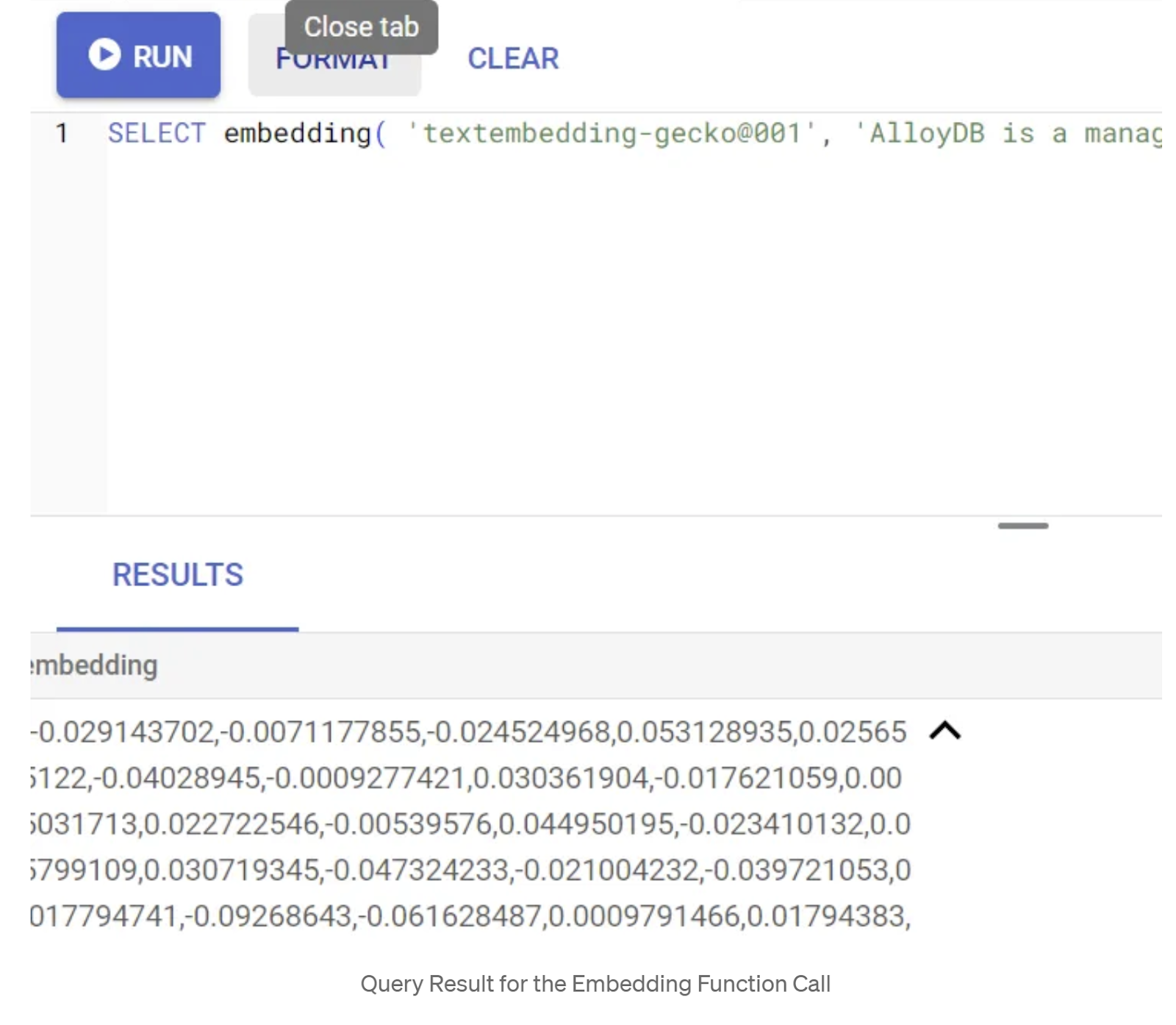
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Esto debería devolver el vector de embeddings, que se ve como un array de números de punto flotante, para el texto de muestra en la búsqueda. Se ve de la siguiente manera:
Actualiza el campo Vector de abstract_embeddings
Ejecuta la siguiente DML para actualizar la descripción del contenido en la tabla con los embeddings correspondientes:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
Es posible que tengas problemas para generar más de unos pocos embeddings (por ejemplo, entre 20 y 25 como máximo) si usas una cuenta de facturación de crédito de prueba para Google Cloud. Por lo tanto, limita la cantidad de filas en la secuencia de comandos de inserción.
