
1. Ringkasan
Ingat perjalanan kita dalam membangun pengalaman retail hybrid dinamis dengan AlloyDB, yang menggabungkan pemfilteran berfacet dan penelusuran vektor? Aplikasi tersebut adalah demonstrasi yang efektif tentang kebutuhan retail modern, tetapi untuk mencapainya — dan melakukan iterasi — diperlukan upaya pengembangan yang signifikan. Bagi developer full-stack, bolak-balik antara editor kode dan alat database sering kali menjadi hambatan, sehingga memperlambat inovasi dan proses penting untuk memahami data Anda.
Solusi
Di sinilah keunggulan pengembangan aplikasi yang dipercepat benar-benar terlihat, dan itulah sebabnya saya sangat antusias untuk membagikan bagaimana MCP (Modern Cloud Platform) Toolbox, yang dapat diakses melalui Gemini CLI yang intuitif, telah menjadi bagian yang sangat penting dari toolkit saya. Bayangkan Anda dapat berinteraksi dengan lancar dengan instance AlloyDB, menulis kueri, dan memahami set data Anda — semuanya langsung dalam Lingkungan Pengembangan Terintegrasi (IDE). Hal ini bukan hanya tentang kemudahan, tetapi juga tentang mengurangi gesekan secara mendasar dalam siklus proses pengembangan, sehingga Anda dapat berfokus pada pembuatan fitur inovatif, bukan berkutat dengan alat eksternal.
Dalam konteks aplikasi e-commerce retail kami, tempat kami perlu membuat kueri data produk secara efisien, menangani pemfilteran yang kompleks, dan memanfaatkan nuansa penelusuran vektor, kemampuan untuk melakukan iterasi dengan cepat pada interaksi database sangatlah penting. MCP Toolbox, yang didukung oleh Gemini CLI, tidak hanya menyederhanakan hal ini, tetapi juga mempercepat, mengubah cara kita menjelajahi, menguji, dan menyempurnakan logika database yang mendasari aplikasi kita. Mari kita pelajari bagaimana kombinasi inovatif ini membuat pengembangan full-stack menjadi lebih cepat, lebih cerdas, dan lebih menyenangkan.
Yang akan Anda pelajari & bangun
Aplikasi Retail Search yang memanfaatkan MCP Toolbox dalam IDE, yang didukung oleh Gemini CLI. Kami akan membahas:
- Cara mengintegrasikan MCP Toolbox langsung ke IDE untuk interaksi AlloyDB yang lancar.
- Contoh praktis penggunaan Gemini CLI untuk menulis dan menjalankan kueri SQL terhadap data retail Anda.
- Manfaatkan Gemini CLI untuk berinteraksi dengan set data e-commerce retail kami, menulis kueri yang biasanya memerlukan alat terpisah, dan melihat hasilnya secara instan.
- Temukan cara baru untuk menyelidiki dan memahami data — mulai dari memeriksa struktur tabel hingga melakukan pemeriksaan kebenaran data cepat — semuanya melalui antarmuka command line yang sudah dikenal dalam IDE kami.
- Bagaimana alur kerja database yang dipercepat ini secara langsung berkontribusi pada siklus pengembangan full-stack yang lebih cepat, sehingga memungkinkan pembuatan prototipe dan iterasi yang cepat.
Techstack
Kami menggunakan:
- AlloyDB untuk database
- MCP Toolbox untuk mengabstraksi fitur AI dan generatif tingkat lanjut dari database dari aplikasi
- Cloud Run untuk deployment serverless.
- Gemini CLI untuk memahami dan menganalisis set data serta membangun bagian database aplikasi e-commerce retail.
Persyaratan
2. Sebelum memulai
Membuat project
- Di Konsol Google Cloud, di halaman pemilih project, pilih atau buat project Google Cloud.
- Pastikan penagihan diaktifkan untuk project Cloud Anda. Pelajari cara memeriksa apakah penagihan telah diaktifkan pada suatu project.
- Anda akan menggunakan Cloud Shell, lingkungan command line yang berjalan di Google Cloud. Klik Activate Cloud Shell di bagian atas konsol Google Cloud.

- Setelah terhubung ke Cloud Shell, Anda dapat memeriksa bahwa Anda sudah diautentikasi dan project sudah ditetapkan ke project ID Anda menggunakan perintah berikut:
gcloud auth list
- Jalankan perintah berikut di Cloud Shell untuk mengonfirmasi bahwa perintah gcloud mengetahui project Anda.
gcloud config list project
- Jika project Anda belum ditetapkan, gunakan perintah berikut untuk menetapkannya:
gcloud config set project <YOUR_PROJECT_ID>
- Aktifkan API yang diperlukan: Ikuti link dan aktifkan API.
Atau, Anda dapat menggunakan perintah gcloud untuk melakukannya. Baca dokumentasi untuk mempelajari perintah gcloud dan penggunaannya.
3. Penyiapan database
Di lab ini, kita akan menggunakan AlloyDB sebagai database untuk data e-commerce. Cloud SQL menggunakan cluster untuk menyimpan semua resource, seperti database dan log. Setiap cluster memiliki instance utama yang menyediakan titik akses ke data. Tabel akan menyimpan data sebenarnya.
Mari kita buat cluster, instance, dan tabel AlloyDB tempat set data e-commerce akan dimuat.
Membuat cluster dan instance
- Buka halaman AlloyDB di Konsol Cloud. Cara mudah untuk menemukan sebagian besar halaman di Konsol Cloud adalah dengan menelusurinya menggunakan kotak penelusuran konsol.
