
1. 概要
AlloyDB を使用してファセット フィルタリングとベクトル検索を組み合わせた動的なハイブリッド小売エクスペリエンスを構築する方法を思い出してください。このアプリケーションは、最新の小売業のニーズを強力に実証するものでしたが、そこに至るまで、そしてそれを反復するには、多大な開発努力が必要でした。フルスタック開発者にとって、コードエディタとデータベース ツールの間を頻繁に行き来することは、イノベーションとデータの理解という重要なプロセスを遅らせるボトルネックになることがよくあります。
解決策
まさに、高速アプリケーション開発の真の力が発揮されるのはこのときです。直感的な Gemini CLI を介してアクセスできる MCP(Modern Cloud Platform)ツールボックスが、私のツールキットに不可欠な一部となった理由を共有できることを、私は非常に嬉しく思っています。統合開発環境(IDE)内で、AlloyDB インスタンスとのシームレスなやり取り、クエリの作成、データセットの理解を直接行うことができるとしたらどうでしょうか。これは単なる利便性の問題ではなく、開発ライフサイクルの摩擦を根本的に軽減し、外部ツールとの格闘ではなく、革新的な機能の構築に集中できるようにするためのものです。
小売業の e コマースアプリのコンテキストでは、商品データの効率的なクエリ、複雑なフィルタリングの処理、ベクトル検索のニュアンスの活用が必要だったため、データベース操作を迅速に反復処理できることが最も重要でした。Gemini CLI を搭載した MCP ツールボックスは、このプロセスを簡素化するだけでなく、加速させ、アプリケーションの基盤となるデータベース ロジックの探索、テスト、改善の方法を変革します。この画期的な組み合わせが、フルスタック開発をより迅速かつスマートに、そしてより楽しくしている様子を見てみましょう。
学習内容と作成するアプリの概要
Gemini CLI を利用した IDE 内の MCP ツールボックスを使用する Retail Search アプリケーション。次の分野について考えます。
- MCP ツールボックスを IDE に直接統合して、AlloyDB とのシームレスなやり取りを実現する方法。
- Gemini CLI を使用して小売データに対して SQL クエリを作成して実行する実践的な例。
- Gemini CLI を活用して小売業の e コマース データセットを操作し、通常は別のツールが必要となるクエリを記述して、結果を即座に確認します。
- テーブル構造の確認からデータの簡単な健全性チェックの実行まで、IDE 内の使い慣れたコマンドライン インターフェースを使用して、データをプローブして理解する新しい方法を見つけましょう。
- この高速化されたデータベース ワークフローが、フルスタック開発サイクルの短縮にどのように直接貢献し、迅速なプロトタイピングとイテレーションを可能にするか。
Techstack
使用しているもの:
- AlloyDB for database
- アプリケーションからデータベースの高度な生成機能と AI 機能を抽象化する MCP ツールボックス
- サーバーレス デプロイ用の Cloud Run。
- Gemini CLI を使用して、データセットを理解して分析し、小売業者の e コマース アプリケーションのデータベース部分を構築します。
要件
2. 始める前に
プロジェクトを作成する
