
1. Présentation
Vous vous souvenez de notre parcours de création d'une expérience hybride dynamique pour le commerce de détail avec AlloyDB, combinant le filtrage par facettes et la recherche vectorielle ? Cette application était une démonstration puissante des besoins du commerce moderne, mais sa création et son itération ont nécessité un effort de développement considérable. Pour les développeurs full stack, les allers-retours constants entre les éditeurs de code et les outils de base de données peuvent souvent constituer un goulot d'étranglement, ralentissant l'innovation et le processus crucial de compréhension de vos données.
Solution
C'est précisément là que la puissance du développement d'applications accéléré brille de mille feux. C'est pourquoi je suis ravi de vous montrer comment la boîte à outils MCP (Modern Cloud Platform), accessible via la Gemini CLI intuitive, est devenue un élément indispensable de ma boîte à outils. Imaginez pouvoir interagir de manière fluide avec votre instance AlloyDB, écrire des requêtes et comprendre votre ensemble de données, le tout directement dans votre environnement de développement intégré (IDE). Il ne s'agit pas seulement de commodité, mais de réduire fondamentalement les frictions dans le cycle de vie du développement, ce qui vous permet de vous concentrer sur la création de fonctionnalités innovantes plutôt que de lutter avec des outils externes.
Dans le contexte de notre application d'e-commerce, où nous devions interroger efficacement les données produit, gérer le filtrage complexe et exploiter les nuances de la recherche vectorielle, la capacité à itérer rapidement sur les interactions avec la base de données était primordiale. MCP Toolbox, optimisé par Gemini CLI, simplifie et accélère ce processus, transformant la façon dont nous explorons, testons et affinons la logique de base de données qui sous-tend nos applications. Découvrons comment cette combinaison révolutionnaire rend le développement full stack plus rapide, plus intelligent et plus agréable.
Points abordés et objectifs de l'atelier
Application Retail Search utilisant MCP Toolbox dans l'IDE, optimisée par Gemini CLI. Au programme :
- Découvrez comment intégrer MCP Toolbox directement dans votre IDE pour une interaction fluide avec AlloyDB.
- Exemples pratiques d'utilisation de Gemini CLI pour écrire et exécuter des requêtes SQL sur vos données de vente au détail.
- Utilisez Gemini CLI pour interagir avec notre ensemble de données sur le commerce de détail en ligne, en écrivant des requêtes qui nécessiteraient normalement des outils distincts et en affichant les résultats instantanément.
- Découvrez de nouvelles façons d'explorer et de comprendre les données : vérifiez les structures de table, effectuez des contrôles de cohérence rapides, le tout grâce à des interfaces de ligne de commande familières dans notre IDE.
- Comment ce workflow de base de données accéléré contribue directement à des cycles de développement full stack plus rapides, permettant un prototypage et une itération rapides.
Techstack
Nous utilisons :
- AlloyDB pour les bases de données
- MCP Toolbox pour abstraire les fonctionnalités avancées d'IA et génératives des bases de données à partir de l'application
- Cloud Run pour le déploiement sans serveur.
- Gemini CLI pour comprendre et analyser l'ensemble de données, et créer la partie base de données de l'application d'e-commerce pour le commerce de détail.
Conditions requises
2. Avant de commencer
Créer un projet
- Dans la console Google Cloud, sur la page du sélecteur de projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
- Vous allez utiliser Cloud Shell, un environnement de ligne de commande exécuté dans Google Cloud. Cliquez sur "Activer Cloud Shell" en haut de la console Google Cloud.

- Une fois connecté à Cloud Shell, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
- Exécutez la commande suivante dans Cloud Shell pour vérifier que la commande gcloud connaît votre projet.
gcloud config list project
- Si votre projet n'est pas défini, utilisez la commande suivante pour le définir :
gcloud config set project <YOUR_PROJECT_ID>
- Activez les API requises : suivez ce lien et activez les API.
Vous pouvez également utiliser la commande gcloud. Consultez la documentation pour connaître les commandes gcloud ainsi que leur utilisation.
3. Configuration de la base de données
Dans cet atelier, nous allons utiliser AlloyDB comme base de données pour les données d'e-commerce. Il utilise des clusters pour stocker toutes les ressources, telles que les bases de données et les journaux. Chaque cluster possède une instance principale qui fournit un point d'accès aux données. Les tables contiennent les données réelles.
Commençons par créer un cluster, une instance et une table AlloyDB dans lesquels l'ensemble de données e-commerce sera chargé.
Créer un cluster et une instance
- Accédez à la page AlloyDB de la console Cloud. Pour trouver la plupart des pages de la console Cloud, le plus simple est de les rechercher à l'aide de la barre de recherche de la console.
- Sélectionnez CRÉER UN CLUSTER sur cette page :

- Un écran semblable à celui ci-dessous s'affiche. Créez un cluster et une instance avec les valeurs suivantes (assurez-vous que les valeurs correspondent si vous clonez le code de l'application à partir du dépôt) :
- ID du cluster : "
vector-cluster" - password : "
alloydb" - PostgreSQL 15 / dernière version recommandée
- Région : "
us-central1" - Networking : "
default"
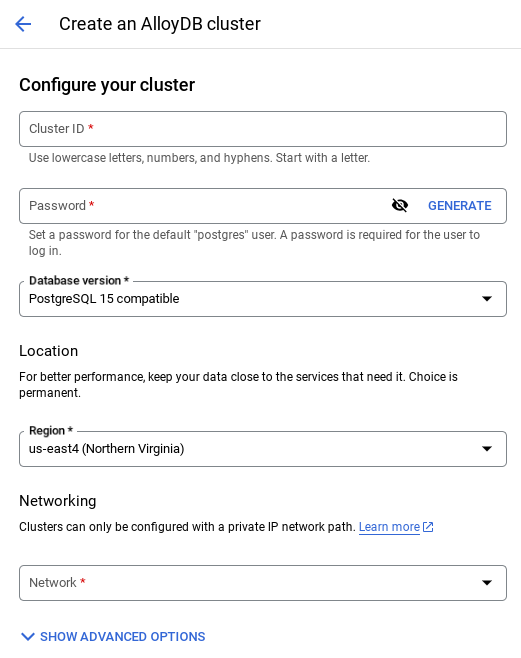
- Lorsque vous sélectionnez le réseau par défaut, un écran semblable à celui ci-dessous s'affiche.