- Pilih CREATE CLUSTER dari halaman tersebut:

- Anda akan melihat layar seperti di bawah. Buat cluster dan instance dengan nilai berikut (Pastikan nilai cocok jika Anda meng-clone kode aplikasi dari repo):
- cluster id: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / versi terbaru yang direkomendasikan
- Region: "
us-central1" - Jaringan: "
default"
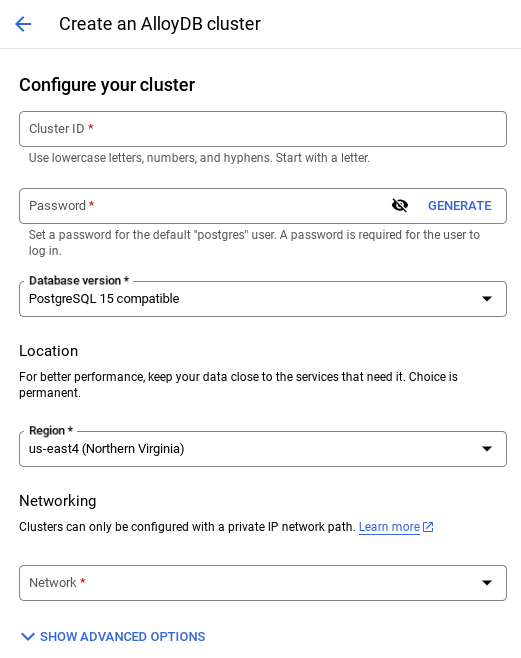
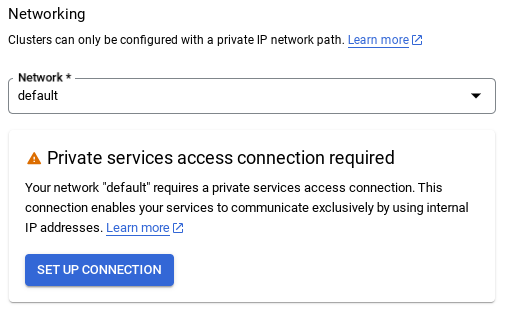
- Saat Anda memilih jaringan default, Anda akan melihat layar seperti di bawah.
Pilih SIAPKAN KONEKSI.
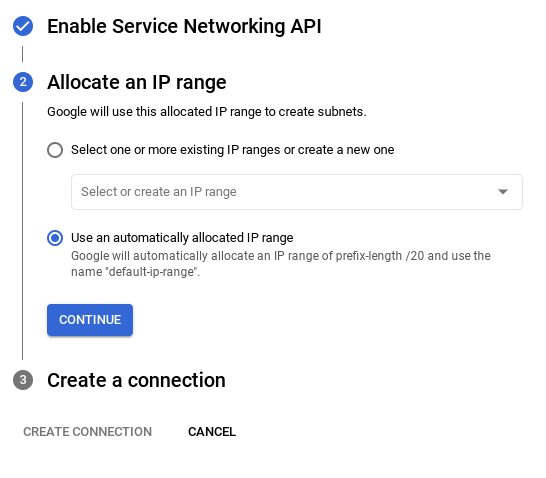
- Dari sana, pilih "Gunakan rentang IP yang dialokasikan secara otomatis" dan Lanjutkan. Setelah meninjau informasi, pilih BUAT KONEKSI.
- Setelah jaringan disiapkan, Anda dapat melanjutkan pembuatan cluster. Klik CREATE CLUSTER untuk menyelesaikan penyiapan cluster seperti yang ditunjukkan di bawah:
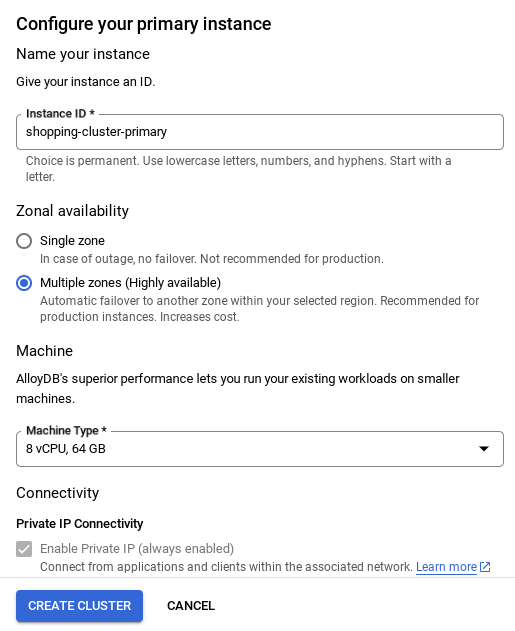
CATATAN PENTING:
- Pastikan untuk mengubah ID instance (yang dapat Anda temukan pada saat konfigurasi cluster / instance) menjadi **
vector-instance**. Jika Anda tidak dapat mengubahnya, ingatlah untuk **menggunakan ID instance Anda** di semua referensi mendatang. - Perhatikan bahwa pembuatan Cluster akan memerlukan waktu sekitar 10 menit. Setelah berhasil, Anda akan melihat layar yang menampilkan ringkasan cluster yang baru saja Anda buat.
4. Penyerapan data
Sekarang saatnya menambahkan tabel dengan data tentang toko. Buka AlloyDB, pilih cluster utama, lalu AlloyDB Studio:
Anda mungkin perlu menunggu hingga instance selesai dibuat. Setelah selesai, login ke AlloyDB menggunakan kredensial yang Anda buat saat membuat cluster. Gunakan data berikut untuk melakukan autentikasi ke PostgreSQL:
- Nama pengguna : "
postgres" - Database : "
postgres" - Sandi : "
alloydb"
Setelah Anda berhasil diautentikasi ke AlloyDB Studio, perintah SQL dimasukkan di Editor. Anda dapat menambahkan beberapa jendela Editor menggunakan tanda plus di sebelah kanan jendela terakhir.
Anda akan memasukkan perintah untuk AlloyDB di jendela editor, menggunakan opsi Jalankan, Format, dan Hapus sesuai kebutuhan.