Si también deseas generar embeddings de imágenes (para realizar búsquedas contextuales multimodales), ejecuta la siguiente actualización:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. MCP Toolbox para bases de datos (AlloyDB)
Tras bambalinas, las herramientas sólidas y una aplicación bien estructurada garantizan un funcionamiento sin problemas.
La caja de herramientas del MCP (Protocolo de contexto del modelo) para bases de datos simplifica la integración de herramientas de IA generativa y de agentes con AlloyDB. Actúa como un servidor de código abierto que optimiza la agrupación de conexiones, la autenticación y la exposición segura de las funciones de la base de datos a los agentes de IA o a otras aplicaciones.
En nuestra aplicación, usamos MCP Toolbox para bases de datos como una capa de abstracción para todas nuestras búsquedas híbridas inteligentes.
Sigue los pasos que se indican a continuación para configurar e implementar Toolbox en nuestro caso de uso:
Puedes ver que una de las bases de datos compatibles con MCP Toolbox para bases de datos es AlloyDB y, como ya la aprovisionamos en la sección anterior, configuremos Toolbox.
- Navega a la terminal de Cloud Shell y asegúrate de que tu proyecto esté seleccionado y se muestre en el mensaje de la terminal. Ejecuta el siguiente comando desde la terminal de Cloud Shell para navegar al directorio de tu proyecto:
mkdir gemini-cli-project
cd gemini-cli-project
- Ejecuta el siguiente comando para descargar e instalar la caja de herramientas en tu carpeta nueva:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
Esto debería crear la caja de herramientas en tu directorio actual. Copia la ruta de acceso a la caja de herramientas.
- Navega al editor de Cloud Shell (para el modo de edición de código) y, en la carpeta raíz del proyecto "gemini-cli-project", agrega un archivo llamado "tools.yaml".
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
Analicemos tools.yaml:
Las fuentes representan las diferentes fuentes de datos con las que una herramienta puede interactuar. Una fuente representa una fuente de datos con la que puede interactuar una herramienta. Puedes definir fuentes como un mapa en la sección sources de tu archivo tools.yaml. Por lo general, una configuración de origen contendrá toda la información necesaria para conectarse con la base de datos y para interactuar con ella.
Las herramientas definen las acciones que puede realizar un agente, como leer y escribir en una fuente. Una herramienta representa una acción que puede realizar tu agente, como ejecutar una sentencia de SQL. Puedes definir herramientas como un mapa en la sección tools de tu archivo tools.yaml. Por lo general, una herramienta requerirá una fuente para actuar.
Para obtener más detalles sobre cómo configurar tu archivo tools.yaml, consulta esta documentación.
Como puedes ver en el archivo Tools.yaml anterior, la herramienta "get-apparels" enumera todos los detalles de las prendas de vestir de la base de datos.
7. Configura Gemini CLI
En el editor de Cloud Shell, crea una carpeta nueva llamada .gemini dentro de la carpeta gemini-cli-project y crea un archivo nuevo llamado settings.json en él.
{
"mcpServers": {
"AlloyDBServer": {
"command": "/home/user/gemini-cli-project/toolbox",
"args": ["--tools-file", "tools.yaml", "--stdio"]
}
}
}
En la sección de comandos del fragmento anterior, reemplaza "/home/user/gemini-cli-project/toolbox" por la ruta de acceso a toolbox.