Sélectionnez CONFIGURER LA CONNEXION.
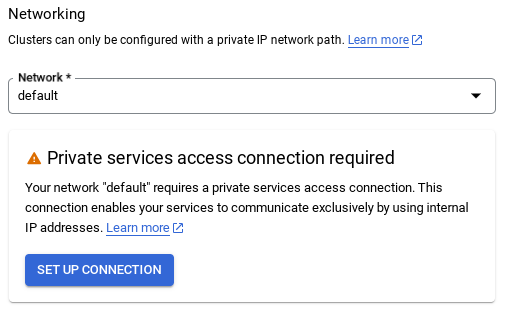
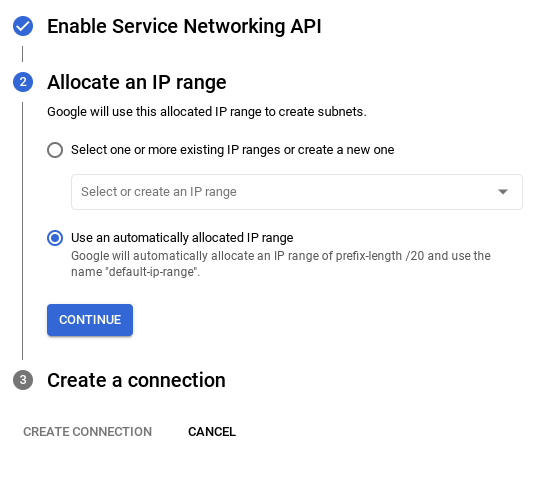
- Sélectionnez ensuite Utiliser une plage d'adresses IP automatiquement allouée, puis cliquez sur "Continuer". Après avoir vérifié les informations, sélectionnez CRÉER UNE CONNEXION.
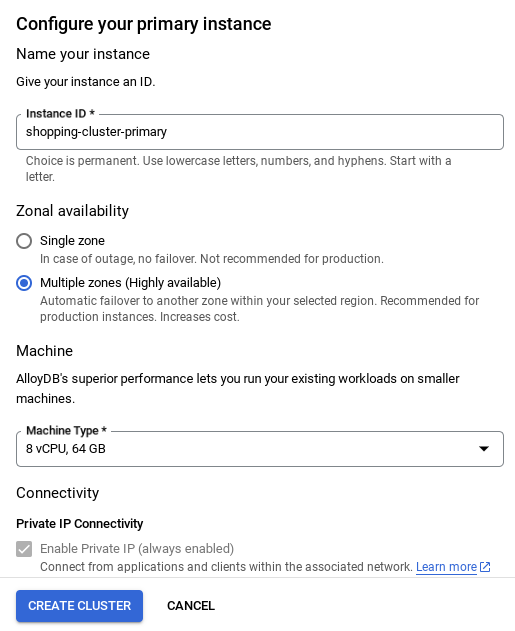
- Une fois votre réseau configuré, vous pouvez continuer à créer votre cluster. Cliquez sur CRÉER UN CLUSTER pour terminer la configuration du cluster, comme indiqué ci-dessous :
REMARQUE IMPORTANTE :
- Veillez à remplacer l'ID d'instance (que vous trouverez lors de la configuration du cluster / de l'instance) par **
vector-instance**. Si vous ne pouvez pas le modifier, n'oubliez pas d'**utiliser votre ID d'instance** dans toutes les références à venir. - Notez que la création du cluster prendra environ 10 minutes. Une fois l'opération terminée, un écran affichant l'aperçu du cluster que vous venez de créer devrait s'afficher.
4. Ingestion de données
Il est maintenant temps d'ajouter un tableau contenant les données sur le magasin. Accédez à AlloyDB, sélectionnez le cluster principal, puis AlloyDB Studio :
Vous devrez peut-être attendre que votre instance soit créée. Une fois le cluster créé, connectez-vous à AlloyDB à l'aide des identifiants que vous avez créés. Utilisez les données suivantes pour vous authentifier auprès de PostgreSQL :
- Nom d'utilisateur : "
postgres" - Base de données : "
postgres" - Mot de passe : "
alloydb"
Une fois l'authentification réussie dans AlloyDB Studio, les commandes SQL sont saisies dans l'éditeur. Vous pouvez ajouter plusieurs fenêtres de l'éditeur en cliquant sur le signe plus à droite de la dernière fenêtre.
Vous saisirez les commandes pour AlloyDB dans les fenêtres de l'éditeur, en utilisant les options "Exécuter", "Mettre en forme" et "Effacer" selon les besoins.
