
۱. مرور کلی
سفر ما برای ساخت یک تجربه خردهفروشی ترکیبی پویا با AlloyDB، با ترکیب فیلترینگ وجهی و جستجوی برداری را به خاطر دارید؟ آن برنامه نمایشی قدرتمند از نیازهای خردهفروشی مدرن بود، اما رسیدن به آنجا - و تکرار آن - نیاز به تلاش توسعهای قابل توجهی داشت. برای توسعهدهندگان فولاستک، رفت و آمد مداوم بین ویرایشگرهای کد و ابزارهای پایگاه داده اغلب میتواند یک گلوگاه باشد و نوآوری و فرآیند حیاتی درک دادههای شما را کند کند.
راه حل
دقیقاً همین جاست که قدرت توسعهی شتابیافتهی اپلیکیشن واقعاً میدرخشد، و به همین دلیل است که من بسیار هیجانزدهام تا به اشتراک بگذارم که چگونه جعبهابزار MCP (پلتفرم ابری مدرن) که از طریق رابط خط فرمان Gemini قابل دسترسی است، به بخش جداییناپذیری از جعبهابزار من تبدیل شده است. تصور کنید که به طور یکپارچه با نمونهی AlloyDB خود تعامل دارید، کوئری مینویسید و مجموعه دادههای خود را درک میکنید - همه اینها مستقیماً در محیط توسعهی یکپارچه (IDE) شما. این فقط مربوط به راحتی نیست؛ بلکه اساساً در مورد کاهش اصطکاک در چرخهی توسعه است و به شما این امکان را میدهد که به جای دست و پنجه نرم کردن با ابزارهای خارجی، بر ساخت ویژگیهای نوآورانه تمرکز کنید.
در زمینه اپلیکیشن تجارت الکترونیک خردهفروشی ما، جایی که نیاز به پرسوجوی کارآمد دادههای محصول، مدیریت فیلترهای پیچیده و بهرهگیری از ظرافتهای جستجوی برداری داشتیم، توانایی تکرار سریع تعاملات پایگاه داده بسیار مهم بود. جعبه ابزار MCP، که توسط Gemini CLI پشتیبانی میشود، نه تنها این کار را ساده میکند، بلکه سرعت میبخشد و نحوه کاوش، آزمایش و اصلاح منطق پایگاه دادهای که زیربنای برنامههای ما است را متحول میکند. بیایید بررسی کنیم که چگونه این ترکیب متحولکننده، توسعه فولاستک را سریعتر، هوشمندانهتر و لذتبخشتر میکند.
آنچه یاد خواهید گرفت و خواهید ساخت
یک برنامه جستجوی خردهفروشی با استفاده از جعبه ابزار MCP در IDE، که توسط Gemini CLI پشتیبانی میشود. ما موارد زیر را پوشش خواهیم داد:
- چگونه جعبه ابزار MCP را مستقیماً در IDE خود برای تعامل یکپارچه با AlloyDB ادغام کنید.
- مثالهای عملی از استفاده از رابط خط فرمان Gemini برای نوشتن و اجرای کوئریهای SQL روی دادههای خردهفروشی شما.
- از رابط خط فرمان Gemini برای تعامل با مجموعه دادههای تجارت الکترونیک خردهفروشی ما، نوشتن کوئریهایی که معمولاً به ابزارهای جداگانه نیاز دارند و مشاهده فوری نتایج، استفاده کنید.
- روشهای جدیدی برای بررسی و درک دادهها - از بررسی ساختارهای جدول گرفته تا انجام بررسیهای سریع صحت دادهها - را از طریق رابطهای خط فرمان آشنا در IDE ما کشف کنید.
- چگونه این گردش کار پایگاه داده شتابیافته مستقیماً به چرخههای توسعه فولاستک سریعتر کمک میکند و امکان نمونهسازی سریع و تکرار را فراهم میکند.
تکاستک
ما استفاده میکنیم:
- AlloyDB برای پایگاه داده
- جعبه ابزار MCP برای انتزاع ویژگیهای پیشرفته تولیدی و هوش مصنوعی پایگاههای داده از برنامه
- Cloud Run برای استقرار بدون سرور.
- رابط خط فرمان Gemini برای درک و تجزیه و تحلیل مجموعه دادهها و ساخت بخش پایگاه داده برنامه تجارت الکترونیک خردهفروشی.
الزامات
۲. قبل از شروع
ایجاد یک پروژه
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید.
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
- شما از Cloud Shell ، یک محیط خط فرمان که در Google Cloud اجرا میشود، استفاده خواهید کرد. روی Activate Cloud Shell در بالای کنسول Google Cloud کلیک کنید.

- پس از اتصال به Cloud Shell، با استفاده از دستور زیر بررسی میکنید که آیا از قبل احراز هویت شدهاید و پروژه روی شناسه پروژه شما تنظیم شده است یا خیر:
gcloud auth list
- دستور زیر را در Cloud Shell اجرا کنید تا تأیید شود که دستور gcloud از پروژه شما اطلاع دارد.
gcloud config list project
- اگر پروژه شما تنظیم نشده است، از دستور زیر برای تنظیم آن استفاده کنید:
gcloud config set project <YOUR_PROJECT_ID>
- فعال کردن API های مورد نیاز: روی لینک کلیک کنید و API ها را فعال کنید.
به عنوان یک روش جایگزین، میتوانید از دستور gcloud برای این کار استفاده کنید. برای مشاهده دستورات و نحوه استفاده از gcloud به مستندات آن مراجعه کنید.
۳. راهاندازی پایگاه داده
در این آزمایش، ما از AlloyDB به عنوان پایگاه داده برای دادههای تجارت الکترونیک استفاده خواهیم کرد. این پایگاه داده از خوشهها برای نگهداری تمام منابع، مانند پایگاههای داده و گزارشها، استفاده میکند. هر خوشه یک نمونه اصلی دارد که یک نقطه دسترسی به دادهها را فراهم میکند. جداول، دادههای واقعی را نگهداری میکنند.
بیایید یک کلاستر، نمونه و جدول AlloyDB ایجاد کنیم که مجموعه دادههای تجارت الکترونیک در آن بارگذاری شود.
ایجاد یک کلاستر و نمونه
- در کنسول ابری، صفحه AlloyDB را پیمایش کنید. یک راه آسان برای یافتن اکثر صفحات در کنسول ابری، جستجوی آنها با استفاده از نوار جستجوی کنسول است.
