
1. 개요
패싯 필터링과 벡터 검색을 결합하여 AlloyDB로 동적 하이브리드 소매 환경을 구축하는 여정을 기억하시나요? 이 애플리케이션은 현대적인 소매업체의 요구사항을 강력하게 보여주었지만, 이를 구현하고 반복하는 데 상당한 개발 노력이 필요했습니다. 풀스택 개발자에게는 코드 편집기와 데이터베이스 도구 간의 끊임없는 전환이 병목 현상이 되어 혁신과 데이터 이해라는 중요한 프로세스를 늦추는 경우가 많습니다.
솔루션
바로 이 지점에서 가속화된 애플리케이션 개발의 힘이 진가를 발휘합니다. 직관적인 Gemini CLI를 통해 액세스할 수 있는 MCP (Modern Cloud Platform) 도구 상자가 내 툴킷의 필수적인 부분이 된 이유를 공유하게 되어 기쁩니다. 통합 개발 환경 (IDE) 내에서 AlloyDB 인스턴스와 원활하게 상호작용하고, 쿼리를 작성하고, 데이터 세트를 이해한다고 상상해 보세요. 이는 편의성뿐만 아니라 개발 수명 주기의 마찰을 근본적으로 줄여 외부 도구와 씨름하는 대신 혁신적인 기능을 빌드하는 데 집중할 수 있도록 지원합니다.
제품 데이터를 효율적으로 쿼리하고, 복잡한 필터링을 처리하고, 벡터 검색의 미묘한 차이를 활용해야 했던 소매 전자상거래 앱의 맥락에서 데이터베이스 상호작용을 빠르게 반복할 수 있는 기능은 매우 중요했습니다. Gemini CLI로 구동되는 MCP Toolbox는 이 과정을 간소화할 뿐만 아니라 애플리케이션을 뒷받침하는 데이터베이스 로직을 탐색, 테스트, 개선하는 방식을 혁신적으로 가속화합니다. 이 획기적인 조합이 풀스택 개발을 더 빠르고, 스마트하고, 즐겁게 만드는 방법을 자세히 살펴보겠습니다.
학습 및 빌드할 항목
Gemini CLI로 구동되는 IDE 내에서 MCP 도구 상자를 활용하는 Retail Search 애플리케이션 살펴보겠습니다.
- 원활한 AlloyDB 상호작용을 위해 MCP 도구 상자를 IDE에 직접 통합하는 방법
- Gemini CLI를 사용하여 소매 데이터에 대해 SQL 쿼리를 작성하고 실행하는 실제 예시
- Gemini CLI를 활용하여 소매 전자상거래 데이터 세트와 상호작용하고, 일반적으로 별도의 도구가 필요한 쿼리를 작성하고, 결과를 즉시 확인할 수 있습니다.
- IDE 내의 친숙한 명령줄 인터페이스를 통해 테이블 구조를 확인하는 것부터 빠른 데이터 유효성 검사를 실행하는 것까지 데이터를 탐색하고 이해하는 새로운 방법을 알아보세요.
- 이러한 가속화된 데이터베이스 워크플로가 빠른 풀 스택 개발 주기에 직접적으로 기여하여 신속한 프로토타입 제작과 반복을 지원하는 방법
Techstack
사용 중인 항목:
- 데이터베이스용 AlloyDB
- 애플리케이션에서 데이터베이스의 고급 생성형 및 AI 기능을 추상화하는 MCP 도구 상자
- 서버리스 배포용 Cloud Run
- Gemini CLI를 사용하여 데이터 세트를 이해하고 분석하며 소매 전자상거래 애플리케이션의 데이터베이스 부분을 빌드합니다.
요구사항
2. 시작하기 전에
프로젝트 만들기
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있어야 하므로 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
- Google Cloud에서 실행되는 명령줄 환경인 Cloud Shell을 사용합니다. Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭합니다.

- Cloud Shell에 연결되면 다음 명령어를 사용하여 이미 인증되었는지, 프로젝트가 프로젝트 ID로 설정되었는지 확인합니다.
gcloud auth list
- Cloud Shell에서 다음 명령어를 실행하여 gcloud 명령어가 프로젝트를 알고 있는지 확인합니다.
gcloud config list project
- 프로젝트가 설정되지 않은 경우 다음 명령어를 사용하여 설정합니다.
gcloud config set project <YOUR_PROJECT_ID>
- 필요한 API 사용 설정: 링크를 따라 API를 사용 설정합니다.
또는 gcloud 명령어를 사용할 수 있습니다. gcloud 명령어 및 사용법은 문서를 참조하세요.
3. 데이터베이스 설정
이 실습에서는 AlloyDB를 전자상거래 데이터의 데이터베이스로 사용합니다. 클러스터를 사용하여 데이터베이스, 로그와 같은 모든 리소스를 보유합니다. 각 클러스터에는 데이터에 대한 액세스 포인트를 제공하는 기본 인스턴스가 있습니다. 테이블에는 실제 데이터가 저장됩니다.
전자상거래 데이터 세트가 로드될 AlloyDB 클러스터, 인스턴스, 테이블을 만들어 보겠습니다.
클러스터 및 인스턴스 만들기
- Cloud 콘솔에서 AlloyDB 페이지로 이동합니다. Cloud 콘솔에서 대부분의 페이지를 쉽게 찾으려면 콘솔의 검색창을 사용하여 검색하면 됩니다.
- 해당 페이지에서 클러스터 만들기를 선택합니다.

- 아래와 같은 화면이 표시됩니다. 다음 값으로 클러스터 및 인스턴스를 만듭니다 (저장소에서 애플리케이션 코드를 클론하는 경우 값이 일치하는지 확인).
