
1. סקירה כללית
זוכרים את התהליך שעברנו כדי ליצור חוויית קמעונאות דינמית והיברידית באמצעות AlloyDB, שמשלבת סינון לפי מאפיינים וחיפוש וקטורי? האפליקציה הזו הייתה הדגמה עוצמתית של הצרכים של קמעונאות מודרנית, אבל כדי להגיע אליה – ולשפר אותה – נדרש מאמץ פיתוח משמעותי. למפתחים שעובדים על כל השלבים בתהליך הפיתוח, המעבר התמידי בין עורכי קוד לבין כלי מסד נתונים יכול לעיתים קרובות להוות צוואר בקבוק, ולהאט את החדשנות ואת התהליך החשוב של הבנת הנתונים.
פתרון
בדיוק כאן נכנסת לתמונה היכולת של פיתוח אפליקציות מואץ, ולכן אני נרגש לשתף איך MCP (Modern Cloud Platform) Toolbox, שאפשר לגשת אליו דרך Gemini CLI האינטואיטיבי, הפך לחלק חיוני בערכת הכלים שלי. תארו לעצמכם שאתם יכולים ליצור אינטראקציה חלקה עם מופע AlloyDB, לכתוב שאילתות ולהבין את מערך הנתונים – והכול ישירות בסביבת הפיתוח המשולבת (IDE). זה לא רק עניין של נוחות, אלא גם של הפחתה משמעותית של הקשיים במחזור החיים של הפיתוח, כדי שתוכלו להתמקד בפיתוח תכונות חדשניות במקום להתמודד עם כלים חיצוניים.
בהקשר של אפליקציית המסחר האלקטרוני הקמעונאית שלנו, שבה היינו צריכים לבצע שאילתות יעילות של נתוני מוצרים, לטפל בסינון מורכב ולנצל את הניואנסים של חיפוש וקטורי, היכולת לבצע איטרציות מהירות על אינטראקציות עם מסד הנתונים הייתה חשובה ביותר. ה-MCP Toolbox, שמבוסס על Gemini CLI, לא רק מפשט את התהליך הזה אלא גם מזרז אותו, ומשנה את האופן שבו אנחנו יכולים לחקור, לבדוק ולשפר את הלוגיקה של מסד הנתונים שעומדת בבסיס האפליקציות שלנו. במאמר הזה נסביר איך השילוב המהפכני הזה הופך את פיתוח ה-Full-Stack למהיר, חכם ומהנה יותר.
מה תלמדו ותבנו
אפליקציית חיפוש קמעונאי שמשתמשת ב-MCP Toolbox בסביבת הפיתוח המשולבת (IDE), שמבוססת על Gemini CLI. הנושאים שעליהם נדון:
- איך משלבים את MCP Toolbox ישירות בסביבת הפיתוח המשולבת (IDE) כדי ליצור אינטראקציה חלקה עם AlloyDB.
- דוגמאות מעשיות לשימוש ב-Gemini CLI כדי לכתוב ולהריץ שאילתות SQL על נתוני הקמעונאות שלכם.
- אפשר להשתמש ב-Gemini CLI כדי ליצור אינטראקציה עם מערך הנתונים שלנו בנושא מסחר אלקטרוני קמעונאי, לכתוב שאילתות שבדרך כלל דורשות כלים נפרדים ולראות את התוצאות באופן מיידי.
- תוכלו לגלות דרכים חדשות לבדוק ולהבין את הנתונים – מבדיקת מבני טבלאות ועד ביצוע בדיקות מהירות של תקינות הנתונים – והכול באמצעות ממשקי שורת פקודה מוכרים בתוך סביבת הפיתוח המשולבת שלנו.
- איך תהליך העבודה המהיר הזה עם מסד הנתונים תורם ישירות לקיצור מחזורי הפיתוח של Full-Stack, ומאפשר יצירת אב טיפוס ואיטרציה מהירים.
Techstack
אנחנו משתמשים ב:
- AlloyDB למסד נתונים
- MCP Toolbox for abstracting advanced generative and AI features of databases from the application
- Cloud Run לפריסה ללא שרת.
- Gemini CLI כדי להבין ולנתח את מערך הנתונים ולבנות את החלק של מסד הנתונים באפליקציית המסחר האלקטרוני הקמעונאי.
דרישות
2. לפני שמתחילים
יצירת פרויקט
- ב-מסוף Google Cloud, בדף לבחירת הפרויקט, בוחרים או יוצרים פרויקט ב-Google Cloud.
- מוודאים שהחיוב מופעל בפרויקט ב-Cloud. כך בודקים אם החיוב מופעל בפרויקט
- תשתמשו ב-Cloud Shell, סביבת שורת פקודה שפועלת ב-Google Cloud. לוחצים על 'הפעלת Cloud Shell' בחלק העליון של מסוף Google Cloud.

- אחרי שמתחברים ל-Cloud Shell, אפשר לבדוק שכבר בוצע אימות ושהפרויקט מוגדר לפי מזהה הפרויקט באמצעות הפקודה הבאה:
gcloud auth list
- מריצים את הפקודה הבאה ב-Cloud Shell כדי לוודא שפקודת gcloud מכירה את הפרויקט.
gcloud config list project
- אם הפרויקט לא מוגדר, משתמשים בפקודה הבאה כדי להגדיר אותו:
gcloud config set project <YOUR_PROJECT_ID>
- מפעילים את ממשקי ה-API הנדרשים: לוחצים על הקישור ומפעילים את ממשקי ה-API.
אפשר גם להשתמש בפקודת gcloud. אפשר לעיין במאמרי העזרה בנושא פקודות gcloud ושימוש בהן.