- از آن صفحه، گزینه CREATE CLUSTER را انتخاب کنید:

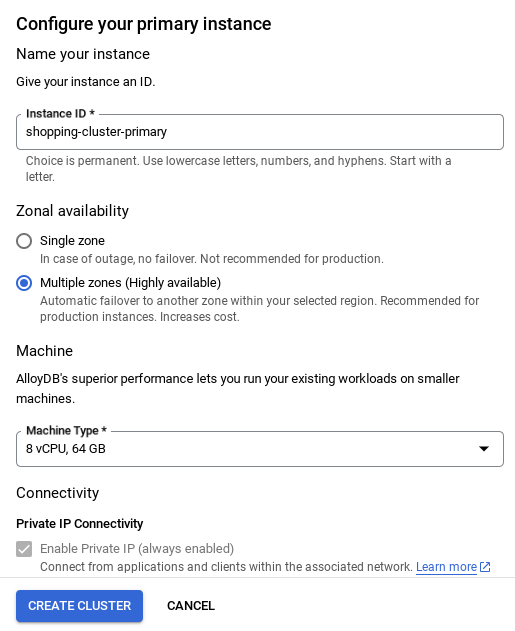
- صفحهای مانند تصویر زیر خواهید دید. یک کلاستر و نمونه با مقادیر زیر ایجاد کنید (مطمئن شوید که مقادیر مطابقت دارند، در صورتی که کد برنامه را از مخزن کپی میکنید):
- شناسه خوشه : "
vector-cluster" - رمز عبور : "
alloydb" - PostgreSQL 15 / آخرین نسخه توصیه شده
- منطقه : "
us-central1" - شبکه : "
default"
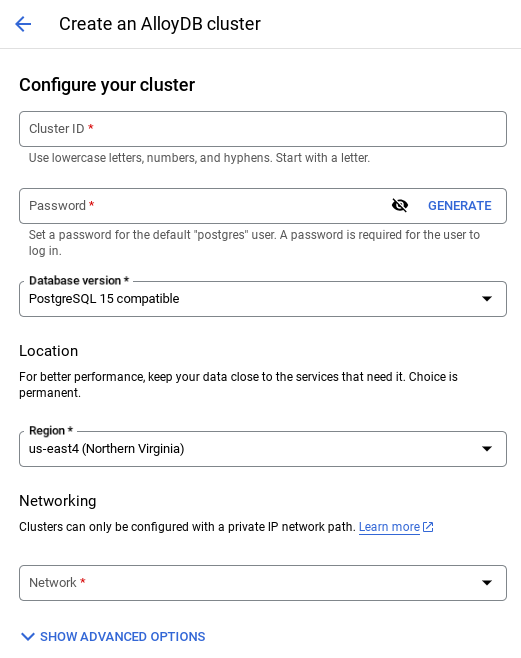
- وقتی شبکه پیشفرض را انتخاب میکنید، صفحهای مانند تصویر زیر مشاهده خواهید کرد.
تنظیم اتصال را انتخاب کنید.
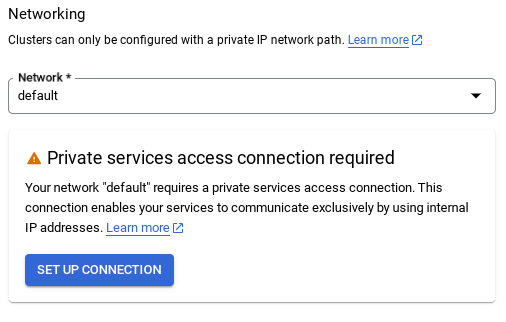
- از آنجا، « استفاده از یک محدوده IP اختصاص داده شده خودکار » را انتخاب کرده و ادامه دهید. پس از بررسی اطلاعات، «ایجاد اتصال» را انتخاب کنید.
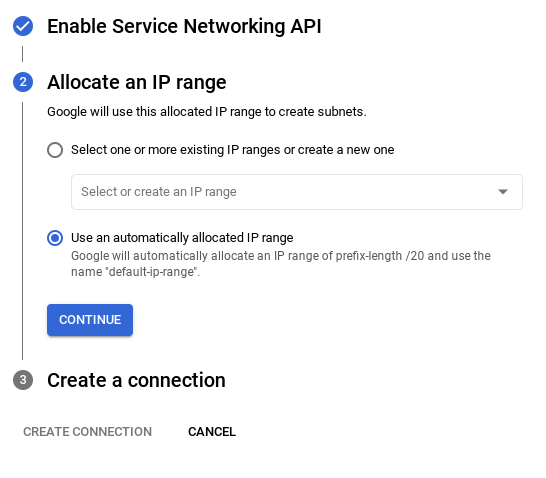
- پس از راهاندازی شبکه، میتوانید به ایجاد خوشه خود ادامه دهید. برای تکمیل راهاندازی خوشه، مطابق شکل زیر، روی CREATE CLUSTER کلیک کنید:
نکته مهم:
- مطمئن شوید که شناسه نمونه (که میتوانید در زمان پیکربندی کلاستر / نمونه آن را پیدا کنید) را به **
vector-instance** تغییر دهید. اگر نمیتوانید آن را تغییر دهید، به یاد داشته باشید که **از شناسه نمونه خود** در تمام ارجاعات بعدی استفاده کنید. - توجه داشته باشید که ایجاد خوشه حدود ۱۰ دقیقه طول خواهد کشید. پس از موفقیتآمیز بودن، باید صفحهای را مشاهده کنید که نمای کلی خوشه ایجاد شده شما را نشان میدهد.
۴. دریافت دادهها
حالا وقت آن رسیده که یک جدول با دادههای مربوط به فروشگاه اضافه کنیم. به AlloyDB بروید، خوشه اصلی و سپس AlloyDB Studio را انتخاب کنید:
ممکن است لازم باشد منتظر بمانید تا نمونه شما به طور کامل ایجاد شود. پس از اتمام این کار، با استفاده از اعتبارنامههایی که هنگام ایجاد خوشه ایجاد کردهاید، وارد AlloyDB شوید. از دادههای زیر برای تأیید اعتبار در PostgreSQL استفاده کنید:
- نام کاربری: "
postgres" - پایگاه داده: "
postgres" - رمز عبور: "
alloydb"
پس از اینکه با موفقیت در AlloyDB Studio احراز هویت شدید، دستورات SQL در ویرایشگر وارد میشوند. میتوانید با استفاده از علامت + در سمت راست آخرین پنجره، چندین پنجره ویرایشگر اضافه کنید.