Mengaktifkan Ekstensi
Untuk membangun aplikasi ini, kita akan menggunakan ekstensi pgvector dan google_ml_integration. Ekstensi pgvector memungkinkan Anda menyimpan dan menelusuri embedding vektor. Ekstensi google_ml_integration menyediakan fungsi yang Anda gunakan untuk mengakses endpoint prediksi Vertex AI guna mendapatkan prediksi di SQL. Aktifkan ekstensi ini dengan menjalankan DDL berikut:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Jika Anda ingin memeriksa ekstensi yang telah diaktifkan di database Anda, jalankan perintah SQL ini:
select extname, extversion from pg_extension;
Membuat tabel
Anda dapat membuat tabel menggunakan pernyataan DDL di bawah di AlloyDB Studio:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
Kolom embedding akan memungkinkan penyimpanan untuk nilai vektor teks.
Berikan Izin
Jalankan pernyataan di bawah untuk memberikan izin eksekusi pada fungsi "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Memberikan PERAN Vertex AI User ke akun layanan AlloyDB
Dari konsol IAM Google Cloud, berikan akses akun layanan AlloyDB (yang terlihat seperti ini: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) ke peran "Pengguna Vertex AI". PROJECT_NUMBER akan memiliki nomor project Anda.
Atau, Anda dapat menjalankan perintah di bawah dari Terminal Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Memuat data ke dalam database
- Salin pernyataan kueri
insertdariinsert scripts sqldi sheet ke editor seperti yang disebutkan di atas. Anda dapat menyalin 10-50 pernyataan penyisipan untuk demo cepat kasus penggunaan ini. Ada daftar sisipan yang dipilih di sini di tab "Selected Inserts 25-30 rows". - Klik Run. Hasil kueri Anda akan muncul di tabel Results.
CATATAN PENTING:
Pastikan untuk menyalin hanya 25-50 data yang akan disisipkan dan pastikan data tersebut berasal dari berbagai jenis kategori, sub_kategori, warna, dan jenis kelamin.
5. Buat Embedding untuk data
Inovasi sebenarnya dalam penelusuran modern terletak pada pemahaman makna, bukan hanya kata kunci. Di sinilah embedding dan penelusuran vektor berperan.
Kami mengubah deskripsi produk dan kueri pengguna menjadi representasi numerik berdimensi tinggi yang disebut "embedding" menggunakan model bahasa terlatih. Embedding ini menangkap makna semantik, sehingga memungkinkan kita menemukan produk yang "mirip maknanya", bukan hanya yang berisi kata-kata yang cocok. Awalnya, kami bereksperimen dengan penelusuran kesamaan vektor langsung pada embedding ini untuk menetapkan dasar, yang menunjukkan kekuatan pemahaman semantik bahkan sebelum pengoptimalan performa.
Kolom embedding akan memungkinkan penyimpanan nilai vektor teks deskripsi produk. Kolom img_embeddings akan memungkinkan penyimpanan embedding gambar (multimodal). Dengan cara ini, Anda juga dapat menggunakan penelusuran berbasis jarak teks terhadap gambar. Namun, kita hanya akan menggunakan embedding teks di lab ini.
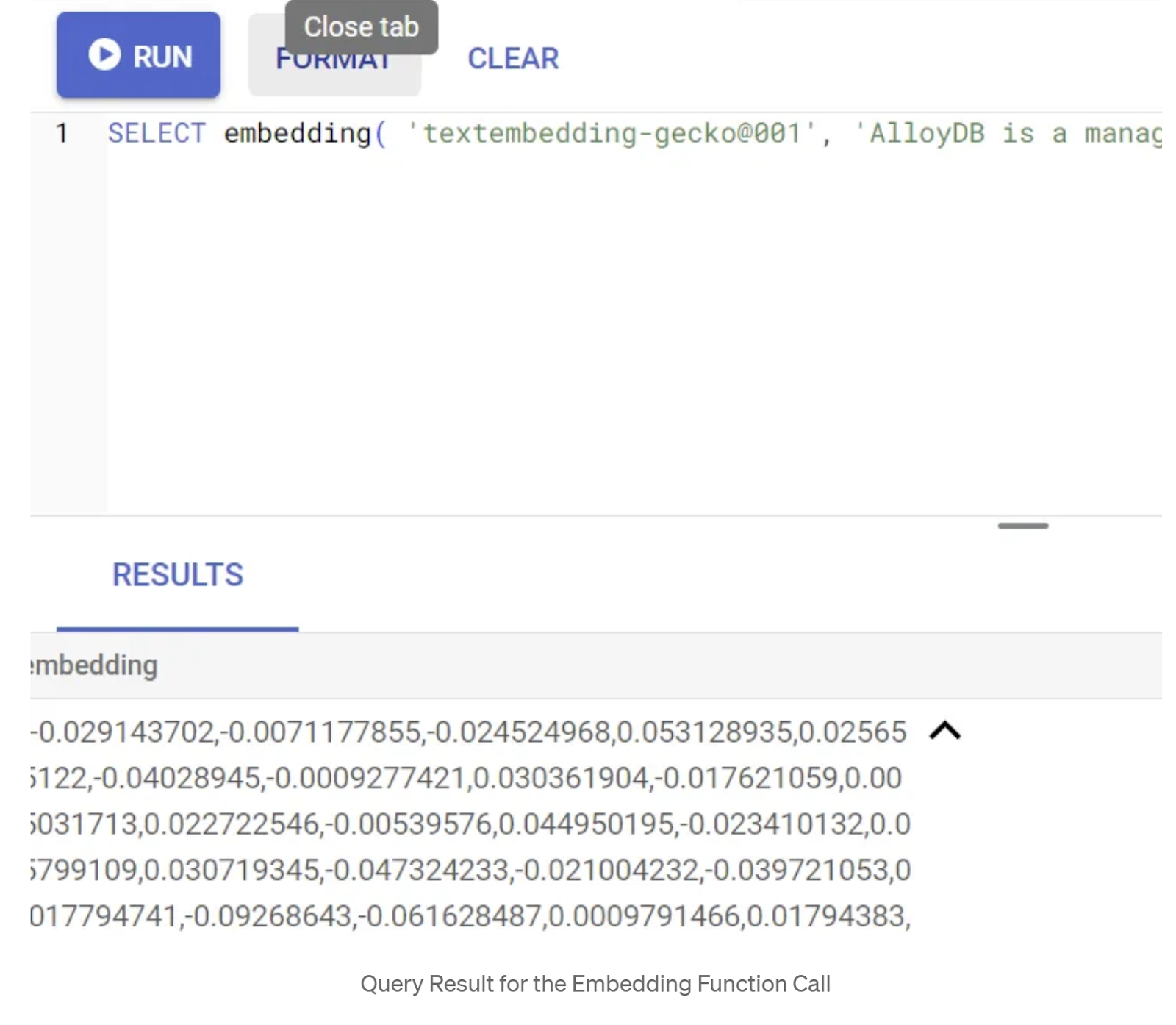
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Ini akan menampilkan vektor embedding, yang terlihat seperti array float, untuk teks contoh dalam kueri. Tampilannya seperti ini:
Perbarui kolom Vektor abstract_embeddings
Jalankan DML di bawah untuk memperbarui deskripsi konten dalam tabel dengan embedding yang sesuai:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
Anda mungkin mengalami masalah saat membuat lebih dari beberapa penyematan (maksimal 20-25) jika menggunakan akun penagihan kredit uji coba untuk Google Cloud. Jadi, batasi jumlah baris dalam skrip penyisipan.
