
1. खास जानकारी
क्या आपको याद है कि हमने AlloyDB की मदद से, फ़ेसटेड फ़िल्टरिंग और वेक्टर सर्च को मिलाकर, डाइनैमिक हाइब्रिड रीटेल अनुभव कैसे बनाया था? उस ऐप्लिकेशन से, मॉडर्न रीटेल की ज़रूरतों के बारे में पता चला. हालांकि, उसे बनाने और बेहतर बनाने में काफ़ी मेहनत लगी. फ़ुल-स्टैक डेवलपर के लिए, कोड एडिटर और डेटाबेस टूल के बीच लगातार स्विच करना अक्सर एक मुश्किल काम होता है. इससे इनोवेशन और डेटा को समझने की ज़रूरी प्रोसेस धीमी हो जाती है.
समाधान
तेज़ी से ऐप्लिकेशन डेवलप करने की सुविधा यहीं काम आती है. इसलिए, मैं यह शेयर करने के लिए बहुत उत्साहित हूँ कि MCP (मॉडर्न क्लाउड प्लैटफ़ॉर्म) टूलबॉक्स, मेरे टूलकिट का एक अहम हिस्सा बन गया है. इसे Gemini CLI के ज़रिए ऐक्सेस किया जा सकता है. कल्पना करें कि आप अपने इंटिग्रेटेड डेवलपमेंट एनवायरमेंट (आईडीई) में, AlloyDB इंस्टेंस के साथ आसानी से इंटरैक्ट कर रहे हैं, क्वेरी लिख रहे हैं, और अपने डेटासेट को समझ रहे हैं. यह सिर्फ़ सुविधा के बारे में नहीं है. इससे डेवलपमेंट के लाइफ़साइकल में आने वाली मुश्किलों को कम किया जा सकता है. इससे आपको बाहरी टूल के साथ काम करने के बजाय, नई सुविधाओं को बनाने पर फ़ोकस करने में मदद मिलती है.
हमारे खुदरा ई-कॉमर्स ऐप्लिकेशन के लिए, हमें प्रॉडक्ट डेटा को कुशलता से क्वेरी करने, जटिल फ़िल्टरिंग को मैनेज करने, और वेक्टर सर्च की बारीकियों का फ़ायदा उठाने की ज़रूरत थी. इसलिए, डेटाबेस के साथ इंटरैक्शन को तेज़ी से दोहराने की क्षमता सबसे अहम थी. Gemini CLI की मदद से काम करने वाला MCP टूलबॉक्स, इस प्रोसेस को न सिर्फ़ आसान बनाता है, बल्कि इसे तेज़ भी करता है. इससे, हम अपने ऐप्लिकेशन के डेटाबेस लॉजिक को एक्सप्लोर, टेस्ट, और बेहतर बना सकते हैं. आइए, जानते हैं कि यह गेम-चेंजिंग कॉम्बिनेशन, फ़ुल-स्टैक डेवलपमेंट को कैसे ज़्यादा तेज़, बेहतर, और मज़ेदार बना रहा है.
आपको क्या सीखने और बनाने को मिलेगा
खुदरा खोज ऐप्लिकेशन, जो आईडीई में एमसीपी टूलबॉक्स का इस्तेमाल करता है. यह Gemini CLI की मदद से काम करता है. हम इन विषयों पर बात करेंगे:
- AlloyDB के साथ आसानी से इंटरैक्ट करने के लिए, एमसीपी टूलबॉक्स को सीधे अपने आईडीई में इंटिग्रेट करने का तरीका.
- Gemini CLI का इस्तेमाल करके, खुदरा कारोबार से जुड़े डेटा के लिए एसक्यूएल क्वेरी लिखने और उन्हें चलाने के व्यावहारिक उदाहरण.
- Gemini CLI का इस्तेमाल करके, हमारे खुदरा ई-कॉमर्स डेटासेट के साथ इंटरैक्ट करें. साथ ही, ऐसी क्वेरी लिखें जिनके लिए आम तौर पर अलग-अलग टूल की ज़रूरत होती है और उनके नतीजे तुरंत देखें.
- डेटा की जांच करने और उसे समझने के नए तरीके जानें. जैसे, टेबल स्ट्रक्चर की जांच करना और डेटा की क्वालिटी की तुरंत जांच करना. ये सभी काम, हमारे आईडीई में मौजूद कमांड-लाइन इंटरफ़ेस की मदद से किए जा सकते हैं.
- यह तेज़ डेटाबेस वर्कफ़्लो, फ़ुल-स्टैक डेवलपमेंट साइकल को तेज़ी से पूरा करने में कैसे मदद करता है. इससे रैपिड प्रोटोटाइपिंग और बार-बार होने वाले बदलावों को लागू करने में मदद मिलती है.
Techstack
हम इनका इस्तेमाल कर रहे हैं:
- डेटाबेस के लिए AlloyDB
- एमसीपी टूलबॉक्स, ऐप्लिकेशन से डेटाबेस की ऐडवांस जनरेटिव और एआई सुविधाओं को ऐब्स्ट्रैक्ट करने के लिए
- बिना सर्वर वाले डिप्लॉयमेंट के लिए Cloud Run.
- Gemini CLI का इस्तेमाल करके, डेटासेट को समझा और उसका विश्लेषण किया जा सकता है. साथ ही, खुदरा ई-कॉमर्स ऐप्लिकेशन का डेटाबेस वाला हिस्सा बनाया जा सकता है.
ज़रूरी शर्तें
2. शुरू करने से पहले
प्रोजेक्ट बनाना
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग चालू हो. किसी प्रोजेक्ट के लिए बिलिंग चालू है या नहीं, यह देखने का तरीका जानें.
- आपको Cloud Shell का इस्तेमाल करना होगा. यह Google Cloud में चलने वाला कमांड-लाइन एनवायरमेंट है. Google Cloud Console में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें.

- Cloud Shell से कनेक्ट होने के बाद, यह देखने के लिए कि आपकी पुष्टि हो चुकी है और प्रोजेक्ट को आपके प्रोजेक्ट आईडी पर सेट किया गया है, इस कमांड का इस्तेमाल करें:
gcloud auth list
- यह पुष्टि करने के लिए कि gcloud कमांड को आपके प्रोजेक्ट के बारे में पता है, Cloud Shell में यह कमांड चलाएं.
gcloud config list project
- अगर आपका प्रोजेक्ट सेट नहीं है, तो इसे सेट करने के लिए इस निर्देश का इस्तेमाल करें:
gcloud config set project <YOUR_PROJECT_ID>
- ज़रूरी एपीआई चालू करें: लिंक पर जाएं और एपीआई चालू करें.
इसके अलावा, इसके लिए gcloud कमांड का इस्तेमाल किया जा सकता है. gcloud कमांड और उनके इस्तेमाल के बारे में जानने के लिए, दस्तावेज़ देखें.
