
1. Panoramica
Ricordi il nostro percorso di creazione di un'esperienza di vendita al dettaglio ibrida dinamica con AlloyDB, che combina il filtro sfaccettato e la ricerca vettoriale? Questa applicazione è stata una potente dimostrazione delle esigenze del retail moderno, ma per realizzarla e migliorarla è stato necessario un notevole sforzo di sviluppo. Per gli sviluppatori full-stack, il continuo scambio di informazioni tra editor di codice e strumenti di database può spesso rappresentare un collo di bottiglia, rallentando l'innovazione e il processo cruciale di comprensione dei dati.
Soluzione
È proprio qui che il potere dello sviluppo accelerato delle applicazioni si manifesta in tutta la sua efficacia ed è per questo che sono così entusiasta di condividere come MCP (Modern Cloud Platform) Toolbox, accessibile tramite l'intuitiva Gemini CLI, sia diventato una parte indispensabile del mio toolkit. Immagina di interagire senza problemi con la tua istanza AlloyDB, scrivere query e comprendere il tuo set di dati, tutto direttamente all'interno del tuo ambiente di sviluppo integrato (IDE). Non si tratta solo di comodità, ma di ridurre radicalmente gli attriti nel ciclo di vita dello sviluppo, consentendoti di concentrarti sulla creazione di funzionalità innovative anziché lottare con strumenti esterni.
Nel contesto della nostra app di e-commerce al dettaglio, in cui dovevamo eseguire query in modo efficiente sui dati di prodotto, gestire filtri complessi e sfruttare le sfumature della ricerca vettoriale, la possibilità di iterare rapidamente sulle interazioni con il database era fondamentale. MCP Toolbox, basato su Gemini CLI, non solo semplifica questa operazione, ma la accelera, trasformando il modo in cui possiamo esplorare, testare e perfezionare la logica del database alla base delle nostre applicazioni. Scopriamo come questa combinazione rivoluzionaria sta rendendo lo sviluppo full-stack più veloce, intelligente e piacevole.
Cosa imparerai e creerai
Un'applicazione Retail Search che utilizza MCP Toolbox all'interno dell'IDE, basata su Gemini CLI. e in particolare:
- Come integrare MCP Toolbox direttamente nel tuo IDE per un'interazione fluida con AlloyDB.
- Esempi pratici di utilizzo della CLI Gemini per scrivere ed eseguire query SQL sui dati di vendita al dettaglio.
- Sfrutta Gemini CLI per interagire con il nostro set di dati di e-commerce al dettaglio, scrivendo query che in genere richiedono strumenti separati e visualizzando immediatamente i risultati.
- Scopri nuovi modi per analizzare e comprendere i dati, dal controllo delle strutture delle tabelle all'esecuzione di controlli di integrità dei dati rapidi, il tutto tramite interfacce a riga di comando familiari all'interno del nostro IDE.
- In che modo questo workflow di database accelerato contribuisce direttamente a cicli di sviluppo full-stack più rapidi, consentendo prototipazione e iterazione rapide.
Techstack
Utilizziamo:
- AlloyDB per database
- MCP Toolbox per l'astrazione delle funzionalità avanzate di AI generativa e AI dei database dall'applicazione
- Cloud Run per il deployment serverless.
- Gemini CLI per comprendere e analizzare il set di dati e creare la parte di database dell'applicazione di e-commerce per la vendita al dettaglio.
Requisiti
2. Prima di iniziare
Crea un progetto
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto.
- Utilizzerai Cloud Shell, un ambiente a riga di comando in esecuzione in Google Cloud. Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud.

- Una volta eseguita la connessione a Cloud Shell, verifica di essere già autenticato e che il progetto sia impostato sul tuo ID progetto utilizzando il seguente comando:
gcloud auth list
- Esegui questo comando in Cloud Shell per verificare che il comando gcloud conosca il tuo progetto.
gcloud config list project
- Se il progetto non è impostato, utilizza il seguente comando per impostarlo:
gcloud config set project <YOUR_PROJECT_ID>
- Abilita le API richieste: segui il link e abilita le API.
In alternativa, puoi utilizzare il comando gcloud. Consulta la documentazione per i comandi e l'utilizzo di gcloud.
3. Configurazione del database
In questo lab utilizzeremo AlloyDB come database per i dati e-commerce. Utilizza i cluster per contenere tutte le risorse, come database e log. Ogni cluster ha un'istanza primaria che fornisce un punto di accesso ai dati. Le tabelle conterranno i dati effettivi.
Creiamo un cluster, un'istanza e una tabella AlloyDB in cui verrà caricato il set di dati di e-commerce.
Crea un cluster e un'istanza
- Vai alla pagina AlloyDB nella console Cloud. Un modo semplice per trovare la maggior parte delle pagine in Cloud Console è cercarle utilizzando la barra di ricerca della console.