Jika Anda ingin membuat embedding gambar (untuk melakukan penelusuran kontekstual multimodal), jalankan update di bawah ini juga:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. MCP Toolbox for Databases (AlloyDB)
Di balik layar, alat yang tangguh dan aplikasi yang terstruktur dengan baik memastikan pengoperasian yang lancar.
Toolbox MCP (Model Context Protocol) for Databases menyederhanakan integrasi alat AI Generatif dan Agentic dengan AlloyDB. Server ini berfungsi sebagai server open source yang menyederhanakan penggabungan koneksi, autentikasi, dan eksposur fungsi database yang aman ke agen AI atau aplikasi lain.
Dalam aplikasi, kita telah menggunakan MCP Toolbox for Databases sebagai lapisan abstraksi untuk semua kueri penelusuran hibrida cerdas.
Ikuti langkah-langkah di bawah untuk menyiapkan dan men-deploy Toolbox untuk kasus penggunaan kita:
Anda dapat melihat bahwa salah satu database yang didukung oleh MCP Toolbox for Databases adalah AlloyDB dan karena kita telah menyediakannya di bagian sebelumnya, mari kita lanjutkan dan siapkan Toolbox.
- Buka Terminal Cloud Shell Anda dan pastikan project Anda dipilih dan ditampilkan di perintah terminal. Jalankan perintah di bawah dari Terminal Cloud Shell untuk membuka direktori project Anda:
mkdir gemini-cli-project
cd gemini-cli-project
- Jalankan perintah di bawah untuk mendownload dan menginstal toolbox di folder baru Anda:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
Tindakan ini akan membuat toolbox di direktori Anda saat ini. Salin jalur ke toolbox.
- Buka Cloud Shell Editor (untuk mode edit kode) dan di folder root project "gemini-cli-project", tambahkan file bernama "tools.yaml".
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
Mari kita pahami tools.yaml:
Sumber mewakili berbagai sumber data yang dapat berinteraksi dengan alat. Sumber mewakili sumber data yang dapat berinteraksi dengan alat. Anda dapat menentukan Sumber sebagai peta di bagian sumber file tools.yaml. Biasanya, konfigurasi sumber akan berisi informasi apa pun yang diperlukan untuk terhubung dan berinteraksi dengan database.
Alat menentukan tindakan yang dapat dilakukan agen – seperti membaca dan menulis ke sumber. Alat merepresentasikan tindakan yang dapat dilakukan agen Anda, seperti menjalankan pernyataan SQL. Anda dapat menentukan Alat sebagai peta di bagian alat pada file tools.yaml. Biasanya, alat akan memerlukan sumber untuk ditindaklanjuti.
Untuk mengetahui detail selengkapnya tentang cara mengonfigurasi tools.yaml, lihat dokumentasi ini.
Seperti yang dapat Anda lihat di file Tools.yaml di atas, alat "get-apparels" mencantumkan semua detail pakaian dari database.
7. Menyiapkan Gemini CLI
Dari Cloud Shell Editor, buat folder baru bernama .gemini di dalam folder gemini-cli-project, lalu buat file baru bernama settings.json di dalamnya.
{
"mcpServers": {
"AlloyDBServer": {
"command": "/home/user/gemini-cli-project/toolbox",
"args": ["--tools-file", "tools.yaml", "--stdio"]
}
}
}
Di bagian perintah dalam cuplikan di atas, ganti "/home/user/gemini-cli-project/toolbox" dengan jalur ke toolbox Anda.
Menginstal Gemini CLI
Terakhir, dari Cloud Shell Terminal, mari kita instal Gemini CLI di direktori yang sama gemini-cli-project dengan menjalankan perintah:
sudo npm install -g @google/gemini-cli
Menetapkan Project ID Anda
Pastikan Anda telah menetapkan project ID aktif di lingkungan:
export GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT_ID>>
Mulai menggunakan Gemini CLI
Dari command line, masukkan perintah:
gemini
Anda akan dapat melihat respons yang mirip dengan di bawah ini:
Lakukan autentikasi dan lanjutkan ke langkah berikutnya.