Activer les extensions
Pour créer cette application, nous allons utiliser les extensions pgvector et google_ml_integration. L'extension pgvector vous permet de stocker et de rechercher des embeddings vectoriels. L'extension google_ml_integration fournit les fonctions que vous utilisez pour accéder aux points de terminaison de prédiction Vertex AI afin d'obtenir des prédictions en SQL. Activez ces extensions en exécutant les LDD suivants :
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Si vous souhaitez vérifier les extensions qui ont été activées dans votre base de données, exécutez la commande SQL suivante :
select extname, extversion from pg_extension;
Créer une table
Vous pouvez créer une table à l'aide de l'instruction LDD ci-dessous dans AlloyDB Studio :
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
La colonne d'embedding permettra de stocker les valeurs vectorielles du texte.
Accorder l'autorisation
Exécutez l'instruction ci-dessous pour accorder l'exécution de la fonction "embedding" :
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Attribuer le RÔLE Utilisateur Vertex AI au compte de service AlloyDB
Dans la console Google Cloud IAM, accordez au compte de service AlloyDB (qui ressemble à ceci : service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) l'accès au rôle "Utilisateur Vertex AI". PROJECT_NUMBER correspondra au numéro de votre projet.
Vous pouvez également exécuter la commande ci-dessous à partir du terminal Cloud Shell :
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Charger des données dans la base de données
- Copiez les instructions de requête
insertdepuisinsert scripts sqldans la feuille vers l'éditeur mentionné ci-dessus. Vous pouvez copier entre 10 et 50 instructions d'insertion pour une démonstration rapide de ce cas d'utilisation. Vous trouverez une sélection d'inserts dans l'onglet "Selected Inserts 25-30 rows" (Inserts sélectionnés, 25 à 30 lignes). - Cliquez sur Exécuter. Les résultats de votre requête s'affichent dans la table Résultats.
REMARQUE IMPORTANTE :
Veillez à ne copier que 25 à 50 enregistrements à insérer et assurez-vous qu'ils proviennent d'une plage de types de catégories, de sous-catégories, de couleurs et de genres.
5. Créer des embeddings pour les données
La véritable innovation dans la recherche moderne réside dans la compréhension du sens, et pas seulement des mots clés. C'est là que les embeddings et la recherche vectorielle entrent en jeu.
Nous avons transformé les descriptions de produits et les requêtes utilisateur en représentations numériques de grande dimension appelées "embeddings" à l'aide de modèles de langage pré-entraînés. Ces embeddings capturent la signification sémantique, ce qui nous permet de trouver des produits dont la signification est similaire, et pas seulement ceux qui contiennent des mots correspondants. Au départ, nous avons testé la recherche directe de similarités vectorielles sur ces embeddings pour établir une référence, ce qui a démontré la puissance de la compréhension sémantique avant même les optimisations des performances.
La colonne d'embedding permettra de stocker les valeurs vectorielles du texte de la description du produit. La colonne "img_embeddings" permettra de stocker les embeddings d'images (multimodaux). Vous pouvez ainsi utiliser la recherche basée sur la distance entre le texte et l'image. Toutefois, nous n'utiliserons que des embeddings de texte dans cet atelier.
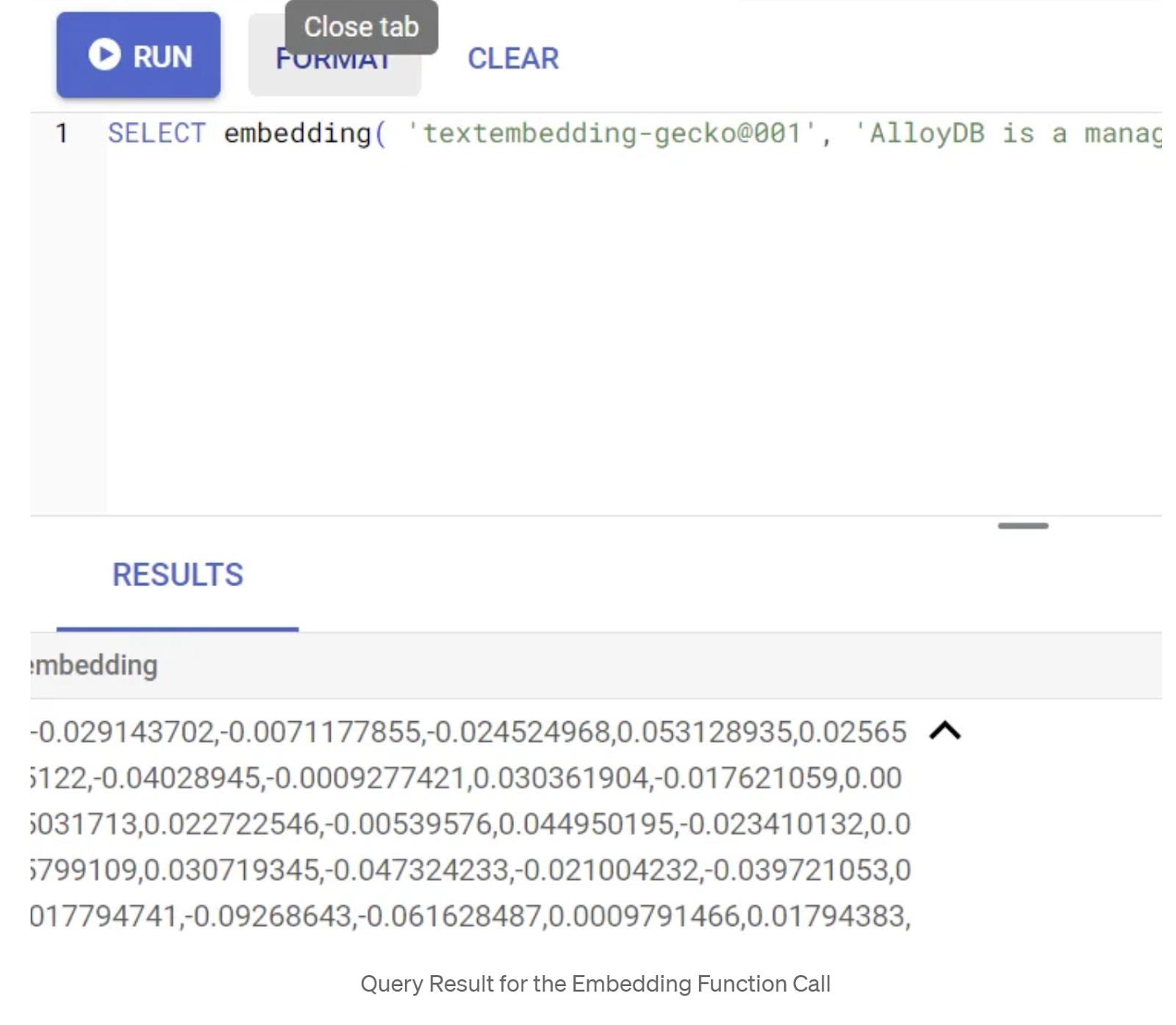
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Cela devrait renvoyer le vecteur d'embedding, qui ressemble à un tableau de valeurs flottantes, pour l'exemple de texte dans la requête. Voici à quoi il ressemble :
Mettre à jour le champ vectoriel "abstract_embeddings"
Exécutez le LMD ci-dessous pour mettre à jour la description du contenu dans le tableau avec les embeddings correspondants :
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
Si vous utilisez un compte de facturation avec crédit d'essai pour Google Cloud, vous risquez de rencontrer des difficultés pour générer plus d'une vingtaine d'embeddings. Limitez donc le nombre de lignes dans le script d'insertion.