- Seleziona CREA CLUSTER da questa pagina:

- Verrà visualizzata una schermata come quella riportata di seguito. Crea un cluster e un'istanza con i seguenti valori (assicurati che i valori corrispondano se cloni il codice dell'applicazione dal repository):
- cluster id: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / ultima versione consigliata
- Region: "
us-central1" - Networking: "
default"
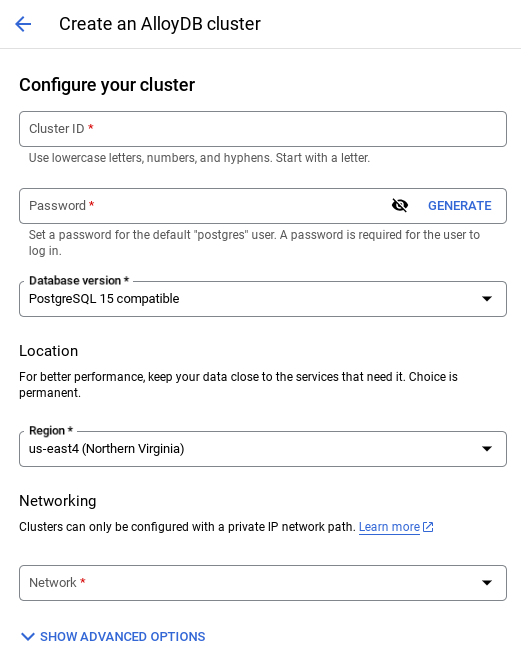
- Quando selezioni la rete predefinita, viene visualizzata una schermata come quella mostrata di seguito.
Seleziona CONFIGURA CONNESSIONE.
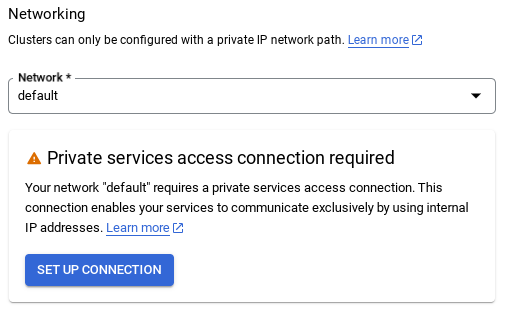
- Da qui, seleziona "Utilizza un intervallo IP allocato automaticamente" e fai clic su Continua. Dopo aver esaminato le informazioni, seleziona CREA CONNESSIONE.
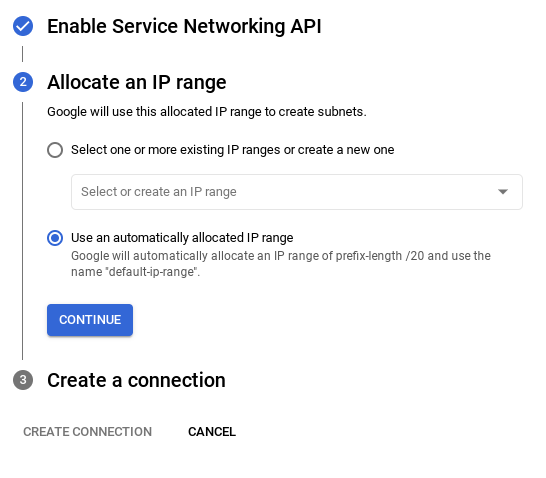
- Una volta configurata la rete, puoi continuare a creare il cluster. Fai clic su CREA CLUSTER per completare la configurazione del cluster come mostrato di seguito:
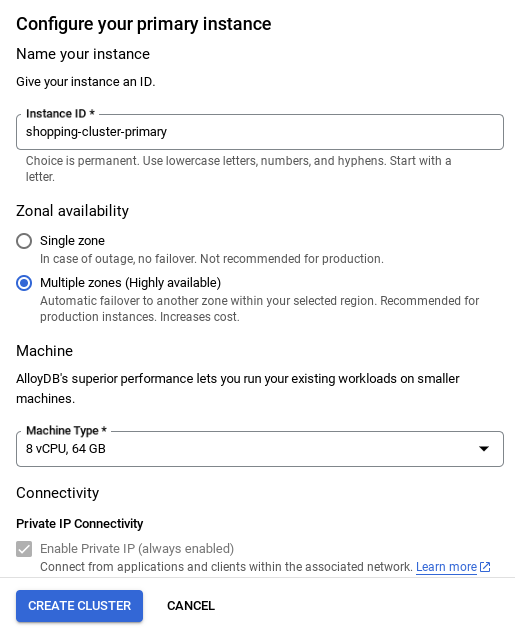
NOTA IMPORTANTE:
- Assicurati di modificare l'ID istanza (che puoi trovare al momento della configurazione del cluster / dell'istanza) in**
vector-instance**. Se non riesci a modificarlo, ricordati di **utilizzare l'ID istanza** in tutti i riferimenti futuri. - Tieni presente che la creazione del cluster richiederà circa 10 minuti. Una volta completata l'operazione, dovresti visualizzare una schermata che mostra la panoramica del cluster che hai appena creato.
4. Importazione dati
Ora è il momento di aggiungere una tabella con i dati del negozio. Vai ad AlloyDB, seleziona il cluster principale e poi AlloyDB Studio:
Potrebbe essere necessario attendere il completamento della creazione dell'istanza. Una volta creato, accedi ad AlloyDB utilizzando le credenziali che hai creato durante la creazione del cluster. Utilizza i seguenti dati per l'autenticazione a PostgreSQL:
- Nome utente : "
postgres" - Database : "
postgres" - Password : "
alloydb"
Una volta eseguita l'autenticazione in AlloyDB Studio, i comandi SQL vengono inseriti nell'editor. Puoi aggiungere più finestre dell'editor utilizzando il segno più a destra dell'ultima finestra.
Inserirai i comandi per AlloyDB nelle finestre dell'editor, utilizzando le opzioni Esegui, Formatta e Cancella in base alle necessità.
Attivare le estensioni
Per creare questa app, utilizzeremo le estensioni pgvector e google_ml_integration. L'estensione pgvector consente di archiviare ed eseguire ricerche di vector embedding. L'estensione google_ml_integration fornisce funzioni che utilizzi per accedere agli endpoint di previsione Vertex AI per ottenere previsioni in SQL. Attiva queste estensioni eseguendo i seguenti DDL:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Se vuoi controllare le estensioni abilitate sul tuo database, esegui questo comando SQL:
select extname, extversion from pg_extension;
Creare una tabella
Puoi creare una tabella utilizzando l'istruzione DDL riportata di seguito in AlloyDB Studio:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
La colonna degli incorporamenti consentirà l'archiviazione dei valori vettoriali del testo.