- 클러스터 ID: '
vector-cluster' - password: "
alloydb" - PostgreSQL 15 / 최신 권장 버전
- 리전: "
us-central1" - 네트워킹: "
default"
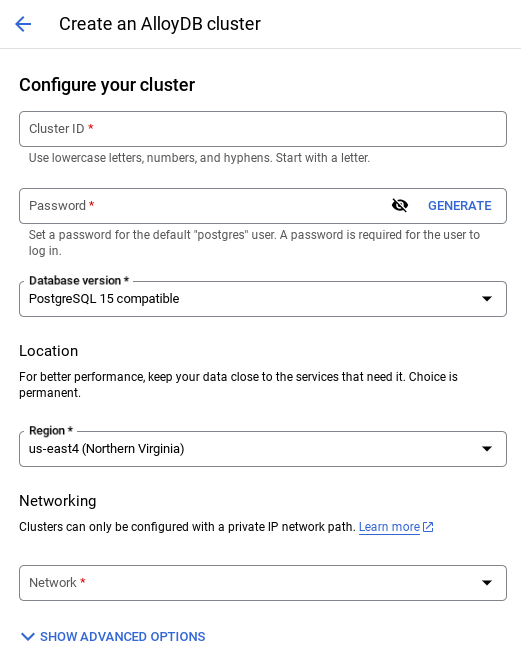
- 기본 네트워크를 선택하면 아래와 같은 화면이 표시됩니다.
연결 설정을 선택합니다.
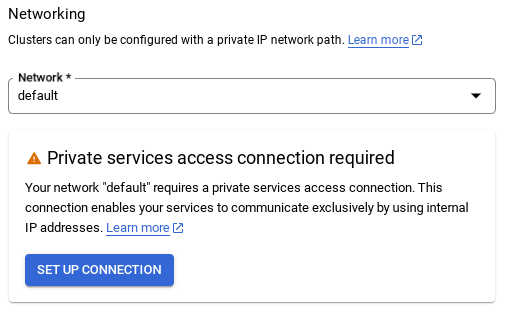
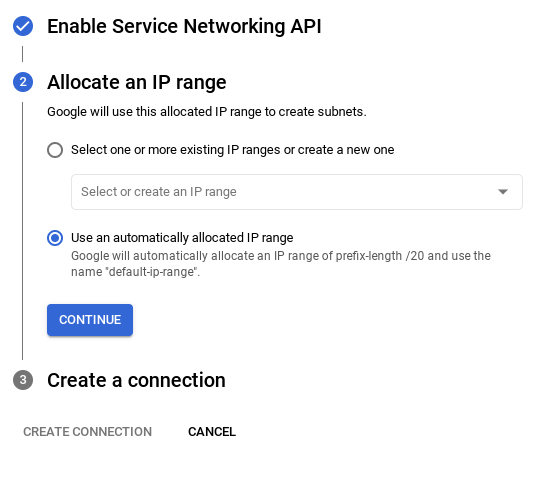
- 여기에서 '자동으로 할당된 IP 범위 사용'을 선택하고 계속을 클릭합니다. 정보를 검토한 후 연결 만들기를 선택합니다.
- 네트워크가 설정되면 클러스터를 계속 만들 수 있습니다. 클러스터 만들기를 클릭하여 아래와 같이 클러스터 설정을 완료합니다.
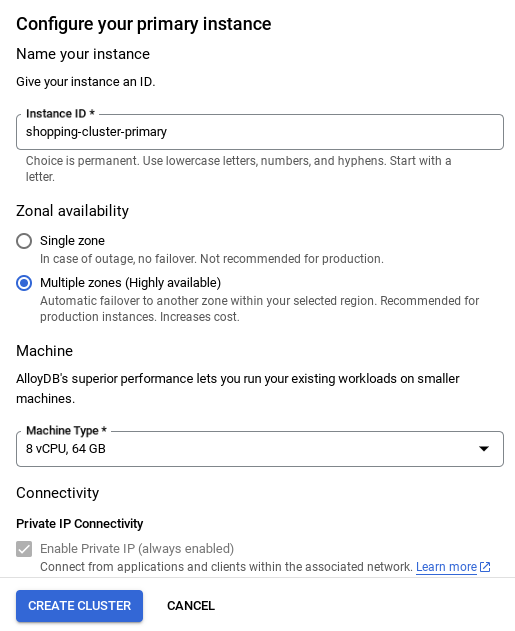
중요:
- 클러스터 / 인스턴스 구성 시 확인할 수 있는 인스턴스 ID를 **
vector-instance로 변경해야 합니다. 변경할 수 없는 경우 앞으로 나오는 모든 참조에서 **인스턴스 ID를 사용**해야 합니다. - 클러스터를 만드는 데 약 10분이 걸립니다. 성공하면 방금 만든 클러스터의 개요가 표시된 화면이 표시됩니다.
4. 데이터 수집
이제 매장에 관한 데이터가 포함된 표를 추가할 차례입니다. AlloyDB로 이동하여 기본 클러스터와 AlloyDB Studio를 선택합니다.
인스턴스 생성이 완료될 때까지 기다려야 할 수 있습니다. 완료되면 클러스터를 만들 때 만든 사용자 인증 정보를 사용하여 AlloyDB에 로그인합니다. PostgreSQL에 인증하려면 다음 데이터를 사용하세요.
- 사용자 이름 : '
postgres' - 데이터베이스 : '
postgres' - 비밀번호 : '
alloydb'
AlloyDB Studio에 인증되면 편집기에 SQL 명령어가 입력됩니다. 마지막 창 오른쪽에 있는 더하기 기호를 사용하여 여러 편집기 창을 추가할 수 있습니다.
필요에 따라 실행, 형식 지정, 지우기 옵션을 사용하여 편집기 창에 AlloyDB 명령어를 입력합니다.
확장 프로그램 사용 설정
이 앱을 빌드하기 위해 확장 프로그램 pgvector 및 google_ml_integration를 사용합니다. pgvector 확장 프로그램을 사용하면 벡터 임베딩을 저장하고 검색할 수 있습니다. google_ml_integration 확장 프로그램은 SQL에서 예측을 수행하기 위해 Vertex AI 예측 엔드포인트에 액세스하는 데 사용하는 함수를 제공합니다. 다음 DDL을 실행하여 이러한 확장 프로그램을 사용 설정합니다.