3. डेटाबेस सेटअप करना
इस लैब में, हम ई-कॉमर्स डेटा के लिए AlloyDB को डेटाबेस के तौर पर इस्तेमाल करेंगे. यह सभी संसाधनों को सेव करने के लिए, क्लस्टर का इस्तेमाल करता है. जैसे, डेटाबेस और लॉग. हर क्लस्टर में एक प्राइमरी इंस्टेंस होता है, जो डेटा का ऐक्सेस पॉइंट उपलब्ध कराता है. टेबल में असल डेटा होगा.
आइए, एक AlloyDB क्लस्टर, इंस्टेंस, और टेबल बनाएं. इसमें ई-कॉमर्स डेटासेट लोड किया जाएगा.
क्लस्टर और इंस्टेंस बनाना
- Cloud Console में AlloyDB पेज पर जाएं. Cloud Console में ज़्यादातर पेजों को आसानी से ढूंढने के लिए, कंसोल के खोज बार का इस्तेमाल करके उन्हें खोजें.
- उस पेज पर जाकर, क्लस्टर बनाएं चुनें:

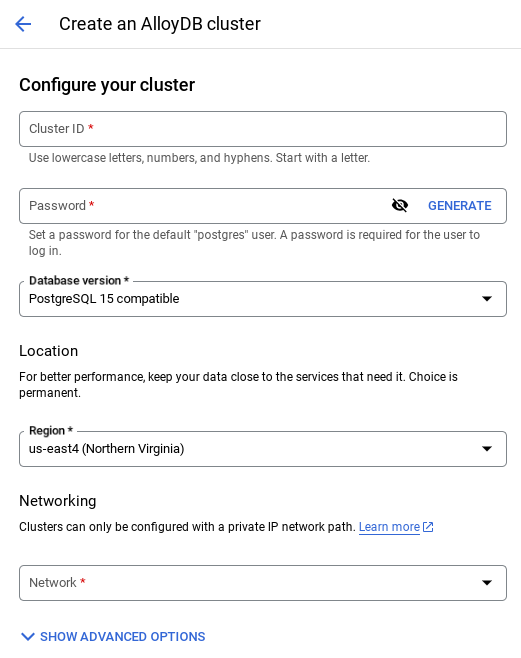
- आपको नीचे दी गई इमेज जैसी स्क्रीन दिखेगी. नीचे दी गई वैल्यू का इस्तेमाल करके, क्लस्टर और इंस्टेंस बनाएं. अगर आपको रिपॉज़िटरी से ऐप्लिकेशन कोड क्लोन करना है, तो पक्का करें कि वैल्यू मैच होती हों:
- क्लस्टर आईडी: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / सुझाया गया नया वर्शन
- इलाका: "
us-central1" - नेटवर्किंग: "
default"
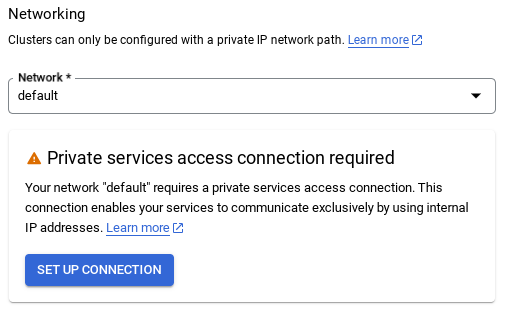
- डिफ़ॉल्ट नेटवर्क चुनने पर, आपको नीचे दी गई इमेज जैसी स्क्रीन दिखेगी.
कनेक्शन सेट अप करें को चुनें.
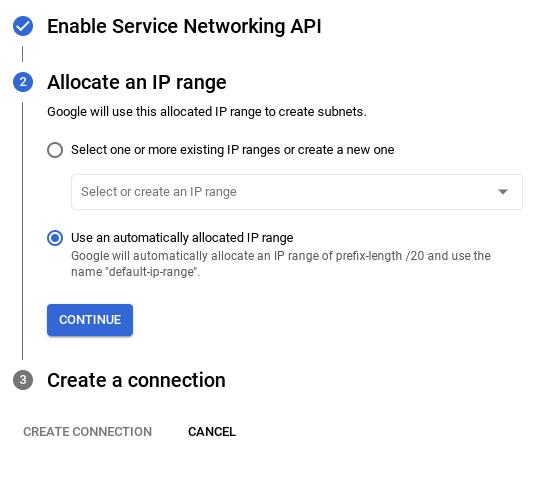
- इसके बाद, "अपने-आप असाइन की गई आईपी रेंज का इस्तेमाल करें" को चुनें और जारी रखें पर क्लिक करें. जानकारी देखने के बाद, कनेक्शन बनाएं को चुनें.
- नेटवर्क सेट अप हो जाने के बाद, क्लस्टर बनाना जारी रखा जा सकता है. नीचे दिए गए तरीके से क्लस्टर सेट अप करने के लिए, क्लस्टर बनाएं पर क्लिक करें:
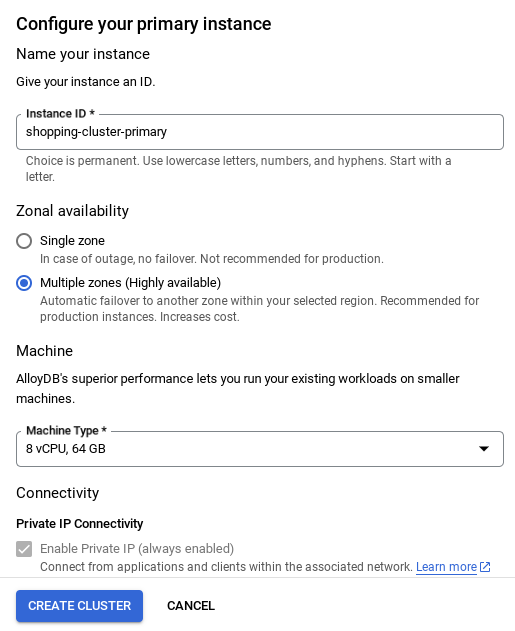
अहम जानकारी:
- इंस्टेंस आईडी को (यह आपको क्लस्टर / इंस्टेंस को कॉन्फ़िगर करते समय मिल सकता है) बदलकर **
vector-instance** करना न भूलें. अगर इसे बदला नहीं जा सकता, तो आने वाले सभी रेफ़रंस में **अपने इंस्टेंस आईडी का इस्तेमाल** करना न भूलें. - ध्यान दें कि क्लस्टर बनने में करीब 10 मिनट लगेंगे. प्रोसेस पूरी होने के बाद, आपको एक स्क्रीन दिखेगी. इसमें, आपके बनाए गए क्लस्टर की खास जानकारी दिखेगी.
4. डेटा डालना
अब स्टोर के बारे में जानकारी देने वाली टेबल जोड़ें. AlloyDB पर जाएं. इसके बाद, प्राइमरी क्लस्टर और फिर AlloyDB Studio चुनें:
आपको इंस्टेंस बनने तक इंतज़ार करना पड़ सकता है. इसके बाद, क्लस्टर बनाते समय बनाए गए क्रेडेंशियल का इस्तेमाल करके, AlloyDB में साइन इन करें. PostgreSQL में पुष्टि करने के लिए, इस डेटा का इस्तेमाल करें:
- उपयोगकर्ता नाम : "
postgres" - डेटाबेस : "
postgres" - पासवर्ड : "
alloydb"
AlloyDB Studio में पुष्टि हो जाने के बाद, SQL कमांड को एडिटर में डाला जाता है. आखिरी विंडो के दाईं ओर मौजूद प्लस आइकॉन का इस्तेमाल करके, एक से ज़्यादा Editor विंडो जोड़ी जा सकती हैं.