Si vous souhaitez générer des embeddings d'images (pour effectuer une recherche contextuelle multimodale), exécutez également la mise à jour ci-dessous :
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. MCP Toolbox for Databases (AlloyDB)
En coulisses, des outils robustes et une application bien structurée assurent un fonctionnement fluide.
La Toolbox MCP (Model Context Protocol) pour les bases de données simplifie l'intégration des outils d'IA générative et agentiques avec AlloyDB. Il agit comme un serveur Open Source qui simplifie le regroupement de connexions, l'authentification et l'exposition sécurisée des fonctionnalités de base de données aux agents d'IA ou à d'autres applications.
Dans notre application, nous avons utilisé MCP Toolbox for Databases comme couche d'abstraction pour toutes nos requêtes de recherche hybride intelligente.
Suivez les étapes ci-dessous pour configurer et déployer Toolbox pour notre cas d'utilisation :
Vous pouvez voir qu'AlloyDB fait partie des bases de données compatibles avec MCP Toolbox for Databases. Comme nous l'avons déjà provisionné dans la section précédente, configurons Toolbox.
- Accédez à votre terminal Cloud Shell et assurez-vous que votre projet est sélectionné et affiché dans l'invite du terminal. Exécutez la commande ci-dessous depuis votre terminal Cloud Shell pour accéder au répertoire de votre projet :
mkdir gemini-cli-project
cd gemini-cli-project
- Exécutez la commande ci-dessous pour télécharger et installer la boîte à outils dans votre nouveau dossier :
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
Cela devrait créer la boîte à outils dans votre répertoire actuel. Copiez le chemin d'accès à la boîte à outils.
- Accédez à l'éditeur Cloud Shell (pour le mode d'édition de code) et, dans le dossier racine du projet "gemini-cli-project", ajoutez un fichier nommé "tools.yaml".
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
Commençons par comprendre tools.yaml :
Les sources représentent les différentes sources de données avec lesquelles un outil peut interagir. Une source représente une source de données avec laquelle un outil peut interagir. Vous pouvez définir des sources sous forme de mappage dans la section "sources" de votre fichier tools.yaml. En règle générale, une configuration de source contient toutes les informations nécessaires pour se connecter à la base de données et interagir avec elle.
Les outils définissent les actions qu'un agent peut effectuer, comme lire et écrire dans une source. Un outil représente une action que votre agent peut effectuer, comme exécuter une instruction SQL. Vous pouvez définir des outils sous forme de mappage dans la section "tools" de votre fichier tools.yaml. En règle générale, un outil a besoin d'une source sur laquelle agir.
Pour en savoir plus sur la configuration de votre fichier tools.yaml, consultez cette documentation.
Comme vous pouvez le voir dans le fichier Tools.yaml ci-dessus, l'outil"get-apparels" liste tous les détails des vêtements de la base de données.
7. Configurer Gemini CLI
Dans l'éditeur Cloud Shell, créez un dossier nommé .gemini dans le dossier gemini-cli-project, puis créez-y un fichier nommé settings.json.
{
"mcpServers": {
"AlloyDBServer": {
"command": "/home/user/gemini-cli-project/toolbox",
"args": ["--tools-file", "tools.yaml", "--stdio"]
}
}
}
Dans la section de commande de l'extrait ci-dessus, remplacez "/home/user/gemini-cli-project/toolbox" par le chemin d'accès à la boîte à outils.
Installer Gemini CLI
Enfin, à partir du terminal Cloud Shell, installons Gemini CLI dans le même répertoire gemini-cli-project en exécutant la commande suivante :
sudo npm install -g @google/gemini-cli
Définir votre ID de projet
Assurez-vous que l'ID du projet actif est défini dans l'environnement :
export GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT_ID>>
Premiers pas avec Gemini CLI
Dans la ligne de commande, saisissez la commande suivante :
gemini
Vous devriez obtenir une réponse semblable à celle-ci :
Authentifiez-vous et passez à l'étape suivante.
8. Commencer à interagir avec Gemini CLI
Utilisez la commande /mcp pour lister les serveurs MCP configurés.