3. הגדרת מסד נתונים
בשיעור ה-Lab הזה נשתמש ב-AlloyDB כמסד הנתונים של נתוני המסחר האלקטרוני. הוא משתמש באשכולות כדי להכיל את כל המשאבים, כמו מסדי נתונים ויומנים. לכל אשכול יש מופע ראשי שמספק נקודת גישה לנתונים. הטבלאות יכילו את הנתונים בפועל.
ניצור אשכול, מכונה וטבלה של AlloyDB שבהם ייטען מערך הנתונים של המסחר האלקטרוני.
יצירת אשכול ומופע
- עוברים לדף AlloyDB במסוף Cloud. דרך קלה למצוא את רוב הדפים ב-Cloud Console היא לחפש אותם באמצעות סרגל החיפוש של המסוף.
- בדף הזה, לוחצים על יצירת אשכול:

- יוצג מסך כמו זה שבהמשך. יוצרים אשכול ומופע עם הערכים הבאים (אם משכפלים את קוד האפליקציה מהמאגר, חשוב לוודא שהערכים זהים):
- cluster id: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / הגרסה המומלצת האחרונה
- אזור: "
us-central1" - רשת: "
default"
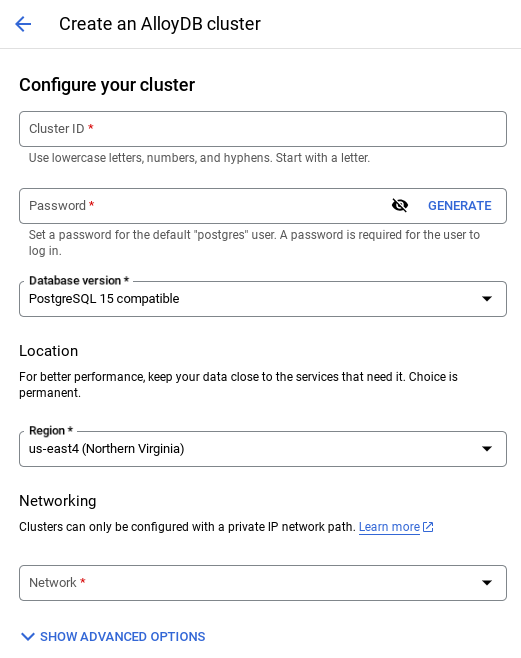
- כשבוחרים את רשת ברירת המחדל, מוצג מסך כמו זה שבהמשך.
לוחצים על הגדרת קישור.
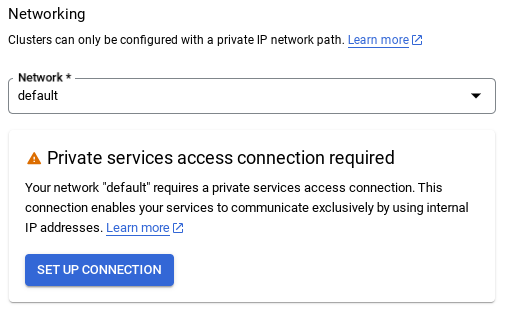
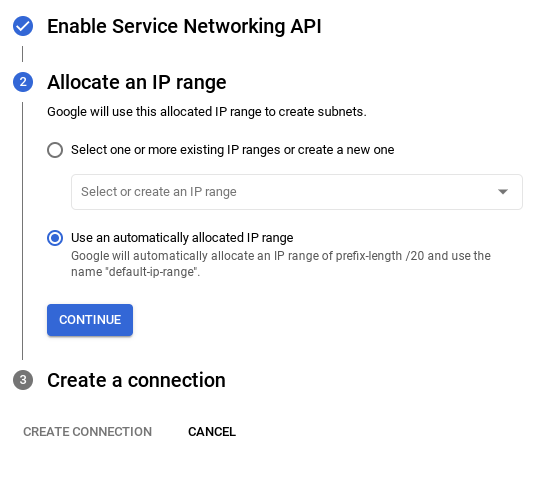
- משם, בוחרים באפשרות שימוש בטווח כתובות IP שהוקצה באופן אוטומטי ולוחצים על 'המשך'. אחרי שבודקים את המידע, לוחצים על CREATE CONNECTION (יצירת חיבור).
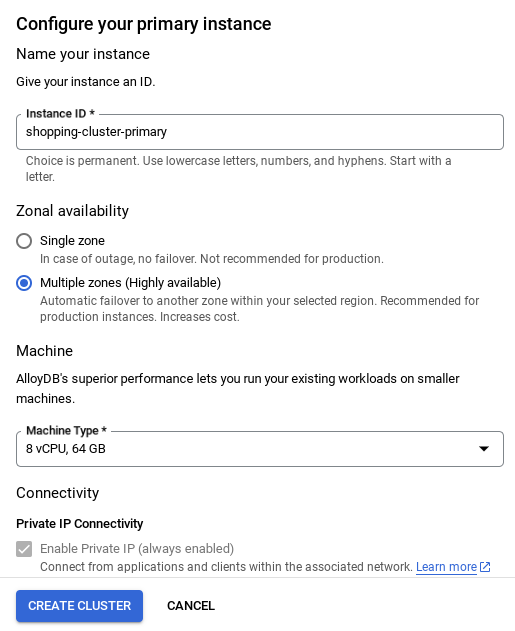
- אחרי שמגדירים את הרשת, אפשר להמשיך ליצור את האשכול. לוחצים על CREATE CLUSTER (יצירת אשכול) כדי להשלים את הגדרת האשכול, כמו שמוצג בהמשך:
הערה חשובה:
- חשוב לשנות את מזהה המופע (שאפשר למצוא בזמן ההגדרה של האשכול או המופע) לערך **
vector-instance**. אם אי אפשר לשנות אותו, חשוב לזכור **להשתמש במזהה המופע** בכל ההפניות הבאות. - שימו לב: תהליך יצירת האשכול יימשך כ-10 דקות. אחרי שהפעולה תסתיים בהצלחה, יוצג מסך עם סקירה כללית של האשכול שיצרתם.