AlloyDB के लिए एडिटर विंडो में कमांड डालें. इसके लिए, ज़रूरत के हिसाब से Run, Format, और Clear विकल्पों का इस्तेमाल करें.
एक्सटेंशन चालू करना
इस ऐप्लिकेशन को बनाने के लिए, हम pgvector और google_ml_integration एक्सटेंशन का इस्तेमाल करेंगे. pgvector एक्सटेंशन की मदद से, वेक्टर एम्बेडिंग को सेव किया जा सकता है और उन्हें खोजा जा सकता है. google_ml_integration एक्सटेंशन, ऐसे फ़ंक्शन उपलब्ध कराता है जिनका इस्तेमाल करके, Vertex AI के अनुमान लगाने वाले एंडपॉइंट को ऐक्सेस किया जा सकता है. इससे एसक्यूएल में अनुमान मिलते हैं. इन एक्सटेंशन को चालू करें. इसके लिए, ये DDL चलाएं:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
अगर आपको अपने डेटाबेस पर चालू किए गए एक्सटेंशन देखने हैं, तो यह एसक्यूएल कमांड चलाएं:
select extname, extversion from pg_extension;
टेबल बनाना
AlloyDB Studio में, नीचे दिए गए डीडीएल स्टेटमेंट का इस्तेमाल करके टेबल बनाई जा सकती है:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
एम्बेडिंग कॉलम में, टेक्स्ट की वेक्टर वैल्यू सेव की जा सकेंगी.
अनुमति दें
"embedding" फ़ंक्शन पर 'लागू करें' की अनुमति देने के लिए, नीचे दिया गया स्टेटमेंट चलाएं:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB सेवा खाते को Vertex AI उपयोगकर्ता की भूमिका असाइन करना
Google Cloud IAM Console में जाकर, AlloyDB सेवा खाते को "Vertex AI User" की भूमिका का ऐक्सेस दें. यह सेवा खाता इस तरह दिखता है: service-<<PROJECT_NUMBER >>@gcp-sa-alloydb.iam.gserviceaccount.com. PROJECT_NUMBER में आपका प्रोजेक्ट नंबर होगा.
इसके अलावा, Cloud Shell टर्मिनल से नीचे दिया गया कमांड भी चलाया जा सकता है:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
डेटाबेस में डेटा लोड करना
- शीट में मौजूद
insert scripts sqlसेinsertक्वेरी स्टेटमेंट को कॉपी करके, ऊपर बताए गए एडिटर में चिपकाएं. इस इस्तेमाल के उदाहरण का तुरंत डेमो देने के लिए, 10 से 50 इंसर्ट स्टेटमेंट कॉपी किए जा सकते हैं. यहां "चुने गए इंसर्ट 25 से 30 लाइनें" टैब में, इंसर्ट की चुनी गई सूची मौजूद है. - चलाएं पर क्लिक करें. आपकी क्वेरी के नतीजे, नतीजे टेबल में दिखते हैं.
अहम जानकारी:
सिर्फ़ 25 से 50 रिकॉर्ड कॉपी करके डालें. साथ ही, पक्का करें कि ये रिकॉर्ड कैटगरी, sub_category, रंग, और लिंग के हिसाब से अलग-अलग टाइप के हों.
5. डेटा के लिए एम्बेडिंग बनाना
मॉडर्न सर्च में असली इनोवेशन, सिर्फ़ कीवर्ड को समझने में नहीं, बल्कि उनके मतलब को समझने में है. ऐसे में, एम्बेडिंग और वेक्टर सर्च की सुविधा काम आती है.
हमने पहले से ट्रेन किए गए लैंग्वेज मॉडल का इस्तेमाल करके, प्रॉडक्ट के ब्यौरे और उपयोगकर्ता की क्वेरी को "एम्बेडिंग" कहे जाने वाले हाई-डाइमेंशनल न्यूमेरिकल रिप्रेजेंटेशन में बदल दिया है. ये एम्बेडिंग, शब्दों के मतलब को कैप्चर करती हैं. इससे हमें ऐसे प्रॉडक्ट ढूंढने में मदद मिलती है जो "मतलब के हिसाब से मिलते-जुलते" हों. ऐसा नहीं है कि सिर्फ़ मिलते-जुलते शब्दों वाले प्रॉडक्ट दिखाए जाते हैं. शुरुआत में, हमने इन एम्बेडिंग पर सीधे तौर पर वेक्टर सिमिलैरिटी सर्च का इस्तेमाल किया, ताकि एक बेसलाइन तैयार की जा सके. इससे यह पता चला कि परफ़ॉर्मेंस ऑप्टिमाइज़ेशन से पहले भी, सिमेंटिक अंडरस्टैंडिंग कितनी अहम होती है.
एम्बेडिंग कॉलम में, प्रॉडक्ट के ब्यौरे के टेक्स्ट की वेक्टर वैल्यू सेव की जा सकेंगी. img_embeddings कॉलम में, इमेज एम्बेडिंग (मल्टीमॉडल) को सेव किया जा सकेगा. इस तरह, इमेज के आस-पास मौजूद टेक्स्ट के आधार पर खोज करने की सुविधा का इस्तेमाल भी किया जा सकता है. हालांकि, इस लैब में हम सिर्फ़ टेक्स्ट एम्बेडिंग का इस्तेमाल करेंगे.