8. Mulai berinteraksi dengan Gemini CLI
Gunakan perintah /mcp untuk mencantumkan server MCP yang dikonfigurasi.
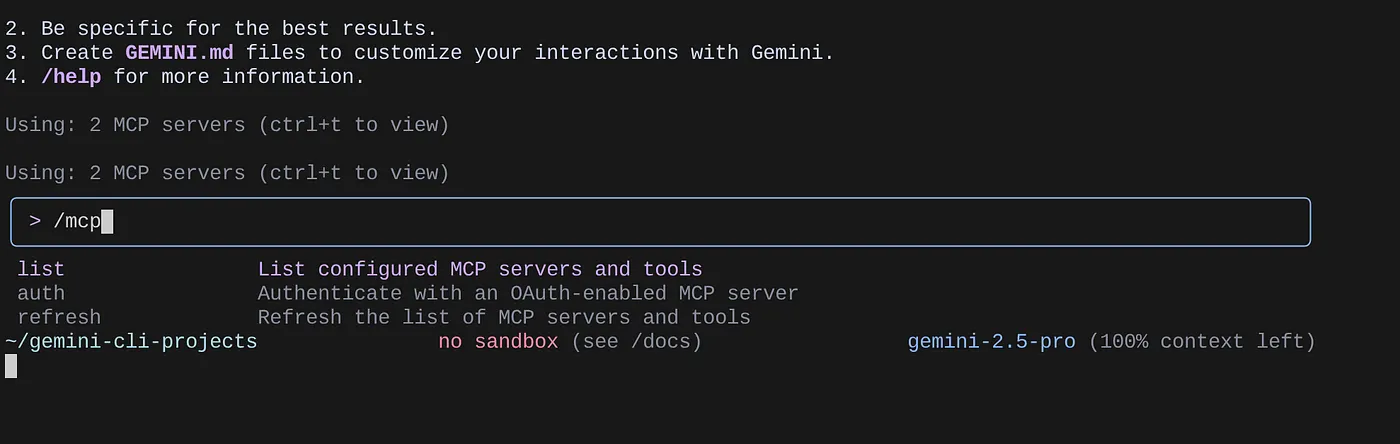
Anda akan dapat melihat 2 server MCP yang kita konfigurasi: GitHub dan MCP Toolbox for Databases yang tercantum bersama alatnya.
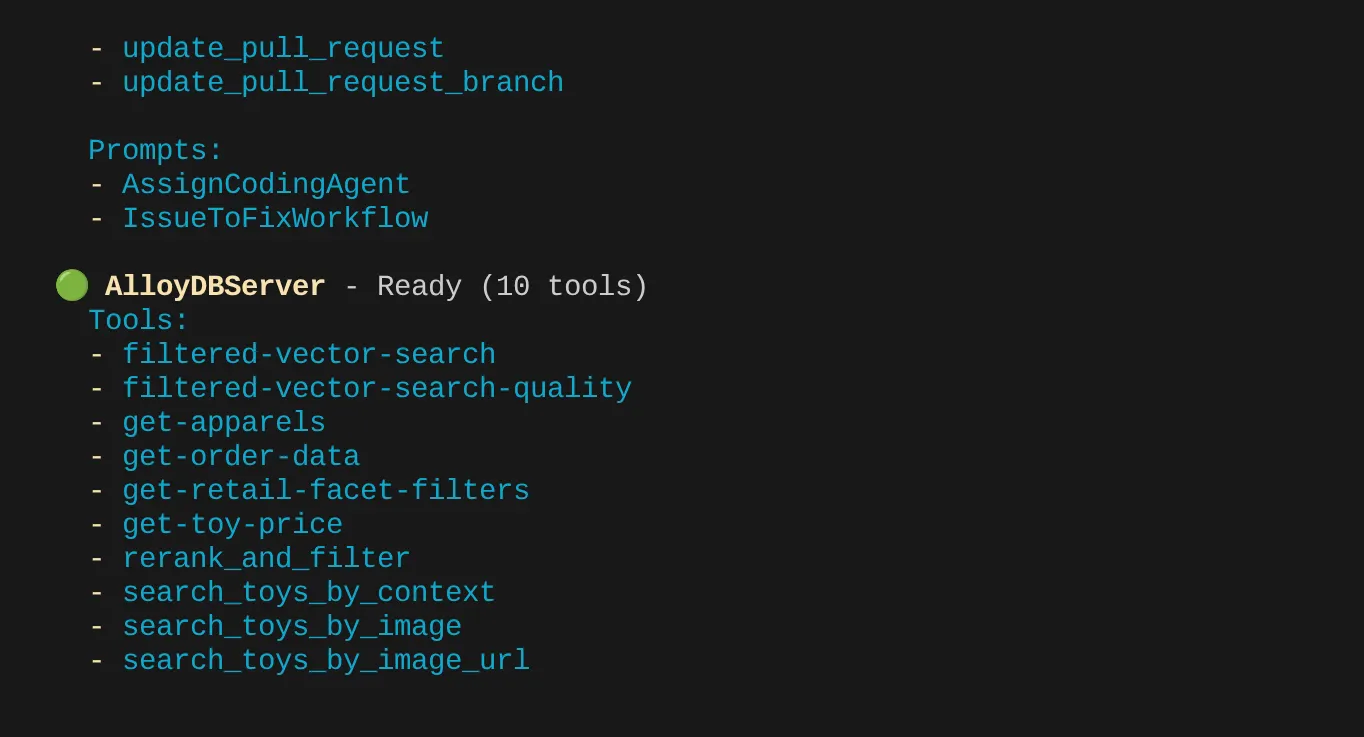
Dalam kasus saya, saya memiliki lebih banyak alat. Jadi, abaikan saja untuk saat ini. Anda akan melihat alat get-apparels di server MCP AlloyDB.