Instala Gemini CLI
Por último, desde la terminal de Cloud Shell, instalemos Gemini CLI en el mismo directorio gemini-cli-project ejecutando el siguiente comando:
sudo npm install -g @google/gemini-cli
Establece el ID del proyecto
Asegúrate de que el ID del proyecto activo esté configurado en el entorno:
export GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT_ID>>
Comienza a usar Gemini CLI
En la línea de comandos, ingresa el siguiente comando:
gemini
Deberías poder ver una respuesta similar a la siguiente:
Realiza la autenticación y continúa con el siguiente paso.
8. Comienza a interactuar con Gemini CLI
Usa el comando /mcp para enumerar los servidores de MCP configurados.
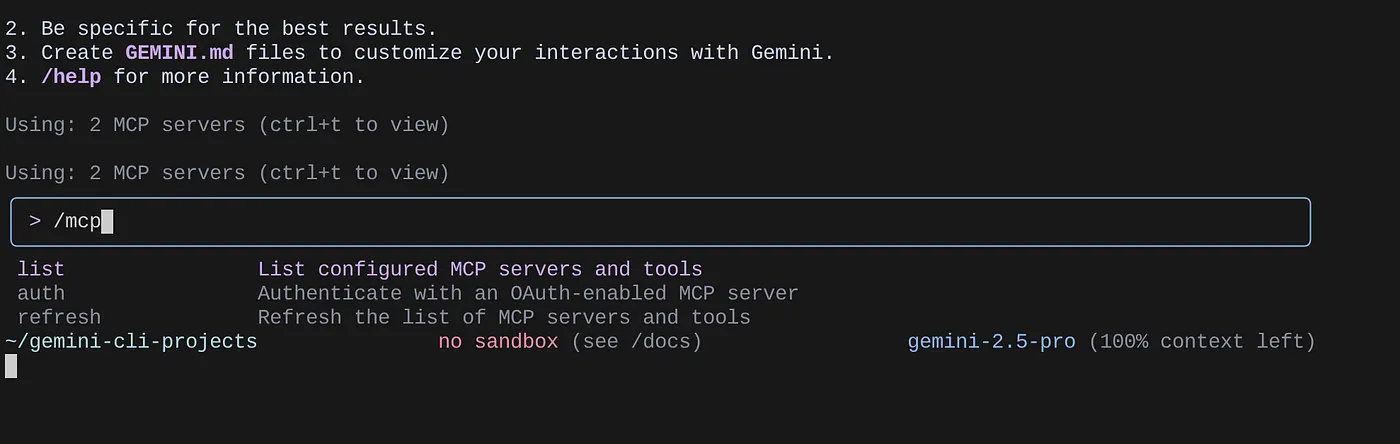
Deberías poder ver los 2 servidores de MCP que configuramos: GitHub y MCP Toolbox for Databases, junto con sus herramientas.