شما میتوانید دستورات AlloyDB را در پنجرههای ویرایشگر وارد کنید و در صورت لزوم از گزینههای Run، Format و Clear استفاده کنید.
فعال کردن افزونهها
برای ساخت این برنامه، از افزونههای pgvector و google_ml_integration استفاده خواهیم کرد. افزونه pgvector به شما امکان ذخیره و جستجوی جاسازیهای برداری را میدهد. افزونه google_ml_integration توابعی را ارائه میدهد که برای دسترسی به نقاط پایانی پیشبینی هوش مصنوعی Vertex برای دریافت پیشبینیها در SQL استفاده میکنید. این افزونهها را با اجرای DDL های زیر فعال کنید :
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
اگر میخواهید افزونههایی که در پایگاه داده شما فعال شدهاند را بررسی کنید، این دستور SQL را اجرا کنید:
select extname, extversion from pg_extension;
ایجاد یک جدول
شما میتوانید با استفاده از دستور DDL زیر در AlloyDB Studio یک جدول ایجاد کنید:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
ستون تعبیهشده امکان ذخیرهسازی مقادیر برداری متن را فراهم میکند.
اعطای مجوز
برای اعطای مجوز اجرا به تابع "embedding"، دستور زیر را اجرا کنید:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
اعطای نقش کاربری Vertex AI به حساب سرویس AlloyDB
از کنسول Google Cloud IAM ، به حساب سرویس AlloyDB (که به این شکل است: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) دسترسی به نقش "Vertex AI User" را بدهید. PROJECT_NUMBER شماره پروژه شما را خواهد داشت.
همچنین میتوانید دستور زیر را از ترمینال Cloud Shell اجرا کنید:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
بارگذاری دادهها در پایگاه داده
- دستورات کوئری
insertرا ازinsert scripts sqlدر برگهای که در بالا ذکر شد، در ویرایشگر کپی کنید. میتوانید ۱۰ تا ۵۰ دستور درج را برای نمایش سریع این مورد استفاده کپی کنید. در اینجا، در تب "Selected Inserts 25-30 rows" فهرستی از درجها وجود دارد . - روی Run کلیک کنید. نتایج پرسوجوی شما در جدول نتایج ظاهر میشود.
نکته مهم:
مطمئن شوید که فقط ۲۵ تا ۵۰ رکورد را برای درج کپی میکنید و مطمئن شوید که از طیف وسیعی از انواع دستهبندی، زیررده، رنگ و جنسیت باشد.
۵. ایجاد جاسازیها برای دادهها
نوآوری واقعی در جستجوی مدرن در درک معنا نهفته است، نه فقط کلمات کلیدی. اینجاست که جاسازیها و جستجوی برداری وارد عمل میشوند.
ما توضیحات محصول و پرسوجوهای کاربر را با استفاده از مدلهای زبانی از پیش آموزشدیده به نمایشهای عددی با ابعاد بالا به نام «جاسازیها» تبدیل کردیم. این جاسازیها معنای معنایی را ثبت میکنند و به ما امکان میدهند محصولاتی را پیدا کنیم که «از نظر معنا مشابه» هستند، نه اینکه فقط حاوی کلمات منطبق باشند. در ابتدا، ما با جستجوی تشابه برداری مستقیم روی این جاسازیها آزمایش کردیم تا یک خط مبنا ایجاد کنیم و قدرت درک معنایی را حتی قبل از بهینهسازیهای عملکرد نشان دهیم.
ستون embedding امکان ذخیرهسازی مقادیر برداری متن توضیحات محصول را فراهم میکند. ستون img_embeddings امکان ذخیرهسازی جاسازیهای تصویر (چندوجهی) را فراهم میکند. به این ترتیب میتوانید از متن در مقابل جستجوی مبتنی بر فاصله تصویر نیز استفاده کنید. اما ما در این تمرین فقط از جاسازیهای متن استفاده خواهیم کرد.
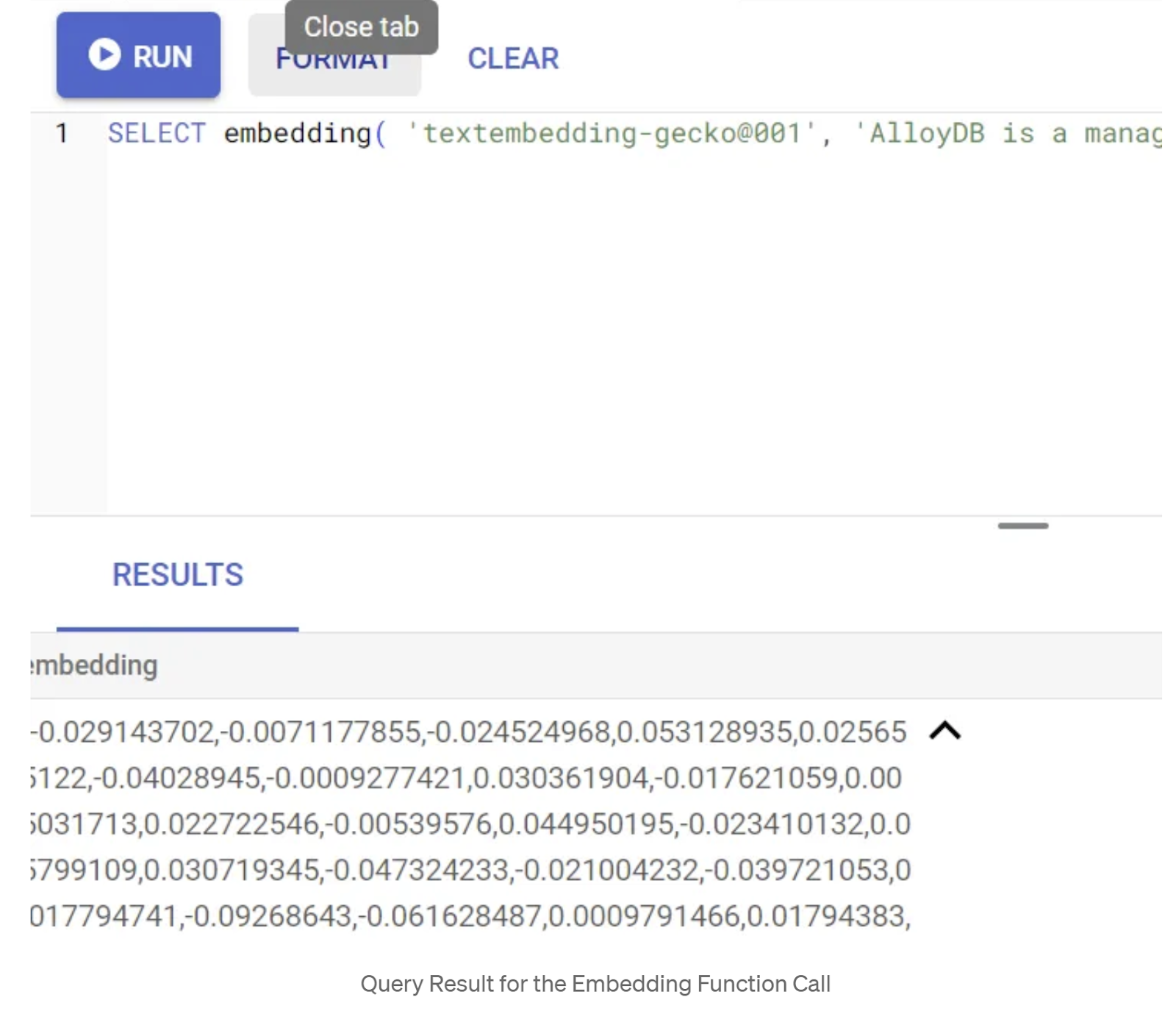
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
این باید بردار جاسازیها را که شبیه آرایهای از اعداد اعشاری است، برای متن نمونه در پرسوجو برگرداند. به این شکل است:
فیلد بردار abstract_embeddings را بهروزرسانی کنید
DML زیر را اجرا کنید تا توضیحات محتوا در جدول با جاسازیهای مربوطه بهروزرسانی شود:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