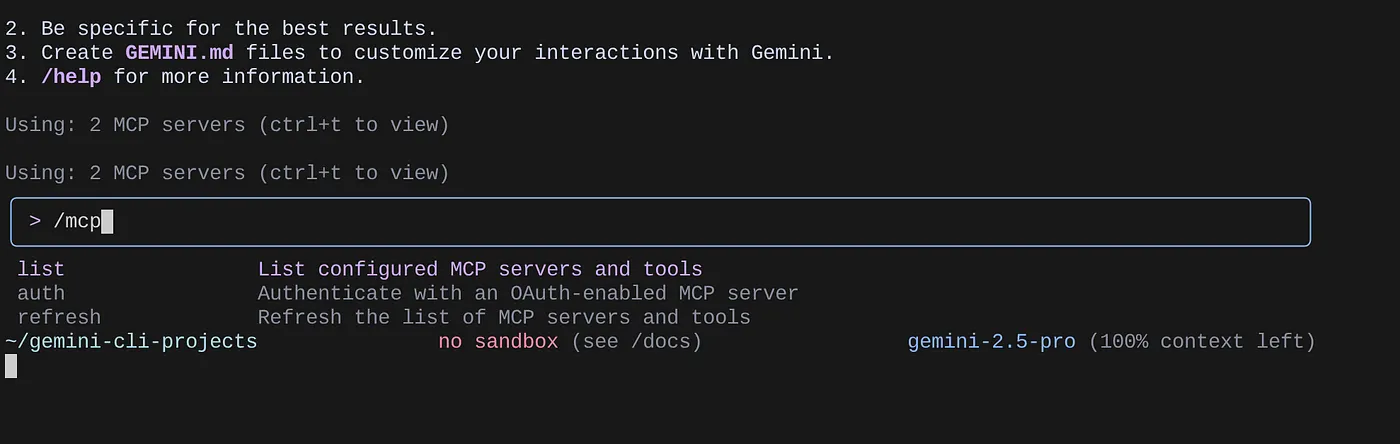
Vous devriez voir les deux serveurs MCP que nous avons configurés : GitHub et MCP Toolbox for Databases, ainsi que leurs outils.
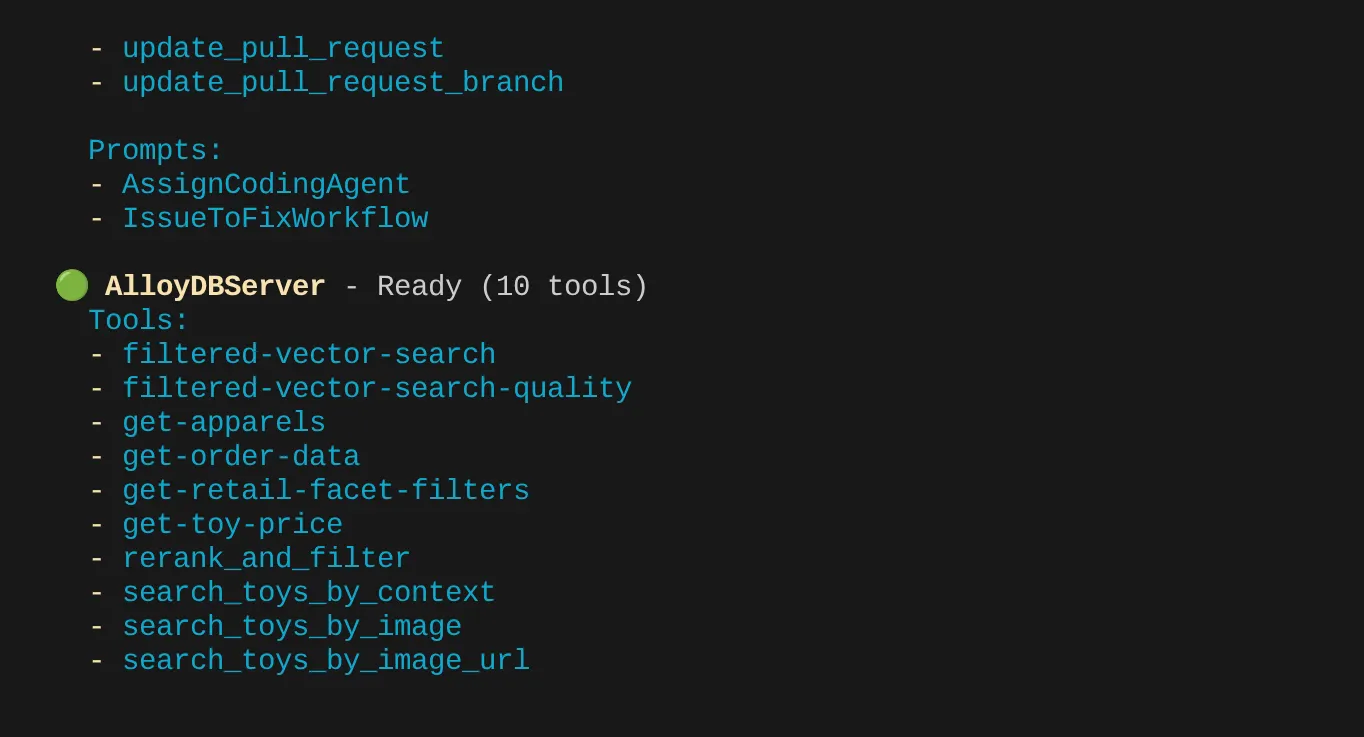
Dans mon cas, j'ai plus d'outils. Ignorez-le pour le moment. L'outil get-apparels devrait s'afficher sur votre serveur AlloyDB MCP.