Mulai kueri database melalui MCP Toolbox
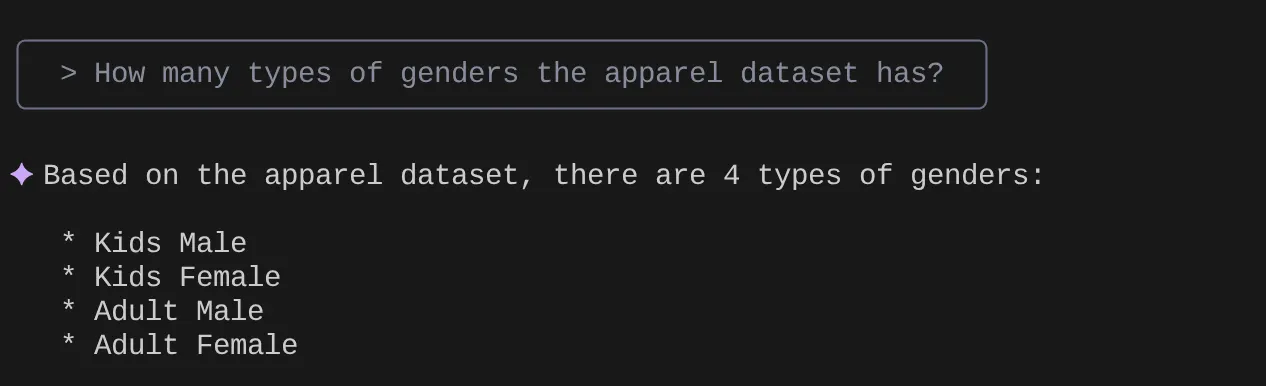
Sekarang coba ajukan pertanyaan dalam bahasa alami untuk mengambil respons dan kueri untuk {i>dataset<i} yang sedang kita kerjakan:
> How many types of genders the apparel dataset has?
> Give me the SQL that I can use to find the number of apparels that are footwear
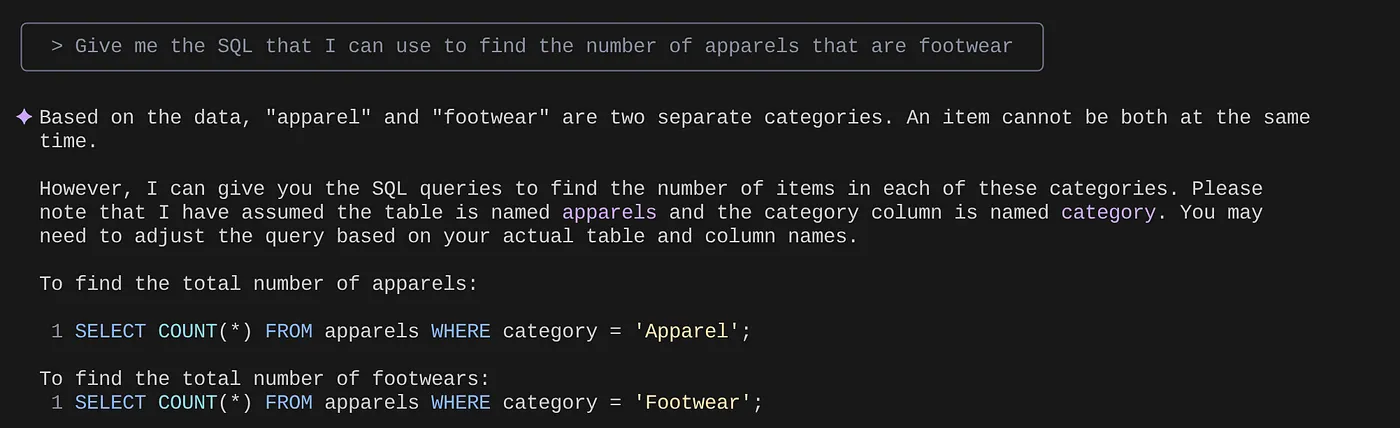
> What are the unique sub categories that are there?
that I can use to find the number of apparels that are footwear
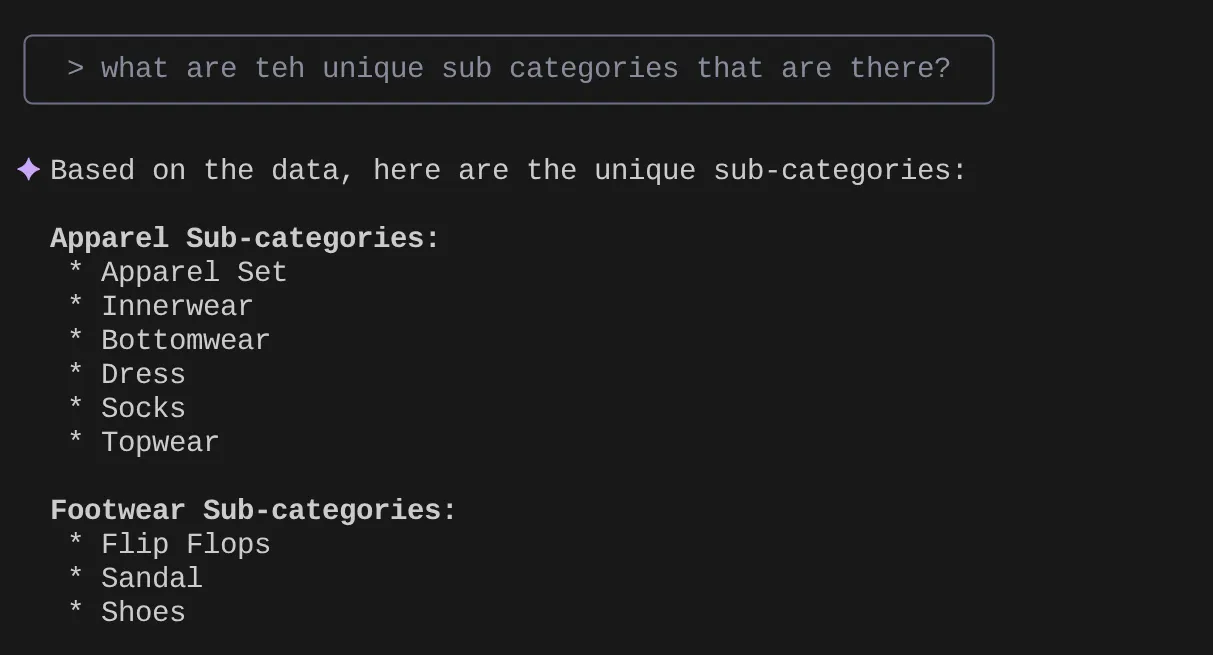
Sekarang, berdasarkan insight saya dan banyak kueri serupa, saya membuat kueri mendetail dan ingin mengujinya. Atau, misalnya, engineer database telah membuat Tools.yaml untuk Anda seperti di bawah ini:
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
filtered-vector-search:
kind: postgres-sql
source: alloydb
description: Get the list of facet filter values from the retail dataset.