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
데이터베이스에서 사용 설정된 확장 프로그램을 확인하려면 다음 SQL 명령어를 실행합니다.
select extname, extversion from pg_extension;
테이블 만들기
AlloyDB Studio에서 아래 DDL 문을 사용하여 테이블을 만들 수 있습니다.
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
임베딩 열을 사용하면 텍스트의 벡터 값을 저장할 수 있습니다.
권한 부여
아래 문을 실행하여 'embedding' 함수에 대한 실행 권한을 부여합니다.
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB 서비스 계정에 Vertex AI 사용자 역할 부여
Google Cloud IAM 콘솔에서 AlloyDB 서비스 계정 (service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com)에 'Vertex AI 사용자' 역할에 대한 액세스 권한을 부여합니다. PROJECT_NUMBER에는 프로젝트 번호가 표시됩니다.
또는 Cloud Shell 터미널에서 아래 명령어를 실행할 수 있습니다.
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
데이터베이스에 데이터 로드
- 시트의
insert scripts sql에서insert쿼리 문을 위의 편집기에 복사합니다. 이 사용 사례를 빠르게 데모하려면 삽입 문을 10~50개 복사하면 됩니다. '선택한 인서트 25~30개 행' 탭에 선택된 인서트 목록이 있습니다. - 실행을 클릭합니다. 쿼리 결과가 결과 테이블에 표시됩니다.
중요:
삽입할 레코드를 25~50개만 복사하고 카테고리, 하위 카테고리, 색상, 성별 유형의 범위에 속하는지 확인합니다.
5. 데이터의 임베딩 만들기
최신 검색의 진정한 혁신은 키워드뿐만 아니라 의미를 이해하는 데 있습니다. 이때 임베딩과 벡터 검색이 사용됩니다.
사전 학습된 언어 모델을 사용하여 제품 설명과 사용자 검색어를 '임베딩'이라는 고차원 수치 표현으로 변환했습니다. 이러한 임베딩은 시맨틱 의미를 포착하여 일치하는 단어가 포함된 제품뿐만 아니라 '의미가 유사한' 제품을 찾을 수 있도록 해줍니다. 처음에 Google은 이러한 임베딩에 대한 직접적인 벡터 유사성 검색을 실험하여 기준을 설정했으며, 성능 최적화 전에도 시맨틱 이해의 강력한 기능을 입증했습니다.
임베딩 열을 사용하면 제품 설명 텍스트의 벡터 값을 저장할 수 있습니다. img_embeddings 열을 사용하면 이미지 임베딩 (멀티모달)을 저장할 수 있습니다. 이렇게 하면 텍스트 대 이미지 거리 기반 검색도 사용할 수 있습니다. 하지만 이 실습에서는 텍스트 임베딩만 사용합니다.
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
그러면 쿼리의 샘플 텍스트에 대한 임베딩 벡터가 반환됩니다. 이 벡터는 부동 소수점 배열과 유사합니다. 다음과 같이 표시됩니다.
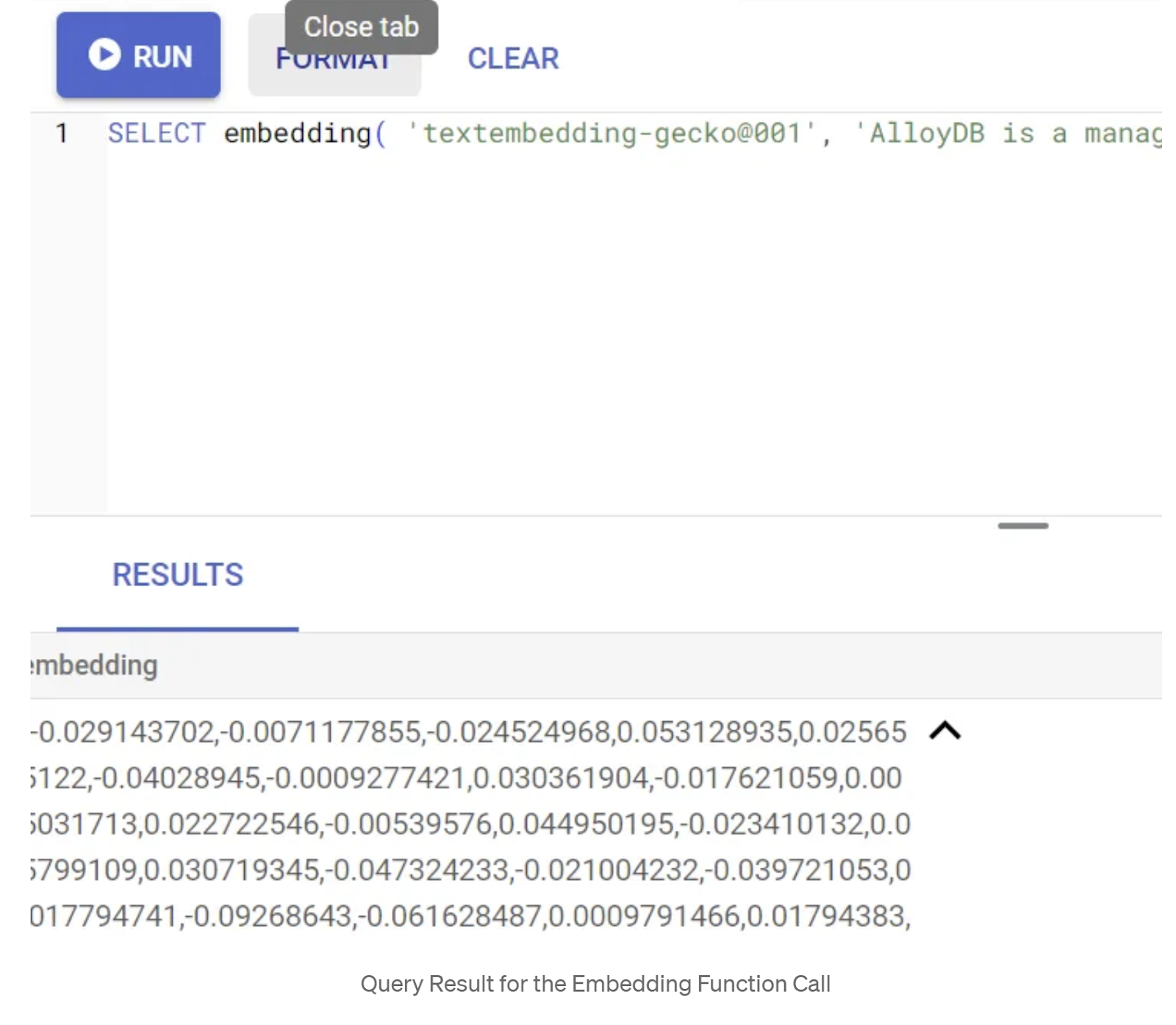
abstract_embeddings 벡터 필드 업데이트
아래 DML을 실행하여 테이블의 콘텐츠 설명을 해당 임베딩으로 업데이트합니다.