Commencer à interroger la base de données via MCP Toolbox
Essayez maintenant de poser des questions en langage naturel pour obtenir des réponses et des requêtes pour l'ensemble de données avec lequel nous travaillons :
> How many types of genders the apparel dataset has?
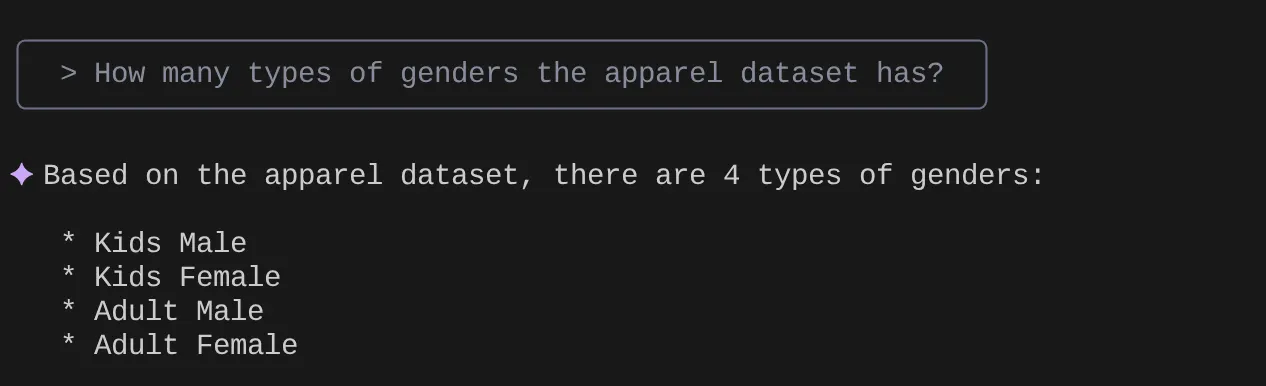
> Give me the SQL that I can use to find the number of apparels that are footwear
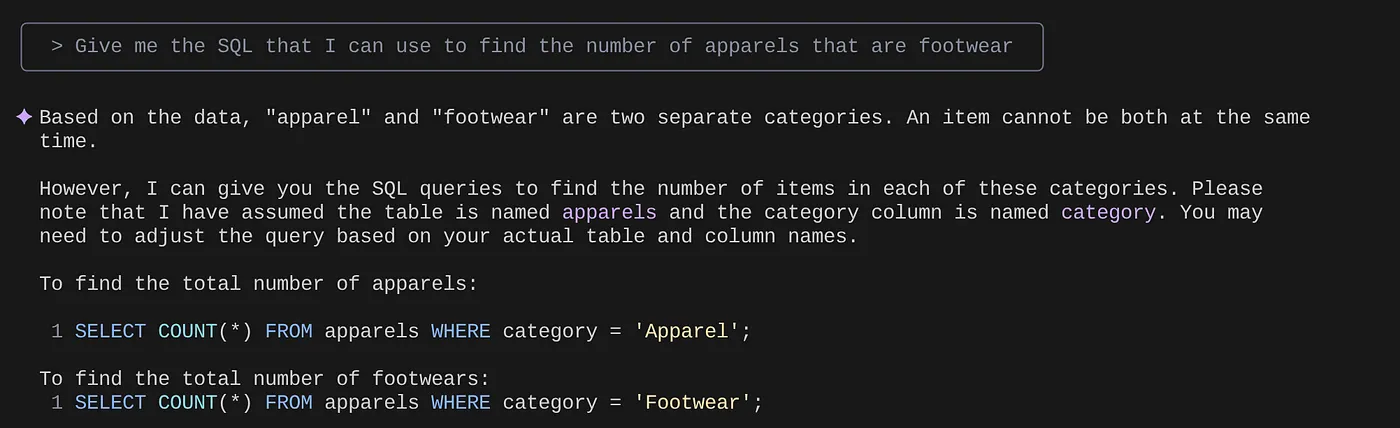
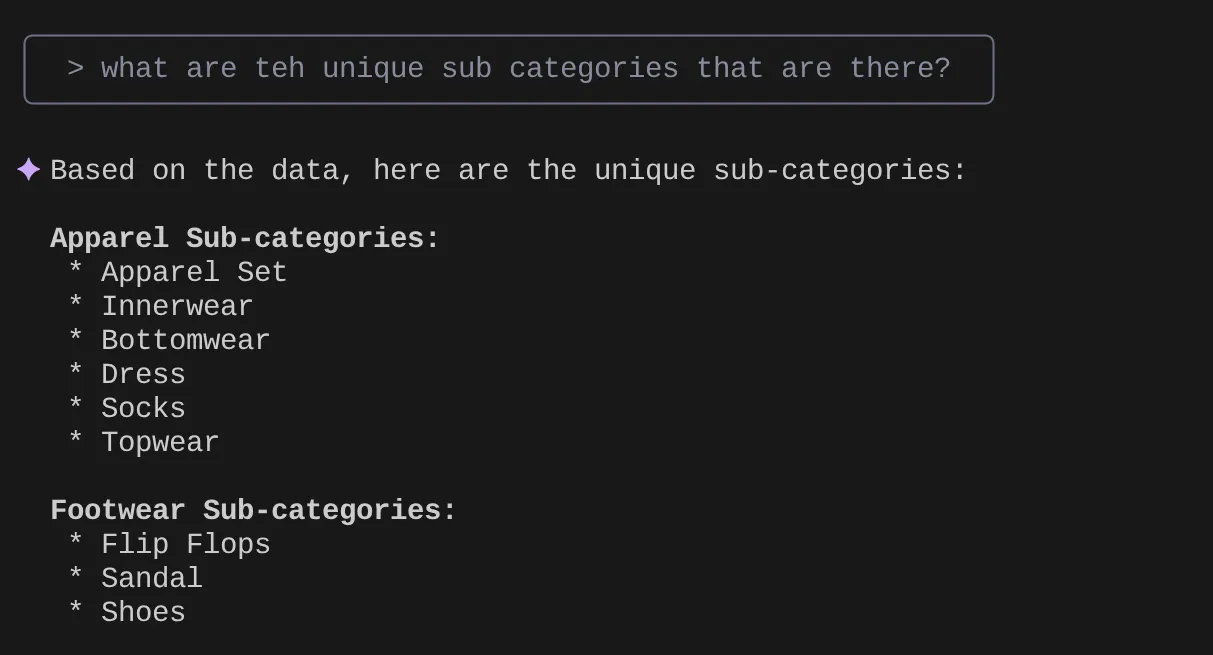
> What are the unique sub categories that are there?