parameters:
- name: categories
type: array
description: List of categories preferred by the user.
items:
name: category
type: string
description: Category value.
- name: subCategories
type: array
description: List of sub-categories preferred by the user.
items:
name: subCategory
type: string
description: Sub-Category value.
- name: colors
type: array
description: List of colors preferred by the user.
items:
name: color
type: string
description: Color value.
- name: genders
type: array
description: List of genders preferred by the user for apparel fitting.
items:
name: gender
type: string
description: Gender name.
- name: searchtext
type: string
description: Description of the product that the user wants to find database matches for.
statement: |
SELECT id, content, uri, category, sub_category,color,gender FROM apparels
where category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005',$5)::vector limit 10
Sekarang, mari kita coba penelusuran natural language:
> How many yellow shirts are there for boys?
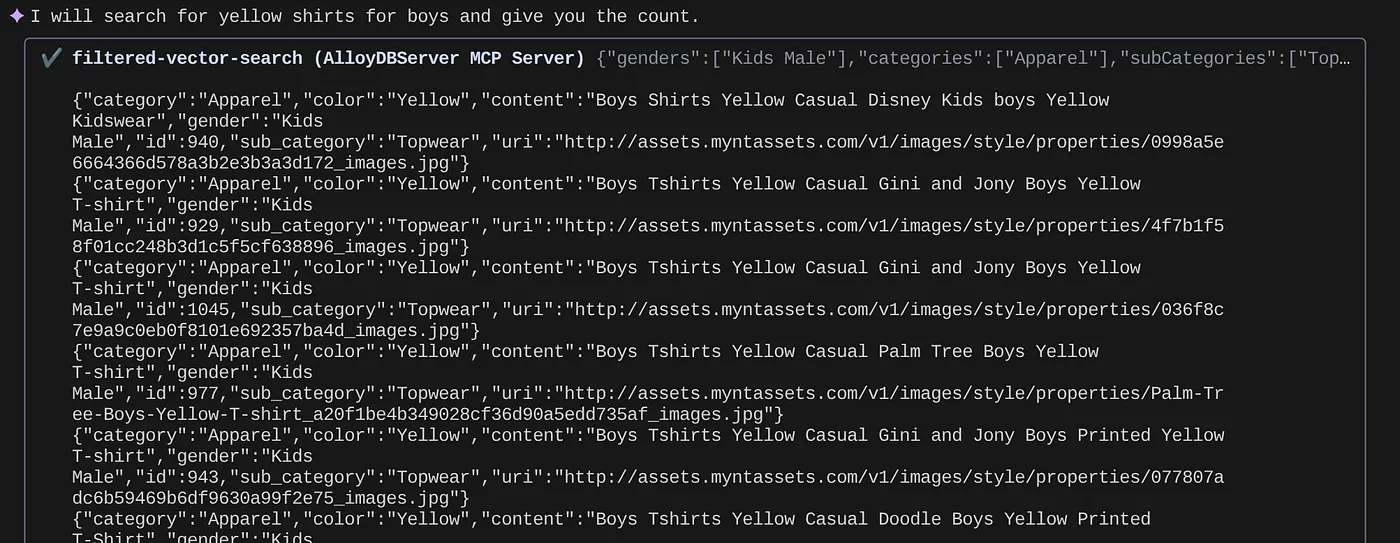

Keren, bukan? Sekarang saya dapat memperbaiki file YAML untuk mendapatkan kemajuan lebih lanjut dalam kueri sambil terus memberikan fungsi baru dalam aplikasi saya dengan jadwal yang dipercepat.
9. Pengembangan Aplikasi yang Dipercepat
Keunggulan menghadirkan kemampuan database langsung ke IDE Anda melalui Gemini CLI dan MCP Toolbox bukan hanya sekadar teori. Hal ini menghasilkan alur kerja yang nyata dan meningkatkan kecepatan, terutama untuk aplikasi kompleks seperti pengalaman retail hybrid kami. Mari kita lihat beberapa skenario:
1. Melakukan Iterasi Cepat pada Logika Pemfilteran Produk
Bayangkan kita baru saja meluncurkan promosi baru untuk "pakaian olahraga musim panas". Kami ingin menguji interaksi filter berfacet (misalnya, menurut merek, ukuran, warna, rentang harga) dengan kategori baru ini.
Tanpa integrasi IDE:
Saya mungkin akan beralih ke klien SQL terpisah, menulis kueri, menjalankannya, menganalisis hasilnya, kembali ke IDE untuk menyesuaikan kode aplikasi, beralih kembali ke klien, dan mengulanginya. Pergantian konteks ini sangat merepotkan.