- Google Cloud コンソールのプロジェクト選択ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。詳しくは、プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
- Google Cloud 上で動作するコマンドライン環境の Cloud Shell を使用します。Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] をクリックします。
![[Cloud Shell をアクティブにする] ボタンの画像](https://codelabs.developers.google.com/static/search-app-with-geminicli/img/7875ca05ca6f7cab.png?hl=ja)
- Cloud Shell に接続したら、次のコマンドを使用して、すでに認証済みであることと、プロジェクトがプロジェクト ID に設定されていることを確認します。
gcloud auth list
- Cloud Shell で次のコマンドを実行して、gcloud コマンドがプロジェクトを認識していることを確認します。
gcloud config list project
- プロジェクトが設定されていない場合は、次のコマンドを使用して設定します。
gcloud config set project <YOUR_PROJECT_ID>
- 必要な API を有効にする: リンクにアクセスして、API を有効にします。
または、この操作に gcloud コマンドを使用することもできます。gcloud コマンドとその使用方法については、ドキュメントをご覧ください。
3. データベースの設定
このラボでは、e コマースデータのデータベースとして AlloyDB を使用します。クラスタを使用して、データベースやログなどのすべてのリソースを保持します。各クラスタには、データへのアクセス ポイントを提供するプライマリ インスタンスがあります。テーブルには実際のデータが格納されます。
e コマース データセットが読み込まれる AlloyDB クラスタ、インスタンス、テーブルを作成しましょう。
クラスタとインスタンスを作成する
- Cloud コンソールの AlloyDB ページに移動します。Cloud コンソールでほとんどのページを簡単に見つけるには、コンソールの検索バーを使用して検索します。
- このページで [クラスタを作成] を選択します。

- 次のような画面が表示されます。次の値を使用してクラスタとインスタンスを作成します(リポジトリからアプリケーション コードを複製する場合は、値が一致していることを確認してください)。
- クラスタ ID: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / 最新の推奨バージョン
- Region: "
us-central1" - Networking: "
default"
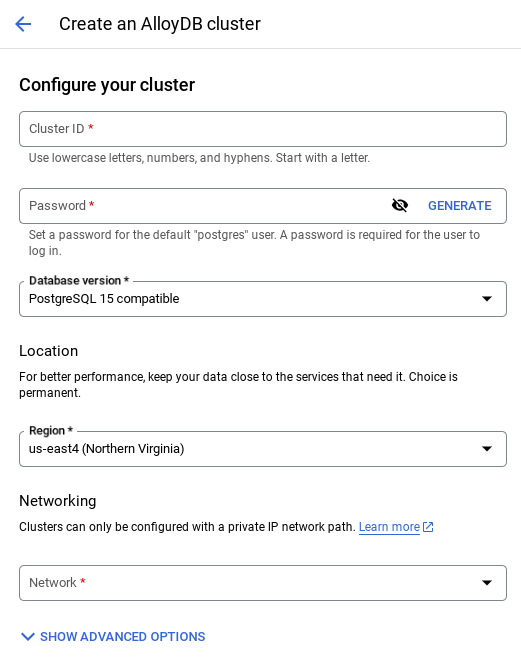
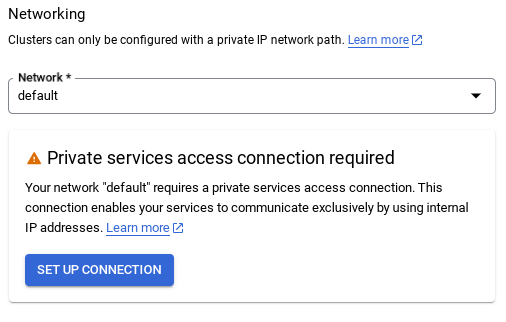
- デフォルトのネットワークを選択すると、次のような画面が表示されます。
[接続の設定] を選択します。
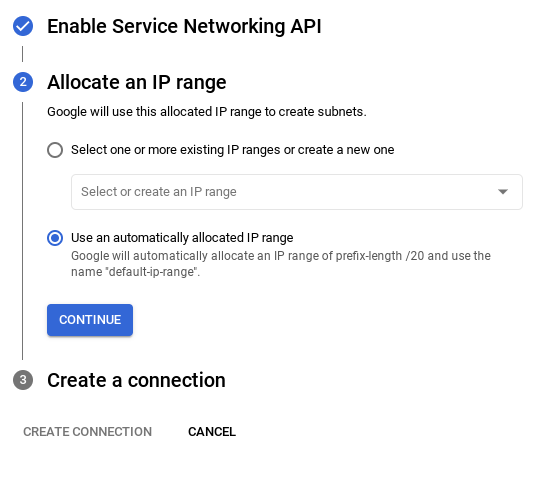