4. הטמעת נתונים
עכשיו צריך להוסיף טבלה עם הנתונים על החנות. עוברים אל AlloyDB, בוחרים את האשכול הראשי ואז את AlloyDB Studio:
יכול להיות שתצטרכו לחכות עד שהמופע שלכם יסיים את תהליך היצירה. אחרי שזה קורה, נכנסים ל-AlloyDB באמצעות פרטי הכניסה שיצרתם כשנוצר האשכול. משתמשים בנתונים הבאים כדי לבצע אימות ב-PostgreSQL:
- שם משתמש : "
postgres" - מסד נתונים : "
postgres" - סיסמה : "
alloydb"
אחרי שתעברו בהצלחה את תהליך האימות ב-AlloyDB Studio, תוכלו להזין פקודות SQL בכלי העריכה. אפשר להוסיף כמה חלונות של Editor באמצעות סימן הפלוס שמימין לחלון האחרון.
מזינים פקודות ל-AlloyDB בחלונות העריכה, ומשתמשים באפשרויות Run (הפעלה), Format (עיצוב) ו-Clear (ניקוי) לפי הצורך.
הפעלת תוספים
כדי ליצור את האפליקציה הזו, נשתמש בתוספים pgvector ו-google_ml_integration. התוסף pgvector מאפשר לכם לאחסן ולחפש הטמעות של וקטורים. התוסף google_ml_integration מספק פונקציות שמשמשות לגישה לנקודות קצה (endpoints) של חיזוי ב-Vertex AI כדי לקבל חיזויים ב-SQL. מפעילים את התוספים האלה על ידי הפעלת פקודות ה-DDL הבאות:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
כדי לבדוק אילו תוספים הופעלו במסד הנתונים, מריצים את פקודת ה-SQL הבאה:
select extname, extversion from pg_extension;
צור טבלה
אתם יכולים ליצור טבלה באמצעות הצהרת ה-DDL שבהמשך ב-AlloyDB Studio:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
בעמודת ההטמעה יאוחסנו ערכי הווקטור של הטקסט.
מתן הרשאה
מריצים את ההצהרה הבאה כדי להעניק הרשאת הפעלה לפונקציה embedding:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
נותנים לחשבון השירות של AlloyDB את התפקיד Vertex AI User
במסוף IAM של Google Cloud, מעניקים לחשבון השירות של AlloyDB (שנראה כך: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) גישה לתפקיד Vertex AI User. PROJECT_NUMBER יכיל את מספר הפרויקט.
לחלופין, אפשר להריץ את הפקודה הבאה מ-Cloud Shell Terminal:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
טעינת נתונים למסד הנתונים
- מעתיקים את הצהרות השאילתה
insertמהגיליוןinsert scripts sqlאל העורך שצוין למעלה. אפשר להעתיק 10-50 הצהרות של insert כדי ליצור הדגמה מהירה של תרחיש השימוש הזה. רשימה נבחרת של תוספים מופיעה כאן בכרטיסייה Selected Inserts 25-30 rows. - לוחצים על Run. התוצאות של השאילתה יופיעו בטבלה Results.
הערה חשובה:
חשוב להקפיד להעתיק רק 25 עד 50 רשומות להוספה, ולוודא שהן מטווח של סוגי קטגוריות, קטגוריות משנה, צבעים ומגדרים.
5. יצירת הטמעות לנתונים
החידוש האמיתי בחיפוש המודרני הוא ההבנה של המשמעות, ולא רק של מילות המפתח. כאן נכנסים לתמונה הטמעות וחיפוש וקטורי.
המרנו תיאורי מוצרים ושאילתות של משתמשים לייצוגים מספריים רב-ממדיים שנקראים 'הטמעות' באמצעות מודלים של שפה שאומנו מראש. ההטמעות האלה מתעדות את המשמעות הסמנטית, ומאפשרות לנו למצוא מוצרים ש "דומים במשמעות" ולא רק מכילים מילים תואמות. בתחילה, ערכנו ניסויים בחיפוש ישיר של דמיון וקטורי בהטמעות האלה כדי ליצור בסיס להשוואה. כך הוכחנו את היכולת של הבנה סמנטית עוד לפני ביצוע אופטימיזציות של הביצועים.
בעמודת ההטמעה יאוחסנו ערכי הווקטור של הטקסט בתיאור המוצר. בעמודה img_embeddings אפשר לאחסן הטמעות של תמונות (מולטימודאליות). כך תוכלו גם להשתמש בחיפוש לפי מרחק בין טקסט לתמונה. אבל בשיעור ה-Lab הזה נשתמש רק בהטמעות טקסט.