Concedi autorizzazione
Esegui l'istruzione riportata di seguito per concedere l'esecuzione della funzione "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Concedi il ruolo Utente Vertex AI al service account AlloyDB
Dalla console Google Cloud IAM, concedi al service account AlloyDB (simile a service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) l'accesso al ruolo "Utente Vertex AI". PROJECT_NUMBER conterrà il numero del tuo progetto.
In alternativa, puoi eseguire il comando riportato di seguito dal terminale Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Carica i dati nel database
- Copia le istruzioni della query
insertdainsert scripts sqlnel foglio all'editor. Puoi copiare da 10 a 50 istruzioni di inserimento per una rapida demo di questo caso d'uso. In questa scheda"Inserti selezionati 25-30 righe" è presente un elenco selezionato di inserti. - Fai clic su Esegui. I risultati della query vengono visualizzati nella tabella Risultati.
NOTA IMPORTANTE:
Assicurati di copiare solo 25-50 record da inserire e che provengano da un intervallo di tipi di categoria, sottocategoria, colore e genere.
5. Crea incorporamenti per i dati
La vera innovazione nella ricerca moderna consiste nel comprendere il significato, non solo le parole chiave. È qui che entrano in gioco gli embedding e la ricerca vettoriale.
Abbiamo trasformato le descrizioni dei prodotti e le query degli utenti in rappresentazioni numeriche ad alta dimensionalità chiamate "incorporamenti" utilizzando modelli linguistici pre-addestrati. Questi embedding acquisiscono il significato semantico, consentendoci di trovare prodotti "simili per significato" anziché contenenti solo parole corrispondenti. Inizialmente, abbiamo sperimentato la ricerca di similarità vettoriale diretta su questi incorporamenti per stabilire una base di riferimento, dimostrando la potenza della comprensione semantica anche prima delle ottimizzazioni del rendimento.
La colonna degli incorporamenti consentirà di memorizzare i valori vettoriali del testo della descrizione del prodotto. La colonna img_embeddings consentirà l'archiviazione degli embedding di immagini (multimodali). In questo modo puoi utilizzare anche la ricerca basata sulla distanza tra testo e immagine. In questo lab, però, utilizzeremo solo gli incorporamenti di testo.
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Dovrebbe restituire il vettore di incorporamento, che ha l'aspetto di un array di numeri in virgola mobile, per il testo di esempio nella query. Ecco come appare:
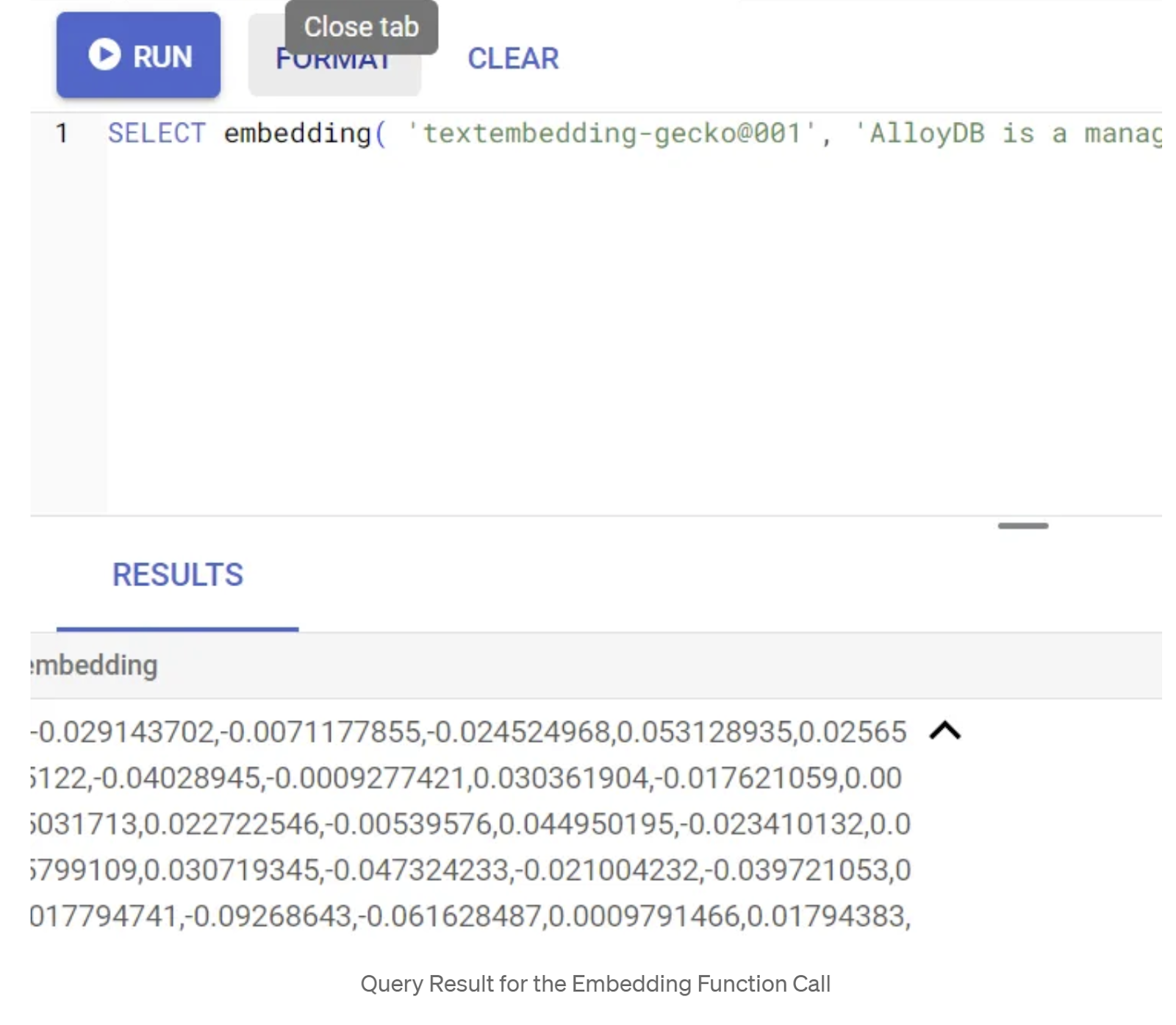
Aggiorna il campo vettoriale abstract_embeddings
Esegui il seguente DML per aggiornare la descrizione dei contenuti nella tabella con gli embedding corrispondenti:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
Se utilizzi un account di fatturazione con credito di prova per Google Cloud, potresti avere difficoltà a generare più di pochi incorporamenti (ad esempio 20-25 al massimo). Pertanto, limita il numero di righe nello script di inserimento.