- [自動的に割り当てられた IP 範囲を使用する] を選択して、[続行] をクリックします。情報を確認したら、[接続を作成] を選択します。
- ネットワークを設定したら、クラスタの作成を続行できます。[CREATE CLUSTER] をクリックして、次のようにクラスタの設定を完了します。
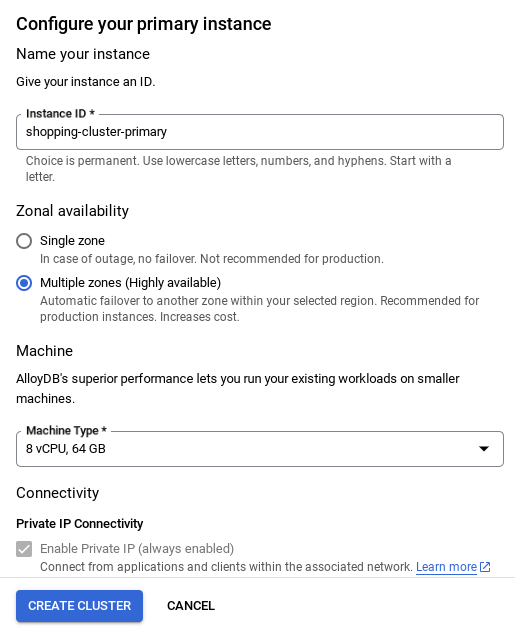
重要な注意事項:
- インスタンス ID を必ず変更してください(クラスタ / インスタンスの構成時に確認できます)。変更先は**
vector-instance** です。変更できない場合は、以降のすべての参照で **インスタンス ID を使用** してください。 - クラスタの作成には 10 分ほどかかります。成功すると、作成したクラスタの概要を示す画面が表示されます。
4. データの取り込み
次に、店舗に関するデータを含むテーブルを追加します。AlloyDB に移動し、プライマリ クラスタと AlloyDB Studio を選択します。
インスタンスの作成が完了するまで待つ必要がある場合があります。完了したら、クラスタの作成時に作成した認証情報を使用して AlloyDB にログインします。PostgreSQL の認証には次のデータを使用します。
- ユーザー名: 「
postgres」 - データベース: 「
postgres」 - パスワード: 「
alloydb」
AlloyDB Studio への認証が成功すると、エディタに SQL コマンドが入力されます。最後のウィンドウの右にあるプラス記号を使用して、複数のエディタ ウィンドウを追加できます。
必要に応じて [実行]、[形式]、[クリア] オプションを使用して、エディタ ウィンドウに AlloyDB のコマンドを入力します。
拡張機能を有効にする
このアプリのビルドには、拡張機能 pgvector と google_ml_integration を使用します。pgvector 拡張機能を使用すると、ベクトル エンベディングを保存して検索できます。google_ml_integration 拡張機能は、Vertex AI 予測エンドポイントにアクセスして SQL で予測を取得するために使用する関数を提供します。次の DDL を実行して、これらの拡張機能を有効にします。
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
データベースで有効になっている拡張機能を確認するには、次の SQL コマンドを実行します。
select extname, extversion from pg_extension;
テーブルを作成する
AlloyDB Studio で次の DDL ステートメントを使用してテーブルを作成できます。
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
エンベディング列を使用すると、テキストのベクトル値を保存できます。
権限を付与
次のステートメントを実行して、「embedding」関数に対する実行権限を付与します。
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB サービス アカウントに Vertex AI ユーザーロールを付与する
Google Cloud IAM コンソールで、AlloyDB サービス アカウント(service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com のような形式)に「Vertex AI ユーザー」ロールへのアクセス権を付与します。PROJECT_NUMBER にはプロジェクト番号が設定されます。