اگر از یک حساب پرداخت اعتباری آزمایشی برای Google Cloud استفاده میکنید، ممکن است در ایجاد بیش از چند جاسازی (مثلاً حداکثر ۲۰ تا ۲۵) مشکل داشته باشید. بنابراین تعداد ردیفها را در اسکریپت درج محدود کنید.
اگر میخواهید جاسازی تصویر ایجاد کنید (برای انجام جستجوی متنی چندوجهی)، بهروزرسانی زیر را نیز اجرا کنید:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
۶. جعبه ابزار MCP برای پایگاههای داده (AlloyDB)
در پشت صحنه، ابزارهای قوی و یک برنامهی کاربردیِ ساختارمند، عملکرد روان را تضمین میکنند.
جعبه ابزار MCP (پروتکل زمینه مدل) برای پایگاههای داده، ادغام ابزارهای هوش مصنوعی مولد و عاملدار را با AlloyDB ساده میکند. این جعبه ابزار به عنوان یک سرور متنباز عمل میکند که جمعآوری اتصال، احراز هویت و ارائه ایمن قابلیتهای پایگاه داده به عاملهای هوش مصنوعی یا سایر برنامهها را ساده میکند.
در برنامه خود، از جعبه ابزار MCP برای پایگاههای داده به عنوان یک لایه انتزاعی برای همه پرسوجوهای جستجوی ترکیبی هوشمند خود استفاده کردهایم.
برای راهاندازی و استقرار Toolbox برای مورد استفاده ما، مراحل زیر را دنبال کنید:
میتوانید ببینید که یکی از پایگاههای دادهای که توسط MCP Toolbox for Databases پشتیبانی میشود، AlloyDB است و از آنجایی که قبلاً آن را در بخش قبلی فراهم کردهایم، بیایید Toolbox را راهاندازی کنیم.
- به ترمینال Cloud Shell خود بروید و مطمئن شوید که پروژه شما انتخاب شده و در اعلان ترمینال نمایش داده میشود. دستور زیر را از ترمینال Cloud Shell خود اجرا کنید تا به دایرکتوری پروژه خود بروید:
mkdir gemini-cli-project
cd gemini-cli-project
- دستور زیر را برای دانلود و نصب toolbox در پوشه جدید خود اجرا کنید:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
این باید جعبه ابزار را در دایرکتوری فعلی شما ایجاد کند. مسیر جعبه ابزار را کپی کنید.
- به ویرایشگر Cloud Shell (برای حالت ویرایش کد) بروید و در پوشه ریشه پروژه "gemini-cli-project"، فایلی به نام "tools.yaml" اضافه کنید.
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
بیایید tools.yaml را درک کنیم:
منابع (Sources) منابع داده مختلف شما را که یک ابزار میتواند با آنها تعامل داشته باشد، نشان میدهند. یک منبع (source) نشان دهنده منبع دادهای است که یک ابزار میتواند با آن تعامل داشته باشد. میتوانید منابع (Sources) را به عنوان یک نقشه (map) در بخش منابع (sources) فایل tools.yaml خود تعریف کنید. به طور معمول، پیکربندی منبع (source configuration) شامل هرگونه اطلاعات مورد نیاز برای اتصال و تعامل با پایگاه داده خواهد بود.
ابزارها اقداماتی را که یک عامل میتواند انجام دهد تعریف میکنند - مانند خواندن و نوشتن در یک منبع. یک ابزار نشان دهنده عملی است که عامل شما میتواند انجام دهد، مانند اجرای یک دستور SQL. میتوانید ابزارها را به عنوان یک نقشه در بخش ابزارهای فایل tools.yaml خود تعریف کنید. معمولاً، یک ابزار برای اقدام به یک منبع نیاز دارد.
برای جزئیات بیشتر در مورد پیکربندی tools.yaml خود، به این مستندات مراجعه کنید.
همانطور که در فایل Tools.yaml بالا مشاهده میکنید، ابزار "get-apparels" تمام جزئیات پوشاک را از پایگاه داده فهرست میکند.
۷. تنظیمات رابط خط فرمان (CLI) جمینی (Gemini) را انجام دهید
از ویرایشگر پوسته ابری (Cloud Shell Editor)، یک پوشه جدید به نام .gemini درون پوشه gemini-cli-project ایجاد کنید و یک فایل جدید به نام settings.json در آن ایجاد کنید.
{
"mcpServers": {
"AlloyDBServer": {
"command": "/home/user/gemini-cli-project/toolbox",
"args": ["--tools-file", "tools.yaml", "--stdio"]
}
}
}
در بخش فرمان در قطعه کد بالا، « /home/user/gemini-cli-project/toolbox » را با مسیر خود به toolbox جایگزین کنید.