Se vuoi generare incorporamenti di immagini (per eseguire la ricerca contestuale multimodale), esegui anche l'aggiornamento riportato di seguito:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. MCP Toolbox for Databases (AlloyDB)
Dietro le quinte, strumenti efficaci e un'applicazione ben strutturata garantiscono un funzionamento ottimale.
La toolbox MCP (Model Context Protocol) per i database semplifica l'integrazione di strumenti di AI generativa e agentici con AlloyDB. Funge da server open source che semplifica il pooling delle connessioni, l'autenticazione e l'esposizione sicura delle funzionalità del database agli agenti AI o ad altre applicazioni.
Nella nostra applicazione abbiamo utilizzato MCP Toolbox for Databases come livello di astrazione per tutte le nostre query di ricerca ibrida intelligente.
Segui i passaggi riportati di seguito per configurare e implementare Toolbox per il nostro caso d'uso:
Puoi notare che uno dei database supportati da MCP Toolbox for Databases è AlloyDB e, poiché l'abbiamo già eseguito il provisioning nella sezione precedente, procediamo con la configurazione di Toolbox.
- Vai al terminale Cloud Shell e assicurati che il progetto sia selezionato e visualizzato nel prompt del terminale. Esegui il comando riportato di seguito dal terminale Cloud Shell per passare alla directory del progetto:
mkdir gemini-cli-project
cd gemini-cli-project
- Esegui il comando riportato di seguito per scaricare e installare toolbox nella nuova cartella:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
In questo modo, la cassetta degli attrezzi dovrebbe essere creata nella directory corrente. Copia il percorso nella casella degli strumenti.
- Vai all'editor di Cloud Shell (per la modalità di modifica del codice) e, nella cartella principale del progetto "gemini-cli-project", aggiungi un file denominato "tools.yaml".
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
Informazioni su tools.yaml:
Le origini rappresentano le diverse origini dati con cui uno strumento può interagire. Un'origine rappresenta un'origine dati con cui uno strumento può interagire. Puoi definire le origini come una mappa nella sezione sources del file tools.yaml. In genere, una configurazione dell'origine contiene tutte le informazioni necessarie per connettersi al database e interagire con esso.
Gli strumenti definiscono le azioni che un agente può intraprendere, ad esempio leggere e scrivere in una sorgente. Uno strumento rappresenta un'azione che l'agente può intraprendere, ad esempio l'esecuzione di un'istruzione SQL. Puoi definire gli strumenti come una mappa nella sezione degli strumenti del file tools.yaml. In genere, uno strumento richiede un'origine su cui agire.
Per ulteriori dettagli sulla configurazione di tools.yaml, consulta questa documentazione.
Come puoi vedere nel file Tools.yaml riportato sopra, lo strumento "get-apparels" elenca tutti i dettagli degli indumenti dal database.
7. Configurare Gemini CLI
Nell'editor di Cloud Shell, crea una nuova cartella denominata .gemini all'interno della cartella gemini-cli-project e crea un nuovo file denominato settings.json al suo interno.
{
"mcpServers": {
"AlloyDBServer": {
"command": "/home/user/gemini-cli-project/toolbox",
"args": ["--tools-file", "tools.yaml", "--stdio"]
}
}
}
Nella sezione dei comandi dello snippet riportato sopra, sostituisci "/home/user/gemini-cli-project/toolbox" con il percorso della tua casella degli strumenti.
Installa Gemini CLI
Infine, dal terminale Cloud Shell, installiamo Gemini CLI nella stessa directory gemini-cli-project eseguendo il comando:
sudo npm install -g @google/gemini-cli
Imposta l'ID progetto
Assicurati di aver impostato l'ID progetto attivo nell'ambiente:
export GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT_ID>>
Inizia a utilizzare Gemini CLI
Dalla riga di comando, inserisci il comando:
gemini
Dovresti visualizzare una risposta simile alla seguente:
Autenticati e vai al passaggio successivo.
8. Inizia a interagire con Gemini CLI
Utilizza il comando /mcp per elencare i server MCP configurati.