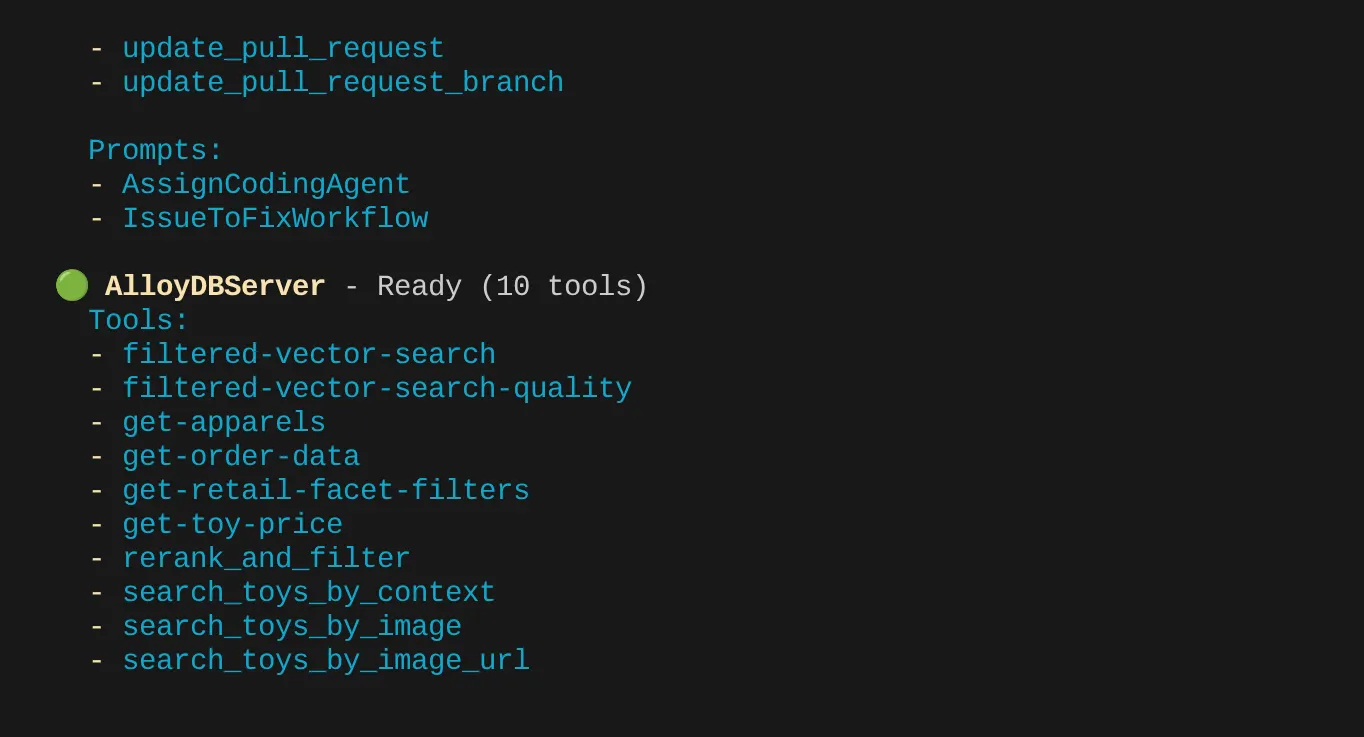
En mi caso, tengo más herramientas. Así que ignóralo por ahora. Deberías ver la herramienta get-apparels en tu servidor de MCP de AlloyDB.
Comienza a consultar la base de datos a través de MCP Toolbox
Ahora intenta hacer preguntas en lenguaje natural para recuperar respuestas y consultas para el conjunto de datos con el que estamos trabajando:
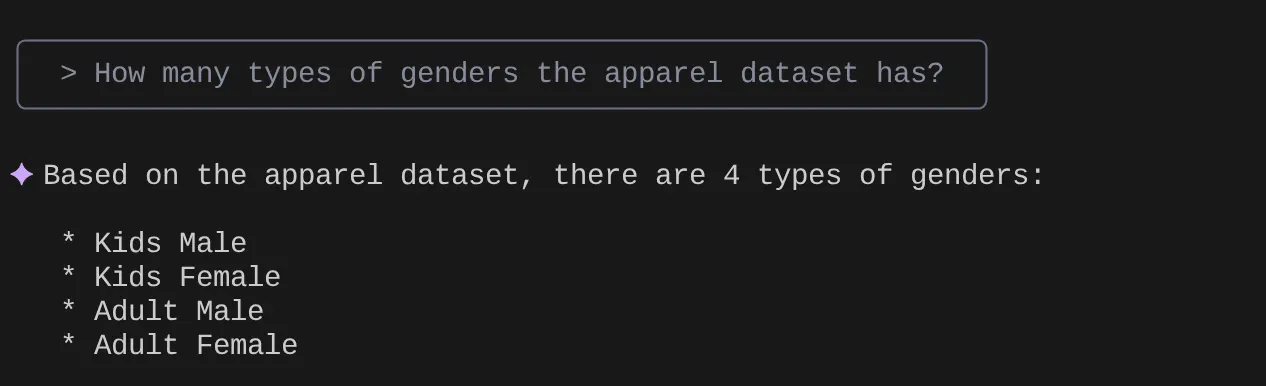
> How many types of genders the apparel dataset has?