نصب رابط خط فرمان Gemini
در نهایت از طریق ترمینال Cloud Shell، با اجرای دستور زیر، Gemini CLI را در همان دایرکتوری gemini-cli-project نصب میکنیم:
sudo npm install -g @google/gemini-cli
شناسه پروژه خود را تنظیم کنید
مطمئن شوید که شناسه پروژه فعال را در محیط تنظیم کردهاید:
export GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT_ID>>
شروع کار با Gemini CLI
از خط فرمان، دستور را وارد کنید:
gemini
شما باید بتوانید پاسخی مشابه زیر را ببینید:
احراز هویت کنید و به مرحله بعدی بروید.
۸. شروع تعامل با رابط خط فرمان Gemini
برای مشاهده لیست سرورهای MCP پیکربندی شده، از دستور /mcp استفاده کنید.
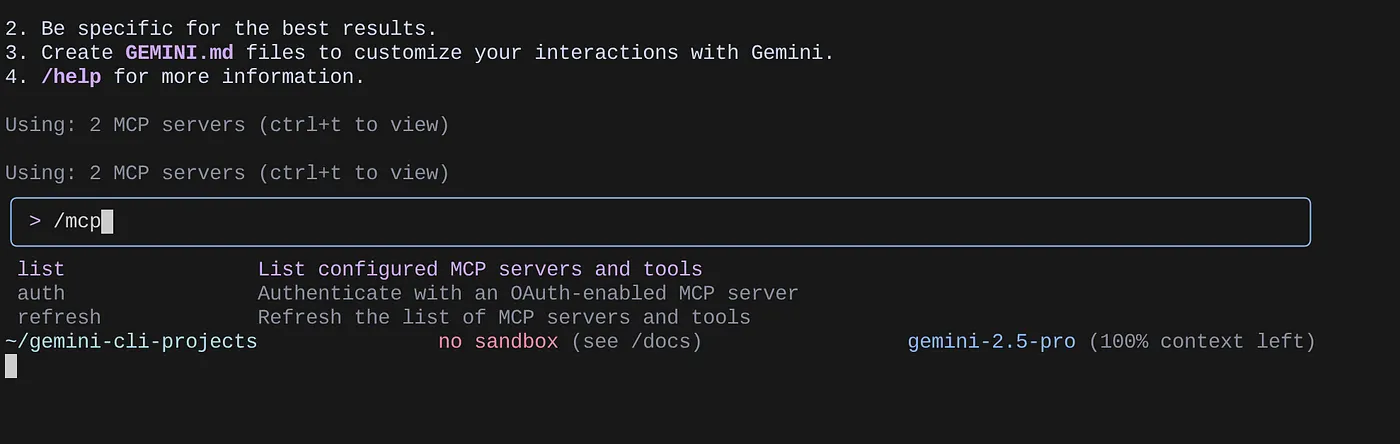
شما باید بتوانید دو سرور MCP که پیکربندی کردهایم را ببینید: GitHub و MCP Toolbox for Databases که به همراه ابزارهایشان فهرست شدهاند.
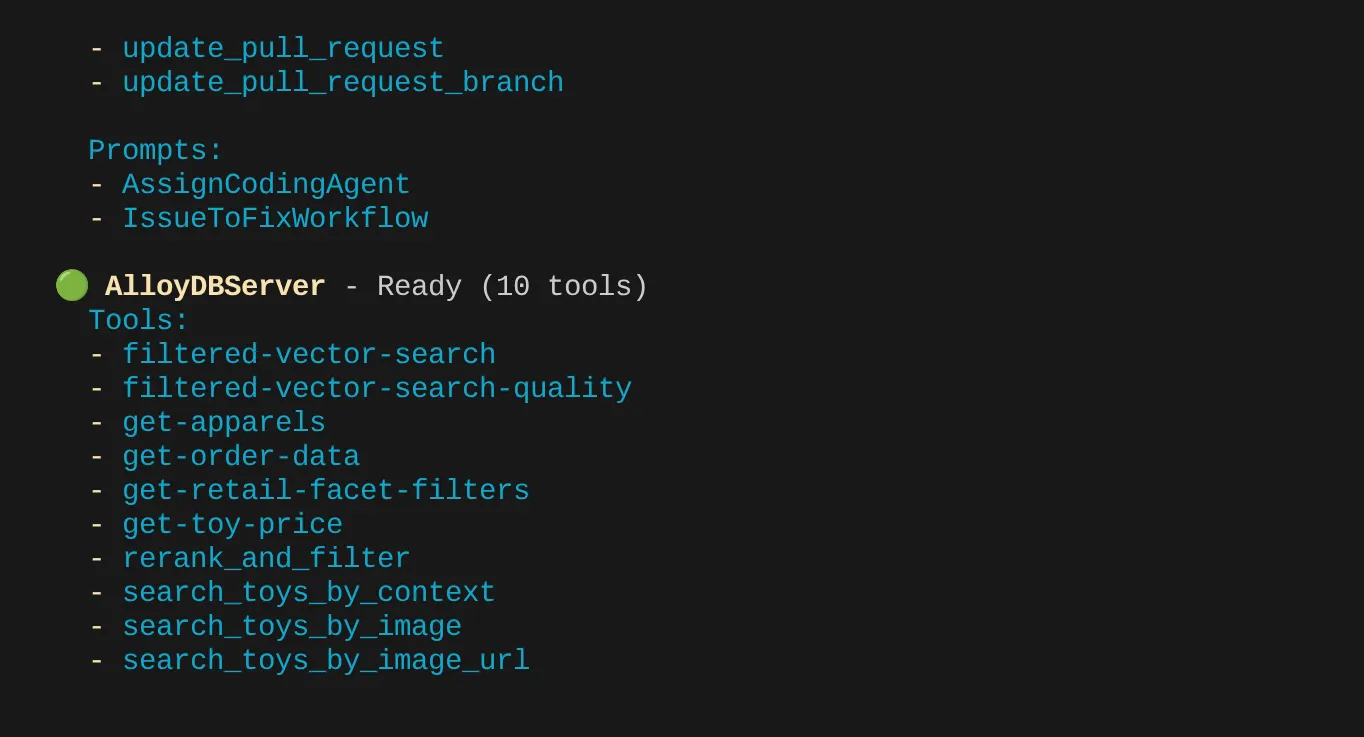
در مورد من، ابزارهای بیشتری دارم. بنابراین فعلاً آن را نادیده بگیرید. باید ابزار get-apparels را در سرور AlloyDB MCP خود ببینید.