that I can use to find the number of apparels that are footwear
Imaginons que, sur la base de mes insights et de nombreuses requêtes de ce type, j'ai créé une requête détaillée et que je souhaite la tester. Supposons que les ingénieurs de base de données aient déjà créé le fichier Tools.yaml pour vous, comme ci-dessous :
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
filtered-vector-search:
kind: postgres-sql
source: alloydb
description: Get the list of facet filter values from the retail dataset.
parameters:
- name: categories
type: array
description: List of categories preferred by the user.
items:
name: category
type: string
description: Category value.
- name: subCategories
type: array
description: List of sub-categories preferred by the user.
items:
name: subCategory
type: string
description: Sub-Category value.
- name: colors
type: array
description: List of colors preferred by the user.
items:
name: color
type: string
description: Color value.
- name: genders
type: array
description: List of genders preferred by the user for apparel fitting.
items:
name: gender
type: string
description: Gender name.
- name: searchtext
type: string
description: Description of the product that the user wants to find database matches for.
statement: |
SELECT id, content, uri, category, sub_category,color,gender FROM apparels
where category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005',$5)::vector limit 10
Essayons maintenant une recherche en langage naturel :
> How many yellow shirts are there for boys?
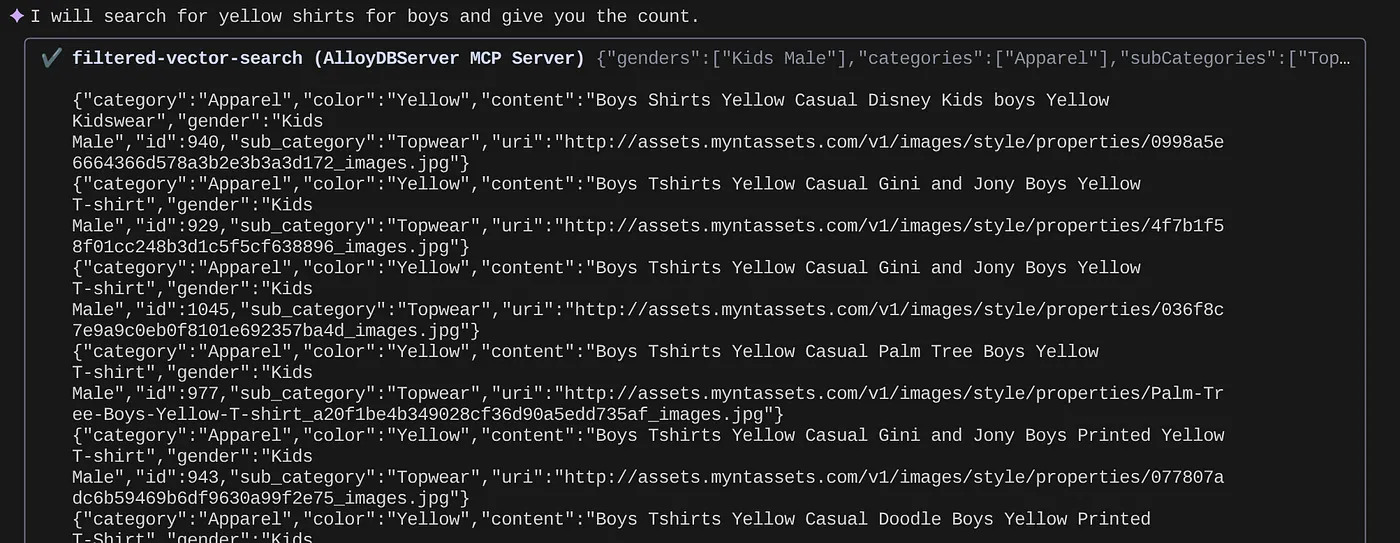

Plutôt cool, non ? Je peux maintenant corriger le fichier YAML pour améliorer les requêtes tout en continuant à fournir de nouvelles fonctionnalités dans mon application plus rapidement.
9. Développement d'applications accéléré
L'intérêt d'intégrer des fonctionnalités de base de données directement dans votre IDE via Gemini CLI et MCP Toolbox n'est pas seulement théorique. Cela se traduit par des workflows concrets qui accélèrent le développement, en particulier pour une application complexe comme notre expérience de vente au détail hybride. Voici quelques exemples :
1. Itérer rapidement la logique de filtrage des produits
Imaginons que nous venons de lancer une nouvelle promotion pour les "vêtements de sport d'été". Nous souhaitons tester l'interaction de nos filtres à facettes (par exemple, par marque, taille, couleur ou tranche de prix) avec cette nouvelle catégorie.