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
Google Cloud의 무료 체험판 크레딧 결제 계정을 사용하는 경우 20~25개 이상의 임베딩을 생성하는 데 문제가 있을 수 있습니다. 따라서 삽입 스크립트의 행 수를 제한하세요.
이미지 임베딩 (멀티모달 컨텍스트 검색 실행)을 생성하려면 아래 업데이트도 실행하세요.
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. 데이터베이스용 MCP 도구 상자 (AlloyDB)
백그라운드에서 강력한 도구와 잘 구성된 애플리케이션을 통해 원활한 작동을 보장합니다.
데이터베이스용 MCP (모델 컨텍스트 프로토콜) 도구 상자를 사용하면 생성형 AI 및 에이전트 도구를 AlloyDB와 더 쉽게 통합할 수 있습니다. 연결 풀링, 인증, 데이터베이스 기능의 AI 에이전트 또는 기타 애플리케이션에 대한 보안 노출을 간소화하는 오픈소스 서버 역할을 합니다.
애플리케이션에서 모든 지능형 하이브리드 검색 쿼리의 추상화 레이어로 데이터베이스용 MCP 도구 상자를 사용했습니다.
아래 단계에 따라 사용 사례에 맞게 Toolbox를 설정하고 배포하세요.
데이터베이스용 MCP 도구 상자에서 지원하는 데이터베이스 중 하나가 AlloyDB이며 이전 섹션에서 이미 프로비저닝했으므로 도구 상자를 설정해 보겠습니다.
- Cloud Shell 터미널로 이동하여 프로젝트가 선택되어 있고 터미널 프롬프트에 표시되는지 확인합니다. Cloud Shell 터미널에서 다음 명령어를 실행하여 프로젝트 디렉터리로 이동합니다.
mkdir gemini-cli-project
cd gemini-cli-project
- 아래 명령어를 실행하여 새 폴더에 툴박스를 다운로드하고 설치합니다.
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
이렇게 하면 현재 디렉터리에 툴박스가 생성됩니다. 툴박스 경로를 복사합니다.
- Cloud Shell 편집기 (코드 수정 모드)로 이동하여 프로젝트 루트 폴더 'gemini-cli-project'에 'tools.yaml'이라는 파일을 추가합니다.
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
tools.yaml을 이해해 보겠습니다.
소스는 도구가 상호작용할 수 있는 다양한 데이터 소스를 나타냅니다. 소스는 도구가 상호작용할 수 있는 데이터 소스를 나타냅니다. tools.yaml 파일의 소스 섹션에서 소스를 맵으로 정의할 수 있습니다. 일반적으로 소스 구성에는 데이터베이스와 연결하고 상호작용하는 데 필요한 모든 정보가 포함됩니다.
도구는 에이전트가 취할 수 있는 작업(예: 소스 읽기 및 쓰기)을 정의합니다. 도구는 상담사가 SQL 문을 실행하는 등의 작업을 수행할 수 있음을 나타냅니다. tools.yaml 파일의 도구 섹션에서 도구를 맵으로 정의할 수 있습니다. 일반적으로 도구는 조치를 취할 소스가 필요합니다.
tools.yaml 구성에 대한 자세한 내용은 이 문서를 참고하세요.
위의 Tools.yaml 파일에서 볼 수 있듯이 'get-apparels' 도구는 데이터베이스의 모든 의류 세부정보를 나열합니다.
7. Gemini CLI 설정
Cloud Shell 편집기에서 gemini-cli-project 폴더 내에 .gemini라는 새 폴더를 만들고 그 안에 settings.json이라는 새 파일을 만듭니다.
{
"mcpServers": {
"AlloyDBServer": {
"command": "/home/user/gemini-cli-project/toolbox",
"args": ["--tools-file", "tools.yaml", "--stdio"]
}
}
}
위 스니펫의 명령어 섹션에서 '/home/user/gemini-cli-project/toolbox'를 도구 상자 경로로 바꿉니다.
Gemini CLI 설치
마지막으로 Cloud Shell 터미널에서 다음 명령어를 실행하여 동일한 디렉터리 gemini-cli-project에 Gemini CLI를 설치합니다.
sudo npm install -g @google/gemini-cli
프로젝트 ID 설정
환경에 활성 프로젝트 ID가 설정되어 있는지 확인합니다.
export GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT_ID>>
Gemini CLI 시작하기
명령줄에서 다음 명령어를 입력합니다.
gemini
다음과 비슷한 응답이 표시됩니다.
인증하고 다음 단계로 진행합니다.