または、Cloud Shell ターミナルから次のコマンドを実行することもできます。
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
データベースにデータを読み込む
- シートの
insert scripts sqlから上記のinsertクエリ ステートメントをエディタにコピーします。このユースケースのクイック デモ用に、10 ~ 50 個の挿入ステートメントをコピーできます。この[Selected Inserts 25-30 rows] タブに、選択した挿入行のリストが表示されます。 - [実行] をクリックします。クエリの結果が [結果] テーブルに表示されます。
重要な注意事項:
挿入するレコードは 25 ~ 50 件のみをコピーし、カテゴリ、サブカテゴリ、色、性別の範囲からコピーするようにしてください。
5. データのエンベディングを作成する
現代の検索の真の革新は、キーワードだけでなく意味を理解することにあります。ここでエンベディングとベクトル検索が役立ちます。
事前トレーニング済みの言語モデルを使用して、商品紹介文とユーザーのクエリを「エンベディング」と呼ばれる高次元の数値表現に変換しました。これらのエンベディングはセマンティックな意味を捉えるため、一致する単語を含むだけでなく、「意味が類似している」商品を見つけることができます。まず、これらのエンベディングで直接ベクトル類似性検索を試してベースラインを確立し、パフォーマンスの最適化を行う前からセマンティック理解の威力を実証しました。
エンベディング列を使用すると、商品説明テキストのベクトル値を保存できます。img_embeddings 列を使用すると、画像エンベディング(マルチモーダル)を保存できます。これにより、テキストと画像の距離に基づく検索も使用できます。ただし、このラボではテキスト エンベディングのみを使用します。
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
これにより、クエリ内のサンプル テキストのエンベディング ベクトル(浮動小数点数の配列)が返されます。次のように表示されます。
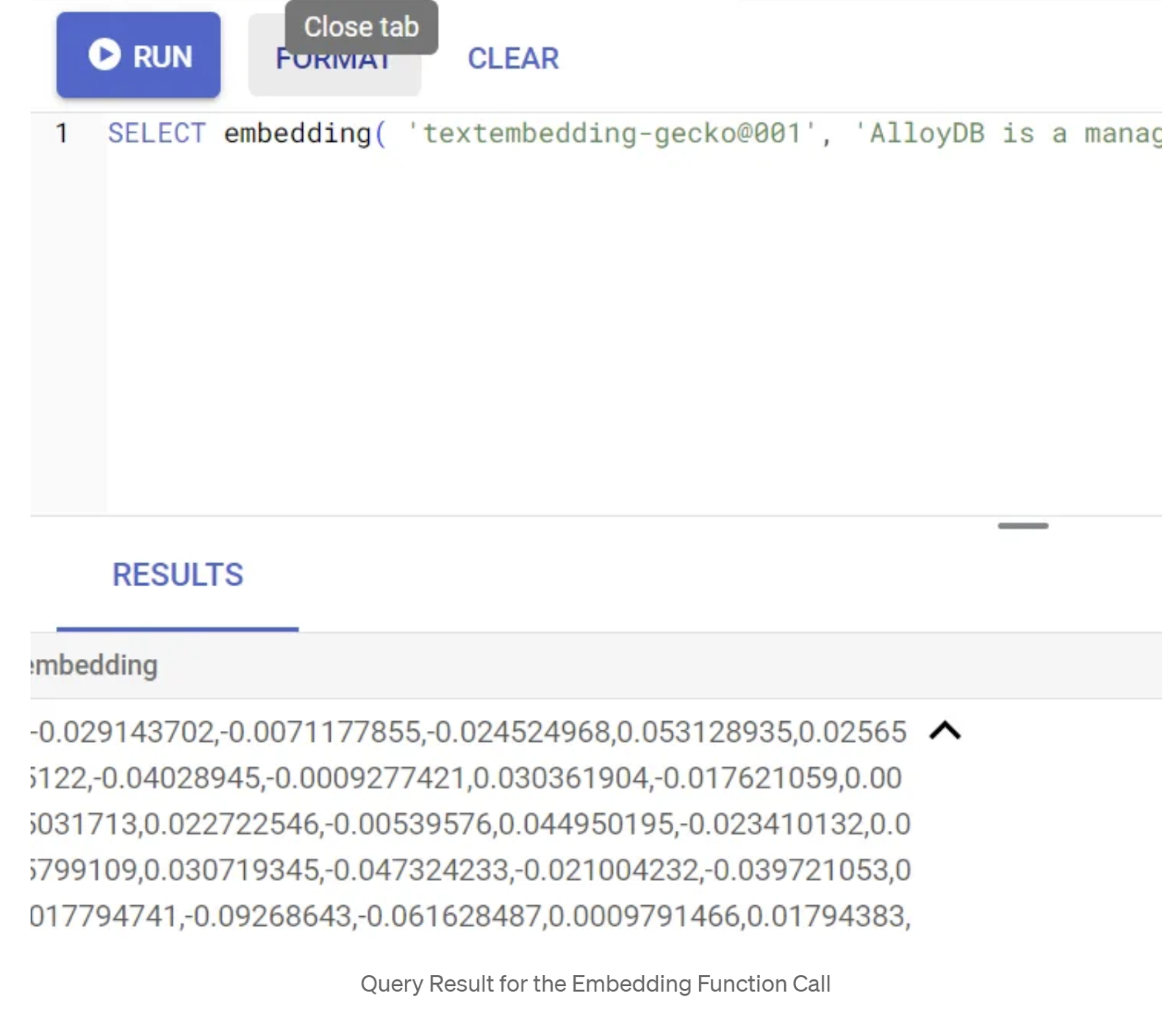
abstract_embeddings ベクトル フィールドを更新する
次の DML を実行して、テーブル内のコンテンツの説明を対応するエンベディングで更新します。
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
Google Cloud のトライアル クレジットの請求先アカウントを使用している場合、少数のエンベディング(最大 20 ~ 25 個)を超えるエンベディングを生成できないことがあります。そのため、挿入スクリプトの行数を制限します。
画像エンベディング(マルチモーダル コンテキスト検索の実行用)を生成する場合は、次の更新も実行します。
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. データベース向け MCP ツールボックス(AlloyDB)
バックエンドでは、堅牢なツールと適切に構造化されたアプリケーションにより、スムーズな運用が実現されています。