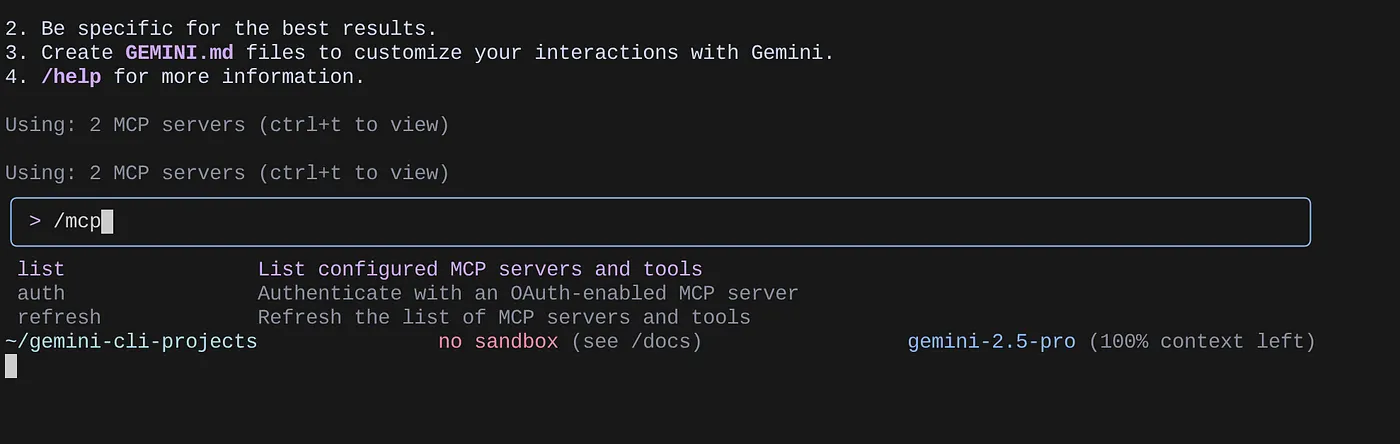
Dovresti visualizzare i due server MCP che abbiamo configurato: GitHub e MCP Toolbox for Databases elencati insieme ai relativi strumenti.
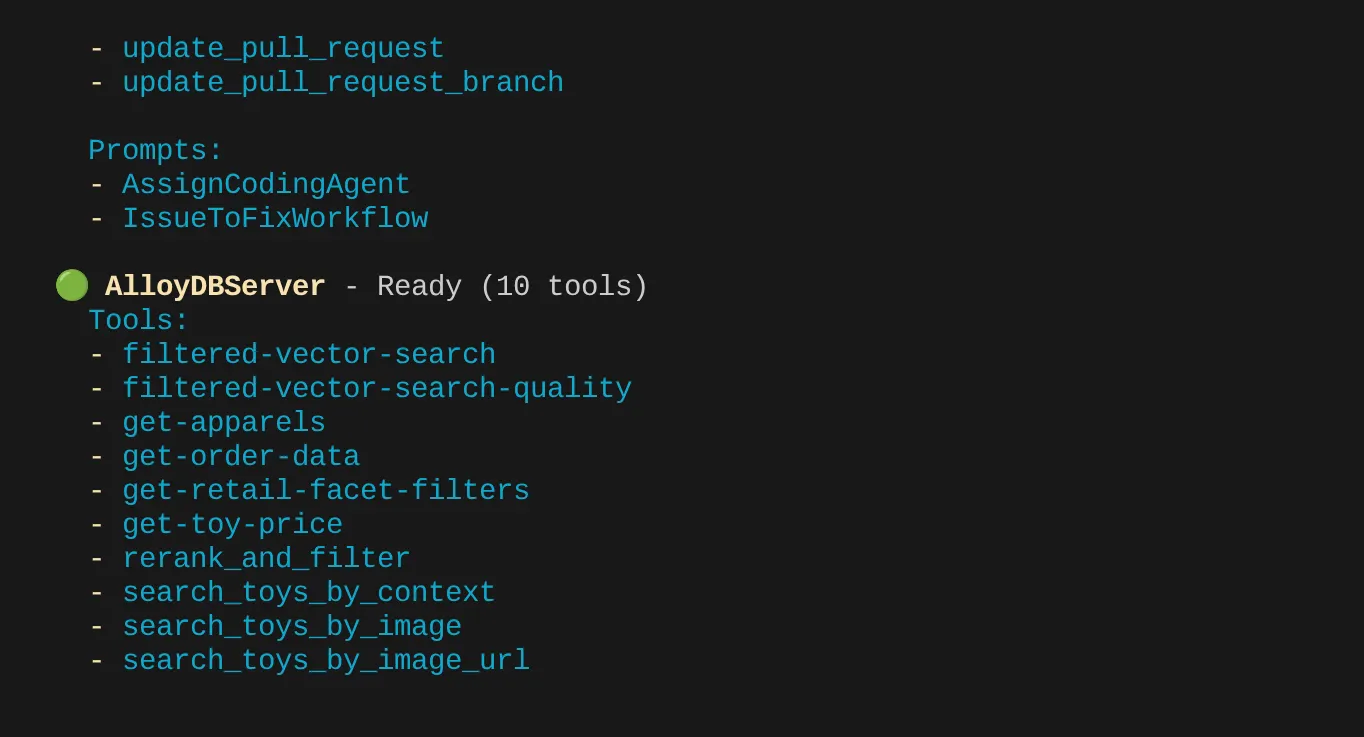
Nel mio caso ho più strumenti. Quindi, per ora ignoralo. Dovresti visualizzare lo strumento get-apparels nel server MCP di AlloyDB.