شروع به پرس و جو از پایگاه داده از طریق جعبه ابزار MCP کنید
حالا سعی کنید سوالات زبان طبیعی بپرسید تا پاسخها و پرسوجوها را برای مجموعه دادهای که با آن کار میکنیم، دریافت کنید:
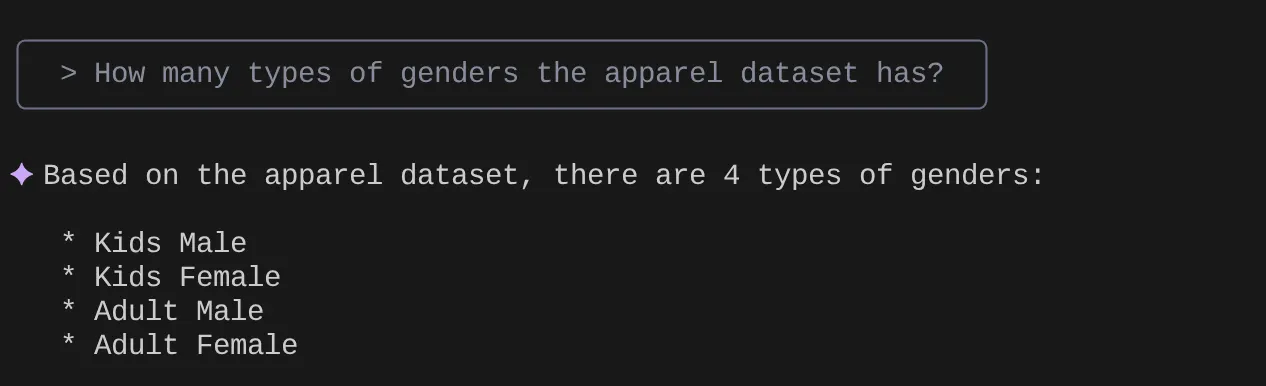
> How many types of genders the apparel dataset has?
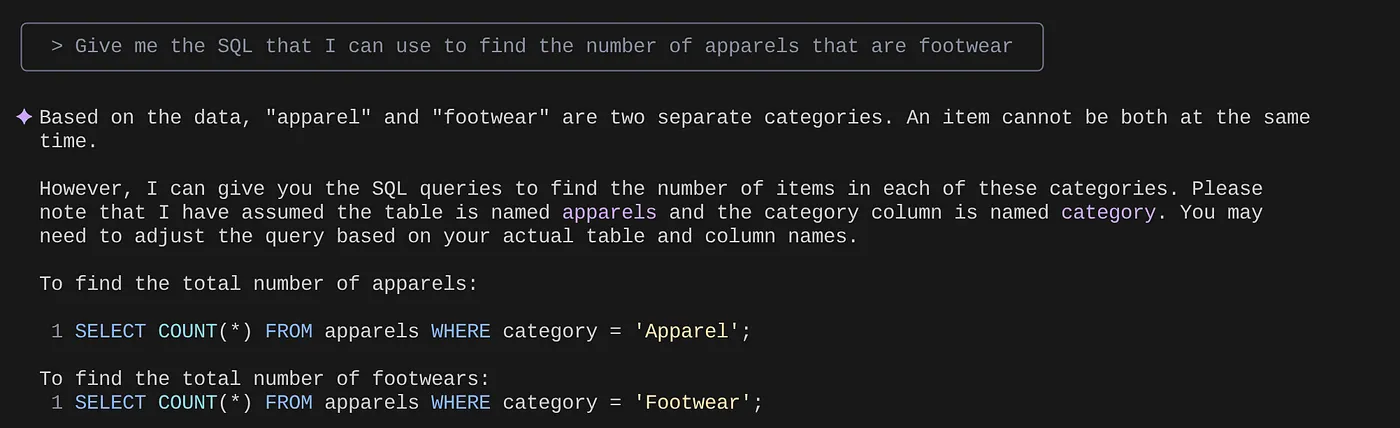
> Give me the SQL that I can use to find the number of apparels that are footwear
> What are the unique sub categories that are there?
that I can use to find the number of apparels that are footwear
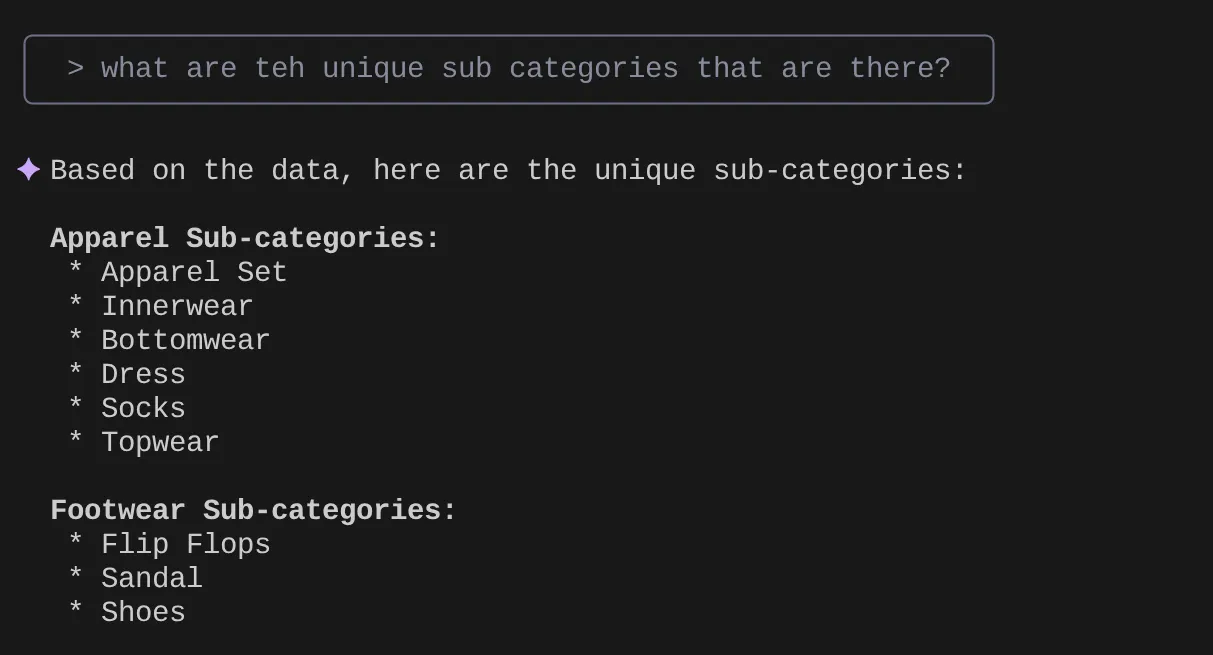
حالا فرض کنید بر اساس بینشهایم و بسیاری از این قبیل پرسوجوها، یک پرسوجوی دقیق ایجاد کردهام و میخواهم آن را آزمایش کنم. یا فرض کنید مهندسان پایگاه داده از قبل Tools.yaml را به صورت زیر برای شما ساختهاند:
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
filtered-vector-search:
kind: postgres-sql
source: alloydb
description: Get the list of facet filter values from the retail dataset.