データベース向け MCP(Model Context Protocol)ツールボックスを使用すると、生成 AI ツールとエージェント ツールを AlloyDB と簡単に統合できます。これは、接続プーリング、認証、データベース機能の AI エージェントや他のアプリケーションへの安全な公開を効率化するオープンソース サーバーとして機能します。
アプリケーションでは、すべてのインテリジェント ハイブリッド検索クエリの抽象化レイヤとして MCP Toolbox for Databases を使用しています。
以下の手順に沿って、ユースケースに合わせて Toolbox を設定してデプロイします。
データベース向け MCP ツールボックスでサポートされているデータベースの 1 つが AlloyDB であることがわかります。前のセクションで AlloyDB をすでにプロビジョニングしているので、ツールボックスの設定に進みましょう。
- Cloud Shell ターミナルに移動し、プロジェクトが選択され、ターミナルのプロンプトに表示されていることを確認します。Cloud Shell ターミナルから次のコマンドを実行して、プロジェクト ディレクトリに移動します。
mkdir gemini-cli-project
cd gemini-cli-project
- 次のコマンドを実行して、新しいフォルダにツールボックスをダウンロードしてインストールします。
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
これにより、現在のディレクトリにツールボックスが作成されます。ツールボックスのパスをコピーします。
- Cloud Shell エディタ(コード編集モード)に移動し、プロジェクトのルートフォルダ「gemini-cli-project」に「tools.yaml」というファイルを追加します。
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
tools.yaml について理解しましょう。
ソースは、ツールが操作できるさまざまなデータソースを表します。ソースは、ツールが操作できるデータソースを表します。tools.yaml ファイルの sources セクションで、ソースをマップとして定義できます。通常、移行元構成には、データベースに接続して操作するために必要な情報が含まれます。
ツールは、エージェントが実行できるアクション(ソースへの読み取りや書き込みなど)を定義します。ツールは、SQL ステートメントの実行など、エージェントが実行できるアクションを表します。tools.yaml ファイルの tools セクションで、ツールをマップとして定義できます。通常、ツールは処理するソースを必要とします。
tools.yaml の構成の詳細については、こちらのドキュメントをご覧ください。
上記の Tools.yaml ファイルでわかるように、ツール「get-apparels」はデータベースからすべての衣料品の詳細を一覧表示します。
7. Gemini CLI を設定する
Cloud Shell エディタで、gemini-cli-project フォルダ内に .gemini という名前の新しいフォルダを作成し、その中に settings.json という名前の新しいファイルを作成します。
{
"mcpServers": {
"AlloyDBServer": {
"command": "/home/user/gemini-cli-project/toolbox",