8. Gemini CLI와 상호작용 시작하기
/mcp 명령어를 사용하여 구성된 MCP 서버를 나열합니다.
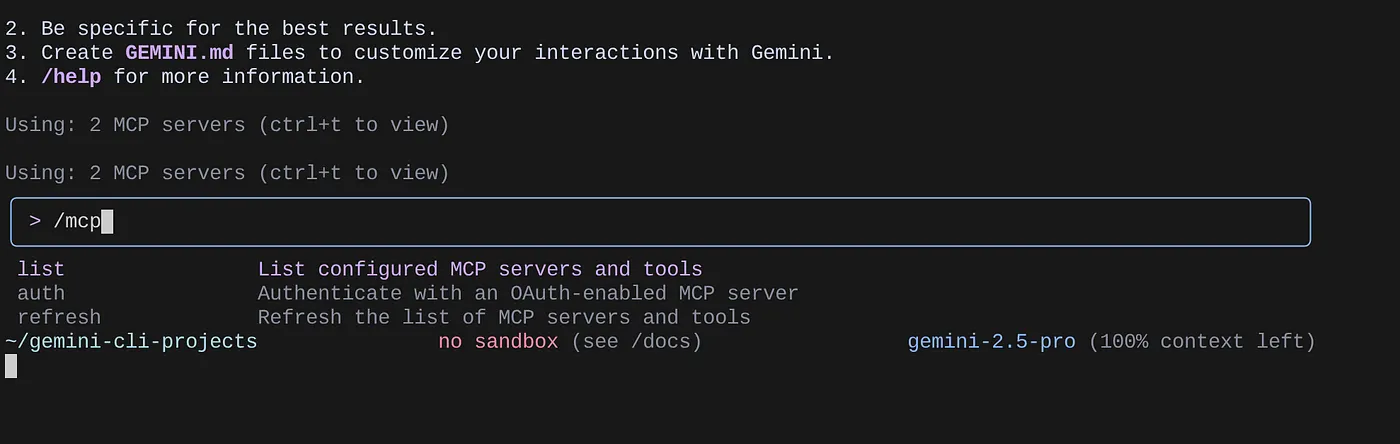
구성한 2개의 MCP 서버(GitHub 및 데이터베이스용 MCP 도구 상자)가 도구와 함께 나열되어 표시됩니다.
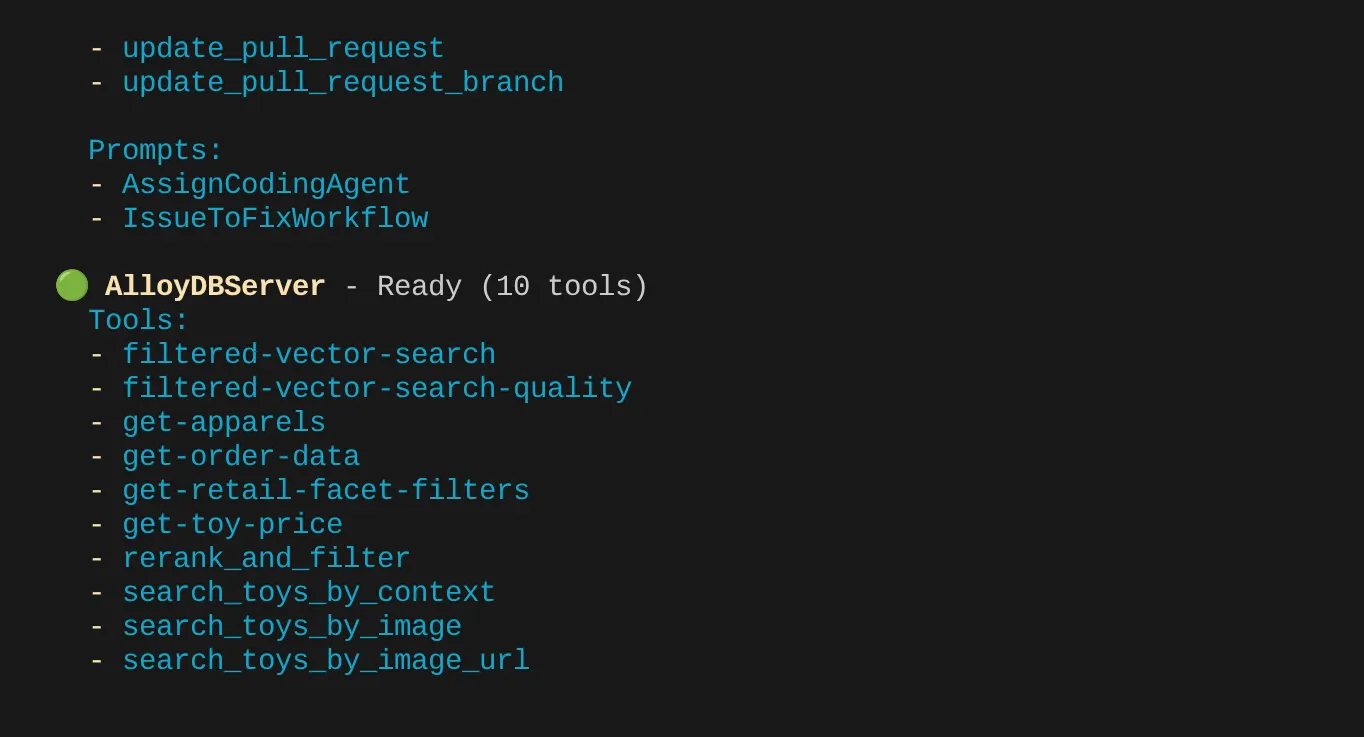
제 경우에는 도구가 더 많습니다. 따라서 지금은 무시하세요. AlloyDB MCP 서버에 get-apparels 도구가 표시됩니다.
MCP 도구 상자를 통해 데이터베이스 쿼리 시작
이제 자연어 질문을 통해 작업 중인 데이터 세트의 응답과 쿼리를 가져와 보세요.