Inizia a eseguire query sul database tramite MCP Toolbox
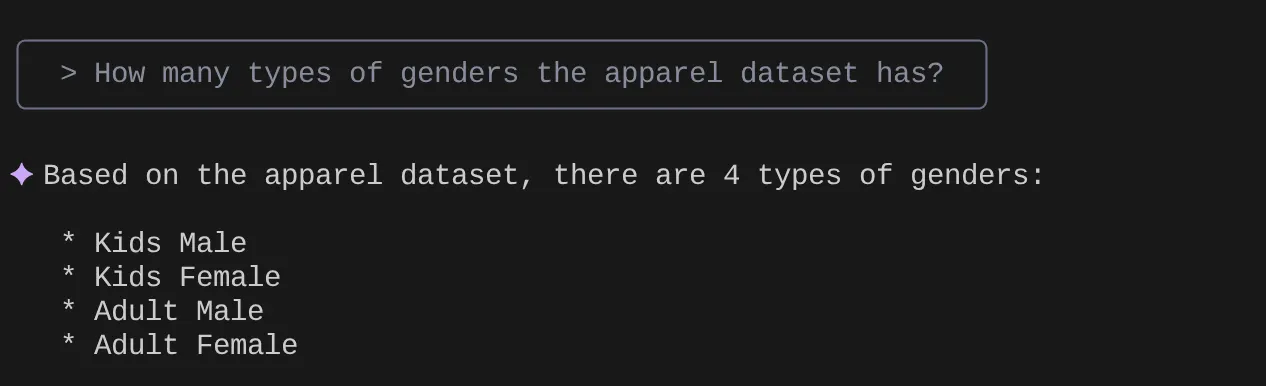
Ora prova a porre domande in linguaggio naturale per recuperare risposte e query per il set di dati con cui stiamo lavorando:
> How many types of genders the apparel dataset has?
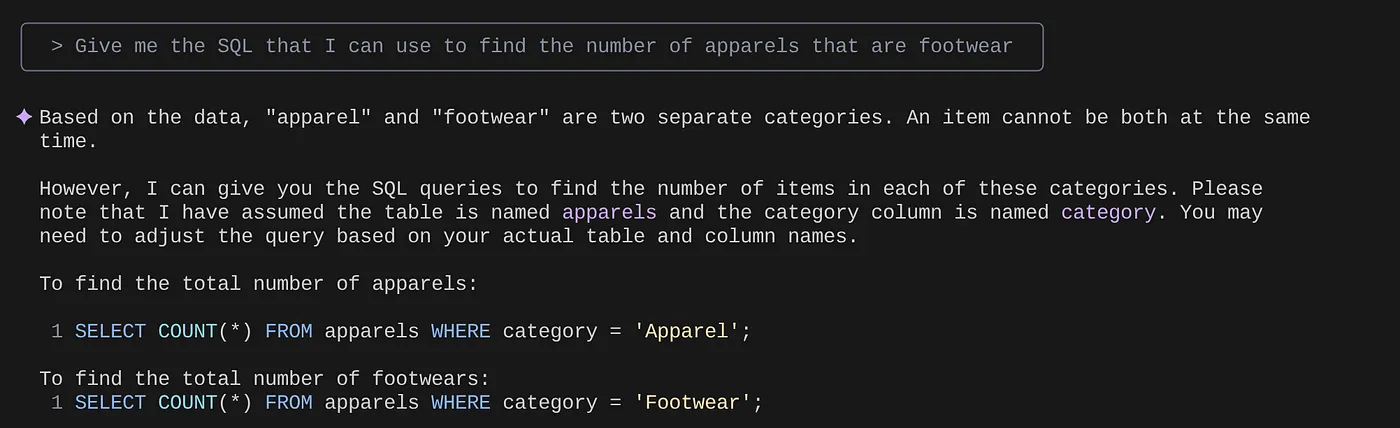
> Give me the SQL that I can use to find the number of apparels that are footwear
> What are the unique sub categories that are there?
that I can use to find the number of apparels that are footwear
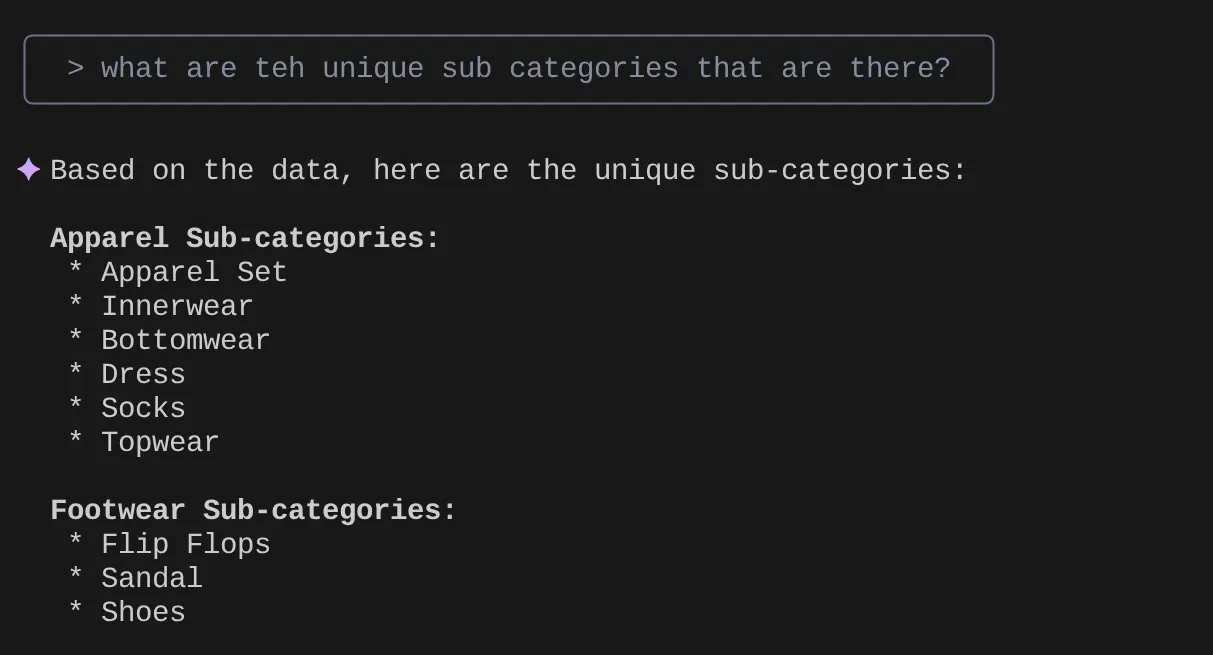
Supponiamo che, in base alle mie informazioni e a molte query di questo tipo, ho creato una query dettagliata e voglio provarla. Supponiamo che gli ingegneri del database abbiano già creato il file Tools.yaml per te come di seguito:
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
filtered-vector-search:
kind: postgres-sql
source: alloydb
description: Get the list of facet filter values from the retail dataset.