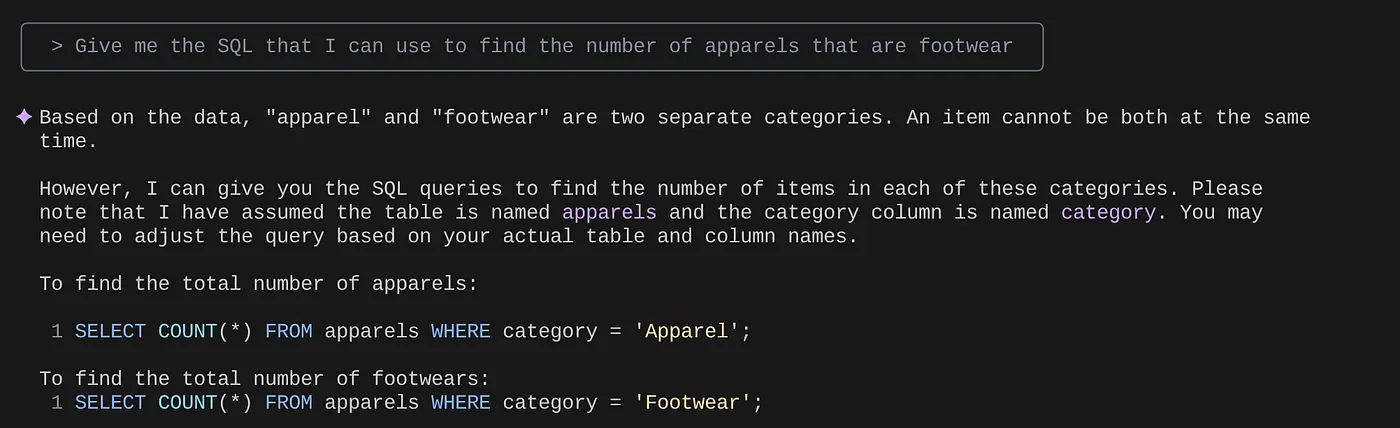
> Give me the SQL that I can use to find the number of apparels that are footwear
> What are the unique sub categories that are there?
that I can use to find the number of apparels that are footwear
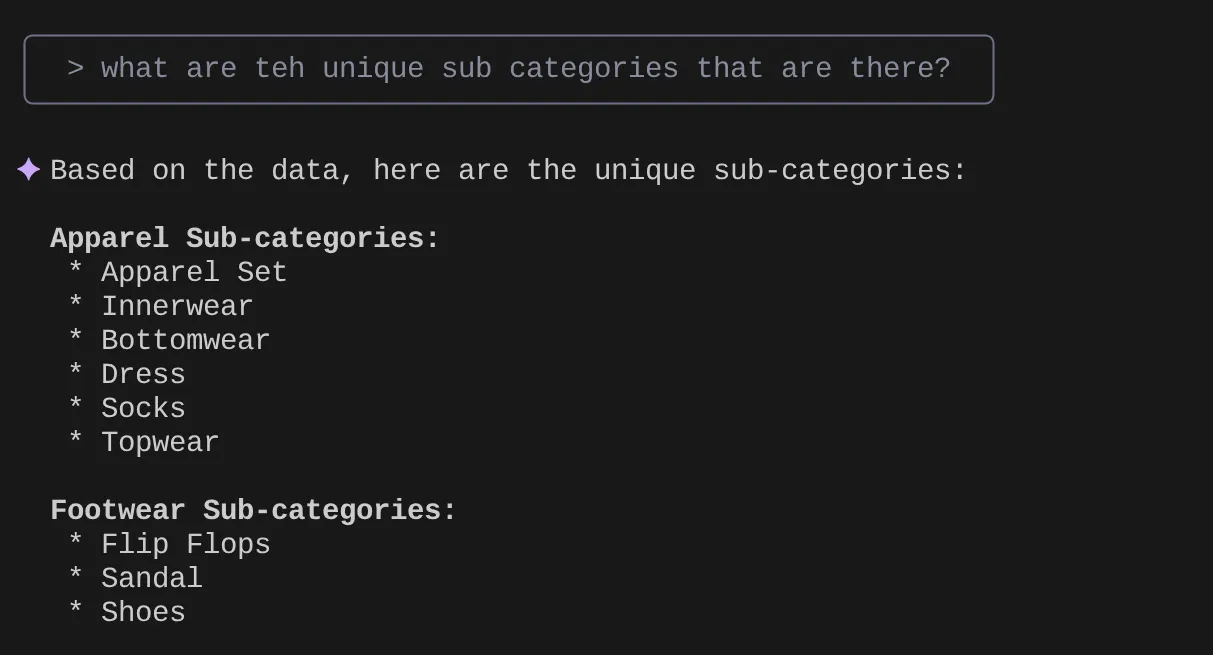
Ahora supongamos que, según mis estadísticas y muchas búsquedas similares, creé una búsqueda detallada y quiero probarla. O supongamos que los ingenieros de bases de datos ya crearon el archivo Tools.yaml para ti, como se muestra a continuación:
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
filtered-vector-search:
kind: postgres-sql
source: alloydb
description: Get the list of facet filter values from the retail dataset.
parameters:
- name: categories
type: array
description: List of categories preferred by the user.
items:
name: category
type: string
description: Category value.
- name: subCategories
type: array
description: List of sub-categories preferred by the user.
items:
name: subCategory
type: string
description: Sub-Category value.
- name: colors
type: array
description: List of colors preferred by the user.
items:
name: color
type: string
description: Color value.
- name: genders
type: array
description: List of genders preferred by the user for apparel fitting.
items:
name: gender
type: string
description: Gender name.
- name: searchtext
type: string
description: Description of the product that the user wants to find database matches for.
statement: |