"args": ["--tools-file", "tools.yaml", "--stdio"]
}
}
}
上記のスニペットのコマンド セクションで、「/home/user/gemini-cli-project/toolbox」を toolbox へのパスに置き換えます。
Gemini CLI をインストールする
最後に、Cloud Shell ターミナルから、次のコマンドを実行して、同じディレクトリ gemini-cli-project に Gemini CLI をインストールします。
sudo npm install -g @google/gemini-cli
プロジェクト ID を設定する
環境にアクティブなプロジェクト ID が設定されていることを確認します。
export GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT_ID>>
Gemini CLI の使用を開始する
コマンドラインで次のコマンドを入力します。
gemini
次のようなレスポンスが表示されます。
認証して次のステップに進みます。
8. Gemini CLI の操作を開始する
/mcp コマンドを使用して、構成済みの MCP サーバーを一覧表示します。
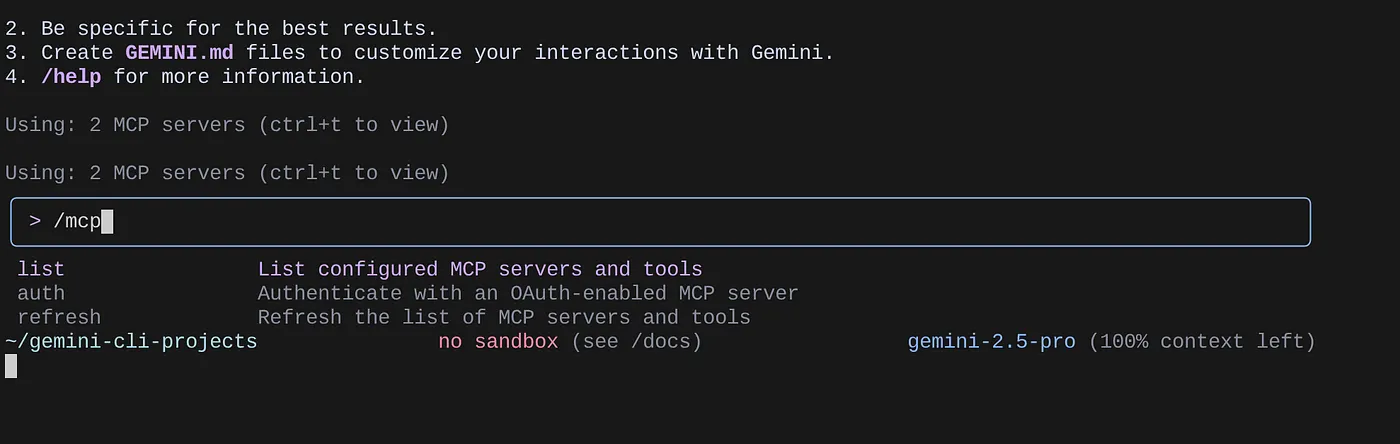
構成した 2 つの MCP サーバー(GitHub と MCP Toolbox for Databases)が、ツールとともに一覧表示されます。
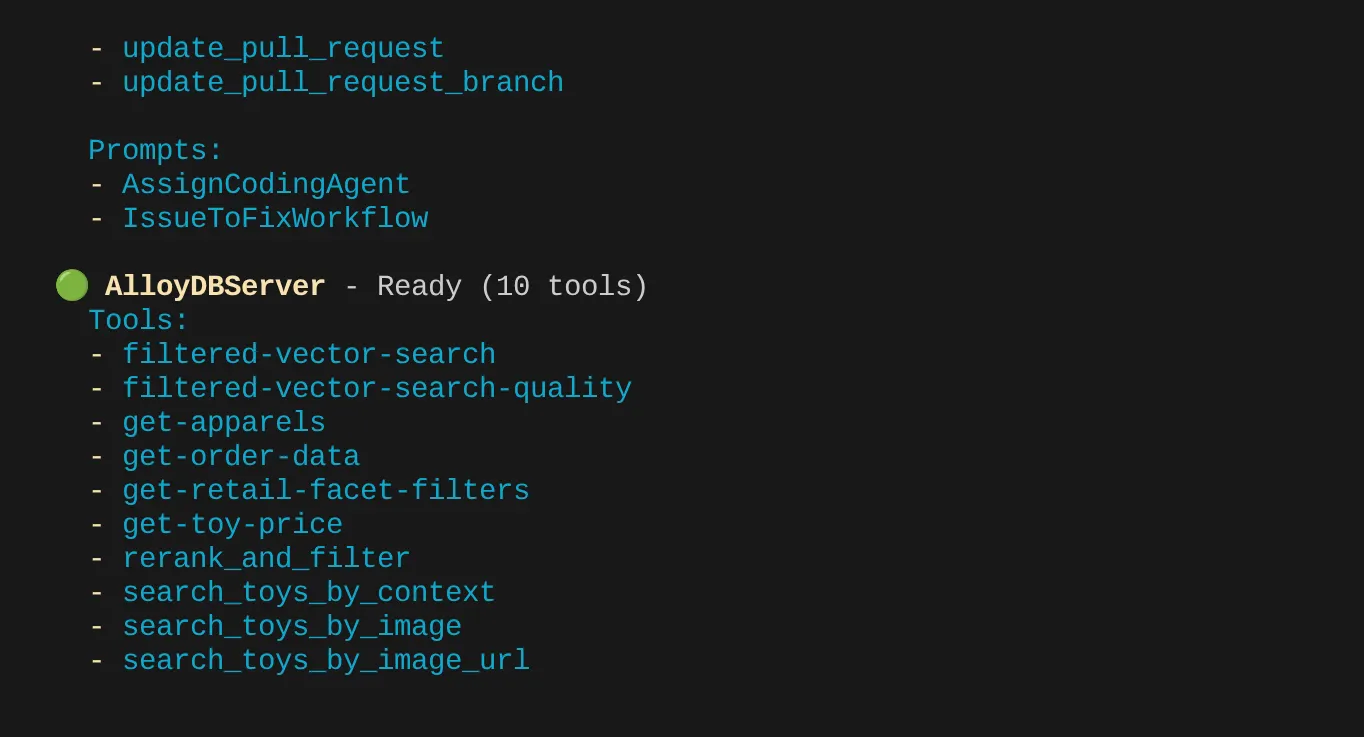
私の場合は、さらに多くのツールがあります。ここでは無視してください。AlloyDB MCP サーバーに get-apparels ツールが表示されます。
MCP ツールボックスを使用してデータベースのクエリを開始する
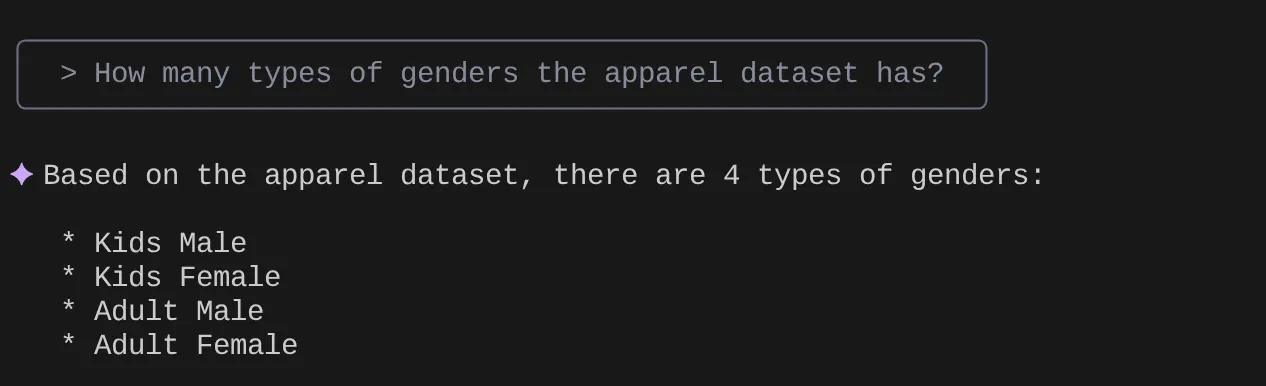
自然言語で質問して、使用しているデータセットの回答とクエリを取得してみましょう。
> How many types of genders the apparel dataset has?
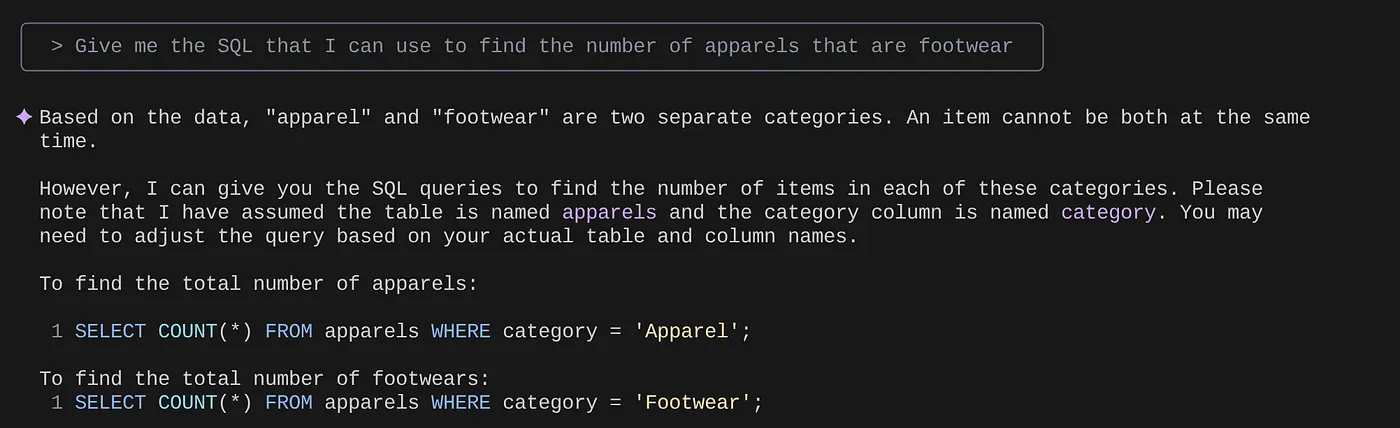
> Give me the SQL that I can use to find the number of apparels that are footwear
> What are the unique sub categories that are there?
that I can use to find the number of apparels that are footwear
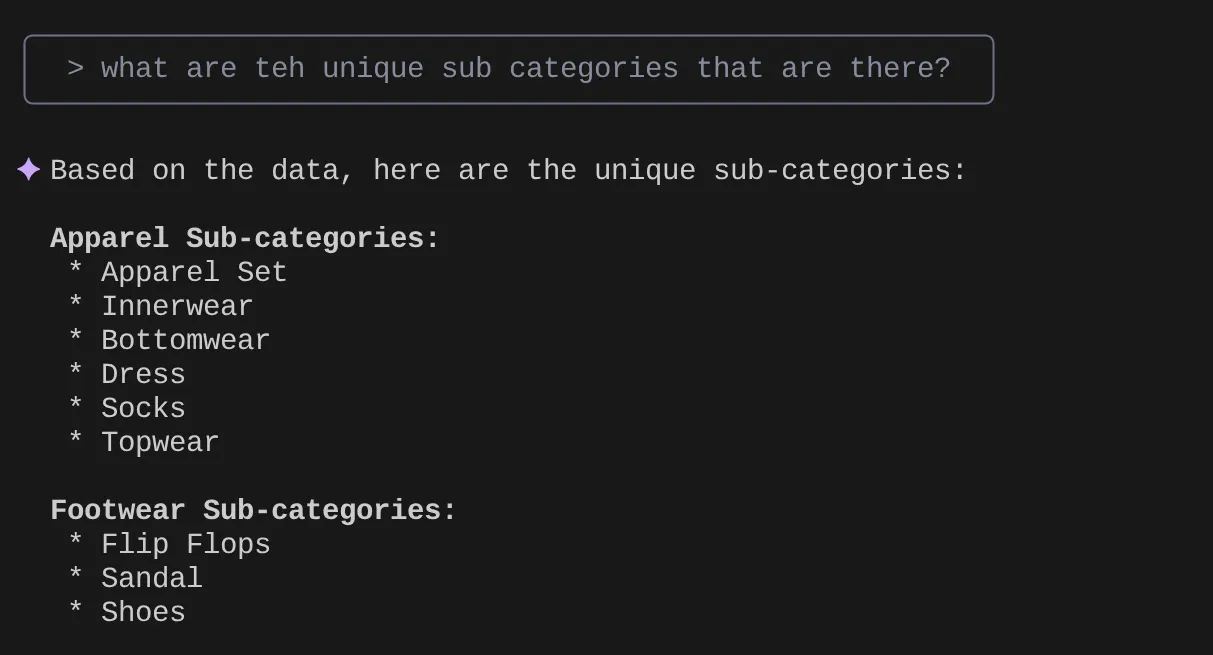
分析情報と多くのクエリに基づいて、詳細なクエリを作成してテストしたいとします。または、データベース エンジニアが次のように Tools.yaml を作成済みであるとします。
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
filtered-vector-search:
kind: postgres-sql
source: alloydb
description: Get the list of facet filter values from the retail dataset.