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
הפונקציה אמורה להחזיר את וקטור ההטמעה, שנראה כמו מערך של מספרים ממשיים, עבור טקסט הדוגמה בשאילתה. כך זה נראה:
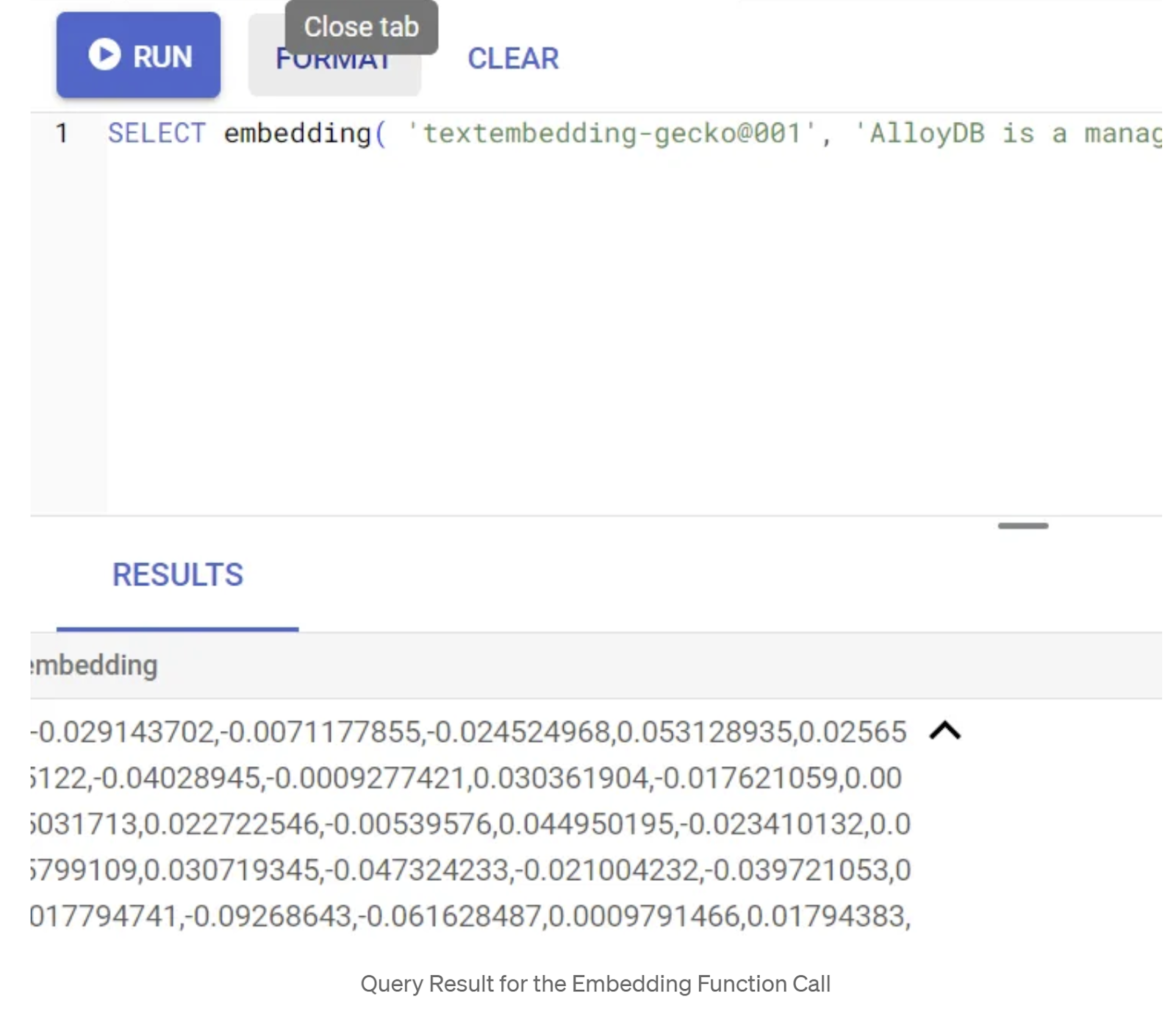
עדכון שדה הווקטור abstract_embeddings
מריצים את פקודת ה-DML הבאה כדי לעדכן את תיאור התוכן בטבלה עם ההטמעות המתאימות:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
אם אתם משתמשים בחשבון לחיוב עם קרדיט לתקופת ניסיון ב-Google Cloud, יכול להיות שתתקשו ליצור יותר מכמה הטמעות (נניח 20-25 לכל היותר). לכן, כדאי להגביל את מספר השורות בסקריפט ההוספה.
אם רוצים ליצור הטמעות של תמונות (לביצוע חיפוש הקשרי מולטי-מודאלי), מריצים גם את העדכון הבא:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. MCP Toolbox for Databases (AlloyDB)
מאחורי הקלעים, כלי פיתוח חזקים ואפליקציה בנויה היטב מבטיחים פעולה חלקה.
MCP (Model Context Protocol) Toolbox for Databases מפשט את השילוב של כלי AI גנרטיבי וכלי סוכנים עם AlloyDB. הוא פועל כשרת קוד פתוח שמייעל את איגום החיבורים, האימות והחשיפה המאובטחת של פונקציות מסד הנתונים לסוכני AI או לאפליקציות אחרות.
באפליקציה שלנו השתמשנו ב-MCP Toolbox for Databases כשכבת הפשטה לכל השאילתות החכמות של החיפוש ההיברידי.
כדי להגדיר ולפרוס את Toolbox לתרחיש השימוש שלנו:
אפשר לראות שאחד ממסדי הנתונים שנתמכים על ידי MCP Toolbox for Databases הוא AlloyDB, ומכיוון שכבר הקצנו אותו בקטע הקודם, נמשיך להגדרת ארגז הכלים.
- עוברים למסוף Cloud Shell ומוודאים שהפרויקט נבחר ומוצג בהנחיה של המסוף. מריצים את הפקודה הבאה מ-Cloud Shell Terminal כדי להיכנס לספריית הפרויקט:
mkdir gemini-cli-project
cd gemini-cli-project
- מריצים את הפקודה הבאה כדי להוריד ולהתקין את ארגז הכלים בתיקייה החדשה:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
הפעולה הזו אמורה ליצור את ארגז הכלים בספרייה הנוכחית. מעתיקים את הנתיב לארגז הכלים.