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
इससे क्वेरी में मौजूद सैंपल टेक्स्ट के लिए, एम्बेडिंग वेक्टर मिलना चाहिए. यह फ़्लोट की एक ऐसी कैटगरी होती है जो ऐरे की तरह दिखती है. यह इस तरह दिखता है:
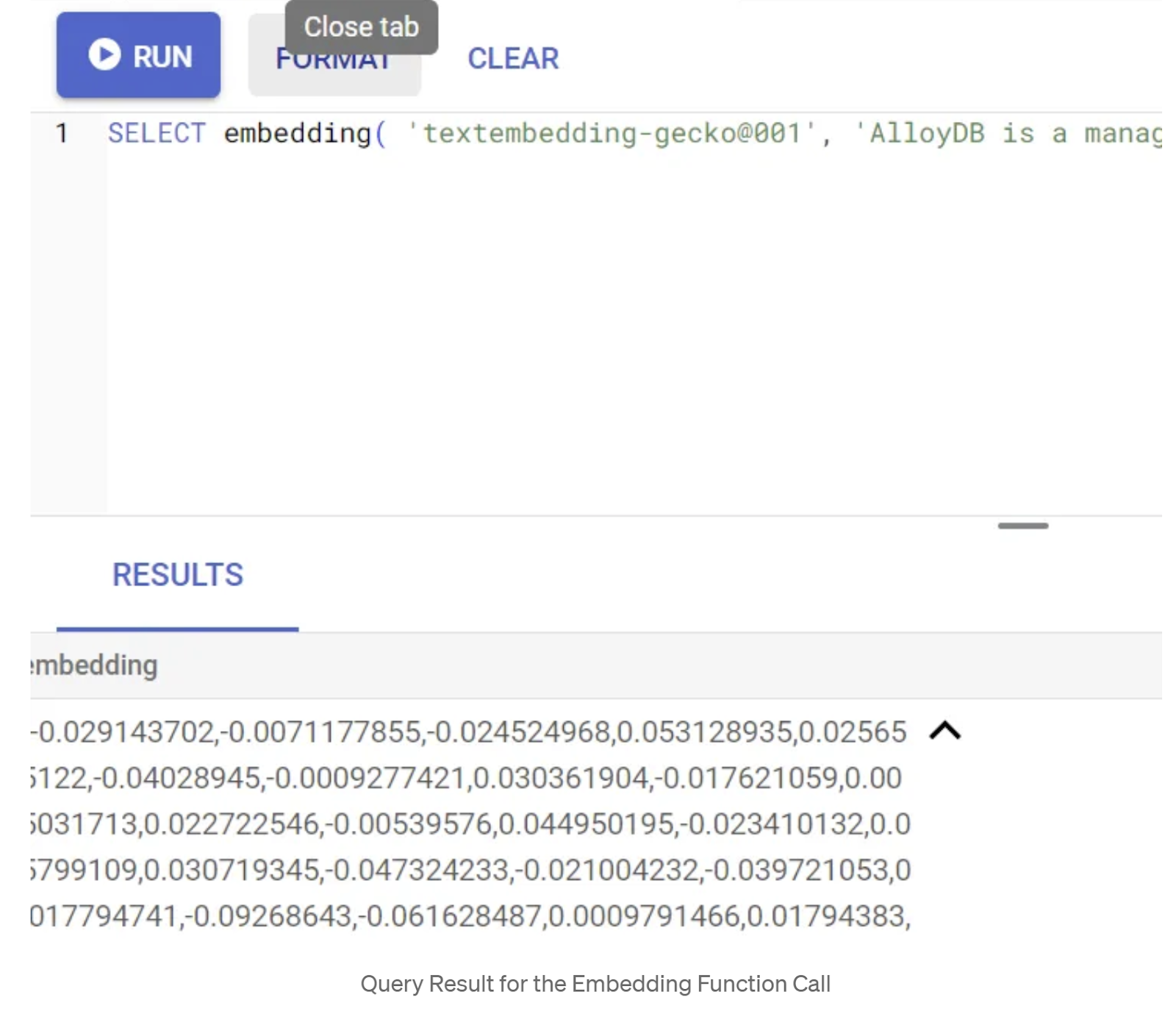
abstract_embeddings वेक्टर फ़ील्ड को अपडेट करना
टेबल में कॉन्टेंट के ब्यौरे को उससे जुड़ी एम्बेडिंग के साथ अपडेट करने के लिए, नीचे दिए गए डीएमएल को चलाएं:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
अगर Google Cloud के लिए, बिना किसी शुल्क के आज़माने की सुविधा वाले क्रेडिट बिलिंग खाते का इस्तेमाल किया जा रहा है, तो आपको कुछ से ज़्यादा एम्बेडिंग (जैसे कि ज़्यादा से ज़्यादा 20-25) जनरेट करने में समस्या आ सकती है. इसलिए, इंसर्ट स्क्रिप्ट में पंक्तियों की संख्या सीमित करें.
अगर आपको इमेज एम्बेडिंग जनरेट करनी हैं, ताकि मल्टीमॉडल कॉन्टेक्स्ट के हिसाब से खोज की जा सके, तो नीचे दिए गए अपडेट को भी चलाएं:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. डेटाबेस (AlloyDB) के लिए MCP Toolbox
बैकग्राउंड में, मज़बूत टूल और अच्छी तरह से स्ट्रक्चर किया गया ऐप्लिकेशन, यह पक्का करता है कि यह सुविधा बिना किसी रुकावट के काम करे.
डेटाबेस के लिए एमसीपी (मॉडल कॉन्टेक्स्ट प्रोटोकॉल) टूलबॉक्स, जनरेटिव एआई और एजेंटिक टूल को AlloyDB के साथ इंटिग्रेट करने की प्रोसेस को आसान बनाता है. यह एक ओपन-सोर्स सर्वर के तौर पर काम करता है. इससे कनेक्शन पूलिंग, पुष्टि करने की प्रोसेस, और डेटाबेस की सुविधाओं को एआई एजेंट या अन्य ऐप्लिकेशन के साथ सुरक्षित तरीके से शेयर करने में मदद मिलती है.
हमने अपने ऐप्लिकेशन में, डेटाबेस के लिए एमसीपी टूलबॉक्स का इस्तेमाल किया है. यह हमारी सभी इंटेलिजेंट हाइब्रिड सर्च क्वेरी के लिए ऐब्स्ट्रैक्शन लेयर के तौर पर काम करता है.
हमारे इस्तेमाल के उदाहरण के लिए, Toolbox को सेट अप और डिप्लॉय करने के लिए, यहां दिया गया तरीका अपनाएं:
आपको दिख रहा होगा कि डेटाबेस के लिए एमसीपी टूलबॉक्स के साथ काम करने वाले डेटाबेस में से एक AlloyDB है. हमने पिछले सेक्शन में इसे पहले ही प्रोविज़न कर दिया है. इसलिए, अब हम टूलबॉक्स को सेट अप करते हैं.
- Cloud Shell टर्मिनल पर जाएं. पक्का करें कि आपका प्रोजेक्ट चुना गया हो और टर्मिनल के प्रॉम्प्ट में दिख रहा हो. अपने प्रोजेक्ट की डायरेक्ट्री में जाने के लिए, Cloud Shell टर्मिनल में यह कमांड चलाएं:
mkdir gemini-cli-project
cd gemini-cli-project
- अपने नए फ़ोल्डर में टूलबॉक्स को डाउनलोड और इंस्टॉल करने के लिए, यहां दिया गया कमांड चलाएं:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
इससे आपकी मौजूदा डायरेक्ट्री में टूलबॉक्स बन जाएगा. टूलबॉक्स का पाथ कॉपी करें.
- कोड में बदलाव करने के मोड के लिए, Cloud Shell Editor पर जाएं. इसके बाद, प्रोजेक्ट के रूट फ़ोल्डर "gemini-cli-project" में, "tools.yaml" नाम की फ़ाइल जोड़ें.
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
आइए, tools.yaml को समझते हैं:
सोर्स, आपके अलग-अलग डेटा सोर्स होते हैं. टूल इनके साथ इंटरैक्ट कर सकता है. सोर्स, ऐसे डेटा सोर्स को दिखाता है जिससे कोई टूल इंटरैक्ट कर सकता है. अपने tools.yaml फ़ाइल के sources सेक्शन में, सोर्स को मैप के तौर पर तय किया जा सकता है. आम तौर पर, सोर्स कॉन्फ़िगरेशन में डेटाबेस से कनेक्ट करने और उससे इंटरैक्ट करने के लिए ज़रूरी जानकारी होती है.