SELECT id, content, uri, category, sub_category,color,gender FROM apparels
where category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005',$5)::vector limit 10
Ahora, probemos una búsqueda en lenguaje natural:
> How many yellow shirts are there for boys?
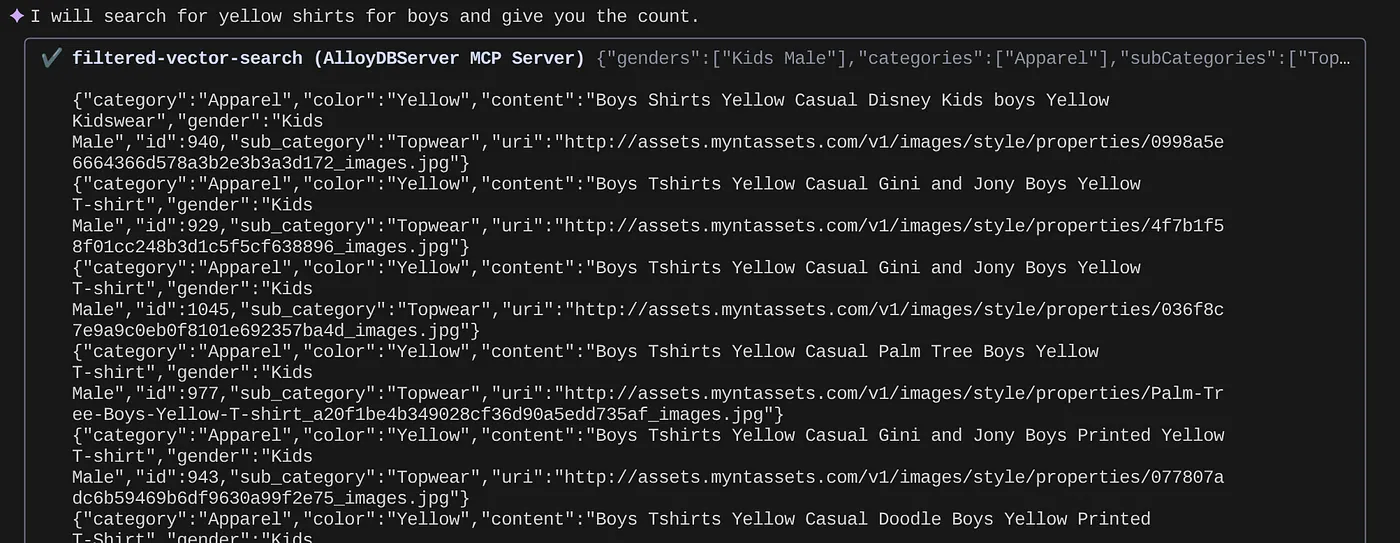

Es genial, ¿verdad? Ahora puedo corregir el archivo YAML para lograr más avances en las consultas mientras sigo entregando nuevas funciones en mi aplicación en un cronograma acelerado.
9. Desarrollo acelerado de apps
La ventaja de incorporar capacidades de bases de datos directamente en tu IDE a través de la CLI de Gemini y la caja de herramientas de MCP no es solo teórica. Esto se traduce en flujos de trabajo tangibles que aumentan la velocidad, en especial para una aplicación compleja como nuestra experiencia de venta minorista híbrida. Veamos algunas situaciones:
1. Iteración rápida en la lógica de filtrado de productos
Imagina que acabamos de lanzar una nueva promoción de "ropa deportiva de verano". Queremos probar cómo interactúan nuestros filtros facetados (p.ej., por marca, tamaño, color o intervalo de precios) con esta nueva categoría.
Sin la integración del IDE:
Probablemente, cambiaría a un cliente SQL independiente, escribiría mi consulta, la ejecutaría, analizaría los resultados, volvería a mi IDE para ajustar el código de la aplicación, volvería al cliente y repetiría el proceso. Este cambio de contexto es un gran inconveniente.