- עוברים אל Cloud Shell Editor (למצב עריכת קוד) ובתיקיית השורש של הפרויקט gemini-cli-project, מוסיפים קובץ בשם tools.yaml.
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
הסבר על הקובץ tools.yaml:
מקורות מייצגים את מקורות הנתונים השונים שהכלי יכול ליצור איתם אינטראקציה. מקור מייצג מקור נתונים שכלי יכול ליצור איתו אינטראקציה. אפשר להגדיר את המקורות כמפה בקטע sources בקובץ tools.yaml. בדרך כלל, הגדרת מקור תכיל את כל המידע שנדרש כדי להתחבר למסד הנתונים ולבצע בו פעולות.
כלים מגדירים אילו פעולות סוכן יכול לבצע – כמו קריאה וכתיבה במקור. כלי מייצג פעולה שהסוכן יכול לבצע, כמו הפעלת הצהרת SQL. אפשר להגדיר כלי כמפה בקטע Tools בקובץ tools.yaml. בדרך כלל, כלי יצטרך מקור כדי לפעול.
פרטים נוספים על הגדרת הקובץ tools.yaml מופיעים במאמר הזה.
כפי שאפשר לראות בקובץ Tools.yaml שלמעלה, הכלי get-apparels מציג את כל פרטי הביגוד ממסד הנתונים.
7. הגדרה של Gemini CLI
ב-Cloud Shell Editor, יוצרים תיקייה חדשה בשם .gemini בתוך התיקייה gemini-cli-project, ויוצרים בה קובץ חדש בשם settings.json.
{
"mcpServers": {
"AlloyDBServer": {
"command": "/home/user/gemini-cli-project/toolbox",
"args": ["--tools-file", "tools.yaml", "--stdio"]
}
}
}
בקטע הפקודה בקטע הקוד שלמעלה, מחליפים את /home/user/gemini-cli-project/toolbox בנתיב שלכם ל-toolbox.
התקנת Gemini CLI
לבסוף, בטרמינל של Cloud Shell, מריצים את הפקודה הבאה כדי להתקין את Gemini CLI באותה ספרייה gemini-cli-project:
sudo npm install -g @google/gemini-cli
הגדרת מזהה הפרויקט
מוודאים שמזהה הפרויקט הפעיל מוגדר בסביבה:
export GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT_ID>>
איך מתחילים להשתמש ב-Gemini CLI
משורת הפקודה, מזינים את הפקודה:
gemini
אמורה להופיע תגובה שדומה לזו:
מאמתים את החשבון וממשיכים לשלב הבא.
8. איך מתחילים אינטראקציה עם Gemini CLI
משתמשים בפקודה /mcp כדי להציג את רשימת שרתי ה-MCP שהוגדרו.
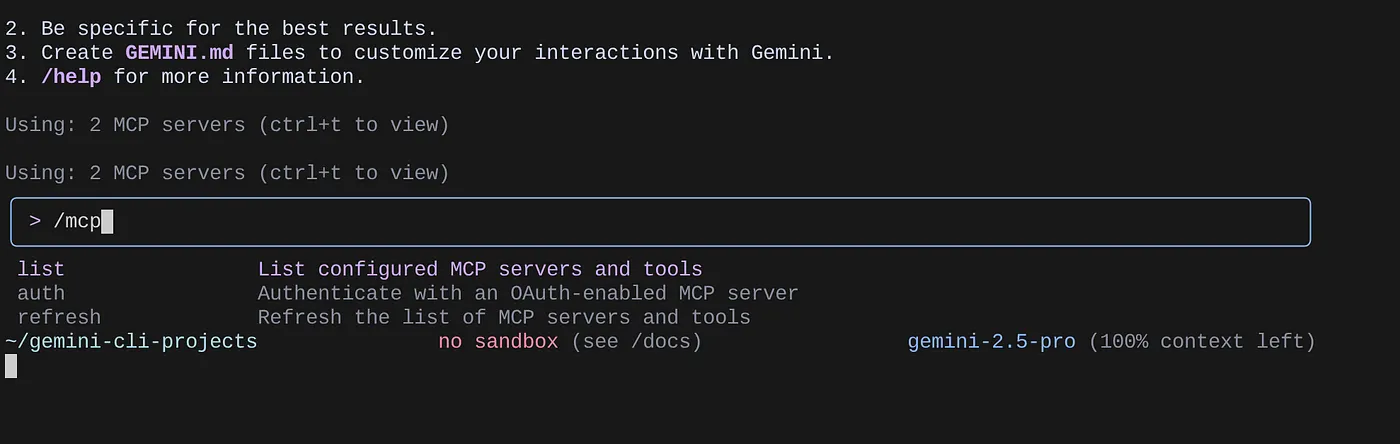
אמורים לראות את שני שרתי ה-MCP שהגדרנו: GitHub ו-MCP Toolbox for Databases, שמופיעים עם הכלים שלהם.