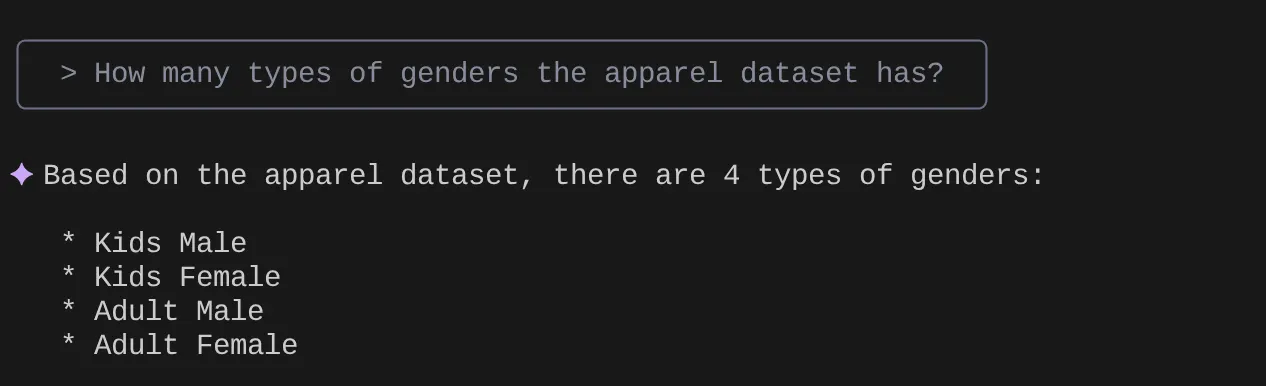
> How many types of genders the apparel dataset has?
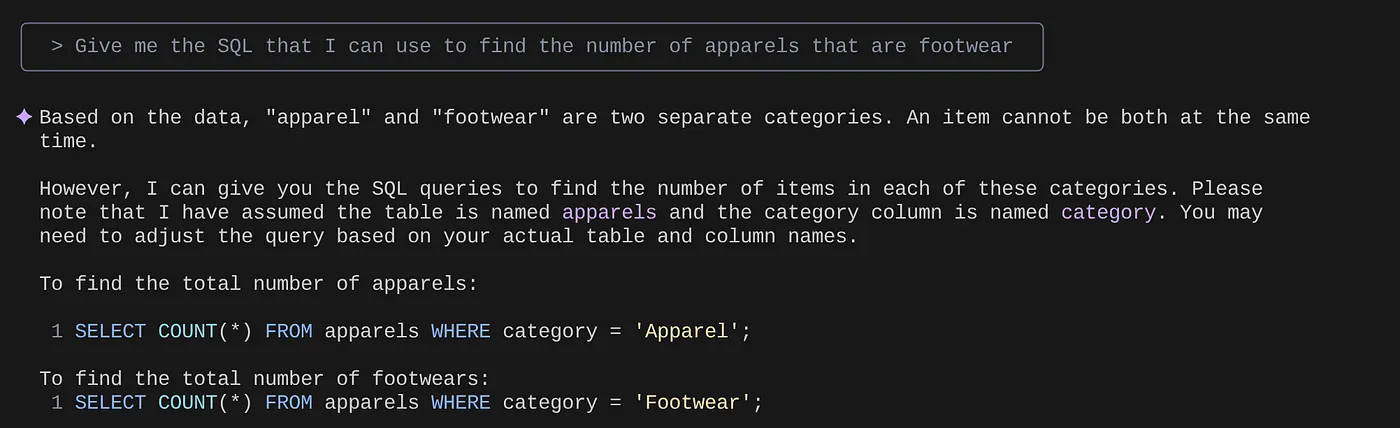
> Give me the SQL that I can use to find the number of apparels that are footwear
> What are the unique sub categories that are there?
that I can use to find the number of apparels that are footwear
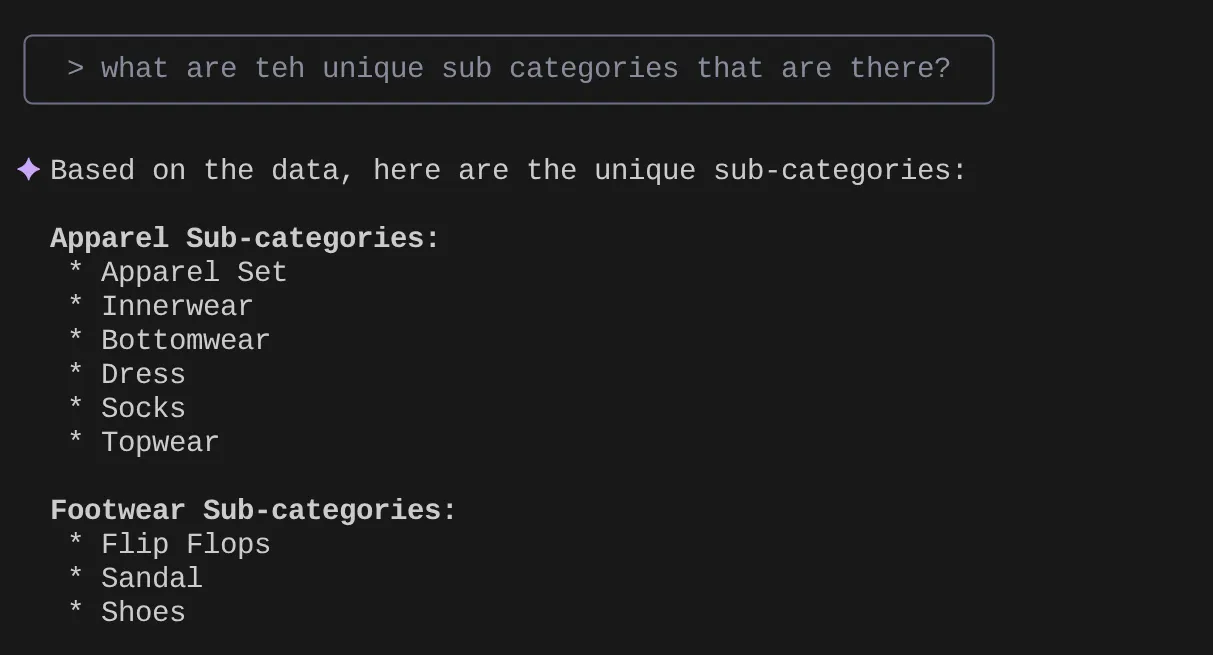
이제 내 통계와 여러 유사한 질문을 바탕으로 자세한 질문을 생각해 냈고 이를 테스트하고 싶다고 가정해 보겠습니다. 또는 데이터베이스 엔지니어가 아래와 같이 Tools.yaml을 이미 빌드했다고 가정해 보겠습니다.