टूल से यह तय होता है कि एजेंट कौनसी कार्रवाइयां कर सकता है. जैसे, किसी सोर्स से जानकारी पढ़ना और उसमें जानकारी लिखना. टूल, ऐसी कार्रवाई को दिखाता है जो आपका एजेंट कर सकता है. जैसे, SQL स्टेटमेंट चलाना. tools.yaml फ़ाइल के टूल सेक्शन में, टूल को मैप के तौर पर तय किया जा सकता है. आम तौर पर, किसी टूल को कार्रवाई करने के लिए सोर्स की ज़रूरत होती है.
tools.yaml को कॉन्फ़िगर करने के बारे में ज़्यादा जानने के लिए, यह दस्तावेज़ पढ़ें.
ऊपर दी गई Tools.yaml फ़ाइल में देखा जा सकता है कि "get-apparels" टूल, डेटाबेस से सभी कपड़ों की जानकारी दिखाता है.
7. Gemini CLI को सेट अप करना
Cloud Shell Editor में, gemini-cli-project फ़ोल्डर के अंदर .gemini नाम का एक नया फ़ोल्डर बनाएं. इसके बाद, इसमें settings.json नाम की एक नई फ़ाइल बनाएं.
{
"mcpServers": {
"AlloyDBServer": {
"command": "/home/user/gemini-cli-project/toolbox",
"args": ["--tools-file", "tools.yaml", "--stdio"]
}
}
}
ऊपर दिए गए स्निपेट में, कमांड सेक्शन में मौजूद "/home/user/gemini-cli-project/toolbox" को टूलबॉक्स के पाथ से बदलें.
Gemini CLI इंस्टॉल करना
आखिर में, Cloud Shell टर्मिनल से, gemini-cli-project डायरेक्ट्री में Gemini CLI इंस्टॉल करें. इसके लिए, यह कमांड चलाएं:
sudo npm install -g @google/gemini-cli
प्रोजेक्ट आईडी सेट करना
पक्का करें कि आपके एनवायरमेंट में चालू प्रोजेक्ट आईडी सेट हो:
export GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT_ID>>
Gemini CLI का इस्तेमाल शुरू करना
कमांड लाइन में यह निर्देश डालें:
gemini
आपको यहां दिए गए जवाब जैसा जवाब दिखेगा:
पुष्टि करें और अगले चरण पर जाएं.
8. Gemini CLI के साथ इंटरैक्ट करना शुरू करना
कॉन्फ़िगर किए गए एमसीपी सर्वर की सूची देखने के लिए, /mcp कमांड का इस्तेमाल करें.
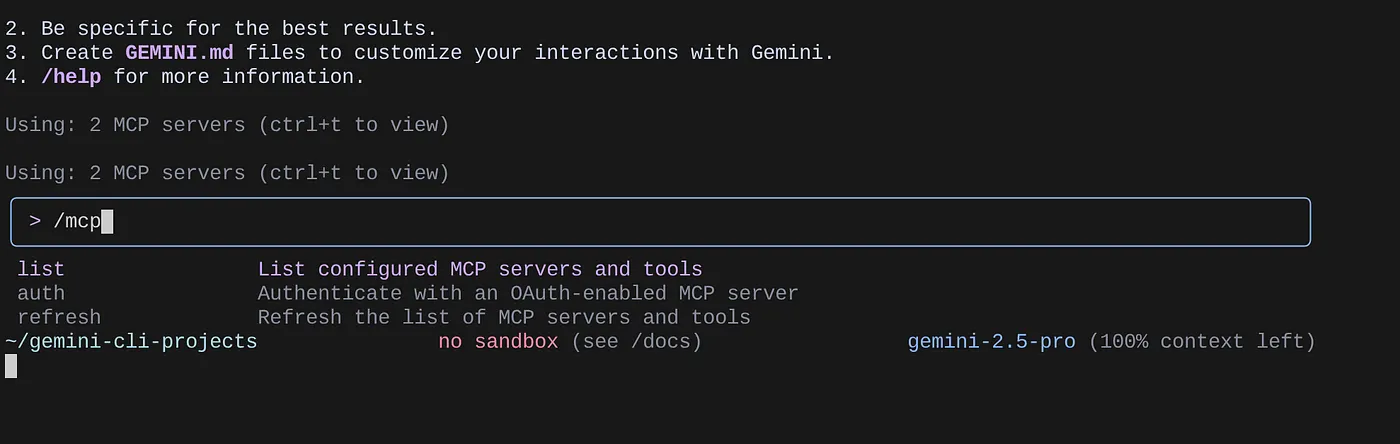
आपको कॉन्फ़िगर किए गए दो एमसीपी सर्वर दिखने चाहिए: GitHub और डेटाबेस के लिए MCP Toolbox. ये सर्वर, उनके टूल के साथ दिखेंगे.
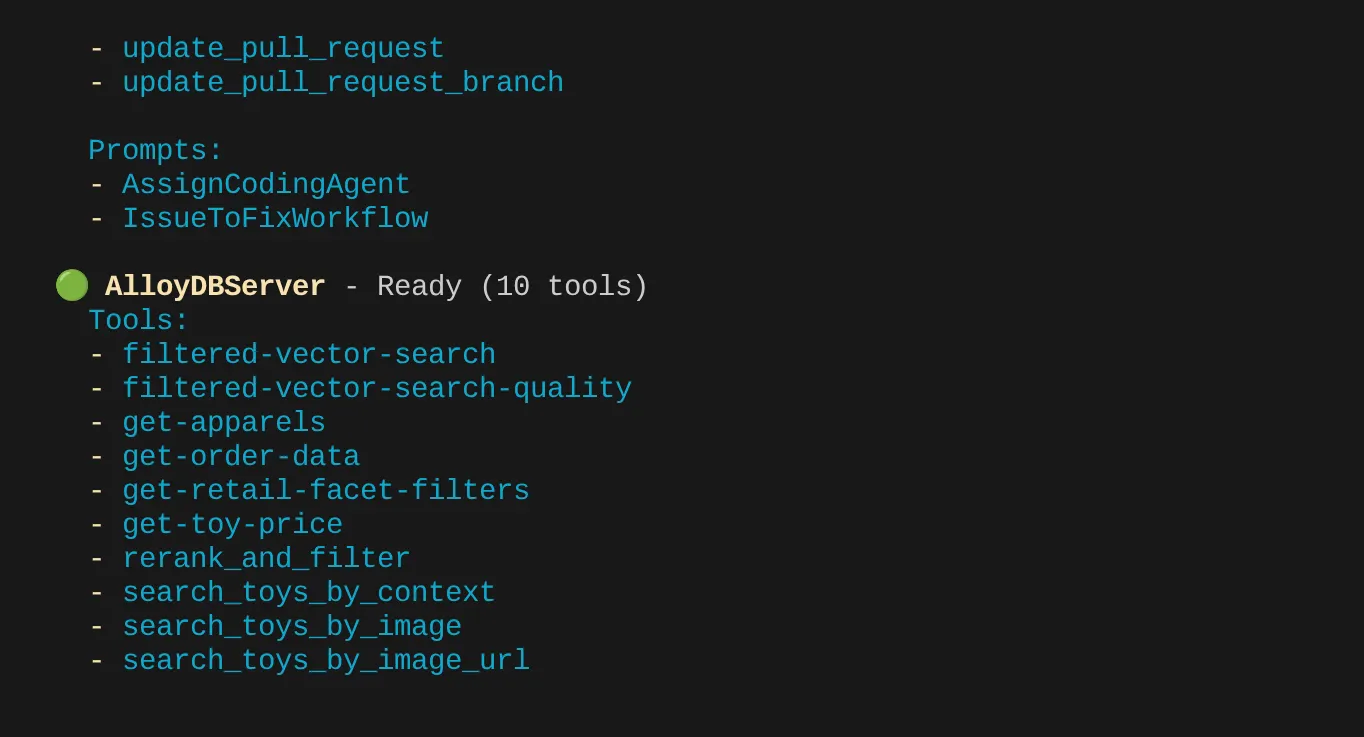
मेरे पास ज़्यादा टूल हैं. इसलिए, फ़िलहाल इसे अनदेखा करें. आपको अपने AlloyDB MCP सर्वर में get-apparels टूल दिखेगा.