parameters:
- name: categories
type: array
description: List of categories preferred by the user.
items:
name: category
type: string
description: Category value.
- name: subCategories
type: array
description: List of sub-categories preferred by the user.
items:
name: subCategory
type: string
description: Sub-Category value.
- name: colors
type: array
description: List of colors preferred by the user.
items:
name: color
type: string
description: Color value.
- name: genders
type: array
description: List of genders preferred by the user for apparel fitting.
items:
name: gender
type: string
description: Gender name.
- name: searchtext
type: string
description: Description of the product that the user wants to find database matches for.
statement: |
SELECT id, content, uri, category, sub_category,color,gender FROM apparels
where category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005',$5)::vector limit 10
それでは、自然言語検索を試してみましょう。
> How many yellow shirts are there for boys?
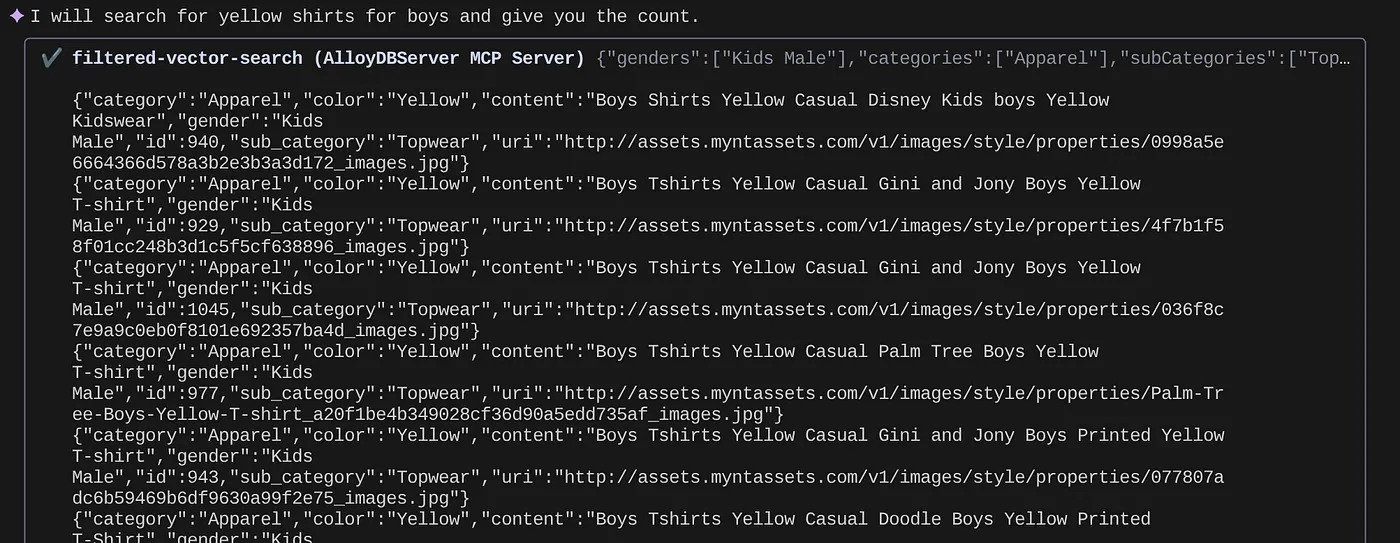

便利だと思いませんか?これで、クエリのさらなる進歩のために yaml ファイルを修正しながら、アプリケーションの新しい機能を加速されたタイムラインで提供し続けることができます。
9. 迅速なアプリ開発
Gemini CLI と MCP ツールボックスを使用してデータベース機能を IDE に直接統合するメリットは、理論的なものだけではありません。これは、特にハイブリッド小売エクスペリエンスのような複雑なアプリケーションにおいて、ワークフローの高速化という具体的なメリットにつながります。いくつかのシナリオを見てみましょう。
1. 商品フィルタリング ロジックの迅速な反復処理
「夏用アクティブウェア」の新しいプロモーションを開始したとします。ファセット フィルタ(ブランド、サイズ、色、価格帯など)がこの新しいカテゴリとどのように連携するかをテストしたいと考えています。
IDE 統合なしの場合:
別の SQL クライアントに切り替えてクエリを作成し、実行して結果を分析し、IDE に戻ってアプリケーション コードを調整し、クライアントに戻って繰り返す、という流れになるでしょう。このコンテキスト切り替えは大きな負担になります。
Gemini CLI と MCP を使用する場合:
IDE などで作業を続けられる:
- クエリ: (仮説データセット)「SELECT DISTINCT brand FROM products WHERE category = ‘activewear' AND season = ‘summer'」を使用して、yaml のクエリをすばやく更新し、ターミナルで直接試すことができます。
- データ探索: 返品されたブランドをすぐに確認できます。特定のブランドとサイズの商品在庫状況を確認する必要がある場合は、別の簡単なクエリを使用します。「SELECT COUNT(*) FROM products WHERE brand = ‘SummitGear' AND size = ‘M' AND category = ‘activewear' AND season = ‘summer'」
- コードの統合: これらの迅速な IDE 内のデータ分析に基づいて、フロントエンドのフィルタリング ロジックやバックエンドの API 呼び出しをすぐに調整できるため、フィードバック ループを大幅に短縮できます。
2. 商品レコメンデーション用のベクトル検索をファインチューニングする