Dengan Gemini CLI & MCP:
Saya dapat tetap berada di IDE dan melakukan lebih banyak hal:
- Membuat kueri: Saya dapat memperbarui kueri dengan cepat di yaml dengan (kumpulan data hipotetis) "SELECT DISTINCT brand FROM products WHERE category = ‘activewear' AND season = ‘summer'" dan mencobanya langsung di terminal saya.
- Eksplorasi Data: Lihat merek yang ditampilkan secara instan. Jika saya perlu melihat ketersediaan produk untuk merek dan ukuran tertentu, kuerinya juga cepat:"SELECT COUNT(*) FROM products WHERE brand = ‘SummitGear' AND size = ‘M' AND category = ‘activewear' AND season = ‘summer'"
- Integrasi Kode: Kemudian, saya dapat langsung menyesuaikan logika pemfilteran front-end atau panggilan API backend berdasarkan insight data yang cepat dan dalam IDE ini, sehingga secara signifikan memperpendek siklus masukan.
2. Menyesuaikan Vector Search untuk Rekomendasi Produk
Penelusuran hybrid kami mengandalkan embedding vektor untuk rekomendasi produk yang relevan. Misalnya, kita melihat penurunan rasio klik-tayang untuk rekomendasi "sepatu lari pria".
Tanpa integrasi IDE:
Saya akan menjalankan skrip atau kueri kustom di alat database untuk menganalisis skor kemiripan sepatu yang direkomendasikan, membandingkannya dengan data interaksi pengguna, dan mencoba mengorelasikan pola apa pun.
Dengan Gemini CLI & MCP:
- Menganalisis Penyematan: Saya dapat langsung membuat kueri untuk penyematan produk dan metadata terkaitnya: "SELECT product_id, name, vector_embedding FROM products WHERE category = ‘running shoes' AND gender = ‘male' LIMIT 10"
- Referensi Silang: Saya juga dapat melakukan pemeriksaan cepat terhadap kesamaan vektor sebenarnya antara produk yang dipilih dan rekomendasinya, di sana. Misalnya, jika produk A direkomendasikan kepada pengguna yang melihat produk B, saya dapat menjalankan kueri untuk mengambil dan membandingkan embedding vektornya.
- Proses debug: Hal ini memungkinkan proses debug dan pengujian hipotesis yang lebih cepat. Apakah model penyematan berperilaku seperti yang diharapkan? Apakah ada anomali dalam data yang memengaruhi kualitas rekomendasi? Saya bisa mendapatkan jawaban awal tanpa keluar dari lingkungan coding.
3. Memahami Skema dan Distribusi Data untuk Fitur Baru
Misalnya, kita berencana menambahkan fitur "ulasan pelanggan". Sebelum menulis API backend, kita perlu memahami data pelanggan yang ada dan bagaimana struktur ulasan.
Tanpa integrasi IDE:
Saya perlu terhubung ke klien database, menjalankan perintah DESCRIBE pada tabel seperti pelanggan dan pesanan, lalu membuat kueri untuk data sampel guna memahami hubungan dan jenis data.
Dengan Gemini CLI & MCP:
- Penjelajahan Skema: Saya cukup membuat kueri tabel dalam file yaml dan menjalankannya langsung di terminal.
- Pengambilan Sampel Data: Kemudian, saya dapat menarik sampel data untuk memahami demografi pelanggan dan histori pembelian: "SELECT customer_id, name, signup_date, total_orders FROM customers ORDER BY signup_date DESC LIMIT 5"
- Perencanaan: Akses cepat ke skema dan distribusi data ini membantu kami membuat keputusan yang tepat tentang cara mendesain tabel ulasan baru, kunci asing yang akan dibuat, dan cara menautkan ulasan ke pelanggan dan produk secara efisien, semuanya sebelum menulis satu baris kode aplikasi untuk fitur baru.
Ini hanyalah beberapa contoh, tetapi menyoroti manfaat inti: mengurangi hambatan dan meningkatkan kecepatan developer. Dengan menghadirkan interaksi AlloyDB langsung ke IDE, Gemini CLI dan MCP Toolbox memungkinkan kita membangun aplikasi yang lebih baik dan responsif dengan lebih cepat.
10. Pembersihan
Agar tidak menimbulkan biaya pada akun Google Cloud Anda untuk resource yang digunakan dalam posting ini, ikuti langkah-langkah berikut:
- Di konsol Google Cloud, buka halaman resource manager.
- Dalam daftar project, pilih project yang ingin Anda hapus, lalu klik Delete.
- Pada dialog, ketik project ID, lalu klik Shut down untuk menghapus project.
- Atau, Anda dapat menghapus cluster AlloyDB (ubah lokasi di hyperlink ini jika Anda tidak memilih us-central1 untuk cluster pada saat konfigurasi) yang baru saja kita buat untuk project ini dengan mengklik tombol DELETE CLUSTER.
11. Selamat
Selamat! Anda telah berhasil mengintegrasikan MCP Toolbox langsung ke IDE untuk interaksi AlloyDB yang lancar dan memanfaatkan Gemini CLI untuk berinteraksi dengan set data e-commerce retail kami untuk menulis kueri yang biasanya memerlukan alat terpisah. Anda telah mempelajari cara baru untuk menyelidiki dan memahami data — mulai dari memeriksa struktur tabel hingga melakukan pemeriksaan kebenaran data cepat — semuanya melalui antarmuka command-line yang sudah dikenal dalam IDE kami.
Lanjutkan dengan meng-clone repo, menganalisis, dan memberi tahu saya jika Anda meningkatkan kualitas aplikasi menggunakan Gemini CLI dan MCP Toolbox for Databases.
Untuk mengetahui aplikasi berbasis data lainnya yang dibuat dengan Gemini CLI, MCP, dan di-deploy di runtime Tanpa Server, daftar ke Code Vipassana musim mendatang, tempat Anda akan mendapatkan sesi praktik yang dipandu instruktur dan codelab lainnya.