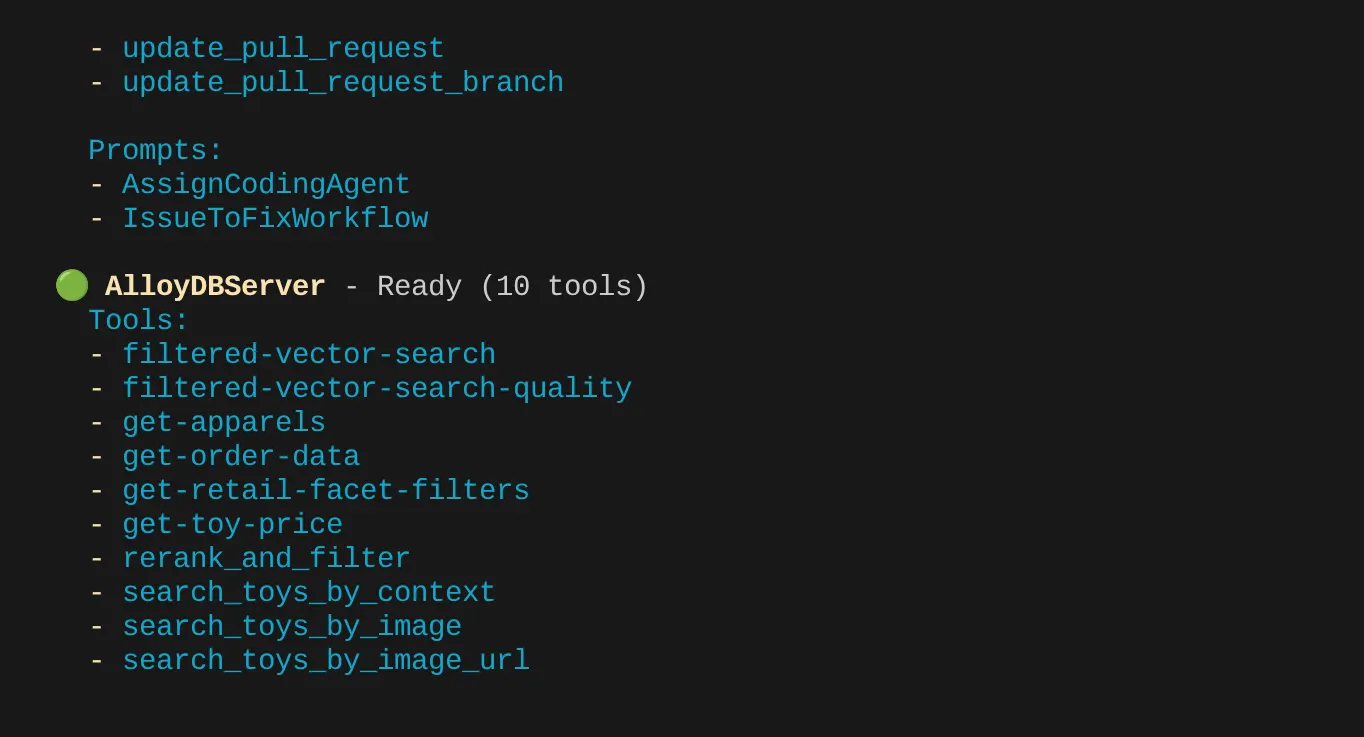
במקרה שלי יש לי עוד כלים. לכן כדאי להתעלם ממנו בשלב הזה. הכלי get-apparels אמור להופיע בשרת ה-MCP של AlloyDB.
התחלת שאילתות במסד הנתונים באמצעות MCP Toolbox
עכשיו נסו לשאול שאלות בשפה טבעית כדי לאחזר תשובות ושאילתות לגבי מערך הנתונים שאיתו אנחנו עובדים:
> How many types of genders the apparel dataset has?
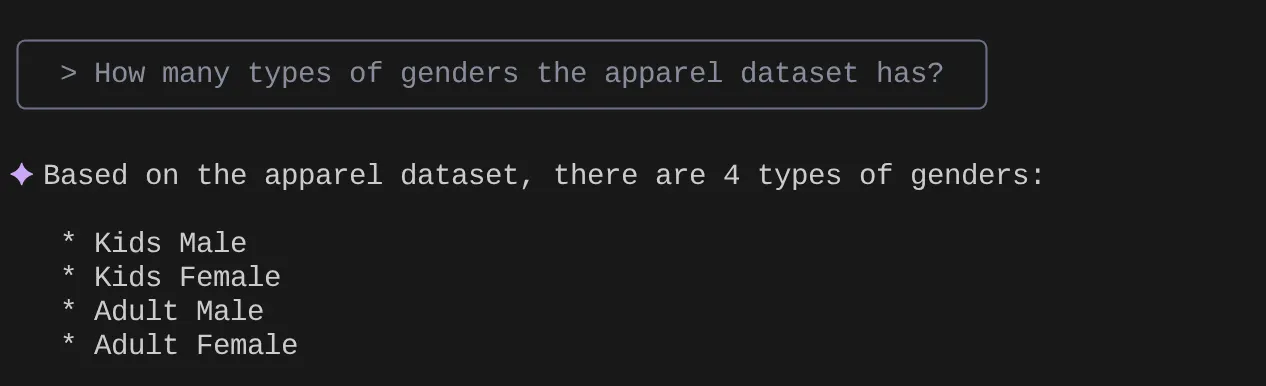
> Give me the SQL that I can use to find the number of apparels that are footwear
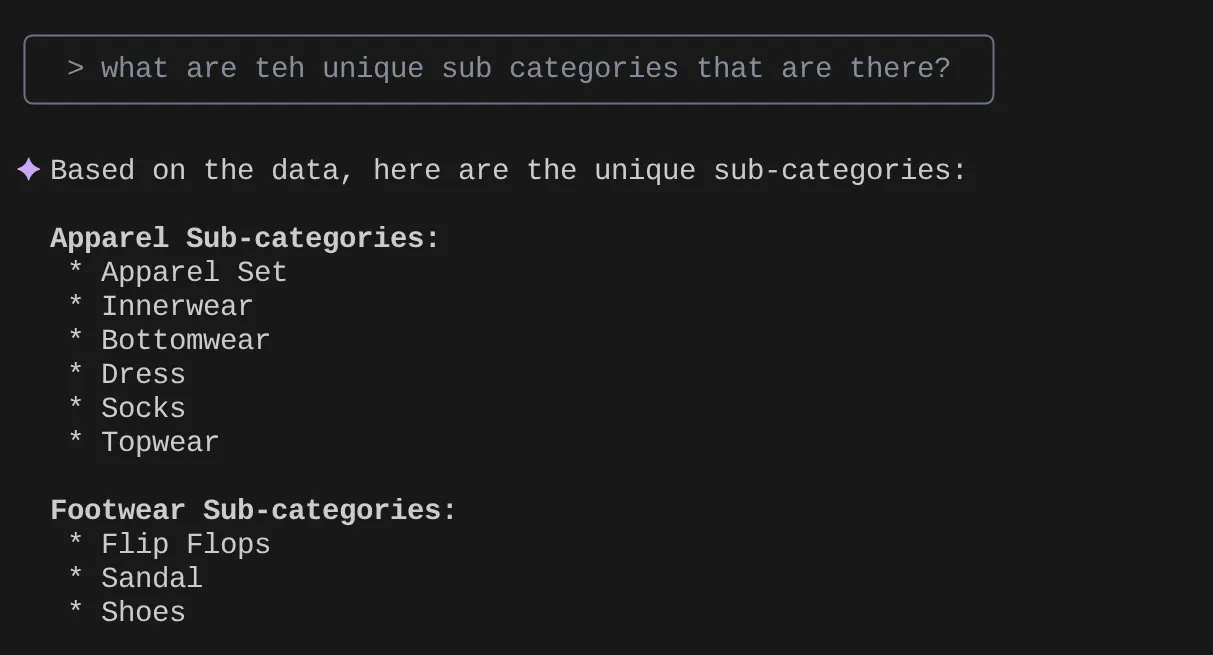
> What are the unique sub categories that are there?