एमसीपी टूलबॉक्स की मदद से डेटाबेस को क्वेरी करना
अब उस डेटासेट के लिए, सामान्य भाषा में सवाल पूछकर जवाब और क्वेरी पाएं जिस पर हम काम कर रहे हैं:
> How many types of genders the apparel dataset has?
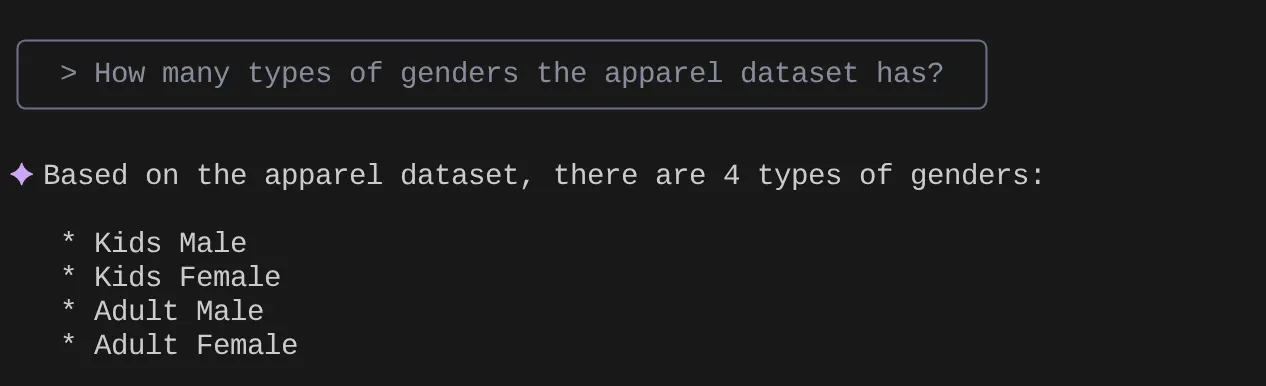
> Give me the SQL that I can use to find the number of apparels that are footwear
> What are the unique sub categories that are there?
that I can use to find the number of apparels that are footwear
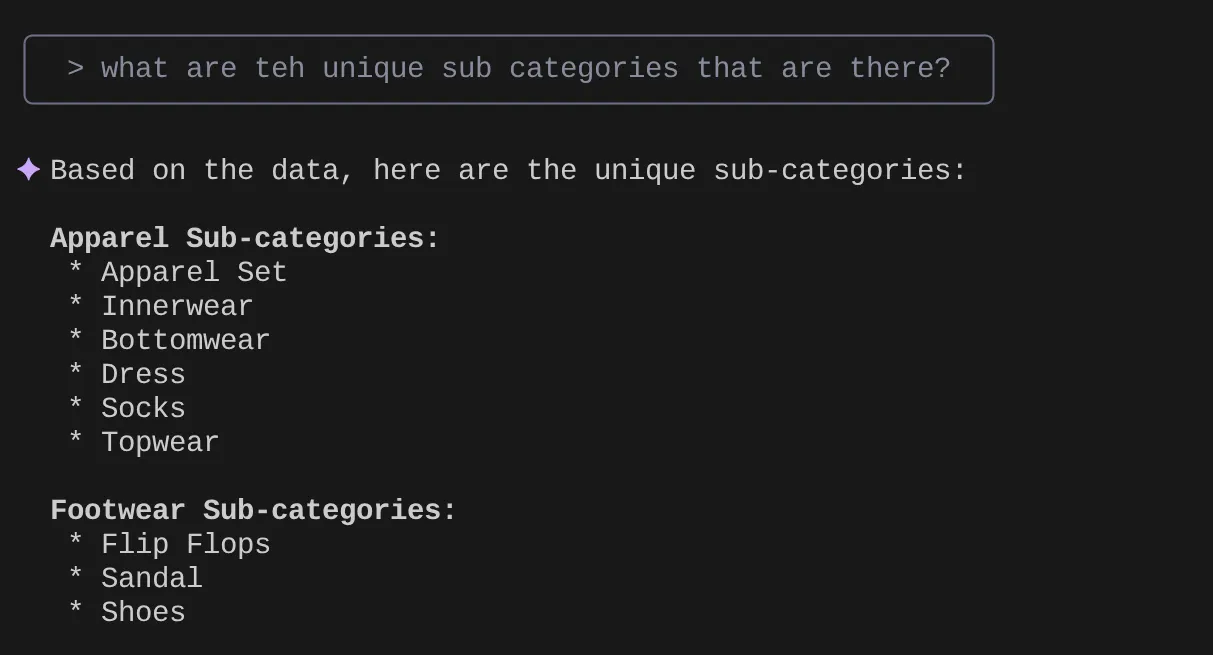
अब मान लें कि मुझे मिली अहम जानकारी और इस तरह की कई क्वेरी के आधार पर, मैंने एक क्वेरी तैयार की है और मुझे इसे आज़माना है. इसके अलावा, मान लें कि डेटाबेस इंजीनियरों ने आपके लिए Tools.yaml फ़ाइल पहले ही बना दी है. यह फ़ाइल इस तरह दिखती है:
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
filtered-vector-search:
kind: postgres-sql
source: alloydb
description: Get the list of facet filter values from the retail dataset.
parameters:
- name: categories
type: array
description: List of categories preferred by the user.
items:
name: category
type: string
description: Category value.
- name: subCategories
type: array
description: List of sub-categories preferred by the user.
items:
name: subCategory
type: string
description: Sub-Category value.
- name: colors
type: array
description: List of colors preferred by the user.
items:
name: color
type: string
description: Color value.
- name: genders
type: array
description: List of genders preferred by the user for apparel fitting.
items:
name: gender
type: string
description: Gender name.