Google のハイブリッド検索では、関連性の高い商品のおすすめにベクトル エンベディングを使用しています。たとえば、「男性用ランニング シューズ」の最適化案のクリック率が低下しているとします。
IDE 統合なしの場合:
データベース ツールでカスタム スクリプトやクエリを実行して、おすすめの靴の類似性スコアを分析し、ユーザー インタラクション データと比較して、パターンを関連付けようとします。
Gemini CLI と MCP を使用する場合:
- エンベディングの分析: 商品エンベディングとその関連メタデータを直接クエリできます。「SELECT product_id, name, vector_embedding FROM products WHERE category = ‘running shoes' AND gender = ‘male' LIMIT 10」
- 相互参照: 選択した商品とその推奨事項の実際のベクトル類似性を、その場で簡単に確認することもできます。たとえば、商品 B を閲覧したユーザーに商品 A がおすすめされた場合、クエリを実行してベクトル エンベディングを取得し、比較できます。
- デバッグ: これにより、デバッグと仮説検証を迅速に行うことができます。エンベディング モデルは想定どおりに動作していますか?推奨事項の品質に影響する異常値がデータに含まれていないか?コーディング環境を離れることなく、最初の回答を得ることができます。
3. 新機能のスキーマとデータ分布を理解する
たとえば、「お客様のレビュー」機能を追加することを計画しているとします。バックエンド API を作成する前に、既存の顧客データとレビューの構造を理解する必要があります。
IDE 統合なしの場合:
データベース クライアントに接続し、顧客や注文などのテーブルで DESCRIBE コマンドを実行してから、サンプルデータをクエリして、関係とデータ型を理解する必要があります。
Gemini CLI と MCP を使用する場合:
- スキーマの探索: yaml ファイル内のテーブルを簡単にクエリして、ターミナルで直接実行できます。
- データ サンプリング: サンプルデータを取得して、顧客のユーザー属性と購入履歴を把握できます。「SELECT customer_id, name, signup_date, total_orders FROM customers ORDER BY signup_date DESC LIMIT 5」
- 計画: スキーマとデータ分布にすばやくアクセスできるため、新しいレビュー テーブルの設計方法、設定する外部キー、レビューと顧客や商品を効率的にリンクする方法について、新しい機能のアプリケーション コードを 1 行も記述する前に、十分な情報に基づいて意思決定を行うことができます。
これらはほんの一例ですが、摩擦を減らしてデベロッパーのベロシティを高めるという主なメリットを強調しています。AlloyDB の操作を IDE に直接組み込むことで、Gemini CLI と MCP ツールボックスを使用して、より優れた応答性の高いアプリケーションをより迅速に構築できます。
10. クリーンアップ
この投稿で使用したリソースについて、Google Cloud アカウントに課金されないようにするには、次の操作を行います。
- Google Cloud コンソールで、[リソース マネージャー] ページに移動します。
- プロジェクト リストで、削除するプロジェクトを選択し、[削除] をクリックします。
- ダイアログでプロジェクト ID を入力し、[シャットダウン] をクリックしてプロジェクトを削除します。
- または、[クラスタを削除] ボタンをクリックして、このプロジェクト用に作成した AlloyDB クラスタを削除することもできます(構成時にクラスタに us-central1 を選択しなかった場合は、このハイパーリンクのロケーションを変更してください)。
11. 完了
おめでとうございます!このラボでは、MCP ツールボックスを IDE に直接統合して AlloyDB とシームレスにやり取りし、Gemini CLI を活用して小売業の e コマース データセットを操作し、通常は別のツールが必要となるクエリを作成しました。テーブル構造の確認からデータの簡単な健全性チェックまで、IDE 内の使い慣れたコマンドライン インターフェースを使用して、データをプローブして理解する新しい方法を学びました。
リポジトリを複製し、分析して、Gemini CLI と MCP Toolbox for Databases を使用してアプリケーションを強化したかどうかを教えてください。
Gemini CLI と MCP を使用して構築され、サーバーレス ランタイムにデプロイされたこのようなデータドリブン アプリケーションの詳細については、Code Vipassana の今後のシーズンにご登録ください。インストラクター主導のハンズオン セッションや、このような Codelab を受講できます。