that I can use to find the number of apparels that are footwear
נניח שעל סמך התובנות שלי והרבה שאילתות כאלה, יצרתי שאילתה מפורטת ואני רוצה לבדוק אותה. לחלופין, נניח שמהנדסי מסד הנתונים כבר בנו בשבילכם את הקובץ Tools.yaml כמו בדוגמה הבאה:
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
filtered-vector-search:
kind: postgres-sql
source: alloydb
description: Get the list of facet filter values from the retail dataset.
parameters:
- name: categories
type: array
description: List of categories preferred by the user.
items:
name: category
type: string
description: Category value.
- name: subCategories
type: array
description: List of sub-categories preferred by the user.
items:
name: subCategory
type: string
description: Sub-Category value.
- name: colors
type: array
description: List of colors preferred by the user.
items:
name: color
type: string
description: Color value.
- name: genders
type: array
description: List of genders preferred by the user for apparel fitting.
items:
name: gender
type: string
description: Gender name.
- name: searchtext
type: string
description: Description of the product that the user wants to find database matches for.
statement: |
SELECT id, content, uri, category, sub_category,color,gender FROM apparels
where category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005',$5)::vector limit 10
עכשיו ננסה חיפוש בשפה טבעית:
> How many yellow shirts are there for boys?


מגניב, נכון? עכשיו אוכל לתקן את קובץ ה-YAML כדי לשפר את השאילתות, ובמקביל להמשיך לספק פונקציות חדשות באפליקציה שלי בלוח זמנים מואץ.
9. פיתוח אפליקציות מואץ
היתרון בשילוב היכולות של מסד הנתונים ישירות בסביבת הפיתוח המשולבת (IDE) באמצעות Gemini CLI ו-MCP Toolbox הוא לא רק תיאורטי. המשמעות היא תהליכי עבודה מוחשיים שמגבירים את המהירות, במיוחד באפליקציה מורכבת כמו חוויית הקמעונאות ההיברידית שלנו. הנה כמה תרחישים:
1. חזרה מהירה על לוגיקת סינון המוצרים
נניח שהשקנו מבצע חדש על "בגדי ספורט לקיץ". אנחנו רוצים לבדוק איך המסננים המורכבים שלנו (למשל, לפי מותג, גודל, צבע, טווח מחירים) פועלים עם הקטגוריה החדשה הזו.
בלי שילוב IDE:
סביר להניח שאעבור ללקוח SQL נפרד, אכתוב את השאילתה, אריץ אותה, אנתח את התוצאות, אחזור ל-IDE כדי לשנות את קוד האפליקציה, אחזור ללקוח ואחזור על הפעולות. המעבר בין ההקשרים האלה הוא בעייתי מאוד.
עם Gemini CLI ו-MCP:
אני יכול להישאר בסביבת הפיתוח המשולבת שלי ועוד:
- שאילתה: אני יכול לעדכן במהירות את השאילתה ב-yaml באמצעות (מערך נתונים היפותטי) "SELECT DISTINCT brand FROM products WHERE category = ‘activewear' AND season = ‘summer'" ולנסות אותה ישירות במסוף.
- ניתוח נתונים: המותגים שמוחזרים מוצגים באופן מיידי. אם אני רוצה לראות את זמינות המוצרים של מותג מסוים במידה מסוימת, אני יכול להשתמש בשאילתה מהירה אחרת:"SELECT COUNT(*) FROM products WHERE brand = ‘SummitGear' AND size = ‘M' AND category = ‘activewear' AND season = ‘summer'"
- שילוב קוד: לאחר מכן אוכל לשנות באופן מיידי את לוגיקת הסינון של הקצה הקדמי או את הקריאות ל-API של הקצה האחורי על סמך תובנות הנתונים המהירות האלה ב-IDE, וכך לקצר משמעותית את לולאת המשוב.
2. שיפור החיפוש הווקטורי להמלצות על מוצרים
החיפוש ההיברידי שלנו מסתמך על הטמעות וקטוריות כדי לספק המלצות רלוונטיות למוצרים. נניח שאנחנו רואים ירידה בשיעורי הקליקים על המלצות ל"נעלי ריצה לגברים".