Con Gemini CLI y MCP:
Puedo permanecer en mi IDE y mucho más:
- Consultas: Puedo actualizar rápidamente la consulta en el archivo YAML con el conjunto de datos hipotético "SELECT DISTINCT brand FROM products WHERE category = ‘activewear' AND season = ‘summer'" y probarla directamente en mi terminal.
- Exploración de datos: Ve las marcas devueltas al instante. Si necesito ver la disponibilidad de productos para una marca y un tamaño específicos, puedo hacer otra consulta rápida:"SELECT COUNT(*) FROM products WHERE brand = 'SummitGear' AND size = 'M' AND category = 'activewear' AND season = 'summer'".
- Integración de código: Luego, puedo ajustar de inmediato la lógica de filtrado del frontend o las llamadas a la API del backend según estas estadísticas rápidas de datos en el IDE, lo que reduce significativamente el ciclo de retroalimentación.
2. Ajuste de la búsqueda de vectores para las recomendaciones de productos
Nuestra búsqueda híbrida se basa en embeddings de vectores para brindar recomendaciones de productos pertinentes. Supongamos que observamos una disminución en las tasas de clics de las recomendaciones de "calzado deportivo para hombres".
Sin la integración del IDE:
Ejecutaría secuencias de comandos o consultas personalizadas en una herramienta de base de datos para analizar las puntuaciones de similitud de los zapatos recomendados, compararlas con los datos de interacción del usuario y tratar de correlacionar cualquier patrón.