- name: searchtext
type: string
description: Description of the product that the user wants to find database matches for.
statement: |
SELECT id, content, uri, category, sub_category,color,gender FROM apparels
where category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005',$5)::vector limit 10
अब सामान्य भाषा में खोज करने की कोशिश करते हैं:
> How many yellow shirts are there for boys?
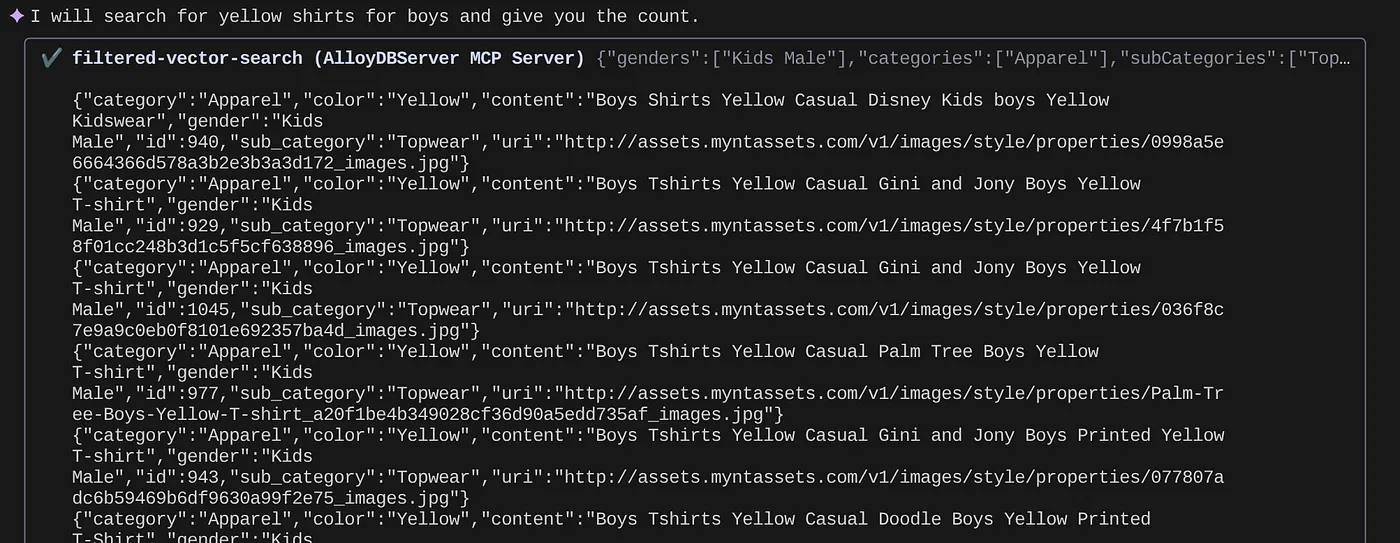

यह काफ़ी अच्छा है, है न? अब मैं क्वेरी में ज़्यादा बेहतर बदलाव करने के लिए, YAML फ़ाइल को ठीक कर सकता हूं. साथ ही, अपने ऐप्लिकेशन में नई सुविधाओं को कम समय में उपलब्ध करा सकता हूं.
9. ऐप्लिकेशन को तेज़ी से डेवलप करना
Gemini CLI और एमसीपी टूलबॉक्स की मदद से, डेटाबेस की सुविधाओं को सीधे अपने आईडीई में इस्तेमाल करने की सुविधा सिर्फ़ सिद्धांत के तौर पर नहीं है. इससे काम करने के तरीके में काफ़ी बदलाव आया है और काम की स्पीड बढ़ी है. खास तौर पर, हमारे हाइब्रिड खुदरा अनुभव जैसे मुश्किल ऐप्लिकेशन के लिए. आइए, कुछ स्थितियों पर नज़र डालते हैं:
1. प्रॉडक्ट फ़िल्टर करने के लॉजिक को तेज़ी से दोहराना
मान लें कि हमने "गर्मियों में पहने जाने वाले स्पोर्ट्स वियर" के लिए, अभी-अभी एक नया प्रमोशन लॉन्च किया है. हमें यह जांच करनी है कि हमारे फ़ैसेट वाले फ़िल्टर (जैसे, ब्रैंड, साइज़, रंग, कीमत सीमा के हिसाब से) इस नई कैटगरी के साथ कैसे इंटरैक्ट करते हैं.
आईडीई इंटिग्रेशन के बिना:
मैं शायद किसी दूसरे एसक्यूएल क्लाइंट पर स्विच करूं, अपनी क्वेरी लिखूं, उसे लागू करूं, नतीजों का विश्लेषण करूं, ऐप्लिकेशन कोड को अडजस्ट करने के लिए अपने आईडीई पर वापस जाऊं, क्लाइंट पर वापस स्विच करूं, और इस प्रोसेस को दोहराऊं. संदर्भ बदलने की इस प्रोसेस में काफ़ी समय लगता है.
Gemini CLI और एमसीपी की मदद से:
मैं अपने आईडीई और अन्य प्लैटफ़ॉर्म पर काम कर सकता हूं:
- क्वेरी करना: मैं yaml में मौजूद क्वेरी को तुरंत अपडेट कर सकता/सकती हूँ. इसके लिए, मुझे (हाइपोथेटिकल डेटासेट) "SELECT DISTINCT brand FROM products WHERE category = ‘activewear' AND season = ‘summer'" का इस्तेमाल करना होगा. इसके बाद, मैं इसे सीधे अपने टर्मिनल में आज़मा सकता/सकती हूँ.
- डेटा एक्सप्लोरेशन: खोज के नतीजों में शामिल ब्रैंड तुरंत देखें. अगर मुझे किसी ब्रैंड और साइज़ के हिसाब से प्रॉडक्ट की उपलब्धता देखनी है, तो इसके लिए एक और क्वेरी का इस्तेमाल किया जा सकता है:"SELECT COUNT(*) FROM products WHERE brand = ‘SummitGear' AND size = ‘M' AND category = ‘activewear' AND season = ‘summer'"
- कोड इंटिग्रेशन: इसके बाद, मैं आईडीई में मौजूद डेटा की इन अहम जानकारी के आधार पर, फ़्रंट-एंड फ़िल्टरिंग लॉजिक या बैकएंड एपीआई कॉल में तुरंत बदलाव कर सकता/सकती हूं. इससे, फ़ीडबैक लूप में काफ़ी कमी आ जाती है.
2. प्रॉडक्ट के सुझावों के लिए, वेक्टर सर्च को बेहतर बनाना
हमारी हाइब्रिड सर्च सुविधा, काम के प्रॉडक्ट के सुझाव देने के लिए वेक्टर एम्बेडिंग पर निर्भर करती है. मान लें कि हमें "पुरुषों के रनिंग शू" के सुझावों के लिए, क्लिक मिलने की दर में गिरावट दिख रही है.