parameters:
- name: categories
type: array
description: List of categories preferred by the user.
items:
name: category
type: string
description: Category value.
- name: subCategories
type: array
description: List of sub-categories preferred by the user.
items:
name: subCategory
type: string
description: Sub-Category value.
- name: colors
type: array
description: List of colors preferred by the user.
items:
name: color
type: string
description: Color value.
- name: genders
type: array
description: List of genders preferred by the user for apparel fitting.
items:
name: gender
type: string
description: Gender name.
- name: searchtext
type: string
description: Description of the product that the user wants to find database matches for.
statement: |
SELECT id, content, uri, category, sub_category,color,gender FROM apparels
where category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005',$5)::vector limit 10
حالا بیایید یک جستجوی زبان طبیعی را امتحان کنیم:
> How many yellow shirts are there for boys?
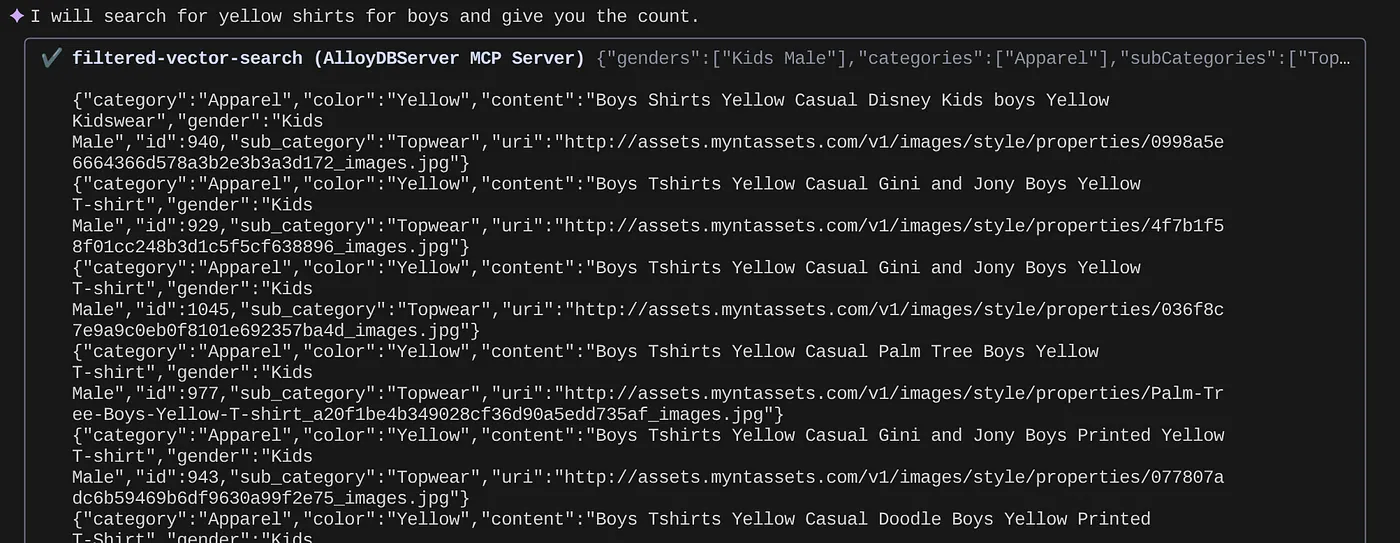

خیلی باحاله، نه؟ حالا میتونم فایل yaml رو برای پیشرفتهای بیشتر در کوئریها اصلاح کنم، در حالی که به ارائه قابلیتهای جدید در برنامهام در یک جدول زمانی سریعتر ادامه میدم.
۹. توسعه سریع اپلیکیشن
زیبایی آوردن قابلیتهای پایگاه داده به طور مستقیم به IDE شما از طریق Gemini CLI و MCP Toolbox فقط در حد تئوری نیست. این قابلیت به گردشهای کاری ملموس و افزایشدهنده سرعت، به ویژه برای یک برنامه پیچیده مانند تجربه خردهفروشی ترکیبی ما، تبدیل میشود. بیایید به چند سناریو نگاه کنیم:
۱. تکرار سریع منطق فیلتر کردن محصولات
تصور کنید که ما به تازگی یک طرح تشویقی جدید برای «لباسهای ورزشی تابستانی» راهاندازی کردهایم. میخواهیم بررسی کنیم که فیلترهای چندوجهی ما (مثلاً بر اساس برند، اندازه، رنگ، محدوده قیمت) چگونه با این دسته جدید تعامل دارند.
بدون ادغام IDE:
احتمالاً به یک کلاینت SQL جداگانه سوئیچ میکنم، کوئریام را مینویسم، آن را اجرا میکنم، نتایج را تجزیه و تحلیل میکنم، به IDE برمیگردم تا کد برنامه را تنظیم کنم، دوباره به کلاینت برمیگردم و تکرار میکنم. این تغییر زمینه یک مشکل اساسی است.
با رابط خط فرمان و MCP جمینی:
من میتوانم در IDE خودم بمانم و کارهای بیشتری انجام دهم:
- پرسوجو: میتوانم به سرعت پرسوجو را در yaml با (مجموعه داده فرضی) "SELECT DISTINCT brand FROM products WHERE category = 'activewear' AND season = 'summer'" بهروزرسانی کنم و آن را مستقیماً در ترمینال خود امتحان کنم.