parameters:
- name: categories
type: array
description: List of categories preferred by the user.
items:
name: category
type: string
description: Category value.
- name: subCategories
type: array
description: List of sub-categories preferred by the user.
items:
name: subCategory
type: string
description: Sub-Category value.
- name: colors
type: array
description: List of colors preferred by the user.
items:
name: color
type: string
description: Color value.
- name: genders
type: array
description: List of genders preferred by the user for apparel fitting.
items:
name: gender
type: string
description: Gender name.
- name: searchtext
type: string
description: Description of the product that the user wants to find database matches for.
statement: |
SELECT id, content, uri, category, sub_category,color,gender FROM apparels
where category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005',$5)::vector limit 10
Ora proviamo una ricerca in linguaggio naturale:
> How many yellow shirts are there for boys?
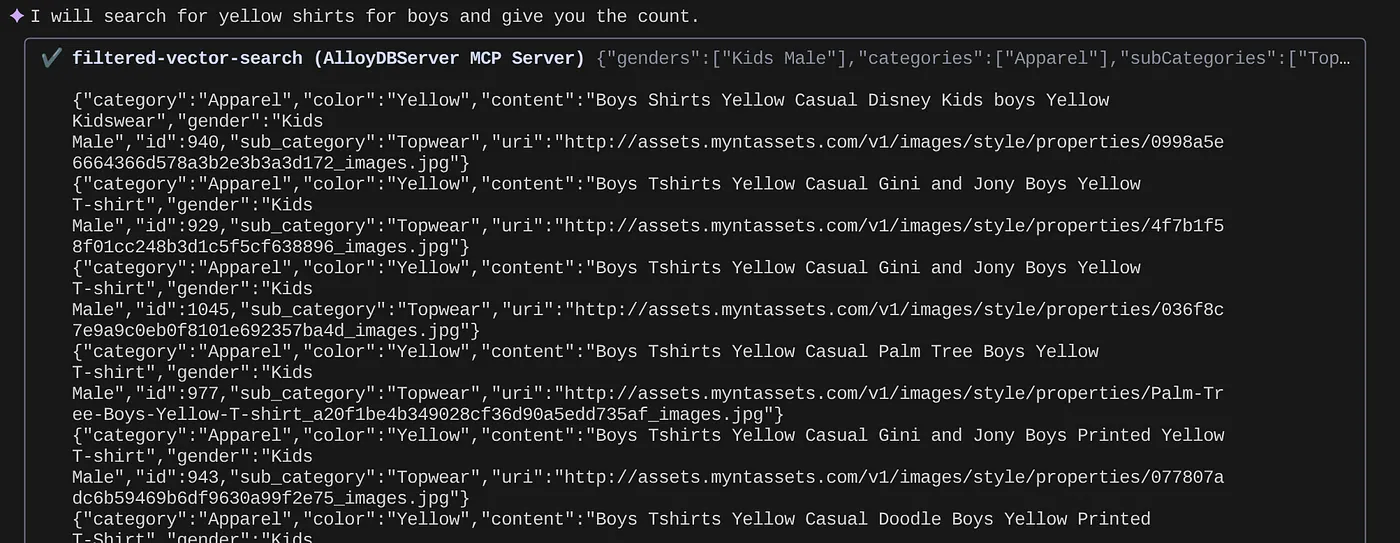

Non male, vero? Ora posso correggere il file YAML per ulteriori progressi nelle query mentre continuo a fornire nuove funzionalità nella mia applicazione in tempi più rapidi.
9. Sviluppo accelerato di app
La bellezza di integrare le funzionalità del database direttamente nel tuo IDE tramite Gemini CLI e MCP Toolbox non è solo teorica. Si traduce in flussi di lavoro tangibili che aumentano la velocità, soprattutto per un'applicazione complessa come la nostra esperienza di vendita al dettaglio ibrida. Vediamo alcuni scenari:
1. Iterazione rapida sulla logica di filtraggio dei prodotti
Immagina di aver appena lanciato una nuova promozione per l'abbigliamento sportivo estivo. Vogliamo testare l'interazione dei nostri filtri sfaccettati (ad es. per brand, taglia, colore, fascia di prezzo) con questa nuova categoria.
Senza l'integrazione con l'IDE:
Probabilmente passerei a un client SQL separato, scriverei la query, la eseguirei, analizzerei i risultati, tornerei al mio IDE per modificare il codice dell'applicazione, tornerei al client e ripeterei l'operazione. Questo cambio di contesto è un grande ostacolo.