בלי שילוב IDE:
אני רוצה להריץ סקריפטים או שאילתות בהתאמה אישית בכלי מסד נתונים כדי לנתח את ציוני הדמיון של נעליים מומלצות, להשוות אותם לנתוני אינטראקציה של משתמשים ולנסות למצוא קשר בין דפוסים.
עם Gemini CLI ו-MCP:
- ניתוח הטמעות: אני יכול לשלוח שאילתה ישירות כדי לקבל הטמעות של מוצרים ואת המטא-נתונים שמשויכים להן: "SELECT product_id, name, vector_embedding FROM products WHERE category = ‘running shoes' AND gender = ‘male' LIMIT 10"
- השוואה בין נתונים: אני יכול גם לבצע בדיקה מהירה של הדמיון הווקטורי בפועל בין מוצר נבחר לבין ההמלצות שלו, ישירות שם. לדוגמה, אם מוצר א' מומלץ למשתמשים שהתעניינו במוצר ב', אפשר להריץ שאילתה כדי לאחזר את הטמעות הווקטורים שלהם ולהשוות ביניהן.
- ניפוי באגים: כך אפשר לבצע ניפוי באגים ובדיקת השערות מהר יותר. האם מודל ההטמעה מתנהג כמצופה? האם יש אנומליות בנתונים שמשפיעות על איכות ההמלצות? אני יכול לקבל תשובות ראשוניות בלי לצאת מסביבת הקידוד שלי.
3. הסבר על סכימה ועל חלוקת נתונים לתכונות חדשות
נניח שאנחנו מתכננים להוסיף תכונה של ביקורות לקוחות. לפני שכותבים את ה-API של ה-Backend, צריך להבין את נתוני הלקוחות הקיימים ואת מבנה הביקורות.
בלי שילוב IDE:
אצטרך להתחבר ללקוח מסד נתונים, להריץ פקודות DESCRIBE בטבלאות כמו customers ו-orders, ואז להריץ שאילתה כדי לקבל נתונים לדוגמה ולהבין את הקשרים ואת סוגי הנתונים.
עם Gemini CLI ו-MCP:
- ניתוח סכימה: אני יכול פשוט לשלוח שאילתה לטבלה בקובץ ה-YAML ולהריץ אותה ישירות במסוף.
- דגימת נתונים: לאחר מכן אוכל לשלוף נתונים לדוגמה כדי להבין את הדמוגרפיה של הלקוחות ואת היסטוריית הרכישות שלהם: "SELECT customer_id, name, signup_date, total_orders FROM customers ORDER BY signup_date DESC LIMIT 5"
- תכנון: הגישה המהירה לסקירה של הסכימה והתפלגות הנתונים עוזרת לנו לקבל החלטות מושכלות לגבי עיצוב טבלת הביקורות החדשה, אילו מפתחות זרים להגדיר ואיך לקשר ביעילות בין ביקורות ללקוחות ולמוצרים, וכל זה לפני שכותבים שורה אחת של קוד אפליקציה לתכונה החדשה.
אלה רק כמה דוגמאות, אבל הן ממחישות את היתרון העיקרי: צמצום החיכוך והגברת מהירות הפיתוח. השילוב של Gemini CLI ו-MCP Toolbox בסביבת הפיתוח המשולבת (IDE) מאפשר לנו ליצור אינטראקציה עם AlloyDB ישירות בסביבה הזו, וכך לבנות אפליקציות טובות יותר, עם תגובה מהירה יותר, בזמן קצר יותר.
10. הסרת המשאבים
כדי לא לצבור חיובים לחשבון Google Cloud על המשאבים שבהם השתמשתם במאמר הזה:
- במסוף Google Cloud, עוברים לדף resource manager.
- ברשימת הפרויקטים, בוחרים את הפרויקט שרוצים למחוק ולוחצים על Delete.
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.
- לחלופין, אפשר פשוט למחוק את אשכול AlloyDB (כדי לשנות את המיקום בהיפר-קישור הזה, אם לא בחרתם ב-us-central1 לאשכול בזמן ההגדרה) שיצרנו זה עתה עבור הפרויקט הזה, על ידי לחיצה על הלחצן 'מחיקת אשכול'.
11. מזל טוב
מעולה! הצלחתם לשלב את MCP Toolbox ישירות בסביבת הפיתוח המשולבת (IDE) כדי ליצור אינטראקציה חלקה עם AlloyDB, והשתמשתם ב-Gemini CLI כדי ליצור אינטראקציה עם מערך הנתונים של המסחר האלקטרוני הקמעונאי שלנו ולכתוב שאילתות שבדרך כלל דורשות כלים נפרדים. למדתם דרכים חדשות לבדוק את הנתונים ולהבין אותם – החל מבדיקת מבני הטבלאות ועד לביצוע בדיקות מהירות של תקינות הנתונים – והכול באמצעות ממשקי שורת פקודה מוכרים בתוך סביבת הפיתוח המשולבת שלנו.
תבצע שיבוט של המאגר, תנתח אותו ותעדכן אותי אם שיפרת את האפליקציה באמצעות Gemini CLI ו-MCP Toolbox for Databases.
כדי לקבל מידע נוסף על אפליקציות מבוססות-נתונים כאלה מבוססות על Gemini שנבנו באמצעות Gemini CLI ו-MCP ונפרסו בסביבות זמן ריצה בלי שרתים, אתם יכולים להירשם לעונה הקרובה של Code Vipassana, שבה תוכלו להשתתף בסדנאות מעשיות בהנחיית איש/אשת הוראה ולקבל עוד Codelabs כאלה!!!