- کاوش دادهها: برندهای بازگشتی را فوراً ببینید. اگر نیاز به مشاهده موجودی محصول برای یک برند و سایز خاص داشته باشم، میتوانم از یک کوئری سریع دیگر استفاده کنم: "SELECT COUNT(*) FROM products WHERE brand = 'SummitGear' AND size = 'M' AND category = 'activewear' AND season = 'summer'"
- یکپارچهسازی کد: سپس میتوانم بلافاصله منطق فیلترینگ front-end یا فراخوانیهای API back-end را بر اساس این بینشهای سریع و درون IDE تنظیم کنم و حلقه بازخورد را به طور قابل توجهی کاهش دهم.
۲. جستجوی برداری تنظیم دقیق برای توصیههای محصول
جستجوی ترکیبی ما برای توصیههای مربوط به محصولات، به جاسازیهای برداری متکی است. فرض کنید شاهد کاهش نرخ کلیک برای توصیههای «کفشهای دویدن مردانه» هستیم.
بدون ادغام IDE:
من اسکریپتها یا کوئریهای سفارشی را در یک ابزار پایگاه داده اجرا میکنم تا امتیاز شباهت کفشهای پیشنهادی را تجزیه و تحلیل کنم، آنها را با دادههای تعامل کاربر مقایسه کنم و سعی کنم هر الگویی را با آن مرتبط کنم.
با رابط خط فرمان و MCP جمینی:
- تحلیل جاسازیها: میتوانم مستقیماً برای جاسازیهای محصول و فرادادههای مرتبط با آنها پرسوجو کنم: "SELECT product_id, name, vector_embedding FROM products WHERE category = 'running shoes' AND gender = 'male' LIMIT 10"
- ارجاع متقابل: من همچنین میتوانم همانجا بررسی سریعی از شباهت برداری واقعی بین یک محصول انتخاب شده و توصیههای آن انجام دهم. برای مثال، اگر محصول A به کاربرانی که محصول B را مشاهده کردهاند توصیه شود، میتوانم یک پرسوجو برای بازیابی و مقایسه جاسازیهای برداری آنها اجرا کنم.
- اشکالزدایی: این امکان اشکالزدایی و آزمایش فرضیه سریعتر را فراهم میکند. آیا مدل جاسازیشده طبق انتظار رفتار میکند؟ آیا ناهنجاریهایی در دادهها وجود دارد که بر کیفیت توصیه تأثیر بگذارد؟ میتوانم بدون ترک محیط کدنویسی خود، پاسخهای اولیه را دریافت کنم.
۳. درک طرحواره و توزیع دادهها برای ویژگیهای جدید
فرض کنید قصد داریم یک ویژگی «نظرات مشتریان» اضافه کنیم. قبل از اینکه API بکاند را بنویسیم، باید دادههای موجود مشتریان و نحوه ساختاردهی نظرات را درک کنیم.
بدون ادغام IDE:
من باید به یک کلاینت پایگاه داده متصل شوم، دستورات DESCRIBE را روی جداولی مانند مشتریان و سفارشات اجرا کنم، و سپس برای درک روابط و انواع دادهها، دادههای نمونه را جستجو کنم.
با رابط خط فرمان و MCP جمینی:
- کاوش در طرحواره: میتوانم به سادگی جدول موجود در فایل yaml را جستجو کنم و آن را مستقیماً در ترمینال اجرا کنم.
- نمونهگیری دادهها: سپس میتوانم از دادههای نمونه برای درک جمعیتشناسی مشتری و تاریخچه خرید استفاده کنم: "SELECT customer_id, name, signup_date, total_orders FROM customers ORDER BY signup_date DESC LIMIT 5"
- برنامهریزی: این دسترسی سریع به طرحواره و توزیع دادهها به ما کمک میکند تا قبل از نوشتن حتی یک خط کد برنامه برای ویژگی جدید، تصمیمات آگاهانهای در مورد نحوه طراحی جدول نظرات جدید، ایجاد کلیدهای خارجی و نحوه پیوند کارآمد نظرات به مشتریان و محصولات بگیریم.
اینها فقط چند نمونه هستند، اما مزیت اصلی را برجسته میکنند: کاهش اصطکاک و افزایش سرعت توسعهدهنده. با آوردن تعامل AlloyDB به طور مستقیم به IDE، Gemini CLI و MCP Toolbox ما را قادر میسازند تا برنامههای بهتر و پاسخگوتری را سریعتر بسازیم.
۱۰. تمیز کردن
برای جلوگیری از تحمیل هزینه به حساب Google Cloud خود برای منابع استفاده شده در این پست، این مراحل را دنبال کنید:
- در کنسول گوگل کلود، به صفحه مدیریت منابع بروید.
- در لیست پروژهها، پروژهای را که میخواهید حذف کنید انتخاب کنید و سپس روی «حذف» کلیک کنید.
- در کادر محاورهای، شناسه پروژه را تایپ کنید و سپس برای حذف پروژه، روی خاموش کردن کلیک کنید.
- از طرف دیگر، میتوانید کلاستر AlloyDB را که برای این پروژه ایجاد کردهایم، با کلیک روی دکمهی DELETE CLUSTER حذف کنید (اگر در زمان پیکربندی، us-central1 را برای کلاستر انتخاب نکردهاید، مکان آن را در این هایپرلینک تغییر دهید).
۱۱. تبریک
تبریک! شما با موفقیت MCP Toolbox را مستقیماً در IDE خود برای تعامل یکپارچه AlloyDB ادغام کردهاید و از Gemini CLI برای تعامل با مجموعه دادههای تجارت الکترونیک خردهفروشی ما برای نوشتن کوئریهایی که معمولاً به ابزارهای جداگانه نیاز دارند، استفاده کردهاید. شما روشهای جدیدی برای بررسی و درک دادهها - از بررسی ساختارهای جدول گرفته تا انجام بررسیهای سریع سلامت دادهها - از طریق رابطهای خط فرمان آشنا در IDE ما آموختهاید.
ادامه دهید و مخزن را کلون کنید، آن را تجزیه و تحلیل کنید و اگر برنامه را با استفاده از Gemini CLI و MCP Toolbox for Databases بهبود بخشیدهاید، به من اطلاع دهید.
برای برنامههای دادهمحور بیشتری که با Gemini CLI و MCP ساخته شدهاند و روی runtimeهای Serverless پیادهسازی شدهاند، در فصل آینده Code Vipassana ما ثبتنام کنید که در آن جلسات عملی با راهنمایی مدرس و codelabهای بیشتری از این دست خواهید داشت!!!