आईडीई इंटिग्रेशन के बिना:
मैं डेटाबेस टूल में कस्टम स्क्रिप्ट या क्वेरी चलाकर, सुझाए गए जूतों के मिलते-जुलते होने के स्कोर का विश्लेषण करूंगा. साथ ही, उनकी तुलना उपयोगकर्ता के इंटरैक्शन डेटा से करूंगा और किसी भी पैटर्न का पता लगाने की कोशिश करूंगा.
Gemini CLI और एमसीपी की मदद से:
- एम्बेडिंग का विश्लेषण करना: मैं प्रॉडक्ट एम्बेडिंग और उनसे जुड़े मेटाडेटा के लिए सीधे तौर पर क्वेरी कर सकता हूं: "SELECT product_id, name, vector_embedding FROM products WHERE category = ‘running shoes' AND gender = ‘male' LIMIT 10"
- क्रॉस-रेफ़रंसिंग: मैं चुने गए किसी प्रॉडक्ट और उसके सुझावों के बीच, वेक्टर की समानता की तुरंत जांच भी कर सकता हूं. उदाहरण के लिए, अगर प्रॉडक्ट B देखने वाले लोगों को प्रॉडक्ट A का सुझाव दिया जाता है, तो मैं उनकी वेक्टर एम्बेडिंग को वापस पाने और उनकी तुलना करने के लिए क्वेरी चला सकता/सकती हूं.
- डीबग करना: इससे डीबग करने और हाइपोथेसिस की जांच करने में मदद मिलती है. क्या एम्बेडिंग मॉडल उम्मीद के मुताबिक काम कर रहा है? क्या डेटा में ऐसी अनियमितताएं हैं जिनसे सुझावों की क्वालिटी पर असर पड़ता है? मुझे कोडिंग एनवायरमेंट से बाहर निकले बिना ही शुरुआती जवाब मिल सकते हैं.
3. नई सुविधाओं के लिए स्कीमा और डेटा डिस्ट्रिब्यूशन को समझना
मान लें कि हमें "खरीदार की समीक्षाएं" सुविधा जोड़नी है. बैकएंड एपीआई लिखने से पहले, हमें मौजूदा ग्राहक डेटा और समीक्षाओं के स्ट्रक्चर को समझना होगा.
आईडीई इंटिग्रेशन के बिना:
मुझे डेटाबेस क्लाइंट से कनेक्ट करना होगा. साथ ही, ग्राहकों और ऑर्डर जैसी टेबल पर DESCRIBE कमांड चलाने के बाद, सैंपल डेटा के लिए क्वेरी करनी होगी, ताकि संबंधों और डेटा टाइप को समझा जा सके.
Gemini CLI और एमसीपी की मदद से:
- स्कीमा एक्सप्लोरेशन: मैं YAML फ़ाइल में मौजूद टेबल को आसानी से क्वेरी कर सकता हूं और उसे सीधे टर्मिनल में एक्ज़ीक्यूट कर सकता हूं.
- डेटा सैंपलिंग: इसके बाद, मैं सैंपल डेटा को पुल करके, ग्राहक की जनसांख्यिकी और खरीदारी के इतिहास को समझ सकता हूं: "SELECT customer_id, name, signup_date, total_orders FROM customers ORDER BY signup_date DESC LIMIT 5"
- प्लानिंग: स्कीमा और डेटा डिस्ट्रिब्यूशन को तुरंत ऐक्सेस करने से, हमें यह तय करने में मदद मिलती है कि नई समीक्षाओं की टेबल को कैसे डिज़ाइन किया जाए, किन फ़ॉरेन की को सेट अप किया जाए, और समीक्षाओं को ग्राहकों और प्रॉडक्ट से कैसे लिंक किया जाए. यह सब, नई सुविधा के लिए ऐप्लिकेशन कोड की एक भी लाइन लिखने से पहले किया जाता है.
ये सिर्फ़ कुछ उदाहरण हैं, लेकिन इनसे मुख्य फ़ायदे के बारे में पता चलता है: डेवलपर के काम में आने वाली रुकावटों को कम करना और डेवलपर की काम करने की रफ़्तार को बढ़ाना. AlloyDB के साथ इंटरैक्ट करने की सुविधा को सीधे तौर पर आईडीई में इंटिग्रेट करने से, Gemini CLI और MCP टूलबॉक्स की मदद से बेहतर और ज़्यादा रिस्पॉन्सिव ऐप्लिकेशन तेज़ी से बनाए जा सकते हैं.
10. व्यवस्थित करें
इस पोस्ट में इस्तेमाल की गई संसाधनों के लिए, अपने Google Cloud खाते से शुल्क न लिए जाने के लिए, यह तरीका अपनाएं:
- Google Cloud Console में, संसाधन मैनेजर पेज पर जाएं.
- प्रोजेक्ट की सूची में, वह प्रोजेक्ट चुनें जिसे आपको मिटाना है. इसके बाद, मिटाएं पर क्लिक करें.
- डायलॉग बॉक्स में, प्रोजेक्ट आईडी टाइप करें. इसके बाद, प्रोजेक्ट मिटाने के लिए बंद करें पर क्लिक करें.
- इसके अलावा, DELETE CLUSTER बटन पर क्लिक करके, इस प्रोजेक्ट के लिए अभी-अभी बनाए गए AlloyDB क्लस्टर को मिटाया जा सकता है. अगर आपने कॉन्फ़िगरेशन के समय क्लस्टर के लिए us-central1 नहीं चुना था, तो इस हाइपरलिंक में जगह की जानकारी बदलें.
11. बधाई हो
बधाई हो! आपने MCP टूलबॉक्स को सीधे तौर पर अपने आईडीई में इंटिग्रेट कर लिया है. इससे AlloyDB के साथ आसानी से इंटरैक्ट किया जा सकता है. साथ ही, आपने Gemini CLI का इस्तेमाल करके, हमारे खुदरा ई-कॉमर्स डेटासेट के साथ इंटरैक्ट किया है. इससे ऐसी क्वेरी लिखी जा सकती हैं जिनके लिए आम तौर पर अलग-अलग टूल की ज़रूरत होती है. आपने डेटा की जांच करने और उसे समझने के नए तरीके सीखे हैं. जैसे, टेबल स्ट्रक्चर की जांच करना और डेटा की क्वालिटी की तुरंत जांच करना. ये सभी काम, हमारे आईडीई में मौजूद कमांड-लाइन इंटरफ़ेस की मदद से किए जा सकते हैं.
आगे बढ़ें और repo को क्लोन करें. साथ ही, विश्लेषण करें और हमें बताएं कि क्या आपने डेटाबेस के लिए Gemini CLI और MCP टूलबॉक्स का इस्तेमाल करके, ऐप्लिकेशन को बेहतर बनाया है.
Gemini सीएलआई और MCP की मदद से बनाए गए और सर्वरलेस रनटाइम पर डिप्लॉय किए गए, डेटा पर आधारित ऐसे और ऐप्लिकेशन के बारे में जानने के लिए, Code Vipassana के आने वाले सीज़न के लिए रजिस्टर करें. यहां आपको इंस्ट्रक्टर की निगरानी में प्रैक्टिकल सेशन और ऐसे कई कोडलैब मिलेंगे!!!