Con Gemini CLI y MCP:
- Análisis de las incorporaciones: Puedo consultar directamente las incorporaciones de productos y sus metadatos asociados: "SELECT product_id, name, vector_embedding FROM products WHERE category = ‘running shoes' AND gender = ‘male' LIMIT 10".
- Referencias cruzadas: También puedo realizar una verificación rápida de la similitud real de los vectores entre un producto elegido y sus recomendaciones, allí mismo. Por ejemplo, si el producto A se recomienda a los usuarios que miraron el producto B, podría ejecutar una consulta para recuperar y comparar sus embeddings de vectores.
- Depuración: Esto permite una depuración y una prueba de hipótesis más rápidas. ¿El modelo de embedding se comporta según lo esperado? ¿Hay anomalías en los datos que afectan la calidad de las recomendaciones? Puedo obtener respuestas iniciales sin salir de mi entorno de programación.
3. Comprensión del esquema y la distribución de datos para las funciones nuevas
Supongamos que planeamos agregar una función de "opiniones de clientes". Antes de escribir la API de backend, debemos comprender los datos de clientes existentes y cómo se podrían estructurar las opiniones.
Sin la integración del IDE:
Tendría que conectarme a un cliente de base de datos, ejecutar comandos DESCRIBE en tablas como clientes y pedidos, y, luego, consultar datos de muestra para comprender las relaciones y los tipos de datos.
Con Gemini CLI y MCP:
- Exploración del esquema: Puedo consultar la tabla en el archivo YAML y ejecutarla directamente en la terminal.
- Muestreo de datos: Luego, puedo extraer datos de muestra para comprender la demografía de los clientes y el historial de compras: "SELECT customer_id, name, signup_date, total_orders FROM customers ORDER BY signup_date DESC LIMIT 5".
- Planificación: Este acceso rápido al esquema y a la distribución de datos nos ayuda a tomar decisiones fundamentadas sobre cómo diseñar la nueva tabla de opiniones, qué claves externas establecer y cómo vincular de manera eficiente las opiniones a los clientes y los productos, todo antes de escribir una sola línea de código de la aplicación para la nueva función.
Estos son solo algunos ejemplos, pero destacan el beneficio principal: reducir la fricción y aumentar la velocidad de los desarrolladores. Al incorporar la interacción con AlloyDB directamente en el IDE, la CLI de Gemini y la caja de herramientas de MCP nos permiten compilar aplicaciones mejores y más responsivas con mayor rapidez.
10. Limpia
Sigue estos pasos para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos que usaste en esta publicación:
- En la consola de Google Cloud, ve a la página del administrador de recursos.
- En la lista de proyectos, elige el proyecto que deseas borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrarlo.
- Como alternativa, puedes borrar el clúster de AlloyDB (cambia la ubicación en este hipervínculo si no elegiste us-central1 para el clúster en el momento de la configuración) que acabamos de crear para este proyecto haciendo clic en el botón BORRAR CLÚSTER.
11. Felicitaciones
¡Felicitaciones! Integraste correctamente la caja de herramientas de MCP directamente en tu IDE para una interacción fluida con AlloyDB y aprovechaste la CLI de Gemini para interactuar con nuestro conjunto de datos de comercio electrónico minorista y escribir consultas que normalmente requerirían herramientas independientes. Aprendiste nuevas formas de explorar y comprender los datos, desde verificar las estructuras de las tablas hasta realizar verificaciones rápidas de la integridad de los datos, todo a través de interfaces de línea de comandos conocidas dentro de nuestro IDE.
Clona el repo, analízalo y avísame si mejoraste la aplicación con Gemini CLI y MCP Toolbox para bases de datos.
Para obtener más información sobre este tipo de aplicaciones basadas en datos con la tecnología de Gemini CLI y MCP, y que se implementan en entornos de ejecución sin servidores, regístrate en nuestra próxima temporada de Code Vipassana, donde podrás participar en sesiones prácticas dirigidas por instructores y realizar más Codelabs como este.