Sans l'intégration de l'IDE :
Je passerais probablement à un client SQL distinct, écrirais ma requête, l'exécuterais, analyserais les résultats, reviendrais à mon IDE pour ajuster le code de l'application, repasserais au client et répéterais l'opération. Ce changement de contexte est une perte de temps considérable.
Avec Gemini CLI et MCP :
Je peux rester dans mon IDE et plus encore :
- Requêtes : je peux rapidement mettre à jour la requête dans le fichier YAML avec l'ensemble de données hypothétique "SELECT DISTINCT brand FROM products WHERE category = 'activewear' AND season = 'summer'" et l'essayer directement dans mon terminal.
- Exploration des données : consultez instantanément les marques renvoyées. Si je dois vérifier la disponibilité d'un produit d'une marque et d'une taille spécifiques, je peux utiliser une autre requête rapide : "SELECT COUNT(*) FROM products WHERE brand = ‘SummitGear' AND size = ‘M' AND category = ‘activewear' AND season = ‘summer'"
- Intégration de code : je peux ensuite ajuster immédiatement la logique de filtrage du frontend ou les appels d'API du backend en fonction de ces insights rapides sur les données dans l'IDE, ce qui réduit considérablement la boucle de rétroaction.
2. Affiner la recherche vectorielle pour les recommandations de produits
Notre recherche hybride s'appuie sur des embeddings vectoriels pour fournir des recommandations de produits pertinentes. Imaginons que nous constations une baisse des taux de clics pour les recommandations de "chaussures de running pour hommes".
Sans l'intégration de l'IDE :
J'exécuterais des scripts ou des requêtes personnalisés dans un outil de base de données pour analyser les scores de similarité des chaussures recommandées, les comparer aux données d'interaction des utilisateurs et essayer de corréler les éventuels modèles.
Avec Gemini CLI et MCP :
- Analyser les embeddings : je peux interroger directement les embeddings de produits et leurs métadonnées associées : "SELECT product_id, name, vector_embedding FROM products WHERE category = 'running shoes' AND gender = 'male' LIMIT 10"
- Référence croisée : je peux également vérifier rapidement la similarité vectorielle réelle entre un produit choisi et ses recommandations, directement sur la page. Par exemple, si le produit A est recommandé aux utilisateurs qui ont consulté le produit B, je peux exécuter une requête pour récupérer et comparer leurs embeddings vectoriels.
- Débogage : cela permet de déboguer et de tester les hypothèses plus rapidement. Le modèle d'embedding se comporte-t-il comme prévu ? Les données présentent-elles des anomalies qui affectent la qualité des recommandations ? Je peux obtenir des réponses initiales sans quitter mon environnement de programmation.
3. Comprendre le schéma et la distribution des données pour les nouvelles fonctionnalités
Supposons que nous prévoyions d'ajouter une fonctionnalité "Avis client". Avant d'écrire l'API backend, nous devons comprendre les données client existantes et la façon dont les avis peuvent être structurés.
Sans l'intégration de l'IDE :
Je devrais me connecter à un client de base de données, exécuter des commandes DESCRIBE sur des tables telles que "customers" et "orders", puis interroger des exemples de données pour comprendre les relations et les types de données.
Avec Gemini CLI et MCP :
- Exploration du schéma : je peux simplement interroger la table dans le fichier YAML et l'exécuter directement dans le terminal.
- Échantillonnage des données : je peux ensuite extraire des exemples de données pour comprendre les données démographiques des clients et leur historique d'achats : "SELECT customer_id, name, signup_date, total_orders FROM customers ORDER BY signup_date DESC LIMIT 5"
- Planification : cet accès rapide au schéma et à la distribution des données nous aide à prendre des décisions éclairées sur la façon de concevoir la nouvelle table des avis, les clés étrangères à établir et la façon de lier efficacement les avis aux clients et aux produits, le tout avant d'écrire une seule ligne de code d'application pour la nouvelle fonctionnalité.
Ces exemples ne sont qu'un aperçu des avantages principaux : réduire les frictions et augmenter la vélocité des développeurs. En intégrant l'interaction AlloyDB directement dans l'IDE, Gemini CLI et MCP Toolbox nous permettent de créer des applications plus performantes et plus réactives plus rapidement.
10. Effectuer un nettoyage
Pour éviter que les ressources utilisées dans cet article soient facturées sur votre compte Google Cloud, procédez comme suit :
- Dans la console Google Cloud, accédez à la page Gestionnaire de ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
- Vous pouvez également supprimer le cluster AlloyDB que nous venons de créer pour ce projet en cliquant sur le bouton "SUPPRIMER LE CLUSTER". (Si vous n'avez pas choisi us-central1 pour le cluster lors de la configuration, modifiez l'emplacement dans cet hyperlien.)
11. Félicitations
Félicitations ! Vous avez intégré MCP Toolbox directement dans votre IDE pour une interaction fluide avec AlloyDB et vous avez utilisé Gemini CLI pour interagir avec notre ensemble de données sur le commerce de détail afin d'écrire des requêtes qui nécessiteraient normalement des outils distincts. Vous avez appris de nouvelles façons d'explorer et de comprendre les données, en vérifiant les structures de table et en effectuant des contrôles de cohérence rapides, le tout à l'aide d'interfaces de ligne de commande familières dans notre IDE.
Clonez le dépôt, analysez-le et dites-moi si vous avez amélioré l'application à l'aide de Gemini CLI et de MCP Toolbox for Databases.
Pour découvrir d'autres applications basées sur les données et conçues avec Gemini CLI et MCP, puis déployées sur des runtimes sans serveur, inscrivez-vous à la prochaine saison de Code Vipassana, qui propose des sessions pratiques dirigées par des instructeurs et d'autres ateliers de programmation.