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
filtered-vector-search:
kind: postgres-sql
source: alloydb
description: Get the list of facet filter values from the retail dataset.
parameters:
- name: categories
type: array
description: List of categories preferred by the user.
items:
name: category
type: string
description: Category value.
- name: subCategories
type: array
description: List of sub-categories preferred by the user.
items:
name: subCategory
type: string
description: Sub-Category value.
- name: colors
type: array
description: List of colors preferred by the user.
items:
name: color
type: string
description: Color value.
- name: genders
type: array
description: List of genders preferred by the user for apparel fitting.
items:
name: gender
type: string
description: Gender name.
- name: searchtext
type: string
description: Description of the product that the user wants to find database matches for.
statement: |
SELECT id, content, uri, category, sub_category,color,gender FROM apparels
where category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005',$5)::vector limit 10
이제 자연어 검색을 시도해 보겠습니다.
> How many yellow shirts are there for boys?
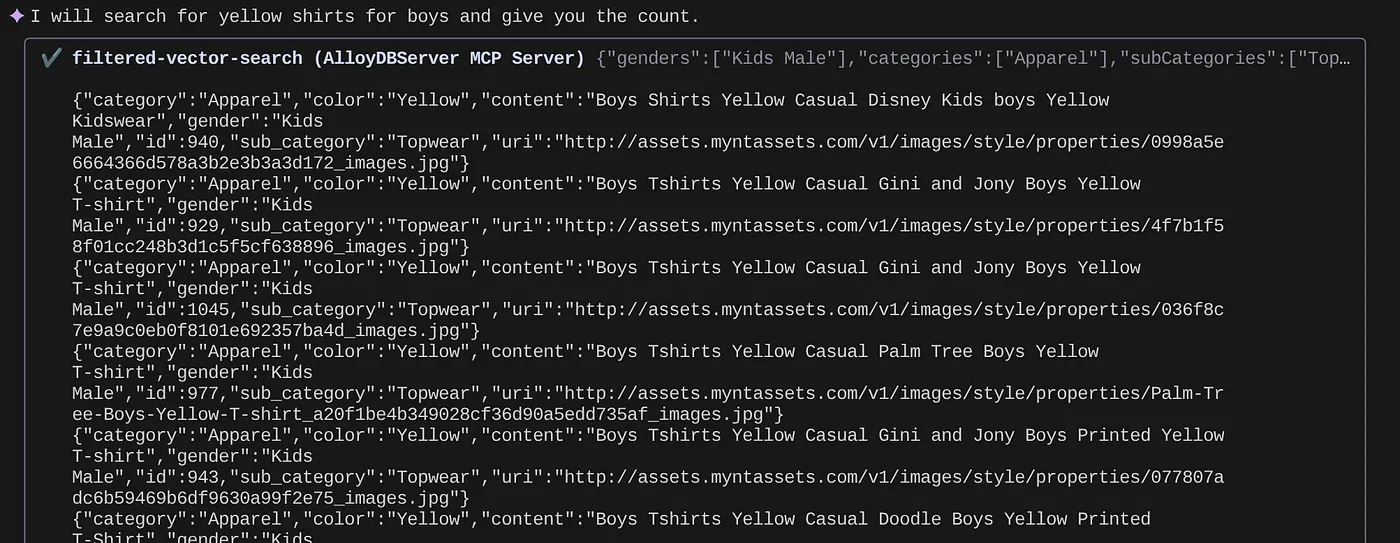

멋지지 않습니까? 이제 쿼리를 더 발전시키기 위해 yaml 파일을 수정하면서도 애플리케이션에서 새로운 기능을 더 빠른 일정으로 계속 제공할 수 있습니다.
9. 앱 개발 가속화
Gemini CLI와 MCP Toolbox를 통해 데이터베이스 기능을 IDE에 직접 통합하는 것은 이론적인 이점만 있는 것이 아닙니다. 특히 하이브리드 소매 환경과 같은 복잡한 애플리케이션의 경우 속도를 높이는 실질적인 워크플로로 이어집니다. 몇 가지 시나리오를 살펴보겠습니다.
1. 제품 필터링 로직을 빠르게 반복
'여름 스포츠웨어'에 대한 새로운 프로모션을 출시했다고 가정해 보겠습니다. 패싯 필터 (예: 브랜드, 사이즈, 색상, 가격대)가 이 새로운 카테고리와 어떻게 상호작용하는지 테스트하려고 합니다.
IDE 통합이 없는 경우:
별도의 SQL 클라이언트로 전환하여 쿼리를 작성하고 실행하고 결과를 분석한 다음 IDE로 돌아가 애플리케이션 코드를 조정하고 클라이언트로 다시 전환하여 반복할 것입니다. 이러한 컨텍스트 전환은 큰 방해 요소입니다.
Gemini CLI 및 MCP 사용:
IDE에서 더 많은 작업을 할 수 있습니다.