Con Gemini CLI e MCP:
Posso rimanere nel mio IDE e altro ancora:
- Query: posso aggiornare rapidamente la query nel file YAML con il (ipotetico set di dati) "SELECT DISTINCT brand FROM products WHERE category = 'activewear' AND season = 'summer'" e provarla direttamente nel mio terminale.
- Esplorazione dei dati: visualizza immediatamente i brand restituiti. Se devo verificare la disponibilità di un prodotto per una marca e una taglia specifiche, posso usare un'altra query rapida:"SELECT COUNT(*) FROM products WHERE brand = ‘SummitGear' AND size = ‘M' AND category = ‘activewear' AND season = ‘summer'"
- Integrazione del codice: posso quindi modificare immediatamente la logica di filtraggio del front-end o le chiamate API di backend in base a queste informazioni rapide sui dati nell'IDE, riducendo significativamente il ciclo di feedback.
2. Ottimizzazione della ricerca vettoriale per i consigli sui prodotti
La nostra ricerca ibrida si basa sugli incorporamenti vettoriali per suggerimenti di prodotti pertinenti. Supponiamo che stiamo registrando un calo delle percentuali di clic per i consigli relativi alle "scarpe da corsa da uomo".
Senza l'integrazione dell'IDE:
Eseguirei script o query personalizzati in uno strumento di database per analizzare i punteggi di somiglianza delle scarpe consigliate, confrontarli con i dati di interazione utente e cercare di correlare eventuali pattern.
Con Gemini CLI e MCP:
- Analisi degli incorporamenti: posso eseguire query direttamente per gli incorporamenti dei prodotti e i relativi metadati: "SELECT product_id, name, vector_embedding FROM products WHERE category = ‘running shoes' AND gender = ‘male' LIMIT 10"
- Riferimenti incrociati: posso anche eseguire un rapido controllo della somiglianza vettoriale effettiva tra un prodotto scelto e i relativi consigli. Ad esempio, se il prodotto A viene consigliato agli utenti che hanno esaminato il prodotto B, posso eseguire una query per recuperare e confrontare i relativi incorporamenti vettoriali.
- Debug: consente di eseguire il debug e testare le ipotesi più rapidamente. Il modello di embedding si comporta come previsto? Esistono anomalie nei dati che influiscono sulla qualità dei consigli? Posso ottenere risposte iniziali senza uscire dal mio ambiente di programmazione.
3. Informazioni sulla distribuzione di schema e dati per le nuove funzionalità
Supponiamo di voler aggiungere una funzionalità "Recensioni dei clienti". Prima di scrivere l'API di backend, dobbiamo comprendere i dati dei clienti esistenti e come potrebbero essere strutturate le recensioni.
Senza l'integrazione con l'IDE:
Devo connettermi a un client di database, eseguire comandi DESCRIBE su tabelle come clienti e ordini e quindi eseguire query per dati di esempio per comprendere relazioni e tipi di dati.
Con Gemini CLI e MCP:
- Esplorazione dello schema:posso semplicemente eseguire una query sulla tabella nel file YAML ed eseguirla direttamente nel terminale.
- Campionamento dei dati:posso quindi estrarre dati di esempio per comprendere i dati demografici e la cronologia degli acquisti dei clienti: "SELECT customer_id, name, signup_date, total_orders FROM customers ORDER BY signup_date DESC LIMIT 5"
- Pianificazione:questo accesso rapido allo schema e alla distribuzione dei dati ci aiuta a prendere decisioni informate su come progettare la nuova tabella delle recensioni, quali chiavi esterne stabilire e come collegare in modo efficiente le recensioni a clienti e prodotti, il tutto prima di scrivere una sola riga di codice dell'applicazione per la nuova funzionalità.
Questi sono solo alcuni esempi, ma evidenziano il vantaggio principale: ridurre gli attriti e aumentare la velocità degli sviluppatori. Integrando l'interazione con AlloyDB direttamente nell'IDE, Gemini CLI e MCP Toolbox ci consentono di creare applicazioni migliori e più reattive più rapidamente.
10. Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo post, segui questi passaggi:
- Nella console Google Cloud, vai alla pagina Resource Manager.
- Nell'elenco dei progetti, seleziona il progetto che vuoi eliminare, quindi fai clic su Elimina.
- Nella finestra di dialogo, digita l'ID progetto, quindi fai clic su Chiudi per eliminare il progetto.
- In alternativa, puoi eliminare il cluster AlloyDB (modifica la posizione in questo collegamento ipertestuale se non hai scelto us-central1 per il cluster al momento della configurazione) che abbiamo appena creato per questo progetto facendo clic sul pulsante ELIMINA CLUSTER.
11. Complimenti
Complimenti! Hai integrato correttamente MCP Toolbox direttamente nel tuo IDE per un'interazione perfetta con AlloyDB e hai sfruttato Gemini CLI per interagire con il nostro set di dati di e-commerce al dettaglio per scrivere query che in genere richiedono strumenti separati. Hai imparato nuovi modi per analizzare e comprendere i dati, dal controllo delle strutture delle tabelle all'esecuzione di controlli di integrità dei dati rapidi, il tutto tramite interfacce a riga di comando familiari all'interno del nostro IDE.
Clona il repository, analizzalo e fammi sapere se hai migliorato l'applicazione utilizzando Gemini CLI e MCP Toolbox per i database.
Per altre applicazioni basate sui dati con Gemini integrato, create con Gemini CLI, MCP e di cui è stato eseguito il deployment su runtime serverless, registrati alla nostra prossima stagione di Code Vipassana, dove potrai partecipare a sessioni pratiche guidate da un istruttore e a molti altri codelab.