- 쿼리: yaml에서 (가상 데이터 세트) 'SELECT DISTINCT brand FROM products WHERE category = ‘activewear' AND season = ‘summer''로 쿼리를 빠르게 업데이트하고 터미널에서 바로 시도할 수 있습니다.
- 데이터 탐색: 반환된 브랜드를 즉시 확인할 수 있습니다. 특정 브랜드와 사이즈의 제품 재고를 확인해야 하는 경우 또 다른 빠른 쿼리를 사용합니다. 'SELECT COUNT(*) FROM products WHERE brand = ‘SummitGear' AND size = ‘M' AND category = ‘activewear' AND season = ‘summer''
- 코드 통합: 그런 다음 이러한 빠른 IDE 내 데이터 통계를 기반으로 프런트엔드 필터링 로직이나 백엔드 API 호출을 즉시 조정하여 피드백 루프를 크게 줄일 수 있습니다.
2. 제품 추천을 위한 벡터 검색 미세 조정
Google의 하이브리드 검색은 관련 제품 추천을 위해 벡터 임베딩을 사용합니다. '남성용 러닝화' 추천의 클릭률이 감소하고 있다고 가정해 보겠습니다.
IDE 통합이 없는 경우:
데이터베이스 도구에서 맞춤 스크립트나 쿼리를 실행하여 추천 신발의 유사성 점수를 분석하고, 사용자 상호작용 데이터와 비교하고, 패턴을 파악하려고 합니다.
Gemini CLI 및 MCP 사용:
- 임베딩 분석: 제품 임베딩과 관련 메타데이터를 직접 쿼리할 수 있습니다. 'SELECT product_id, name, vector_embedding FROM products WHERE category = 'running shoes' AND gender = 'male' LIMIT 10'
- 상호 참조: 선택한 제품과 추천 제품 간의 실제 벡터 유사성을 바로 확인할 수도 있습니다. 예를 들어 제품 B를 살펴본 사용자에게 제품 A가 추천되는 경우 쿼리를 실행하여 벡터 임베딩을 가져와 비교할 수 있습니다.
- 디버깅: 이를 통해 더 빠른 디버깅과 가설 테스트가 가능합니다. 삽입 모델이 예상대로 작동하나요? 추천 품질에 영향을 미치는 데이터 이상치가 있나요? 코딩 환경을 벗어나지 않고도 초기 답변을 받을 수 있습니다.
3. 새 기능의 스키마 및 데이터 분포 이해
'고객 리뷰' 기능을 추가할 계획이라고 가정해 보겠습니다. 백엔드 API를 작성하기 전에 기존 고객 데이터와 리뷰가 어떻게 구성되어 있는지 이해해야 합니다.
IDE 통합이 없는 경우:
데이터베이스 클라이언트에 연결하고 고객 및 주문과 같은 테이블에서 DESCRIBE 명령어를 실행한 다음 샘플 데이터를 쿼리하여 관계와 데이터 유형을 파악해야 합니다.
Gemini CLI 및 MCP 사용:
- 스키마 탐색: yaml 파일에서 테이블을 쿼리하고 터미널에서 직접 실행할 수 있습니다.
- 데이터 샘플링: 그런 다음 샘플 데이터를 가져와 고객 인구통계 및 구매 내역을 파악할 수 있습니다. 'SELECT customer_id, name, signup_date, total_orders FROM customers ORDER BY signup_date DESC LIMIT 5'
- 계획: 스키마와 데이터 분포에 빠르게 액세스할 수 있으므로 새로운 리뷰 테이블을 설계하는 방법, 설정할 외래 키, 리뷰를 고객 및 제품에 효율적으로 연결하는 방법을 새로운 기능의 애플리케이션 코드를 한 줄도 작성하지 않고도 정보에 입각하여 결정할 수 있습니다.
이는 몇 가지 예에 불과하지만, 마찰을 줄이고 개발자 속도를 높이는 핵심 이점을 보여줍니다. AlloyDB 상호작용을 IDE에 직접 통합함으로써 Gemini CLI와 MCP Toolbox를 통해 더 나은 응답성 높은 애플리케이션을 더 빠르게 빌드할 수 있습니다.
10. 삭제
이 게시물에서 사용한 리소스의 비용이 Google Cloud 계정에 청구되지 않도록 하려면 다음 단계를 따르세요.
- Google Cloud 콘솔에서 리소스 관리자 페이지로 이동합니다.
- 프로젝트 목록에서 삭제할 프로젝트를 선택하고 삭제를 클릭합니다.
- 대화상자에서 프로젝트 ID를 입력하고 종료를 클릭하여 프로젝트를 삭제합니다.
- 또는 클러스터 삭제 버튼을 클릭하여 이 프로젝트를 위해 방금 만든 AlloyDB 클러스터 (구성 시 클러스터에 us-central1을 선택하지 않은 경우 이 하이퍼링크의 위치를 변경)를 삭제하면 됩니다.
11. 마무리
축하합니다. 원활한 AlloyDB 상호작용을 위해 MCP Toolbox를 IDE에 직접 통합하고 Gemini CLI를 활용하여 일반적으로 별도의 도구가 필요한 쿼리를 작성하기 위해 소매 전자상거래 데이터 세트와 상호작용했습니다. 테이블 구조 확인부터 빠른 데이터 유효성 검사 실행까지, IDE 내의 친숙한 명령줄 인터페이스를 통해 데이터를 조사하고 이해하는 새로운 방법을 배웠습니다.
저장소를 클론하고, Gemini CLI와 데이터베이스용 MCP 도구 상자를 사용하여 애플리케이션을 개선했는지 분석하여 알려주세요.
Gemini CLI, MCP로 빌드되고 서버리스 런타임에 배포된 이러한 데이터 기반 애플리케이션에 대해 자세히 알아보려면 예정된 Code Vipassana 시즌에 등록하세요. 강사 주도의 실습 세션과 이러한 Codelab을 자세히 알아볼 수 있습니다.